
Let's again look at the problem of generating the Mandelbrot set from Chapter 1, Why GPU Programming?. The original code is available under the 1 folder in the repository, with the filename mandelbrot0.py, which you should take another look at before we continue. We saw that there were two main components of this program: the first being the generation of the Mandelbrot set, and the second concerning dumping the Mandelbrot set into a PNG file. In the first chapter, we realized that we could parallelize only the generation of the Mandelbrot set, and considering that this takes the bulk of the time for the program to do, this would be a good candidate for an algorithm to offload this onto a GPU. Let's figure out how to do this. (We will refrain from re-iterating over the definition of the Mandelbrot set, so if you need a deeper review, please re-read the Mandelbrot revisited section of Chapter 1, Why GPU Programming?)
First, let's make a new Python function based on simple_mandelbrot from the original program. We'll call it gpu_mandelbrot, and this will take in the same exact input as before:
def gpu_mandelbrot(width, height, real_low, real_high, imag_low, imag_high, max_iters, upper_bound):
We will proceed a little differently from here. We will start by building a complex lattice that consists of each point in the complex plane that we will analyze.
Here, we'll use some tricks with the NumPy matrix type to easily generate the lattice, and then typecast the result from a NumPy matrix type to a two-dimensional NumPy array (since PyCUDA can only handle NumPy array types, not matrix types). Notice how we are very carefully setting our NumPy types:
real_vals = np.matrix(np.linspace(real_low, real_high, width), dtype=np.complex64)
imag_vals = np.matrix(np.linspace( imag_high, imag_low, height), dtype=np.complex64) * 1j
mandelbrot_lattice = np.array(real_vals + imag_vals.transpose(), dtype=np.complex64)
So, we now have a two-dimensional complex array that represents the lattice from which we will generate our Mandelbrot set; as we will see, we can operate on this very easily within the GPU. Let's now transfer our lattice to the GPU and allocate an array that we will use to represent our Mandelbrot set:
# copy complex lattice to the GPU
mandelbrot_lattice_gpu = gpuarray.to_gpu(mandelbrot_lattice)
# allocate an empty array on the GPU
mandelbrot_graph_gpu = gpuarray.empty(shape=mandelbrot_lattice.shape, dtype=np.float32)
To reiterate—the gpuarray.to_array function only can operate on NumPy array types, so we were sure to have type-cast this beforehand before we sent it to the GPU. Next, we have to allocate some memory on the GPU with the gpuarray.empty function, specifying the size/shape of the array and the type. Again, you can think of this as acting similarly to malloc in C; remember that we won't have to deallocate or free this memory later, due to the gpuarray object destructor taking care of memory clean-up automatically when the end of the scope is reached.
We're now ready to launch the kernel; the only change we have to make is to change the
We haven't written our kernel function yet to generate the Mandelbrot set, but let's just write how we want the rest of this function to go:
mandel_ker( mandelbrot_lattice_gpu, mandelbrot_graph_gpu, np.int32(max_iters), np.float32(upper_bound))
mandelbrot_graph = mandelbrot_graph_gpu.get()
return mandelbrot_graph
So this is how we want our new kernel to act—the first input will be the complex lattice of points (NumPy complex64 type) we generated, the second will be a pointer to a two-dimensional floating point array (NumPy float32 type) that will indicate which elements are members of the Mandelbrot set, the third will be an integer indicating the maximum number of iterations for each point, and the final input will be the upper bound for each point used for determining membership in the Mandelbrot class. Notice that we are very careful in typecasting everything that goes into the GPU!
The next line retrieves the Mandelbrot set we generated from the GPU back into CPU space, and the end value is returned. (Notice that the input and output of gpu_mandelbrot is exactly the same as that of simple_mandelbrot).
Let's now look at how to properly define our GPU kernel. First, let's add the appropriate include statements to the header:
import pycuda.autoinit
from pycuda import gpuarray
from pycuda.elementwise import ElementwiseKernel
We are now ready to write our GPU kernel! We'll show it here and then go over this line-by-line:
mandel_ker = ElementwiseKernel(
"pycuda::complex<float> *lattice, float *mandelbrot_graph, int max_iters, float upper_bound",
"""
mandelbrot_graph[i] = 1;
pycuda::complex<float> c = lattice[i];
pycuda::complex<float> z(0,0);
for (int j = 0; j < max_iters; j++)
{
z = z*z + c;
if(abs(z) > upper_bound)
{
mandelbrot_graph[i] = 0;
break;
}
}
""",
"mandel_ker")
First, we set our input with the first string passed to ElementwiseKernel. We have to realize that when we are working in CUDA-C, particular C datatypes will correspond directly to particular Python NumPy datatypes. Again, note that when arrays are passed into a CUDA kernel, they are seen as C pointers by CUDA. Here, a CUDA C int type corresponds exactly to a NumPy int32 type, while a CUDA C float type corresponds to a NumPy float32 type. An internal PyCUDA class template is then used for complex types—here PyCUDA ::complex<float> corresponds to Numpy complex64.
Let's look at the content of the second string, which is deliminated with three quotes ("""). This allows us to use multiple lines within the string; we will use this when we write larger inline CUDA kernels in Python.
While the arrays we have passed in are two-dimensional arrays in Python, CUDA will only see these as being one-dimensional and indexed by i. Again, ElementwiseKernel indexes i across multiple cores and threads for us automatically. We initialize each point in the output to one with mandelbrot_graph[i] = 1;, as i will be indexed over every single element of our Mandelbrot set; we're going to assume that every point will be a member unless proven otherwise. (Again, the Mandelbrot set is over two dimensions, real and complex, but ElementwiseKernel will automatically translate everything into a one-dimensional set. When we interact with the data again in Python, the two-dimensional structure of the Mandelbrot set will be preserved.)
We set up our c value as in Python to the appropriate lattice point with pycuda::complex<float> c = lattice[i]; and initialize our z value to 0 with pycuda::complex<float> z(0,0); (the first zero corresponds to the real part, while the second corresponds to the imaginary part). We then perform a loop over a new iterator, j, with for(int j = 0; j < max_iters; j++). (Note that this algorithm will not be parallelized over j or any other index—only i! This for loop will run serially over j—but the entire piece of code will be parallelized across i.)
We then set the new value of z with z = z*z + c; as per the Mandelbrot algorithm. If the absolute value of this element exceeds the upper bound ( if(abs(z) > upper_bound) ), we set this point to 0 ( mandelbrot_graph[i] = 0; ) and break out of the loop with the break keyword.
In the final string passed into ElementwiseKernel we give the kernel its internal CUDA C name, here "mandel_ker".
We're now ready to launch the kernel; the only change we have to make is to change the reference from simple_mandelbrot in the main function to gpu_mandelbrot, and we're ready to go. Let's launch this from IPython:

Let's check the dumped image to make sure this is correct:
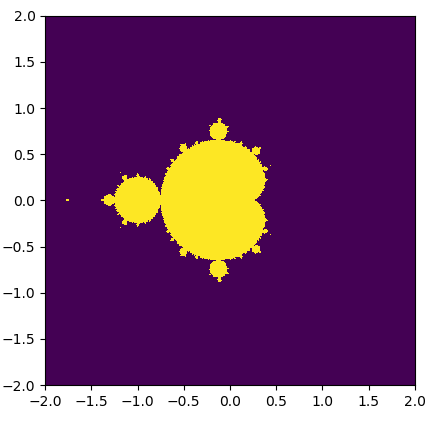
This is certainly the same Mandelbrot image that is produced in the first chapter, so we have successfully implemented this onto a GPU! Let's now look at the speed increase we're getting: in the first chapter, it took us 14.61 seconds to produce this graph; here, it only took 0.894 seconds. Keep in mind that PyCUDA also has to compile and link our CUDA C code at runtime, and the time it takes to make the memory transfers to and from the GPU. Still, even with all of that extra overhead, it is a very worthwhile speed increase! (You can view the code for our GPU Mandelbrot with the file named gpu_mandelbrot0.py in the Git repository.)