
CHAPTER 8
![]()
Working with Textual Data
Chapters 2 and 3 introduced the F# type for strings. While F#’s specialty is in programming with structured data, unstructured or semi-structured textual data are exceptionally common in programming, both as a data format and as working representation internally in algorithms that work over documents and text. In this section, you will learn some of the techniques available for working with textual data in F# programs, including working with the XML and JSON structured data formats, which are initially represented as text.
Building Strings and Formatting Data
In Chapter 3, you saw the different forms of string literals (strings with escape characters and verbatim strings) and the most typical operations, such as concatenation using string builders. You may also remember that string values are immutable and that string operations that seem to change their input actually return a new string that represents the result. The following sections cover further ways to work with strings.
Building Strings
In Chapter 3, you saw how the + operator is one simple tool for building strings, and you saw a number of simple string literals. You can also build strings using objects of the type System.Text.StringBuilder. These objects are mutable buffers that you can use to accumulate and modify text, and they’re more efficient than repeated uses of the + operator. Here’s an example:
> let buf = new System.Text.StringBuilder();;
val buf : System.Text.StringBuilder
> buf.Append("Humpty Dumpty");;
> buf.Append(" sat on the wall");;
> buf.ToString();;
val it : string = "Humpty Dumpty sat on the wall"
More about String Literals
The F# type string is an abbreviation for the type System.String and represents a sequence of Unicode UTF-16 characters. The following sections briefly introduce strings and the most useful functions for formatting them. Table 8-1 shows the different forms for writing string literals.

As shown in Table 8-1, a literal form is also available for arrays of bytes: the characters are interpreted as ASCII characters, and non-ASCII characters can be embedded using escape codes. This can be useful when you’re working with binary protocols. Verbatim string literals are particularly useful for file and path names that contain the backslash character ():
> "MAGIC"B;;
val it : byte [] = [|77uy; 65uy; 71uy; 73uy; 67uy|]
> let dir = @"c:Program Files";;
val dir : string = "c:Program Files"
> let text = """I "like" you""";;
val text : string = "I "like" you"
Triple-quote string literals can contain both embedded quotation marks (“) and backslashes () without escape, and include all the text until the terminating triple quote. You can also use multiline string literals:
> let s = "All the kings horses
- and all the kings men";;
val s : string = " All the kings horses
and all the kings men"
> let s2 = """All the kings' "horses"
- and all the kings men""";;
val s2 : string = "All the kings' "horses"
- and all the kings men"
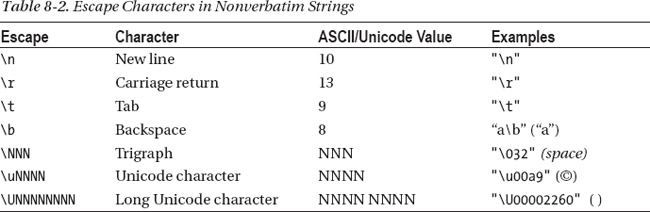
Table 8-2 shows the escape characters you can use in strings and characters.
Using printf and Friends
Throughout this book, you’ve used the printfn function, which is one way to print strings from F# values. This is a powerful, extensible technique for type-safe formatting. A related function called sprintf builds strings:
> sprintf "Name: %s, Age: %d" "Anna" 3;;
val it : string = "Name: Anna, Age: 3"
The format strings accepted by printf and sprintf are recognized and parsed by the F# compiler, and their use is statically type checked to ensure that the arguments given for the formatting holes are consistent with the formatting directives. For example, if you use an integer where a string is expected, you see a type error:
> sprintf "Name: %s, Age: %d" 3 10;;
error FS0001: This expression was expected to have type
string
but here has type
int
Several printf-style formatting functions are provided in the Microsoft.FSharp.Text.Printf module. Table 8-3 shows the most important of these.
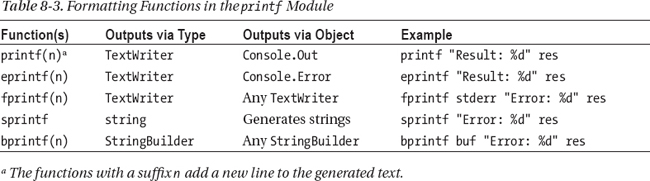
Table 8-4 shows the basic formatting codes for printf-style formatting.

Any value can be formatted using a %O or %A pattern; these patterns are extremely useful when you’re prototyping or examining data. %O converts the object to a string using the Object.ToString() function supported by all values. For example:
// The formatting of dates and times varies by region.
> System.DateTime.Now.ToString();;
val it : string = "28/06/20.. 17:14:07 PM"
> sprintf "It is now %O" System.DateTime.Now;;
val it : string = "It is now 28/06/20... 17:14:09"
![]() Note The format strings used with
Note The format strings used with printf are scanned by the F# compiler during type checking, which means the use of the formats are type safe; if you forget arguments, a warning is given, and if your arguments are of the wrong type, an error is given. The format strings may also include the usual range of specifiers for padding and alignment used by languages such as C, as well as some other interesting specifiers for computed widths and precisions. You can find the full details in the F# library documentation for the Printf module.
Generic Structural Formatting
Object.ToString() is a somewhat undirected way of formatting data. Structural types—such as tuples, lists, records, discriminated unions, collections, arrays, and matrices—are often poorly formatted by this technique. The %A pattern uses .NET reflection to format any F# value as a string based on the structure of the value. For example:
> printf "The result is %A
" [1; 2; 3];;
The result is [1; 2; 3]
Generic structural formatting can be extended to work with any user-defined data types, a topic covered on the F# Web site. This is covered in detail in the F# library documentation for the printf function.
Formatting Strings Using .NET Formatting
Throughout this book, you’ve used F# printf format strings to format text and output; Chapter 4 and the section above introduced the basic format specifiers for this kind of text formatting. Functions such as printf and printfn are located in the Microsoft.FSharp.Text.Printf module.
Another way to format strings is to use the System.String.Format static method or the other .NET composite formatting functions, such as System.Console.WriteLine and TextWriter.WriteLine. This is a distinct set of formatting functions and directives redesigned and implemented from the ground up for the .NET platform. Like printf, these methods take a format specifier and the objects to be formatted. The format specifier is a string with any number of format items acting as placeholders and designating which object is to be formatted and how. Consider this simple example:
> System.String.Format("{0} {1} {2}", 12, "a", 1.23);;
val it : string = "12 a 1.23"
Each format item is enclosed in braces giving the index of the object to be formatted, and each can include an optional alignment specification (always preceded by a comma after the index, giving the width of the region in which the object is to be inserted, as in {0, 10}) and a format type that guides how the given object is formatted (as in {0:C}, where C formats as a system currency). The general syntax of the format item is:
{index[,alignment][:formatType]}
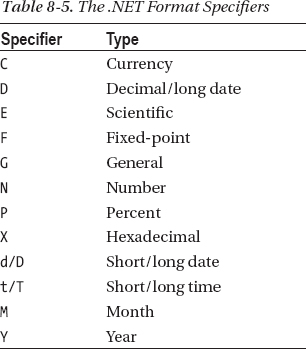
You can use the alignment value to pad the formatted object with spaces; text alignment is left if its value is negative and right if positive. Table 8-5 summarizes the most-often-used format types.
You can find more information about .NET composite formatting at www.expert-fsharp.com/Topics/TextFormatting.
Parsing Strings and Textual Data
Parsing Basic Values
The following session shows some sample uses of the DateTime type:
> open System;;
> DateTime.Parse("13 July 1968");;
val it : DateTime = 13/07/1968 00:00:00
> let date x = DateTime.Parse(x);;
val date : x:string -> DateTime
> printfn "date = %A" (date "13 July 1968");;
date = 13/07/1968 00:00:00
> printfn "birth = %A" (date "18 March 2003, 6:21:01pm");;
birth = 18/03/2003 18:21:01
Note that formatting dates depends on the user’s localization settings; you can achieve more explicit formatting by using the System.DateTime.ToString overload that accepts explicit format information.
Here you use the System.Uri type to parse a URL:
> open System;;
> Uri.TryCreate("http://www.thebritishmuseum.ac.uk/", UriKind.Absolute);;
val it : bool * Uri =
(true,
http://www.thebritishmuseum.ac.uk/)
> Uri.TryCreate("e3£%//ww.gibberish.com", UriKind.Absolute);;
val it : bool * Uri = (false, null)
Processing Line-Based Input
A common, simple case of parsing and lexing occurs when you’re working with an existing line-based, text-file format. In this case, parsing is often as easy as splitting each line of input at a particular separator character and trimming whitespace off the resulting partial strings:
> let line = "Smith, John, 20 January 1986, Software Developer";;
val line : string = "Smith, John, 20 January 1986, Software Developer"
> line.Split ',';;
val it : string [] = [|"Smith"; " John"; " 20 January 1986"; " Software Developer"|]
> line.Split ',' |> Array.map (fun s -> s.Trim());;
val it : string [] = [|"Smith"; "John"; "20 January 1986"; "Software Developer"|]
You can then process each column in the data format:
let splitLine (line : string) =
line.Split [|','|] |> Array.map (fun s -> s.Trim())
let parseEmployee (line : string) =
match splitLine line with
| [|last; first; startDate; title|] ->
last, first, System.DateTime.Parse(startDate), title
| _ ->
failwithf "invalid employee format: '%s'" line
The type of this function is:
val parseEmployee : line:string -> string * string * DateTime * string
Here is an example use:
> parseEmployee line;;
val it : string * string * DateTime * string
= ("Smith", "John", 20/01/1986 00:00:00 { ... }, "Software Developer")
You can now use on-demand reading of files to turn a file into an on-demand sequence of results. The following example takes the first three entries from an artificially generated file containing 10,000 copies of the same employee, sets up a processing pipeline for the lines of the file, and then truncates that to the first three elements.
open System.IO
File.WriteAllLines("employees.txt", Array.create 10000 line)
let readEmployees (fileName : string) =
fileName |> File.ReadLines |> Seq.map parseEmployee
let firstThree = readEmployees "employees.txt" |> Seq.truncate 3 |> Seq.toList
> firstThree |> Seq.iter (fun (last, first, startDate, title) ->
printfn "%s %s started on %A" first last startDate);;
John Smith started on 20/01/1986 00:00:00
John Smith started on 20/01/1986 00:00:00
John Smith started on 20/01/1986 00:00:00
This technique often is used to do exploratory analysis of large data files. After the algorithm is refined using a prefix of the data, the analysis can then be run directly over the full data file by removing the Seq.truncate 3 step.
Using Regular Expressions to Parse Lines
Another technique that’s frequently used to extract information from strings is to use regular expressions. The System.Text.RegularExpressions namespace provides convenient string-matching and -replacement functions. For example, let’s say you have a log file containing a record of HTML GET requests. Here is a sample request:
GET /favicon.ico HTTP/1.1
The following code captures the name of the requested resource (favicon.ico) and the lower version number of the HTML protocol (1) used:
open System.Text.RegularExpressions
let parseHttpRequest line =
let result = Regex.Match(line, @"GET (.*?) HTTP/1.([01])$")
let file = result.Groups.[1].Value
let version = result.Groups.[2].Value
file, version
The relevant fields are extracted by using the Groups attribute of the regular expression match to access the matched strings for each parenthesized group in the regular expression.
More on Matching with System.Text.RegularExpressions
One of the most popular ways of working with strings as data is through the use of regular expressions. You do this using the functionality from the .NET System.Text.RegularExpressions namespace. To get started, first note that the F# library includes the following definition:
open System.Text.RegularExpressions
let regex s = new Regex(s)
To this, you can add the following Perl-like operators:
let (=~) s (re:Regex) = re.IsMatch(s)
let (<>~) s (re:Regex) = not (s =~ re)
Here, the inferred types are:
val regex : s:string -> Regex
val ( =~ ) : s:string -> re:Regex -> bool
val ( <>~ ) : s:string -> re:Regex -> bool
The infix operators allow you to test for matches:
> let samplestring = "This is a string";;
val samplestring : string = "This is a string"
> if samplestring =~ regex "his" then
printfn "A Match! ";;
A Match!
Regular expressions can include *, +, and ? symbols for zero or more occurrences, one or more occurrences, and zero or one occurrences of the immediately preceding regular expression, respectively, and they can include parentheses to group regular expressions. For example:
> "This is a string" =~ regex "(is )+";;
val it : bool = true
Regular expressions also can be used to split strings:
> regex(" ").Split("This is a string");;
val it : string [] = [|"This"; "is"; "a"; "string"|]
Here, you use the regular expression " " for whitespace. In reality, you probably want to use the regular expression " +" to match multiple spaces. Better still, you can match any Unicode whitespace character using s, including end-of-line markers. When using escape characters, however, you should use verbatim strings to specify the regular expression, such as @"s+". Let’s try:
> regex(@"s+").Split("I'm a little teapot");;
val it : string [] = [|"I'm"; "a"; "little"; "teapot"|]
> regex(@"s+").Split("I'm a little
teapot");;
val it : string [] = [|"I'm"; "a"; "little"; "teapot"|]
Here’s how to match by using the method Match instead of using =~ and IsMatch. This lets you examine the positions of a match:
> let m = regex("joe").Match("maryjoewashere");;
val m : Match = joe
> if m.Success then
printfn "Matched at position %d" m.Index;;
Matched at position 4
Replacing text is also easy:
> let text = "was a dark and stormy night";;
val text : string = "was a dark and stormy night"
> let t2 = regex(@"w+").Replace(text, "WORD");;
val t2: string = "WORD WORD WORD WORD WORD WORD"
Here, you use the regular expression "w+" for a sequence of word characters.
Table 8-6 shows the broad range of specifiers you can use with .NET regular expressions.


You can specify case-insensitive matches by using (?i) at the start of a regular expression:
> samplestring =~ regex "(?i)HIS";;
val it : bool = true
> samplestring =~ regex "HIS";;
val it : bool = false
This final example shows the use of named groups:
let entry = @"
Jolly Jethro
13 Kings Parade
Cambridge, Cambs CB2 1TJ
"
let re =
regex @"(?<=
)s*(?<city>[^
]+)s*,s*(?<county>w+)s+(?<pcode>.{3}s*.{3}).*$"
You can now use this regular expression to match the text and examine the named elements of the match:
> let r = re.Match(entry);;
val r : Match = Cambridge, Cambs CB2 1TJ
> r.Groups.["city"].Value;;
val it : string = "Cambridge"
> r.Groups.["county"].Value;;
val it : string = "Cambs"
> r.Groups.["pcode"].Value;;
val it : string = "CB2 1TJ"
You can also combine regular expression matching with active patterns, which are described in Chapter 9. For example:
let (|IsMatch|_|) (re : string) (inp : string) =
if Regex(re).IsMatch(inp) then Some() else None
This active pattern can now be used as:
> match "This is a string" with
| IsMatch "(?i)HIS" -> "yes, it matched"
| IsMatch "ABC" -> "this would not match"
| _ -> "nothing matched"
val it : string = "yes, it matched "
Likewise, you can define functions or active patterns that extract and return named results from the match:
let firstAndSecondWord (inp : string) =
let re = regex "(?<word1>w+)s+(?<word2>w+)"
let results = re.Match(inp)
if results.Success then
Some (results.Groups.["word1"].Value, results.Groups.["word2"].Value)
else
None
> firstAndSecondWord "This is a super string"
val it : (string * string) option = Some ("This", "is")
The string-based lookup of group names “word1” and “word2” in the result set is a little dissatisfying in a strongly typed language, and there are a couple of things you can do to improve this. First, you can use the dynamic operator, described in Chapter 17, to make the lookups slightly more natural. This code requires
let (?) (results : Match) (name : string) =
results.Groups.[name].Value
let firstAndSecondWord (inp : string) =
let re = regex "(?<word1>w+)s+(?<word2>w+)"
let results = re.Match(inp)
if results.Success then
Some (results ? word1, results ? word2)
else
None
![]() Note .NET regular expressions have many more features than those described here. For example, you can compile regular expressions to make them match very efficiently. You can also use regular expressions to define sophisticated text substitutions.
Note .NET regular expressions have many more features than those described here. For example, you can compile regular expressions to make them match very efficiently. You can also use regular expressions to define sophisticated text substitutions.
Encoding and Decoding Unicode Strings
It’s often necessary to convert string data between different formats. For example, files read using the ReadLine method on the System.IO.StreamReader type are read with respect to a Unicode encoding. You can specify this when creating the StreamReader. If left unspecified, the .NET libraries attempt to determine the encoding for you.
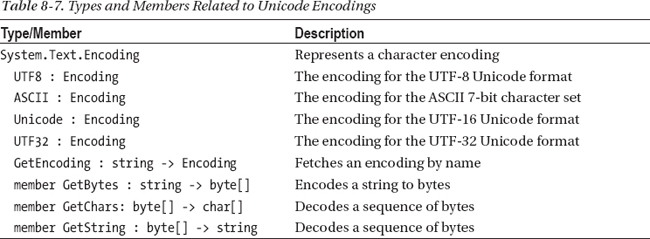
One common requirement is to convert strings to and from ASCII representations, assuming that all the characters in the strings are in the ASCII range 0 to 127. You can do this using System.Text.Encoding.ASCII.GetString and System.Text.Encoding.ASCII.GetBytes. Table 8-7 shows the predefined encodings and commonly used members in the System.Text.Encoding type.
Encoding and Decoding Binary Data
Another common requirement is to convert binary data to and from the standard 64-character, string-encoded representation of binary data used in XML, e-mail, and other formats. You can do this using System.Convert.FromBase64String and System.Convert.ToBase64String.
Using XML as a Concrete Language Format
One common source of structured data in a textual format is the data formatted in the Extensible Markup Language (XML). F# comes with well-engineered libraries for reading and generating XML, which you can use to manipulate a typed abstract representation of an XML document in memory, without having to worry about parsing/generating strings corresponding to the XML.
Using the System.Xml Namespace
XML is a general-purpose markup language; it is extensible, because it allows its users to define their own tags. Its primary purpose is to facilitate the sharing of data across different information systems, particularly via the Internet. Here is a sample fragment of XML, defined as a string directly in F#:
let inp = """<?xml version="1.0" encoding="utf-8" ?>
<Scene>
<Composite>
<Circle radius='2' x='1' y='0'/>
<Composite>
<Circle radius='2' x='4' y='0'/>
<Square side='2' left='-3' top='0'/>
</Composite>
<Ellipse top='2' left='-2' width='3' height='4'/>
</Composite>
</Scene>"""
The backbone of an XML document is a hierarchical structure, and each node is decorated with attributes keyed by name. You can parse XML using the types and methods in the System.Xml namespace provided by the .NET libraries and then examine the structure of the XML interactively:
> open System.Xml;;
> let doc = new XmlDocument();;
val doc : XmlDocument
> doc.LoadXml(inp);;
val it : unit = ()
> doc.ChildNodes;;
val it : XmlNodeList =
seq [seq []; seq [seq [seq []; seq [seq []; seq []]; seq []]]]
The default F# Interactive display for the XmlNode type isn’t particularly useful. Luckily, you can add an interactive printer to the fsi.exe session using the AddPrinter method on the fsi object:
> fsi.AddPrinter(fun (x:XmlNode) -> x.OuterXml);;
> doc.ChildNodes;;
val it : XmlNodeList =
seq
[<?xml version="1.0" encoding="utf-8"?>;
<Scene><Composite><Circle radius="2" x="1" y="0" /><Composite>...</Scene>]
> doc.ChildNodes.Item(1);;
val it : XmlNode =
<Scene><Composite><Circle radius="2" x="1" y="0" /><Composite>...</Scene>
> doc.ChildNodes.Item(1).ChildNodes.Item(0);;
val it : XmlNode =
<Composite><Circle radius="2" x="1" y="0" />...</Composite>
> doc.ChildNodes.Item(1).ChildNodes.Item(0).ChildNodes.Item(0);;
val it : XmlNode = <Circle radius="2" x="1" y="0" />
> doc.ChildNodes.Item(1).ChildNodes.Item(0).ChildNodes.Item(0).Attributes;;
val it : XmlAttributeCollection = seq [radius="2"; x="1"; y="0"]
Table 8-8 shows the most commonly used types and members from the System.Xml namespace.

From Concrete XML to Abstract Syntax
Often, your first task in processing a concrete language is to bring the language fragments under the type discipline of F#. This section shows how to transform the data contained in the XML from the previous section into an instance of the recursive type shown here. This kind of type is usually called an abstract syntax tree (AST):
open System.Drawing
type Scene =
| Ellipse of RectangleF
| Rect of RectangleF
| Composite of Scene list
This example uses the types PointF and RectangleF from the System.Drawing namespace, although you can equally define your own types to capture the information carried by the leaves of the tree. Listing 8-1 shows a recursive transformation to convert XML documents like the one used in the previous section into the type Scene.
Listing 8-1. Converting XML into a Typed Format Using the System.Xml Namespace
open System.Xml
open System.Drawing
type Scene =
| Ellipse of RectangleF
| Rect of RectangleF
| Composite of Scene list
/// A derived constructor
static member Circle(center : PointF, radius) =
Ellipse(RectangleF(center.X - radius, center.Y - radius,
radius * 2.0f, radius * 2.0f))
/// A derived constructor
static member Square(left, top, side) =
Rect(RectangleF(left, top, side, side))
/// Extract a number from an XML attribute collection
let extractFloat32 attrName (attribs : XmlAttributeCollection) =
float32 (attribs.GetNamedItem(attrName).Value)
/// Extract a Point from an XML attribute collection
let extractPointF (attribs : XmlAttributeCollection) =
PointF(extractFloat32 "x" attribs, extractFloat32 "y" attribs)
/// Extract a Rectangle from an XML attribute collection
let extractRectangleF (attribs : XmlAttributeCollection) =
RectangleF(extractFloat32 "left" attribs, extractFloat32 "top" attribs,
extractFloat32 "width" attribs, extractFloat32 "height" attribs)
/// Extract a Scene from an XML node
let rec extractScene (node : XmlNode) =
let attribs = node.Attributes
let childNodes = node.ChildNodes
match node.Name with
| "Circle" ->
Scene.Circle(extractPointF(attribs), extractFloat32 "radius" attribs)
| "Ellipse" ->
Scene.Ellipse(extractRectangleF(attribs))
| "Rectangle" ->
Scene.Rect(extractRectangleF(attribs))
| "Square" ->
Scene.Square(extractFloat32 "left" attribs, extractFloat32 "top" attribs,
extractFloat32 "side" attribs)
| "Composite" ->
Scene.Composite [for child in childNodes -> extractScene(child)]
| _ -> failwithf "unable to convert XML '%s'" node.OuterXml
/// Extract a list of Scenes from an XML document
let extractScenes (doc : XmlDocument) =
[for node in doc.ChildNodes do
if node.Name = "Scene" then
yield (Composite
[for child in node.ChildNodes -> extractScene(child)])]
The inferred types of these functions are:
type Scene =
| Ellipse of RectangleF
| Rect of RectangleF
| Composite of Scene list
with
static member Circle : center:PointF * radius:float32 -> Scene
static member Square : left:float32 * top:float32 * side:float32 -> Scene
end
val extractFloat32 :
attrName:string -> attribs:XmlAttributeCollection -> float32
val extractPointF : attribs:XmlAttributeCollection -> PointF
val extractRectangleF : attribs:XmlAttributeCollection -> RectangleF
val extractScene : node:XmlNode -> Scene
val extractScenes : doc:XmlDocument -> Scene list
The definition of extractScenes in Listing 8-1 generates lists using sequence expressions, which are covered in Chapter 3. You can now apply the extractScenes function to the original XML. (You first add a pretty-printer to the F# Interactive session for the RectangleF type using the AddPrinter function on the fsi object.)
> fsi.AddPrinter(fun (r:RectangleF) ->
sprintf "[%A,%A,%A,%A]" r.Left r.Top r.Width r.Height);;
> extractScenes doc;;
val it : Scene list
= [Composite
[Composite
[Ellipse [-1.0f,-2.0f,4.0f,4.0f];
Composite [Ellipse [2.0f,-2.0f,4.0f,4.0f]; Rect [-3.0f,0.0f,2.0f,2.0f]];
Ellipse [-2.0f,2.0f,3.0f,4.0f]]]]
The following sections more closely explain some of the choices we’ve made in the abstract syntax design for the type Scene.
![]() Tip Translating to a typed representation isn’t always necessary: some manipulations and analyses are better performed directly on heterogeneous, general-purpose formats, such as XML or even on strings. For example, XML libraries support XPath, accessed via the
Tip Translating to a typed representation isn’t always necessary: some manipulations and analyses are better performed directly on heterogeneous, general-purpose formats, such as XML or even on strings. For example, XML libraries support XPath, accessed via the SelectNodes method on the XmlNode type. If you need to query a large, semistructured document whose schema is frequently changing in minor ways, using XPath is the right way to do it. Likewise, if you need to write a significant amount of code that interprets or analyzes a tree structure, converting to a typed abstract syntax tree is usually better.
Some Recursive Descent Parsing
Sometimes, you want to tokenize and parse a nonstandard language format, such as XML or JSON. The typical task is to parse the user input into your internal representation by breaking down the input string into a sequence of tokens (“lexing”) and then constructing an instance of your internal representation based on a grammar (“parsing”). Lexing and parsing don’t have to be separated, and there are often convenient .NET methods for extracting information from text in particular formats, as shown in this chapter. Nevertheless, it’s often best to treat the two processes separately.
In this section, you implement a simple tokenizer and parser for a language of polynomial expressions for input text fragments, such as
x^5 – 2x^3 + 20
or
x + 3
The aim is simply to produce a structured value that represents the polynomial to permit subsequent processing. For example, this may be necessary when writing an application that performs simple symbolic differentiation—say, on polynomials only. You want to read polynomials, such as x^5 - 2x^3 + 20, as input from your users, which in turn is converted to your internal polynomial representation so that you can perform symbolic differentiation and pretty-print the result to the screen. One way to represent polynomials is as a list of terms that are added or subtracted to form the polynomial:
type Term =
| Term of int * string * int
| Const of int
type Polynomial = Term list
For instance, the polynomial x^5 – 2x^3 + 20 is represented as:
[Term (1,"x",5); Term (-2,"x",3); Const 20]
A Simple Tokenizer
First, you implement a tokenizer for the input, using regular expressions:
Listing 8-2. Tokenizer for Polynomials Using Regular Expressions
type Token =
| ID of string
| INT of int
| HAT
| PLUS
| MINUS
let tokenR = regex @"((?<token>(d+|w+|^|+|-))s*)*"
let tokenize (s : string) =
[for x in tokenR.Match(s).Groups.["token"].Captures do
let token =
match x.Value with
| "^" -> HAT
| "-" -> MINUS
| "+" -> PLUS
| s when System.Char.IsDigit s.[0] -> INT (int s)
| s -> ID s
yield token]
The inferred type of the function is:
val tokenize : s:string -> Token list
We can now test the tokenizer on some sample inputs:
> tokenize "x^5 - 2x^3 + 20";;
val it : Token list =
[ID "x"; HAT; INT 5; MINUS; INT 2; ID "x"; HAT; INT 3; PLUS; INT 20]
The tokenizer works by simply matching the entire input string, and for each text captured by the labeled “token” pattern, we yield an appropriate token depending on the captured text.
Recursive-Descent Parsing
You can now turn your attention to parsing. In Listing 8-2, you built a lexer and a token type suitable for generating a token stream for the input text (shown as a list of tokens here):
Listing 8-3 shows a recursive-decent parser that consumes this token stream and converts it into the internal representation of polynomials. The parser works by generating a lazy list for the token stream. Lazy lists are a data structure in the F# library module Microsoft.FSharp.Collections.LazyList, and they’re a lot like sequences, with one major addition—lazy lists effectively allow you to pattern-match on a sequence and return a residue lazy list for the tail of the sequence.
Listing 8-3. Recursive-descent Parser for Polynomials
type Term =
| Term of int * string * int
| Const of int
type Polynomial = Term list
type TokenStream = Token list
let tryToken (src : TokenStream) =
match src with
| tok :: rest -> Some(tok, rest)
| _ -> None
let parseIndex src =
match tryToken src with
| Some (HAT, src) ->
match tryToken src with
| Some (INT num2, src) ->
num2, src
| _ -> failwith "expected an integer after '^'"
| _ -> 1, src
let parseTerm src =
match tryToken src with
| Some (INT num, src) ->
match tryToken src with
| Some (ID id, src) ->
let idx, src = parseIndex src
Term (num, id, idx), src
| _ -> Const num, src
| Some (ID id, src) ->
let idx, src = parseIndex src
Term(1, id, idx), src
| _ -> failwith "end of token stream in term"
let rec parsePolynomial src =
let t1, src = parseTerm src
match tryToken src with
| Some (PLUS, src) ->
let p2, src = parsePolynomial src
(t1 :: p2), src
| _ -> [t1], src
let parse input =
let src = tokenize input
let result, src = parsePolynomial src
match tryToken src with
| Some _ -> failwith "unexpected input at end of token stream!"
| None -> result
The functions here have these types (using the type aliases you defined):
val tryToken : src:TokenStream -> (Token * Token list) option
val parseIndex : src:TokenStream -> int * Token list
val parseTerm : src:TokenStream -> Term * Token list
val parsePolynomial : src:TokenStream -> Term list * Token list
val parse : input:string -> Term list
Note in the previous examples that you can successfully parse either constants or complete terms, but after you locate a HAT symbol, a number must follow. This sort of parsing, in which you look only at the next token to guide the parsing process, is referred to as LL(1), which stands for left-to-right, leftmost derivation parsing; 1 means that only one look-ahead symbol is used. To conclude, you can look at the parse function in action:
> parse "1+3";;
val it : Term list = [Const 1; Const 3]
> parse "2x^2+3x+5";;
val it : Term list = [Term (2,"x",2); Term (3,"x",1); Const 5]
Binary Parsing and Formatting
One final case of parsing is common when working with binary data. That is, say you want to work with a format that is conceptually relatively easy to parse and generate (such as a binary format) but in which the process of actually writing the code to crack and encode the format is somewhat tedious. This section covers a useful set of techniques to write readers and writers for binary data quickly and reliably.
The running example shows a set of pickling (also called marshalling) and unpickling combinators to generate and read a binary format of our design. You can easily adapt the combinators to work with existing binary formats, such as those used for network packets. Picklers and unpicklers for different data types are function values that have signatures as follows:
type OutState = System.IO.BinaryWriter
type InState = System.IO.BinaryReader
type Pickler<'T> = 'T -> OutState -> unit
type Unpickler<'T> = InState -> 'T
Here, OutState and InState are types that record information during the pickling or unpickling process. In this section, these are just binary readers and writers; more generally, they can be any type that can collect information and help compact the data during the writing process, such as by ensuring that repeated strings are given unique identifiers during the pickling process.
At the heart of every such library lies a set of primitive leaf functions for the base cases of aggregate data structures. For example, when you’re working with binary streams, this is the usual set of primitive read/write functions:
// P is the suffix for pickling and U is the suffix for unpickling
let byteP (b : byte) (st : OutState) = st.Write(b)
let byteU (st : InState) = st.ReadByte()
You can now begin to define additional pickler/unpickler pairs:
let boolP b st = byteP (if b then 1uy else 0uy) st
let boolU st = let b = byteU st in (b = 1uy)
let int32P i st =
byteP (byte (i &&& 0xFF)) st
byteP (byte ((i >>> 8) &&& 0xFF)) st
byteP (byte ((i >>> 16) &&& 0xFF)) st
byteP (byte ((i >>> 24) &&& 0xFF)) st
let int32U st =
let b0 = int (byteU st)
let b1 = int (byteU st)
let b2 = int (byteU st)
let b3 = int (byteU st)
b0 ||| (b1 <<< 8) ||| (b2 <<< 16) ||| (b3 <<< 24)
These functions have the following types (to keep output readable, Pickler and Unpickler types are used in the output instead of their expanded version that is reported by F# Interactive):
val byteP : Pickler<byte>
val byteU : Unpickler<byte>
val boolP : Pickler<bool>
val boolU : Unpickler<bool>
val int32P : Pickler<int>
val int32U : Unpickler<int>
So far, so simple. One advantage of this approach comes as you write combinators that put these together in useful ways. For example, for tuples:
let tup2P p1 p2 (a, b) (st : OutState) =
(p1 a st : unit)
(p2 b st : unit)
let tup3P p1 p2 p3 (a, b, c) (st : OutState) =
(p1 a st : unit)
(p2 b st : unit)
(p3 c st : unit)
let tup2U p1 p2 (st : InState) =
let a = p1 st
let b = p2 st
(a, b)
let tup3U p1 p2 p3 (st : InState) =
let a = p1 st
let b = p2 st
let c = p3 st
(a, b, c)
and for lists:
/// Outputs a list into the given output stream by pickling each element via f.
/// A zero indicates the end of a list, a 1 indicates another element of a list.
let rec listP f lst st =
match lst with
| [] -> byteP 0uy st
| h :: t -> byteP 1uy st; f h st; listP f t st
// Reads a list from a given input stream by unpickling each element via f.
let listU f st =
let rec loop acc =
let tag = byteU st
match tag with
| 0uy -> List.rev acc
| 1uy -> let a = f st in loop (a :: acc)
| n -> failwithf "listU: found number %d" n
loop []
These functions conform to the types:
val tup2P : Pickler<'a> -> Pickler<'b> -> Pickler<'a * 'b>
val tup3P : Pickler<'a> -> Pickler<'b> -> Pickler<'c> -> Pickler<'a * 'b * 'c>
val tup2U : Unpickler<'a> -> Unpickler<'b> -> Unpickler<'a * 'b>
val tup3U : Unpickler<'a> -> Unpickler<'b> -> Unpickler<'c> -> Unpickler<'a* 'b* 'c>
val listP : Pickler<'a> -> Pickler<'a list>
val listU : Unpickler<'a> -> Unpickler<'a list>
It’s now beginning to be easy to pickle and unpickle aggregate data structures using a consistent format. For example, imagine that the internal data structure is a list of integers and Booleans:
type format = list<int32 * bool>
let formatP = listP (tup2P int32P boolP)
let formatU = listU (tup2U int32U boolU)
open System.IO
let writeData file data =
use outStream = new BinaryWriter(File.OpenWrite(file))
formatP data outStream
let readData file =
use inStream = new BinaryReader(File.OpenRead(file))
formatU inStream
You can now invoke the pickle/unpickle process:
> writeData "out.bin" [(102, true); (108, false)] ;;
val it : unit = ()
> readData "out.bin";;
val it : (int * bool) list = [(102, true); (108, false)]
Combinator-based pickling is a powerful technique that can be taken well beyond what has been shown here. For example, it’s possible to:
- Ensure data are compressed and shared during the pickling process by keeping tables in the input and output states. Sometimes this requires two or more phases in the pickling and unpickling process.
- Build in extra-efficient primitives that compress leaf nodes, such as writing out all integers using
BinaryWriter.Write7BitEncodedIntandBinaryReader.Read7BitEncodedInt.- Build extra combinators for arrays, sequences, and lazy values and for lists stored in binary formats other than the 0/1 tag scheme used here.
- Build combinators that allow dangling references to be written to the pickled data, usually written as a symbolic identifier. When the data are read, the identifiers must be resolved and relinked, usually by providing a function parameter that performs the resolution. This can be a useful technique when processing independent compilation units.
Combinator-based pickling is used mainly because it allows data formats to be created and read in a relatively bug-free manner. It isn’t always possible to build a single pickling library suitable for all purposes, and you should be willing to customize and extend code samples, such as those listed previously, in order to build a set of pickling functions suitable for your needs.
![]() Note Combinator-based parsing borders on a set of techniques called parser combinators that we don’t cover in this book. The idea is very much the same as the combinators presented here; parsing is described using a compositional set of functions. You also can write parser combinators using the workflow notation described in Chapter 17.
Note Combinator-based parsing borders on a set of techniques called parser combinators that we don’t cover in this book. The idea is very much the same as the combinators presented here; parsing is described using a compositional set of functions. You also can write parser combinators using the workflow notation described in Chapter 17.
Summary
In this chapter, you explored several topics related to working with textual data. You learned about formatting text using both F# type-safe formatting and .NET formatting, some simple techniques to parse data to primitive types, and the basics of working with regular expressions. You also learned how to work with XML as a concrete text format for structured data. Finally, you learned how to use recursive descent parsing and some combinator-based approaches for generating and reading binary data to/from structured data types. The next chapter goes deeper into working with structured data itself using the strongly typed functional-programming facilities of .NET.