
Now, we define a class called MAML where we implement the MAML algorithm. In the __init__ method, we will initialize all of the necessary variables. Then, we define our sigmoid activation function. Following this we define our train function.
We define the class for implementing MAML:
class MAML(object):
We define the __init__ method and initialize all of the necessary variables:
def __init__(self):
We initialize a number of tasks—that is, the number of tasks we need in each batch of tasks:
self.num_tasks = 10
Following is the number of samples—that is, number of shots—a number of data points (k) we need to have in each task:
self.num_samples = 10
Following is the number of epochs, that is, training iterations:
self.epochs = 1000
Following is the hyperparameter for the inner loop (inner gradient update):
self.alpha = 0.0001
Following is the hyperparameter for the outer loop (outer gradient update)—that is, the meta optimization:
self.beta = 0.0001
Then, we randomly initialize our model parameter θ:
self.theta = np.random.normal(size=50).reshape(50, 1)
We define our sigmoid activation function:
def sigmoid(self,a):
return 1.0 / (1 + np.exp(-a))
Now, let's get to training:
def train(self):
For the number of epochs:
for e in range(self.epochs):
self.theta_ = []
For task i in batch of tasks:
for i in range(self.num_tasks):
Sample k data points and prepare our train set—that is,  :
:
XTrain, YTrain = sample_points(self.num_samples)
We predict the value of YHat by a single layer neural network:
a = np.matmul(XTrain, self.theta)
YHat = self.sigmoid(a)
Since we are performing classification, we use cross entropy loss as our loss function:
loss = ((np.matmul(-YTrain.T, np.log(YHat)) - np.matmul((1 -YTrain.T), np.log(1 - YHat)))/self.num_samples)[0][0]
We minimize the loss by calculating gradients:
gradient = np.matmul(XTrain.T, (YHat - YTrain)) / self.num_samples
We update the gradients and find the optimal parameter θ' for each of tasks Ti, where 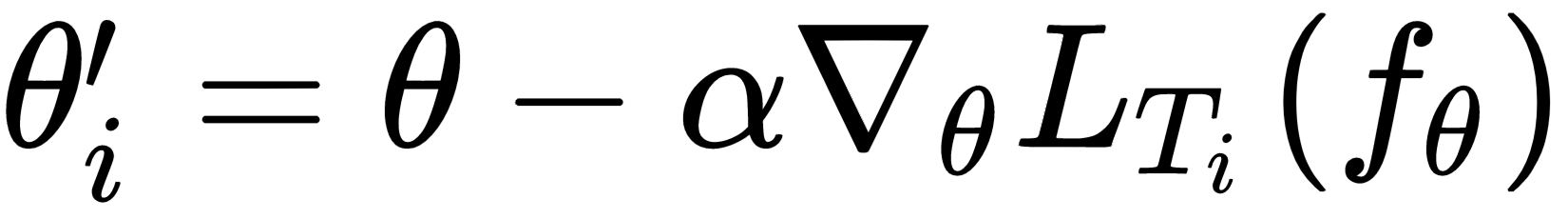 :
:
self.theta_.append(self.theta - self.alpha*gradient)
We initialize the meta gradients:
meta_gradient = np.zeros(self.theta.shape)
Then we sample k data points and prepare our test set (meta-train set) for meta training—that is,  :
:
for i in range(self.num_tasks):
XTest, YTest = sample_points(10)
We predict the value of YPred by a single layer neural network:
a = np.matmul(XTest, self.theta_[i])
YPred = self.sigmoid(a)
We compute the meta gradients:
meta_gradient += np.matmul(XTest.T, (YPred - YTest)) / self.num_samples
We update our randomly initialized model parameter θ with the meta gradients:

self.theta = self.theta-self.beta*meta_gradient/self.num_tasks
We print our loss after every 1,000 epochs:
if e%1000==0:
print "Epoch {}: Loss {} ".format(e,loss)
print 'Updated Model Parameter Theta '
print 'Sampling Next Batch of Tasks '
print '--------------------------------- '
The complete code for MAML class is as follows:
class MAML(object):
def __init__(self):
#initialize number of tasks i.e number of tasks we need in each batch of tasks
self.num_tasks = 10
#number of samples i.e number of shots -number of data points (k) we need to have in each task
self.num_samples = 10
#number of epochs i.e training iterations
self.epochs = 10000
#hyperparameter for the inner loop (inner gradient update)
self.alpha = 0.0001
#hyperparameter for the outer loop (outer gradient update) i.e meta optimization
self.beta = 0.0001
#randomly initialize our model parameter theta
self.theta = np.random.normal(size=50).reshape(50, 1)
#define our sigmoid activation function
def sigmoid(self,a):
return 1.0 / (1 + np.exp(-a))
#now let's get to the interesting part i.e training
def train(self):
#for the number of epochs,
for e in range(self.epochs):
self.theta_ = []
#for task i in batch of tasks
for i in range(self.num_tasks):
#sample k data points and prepare our train set
XTrain, YTrain = sample_points(self.num_samples)
a = np.matmul(XTrain, self.theta)
YHat = self.sigmoid(a)
#since we are performing classification, we use cross entropy loss as our loss function
loss = ((np.matmul(-YTrain.T, np.log(YHat)) - np.matmul((1 -YTrain.T), np.log(1 - YHat)))/self.num_samples)[0][0]
#minimize the loss by calculating gradients
gradient = np.matmul(XTrain.T, (YHat - YTrain)) / self.num_samples
#update the gradients and find the optimal parameter theta' for each of tasks
self.theta_.append(self.theta - self.alpha*gradient)
#initialize meta gradients
meta_gradient = np.zeros(self.theta.shape)
for i in range(self.num_tasks):
#sample k data points and prepare our test set for meta training
XTest, YTest = sample_points(10)
#predict the value of y
a = np.matmul(XTest, self.theta_[i])
YPred = self.sigmoid(a)
#compute meta gradients
meta_gradient += np.matmul(XTest.T, (YPred - YTest)) / self.num_samples
#update our randomly initialized model parameter theta with the meta gradients
self.theta = self.theta-self.beta*meta_gradient/self.num_tasks
if e%1000==0:
print "Epoch {}: Loss {} ".format(e,loss)
print 'Updated Model Parameter Theta '
print 'Sampling Next Batch of Tasks '
print '--------------------------------- '
Now, let's create an instance to our MAML class:
model = MAML()
We start training the model:
model.train()
We can see the output as follows; we can notice that the loss drastically reduces from 2.71 on epoch 0 to 0.5 in epoch 3,000:
Epoch 0: Loss 2.71883405043 Updated Model Parameter Theta Sampling Next Batch of Tasks --------------------------------- Epoch 1000: Loss 1.7829716017 Updated Model Parameter Theta Sampling Next Batch of Tasks --------------------------------- Epoch 2000: Loss 1.29532754055 Updated Model Parameter Theta Sampling Next Batch of Tasks --------------------------------- Epoch 3000: Loss 0.599713728648 Updated Model Parameter Theta Sampling Next Batch of Tasks ---------------------------------