
3 Version control is the only way to roll
- understanding why version control is essential to CD
- keeping your software in a releasable state by keeping version control green and triggering pipelines based on changes in version control
- defining config as code
- enabling automation by storing all configuration in version control
We’re going to start your continuous delivery (CD) journey at the very beginning, with the tool that we need for the basis of absolutely everything we’re going to do next: version control. In this chapter, you’ll learn why version control is crucial to CD and how to use it to set up you and your team for success.
Sasha and Sarah’s start-up
Recent university grads Sasha and Sarah have just gotten funding for an ambitious start-up idea: Watch Me Watch, a social networking site based around TV and movie viewing habits. With Watch Me Watch, users can rate movies and TV shows as they watch them, see what their friends like, and get personalized recommendations for what to watch next.

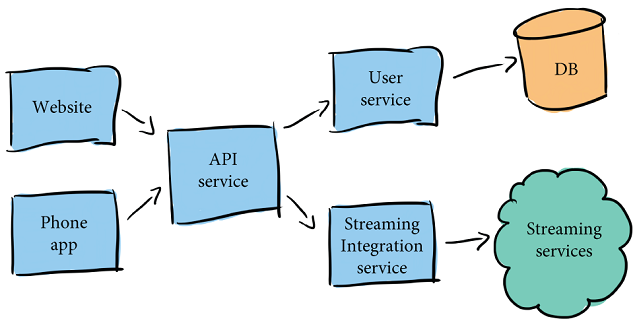
Sasha and Sarah want the user experience to be seamless, so they are integrating with popular streaming providers. Users don’t have to tediously add movies and TV shows as they watch them, because all of their viewing will automatically be uploaded to the app! Before Sasha and Sarah get started, they’ve sketched out the architecture they want to build:
They’re going to break up the backend logic into three services:
-
The Watch Me Watch API service, which handles all requests from the frontends
-
The User service, which holds data about users
-
The Streaming Integration service, which integrates with popular streaming providers
Sasha and Sarah also plan to provide two frontends for interacting with Watch Me Watch, a website and a phone app.
All kinds of data
As they stare proudly at this architecture diagram on their newly purchased whiteboard, they realize that all the code they need to build is going to have to live somewhere. And they’re going to both be making changes to it, so they’ll need some kind of coordination. They are going to create three services, which are designed and built in roughly the same way: they are written in Go, and executed as running containers.

They’ll also run a website and create and distribute a phone app, both of which will be ways for users to use Watch Me Watch.

The data to define the three services, the app, and the website will include the following:
-
Source code and tests written in Go
-
READMEs and other docs written in Markdown
-
Container image definitions (Dockerfiles) for the services
-
Images for the website and phone app
-
Task and pipeline definitions for testing, building, and deploying

The database (which will be running in the cloud) is going to need the following:
-
Versioned schemas
-
Task and pipeline definitions for deploying

To connect to the streaming services Sasha and Sarah will be integrating with, they’re also going to need API keys and connection information.
Source and software
Even before they’ve written a single line of code, while gazing at their architecture diagram and thinking about what each piece is going to need, Sasha and Sarah realize they are going to have a lot of data to store:
-
Source code
-
Tests
-
Dockerfiles
-
Markdown files
-
Tasks and pipelines
-
Versioned schemas
-
API keys
-
Connection information

That’s a lot! (And this is for a fairly straightforward system!) But what do all of these items have in common? They’ll all data. And in fact, one step further than that, they are all plain text.
Although each is used differently, each is represented by plain-text data. And when you’re working on building and maintaining software, like Sasha and Sarah are about to be, you need to manage all that plain-text data somehow.
And that’s where version control comes in. Version control (also called source control) stores this data and tracks changes to it. It stores all of the data your software needs: the source code, the configuration you use to run it, supporting data like documentation and scripts—all the data you need to define, run, and interact with your software.
![]() Vocab time
Vocab time
Plain text is data in the form of printable (or human-readable) characters. In the context of software, plain text is often contrasted with binary data, which is stored as sequences of bits that are not plain text. More simply: plain text is human-readable data, and the rest is binary data. Version control could be used for any data but is usually optimized for plain text, so it doesn’t handle binary data very well. This means you can use it to store binary data if you want, but some features (e.g., showing differences between changes) won’t work, or won’t work well.
Repositories and versions
Version control is software for tracking changes to plain text, where each change is identified by a version, also called a commit or a revision. Version control gives you (at least) these two features for your software:
-
A central location to store everything, usually called the repository (or repo for short!)
-
A history of all changes, with each change (or set of changes) resulting in a new, uniquely identifiable version
The configuration and source code needed for projects can often be stored in multiple repos. Sticking to just one repo for everything is exceptional enough that this has its own name: a monorepo.
Sasha and Sarah decide to have roughly one repo per service in their architecture, and they decide that they first repo they’ll create will be for their User service.

Continuous delivery and version control
Version control is the foundation for CD. I like the idea of treating CD as a practice, asserting that if you’re doing software development, you’re already doing CD (at least to some extent). However, the one exception I’ll make to that statement is that if you’re not using version control, you’re not doing CD.
To be doing continuous delivery, you must use version control.
Why is version control so important for CD? Remember that CD is all about getting to a state where
-
you can safely deliver changes to your software at any time.
-
delivering that software is as simple as pushing a button.
In chapter 1, we looked at what was required to achieve the first condition—specifically, CI, which we defined as follows:
The process of combining code changes frequently, with each change verified on check-in.
We glossed over what check-in means here. In fact, we already assumed version control was involved! Let’s try to redefine CI without assuming version control is present:
The process of combining code changes frequently, with each change verified when it is added to the already accumulated and verified changes.
This definition suggests that to do CI, we need the following:
-
A way to combine changes
-
Somewhere to store (and add to) changes
And how do we store and combine changes to software? You guessed it: using version control. In every subsequent chapter, as we discuss elements you’ll want in your CD pipelines, we’ll be assuming that we’re starting from changes that are tracked in version control.
![]() Takeaway
Takeaway
To be doing continuous delivery, you must use version control.
![]() Takeaway
Takeaway
Writing and maintaining software means creating and editing a lot of data, specifically plain-text data. Use version control to store and track the history of your source code and configuration—all the data you need to define your software. Store the data in one or more repositories, with each change uniquely identified by a version.
Git and GitHub
Sarah and Sasha are going to be using Git for version control. The next question is where their repository will be hosted and how they will interact with it. Sarah and Sasha are going to be using GitHub to host this repository and the other repositories they will create.
Which version control should I use?
At the time of writing, Git is widely supported and popular and would be a great choice!
Git is a distributed version control system. When you clone (copy) a repository onto your own machine, you get a full copy of the entire repository that can be used independently of the remote copy. Even the history is separate.
While we’re using GitHub for our examples, other appealing options exist as well, with different tradeoffs. See appendix B for an overview of other options.
Sarah creates the project’s first repository on GitHub and then clones the repo; this makes another copy of the repo on her machine, with all the same commits (none so far), but she can make changes to it independently. Sasha does the same thing, and they both have clones of the repo they can work on independently, and use to push changes back to the repo in GitHub.

Software configuration management and source code management
Fun fact! Version control software is part of software configuration management (SCM), the process of tracking changes to the configuration that is used to build and run your software. In this context, configuration refers to details about all of the data in the repo, including source code, and the practice of configuration management for computers dates back to at least the 1970s. This terminology has fallen out of favor, leading both to a rebirth in infrastructure as code and later configuration as code (more on this in a few pages) and a redefining of SCM as source code management. SCM is now often used interchangeably with version control and sometimes used to refer to systems like GitHub, which offer version control coupled with features like issue tracking and code review.
An initial commit—with a bug!
Sarah and Sasha both have clones of the User service repo and are ready to work. In a burst of inspiration, Sarah starts working on the initial User class in the repo. She intends for it to be able to store all of the movies a user has watched, and the ratings that a given user has explicitly given to movies.
The User class she creates stores the name of the user, and she adds a method rate_movie, which will be called when a user wants to rate a movie. The method takes the name of the movie to rate, and the score (as a floating-point percentage) to give the movie. It tries to store these in the User object, but her code has a bug: the method tries to use self.ratings, but that object hasn’t been initialized anywhere.
class User:
def __init__(self, name):
self.name = name
def rate_movie(self, movie, score):
self.ratings[movie] = score ❶❶ There’s a bug here: the dictionary self.ratings hasn’t been initialized, so trying to store a key in it is going to raise an exception!
Sarah wrote a bug into this code, but she also wrote a unit test that will catch that error. The test (test_rate_movie) tries to rate a movie and then verifies that the rating has been added:
def test_rate_movie(self):
u = User("sarah")
u.rate_movie("jurassic park", 0.9)
self.assertEqual(u.ratings["jurassic park"], 0.9)By default, the first branch created in Git is called main. This default branch is used as the source of truth (the authoritative version of the code), and all changes are ultimately integrated here. See chapter 8 for a discussion of other branching strategies.
Unfortunately, Sarah forgets to actually run the test before she commits this new code! She adds these changes to her local repo, creating a new commit with ID abcd0123abcd0123. She commits this to the main branch on her repo, then pushes the commit back to the main branch in GitHub’s repo.

These example commit IDs are just for show; actual Git commit IDs are the SHA-1 hash of the commit.
![]() Vocab time
Vocab time
Pushing changes into a branch from another branch is often called merging. Sarah’s changes from her main branch are merged into GitHub’s main branch.
Breaking main
Shortly after Sarah pushes her new code (and her bug!), Sasha pulls the main branch from GitHub to her local repo, pulling in the new commit.

Sasha is excited to see the changes Sarah made:
class User:
def __init__(self, name):
self.name = name
def rate_movie(self, movie, score):
self.ratings[movie] = scoreSasha tries to use them right away, but as soon as she tries to use rate_movie, she runs smack into the bug, seeing the following error:
AttributeError: 'User' object has no attribute 'ratings'
“I thought I saw that Sarah included a unit test for this method,” wonders Sasha. “How could it be broken?”
def test_rate_movie(self):
u = User("sarah")
u.rate_movie("jurassic park", 0.9)
self.assertEqual(u.ratings["jurassic park"], 0.9)Sasha runs the unit test and, lo and behold, the unit test fails, too:
Traceback (most recent call last):
File "test_user.py", line 21, in test_rate_movie
u.rate_movie("jurassic park", 0.9)
File "test_user.py", line 12, in rate_movie
self.ratings[movie] = score
AttributeError: 'User' object has no attribute 'ratings'Sasha realizes that the code in the GitHub repo is broken.
Pushing and pulling
Let’s look again at the pushing and pulling that occurred in the last couple of pages. After Sarah made her change and committed it locally, the repos looked like this:

To update the repository in GitHub with the commit that she made, Sarah pushed the commit to the remote repo (aka merged it). Git will look at the contents and history of the remote repo, compare it to Sarah’s local copy, and push (upload) all missing commits to the repo. After the push, the two repos have the same contents:

In order for Sasha to get Sarah’s changes, she needs to pull the main branch from GitHub. Git will look at the contents and history of GitHub’s repo, compare it to Sasha’s local copy, and pull all the missing commits to Sasha’s repo:

Now all three repos have the same commits. Sarah pushed her new commit to GitHub, and Sasha pulled the commit from there.
![]() Pull requests
Pull requests
You may have noticed that Sarah pushed her changes directly to the main branch in the repo on GitHub. A safer practice than directly pushing changes is to have an intermediate stage in which changes are proposed before being added, which provides an opportunity for code review and for CI to verify changes before they go in.
In this chapter, we’ll look at triggering CI on pushed changes to version control, but in subsequent chapters, we’ll look at running CI on changes before they are added to the main branch.
Being able to propose, review and verify changes is done with pull requests (often called PRs), and you’ll see PRs referred to frequently in the rest of the book. (See appendix B for more on the term and how it is used in different hosted version control systems.)
If Sarah and Sasha were using PRs, the previous process would have looked like this:

Instead of pushing her change directly to GitHub’s main branch, Sarah would open a pull request; she’d create a proposal requesting that her change be pulled into GitHub’s main branch:

This would give Sasha a chance to review the changes and allow for verification of the changes before GitHub’s main is updated.
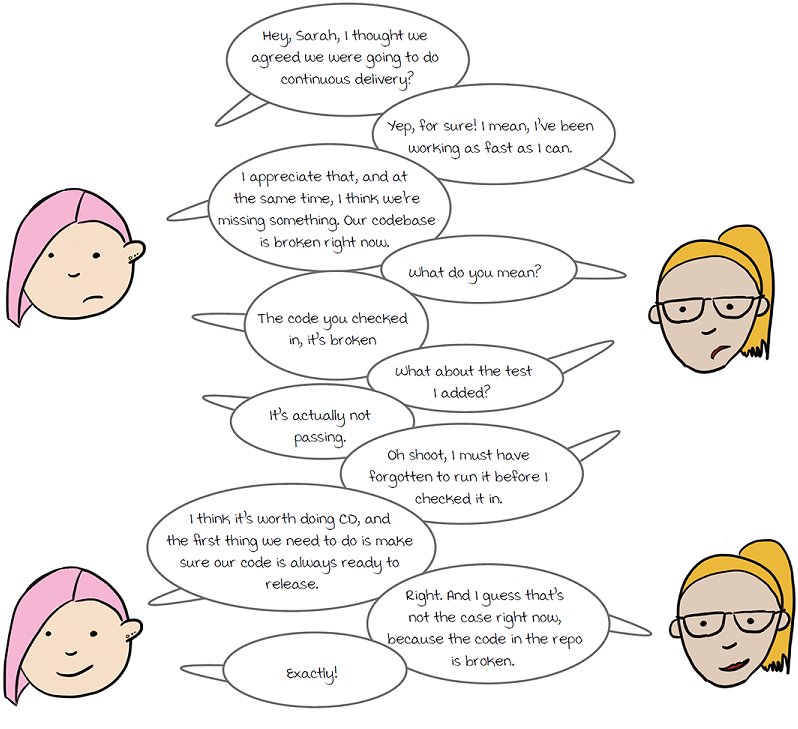
Are we doing continuous delivery?
Sasha is a bit frustrated after learning that the User service code in the GitHub repo is broken and brings up the issue with Sarah.
Keep version control releasable
Sarah and Sasha have realized that by allowing broken code to be committed to the User service repo in GitHub, they’re violating one of two pillars of CD. Remember, to be doing CD, you want to be trying to get to a state where
-
you can safely deliver changes to your software at any time.
-
delivering that software is as simple as pushing a button.
Won’t there always be broken code?
You’ll never catch every single bug, so in some sense, broken code will always be committed to version control. The key is to always keep version control in a state that lets you feel confident releasing; introducing the occasional bug is par for the course, but the goal is to have your code in a state that has a minimal need to roll back and low risks associated with a release or deployment. See chapters 8 and 10 for more on releasing.
The User service cannot be safely delivered until the bug Sarah introduced is fixed. This means the service is not in a state that is safe to deliver.
Sarah is able to fix it and quickly push a commit with the fix, but how can Sarah and Sasha make sure this doesn’t happen again? After all, Sarah had written a test that caught the problem she introduced, and that wasn’t enough to stop the bug from getting in.
No matter how hard Sarah tries, she might forget to run the tests before committing at some point in the future—and Sasha might too. They’re only human, after all!
What Sasha and Sarah need to do is to guarantee that the tests will be run. When you need to guarantee that something happens (and if it’s possible to automate that thing), your best bet is to automate it.
If you rely on humans to do something that always without fail needs to be done, sometimes they’ll make mistakes—which is totally okay, because that’s how humans work! Let humans be good at what humans do, and when you need to guarantee that the same thing is done in the exact same way every time, and happens without fail, use automation.
![]() Takeaway
Takeaway
When you need to guarantee that something happens, use automation. Human beings are not machines, and they’re going to make mistakes and forget to do things. Instead of blaming the person for forgetting to do something, try to find a way to make it so they don’t have to remember.
Trigger on changes to version control
Looking at what led to the User service repo being in an unsafe state, we realize that the point where Sarah went wrong wasn’t when she introduced the bug, or even when she committed it. The problems started when she pushed the broken code to the remote repo:
-
Sarah writes the buggy code. (a)
-
Sarah commits the code to her own repo. (b)
-
Sarah pushes the commit to the GitHub repo. (c)
-
Sasha tries to use the new code and finds the bug. (d)
(a) Still doing CD; bugs happen!
(b) Still okay. So she forgot to run the tests; it happens.
(c) Now the User service can’t be released safely, and we’re getting further away from CD.
(d) Not only is it unsafe to release: before this, no one knows it's unsafe. It would be totally reasonable to release the software at this point—and so this is where things have really gone wrong.
So what’s the missing piece between steps 3 and 4 that would let Sarah and Sasha do CD?
Can something be done even earlier to stop step 3 from happening at all?
Absolutely! Becoming aware of when problems are introduced is a good first step, but even better is to stop the problems from being introduced at all. This can be done by running pipelines before commits are introduced to the remote main branch. See chapter 7 for more on this.
In chapter 2, you learned an important principle for what to do when breaking changes are introduced:
When the pipeline breaks, stop pushing changes.
But what pipeline? Sasha and Sarah don’t have any kind of pipeline or automation set up at all. They have to rely on manually running tests to figure out when anything is wrong. And that’s the missing piece that Sasha and Sarah need—not just having a pipeline to automate that manual effort and make it reliable, but setting it up to be triggered on changes to the remote repo:
Trigger pipelines on changes to version control.
If Sasha and Sarah had a pipeline that ran the unit tests whenever a change was pushed to the GitHub repo, Sarah would have immediately been notified of the problem she introduced.
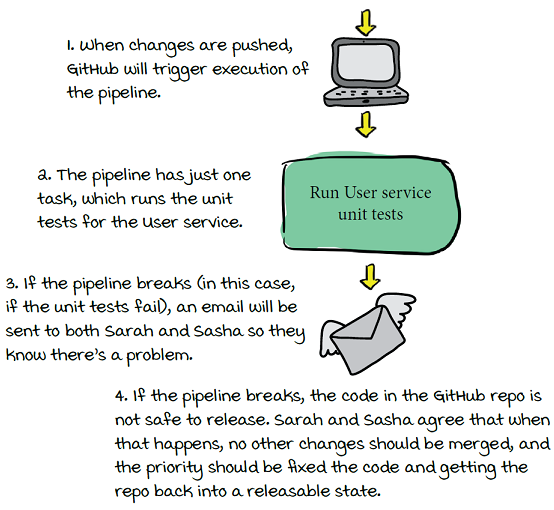
Triggering the User service pipeline
Sasha and Sarah create a pipeline. For now, it has just one task to run their unit tests. They set up webhook triggering so that the pipeline will be automatically run every time commits are pushed to the repo in GitHub, and if the pipeline is unsuccessful, an email notification will be sent to both of them.
Now if any breaking changes are introduced, they’ll find out right away. They agree to adopt a policy of dropping everything to fix any breakages that are introduced:
When the pipeline breaks, stop pushing changes.
Where does their pipeline run?
We’re not going to get into the details of the CD system Sasha and Sarah chose; see the appendices at the end of the book for some of the options they considered. Since they’re already using GitHub, GitHub Actions would be a quick and easy way for them to get their pipeline up and running!
![]() Takeaway
Takeaway
Trigger pipelines on changes to version control. Just writing tests isn’t enough; they need to be running regularly. Relying on people to remember to run them manually is error prone. Version control is not just the source of truth for the state of your software; it’s also the jumping-off point for all the CD automation we’ll look at in this book.
Building the User service
Sarah and Sasha now have a (small) pipeline in place that will make sure they know immediately if something breaks. But the User service code isn’t doing them any good unless they’re doing something with it! So far this pipeline has been helping them with the first part of CD:
You can safely deliver changes to your software at any time.
Having a pipeline and automation to trigger it will also help them with the second part of CD:
Delivering that software is as simple as pushing a button.
They need to add tasks to their pipeline to build and publish the User service. They decide to package the User service as a container image and push it to an image registry.

By adding this to their pipeline, they make this “as simple as pushing a button” (or in this case, even simpler, since it will be triggered by changes to version control).
Now on every commit, the unit tests will be run, and if they are successful, the User service will be packaged up and pushed as an image.
The User service in the cloud
The last question Sarah and Sasha need to answer for the User service is how the image they are now automatically building will run. They decide they’ll run it using the popular cloud provider RandomCloud.
RandomCloud provides a service for running containers, so running the User service will be easy—except that in order to be able to run, the User service also needs access to a database, where it stores information about users and movies:

Fortunately, like most cloud offerings, RandomCloud provides a database service that Sarah and Sasha can use with the User service:

With the User service pipeline automatically building and publishing the User service image, all they need to do now is configure the User service container to use RandomCloud’s database service.
Connecting to the RandomCloud database
To get the User service up and running in RandomCloud, Sasha and Sarah need to configure the User service container to connect to RandomCloud’s database service. To pull this off, two pieces need to be in place:
-
It needs to be possible to configure the User service with the information the service needs to connect to a database.
-
When running the User service, it needs to be possible to provide the specific configuration that allows it to Random Cloud’s database service.
For the first piece, Sasha adds command-line options that the User service uses to determine what database to connect to:
./user_service.py
--db-host=10.10.10.10
--db-username=some-user
--db-password=some-password
--db-name=watch-me-watch-users ❶❶ The database connection information is provided as command-line arguments.
For the second piece, the specifics of RandomCloud’s database service can be provided via the configuration that RandomCloud uses to run the User service container:
apiVersion: randomcloud.dev/v1 kind: Container spec: image: watchmewatch/userservice:latest ❶ args: - --db-host=10.10.10.10 - --db-username=some-user - --db-password=some-password - --db-name=watch-me-watch-users ❷
❶ This image is built and pushed as part of the User service pipeline. It contains and runs user_service.py.
❷ These are the same arguments as in the preceding code, now provided as part of the RandomCloud configuration.
Always deploying the latest image has serious downsides. See chapter 9 for what those are and what you can do instead.
Should they be passing around passwords in plain text?
The short answer is no. Sasha and Sarah are about to learn that they want to store this configuration in version control, and they definitely don’t want to commit the password there. More on this in a bit.
Managing the User service
Sarah and Sasha are all set to run the User service as a container by using popular cloud provider RandomCloud.

See chapter 10 for more on deployment automation!
For the first couple of weeks, every time they want to do a launch, they use the RandomCloud UI to update the container configuration with the latest version, sometimes changing the arguments as well.
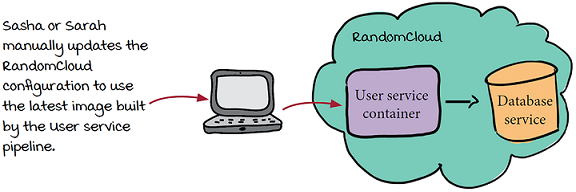
Soon Sarah and Sasha decide to invest in their deployment tooling a bit more, and so they pay for a license with Deployaker, a service that allows them to easily manage deployments of the User service (and later the other services that make up Watch Me Watch as well).

The User service is now running in a container on RandomCloud, and that service is managed by Deployaker. Deployaker continually monitors the state of the User service and makes sure that it is always configured as expected.
The User service outage
One Thursday afternoon, Sasha gets an alert on her phone from RandomCloud, telling her the User service is down. Sasha looks at the logs from the User service and realizes that it can no longer connect to the database service. The database called watch-me-watch-users no longer exists!

Sasha races to fix the configuration—but she makes a crucial mistake. She completely forgets that Deployaker is managing the User service now. Instead of using Deployaker to make the update, she makes the fix directly in the RandomCloud UI:
apiVersion: randomcloud.dev/v1
kind: Container
spec:
image: watchmewatch/userservice:latest
args:
- --db-host=10.10.10.10
- --db-username=some-user
- --db-password=some-password
- --db-name=users ❶❶ Sasha updates the configuration to use the correct database, but she makes the change directly to RandomCloud and forgets about Deployaker completely.
The User service is fixed, and the alerts from RandomCloud stop.
What’s Deployaker?
Deployaker is an imaginary piece of software based on the real-world open source deployment tool Spinnaker. See chapter 10 for more on deploying.
Outsmarted by automation
Sasha has rushed in a fix to the RandomCloud configuration to get the User service back up and running, but she completely forgot that Deployaker is running behind the scenes. That night, Sarah is sleeping soundly when she is suddenly woken up by another alert from RandomCloud. The User service is down again!

Sarah opens up the Deployaker UI and looks at the configuration it is using for the User service:
apiVersion: randomcloud.dev/v1
kind: Container
spec:
image: watchmewatch/userservice:latest
args:
- --db-host=10.10.10.10
- --db-username=some-user
- --db-password=some-password
- --db-name=watch-me-watch-users ❶❶ This configuration is still using the database that Sarah deleted!
In spite of being so tired that she can’t think properly, Sarah realizes what happened. Sasha fixed the configuration in RandomCloud but didn’t update it in Deployaker. Deployaker periodically checks the deployed User service to make sure it is deployed and configured as expected. Unfortunately, when Deployaker checked that night, it saw the change Sarah had made—which didn’t match what it expected to see. So Deployaker resolved the problem by overwriting the fixed configuration with the configuration it had stored, triggering the same outage again! Sarah sighs and makes the fix in Deployaker:
apiVersion: randomcloud.dev/v1
kind: Container
spec:
image: watchmewatch/userservice:latest
args:
- --db-host=10.10.10.10
- --db-username=some-user
- --db-password=some-password
- --db-name=users ❶❶ Now the correct configuration is stored in Deployaker, and Deployaker will ensure that the service running in RandomCloud uses this configuration.
The alerts stop, and she can finally go back to sleep.
What’s the source of truth?
The next morning, bleary eyed over coffee, Sarah tells Sasha what happened.

The configuration that they are talking about is the RandomCloud configuration for the User service container that needed to be changed to fix the outages the previous day:
apiVersion: randomcloud.dev/v1 kind: Container spec: image: watchmewatch/userservice:latest args: - --db-host=10.10.10.10 - --db-username=some-user - --db-password=some-password - --db-name=users # OR --db-name=watch-me-watch-users
This configuration has two sources of truth:
-
The configuration that RandomCloud was using
-
The configuration stored in Deployaker, which it would use to overwrite whatever RandomCloud was using if it didn’t match
Sasha has suggested that maybe they can store this configuration in the GitHub repo alongside the User service source code. But would this just end up being a third source of truth?
The final missing piece is to configure Deployaker to use the configuration in the GitHub repo as its source of truth as well.
![]() Version control and security
Version control and security
As a rule of thumb, all plain-text data should go into version control. But what about sensitive data, like secrets and passwords? Usually, you wouldn’t want everyone with access to the repo to have access to this kind of information (and they usually don’t need it). Plus, adding this information to version control will store it indefinitely in the history of the repo!
For Sasha and Sarah, the configuration for the User service contains sensitive data, the username and password for connecting to the database service:
user-service.yaml
apiVersion: randomcloud.dev/v1 kind: Container spec: image: watchmewatch/userservice:latest args: - --db-host=10.10.10.10 - --db-username=some-user ❶ - --db-password=some-password ❶ - --db-name=users
❶ Sasha and Sarah want this config file in version control, but they don’t want to commit these sensitive values.
But they want to commit this config file to version control; how do they do that without committing the username and password? The answer is to store that information somewhere else and have it managed and populated for you. Most clouds provide mechanisms for storing secure information, and many CD systems will allow you to populate these secrets safely—which will mean trusting the CD system enough to give it access.
Sasha and Sarah decide to store the username and password in a storage bucket in RandomCloud, and they configure Deployaker so that it can access the values in this bucket and populate them at deploy time:
user-service.yaml
apiVersion: randomcloud.dev/v1
kind: Container
spec:
image: watchmewatch/userservice:latest
args:
- --db-host=10.10.10.10
- --db-username=randomCloud:watchMeWatch:userServiceDBUser ❶
- --db-password=randomCloud:watchMeWatch:userServiceDBPass
- --db-name=users❶ These keywords indicate to Deployaker that it needs to fetch the real values from RandomCloud.
User service config as code
Now that Sasha and Sarah have set up Deployaker such that it can fetch sensitive data (the User service database username and password) from RandomCloud, they want to commit the config file for the User service repo:
user-service.yaml
apiVersion: randomcloud.dev/v1 kind: Container spec: image: watchmewatch/userservice:latest args: - --db-host=10.10.10.10 - --db-username=randomCloud:watchMeWatch:userServiceDBUser - --db-password=randomCloud:watchMeWatch:userServiceDBPass - --db-name=users
They make a new directory in the User service repo called config, where they store this config file, and they’ll put any other configuration they discover that they need along the way. Now the User service repo structure looks like this:
docs/ ❶ config/ user-service.yaml service/ ❷ test/ setup.py LICENSE README.md requirements.txt
❶ This new directory will hold the User Service configuration used by Deployaker as well as any other configuration they need to add in the future.
❷ All of the source code is in the service directory.
Can I store the configuration in a separate repo instead?
Sometimes this makes sense, especially if you are dealing with multiple services and you want to manage the configuration for all of them in the same place. However, keeping the configuration near the code it configures makes it easier to change both in tandem. Start with using the same repo, and move the configuration to a separate one only if you later find you need to.
![]() Hardcoded data
Hardcoded data
apiVersion: randomcloud.dev/v1
kind: Container
spec:
image: watchmewatch/userservice...
args:
- --db-host=10.10.10.10
- --db-username=randomCloud:watchMeWatch:userServiceDBUser ❶
- --db-password=randomCloud:watchMeWatch:userServiceDBPass
- --db-name=users❶ Even if Deployaker popluates some of these values, the database connection information is essentially hardcoded and this config can’t be used in other environments.
With the database connection information hardcoded, it can’t be used in any other environments—for example, when spinning up a test environment or developing locally. This defeats one of the advantages to config as code, which is that by tracking the configuration you are using when you run your software in version control, you can use this exact configuration when you develop and test. But what can you do about those hardcoded values?
The answer is usually to make it possible to provide different values at runtime (when the software is being deployed), usually by doing one of the following:
- Using templating—For example, instead of hardcoding
--db-host=10.10.10.10, you’d use a templating syntax such as--db-host={{ $db-host }}and use a tool to populate the value of$db-hostas part of deployment. - Using layering—Some tools for configuration allow you to define layers that override each other—for example, commiting the hardcoded
--db-host=10.10.10.10to the repo for when the User service is deployed, and using tools to override certain values when running somewhere else (e.g., something like--db-host=localhost:3306when running locally).
Both of these approaches have the downside of the configuration in version control not representing entirely the actual configuration being run. For this reason, sometimes people will choose instead to add steps to their pipelines to explicitly hydrate (fully populate the configuration with the actual values for a particular environment) and commit this hydrated configuration back to version control.
Configuring Deployaker
Now that the User service configuration is committed to GitHub, Sasha and Sarah no longer need to supply this configuration to Deployaker. Instead, they configure Deployaker to connect to the User service GitHub repo and give it the path to the config file for the User service: user-service.yaml.
This way, Sarah and Sasha never need to make any changes directly in RandomCloud or Deployaker. They commit the changes to the GitHub repo, and Deployaker picks up the changes from there and rolls them out to RandomCloud.

Is it reasonable to expect CD tools to use configuration in version control?
Absolutely! Many tools will let you point them directly at files in version control, or at the very least will be programmatically configurable so you can use other tools to update them from config in version control. In fact, it’s a good idea to look for these features when evaluating CD tooling and steer clear of tools that let you configure them only through their UIs.
Wait, what about the config that tells Deployaker’s how to find the service config in the repo? Should that be in version control, too?
Good question. To a certain extent, you need to draw a line somewhere, and not everything will be in version control (e.g., sensitive data). That being said, Sasha and Sarah would benefit from at least writing some docs on how Deployaker is configured and committing those to version control, to record how everything works for themselves and new team members, or if they ever need to set up Deployaker again. Plus, there’s a big difference between configuring Deployaker to connect to a few Git repos and pasting and maintaining all of the Watch Me Watch service configuration in it.
Config as code
How does configuration fit into CD? Remember that the first half of CD is about getting to a state where
you can safely deliver changes to your software at any time.
When many people think about delivering their software, they think about only the source code. But as we saw at the beginning of this chapter, all kinds of plain-text data make up your software—and that includes the configuration you use to run it.
We also took a look at CI to see why version control is key. CI is the following:
The process of combining code changes frequently, with each change verified when it is added to the already accumulated and verified changes.
Config as code is not a new idea! You may remember earlier in the chapter I mentioned that configuration management for computers dates back to at least the 1970s. Sometimes we forget the ideas we’ve already discovered and have to rediscover them with new names.
To really be sure you can safely deliver changes to your software, you need to be accumulating and verifying changes to all the plain-text data that makes up your software, including the configuration.
This practice of treating software configuration the same way you treat source code (storing it in version control and verifying it with CI) is often called config as code. Doing config as code is key to practicing CD, and doing config as code is as simple as versioning your configuration in version control, and as much as you can, applying verification to it such as linting and using it when spinning up test environments.
What’s the difference between infrastructure as code and config as code?
The idea of infrastructure as code came along first, but config as code was hot on its heels. The basic idea with infrastructure as code is to use code/configuration (stored in version control) to define the infrastructure your software runs on (e.g., machine specs and firewall configuration). Whereas config as code is all about configuring the running software, infrastructure as code is more about defining the environment the software runs in (and automating its creation). The line between the two is especially blurry today, when so much of the infrastructure we use is cloud-based. When you deploy your software as a container, are you defining the infrastructure or configuring the software? But the core principles of both are the same: treat everything required to run your software “like code”: store it in version control and verify it.
Rolling out software and config changes
Sarah and Sasha have begun doing config as code by storing the User service configuration in Deployaker. They almost immediately see the payoff a few weeks later, when they decide that they want to separate the data they are storing in the database into two separate databases. Instead of one giant User database, they want a User database and a Movie database. To do this, they need to make two changes:
-
The User service previously took only one argument for the database name:
--db-name; now it needs to take two arguments:./user_service.py --db-host=10.10.10.10 --db-username=some-user --db-password=some-password --db-users-name=users ❶ --db-movies-name=movies❶ The User service has to be updated to recognize these two new arguments.
-
The configuration for the User service needs to be updated to use the two arguments instead of just the
--db-nameargument it is currently using:apiVersion: randomcloud.dev/v1 kind: Container spec: image: watchmewatch/userservice:latest args: - --db-host=10.10.10.10 - --db-username=some-user - --db-password=some-password - --db-users-name=users ❶ - --db-movies-name=movies❶ And the configuration has to be updated to use the new arguments as well.
Back when they were making configuration changes directly in Deployaker, they would have had to roll out these changes out in two phases:
-
After making the source code changes to the User service, they’d need to build a new image.
-
At this point, the new image would be incompatible with the config in Deployaker; they wouldn’t be able to do any deployments until Deployaker was updated.
But now that they source code and the configuration live in version control together, Sasha and Sarah can make all the changes at once, and they’ll all be smoothly rolled out together by Deployaker!
![]() Takeaway
Takeaway
Use tools that let you store their configuration in version control. Some tools assume you’ll interact with configuration only via their UIs (e.g., websites and CLIs); this can be fine for getting something up and running quickly, but in the long run, to practice continuous delivery, you’ll want to be able to store this configuration in version control. Avoid tools that don’t let you.
![]() Takeaway
Takeaway
Treat all the plain-text data that defines your software like code and store it in version control. You’ll run into some challenges in this approach around sensitive data and environment-specific values, but the extra tooling you’ll need to fill these gaps is well worth the effort. By storing everything in version control, you can be confident that you are always in a safe state to release—accounting for all the data involved, not just the source code.
Conclusion
Even though it’s early days for Watch Me Watch, Sarah and Sasha quickly learned how critical version control is to CD. They learned that far from being just passive storage, it’s the place where the first piece of CD happens: it’s where code changes are combined, and those changes are the triggering point for verification—all to make sure that the software remains in a releasable state.
Though at first they were only storing source code in version control, they realized that they could get a lot of value from storing configuration there as well—and treating it like code.
As the company grows, they’ll continue to use version control as the single source of truth for their software. Changes made in version control will be the jumping-off point for any and all of the automation they add from this point forward, from automatically running unit tests to doing canary deployments.
Summary
-
You must use version control in order to be doing continuous delivery.
-
Trigger CD pipelines on changes to version control.
-
Version control is the source of truth for the state of your software, and it’s also the foundation for all the CD automation in this book.
-
Practice config as code and store all plain-text data that defines your software (not just source code but configuration too) in version control. Avoid tools that don’t let you do this.
Up next . . .
In the next chapter, we’ll look at how to use linting in CD pipelines to avoid common bugs and enforce quality standards across codebases, even with many contributors.