
Let's say we've a dataset set 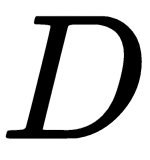 containing samples without labels:
containing samples without labels:  . Now we need to create labels for our dataset. How can we do that? First, we learn the embeddings of each of the data points in our dataset using some embedding function. The embedding function can be any feature extractor. Say our input is an image, then we can use CNN as our embedding function for extracting an image feature vector.
. Now we need to create labels for our dataset. How can we do that? First, we learn the embeddings of each of the data points in our dataset using some embedding function. The embedding function can be any feature extractor. Say our input is an image, then we can use CNN as our embedding function for extracting an image feature vector.
After generating the embeddings for each of the data points, how can we find the labels for them? A naive and simple approach would be to partition our dataset  into some
into some  partitions with some random hyperplanes and then we can treat each of these partitioned subsets of a dataset as a separate class.
partitions with some random hyperplanes and then we can treat each of these partitioned subsets of a dataset as a separate class.
But the problem with this method is that, since we're using random hyperplanes, our classes may contain completely different embeddings and it also keeps the related embeddings in different classes. So, instead of using random hyperplanes to partition our dataset, we can use a clustering algorithm. We use k-means clustering as our clustering algorithm to partition our dataset. We run k-means clustering for several iterations and get the k clusters (partitions).
We can treat each of these clusters as a separate class. So, what's next? How can we generate the task? Let's say that, as a result of clustering, we have five clusters. We sample n clusters from these five clusters. Then, we sample r data points from each of the n clusters without replacement; this can be represented as  . After that, we sample a permutation of n one-hot task-specific labels,
. After that, we sample a permutation of n one-hot task-specific labels,  , for assigning labels for each of the n sampled clusters. So now we'll have a data point, , and a label, .
, for assigning labels for each of the n sampled clusters. So now we'll have a data point, , and a label, .
Finally, we can define our task T as 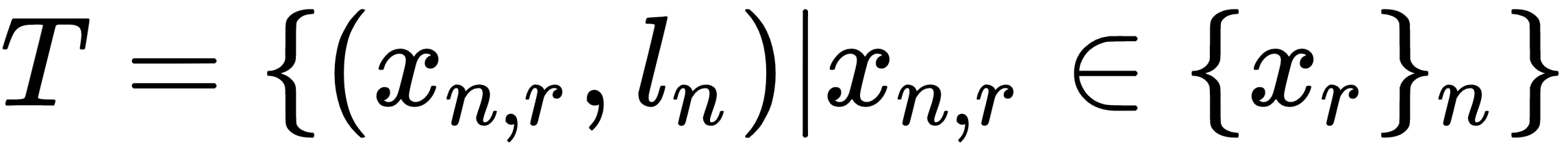 .
.