In order to integrate our sensor reading code into our server, first. let's understand what is happening under the hood whenever we execute the node script that takes our sensor readings. Let's review the snippet of code that actually called for the sensor readings:
/*
Section A
*/
sensor.read(11, 4, function(err, temperature, humidity) {
/*
Section B
*/
//After reading the sensor, we get the temperature
and humidity readings
if (!err) {
//If there is no error, log the readings to the
console
console.log('temp: ' + temperature.toFixed(1) +
'°C, ' +
'humidity: ' + humidity.toFixed(1) + '%'
)
}
});
/*
Section C
*/
Immediately, we can see that the sensor.read method is not synchronous; that is, it does not immediately return the result upon invocation. This is because it isn't actually the node script that obtains the readings from the pin. Rather, it makes use of a third-party library that runs native code to do this (this is the bcm2835 C library that we installed in the previous chapter). This native code, on running and producing results, then passes it back to our node process, which can run further processing.
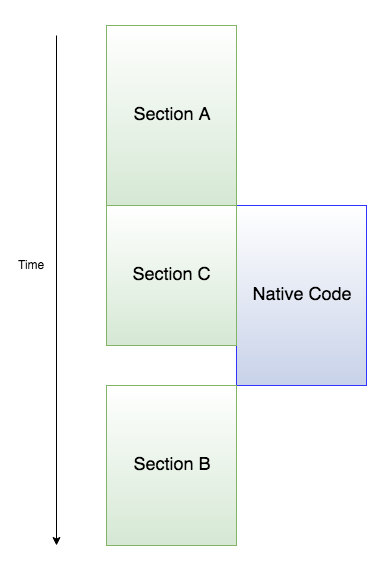
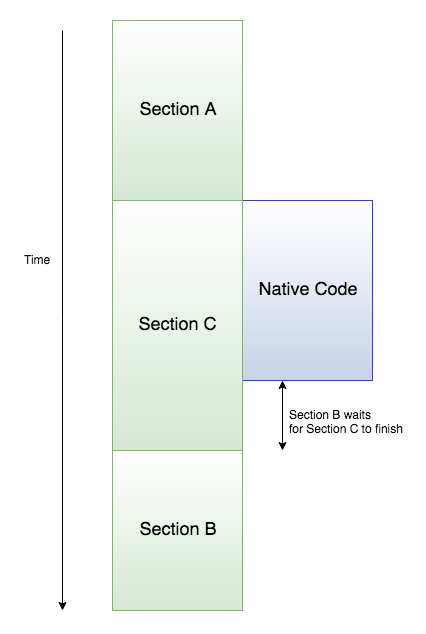
As we can see from the preceding timing diagram, Section A calls the native library to execute some instructions, which, in our case, is obtaining readings from the sensor pins. Node.js executes this operation asynchronously, which means that it does not wait for the native code to return our results to us and moves on with code execution. This means that any code written outside the callback will be executed while the node process waits for the native process to return our results to us.
Finally, after the sensor readings are made available by the native library, the code inside the callback (Section B) is called.
An interesting piece of information to note is that the node works on the basis of event loops, which are functions, or pieces of code, that get pushed into the queue and are executed one after the other.
Node is also single threaded, which means that any of these pieces of code cannot be executed at the same time. Although we saw that the native code and Section C were executed together, the native code was not on the same thread as the node process. What this can potentially mean is that Section B would have to wait for Section C to finish its execution before it executes (even if the native code fetches results sooner) because Section C was pushed into the queue before it was.