
Chapter 20
Estimating Software Testing
From an estimating standpoint, estimating testing effort, testing schedules, and testing costs are rather complex topics because of the many different forms of testing that might be performed, and the fact that the numbers of discrete test stages for applications can run from a single perfunctory form of testing up to a high of about 18 formal test operations.
Test estimation is also complicated by the fact that the defects that are actually present when testing begins can vary widely. For example, projects that use formal design and code inspections enter testing with about 80 percent fewer defects than projects that do not use inspections.
The best way to start a discussion of software test estimating is to show the approximate volumes of defects in various kinds of software applications. Then it is useful to show the typical patterns of software defect removal and testing activities that are likely to occur. Table 20.1 shows defects from all major sources, while Table 20.2 illustrates typical patterns of defect removal and testing.
The typical sequence is to estimate defect volumes for a project, and then to estimate the series of reviews, inspections, and tests that the project utilizes. The defect-removal efficiency of each step will also be estimated. The effort and costs for preparation, execution, and defect repairs associated with each removal activity will also be estimated.
Table 20.1 illustrates the overall distribution of software errors among the six project types. In Table 20.1 bugs or defects are shown from five sources: requirements errors, design errors, coding errors, user documentation errors, and “bad fixes.” A “bad fix” is a secondary defect accidentally injected in a bug repair. In other words, a bad fix is a failed attempt to repair a prior bug that accidentally contains a new bug. On average about 7 percent of defect repairs will themselves accidentally inject a new defect, although the range is from less than 1 percent to more than 20 percent bad-fix injections.
TABLE 20.1 Average Defect Potentials for Six Application Types (Data expressed in terms of “defects per function point”)
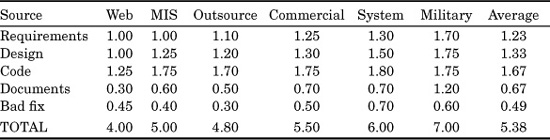
(The data in Table 20.1, and in the other tables in this chapter, are based on a total of about 12,000 software projects examined by the author and his colleagues circa 1984–2007. Additional information on the sources of data can be found in other publications by the author and by Stephen H. Kan, as listed in the References section at the end of this chapter.)
Table 20.1 presents approximate average values, but the range for each defect category is more than 2 to 1. For example, software projects developed by companies who are at level 5 on the capability maturity model (CMM) might have less than half of the potential defects shown in Table 20.1. Similarly, companies with several years of experience with the “six-sigma” quality approach will also have lower defect potentials than those shown in Table 20.1. Several commercial estimating tools make adjustments for such factors.
A key factor for accurate estimation involves the removal of defects via reviews, inspections, and testing. The measurement of defect removal is actually fairly straightforward, and many companies now do this. The U.S. average is about 85 percent, but leading companies can average more than 95 percent removal efficiency levels.
Measuring defect-removal efficiency levels is actually one of the easiest forms of measurement. For example, suppose a programmer finds 90 bugs or defects during the unit test of a small program. Then the program is turned over to its client, who finds an additional 10 bugs in the first three months of use. Calculating defect-removal efficiency only requires adding the number of bugs found during a particular test step to the bugs found afterwards, and deriving the percentage. Thus, in this simple example the 90 bugs found during unit test and the 10 bugs found afterwards total to 100 defects. As can be seen, the removal efficiency of this unit test was 90 percent.
In real life the calculations are not quite so simple, because a percentage of the bug repairs will accidentally inject new bugs back into the software. (The U.S. average for such “bad fixes” is about 7 percent.) Even so, measuring defect-removal efficiency is fairly straightforward. Measuring defect-removal efficiency does not even require knowledge of lines of code, function points, object points, or other metrics. It is one of the simplest and yet most revealing of all forms of software measurement.
It is much easier to estimate software projects that use sophisticated quality control and have high levels of defect removal in the 95 percent range. This is because there usually are no disasters occurring late in development when unexpected defects are discovered. Thus projects performed by companies at the higher CMM levels or by companies with extensive six-sigma experience for software often have much greater precision than average.
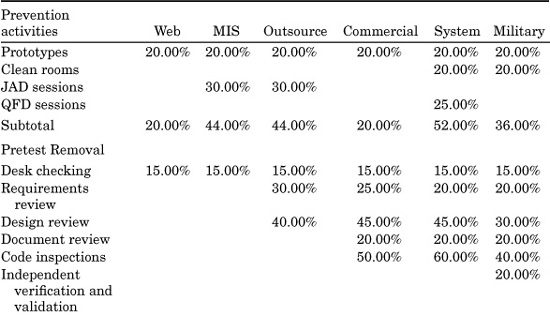
Table 20.2 illustrates the variations in typical defect prevention and defect-removal methods among the six kinds of projects shown in Table 20.1. Of course, many variations in these patterns can occur. Therefore, it is important to adjust the set of activities, and their efficiency levels, to match the realities of the projects being estimated. However, since defect removal in total has been the most expensive cost element of large software applications for more than 50 years, it is not possible to achieve accurate estimates without being very thorough in estimating defect-removal patterns.
(The cumulative efficiency values in Table 20.2 are calculated as follows. If the starting number of defects is 100, and there are two consecutive test stages that each remove 50 percent of the defects present, then the first test will remove 50 defects and the second test will remove 25 defects. The cumulative efficiency of both tests is 75 percent, because 75 out of a possible 100 defects were eliminated.)
Readers who are not experienced quality-assurance or test personnel may be surprised by the low average levels of defect-removal efficiency shown in Table 20.2. However, the data is derived from empirical studies of reviews, inspections, and tests taken from many large corporations. It is an unfortunate fact of life that most forms of testing are less than 50 percent efficient in finding bugs or defects and many are less than 30 percent efficient. Formal design and code inspections have the highest measured removal efficiencies of any known form of defect elimination and are usually at least twice as efficient as any standard test stage such as new function testing or regression testing.
The comparatively low average values for defect-removal efficiency levels explains why leading companies typically deploy several kinds of inspections before testing begins, and up to 10 discrete testing steps. For really critical applications such as military weapons systems there may be as many as six inspection stages and a dozen discrete testing stages utilized.
Table 20.2 oversimplifies the situation, since defect-removal activities have varying efficiencies for requirements, design, code, documentation, and bad-fix defect categories. Also, bad fixes during testing will be injected back into the set of undetected defects.
TABLE 20.2 Patterns of Defect Prevention and Removal Activitie
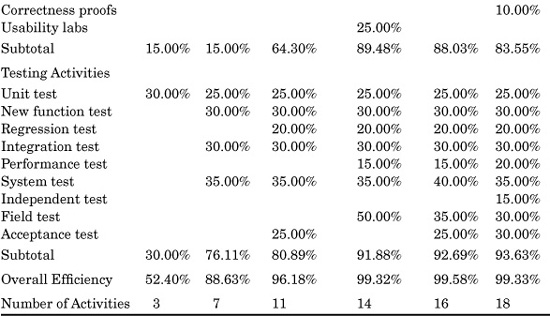
The low efficiency of most forms of defect removal explains why a lengthy series of defect removal activities is needed. This in turn explains why estimating defect removal is critical for overall accuracy of software cost estimation for large systems. Below 1000 function points, the series of defect removal operations may be as few as three. Above 10,000 function points the series may include more than 15 kinds of review, inspection, and test activity.
Table 20.3 provides some nominal default values for estimating testing activities, although these defaults need to be adjusted and applied to each specific form of testing, as will be discussed later in this chapter.
TABLE 20.3 Nominal Default Values for Testin
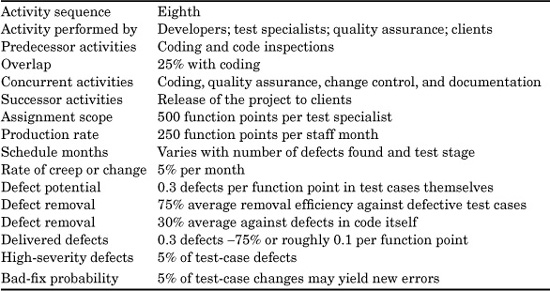
It is obvious from Table 20.3 that testing can vary significantly in who performs it, and even more significantly in the number of kinds of tests that are likely to be performed. Let us consider the implications of these test estimating complexities.
The exact definition of what testing means is quite ambiguous. In this book and the author’s previous books on software quality and software measurement the basic definition of testing is:
The dynamic execution of software and the comparison of the results of that execution against a set of known, predetermined criteria. Determining the validity of a specific application output in response to a specific application input is termed a test case.
Under this definition of testing, static defect-removal methods, such as formal design and code inspections, are not viewed as testing. However, under a broader definition of defect removal, both inspections and testing would be considered as complementary activities. Formal inspections actually have higher levels of defect-removal efficiency than almost any form of testing.
It may also be significant to define what software means in a testing context. The term software can mean any of the following:
![]() An individual instruction (about .001 function points)
An individual instruction (about .001 function points)
![]() A small subroutine of perhaps 10 instructions in length (about .01 function points)
A small subroutine of perhaps 10 instructions in length (about .01 function points)
![]() A module of perhaps 100 instructions in length (about 1 function point)
A module of perhaps 100 instructions in length (about 1 function point)
![]() A complete program of perhaps 1000 instructions in length (10 function points)
A complete program of perhaps 1000 instructions in length (10 function points)
![]() A component of a system of perhaps 10,000 instructions in length (100 function points)
A component of a system of perhaps 10,000 instructions in length (100 function points)
![]() An entire software system of perhaps 100,000 instructions
An entire software system of perhaps 100,000 instructions
![]() A mega-system of perhaps 1 to more than 10 million instructions in length
A mega-system of perhaps 1 to more than 10 million instructions in length
Any one of these software groupings can be tested, and often tested many times, in the course of software development activities.
Also significant in a testing context is the term execution. As used here, the term execution means running the software on a computer with or without any form of instrumentation or test-control software being present.
The phrase predetermined criteria means that what the software is supposed to do is known prior to its execution, so that what the software actually does can be compared against the anticipated results to judge whether or not the software is behaving correctly.
The term test case means recording a known set of conditions so that the response of the application to a specific input combination is evaluated to determine that the outputs are valid and fall within predetermined, acceptable ranges.
There are dozens of possible forms of testing, but they can be aggregated into three forms of testing that can be defined as the following broad categories:
![]() General testing of applications for validity of outputs in response to inputs
General testing of applications for validity of outputs in response to inputs
![]() Specialized testing for specific kinds of problems, such as performance or capacity
Specialized testing for specific kinds of problems, such as performance or capacity
![]() Testing that involves the users or clients themselves to evaluate ease of use
Testing that involves the users or clients themselves to evaluate ease of use
The general forms of testing are concerned with almost any kind of software and seek to eliminate common kinds of bugs, such as branching errors, looping errors, incorrect outputs, and the like.
The specialized forms of testing are more narrow in focus and seek specific kinds of errors, such as problems that only occur under full load, or problems that might slow down performance.
The forms of testing involving users are aimed primarily at usability problems and at ensuring that all requirements have, in fact, been implemented.
Not every form of testing is used on every software project, and some forms of testing are used on only 1 project out of every 25 or so.
TABLE 20.4 Distribution of Testing Methods for Large Software Project
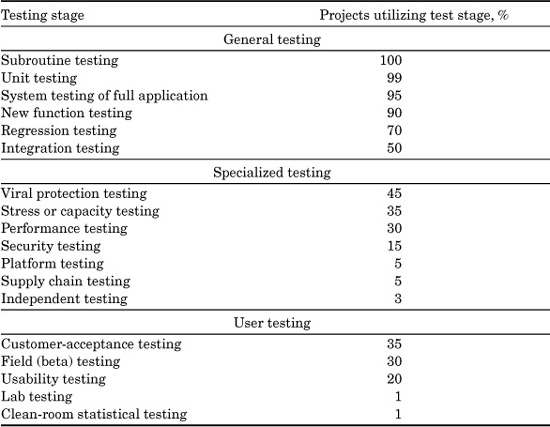
The distribution in Table 20.4 shows the frequency with which various test forms have been noted among SPR’s clients for projects of 500 function points or larger.
It is interesting to note that the only form of testing that is truly universal is testing of individual subroutines. Unit testing of entire modules is almost universal, although a few projects have not utilized this method (such as those using the clean-room method). Testing of the entire application upon completion is also very common, although here, too, not every project has done so.
For the other and more specialized forms of testing, such as performance testing or security testing, only a minority of projects among SPR’s clients perform such testing. Sometimes the specialized forms of testing are not needed, but sometimes they are needed and are skipped over due to schedule pressure or poor decision making by project managers.
General Forms of Software Testing
The general forms of software testing occur for almost every kind of software: systems software, commercial software, military software, information systems, or anything else.
While the general forms of software testing are common and well understood, not all companies use the same vocabulary to describe them. The following brief definitions explain the general meanings of the general forms of testing discussed here.
Subroutine Testing
This is the lowest-level form of testing noted among SPR’s clients. Recall that a subroutine is a small collection of code that may constitute less than ten statements, or perhaps one-tenth of a function point.
Subroutine testing is performed almost spontaneously by developers, and is very informal. Essentially, this form of testing consists of executing a just-completed subroutine to see if it compiles properly and performs as expected. Subroutine testing is a key line of defense against errors in algorithms in spite of its being informal and underreported in the testing literature.
Subroutine testing is too informal to be included in test plans and because it is done by developers themselves, there is usually no data kept on either effort or efficiency in terms of numbers of bugs found. However, since subroutine testing is done immediately after the code is written, it is a key first-line defense against coding defects.
Unit Testing
This is the lowest-level form of testing normally discussed in the testing literature. Unit testing is the execution of a complete module or small program that will normally range from perhaps 100 to 1000 source code statements, or roughly from 1 to 10 function points.
Although unit testing may often be performed informally, it is also the stage at which actual test planning and deliberate test-case construction begins. Unit testing is usually performed by the programmers who write the module and, hence, seldom includes data on defect levels or removal efficiency. (Note that for testing under clean-room concepts, unit testing is not performed by the developers, so data on defect removal may be recorded in this situation.)
One of the interesting attributes of XP is that unit tests are written before the code itself. The hypothesis is that starting with test cases focuses the mind of the programmers on various kinds of error conditions, and leads to few defects. Although the evidence is incomplete, the concept of starting with test cases does seem to provide value in terms of reduced defects and higher levels of defect-removal efficiency.
Even in the normal situation of unit testing being performed by developers, enough companies have used volunteers who record the defects found during unit testing to have at least an idea of how efficient this form of testing is. Unit testing is also often plagued by bad test cases, which themselves contain errors. Unit testing is the lowest-level form of testing provided for by software estimating tools.
New Function Testing
This is often teamed with regression testing, and both forms are commonly found when existing applications are being updated or modified. As the name implies, new function testing is aimed at validating new features that are being added to a software package.
For entirely new projects, as opposed to enhancements, this form of testing is also known as component testing because it tests the combined work of multiple programmers whose programs in aggregate may comprise a component of a larger system.
This form of testing would roughly be tests against perhaps half a dozen or more use cases, or perhaps five user stories. In other words, while new function testing is not aimed at a full system, it does aim at testing common usage patterns.
New function testing is often performed by testing specialists because it covers the work of a number of programmers. For example, typical size ranges of major new functions added to existing software packages can exceed 10,000 source code statements, 100 function points, or five detailed use cases.
New function testing is normally supported by formal test plans and planned test cases, and is performed on software that is under full configuration control. Also, defect reporting for new function testing is both common and reasonably accurate.
New function testing is a key line of defense against errors in intermodule interfaces and the movement of data from place to place through an application. New function testing is also intended to verify that the new or added features work correctly.
Regression Testing
This is the opposite of new function testing. The word regression means to slip back, and in the context of testing regression means accidentally damaging an existing feature as an unintended by-product of adding a new feature. Regression testing also checks to ensure that prior known bugs have not inadvertently stayed in the software after they should have been removed.
After a few years of software evolution, regression testing becomes one of the most extensive forms of testing because the library of available test cases from prior releases tends to grow continuously. Also, regression testing involves the entire base code of the application, which for major systems can exceed 10 million lines of code or 100,000 function points.
Regression testing can be performed by developers, professional test personnel, or software quality-assurance personnel. Regardless of who performs regression testing, the application is usually under full configuration control.
Regression test libraries, though often extensive, are sometimes troublesome and have both redundant test cases and test cases that themselves contain errors.
Regression testing is a key line of defense as systems evolve and age. It should be noted that the average growth rate of new features in software after the initial release is about 7 percent per calendar year. Each new feature or change includes a small chance of damaging some existing feature. Therefore, regression testing is a very common and important test activity.
Integration Testing
As the name implies, this is testing on a number of modules or programs that have come together to comprise an integrated software package. Since integration testing may cover the work of dozens, or even hundreds, of programmers, it also deals with rather large numbers of test cases.
Integration testing often occurs in waves as new builds of an evolving application are created. Microsoft, for example, performs daily integration of developing software projects and, hence, also performs daily integration testing. Other companies may have longer intervals between builds, such as weekly or even monthly builds.
Applications undergoing integration testing are usually under formal configuration control. Integration testing normally makes use of formal test plans, formal test scripts, planned suites of test cases, and formal defect-reporting procedures. Integration testing can be performed by developers themselves, by professional test personnel, or by software quality-assurance personnel, but professional test or Quality assurance (QA) personnel are usually more efficient and effective than developers.
System Testing of Full Application
This is usually the last form of internal testing before customers get involved with field testing (beta testing). For large systems, a formal system test can take many months and can involve large teams of test personnel. Also, the entire set of development programmers may be needed in order to fix bugs that are found during this critical test stage.
System testing demands formal configuration control and also deserves formal defect-tracking support. System testing can be performed by developers, professional test personnel, or quality-assurance personnel.
For software that controls physical devices (such as telephone switching systems) the phrase system test may include concurrent testing of hardware components. In this case, other engineering and quality-assurance specialists may also be involved, such as electrical or aeronautical engineers dealing with the hardware. Microcode may also be part of system testing. For complex hybrid products, system testing is a key event.
System testing may sometimes overlap a specialized form of testing termed lab testing, where special laboratories are used to house complex new hardware and software products that will be tested by prospective clients under controlled conditions.
Specialized Forms of Software Testing
These specialized forms of software testing occur with less frequency than the general forms. The specialized forms of testing are most common for systems software, military software, commercial software, contract software, and software with unusually tight criteria for things like high performance or ease of use.
Stress or Capacity Testing
This is a specialized form of testing aimed at judging the ability of an application to function when nearing the boundaries of its capabilities in terms of the volume of information used. For example, capacity testing of the word processor used to create this book (Microsoft Word for Windows Version 7) might entail tests against individual large documents of perhaps 300 to 600 pages to judge the upper limits that can be handled before MS Word becomes cumbersome or storage is exceeded.
It might also entail dealing with even larger documents, say 2000 pages, segmented into master documents and various sections. For a database application, capacity testing might entail loading the database with 10,000; 100,000; or 1 million records to judge how it operates when fully populated with information.
Capacity testing is often performed by testing specialists rather than developers primarily because ordinary developers may not know how to perform this kind of testing. Capacity testing may either be a separate test stage, or be performed as a subset of integration or system testing. Usually, it cannot be performed earlier, since the full application is necessary.
Performance Testing
This is a specialized form of testing aimed at judging whether or not an application can meet the performance goals set for it. For many applications performance is only a minor issue, but for some kinds of applications it is critical. For example, weapons systems, aircraft flight control systems, fuel injection systems, access methods, and telephone switching systems must meet stringent performance goals or the devices the software is controlling may not work.
Performance testing is also important for information systems that need to process large volumes of information rapidly, such as credit card authorizations, airline reservations, and bank ATM transactions.
Performance testing is often performed by professional testers and sometimes is supported by performance or tuning specialists. Some aspects of performance testing can be done at the unit-test level, but the bulk of performance testing is associated with integration and system testing because interfaces within the full product affect performance.
Note that in addition to performance testing, software systems with high performance needs that run on mainframe computers are often instrumented by using either hardware or software performance monitoring equipment. Some of these performance monitors can analyze the source code and find areas that may slow down processing, which can then be streamlined or modified.
However, some forms of software with real-time, high-speed requirements are not suitable for performance-monitoring equipment. For example, the onboard flight control software package of a cruise missile has high performance requirements but needs to achieve those requirements prior to deployment.
Viral Spyware Protection Testing
This is rapidly moving from a specialized form of testing to a general one, although it still has been noted on less than half of SPR’s client’s projects. The introduction of software viruses or spyware by malicious hackers has been a very interesting sociological phenomena in the software world. Viruses number in the thousands, and more are being created daily. Spyware also numbers in the thousands.
Virus and spyware protection has now become a growing sub-industry of the software domain. Virus testing is a white-box form of testing. Although commercial virus protection software can be run by anybody, major commercial developers of software also use special proprietary tools to ensure that master copies of software packages do not contain viruses.
Security Testing
This is most common and most sophisticated for military software, followed by software that deals with very confidential information, such as bank records, medical records, tax records, and the like.
The organizations most likely to utilize security testing include the military services, the National Security Agency (NSA), the Central Intelligence Agency (CIA), the Federal Bureau of Investigation (FBI), and other organizations that utilize computers and software for highly sensitive purposes.
Security testing is usually performed by highly trained specialists. Indeed, some military projects use penetration teams that attempt to break the security of applications by various covert means, including but not limited to hacking, theft, bribery, and even picking locks or breaking into buildings. ch20.indd 496 3/17/07 4:35:19 PM
It has been noted that one of the easiest ways to break into secure systems involves finding disgruntled employees, so security testing may have psychological and sociological manifestations.
Platform Testing
This is a specialized form of testing found among companies whose software operates on different hardware platforms under different operating systems. Many commercial software vendors market the same applications for Windows XP, the Macintosh, UNIX, LINUX, and sometimes for other platforms as well.
While the features and functions of the application may be identical on every platform, the mechanics of getting the software to work on various platforms requires separate versions and separate test stages for each platform. Platform testing is usually a white-box form of testing.
Another aspect of platform testing is ensuring that the software package correctly interfaces with any other software packages that might be related to it. For example, when testing software cost-estimating tools, this stage of testing would verify that data can be passed both ways between the estimating tool and various project management tools. For example, suppose cost-estimating tools, such as CHECKPOINT or KnowledgePlan, are intended to share data with Microsoft Project under Windows XP. This is the stage where the interfaces between the two would be verified.
Platform testing is also termed compatibility testing by some companies. Regardless of the nomenclature used, the essential purpose remains the same: to ensure that software that operates on multiple hardware platforms, under multiple operating systems, and interfaces with multiple tools can handle all varieties of interconnection.
Independent Testing
This is very common for military software, because it was required by Department of Defense standards. It can also be done for commercial software, and indeed there are several commercial testing companies that do testing on a fee basis. However, independent testing is very rare for management information systems, civilian systems software projects, and outsourced or contracted software. Independent testing, as the name implies, is performed by a separate company or at least a separate organization from the one that built the application. Both white-box and black-box forms of independent testing are noted.
A special form of independent testing may occur from time to time as part of litigation when a client charges that a contractor did not achieve acceptable levels of quality. The plaintiff, defendant, or both may commission a third party to test the software.
Another form of independent testing is found among some commercial software vendors who market software developed by subcontractors or other commercial vendors. The primary marketing company usually tests the subcontracted software to ensure that it meets the company’s quality criteria.
Forms of Testing Involving Users or Clients
For many software projects, the clients or users are active participants at various stages along the way, including but not limited to requirements gathering, prototyping, inspections, and several forms of testing. The testing stages where users participate are generally the following.
Usability Testing
This is a specialized form of testing sometimes performed in usability laboratories. Usability testing involves actual clients who utilize the software under controlled and sometimes instrumented conditions so that their actions can be observed. Usability testing is common for commercial software produced by large companies, such as IBM and Microsoft. Usability testing can occur with any kind of software, however. Usability testing usually occurs at about the same time as system testing. Sometimes usability testing and beta testing are concurrent, but it is more common for usability testing to precede beta testing.
Field (Beta) Testing
This is a common testing technique for commercial software. Beta is the second letter in the Greek alphabet. Its use in testing stems from a testing sequence used by hardware engineers that included alpha, beta, and gamma testing. For software, alpha testing more or less dropped out of the lexicon circa 1980, and gamma testing was almost never part of the software test cycle. Thus, beta is the only one left for software, and is used to mean an external test involving customers.
Microsoft has become famous by conducting the most massive external beta tests in software history, with more than 10,000 customers participating. High-volume beta testing with thousands of customers is very efficient in terms of defect-removal efficiency levels and can exceed 85 percent removal efficiency if there are more than 1000 beta-test participants. However, if beta-test participation comprises less than a dozen clients, removal efficiency is usually around 35 to 50 percent.
Beta testing usually occurs after system testing, although some companies start external beta tests before system testing is finished (to the dismay of their customers). External beta testing and internal usability testing may occur concurrently. However, beta testing may involve special agreements with clients to avoid the risk of lawsuits should the software manifest serious problems.
Lab Testing
This is a special form of testing found primarily with hybrid products that consist of complex physical devices that are controlled by software, such as telephone switching systems, weapons systems, and medical instruments. It is obvious that conventional field testing or beta testing of something like a PBX switch, a cruise missile, or a CAT scanner is infeasible due to the need for possible structural modifications to buildings, special electrical wiring, and heating and cooling requirements, to say nothing of zoning permits and authorization by various boards and controlling bodies.
Therefore, the companies that build such devices often have laboratories where clients can test out both the hardware and the software prior to having the equipment installed on their own premises.
Customer-Acceptance Testing
This is commonly found for contract software and often is found for management information systems, software, and military software. The only form of software where acceptance testing is rare or does not occur is high-volume commercial shrink-wrapped software. Even here, some vendors and retail stores provide a money-back guarantee, which permits a form of acceptance testing. How the customers go about acceptance testing varies considerably. Customer-acceptance testing is not usually part of software cost estimates, since the work is not done by the software vendors but rather by the clients. However, the time in the schedule is still shown, and the effort for fixing client-reported bugs is shown.
Clean-Room Statistical Testing
This is found only in the context of clean-room development methods. The clean-room approach is unusual in that the developers do not perform unit testing, and the test cases themselves are based on statistical assertions of usage patterns. Clean-room testing is inextricably joined with formal specification methods and proofs of correctness. Clean-room testing is always performed by testing specialists or quality-assurance personnel rather than the developers themselves, because under the clean-room concept developers do no testing.
Number of Testing Stages
Looking at the data from another vantage point, if each specific kind of testing is deemed a testing stage, it is interesting to see how many discrete testing stages occur for software projects (see Table 20.5). The overall range of testing stages among SPR’s clients and their software projects runs from a low of 1 to a high of 16 out of the total number of 18 testing stages discussed here.
TABLE 20.5 Approximate Distribution of Testing Stages for U.S. Software Project

As can be seen from the distribution of results, the majority of software projects in the United States (70 percent) use six or fewer discrete testing stages, and the most common pattern of testing observed includes the following:
![]() Subroutine testing
Subroutine testing
![]() Unit testing
Unit testing
![]() New function testing
New function testing
![]() Regression testing
Regression testing
![]() Integration testing
Integration testing
![]() System testing
System testing
These six forms of testing are very common on applications of 1000 function points or larger. These six also happen to be generalized forms of testing that deal with broad categories of errors and issues.
Below 1000 function points, and especially below 100 function points, sometimes only three testing stages are found, assuming the project in question is new and not an enhancement:
![]() Subroutine testing
Subroutine testing
![]() Unit testing
Unit testing
![]() New function testing
New function testing
The other forms of testing that are less common are more specialized, such as performance testing or capacity testing, and deal with a narrow band of problems that not every application is concerned with.
Testing Pattern Variations by Industry and Type of Software
There are, of course, very significant variations between industries and between various kinds of software in terms of typical testing patterns utilized, as follows.
End-User Software
This is the sparsest in terms of testing, and the usual pattern includes only two test stages: subroutine testing and unit testing. Of course, end-user software is almost always less than 100 function points in size.
Web Software
These new kinds of applications are beginning to develop some new and specialized kinds of testing. With web sites that link to many other sites, or that use animation and sound, it is obvious that these features need to be tested to work correctly. Also, web applications that are intended to accept customer orders or payments need special security testing and also various kinds of encryption. Usually, five to ten kinds of testing will occur for large web sites. Small personal web sites will probably use two to five kinds of testing. Some of the kinds of testing include subroutine testing, unit testing, new function testing, regression testing, user interface testing, hyperlink testing, performance testing, and security testing.
Management Information Systems (MIS)
MIS software projects use from three up to perhaps eight forms of testing. A typical MIS testing-stage pattern would include subroutine testing, unit testing, new function testing, regression testing, system testing, and user-acceptance testing. MIS testing is usually performed by the developers themselves, so that testing by professional test personnel or by quality-assurance personnel is a rarity in this domain.
Outsource Software
Vendors doing information systems are similar to their clients in terms of testing patterns. MIS outsource vendors use typical MIS patterns; systems software vendors use typical systems software patterns; and military outsource vendors use typical military test patterns. This means that the overall range of outsource testing can run from as few as 3 kinds of testing up to a high of 16 kinds of testing. Usually, the outsource vendors utilize at least one more stage of testing than their clients.
Commercial Software
Commercial software developed by major vendors, such as Microsoft, IBM, and Computer Associates, will typically use a 12-stage testing series: (1) subroutine testing, (2) unit testing, (3) new function testing, (4) regression testing, (5) performance testing, (6) stress testing, (7) integration testing, (8) usability testing, (9) platform testing, (10) system testing, (11) viral testing, and (12) field testing, which is often called external or beta testing.
However, small software vendors who develop small applications of less than 1000 function points may only use six testing stages: (1) subroutine testing, (2) unit testing, (3) new function testing, (4) regression testing, (5) system testing, and (6) beta testing.
Major software vendors, such as Microsoft and IBM, utilize large departments of professional testers who take over after unit testing and perform the major testing work at the higher levels, such as integration testing, system testing, and such specialized testing as performance testing or stress testing.
Systems Software
This is often extensively tested and may use as many as 14 different testing stages. A typical testing pattern for a software system in the 10,000–function point range would include subroutine testing, unit testing, new function testing, regression testing, performance testing, stress/capacity testing, integration testing, usability testing, system testing, viral testing, security testing, special date tests such as daylight savings, and lab testing and/or field testing, which is often called external or beta testing.
The larger systems software companies such as AT&T, Siemens-Nixdorf, IBM, and the like, typically utilize professional testing personnel after unit testing. Also, the systems software domain typically has the largest and best-equipped software quality-assurance groups and the only quality-assurance research labs.
Some of the large systems software organizations may have three different kinds of quality-related laboratories:
![]() Quality research labs
Quality research labs
![]() Usability labs
Usability labs
![]() Hardware and software product testing labs
Hardware and software product testing labs
Indeed, the larger systems software groups are among the few kinds of organizations that actually perform research on software quality, in the classical definition of research as formal experiments using trial and error methods to develop improved tools and practices.
Military Software
This uses the most extensive suite of test stages, and large weapons or logistics systems may include 16 discrete testing stages: (1) subroutine testing; (2) unit testing; (3) new function testing; (4) regression testing; (5) performance testing; (6) stress testing; (7) integration testing; (8) independent testing; (9) usability testing; (10) lab testing; (11) system testing; (12) viral testing; (13) security testing; (14) special date testing; (15) field testing, which is often called external or beta testing; and (16) customer-acceptance testing.
Only military projects routinely utilize independent testing, or testing by a separate company external to the developing or contracting organization. Military projects often utilize the services of professional testing personnel and also quality-assurance personnel.
However, there are several companies that perform independent testing for commercial software organizations. Often, smaller software companies that lack full in-house testing capabilities will utilize such external testing organizations.
Testing Pattern Variations by Size of Application
Another interesting way of looking at the distribution of testing stages is to look at the ranges and numbers of test stages associated with the various sizes of software applications, as shown in Table 20.6.
As can be seen, the larger applications tend to utilize a much more extensive set of testing stages than do the smaller applications, which is not unexpected.
It is interesting to consolidate testing variations by industry and testing variations by size of application. The following table shows the typical number of test stages observed for six size plateaus and six software classes (see Table 20.7).
There are wide variations in testing patterns, so this table has a significant margin of error. However, the data is interesting and explains why the commercial, systems, and military software domains often have higher reliability levels than others.
TABLE 20.6 Ranges of Test Stages Associated with the Size of Software Application
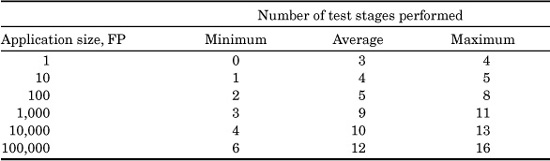
TABLE 20.7 Average Number of Tests Observed by Application Size and Class of Software (Application size in function points)
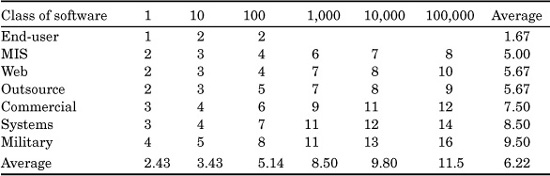
This table also illustrates that there is no single pattern of testing that is universally appropriate for all sizes of software and all classes of software. The optimal pattern of defect-removal and testing stages must be matched to the nature of the application.
Testing Stages Noted in Lawsuits Alleging Poor Quality
It is an interesting observation that for outsourced, military, and systems software that ends up in court for litigation involving assertions of unacceptable or inadequate quality, the number of testing stages is much smaller, while formal design and code inspections are not utilized at all.
Table 20.8 shows the typical patterns of defect-removal activities for software projects larger than 1000 function points in size where the developing organization was sued by the client for producing software of inadequate quality.
TABLE 20.8 Defect Removal and Testing Stages Noted During Litigation for Poor Qualit
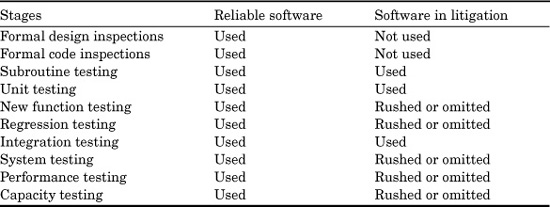
The table simply compares the pattern of defect-removal operations observed for reliable software packages with high quality levels to the pattern noted during lawsuits where poor quality and low reliability were at issue. The phrase rushed or omitted indicates that the vendor departed from best standard practices by eliminating a stage of defect removal or by rushing it in order to meet an arbitrary finish date or commitment to the client.
It is interesting that during the depositions and testimony of litigation, the vendor often countercharges that the shortcuts were made at the direct request of the client. Sometimes the vendor asserts that the client ordered the shortcuts even in the face of warnings that the results might be hazardous.
As can be seen, software developed under contractual obligations is at some peril if quality control and testing approaches are not carefully performed.
Using Function Points to Estimate Test-Case Volumes
IFPUG function points and related metrics such as COSMIC function points, object points, and use case points are starting to provide some preliminary but interesting insights into test-case volumes. This is not unexpected, because the fundamental parameters of both function points and feature points all represent topics that need test coverage, as follows:
![]() Inputs
Inputs
![]() Outputs
Outputs
![]() Inquires
Inquires
![]() Logical files
Logical files
![]() Interfaces
Interfaces
![]() Algorithms (feature points only)
Algorithms (feature points only)
Since function points can be derived during the requirements and early design stages, this approach offers a method of predicting test-case numbers fairly early. The method is still somewhat experimental, but the approach is leading to interesting results and its usage is expanding. Currently, IFPUG function points have the largest numbers of examples for estimating test cases.
Table 20.9 shows preliminary data on the number of test cases that have been noted among SPR’s clients, using test cases per function point as the normalizing metric. This table has a high margin of error, but as with any other set of preliminary data points, it is better to publish the results in the hope of future refinements and corrections than to wait until the data is truly complete.
TABLE 20.9 Ranges of Test Cases per IFPUG Function Point (Version 4.1
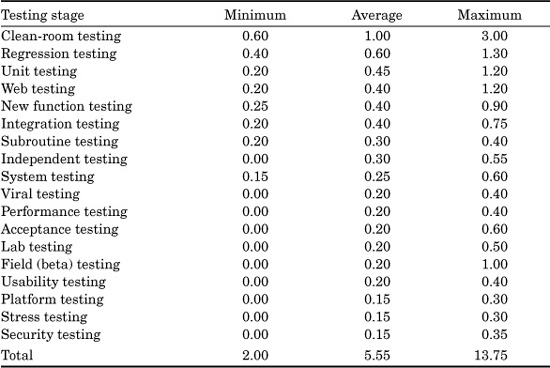
The usage of function point metrics also provides some rough rules of thumb for predicting the overall volumes of test cases that are likely to be created for software projects.
![]() Raising the function point total of the application to the 1.15 power will give an approximation of the minimum number of test cases.
Raising the function point total of the application to the 1.15 power will give an approximation of the minimum number of test cases.
![]() Raising the function point total to the 1.2 power gives an approximation of the average number of test cases.
Raising the function point total to the 1.2 power gives an approximation of the average number of test cases.
![]() Raising the function point total to the 1.3 power gives an approximation of the maximum number of test cases.
Raising the function point total to the 1.3 power gives an approximation of the maximum number of test cases.
These rules of thumb are based on observations of software projects whose sizes range between about 100 and 10,000 function points. Rules of thumb are not accurate enough for serious business purposes, such as contracts, but are useful in providing estimating sanity checks. See the section on “Function Point Sizing Rules of Thumb” in Chapter 6 for additional rules of thumb involving these versatile metrics.
Because of combinatorial complexity, it is usually impossible to write and run enough test cases to fully exercise a software project larger than about 100 function points in size. The number of permutations of inputs, outputs, and control-flow paths quickly becomes astronomical.
For really large systems that approach 100,000 function points in size, the total number of test cases needed to fully test every condition can be regarded, for practical purposes, as infinite. Also, the amount of computing time needed to run such a test suite would also be an infinite number, or at least a number so large that there are not enough computers in any single company to approach the capacity needed.
Therefore, the volumes of test cases shown here are based on empirical observations and the numbers assume standard reduction techniques, such as testing boundary conditions rather than all intermediate values and compressing related topics into equivalency classes.
Using Function Points to Estimate the Numbers of Test Personnel
One of the newest but most interesting uses of function point metrics in a testing context is for predicting the probable number of test personnel that might be needed for each test stage, and then for the overall product.
Table 20.10 has a high margin of error, but the potential value of using function points for test-staffing prediction is high enough to make publication of preliminary data useful.
This table is a bit misleading. While the average test stage might have a ratio of about 1300 function points for every tester, the range is very broad. Also, the table does not show the ratio of testers to software for testing performed in parallel.
TABLE 20.10 Ranges in Number of Function Points per Software Teste
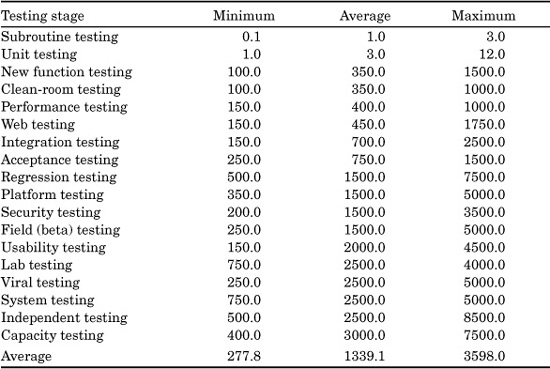
For example, if a common four-stage combination of test stages where professional testers or quality-assurance personnel handle the testing is done in parallel rather than sequentially, the ratio for the entire combination is in the range of one testing staff member for about every 250 function points for the following test stages:
![]() New function testing
New function testing
![]() Regression testing
Regression testing
![]() Integration testing
Integration testing
![]() System testing
System testing
For some of the test stages, such as subroutine testing and unit testing, the normal practice is for the testing to be performed by developers. In this case, the data simply indicates the average sizes of subroutines and standalone programs.
Testing and Defect-Removal Efficiency Levels
Most forms of testing, such as unit testing by individual programmers, are less than 30 percent efficient in finding bugs. That is, less than one bug out of three will be detected during the test period. Sometimes a whole string of test steps (unit testing, function testing, integration testing, and system testing) will find less than 50 percent of the bugs in a software product. By itself, testing alone has never been sufficient to ensure really high quality levels.
Consider also the major categories of defects that affect software:
![]() Errors of omission
Errors of omission
![]() Errors of commission
Errors of commission
![]() Errors of clarity or ambiguity
Errors of clarity or ambiguity
![]() Errors of speed
Errors of speed
![]() Errors of capacity
Errors of capacity
Table 20.11 shows the approximate defect-removal efficiency level of the common forms of testing against these five error categories (with a very large margin of error).
This data is derived in part from measurements by the author’s clients, and in part from discussion with software testing and quality-assurance personnel in a number of companies. The data is based on anecdotes rather than real statistical results because none of the author’s clients actually record this kind of information. However, the overall picture the data gives of testing is interesting and clarifies testing’s main strengths and weaknesses.
TABLE 20.11 Average Defect-Removal Efficiency Levels of Software Test Stages Against Five Defect Types (Percentage of defects removed)
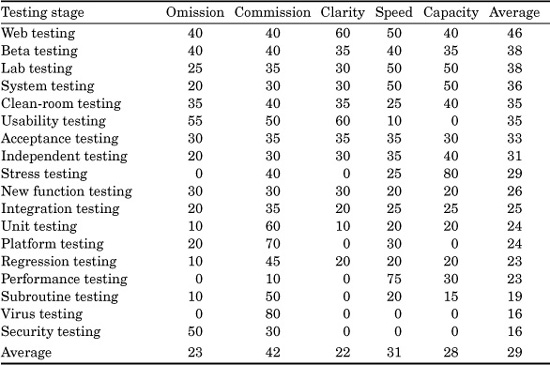
This table is ranked in descending order of overall efficiency against all forms of defects and, hence, is slightly misleading. Some of the specialized forms of testing, such as stress and performance testing or viral protection testing, are highly efficient but against only one narrow class of problem.
The most obvious conclusion from this table is that testing is much more effective in finding errors of commission, or things that are done wrong, than it is in finding errors of omission, or things that are left out by accident.
Note that there are wide ranges of observed defect-removal efficiency over and above the approximate averages shown here. Any given form of testing can achieve defect-removal efficiency levels that are perhaps 15 percent higher than these averages, or about 10 percent lower. However, no known form of testing has yet exceeded 90 percent in defect-removal efficiency, so a series of inspections plus a multistage series of tests is needed to achieve really high levels of defect-removal efficiency, such as 99.9999 percent.
Although testing is often the only form of defect removal utilized for software, the performance of testing is greatly enhanced by the use of formal design and code inspections, both of which tend to elevate testing efficiency levels in addition to finding defects themselves.
Using Function Points to Estimate Testing Effort and Costs
Another use of the function point metric in a testing context is to estimate and later measure testing effort and costs. A full and formal evaluation of testing requires analysis of three discrete activities:
![]() Test preparation
Test preparation
![]() Test execution
Test execution
![]() Defect repair
Defect repair
Test preparation involves creating test cases, validating them, and putting them into a test library.
Test execution involves running the test cases against the software and recording the results. Note that testing is an iterative process, and the same test cases can be run several times if needed, or even more.
Defect repair concerns fixing any bugs that are found via testing, validating the fix, and then rerunning the test cases that found the bugs to ensure that the bugs have been repaired and that no bad fixes have inadvertently been introduced.
With a total of 18 different kinds of testing to consider, the actual prediction of testing effort is too complex for simplistic rules of thumb. Several commercial estimating tools, such as CHECKPOINT, COCOMO II, KnowledgePlan, PRICE-S, SEER, and SLIM, can predict testing costs for each test stage and then aggregate overall testing effort and expenses for any kind or size of software project. These same tools and others within this class can also predict testing defect-removal efficiency levels.
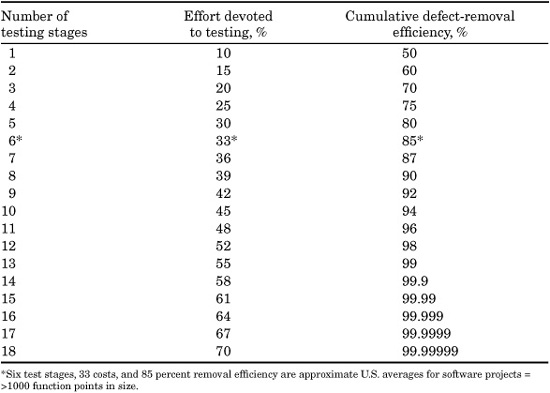
There are too many variables involved for a static representation in a published table or graph to be really accurate. Therefore, for the purposes of this book, a major simplifying assumption will be used. The assumption is that the proportion of total software effort devoted to testing correlates exactly with the number of test stages that are utilized. This assumption has a few exceptions, but seems to work well enough to have practical value.
The percentages shown in Table 20.12 for testing are based on the total development budget for the software project in question.
The same table also shows the approximate defect-removal efficiency correlated with number of test stages for coding defects. Here, too, as the number of test stages grows larger, defect-removal efficiency levels increase. The essential message is that if you want to approach zero-defect levels, be prepared to perform quite a few testing stages.
TABLE 20.12 Number of Testing Stages, Testing Effort, and Defect-Removal Efficienc
This simplified approach is not accurate enough for serious project planning or for contracts, but it shows overall trends well enough to make the economic picture understandable.
This table also explains why large systems have higher testing costs than small applications, and why systems and military software have higher testing costs than information systems: More testing stages are utilized.
Note, however, that the table does not show the whole picture (which is why commercial estimating tools are recommended). For example, if formal pre-test design and code inspections are also utilized, they alone can approach 80 percent in defect-removal efficiency and also raise the efficiency of testing.
Thus, projects that utilize formal inspections plus testing can top 99 percent in cumulative defect-removal efficiency with fewer stages than shown here, since this table illustrates only testing. See Chapters 16 and 18 for additional information.
There is no shortage of historical data that indicates that formal inspections continue to be one of the most powerful software defect-removal operations since the software industry began.
Testing by Developers or by Professional Test Personnel
One of the major questions concerning software testing is who should do it. The possible answers to this question include:
![]() The developers themselves
The developers themselves
![]() Professional test personnel
Professional test personnel
![]() Professional quality-assurance personnel
Professional quality-assurance personnel
![]() Some combination of the three
Some combination of the three
Note that several forms of testing, such as external beta testing and customer-acceptance testing, are performed by clients themselves or by consultants that the clients hire to do the work.
There is no definitive answer to this question, but some empirical observations may be helpful.
![]() The defect-removal efficiency of almost all forms of testing is higher when performed by test personnel or by quality-assurance personnel rather than by the developers themselves. The only exceptions are subroutine and unit tests.
The defect-removal efficiency of almost all forms of testing is higher when performed by test personnel or by quality-assurance personnel rather than by the developers themselves. The only exceptions are subroutine and unit tests.
![]() For usability problems, testing by clients themselves outranks all other forms of testing.
For usability problems, testing by clients themselves outranks all other forms of testing.
![]() The defect-removal efficiency of specialized kinds of testing, such as special date testing or viral protection testing, is highest when performed by professional test personnel rather than by the developers themselves.
The defect-removal efficiency of specialized kinds of testing, such as special date testing or viral protection testing, is highest when performed by professional test personnel rather than by the developers themselves.
Table 20.13 shows the author’s observations of who typically performs various test stages from among SPR’s client organizations. Note that since SPR’s clients include quite a few systems software, military software, and commercial software vendors, there probably is a bias in the data. The systems, commercial, and military software domains are much more likely to utilize the services of professional testing and quality-assurance (QA) personnel than are the MIS and outsource domains.
The table is sorted in descending order of the development column. Note that this order illustrates that the early testing is most often performed by development personnel, but the later stages of testing are most often performed by testing or quality-assurance specialists.
As can be seen from this table, among SPR’s clients testing by developers and testing by professional test personnel are equal in frequency, followed by testing involving software quality-assurance personnel, and, finally, testing by customers or their designated testers.
TABLE 20.13 Observations on Performance of Test Stages by Occupation Group
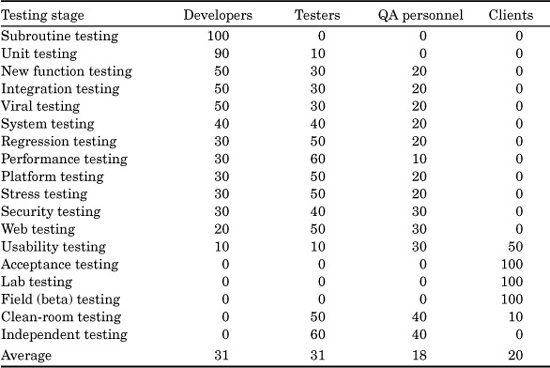
Testing by development personnel is much more common for the smaller forms of testing, such as subroutine and unit testing. Testing by development personnel is also more common for the Agile development methods and for XP. For the larger forms (i.e., system testing) and for the specialized forms (i.e., performance testing, stress testing, etc.), testing by professional test personnel or by quality-assurance personnel become more common.
Testing should be part of a synergistic and integrated suite of defect-prevention and defect-removal operations that may include prototyping, quality-assurance reviews, pretest inspections, formal test planning, multistage testing, and measurement of defect levels and severities.
For those who have no empirical data on quality, the low average defect-removal efficiency levels of most forms of testing will be something of a surprise. However, it is because each testing step is less than 100 percent efficient that multiple test stages are necessary in the first place.
Testing is an important technology for software. For many years, progress in testing primarily occurred within the laboratories of major corporations who built systems software. However, in recent years a new sub-industry of commercial testing tool and testing-support companies has appeared. This new sub-industry is gradually improving software test capabilities as the commercial vendors of testing tools and methodologies compete within a fast-growing market for test-support products and services.
Test Case Coverage
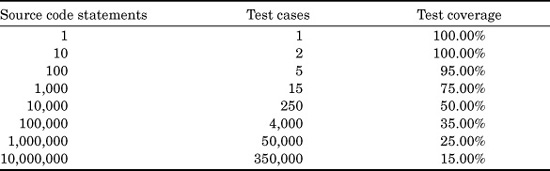
One of the reasons that test stages only average about 30 percent in defect-removal efficiency is because testing does not actually cover all of the code in large applications. It is theoretically possible to test every instruction in a software application for applications up to about 1000 logical statements in size. Above that size, testing coverage declines sharply.
Table 20.14 shows the approximate relationships between volumes of source code, numbers of test cases, and test coverage or the percentage of code actually tested when running the test case suite.
What happens, of course, is that as applications get larger in size the number of paths through the code grows geometrically. It is not economically feasible to write enough test cases to cover all of the paths and every individual instruction in really large software applications.
Also, other factors tend to drive up the numbers of test cases too. Software that is high in cyclomatic and essential complexity will need more test cases for a given number of source code statements than would the same volume of code with lower complexity scores.
There is no simple method for predicting number of test cases, number of test runs, and number of bugs that will be detected and need repairs. The rules for predicting these variables are numerous and complex, and this is why automated estimating tools usually outperform individual project managers and quality-assurance personnel.
The Factors That Affect Testing Performance
The key factors that affect testing from the point of view of estimating test schedules, costs, and efficiency levels include the following:
![]() The number of bugs or defects in the application being testing
The number of bugs or defects in the application being testing
![]() The number of test stages selected for the application
The number of test stages selected for the application
TABLE 20.14 Application Size, Test Cases, and Test Coverage
![]() The structure of the application, measured with cyclomatic and essential complexity
The structure of the application, measured with cyclomatic and essential complexity
![]() The test-tool suite available to the testing personnel
The test-tool suite available to the testing personnel
![]() The training and experience of the testing personnel
The training and experience of the testing personnel
![]() Whether or not precursor code inspections were utilized
Whether or not precursor code inspections were utilized
![]() The amount of time allotted to testing in project schedules
The amount of time allotted to testing in project schedules
![]() The number of defects found during each test stage
The number of defects found during each test stage
![]() The method used to route defects to the appropriate repair team
The method used to route defects to the appropriate repair team
![]() Interruptions that might occur during testing or defect repairs
Interruptions that might occur during testing or defect repairs
Unfortunately, these ten factors tend to be independent variables and each of them can vary significantly. It is interesting to bracket the possible outcomes by means of best-case, expected-case, and worst-case scenarios for a generic application of 1000 function points or 100,000 procedural source code statements.
The best-case scenario would comprise a combination of experienced test personnel with very sophisticated test tools performing a sequence of at least eight test stages on software that is well structured and low in defects.
The forms of testing used in the best-case scenario would include (at a minimum) subroutine testing, unit testing, new function testing, regression testing, integration testing, system testing, performance testing, and external testing. Note that with the best-case scenario, there is a high probability that formal inspections would also have been utilized.
The expected-case scenario would include moderately experienced personnel using a few test tools, such as record/playback tools and test execution monitors, performing half a dozen test stages on fairly well structured code that contains a moderate quantity of defects. The forms of testing used would include subroutine testing, unit testing, new function testing, regression testing, system testing, and external testing.
The worst-case scenario would consist of inexperienced test personnel with few test tools, attempting to test a very buggy, poorly structured application under tremendous schedule pressure.
However, under the worst-case scenario it is likely that only five kinds of testing might be performed: subroutine testing, unit testing, new function testing, system testing, and external testing.
References
Beizer, Boris: Software Testing Techniques, Van Nostrand Reinhold, New York, 1988. Black, Rex: Managing the Testing Process, Second Edition, Wiley, Indianapolis, Indiana, 2002.
———: Black Box Testing, IEEE Computer Society Press, Los Alamitos, Calif., 1995.
Boehm, Barry: Software Engineering Economics, Prentice-Hall, Englewood Cliffs, N.J., 1981.
Brown, Norm (ed.): The Program Manager’s Guide to Software Acquisition Best Practices, Version 1.0, U.S. Department of Defense, Washington, D.C., July 1995.
DeMarco, Tom: Controlling Software Projects, Yourdon Press, New York, 1982.
Department of the Air Force: Guidelines for Successful Acquisition and Management of Software Intensive Systems, vols. 1 and 2, Software Technology Support Center, Hill Air Force Base, Utah, 1994.
Dreger, Brian: Function Point Analysis, Prentice-Hall, Englewood Cliffs, N.J., 1989.
Dustin, Elfriede, Jeff Rashka, and John Paul: Automated Software Testing: Introduction, Management, and Performance, Addison-Wesley, Boston, Mass., 1999.
Grady, Robert B.: Practical Software Metrics for Project Management and Process Improvement, Prentice-Hall, Englewood Cliffs, N.J., 1992.
———, and Deborah L. Caswell: Software Metrics: Establishing a Company-Wide Program, Prentice-Hall, Englewood Cliffs, N.J., 1987.
Howard, Alan (ed.): Software Testing Tools, Applied Computer Research (ACR), Phoenix, Ariz., 1997.
Hutchinson, Marnie L.: Software Testing Methods and Metrics, McGraw-Hill, New York, 1997.
———: Software Testing Fundamentals, Wiley, 2003.
Jones, Capers: New Directions in Software Management, Information Systems Management Group, Carlsbad, California 1993.
———: Assessment and Control of Software Risks, Prentice-Hall, Englewood Cliffs, N.J.,1994.
———: Patterns of Software System Failure and Success, International Thomson Computer Press, Boston, Mass., 1995.
———: Applied Software Measurement, Second Edition, McGraw-Hill, New York, 1996a.
———: Table of Programming Languages and Levels (8 Versions from 1985 through July 1996), Software Productivity Research, Burlington, Mass., 1996.
———: The Economics of Object-Oriented Software, Software Productivity Research, Burlington, Mass., April 1997a.
———: Software Quality—Analysis and Guidelines for Success, International Thomson Computer Press, Boston, Mass., 1997b.
———: The Year 2000 Software Problem—Quantifying the Costs and Assessing the Consequences, Addison-Wesley, Reading, Mass., 1998.
———: Software Assessments, Benchmarks, and Best Practices, Addison-Wesley Longman, Boston, Mass., 2000.
———: Conflict and Litigation Between Software Clients and Developers, Software Productivity Research, Burlington, Mass., 2003.
Kan, Stephen H.: Metrics and Models in Software Quality Engineering, Second Edition, Addison-Wesley Longman, Boston, Mass., 2003.
Kaner, C., J. Faulk, and H. Q. Nguyen: Testing Computer Software, International Thomson Computer Press, Boston, Mass., 1997.
Kaner, Cem, James Bach, and Bret Pettichord: Lessons Learned in Software Testing, Wiley, Indianapolis, Indiana, 2001.
Linegaard, G.: Usability Testing and System Evaluation, International Thomson Computer Press, Boston, Mass., 1997.
Love, Tom: Object Lessons, SIGS Books, New York, 1993.
Marciniak, John J. (ed.): Encyclopedia of Software Engineering, vols. 1 and 2, John Wiley & Sons, New York, 1994.
McCabe, Thomas J.: “A Complexity Measure,” IEEE Transactions on Software Engineering, December 1976, pp. 308–320.
Mills, H., M. Dyer, and R. Linger: “Cleanroom Software Engineering,” IEEE Software, 4, 5 (Sept. 1987), pp. 19–25.
Mosley, Daniel J.: The Handbook of MIS Application Software Testing, Yourdon Press/Prentice-Hall, Englewood Cliffs, N.J., 1993.
Perry, William: Effective Methods for Software Testing, IEEE Computer Society Press, Los Alamitos, Calif., 1995.
Pressman, Roger: Software Engineering—A Practitioner’s Approach, Sixth Edition, McGraw-Hill, New York, 2005.
Putnam, Lawrence H.: Measures for Excellence—Reliable Software on Time, Within Budget, Yourdon Press/Prentice-Hall, Englewood Cliffs, N.J., 1992.
———, and Ware Myers: Industrial Strength Software—Effective Management Using Measurement, IEEE Press, Los Alamitos, Calif., 1997.
Rethinking the Software Process, CD-ROM, Miller Freeman, Lawrence, Kans., 1996. (This CD-ROM is a book collection jointly produced by the book publisher, Prentice-Hall, and the journal publisher, Miller Freeman. It contains the full text and illustrations of five Prentice-Hall books: Assessment and Control of Software Risks by Capers Jones; Controlling Software Projects by Tom DeMarco; Function Point Analysis by Brian Dreger; Measures for Excellence by Larry Putnam and Ware Myers; and Object-Oriented Software Metrics by Mark Lorenz and Jeff Kidd.)
Symons, Charles R.: Software Sizing and Estimating—Mk II FPA (Function Point Analysis), John Wiley & Sons, Chichester, U.K., 1991.
Whittaker, James: How to Break Software: A Practical Guide to Testing, Addison-Wesley, Boston, Mass., 2002.