
This chapter explores how network programming intersects with the general tools and techniques that Python developers use to write long-running daemons that can perform significant amounts of work by keeping a computer and its processors busy.
Instead of making you read through this entire chapter to learn the landscape of design options that I will explore, let me outline them quickly.
Most of the network programs in this book—and certainly all of the ones you have seen so far—use a single sequence of Python instructions to serve one network client at a time, operating in lockstep as requests come in and responses go out. This, as we will see, will usually leave the system CPU mostly idle.
There are two changes you can make to a network program to improve this situation, and then a third, big change that you can make outside your program that will allow it to scale even further.
The two changes you can make to your program are either to rewrite it in an event-driven style that can accept several client connections at once and then answer whichever one is ready for an answer next, or to run several copies of your single-client server in separate threads or processes. An event-driven style does not impose the expense of operating system context switches, but, on the other hand, it can saturate at most only one CPU, whereas multiple threads or processes—and, with Python, especially processes—can keep all of your CPU cores busy handling client requests.
But once you have crafted your server so that it keeps a single machine perfectly busy answering clients, the only direction in which you can expand is to balance the load of incoming connections across several different machines, or even across data centers. Some large Internet services do this with proxy devices sitting in front of their server racks; others use DNS round-robin, or nameservers that direct clients to servers in the same geographic location; and we will briefly discuss both approaches later in this chapter.
Part of the task of writing a network daemon is, obviously, the part where you write the program as a daemon rather than as an interactive or command-line tool. Although this chapter will focus heavily on the "network" part of the task, a few words about general daemon programming seem to be in order.
First, you should realize that creating a daemon is a bit tricky and can involve a dozen or so lines of code to get completely correct. And that estimate assumes a POSIX operating system; under Windows, to judge from the code I have seen, it is even more difficult to write what is called a "Windows service" that has to be listed in the system registry before it can even run.
On POSIX systems, rather than cutting and pasting code from a web site, I encourage you to use a good Python library to make your server a daemon. The official purpose of becoming a daemon, by the way, is so that your server can run independently of the terminal window and user session that were used to launch it. One approach toward running a service as a daemon—the one, in fact, that I myself prefer—is to write a completely normal Python program and then use Chris McDonough's supervisord daemon to start and monitor your service. It can even do things like re-start your program if it should die, but then give up if several re-starts happen too quickly; it is a powerful tool, and worth a good long look: http://supervisord.org/.
You can also install python-daemon from the Package Index (a module named daemon will become part of the Standard Library in Python 3.2), and its code will let your server program become a daemon entirely on its own power.
If you are running under supervisord, then your standard output and error can be saved as rotated log files, but otherwise you will have to make some provision of your own for writing logs. The most important piece of advice that I can give in that case is to avoid the ancient syslog Python module, and use the modern logging module, which can write to syslog, files, network sockets, or anything in between. The simplest pattern is to place something like this at the top of each of your daemon's source files:
import logging log = logging.getLogger(__name__)
Then your code can generate messages very simply:
log.error('the system is down')This will, for example, induce a module that you have written that is named serv.inet to produce log messages under its own name, which users can filter either by writing a specific serv.inet handler, or a broader serv handler, or simply by writing a top-level rule for what happens to all log messages. And if you use the logger module method named fileConfig() to optionally read in a logging.conf provided by your users, then you can leave the choice up to them about which messages they want recorded where. Providing a file with reasonable defaults is a good way to get them started.
For information on how to get your network server program to start automatically when the system comes up and shut down cleanly when your computer halts, check your operating system documentation; on POSIX systems, start by reading the documentation surrounding your operating system's chosen implementation of the "init scripts" subsystem.
I have designed a very simple network service to illustrate this chapter so that the details of the actual protocol do not get in the way of explaining the server architectures. In this minimalist protocol, the client opens a socket, sends across one of the three questions asked of Sir Launcelot at the Bridge of Death in Monty Python's Holy Grail movie, and then terminates the message with a question mark:
What is your name?
The server replies by sending back the appropriate answer, which always ends with a period:
My name is Sir Launcelot of Camelot.
Both question and answer are encoded as ASCII.
Listing 7-1 defines two constants and two functions that will be very helpful in keeping our subsequent program listings short. It defines the port number we will be using; a list of question-answer pairs; a recv_until() function that keeps reading data from a network socket until it sees a particular piece of punctuation (or any character, really, but we will always use it with either the '.' or '?' character); and a setup() function that creates the server socket.
Example 7.1. Constants and Functions for the Launcelot Protocol
#!/usr/bin/env python # Foundations of Python Network Programming - Chapter 7 - launcelot.py # Constants and routines for supporting a certain network conversation. import socket, sys
PORT = 1060
qa = (('What is your name?', 'My name is Sir Launcelot of Camelot.'),
» ('What is your quest?', 'To seek the Holy Grail.'),
» ('What is your favorite color?', 'Blue.'))
qadict = dict(qa)
def recv_until(sock, suffix):
» message = ''
» while not message.endswith(suffix):
» » data = sock.recv(4096)
» » if not data:
» » » raise EOFError('socket closed before we saw %r' % suffix)
» » message += data
» return message
def setup():
» if len(sys.argv) != 2:
» » print >>sys.stderr, 'usage: %s interface' % sys.argv[0]
» » exit(2)
» interface = sys.argv[1]
» sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
» sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
» sock.bind((interface, PORT))
» sock.listen(128)
» print 'Ready and listening at %r port %d' % (interface, PORT)
» return sockNote in particular that the recv_until() routine does not require its caller to make any special check of its return value to discover whether an end-of-file has occurred. Instead, it raises EOFError (which in Python itself is raised only by regular files) to indicate that no more data is available on the socket. This will make the rest of our code a bit easier to read.
With the help of these routines, and using the same TCP server pattern that we learned in Chapter 3, we can construct the simple server shown in Listing 7-2 using only a bit more than a dozen lines of code.
Example 7.2. Simple Launcelot Server
#!/usr/bin/env python # Foundations of Python Network Programming - Chapter 7 - server_simple.py # Simple server that only serves one client at a time; others have to wait. import launcelot def handle_client(client_sock): » try: » » while True: » » » question = launcelot.recv_until(client_sock, '?') » » » answer = launcelot.qadict[question] » » » client_sock.sendall(answer) » except EOFError: » » client_sock.close() def server_loop(listen_sock): » while True:
» » client_sock, sockname = listen_sock.accept() » » handle_client(client_sock) if __name__ == '__main__': » listen_sock = launcelot.setup() » server_loop(listen_sock)
Note that the server is formed of two nested loops. The outer loop, conveniently defined in a function named server_loop() (which we will use later in some other program listings), forever accepts connections from new clients and then runs handle_client() on each new socket—which is itself a loop, endlessly answering questions that arrive over the socket, until the client finally closes the connection and causes our recv_until() routine to raise EOFError.
By the way, you will see that several listings in this chapter use additional ink and whitespace to include __name__ == '__main__' stanzas, despite my assertion in the preface that I would not normally do this in the published listings. The reason, as you will soon discover, is that some of the subsequent listings import these earlier ones to avoid having to repeat code. So the result, overall, will be a savings in paper!
Anyway, this simple server has terrible performance characteristics.
What is wrong with the simple server? The difficulty comes when many clients all want to connect at the same time. The first client's socket will be returned by accept(), and the server will enter the handle_client() loop to start answering that first client's questions. But while the questions and answers are trundling back and forth across the network, all of the other clients are forced to queue up on the queue of incoming connections that was created by the listen() call in the setup() routine of Listing 7-1.
The clients that are queued up cannot yet converse with the server; they remain idle, waiting for their connection to be accepted so that the data that they want to send can be received and processed.
And because the waiting connection queue itself is only of finite length—and although we asked for a limit of 128 pending connections, some versions of Windows will actually support a queue only 5 items long—if enough incoming connections are attempted while others are already waiting, then the additional connections will either be explicitly refused or, at least, quietly ignored by the operating system. This means that the three-way TCP handshakes with these additional clients (we learned about handshakes in Chapter 3) cannot even commence until the server has finished with the first client and accepted another waiting connection from the listen queue.
We will tackle the deficiencies of the simple server shown in Listing 7-2 in two discussions. First, in this section, we will discuss how much time it spends waiting even on one client that needs to ask several questions; and in the next section, we will look at how it behaves when confronted with many clients at once.
A simple client for the Launcelot protocol is shown in Listing 7-3. It connects, asks each of the three questions once, and then disconnects.
Example 7.3. A Simple Three-Question Client
#!/usr/bin/env python # Foundations of Python Network Programming - Chapter 7 - client.py # Simple Launcelot client that asks three questions then disconnects. import socket, sys, launcelot def client(hostname, port):
» s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) » s.connect((hostname, port)) » s.sendall(launcelot.qa[0][0]) » answer1 = launcelot.recv_until(s, '.') # answers end with '.' » s.sendall(launcelot.qa[1][0]) » answer2 = launcelot.recv_until(s, '.') » s.sendall(launcelot.qa[2][0]) » answer3 = launcelot.recv_until(s, '.') » s.close() » print answer1 » print answer2 » print answer3 if __name__ == '__main__': » if not 2 <= len(sys.argv) <= 3: » » print >>sys.stderr, 'usage: client.py hostname [port]' » » sys.exit(2) » port = int(sys.argv[2]) if len(sys.argv) > 2 else launcelot.PORT » client(sys.argv[1], port)
With these two scripts in place, we can start running our server in one console window:
$ python server_simple.py localhost
We can then run our client in another window, and see the three answers returned by the server:
$ python client.py localhost My name is Sir Launcelot of Camelot. To seek the Holy Grail. Blue.
The client and server run very quickly here on my laptop. But appearances are deceiving, so we had better approach this client-server interaction more scientifically by bringing real measurements to bear upon its activity.
To dissect the behavior of this server and client, I need two things: more realistic network latency than is produced by making connections directly to localhost, and some way to see a microsecond-by-microsecond report on what the client and server are doing.
These two goals may initially seem impossible to reconcile. If I run the client and server on the same machine, the network latency will not be realistic. But if I run them on separate servers, then any timestamps that I print will not necessarily agree because of slight differences between the machines' clocks.
My solution is to run the client and server on a single machine (my Ubuntu laptop, in case you are curious) but to send the connection through a round-trip to another machine (my Ubuntu desktop) by way of an SSH tunnel. See Chapter 16 and the SSH documentation itself for more information about tunnels. The idea is that SSH will open local port 1061 here on my laptop and start accepting connections from clients. Each connection will then be forwarded across to the SSH server running on my desktop machine, which will connect back using a normal TCP connection to port 1060 here on my laptop, whose IP ends with .5.130. Setting up this tunnel requires one command, which I will leave running in a terminal window while this example progresses:
$ ssh -N -L 1061:192.168.5.130:1060 kenaniah
Now that I can build a connection between two processes on this laptop that will have realistic latency, I can build one other tool: a Python source code tracer that measures when statements run with microsecond accuracy. It would be nice to have simply been able to use Python's trace module from the Standard Library, but unfortunately it prints only hundredth-of-a-second timestamps when run with its -g option.
And so I have written Listing 7-4. You give this script the name of a Python function that interests you and the name of the Python program that you want to run (followed by any arguments that it takes); the tracing script then runs the program and prints out every statement inside the function of interest just before it executes. Each statement is printed along with the current second of the current minute, from zero to sixty. (I omitted minutes, hours, and days because such long periods of time are generally not very interesting when examining a quick protocol like this.)
Example 7.4. Tracer for a Python Function
#!/usr/bin/env python
# Foundations of Python Network Programming - Chapter 7 - my_trace.py
# Command-line tool for tracing a single function in a program.
import linecache, sys, time
def make_tracer(funcname):
» def mytrace(frame, event, arg):
» » if frame.f_code.co_name == funcname:
» » » if event == 'line':
» » » » _events.append((time.time(), frame.f_code.co_filename,
» » » » » » » » frame.f_lineno))
» » » return mytrace
» return mytrace
if __name__ == '__main__':
» _events = []
» if len(sys.argv) < 3:
» » print >>sys.stderr, 'usage: my_trace.py funcname other_script.py ...'
» » sys.exit(2)
» sys.settrace(make_tracer(sys.argv[1]))
» del sys.argv[0:2] # show the script only its own name and arguments
» try:
» » execfile(sys.argv[0])
» finally:
» » for t, filename, lineno in _events:
» » » s = linecache.getline(filename, lineno)
» » » sys.stdout.write('%9.6f %s' % (t % 60.0, s))Note that the tracing routine is very careful not to perform any expensive I/O as parts of its activity; it neither retrieves any source code, nor prints any messages while the subordinate script is actually running. Instead, it saves the timestamps and code information in a list. When the program finishes running, the finally clause runs leisurely through this data and produces output without slowing up the program under test.
We now have all of the pieces in place for our trial! We first start the server, this time inside the tracing program so that we will get a detailed log of how it spends its time inside the handle_client() routine:
$ python my_trace.py handle_client server_simple.py ''
Note again that I had it listen to the whole network with '', and not to any particular interface, because the connections will be arriving from the SSH server over on my desktop machine. Finally, I can run a traced version of the client that connects to the forwarded port 1061:
$ python my_trace.py client client.py localhost 1061
The client prints out its own trace as it finishes. Once the client finished running, I pressed Ctrl+C to kill the server and force it to print out its own trace messages. Both machines were connected to my wired network for this test, by the way, because its performance is much better than that of my wireless network.
Here is the result. I have eliminated a few extraneous lines—like the try and while statements in the server loop—to make the sequence of actual network operations clearer, and I have indented the server's output so that we can see how its activities interleaved with those of the client. Again, it is because they were running on the same machine that I can so confidently trust the timestamps to give me a strict ordering:
Client / Server (times in seconds) -------------------------------------------------------------------- 14.225574 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 14.225627 s.connect((hostname, port)) 14.226107 s.sendall(launcelot.qa[0][0]) 14.226143 answer1 = launcelot.recv_until(s, '.') # answers end with '.' 14.227495 question = launcelot.recv_until(client_sock, '?') 14.228496 answer = launcelot.qadict[question] 14.228505 client_sock.sendall(answer) 14.228541 question = launcelot.recv_until(client_sock, '?') 14.229348 s.sendall(launcelot.qa[1][0]) 14.229385 answer2 = launcelot.recv_until(s, '.') 14.229889 answer = launcelot.qadict[question] 14.229898 client_sock.sendall(answer) 14.229929 question = launcelot.recv_until(client_sock, '?') 14.230572 s.sendall(launcelot.qa[2][0]) 14.230604 answer3 = launcelot.recv_until(s, '.') 14.231200 answer = launcelot.qadict[question] 14.231207 client_sock.sendall(answer) 14.231237 question = launcelot.recv_until(client_sock, '?') 14.231956 s.close() 14.232651 client_sock.close()
When reading this trace, keep in mind that having tracing turned on will have made both programs slower; also remember that each line just shown represents the moment that Python arrived at each statement and started executing it. So the expensive statements are the ones with long gaps between their own timestamp and that of the following statement.
Given those caveats, there are several important lessons that we can learn from this trace.
First, it is plain that the very first steps in a protocol loop can be different than the pattern into which the client and server settle once the exchange has really gotten going. For example, you can see that Python reached the server's question = line twice during its first burst of activity, but only once per iteration thereafter. To understand the steady state of a network protocol, it is generally best to look at the very middle of a trace like this where the pattern has settled down and measure the time it takes the protocol to go through a cycle and wind up back at the same statement.
Second, note how the cost of communication dominates the performance. It always seems to take less than 10 µs for the server to run the answer = line and retrieve the response that corresponds to a particular question. If actually generating the answer were the client's only job, then we could expect it to serve more than 100,000 client requests per second!
But look at all of the time that the client and server spend waiting for the network: every time one of them finishes a sendall() call, it takes between 500 µs and 800 µs before the other conversation partner is released from its recv() call and can proceed. This is, in one sense, very little time; when you can ping another machine and get an answer in around 1.2 ms, you are on a pretty fast network. But the cost of the round-trip means that, if the server simply answers one question after another, then it can answer at most around 1,000 requests per second—only one-hundredth the rate at which it can generate the answers themselves!
So the client and server both spend most of their time waiting. And given the lockstep single-threaded technique that we have used to design them, they cannot use that time for anything else.
A third observation is that the operating system is really very aggressive in taking tasks upon itself and letting the programs go ahead and get on with their lives—a feature that we will use to great advantage when we tackle event-driven programming. Look, for example, at how each sendall() call uses only a few dozen microseconds to queue up the data for transmission, and then lets the program proceed to its next instruction. The operating system takes care of getting the data actually sent, without making the program wait.
Finally, note the wide gulfs of time that are involved in simply setting up and tearing down the socket. Nearly 1,900 µs pass between the client's initial connect() and the moment when the server learns that a connection has been accepted and that it should start up its recv_until() routine. There is a similar delay while the socket is closed down. This leads to designers adding protocol features like the keep-alive mechanism of the HTTP/1.1 protocol (Chapter 9), which, like our little Launcelot protocol here, lets a client make several requests over the same socket before it is closed.
So if we talk to only one client at a time and patiently wait on the network to send and receive each request, then we can expect our servers to run hundreds or thousands of times more slowly than if we gave them more to do. Recall that a modern processor can often execute more than 2,000 machine-level instructions per microsecond. That means that the 500 µs delay we discussed earlier leaves the server idle for nearly a half-million clock cycles before letting it continue work!
Through the rest of this chapter, we will look at better ways to construct servers in view of these limitations.
Having used microsecond tracing to dissect a simple client and server, we are going to need a better system for comparing the subsequent server designs that we explore. Not only do we lack the space to print and analyze increasingly dense and convoluted timestamp traces, but that approach would make it very difficult to step back and to ask, "Which of these server designs is working the best?"
We are therefore going to turn now to a public tool: the FunkLoad tool, written in Python and available from the Python Package Index. You can install it in a virtual environment (see Chapter 1) with a simple command:
$ pip install funkload
There are other popular benchmark tools available on the Web, including the "Apache bench" program named ab, but for this book it seemed that the leading Python load tester would be a good choice.
FunkLoad can take a test routine and run more and more copies of it simultaneously to test how the resources it needs struggle with the rising load. Our test routine will be an expanded version of the simple client that we used earlier: it will ask ten questions of the server instead of three, so that the network conversation itself will take up more time relative to the TCP setup and teardown times that come at the beginning and end. Listing 7-5 shows our test routine, embedded in a standard unittest script that we can also run on its own.
Example 7.5. Test Routine Prepared for Use with FunkLoad
#!/usr/bin/env python
# Foundations of Python Network Programming - Chapter 7 - launcelot_tests.py
# Test suite that can be run against the Launcelot servers.
from funkload.FunkLoadTestCase import FunkLoadTestCase
import socket, os, unittest, launcelot
SERVER_HOST = os.environ.get('LAUNCELOT_SERVER', 'localhost')
class TestLauncelot(FunkLoadTestCase):
» def test_dialog(self):
» » sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
» » sock.connect((SERVER_HOST, launcelot.PORT))
» » for i in range(10):
» » » question, answer = launcelot.qa[i % len(launcelot.qa)]
» » » sock.sendall(question)
» » » reply = launcelot.recv_until(sock, '.')
» » » self.assertEqual(reply, answer)
» » sock.close()
if __name__ == '__main__':
» unittest.main()The IP address to which the test client connects defaults to localhost but can be adjusted by setting a LAUNCELOT_SERVER environment variable (since I cannot see any way to pass actual arguments through to tests with FunkLoad command-line arguments).
Because FunkLoad itself, like other load-testing tools, can consume noticeable CPU, it is always best to run it on another machine so that its own activity does not slow down the server under test. Here, I will use my laptop to run the various server programs that we consider, and will run FunkLoad over on the same desktop machine that I used earlier for building my SSH tunnel. This time there will be no tunnel involved; FunkLoad will hit the server directly over raw sockets, with no other pieces of software standing in the way.
So here on my laptop, I run the server, giving it a blank interface name so that it will accept connections on any network interface:
$ python server_simple.py ''
And on the other machine, I create a small FunkLoad configuration file, shown in Listing 7-6, that arranges a rather aggressive test with an increasing number of test users all trying to make repeated connections to the server at once—where a "user" simply runs, over and over again, the test case that you name on the command line. Read the FunkLoad documentation for an explanation, accompanied by nice ASCII-art diagrams, of what the various parameters mean.
Example 7.6. Example FunkLoad Configuration
# TestLauncelot.conf [main] title=Load Test For Chapter 7 description=From the Foundations of Python Network Programming url=http://localhost:1060/ [ftest] log_path = ftest.log
result_path = ftest.xml sleep_time_min = 0 sleep_time_max = 0 [bench] log_to = file log_path = bench.log result_path = bench.xml cycles = 1:2:3:5:7:10:13:16:20 duration = 8 startup_delay = 0.1 sleep_time = 0.01 cycle_time = 10 sleep_time_min = 0 sleep_time_max = 0
Note that FunkLoad finds the configuration file name by taking the class name of the test case—which in this case is TestLauncelot—and adding .conf to the end. If you re-name the test, or create more tests, then remember to create corresponding configuration files with those class names.
Once the test and configuration file are in place, the benchmark can be run. I will first set the environment variable that will alert the test suite to the fact that I want it connecting to another machine. Then, as a sanity check, I will run the test client once as a normal test to make sure that it succeeds:
$ export LAUNCELOT_SERVER=192.168.5.130 $ fl-run-test launcelot_tests.py TestLauncelot.test_dialog . ---------------------------------------------------------------------- Ran 1 test in 0.228s OK
You can see that FunkLoad simply expects us to specify the Python file containing the test, and then specify the test suite class name and the test method separated by a period. The same parameters are used when running a benchmark:
$ fl-run-bench launcelot_tests.py TestLauncelot.test_dialog
The result will be a bench.xml file full of XML (well, nobody's perfect) where FunkLoad stores the metrics generated during the test, and from which you can generate an attractive HTML report:
$ fl-build-report --html bench.xml
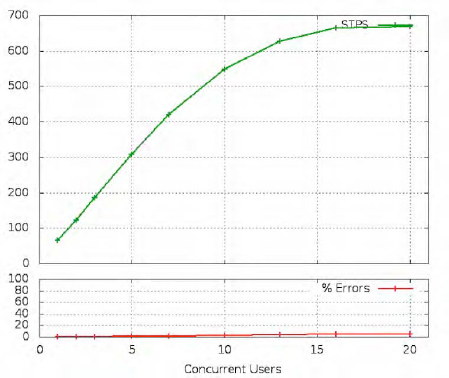
Had we been testing a web service, the report would contain several different analyses, since FunkLoad would be aware of how many web pages each iteration of the test had downloaded. But since we are not using any of the web-specific test methods that FunkLoad provides, it cannot see inside our code and determine that we are running ten separate requests inside every connection. Instead, it can simply count how many times each test runs per second; the result is shown in Figure 7-1.

Since we are sending ten Launcelot questions per test trial, the 325 test-per-second maximum that the simple server reaches represents 3,250 questions and answers—more than the 1,000 per second that we guessed were possible when testing server_simple.py over the slower SSH tunnel, but still of the same order of magnitude.
In interpreting this report, it is critical to understand that a healthy graph shows a linear relationship between the number of requests being made and the number of clients that are waiting. This server shows great performance all the way up to five clients. How can it be improving its performance, when it is but a single thread of control stuck talking to only one client at a time? The answer is that having several clients going at once lets one be served while another one is still tearing down its old socket, and yet another client is opening a fresh socket that the operating system will hand the server when it next calls accept().
But the fact that sockets can be set up and torn down at the same time as the server is answering one client's questions only goes so far. Once there are more than five clients, disaster strikes: the graph flatlines, and the increasing load means that a mere 3,250 answers per second have to be spread out over 10 clients, then 20 clients, and so forth. Simple division tells us that 5 clients see 650 questions answered per second; 10 clients, 325 questions; and 20 clients, 162 questions per second. Performance is dropping like a rock.
So that is the essential limitation of this first server: when enough clients are going at once that the client and server operating systems can pipeline socket construction and socket teardown in parallel, the server's insistence on talking to only one client at a time becomes the insurmountable bottleneck and no further improvement is possible.
The simple server we have been examining has the problem that the recv() call often finds that no data is yet available from the client, so the call "blocks" until data arrives. The time spent waiting, as we have seen, is time lost; it cannot be spent usefully by the server to answer requests from other clients.
But what if we avoided ever calling recv() until we knew that data had arrived from a particular client—and, meanwhile, could watch a whole array of connected clients and pounce on the few sockets that were actually ready to send or receive data at any given moment? The result would be an event-driven server that sits in a tight loop watching many clients; I have written an example, shown in Listing 7-7.
Example 7.7. A Non-blocking Event-Driven Server
#!/usr/bin/env python
# Foundations of Python Network Programming - Chapter 7 - server_poll.py
# An event-driven approach to serving several clients with poll().
import launcelot
import select
listen_sock = launcelot.setup()
sockets = { listen_sock.fileno(): listen_sock }
requests = {}
responses = {}
poll = select.poll()
poll.register(listen_sock, select.POLLIN)
while True:
» for fd, event in poll.poll():
» » sock = sockets[fd]
» » # Removed closed sockets from our list.
» » if event & (select.POLLHUP | select.POLLERR | select.POLLNVAL):
» » » poll.unregister(fd)
» » » del sockets[fd]
» » » requests.pop(sock, None)
» » » responses.pop(sock, None)
» » # Accept connections from new sockets.
» » elif sock is listen_sock:
» » » newsock, sockname = sock.accept()
» » » newsock.setblocking(False)
» » » fd = newsock.fileno()
» » » sockets[fd] = newsock
» » » poll.register(fd, select.POLLIN)
» » » requests[newsock] = ''
» » # Collect incoming data until it forms a question.
» » elif event & select.POLLIN:
» » » data = sock.recv(4096)
» » » if not data: # end-of-file
» » » » sock.close() # makes POLLNVAL happen next time
» » » » continue
» » » requests[sock] += data
» » » if '?' in requests[sock]:
» » » » question = requests.pop(sock)
» » » » answer = dict(launcelot.qa)[question]
» » » » poll.modify(sock, select.POLLOUT)
» » » » responses[sock] = answer» » # Send out pieces of each reply until they are all sent. » » elif event & select.POLLOUT: » » » response = responses.pop(sock) » » » n = sock.send(response) » » » if n < len(response): » » » » responses[sock] = response[n:] » » » else: » » » » poll.modify(sock, select.POLLIN) » » » » requests[sock] = ''
The main loop in this program is controlled by the poll object, which is queried at the top of every iteration. The poll() call is a blocking call, just like the recv() call in our simple server; so the difference is not that our first server used a blocking operating system call and that this second server is somehow avoiding that. No, this server blocks too; the difference is that recv() has to wait on one single client, while poll() can wait on dozens or hundreds of clients, and return when any of them shows activity.
You can see that everywhere that the original server had exactly one of something—one client socket, one question string, or one answer ready to send—this event-driven server has to keep entire arrays or dictionaries, because it is like a poker dealer who has to keep cards flying to all of the players at once.
The way poll() works is that we tell it which sockets we need to monitor, and whether each socket interests us because we want to read from it or write to it. When one or more of the sockets are ready, poll() returns and provides a list of the sockets that we can now use.
To keep things straight when reading the code, think about the lifespan of one particular client and trace what happens to its socket and data.
The client will first do a
connect(), and the server'spoll()call will return and declare that there is data ready on the main listening socket. That can mean only one thing, since—as we learned in Chapter 3—actual data never appears on a stream socket that is being used tolisten(): it means that a new client has connected. So weaccept()the connection and tell ourpollobject that we want to be notified when data becomes available for reading from the new socket. To make sure that therecv()andsend()methods on the socket never block and freeze our event loop, we call thesetblocking()socket method with the valueFalse(which means "blocking is not allowed").When data becomes available, the incoming string is appended to whatever is already in the
requestsdictionary under the entry for that socket. (Yes, sockets can safely be used as dictionary keys in Python!)We keep accepting more data until we see a question mark, at which point the Launcelot question is complete. The questions are so short that, in practice, they probably all arrive in the very first
recv()from each socket; but just to be safe, we have to be prepared to make severalrecv()calls until the whole question has arrived. We then look up the appropriate answer, store it in theresponsesdictionary under the entry for this client socket, and tell thepollobject that we no longer want to listen for more data from this client but instead want to be told when its socket can start accepting outgoing data.Once a socket is ready for writing, we send as much of the answer as will fit into one
send()call on the client socket. This, by the way, is a big reasonsend()returns a length: because if you use it in non-blocking mode, then it might be able to send only some of your bytes without making you wait for a buffer to drain back down.Once this server has finished transmitting the answer, we tell the
pollobject to swap the client socket back over to being listened to for new incoming data.After many question-answer exchanges, the client will finally close the connection. Oddly enough, the
POLLHUP, POLLERR, andPOLLNVALcircumstances thatpoll()can tell us about—all of which indicate that the connection has closed one way or another—are returned only if we are trying to write to the socket, not read from it. So when an attempt to read returns zero bytes, we have to tell thepollobject that we now want to write to the socket so that we receive the official notification that the connection is closed.
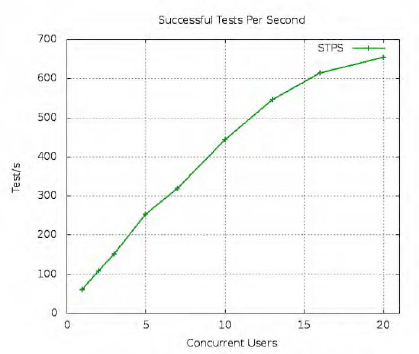
The performance of this vastly improved server design is shown in Figure 7-2. By the time its throughput begins to really degrade, it has achieved twice the requests per second of the simple server with which we started the chapter.
Of course, this factor-of-two improvement is very specific to the design of this server and the particular memory and processor layout of my laptop. Depending on the length and cost of client requests, other network services could see much more or much less improvement than our Launcelot service has displayed here. But you can see that a pure event-driven design like this one turns the focus of your program away from the question of what one particular client will want next, and toward the question of what event is ready to happen regardless of where it comes from.
A slightly older mechanism for writing event-driven servers that listen to sockets is to use the select() call, which like poll() is available from the Python select module in the Standard Library. I chose to use poll() because it produces much cleaner code, but many people choose select() because it is supported on Windows.
As servers today are being asked to support greater and greater numbers of clients, some people have abandoned both select() and poll() and have opted for the epoll() mechanism provided by Linux or the kqueue() call under BSD. Some programmers have made this switch with solid numbers to back them up; other developers seem to switch simply because the latter calls are newer, but never actually check whether they will improve performance in their specific case.
Which mechanism should you use in your own code?
My advice is actually to avoid both of them! In my opinion, unless you have very specialized needs, you are not using your time well if you are sitting down and writing anything that looks like Listing 7-7. It is very difficult to get such code right—you will note that I myself did not include any real error handling, because otherwise the code would have become well-nigh unreadable, and the point of the listing is just to introduce the concept.
Instead of sitting down with W. Richard Stevens's Advanced Programming in the UNIX Environment and the manual pages for your operating system and trying to puzzle out exactly how to use select() or poll() with correct attention to all of the edge cases on your particular platform, you should be using an event-driven framework that does the work for you.
But we will look at frameworks in a moment; first, we need to get some terminology straight.
I should add a quick note about how recv() and send() behave in non-blocking mode, when you have called setblocking(False) on their socket. A poll() loop like the one just shown means that we never wind up calling either of these functions when they cannot accept or provide data. But what if we find ourselves in a situation where we want to call either function in non-blocking mode and do not yet know whether the socket is ready?
For the recv() call, these are the rules:
If data is ready, it is returned.
If no data has arrived,
socket.erroris raised.If the connection has closed,
''is returned.
This behavior might surprise you: a closed connection returns a value, but a still-open connection raises an exception. The logic behind this behavior is that the first and last possibilities are both possible in blocking mode as well: either you get data back, or finally the connection closes and you get back an empty string. So to communicate the extra, third possibility that can happen in non-blocking mode—that the connection is still open but no data is ready yet—an exception is used.
The behavior of non-blocking send() is similar:
Some data is sent, and its length is returned.
The socket buffers are full, so
socket.erroris raised.If the connection is closed,
socket.erroris also raised.
This last possibility may introduce a corner case that Listing 7-7 does not attempt to detect: that poll() could say that a socket is ready for sending, but a FIN packet from the client could arrive right after the server is released from its poll() but before it can start up its send() call.
The terminology surrounding event-driven servers like the one shown in Listing 7-7 has become quite tangled. Some people call them "non-blocking," despite the fact that the poll() call blocks, and others call them "asynchronous" despite the fact that the program executes its statements in their usual linear order. How can we keep these claims straight?
First, I note that everyone seems to agree that it is correct to call such a server "event-driven," which is why I am using that term here.
Second, I think that when people loosely call these systems "non-blocking," they mean that it does not block waiting for any particular client. The calls to send and receive data on any one socket are not allowed to pause the entire server process. But in this context, the term "non-blocking" has to be used very carefully, because back in the old days, people wrote programs that indeed did not block on any calls, but instead entered a "busy loop" that repeatedly polled a machine's I/O ports watching for data to arrive. That was fine if your program was the only one running on the machine; but such programs are a disaster when run under modern operating systems. The fact that event-driven servers can choose to block with select() or poll() is the very reason they can function as efficient services on the machine, instead of being resource hogs that push CPU usage immediately up to 100%.
Finally, the term "asynchronous" is a troubled one. At least on Unix systems, it was traditionally reserved for programs that interacted with their environment by receiving signals, which are violent interruptions that yank your program away from whatever statement it is executing and run special signal-handling code instead. Check out the signal module in the Standard Library for a look at how Python can hook into this mechanism. Programs that could survive having any part of their code randomly interrupted were rather tricky to write, and so asynchronous programming was quite correctly approached with great caution. And at bottom, computers themselves are inherently asynchronous. While your operating system does not receive "signals," which are a concept invented for user-level programs, they do receive IRQs and other hardware interrupts. The operating system has to have handlers ready that will correctly respond to each event without disturbing the code that will resume when the handler is complete.
So it seems to me that enough programming is really asynchronous, even today, that the term should most properly be reserved for the "hard asynchrony" displayed by IRQs and signal handlers. But, on the other hand, one must admit that while the program statements in Listing 7-7 are synchronous with respect to one another—they happen one right after the other, without surprises, as in any Python program—the I/O itself does not arrive in order. You might get a string from one client, then have to finish sending an answer to a second client, then suddenly find that a third client has hung up its connection. So we can grudgingly admit that there is a "soft asynchrony" here that involves the fact that network operations happen whenever they want, instead of happening lockstep in some particular order.
So in peculiar and restricted senses, I believe, an event-driven server can indeed be called non-blocking and asynchronous. But those terms can also have much stronger meanings that certainly do not apply to Listing 7-7, so I recommend that we limit ourselves to the term "event-driven" when we talk about it.
I mentioned earlier that you are probably doing something wrong if you are sitting down to wrestle with select() or poll() for any reason other than to write a new event-driven framework. You should normally treat them as low-level implementation details that you are happy to know about—having seen and studied Listing 7-7 makes you a wiser person, after all—but that you also normally leave to others. In the same way, understanding the UTF-8 string encoding is useful, but sitting down to write your own encoder in Python is probably a sign that you are re-inventing a wheel.
Now it happens that Python comes with an event-driven framework built into the Standard Library, and you might think that the next step would be for me to describe it. In fact, I am going to recommend that you ignore it entirely! It is a pair of ancient modules, asyncore and asynchat, that date from the early days of Python—you will note that all of the classes they define are lowercase, in defiance of both good taste and all subsequent practice—and that they are difficult to use correctly. Even with the help of Doug Hellmann's "Python Module of the Week" post about each of them, it took me more than an hour to write a working example of even our dead-simple Launcelot protocol.
If you are curious about these old parts of the Standard Library, then download the source bundle for this book and look for the program in the Chapter 7 directory named server_async.py, which is the result of my one foray into asyncore programming. But here in the book's text, I shall say no more about them.
Instead, we will talk about Twisted Python.
Twisted Python is not simply a framework; it is almost something of a movement. In the same way that Zope people have their own ways of approaching Python programming, the Twisted community has developed a way of writing Python that is all their own. Take a look at Listing 7-8 for how simple our event-driven server can become if we leave the trouble of dealing with the low-level operating system calls to someone else.
Example 7.8. Implementing Launcelot in Twisted
#!/usr/bin/env python
# Foundations of Python Network Programming - Chapter 7 - server_twisted.py
# Using Twisted to serve Launcelot users.
from twisted.internet.protocol import Protocol, ServerFactory
from twisted.internet import reactor
import launcelot
class Launcelot(Protocol):
» def connectionMade(self):
» » self.question = ''
» def dataReceived(self, data):
» » self.question += data
» » if self.question.endswith('?'):
» » » self.transport.write(dict(launcelot.qa)[self.question])
» » » self.question = ''
factory = ServerFactory()
factory.protocol = Launcelot
reactor.listenTCP(1060, factory)
reactor.run()Since you have seen Listing 7-7, of course, you know what Twisted must be doing under the hood: it must use select() or poll() or epoll()—and the glory of the approach is that we do not really care which—and then instantiate our Launcelot class once for every client that connects. From then on, every event on that socket is translated into a method call to our object, letting us write code that appears to be thinking about just one client at a time. But thanks to the fact that Twisted will create dozens or hundreds of our Launcelot protocol objects, one corresponding to each connected client, the result is an event loop that can respond to whichever client sockets are ready.
It is clear in Listing 7-8 that we are accumulating data in a way that keeps the event loop running; after all, dataReceived() always returns immediately while it is still accumulating the full question string. But what stops the server from blocking when we call the write() method of our data transport? The answer is that write() does not actually attempt any immediate socket operation; instead, it schedules the data to be written out by the event loop as soon as the client socket is ready for it, exactly as we did in our own event-driven loop.
There are more methods available on a Twisted Protocol class than we are using here—methods that are called when a connection is made, when it is closed, when it closes unexpectedly, and so forth. Consult their documentation to learn all of your options.
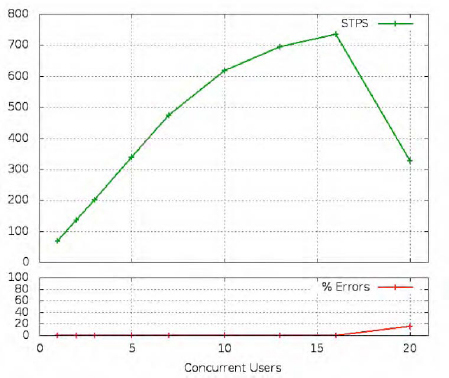
The performance of Twisted, as you can see from Figure 7-3, is somewhat lower than that of our handwritten event loop, but, of course, it is doing a lot more work. And if we actually padded out our earlier loop to include all of the error handling and compatibility that are supported by Twisted, then the margin would be closer.
The real magic of Twisted—which we lack the space to explore here—happens when you write protocols that have to speak to several partners at once rather than just one. Our Launcelot service can generate each reply immediately, by simply looking in a dictionary; but what if generating an answer involved reading from disk, or querying another network service, or talking to a local database?
When you have to invoke an operation that actually takes time, Twisted lets you provide it with one or more callback functions that it calls deferreds. And this is really the art of writing with Twisted: the craft of putting together short and long series of deferred functions so that, as blocks of data roll in from the disk or replies come back from a database server, all the right functions fire to construct an answer and get it delivered back to your client. Error handling becomes the practice of making sure that appropriate error callbacks are always available in case any particular network or I/O operation fails.
Some Python programmers find deferreds to be an awkward pattern and prefer to use other mechanisms when they need to serve many network clients at once; the rest of this chapter is dedicated to them. But if the idea of chaining callback functions intrigues you or seems to fit your mind—or if you simply want to benefit from the long list of protocols that Twisted has already implemented, and from the community that has gathered around it—then you might want to head off to the Twisted web site and try tackling its famous tutorial: http://twistedmatrix.com/documents/current/core/howto/tutorial/.
I myself have never based a project on Twisted because deferreds always make me feel as though I am writing my program backward; but many people find it quite pleasant once they are used to it.
Event-driven servers take a single process and thread of control and make it serve as many clients as it possibly can; once every moment of its time is being spent on clients that are ready for data, a process really can do no more. But what if one thread of control is simply not enough for the load your network service needs to meet?
The answer, obviously, is to run several instances of your service and to distribute clients among them. This requires a key piece of software: a load balancer that runs on the port to which all of the clients will be connecting, and which then turns around and gives each of the running instances of your service the data being sent by some fraction of the incoming clients. The load balancer thus serves as a proxy: to network clients it looks like your server, but to your server it looks like a client, and often neither side knows the proxy is even there.
Load balancers are such critical pieces of infrastructure that they are often built directly into network hardware, like that sold by Cisco, Barracuda, and f5. On a normal Linux system, you can run software like HAProxy or delve into the operating system's firewall rules and construct quite efficient load balancing using the Linux Virtual Server (LVS) subsystem.
In the old days, it was common to spread load by simply giving a single domain name several different IP addresses; clients looking up the name would be spread randomly across the various server machines. The problem with this, of course, is that clients suffer when the server to which they are assigned goes down; modern load balancers, by contrast, can often recover when a back-end server goes down by moving its live connections over to another server without the client even knowing.
The one area in which DNS has retained its foothold as a load-balancing mechanism is geography. The largest service providers on the Internet often resolve hostnames to different IP addresses depending on the continent, country, and region from which a particular client request originates. This allows them to direct traffic to server rooms that are within a few hundred miles of each customer, rather than requiring their connections to cross the long and busy data links between continents.
So why am I mentioning all of these possibilities before tackling the ways that you can move beyond a single thread of control on a single machine with threads and processes?
The answer is that I believe load balancing should be considered up front in the design of any network service because it is the only approach that really scales. True, you can buy servers these days of more than a dozen cores, mounted in machines that support massive network channels; but if, someday, your service finally outgrows a single box, then you will wind up doing load balancing. And if load balancing can help you distribute load between entirely different machines, why not also use it to help you keep several copies of your server active on the same machine?
Threading and forking, it turns out, are merely limited special cases of load balancing. They take advantage of the fact that the operating system will load-balance incoming connections among all of the threads or processes that are running accept() against a particular socket. But if you are going to have to run a separate load balancer in front of your service anyway, then why go to the trouble of threading or forking on each individual machine? Why not just run 20 copies of your simple single-threaded server on 20 different ports, and then list them in the load balancer's configuration?
Of course, you might know ahead of time that your service will never expand to run on several machines, and might want the simplicity of running a single piece of software that can by itself use several processor cores effectively to answer client requests. But you should keep in mind that a multi-threaded or multi-process application is, within a single piece of software, doing what might more cleanly be done by configuring a proxy standing outside your server code.
The essential idea of a threaded or multi-process server is that we take the simple and straightforward server that we started out with—the one way back in Listing 7-2, the one that waits repeatedly on a single client and then sends back the information it needs—and run several copies of it at once so that we can serve several clients at once, without making them wait on each other.
The event-driven approaches in Listings 7-7 and 7-8 place upon our own program the burden of figuring out which client is ready next, and how to interleave requests and responses depending on the order in which they arrive. But when using threads and processes, you get to transfer this burden to the operating system itself. Each thread controls one client socket; it can use blocking recv() and send() calls to wait until data can be received and transmitted; and the operating system then decides which workers to leave idle and which to wake up.
Using multiple threads or processes is very common, especially in high-capacity web and database servers. The Apache web server even comes with both: its prefork module offers a pool of processes, while the worker module runs multiple threads instead.
Listing 7-9 shows a simple server that creates multiple workers. Note how pleasantly symmetrical the Standard Library authors have made the interface between threads and processes, thanks especially to Jesse Noller and his recent work on the multiprocessing module. The main program logic does not even know which solution is being used; the two classes have a similar enough interface that either Thread or Process can here be used interchangeably.
Example 7.9. Multi-threaded or Multi-process Server
#!/usr/bin/env python
# Foundations of Python Network Programming - Chapter 7 - server_multi.py
# Using multiple threads or processes to serve several clients in parallel.
import sys, time, launcelot
from multiprocessing import Process
from server_simple import server_loop
from threading import Thread
WORKER_CLASSES = {'thread': Thread, 'process': Process}
WORKER_MAX = 10
def start_worker(Worker, listen_sock):
» worker = Worker(target=server_loop, args=(listen_sock,))
» worker.daemon = True # exit when the main process does
» worker.start()
» return worker
if __name__ == '__main__':
» if len(sys.argv) != 3 or sys.argv[2] not in WORKER_CLASSES:
» » print >>sys.stderr, 'usage: server_multi.py interface thread|process'
» » sys.exit(2)
» Worker = WORKER_CLASSES[sys.argv.pop()] # setup() wants len(argv)==2
» # Every worker will accept() forever on the same listening socket.
» listen_sock = launcelot.setup()
» workers = []
» for i in range(WORKER_MAX):
» » workers.append(start_worker(Worker, listen_sock))
» # Check every two seconds for dead workers, and replace them.
» while True:
» » time.sleep(2)» » for worker in workers: » » » if not worker.is_alive(): » » » » print worker.name, "died; starting replacement" » » » » workers.remove(worker) » » » » workers.append(start_worker(Worker, listen_sock))
First, notice how this server is able to re-use the simple, procedural approach to answering client requests that it imports from the launcelot.py file we introduced in Listing 7-2. Because the operating system keeps our threads or processes separate, they do not have to be written with any awareness that other workers might be operating at the same time.
Second, note how much work the operating system is doing for us! It is letting multiple threads or processes all call accept() on the very same server socket, and instead of raising an error and insisting that only one thread at a time be able to wait for an incoming connection, the operating system patiently queues up all of our waiting workers and then wakes up one worker for each new connection that arrives. The fact that a listening socket can be shared at all between threads and processes, and that the operating system does round-robin balancing among the workers that are waiting on an accept() call, is one of the great glories of the POSIX network stack and execution model; it makes programs like this very simple to write.
Third, although I chose not to complicate this listing with error-handling or logging code—any exceptions encountered in a thread or process will be printed as tracebacks directly to the screen—I did at least throw in a loop in the master thread that checks the health of the workers every few seconds, and starts up replacement workers for any that have failed.
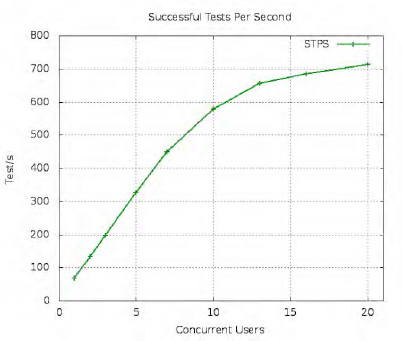
Figure 7-4 shows the result of our efforts: performance that is far above that of the single-threaded server, and that also beats slightly both of the event-driven servers we looked at earlier.
Again, given the limitations of my small duo-core laptop, the server starts falling away from linear behavior as the load increases from 5 to 10 simultaneous clients, and by the time it reaches 15 concurrent users, the number of 10-question request sequences that it can answer every second has fallen from around 70 per client to less than 50. And then—as will be familiar to anyone who has studied queuing theory, or run benchmarks like this before—its performance goes tumbling off of a cliff as the expense of trying to serve so many clients at once finally starts to overwhelm its ability to get any work done.
Note that running threads under standard C Python will impose on your server the usual limitation that no more than one thread can be running Python code at any given time. Other implementations, like Jython and IronPython, avoid this problem by building on virtual machine runtimes that lock individual data structures to protect them from simultaneous access by several threads at once. But C Python has no better approach to concurrency than to lock the entire Python interpreter with its Global Interpreter Lock (GIL), and then release it again when the code reaches a call like accept(), recv(), or send() that might wait on external I/O.
How many children should you run? This can be determined only by experimentation against your server on the particular machine that will be running it. The number of server cores, the speed or slowness of the clients that will be connecting, and even the speed of your RAM bus can affect the optimum number of workers. I recommend running a series of benchmarks with varying numbers of workers, and seeing which configuration seems to give you the best performance.
Oh—and, one last note: the multiprocessing module does a good job of cleaning up your worker processes if you exit from it normally or kill it softly from the console with Ctrl+C. But if you kill the main process with a signal, then the children will be orphaned and you will have to kill them all individually. The worker processes are normally children of the parent (here I have briefly changed WORKER_MAX to 3 to reduce the amount of output):
$ python server_multi.py localhost process $ ps f|grep 'python server_[m]ulti' 11218 pts/2 S+ 0:00 \_ python server_multi.py localhost process 11219 pts/2 S+ 0:00 \_ python server_multi.py localhost process 11220 pts/2 S+ 0:00 \_ python server_multi.py localhost process 11221 pts/2 S+ 0:00 \_ python server_multi.py localhost process
Running ps on a POSIX machine with the f option shows processes as a family tree, with parents above their children. And I randomly added square brackets to the m in the grep pattern so that the pattern does not match itself; it is always annoying when you grep for some particular process, and the grep process also gets returned because the pattern matches itself.
If I violently kill the parent, then unfortunately all three children remain running, which not only is annoying but also stops me from re-running the server since the children continue to hold open the listening socket:
$ kill 11218 $ ps f|grep 'python server_[m]ulti' 11228 pts/2 S 0:00 python server_multi.py localhost process 11227 pts/2 S 0:00 python server_multi.py localhost process 11226 pts/2 S 0:00 python server_multi.py localhost process
So manually killing them is the only recourse, with something like this:
$ kill $(ps f|grep 'python server_[m]ulti'|awk '{print$1}')If you are concerned enough about this problem with the multiprocessing module, then look on the Web for advice about how to use signal handling (the kill command operates by sending a signal, which the parent process is failing to intercept) to catch the termination signal and shut down the workers.
As usual, many programmers prefer to let someone else worry about the creation and maintenance of their worker pool. While the multiprocessing module does have a Pool object that will distribute work to several child processes (and it is rumored to also have an undocumented ThreadPool), that mechanism seems focused on distributing work from the master thread rather than on accepting different client connections from a common listening socket. So my last example in this chapter will be built atop the modest SocketServer module in the Python Standard Library.
The SocketServer module was written a decade ago, which is probably obvious in the way it uses multiclassing and mix-ins—today, we would be more likely to use dependency injection and pass in the threading or forking engine as an argument during instantiation. But the arrangement works well enough; in Listing 7-10, you can see how small our multi-threaded server becomes when it takes advantage of this framework. (There is also a ForkingMixIn that you can use if you want it to spawn several processes—at least on a POSIX system.)
Example 7.10. Using the Standard Library Socket Server
#!/usr/bin/env python
# Foundations of Python Network Programming - Chapter 7 - server_SocketServer.py
# Answering Launcelot requests with a SocketServer.
from SocketServer import ThreadingMixIn, TCPServer, BaseRequestHandler
import launcelot, server_simple, socket
class MyHandler(BaseRequestHandler):
» def handle(self):
» » server_simple.handle_client(self.request)
class MyServer(ThreadingMixIn, TCPServer):
» allow_reuse_address = 1
» # address_family = socket.AF_INET6 # if you need IPv6
server = MyServer(('', launcelot.PORT), MyHandler)
server.serve_forever()Note that this framework takes the opposite tack to the server that we built by hand in the previous section. Whereas our earlier example created the workers up front so that they were all sharing the same listening socket, the SocketServer does all of its listening in the main thread and creates one worker each time accept() returns a new client socket. This means that each request will run a bit more slowly, since the client has to wait for the process or thread to be created before it can receive its first answer; and this is evident in Figure 7-5, where the volume of requests answered runs a bit lower than it did in Figure 7-4.
A disadvantage of the SocketServer classes, so far as I can see, is that there is nothing to stop a sudden flood of client connections from convincing the server to spin up an equal number of threads or processes—and if that number is large, then your computer might well slow to a crawl or run out of resources rather than respond constructively to the demand. Another advantage to the design of Listing 7-9, then, is that it chooses ahead of time how many simultaneous requests can usefully be underway, and leaves additional clients waiting for an accept() on their connections before they can start contributing to the load on the server.
I have written this chapter with the idea that each client request you want to handle can be processed independently, and without making the thread or process that is answering it share any in-memory data structures with the rest of your threads.
This means that if you are connecting to a database from your various worker threads, I assume that you are using a thread-safe database API. If your workers need to read from disk or update a file, than I assume that you are doing so in a way that will be safe if two, or three, or four threads all try using the same resource at once.
But if this assumption is wrong—if you want the various threads of control in your application to share data, update common data structures, or try to send messages to each other—then you have far deeper problems than can be solved in a book on network programming. You are embarking, instead, on an entire discipline of its own known as "concurrent programming," and will have to either restrict yourself to tools and methodologies that make concurrency safe, or be fiendishly clever with low-level mechanisms like locks, semaphores, and condition variables.
I have four pieces of advice if you think that you will take this direction.
First, make sure that you have the difference between threads and processes clear in your head. Listing 7-9 treated the two mechanisms as equivalent because it was not trying to maintain any shared data structures that the workers would have to access. But if your workers need to talk to one another, then threads let them do so in-memory—any global variables in each module, as well as changes to such variables, will be immediately visible to all other threads—whereas multiple processes can share only data structures that you explicitly create for sharing using the special mechanisms inside the multiprocessing module. On the one hand, this makes threading more convenient since data is shared by default. On the other hand, this makes processes far more safe, since you explicitly have to opt-in each data structure to being shared, and cannot get bitten by state that gets shared accidentally.
Second, use high-level data structures whenever possible. Python provides queues, for example, that can operate either between normal threads (from the queue module) or between processes (see the multiprocessing module). Passing data back and forth with these well-designed tools is far less complicated than trying to use locks and semaphores on your own to signal when data is ready to be consumed.
Third, limit your use of shared data to small and easily protected pieces of code. Under no circumstances should you be spreading primitive semaphores and condition variables across your entire code base and hope that the collective mass that results will somehow operate correctly and without deadlocks or data corruption. Choose a few conceptually small points of synchronization where the gears of your program will mesh together, and do your hard thinking there in one place to make sure that your program will operate correctly.
Finally, look very hard at both the Standard Library and the Package Index for evidence that some other programmer before you has faced the data pattern you are trying to implement and has already taken the time to get it right. Well-maintained public projects with several users are fun to build on, because their users will already have run into many of the situations where they break long before you are likely to run into these situations in your own testing.
But most network services are not in this class. Examine, for instance, the construction of most view functions or classes in a typical Python web framework: they manipulate the parameters that have been passed in to produce an answer, without knowing anything about the other requests that other views are processing at the same time. If they need to share information or data with the other threads or processes running the same web site, they use a hardened industrial tool like a database to maintain their shared state in a way that all of their threads can get to without having to manage their own contention. That, I believe, is the way to go about writing network services: write code that concerns itself with local variables and local effects, and that leaves all of the issues of locking and concurrency to people like database designers that are good at that sort of thing.
For old times' sake, I should not close this chapter without mentioning inetd, a server used long ago on Unix systems to avoid the expense of running several Internet daemons. Back then, the RAM used by each running process was a substantial annoyance. Today, of course, even the Ubuntu laptop on which I am typing is running dozens of services just to power things like the weather widget in my toolbar, and the machine's response time seems downright snappy despite running—let's see—wow, 229 separate processes all at the same time. (Yes, I know, that count includes one process for each open tab in Google Chrome.)
So the idea was to have an /etc/inetd.conf file where you could list all of the services you wanted to provide, along with the name of the program that should be run to answer each request. Thus, inetd took on the job of opening every one of those ports; using select() or poll() to watch all of them for incoming client connections; and then calling accept() and handing the new client socket off to a new copy of the process named in the configuration file.
Not only did this arrangement save time and memory on machines with many lightly used services, but it became an important step in securing a machine once Wietse Venema invented the TCP Wrappers (see Chapter 6). Suddenly everyone was rewriting their inetd.conf files to call Wietse's access-control code before actually letting each raw service run. The configuration files had looked like this:
ftp stream tcp nowait root in.ftpd in.ftpd -l -a telnet stream tcp nowait root in.telnetd in.telnetd talk dgram udp wait nobody in.talkd in.talkd finger stream tcp nowait nobody in.fingerd in.fingerd
Once Wietse's tcpd binary was installed, the inetd.conf file would be rewritten like this:
ftp stream tcp nowait root /usr/sbin/tcpd in.ftpd -l -a telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd talk dgram udp wait nobody /usr/sbin/tcpd in.talkd finger stream tcp nowait nobody /usr/sbin/tcpd in.fingerd
The tcpd binary would read the /etc/hosts.allow and hosts.deny files and enforce any access rules it found there—and also possibly log the incoming connection—before deciding to pass control through to the actual service being protected.
If you are writing a Python service to be run from inetd, the client socket returned by the inetd accept() call will be passed in as your standard input and output. If you are willing to have standard file buffering in between you and your client—and to endure the constant requirement that you flush() the output every time that you are ready for the client to receive your newest block of data—then you can simply read from standard input and write to the standard output normally. If instead you want to run real send() and recv() calls, then you will have to convert one of your input streams into a socket and then close the originals (because of a peculiarity of the Python socket fromfd() call: it calls dup() before handing you the socket so that you can close the socket and file descriptor separately):
import socket, sys sock = socket.fromfd(sys.stdin.fileno(), socket.AF_INET, socket.SOCK_STREAM) sys.stdin.close()
In this sense, inetd is very much like the CGI mechanism for web services: it runs a separate process for every request that arrives, and hands that program the client socket as though the program had been run with a normal standard input and output.
Network servers typically need to run as daemons so that they do not exit when a particular user logs out, and since they will have no controlling terminal, they will need to log their activity to files so that administrators can monitor and debug them. Either supervisor or the daemon module is a good solution for the first problem, and the standard logging module should be your focus for achieving the second.
One approach to network programming is to write an event-driven program, or use an event-driven framework like Twisted Python. In both cases, the program returns repeatedly to an operating system–supported call like select() or poll() that lets the server watch dozens or hundreds of client sockets for activity, so that you can send answers to the clients that need it while leaving the other connections idle until another request is received from them.
The other approach is to use threads or processes. These let you take code that knows how to talk to one client at a time, and run many copies of it at once so that all connected clients have an agent waiting for their next request and ready to answer it. Threads are a weak solution under C Python because the Global Interpreter Lock prevents any two of them from both running Python code at the same time; but, on the other hand, processes are a bit larger, more expensive, and difficult to manage.
If you want your processes or threads to communicate with each other, you will have to enter the rarefied atmosphere of concurrent programming, and carefully choose mechanisms that let the various parts of your program communicate with the least chance of your getting something wrong and letting them deadlock or corrupt common data structures. Using high-level libraries and data structures, where they are available, is always far preferable to playing with low-level synchronization primitives yourself.
In ancient times, people ran network services through inetd, which hands each server an already-accepted client connection as its standard input and output. Should you need to participate in this bizarre system, be prepared to turn your standard file descriptors into sockets so that you can run real socket methods on them.