
CHAPTER 11
![]()
Reactive, Asynchronous, and Parallel Programming
So far in this book, you've seen functions and objects that process their inputs immediately using a single thread of execution in which the code runs to completion and produces useful results or state changes. In this chapter, you turn your attention to concurrent, parallel, asynchronous, and reactive programs. These represent substantially different approaches to programming from those you've seen so far. Some reasons for turning to these techniques are:
- To achieve better responsiveness in a graphical user interface (GUI)
- To report progress results during a long-running computation and to support cancellation of these computations
- To achieve greater throughput in a reactive application or service
- To achieve faster processing rates on a multiprocessor machine or cluster
- To take advantage of the I/O parallelism available in modern disk drives or network connections
- To sustain processing while network and disk I/O operations are in process
This chapter covers some techniques that can help achieve these outcomes:
- Using threads and the
BackgroundWorkerclass for background computations- Using events and messages to report results back to a GUI
- Using F# asynchronous workflows and the “thread pool” to handle network requests and other asynchronous I/O operations
- Using F# pattern matching to process message queues
- Using low-level shared-memory primitives to implement new concurrency techniques and control access to mutable data structures
In Chapter 2, you saw a very simple sample of the most common type of reactive programs: GUI programs that respond to events raised on the GUI thread. The inner loop of such an application (contained in the Windows Forms library) spends most of its time blocked and waiting for the underlying operating system to notify it of a relevant event, such as a click from the user or a timer event from the operating system. This notification is received as an event in a message queue. Many GUI programs have only a single thread of execution, so all computation happens on the GUI thread. This can lead to problems, such as nonresponsive user interfaces. This is one of many reasons it's important to master some techniques of concurrent and asynchronous programming.
Introducing Some Terminology
Let's begin by looking more closely at some terminology:
- Processes are, in the context of this chapter, standard operating system (OS) processes. Each instance of the .NET Common Language Runtime (CLR) runs in its own process, and multiple instances of the .NET CLR are often running on the same machine.
- Threads are, in the context of this chapter, standard .NET threads. On most implementations of .NET, these correspond to operating system threads. Each .NET process has many threads running within the one process.
- Concurrent programs are ones with multiple threads of execution, each typically executing different code, or at different execution points within the same code. Simultaneous execution may be simulated by scheduling and descheduling the threads, which is done by the OS. For example, most OS services and GUI applications are concurrent.
- Parallel programs are one or more processes or threads executing simultaneously. For example, many modern microprocessors have two or more physical CPUs capable of executing processes and threads in parallel. Parallel programs can also be data parallel. For example, a massively parallel device, such as a graphics processor unit (GPU), can process arrays and images in parallel. Parallel programs can also be a cluster of computers on a network, communicating via message passing. Historically, some parallel scientific programs have even used e-mail for communication.
- Asynchronous programs perform requests that don't complete immediately but that are fulfilled at a later time and where the program issuing the request has to do meaningful work in the meantime. For example, most network I/O is inherently asynchronous. A web crawler is also a highly asynchronous program, managing hundreds or thousands of simultaneous network requests.
- Reactive programs are ones whose normal mode of operation is to be in a state of waiting for some kind of input, such as waiting for user input or for input from a message queue via a network socket. For example, GUI applications and web servers are reactive programs.
Parallel, asynchronous, concurrent, and reactive programs bring many challenges. For example, these programs are nearly always nondeterministic. This makes debugging more challenging, because it's difficult to step through a program; even pausing a running program with outstanding asynchronous requests may cause timeouts. Most dramatically, incorrect concurrent programs may deadlock, which means that all threads are waiting for results from some other thread, and no thread can make progress. Programs may also livelock, in which processing is occurring and messages are being sent between threads, but no useful work is being performed.
Events
One recurring idiom in .NET programming (and, for example, JavaScript) is that of events. An event is something you can listen to by registering a callback with the event. For example, here's how you can create a WinForms form and listen to mouse clicks on the form:
> open System.Windows.Forms;;
> let form = new Form(Text = "Click Form", Visible = true, TopMost = true);;
val form : Form = System.Windows.Forms.Form, Text: Click Form
> form.Click.Add(fun evArgs -> printfn "Clicked!");;
When you run this code in F# Interactive, a window appears; and each time you click the window with the mouse, you see “Clicked!” printed to the console. In .NET terminology, form.Click is an event, and form.Click.Add registers an event handler, also known as callback, with the event. You can register multiple callbacks with the same event, and many objects publish many events. For example, when you add the following, you see a stream of output when you move the mouse over the form:
> form.MouseMove.Add(fun args -> printfn "Mouse, (X, Y) = (%A, %A)" args.X args.Y);;
If necessary, you can remove event handlers by first adding them using the AddHandler method and then removing them by using RemoveHandler.
The process of clicking the form triggers (or fires) the event, which means that the callbacks are called in the order they were registered. Events can't be triggered from the outside. In other words, you can't trigger the Click event on a form; you can only handle it. Events also have event arguments. In the first example shown previously, the event arguments are called evArgs, and they are ignored. .NET events usually pass arguments of type System.EventArgs or some related type, such as System.Windows.Forms.MouseEventArgs or System.Windows.Forms.PaintEventArgs. These arguments usually carry pieces of information. For example, a value of type MouseEventArgs has the properties Button, Clicks, Delta, Location, X, and Y.
![]() Note: NET event handlers also have an argument meant to bring information about the object source of the event. F# hides this argument in the process of making events first class and allowing their composition, as is explained later.
Note: NET event handlers also have an argument meant to bring information about the object source of the event. F# hides this argument in the process of making events first class and allowing their composition, as is explained later.
Events occur throughout the design of the .NET class libraries. Table 11-1 shows some of the more important events.
Table 11-1. A selection of events from the .NET libraries


Events as First-Class Values
In F#, an event such as form.Click is a first-class value, which means you can pass it around like any other value. The main advantage this brings is that you can use the combinators in the F# library module Microsoft.FSharp.Control.Event to map, filter, and otherwise transform the event stream in compositional ways. For example, the following code filters the event stream from form.MouseMove so that only events with X > 100 result in output to the console:
form.MouseMove
|> Event.filter (fun args -> args.X > 100)
|> Event.listen (fun args -> printfn "Mouse, (X, Y) = (%A, %A)" args.X args.Y)
If you work with events a lot, you find yourself factoring out useful portions of code into functions that preprocess event streams. Table 11-2 shows some functions from the F# Event module. One interesting combinator is Event.partition, which splits an event into two events based on a predicate.

Creating and Publishing Events
As you write code in F#, particularly object-oriented code, you need to implement, publish, and trigger events. The normal idiom for doing this is to call new Event<_>(). Listing 11-1 shows how to define an event object that is triggered at random intervals.
Listing 11-1. Creating a RandomTicker that defines, publishes, and triggers an event
open System
open System.Windows.Forms
type RandomTicker(approxInterval) =
let timer = new Timer()
let rnd = new System.Random(99)
let tickEvent = new Event<int> ()
let chooseInterval() : int =
approxInterval + approxInterval / 4 - rnd.Next(approxInterval / 2)
do timer.Interval <- chooseInterval()
do timer.Tick.Add(fun args ->
let interval = chooseInterval()
tickEvent.Trigger interval;
timer.Interval <- interval)
member x.RandomTick = tickEvent.Publish
member x.Start() = timer.Start()
member x.Stop() = timer.Stop()
interface IDisposable with
member x.Dispose() = timer.Dispose()
Here's how you can instantiate and use this type:
> let rt = new RandomTicker(1000);;
val rt : RandomTicker
> rt.RandomTick.Add(fun nextInterval -> printfn "Tick, next = %A" nextInterval);;
> rt.Start();;
Tick, next = 1072
Tick, next = 927
Tick, next = 765
...
> rt.Stop();;
Events are idioms understood by all .NET languages. F# event values are immediately compiled in the idiomatic .NET form. This is because F# allows you to go one step further and use events as first-class values. If you need to ensure that your events can be used by other .NET languages, do both of the following:
- Create the events using
new Event<DelegateType, Args>instead ofnew Event<Args>.- Publish the event as a property of a type with the
[<CLIEvent>]attribute.
Events are used in most of the later chapters of this book, and you can find many examples there.
![]() Note: Because events allow you to register callbacks, it's sometimes important to be careful about the thread on which an event is being raised. This is particularly true when you're programming with multiple threads or the .NET thread pool. Events are usually fired on the GUI thread of an application.
Note: Because events allow you to register callbacks, it's sometimes important to be careful about the thread on which an event is being raised. This is particularly true when you're programming with multiple threads or the .NET thread pool. Events are usually fired on the GUI thread of an application.
Using and Designing Background Workers
One of the easiest ways to get going with concurrency and parallelism is to use the System.ComponentModel.BackgroundWorker class of the .NET Framework. A BackgroundWorker class runs on its own dedicated operating system thread. These objects can be used in many situations, but they are especially useful for coarse-grained concurrency and parallelism, such as checking the spelling of a document in the background. This section shows some simple uses of BackgroundWorker and how to build similar objects that use BackgroundWorker internally.
Listing 11-2 shows a simple use of BackgroundWorker that computes the Fibonacci numbers on the worker thread.
Listing 11-2. A simple BackgroundWorker
open System.ComponentModel
open System.Windows.Forms
let worker = new BackgroundWorker()
let numIterations = 1000
worker.DoWork.Add(fun args ->
let rec computeFibonacci resPrevPrev resPrev i =
// Compute the next result
let res = resPrevPrev + resPrev
// At the end of the computation write the result into mutable state
if i = numIterations then
args.Result <- box res
else
// Compute the next result
computeFibonacci resPrev res (i + 1)
computeFibonacci 1 1 2)
worker.RunWorkerCompleted.Add(fun args ->
MessageBox.Show(sprintf "Result = %A" args.Result) |> ignore)
// Execute the worker
worker.RunWorkerAsync()
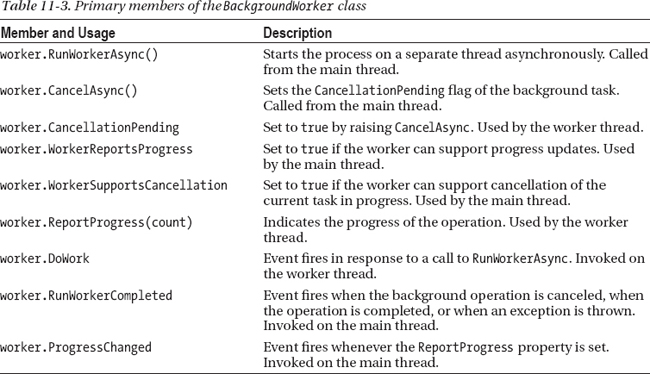
Table 11-3 shows the primary members of a BackgroundWorker object. The execution sequence of the code in Listing 11-2 is:
- The main application thread creates and configures a
BackgroundWorkerobject. - After configuration is complete, the main application thread calls the
RunWorkerAsyncmethod on theBackgroundWorkerobject. This causes theDoWorkevent to be raised on the worker thread. - The
DoWorkevent handler is executed in the worker thread and computes the 1,000th Fibonacci number. At the end of the computation, the result is written intoargs.Result, a mutable storage location, in the event arguments for theDoWorkevent. TheDoWorkevent handler then completes. - At some point after the
DoWorkevent handler completes, theRunWorkerCompletedevent is automatically raised on the main application thread. This displays a message box with the result of the computation, retrieved from theargsfield of the event arguments.
![]() Note: An object such as a
Note: An object such as a BackgroundWorker is two-faced: it has some methods and events that are for use from the main thread and some that are for use on the worker thread. This is common in concurrent programming. In particular, understand which thread an event is raised on. For BackgroundWorker, the RunWorkerAsync and CancelAsync methods are for use from the GUI thread, and the ProgressChanged and RunWorkerCompleted events are raised on the GUI thread. The DoWork event is raised on the worker thread, and the ReportProgress method and the CancellationPending property are for use from the worker thread when handling this event.
The members in Table 11-3 show two additional facets of BackgroundWorker objects: they can optionally support protocols for both cancellation and for reporting progress. To report progress percentages, a worker must call the ReportProgress method, which raises the ProgressChanged event in the GUI thread. For cancellation, a worker computation need only check the CancellationPending property at regular intervals, exiting the computation as a result.
Building a Simpler Iterative Worker
Capturing common control patterns, such as cancellation and progress reporting, is an essential part of mastering concurrent programming. One problem with .NET classes such as BackgroundWorker, however, is that they're often more imperative than you may want, and they force other common patterns to be captured by using mutable data structures shared between threads. This leads to the more difficult topic of shared-memory concurrency, discussed later in this chapter. Furthermore, the way BackgroundWorker handles cancellation means that you must insert flag-checks and early-exit paths in the executing background process. Finally, BackgroundWorker isn't useful for background threads that perform asynchronous operations, because the background thread exits too early, before the callbacks for the asynchronous operations have executed.
For this reason, it can often be useful to build abstractions that are similar to BackgroundWorker but that capture richer or different control patterns, preferably in a way that doesn't rely on the use of mutable state and that interferes less with the structure of the overall computation. Much of the rest of this chapter looks at various techniques to build these control structures.
You start with a case study in which you build a type IterativeBackgroundWorker that represents a variation on the BackgroundWorker design pattern. Listing 11-3 shows the code.
Listing 11-3. A variation on the BackgroundWorker design pattern for iterative computations
open System.ComponentModel
open System.Windows.Forms
/// An IterativeBackgroundWorker follows the BackgroundWorker design pattern
/// but instead of running an arbitrary computation it iterates a function
/// a fixed number of times and reports intermediate and final results.
/// The worker is paramaterized by its internal state type.
///
/// Percentage progress is based on the iteration number. Cancellation checks
/// are made at each iteration. Implemented via an internal BackgroundWorker.
type IterativeBackgroundWorker<'T>(oneStep : ('T -> 'T),
initialState : 'T,
numIterations : int) =
let worker = new BackgroundWorker(WorkerReportsProgress = true,
WorkerSupportsCancellation = true)
// Create the events that we will later trigger
let completed = new Event<_>()
let error = new Event<_>()
let cancelled = new Event<_>()
let progress = new Event<_>()
do worker.DoWork.Add(fun args ->
// This recursive function represents the computation loop.
// It runs at "maximum speed", i.e., is an active rather than
// a reactive process, and can only be controlled by a
// cancellation signal.
let rec iterate state i =
// At the end of the computation, terminate the recursive loop
if worker.CancellationPending then
args.Cancel <- true
elif i < numIterations then
// Compute the next result
let state' = oneStep state
// Report the percentage computation and the internal state
let percent = int ((float (i + 1) / float numIterations) * 100.0)
do worker.ReportProgress(percent, box state);
// Compute the next result
iterate state' (i + 1)
else
args.Result <- box state
iterate initialState 0)
do worker.RunWorkerCompleted.Add(fun args ->
if args.Cancelled then cancelled.Trigger()
elif args.Error <> null then error.Trigger args.Error
else completed.Trigger (args.Result :?> 'T))
do worker.ProgressChanged.Add(fun args ->
progress.Trigger (args.ProgressPercentage,(args.UserState :?> 'T)))
member x.WorkerCompleted = completed.Publish
member x.WorkerCancelled = cancelled.Publish
member x.WorkerError = error.Publish
member x.ProgressChanged = progress.Publish
// Delegate the remaining members to the underlying worker
member x.RunWorkerAsync() = worker.RunWorkerAsync()
member x.CancelAsync() = worker.CancelAsync()
The types inferred for the code in Listing 11-3 are:
type IterativeBackgroundWorker<'T> =
class
new : oneStep:('T -> 'T) * initialState:'T * numIterations:int ->
IterativeBackgroundWorker<'T>
member CancelAsync : unit -> unit
member RunWorkerAsync : unit -> unit
member ProgressChanged : IEvent<int * 'T>
member WorkerCancelled : IEvent<unit>
member WorkerCompleted : IEvent<'T>
member WorkerError : IEvent<exn>
end
Let's look at this signature first, because it represents the design of the type. The worker constructor is given a function of type 'State -> 'State to compute successive iterations of the computation, plus an initial state and the number of iterations to compute. For example, you can compute the Fibonacci numbers using the iteration function:
let fibOneStep (fibPrevPrev : bigint, fibPrev) = (fibPrev, fibPrevPrev + fibPrev);;
The type of this function is:
val fibOneStep :
fibPrevPrev:bigint * fibPrev:Numerics.BigInteger ->
Numerics.BigInteger * Numerics.BigInteger
The RunWorkerAsync and CancelAsync members follow the BackgroundWorker design pattern, as do the events, except that you expand the RunWorkerCompleted event into three events to correspond to the three termination conditions and modify the ProgressChanged to include the state. You can instantiate the type as:
> let worker = new IterativeBackgroundWorker<_>(fibOneStep, (1I, 1I), 100);;
val worker : IterativeBackgroundWorker<bigint * Numerics.BigInteger>
> worker.WorkerCompleted.Add(fun result ->
MessageBox.Show(sprintf "Result = %A" result) |> ignore);;
> worker.ProgressChanged.Add(fun (percentage, state) ->
printfn "%d%% complete, state = %A" percentage state);;
> worker.RunWorkerAsync();;
1% complete, state = (1I, 1I)
2% complete, state = (1I, 2I)
3% complete, state = (2I, 3I)
4% complete, state = (3I, 5I)
...
98% complete, state = (135301852344706746049I, 218922995834555169026I)
99% complete, state = (218922995834555169026I, 354224848179261915075I)
100% complete, state = (354224848179261915075I, 573147844013817084101I)
One difference here is that cancellation and percentage progress reporting are handled automatically, based on the iterations of the computation. This is assuming that each iteration takes roughly the same amount of time. Other variations on the BackgroundWorker design pattern are possible. For example, reporting percentage completion of fixed tasks such as installation is often performed by timing sample executions of the tasks and adjusting the percentage reports appropriately.
![]() Note: You implement
Note: You implement IterativeBackgroundWorker via delegation rather than inheritance. This is because its external members are different from those of BackgroundWorker. The .NET documentation recommends that you use implementation inheritance for this, but we disagree. Implementation inheritance can only add complexity to the signature of an abstraction and never makes things simpler, whereas an IterativeBackgroundWorker is in many ways simpler than using a BackgroundWorker, despite the fact that it uses an instance of the latter internally. Powerful, compositional, simple abstractions are the primary building blocks of functional programming.
Raising Additional Events from Background Workers
Often, you need to raise additional events from objects that follow the BackgroundWorker design pattern. For example, let's say you want to augment IterativeBackgroundWorker to raise an event when the worker starts its work and for this event to pass the exact time that the worker thread started as an event argument. Listing 11-4 shows the extra code you need to add to the IterativeBackgroundWorker type to make this happen. You use this extra code in the next section.
Listing 11-4. Code to raise GUI-thread events from an IterativeBackgroundWorker object
open System
open System.Threading
// Pseudo-code for adding event-raising to this object
type IterativeBackgroundWorker<'T>(...) =
let worker = ...
// The constructor captures the synchronization context. This allows us to post
// messages back to the GUI thread where the BackgroundWorker was created.
let syncContext = SynchronizationContext.Current
do if syncContext = null then failwith "no synchronization context found"
let started = new Event<_>()
// Raise the event when the worker starts. This is done by posting a message
// to the captured synchronization context.
do worker.DoWork.Add(fun args ->
syncContext.Post(SendOrPostCallback(fun _ -> started.Trigger(DateTime.Now)),
state = null)
...
/// The Started event gets raised when the worker starts. It is
/// raised on the GUI thread (i.e. in the synchronization context of
/// the thread where the worker object was created).
// It has type IEvent<DateTime>
member x.Started = started.Publish
The simple way to raise additional events is often wrong. For example, it's tempting to create an event, arrange for it to be triggered, and publish it, as you would do for a GUI control. If you do that, however, you end up triggering the event on the background worker thread, and its event handlers run on that thread. This is dangerous, because most GUI objects, and many other objects, can be accessed only from the thread they were created on; this is a restriction enforced by most GUI systems.
![]() Note: One nice feature of the
Note: One nice feature of the BackgroundWorker class is that it automatically arranges to raise the RunWorkerCompleted and ProgressChanged events on the GUI thread. Listing 11-4 shows how to achieve this. Technically speaking, the extended IterativeBackgroundWorker object captures the synchronization context of the thread where it was created and posts an operation back to that synchronization context. A synchronization context is an object that lets you post operations back to another thread. For threads such as a GUI thread, this means that posting an operation posts a message through the GUI event loop.
Connecting a Background Worker to a GUI
To round off this section on the BackgroundWorker design pattern, Listing 11-5 shows the full code required to build a small application with a background worker task that supports cancellation and reports progress.
Listing 11-5. Connecting an IterativeBackgroundWorker to a GUI
open System.Drawing
open System.Windows.Forms
let form = new Form(Visible = true, TopMost = true)
let panel = new FlowLayoutPanel(Visible = true,
Height = 20,
Dock = DockStyle.Bottom,
BorderStyle = BorderStyle.FixedSingle)
let progress = new ProgressBar(Visible = false,
Anchor = (AnchorStyles.Bottom ||| AnchorStyles.Top),
Value = 0)
let text = new Label(Text = "Paused",
Anchor = AnchorStyles.Left,
Height = 20,
TextAlign = ContentAlignment.MiddleLeft)
panel.Controls.Add(progress)
panel.Controls.Add(text)
form.Controls.Add(panel)
let fibOneStep (fibPrevPrev : bigint, fibPrev) = (fibPrev, fibPrevPrev + fibPrev)
// Run the iterative algorithm 500 times before reporting intermediate results
let rec repeatMultipleTimes n f s =
if n <= 0 then s else repeatMultipleTimes (n - 1) f (f s)
// Burn some additional cycles to make sure it runs slowly enough
let rec burnSomeCycles n f s =
if n <= 0 then f s else ignore (f s); burnSomeCycles (n - 1) f s
let step = (repeatMultipleTimes 500 (burnSomeCycles 1000 fibOneStep))
// Create the iterative worker.
let worker = new IterativeBackgroundWorker<_>(step, (1I, 1I), 80)
worker.ProgressChanged.Add(fun (progressPercentage, state)->
progress.Value <- progressPercentage)
worker.WorkerCompleted.Add(fun (_, result) ->
progress.Visible <- false;
text.Text <- "Paused";
MessageBox.Show(sprintf "Result = %A" result) |> ignore)
worker.WorkerCancelled.Add(fun () ->
progress.Visible <- false;
text.Text <- "Paused";
MessageBox.Show(sprintf "Cancelled OK!") |> ignore)
worker.WorkerError.Add(fun exn ->
text.Text <- "Paused";
MessageBox.Show(sprintf "Error: %A" exn) |> ignore)
form.Menu <- new MainMenu()
let workerMenu = form.Menu.MenuItems.Add("&Worker")
workerMenu.MenuItems.Add(new MenuItem("Run", onClick = (fun _ args ->
text.Text <- "Running";
progress.Visible <- true;
worker.RunWorkerAsync())))
workerMenu.MenuItems.Add(new MenuItem("Cancel", onClick = (fun _ args ->
text.Text <- "Cancelling";
worker.CancelAsync())))
form.Closed.Add(fun _ -> worker.CancelAsync())
When you run the code in F# Interactive, a window appears, as shown in Figure 11-1.
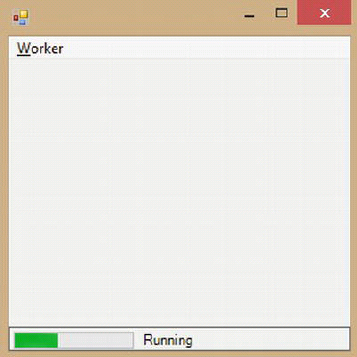
Figure 11-1. A GUI window with a BackgroundWorker reporting progress percentage
![]() Note: Forcibly aborting computations uncooperatively isn't recommended in .NET programming. You can attempt to do this using
Note: Forcibly aborting computations uncooperatively isn't recommended in .NET programming. You can attempt to do this using System.Threading.Thread.Abort(), but this may have many unintended consequences, discussed later in this chapter.
Introducing Asynchronous and Parallel Computations
The two background worker samples shown so far run at full throttle. In other words, the computations run on the background threads as active loops, and their reactive behavior is limited to flags that check for cancellation. In reality, background threads often have to do different kinds of work: by responding to completed asynchronous I/O requests, by processing messages, by sleeping, or by waiting to acquire shared resources. Fortunately, F# comes with a powerful set of techniques for structuring asynchronous programs in a natural way. These are called asynchronous workflows. The next three sections cover how to use asynchronous workflows to structure asynchronous and message-processing tasks in ways that preserve the essential logical structure of your code.
Fetching Multiple Web Pages in Parallel, Asynchronously
One of the most intuitive asynchronous tasks is fetching a Web page; we all use Web browsers that can fetch multiple pages simultaneously. The samples in Chapter 2 show how to fetch pages synchronously. This is useful for many purposes, but browsers and high-performance Web crawlers have tens or thousands of connections in flight at once.
The type Microsoft.FSharp.Control.Async<'T> lies at the heart of F# asynchronous workflows. A value of type Async<'T> represents a program fragment that will generate a value of type 'T at some point in the future. Listing 11-6 shows how to use asynchronous workflows to fetch several Web pages simultaneously.
Listing 11-6. Fetching three Web pages simultaneously
open System.Net
open System.IO
let museums = ["MOMA", "http://moma.org/";
"British Museum", "http://www.thebritishmuseum.ac.uk/";
"Prado", "http://www.museodelprado.es/"]
let fetchAsync(nm, url : string) = async {
printfn "Creating request for %s..." nm
let req = WebRequest.Create(url)
let! resp = req.AsyncGetResponse()
printfn "Getting response stream for %s..." nm
let stream = resp.GetResponseStream()
printfn "Reading response for %s..." nm
let reader = new StreamReader(stream)
let! html = reader.AsyncReadToEnd()
printfn "Read %d characters for %s..." html.Length nm}
Async.Parallel [for nm, url in museums -> fetchAsync(nm, url)]
|> Async.Ignore
|> Async.RunSynchronously
The types of these functions and values are:
val museums : (string * string) list
val fetchAsync : nm:string * url:string -> Async<unit>
When run on one of our machines via F# Interactive, the output of the code from Listing 11-6 is:
Creating request for MOMA...
Creating request for British Museum...
Creating request for Prado...
Getting response for MOMA...
Reading response for MOMA...
Getting response for Prado...
Reading response for Prado...
Read 188 characters for Prado...
Read 41635 characters for MOMA...
Getting response for British Museum...
Reading response for British Museum...
Read 24341 characters for British Museum...
The heart of the code in Listing 11-6 is the construct introduced by async { ... }. This is an application of the workflow syntax that is covered in Chapter 17.
Let's take a closer look at Listing 11-6. The key operations are the two let! operations within the workflow expression:
async { ...
let! resp = req.AsyncGetResponse()
...
let! html = reader.AsyncReadToEnd()
... }
Within asynchronous workflow expressions, the language construct let! var = expr in body means “perform the asynchronous operation expr and bind the result to var when the operation completes. Then, continue by executing the rest of the computation body.”
With this in mind, you can now see what fetchAsync does:
- It synchronously requests a Web page.
- It asynchronously awaits a response to the request.
- It gets the response
StreamandStreamReadersynchronously after the asynchronous request completes.- It reads to the end of the stream asynchronously.
- After the read completes, it prints the total number of characters read synchronously.
Finally, you use the method Async.RunSynchronously to initiate the execution of a number of asynchronous computations. This works by queueing the computations in the .NET thread pool. The following section explains the .NET thread pool in more detail.
Understanding Thread Hopping
Asynchronous computations are different from normal, synchronous computations: an asynchronous computation tends to hop between different underlying .NET threads. To see this, let's augment the asynchronous computation with diagnostics that show the ID of the underlying .NET thread at each point of active execution. You can do this by replacing uses of printfn in the function fetchAsync with uses of the function:
let tprintfn fmt =
printf "[.NET Thread %d]" System.Threading.Thread.CurrentThread.ManagedThreadId;
printfn fmt
After doing this, the output changes to:
[.NET Thread 12]Creating request for MOMA...
[.NET Thread 13]Creating request for British Museum...
[.NET Thread 12]Creating request for Prado...
[.NET Thread 8]Getting response for MOMA...
[.NET Thread 8]Reading response for MOMA...
[.NET Thread 9]Getting response for Prado...
[.NET Thread 9]Reading response for Prado...
[.NET Thread 9]Read 188 characters for Prado...
[.NET Thread 8]Read 41635 characters for MOMA...
[.NET Thread 8]Getting response for British Museum...
[.NET Thread 8]Reading response for British Museum...
[.NET Thread 8]Read 24341 characters for British Museum...
Note how each individual Async program hops between threads; the MOMA request started on .NET thread 12 and finished life on .NET thread 8. Each asynchronous computation in Listing 11-6 executes in the same way:
- It starts life as a work item in the .NET thread pool. (The .NET thread pool is explained in “What Is the .NET Thread Pool?” These are processed by a number of .NET threads.
- When the asynchronous computations reach the
AsyncGetResponseandAsyncReadToEndcalls, the requests are made, and the continuations are registered as I/O completion actions in the .NET thread pool. No thread is used while the request is in progress.- When the requests complete, they trigger a callback in the .NET thread pool. These may be serviced by threads other than those that originated the calls.
WHAT IS THE .NET THREAD POOL?
Under the Hood: What Are Asynchronous Computations?
Async<'T> values, the result of async workflows, are essentially a way of writing continuation-passing or callback programs explicitly. Continuations themselves were described in Chapter 9 along with techniques to pass them explicitly. Async<'T> computations call a success continuation when the asynchronous computation completes and an exception continuation if it fails. They provide a form of managed asynchronous computation, in which managed means that several aspects of asynchronous programming are handled automatically:
- Exception propagation is added for free: If an exception is raised during an asynchronous step, the exception terminates the entire asynchronous computation and cleans up any resources declared using
use, and the exception value is then handed to a continuation. Exceptions may also be caught and managed within the asynchronous workflow by usingtry/with/finally.- Cancellation checking is added for free: The execution of an
Async<'T>workflow automatically checks a cancellation flag at each asynchronous operation. Cancellation can be controlled through the use of cancellation tokens.- Resource lifetime management is fairly simple: You can protect resources across parts of an asynchronous computation by using
useinside the workflow syntax.
If you put aside the question of cancellation, values of type Async<'T> are effectively identical to the type:
type Async<'T> = Async of ('T -> unit) * (exn -> unit) -> unit
Here, the functions are the success continuation and exception continuations, respectively. Each value of type Async<'T> should eventually call one of these two continuations. The async object is of type AsyncBuilder and supports the following methods, among others:
type AsyncBuilder with
member Return : value: 'T -> Async<'T>
member Delay : generator:(unit -> Async<'T>) -> Async<'T>
member Using: resource:'T * binding:('T -> Async<'U>) -> Async<'U> when 'T :> System.IDisposable
member Bind: computation:Async<'T> * binder:('T -> Async<'U>) -> Async<'U>
The full definition of Async<'T> values and the implementations of these methods for the async object are given in the F# library source code. Builder objects, such as async, that contain methods like those shown previously mean that you can use the syntax async { ... } as a way of building Async<'T> values (see Chapter 17 for more on builder objects).
Table 11-4 shows the common constructs used in asynchronous workflow expressions. For example, the asynchronous workflow
async {let req = WebRequest.Create("http://moma.org/")
let! resp = req.AsyncGetResponse()
let stream = resp.GetResponseStream()
let reader = new StreamReader(stream)
let! html = reader.AsyncReadToEnd()
html}
is shorthand for the code
async.Delay(fun () ->
let req = WebRequest.Create("http://moma.org/")
async.Bind(req.AsyncGetResponse(), (fun resp ->
let stream = resp.GetResponseStream()
let reader = new StreamReader(stream)
async.Bind(reader.AsyncReadToEnd(), (fun html ->
async.Return html)))))
As you will see in Chapter 17, the key to understanding the F# workflow syntax is always to understand the meaning of let!. In the case of async workflows, let! executes one asynchronous computation and schedules the next computation for execution after the first asynchronous computation completes. This is syntactic sugar for the Bind operation on the async object.

Parallel File Processing Using Asynchronous Workflows
This section shows a slightly longer example of asynchronous I/O processing. The running sample is an application that must read a large number of image files and perform some processing on them. This kind of application may be compute bound (if the processing takes a long time and the file system is fast) or I/O bound (if the processing is quick and the file system is slow). Using asynchronous techniques tends to give good overall performance gains when an application is I/O bound and can also give performance improvements for compute-bound applications if asynchronous operations are executed in parallel on multicore machines.
Listing 11-7 shows a synchronous implementation of the image-transformation program.
Listing 11-7. A synchronous image processor
open System.IO
let numImages = 200
let size = 512
let numPixels = size * size
let makeImageFiles () =
printfn "making %d %dx%d images... " numImages size size
let pixels = Array.init numPixels (fun i -> byte i)
for i = 1 to numImages do
System.IO.File.WriteAllBytes(sprintf "Image%d.tmp" i, pixels)
printfn "done."
let processImageRepeats = 20
let transformImage (pixels, imageNum) =
printfn "transformImage %d" imageNum;
// Perform a CPU-intensive operation on the image.
for i in 1 .. processImageRepeats do
pixels |> Array.map (fun b -> b + 1uy) |> ignore
pixels |> Array.map (fun b -> b + 1uy)
let processImageSync i =
use inStream = File.OpenRead(sprintf "Image%d.tmp" i)
let pixels = Array.zeroCreate numPixels
let nPixels = inStream.Read(pixels,0,numPixels);
let pixels' = transformImage(pixels,i)
use outStream = File.OpenWrite(sprintf "Image%d.done" i)
outStream.Write(pixels',0,numPixels)
let processImagesSync () =
printfn "processImagesSync...";
for i in 1 .. numImages do
processImageSync(i)
You assume the image files already are created using the code:
> System.Environment.CurrentDirectory <- __SOURCE_DIRECTORY__;;
> makeImageFiles();;
You leave the transformation on the image largely unspecified, such as the function transformImage. By changing the value of processImageRepeats, you can adjust the computation from compute bound to I/O bound.
The problem with this implementation is that each image is read and processed sequentially, when in practice, multiple images can be read and transformed simultaneously, giving much greater throughput. Listing 11-8 shows the implementation of the image processor using an asynchronous workflow.
Listing 11-8. The asynchronous image processor
let processImageAsync i =
async {use inStream = File.OpenRead(sprintf "Image%d.tmp" i)
let! pixels = inStream.AsyncRead(numPixels)
let pixels' = transformImage(pixels, i)
use outStream = File.OpenWrite(sprintf "Image%d.done" i)
do! outStream.AsyncWrite(pixels')}
let processImagesAsync() =
printfn "processImagesAsync...";
let tasks = [for i in 1 .. numImages -> processImageAsync(i)]
Async.RunSynchronously (Async.Parallel tasks) |> ignore
printfn "processImagesAsync finished!"
On one of our machines, the asynchronous version of the code ran up to three times as fast as the synchronous version (in total elapsed time) when processImageRepeats is 20 and numImages is 200. A factor of 2 was achieved consistently for any number of processImageRepeats, because this machine had two CPUs.
Let's take a closer look at this code. The call Async.RunSynchronously (Async.Parallel ...) executes a set of asynchronous operations in the thread pool, collects their results (or their exceptions), and returns the overall array of results to the original code. The core asynchronous workflow is introduced by the async { ... } construct. Let's look at the inner workflow line by line:
async { use inStream = File.OpenRead(sprintf "Image%d.tmp" i)
... }
This line opens the input stream synchronously using File.OpenRead. Although this is a synchronous operation, the use of use indicates that the lifetime of the stream is managed over the remainder of the workflow. The stream is closed when the variable is no longer in scope—that is, at the end of the workflow, even if asynchronous activations occur in between. If any step in the workflow raises an uncaught exception, the stream is also closed while handling the exception.
The next line reads the input stream asynchronously using inStream.AsyncRead:
async { use inStream = File.OpenRead(sprintf "Image%d.tmp" i)
let! pixels = inStream.AsyncRead(numPixels)
... }Stream.AsyncRead is an extension method added to the .NET System.IO.Stream class defined in the F# library, and it generates a value of type Async<byte[]>. The use of let! executes this operation asynchronously and registers a callback. When the callback is invoked, the value pixels is bound to the result of the operation, and the remainder of the asynchronous workflow is executed. The next line transforms the image synchronously using transformImage:
async { use inStream = File.OpenRead(sprintf "Image%d.tmp" i)
let! pixels = inStream.AsyncRead(numPixels)
let pixels' = transformImage(pixels, i)
... }
Like the first line, the next line opens the output stream. Using use guarantees that the stream is closed by the end of the workflow regardless of whether exceptions are thrown in the remainder of the workflow:
async { use inStream = File.OpenRead(sprintf "Image%d.tmp" i)
let! pixels = inStream.AsyncRead(numPixels)
let pixels' = transformImage(pixels, i)
use outStream = File.OpenWrite(sprintf "Image%d.done" i)
... }
The final line of the workflow performs an asynchronous write of the image. Once again, AsyncWrite is an extension method added to the .NET System.IO.Stream class defined in the F# library:
async { use inStream = File.OpenRead(sprintf "Image%d.tmp" i)
let! pixels = inStream.AsyncRead(numPixels)
let pixels' = transformImage(pixels,i)
use outStream = File.OpenWrite(sprintf "Image%d.done" i)
do! outStream.AsyncWrite(pixels') }
If you now return to the first part of the function, you can see that the overall operation of the function is to create numImages individual asynchronous operations, using a sequence expression that generates a list:
let tasks = [ for i in 1 .. numImages -> processImageAsync(i) ]
You can compose these tasks in parallel using Async.Parallel and then run the resulting process using Async.RunSynchronously. This waits for the overall operation to complete and returns the result:
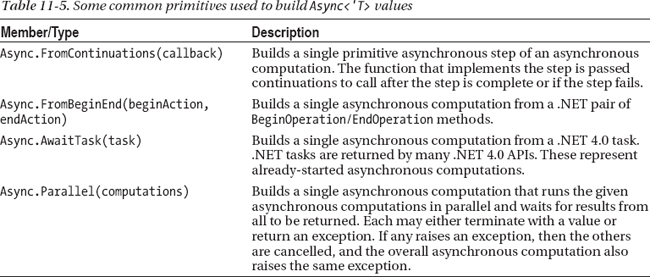
Table 11-5 shows some of the primitives and combinators commonly used to build asynchronous workflows. Take the time to compare Listings 11-8 and 11-7. Notice:
- The overall structure and flow of the core of Listing 11-8 is similar to Listing 11-7: that is, the synchronous algorithm, even though it includes steps executed asynchronously.
- The performance characteristics of Listing 11-8 are the same as those of Listing 11-7. Any overhead involved in executing the asynchronous workflow is easily dominated by the overall cost of I/O and image processing. It's also much easier to experiment with modifications, such as making the write operation synchronous.
Running Asynchronous Computations
Values of type Async<'T> are usually run using the functions listed in Table 11-6. You have seen samples of Async.RunSynchronoulsy earlier in this chapter.
The most important function in this list is Async.StartImmediate. This starts an asynchronous computation using the current thread to run the prefix of the computation. For example, if you start an asynchronous computation from a GUI thread, this will run the prefix of the computation on the GUI thread. This should be your primary way of starting asynchronous computations when doing GUI programming or when implementing server-side asynchronous processes using systems such as ASP.NET that have a dedicated “page handling” thread.


Common I/O Operations in Asynchronous Workflows
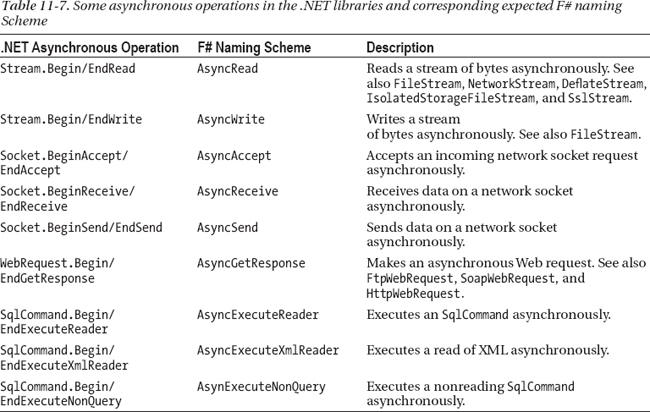
Asynchronous programming is becoming more widespread because of the use of multicore machines and networks in applications, and many .NET APIs now come with both synchronous and asynchronous versions of their functionality. For example, all Web-service APIs generated by .NET tools have asynchronous versions of their requests. A quick scan of the .NET API documentation on the Microsoft Web site reveals the asynchronous operations listed in Table 11-7. These all have equivalent Async<'T> operations defined in the F# libraries as extensions to the corresponding .NET types.
Sometimes, you may need to write a few primitives to map .NET asynchronous operations into the F# asynchronous framework. You will see some examples later in this section.
Using Tasks with Asynchronous Programming
In C# 5.0 and .NET 4.0, the .NET Framework was updated with asynchronous programming using tasks. Tasks represent already-started asynchronous computations, and many tasks are returned by many .NET 4.0 APIs. In F#, the best way to deal with tasks is normally to immediately consume tasks in an asynchronous computation by using Async.AwaitTask, and you publish F# asynchronous computations as tasks by using Async.StartAsTask.

It can also sometimes be useful to program with tasks directly using the library primitives available in the .NET libraries. In particular, tasks support a rich (and somewhat bewildering) number of primitives for controlling timing and scheduling of computations. Examples of doing this can be found in C# programming guides on the web, and they can readily be translated to F#.
Understanding Exceptions and Cancellation
Two recurring topics in asynchronous programming are exceptions and cancellation. Let's first explore some of the behavior of asynchronous programs with regard to exceptions:
> let failingTask = async { do failwith "fail" };;
val failingTask: Async<unit>
> Async.RunSynchronously failingTask;;
System.Exception
Stopped due to error
> let failingTasks = [async {do failwith "fail A"};
async {do failwith "fail B"}];;
val failingTasks : Async<unit> list
> Async.RunSynchronously (Async.Parallel failingTasks);;
System.Exception: fail A
stopped due to error
> Async.RunSynchronously (Async.Parallel failingTasks);;
System.Exception: fail B
stopped due to error
From these examples, you can see:
- Tasks fail only when they're actually executed. The construction of a task using the
async { ... }syntax never fails.- Tasks that are run using
Async.RunSynchronouslyreport any failure back to the controlling thread as an exception.- It's nondeterministic which task will fail first.
- Tasks composed using
Async.Parallelreport the first failure from among the collected set of tasks. An attempt is made to cancel other tasks by setting the cancellation flag for the group of tasks, and any further failures are ignored.
You can wrap a task using the Async.Catch combinator. This has the type:
static member Catch : computation:Async<'T> -> Async<Choice<'T,exn>>
For example:
> Async.RunSynchronously (Async.Catch failingTask);;
val it : Choice<unit,exn> =
Choice2Of2
System.Exception: fail
You can also handle errors by using try/finally in an async { ... } workflow.
Under the Hood: Implementing Async.Parallel
Async.Parallel can appear magical. Computation tasks are created, executed, and resynchronized almost without effort. Listing 11-9 shows that a basic implementation of this operator is simple and again helps you see how Async<'T> values work under the hood.
Listing 11-9. A basic implementation of a fork-join parallel operator
let forkJoinParallel(taskSeq) =
Async.FromContinuations (fun (cont, econt, ccont) ->
let tasks = Seq.toArray taskSeq
let count = ref tasks.Length
let results = Array.zeroCreate tasks.Length
tasks |> Array.iteri (fun i p ->
Async.Start
(async {let! res = p
results.[i] <- res;
let n = System.Threading.Interlocked.Decrement(count)
if n = 0 then cont results})))
This basic implementation first converts the input task sequence to an array and then creates mutable state count and results to record the progress of the parallel computations. It then iterates through the tasks and queues each for execution in the .NET thread pool. Upon completion, each writes its result and decrements the counter using an atomic Interlocked.Decrement operator, discussed further in the section “Using Shared-Memory Concurrency” at the end of this chapter. The last process to finish calls the continuation with the collected results.
In practice, Async.Parallel is implemented more efficiently and takes into account exceptions and cancellation; again, see the F# library code for full details.
Using async for CPU Parallelism with Fixed Tasks
One of the great advantages of F# async programming is that it can be used for both CPU and I/O parallel-programming tasks. For example, you can use it for many CPU parallelism tasks that don't perform any I/O but rather carry out straight CPU-bound computations.
For optimized, partitioned CPU parallelism, this is often done by using Async.Parallel with a number of tasks that exactly matches the number of physical processors on a machine. For example, the following code shows parallel initialization of an array in which each cell is filled by running the input function. The implementation of this function makes careful use of shared-memory primitives (a topic discussed later in this book) and is highly efficient:
open System.Threading
open System
// Initialize an array by a parallel init using all available processors
// Note, this primitive doesn't support cancellation.
let parallelArrayInit n f =
let currentLine = ref -1
let res = Array.zeroCreate n
let rec loop () =
let y = Interlocked.Increment(currentLine)
if y < n then res.[y] <- f y; loop()
// Start just the right number of tasks, one for each physical CPU
Async.Parallel [for i in 1 .. Environment.ProcessorCount -> async {do loop()}]
|> Async.Ignore
|> Async.RunSynchronously
res
> let rec fib x = if x < 2 then 1 else fib (x - 1) + fib (x - 2)
> parallelArrayInit 25 (fun x -> fib x);;
val it : int [] =
[|1; 1; 2; 3; 5; 8; 13; 21; 34; 55; 89; 144; 233; 377; 610; 987; 1597; 2584;
4181; 6765; 10946; 17711; 28657; 46368; 75025; 121393; 196418; 317811;
514229; 832040|]
Agents
A distinction is often made between shared-memory concurrency and message passing concurrency. The former is often more efficient on local machines and is covered in the section “Using Shared-Memory Concurrency” later in this chapter. The latter scales to systems in which there is no shared memory—for example, distributed systems—and also can be used to avoid performance problems associated with shared memory. Asynchronous message passing and processing is a common foundation for concurrent programming, and this section looks at some simple examples of message-passing programs.
Introducing Agents
In a sense, you've already seen a good deal of message passing in this chapter. For example:
- In the
BackgroundWorkerdesign pattern, theCancelAsyncmethod is a simple kind of message.- Whenever you raise events on a GUI thread from a background thread, you are, under the hood, posting a message to the GUI's event queue. On Windows, this event queue is managed by the OS, and the processing of the events on the GUI thread is called the Windows event loop.
This section covers a simple kind of message processing called mailbox processing that's popular in languages such as Erlang. A mailbox is a message queue that you can scan for a message that is particularly relevant to the message-processing agent you're defining. Listing 11-10 shows a concurrent agent that implements a simple counter by processing a mailbox as messages arrive. The type MailboxProcessor is defined in the F# library—in this book, we use the name Agent for this type, through the use of a type alias.
Listing 11-10. Implementing a counter using an agent
type Agent<'T> = MailboxProcessor<'T>
let counter =
new Agent<_>(fun inbox ->
let rec loop n =
async {printfn "n = %d, waiting..." n
let! msg = inbox.Receive()
return! loop (n + msg)}
loop 0)
The type of counter is Agent<int>, in which the type argument indicates that this object expects to be sent messages of type int:
type Agent<'T> = MailboxProcessor<'T>
val counter : Agent<int>
The “Message Processing and State Machines” sidebar describes the general pattern of Listing 11-10 and the other MailboxProcessor examples in this chapter, all of which can be thought of as state machines. With this in mind, let's take a closer look at Listing 11-10. First, let's use counter on some simple inputs:
> counter.Start();;
n = 0, waiting...
> counter.Post(1);;
n = 1, waiting...
> counter.Post(2);;
n = 3, waiting...
> counter.Post(1);;
n = 4, waiting...
Looking at Listing 11-10, note that calling the Start method causes the processing agent to enter loop with n = 0. The agent then performs an asynchronous Receive request on the inbox for the MailboxProcessor; that is, the agent waits asynchronously until a message has been received. When the message msg is received, the program calls loop (n+msg). As additional messages are received, the internal counter (actually an argument) is incremented further.
You post messages to the agent using counter.Post. The type of inbox.Receive is:
member Receive: ?timeout:int -> Async<'Message>
Using an asynchronous receive ensures that no real threads are blocked for the duration of the wait. This means the previous techniques scale to many thousands of concurrent agents.
MESSAGE PROCESSING AND STATE MACHINES
Creating Objects That React to Messages
Often, it's wise to hide the internals of an asynchronous computation behind an object, because the use of message passing can be seen as an implementation detail. Listing 11-10 doesn't show you how to retrieve information from the counter, except by printing it to the standard output. Furthermore, it doesn't show how to ask the processing agent to exit. Listing 11-11 shows how to implement an object wrapping an agent that supports Increment, Stop, and Fetch messages.
Listing 11-11. Hiding a mailbox and supporting a fetch method
/// The internal type of messages for the agent
type internal msg = Increment of int | Fetch of AsyncReplyChannel<int> | Stop
type CountingAgent() =
let counter = MailboxProcessor.Start(fun inbox ->
// The states of the message-processing state machine...
let rec loop n =
async {let! msg = inbox.Receive()
match msg with
| Increment m ->
// increment and continue...
return! loop(n + m)
| Stop ->
// exit
return ()
| Fetch replyChannel ->
// post response to reply channel and continue
do replyChannel.Reply n
return! loop n}
// The initial state of the message-processing state machine...
loop(0))
member a.Increment(n) = counter.Post(Increment n)
member a.Stop() = counter.Post Stop
member a.Fetch() = counter.PostAndReply(fun replyChannel -> Fetch replyChannel)
The inferred public types indicate how the presence of a concurrent agent is successfully hidden by the use of an object:
type CountingAgent =
class
new : unit -> CountingAgent
member Fetch : unit -> int
member Increment : n:int -> unit
member Stop : unit -> unit
end
Here, you can see an instance of this object in action:
> let counter = new CountingAgent();;
val counter : CountingAgent
> counter.Increment(1);;
> counter.Fetch();;
val it : int = 1
> counter.Increment(2);;
> counter.Fetch();;
val it : int = 3
> counter.Stop();;
Listing 11-11 shows several important aspects of message passing and processing using the mailbox-processing model:
- Internal message protocols are often represented using discriminated unions. Here, the type
msghas casesIncrement,Fetch, andStop, corresponding to the three methods accepted by the object that wraps the overall agent implementation.- Pattern matching over discriminated unions gives a succinct way to process messages. A common pattern is a call to
inbox.Receive()orinbox.TryReceive()followed by a match on the message contents.- The
PostAndReplyon theMailboxProcessortype gives a way to post a message and wait for a reply. The temporary reply channel created should form part of the message. A reply channel is an object of typeMicrosoft.FSharp.Control.AsyncReplyChannel<'reply>, which in turn supports aPostmethod. TheMailboxProcessorcan use this to post a reply to the waiting caller. In Listing 11-11, the channel is sent to the underlying message-processing agentcounteras part of theFetchmessage.
Table 11-9 summarizes the most important members available on the MailboxProcessor type.

Scanning Mailboxes for Relevant Messages
It's common for a message-processing agent to end up in a state in which it's not interested in all messages that may appear in a mailbox but only in a subset of them. For example, you may be awaiting a reply from another agent and aren't interested in serving new requests. In this case, it's essential that you use MailboxProcessor.Scan rather than MailboxProcessor.Receive. Table 11-9 shows the signatures of both of these. The former lets you choose between available messages by processing them in order, whereas the latter forces you to process every message. Listing 11-12 shows an example of using MailboxProcessor.Scan.
Listing 11-12. Scanning a mailbox for relevant messages
type Message =
| Message1
| Message2 of int
| Message3 of string
let agent =
MailboxProcessor.Start(fun inbox ->
let rec loop() =
inbox.Scan(function
| Message1 ->
Some (async {do printfn "message 1!"
return! loop()})
| Message2 n ->
Some (async {do printfn "message 2!"
return! loop()})
| Message3 _ ->
None)
loop())
You can now post these agent messages, including messages of the ignored kind Message3:
> agent.Post(Message1);;
message 1!
val it : unit = ()
> agent.Post(Message2(100));;
message 2!
val it : unit = ()
> agent.Post(Message3("abc"));;
val it : unit = ()
> agent.Post(Message2(100));;
message 2!
val it : unit = ()
> agent.CurrentQueueLength;;
val it : int = 1
When you send Message3 to the message processor, the message is ignored. The last line, however, shows that the unprocessed Message3 is still in the message queue, which you could examine using the backdoor property UnsafeMessageQueueContents.
Example: Asynchronous Web Crawling
At the start of this chapter, we mentioned that the rise of the Web and other forms of networks is a major reason for the increasing importance of concurrent and asynchronous programming. Listing 11-13 shows an implementation of a Web crawler using asynchronous programming and mailbox-processing techniques.
Listing 11-13. A scalable, controlled, asynchronous Web crawler
open System.Collections.Generic
open System.Net
open System.IO
open System.Threading
open System.Text.RegularExpressions
let limit = 50
let linkPat = "href=s*"[^"h]*(http://[^&"]*)""
let getLinks (txt:string) =
[ for m in Regex.Matches(txt,linkPat) -> m.Groups.Item(1).Value ]
// A type that helps limit the number of active web requests
type RequestGate(n:int) =
let semaphore = new Semaphore(initialCount=n,maximumCount=n)
member x.AsyncAcquire(?timeout) =
async { let! ok = Async.AwaitWaitHandle(semaphore,
?millisecondsTimeout=timeout)
if ok then
return
{ new System.IDisposable with
member x.Dispose() =
semaphore.Release() |> ignore }
else
return! failwith "couldn't acquire a semaphore" }
// Gate the number of active web requests
let webRequestGate = RequestGate(5)
// Fetch the URL, and post the results to the urlCollector.
let collectLinks (url:string) =
async { // An Async web request with a global gate
let! html =
async { // Acquire an entry in the webRequestGate. Release
// it when 'holder' goes out of scope
use! holder = webRequestGate.AsyncAcquire()
let req = WebRequest.Create(url,Timeout=5)
// Wait for the WebResponse
use! response = req.AsyncGetResponse()
// Get the response stream
use reader = new StreamReader(response.GetResponseStream())
// Read the response stream (note: a synchronous read)
return reader.ReadToEnd() }
// Compute the links, synchronously
let links = getLinks html
// Report, synchronously
do printfn "finished reading %s, got %d links" url (List.length links)
// We're done
return links }
/// 'urlCollector' is a single agent that receives URLs as messages. It creates new
/// asynchronous tasks that post messages back to this object.
let urlCollector =
MailboxProcessor.Start(fun self ->
// This is the main state of the urlCollector
let rec waitForUrl (visited : Set<string>) =
async { // Check the limit
if visited.Count < limit then
// Wait for a URL...
let! url = self.Receive()
if not (visited.Contains(url)) then
// Start off a new task for the new url. Each collects
// links and posts them back to the urlCollector.
do! Async.StartChild
(async { let! links = collectLinks url
for link in links do
self.Post link }) |> Async.Ignore
// Recurse into the waiting state
return! waitForUrl(visited.Add(url)) }
// This is the initial state.
waitForUrl(Set.empty))
You can initiate a web crawl from a particular URL as follows:
> urlCollector.Post "http://news.google.com";;
finished reading http://news.google.com, got 191 links
finished reading http://news.google.com/?output=rss, got 0 links
finished reading http://www.ktvu.com/politics/13732578/detail.html, got 14 links
finished reading http://www.washingtonpost.com/wp-dyn/content/art..., got 218 links
finished reading http://www.newsobserver.com/politics/story/646..., got 56 links
finished reading http://www.foxnews.com/story/0,2933,290307,0...l, got 22 links
...
The key techniques shown in Listing 11-13 are:
- The type
RequestGateencapsulates the logic needed to ensure that you place a global limit on the number of active Web requests occurring at any point.. This is instantiated to the particular instancewebRequestGatewith limit 5. This uses aSystem.Threading.Semaphoreobject to coordinate access to this shared resource. Semaphores are discussed in more detail in “Using Shared-Memory Concurrency.”- The
RequestGatetype ensures that Web requests sitting in the request queue don't block threads but rather wait asynchronously as callback items in the thread pool until a slot in thewebRequestGatebecomes available.- The
collectLinksfunction is a regular asynchronous computation. It first enters theRequestGate(that is, acquires one of the available entries in theSemaphore). After a response has been received, it reads off the HTML from the resulting reader, scrapes the HTML for links using regular expressions, and returns the generated set of links.- The
urlCollectoris the only message-processing program. It's written using aMailboxProcessor. In its main state, it waits for a fresh URL and spawns a new asynchronous computation to callcollectLinksonce one is received. For each collected link, a new message is sent back to theurlCollector's mailbox. Finally, you recurse to the waiting state, having added the fresh URL to the overall set of URLs you've traversed so far.- The operator
<--is used as shorthand for posting a message to an agent. This is a recommended abbreviation in F# asynchronous programming.- The
AsyncAcquiremethod of theRequestGatetype uses a design pattern called a holder. The object returned by this method is anIDisposableobject that represents the acquisition of a resource. This holder object is bound usinguse, and this ensures that the resource is released when the computation completes or when the computation ends with an exception.
Listing 11-13 shows that it's relatively easy to create sophisticated, scalable asynchronous programs using a mix of message passing and asynchronous I/O techniques. Modern Web crawlers have thousands of outstanding open connections, indicating the importance of using asynchronous techniques in modern scalable Web-based programming.
Observables
As you learned earlier in this chapter, events are a central F# idiom to express configurable callback structures. F# also supports a more advanced mechanism for configurable callbacks that is more compositional than events. These are called observables, and in particular, they are characterized by the System.IObservable and System.IObserver types in the core libraries.
F# makes working with observables very easy, because all event objects also implement these interfaces and so can be used as observables. F# has only a limited library of combinators for working with observables in its core library, however. For example, here's how you can use observables to work with click events raised by a form:
> open System.Windows.Forms;;
> let form = new Form(Text = "Click Form", Visible = true, TopMost = true);;
val form : Form
> form.Click |> Observable.add (fun evArgs -> printfn "Clicked!");;
val it : unit = ()
When you run this code in F# Interactive, you see the expected printing each time the form is clicked. Likewise, you can filter and map using Observable.filter and Observable.map observables.
Programming with observables is powerful and compositional, and many further combinators are supported by the Rx programming library, available through the Rx library website on www.codeplex.com.
Using Shared-Memory Concurrency
The final topics covered in this chapter are the various primitive mechanisms used for threads, shared-memory concurrency, and signaling. In many ways, these are the assembly language of concurrency.
This chapter has concentrated mostly on techniques that work well with immutable data structures. That isn't to say you should always use immutable data structures. It is, for example, perfectly valid to use mutable data structures as long as they're accessed from only one particular thread. Furthermore, private mutable data structures can often be safely passed through an asynchronous workflow, because at each point the mutable data structure is accessed by only one thread, even if different parts of the asynchronous workflow are executed by different threads. This doesn't apply to workflows that use operators, such as Async.Parallel and Async.StartChild, that start additional threads of computation.
This means we've largely avoided covering shared-memory primitives so far, because F# provides powerful declarative constructs, such as asynchronous workflows and message passing, that often subsume the need to resort to shared-memory concurrency. A working knowledge of thread primitives and shared-memory concurrency is still very useful, however, especially if you want to implement your own basic constructs or highly efficient concurrent algorithms on shared-memory hardware.
Creating Threads Explicitly
This chapter has avoided showing how to work with threads directly, instead relying on abstractions, such as BackgroundWorker and the .NET thread pool. If you want to create threads directly, here is a short sample:
open System.Threading
let t = new Thread(ThreadStart(fun _ ->
printfn "Thread %d: Hello" Thread.CurrentThread.ManagedThreadId));
t.Start();
printfn "Thread %d: Waiting!" Thread.CurrentThread.ManagedThreadId
t.Join();
printfn "Done!"
When run, this gives:
val t : Thread
Thread 1: Waiting!
Thread 10: Hello
Done!
![]() Caution: Always avoid using
Caution: Always avoid using Thread.Suspend, Thread. Resume, and Thread.Abort. These are guaranteed to put obscure concurrency bugs in your program. The MSDN Web site has a good description of why Thread.Abort may not even succeed. One of the only compelling uses for Thread.Abort is to implement Ctrl+C in an interactive development environment for a general-purpose language, such as F# Interactive.
Shared Memory, Race Conditions, and the .NET Memory Model
Many multithreaded applications use mutable data structures shared among multiple threads. Without synchronization, these data structures will almost certainly become corrupt: threads may read data that have been only partially updated (because not all mutations are atomic), or two threads may write to the same data simultaneously (a race condition). Mutable data structures are usually protected by locks, although lock-free mutable data structures are also possible.
Shared-memory concurrency is a difficult and complicated topic, and a considerable amount of good material on .NET shared-memory concurrency is available on the Web. All this material applies to F# when you're programming with mutable data structures such as reference cells, arrays, and hash tables, and the data structures can be accessed from multiple threads simultaneously. F# mutable data structures map to .NET memory in fairly predictable ways; for example, mutable references become mutable fields in a .NET class, and mutable fields of word size can be assigned atomically.
On modern microprocessors, multiple threads can see views of memory that aren't consistent; that is, not all writes are propagated to all threads immediately. The guarantees given are called a memory model and are usually expressed in terms of the ordering dependencies among instructions that read/write memory locations. This is, of course, deeply troubling, because you have to think about a huge number of possible reorderings of your code, and it's one of the main reasons why shared mutable data structures are difficult to work with. You can find further details on the .NET memory model at www.expert-fsharp.net/topics/MemoryModel.
Using Locks to Avoid Race Conditions
Locks are the simplest way to enforce mutual exclusion between two threads attempting to read or write the same mutable memory location. Listing 11-14 shows an example of code with a race condition.
Listing 11-14. Shared-memory code with a race condition
type MutablePair<'T, 'U>(x : 'T, y : 'U) =
let mutable currentX = x
let mutable currentY = y
member p.Value = (currentX, currentY)
member p.Update(x, y) =
// Race condition: This pair of updates is not atomic
currentX <- x
currentY <- y
let p = new MutablePair<_, _>(1, 2)
do Async.Start (async {do (while true do p.Update(10, 10))})
do Async.Start (async {do (while true do p.Update(20, 20))})
Here is the definition of the F# lock function:
open System.Threading
let lock (lockobj : obj) f =
Monitor.Enter lockobj
try
f()
finally
Monitor.Exit lockobj
The pair of mutations in the Update method isn't atomic; that is, one thread may have written to currentX, another then writes to both currentX and currentY, and the final thread then writes to currentY, leaving the pair holding the value (10,20) or (20,10). Mutable data structures are inherently prone to this kind of problem if shared among multiple threads. Luckily, F# code tends to have fewer mutations than imperative languages, because functions normally take immutable values and return a calculated value. When you do use mutable data structures, they shouldn't be shared among threads, or you should design them carefully and document their properties with respect to multithreaded access.
Here is one way to use the F# lock function to ensure that updates to the data structure are atomic. Locks are also required on uses of the property p.Value:
do Async.Start (async { do (while true do lock p (fun () -> p.Update(10,10))) })
do Async.Start (async { do (while true do lock p (fun () -> p.Update(20,20))) })
![]() Caution: If you use locks inside data structures, do so only in a simple way that uses them to enforce the concurrency properties you've documented. Don't lock just for the sake of it, and don't hold locks longer than necessary. In particular, beware of making indirect calls to externally supplied function values, interfaces, or abstract members while a lock is held. The code providing the implementation may not be expecting to be called when a lock is held, and it may attempt to acquire further locks in an inconsistent fashion.
Caution: If you use locks inside data structures, do so only in a simple way that uses them to enforce the concurrency properties you've documented. Don't lock just for the sake of it, and don't hold locks longer than necessary. In particular, beware of making indirect calls to externally supplied function values, interfaces, or abstract members while a lock is held. The code providing the implementation may not be expecting to be called when a lock is held, and it may attempt to acquire further locks in an inconsistent fashion.
Using ReaderWriterLock
It's common for mutable data structures to be read more than they're written. Indeed, mutation often is used only to initialize a mutable data structure. In this case, you can use a .NET ReaderWriterLock to protect access to a resource. For example, consider the functions:
open System.Threading
let readLock (rwlock : ReaderWriterLock) f =
rwlock.AcquireReaderLock(Timeout.Infinite)
try
f()
finally
rwlock.ReleaseReaderLock()
let writeLock (rwlock : ReaderWriterLock) f =
rwlock.AcquireWriterLock(Timeout.Infinite)
try
f()
Thread.MemoryBarrier()
finally
rwlock.ReleaseWriterLock()
Listing 11-15 shows how to use these functions to protect the MutablePair class.
Listing 11-15. Shared-memory code with a race condition
type MutablePair<'T, 'U>(x : 'T, y : 'U) =
let mutable currentX = x
let mutable currentY = y
let rwlock = new ReaderWriterLock()
member p.Value =
readLock rwlock (fun () ->
(currentX, currentY))
member p.Update(x, y) =
writeLock rwlock (fun () ->
currentX <- x
currentY <- y)
Some Other Concurrency Primitives
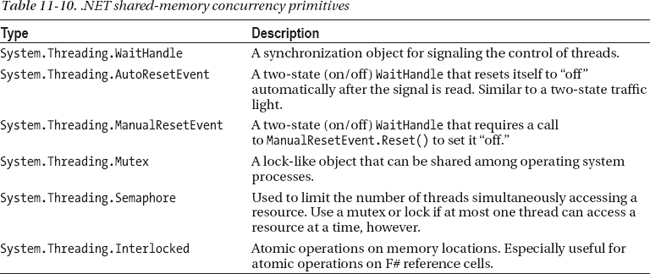
Table 11-10 shows some other shared-memory concurrency primitives available in the .NET Framework.
Summary
This chapter covered concurrent, reactive, and asynchronous programming, topics of growing importance in modern programming because of the widespread adoption of multicore microprocessors, network-aware applications, and asynchronous I/O channels. It discussed, in depth, background processing and a powerful F# construct called asynchronous workflows. Finally, the chapter covered applications of asynchronous workflows to message-processing agents and Web crawling, and it examined some of the shared-memory primitives for concurrent programming on the .NET platform. The next chapter returns to look at further applied topics in symbolic programming.