
Let's say we have some task, T. We use a model,  , parameterized by some parameter,
, parameterized by some parameter,  , and train the model to minimize the loss. We minimize the loss using gradient descent and find the optimal parameter
, and train the model to minimize the loss. We minimize the loss using gradient descent and find the optimal parameter  for the model.
for the model.
Let's recall the update rule of a gradient descent:

So, what are the key elements that make up our gradient descent? Let's see:
- Parameter

- Learning rate

- Update direction
We usually set the parameter  to some random value and try to find the optimal value during our training process, and we set the value of learning rate
to some random value and try to find the optimal value during our training process, and we set the value of learning rate  to a small number or decay it over time and an update direction that follows the gradient. Can we learn all of these key elements of the gradient descent by meta learning so that we can learn quickly from a few data points? We've already seen, in the last chapter, how MAML finds the optimal initial parameter
to a small number or decay it over time and an update direction that follows the gradient. Can we learn all of these key elements of the gradient descent by meta learning so that we can learn quickly from a few data points? We've already seen, in the last chapter, how MAML finds the optimal initial parameter  that's generalizable across tasks. With the optimal initial parameter, we can take fewer gradient steps and learn quickly on a new task.
that's generalizable across tasks. With the optimal initial parameter, we can take fewer gradient steps and learn quickly on a new task.
So, now can we learn the optimal learning rate and update direction that're generalizable across tasks so we can achieve faster convergence and training? Let's see how we can learn this in Meta-SGD by comparing it with MAML. If you recall, in the MAML inner loop, find the optimal parameter  for each task
for each task  by minimizing the loss through gradient descent:
by minimizing the loss through gradient descent:

For Meta-SGD, we can rewrite the previous equation as follows:

But what's the difference? Here  is not just a scalar small value but a vector. We initialize
is not just a scalar small value but a vector. We initialize  randomly with same shape as
randomly with same shape as  We call
We call  as an initial parameter and
as an initial parameter and  as an adaptation term. So, the adaptation term
as an adaptation term. So, the adaptation term  represents the update direction and its length becomes the learning rate. We update our values in the
represents the update direction and its length becomes the learning rate. We update our values in the  direction instead of the gradient direction,
direction instead of the gradient direction, 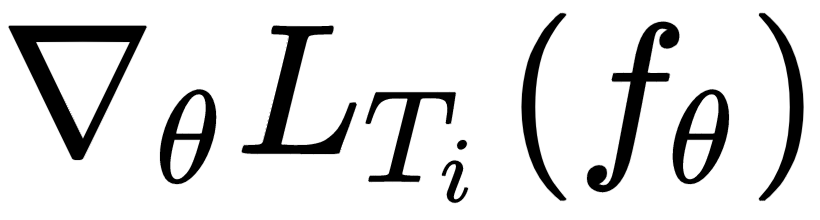 , and our learning rate is implicitly implemented in the adaptation term.
, and our learning rate is implicitly implemented in the adaptation term.
So, in Meta-SGD, we don't initialize a learning rate  with some small scalar value. Instead, we initialize the learning rate with random values with the same shape as
with some small scalar value. Instead, we initialize the learning rate with random values with the same shape as  and learn them along with . We sample some batch of tasks and, for each task, we sample some k data points and minimize the loss using gradient descent, but our update equation becomes the following:
and learn them along with . We sample some batch of tasks and, for each task, we sample some k data points and minimize the loss using gradient descent, but our update equation becomes the following:
That is, our update direction is the adaptation term direction and not the gradient direction, and we learn along with  .
.
Now, in the outer loop, we perform meta optimization—that is, we calculate gradients of loss with respect to optimal parameters  and update our randomly initialized model parameter
and update our randomly initialized model parameter  . In Meta-SGD, instead of updating alone, we also update our randomly initialized , as follows:
. In Meta-SGD, instead of updating alone, we also update our randomly initialized , as follows:


As you can see, Meta-SGD is just a small tweak over MAML. In MAML, we randomly initialize the model parameter  and try to find the optimal parameter that's generalizable across tasks. In Meta-SGD, instead of just learning the model parameter , we also learn the learning rate and update direction, which is implicitly implemented in the adaptation term.
and try to find the optimal parameter that's generalizable across tasks. In Meta-SGD, instead of just learning the model parameter , we also learn the learning rate and update direction, which is implicitly implemented in the adaptation term.