
Suppose that we have to build a web crawler that can be used to index content from various websites. The process of doing that involves setting up a list of target sites and then kicking off the crawler. Let's create a module with the structure, as follows:
module WebCrawler
using Dates
# public interface
export Target
export add_site!, crawl_sites!, current_sites, reset_crawler!
# == insert global variables and functions here ==
end # module
Our programming interface is quite simple. Let's see how to do this:
- Target is a data type that represents the website being crawled. Then, we can use the add_site! function to add new target sites to the list.
- When ready, we just call the crawl_sites! function to visit all sites.
- For convenience, the current_sites function can be used to review the current list of target sites and their crawling status.
- Finally, the reset_crawler! function can be used to reset the state of the web crawler.
Let's take a look at the data structure now. The Target type is used to maintain the URL of the target website. It also contains a Boolean variable regarding the status and the time it finished crawling. The struct is defined as follows:
Base.@kwdef mutable struct Target
url::String
finished::Bool = false
finish_time::Union{DateTime,Nothing} = nothing
end
In order to keep track of the current target sites, a global variable is used:
const sites = Target[]
To complete the web crawler implementation, we have the following functions defined in the module:
function add_site!(site::Target)
push!(sites, site)
end
function crawl_sites!()
for s in sites
index_site!(s)
end
end
function current_sites()
copy(sites)
end
function index_site!(site::Target)
site.finished = true
site.finish_time = now()
println("Site $(site.url) crawled.")
end
function reset_crawler!()
empty!(sites)
end
To use the web crawler, first, we can add some sites, as follows:
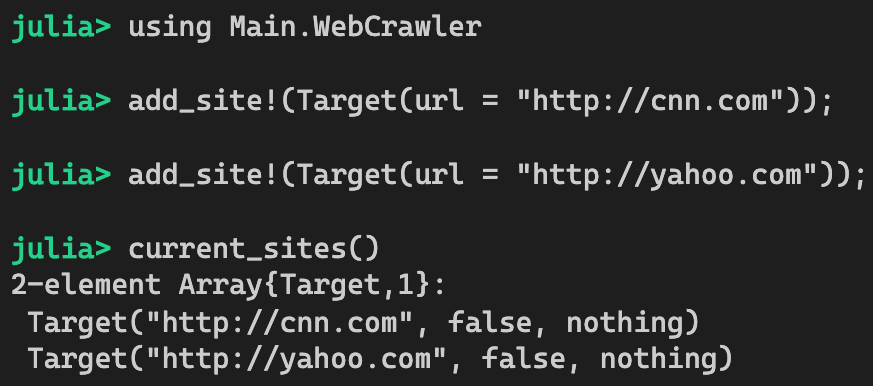
Then, we can just run the crawler and retrieve the results afterward:

The current implementation is not bad, but it has the following two access-related issues:
- The global variable, sites, is visible to the outside world, which means that anyone can get a handle of the variable and mess it up, for example, by inserting a malicious website.
- The index_site! function should be considered a private function and should not be included as part of the public API.
Now that we have set the stage, we will demonstrate how to address these problems in the next section.