
7 Give the right signals at the right times
- identifying the points in a change’s life cycle when bugs can be introduced
- guaranteeing that bugs will not be introduced by conflicting changes
- weighing the pros and cons of conflict mitigation techniques
- catching bugs at all points in a change’s life cycle by running CI before merging, after merging, and periodically
In the previous chapters, you’ve seen CI pipelines running at different stages in a change’s life cycle. You’ve seen them run after a change is committed, leading to an important rule: when the pipeline breaks, stop merging. You’ve also seen cases where linting and tests are made to run before changes are merged, ideally to prevent getting to a state where the codebase is broken.
In this chapter, I’ll show the life cycle of a change. You’ll learn about all the places where bugs can be introduced, and how to run pipelines at the right times to get the signal if bug exists—and fix it as quickly as possible.
CoinExCompare
CoinExCompare is a website that publishes exchange rates between digital currencies. Users can log onto the website and compare exchange rates—for example, between currencies such as CatCoin and DogCoin.

The company has been growing rapidly, but lately has been facing bugs and outages. The engineers are especially confused because they’ve been looking carefully at their pipelines, and they think they’ve done a pretty good job of covering all the bases.
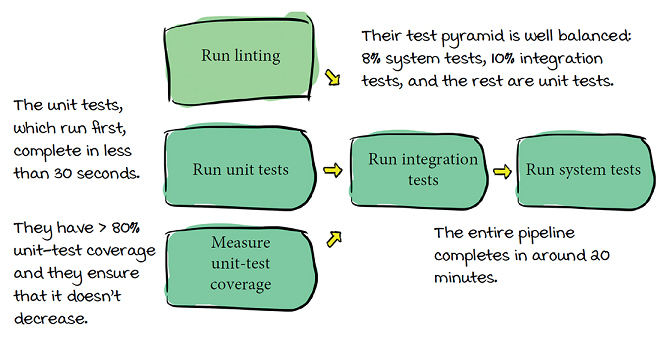
With a great CI pipeline like that, what could they be doing wrong?
Life cycle of a change
To figure out what might be going wrong for CoinExCompare, the engineers map out the timeline of a change, so they can think about what might go wrong along the way. They use trunk-based development (more in chapter 8) with very short-lived branches and PRs:

The life cycle of the change in the commit itself over time looks like this:

![]() Vocab time
Vocab time
The term production is used to refer to the environment where you make your software available to your customers. If you run a service, the endpoint(s) available to your customers can be referred to as production. Artifacts such as images and binaries that run in this environment (or are distributed directly to your customers) can be called production artifacts (e.g., production images). This term is used to contrast with any intermediate environments (e.g., a staging environment) or artifacts that may be used for verification or testing along the way, but aren’t ever made directly available to your customers.
CI only before merge
If you’re starting from no automation at all, the easiest place to start running CI is often right after a change is merged.
Whether starting with CI after a change is merged is the easiest first step depends on what tools you’re already using. Some tools, like GitHub, make it very easy to set up PR-based CI, which, as you’ll see in this chapter, can give a signal earlier.
You saw this in chapter 2, when Topher set up webhook automation for Cat Picture Website that would run tests whenever a change was pushed. This quickly led to the team adopting an important rule:
When the pipeline breaks, stop pushing changes.
This is still a great place to start and the easiest way to hook in automation, especially if you’re using version control software that doesn’t come with additional automation features out of the box and you need to build it yourself (as Topher did in chapter 2). However, it has some definite downsides:
-
You will find out about problems only after they are already added to the codebase. Therefore, your codebase can get into a state that isn’t safe to release—and part of continuous delivery (CD) is getting to a state where you can safely deliver changes to your software at any time. Allowing your codebase to become broken on a regular basis directly interferes with that goal.
-
Requiring that everyone stop pushing changes when the CI breaks stops everyone from being able to make progress, which is at best frustrating and at worst, expensive.
This is where CoinExCompare was about six months ago. But the company decided to invest in automation that would allow it to run its CI before merging instead, so the engineers could prevent their codebase from getting into a broken state. This mitigates the two downsides of running CI after the changes are already merged:
-
Instead of finding out about problems after they’ve already been added, stop them from being added to the main codebase at all.
-
Avoid blocking everyone when a change is bad; instead, let the author of the change deal with the problem. Once it’s fixed, the author will be able to merge the change.
This is where CoinExCompare is today: the team members run CI before changes are merged, and they don’t merge changes until the CI passes.
Timeline of a change’s bugs
CoinExCompare requires CI to pass before a change is merged, but is still running into bugs in production. How can that be? To understand, let’s take a look at all the places bugs can be introduced for a change—i.e., all the places where you need a signal when something goes wrong:

CI only before merging misses bugs
CoinExCompare is currently blocking PR merges on CI passing, but that is the only time it’s running the CI. And as it turns out, bugs can creep into a few more places after that point:
-
Divergence from the main branch—If CI runs only before a change is integrated back into the main branch, there might be changes in main that the new change didn’t take into account, and CI was never run for.
-
Changes to dependencies—Most artifacts will require packages and libraries outside their own codebase in order to operate. When building production artifacts, some version of these dependencies will be pulled in. If these are not the same version that you ran CI with, new bugs can be introduced.
-
Nondeterminism—This pops up both in the form of flakes that aren’t caught and in subtle differences from one artifact build to the next that have the potential to introduce bugs.
Looking at the change timeline, you can see how these three sources of bugs can creep in even after the PR-based CI passes:

The right signals
For each of the places where bugs can sneak in, you want to set up your CD pipelines so that you can get a signal as early as possible—ideally, immediately before the problem is even introduced. Getting the signal that something has gone wrong, or is about to, will give you the chance to intervene and fix it. See chapter 5 for more on signals.
A tale of two graphs: Default to seven days
Let’s see how CoinExCompare can tackle each source of bugs. CoinExCompare recently ran into a production bug that was caused by the first source of post-merge bugs:
Divergence from the main branch.
Nia has been working on a feature to graph the last seven days of coin activity for a particular coin. For example, if a user went to the landing page for DogCoin, they would see a graph like this, showing the closing price of the coin in USD on each of the last seven days:

While she’s working on this functionality, she finds an existing function that looks like it’ll make her job a lot easier. The get_daily_rates function will return the peak daily rates for a particular coin (relative to USD) for some period of time. By default, the function will return the rates for all time, indicated by a value of 0 (aka MAX):
MAX=0 def get_daily_rates(coin, num_days=MAX): rate_hub = get_rate_hub(coin) rates = rate_hub.get_rates(num_days) return rates
Looking around the codebase, Nia is surprised to see that none of the callers are making use of the logic that defaults num_days to MAX. Since she has to call this function a few times, she decides that defaulting to seven days is reasonable, and it gives her the functionality she needs, so she changes the function to default to 7 days instead of MAX and adds a unit test to cover it:
def get_daily_rates(coin, num_days=7):
rate_hub = get_rate_hub(coin)
rates = rate_hub.get_rates(num_days)
return rates
...
def test_get_daily_rates_default(self):
rates = get_daily_rates("catcoin")
self.assertEqual(rates, [2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0])All the tests, including her new one, pass, so she feels good about opening up a PR for her change.
A tale of two graphs: Default to 30 days
But Nia doesn’t realize that someone else is making changes to the same code! Fellow CoinExCompare employee Zihao is working on a graph feature for another page. This feature shows the last 30 days of data for a particular coin.
Unfortunately, neither Nia nor Zihao realize that more than one person is working on this very similar logic! And great minds think alike: Zihao also notices the same function that Nia did and thinks it will give him exactly what he needs:
MAX=0 def get_daily_rates(coin, num_days=MAX): rate_hub = get_rate_hub(coin) rates = rate_hub.get_rates(num_days) return rates
You just saw that Nia changed this function, but her changes haven’t been merged yet, so Zihao isn’t at all aware of them.
Zihao does the same investigation that Nia did, and notices that no one is using the default behavior of this function. Since he has to call it a few times, he feels it’s reasonable to change the default behavior of the function so that it will return rates for the last 30 days instead of for all time. He makes the change a bit differently than Nia:
MAX=0 def get_daily_rates(coin, num_days=MAX): rate_hub = get_rate_hub(coin) rates = rate_hub.get_rates(30 if num_days==MAX else num_days) return rates
Zihao also adds a unit test to cover his changes:
def test_get_daily_rates_default_thirty_day(self):
rates = get_daily_rates("catcoin")
self.assertEqual(rates, [2.0]*30)Both Nia and Zihao have changed the same function to behave differently, and are relying on the changes they’ve made. Nia is relying on the function returning 7 days of rates by default, and Zihao is relying on it returning 30 days of data.
Who changed it better?
Nia changed the argument default, while Zihao left the argument default alone and changed the place where the argument was used. Nia’s change is the better approach: in Zihao’s version, the default is being set twice to two different values—not to mention that the MAX argument will no longer work because even if someone provides it explicitly, the logic will return 30 days instead. This is the sort of thing that hopefully would be pointed out in code review. In reality, this example is a bit contrived so that I can demonstrate what happens when conflicting changes are made but not caught by version control.
Conflicts aren’t always caught
Nia and Zihao have both changed the defaulting logic in the same function, but at least when it comes time to merge, these conflicting changes will be caught, right?
Unfortunately, no! For most version control systems, the logic to find conflicts is simple and has no awareness of the actual semantics of the changes involved. When merging changes together, if exactly the same lines are changed, the version control system will realize that something is wrong, but it can’t go much further than that.
Nia and Zihao changed different lines in the get_daily_rates function, so the changes can actually be merged together without conflict! Zihao merges his changes first, changing the state of get_daily_rates in the main branch to have his new defaulting logic:
MAX=0 def get_daily_rates(coin, num_days=MAX): rate_hub = get_rate_hub(coin) rates = rate_hub.get_rates(30 if num_days==MAX else num_days) return rates
Meanwhile, Nia merges her changes in as well. Zihao’s changes are already present in main, so her changes to the line two lines above Zihao’s changes are merged in, resulting in this function:
MAX=0 def get_daily_rates(coin, num_days=7): ❶ rate_hub = get_rate_hub(coin) rates = rate_hub.get_rates(30 if num_days==MAX else num_days) ❷ return rates
❶ Nia’s change sets the default value for the argument.
❷ Meanwhile, Zihao was relying on the argument defaulting to MAX.
The result is that Zihao’s graph feature is merged first, and it works just fine, until Nia’s changes are merged, resulting in the preceding function. Nia’s changes break Zihao’s: now that the default value is 7 instead of MAX, Zihao’s ternary condition will be false (unless some unlucky caller tries to explicitly pass in MAX), and so the function will now return seven days of data by default. This means Nia’s functionality will work as expected, but Zihao’s is now broken.
Does this really happen?
It sure does! This example is a little contrived since the more obvious solution for Zihao would be to also change the default argument value, which would have immediately been caught as a conflict. A more realistic scenario that comes up more frequently in day-to-day development might involve changes that span multiple files—for example, making changes that depend on a specific function, while someone else makes changes to that function.
What about the unit tests?
Nia and Zihao both added unit tests as well. Surely this means that the conflicting changes will be caught?
If they had added the tests at the same point in the file, the version control system would catch this as a conflict, since they would both be changing the same lines. Unfortunately in our example, the unit tests were introduced at different points in the file, so no conflict was caught! The end result of the merges would be both unit tests being present:
def test_get_daily_rates_default(self):
rates = get_daily_rates("catcoin")
self.assertEqual(rates, [2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0]) ❶
...
def test_get_daily_rates_default_thirty_day(self):
rates = get_daily_rates("catcoin")
self.assertEqual(rates, [2.0]*30) ❶❶ Nia’s unit test expects the function to return 7 days, worth of data by default.
❶ Zihao’s unit test expects the exact same function, called with exactly the same arguments, to return 30 days of data.
The version control system couldn’t catch the conflict, but at least it should be impossible for both tests to pass, right? So, surely, the problem will be caught when the tests are run?
Yes and no! If both of these tests are run at the same time, one will fail (it is impossible for both to pass unless something nondeterministic is happening). But will both tests be run together? Let’s look at a timeline of what happens to Nia and Zihao’s changes and when the tests will be run:

Tests are run automatically for each PR only. CoinExCompare is relying solely on running its CI (including tests) on each PR, but there is no automation to run CI on the combined changes after they have been merged together.
PR triggering still lets bugs sneak in
Running CI triggered by PRs is a great way to catch bugs before they are introduced into the main branch. But as you saw with Nia and Zihao, the longer your changes are in your own branch and aren’t integrated back into the main branch, the greater the chance that a conflicting change will be introduced that will cause unforeseen bugs.
Another way to mitigate this risk is to merge back into main as quickly as possible. More on this in the next chapter.

I regularly pull in changes from main as I work; doesn’t that fix the problem?
That certainly reduces the chances of missing conflicting changes introduced into main. But unless you can guarantee that the latest changes are pulled in, CI is run immediately before the merge, and no further changes sneak in during that time, there is still a chance you’ll miss something with only PR-triggered CI.
![]() Takeaway
Takeaway
Running CI on PRs before merging won’t catch all conflicting changes. If the conflicting changes are changing exactly the same lines, version control can catch the conflict and force updating (and rerunning CI) before merging, but if the changes are on different lines—or in different files—you can end up in a situation where CI has passed before merge, but after merging, the main branch is in a broken state.
CI before AND after merge
What can CoinExCompare do to get the signal that theses conflicts exist, and avoid getting into a state where main is broken? Both Nia and Zihao added tests to cover their functionality. If those tests had been run after the changes had been combined (merged), the issue would have been caught right away. CoinExCompare sets a new goal:
Require changes to be combined with the latest main and pass CI before merging.
What can CoinExCompare do to meet this goal? It has a few options:
-
Run CI periodically on main.
-
Require branches to be up-to-date before they can be merged into main.
-
Use automation to merge changes with main and rerun CI before merging (aka using a merge queue).
In the next few pages, I’ll show each option in more detail, but here’s a sneak peek at the tradeoffs for each:
-
Option 1 will catch these errors, but only after they’ve been introduced into main; this means main can still get into a broken state.
-
Option 2 will prevent the kind of errors that we’ve been looking at from getting in, and it’s supported out of the box by some version control systems (for example, GitHub). But in practical application, it can be a huge nuisance.
-
Option 3, if implemented correctly, can also prevent these errors from getting in. As an out-of-the box feature, it works very well, but it can be complicated if you need to implement and maintain it yourself.
Option 1: Run CI periodically
Let’s look at the first option in more detail. With Nia and Zihao’s situation, one of the most frustrating aspects is that the issue wasn’t caught until it was seen in production—even though there were unit tests that could have caught it!
With this option, you focus less on stopping this edge case from happening, and more on easily detecting it if it does. The truth is that bugs like these, which are caused by the interaction of multiple changes, are unlikely to happen very often.
An easy way to detect these problems is to run your CI periodically against main, in addition to running it against PRs. This could look like a nightly run of the CI, or even more often (e.g., hourly) if the tasks are fast enough. Of course, it has a couple of downsides:
-
This approach will let main get into a broken state.
-
This requires someone to monitor these periodic tests, or at least be responsible for acting on them when they break.
What would it look like for Nia and Zihao if CoinExCompare decided to use periodic CI as its solution to addressing these conflicting changes? Let’s say CoinExCompare decides to run periodic tests every hour:

At least now the problem will be caught and might be stopped before it makes it to production, but does this meet CoinExCompare’s goal?
Require changes to be combined with the latest main and pass CI before merging.
Since everything happens post merge, option 1 doesn’t meet the bar.
Option 1: Setting up periodic CI
CoinExCompare isn’t going to move ahead with periodic CI (yet), but before I move on to the other options, let’s take a quick look at what it would take to set this up. CoinExCompare is using GitHub Actions, so making this change is easy. Say the engineers wanted to run the pipeline every hour. In their GitHub Actions workflow, they can use the schedule syntax to do by including a schedule directive in the on triggering section:
on:
schedule:
- cron: ‘0 * * * *’❶ The GitHub Actions schedule directive uses cron tab syntax to express when to run.
Stay tuned: running CI periodically has other upsides, which I’ll show a bit later in this chapter.
Though it’s easy to set up the periodic (aka scheduled) triggering, the bigger challenge is doing something with the results. When running CI against a PR, it’s much clearer who needs to take action when it fails: the author(s) of the PR itself. And they will be motivated to do this because they need the CI to pass before they can merge.
With periodic CI, the responsibility is much more diffused. To make your CI useful, you need someone to be notified when failures occur, and you need a process for determining who needs to fix the failures. Notifications could be handled through a mailing list or by creating a dashboard; the harder part is deciding who needs to take action and fix the problems.
A common way to handle this is to set up a rotation (similar to being on call for production issues) and share the responsibility across the team. When failures occur, whoever is currently responsible needs to decide how to triage and deal with the issue.
If the periodic CI frequently has problems, dealing with the issues that pop up can have a significant negative impact on the productivity of whoever has to handle them and can be a drain on morale. This makes it (even more) important to make a concerted effort to make CI reliable so that the interruptions are infrequent.
See chapter 5 for techniques for fixing noisy CI.
![]() Takeaway
Takeaway
Running CI periodically can catch (but not prevent) this class of bugs. While it is very easy to get up and running, for CI to be effective, you need someone to be monitoring these periodic tests and acting on failures.
Option 2: Require branches to be up-to-date
Option 1 will detect the problem but won’t stop it from happening. In option 2, you are guaranteed that problems won’t sneak in. This works because if the base branch is updated, you’ll be forced to update your branch before you can merge—and at the point that you update your branch, CI will be triggered.
Would this have fixed Nia and Zihao’s problem? Let’s take a look at what would have happened.

As soon as Zihao merges, Nia will be blocked from merging until she pulls in the latest main, including Zihao’s changes. This would trigger CI to run again—which would run both Nia and Zihao’s unit tests. Zihao’s would fail, and the problem would be caught!
This strategy comes with an additional cost, though: any time main is updated, all PRs for branches that don’t contain these changes will need to be updated. In Nia and Zihao’s case, this is important because their changes conflict, but this policy will be universally applied, whether it is important to pull in the changes or not.
Can you automate updating every single branch?
Automating the update of all branches is possible (and this would be a nice feature for version control systems to support). However, remember that for distributed version control systems like Git, the branch that is backing the PR is a copy of the branch that the developer has been editing on their machine. Therefore, the developer will need to pull any changes automatically added if they need to continue working—not a deal breaker, but an extra complication. Also, with this kind of automation, we’re starting to get into the territory of option 3.
Option 2: At what cost?
Requiring that a branch be up-to-date with main before being merged would have caught Nia and Zihao’s problem, but this approach also would impact every PR and every developer. Is it worth the cost? Let’s see how this policy would impact several PRs:

Each time a PR is merged, it impacts (and blocks) all other open PRs! CoinExCompare has around 50 developers, and each tries to merge their changes back into main every day or so. This means there are around 20–25 merges into main per day.
See chapter 8 to understand why it’s a good idea to merge so frequently.
Imagine that 20 PRs are open at any given time, and the authors try to merge them within a day or so of opening. Each time a PR is merged, it will block the other 19 open PRs until they are updated with the latest changes.
The strategy in option 2 will guarantee that CI always runs with the latest changes, but at the cost of potentially a lot of tedious updates to all open PRs. In the worst case, developers will find themselves constantly racing to get their PRs in so they don’t get blocked by someone else’s changes.
![]() Takeaway
Takeaway
Requiring the branch to be up-to-date before changes can be merged will prevent conflicting changes from sneaking in, but it is most effective when only a few people are contributing to a codebase. Otherwise, the headache may not be worth the gain.
Option 3: Automated merge CI
CoinExCompare decides that the additional overhead and frustration of always requiring branches to be up-to-date before merging isn’t worth the benefit. What else can the team do?
With CoinExCompare’s current setup, tests run against both Nia and Zihao’s PRs before merging. Those tests would be triggered to run again if anything in those PRs changed. This worked out just fine for Zihao’s changes, but didn’t catch the issues introduced when Nia’s changes were added. If only Nia’s CI had been triggered to run one more time before merging, and had included the latest changes from main when running those tests, the problem would have been caught.
So another solution to the problem is to introduce automation to run CI that runs a final time before merging, against the changes merged with the latest code from main. Accomplish this by doing the following:
-
Before merging, even if the CI has passed previously, run the CI again, including the latest state of main (even if the branch itself isn’t up-to-date).
-
If the main branch changes during this final run, run it again. Repeat until it has been run successfully with exactly the state of main that you’ll be merging into.
What would have happened to Nia and Zihao’s changes if they’d had this automation?

With the CI pulling in the latest main (with Zihao’s changes) and running a final time before allowing Nia to merge, the conflicting changes would be caught and won’t make it into main.
Option 3: Running CI with the latest main
In theory, it makes sense to run CI before merging, with the latest main, and make sure main can’t change without rerunning CI, but how do you pull this off? I can break the elements down a little further. We need the following:
-
A mechanism to combine the branch with the latest changes in main that CI can use
-
Something to run CI before a merge and to block the merge from occurring until CI passes
-
A way to detect updates to main (and trigger the pre-merge CI process again) or a way to prevent main from changing while the pre-merge CI is running
How do you combine your branch with the latest changes in main? One way is to do this yourself in your CI tasks by pulling the main branch and doing a merge.
But you often don’t need to because some version control systems will take care of this for you. For example, when GitHub triggers webhook events (or when using GitHub Actions), GitHub provides a merged commit to test again: it creates a commit that merges the PR changes with main.

Using this merged commit for all CI triggered by PRs will increase the chances of catching these sneaky conflicts.
As long as your tasks fetch this merge commit (provided as the GITHUB_SHA in the triggering event), you’ve got (1) covered!
A different way of looking at option 3 (automated merge CI) is that it’s an alternative approach to option 2. Option 2 requires branches to be up-to-date before merging, and option 3 makes sure branches are up-to-date when CI runs by introducing automation to update the branch to that state before running CI, rather than blocking and waiting for the author to update their PR with the latest changes.
Option 3: Merge events
Now that I’ve covered the first piece of the recipe, let’s look at the rest. We still need the following:
-
Something to run CI before a merge and to block the merge from occurring until CI passes
-
A way to detect updates to main (and trigger the pre-merge CI process again) or a way to prevent main from changing while the pre-merge CI is running
Most version control systems will give you some way to run CI in response to events, such as when a PR is opened, when it is updated, or in this case, when it is merged, aka a merge event. If you run your CI in response to the merge event, you can be alerted when a merge occurs, and run your CI in response. However, this doesn’t quite address the requirements:
-
The merge event will be triggered after the merge occurs (after the PR is merged back into main), so if a problem is found, it will have already made its way into the main branch. At least you’ll know about it, but main will be broken.
-
There is no mechanism to ensure that any changes to main that occur while this automation is running will trigger the CI to run again, so conflicts can still slip through the cracks.
GitHub makes triggering on a merge a bit complex: the equivalent of the merge event is a pull_request event with the activity of type close when the merged field inside the payload has the value true. Not terribly straightforward!
What would this look like for Nia and Zihao’s scenario?

So, unfortunately, triggering on merges won’t give us exactly what we’re looking for. It will increase the chances that we’ll catch conflicts, but only after they’ve been introduced, and more conflicts can still sneak in while the automation is running.
Option 3: Merge queues
If triggering on the merge event doesn’t give us the whole recipe, what else can you do? The complete recipe we are looking for requires the following:
-
A mechanism to combine the branch with the latest changes in main that CI can use
-
Something to block the merge from occurring until CI passes
-
A way to detect updates to main (and trigger the pre-merge CI process again) or a way to prevent main from changing while the pre-merge CI is running
We have an answer for the first requirement, but the complete solution for the other two is lacking. The answer is to create automation that is entirely responsible for merging PRs. This automation is often referred to as a merge queue or merge train; merging is never done manually, but is always handled by automation that enforces the last two requirements.
See appendix B for a look at features like merge queues and event based triggering across version control systems.
You can get this functionality by building the merge queue yourself, but, fortunately, you shouldn’t need to! Many version control systems now provide a merge queue feature out of the box.
Merge queues, as their name implies, will manage queues of PRs that are eligible to merge (e.g., they’ve passed all the required CI):
-
Each eligible PR is added to the merge queue.
-
For each PR in order, the merge queue creates a temporary branch that merges the changes into main (using the same logic as GitHub uses to create the merged commit it provides in PR events).
-
The merge queue runs the required CI on the temporary branch.
-
If CI passes, the merge queue will go ahead and do the merge. If it fails, it won’t. Nothing else can merge while this is happening because all merges need to happen through the merge queue.
For very busy repos, some merge queues optimize by batching together PRs for merging and running CI. If the CI fails, an approach like binary search can be used to quickly isolate the offending PRs—for example, split the batch into two groups, rerun CI on each, and repeat until you discover which PR(s) broke the CI. Given how rare post merge conflicts are, this optimization can save a lot of time if enough PRs are in flight that waiting or the merge queue becomes tedious.
Option 3: Merge queue for CoinExCompare
Let’s see how a merge queue would have addressed Nia and Zihao’s conflict:

![]() Building your own merge queue
Building your own merge queue
Building your own merge queue is doable but a lot of work. At a high level, you would need to do the following: create a system that is aware of the state of all PRs in flight; block your PRs on merging (e.g., via branch-protection rules) until this system gives the green light; have this system select PRs that are ready to merge, merge them with main, and run CI; and finally, have this system do the actual merging. This complexity has a lot of potential for error, but if you absolutely need to guarantee that conflicts do not sneak in, and you’re not using a version control system with merge queue support, it might be worth the effort.
![]() Takeaway
Takeaway
Merge queues prevent conflicting changes from sneaking in by managing merging and ensuring CI passes for the combination of the changes being merged and the latest state of main. Many version control systems provide this functionality, which is great because building your own may not be worth the effort.
![]() It’s your turn: Match the downsides
It’s your turn: Match the downsides
Let’s look again at the three options for catching conflicts that are introduced between merges:
-
Run CI periodically.
-
Require branches to be up-to-date.
-
Use a merge queue
For each of the preceding three options, select the two downsides from the following list that fit best:
![]() Answers
Answers
-
Run CI periodically: Downsides B and D fit best. Conflicts introduced between PRs will be caught when the periodic CI runs, after the merge into main has already occurred. If no one pays attention to the periodic runs, they’ll have no benefit.
-
Require branches to be up-to-date: Downsides C and F fit best. Every time a merge happens, all other open PRs will be blocked until they update. When only a few developers are involved, this is feasible, but for a larger team, this can be tedious.
-
Use a merge queue: Downsides A and E fit best. Every PR will need to run CI an additional time before merging, and may need to wait for PRs ahead of it in the queue. Creating your own merge queue system can be complex.
Where can bugs still happen?
CoinExCompare decides to use a merge queue, and with GitHub the engineers are able to opt into this functionality quite easily by adding the setting to their branch-protection rules for main to require merge queue.
Now that they are using a merge queue, have the folks at CoinExCompare successfully identified and mitigated all the places where bugs can be introduced? Let’s take a look again at the timeline of a change and when bugs can be introduced:

Even with the introduction of a merge queue, several potential sources of bugs remain that CoinExCompare hasn’t tackled:
-
Divergence from and integration with the main branch (Now handled!)
-
Changes to dependencies
-
Nondeterminism: in code and/or tests (i.e., flakes), and/or how artifacts are built
Flakes and PR-triggered CI
You learned in chapter 5 that flakes occur when tests fail inconsistently: sometimes they pass, and sometimes they fail. You also learned that this can be caused equally by a problem in the test or by a problem in the code under test, so the best strategy is to treat these like bugs and investigate them fully. But since flakes don’t happen all the time, they can be hard to catch!
CoinExCompare now runs CI on each PR and before a PR is merged. This is where flakes would show up, and the truth is that they would often get ignored. It’s hard to resist the temptation to just run the tests again, merge, and call it a day—especially if your changes don’t seem to be involved.
Is there a more effective way CoinExCompare can expose and deal with these flakes? A few pages ago, we looked at periodic CI, and decided it wasn’t the best way to address sneaky conflicts. However, it turns out that periodic CI can be a great way to expose flakes. Imagine a test that flakes only once out of every 500 runs.

CoinExCompare developers have about 20–25 PRs open per day. Let’s say the CI runs at least three times against each PR: once initially, once with changes, and finally again in the merge queue. This means every day there are about 25 PRs × 3 runs = 75 chances to hit the failing test.

Over a period of about 7 days, that’s 525 changes to fail, so this test will likely fail one of those PRs. (And the developer who created the PR will also just likely ignore it and run the CI again!)

Catching flakes with periodic tests
When relying only on tests that are based on PR triggering and merge queues to uncover flakes, CoinExCompare will be able to reproduce a flake that occurs once every 500 times, around once every seven days. And when the flake is reproduced, there’s a good chance that the author of the impacted PR will simply decide to run the tests again and move on.

Is there anything that CoinExCompare can do to make it easier to reproduce flakes and not have to rely on the good behavior of the impacted engineer to fix it? A few pages back I talked about periodic tests, and how they were not the best way to prevent conflicts from sneaking in, but it turns out that catching flakes with periodic tests works really well! What if CoinExCompare sets up periodic CI to run once an hour? With the periodic CI running once an hour, it would run 24 times a day.

The flaky test fails 1 / 500 runs, so it would take 500 / 24 days, or approximately 21 days, to reproduce the failure.

Reproducing the failure once every 21 days via periodic CI might not seem like a big improvement, but the main appeal is that if the periodic tests catch the flake, they aren’t blocking someone’s unrelated work. As long as the team has a process for handling failures discovered by the periodic CI, a flake discovered this way has a better chance of being handled and investigated thoroughly than when it pops up and blocks someone’s unrelated work.
![]() Takeaway
Takeaway
Periodic tests help identify and fix nondeterministic behavior in code and tests, without blocking unrelated work.
Bugs and building
By adding a merge queue and periodic tests, CoinExCompare has successfully eliminated most of its potential sources of bugs, but bugs still have ways to sneak in:
-
Divergence from and integration with the main branch
-
Changes to dependencies
-
Nondeterminism: in code and/or tests (i.e., flakes) (caught via periodic tests), and/or how artifacts are built
Both of these sources of bugs revolve around the build process. In chapter 9, I’m going to show how to structure your build process to avoid these problems, but in the meantime, without overhauling how CoinExCompare builds its images, what can be done to catch and fix bugs introduced at build time? Let’s take a look again at the pipeline:
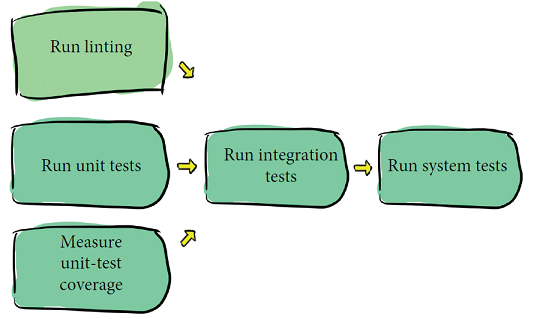
Spoiler: The best answer to dealing with bugs introduced through dependency changes is to always pin your dependencies. See chapter 9.
The last task in the pipeline runs the system tests. As with any system tests, these tests test the CoinExCompare system as a whole. System tests need something to run against, so part of this task must include setting up the system under test (SUT). To create the SUT, the task needs to build the images used by CoinExCompare.
![]() Vocab time
Vocab time
The system under test (SUT) is the system being tested in order to verify its correct operation.
The types of bugs we’re currently looking at sneak in while the images are being built—so can they be caught by the system tests? The answer is yes, but the problem is that that the images being built for the system tests are not the same as the ones being built and deployed to production. Those images will be built later, at which point the bugs can sneak back in.
CI vs. build and deploy
In chapter 2, you saw examples of two kinds of tasks: gates and transformations.

CoinExCompare separates its gate and transformation tasks into two pipelines. The purpose of the pipeline we’ve been looking at so far, the CI pipeline, is to verify code changes (aka gating code changes). CoinExCompare uses a different pipeline to build and deploy its production image (aka transforming the source code into a running container):

See chapter 13 for more on pipeline design.
The reality is that the line between these two kinds of tasks can blur. If you want to be confident in the decisions made by your gate tasks (your CI), you need to do a certain amount of transformation in your CI as well. This often shows up in system tests, which are often secretly doing a certain amount of building and deploying.
Build and deploy with the same logic
The CoinExCompare system test task is doing a few things:
-
Setting up an environment to run the system under test
-
Building an image
-
Pushing the image to a local registry
-
Running the image
-
And only then running the system tests against the running container
But—and this is very common—it’s not using the same logic that the release pipeline is using to build and deploy the images. If it were, it would be using the same tasks that are used in that pipeline:

This means bugs could sneak in when the actual images are built and deployed, specifically:
-
Differences based on when the build happens—for example, pulling in the latest version of a dependency during the system tests, but when the production image is built, an even newer version is pulled in.
-
Differences based on the build environment—for example, running the build on a different version of the underlying operating system.
CoinExCompare can make two changes to minimize these differences:
-
Run the deployment tasks periodically as well
-
Use the same tasks to build and deploy for the system tests as are used for the actual build and deployment
Improved CI pipeline with building
CoinExCompare updates its CI pipeline so that the system tests will use the same tasks used for production building and deploying. The updated pipeline looks like this:
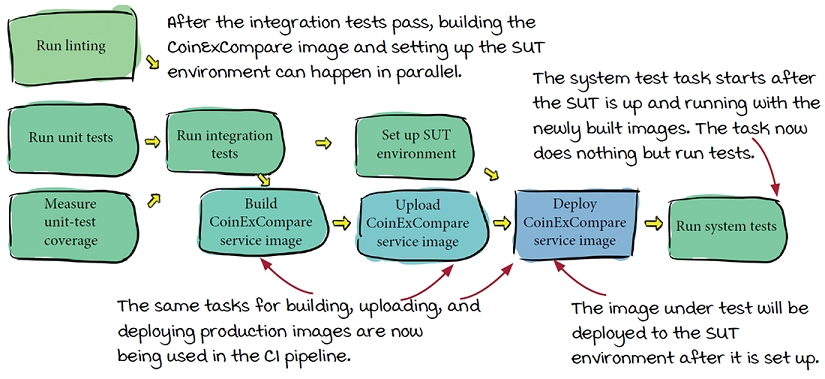
Their periodic tests will run this CI pipeline every hour, and now that the engineers have updated their CI pipeline to also build and deploy, this means they’re automatically now running the deployment tasks periodically as well.
CoinExCompare isn’t using continuous deployment; see chapter 10 for more on different deployment techniques.
Have they mitigated all of their potential sources of bugs? Let’s look again at the kinds of bugs they were trying to squash:
-
Divergence from and integration with the main branch
-
Changes to dependencies
-
Nondeterminism: in code and/or tests (i.e., flakes) , and/or how artifacts are built
They may still have some bugs related to either of these. But since the release pipeline runs at a different time and is run with different parameters, the chances of either of these types of bugs coming in has now been greatly reduced:
-
Changes in dependencies are mitigated because the images are now being built (and tested) every hour. If a change in a dependency introduces a bug, there is now a window of only about an hour for the bug to sneak through, and the bug will likely be caught the next time the periodic CI runs.
-
Nondeterministic builds are mitigated because by using exactly the same tasks to build images for CI, we’ve reduced the number of variables that can differ.
(See chapter 9 for more on how to completely defeat these risks.)
Timeline of a change revisited
Are all of the potential places bugs can sneak through now covered? The folks at CoinExCompare sit down to look one final time at all the places a bug could be introduced:

CoinExCompare has successfully eliminated or at least mitigated all of the places that bugs can sneak in by doing the following:
-
Continuing to use its existing PR-triggered CI
-
Adding a merge queue
-
Running CI periodically
-
Updating the CI pipelines to use the same logic for building and deploying as for its production release pipeline
With these additional elements in place, the engineers at CoinExCompare are very happy to see a dramatic reduction in their production bugs and outages.
Treating periodic CI artifacts as release candidates
The last two sources of bugs have only been mitigated, not completely removed. Something quick and easy that CoinExCompare could do is to start treating the artifacts of its periodic CI as release candidates, and releasing those images as-is—i.e., no longer running a separate pipeline to build again before releasing.
![]() It’s your turn: Identify the gaps
It’s your turn: Identify the gaps
For each of the following triggering setups, identify bugs that can sneak in and any glaring downsides to this approach (assume no other CI triggering):
-
Triggering CI to run periodically
-
Triggering CI to run after a merge to main
-
PR-triggered CI
-
PR-triggered CI with merge queues
-
Triggering CI to run as part of a production build-and-deploy pipeline
![]() Answers
Answers
-
Periodic CI alone will catch errors and will sometimes catch flakes; however, this will be after they are already introduced to main. Making periodic CI alone work will require having people paying attention to periodic CI who will need to triage errors that occur back to their source.
-
Triggering after a merge to main will catch errors, but only after they are introduced to main. Since this triggering happens immediately after merging, identifying who is responsible for the changes will be easier, but also chances are high that any flakes revealed will be ignored. This will also require a “don’t merge to main when CI is broken” policy, or errors can compound on each other and grow.
-
PR-triggered CI is quite effective but will miss conflicts introduced between PRs. Flakes that are revealed are likely to be ignored.
-
Adding a merge queue to PR-triggered CI will eliminate conflicts between PRs, but flakes will likely still be ignored.
-
Running CI as part of a production release pipeline will ensure that errors introduced by updated dependencies (and some nondeterministic elements) are caught before a release, but following up on these errors will interrupt the release process. If they can’t be immediately fixed, and rerunning makes the error appear to disappear, there is a good chance they will be ignored.
Conclusion
CoinExCompare engineers thought that running CI triggered on each PR was enough to ensure that they would always get the signal when an error is introduced by a change. However, on closer examination, they realized that this approach can’t catch everything. By using merge queues, adding periodic tests, and updating their CI to use the same logic as their release pipelines, they now have just about everything covered!
Summary
-
Bugs can be introduced as part of the changes themselves, as conflicts between the changes and a diverging main branch, and as part of the build process.
-
Merge queues are a very effective way to prevent changes that conflict between PRs from sneaking in. If merge queues aren’t available in your version control system, requiring branches to be up-to-date can work well for small teams, or periodic tests are effective (though this means main may get into a broken state).
-
Periodic tests are worth adding regardless, as they can be a way to identify flakes without interrupting unrelated PRs, but using them effectively requires setting up a process around them.
-
Building and deploying in your CI pipelines in the same way as in your production releases will mitigate the errors that can sneak in between running the CI and release pipelines.
Up next . . .
In the next chapter, I’ll start transitioning into looking at the details of CD pipelines that go beyond CI: the transformation tasks that are used to build and deploy your code. The next chapter will dive into effective approaches to version control that can make the process run more smoothly, and how to measure that effectiveness.