
The gradient agreement algorithm is an interesting and recently introduced algorithm that acts as an enhancement to meta learning algorithms. In MAML and Reptile, we try to find a better model parameter that's generalizable across several related tasks so that we can learn quickly with fewer data points. If we recollect what we've learned in the previous chapters, we've seen that we randomly initialize the model parameter and then we sample a random batch of tasks,  from the task distribution,
from the task distribution,  . For each of the sampled tasks, , we minimize the loss by calculating gradients and we get the updated parameters,
. For each of the sampled tasks, , we minimize the loss by calculating gradients and we get the updated parameters,  , and that forms our inner loop:
, and that forms our inner loop:

After calculating the optimal parameter for each of the sampled tasks, we perform meta optimization— that is, we perform meta optimization by calculating loss in a new set of tasks, we minimize loss by calculating gradients with respect to the optimal parameters  , which we obtained in the inner loop, and we update our initial model parameter
, which we obtained in the inner loop, and we update our initial model parameter  :
:

What's really going in the previous equation? If you closely examine this equation, you'll notice that we're merely taking an average of gradients across tasks and updating our model parameter  , which implies all tasks contribute equally in updating our model parameter.
, which implies all tasks contribute equally in updating our model parameter.
But what's wrong with this? Let's say we've sampled four tasks, and three tasks have a gradient update in one direction, but one task has a gradient update in a direction that completely differs from the other tasks. This disagreement can have a serious impact on updating the model's initial parameter since the gradient of all of the tasks contributes equally in updating the model parameter. As you can see in the following diagram, all tasks from  to
to  have a gradient in one direction but task
have a gradient in one direction but task  has a gradient in a completely different direction compared to the other tasks:
has a gradient in a completely different direction compared to the other tasks:

So, what should we do now? How can we understand which task has a strong gradient agreement and which tasks have a strong disagreement? If we associate weights with the gradients, can we understand the importance? So, we rewrite our outer gradient update equation by adding the weights multiplied with each of the gradients as follows:
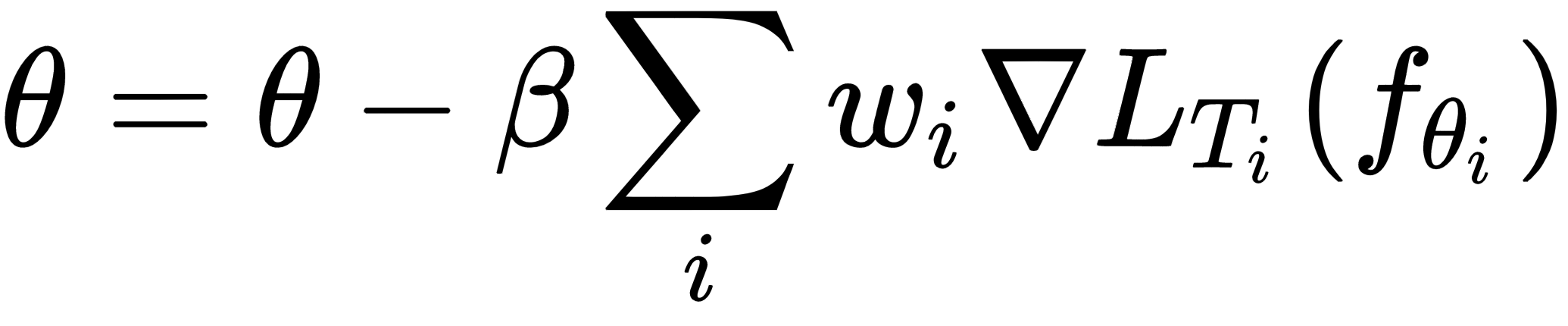
Okay, how do we calculate these weights? These weights are proportional to the inner product of the gradients of a task and an average of gradients of all of the tasks in the sampled batch of tasks. But what does this imply?
It implies that if the gradient of a task is in the same direction as the average gradient of all tasks in a sampled batch of tasks, then we can increase its weights so that it'll contribute more in updating our model parameter. Similarly, if the gradient of a task is in the direction that's greatly different from the average gradient of all tasks in a sampled batch of tasks, then we can decrease its weights so that it'll contribute less in updating our model parameter. We'll see how exactly these weights are computed in the following section.
We can not only apply our gradient agreement algorithm to MAML, but also to the Reptile algorithm. So, our Reptile update equation becomes as follows:
