
Introduction
Abstract
This chapter introduces embedded systems and embedded computing in general while highlighting their importance in everyday life. We provide an overview of their main characteristics and possible external environment interfaces. In addition to introducing these topics, this chapter highlights the trends in terms of target architectures and design flows. The chapter explains the objectives of the book, its major target audience, the dependences in terms of prior knowledge, and using this book within different contexts and readers’ aptitudes.
Keywords
Embedded computing; Embedded systems; High-performance embedded computing; Embedded computing trends
1.1 Overview
Embedded computing systems permeate our lives from consumer devices, such as smartphones and game consoles, to less visible electronic devices that control, for instance, different aspects of a car's operation. Applications executing on current embedded systems exhibit a sophistication on par with applications running on desktop computers. In particular, mobile devices now support computationally intensive applications, and the trend points to a further increase in application complexity to meet the growing expectations of their users. In addition to performance requirements, energy and power consumption are of paramount importance for embedded applications, imposing restrictions on how applications are developed and which algorithms can be used.
Fig. 1.1 presents a generic and simplified architecture of an embedded computing system. A key distinguishing feature of an embedded system lies in the diversity of its input and output devices, generically known as sensors and actuators, fueled by the need to customize their use for each specific domain. In this diagram, we have a bus-based computing core system consisting of a RAM, ROM, and a processor unit. The computing core system interacts with its physical environment via a set of actuators and sensors using Analog-to-Digital (ADC) and Digital-to-Analog (DAC) converter units. At the software level, the operating system and application software are stored in ROM or in Flash memory, possibly running a customized version of the Linux operating system able to satisfy specific memory and/or real-time requirements [1] and can support additional software components, such as resident monitors, required by the embedded system.
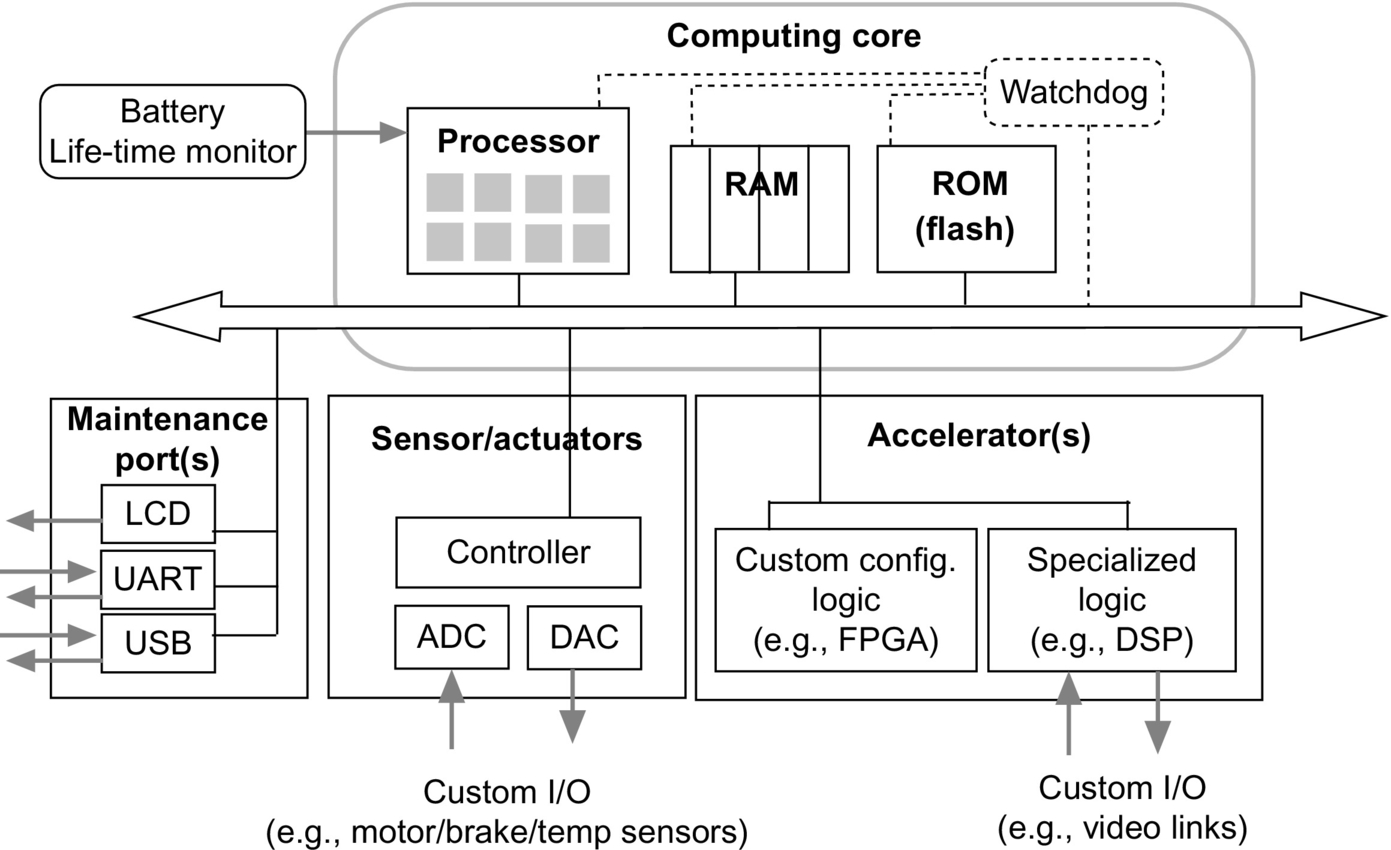
Developing applications in heavily constrained environments, which are typical targets of embedded applications, requires considerable programming skills. Not only programmers need to understand the limitations of the underlying hardware and accompanying runtime support, but they must also develop solutions able to meet stringent nonfunctional requirements, such as performance. Developing these interdisciplinary skills is nontrivial and not surprisingly there is a lack of textbooks addressing the development of the relevant competences. These aptitudes are required when developing and mapping high-performance applications to current and emerging embedded computing systems. We believe that this textbook is a step in this direction.
1.2 Embedded Systems in Society and Industry
While not necessarily comprehensive, Fig. 1.2 illustrates the diversity of the domains and environments in which embedded systems operate. At home, embedded systems are used to control and monitor our appliances from the simple stand-alone microwave oven, washing machine, and thermostat, to the more sophisticated and sensitive security system that monitors cameras and possibly communicates with remote systems via the Internet. Embedded systems also control our vehicles from the fuel injection control to the monitoring of emissions while managing a plethora of information using visual aids to display the operation of our vehicles. In our cities, embedded systems monitor public transportation systems which are ubiquitously connected to central stations performing online scheduling of buses and trains and provide real-time updates of arrival times across all stops for all transportation lines. At the office, embedded systems handle small electronic devices such as printers, cameras, and security systems as well as lighting.
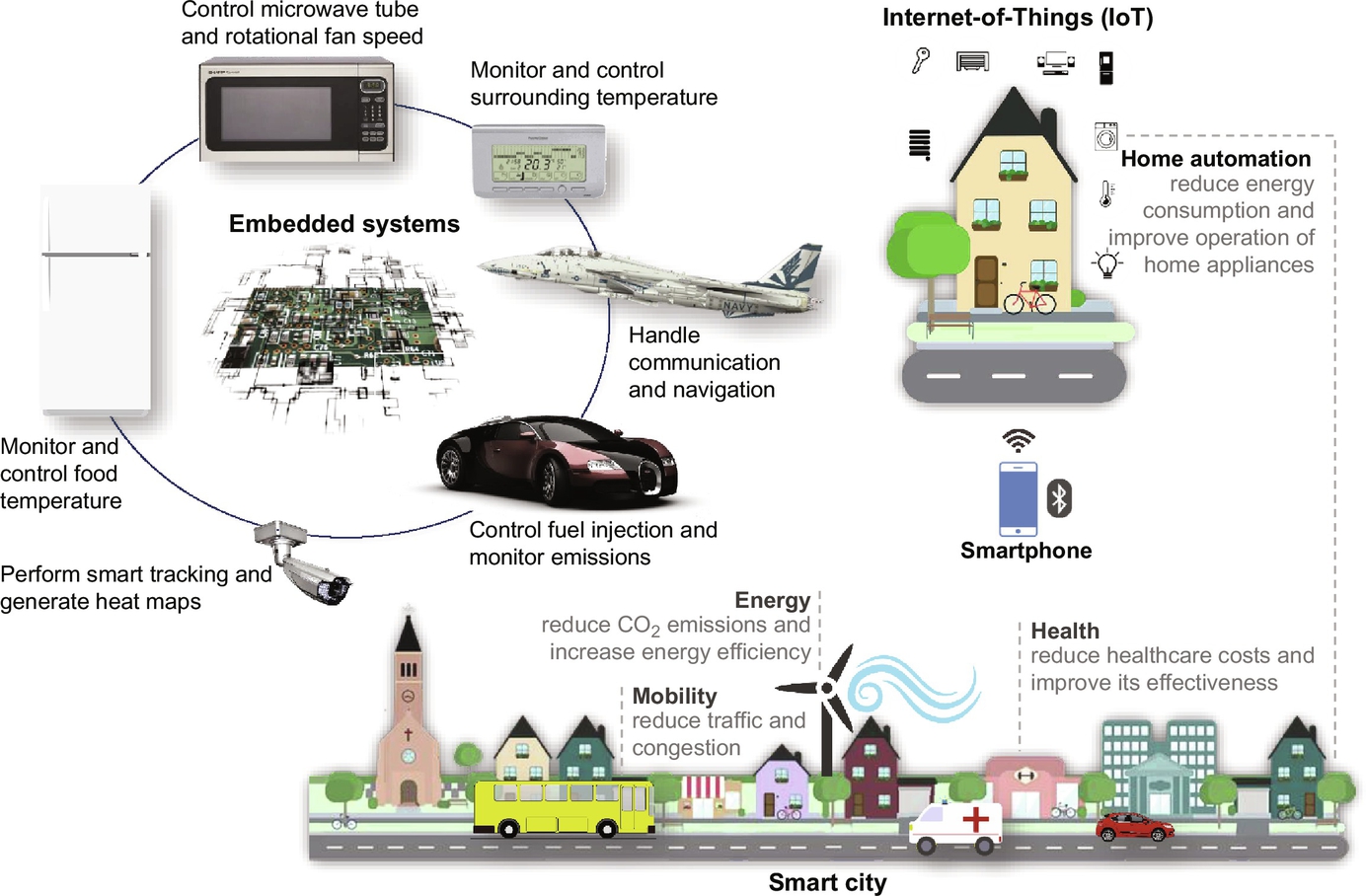
Moreover, today's smartphones are a marvel of technological integration and software development. These high-end embedded systems now include multicore processor(s), WiFi, Bluetooth, touch screens, and have performance commensurate to the performance of high-end multiprocessing systems available just a few years ago to solve scientific and engineering computing problems.
1.3 Embedded Computing Trends
Over the last decades, the seemingly limitless availability of transistors has enabled the development of impressive computing architectures with a variety and heterogeneity of devices. This resulted in the ability to combine, on a single integrated circuit, computing and storage capacity, previously unimaginable in terms of raw hardware performance and consequently in terms of software complexity and functionality. Various empirical laws have highlighted and captured important trends and are still relevant today in the context of embedded systems. These empirical laws include:
- Moore's Law—“The number of components in integrated circuits doubles every 18 months.” Moore's Law is one of the driving forces leading to the miniaturization of electronic components and to their increasing complexity;
- Gustafson's Law—“Any sufficiently large problem can be efficiently parallelized.” Due to the increasing complexity of embedded applications, the potential to use the many- and multicore architectures has also increased;
- Wirth's Law—“Software gets slower faster than hardware gets faster.” This observation is supported by the fast advances of multicore systems and custom computing and hardware accelerators when compared with the availability of effective development tools and APIs (Application Programming Interfaces) to exploit the target architectures;
- Gilder's Law—“Bandwidth grows at least three times faster than computer power.” This observation points to the advances in data transmission which amplify the advances of computing and storage technologies, forming the basis of technologies such as cloud computing and the Internet of Things (IoT).
One of the key trends in embedded systems has been the growing reliance on multicore heterogeneous architectures to support computationally intensive applications while ensuring long battery lifetimes. This increase in computing power coupled with the ever increase desire to be connected has fueled a fundamental transition from embedded systems, mostly operating in stand-alone environments, to a context where they are ubiquitously connected to other devices and communication infrastructures, in what has been coined as the Internet of Things (IoT).
As with the evolution of hardware, IoT software requirements have also evolved to support more application domains. While in the past years, the focus has been on digital signal and image processing, embedded systems are now expected to interact with other devices on the network and to support a variety of applications, e.g., with the capability to search remote databases and to compute using geographically distributed data.
Not surprisingly, the computational demands of mobile applications have also increased exponentially [2], thus exacerbating the complexity of mapping these applications to mobile architectures. It is believed (see, e.g., [3]) that in some domains neither hardware scaling nor hardware replication is enough to satisfy the performance requirements of advanced mobile applications. Therefore, in addition to the research and development of next-generation hardware architectures, it will be critical to revisit the development and mapping process of applications on resource-constrained devices. In particular, a key step ahead, when considering algorithmic and/or target hardware system changes, is the evaluation of code transformations and compiler optimizations that fully leverage the acceleration capabilities of the target system.
Another critical issue for companies is time-to-market [4] (see Fig. 1.3). Delays entering the market mean smaller overall sales as products have less time to benefit from the market before it starts to decline. Thus, a fast and efficient process to develop applications is one of the key factors for success in such competitive markets.

1.4 Embedded Systems: Prototyping and Production
Fig. 1.4 illustrates a design flow for embedded systems. Developing a high-performance application for an embedded platform requires developers to exploit sophisticated tool flows and to master different levels of abstraction across the various stages of application development, including deployment and maintenance. In our example, the development flow begins by capturing the user requirements followed by the actual development of the application. A first proof-of-concept prototype is usually validated on a desktop computer, possibly using a programming language with features that facilitate early prototyping such as MATLAB, and relying on the emulation of external interfaces (e.g., instead of using the real camera, one can use prerecorded videos or simple sequences of images stored as files). If this initial prototype does not meet its functional requirements, the developer must iterate and modify the application, possibly changing its data types (e.g., converting double to single floating-point precision), and applying code transformations and/or refactoring code to meet the desired requirements. This process is guided by developers’ knowledge about the impact of these modifications on the final embedded version. Depending on the project at hand, the prototype may be developed in the same programming language used for the embedded version, but possibly using different APIs.

The next step of the development process involves modifying the prototype code to derive an embedded code implementation. This includes using emulators, simulators, and/or virtual platforms to validate the embedded version and to optimize it if needed. At this stage, developers must consider the full set of nonfunctional requirements. It is also typical at this stage to explore and test hardware accelerators. This step partitions and maps the selected computations to available accelerators. If this validation stage is successful, the application is then deployed to the target embedded system or to a hardware system emulator, and a second stage of validation is performed. If this second level validation is successful, then the application is ready to be deployed as a product.
Depending on the application, target system requirements and nonfunctional requirements (in some of the development stages described earlier) might be merged. One of the barriers preventing an effective integration of these development stages is the lack of interfaces between the corresponding tools to allow them to be truly interoperable. This limitation forces developers to manually relate the effects of the transformations and analyses across them, in an error-prone process.
The development and mapping of applications to high-performance embedded systems must consider a myriad of design choices. Typically, developers must analyze the application and partition its code among the most suitable system components through a process commonly known as hardware/software partitioning [5]. In addition, developers have to deal with multiple compilation tools (subchains) for targeting each specific system component. These problems are further exacerbated when dealing with FPGAs (Field-Programmable Gate Arrays), a technology for hardware acceleration and for fast prototyping as it combines the performance of custom hardware with the flexibility of software [5,6]. As embedded platforms are becoming increasingly more heterogeneous, developers must also explore code and mapping transformations specific to each architecture so that the resulting solutions meet their overall requirements.
One of the key stages of the mapping process is to profile the code to understand its behavior (see, e.g., [7]), which is commonly achieved by extensive code instrumentation and monitoring. In addition, the development of applications targeting high-performance embedded systems leads to source code transformed by the extensive use of architecture-specific transformations and/or by the use of tool-specific compilation directives. Such practices require developer expertize in order to understand when transformations may limit portability, as otherwise when the underlying architecture changes, developers may need to restart the design process. Another issue contributing to development complexity is the presence of different product lines for the same application in order to support multiple target platforms and/or multiple application scenarios.
A key aspect for enhancing performance is exploiting parallelism available in the computing platform. In this context, when improving the performance of an application, developers need to consider Amdahl's law [8,9] and its extensions to the multicore era [10,11] to guide code transformations and optimizations, as well as code partitioning and mapping.
1.5 About LARA: An Aspect-Oriented Approach
LARA is an aspect-oriented language able to express code transformations and mapping strategies, allowing developers to codify nonfunctional concerns in a systematic fashion, which can be subsequently applied in an automated way on their application code.
The use of Aspect-Oriented Programming (AOP) mechanisms allows LARA descriptions to be decoupled from the application code itself—an important feature to improve maintainability and program portability across target platforms. In addition, LARA descriptions can be easily composed to create increasingly sophisticated design space exploration (DSE) strategies using native LARA looping and reporting analysis constructs. In short, LARA provides a more formal vehicle to specify the strategies for the various stages of an application's design flow, in what can be seen as executable strategies.1
Many of the descriptions of code instrumentation and transformations in this book use the LARA language [12]. Despite the many advantages of LARA as a transformation description language, this book is not about LARA. In other texts, many if not all of the mapping techniques and code transformations used when targeting high-performance embedded systems have been described in an informal, often ad hoc fashion, using abstractions of the underlying hardware and even runtime systems. The LARA descriptions presented in this book can thus be viewed as a vehicle to help the reader to clearly and unambiguously understand the various code and data transformations used in a complex mapping process. Furthermore, LARA has been developed and validated in the context of many research projects targeting real computing systems, and supports popular languages such as C and MATLAB to target heterogeneous systems including both GPUs and FPGAs.
1.6 Objectives and Target Audience
This book aims at providing Informatics Engineering, Computer Science, Computer Engineering undergraduate and graduate students, practitioners, and engineers with the knowledge to analyze and to efficiently map computations described in high-level programming languages to the architectures used in high-performance embedded computing (HPEC) domains. The required skills are transversal to various areas encompassing algorithm analysis, target architectures, compiler transformations, and optimizations. This book has also been designed to address specific trends regarding technical competences required by industry, and thus prepare computer science and informatics engineering students with the necessary skills.
This book focuses mainly on code transformations and optimizations suitable to improve performance and/or to achieve energy savings in the context of embedded computing. The topics include ways to describe computations in order for compilers and mapping tools to exploit heterogeneous architectures and hardware accelerators effectively. Specifically, the book considers the support of data and task parallelism provided by multicore architectures and the use of GPUs and FPGAs for hardware acceleration (via C and OpenCL code).
In the description of the various topics, it has been our intention to focus on concepts rather than on actual implementations using current technologies to avoid making the contents of this book obsolete in the short term. Still, we provide over the various chapters “sideboxes” with specific examples to connect the concepts to current implementations or technologies. In addition, we also provide complementary online material regarding each chapter, including in many cases complete source code examples, highlighting in more depth the use of the concepts using today's technologies.
1.7 Complementary Bibliography
Although there exists a number of technical textbooks (e.g., [4,13–15]) supporting embedded system courses, the topics covered in this book are only partially addressed by other volumes. Conversely, other texts, such as Refs. [16–18], cover complementary topics not addressed in this text.
The texts about compilation techniques for high-performance systems [14], embedded computing [19], performance tuning [20], high-performance computing [21], the AOP approach provided by LARA [22], hardware/software codesign [23], and reconfigurable computing [5,24], also address topics relevant to the topics addressed in this book and can thus serve as complementary bibliography.
Other relevant texts in the context of optimizations for high-performance computing (HPC) include the books from Crawford and Wadleigh [25], from Garg and Sharapov [26], and from Gerber et al. [27].
1.8 Dependences in Terms of Knowledge
In order to follow the topics addressed in this book, readers should have basic knowledge on high-level programming, data structures and algorithms, digital systems, computer architecture, operating systems, and compilers. Fig. 1.5 illustrates the dependences between these topics in general, and high-performance embedded computing (HPEC) in particular. Topics related to parallel computing and reconfigurable computing are seen as complementary, and readers with those skills are able to work on more advanced HPEC projects and/or to focus their work on specific technologies.

1.9 Examples and Benchmarks
While the computing industry uses commercial benchmarks such as the ones provided by EEMBC,2 there are, however, several benchmark repositories that can be used and have been adopted by many research groups. The most used benchmarks are MiBench3 [28], MediaBench4 [29], PolyBench,5 SNU-RT,6 HPEC Challenge Benchmark Suite7 [30], CHStone,8 UTDSP,9 and SD-VBS10 [31]. All of them include the source code and input/output data.
In order to provide examples and to draw the attention of the readers to specific optimizations while illustrating their impact in terms of performance, this book sometimes uses code kernels and/or applications from these benchmark repositories. Accompanying material provides full source code for illustrative examples, allowing readers to work with fully functional versions of the sample applications or code kernels.
1.10 Book Organization
This book consists of eight chapters. Each chapter provides a selection of references we think can be used as complementary reading about specific topics. In each chapter (except this one), we include a “Further Reading” section where we give references and paths for readers interested to know more about specific topics. It is in these sections that we make the connection to research efforts and findings. In addition to the eight chapters, we include a Glossary to briefly describe relevant terms and concepts present through the book.
The eight chapters of the book are as follows:
- Chapter 1 introduces embedded systems and embedded computing in general while highlighting their importance in everyday life. We provide an overview of their main characteristics and possible external environment interfaces. In addition to introducing these topics, this chapter highlights the trends in terms of target architectures and design flows. The chapter explains the objectives of the book, its major target audience, the dependences in terms of prior knowledge, and using this book within different contexts and readers’ aptitudes.
Keywords: Embedded computing, Embedded systems, High-performance embedded computing, Embedded computing trends.
- Chapter 2 provides an overview of the main concepts and representative computer architectures for high-performance embedded computing systems. As the multicore and manycore trends are shaping the organization of computing devices on all computing domain spectrums, from high-performance computing (HPC) to embedded computing, this chapter briefly describes some of the common CPU architectures, including platforms containing multiple cores/processors. In addition, this chapter introduces heterogeneous architectures, including hardware accelerators (GPUs and FPGAs) and system-on-a-chip (SoC) reconfigurable devices. The chapter highlights the importance of the Amdahl's law and its implications when offloading computations to hardware accelerators. Lastly, this chapter describes power/energy and performance models.
Keywords: Computer architectures, Hardware accelerators, FPGAs, GPUs, Profiling, Amdahl's law.
- Chapter 3 focuses on the need to control and guide design flows to achieve efficient application implementations. The chapter highlights the importance of starting and dealing with high abstraction levels when developing embedded computing applications. The MATLAB language is used to illustrate typical development processes, especially when high levels of abstraction are used in a first stage of development. In such cases, there is the need to translate these models to programming languages with efficient toolchain support to target common embedded computer architectures. The chapter briefly addresses the mapping problem and highlights the importance of hardware/software partitioning as a prime task to optimize computations on a heterogeneous platform consisting of hardware and software components. We motivate the need for domain-specific languages and productivity tools to deal with code maintenance complexity when targeting multiple and heterogeneous architectures. We also introduce LARA, an aspect-oriented domain-specific language used throughout the remaining chapters to describe design flow strategies and to provide executable specifications for examples requiring code instrumentation and compiler transformations.
Keywords: Models, High levels of abstraction, Prototyping, MATLAB, LARA, Optimization strategies, Hardware/software partitioning.
- Chapter 4 describes source code analysis and instrumentation techniques to uncover runtime data later used to decide about the most suitable compilation and/or execution strategy. We describe program metrics derived by static analysis and runtime profiling. This chapter introduces data dependence analysis and graph-based representations to capture both static and dynamic program information. Finally, we highlight the importance of customized profiling and present LARA examples that capture customized profiling strategies to extract complex code metrics.
Keywords: Instrumentation, Profiling, Software metrics, Code analysis, Data dependences.
- Chapter 5 describes relevant code transformations and optimizations, and how they can be used in real-life codes. We include descriptions of the various high-level code transformations and their main benefits and goals. We emphasize on the use of loop and function-based transformations for performance improvement using several illustrative examples. We include code specialization as one of the most important sources of performance improvements. In addition, the chapter describes some of the most representative transformations regarding data structures. Our goal in this chapter is to provide a comprehensive catalog of code transformations and to serve as a reference for readers and developers needing to know and apply code transformations. Finally, we include a set of LARA strategies to exemplify possible uses of LARA regarding the main topics of this chapter.
Keywords: Code transformations, Code optimizations, Loop transformations, Code refactoring.
- Chapter 6 focuses on the problem of mapping applications to CPU-based platforms, covering general code retargeting mechanisms, compiler options and phase ordering, loop vectorization, exploiting multicore/multiprocessor platforms, and cache optimizations. This chapter provides the fundamental concepts used for code targeting for shared and/or distributed memory architectures including the use of OpenMP and MPI, and thus covers important and actual topics required by programmers when developing or tuning applications for high-performance computing systems. We consider the topic of code retargeting important, as most high-level languages such as C/C++ do not have the adequate compiler support to automatically harness the full computational capacity of today's platforms.
Keywords: Loop vectorization, Targeting multicore and multiprocessor architectures, Compiler options, Compiler flags, Phase ordering, Directive-driven programming models, OpenMP, MPI.
- Chapter 7 covers code retargeting for heterogeneous platforms, including the use of directives and DSLs specific to GPUs as well as FPGA-based accelerators. This chapter highlights important aspects when mapping computations described in C/C++ programming languages to GPUs and FPGAs using OpenCL and high-level synthesis (HLS) tools, respectively. We complement this chapter by revisiting the roofline model and describing its importance when targeting heterogeneous architectures. This chapter also presents performance models and program analysis methodologies to support developers in deciding when to offload computations to GPU- and FPGA-based accelerators.
Keywords: FPGAs, GPUs, Reconfigurable fabrics, Directive-driven programming models, High-level synthesis, Hardware compilation, Accelerator code offloading, OpenCL.
- Chapter 8 describes additional topics, such as design space exploration (DSE), hardware/software codesign, runtime adaptability, and performance/energy autotuning (offline and online). More specifically, this chapter provides a starting point for developers needing to apply these concepts, especially in the context of high-performance embedded computing. More specifically, this chapter explains how autotuning can assist developers to find the best compiler optimizations given the target objective (e.g., execution time reductions, energy savings), and how static and dynamic adaptability can be used to derive optimized code implementations. Furthermore, it covers simulated annealing, which is an important and easily implementable optimization technique that can be used in the context of DSE and offline autotuning. In addition, this chapter covers multiobjective optimizations and Pareto frontiers which we believe provides a foundation for readers and developers to deal with more complex DSE problems. Although we cannot possibly cover all of the aforementioned topics in detail due to their nature and complexity, we expect that this chapter provides a useful introduction to them, and as the final chapter to this book, that it brings interesting points of discussion on top of topics presented in previous chapters.
Keywords: Design space exploration (DSE), Autotuning, Runtime adaptivity, Simulated annealing, Multiobjective optimization, Multicriteria optimization, Multiversioning.
1.11 Intended Use
This book has multiple intended uses. Readers with a solid background on computer architecture, hardware accelerators, and energy and power consumption may skip Chapter 2. Readers with an interest on code transformations, compiler optimizations, and the use of directive-driven programming models or directives to guide tools may focus on Chapters 5, 6, or 7, respectively. Chapter 8 describes advanced topics, such as design space exploration, runtime adaptivity, and autotuning, which may be of interest to readers as an introduction to those topics. Lastly, while we have used LARA specifications throughout this book, readers without a particular interest in this DSL, which is used to capture and automate strategies, can still grasp the concepts of this book by following the examples described in this language.
1.12 Summary
This chapter introduced the high-performance embedded computing topics covered in this book, which places a strong emphasis on the interplay between theory and practice with real-life examples and lab experiments. This book has been designed to address competences that are becoming of paramount importance and are not commonly addressed by courses in the curricula currently offered by most Informatics Engineering, Computer Engineering, and Computer Science programs.