
Code retargeting for CPU-based platforms
Abstract
This chapter focuses on the problem of mapping applications to CPU-based platforms, covering general code retargeting mechanisms, compiler options and phase ordering, loop vectorization, exploiting multicore/multiprocessor platforms, and cache optimizations. This chapter provides the fundamental concepts used for code targeting for shared and/or distributed memory architectures including the use of OpenMP and MPI, and thus covers important and actual topics required by programmers when developing or tuning applications for high-performance computing systems. We consider the topic of code retargeting important, as most high-level language like C/C++ do not have the necessary compiler support to automatically harness the full computational capacity of today's platforms.
Keywords
Loop vectorization; Targeting multicore and multiprocessor architectures; Compiler options; Compiler flags; Phase ordering; Directive-driven programming models; OpenMP; MPI
6.1 Introduction
In this chapter, we focus exclusively on code retargeting issues in the context of CPU-based architectures and where the application source code is optimized to execute more efficiently on a given platform. In Chapter 7, we extend the topic of code retargeting to cover heterogeneous platforms, such as GPUs and FPGAs.
Here, we assume as input the application's source code, written in a high-level language such as C/C++, possibly even translated from higher levels of abstraction as described in Chapter 3. This source code captures the algorithmic behavior of the application while being independent of the target platform. As a first step, this code version is compiled and executed on a CPU platform, allowing developers to test the correctness of the application with respect to its specification.
However, as computer architectures are becoming increasingly complex, with more processing cores, more heterogeneous and more distributed, applications compiled for existing machines will not fully utilize the target platform resources, even when binary compatibility is guaranteed, and thus do not run as efficiently as they could. In particular, modern-day computing platforms (see Chapter 2 for a brief overview) support many independent computational units to allow parallel computations, contain specialized architectural features to improve concurrency and computational efficiency, support hierarchical memories to increase data locality and reduce memory latency, and include fast interconnects and buses to reduce data movement overhead. Hence, to maximize performance and efficiency it is imperative to leverage all the underlying features of a computing platform.
While imperative languages, such as C and C++, allow developers to write portable applications using high-level abstractions, the complexity of modern computing platforms makes it hard for compilers to derive optimized1 and efficient code for each platform architecture. Retargetable compilers do exist, but they typically limit themselves to generate code for different CPU instruction set architectures. This limitation forces developers to manually optimize and refine their applications to support the target computation platform. This process requires considerable expertise to port the application, including applying code optimization strategies based on best practices, understanding available retargeting mechanisms, and deploying and testing the application. The resulting code, while being more efficient, often becomes difficult to maintain since it becomes polluted with artifacts used for optimization (e.g., with new API calls and data structures, code transformations). For this reason, developers often keep two versions of their source code: a functional version used to verify correctness and an optimized version which runs more efficiently on a specific platform.
This chapter is organized as follows. In Section 6.2, we provide a brief overview of common retargeting mechanisms. Section 6.3 briefly describes parallelism opportunities in CPU-based platforms and compiler options, including phase selection and ordering. Section 6.4 focuses on loop vectorization to maximize single-threaded execution. Section 6.5 covers multithreading on shared memory multicore architectures, and Section 6.6 describes how to leverage platforms with multiprocessors using distributed memory. Section 6.7 explains CPU cache optimizations. Section 6.8 presents examples of LARA strategies related to code retargeting. The remaining sections provide further reading on the topics presented in this chapter.
To illustrate the various retargeting mechanisms described in the following sections, we consider the multiplication of two matrices A (nX rows and nY columns) and B (nY rows and nZ columns) producing a matrix C (nX rows and nZ columns), generically described as follows:

This matrix product computation is a key operation in many algorithms and can be potentially time consuming for very large matrix size inputs. Although several optimized algorithms have been proposed for the general matrix multiplication operation, we focus, as a starting point, on a simple implementation in C, described as follows:

To compute each element of matrix C (see Fig. 6.1), the algorithm iterates over row i of matrix A and column j of matrix B, multiplying in a pair-wise fashion the elements from both matrices, and then adding the resulting products to obtain Cij.

Although this is a simple example, it provides a rich set of retargeting and optimization opportunities (clearly not exhaustively) on different platforms. Yet, its use is not meant to provide the most effective implementation for each target system. In practice, we recommend using domain-specific libraries, such as BLAS [1], whenever highly optimized implementations are sought.
6.2 Retargeting Mechanisms
Developers have at their disposal different mechanisms to optimize and fine-tune their applications for a given computing platform. Given the complexity of today's platforms and the lack of design tools to fully automate the optimization process, there is often a trade-off between how much effort an expert developer spends optimizing their application and how portable the optimized code becomes. In this context we can identify the following retargeting mechanisms:
1. Compiler control options. This mechanism controls the code optimization process by configuring the platform's toolchain options. For instance, some options select the target processor architecture (e.g., 32- or 64-bit), others select the use of a specific set of instructions (e.g., SSE, SSE2, AVX, AVX2), or to set the level of optimization (favoring, for instance, faster generated code over code size). Additional options enable language features and language standards (including libraries). In general, this mechanism requires the least amount of developer effort, but it is also the least effective in fully exploiting the capabilities of modern-day computation platforms given the inherent limitations of today's compilers.
2. Code transformations. Programmers often need to manually rewrite their code to adopt practices and code styles specific to the platform's toolchain and runtime system. This is the case, for instance, with the use of hardware compilation tools for application-specific architectures on FPGAs. These tools typically impose restrictions on the use of certain programming language constructs and styles (e.g., arrays instead of pointers), as otherwise they can generate inefficient hardware designs. There are also transformations (see Chapter 5) one can apply systematically to optimize the application on a hardware platform while guaranteeing compilation correctness with respect to the original code. Even when performing automatic code transformations by a compiler, developers might need to identify a sequence of code transformations with the correct parametrization (e.g., loop unroll factors) to derive implementations complying with given nonfunctional requirements. There are instances, however, when developers must completely change the algorithm to better adapt to a platform, for example, by replacing a recursive algorithm with an iterative stream-based version when targeting an FPGA-based accelerator.
3. Code annotations. Developers can annotate their programs using comments or directives (e.g., pragmas in C/C++) to support a programming model or to guide a compiler optimization process. Code annotations are not invasive and usually do not require changing the code logic. Nonetheless, this method has been successfully used by developers to parallelize their sequential applications by identifying all the concurrent regions of their code. Such approaches include directive-driven programming models as is the example of OpenMP [21]. The code annotation mechanism has the advantage to allow programs to preserve a high degree of portability since code annotations can be easily removed or ignored if not activated or even supported.
4. Domain-specific libraries. Libraries are often employed to extend the compiler capabilities and generate efficient code. In contrast with code annotations, integrating a library into an application often requires considerable changes in the application source code, including introducing new data structures and replacing existing code with library calls. Hence, portability can become an issue if the library is not widely supported on different platforms. Still, libraries can provide an abstraction layer for an application domain, allowing developers to write applications using the library interface without having to provide implementation details. This way, applications can be ported with little effort to a different platform as long as an optimized library implementation is available for that platform, thus also providing some degree of performance portability. An example of a portable application domain library is ATLAS [2] for linear algebra, which is available for many platforms. In addition, libraries can support a programming model for a specific computation platform, allowing the generation of efficient code. The MPI library [22], for instance, supports platforms with distributed memory.
5. Domain-specific languages. Another mechanism for retargeting applications involves rewriting parts of the source code using a domain-specific language (DSL) [3] to support an application domain or a specific type of platform. DSLs can be embedded within the host language (e.g., C++, Scala), often leading to “cleaner” code when compared to code that results from the use of domain-specific libraries. Alternatively, DSLs can be realized using a separate language and/or programming model (e.g., OpenCL) than the one employed by the host. In this case, the DSL requires its own toolchain support.
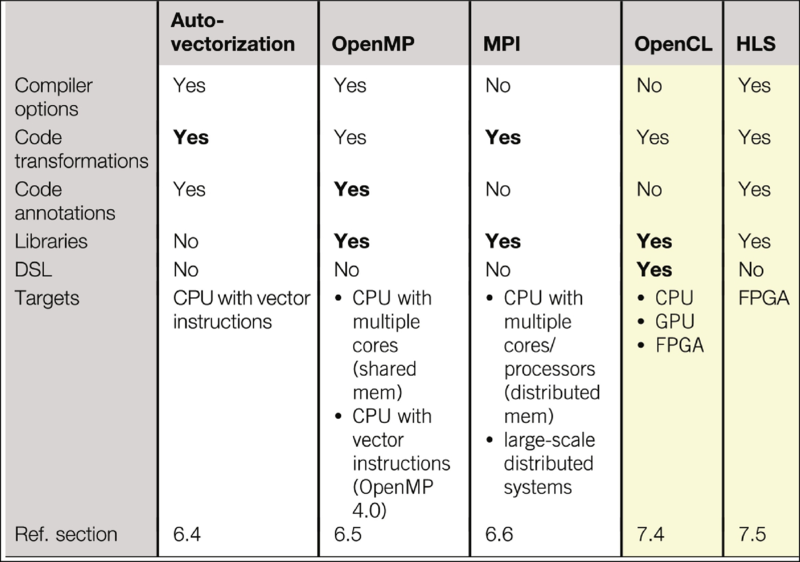
Other widely used approaches to assist code retargeting include: compiler auto-vectorization (in the context of CPU SIMD units), OpenMP (in the context of parallelization using shared memory architectures), OpenCL (in the context of CPUs, GPUs, and FPGAs), MPI (in the context of distributed memory architectures), and High-Level Synthesis (HLS) tools to translate C programs to reconfigurable hardware provided by FPGAs.
Table 6.1 summarizes these approaches and the retargeting mechanisms used by each of them: the auto-vectorization process is mainly driven by code transformations—manual or automatic—to infer CPU vector instructions; OpenMP requires code annotations and library calls to parallelize code targeting multicore/processor platforms with shared memory, and with the latest OpenMP specification the support for vectorization; MPI requires library calls to query the environment and trigger communication between nodes, and code must be restructured to support the MPI model; OpenCL requires modifying the host code to query the platform and configure the devices for execution and translating hotspots into OpenCL kernels; HLS requires the use of directives and code transformations to make the source code more amenable to FPGA acceleration by the HLS tool, and the host code must be modified to interface to the hardware accelerator.

6.3 Parallelism and Compiler Options
While there have been considerable advances in compiler technology targeting CPU platforms, many of the optimizations performed automatically are limited to single-threaded execution, thus missing out vast amounts of computational capacity one can attain from multicore and distributed computing. As such, developers must manually exploit the architectural features of CPUs to attain the maximum possible performance to satisfy stringent application requirements, such as handling very large workloads.
6.3.1 Parallel Execution Opportunities
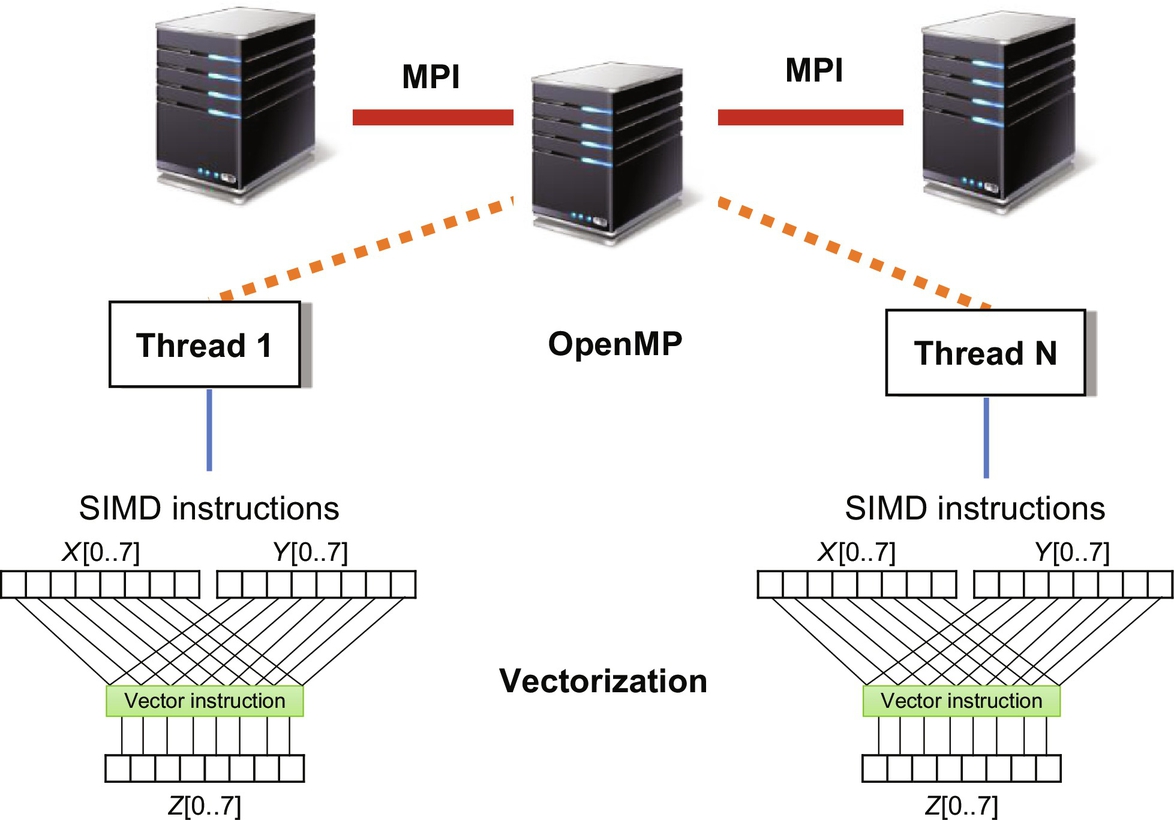
Fig. 6.2 illustrates the different parallelization opportunities for commodity CPU platforms. At the bottom of this figure, we have SIMD processing units available in each CPU core which simultaneously execute the same operation on multiple data elements, thus exploiting data-level parallelism. To enable this level of parallelism, compilers automatically convert scalar instructions into vector instructions in a process called auto-vectorization (Section 6.4). Data-level parallelism can also be enabled in the context of multicore architectures where multiple instances of a region of computations, each one processing a distinct set of data elements, can be executed in parallel using thread-level approaches such as OpenMP (Section 6.5). Next, we have task-level parallelism, which requires developers to explicitly define multiple concurrent regions of their application also using approaches such as OpenMP. These concurrent regions of an application, implemented in OpenMP as threads, share the same address space and are scheduled by the operating system to the available CPU cores. Large workloads can be further partitioned to a multiprocessor platform with distributed memory, where each processor has its own private memory and address space, and communicate with each other using message-passing, such as MPI (Section 6.6). Finally, data movement is an important consideration to ensure data arrives at high enough rates to sustain a high computational throughput. For CPU platforms, one important source of optimization at this level is to leverage their hierarchical cache memory system (Section 6.7).
6.3.2 Compiler Options
The most popular CPU compilers and tools supporting high-level descriptions (e.g., in C, C++) include GCC, LLVM, and ICC (Intel C/C++ compiler). These compilers support command-line options to control and guide the code generation process, for instance, by selecting a predefined sequence of compiler optimizations aimed at maximizing the performance of the application or alternatively reducing its size. As an example, the widely popular GNU GCC compiler includes 44 optimizations enabled using the flag –O1, an additional 43 if –O2 is used, and an additional 12 if –O3 is used (see Ref. [4]). Moreover, the programmer may explicitly invoke other transformations at the command-line compiler invocation. Examples of compilation options include:
• Compiling for reduced program size (e.g., gcc –Os). Here the compiler tries to generate code with the fewest number of instructions as possible and without considering performance improvements. This might be important when targeting computing systems with strict storage requirements;
• Compiling with a minimal set of optimizations, i.e., using only simple compiler passes (e.g., gcc –O0), which can assist debugging;
• Compiling with optimizations that do not substantially affect the code size but in general improve performance (e.g., gcc –O1);
• Compiling with a selected few optimizations, such that do not lead to numerical accuracy issues (e.g., gcc –O2);
• Compiling with more aggressive optimizations, e.g., considering loop unrolling, function inlining, and loop vectorization (e.g., gcc –O3);
• Compiling with more advanced optimizations, possibly with a significant impact on accuracy for certain codes where the sequence of arithmetic instructions may be reordered (e.g., gcc –Ofast);
Overall, these compilation options offer developers a simple mechanism to find suitable trade-offs between code size and performance. However, such mechanisms are not extended to support compiler options aiming at minimizing power and/or energy consumption. Still, optimizations aimed at reducing the total amount of work tend to minimize both energy consumption and execution time.
Compilers also allow users to select specific compilation options from a vast repertory of flags, often controlled using their command-line interface. The order in which the transformations associated with these flags are applied is not, however, typically controlled by the user (i.e., users may select some of the compilation phases but not their ordering). Common compiler flags control the following compiler functionality:
• Function inlining and heuristics to control function inlining (e.g., maximum number of statements and maximum number of instructions of the function to be inlined)—in gcc, passed as arguments using the “-param” command-line option.
• Loop unrolling and heuristics to control loop unrolling, such as the unrolling factor.
• Loop vectorization and the SIMD unit to be targeted (this depends on backward compatibility and is mostly used when targeting ×86 architectures).
• Math options which may result in accuracy loss. The associated compiler flags may also be needed to enable the use of FMA units.
• Target a specific machine which may improve results but may lead to code incompatible with other machines.
We note that it is common for these compiler flags to also require the internal execution of specific compiler analyses and preparation phases, as well as their corresponding phase orderings.
The number of available compiler flags is typically in the order of hundreds, and there are several options to report analysis information on the use of compiler optimizations (e.g., report on attempts to auto-vectorize loops in the application code). Usually, most of these flags can also be activated with the use of source code directives (e.g., using pragmas in the case of the C programming language). Note that each compiler supports its own set of pragmas for controlling the compiler options.
6.3.3 Compiler Phase Selection and Ordering
The problem of selecting a set of optimizations and a sequence of such optimizations is known as phase selection and phase ordering, respectively, and has been a long-standing research problem in the compiler community.
While some combinations of transformations are clearly synergistic (such as constant propagation followed by algebraic simplification and strength reduction), the feasibility and profitability of other transformation sequences are far less obvious since many transformations adversely interact.
Not surprisingly, there has been an extensive body of research in this area with the use of optimization techniques, ranging from generalized optimization [5] to machine learning [6,7] and genetic algorithms [8,9], as well as random-based search. Mainly, the specialization of phase ordering, taking into account specific function properties and/or application domain, may provide significant improvements in performance, power, and energy, when compared to the best achievements using general predefined optimization sequences provided by –Ox options and compiler flags.
Very few compilers allow developers to define a specific ordering of its phases. An example of a compiler without user's support for specifying a specific phase ordering is the GCC compiler. The ordering can be, however, specified by modifying the compiler itself, but this requires general expertize about the inner works of a compiler, the compiler source code, and deep knowledge about target compiler architecture. In contrast, the LLVM compiler infrastructure [10] allows developers to specify the ordering of the compiler optimizations in addition to the predefined optimization sequence options.
Phase Selection and Ordering in LLVM
The LLVM compiler infrastructure [10]a provides a tool named optb that receives as input a sequence of optimizationsc and applies that sequence to the LLVM IR (e.g., stored in a file using the bitcoded format, which is the binary format used by LLVM to store the IR and that can be generated by the clang frontend). This IR can then be translated to assembly code using the llc tool.e
An example of a compiler sequence (phase order) that can be applied with opt is presented below. In this example, we consider a C program named x.c. The clang tool translates this program to the LLVM representation which is then passed to the opt tool. The opt tool then applies a sequence of compiler optimizations specified through the command line to generate an LLVM IR file. Finally, llc translates this LLVM IR file to assembly code, which is subsequently translated to an executable by gcc.

6.4 Loop Vectorization
Loop vectorization is the process of translating scalar operations inside a loop body into vector (SIMD) instructions (see Chapter 2). Since a vector instruction can simultaneously operate on multiple pairs of operands, this technique can be used to speedup applications if data parallelism can be exploited. Most modern CPUs feature vector processing instructions, including Intel x86's MMX, SSE and AVX instructions, MIPS' MSA, SPARC's VIS, and ARM NEON extensions.
To understand why vectorization can improve performance, consider the following code:

Assume arrays x, y, and z are 32-bit single precision arrays, and the CPU supports 128-bit SIMD registers. Without vectorization, the scalar multiplication instruction is executed 100 times, using only 1/4 of each SIMD register:

With vectorization, all SIMD registers are used to perform four multiplications at once in a single vector instruction:

Hence, in our earlier example, we only need to execute 25 multiply instructions instead of the original 100 instructions, thus increasing the performance of this loop.
In C/C++, developers can manually perform the vectorization process by translating the selected code into a sequence of assembly vector instructions, or using intrinsic functions (e.g., for SSE) provided by some compilers. These intrinsic functions include a set of C functions and associated data types providing direct access to vector instructions. Unfortunately, vectorizing by hand requires considerable effort and results in unreadable, unportable, and unmaintainable code. For this reason, it is far more convenient to allow compilers to perform the vectorization process automatically.
Assembly and Intrinsic Functions
The C programming language allows to embed assembly code using asm (or “__asm”) statements as in the following example:

or

Another way is the use of intrinsic functions (also known as intrinsics). An intrinsic function is a function that is handled by the compiler in a special fashion, e.g., substituting it by a sequence of assembly instructions. Following are examples of intrinsics in C code targeting an ARM CPU.a

When auto-vectorization is enabled, compilers analyze the code to verify whether vectorization can be performed such that the code generated is correct with respect to the original scalar version. Further analysis determines whether vectorization is profitable. For instance, if the computation performs noncontiguous memory accesses, then vectorization may not be beneficial. To support vectorization, the compiler may need to apply a set of transformations, such as loop peeling and loop unrolling (see Chapter 5).
Although the auto-vectorization process has improved considerably over the years, the level of support and efficiency is not consistent across different C/C++ compilers. Some compilers are still not able to vectorize code if it does not conform to specific idioms or style, thus requiring manual effort to make the code more amenable to auto-vectorization.
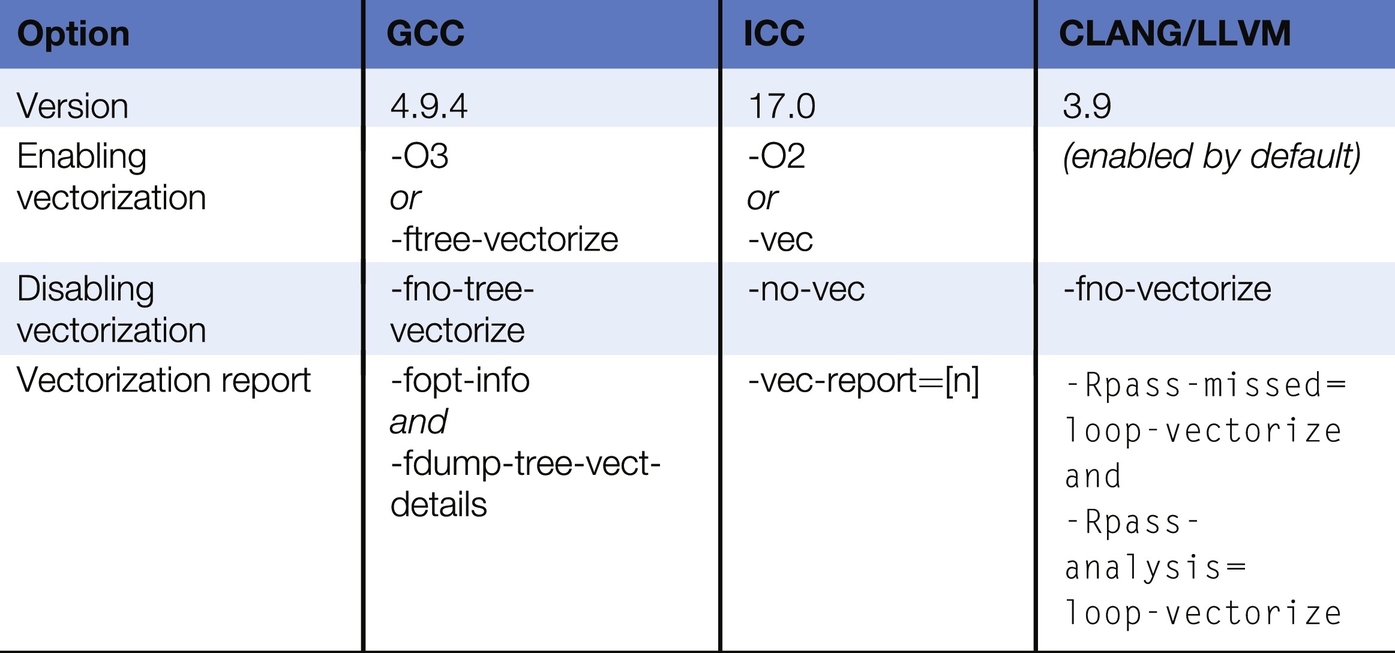
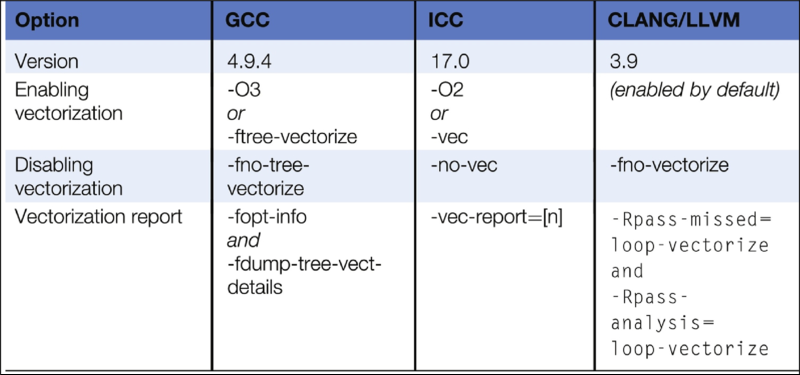
The compiler options presented in Table 6.2 control the auto-vectorization process for popular C compilers, namely, GNU C Compiler (GCC) [11], Intel C Compiler (ICC) [12], and CLANG/LLVM [13]. As can be seen, each compiler has its own set of options to control auto-vectorization. For instance, auto-vectorization can be enabled implicitly when specifying a high optimization level (-O2 or -O3) or can be enabled explicitly (e.g., -ftree-vectorize). There are also options to disable auto-vectorization and to report how auto-vectorization was applied to each loop. Depending on the verbose level used, if the loop was not vectorized, developers are informed what prevented the loop from being vectorized so that they can revise the code accordingly. In addition to compiler options, developers can also provide hints to the auto-vectorization process using code annotations.
The following are general guidelines applicable to all the aforementioned compilers to improve the chances of a loop being auto-vectorized:
1. Loop count. The number of loop iterations should be constant and preferably known at compile time.
2. Control flow. The loop body should have one entry point and one exit point. Furthermore, it is advisable to not include control statements, such as conditionals (e.g., if statements). However, some conditionals may be removed automatically by the compiler using predication, where control statements (e.g., if (c) { y=f(x); } else { y=g(x); }) are converted to predicated expressions (e.g., y = (c? f(x) : g(x)).
3. Function calls. Function calls also prevent vectorization unless the compiler supports vectorized versions of these functions. These usually include math functions, supporting single and double precision, such as sin(), pow(), and round().
4. Data dependences. Since each SIMD instruction operates on data elements from multiple iterations at once, the vectorization process must ensure this order change maintains the result of the original scalar version. For this purpose, the compiler must compute the dependences between loop iterations and ensure there are no read-after-write and write-after-write loop-carried dependences that prevent vectorization. Note that compilers can vectorize code with dependences when reduction idioms can be detected, e.g., sum = sum + A[i].
5. Memory accesses. Vectorizing can be more efficient if memory load instructions access contiguous memory addresses, allowing a single SIMD instruction to load them directly, rather than using multiple load instructions.
Overall, these guidelines aim at ensuring that each data lane associated with a loop iteration executes the same set of operations, thus allowing them to be executed in parallel. Let us consider the following loop, which infringes the earlier guidelines, thus preventing auto-vectorization:

First, the loop has a read-after-write dependence between consecutive iterations (a[i] and a[i-1]). Second, the break statement inside the if statement implies the loop count is unknown and there is more than one loop exit point. Finally, there is a call to a function f.
There are other techniques which can be applied manually to enhance the applicability of the auto-vectorization of loops (see, e.g., Refs. [11–13]), including: (a) using loop indices in array accesses instead of pointers or pointer arithmetic, (b) minimizing indirect addressing in array accesses, (c) aligning data structures to 16 byte boundaries (SSE instructions) or 32 byte boundaries (AVX instructions), (d) favoring the use of structures of arrays (SoA) over arrays of structures (AoS).
While the auto-vectorization process is performed at compile time, not all information may be available when compiling. For instance, the compiler might not know whether two pointers reference the same memory position inside a loop, thus creating a dependence and preventing vectorization. In this case, the compiler may generate a vectorized and a nonvectorized version, and invoke one of them at runtime depending on the addresses of the pointers (see Chapter 5).
Memory Alignment
Memory alignment is important as it allows the concurrent execution of load/store operations from/to successive memory positions.
Alignment supporta for dynamically allocated memory is provided by specific functions (see the following examples), such as aligned_alloc and _alligned_malloc for Linux and Windows, respectively.

In case of a static memory allocation of array variables, it is common to provide support via attributes as depicted in the following example.

Additional alignment information can be conveyed via the use of special built-in functions to instruct the compiler to assume aligned data as in the following example.

Regarding the implementation of auto-vectorization, we can distinguish two general techniques, namely, loop level and block level. Consider the following code:

With the loop-level vectorization technique, the compiler first determines whether the loop can be vectorized. Then, it performs loop stripmining by a factor corresponding to the number of scalars that can fit into a SIMD register. This step is followed by loop distribution, which generates a sequence of loops replaced with the vector instructions, as follows:

The block-level technique, on the other hand, is a more general technique focused on vectorizing basic block statements. As such, it relies on unrolling the innermost loop body by a factor corresponding to the vector register size (the same factor used in stripmining with the loop-level technique), packing all scalar instructions performing the same operation into vector instructions if dependences are not violated.

The use of both techniques generates the following vectorized code:

Restrict Keyword
The restrict keyword is part of the C programming language introduced in the C99 standard. This keyword is used when declaring pointers to convey to compilers that these pointers do not address memory regions that overlap with regions addressed by other pointers and are therefore un-aliased by other pointers. Note that C++ does not support the restrict keyword. Hence, compilers such as GCC and CLANG/LLVM support the __restrict__ directive that works on both C and C++ codes.

We now revisit the matrix multiplication example presented in Section 6.1. When using the GCC compiler (4.8) and enabling auto-vectorization with the report generation option, GCC will report that none of the three loops are vectorized as shown below:

A close inspection of the code reveals two problems. First, matrices A, B, and C are passed to the matrix_mult function as pointers. Without additional information about the relative location of the corresponding storage addresses they point to, the compiler is unable to determine whether or not they point to the same memory location, e.g., if pointer to C is an alias of A. For instance, if these pointers were aliased, the loop would carry a dependence, thus preventing vectorization. In the previous example, the pointers are unaliased, i.e., A, B, and C point to disjoint memory locations, hence programmers must include the __restrict__ directive in their declaration to indicate that there are no dependencies between them. The second problem is that in the original code the loop bounds were not defined as constants, even though they were initialized in the global scope. The compiler decided not to vectorize the loops as it cannot identify the exact number of iterations. Programmers can address this issue by specifying the bounds as const in the corresponding variable declaration. The final code is as follows:

With these two changes, the compiler is now able to automatically generate vector instructions to multiply and add the elements of A and B.
Note that directives to support and guide the auto-vectorization process are not standardized across compilers. Furthermore, support for auto-vectorization keeps improving with new compiler version releases, both in terms of analysis and transformations performed. It is therefore important to read the latest guidelines for auto-vectorization for each compiler used.
6.5 Shared Memory (Multicore)
OpenMP [21] is an API that allows programmers to exploit data- and task-level parallelism on multicore platforms with shared memory (see Chapter 2). One of the key features of OpenMP is that programs can be parallelized incrementally from an initial sequential version. Once developers identify the regions of code that can benefit from parallel execution (e.g., hotspots), the code can be annotated with OpenMP directives to define how computations can be distributed across different cores and what data are accessed within each core.
OpenMP provides a set of compiler directives, a routine library, and a runtime to implement its execution model (Fig. 6.3). The OpenMP runtime supports parallelism using threads. A thread is an autonomous subroutine that can be executed in parallel within the context of a process and is transparently scheduled by the operating system taking into account available resources and resource utilization. Unlike processes, multiple threads share the same address space. One of the design goals of OpenMP has been portability: a well-constructed OpenMP program outputs the same result whether it uses one thread or multiple threads, affecting only the performance according to the level of parallelism attained. To maximize performance, the number of threads is usually set as a function of the number of cores available in the platform and the workload size. Hence, an OpenMP application can be developed such that its workload is efficiently distributed across the available compute resources without having to be recompiled.

To allow applications to adjust to available resources, OpenMP uses the fork-join execution model [14] (see Fig. 6.4). All OpenMP programs start execution within the master thread which runs the code sequentially. When a parallel region is found, the master thread creates a team of threads of a given number, with the master thread also part of this team of threads. The operating system will then schedule these threads, assigning them to available processor cores. As thread management incurs an overhead, developers must adjust the number of threads so that the workload distribution is properly balanced and each thread maximizes core utilization. When a thread in the parallel region completes execution, it waits for all other threads to complete. At this point, sequential execution resumes within the master thread. In OpenMP, developers are required to specify the parallel regions of their programs explicitly and may control the number of threads associated in each parallel region. The OpenMP runtime and the operating system coordinate the parallel execution.

Developers identify parallel regions with OpenMP code directives. In C/C++, compiler directives are controlled by source code #pragma annotations to identify: (i) concurrency, (ii) how work can be distributed between threads, and (iii) synchronization points. An OpenMP directive has the following syntax format in C/C++:

An OpenMP directive typically annotates the statement that directly follows it, including a code bock {…}. In addition to OpenMP directives, developers can use a set of OpenMP library routines to control and query the underlying execution platform about its available resources, including: (i) getting the number of threads operating on a particular program execution point, the executing thread id and nested level; (ii) setting the number of threads; (iii) setting and terminating locks and nested locks. Note that if the platform is not configured explicitly in the program, such as setting the number of threads, then the default behavior can be overridden by environment variables.
We now consider a simple OpenMP program:

All OpenMP programs must be compiled with the -fopenmp option when using the GCC compiler or /Qopenmp with the ICC compiler. When these options are used, the compiler processes the OpenMP directives and links the program against the OpenMP library. The first source code line of this example inserts the OpenMP header to allow access to its library routines. Inside the main function, the program sets the number of threads of any subsequent parallel region to match the number of available processors (cores). Next, the program defines a code block as a parallel region using the parallel directive. When running this program, an instance of this code block is executed by each thread in the parallel region as illustrated in Fig. 6.5.
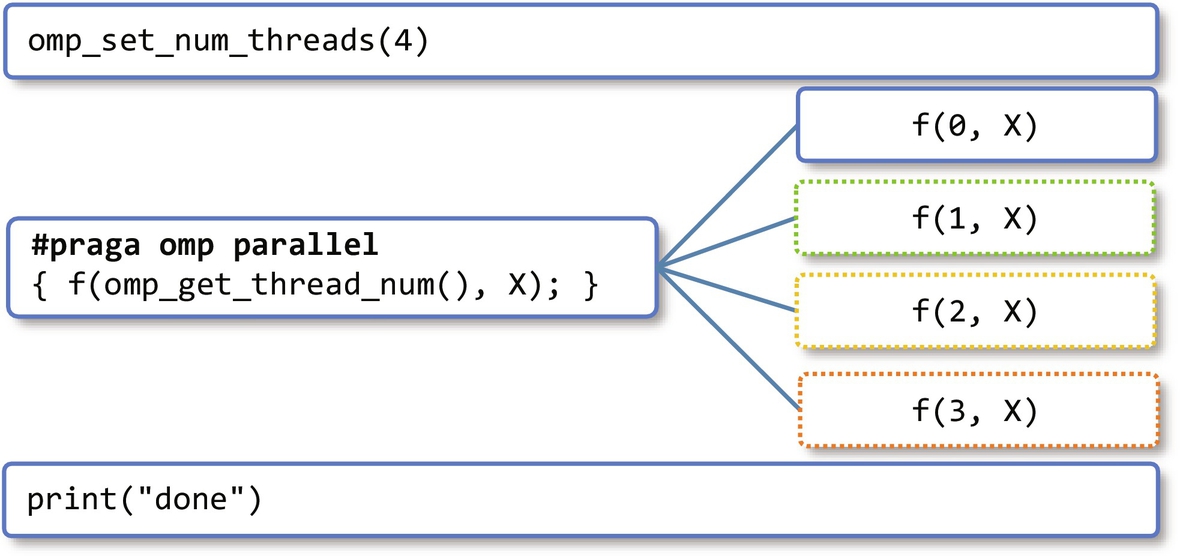
In this example, four threads execute the same code in parallel. Each thread waits until all of them complete. At this point, the parallel region completes execution, and the main thread prints the word “done.” Note that OpenMP places an implicit barrier at the end of any parallel region, in which all threads are joined. Another noteworthy aspect is the use of two arguments in function f: the first, ID, is a private variable visible only to the assigned thread as it was defined locally, the second, X, is a shared variable as it was defined outside the parallel block. Shared variables can be accessed by all threads in the team and can be used for interthread communication, however special care is required to avoid data races. In this example, the parallel directive creates a SPMD (single program, multiple data) computation where each thread executes the same code on different data items.
In addition to providing an interface to expose concurrency, OpenMP also supports directives for workload distribution between threads within a team. Specifically, OpenMP supports different forms of worksharing: (1) loop, (2) sections, and (3) tasks, which we explain next.
Loops are often the hotspots in a program, and are therefore prime candidates for optimization and parallelization. The loop worksharing directive omp parallel for distributes loop iterations across all threads in a team (Fig. 6.6) as follows:


With the omp parallel for directive, the loop iteration space is divided by the number of threads available in the parallel region, and therefore iterations cannot have dependences between them. In many cases, output- and anti-dependences can be removed with techniques such as variable renaming, scalar expansion, node splitting, and induction variable substitution. Other techniques to remove dependences require complex data dependence analysis and code restructuring, e.g., reordering statements, to parallelize loops. OpenMP, however, supports parallelization of loops exhibiting true loop-carried dependences that stem from reduction operations. In particular, the reduction(op:list) clause is used to specify a reduction operation, where op is a reduction operator (e.g., +, ⁎, −) and list is a sequence of variables separated by commas.
As an example of reduction support in OpenMP, consider the following code which computes the average of a list of floating-point numbers:

In this example, the loop exhibits a true loop-carried dependency caused by the variable avg, where the result of the accumulation is used in the subsequent iteration. With the reduction clause, a local copy of each list variable (avg) is assigned to each thread in the team and initialized depending on the operation (op) used (e.g., for the sum operation, the initial value is 0). Each thread then performs the reduction over their local copy. At the end, the result of every local copy is reduced to a single value (using the operator specified as a parameter in the OpenMP directive) and assigned to the original global variable (avg).
One important aspect of loop worksharing is the distribution of loop iterations among threads. In OpenMP, this distribution is controlled by developers using the schedule([type][,chunk_size]) clause. There are three main schedule types, namely: (1) the static schedule type divides the loop iterations into equal-sized chunks at compile time. By default, the chunk size is the ratio between the loop count and the number of threads. (2) The dynamic schedule type uses an internal work queue in which each thread retrieves a block of iterations of chunk size (by default it is 1). When a thread terminates, it retrieves the next block at the top of the queue. (3) The guided schedule type is similar to the dynamic type, however it starts with a large chunk size and then decreases it to balance the load. The choice of type of schedule and chunk size is aimed at maximizing load balancing while limiting its runtime overhead. In general, the static schedule type has the lowest overhead but is more vulnerable to load imbalances, while the dynamic schedule type has the highest runtime overhead but provides better load balancing. Additionally, OpenMP supports the auto schedule type, in which an OpenMP runtime implementation automatically determines the scheduling policy.
We now focus on the remaining two OpenMP workshare constructs, namely, sections and tasks. OpenMP sections allows regions of code to run in parallel by assigning each section to a thread and are identified using the omp parallel sections directive.
We illustrate the use of the sections construct with the following code example:

Assuming that alice() and bob() perform independent computations, the code can be structured into sections as follows:

In this case, each section is assigned to an available thread.
For more complex scenarios involving, for instance, unbounded loops, recursive algorithms, and producer/consumer interactions, it is more appropriate to use task worksharing, which is specified using the omp task directive. An OpenMP task defines an independent unit of work executed by a thread. The OpenMP runtime decides whether a task might be executed immediately or be deferred.
We illustrate the use of the task construct with the following code example, which iterates over a linked list to process each of its nodes:

The first directive, omp parallel, creates a team of threads. The second directive, omp single, assigns a single thread to execute block A. This thread is responsible for iterating the list and instantiating the tasks that process each element independently. The call to function process() is annotated with the omp task directive, which implies that each invocation of this function instantiates a task. As a result, each task instantiation is executed by a thread in the parallel region.
As previously mentioned, it is important in this programming model to distinguish between which variables are shared by all threads in a team, and which variables are private within the scope of a thread. By default, all variables defined outside a parallel region, including static and global variables, are shared. Loop index variables and stack variables in subroutines called from within parallel regions are private. The scope of variables can be defined explicitly through data scope attribute clauses in conjunction with parallel and worksharing constructs. For instance, in the previous example, variable p was defined as a private variable. The general format of the data scope attribute is data_scope(var1<, var2, …>). Data scope attributes include shared, private, firstprivate, and lastprivate. The latter three attribute types create an instance of a variable for each thread. However, a private variable is not initialized and its result is not exposed outside the parallel or workshare region. A firstprivate variable will have its value initialized with the value of the variable defined before the parallel construct, while the value of the lastprivate variable is set by the thread that executed the last section or the last loop iteration. In the previous example, p was explicitly declared as a private variable, and lst as a shared variable.
OpenMP also provides directives to synchronize thread execution to ensure threads wait until their dependences are met. Constructs like for loops and statements annotated with the omp single directive have implicit barriers at the end of their execution. Unnecessary barriers, however, lead to performance loss and can be removed with the nowait clause. As the following example illustrates, without the nowait clause, there would be an implicit barrier at the end of the first loop. This barrier would have prevented any idle threads (having completed the first loop) to start executing the second loop.

There are cases, however, when programmers need to enforce a barrier, so that execution waits until all threads arrive at the barrier. This is achieved with the omp barrier directive. For instance, in the following code, g() is only invoked after f() so that the dependence from B is correctly handled:

With the use of OpenMP concurrency constructs, programmers are responsible for ensuring that their programs do not exhibit data races if they wish to guarantee deterministic execution. Race conditions arise when two or more threads simultaneously access a shared variable possibly leading to nondeterministic behavior. To protect shared data against race conditions, programmers can define critical regions using the omp critical directive.
To illustrate the use of the critical directive, consider the following code where a loop has been annotated with a parallel for loop directive. Each iteration of this loop updates the value of the variable sum. With the critical directive, only one of the concurrent threads can enter the critical region at a given time ensuring that the updates to the sum variable are thus performed atomically and are race free.

Note that while omp critical can serialize any region of code, it exhibits an overhead. As an alternative, when the critical region is an expression statement updating a single memory location, the omp atomic clause may be used to provide lightweight locks. In OpenMP there are four atomic mode clauses: read, write, update, and capture. The read clause guarantees an atomic read operation, while the write clause ensures an atomic write operation. As an example, x is read atomically in the case of y = x + 5. The update clause guarantees an atomic update of a variable, e.g., y in the case of y = y + 1. Finally, the capture clause ensures an atomic update of a variable as well and the final value of the variables. For instance, if the capture clause is used with y = x++, then x is atomically updated and the value of y is captured.
Although shared variables can be accessed by all threads in a parallel region, OpenMP supports a relaxed consistency memory model, where at any point in time threads may not have the same view of the state of shared variables. This is because write operations performed in each thread may not immediately store data in main memory, opting instead to buffer the results to hide memory latency. To enforce a consistent view of shared variables at specific points in the thread execution, programmers need to use the omp flush [(a,b,c)] directive with the list of variables to be committed to main memory. If the list of variables is not specified, then all variables are flushed. As an example, consider the following code with two threads sharing two variables, x and y.

To ensure that only one thread has access to the “critical section,” the program must flush both variables to ensure the values observed by one thread are also observed by the other thread. While only one of the threads accesses the critical section, there is also a chance that neither will access the critical section. Memory flushes are thus not meant to synchronize different threads, but to ensure thread state is consistent with other threads. In general, a flush directive is required whenever shared data is accessed between multiple threads: after a write and before a read. Assuming a program with two threads T1 and T2 that share variable x, then the following sequence of operations must occur to ensure that both threads share a consistent view of that variable:

Since data sharing between threads can lead to an inconsistent view of state upon termination, OpenMP implicitly executes a flush operation in barriers, and when entering and exiting the following regions: parallel, worksharing (unless nowait is invoked), omp critical, and omp atomic.
In addition to the basic fork-join model described at the beginning of this section, the more recent release of OpenMP 3.0 supports nested parallelism. This nested parallelism can be enabled in two ways, namely, by invoking the library routine omp_set_nested(1) (as shown in the following code example) or by setting the OMP_NESTED environment variable. If nested parallelism is enabled, when a thread within a parallel region encounters a new omp parallel pragma statement, an additional team of threads is spawned, and the original thread becomes their master. If nested parallelism is disabled, then a thread inside a parallel region ignores any parallel pragma construct it encounters. It is important to understand the impact of nesting parallel regions, since they can quickly spawn a large number of threads. In general, nested parallelism incurs a larger overhead than using a single parallel region. Yet, they can be useful in execution scenarios with load unbalanced problems, and where one code region can be further parallelized.

We now focus on how to accelerate the matrix multiplication example presented in Section 6.1 using OpenMP. One possible solution to parallelize this example with OpenMP is as shown below:

Here, we simply annotate the outermost loop body with a parallel omp for pragma. Because the iteration space size is known at compile time, we use the static schedule, which will partition the outermost loop iterations according to the specified number of threads. Specifying a parallel pragma in any of the inner loops would reduce the work done by each thread, and unnecessarily serialize the computation, since we can compute each element of the matrix in parallel. One further change in the original code includes the use of a temporary variable (sum) to store the inner product of a row of the matrix A and a column of the matrix B. This precludes having multiple threads writing to memory at every iteration of the innermost loop. We invite the reader to experiment combining vectorization (discussed in the previous section) with OpenMP directives to further speedup this matrix multiplication code on multiple cores and using larger matrix sizes.
6.6 Distributed Memory (Multiprocessor)
In the previous section, we covered the OpenMP programming model which allows the development of multithreaded applications. The OpenMP model is used within the context of a process, allowing multiple threads to execute on available processor cores and share the same memory space (intraprocess parallelization).
In this section, we cover the MPI (Message Passing Interface) model, which is suitable for parallelizing computations distributed across a set of processes, where each process has its own memory space and execution environment (interprocess parallelization). These processes can run on the same computing platform or across different computing platforms. As processes do not share the same memory space, MPI offers an interprocess communication API supporting synchronization and data movement from one process memory space to another. With this API, interaction between processes is made via explicit message exchanges. MPI is therefore suitable for harnessing the computation capacity of multiple (and potentially heterogeneous) processing elements connected via fast interconnects, from many-core architectures to distributed system platforms.
To use MPI, developers must adapt their applications to conform to the MPI communication model with supplied library routines. The MPI library is based on a well-established standard, making MPI programs portable across a wide range of parallel computing platforms with support for C/C++ and Fortran. This portability feature means that MPI code are designed to preserve functional behavior when they are recompiled to different parallel architecture platforms. However, to maximize performance on a given platform, MPI applications must be designed to be scalable and match workload requirements to available resources.
We now illustrate the use of MPI with the problem of adding the elements of a vector of N integers. One way to parallelize this computation is to have a master process to partition a vector of N integer elements to available worker processes. Each worker then adds the values within its partition and sends the result back to the master process. The master process then adds all the workers' results to produce the final result. This example uses a common distributed computing pattern called map-reduce or scather-gather, which decomposes a big problem into smaller parts (shards) that are computed independently and then reduced to a single result. The following code shows an MPI implementation of this program using the scatter-gather pattern:

In the previous example, we divided the main function into four stages (Fig. 6.7):
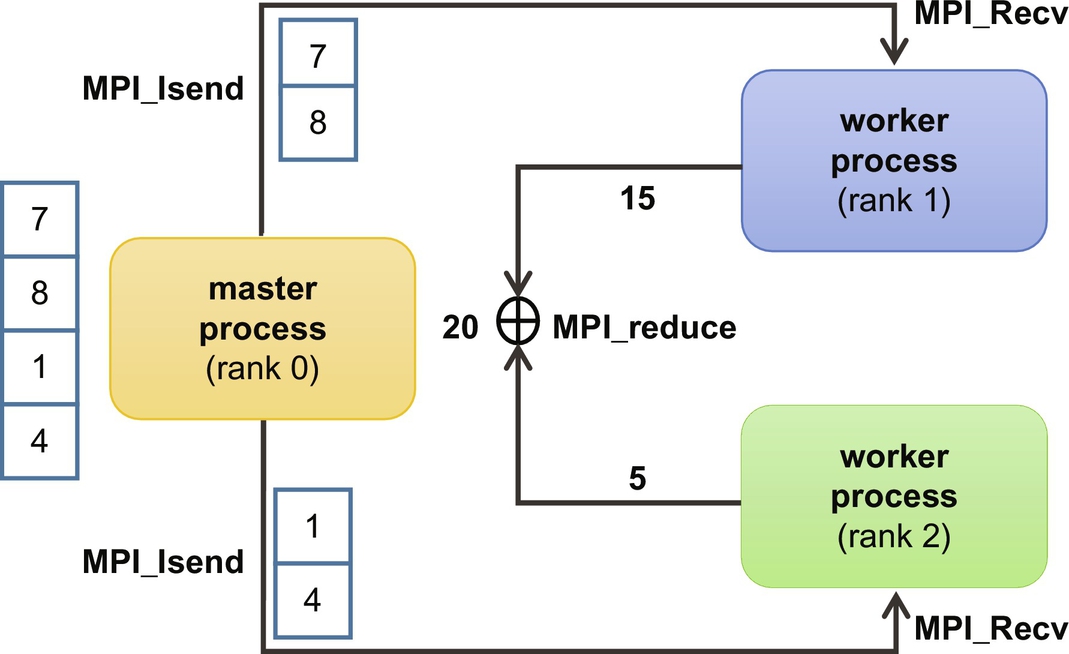
• Stage 1 initializes the MPI environment (MPI_Init), gets the process rank (MPI_Comm_rank), and the number of processes spawned (MPI_Comm_size) within the communicatorMPI_COMM_WORLD. A communicator defines a group of processes that can communicate with each other. Each process in a communicator is assigned a unique rank. Processes communicate with each other explicitly using their ranks. The MPI_COMM_WORLD communicator corresponds to all processes within an MPI job. Unless a more complex communication pattern is required, an MPI program typically begins with these three lines of code, as they offer a full view of all processes in an MPI job and their associated ranks.
• In stage 2, the master process (identified by rank 0) partitions the vector among the workers (remaining processes). The master process sends a partition (part of the vector) to each available worker using the MPI_Isend function. This function sends data without waiting until it is received. The process of sending the partition to each worker is performed in two steps: first, the size of the partition is sent, followed by the partition itself. If the vector cannot be evenly divided by the number of workers, then the last worker is assigned a larger partition. Conversely, the workers receive the partition from the master worker with the MPI_Recv function, which blocks execution until data is received. This process mirrors the protocol used by the master in this stage: first the worker receives the size of the partition, and then the partition. Each worker will then add the values in their assigned partition.
• In stage 3, the results from all workers are sent back to the master using the reduction collective communication primitive, MPI_Reduce, which automatically adds the results into a single value for the master process. The reduction operation, in this case MPI_SUM, must be supplied in the MPI_Reduce call.
• Finally, in stage 4, the MPI_Finalize routine is invoked to clean up all MPI states, and free all used resources. After this call, no other MPI routine can be invoked.
There are many available implementations of MPI, including Open MPI, Intel MPI, and MS-MPI. However, the most popular MPI implementation is MPICH, which is available for both Linux and Windows distributions. To verify if MPI has been properly installed on a specific system, programmers can use the following command:

To compile MPI applications, the MPI framework includes the mpicc and mpicxx tools which wrap the default C and C++ compilers, respectively. These tools automatically configure the location of the MPI framework (headers and libraries) and automatically link the application with the MPI-specific libraries. The parameters to these tools are the same as the ones used for the underlying C/C++ compilers:

Once built, multiple processes can be launched on the same machine invoking the mpiexec tool as follows (using the MPICH implementation):

The −n parameter allows the user to specify the number of processes for the MPI job, which is then supplied to the application through the MPI_Comm_size routine. Note that in our example, it is expected the MPI job executes with at least two processes, since one of the processes acts as the master, and the remaining processes act as the workers. We can spawn processes across multiple machine nodes by supplying a file capturing information about all available hosts:

The machines file has the following format:

In this file, “host1” and “host2” are the hostnames of the machine nodes we want to deploy the MPI job. The “:2” specifies the maximum number of processes that can be spawned in a specific machine, usually taking into account the number of available cores. If the number of processes is not specified, then “:1” is assumed. Note that the master node (machine) is where the MPI job is launched (i.e., where mpiexec is executed), and it should have ssh access to all slave nodes, typically not requiring password (though SSH key authentication). In cases where an MPI job requires slave nodes to store data, then the NFS distributed file system can be used on cluster nodes.
MPI supports two types of communication: point to point and collective. Point-to-point communication involves two processes: the sender process which packs all the necessary data and uses the MPI_Send (blocking) or MPI_Isend (nonblocking) routines to initiate the transmission; and the receiver process which acknowledges that it is to receive this data with the MPI_Recv (blocking) or MPI_Irecv (nonblocking). The collective communication, on the other hand, involves all the processes in a communicator. Examples of collective communication include MPI_Bcast which sends the same data from one process to all other processes in a communicator, MPI_Scatter which sends chunks of an array to different processes, MPI_Gather which receives data from different processes and gathers them to a single process, and MPI_Reduce, which, as we have seen in our example, performs an operation on data received from different processes.
Both types of communication routines, point to point and collective, allow the implementation of a diverse set of well-known distributed computing patterns, such as master-slave, scatter-gather, stencil, pipeline, and ring, as illustrated in Fig. 6.8. The master-slave pattern employs a coordinator process which is responsible for distributing workload to the remaining processes. The scatter-gather pattern, as previously mentioned, is a variant of the master-slave pattern in which a process (e.g., the master) performs the reduce phase. The stencil pattern allows processes to communicate with their neighbors, while the pipeline pattern decomposes computations into a set of stages that performs in parallel. The ring pattern distributes the workload similarly to the pipeline pattern; however, the last process (stage) communicates with the first.

In MPI, the selection of which distributed pattern to use depends largely on two factors, namely, the level of concurrency inherent in the application and which pattern can maximize workload distribution. The level of concurrency can be derived by using dataflow analyses and/or other techniques (such as polyhedral analysis) to uncover potential concurrency. If the algorithm is embarrassingly parallel, meaning that it exhibits no data dependences, then patterns such as master-slave or scatter-gather are often used. Other forms of concurrency patterns, such as the stencil pattern, occur in algorithms that update all array elements at regular time steps, such as in image processing. Nonparallel loops may still be optimized using the pipeline or ring execution patterns, which preserve the order of execution of the iterations, but execute parts of the loop body in parallel in a sequence of stages (P1, P2, P3…).
A fundamental issue of any form of parallel execution consists in maximizing performance. To achieve it, programmers must ensure that computational resources are adjusted to support a given workload and not the converse. In other words, the workload size and type should dictate what and which (of the available) resources should be used. In addition, when parallelizing a program and distributing its workload, programmers need to ensure that all resources operate as close to their peak performance as possible. A common issue when decomposing a problem into work chunks and mapping them to available processors is the potential reduction in arithmetic intensity, as each processor performs less work and thus becomes more prone to be bound by memory or I/O operations. Hence, the number of processors used in an MPI job must be adjusted to the given workload. This is not the case with the example provided at the beginning of this section, which is designed to use all processing elements available regardless of the vector size, and where the partition size is computed as a function of the number of processing elements available. This simple partition strategy leads to nonoptimal performance when the number of processing elements is comparably larger than the size of the vector.
To address the issue of adjusting resources to workload, programmers can use performance models to estimate how the application performs for a given workload size and number (and type) of resources. These performance models are derived by profiling the application on a set of representative workloads and then applying statistical analysis (such as regression). More details about workload distribution are provided in Chapter 7 in the context of heterogeneous platforms.
Regarding the running example described in Section 6.1—matrix multiplication (![]() ), an obvious way to parallelize this problem consists in using the master-slave pattern: each worker computes a set of rows of matrix C independently, provided it has the necessary rows from matrix A and a copy of matrix B. The master therefore needs to partition matrix A and send the corresponding partition to each worker:
), an obvious way to parallelize this problem consists in using the master-slave pattern: each worker computes a set of rows of matrix C independently, provided it has the necessary rows from matrix A and a copy of matrix B. The master therefore needs to partition matrix A and send the corresponding partition to each worker:

Next, matrix B is broadcasted from the master to all the workers. This requires a single routine call which must be performed by all participants (workers and master):

Once the workers receive their corresponding portion of matrix A, they can compute the sections of the matrix C independently:

The master now gathers different sections of the computed C matrix to assemble or produce the final result:

This implementation is not optimal, as it requires sending matrix B over the network for every worker. Given its importance, there has been considerable research on how to reduce communication bandwidth and increase parallelism for this problem, including using stencil distributed patterns and performing block matrix decompositions [15].
6.7 Cache-based Program Optimizations
Despite considerable advances in computer architectures and in compilation techniques aimed at accelerating computations, often the bottleneck in performance lies in the relatively long latencies of memory and I/O, with data not arriving fast enough to the CPU to be processed at full computational rate. In this context, it is important to leverage the different types of memories available in the system, in particular to use as much as possible faster memories or caches. Because data is transferred transparently (without manual intervention) between slower and faster memories, it is important to understand how they operate to make effective use of them.
Caches exploit the principle of locality. This principle takes into consideration two aspects. The first, temporal locality, states that individual memory locations once referenced are likely to be referenced again. The second, spatial locality, states that if a location is referenced, then it is likely that nearby locations will be referenced as well. Hence, whenever a data element or an instruction is sought, the system first verifies if it is in the cache, otherwise the system loads it automatically from the slower memories (e.g., RAM) to the faster memories (e.g., cache L3, L2, and L1), including data or instructions from nearby locations. The goal is to maximize the use of the cache (minimizing the number of cache misses), thus increasing the performance of the application.
In the example described in Section 6.1, the matrix multiplication algorithm accesses all columns of matrix B to compute each row of matrix C. This leads to nonoptimal use of the cache if the number of columns of B is considerably larger than the cache size. In this case, every access of matrix B will lead to a cache miss and thus never use the fast memory. One way to solve this problem is to ensure that matrix B is accessed row-wise, and this can be achieved by performing loop interchange between the two inner loops. This is a legal operation since it does not violate the dependences of the original program:

Optimized libraries, however, often rely on a technique called blocking, which involves fitting data structures in the cache. The key idea behind blocking is to completely fill the cache with a subset of a larger dataset and maximize its reuse to reduce unnecessary loads from slower memories. This blocking technique can often be performed on 1D, 2D, or 3D data structures, typically involving the loop tiling code transformation (see Chapter 5). A key factor in this optimization is determining the block (tile) size, which should match the cache size of the target machine.
For our matrix multiplication example, if n corresponds to both the number of rows and columns of the input matrices, we can see our algorithm employs 2n3 arithmetic operations (adders and multipliers) and refers to 3n2 data values. While this shows that the computation exhibits considerable data reuse, it may not entirely fit the cache. The following code uses loop tiling to partition the iteration space into smaller blocks of size blk:

Although this code executes using the same operations as the unblocked version, the sequence of independent operations is performed differently. In this case, each iteration (i0, j0, k0) performs ![]() memory accesses. We can now choose a blk value small enough such that
memory accesses. We can now choose a blk value small enough such that ![]() data fit in the target machine cache. Note that optimized libraries are likely to further partition the loop iteration space into more levels to make a more effective use of the cache hierarchy.
data fit in the target machine cache. Note that optimized libraries are likely to further partition the loop iteration space into more levels to make a more effective use of the cache hierarchy.
6.8 LARA Strategies
In this section, we consider three problems based on topics covered in this chapter: controlling code optimizations (Section 6.8.1), leveraging a multicore CPU architecture with OpenMP (Section 6.8.2), and monitoring the execution of MPI applications (Section 6.8.3). We use LARA aspects to capture strategies that address these problems, allowing them to be applied automatically and systematically to different application codes with the appropriate weaver infrastructure.
6.8.1 Capturing Heuristics to Control Code Transformations
As discussed in Section 6.3.2, compilers have their own internal heuristics for applying a specific set of optimizations. With LARA, developers can describe their own strategies without changing the compiler's internal logic or manually applying them.
In the following aspect definition, we present a simple LARA example that inlines all calls of a function when specific criteria are satisfied. The target function name is specified through the aspect input parameter. In this example, we only wish to inline invoked functions if the target function (the caller) does not contain loops. It is easy to modify this strategy to include other criteria, such as based on function properties and/or to consider all the functions in the input program instead of only targeting a specific function passed as argument to the aspect.
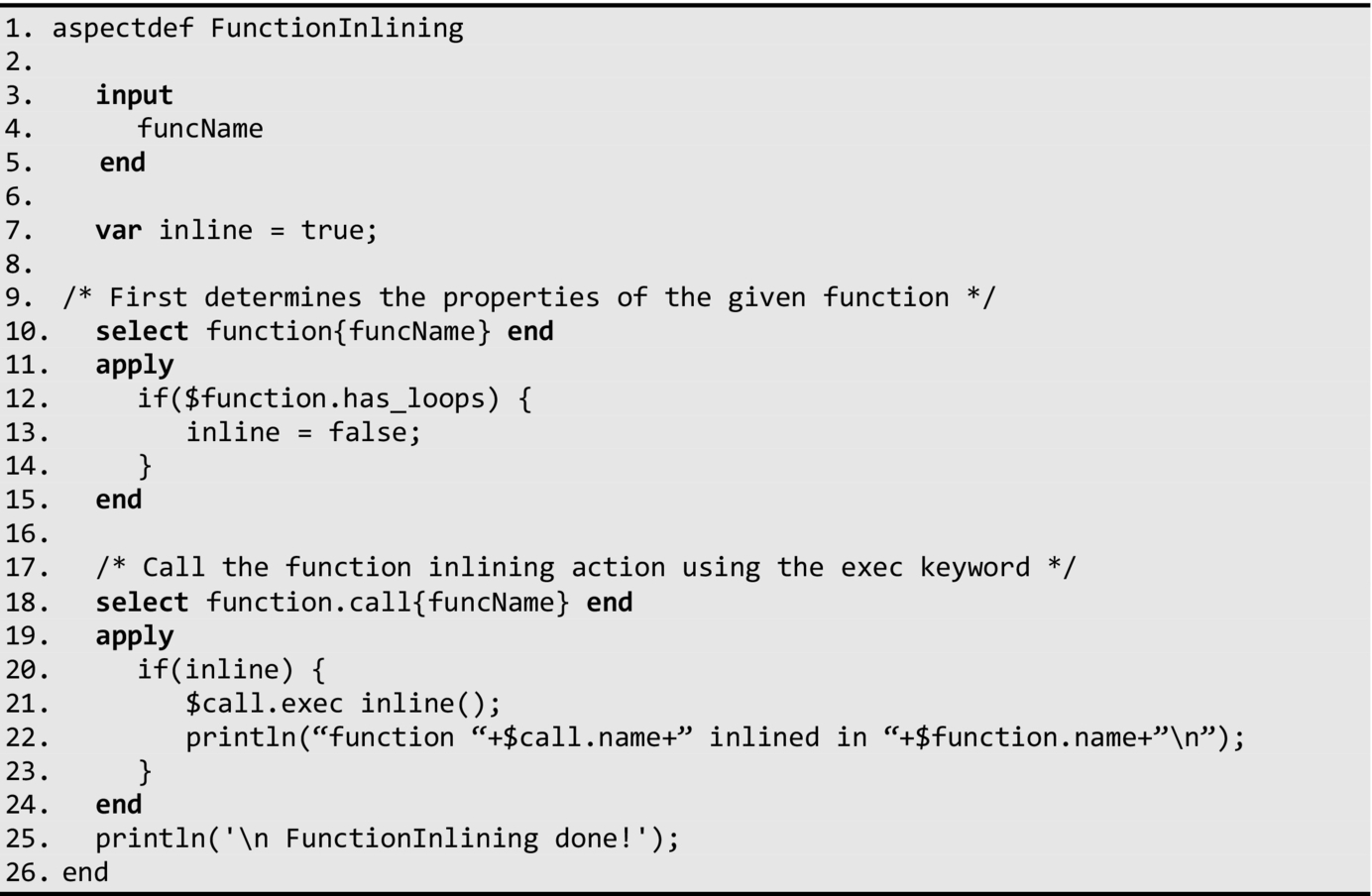
In this aspect, we use the inline variable to identify whether the target function should be inlined or not. This is verified in lines 10–15, which checks whether the function code has loops. If it does not then the aspect invokes the inline action for each call in the target function (line 21).
6.8.2 Parallelizing Code With OpenMP
As described in Section 6.5, OpenMP offers several mechanisms to parallelize sequential descriptions on multicore CPU architectures. The choice of which mechanism to use depends largely on how the original code is structured and the level of concurrency that can be attained from the code.
In the following example, we target loops using OpenMP's loop worksharing directive omp parallel for which distributes loop iterations through a specified number of threads. The operating system will then schedule these threads to the available processing cores. There are two considerations to take into account in our optimization strategy. First, we need to decide which loops should be optimized; and second, how many threads should we allocate to each loop selected for optimization. Both considerations are meant to ensure that computations can benefit from parallelization, which can be adversely affected if there is not enough computational workload. The LARA aspect definition that captures our strategy is presented as follows:
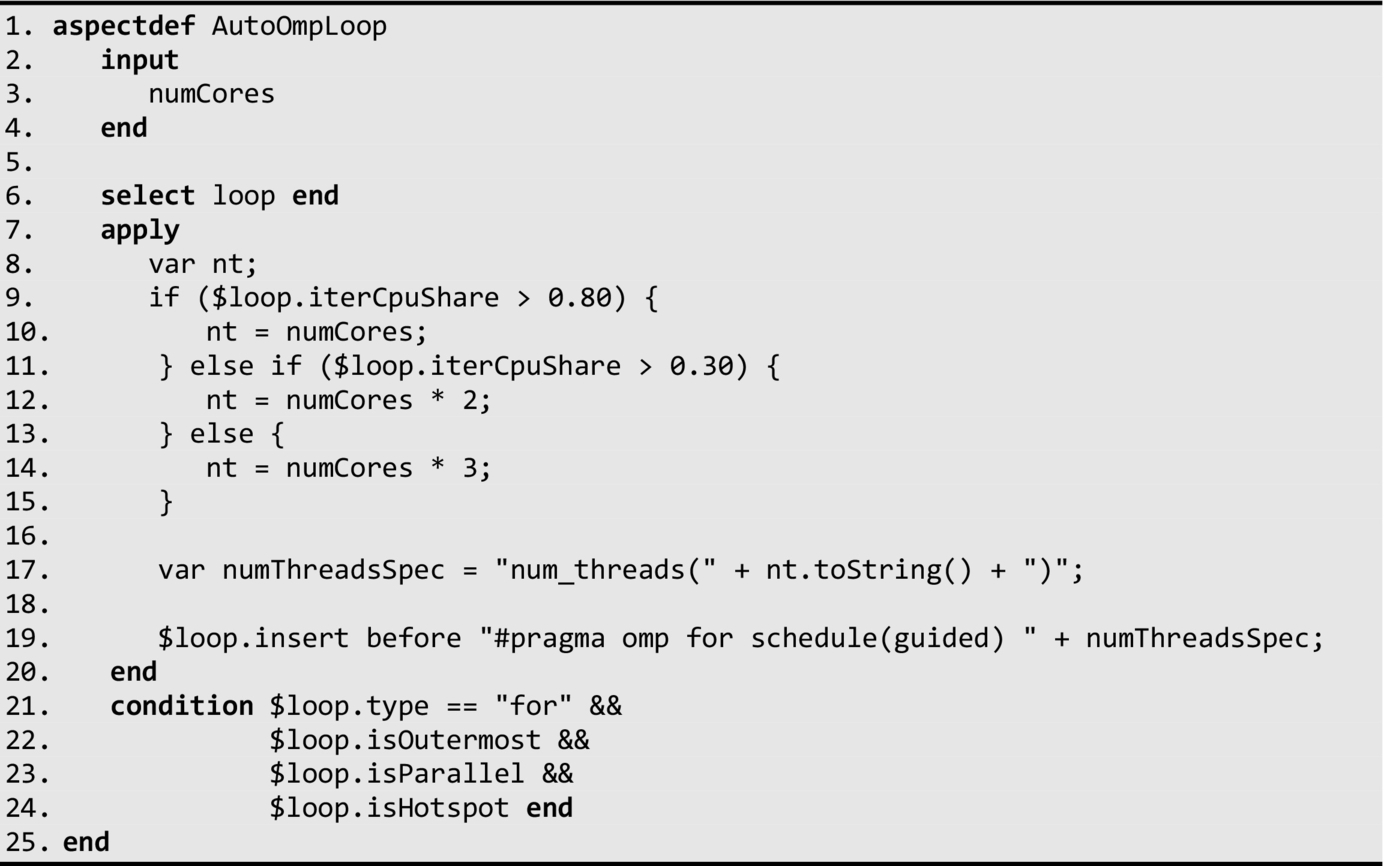
This aspect selects all loops in the program (line 6) and then filters this list according to the criteria defined (lines 21–24). We are interested in outermost “for” loops which are parallel and have been identified as hotspots. The type of loop (e.g., “for”) and its nested level are static attributes of the loop that can be determined directly by a weaver at compile time through a simple inspection of the code structure. We can also determine whether a loop is parallel (i.e., all its iterations can execute in any order) by statically analyzing the code, either directly through the weaver, or through an external tool (see Section 3.5.5). This information is then integrated as an attribute (in this case isParallel) of each corresponding loop in the context of the weaver. The isHotspot attribute must be computed dynamically by profiling the application with a representative input dataset identifying the fraction of execution time over the total execution time threshold in which each part of the code becomes a hotspot. The profiling can be carried out by an external tool using a similar process as described for the parallel attribute or by LARA aspects that instrument the application to time its execution as described in Section 4.5.1.
Once loops have been selected for optimization, we still wish to compute the number of threads to assign for its execution (lines 8–17). For this purpose, we parameterize this aspect to get the number of available cores in this system (line 3). Our strategy for determining the number of threads is empirical and requires the iterCpuShare attribute, which must also be computed dynamically in a similar process as the isHotspot attribute and determines the CPU share of running a single iteration sequentially. The iterCpuShare attribute indicates whether the iteration is compute bound—say running 80% or more of the CPU share, or memory/IO bound in this case running 20% or less. Intuitively, if the computation is compute bound, we want to match the number of threads to the number of available cores. If it is memory or IO bound, we use more threads to reduce the number of idle cores. The heuristics used to determine the number of threads can be easily changed or adapted in this aspect to capture more complex conditions and metrics. Finally, we instrument selected loops (line 19) with the OpenMP directive #pragma omp for with the identified number of threads.
6.8.3 Monitoring an MPI Application
MPI applications can be difficult to monitor and debug since they consist of multiple communicating parallel processes, each of them running in their own memory space. A simple strategy for monitoring and tracing execution, as mentioned in Chapter 4, is to wrap library functions with augmented functionality, which in this case would monitor the behavior of each MPI process.
In our strategy, we develop a new monitoring library, e.g., TrackMPI, for tracking the behavior of each MPI routine used in the program. To ease the integration of TrackMPI on existing MPI programs, we name each monitoring routine after the corresponding MPI routine, prefixing it with “Track.” Hence, TrackMPI_Recv tracks calls to MPI_Recv. All that remains is to replace the original MPI calls with the corresponding monitoring calls, which is performed by the following aspect:

In this aspect, we include the TrackMPI header (lines 3–6) containing all the declarations of this library at the beginning of every source file. Next, we declare a list of all MPI functions we wish to track (lines 8–18). Finally, we find all function calls in the source code (line 20) and add the prefix “Track” to its name (line 25).
Note that this simple aspect assumes that each TrackMPI routine has the same prototype declaration as its corresponding MPI routine and that it invokes this MPI routine before or after tracking its activity. One implementation of TrackMPI could involve tracking the name of the routine called, place a timestamp, and add additional information such as the rank of the participant and the size of data received or transferred. Because each MPI process runs independently, information generated by each process needs to be merged when terminating the MPI job. This can be done transparently by TrackMPI_Finalize when invoked by the process with rank 0 (by definition, the master process). A more complex TrackMPI library could generate a graph capturing the skeleton of the MPI job, tracking the total amount of data in and out of each process. Such powerful tracking tool can still use the same aspect presented earlier, regardless of the size and complexity of the application.
6.9 Summary
This chapter described compiler options, optimizations, and the use of developer's knowledge to guide compilers when targeting CPU-based computing platforms. In the topic of compiler options, we restrict our focus on optimizations most compilers provide, as opposed to code transformations and optimizations covered extensively in Chapter 5 and that need to be applied manually or by specialized source-to-source compilers.
This chapter also focused on loop vectorization as an important optimization to support SIMD units in contemporary CPUs (see Chapter 2). Given the multicore and multiple CPU trends, this chapter described the use of OpenMP and MPI to target shared and distributed memory architectures, respectively, and how they address concurrency. Lastly, this chapter introduced cache optimizations, as an important transformation to accelerate applications targeting the hierarchical memory organization of most CPU-based computing platforms.
6.10 Further Reading
The selection of compiler flags and compiler sequences that can optimize the performance of specific types of applications has been the focus of many research efforts.
For example, the exploration of compiler sequences (phase ordering) has been recently addressed by many authors, and some research efforts address this problem using machine learning techniques (see, e.g., [6] and [24]). Compiler phase selection and phase ordering has been explored by many authors (see, e.g., [5,9][25]). Purini and Jain [25] proposed a method to generate N-compiler sequences that for a set of applications offer better results than the predefined optimization sequences provided by the –Ox options. The approach in Ref. [5] has mainly the goal of providing a compiler sequence for each function using clustering to reduce the size of the design space.
With respect to the selection of compiler flags, the work in Ref. [26] provides an overview of machine learning techniques for selecting the compiler flags that are more effective in improving performance when compared to the ones used by –Ox options.
Loop auto-vectorization has been focused by many researchers (see, e.g., Ref. [16–18]), including the vectorization of outer loops (see, e.g., Ref. [19]).
For further reading about OpenMP we suggest the book by Chapman et al. [20] and the resources provided at Ref. [21]. For MPI, we suggest the books by Pacheco [22] and Gropp et al. [23].