
8 Easy delivery starts with version control
- using the DORA metrics that measure velocity: deployment frequency and lead time for changes
- increasing speed and communication by avoiding long-lived feature branches and code freezes
- decreasing lead time for changes by using small, frequent commits
- increasing deployment frequency safely by using small, frequent commits
In the previous chapters, I’ve been focusing on continuous integration (CI), but from this chapter onward, I’ll transition to the rest of the activities in a continuous delivery (CD) pipeline—specifically, the transformation tasks that are used to build, deploy, and release your code.
Good CI practices have a direct impact on the rest of your CD. In this chapter, I’ll dive into effective approaches to version control to make CD run more smoothly, and how to measure that effectiveness.
Meanwhile at Watch Me Watch
Remember the start-up Watch Me Watch from chapter 3? Well it’s still going strong, and, in fact, growing! In the past two years, the company has grown from just Sasha and Sarah to more than 50 employees.

From the very beginning, Watch Me Watch invested in automating its deployments. But as the company has grown, the engineers have gotten nervous that these deployments are riskier and riskier, so they’ve been slowing them down.
Each of their services is now released during only specific windows, once every two months. For a week before a release, the codebase is frozen, and no new changes can go in.

In spite of these changes, somehow it feels like the problem is only getting worse: every deployment still feels extremely risky, and even worse, features are taking too long to get into production. Since Sasha and Sarah started on their initial vision, competitors have sprung up, and with the slow pace of features being released, it feels like the competitors are getting ahead! It feels like no matter what they do, they’re going slower and slower.
The DORA metrics
Sasha and Sarah are stumped, but new employee Sandy (they/them) has some ideas of what the company can do differently. One day, Sandy approaches Sasha in the hallway.

As they both stand in the hallway and Sandy starts to explain the DORA metrics (https://www.devops-research.com/research.html), Sasha realizes that the whole team could really benefit from what Sandy knows, and asks Sandy if they’d mind giving a presentation to the company. Sandy eagerly puts some slides together and gives everyone a quick introduction to the DORA metrics:
Velocity at Watch Me Watch
After their presentation on the DORA metrics, Sandy continues to discuss them with Sarah and Sasha, and how the metrics can help with the problems Watch Me Watch is facing around how slowly the company is moving. Sandy suggests that the company focus on the two velocity-related DORA metrics and measure them for Watch Me Watch.
Wondering about the other two DORA metrics (for stability)? I’ll be discussing them in more detail in chapter 10 when I discuss deploying.
|
The DORA metrics for velocity Velocity is measured by two metrics:
|
To measure these, Sandy needs to look at them in a bit more detail:
-
Deployment frequency measures how often an organization successfully releases to production.
-
Lead time for changes measures the amount of time it takes a commit to get into production.
Production refers to the environment where you make your software available to your customers (as compared to intermediate environments you might use for other purposes, such as testing). See chapter 7 for a more detailed definition.
At Watch Me Watch, deployments can occur only as frequently as the deployment windows, which are every two months. So for Watch Me Watch, the deployment frequency is once every two months.
![]() What if I don’t run a service?
What if I don’t run a service?
If you work on a project that you don’t host and run as a service (see chapter 1 for more information on the kinds of software you can deliver, including libraries, binaries, configuration, images, and services), you might be wondering if these DORA metrics apply to you.
The DORA metrics are definitely defined with running services in mind. However, the same principles still apply, with a bit of creative rewording of the metrics themselves. When looking at the velocity-related metrics, you can apply them to other software (e.g., libraries and binaries) like this:
-
Deployment frequency becomes release frequency. To be consistent with the definitions outlined in chapter 1 (publishing versus deploying versus releasing), calling this metric release frequency is a better overall representation of its intent: how frequently are changes made available to users, i.e., released? (And remember from chapter 1 that what is often referred to as deployment can sometimes be more accurately referred to as releasing: when we talk about continuous deployment, what we are really talking about is continuous releasing.) If you host and run your software as a service, this is done by deploying the changes to production and making them available to users, but if you work on other software such as libraries and binaries, this is done by making new releases of your software available.
-
Lead time for changes stays the same, but instead of thinking of it as the time it takes a commit to get into production, think about it as the time it takes a commit to get into the hands of users. For example, in the case of libraries, that would be users who are using the libraries in their own projects. How long does it take between when a commit is created, and when the contents of that commit are available to use in a released version of the library?
The remaining question is whether the values for elite, high, medium, and low performers across these metrics apply equally for software running as a service as for software distributed as libraries and binaries. The answer is that we don’t know, but the principles remain the same: the more frequently you get your changes out to users, the less risk you’re dealing with every time you release.
Lead time for changes
To measure lead time for changes, Sandy needs to understand a bit about the development process at Watch Me Watch. Most features are created in a feature branch, and that branch is merged back into main when development has finished on the feature. Some features can be completed in as little as a week, but most take at least a few weeks. Here is what this process looks like for a two recent features, which were developed in Feature Branch 1 and Feature Branch 2:

The lead time for the changes in Feature Branch 1 was 20 days. Even though Feature Branch 2 was completed immediately before a deployment window, this was during the code freeze window, so it couldn’t be merged until after that, delaying the deployment until the next deployment window, two months later. This made the lead time for the changes in Feature Branch 2 two months, or around 60 days. Looking across the last year’s worth of features and feature branches, Sandy finds that the average lead time for changes is around 45 days.
![]() Vocab time
Vocab time
Feature branching is a branching policy whereby when development starts on a new feature, a new branch (called a feature branch) is created. Development on this feature in this separate branch continues until the feature is completed, at which point it is merged into the main codebase. You’ll learn more on this in a few pages.
Watch Me Watch and elite performers
Sandy has measured the two velocity-related DORA metrics for Watch Me Watch:
-
Deployment frequency—Once every two months
-
Lead time for changes—45 days

Looking at these values in isolation, it’s hard to draw any conclusions or take away anything actionable. As part of determining these metrics, the DORA team members also ranked the teams they were measuring in terms of overall performance and put them into four buckets: low-, medium-, high-, and elite-performing teams.
For each metric, they reported what that metric looked like for teams in each bucket. For the velocity metrics, the breakdown (from the 2021 report) looked like this:
On the elite end of the spectrum, multiple deployments happen every day, and the lead time for changes is less than an hour! On the other end, low performers deploy less frequently than once every six months, and changes take more than six months to get to production. Comparing the metrics at Watch Me Watch with these values, the company is solidly aligned with the medium performers.
|
Metric |
Elite |
High |
Medium |
Low |
|
Deployment frequency |
Multiple times a day |
Once per week to once per month |
Once per month to once every six months |
Fewer than once every six months |
|
Lead time for changes |
Less than an hour |
One day to one week |
One month to six months |
More than six months |
What if I’m between two buckets?
The results reported by the DORA team members are clustered such that there is a slight gap between buckets. This is based on the values they saw in the teams that they surveyed, and isn’t meant to be an absolute guideline. If you find your values falling between buckets, it’s up to you whether you want to consider yourself on the high end of the lower bucket or the low end of the higher bucket. It might be more interesting to step back and look at your values across all of the metrics to get an overall picture of your performance.
Increasing velocity at Watch Me Watch

Sandy sets out to create a plan to improve the velocity at Watch Me Watch:
-
Deployment frequency—To move from being a medium performer to a high performer, the team needs to go from deploying once every two months to deploying at least once a month.
-
Lead time for changes—To move from being a medium to a high performer, the team needs to go from an average lead time of 45 days to one week or less.
Their deployment frequency is currently determined by the fixed deployment windows they use, once every two months. And their lead time for changes is impacted by this as well: feature branches aren’t merged until the entire feature is complete, and can be merged only between code freezes, and if the author misses a deployment window, their changes are delayed by two months until the next one.
Sandy theorizes that both metrics are heavily influenced by the deployment windows (and the code freeze immediately before deployment), and made worse by the use of feature branches.
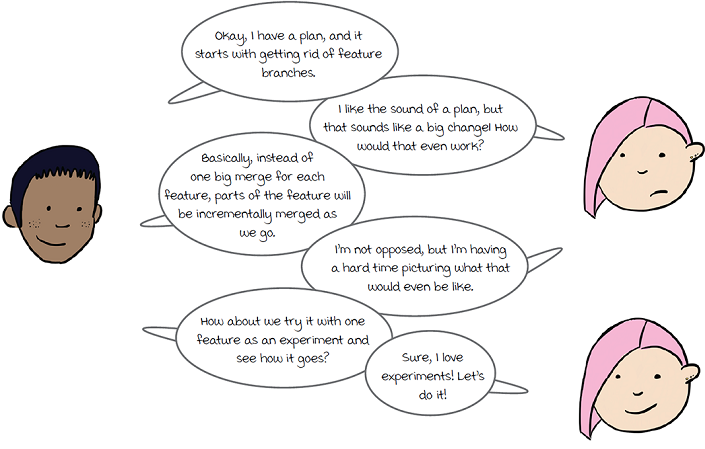
Integrating with AllCatsAllTheTime
To experiment with getting rid of feature branches, Sandy starts to work with Jan to try out this new approach for the next feature he’s working on. Jan has taken on integrating with the new streaming provider AllCatsAllTheTime (a streaming provider featuring curated cat-related content). To understand the changes Jan will need to make, let’s look again at the overall architecture of Watch Me Watch. Even though the company has grown since you last looked at its architecture, the original plans that Sasha and Sarah created have been working well for them, so the architecture hasn’t changed:

Integrating AllCatsAllTheTime as a new streaming service provider means changing the Streaming Integration service. Inside the Streaming Integration service codebase, each integrated streaming service is implemented as a separate class, and is expected to inherit from the class StreamingService, implementing the following methods:
def getCurrentlyWatching(self): ❶ ... ❶ def getWatchHistory(self, time_period): ❶ ... ❶ def getDetails(self, show_or_movie): ❶ ... ❶
❶ This interface enables most functionality that Watch Me Watch needs from streaming service providers: revealing what a user has been watching, and getting details for particular shows or movies the user has watched.
![]() Trunk-based development
Trunk-based development
The approach Sandy is advocating for is trunk-based development, whereby developers frequently merge back into the trunk of the repository, aka the main branch. This is done instead of feature branching, where long-lived branches are created per feature, and changes are committed to the branch as the feature is developed. Eventually, at some point, the entire branch is merged back into the main branch. Feature branching looks like this:

With trunk-based development, commits are made back to main as frequently as possible, even if an entire feature is not yet complete (though each change should still be complete, which you’ll see in action in this chapter):

Incremental feature delivery
Sandy and Jan talk through how Jan would normally approach this feature:
-
Make a feature branch off of main.
-
Start work on end-to-end tests.
-
Fill in the skeleton of the new streaming service class, with tests.
-
Start making each individual function work, with more tests and new classes.
-
If he remembers, from time to time, he’ll merge in changes from main.
-
When it’s all ready to go, merge the feature back into main.
With the approach Sandy is suggesting, Jan will still create branches, but these branches will be merged back to main as quickly as possible, multiple times a day if he can. Since this is so different from how he usually works, they talk through how he’s going to do this initially.

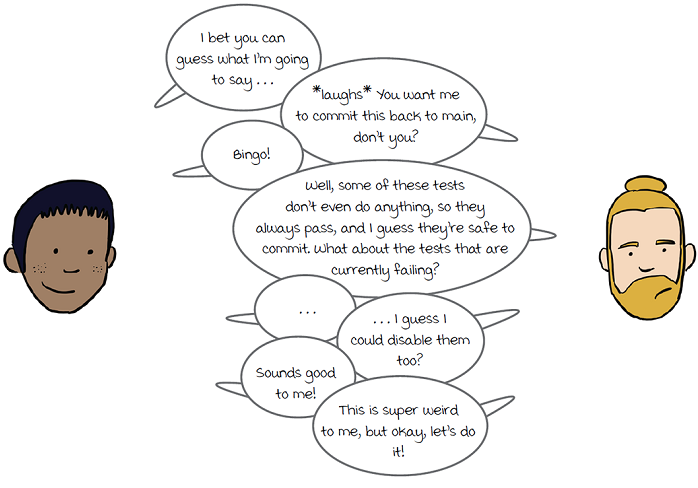
Committing skipped tests
Sandy convinces Jan that he can create his initial end-to-end tests, and even though they won’t all pass until the feature is done, he can commit them back to main as disabled tests. This will allow him to commit quickly back to main instead of keeping the tests in a long-lived feature branch.
Jan creates his initial set of end-to-end tests for the new AllCatsAllTheTime integration. These tests will interact with the real AllCatsAllTheTime service, so he sets up a test account (WatchMeWatchTest01) and seeds the account with some viewing activity that his tests can interact with. For example, this is one of the end-to-end tests that covers the getWatchHistory method:
def test_get_watch_history(self):
service = AllCatsAllTheTime(ACATT_TEST_USER)
history = service.getWatchHistory(ALL_TIME)
self.assertEqual(len(history), 3)
self.assertEqual(history[0].name, "Real Cats of NYC")When he runs the tests, they of course fail, because he hasn’t actually implemented any of the functions that the tests are calling. He feels very skeptical about it, but he does what Sandy suggested and disables the tests by using unittest.skip, with a message explaining that the implementation is a work in progress. He includes a link to the issue for the AllCatsAllTheTime integration in the issue tracking system (#2387) so other engineers can find more information if they need to:
@unittest.skip("(#2387) AllCatsAllTheTime integration WIP")
def test_get_watch_history(self):
Jan is so skeptical! Is he a bad engineer?
Absolutely not! It’s natural to be skeptical when trying new things, especially if you have a lot of experience doing things differently. The important thing is that Jan is willing to try things out. In general, being willing to experiment and give new ideas a fair shot is the key element you need to make sure you and your team can keep growing and learning. And that doesn’t mean everyone has to like every new idea right away.
Code review and “incomplete” code
How does taking an approach like this work with code review? Surely, tiny incomplete commits like this are hard to review? Let’s see what happens!
Jan creates a PR that contains his new skipped end-to-end tests and submits it for review. When another engineer from his team, Melissa, goes to review the PR, she’s a understandably a bit confused, because she’s used to reviewing complete features. Her initial round of feedback reflects her confusion:
|
Hey Jan, I’m not sure how to review this; it doesn’t seem like the PR is complete. Are there maybe some files you forgot to add? |
Up until this point, engineers working on Watch Me Watch have expected that a complete PR includes a working feature, and all the supporting tests (all passing and none skipped) and documentation for that feature.
Getting used to a more incremental approach will mean redefining complete. Sandy lays some groundwork for how to move forward by redefining a complete PR as follows:
-
All code complies with linting checks.
-
Docstrings for incomplete functions explain why they are incomplete.
-
Each code change is supported by tests and documentation.
-
Disabled tests include an explanation and refer to a tracking issue.
Sandy and Jan meet with Melissa and the rest of the team to explain what they are trying to do and share their new definition of complete. After the meeting, Melissa goes back to the PR and leaves some new feedback:
|
Okay, I think I get it now! With this new incremental approach, I think the only thing missing is an update to our streaming service integration docs? |
Jan realizes Melissa is right: he’s added tests, but the documentation in the repo that explains their streaming service integrations hasn’t been updated, so he adds a change to the PR to add some very cursory initial docs:
* AllCatsAllTheTime - (#2387) a WIP integration with the provider of cat related content
Melissa approves the changes, and the disabled end-to-end tests are merged.
![]() But isn’t dead code bad?
But isn’t dead code bad?
Many organizations have policies against allowing dead code to exist in the codebase, with good reason! Dead code is code that is committed into the repo, but isn’t reachable; it isn’t called by any code paths that execute at runtime. (It can also refer to code that is executed but doesn’t change anything, but that’s not the definition I’m using here.)
It’s useful to understand why you want to avoid having dead code in the codebase. The main reason relates to the maintenance of the codebase over time. As developers contribute new code, they will encounter this dead code and will have to at the very least read it and understand it’s not being used, and in the worst case, waste time updating it. But this is a waste only if the code is truly dead (it’s not going to be used in the future). In our scenario, some of the code Jan is adding may seem dead in that it isn’t being used, but it simply isn’t being used yet. Any time that other developers put into maintaining this code is not wasted; in fact, as you’ll see in a few pages, it is extremely useful.
Dead code is bad only if its presence in the codebase causes time to be wasted on its maintenance.
That being said, it is worth the effort to avoid leaving dead code in the codebase. (Imagine, for example, that Watch Me Watch decides not to integrate with AllCatsAllTheTime after all, and Jan stops working on this feature. Leaving that code in the codebase would result in noise and wasted time.) There are two ways to ensure you don’t allow dead code to clutter your codebase:
-
Completely disallow dead code (unreachable, unexecuted code) from being committed to your codebase by detecting it pre-merge and blocking it from being merged in.
-
Run automation on a regular basis to detect dead code and clean it up automatically. The best option is to have the automation propose the changes to remove the code but not actually merge them, allowing developers to make the call about whether the code should stick around.
The second option is the most flexible and will allow you to use an approach like Jan is using, balanced with the safeguards to make sure the code gets removed if it ends up never being used.
If your organization takes the first option, you can still take an incremental approach to feature development, but it will look a bit different. See some tips on how in a few pages in the “You can commit frequently!” box.
Keeping up the momentum
Jan merges his initial (disabled) end-to-end tests. What’s next? Jan’s still taking the same approach he would to implementing a new feature, but without a dedicated feature branch:
-
Make a feature branch off of main (Not using feature branches.)
-
Start work on end-to-end tests (Done, merged to main.)
-
Fill in the skeleton of the new streaming service class, with tests. (a)
-
Start making each individual function work, with more tests and new classes.
-
If he remembers, from time to time, he’ll merge in changes from main.
-
When it’s all ready to go, merge the feature back into main.
(a) The next step
Jan’s next step is to start working on implementing the skeleton of the new streaming service and associated unit tests. After a couple days of work, Sandy checks in:

For the record, Sandy hates to micromanage and wouldn’t normally butt in like this!
Committing work-in-progress code
So far, Jan has some initial methods for the class AllCatsAllTheTime:
class AllCatsAllTheTime(StreamingService):
def __init__(self, user):
super().__init__(user)
def getCurrentlyWatching(self):
"""Get shows/movies AllCatsAllTheTime considers self.user to be watching"""
return []
def getWatchHistory(self, time_period):
"""Get shows/movies AllCatsAllTheTime recorded self.user to have watched"""
return []
def getDetails(self, show_or_movie):
"""Get all attributes of the show/movie as stored by AllCatsAllTheTime"""
return {}He’s also created unit tests for getDetails (which fail because nothing is implemented yet) and has some initial unit tests for the other functions that are totally empty and always pass. He shows this work to Sandy, who some feedback:
Shouldn’t Jan have more to show for several days of work?
Maybe (also maybe not, as creating mocks and getting unit tests working can be a lot of work). But the real reason I’m keeping these examples short is so I can fit them into the chapter. The idea being demonstrated holds true even for these small examples, i.e., to get used to making small frequent commits, even commits as small as the ones Jan will be making.
Reviewing work-in-progress code
Jan opens a PR with his changes: the empty skeleton of the new class, a disabled failing unit test, and several unit tests that do nothing but pass. By this point Melissa understands why so much of the PR is in progress and isn’t phased. She immediately comes back with some feedback:
|
Can we include some more documentation? The autogenerated docs are going to pick up this new class, and all the docstrings are pretty much empty. |
Jan is pleasantly surprised that a PR with so little content can get useful feedback. He starts filling in docstrings for the empty functions, describing what they are intended to do, and what they currently do; for example, he adds this docstring in the new class AllCatsAllTheTime:
def getWatchHistory(self, time_period):
"""
Get shows/movies AllCatsAllTheTime recorded self.user to have watched
AllCatsAllTime will hold the complete history of all shows and movies
watched by a user from the time they sign up until the current time,
so this function can return anywhere from 0 results to a list of
unbounded length.
The AllCatsAllTheTime integration is a work in progress (#2387) so
currently this function does nothing and always returns an empty list.
:param time_period: Either a value of ALL_TIME to return the complete
watch history or an instance of TimePeriod which specifies the start
and end datetimes to retrieve the history for
:returns: A list of Show objects, one for each currently being watched
"""
return []At Watch Me Watch, docstrings are in reStructuredText format.
Once Jan updates the PR with the docstrings, Melissa approves it, and it’s merged into main.

Isn’t this a waste of time for Melissa, reviewing all these incomplete changes?
Short answer: no! It’s much easier for Melissa to review these tiny PRs than it is to review a giant feature branch! Also, she can spend more time reviewing the interfaces (e.g., method signatures) and give feedback on them early, before they’re fully fleshed out. Making changes to code before it is written is easier than making the changes after!
Meanwhile, back at the end-to-end tests
Meanwhile, unbeknownst to Jan, Sandy, and Melissa, other code changes are brewing in the repo! Jan creates a new branch to start on his next phase of work, and when he opens the end-to-end tests, and the skeleton service he’s been working on so far, he’s surprised to see new changes to the code that he’s already committed—changes made by someone else!
In the end-to-end test, he notices the call to AllCatsAllTheTime. getWatchHistory has some new arguments:
def getWatchHistory(self, time_period, max, index): ❶
...
:param time_period: Either a value of ALL_TIME to return the complete
watch history or an instance of TimePeriod which specifies the start
and end datetimes to retrieve the history for
:param max: The maximum number of results to return
:param index: The index into the total number of results from which to
return up to max results
...❶ Arguments have been added to getWatchHistory to support paginating the results.
These new arguments have been added to the skeleton service as well:
def getWatchHistory(self, time_period, max, index):
return []And there are even a couple of new unit tests:
def test_get_watch_history_paginated_first_page(self):
service = AllCatsAllTheTime(ACATT_TEST_USER)
history = service.getWatchHistory(ALL_TIME, 2, 0)
# TODO(#2387) assert that the first page of results is returned ❶
def test_get_watch_history_paginated_last_page(self):
service = AllCatsAllTheTime(ACATT_TEST_USER)
history = service.getWatchHistory(ALL_TIME, 2, 1)
# TODO(#2387) assert that the first page of results is returned❶ These tests always pass because their bodies haven’t been filled in, but the author has indicated what needs to be done.
Looking at the history of the changes, Jan sees that Louis merged a PR the day before that added pagination to getWatchHistory for all streaming services. He notices he has a chat message from Louis as well:
|
Hey, thanks for merging |
Because Jan merged his code early, Louis was able to contribute to it right away. If Jan had kept this code in a feature branch, Louis wouldn’t have known about AllCatsAllTheTime, and Jan wouldn’t have known about the pagination changes. When he finally went to merge those changes in, weeks or even months later, he’d have to deal with the conflict with Louis’s changes. But this way, Louis dealt with them right away!
Seeing the benefits

In this chapter, we’re starting to move beyond CI to the processes that happen after the fact (i.e., the rest of CD), but the truth is that the line is blurry, and choices your team makes in CI processes have downstream ripple impacts on the entire CD process. Although Sandy’s overall goal is to improve velocity, as they just pointed out to Jan, taking the incremental approach means that the team's CI processes are now much closer to the ideal. What is that? Let’s look briefly back on the definition of continuous integration:
The process of combining code changes frequently, with each change verified on check-in.
With long-lived feature branches, code changes are combined only as frequently as the feature branches are brought back to main. But by committing back to main as often as he can, Jan is combining his code changes with the content of main (and enabling other developers to combine their changes with his) frequently instead!
![]() Takeaway
Takeaway
Improving deployment often means improving CI first.
![]() Takeaway
Takeaway
Avoiding long-lived feature branches and taking an incremental approach, with frequent merges back to main (using trunk-based development), not only improves CD overall but also provides better CI.
![]() You can commit frequently!
You can commit frequently!
If you are looking at the approach Jan and Sandy are taking, thinking to yourself, “This will never fly on my project,” don’t despair! Their approach isn’t the only option for avoiding feature branches and merging incremental progress frequently. To take an incremental approach without committing work-in-progress code, focus on the principle that Jan and Sandy are trying to achieve:
Development and deployment are easier and faster when changes are committed back to the codebase as frequently as possible.
The goal is to commit back to the repo as frequently as possible, and what’s possible for you and your situation might not be the same as for this project. The most effective approach is to break your work into discrete chunks, each of which can be completed in less than a day. This is a good practice for software development regardless, as it facilitates thinking your work through and makes it easier to collaborate (for example, allowing multiple team members to contribute to the same feature).
That being said, it’s hard! And it can feel easier not to do it. Here are some tips that can directly help with creating small, frequent PRs (see books on software development processes, such as Agile, for more):
-
Get unknowns out of the way early by starting with quick and dirty proof of concepts (POCs), versus trying to write production-ready software and explore new technology at the same time (e.g., Jan could have created a POC integration with AllCatsAllTheTime before starting to work in the streaming integration codebase).
-
Break your work into discrete tasks, each taking a few hours or a day at most. Think about the small, self-contained PRs you can create for them (each complete with docs and tests).
-
When you refactor, do it in a separate PR and merge it quickly.
-
If you can’t avoid working from one big feature branch, keep an eye out as you go for pieces that can be committed back and take the time to create and merge separate PRs for them.
-
Use feature flags to prevent work-in-progress features from being exposed to users, and/or use build flags to prevent them from being compiled into the codebase at all.
In a nutshell: take the time to think up front about how you can break up your work and commit it back quickly, and take the time to create the small, self-contained PRs required to support this. It’s well worth the effort!
Decreasing lead time for changes
By getting closer to the CI ideal, Sandy and Jan are having a direct impact on the entire CD process. Specifically, they are having a positive impact on Watch Me Watch’s DORA metrics. Remember Sandy’s goals:
-
Deployment frequency—Move from being a medium to high performer by going from deploying once every two months to deploying at least once a month.
-
Lead time for changes—Move from being a medium to a high performer by going from an average lead time of 45 days to one week or less.
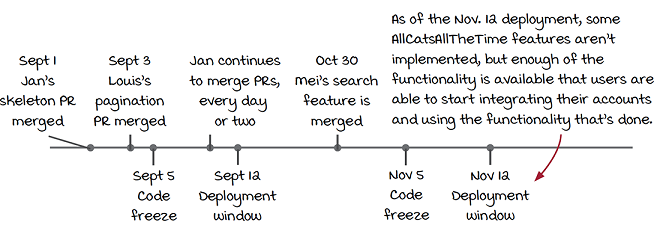
Jan’s most recent PR (including a skeleton of the new streaming class and some work-in-progress unit tests) was only a couple of days before a code freeze and the subsequent deployment window. The result is that Jan’s new integration code made it to production as part of that deployment.
Of course, the new integration code doesn’t do actually anything yet, but, regardless, the changes Jan is making are making it into production. Sandy takes a look at the lead time for these changes:

Jan merged the skeleton class four days before the code freeze. Two days before the code freeze, Louis updated getWatchHistory to take pagination arguments. The code freeze started two days later, and one week after that was a deployment.
The entire lead time for the skeleton class change started when Jan merged on September 1 and ended with the deployment on September 12, for a total of an 11-day lead time.
Let’s compare that to the lead time for the changes Louis was working on. He’d been working in a feature branch since before the last deployment window, which was July 12. He’d started on July 8, so the entire lead time for his changes was from July 8 to September 12, or 66 days.
While Jan’s changes are incremental (and currently not functional), Jan was able to reduce the lead time for each individual change to 11 days, while Louis’s changes had to wait 66 days.
Continuing AllCatsAllTheTime
Jan continued to work with Sandy to use an incremental approach to implementing the rest of the AllCatsAllTheTime integration. He worked method by method, implementing the method, fleshing out the unit tests, and enabling end-to-end tests as he went. A few weeks into the work, another team member, Mei, is working on a search feature and adds a new method to the StreamingService interface:
class StreamingService:
...
@staticmethod
def search(show_or_movie):
passThis new method will allow users to search for specific movies and shows across streaming providers, and the author of the change adds the new method to every existing streaming service integration. Since Jan has been incrementally committing the AllCatsAllTheTime class as he goes, Mei is able to add the search method to the existing AllCatsAllTheTime class; she doesn’t even need to tell Jan about the change at all! One day Jan creates a new branch to start work on the getDetails method and sees the code that Mei has added.
That’s two major features that have been integrated with Jan’s changes as he developed (pagination and search) that normally Jan would have to deal with at merge time with his normal feature branch approach. In addition, after the next deployment (November 12), even though the integration isn’t complete, enough functionality is present for users to start using it and for marketing to start advertising the integration.

Deployment windows and code freezes
Sandy and Jan present the results of their experiment back to Sasha and Sarah. They show that by avoiding long-lived feature branches and merging features incrementally, they’ve encountered multiple benefits:
-
The lead time for changes is decreased.
-
Multiple features can be integrated sooner and more easily.
-
Users can get access to features earlier.
Sasha and Sarah agree to try this policy across the company and see what happens, so Sandy and Jan set about training the rest of the developers in how to avoid feature branches and use an incremental approach.
A few months later, Sandy revisits the lead-time metrics for all the changes to see how they’ve improved. The average lead time has decreased significantly, from 45 days down to 18 days. Individual changes are making it into main faster, but they still get blocked by the code freeze, and if they are merged soon after a deployment, they have to wait nearly two months to make it into the next deployment. While the metric has improved, it still falls short of Sandy’s goal to upgrade their lead time for changes from being aligned with DORA medium performers to high performers (one week or less).

They discuss a plan and agree to try doing weekly deployments and to remove the code freeze entirely.
See chapter 10 for more on deploying, minimizing risk, and ways to deploy safely.
Increased velocity
Sandy keeps track of metrics for the next few months and observes feature development to see if things are speeding up and where their DORA metrics land without code freezes and with more frequent deployments.
Melissa works on integration with a new streaming provider, Home Movie Theatre Max. The integration takes her about five weeks to completely implement, and during that time, four deployments happen, each of which includes some of her changes.

The lead time for Melissa’s changes is a maximum of five days. Some changes are deployed as quickly as one day after being merged.
Sandy looks at the stats for Watch Me Watch overall and finds that the maximum lead time for changes is eight days, but this is rare since most engineers have gotten into the habit of merging back into main every day or two. The averages are as follows:
-
Deployment frequency—Once a week (a)
-
Lead time for changes—Four days
(a) Getting to high performance with this metric was as easy as changing the intervals between deployment windows.
Sandy has accomplished their goal: as far as velocity is concerned, Watch Me Watch is now aligned with the DORA high performers!

Sasha, Sarah, and Sandy also wonder how they can move beyond being high performers to being elite performers, but I’ll save that for chapter 10!
Conclusion
Watch Me Watch introduced code freezes and infrequent deployment windows with the hope of making development safer. However, this approach just made development slow. By looking at its processes through the lens of the DORA metrics—specifically, the velocity-related metrics—the developers were able to chart a path toward moving more quickly.
Moving away from long-lived feature branches, removing code freezes, and increasing deployment frequency directly improved their DORA metrics. The new approach rescued the company from the feeling that features were taking longer and longer, allowing their competition to get ahead of them—not to mention, the engineers realized this was a more satisfying way to work!
Summary
-
The DevOps Research and Assessment (DORA) team has identified four key metrics to measure software team performance and correlated these with elite, high, medium, and low performance.
-
Deployment frequency, one of two velocity-related DORA metrics, measures how frequently deployments to production occur.
-
Lead time for changes, the other velocity-related DORA metric, measures the time from which a change has been completed to when it gets to production.
-
Decreasing lead time for changes requires revisiting and improving CI practices. The better your CI, the better your lead time for changes.
-
Improving the CD practices beyond CI often means revisiting CI as well.
-
Deployment frequency has a direct impact on lead time for changes; increasing deployment frequency will likely decrease lead time for changes.
Up next . . .
In the next chapter, I’ll examine the main transformation that happens to source code in a CD pipeline: building that source code into the final artifact that will be released (and possibly deployed) and how to build that artifact securely.