
How can we apply MAML in a reinforcement learning (RL) setting? In RL, our objective is to find the right policy function that will tell us what actions to perform in each state. But how can we apply meta learning in RL? Let's say we trained our agent to solve the two-armed bandit problem. However, we can't use the same agent to solve the four-armed bandit problem. We have to train the agent again from scratch to solve this new four-armed bandit problem. This is the same case when another n-armed bandit comes in. We keep training our agent from scratch to solve new problems even though it is closely related to the problem that the agent has already learned to solve. So, instead of doing this, we can apply meta learning and train our agent on a set of related tasks so that the agent can leverage its previous knowledge to learn new related tasks in minimal time without having to train from scratch.
In RL, we can call a trajectory as a tuple containing a sequence of observations and actions. So, we train our model on these trajectories to learn the optimal policy. But, again, which algorithm should we use to train our model? For MAML, we can use any RL algorithm that can be trained with gradient descent. We use policy gradients for training our model. Policy gradients find the optimal policy by directly parameterizing the policy π with some parameter θ as πθ. So, using MAML, we try to find this optimal parameter θ that is generalizable across tasks.
But what should our loss function be? In RL, our goal is to find the optimal policy by maximizing positive rewards and minimizing negative rewards, so our loss function becomes minimizing the negative rewards and it can be expressed as follows:
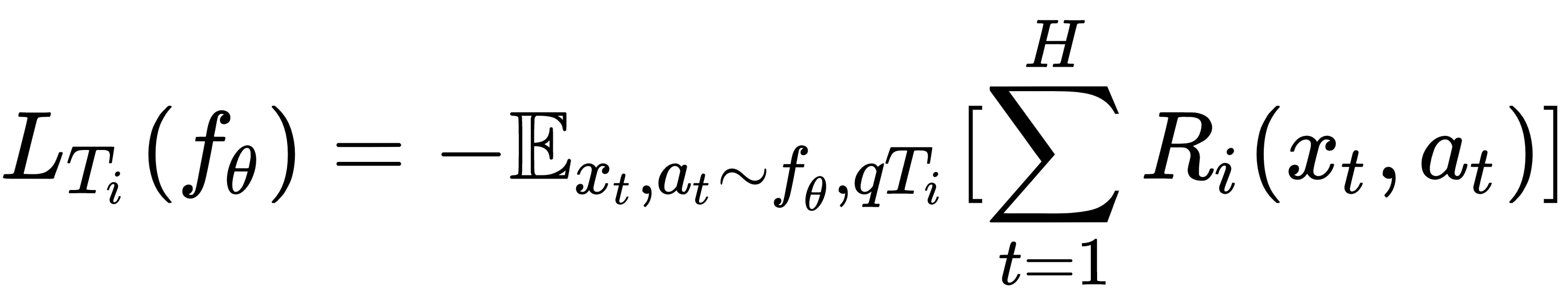
But what's going on in the previous equation? R(xy, at) implies the reward for the state x with action a at the time t, and t=1 to H implies our time step where H is the horizon—our final time step.
Let's say we have a model f parameterized by θ—that is, fθ()—and distribution over tasks p(T). First, we initialize our parameter θ with some random values. Next, we sample some batch of tasks Ti from a distribution over tasks: Ti ∼ p(T).
Then, for each task, we sample k trajectories and build our train and test sets:  . Our dataset basically contains the trajectory information such as observations and actions. We minimize the loss on the train set
. Our dataset basically contains the trajectory information such as observations and actions. We minimize the loss on the train set 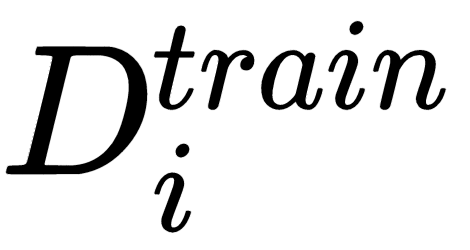 by performing gradient descent and find the optimal parameters θ':
by performing gradient descent and find the optimal parameters θ':

Now, before sampling the next batch of tasks, we perform the meta update—that is, we try to minimize the loss on our test set  by calculating gradients of the loss with respect to our optimal parameter
by calculating gradients of the loss with respect to our optimal parameter  and update our randomly initialized parameter θ:
and update our randomly initialized parameter θ:
