


Managing daily operations of IBM Spectrum Archive Enterprise Edition
In this chapter, the day-to-day management of the IBM Spectrum Archive Enterprise Edition (IBM Spectrum Archive EE) environment is described.
This chapter includes the following topics:
|
Note: The steps that you perform are the same as we describe in this Redbooks publication. You might see slightly different output responses in your environment, depending on your version and release of the product.
|
6.1 Overview
The following terms specific to IBM Spectrum Archive EE operations are used in this chapter:
Migration The movement of files from the IBM Spectrum Scale file system on disk to IBM Linear Tape File System tape cartridges, which leaves behind a stub file.
Premigration The movement of files from GPFS file systems on disk to LTFS tape cartridges without replacing them with stub files on the GPFS file system. Identical copies of the files are on the GPFS file system and in LTFS storage.
Recall The movement of migrated files from tape cartridges back to the originating GPFS file system on disk, which is the reverse of migration.
Reconciliation The process of synchronizing a GPFS file system with the contents of an LTFS tape cartridge and removing old and obsolete objects from the tape cartridge. You must run reconciliation when a GPFS file is deleted, moved, or renamed.
Reclamation The process of defragmenting a tape cartridge. The space on a tape cartridge that is occupied by deleted files is not reused during normal LTFS operations. New data is always written after the last index on tape. The process of reclamation is similar to the same named process in IBM Spectrum Protect from the IBM Spectrum Archive family. All active files are consolidated onto a second tape cartridge, which improves overall tape usage.
Library rescan The process of triggering IBM Spectrum Archive EE to retrieve information about physical resources from the tape library. This process is scheduled to occur automatically at regular intervals, but can be run manually.
Tape validate The process of validating the current condition of a tape by loading it to the tape drive and updating the tape state.
Tape replace The process of moving the contents of a tape that previously suffered some error to another tape in the same pool.
Import The addition of an LTFS tape cartridge to IBM Spectrum Archive EE.
Export The removal of an LTFS tape cartridge from IBM Spectrum Archive EE.
Data migration The new method of technology migration of tape drives and cartridges.
There are two ways to perform data migration:
- within a pool
- pool to pool
- pool to pool
6.1.1 IBM Spectrum Archive EE command summaries
Use IBM Spectrum Archive EE commands to configure IBM Spectrum Archive EE tape cartridge pools and perform IBM Spectrum Archive EE administrative tasks. The commands use the following two syntaxes eeadm <resource_type> <action> [options], and eeadm <subcommand> [options].
The following eeadm command options are available. All options, except listing resource types, can be run only with root user permissions:
•eeadm cluster start
Use this command to start the process of the IBM Spectrum Archive EE system on all configured servers, or on a specific library.
|
Important: If the eeadm cluster start command does not return after several minutes, it might be because the firewall is running or tapes are being unmounted from the drives. The firewall service must be disabled on the IBM Spectrum Archive EE nodes. For more information, see 4.3.2, “Installing, upgrading, or uninstalling IBM Spectrum Archive EE” on page 78.
|
•eeadm cluster stop
Use this command to Stop the process of the IBM Spectrum Archive EE system on all configured servers, or on a specific library.
•eeadm cluster failover
Use this command to manually initiate a node failover process.
•eeadm cluster set
Use this command to change the global configuration attributes of IBM Spectrum Archive cluster.
•eeadm cluster show
Use this command to display the global configuration attributes of IBM Spectrum Archive cluster.
•eeadm drive assign
Use this command to assign tape drives to the IBM Spectrum Archive EE server.
•eeadm drive unassign
Use this command to unassign tape drives from the IBM Spectrum Archive EE server.
•eeadm drive up
Use this command to enable a tape drive. The enabled drive can be used as a part of the IBM Spectrum Archive EE system.
•eeadm drive down
Use this command to disable a tape drive. The disabled drive cannot be used as a part of the IBM Spectrum Archive EE system.
•eeadm drive list
Use this command to list all the configured tape drives.
•eeadm drive set
Use this command to change the configuration attributes of a tape drive.
•eeadm drive show
Use this command to display the configuration attributes of a tape drive.
•eeadm file state
Use this command to display the current data placement of files. Each file is in one of the following states:
– resident: The data is on disk
– premigrated: The data is both on disk and tapes
– migrated: The data is on tapes while its stub file remains on disk.
•eeadm library list
Use this command to list all the managed tape libraries.
•eeadm library rescan
Use this command to force the tape library to check and report its physical resources, and update the resource information kept in IBM Spectrum Archive EE.
•eeadm library show
Use this command to display the configuration attributes of a tape library
•eeadm node down
Use this command to disable one of the IBM Spectrum Archive EE servers temporarily for maintenance. The disabled node does not participate in the system.
•eeadm node list
Use this command to list the configuration and status of all the configured nodes.
•eeadm node show
Use this command to display the configuration attributes of the node.
•eeadm node up
Use this command to enable one of the IBM Spectrum Archive EE servers. The enabled node can be used as a part of the IBM Spectrum Archive EE system.
•eeadm nodegroup list
Use this command to list all the configured node groups.
•eeadm pool create
Use this command to create a tape pool.
•eeadm pool delete
Use this command to delete a tape pool to which no tapes are assigned.
•eeadm pool list
Use this command to list all the configured tape pools
•eeadm pool set
Use this command to change the configuration attributes of a pool.
•eeadm pool show
Use this command to display the configuration attributes of the tape pool.
•eeadm tape list
Use this command to list the configuration and status of all the tapes.
•eeadm tape set
Use this command to change the configuration attribute of a tape.
•eeadm tape show
Use this command to display the configuration attributes of a tape that is already assigned to the tape pool.
•eeadm tape assign
Use this command to format the tapes and assign it to the tape pool. The command fails if it contains any file object unless the -f option is used. Use the eeadm tape import command to make the tape that contains files a new member of the pool.
•eeadm tape export
Use this command to export the tape permanently from the IBM Spectrum Archive EE system and purges the GPFS files referring to the tape. The command internally runs the reconciliation process and identifies the active GPFS files in migrated or premigrated states. If a file refers to the tape to be exported and if the tape contains the last replica of the file, it deletes the GPFS file. After the successful completion of the command, the tape is unassigned from the tape pool, and the tape state becomes exported. Prior to running this command, all GPFS file systems must be mounted so that the command is able to check for the existence of the files on disk.
•eeadm tape import
Use this command to import tapes created and managed by other system to the IBM Spectrum Archive EE system, and makes the files on tape accessible from the GPFS namespace. The command will create the stub files and leave the files in the migrated state without transferring the file data back to disk immediately.
•eeadm tape move
Use this command to move the tape physically within the tape library. The command can move the tape to its home slot either from the tape drive or from the I/E slot (or I/O station) of the tape library. It can move the tape to I/E slot if the tape is:
– in the offline state
– the tape belongs to a tape pool that is undergoing pool relocation
– tape is currently not assigned to a pool
•eeadm tape offline
Use this command to set the tape to the offline state to prepare for moving the tape temporarily out of the tape library, until access to the data is required. The tape needs to come back to the original IBM Spectrum Archive EE system by using the eeadm tape online command.
•eeadm tape online
Use this command to make the offline tape accessible from the IBM Spectrum Archive EE system.
•eeadm tape unassign
Use this command to unassign the member tapes from the tape pool.
•eeadm tape datamigrate
Use this command to move the active contents of specified tapes to a different tape pool and updates the stub files on disk to point to the new data location. After the successful completion of the command, the tape is automatically unassigned from the source tape pool. The datamigrate command can be used to move the data on older technology tapes in the source tape pool to newer technology tapes in the destination tape pool.
•eeadm tape reclaim
Use this command to reclaim the unreferenced space of the specified tapes. It moves the active contents on the tapes to different tapes, then recycles the specified tapes. If the --unassign option is specified, the tape is automatically unassigned from the tape pool after the successful completion of the.eeadm tape reconcile command.
Use this command to compare the contents of the tape with the files on the GPFS file systems, and reconciles the differences between them.
•eeadm tape replace
Use this command to move the contents of a tape that previously suffered some error to another tape in the same pool. This command is used on tapes in the require_replace or need_replace state. After the successful completion of the replacement process, the tape that had the error is automatically unassigned from the tape pool.
•eeadm tape validate
Use this command to validate the current condition of a tape by loading it to the tape drive, and update the tape state. The tape must be a member of the tape pool and online.
•eeadm task cancel
Use this command to cancel the active task. The command supports the cancellation of reclaim and datamigrate tasks only.
•eeadm task clearhistory
Use this command to delete the records of completed tasks to free up disk space.
•eeadm task list
Use this command to list the active or completed tasks.
•eeadm task show
Use this command to show the detailed information of the specified task.
•eeadm migrate
Use this command to move the file data to the tape pools to free up disk space, and sets the file state to migrated.
•eeadm premigrate
Use this command to copy the file data to the tape pools, and sets the file state to premigrated.
•eeadm recall
Use this command to recall the file data back from the tape and places the file in the premigrated state, or optionally in the resident state.
•eeadm save
Use this command to save the name of empty files, empty directories, and symbolic links on the tape pools.
6.1.2 Using the command-line interface
The IBM Spectrum Archive EE system provides a command-line interface (CLI) that supports the automation of administrative tasks, such as starting and stopping the system, monitoring its status, and configuring tape cartridge pools. The CLI is the primary method for administrators to manage IBM Spectrum Archive EE. There is no GUI available as of this writing which allows administrators to perform operations, see“IBM Spectrum Archive EE dashboard” on page 34 for more info.
In addition, the CLI is used by the IBM Spectrum Scale mmapplypolicy command to trigger migrations or premigrations. When this action occurs, the mmapplypolicy command calls IBM Spectrum Archive EE when an IBM Spectrum Scale scan occurs, and passes the file name of the file that contains the scan results and the name of the target tape cartridge pool.
The eeadm command uses the following two syntax:
eeadm <resource_type> <action> [options], and eeadm <subcommand> [options]
|
Reminder: All of the command examples use the command without the full file path name because we added the IBM Spectrum Archive EE directory (/opt/ibm/ltfsee/bin) to the PATH variable.
|
For more information, see 10.1, “Command-line reference” on page 316.
6.2 Status information
This section describes the process that is used to determine whether each of the major components of IBM Spectrum Archive EE is running correctly. For more information about troubleshooting IBM Spectrum Archive EE, see Chapter 9, “Troubleshooting IBM Spectrum Archive Enterprise Edition” on page 293.
The components should be checked in the order that is shown here because a stable, active GPFS file system is a prerequisite for starting IBM Spectrum Archive EE.
6.2.1 IBM Spectrum Scale
The following IBM Spectrum Scale commands are used to obtain cluster state information:
•The mmdiag command obtains basic information about the state of the GPFS daemon.
•The mmgetstate command obtains the state of the GPFS daemon on one or more nodes.
•The mmlscluster and mmlsconfig commands show detailed information about the GPFS cluster configuration.
This section describes how to obtain GPFS daemon state information by running the GPFS command mmgetstate. For more information about the other GPFS commands, see the following publications:
•General Parallel File System Version 4 Release 1.0.4 Advanced Administration Guide, SC23-7032
The node on which the mmgetstate command is run must have the GPFS mounted. The node must also run remote shell commands on any other node in the GPFS/IBM Spectrum Scale cluster without the use of a password and without producing any extraneous messages.
Example 6-1 shows how to get status about the GPFS/IBM Spectrum Scale daemon on one or more nodes.
Example 6-1 Check the GPFS/IBM Spectrum Scale status
[root@ltfs97 ~]# mmgetstate -a
Node number Node name GPFS state
------------------------------------------
1 htohru9 down
The -a argument shows the state of the GPFS/IBM Spectrum Scale daemon on all nodes in the cluster.
|
Permissions: Retrieving the status for GPFS/IBM Spectrum Scale requires root user permissions.
|
The following GPFS/IBM Spectrum Scale states are recognized and shown by this command:
•Active: GPFS/IBM Spectrum Scale is ready for operations.
•Arbitrating: A node is trying to form a quorum with the other available nodes.
•Down: GPFS/IBM Spectrum Scale daemon is not running on the node or is recovering from an internal error.
•Unknown: Unknown value. The node cannot be reached or some other error occurred.
If the GPFS/IBM Spectrum Scale state is not active, attempt to start GPFS/IBM Spectrum Scale and check its status, as shown in Example 6-2.
Example 6-2 Start GPFS/IBM Spectrum Scale
[root@ltfs97 ~]# mmstartup -a
Tue Apr 2 14:41:13 JST 2013: mmstartup: Starting GPFS ...
[root@ltfs97 ~]# mmgetstate -a
Node number Node name GPFS state
------------------------------------------
1 htohru9 active
If the status is active, also check the GPFS/IBM Spectrum Scale mount status by running the command that is shown in Example 6-3.
Example 6-3 Check the GPFS/IBM Spectrum Scale mount status
[root@ltfs97 ~]# mmlsmount all
File system gpfs is mounted on 1 nodes.
The message confirms that the GPFS file system is mounted.
6.2.2 IBM Spectrum Archive Library Edition component
IBM Spectrum Archive EE constantly checks to see whether the IBM Spectrum Archive Library Edition (LE) component is running. If the IBM Spectrum Archive LE component is running correctly, you can see whether the LTFS file system is mounted by running the mount command or the df command, as shown in Example 6-4. The IBM Spectrum Archive LE component must be running on all EE nodes.
Example 6-4 Check the IBM Spectrum Archive LE component status (running)
[root@ltfs97 ~]# df -m
Filesystem 1M-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root
33805 5081 27007 16% /
tmpfs 1963 0 1963 0% /dev/shm
/dev/vda1 485 36 424 8% /boot
/dev/gpfs 153600 8116 145484 6% /ibm/glues
ltfs:/dev/sg2 2147483648 0 2147483648 0% /ltfs
To start IBM Spectrum Archive LE run the eeadm cluster start command. If errors occur during the start of the IBM Spectrum Archive EE system, run the eeadm node list command to display which component failed to start. For more information about the updated eeadm node list command, see 6.7, “IBM Spectrum Archive EE automatic node failover” on page 153.
6.2.3 Hierarchical Space Management
Hierarchical Space Management (HSM) must be running before you start IBM Spectrum Archive EE. You can verify that HSM is running by checking whether the watch daemon (dsmwatchd) and at least three recall daemons (dsmrecalld) are active. Query the operating system to verify that the daemons are active by running the command that is shown in Example 6-5.
Example 6-5 Check the HSM status by running ps
[root@ltfs97 /]# ps -ef|grep dsm
root 1355 1 0 14:12 ? 00:00:01 /opt/tivoli/tsm/client/hsm/bin/dsmwatchd nodetach
root 5657 1 0 14:41 ? 00:00:00 /opt/tivoli/tsm/client/hsm/bin/dsmrecalld
root 5722 5657 0 14:41 ? 00:00:00 /opt/tivoli/tsm/client/hsm/bin/dsmrecalld
root 5723 5657 0 14:41 ? 00:00:00 /opt/tivoli/tsm/client/hsm/bin/dsmrecalld
The dsmmigfs command also provides the status of HSM, as shown by the output in Example 6-6.
Example 6-6 Check the HSM status by using dsmmigfs
[root@yurakucho ~]# dsmmigfs query -detail
IBM Spectrum Protect
Command Line Space Management Client Interface
Client Version 8, Release 1, Level 11.0
Client date/time: 03/06/21 05:25:59
(c) Copyright by IBM Corporation and other(s) 1990, 2020. All Rights Reserved.
The local node has Node ID: 1
The failover environment is active on the local node.
The recall distribution is enabled.
The monitoring of local space management daemons is active.
File System Name: /ibm/gpfs_data
High Threshold: 90
Low Threshold: 80
Premig Percentage: 10
Quota: 21273588
Stub Size: 0
Read Starts Recall: no
Preview Size: 0
Server Name: SERVER_A
Max Candidates: 100
Max Files: 0
Read Event Timeout: 600
Stream Seq: 0
Min Partial Rec Size: 0
Min Stream File Size: 0
Min Mig File Size: 0
Inline Copy Mode: MIG
Preferred Node: yurakucho Node ID: 1
Owner Node: yurakucho Node ID: 1
File System Name: /ibm/gpfs_meta
High Threshold: 90
Low Threshold: 80
Premig Percentage: 10
Quota: 1100800
Stub Size: 0
Read Starts Recall: no
Preview Size: 0
Server Name: SERVER_A
Max Candidates: 100
Max Files: 0
Read Event Timeout: 600
Stream Seq: 0
Min Partial Rec Size: 0
Min Stream File Size: 0
Min Mig File Size: 0
Inline Copy Mode: MIG
Preferred Node: yurakucho Node ID: 1
Owner Node: yurakucho Node ID: 1
You can also ensure that the GPFS file system (named gpfs in this example) is managed by HSM by running the command that is shown in Example 6-7.
Example 6-7 Check GPFS file system
[root@ltfs97 /] mmlsfs gpfs|grep DMAPI
-z Yes Is DMAPI enabled?
To manage a file system with IBM Spectrum Archive EE, it must be data management application programming interface (DMAPI) enabled. A file system is managed by IBM Spectrum Archive EE by running the ltfsee_config command, which is described in 5.2, “Configuring IBM Spectrum Archive EE” on page 105.
|
Permissions: Starting HSM requires root user permissions.
|
If the HSM watch daemon (dsmwatchd) is not running, Example 6-8 shows you how to start it.
Example 6-8 Start the HSM watch daemon
[root@ltfsrl1 ~]# systemctl start hsm.service
[root@ltfsrl1 ~]# ps -afe | grep dsm
root 7687 1 0 08:46 ? 00:00:00 /opt/tivoli/tsm/client/hsm/bin/dsmwatchd nodetach
root 8405 6621 0 08:46 pts/1 00:00:00 grep --color=auto dsm
If the HSM recall daemons (dsmrecalld) are not running, Example 6-9 shows you how to start them.
Example 6-9 Start HSM
[root@yurakucho ~]# dsmmigfs start
IBM Spectrum Protect
Command Line Space Management Client Interface
Client Version 8, Release 1, Level 11.0
Client date/time: 03/06/21 05:29:22
(c) Copyright by IBM Corporation and other(s) 1990, 2020. All Rights Reserved.
If failover operations within the IBM Spectrum Scale cluster are wanted on the node, run the dsmmigfs enablefailover command after you run the dsmmigfs start command.
6.2.4 IBM Spectrum Archive EE
After IBM Spectrum Archive EE is started, you can retrieve details about the node that the multi-tape management module (MMM) service was started on by running the eeadm node list command. You can also use this command to determine whether any component required for IBM Spectrum Archive EE failed to start. The MMM is the module that manages configuration data and physical resources of IBM Spectrum Archive EE.
|
Permissions: Retrieving the status for the MMM service does not require root user permissions.
|
If the MMM service is running correctly, you see a message similar to the message shown in Example 6-10.
Example 6-10 Check the IBM Spectrum Archive EE status
[root@ltfsml1 ~]# eeadm node list
Node ID State Node IP Drives Ctrl Node Library Node Group Host Name
1 available 9.11.244.46 3 yes(active) libb G0 lib_ltfsml1
If the MMM service is not running correctly, you may see a message that is similar to the message shown in Example 6-11.
Example 6-11 Check the IBM Spectrum Archive EE status
[root@ltfsml1 ~]# eeadm node list
Spectrum Archive EE service (MMM) for library libb fails to start or is not running on lib_ltfsml1 Node ID:1
Problem Detected:
Node ID Error Modules
1 LE; MMM;
In Example 6-11, IBM Spectrum Archive EE failed to start MMM because it was unable to mount LE. In this example, MMM failure to mount LE was caused by the server having no control path drives connected; therefore, the work around is to assign a control path drive to the server and have the monitor daemon automatically mount LE.
To monitor the process of IBM Spectrum Archive EEs start, run the eeadm node list command. If IBM Spectrum Archive EE is taking too long to recover, stop and start the process by using the eeadm cluster stop/start command. Example 6-12 shows the process of IBM Spectrum Archive EE recovering after a control path drive was connected.
Example 6-12 Start IBM Spectrum Archive EE
[root@ltfsml1 ~]# eeadm node list
Spectrum Archive EE service (MMM) for library libb fails to start or is not running on lib_ltfsml1 Node ID:1
Problem Detected:
Node ID Error Modules
1 LE(Starting); MMM;
[root@kyoto ~]# eeadm node list
Node ID State Node IP Drives Ctrl Node Library Node Group Host Name
1 available 9.11.244.46 3 yes(active) libb G0 lib_ltfsml1
|
Important: If the eeadm cluster start command does not return after several minutes, it might be because the firewall is running or tapes are being unmounted from the drives. The firewall service must be disabled on the IBM Spectrum Archive EE nodes. For more information, see 4.3.2, “Installing, upgrading, or uninstalling IBM Spectrum Archive EE” on page 78.
|
6.3 Upgrading components
The following sections describe the process that is used to upgrade IBM Spectrum Scale and other components of IBM Spectrum Archive EE.
6.3.1 IBM Spectrum Scale
Complete this task if you must update your version of IBM Spectrum Scale that is used with IBM Spectrum Archive EE.
Before any system upgrades or major configuration changes are made to your IBM Spectrum Scale cluster, review your IBM Spectrum Scale documentation and consult the IBM Spectrum Scale frequently asked question (FAQ) information that applies to your version of IBM Spectrum Scale.
For more information about the IBM Spectrum Scale FAQ, see IBM Documentation and select the IBM Spectrum Scale release under the Cluster product libraries topic in the navigation pane that applies to your installation.
To update IBM Spectrum Scale, complete the following steps:
1. Stop IBM Spectrum Archive EE by running the command that is shown in Example 6-13.
Example 6-13 Stop IBM Spectrum Archive EE
[root@ltfsml1 ~]# eeadm cluster stop
Library name: libb, library serial: 0000013400190402, control node (ltfsee_md) IP address: 9.11.244.46.
Stopping - sending request and waiting for the completion.
..
Stopped the IBM Spectrum Archive EE services for library libb.
2. Run the pidof mmm command on all EE Control Nodes until all MMM processes have been terminated.
3. Run the pidof ltfs command on all EE nodes until all ltfs processes are stopped.
4. Disable DSM failover by running the command that is shown in Example 6-14.
Example 6-14 Disable failover
[root@ltfsml1 ~]# dsmmigfs disablefailover
IBM Spectrum Protect
Command Line Space Management Client Interface
Client Version 8, Release 1, Level 0.0
Client date/time: 04/20/2017 11:31:18
(c) Copyright by IBM Corporation and other(s) 1990, 2016. All Rights Reserved.
Automatic failover is disabled on this node.
5. Stop the IBM Spectrum Protect for Space Management HSM by running the command that is shown in Example 6-15.
Example 6-15 Stop HSM
[root@ltfsml1~]# dsmmigfs stop
IBM Spectrum Protect
Command Line Space Management Client Interface
Client Version 8, Release 1, Level 11.0
Client date/time: 03/06/21 05:35:38
(c) Copyright by IBM Corporation and other(s) 1990, 2020. All Rights Reserved.
This command must be run on every IBM Spectrum Archive EE node.
6. Stop the watch daemon by running the command that is shown in Example 6-16.
Example 6-16 Stop the watch daemon
[root@ltfsml1 ~]# systemctl stop hsm.service
This command must be run on every IBM Spectrum Archive EE node.
7. Unmount GPFS by running the command that is shown in Example 6-17.
Example 6-17 Stop GPFS
[root@ltfs97 ~]# mmumount all
Tue Apr 16 23:43:29 JST 2013: mmumount: Unmounting file systems ...
If the mmumount all command results show that processes are still being used (as shown in Example 6-18), you must wait for them to finish and then run the mmumount all command again.
Example 6-18 Processes running that prevent the unmounting of the GPFS file system
[root@ltfs97 ~]# mmumount all
Tue Apr 16 23:46:12 JST 2013: mmumount: Unmounting file systems ...
umount: /ibm/glues: device is busy.
(In some cases useful info about processes that use
the device is found by lsof(8) or fuser(1))
umount: /ibm/glues: device is busy.
(In some cases useful info about processes that use
the device is found by lsof(8) or fuser(1))
8. Shut down GPFS by running the command that is shown in Example 6-19.
Example 6-19 Shut down GPFS
[root@ltfs97 ~]# mmshutdown -a
Tue Apr 16 23:46:51 JST 2013: mmshutdown: Starting force unmount of GPFS file systems
Tue Apr 16 23:46:56 JST 2013: mmshutdown: Shutting down GPFS daemons
htohru9.ltd.sdl: Shutting down!
htohru9.ltd.sdl: 'shutdown' command about to kill process 3645
htohru9.ltd.sdl: Unloading modules from /lib/modules/2.6.32-220.el6.x86_64/extra
htohru9.ltd.sdl: Unloading module mmfs26
htohru9.ltd.sdl: Unloading module mmfslinux
htohru9.ltd.sdl: Unloading module tracedev
Tue Apr 16 23:47:03 JST 2013: mmshutdown: Finished
9. Download the IBM Spectrum Scale update from IBM Fix Central. Extract the IBM Spectrum Scale .rpm files and install the updated .rpm files by running the command that is shown in Example 6-20.
Example 6-20 Update IBM Spectrum Scale
rpm -Uvh *.rpm
10. Rebuild and install the IBM Spectrum Scale portability layer by running the command that is shown in Example 6-21.
Example 6-21 Rebuild GPFS
mmbuildgpl
11. Start GPFS by running the command that is shown in Example 6-22.
Example 6-22 Start GPFS
[root@ltfs97 ~]# mmstartup -a
Tue Apr 16 23:47:42 JST 2013: mmstartup: Starting GPFS ...
12. Mount the GPFS file system by running the command that is shown in Example 6-23.
Example 6-23 Mount GPFS file systems
[root@ltfs97 ~]# mmmount all
Tue Apr 16 23:48:09 JST 2013: mmmount: Mounting file systems ...
13. Start the watch daemon by running the command that is shown in Example 6-24.
Example 6-24 Start the watch daemon
[root@ltfsml1 ~]# systemctl start hsm.service
This command must be run on every IBM Spectrum Archive EE node.
14. Start the HSM by running the command that is shown in Example 6-25.
Example 6-25 Start HSM
[root@yurakucho ~]# dsmmigfs start
IBM Spectrum Protect
Command Line Space Management Client Interface
Client Version 8, Release 1, Level 11.0
Client date/time: 03/06/21 05:42:15
(c) Copyright by IBM Corporation and other(s) 1990, 2020. All Rights Reserved.
This command must be run on every IBM Spectrum Archive EE node.
15. Enable failover by running the command that is shown in Example 6-26.
Example 6-26 Enable failover
[root@ltfsml1 ~]# dsmmigfs enablefailover
IBM Spectrum Protect
Command Line Space Management Client Interface
Client Version 8, Release 1, Level 0.0
Client date/time: 04/20/2017 14:51:05
(c) Copyright by IBM Corporation and other(s) 1990, 2016. All Rights Reserved.
Automatic failover is enabled on this node in mode ENABLED.
16. Start IBM Spectrum Archive EE by running the command that is shown in Example 6-27.
Example 6-27 Start IBM Spectrum Archive EE
[root@ltfsml1 ~]# eeadm cluster start
Library name: libb, library serial: 0000013400190402, control node (ltfsee_md) IP address: 9.11.244.46.
Starting - sending a startup request to libb.
Starting - waiting for startup completion : libb.
Starting - opening a communication channel : libb.
.
Starting - waiting for getting ready to operate : libb.
......................
Started the IBM Spectrum Archive EE services for library libb with good status.
Optionally, you can check the status of each component when it is started, as described in 6.2, “Status information” on page 136.
6.3.2 IBM Spectrum Archive LE component
For more information about how to upgrade the IBM Spectrum Archive LE component, see 4.3.2, “Installing, upgrading, or uninstalling IBM Spectrum Archive EE” on page 78. Because the IBM Spectrum Archive LE component is a component of IBM Spectrum Archive EE, it is upgraded as part of the IBM Spectrum Archive EE upgrade.
6.3.3 Hierarchical Storage Management
For more information about how to upgrade HSM, see 4.3.2, “Installing, upgrading, or uninstalling IBM Spectrum Archive EE” on page 78. Because HSM is a component of IBM Spectrum Archive EE, it is upgraded as part of the IBM Spectrum Archive EE upgrade.
6.3.4 IBM Spectrum Archive EE
For more information about how to upgrade IBM Spectrum Archive EE, see 4.3.2, “Installing, upgrading, or uninstalling IBM Spectrum Archive EE” on page 78.
6.4 Starting and stopping IBM Spectrum Archive EE
This section describes how to start and stop IBM Spectrum Archive EE.
6.4.1 Starting IBM Spectrum Archive EE
Run the eeadm cluster start command to start the IBM Spectrum Archive the IBM Spectrum Archive EE system. The HSM components must be running before you can use this command. You can run the eeadm cluster start command on any IBM Spectrum Archive EE node in the cluster.
For example, to start IBM Spectrum Archive EE, run the command that is shown in Example 6-28.
Example 6-28 Start IBM Spectrum Archive EE
[root@ltfsml1 ~]# eeadm cluster start
Library name: libb, library serial: 0000013400190402, control node (ltfsee_md) IP address: 9.11.244.46.
Starting - sending a startup request to libb.
Starting - waiting for startup completion : libb.
Starting - opening a communication channel : libb.
.
Starting - waiting for getting ready to operate : libb.
......................
Started the IBM Spectrum Archive EE services for library libb with good status.
|
Important: If the eeadm cluster start command does not return after several minutes, it might be because the firewall is running or unmounting tapes from drives. The firewall service must be disabled on the IBM Spectrum Archive EE nodes. For more information, see 4.3.2, “Installing, upgrading, or uninstalling IBM Spectrum Archive EE” on page 78.
|
You can confirm that IBM Spectrum Archive EE is running by referring to the steps in Example 6-10 on page 140 or by running the command in Example 6-29.
Example 6-29 Check the status of all available IBM Spectrum Archive EE nodes
[root@ltfsml1 ~]# eeadm node list
Node ID State Node IP Drives Ctrl Node Library Node Group Host Name
1 available 9.11.244.46 3 yes(active) libb G0 lib_ltfsml1
6.4.2 Stopping IBM Spectrum Archive EE
The eeadm cluster stop command stops the IBM Spectrum Archive EE system on all EE Control Nodes.
For example, to start IBM Spectrum Archive EE, run the command that is shown in Example 6-30.
Example 6-30 Stop IBM Spectrum Archive EE
[root@ltfsml1 ~]# eeadm cluster stop
Library name: libb, library serial: 0000013400190402, control node (ltfsee_md) IP address: 9.11.244.46.
Stopping - sending request and waiting for the completion.
..
Stopped the IBM Spectrum Archive EE services for library libb.
In some cases, you might see the GLESM658I informational message if there are active tasks on the task queue in IBM Spectrum Archive EE:
There are still tasks in progress.
To terminate IBM Spectrum Archive EE for this library,
run the "eeadm cluster stop" command with the "-f" or "--force" option.
If you are sure that you want to stop IBM Spectrum Archive EE, run the eeadm cluster stop command with the -f option, which forcefully stops any running IBM Spectrum Archive EE tasks abruptly. Note that this option will stop all tasks that are currently running on EE, and will need to be manually re-run if necessary once the cluster has restarted.
6.5 Task command summaries
For any IBM Spectrum Archive EE commands that generates a task, the eeadm task list and eeadm task show commands will be used to display the task information. For the list of task generating commands, refer to “User Task Reporting” on page 7. The eeadm task list and eeadm task show commands has replaced the ltfsee info scans and ltfsee info jobs commands.
6.5.1 eeadm task list
The most common use will be to get the list of active tasks which will either be in the running, waiting, or interrupted status. The output will be sorted by status in the following order:
1. Running
2. Waiting or interrupted
Within each status group, the entries will be sorted by Priority (H, M, L order).
– H will be any transparent or selective recall commands
– M will be any premigration, migration, or save commands
– L will be everything else (general commands)
Within Running status, within the same Priority, the entries are sorted by Started Time (oldest at the top).
Example 6-31 shows active tasks.
Example 6-31 Viewing active tasks
[root@kyoto ~]# eeadm task list
TaskID Type Priority Status #DRV CreatedTime(-0700) StartedTime(-0700)
18822 selective_recall H running 1 2019-01-07_11:43:04 2019-01-07_11:43:04
18823 selective_recall H waiting 0 2019-01-07_11:43:09 2019-01-07_11:43:09
18824 migrate M waiting 0 2019-01-07_11:43:11 2019-01-07_11:43:11
The other common use will be to get the list of completed tasks which returns the prior task IDs, result, and date/time information, sorted by completed time (oldest at the top). For administrators, this allows a quick view into task IDs, the history of what task has been executed recently and their results. For more information about the specified task, see “eeadm task show” on page 148.
Example 6-32 shows five completed tasks.
Example 6-32 View previous 5 completed tasks
[root@kyoto ~]# eeadm task list -c -n 5
TaskID Type Result CreatedTime(-0700) StartedTime(-0700) CompletedTime(-0700)
18819 selective_recall succeeded 2019-01-07_10:56:23 2019-01-07_10:56:23 2019-01-07_10:57:51
18820 selective_recall succeeded 2019-01-07_11:39:03 2019-01-07_11:39:03 2019-01-07_11:39:58
18822 selective_recall succeeded 2019-01-07_11:43:04 2019-01-07_11:43:04 2019-01-07_11:44:31
18823 selective_recall succeeded 2019-01-07_11:43:09 2019-01-07_11:43:09 2019-01-07_11:45:49
18824 migrate succeeded 2019-01-07_11:43:11 2019-01-07_11:43:11 2019-01-07_11:45:58
For more information about the task status, see “User Task Reporting” on page 7.
6.5.2 eeadm task show
The most common use will be to get the detailed information of the specified task, including a verbose option which shows the output messages and subtask information. For any failed tasks, the administrator can preform resubmission of those tasks or next step recovery procedures. Example 6-33 shows the output verbosely from an active migration task.
Example 6-33 Verbose output of an active migration task
[root@kyoto ~]# eeadm task show 18830 -v
=== Task Information ===
Task ID: 18830
Task Type: migrate
Command Parameters: eeadm migrate mig3 -p pool1
Status: running
Result: -
Accepted Time: Mon Jan 7 11:58:34 2019 (-0700)
Started Time: Mon Jan 7 11:58:34 2019 (-0700)
Completed Time: -
In-use Resources: 1068045923(D00369L5):pool1:G0:libb
Workload: 100 files. 1 replicas.
7545870371 bytes to copy. 1 copy tasklets on pool1@libb.
Progress: -
0/1 copy tasklets completed on pool1@libb.
Result Summary: -
Messages:
2019-01-07 11:58:34.231005 GLESM896I: Starting the stage 1 of 3 for migration task 18830 (qualifying the state of migration candidate files).
2019-01-07 11:58:37.133670 GLESM897I: Starting the stage 2 of 3 for migration task 18830 (copying the files to 1 pools).
--- Subtask(level 1) Info ---
Task ID: 18831
Task Type: copy_replica
Status: running
Result: -
Accepted Time: Mon Jan 7 11:58:37 2019 (-0700)
Started Time: Mon Jan 7 11:58:37 2019 (-0700)
Completed Time: -
In-use Libraries: libb
In-use Node Groups: G0
In-use Pools: pool1
In-use Tape Drives: 1068045923
In-use Tapes: D00369L5
Workload: 7545870371 bytes to copy. 1 copy tasklets on pool1@libb.
Progress: 0/1 copy tasklets completed on pool1@libb.
Result Summary: -
Messages:
2019-01-07 11:58:37.196346 GLESM825I: The Copy tasklet (0x3527880) will be dispatched on drive 1068045923 from the write queue (tape=D00369L5).
2019-01-07 11:58:37.202930 GLESM031I: A list of 100 file(s) has been added to the migration and recall queue.
Example 6-34 shows the output verbosely of a completed migration task.
Example 6-34 Verbose output of a completed migration task
[root@kyoto ~]# eeadm task show 18830 -v
=== Task Information ===
Task ID: 18830
Task Type: migrate
Command Parameters: eeadm migrate mig3 -p pool1
Status: completed
Result: succeeded
Accepted Time: Mon Jan 7 11:58:34 2019 (-0700)
Started Time: Mon Jan 7 11:58:34 2019 (-0700)
Completed Time: Mon Jan 7 11:59:34 2019 (-0700)
Workload: 100 files. 1 replicas.
7545870371 bytes to copy. 1 copy tasklets on pool1@libb.
Progress: -
1/1 copy tasklets completed on pool1@libb.
Result Summary: 100 succeeded, 0 failed, 0 duplicate, 0 duplicate wrong pool, 0 not found, 0 too small, 0 too early.
(GLESM899I) All files have been successfully copied on pool1/libb.
Messages:
2019-01-07 11:58:34.231005 GLESM896I: Starting the stage 1 of 3 for migration task 18830 (qualifying the state of migration candidate files).
2019-01-07 11:58:37.133670 GLESM897I: Starting the stage 2 of 3 for migration task 18830 (copying the files to 1 pools).
2019-01-07 11:59:30.564568 GLESM898I: Starting the stage 3 of 3 for migration task 18830 (changing the state of files on disk).
2019-01-07 11:59:34.123713 GLESL038I: Migration result: 100 succeeded, 0 failed, 0 duplicate, 0 duplicate wrong pool, 0 not found, 0 too small to qualify for migration, 0 too early for migration.
--- Subtask(level 1) Info ---
Task ID: 18831
Task Type: copy_replica
Status: completed
Result: succeeded
Accepted Time: Mon Jan 7 11:58:37 2019 (-0700)
Started Time: Mon Jan 7 11:58:37 2019 (-0700)
Completed Time: Mon Jan 7 11:59:30 2019 (-0700)
Workload: 7545870371 bytes to copy. 1 copy tasklets on pool1@libb.
Progress: 1/1 copy tasklets completed on pool1@libb.
Result Summary: (GLESM899I) All files have been successfully copied on pool1/libb.
Messages:
2019-01-07 11:58:37.196346 GLESM825I: The Copy tasklet (0x3527880) will be dispatched on drive 1068045923 from the write queue (tape=D00369L5).
2019-01-07 11:58:37.202930 GLESM031I: A list of 100 file(s) has been added to the migration and recall queue.
2019-01-07 11:59:30.556694 GLESM134I: Copy result: 100 succeeded, 0 failed, 0 duplicate, 0 duplicate wrong pool, 0 not found, 0 too small to qualify for migration, 0 too early for migration.
2019-01-07 11:59:30.556838 GLESM899I: All files have been successfully copied on pool1/libb.
The other common use will be to show the file results of each individual file from any premigration, migration or recall tasks. With this information, the administrator can determine which files were successful and which files failed including the error code (reason) and date/time the error occurred. The administrator can quickly determine which files failed, and take corrective actions including resubmission for those failed files. Example 6-35 shows the completed task results.
Example 6-35 Completed task results
[root@kyoto prod]# eeadm task show 18835 -r
Result Failure Code Failed time Node File name
Success - - - /ibm/gpfs/prod/LTFS_EE_FILE_1iv1y5z3SkWhzD_48fp5.bin
Success - - - /ibm/gpfs/prod/LTFS_EE_FILE_eMBse7fTbESNileaQnhHvOK6V62lWuTxs_zQl.bin
Success - - - /ibm/gpfs/prod/LTFS_EE_FILE_ZYyoDMD3WnwRyN5Oj59wJxjARox66YKqlOMw_NsE.bin
Success - - - /ibm/gpfs/prod/LTFS_EE_FILE_h7SaXit1Of9vrUo_3yYT.bin
Success - - - /ibm/gpfs/prod/LTFS_EE_FILE_RPrsQ0xxKAu3nJ9_xResu.bin
Success - - - /ibm/gpfs/prod/LTFS_EE_FILE_CLS7aXD9YBwUNHhhfLlFSaVf4q7eMBtwHYVnMpcAWR6XwnPYL_rsQ.bin
Success - - - /ibm/gpfs/prod/LTFS_EE_FILE_XEvHOLABXWx4CZY7cmwnvyT9W5i5uu_bUvNC.bin
Success - - - /ibm/gpfs/prod/LTFS_EE_FILE_3_wjhe.bin
Fail GLESC012E 2019/01/07T12:06:49 1 /ibm/gpfs/prod/LTFS_EE_FILE_7QVSfmURbFlkQZJAYNvlPx82frnUelfyKSH0c7ZqJNsl_swA.bin
Fail GLESC012E 2019/01/07T12:06:49 1 /ibm/gpfs/prod/LTFS_EE_FILE_8hB1_B.bin
Fail GLESC012E 2019/01/07T12:06:49 1 /ibm/gpfs/prod/LTFS_EE_FILE_nl9T7Y4Z_1.bin
Fail GLESC012E 2019/01/07T12:06:49 1 /ibm/gpfs/prod/LTFS_EE_FILE_W2E77x4f3CICypMbLewnUzQq91hDojdQVJHymiXZuHMJKPY_X.bin
Fail GLESC012E 2019/01/07T12:06:49 1 /ibm/gpfs/prod/LTFS_EE_FILE_sOyPUWwKaMu3Y_VzS.bin
Fail GLESC012E 2019/01/07T12:06:49 1 /ibm/gpfs/prod/LTFS_EE_FILE_tc5xwElJ1SM_x.bin
Fail GLESC012E 2019/01/07T12:06:49 1 /ibm/gpfs/prod/LTFS_EE_FILE_yl_73YEI.bin
Fail GLESC012E 2019/01/07T12:06:49 1 /ibm/gpfs/prod/LTFS_EE_FILE_UR65_nyJ.bin
Fail GLESC012E 2019/01/07T12:06:49 1 /ibm/gpfs/prod/LTFS_EE_FILE_DXhfSFK8N2TrN7bhr0tNfNARwT3K1tZbp5SmBb8RbK_d.bin
Fail GLESC012E 2019/01/07T12:06:49 1 /ibm/gpfs/prod/LTFS_EE_FILE_ZRthniqdYS70yoblcUKc9uz9NECTtLnC8lNODxsQhj_QEWas.bin
For more information about the task status, see “User Task Reporting” on page 7.
6.6 IBM Spectrum Archive EE database backup
IBM Spectrum Archive EE uses databases to store important system states and configurations for healthy operations. Starting with IBM Spectrum Archive EE v1.2.4.0, database backup is performed automatically and stores as many as three backups. The backup files can be found under the /var/opt/ibm/ltfsee/local/dbbackup directory.
Database backup is performed automatically whenever a significant modification is performed to the cluster that requires updating the original database. These changes include the following commands:
•eeadm pool create
•eeadm pool delete
•eeadm tape assign
•eeadm tape unassign
•eeadm drive assign
•eeadm drive unassign
•ltfsee_config -m ADD_CTRL_NODE
•ltfsee_config -m ADD_NODE
•ltfsee_config -m REMOVE_NODE
•ltfsee_config -m SET_CTRL_NODE
The backups are performed when IBM Spectrum Archive EE is running, part of the monitor daemon checks periodically if the original database files have been modified by the above operations. If the thread detects that there has been a modification, then it will go into a grace period. If no further modifications are performed during a set amount of time during this grace period, a backup will then occur.
This technique is intended to prevent repeating backups in a short amount of time, for example when multiple tapes are being added to a pool when users perform eeadm tape assign on multiple tapes. Instead, it performs a backup after the command finished executing and no further changes are made in a set time limit.
These backups are crucial in rebuilding an IBM Spectrum Archive EE cluster if a server gets corrupted or the GPFS file system needs to be rebuilt. After reinstalling the IBM Spectrum Archive EE onto the server, replace the .global and .lib database files under the <path to GPFS filesysytem>.ltfsee/config directory with the database files backed up from the /var/opt/ibm/ltfsee/local/dbbackup/ directory.
6.7 IBM Spectrum Archive EE automatic node failover
This section describes IBM Spectrum Archive EE automatic failover features, and the new LTFSEE monitoring daemon and the updated commands to display any nodes that are having issues.
6.7.1 IBM Spectrum Archive EE monitoring daemon
When IBM Spectrum Archive EE is started, a monitoring daemon is started on each node to monitor various critical components that make up the software:
•MMM
•IBM Spectrum Archive LE
•Remote IBM Spectrum Archive EE monitoring daemons
•IBM Spectrum Scale (GPFS) daemon called mmfsd
•IBM Spectrum Protect for Space Management (HSM) recall daemon called dsmrecalld
•Rpcbind
•Rsyslog
•SSH
Components, such as MMM, IBM Spectrum Archive LE, and remote monitoring daemons, have automatic recovery features. If one of those three components is hung, or has crashed, the monitor daemon performs a recovery to restart it. In an environment where a redundant control node is available and MMM is no longer responding or alive, an attempt to restart the MMM service on the current node is made and if it fails a failover takes place and the redundant control node becomes the new active control node.
If there is only one control node available in the cluster, then an in-place failover occurs to bring back the MMM process on that control node.
|
Note: Only the active control node and the redundant control node’s monitor daemon monitors each other, while the active control node also monitors non control node’s monitoring daemon.
If the monitoring daemon has hung or been killed and there is no redundant control node, restart IBM Spectrum Archive EE to start a new monitoring daemon.
|
As for the rest of the components, currently there are no automatic recovery actions that can be performed. If GPFS, HSM, rpcbind, or rsyslog are having problems, the issues can be viewed by using the eeadm node list command.
Example 6-36 shows output from running eeadm node list when one node has not started rpcbind. To correct this error, start rpcbind on the designated node and EE will refresh itself and the node will become available.
Example 6-36 The eeadm info nodes output
[root@daito ~]# eeadm node list
Spectrum Archive EE service (MMM) for library libb fails to start or is not running on daito Node ID:1
Problem Detected:
Node ID Error Modules
1 MMM; rpcbind;
Node ID State Node IP Drives Ctrl Node Library Node Group Host Name
2 available 9.11.244.62 2 yes(active) liba G0 nara
In addition to the automatic failover, there is also an option to perform a manual failover by running the eeadm cluster failover command. This command is used to fail over the MMM process to a redundant control node. This command is only available for use when a redundant control node exists. Example 6-37 shows output from running the eeadm cluster failover command.
Example 6-37 The eeadm failover command
[root@kyoto ~]# eeadm cluster failover
2019-01-07 13:22:12 GLESL659I: Failover on library lto is requested to start.
Use the "eeadm node list" command to see if the control node is switched over.
6.8 Tape library management
This section describes how to use eeadm commands to add and remove tape drives and tape cartridges from your LTFS library.
6.8.1 Adding tape cartridges
This section describes how to add tape cartridges in IBM Spectrum Archive EE. An unformatted tape cartridge cannot be added to the IBM Spectrum Archive EE library. However, you can format a tape when you add it to a tape cartridge pool. The process of formatting a tape in LTFS creates the required LTFS partitions on the tape.
After tape cartridges are added through the I/O station, or after they are inserted directly into the tape library, you might have to run an eeadm library rescan command. First, run the eeadm tape list command. If the tape cartridges are missing, run the eeadm library rescan command, which synchronizes the data for these changes between the IBM Spectrum Archive EE system and the tape library.
This process occurs automatically. However, if the tape does not appear within the eeadm tape list command output, you can force a rebuild of the inventory (synchronization of IBM Spectrum Archive EE inventory with the tape library’s inventory).
Data tape cartridge
To add a tape cartridge (that was previously used by LTFS) to the IBM Spectrum Archive EE system, complete the following steps:
1. Insert the tape cartridge into the I/O station.
2. Run the eeadm tape list command to see whether your tape appears in the list, as shown in Example 6-38 on page 155. In this example, the -l option is used to limit the tapes to one tape library.
Example 6-38 Run the eeadm tape list command to check whether a tape cartridge must be synchronized
[root@mikasa1 ~]# eeadm tape list -l lib_saitama
Tape ID Status State Usable(GiB) Used(GiB) Available(GiB) Reclaimable% Pool Library Location Task ID
JCA224JC ok appendable 6292 0 6292 0% pool1 lib_saitama homeslot -
JCC093JC ok appendable 6292 496 5796 0% pool1 lib_saitama homeslot -
JCB745JC ok appendable 6292 0 6292 0% pool2 lib_saitama homeslot -
Tape cartridge JCA561JC is not in the list.
3. Because tape cartridge JCA561JC is not in the list, synchronize the data in the IBM Spectrum Archive EE inventory with the tape library by running the eeadm library rescan command, as shown in Example 6-39.
Example 6-39 Synchronize the tape
[[root@mikasa1 ~]# eeadm library rescan
2019-01-07 13:41:34 GLESL036I: library rescan for lib_saitama completed. (id=ebc1b34a-1bd8-4c86-b4fb-bee7b60c24c7, ip_addr=9.11.244.44)
2019-01-07 13:41:47 GLESL036I: library rescan for lib_mikasa completed. (id=8a59cc8b-bd15-4910-88ae-68306006c6da, ip_addr=9.11.244.42)
4. Repeating the eeadm tape list command shows that the inventory was corrected, as shown in Example 6-40.
Example 6-40 Tape cartridge JCA561JC is synchronized
[root@mikasa1 ~]# eeadm tape list -l lib_saitama
Tape ID Status State Usable(GiB) Used(GiB) Available(GiB) Reclaimable% Pool Library Location Task ID
JCA224JC ok appendable 6292 0 6292 0% pool1 lib_saitama homeslot -
JCC093JC ok appendable 6292 496 5796 0% pool1 lib_saitama homeslot -
JCB745JC ok appendable 6292 0 6292 0% pool2 lib_saitama homeslot -
JCA561JC ok unassigned 0 0 0 0% - lib_saitama ieslot -
5. If necessary, move the tape cartridge from the I/O station to a storage slot by running the eeadm tape move command (see Example 6-41) with the -L homeslot option. The example also requires a -l option because of multiple tape libraries.
Example 6-41 Move tape to homeslot
[root@mikasa1 ~]# eeadm tape move JCA561JC -L homeslot -l lib_saitama
2019-01-07 14:02:36 GLESL700I: Task tape_move was created successfully, task id is 6967.
2019-01-07 14:02:50 GLESL103I: Tape JCA561JC is moved successfully.
6. Add the tape cartridge to a tape cartridge pool. If the tape cartridge contains actual data to be added to LTFS, you must import it first before you add it. Run the eeadm tape import command to add the tape cartridge into the IBM Spectrum Archive EE library and import the files on that tape cartridge into the IBM Spectrum Scale namespace as stub files.
If you have no data on the tape cartridge (but it is already formatted for LTFS), add it to a tape cartridge pool by running the eeadm tape assign command.
Scratch cartridge
To add a scratch cartridge to the IBM Spectrum Archive EE system, complete the following steps:
1. Insert the tape cartridge into the I/O station.
2. Synchronize the data in the IBM Spectrum Archive EE inventory with the tape library by running the eeadm library rescan command, as shown in Example 6-39 on page 155.
3. If necessary, move the tape cartridge from the I/O station to a storage slot by running the eeadm tape move command with the -L homeslot option, as shown in Example 6-41 on page 155.
4. The eeadm tape assign command automatically formats tapes when assigning them to a pool. Use the -f or --format option only when the user is aware that the tapes still contain files and are no longer needed. For example, Example 6-42 shows the output of the eeadm tape assign command.
Example 6-42 Format a scratch tape
[root@mikasa1 ~]# eeadm tape assign JCA561JC -p pool1 -l lib_saitama
2019-01-07 14:06:23 GLESL700I: Task tape_assign was created successfully, task id is 6968.
2019-01-07 14:11:14 GLESL087I: Tape JCA561JC successfully formatted.
2019-01-07 14:11:14 GLESL360I: Assigned tape JCA561JC to pool pool1 successfully.
|
Note: Media optimization will run on the each initial assignment starting from LTO 9, which may take some more time. Refer to 7.29, “LTO 9 Media Optimization” on page 272 for more information.
|
For more information about other formatting options, see 6.8.3, “Formatting tape cartridges” on page 158.
6.8.2 Moving tape cartridges
This section summarizes the IBM Spectrum Archive EE commands that can be used for moving tape cartridges.
Moving to different tape cartridge pools
If a tape cartridge contains any files, IBM Spectrum Archive EE will not allow you to move a tape cartridge from one tape cartridge pool to another. If this move is attempted, you receive an error message, as shown in Example 6-43.
Example 6-43 Error message when removing a tape cartridge from a pool with migrated/saved files
[root@mikasa1 ~]# eeadm tape unassign JCC093JC -p pool1 -l lib_saitama
2019-01-07 15:10:36 GLESL700I: Task tape_unassign was created successfully, task id is 6970.
2019-01-07 15:10:36 GLESL357E: Tape JCC093JC has migrated files or saved files. It has not been unassigned from the pool.
However, you can remove an empty tape cartridge from one tape cartridge pool and add it to another tape cartridge pool, as shown in Example 6-44.
Example 6-44 Remove an empty tape cartridge from one tape cartridge pool and add it to another
[root@mikasa1 ~]# eeadm tape unassign JCA561JC -p pool1 -l lib_saitama
2019-01-07 15:11:26 GLESL700I: Task tape_unassign was created successfully, task id is 6972.
2019-01-07 15:11:26 GLESM399I: Removing tape JCA561JC from pool pool1 (Normal).
2019-01-07 15:11:26 GLESL359I: Unassigned tape JCA561JC from pool pool1 successfully.
[root@mikasa1 ~]# eeadm tape assign JCA561JC -p pool2 -l lib_saitama
2019-01-07 15:12:10 GLESL700I: Task tape_assign was created successfully, task id is 6974.
2019-01-07 15:16:56 GLESL087I: Tape JCA561JC successfully formatted.
2019-01-07 15:16:56 GLESL360I: Assigned tape JCA561JC to pool pool2 successfully.
Before you remove a tape cartridge from one tape cartridge pool and add it to another tape cartridge pool, reclaim the tape cartridge to ensure that no files remain on the tape when it is removed. For more information, see 6.17, “Reclamation” on page 200.
Moving to the homeslot
To move a tape cartridge from a tape drive to its homeslot in the tape library, use the command that is shown in Example 6-45. You might want to use this command in cases where a tape cartridge is loaded in a tape drive and you want to unload it.
Example 6-45 Move a tape cartridge from a tape drive to its homeslot
[root@kyoto prod]# eeadm tape move D00369L5 -p pool1 -L homeslot
2019-01-07 15:47:26 GLESL700I: Task tape_move was created successfully, task id is 18843.
2019-01-07 15:49:14 GLESL103I: Tape D00369L5 is moved successfully.
Moving to the I/O station
The command that is shown in Example 6-46 moves a tape cartridge to the ieslot (I/O station). This might be required when tape cartridges are exported, offline, or unassigned.
Example 6-46 Move a tape cartridge to the ieslot after an offline operation
[root@mikasa1 ~]# eeadm tape offline JCA561JC -p pool2 -l lib_saitama
2019-01-07 15:50:17 GLESL700I: Task tape_offline was created successfully, task id is 6976.
2019-01-07 15:50:17 GLESL073I: Offline export of tape JCA561JC has been requested.
2019-01-07 15:51:51 GLESL335I: Updated offline state of tape JCA561JC to offline.
[root@mikasa1 ~]# eeadm tape move JCA561JC -p pool2 -l lib_saitama -L ieslot
2019-01-07 15:53:45 GLESL700I: Task tape_move was created successfully, task id is 6978.
2019-01-07 15:53:45 GLESL103I: Tape JCA561JC is moved successfully.
The move can be between homeslot and ieslot or tape drive and homeslot. If the tape cartridge belongs to a tape cartridge pool and online (not in the Offline state), the request to move it to the ieslot fails. After a tape cartridge is moved to ieslot, the tape cartridge cannot be accessed from IBM Spectrum Archive EE. If the tape cartridge contains migrated files, the tape cartridge should not be moved to ieslot without first exporting or offlining the tape cartridge.
A tape cartridge in ieslot cannot be added to a tape cartridge pool. Such a tape cartridge must be moved to home slot before adding it.
6.8.3 Formatting tape cartridges
This section describes how to format a medium in the library for the IBM Spectrum Archive EE. To format a scratch tape use the eeadm tape assign command, and only use the -f/--format option when the user no longer requires access to the data on the tape.
If the tape cartridge is already formatted for IBM Spectrum Archive EE and contains file objects, the format fails, as shown in Example 6-47.
Example 6-47 Format failure
[root@kyoto prod]# eeadm tape assign 1FB922L5 -p pool2
2019-01-08 08:29:08 GLESL700I: Task tape_assign was created successfully, task id is 18850.
2019-01-08 08:30:21 GLESL138E: Failed to format the tape 1FB922L5, because it is not empty.
When the formatting is requested, IBM Spectrum Archive EE attempts to mount the target medium to obtain the medium condition. The medium is formatted if the mount command finds any of the following conditions:
•The medium was not yet formatted for LTFS.
•The medium was previously formatted for LTFS and has no data written.
•The medium has an invalid label.
•Labels in both partitions do not have the same value.
If none of these conditions are found, the format fails. If the format fails because files exist on the tape, the user should add the tape to their designated pool by using the eeadm tape import command. If the user no longer requires what is on the tape, the -f/--format option can be added to the eeadm tape assign command to force a format.
Example 6-48 shows a tape cartridge being formatted by using the -f option.
Example 6-48 Forced format
[root@kyoto prod]# eeadm tape assign 1FB922L5 -p pool2 -f
2019-01-08 08:32:42 GLESL700I: Task tape_assign was created successfully, task id is 18852.
2019-01-08 08:35:08 GLESL087I: Tape 1FB922L5 successfully formatted.
2019-01-08 08:35:08 GLESL360I: Assigned tape 1FB922L5 to pool pool2 successfully.
Multiple tape cartridges can be formatted by specifying multiple tape VOLSERs. Example 6-49 shows three tape cartridges that are formatted sequentially or simultaneously.
Example 6-49 Format multiple tape cartridges
[root@mikasa1 ~]# eeadm tape assign JCC075JC JCB610JC JCC130JC -p pool1 -l lib_saitama
2019-01-08 09:25:32 GLESL700I: Task tape_assign was created successfully, task id is 6985.
2019-01-08 09:30:26 GLESL087I: Tape JCB610JC successfully formatted.
2019-01-08 09:30:26 GLESL360I: Assigned tape JCB610JC to pool pool1 successfully.
2019-01-08 09:30:33 GLESL087I: Tape JCC130JC successfully formatted.
2019-01-08 09:30:33 GLESL360I: Assigned tape JCC130JC to pool pool1 successfully.
2019-01-08 09:30:52 GLESL087I: Tape JCC075JC successfully formatted.
2019-01-08 09:30:52 GLESL360I: Assigned tape JCC075JC to pool pool1 successfully.
When multiple format tasks are submitted, IBM Spectrum Archive EE uses all available drives with the ‘g’ drive attribute for the format tasks, which are done in parallel.
Active file check before formatting tape cartridges
Some customers (such as those in the video surveillance industry) might want to retain data only for a certain retention period and then reuse the tape cartridges. Running the reconciliation and reclamation commands are the most straightforward method. However, this process might take a long time if there are billions of small files in GPFS, because the command checks every file in GPFS and deletes files on the tape cartridge one by one.
The fastest method is to manage the pool and identify data in tape cartridges that has passed the retention period. Customers can then remove the tape cartridge and add to a new pool by reformatting the entire tape cartridge. This approach saves time, but customers need to be certain that the tape cartridge does not have any active data.
To be sure that a tape cartridge is format-ready, this section uses the -E option, to the eeadm tape unassign command. When ran, this command checks whether the tape cartridge contains any active data. For example, if all files that were migrated on the tape has been made resident, there will be no active data on tape. If there is no active data, or if all files in the tape cartridge have already been deleted in GPFS, the command determines that the tape cartridge is effectively empty and removes the tape cartridge from the pool. If the tape cartridge still has active data, the command will not remove it. No reconciliation command is necessary before this command.
When -E is ran, the command performs the following steps:
1. Determine whether the specified tape cartridge is in the specified pool and is not mounted.
2. Reserve the tape cartridge so that no migration will occur to the tape.
3. Read the volume cache (GPFS file) for the tape cartridge. If any file entries exist in the volume cache, check whether the corresponding GPFS stub file exists, as-is or renamed.
4. If the tape cartridge is empty or has files but all of them have already been deleted in GPFS (not renamed), remove the tape cartridge from the pool.
Example 6-50 shows the output of the eeadm tape unassign -E command with a tape which contains files but all files on the gpfs file system deleted.
Example 6-50 Removing tape cartridge from pool with active file check
[root@mikasa1 prod]# eeadm tape unassign JCB350JC -p test2 -l lib_saitama -E
2019-01-08 10:20:07 GLESL700I: Task tape_unassign was created successfully, task id is 7002.
2019-01-08 10:20:09 GLESM399I: Removing tape JCB350JC from pool test2 (Empty_Force).
2019-01-08 10:20:09 GLESL572I: Unassign tape JCB350JC from pool test2 successfully. Format the tape when assigning it back to a pool.
5. If the tape cartridge has a valid, active file, the check routine aborts on the first hit and goes on to the next specified tape cartridge. The command will not remove the tape cartridge from the pool.
Example 6-51 shows the output of the eeadm tape unassign -E command with a tape which contains active files.
Example 6-51 Tape cartridges containing inactive data are removed from the pool
[root@mikasa1 prod]# eeadm tape unassign JCB350JC -p test2 -l lib_saitama -E
2019-01-08 10:17:15 GLESL700I: Task tape_unassign was created successfully, task id is 6998.
2019-01-08 10:17:16 GLESL357E: Tape JCB350JC has migrated files or saved files. It has not been unassigned from the pool.
The active file check applies to all data types that the current IBM Spectrum Archive EE might store to a tape cartridge:
•Normal migrated files
•Saved objects such as empty directory and link files
Another approach is to run mmapplypolicy to list all files that have been migrated to the designated tape cartridge ID. However, if the IBM Spectrum Scale file system has over 1 billion files, the mmapplypolicy scan might take a long time.
6.8.4 Removing tape drives
When the LTFS mounts the library, all tape drives are inventoried by default. The following procedure can be started when a tape drive requires replacing or repairing and must be physically removed from the library. The same process also must be carried out when firmware for the tape drive is upgraded. If a tape is in the drive and a task is in-progress, the tape is unloaded automatically when the task completes.
After mounting the library, the user can run eeadm commands to manage the library and to correct a problem if one occurs.
To remove a tape drive from the library, complete the following steps:
1. Remove the tape drive from the IBM Spectrum Archive EE inventory by running the eeadm drive unassign command, as shown in Example 6-52. A medium in the tape drive is automatically moved to the home slot (if one exists).
Example 6-52 Remove a tape drive
[root@yurakucho ~]# eeadm drive list -l lib1
Drive S/N Status State Type Role Library Node ID Tape Node Group Task ID
00078DF0CF ok not_mounted LTO8 mrg lib1 1 - G0 -
00078DF0D3 ok not_mounted LTO8 mrg lib1 1 - G0 -
00078DF0DC ok not_mounted LTO8 mrg lib1 1 - G0 -
00078DF0E2 ok not_mounted LTO8 mrg lib1 1 - G0 -
1013000508 ok not_mounted LTO8 mrg lib1 1 - G0 -
[root@yurakucho ~]# eeadm drive unassign 00078DF0E2 -l lib1
2021-03-06 06:48:13 GLESL700I: Task drive_unassign was created successfully, task ID is 2916.
2021-03-06 06:48:13 GLESL817I: Disabling drive 00078DF0E2.
2021-03-06 06:48:14 GLESL813I: Drive 00078DF0E2 is disabled successfully.
2021-03-06 06:48:14 GLESL819I: Unassigning drive 00078DF0E2.
2021-03-06 06:48:14 GLESL121I: Drive 00078DF0E2 is unassigned successfully.
[root@yurakucho ~]# eeadm drive list -l lib1
Drive S/N Status State Type Role Library Node ID Tape Node Group Task ID
00078DF0CF ok not_mounted LTO8 mrg lib1 1 - G0 -
00078DF0D3 ok not_mounted LTO8 mrg lib1 1 - G0 -
00078DF0DC ok not_mounted LTO8 mrg lib1 1 - G0 -
00078DF0E2 info unassigned NONE --- lib1 - - - -
1013000508 ok not_mounted LTO8 mrg lib1 1 - G0 -
2. Physically remove the tape drive from the tape library.
For more information about how to remove tape drives, see the IBM Documentation website for your IBM tape library.
6.8.5 Adding tape drives
Add the tape drive to the LTFS inventory by running the eeadm drive assign command, as shown in Example 6-53.
Optionally, drive attributes can be set when adding a tape drive. Drive attributes are the logical OR of the attributes: migrate(4), recall(2), and generic(1). If the individual attribute is set, any corresponding tasks on the task queue can be run on that drive. The drive attributes can be specified using the -r option and must be a decimal number or the combination of the letters m, r, and g.
In Example 6-53, 6 is the logical OR of migrate(4) and recall(2), so migration tasks and recall tasks can be performed on this drive. For more information, see 6.20, “Drive Role settings for task assignment control” on page 207.
The node ID is required for the eeadm drive assign command.
Example 6-53 Add a tape drive
[root@yurakucho ~]# eeadm drive assign 00078DF0E2 -r 6 -n 1 -l lib1
2021-03-06 06:53:06 GLESL700I: Task drive_assign was created successfully, task ID is 2918.
2021-03-06 06:53:06 GLESL818I: Assigning drive 00078DF0E2 to node 1.
2021-03-06 06:53:06 GLESL119I: Drive 00078DF0E2 assigned successfully.
2021-03-06 06:53:06 GLESL816I: Enabling drive 00078DF0E2.
2021-03-06 06:53:06 GLESL812I: Drive 00078DF0E2 is enabled successfully.
[root@yurakucho ~]# eeadm drive list -l lib1
Drive S/N Status State Type Role Library Node ID Tape Node Group Task ID
00078DF0CF ok not_mounted LTO8 mrg lib1 1 - G0 -
00078DF0D3 ok not_mounted LTO8 mrg lib1 1 - G0 -
00078DF0DC ok not_mounted LTO8 mrg lib1 1 - G0 -
00078DF0E2 ok not_mounted LTO8 mr- lib1 1 - G0 -
1013000508 ok not_mounted LTO8 mrg lib1 1 - G0 -
6.9 Tape storage pool management
This section describes how to use the eeadm pool command to manage tape cartridge pools with IBM Spectrum Archive EE.
|
Permissions: Managing tape cartridge pools by running the eeadm pool command requires root user permissions.
|
To perform file migrations, it is first necessary to create and define tape cartridge pools, which are the targets for migration. It is then possible to add or remove tape cartridges to or from the tape cartridge pools.
Consider the following rules and recommendations for tape cartridge pools:
•Before adding tape cartridges to a tape cartridge pool, the tape cartridge must first be in the homeslot of the tape library. For more information about moving to the homeslot, see 6.8.2, “Moving tape cartridges” on page 156.
•Multiple tasks can be performed in parallel when more than one tape cartridge is defined in a tape cartridge pool. Have multiple tape cartridges in each tape cartridge pool to increase performance.
•The maximum number of drives in a node group that is used for migration for a particular tape cartridge pool can be limited by setting the mountlimit attribute for the tape cartridge pool. The default is 0, which is unlimited. For more information about the mountlimit attribute, see 7.2, “Maximizing migration performance with redundant copies” on page 235.
•After a file is migrated to a tape cartridge pool, it cannot be migrated again to another tape cartridge pool before it is recalled.
•When tape cartridges are removed from a tape cartridge pool but not exported from IBM Spectrum Archive EE, they are no longer targets for migration or recalls.
•When tape cartridges are exported from IBM Spectrum Archive EE system by running the eeadm tape export command, they are removed from their tape cartridge pool and the files are not accessible for recall.
6.9.1 Creating tape cartridge pools
This section describes how to create tape cartridge pools for use with IBM Spectrum Archive EE. Tape cartridge pools are logical groupings of tape cartridges within IBM Spectrum Archive EE. The groupings might be based on their intended function (for example, OnsitePool and OffsitePool) or based on their content (for example, MPEGpool and JPEGpool). However, you must create at least one tape cartridge pool.
You create tape cartridge pools by using the create option of the eeadm pool command. For example, the command that is shown in Example 6-54 creates the tape cartridge pool named MPEGpool.
Example 6-54 Create a tape cartridge pool
[root@kyoto prod]# eeadm pool create MPEGpool
For single tape library systems, the -l option (library name) can be omitted. For two tape library systems, the -l option is used to specify the library name.
For single node group systems, the -g option (node group) can be omitted. For multiple node group systems, the -g option is used to specify the node group.
The default tape cartridge pool type is a regular pool. If a WORM pool is wanted, supply the --worm physical option.
The pool names are case-sensitive and can be duplicated in different tape libraries. No informational messages are shown at the successful completion of the command. However, you can confirm that the pool was created by running the eeadm pool list command.
6.9.2 Deleting tape cartridge pools
This section describes how to delete tape cartridge pools for use with IBM Spectrum Archive EE. Delete tape cartridge pools by using the eeadm pool delete command. For example, the command in Example 6-55 on page 163 deletes the tape cartridge pool that is named MPEGpool.
Example 6-55 Delete a tape cartridge pool
[root@kyoto prod]# eeadm pool delete MPEGpool
For single tape library systems, the -l option (library name) can be omitted. For two tape library systems, the -l option is used to specify the library name.
When deleting a tape cartridge pool, the -g option (node group) can be omitted.
No informational messages are shown after the successful completion of the command.
|
Important: If the tape cartridge pool contains tape cartridges, the tape cartridge pool cannot be deleted until the tape cartridges are removed.
|
You cannot use IBM Spectrum Archive EE to delete a tape cartridge pool that still contains data.
To allow the deletion of the tape cartridge pool, you must remove all tape cartridges from it by running the eeadm tape unassign command, as described in 6.8.2, “Moving tape cartridges” on page 156.
6.10 Pool capacity monitoring
IBM Spectrum Archive EE allows users the ability to automatically monitor the capacity of designated pools for low space threshold or if a pool has ran out of space due to a migration failure. This feature uses SNMP traps to inform administrators of such occurrences. The pool capacity monitoring feature benefits customers by giving them enough time to plan ahead before pool space is depleted.
To enable the pool capacity monitoring feature, use the eeadm pool set command with the lowspacewarningenable yes and the nospacewarningenable yes option, then set a threshold limit for the pool with the lowspacewarningthreshold option. The value for the lowspacewarningthreshold must be an integer and is in TiB. The pool capacity monitor thread checks each set pool for a low capacity every 30 minutes, and sends a trap every 24 hours.
Run the eeadm pool show <pool_name> command to view the current attributes for your pools. Example 6-56 shows the output of the attributes of a pool from the eeadm pool show command.
Example 6-56 The eeadm pool show command
[root@ltfseesrv1 ~]# eeadm pool show pool1
Attribute Value
poolname pool1
poolid aefeaa24-661e-48ba-8abd-d4948b020d74
devtype LTO
mediarestriction none
format Not Applicable (0xFFFFFFFF)
worm no (0)
nodegroup G0
fillpolicy Default
owner System
mountlimit 0
lowspacewarningenable yes
lowspacewarningthreshold 0
nospacewarningenable yes
mode normal
By default, the lowspacewarningenable and nospacewarningenable attributes are set to yes, and lowspacewarningthreshold is set to 0, which indicates no traps will be sent for a a pool with low space. An SNMP trap is sent for no space remaining in the pool when migrations failed due to pool space being depleted.
The lowspacewarningthreshold attribute value is set in TiB. To modify the attributes in each pool, use the eeadm pool set <pool_name> -a <attribute> -v <value> command.
Example 6-57 Output of modifying pool1’s lowspacewarningthreshold attribute
[root@kyoto prod]# eeadm pool set pool1 -a lowspacewarningthreshold -v 30
[root@kyoto prod]# eeadm pool show pool1
Attribute Value
poolname pool1
poolid 93499f33-c67f-4aae-a07e-13a56629b057
devtype LTO
mediarestriction none
format Not Applicable (0xFFFFFFFF)
worm no (0)
nodegroup G0
fillpolicy Default
owner System
mountlimit 0
lowspacewarningenable yes
lowspacewarningthreshold 30
nospacewarningenable yes
mode normal
With lowspacewarningthreshold set to 30 TiB, when pool1’s capacity drops below 30 TiB, a trap will be sent to the user when the next check cycle occurs. Example 6-58 shows the traps generated when pool1’s capacity drops below 30 TiB.
Example 6-58 Traps sent when pool capacity is below the set threshold 
2018-11-26 09:08:42 tora.tuc.stglabs.ibm.com [UDP: [9.11.244.63]:60811->[9.11.244.63]:162]:
DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (147206568) 17 days, 0:54:25.68 SNMPv2-MIB::snmpTrapOID.0 = OID: IBMSA-MIB::ibmsaWarnM609PoolLowSpace IBMSA-MIB::ibmsaMessageSeverity.0 = INTEGER: warning(40) IBMSA-MIB::ibmsaJob.0 = INTEGER: other(7) IBMSA-MIB::ibmsaEventNode.0 = STRING: "tora.tuc.stglabs.ibm.com" IBMSA-MIB::ibmsaMessageText.0 = STRING: "GLESM609W: Pool space is going to be small, library: lib_tora, pool: pool1, available capacity: 23.6(TiB), threshold: 30(TiB)"
6.11 Migration
The migration process is the most significant reason for using IBM Spectrum Archive EE. Migration is the movement of files from IBM Spectrum Scale (on disk) to LTFS tape cartridges in tape cartridge pools, which leaves behind a small stub file on the disk. This process has the obvious effect of reducing the usage of file system space of IBM Spectrum Scale. You can move less frequently accessed data to lower-cost, lower-tier tape storage from where it can be easily recalled.
IBM Spectrum Scale policies are used to specify files in the IBM Spectrum Scale namespace (through a GPFS scan) to be migrated to the LTFS tape tier. For each specified GPFS file, the file content, GPFS path, and user-defined extended attributes are stored in LTFS so that they can be re-created at import. Empty GPFS directories or files are not migrated.
In addition, it is possible to migrate an arbitrary list of files directly by running the eeadm migrate command. This task is done by specifying the file name of a scan list file that lists the files to be migrated and specifying the designated pools as command options.
|
Important: Running the IBM Spectrum Protect for Space Management dsmmigrate command directly is not supported.
|
To migrate files, the following configuration and activation prerequisites must be met:
•Ensure that the MMM service is running on an LTFS node. For more information, see 6.2.4, “IBM Spectrum Archive EE” on page 140.
•Ensure that one or more storage pools are created and each has one or more assigned tapes. For more information, see 6.9.1, “Creating tape cartridge pools” on page 162.
•Ensure that space management is turned on. For more information, see 6.2.3, “Hierarchical Space Management” on page 138.
•Activate one of the following mechanisms to trigger migration:
– Automated IBM Spectrum Scale policy-driven migration that uses thresholds.
– Manual policy-based migration by running the mmapplypolicy command.
– Manual migration by running the eeadm migrate command and a prepared list of files and tape cartridge pools.
IBM Spectrum Archive EE uses a semi-sequential fill policy for tapes that enables multiple files to be written in parallel by using multiple tape drives within the tape library. Tasks are put on the queue and the scheduler looks at the queue to decide which tasks should be run. If one tape drive is available, all of the migration goes on one tape cartridge. If there are three tape drives available, the migrations are spread among the three tape drives. This configuration improves throughput and is a more efficient usage of tape drives.
IBM Spectrum Archive EE internally groups files into file lists and schedules these lists on the task queue. The lists are then distributed to available drives to perform the migrations.
The grouping is done by using two parameters: A total file size and a total number of files. The default settings for the file lists are 20 GB or 20,000 files. This requirement means that a file list can contain either 20 GB of files or 20,000 number of files, whichever fills up first, before creating a new file list. For example, if you have 10 files to migrate and each file is 10 GB in size, then when migration is kicked off, IBM Spectrum Archive EE internally generates five file lists containing two files each because the two files reach the 20 GB limit that a file list can have. It then schedules those file lists to the task queue for available drives.
For more information about performance references, see 3.7.4, “Performance” on page 65.
|
Note: Files that are recently created need to wait two minutes before being migrated. Otherwise, the migrations will fail.
|
Example 6-59 shows the output of running the mmapplypolicy command that uses a policy file called sample_policy.txt.
Example 6-59 Output of the mmapplypolicy command
[root@kyoto ~]# mmapplypolicy /ibm/gpfs/prod -P sample_policy.txt
[I] GPFS Current Data Pool Utilization in KB and %
Pool_Name KB_Occupied KB_Total Percent_Occupied
system 1489202176 15435038720 9.648192033%
[I] 682998 of 16877312 inodes used: 4.046841%.
[I] Loaded policy rules from cmt_policy.txt.
Evaluating policy rules with CURRENT_TIMESTAMP = 2019-01-08@22:26:33 UTC
Parsed 3 policy rules.
RULE 'SYSTEM_POOL_PLACEMENT_RULE' SET POOL 'system'
RULE EXTERNAL POOL 'md1'
EXEC '/opt/ibm/ltfsee/bin/eeadm'
OPTS '-p pool3@libb'
RULE 'LTFS_EE_FILES' MIGRATE FROM POOL 'system'
TO POOL 'md1'
WHERE FILE_SIZE > 0
AND NAME LIKE '%.bin'
AND PATH_NAME LIKE '/ibm/gpfs/%'
/*AND (is_cached)
AND NOT (is_dirty)*/
AND ((NOT MISC_ATTRIBUTES LIKE '%M%')
OR (MISC_ATTRIBUTES LIKE '%M%' AND MISC_ATTRIBUTES NOT LIKE '%V%')
)
AND NOT ((NAME = 'dsmerror.log' OR NAME LIKE '%DS_Store%')
)
AND (NOT ((
FALSE
OR PATH_NAME LIKE '/ibm/gpfs/.ltfsee/%'
OR PATH_NAME LIKE '%/.SpaceMan/%'
)
) OR ((
FALSE
)
))
[I] 2019-01-08@22:26:33.153 Directory entries scanned: 22.
[I] Directories scan: 21 files, 1 directories, 0 other objects, 0 'skipped' files and/or errors.
[I] 2019-01-08@22:26:33.157 Sorting 22 file list records.
[I] Inodes scan: 21 files, 1 directories, 0 other objects, 0 'skipped' files and/or errors.
[I] 2019-01-08@22:26:33.193 Policy evaluation. 22 files scanned.
[I] 2019-01-08@22:26:33.197 Sorting 10 candidate file list records.
[I] 2019-01-08@22:26:33.197 Choosing candidate files. 10 records scanned.
[I] Summary of Rule Applicability and File Choices:
Rule# Hit_Cnt KB_Hit Chosen KB_Chosen KB_Ill Rule
0 10 953344 10 953344 0 RULE 'LTFS_EE_FILES' MIGRATE FROM POOL 'system' TO POOL 'md1' WHERE(.)
[I] Filesystem objects with no applicable rules: 12.
[I] GPFS Policy Decisions and File Choice Totals:
Chose to migrate 953344KB: 10 of 10 candidates;
Predicted Data Pool Utilization in KB and %:
Pool_Name KB_Occupied KB_Total Percent_Occupied
system 1488248832 15435038720 9.642015540%
2019-01-08 15:26:33 GLESL700I: Task migrate was created successfully, task id is 18860.
2019-01-08 15:26:33 GLESM896I: Starting the stage 1 of 3 for migration task 18860 (qualifying the state of migration candidate files).
2019-01-08 15:26:33 GLESM897I: Starting the stage 2 of 3 for migration task 18860 (copying the files to 1 pools).
2019-01-08 15:27:18 GLESM898I: Starting the stage 3 of 3 for migration task 18860 (changing the state of files on disk).
2019-01-08 15:27:19 GLESL038I: Migration result: 10 succeeded, 0 failed, 0 duplicate, 0 duplicate wrong pool, 0 not found, 0 too small to qualify for migration, 0 too early for migration.
[I] 2019-01-08@22:27:20.722 Policy execution. 10 files dispatched.
[I] A total of 10 files have been migrated, deleted or processed by an EXTERNAL EXEC/script;
0 'skipped' files and/or errors.
6.11.1 Managing file migration pools
A file can be migrated to one pool or to multiple pools if replicas are configured. However, after the file is in the migrated state, it cannot be migrated again to other tape cartridge pools before it is recalled and made resident again by using the eeadm recall command with the --resident option. For more information about creating replicas, see 6.11.4, “Replicas and redundant copies” on page 177. Recalling the file into resident state invalidates the LTFS copy from the reconcile and export perspective.
6.11.2 Threshold-based migration
This section describes how to use IBM Spectrum Scale policies for threshold-based migrations with IBM Spectrum Archive EE.
Automated IBM Spectrum Scale policy-driven migration is a standard IBM Spectrum Scale migration procedure that allows file migration from IBM Spectrum Scale disk pools to external pools. IBM Spectrum Archive EE is configured as an external pool to IBM Spectrum Scale by using policy statements.
After you define an external tape cartridge pool, migrations or deletion rules can refer to that pool as a source or target tape cartridge pool. When the mmapplypolicy command is run and a rule dictates that data should be moved to an external pool, the user-provided program that is identified with the EXEC clause in the policy rule starts. That program receives the following arguments:
•The command to be run. IBM Spectrum Scale supports the following subcommands:
– LIST: Provides arbitrary lists of files with no semantics on the operation.
– MIGRATE: Migrates files to external storage and reclaims the online space that is allocated to the file.
– PREMIGRATE: Migrates files to external storage, but does not reclaim the online space.
– PURGE: Deletes files from both the online file system and the external storage.
– RECALL: Recall files from external storage to the online storage.
– TEST: Tests for presence and operation readiness. Returns zero for success and returns nonzero if the script should not be used on a specific node.
•The name of a file that contains a list of files to be migrated.
|
Important: IBM Spectrum Archive EE supports only the LIST, MIGRATE, PREMIGRATE, and RECALL subcommands.
|
•Any optional parameters that are specified with the OPTS clause in the rule. These optional parameters are not interpreted by the IBM Spectrum Scale policy engine, but by the method that IBM Spectrum Archive EE uses to pass the tape cartridge pools to which the files are migrated.
To set up automated IBM Spectrum Scale policy-driven migration to IBM Spectrum Archive EE, you must configure IBM Spectrum Scale to be managed by IBM Spectrum Archive EE. In addition, a migration callback must be configured.
Callbacks are provided primarily as a method for system administrators to take notice when important IBM Spectrum Scale events occur. It registers a user-defined command that IBM Spectrum Scale runs when certain events occur. For example, an administrator can use the low disk event callback to inform system administrators when a file system is getting full.
The migration callback is used to register the policy engine to be run if a high threshold in a file system pool is met. For example, after your pool usage reaches 80%, you can start the migration process. You must enable the migration callback by running the mmaddcallback command.
In the mmaddcallback command in Example 6-60, the --command option points to a sample script file called /usr/lpp/mmfs/bin/mmapplypolicy. Before you run this command, you must ensure that the specified sample script file exists. The --event option registers the events for which the callback is configured, such as the “low disk space” events that are in the command example.
For more information about how to create and set a fail-safe policy, see 7.10, “Use cases for mmapplypolicy” on page 244.
Example 6-60 A mmaddcallback example
mmaddcallback MIGRATION --command /usr/lpp/mmfs/bin/mmapplypolicy --event lowDiskSpace --parms “%fsName -B 20000 -m <2x the number of drives> --single-instance”
For more information, see the following publications:
•IBM Spectrum Scale: Administration and Programming Reference Guide, which is available at IBM Documentation
After the file system is configured to be managed by IBM Spectrum Archive EE and the migration callback is configured, a policy can be set up for the file system. The placement policy that defines the initial placement of newly created files and the rules for placement of restored data must be installed into IBM Spectrum Scale by using the mmchpolicy command. If an IBM Spectrum Scale file system does not have a placement policy installed, all the data is stored in the system storage pool.
You can define the file management rules and install them in the file system together with the placement rules by running the mmchpolicy command. You also can define these rules in a separate file and explicitly provide them to the mmapplypolicy command by using the -P option. The latter option is described in 6.11.3, “Manual migration” on page 173.
In either case, policy rules for placement or migration can be intermixed. Over the life of the file, data can be migrated to a different tape cartridge pool any number of times, and files can be deleted or restored.
The policy must define IBM Spectrum Archive EE (/opt/ibm/ltfsee/bin/eeadm) as an external tape cartridge pool.
|
Tip: Only one IBM Spectrum Scale policy, which can include one or more rules, can be set up for a particular GPFS file system.
|
After a policy is entered into a text file (such as policy.txt), you can apply the policy to the file system by running the mmchpolicy command. You can check the syntax of the policy before you apply it by running the command with the -I test option, as shown in Example 6-61.
Example 6-61 Test an IBM Spectrum Scale policy
mmchpolicy /dev/gpfs policy.txt -t "System policy for LTFS EE" -I test
After you test your policy, run the mmchpolicy command without the -I test to set the policy. After a policy is set for the file system, you can check the policy by displaying it with the mmlspolicy command, as shown in Example 6-62. This policy migrates all files in groups of 20 GiB after the IBM Spectrum Archive disk space reaches a threshold of or above 80% in the /ibm/glues/archive directory to tape.
Example 6-62 List an IBM Spectrum Scale policy
[root@ltfs97]# mmlspolicy /dev/gpfs -L
/* LTFS EE - GPFS policy file */
define(
user_exclude_list,
PATH_NAME LIKE '/ibm/glues/0%'
OR NAME LIKE '%&%')
define(
user_include_list,
FALSE)
define(
exclude_list,
NAME LIKE 'dsmerror.log')
/* define is_premigrated uses GPFS inode attributes that mark a file
as a premigrated file. Use the define to include or exclude premigrated
files from the policy scan result explicitly */
define(
is_premigrated,
MISC_ATTRIBUTES LIKE '%M%' AND MISC_ATTRIBUTES NOT LIKE '%V%')
/* define is_migrated uses GPFS inode attributes that mark a file
as a migrated file. Use the define to include or exclude migrated
files from the policy scan result explicitly */
define(
is_migrated,
MISC_ATTRIBUTES LIKE '%V%')
RULE 'SYSTEM_POOL_PLACEMENT_RULE' SET POOL 'system'
RULE EXTERNAL POOL 'Archive_files'
EXEC '/opt/ibm/ltfsee/bin/eeadm'
OPTS -p 'pool1@libb'
SIZE(20971520)
RULE 'ARCHIVE_FILES' MIGRATE FROM POOL 'system'
THRESHOLD(80,50)
TO POOL 'Archive_files'
WHERE PATH_NAME LIKE '/ibm/glues/archive/%'
AND NOT (exclude_list)
AND (NOT (user_exclude_list) OR (user_include_list))
AND (is_migrated OR is_premigrated)
To ensure that a specified file system is migrated only once, run the mmapplypolicy command with the --single-instance option. If this is not done, IBM Spectrum Archive EE attempts to start another migration process every two minutes. This occurs in cases where migrations are continuously called while the past migrations has not finished, because this state may appear for the values to be still over the threshold.
As a preferred practice, the user should not use overlapping IBM Spectrum Scale policy rules within different IBM Spectrum Scale policy files that select the same files for migration to different tape cartridge pools. If a file is already migrated, later migration attempts fail, which is the standard HSM behavior. However, this is not normally done, due to incorporating thresholds.
|
Important: If a single IBM Spectrum Scale file system is used and the metadata directory is stored in the same file system that is space-managed with IBM Spectrum Archive EE, migration of the metadata directory must be prevented. The name of metadata directory is <GPFS mount point>/.ltfsee/.
|
By combining the attributes of THRESHOLD and WEIGHT in IBM Spectrum Scale policies, you can have a great deal of control over the migration process. When an IBM Spectrum Scale policy is applied, each candidate file is assigned a weight (based on the WEIGHT attribute). All candidate files are sorted by weight and the highest weight files are chosen to MIGRATE until the low occupancy percentage (based on the THRESHOLD attribute) is achieved, or there are no more candidate files.
Example 6-63 shows a policy that starts migration of all files when the file system pool named “system” reaches 80% full (see the THRESHOLD attribute), and continues migration until the pool is reduced to 60% full or less by using a weight that is based on the date and time that the file was last accessed (refer to the ACCESS_TIME attribute). The file system usage is checked every two minutes.
All files to be migrated must have more than 5 MB of disk space that is allocated for the file (see the KB_ALLOCATED attribute). The migration is performed to an external pool, presented by IBM Spectrum Archive EE (/opt/ibm/ltfsee/bin/eeadm), and the data that is migrated is sent to the IBM Spectrum Archive EE tape cartridge pool named Tapepool1. In addition, this example policy excludes some system files and directories.
Example 6-63 Threshold-based migration in an IBM Spectrum Scale policy file
define
(
exclude_list,
(
PATH_NAME LIKE '%/.SpaceMan/%'
OR PATH_NAME LIKE '%/.ctdb/%'
OR PATH_NAME LIKE '/ibm/glues/.ltfsee/%'
OR NAME LIKE 'fileset.quota%'
OR NAME LIKE 'group.quota%'
)
)
RULE EXTERNAL POOL 'ltfsee'
EXEC '/opt/ibm/ltfsee/bin/eeadm'
OPTS -p 'Tapepool1@liba' /* This is our pool in LTFS Enterprise Edition */
SIZE(20971520)
/* The following statement is the migration rule */
RULE 'ee_sysmig' MIGRATE FROM POOL 'system'
THRESHOLD(80,60)
WEIGHT(CURRENT_TIMESTAMP - ACCESS_TIME)
TO POOL 'ltfsee'
WHERE (KB_ALLOCATED > 5120)
AND NOT (exclude_list)
/* The following statement is the default placement rule that is required for a system migration */
RULE 'default' set pool 'system'
In addition to monitoring the file system’s overall usage in Example 6-63, you can monitor how frequently a file is accessed with IBM Spectrum Scale policies. A file’s access temperature is an attribute for a policy that provides a means of optimizing tiered storage. File temperatures are a relative attribute, which indicates whether a file is “hotter” or “colder” than the others in its pool.
The policy can be used to migrate hotter files to higher tiers and colder files to lower. The access temperature is an exponential moving average of the accesses to the file. As files are accessed, the temperature increases. Likewise, when the access stops, the file cools. File temperature is intended to optimize nonvolatile storage, not memory usage. Therefore, cache hits are not counted. In a similar manner, only user accesses are counted.
The access counts to a file are tracked as an exponential moving average. A file that is not accessed loses a percentage of its accesses each period. The loss percentage and period are set through the configuration variables fileHeatLossPercent and fileHeatPeriodMinutes. By default, the file access temperature is not tracked.
To use access temperature in policy, the tracking must first be enabled. To do this, set the following configuration variables:
•fileHeatLossPercent
The percentage (0 - 100) of file access temperature that is dissipated over the fileHeatPeriodMinutes time. The default value is 10.
•fileHeatPeriodMinutes
The number of minutes that is defined for the recalculation of file access temperature. To turn on tracking, fileHeatPeriodMinutes must be set to a nonzero value from the default value of 0. You use WEIGHT(FILE_HEAT) with a policy MIGRATE rule to prioritize migration by file temperature.
The following example sets fileHeatPeriodMinutes to 1440 (24 hours) and fileHeatLossPercent to 10, meaning that unaccessed files lose 10% of their heat value every 24 hours, or approximately 0.4% every hour (because the loss is continuous and “compounded” geometrically):
mmchconfig fileheatperiodminutes=1440,fileheatlosspercent=10
|
Note: If the updating of the file access time (atime) is suppressed or if relative atime semantics are in effect, proper calculation of the file access temperature might be adversely affected.
|
These examples provide only an introduction to the wide range of file attributes that migration can use in IBM Spectrum Scale policies. IBM Spectrum Scale provides a range of other policy rule statements and attributes to customize your IBM Spectrum Scale environment, but a full description of all these is outside the scope for this publication.
For syntax definitions for IBM Spectrum Scale policy rules, which correspond to constructs in this script (such as EXEC, EXTERNAL POOL, FROM POOL, MIGRATE, RULE, OPTS, THRESHOLD, TO POOL, WEIGHT, and WHERE), see the information about policy rule syntax definitions in IBM Spectrum Scale: Administration Guide at IBM Documentation.
For more information about IBM Spectrum Scale SQL expressions for policy rules, which correspond to constructs in this script (such as CURRENT_TIMESTAMP, FILE_SIZE, MISC_ATTRIBUTES, NAME, and PATH_NAME), see the information about SQL expressions for policy rules in IBM Spectrum Scale: Administration Guide at IBM Documentation.
6.11.3 Manual migration
In contrast to the threshold-based migration process that can be controlled only from within IBM Spectrum Scale, the manual migration of files from IBM Spectrum Scale to LTFS tape cartridges can be accomplished by running the mmapplypolicy command or the eeadm command. The use of these commands is documented in this section. Manual migration is more likely to be used for ad hoc migration of a file or group of files that do not fall within the standard IBM Spectrum Scale policy that is defined for the file system.
Using mmapplypolicy
This section describes how to manually start file migration while using an IBM Spectrum Scale policy file for file selection.
You can apply a manually created policy by manually running the mmapplypolicy command, or by scheduling the policy with the system scheduler. You can have multiple different policies, which can each include one or more rules. However, only one policy can be run at a time.
|
Important: Prevent migration of the .SPACEMAN directory of a GPFS file system by excluding the directory with an IBM Spectrum Scale policy rule.
|
You can accomplish manual file migration for an IBM Spectrum Scale file system that is managed by IBM Spectrum Archive EE by running the mmapplypolicy command. This command runs a policy that selects files according to certain criteria, and then passes these files to IBM Spectrum Archive EE for migration. As with automated IBM Spectrum Scale policy-driven migrations, the name of the target IBM Spectrum Archive EE tape cartridge pool is provided as the first option of the pool definition rule in the IBM Spectrum Scale policy file.
The following phases occur when the mmapplypolicy command is started:
1. Phase 1: Selecting candidate files
In this phase of the mmapplypolicy job, all files within the specified GPFS file system device (or below the input path name) are scanned. The attributes of each file are read from the file’s GPFS inode structure.
2. Phase two: Choosing and scheduling files
In this phase of the mmapplypolicy job, some or all of the candidate files are chosen. Chosen files are scheduled for migration, accounting for the weights and thresholds that are determined in phase one.
3. Phase three: Migrating and premigrating files
In the third phase of the mmapplypolicy job, the candidate files that were chosen and scheduled by the second phase are migrated or premigrated, each according to its applicable rule.
For more information about the mmapplypolicy command and other information about IBM Spectrum Scale policy rules, see the IBM Spectrum Scale: Administration Guide, which is available at IBM Documentation.
|
Important: In a multicluster environment, the scope of the mmapplypolicy command is limited to the nodes in the cluster that owns the file system.
|
Hints and tips
Before you write and apply policies, consider the following points:
•Always test your rules by running the mmapplypolicy command with the -I test option and the -L 3 (or higher) option before they are applied in a production environment. This step helps you understand which files are selected as candidates and which candidates are chosen.
•To view all selected files that have been chosen for migration, run the mmapplypolicy command with the -I defer and the -f /tmp options. The -I defer option runs the actual policy without making any data movements. The -f /tmp option specifies a directory or file to which each migration rule is output. This option is helpful when dealing with many files.
•Do not apply a policy to an entire file system of vital files until you are confident that the rules correctly express your intentions. To test your rules, find or create a subdirectory with a modest number of files, some that you expect to be selected by your SQL policy rules and some that you expect are skipped.
Run the following command:
mmapplypolicy /ibm/gpfs/TestSubdirectory -P test_policy.txt -L 6 -I test
The output shows you exactly which files are scanned and which ones match rules.
Testing an IBM Spectrum Scale policy
Example 6-64 shows a mmapplypolicy command that tests, but does not apply, an IBM Spectrum Scale policy by using the testpolicy policy file.
Example 6-64 Test an IBM Spectrum Scale policy
[root@kyoto ~]# mmapplypolicy /ibm/gpfs/prod -P sample_policy.txt -I test
[I] GPFS Current Data Pool Utilization in KB and %
Pool_Name KB_Occupied KB_Total Percent_Occupied
system 1489192960 15435038720 9.648132324%
[I] 683018 of 16877312 inodes used: 4.046960%.
[I] Loaded policy rules from cmt_policy.txt.
Evaluating policy rules with CURRENT_TIMESTAMP = 2019-01-08@22:34:42 UTC
Parsed 3 policy rules.
RULE 'SYSTEM_POOL_PLACEMENT_RULE' SET POOL 'system'
RULE EXTERNAL POOL 'md1'
EXEC '/opt/ibm/ltfsee/bin/eeadm'
OPTS '-p copy_ltfsml1@lib_ltfsml1'
RULE 'LTFS_EE_FILES' MIGRATE FROM POOL 'system'
THRESHOLD(50,0)
TO POOL 'COPY_POOL'
WHERE FILE_SIZE > 5242880
AND NAME LIKE ‘%.IMG’
AND ((NOT MISC_ATTRIBUTES LIKE '%M%') OR (MISC_ATTRIBUTES LIKE '%M%' AND MISC_ATTRIBUTES NOT LIKE '%V%'))
AND NOT ((PATH_NAME LIKE '/ibm/gpfs/.ltfsee/%' OR PATH_NAME LIKE '%/.SpaceMan/%'))
[I] 2019-01-08@22:34:42.327 Directory entries scanned: 22.
[I] Directories scan: 21 files, 1 directories, 0 other objects, 0 'skipped' files and/or errors.
[I] 2019-01-08@22:34:42.330 Sorting 22 file list records.
[I] Inodes scan: 21 files, 1 directories, 0 other objects, 0 'skipped' files and/or errors.
[I] 2019-01-08@22:34:42.365 Policy evaluation. 22 files scanned.
[I] 2019-01-08@22:34:42.368 Sorting 10 candidate file list records.
[I] 2019-01-08@22:34:42.369 Choosing candidate files. 10 records scanned.
[I] Summary of Rule Applicability and File Choices:
Rule# Hit_Cnt KB_Hit Chosen KB_Chosen KB_Ill Rule
0 10 947088 10 947088 0 RULE 'LTFS_EE_FILES' MIGRATE FROM POOL 'system' TO POOL 'md1' WHERE(.)
[I] Filesystem objects with no applicable rules: 12.
[I] GPFS Policy Decisions and File Choice Totals:
Chose to migrate 947088KB: 10 of 10 candidates;
Predicted Data Pool Utilization in KB and %:
Pool_Name KB_Occupied KB_Total Percent_Occupied
system 1488245872 15435038720 9.641996363%
The policy in Example 6-64 on page 175 is configured to select files that have the file extension .IMG for migration to the IBM Spectrum Archive EE tape cartridge pool named copy_ltfsml1 in library name lib_ltfsml1 if the usage of the /ibm/gpfs file system exceeds 50% for any .IMG file that exceeds 5 MB.
Using eeadm
The eeadm migrate command requires a migration list file that contains a list of files to be migrated with the name of the target tape cartridge pool. Unlike migrating files by using IBM Spectrum Scale policy, it is not possible to use wildcards in place of file names. The name and path of each file to be migrated must be specified in full. The file must be in the following format:
•/ibm/glues/file1.mpeg
•/ibm/glues/file2.mpeg
Example 6-65 shows the output of running such a migrate command.
Example 6-65 Manual migration by using a scan result file
[root@kyoto prod]# eeadm migrate gpfs-scan.txt -p MPEGpool
2019-01-08 15:40:44 GLESL700I: Task migrate was created successfully, task id is 18864.
2019-01-08 15:40:44 GLESM896I: Starting the stage 1 of 3 for migration task 18864 (qualifying the state of migration candidate files).
2019-01-08 15:40:44 GLESM897I: Starting the stage 2 of 3 for migration task 18864 (copying the files to 1 pools).
2019-01-08 15:40:56 GLESM898I: Starting the stage 3 of 3 for migration task 18864 (changing the state of files on disk).
2019-01-08 15:40:57 GLESL038I: Migration result: 10 succeeded, 0 failed, 0 duplicate, 0 duplicate wrong pool, 0 not found, 0 too small to qualify for migration, 0 too early for migration.
Using a cron job
Migrations that use the eeadm and mmapplypolicy commands can be automated by scheduling cron jobs, which is possible by setting a cron job that periodically triggers migrations by calling mmapplypolicy with eeadm as an external program. In this case, the full path to eeadm must be specified. The following are steps to start the crond process and create a cron job:
1. Start the crond process from by running /etc/rc.d/init.d/crond start or /etc/init.d/crond start.
2. Create a crontab job by opening the crontab editor with the crontab -e command. If using VIM to edit the jobs, press i to enter insert mode to start typing.
3. Enter the frequency and command that you would like to run.
4. After entering the jobs you would like to run, exit the editor. If using VIM, press the Escape key and enter :wq. If using nano, press Ctrl + x. This combination opens the save options. Then, press y to save the file and then Enter to override the file name.
5. View that the cron job has been created by running crontab -l.
The syntax for a cron job is m h dom mon dow command. In this syntax, m stands for minutes, h stands for hours, dom stands for day of month, mon stands for month, and dow stands for day of week. The hour parameter is in a 24-hour period, so 0 represents midnight and 12 represents noon.
Example 6-66 shows how to start the crond process and create a single cron job that performs migrations every six hours.
Example 6-66 Creating a cron job for migrations to run every 6 hours
[root@ltfseesrv ~]# /etc/rc.d/init.d/crond start
Starting crond: [ OK ]
[root@ltfseesrv ~]# crontab -e
00 0,6,12,18 * * * /usr/lpp/mmfs/bin/mmapplypolicy gpfs -P /root/premigration_policy.txt -B 20000 -m 16
crontab: installing new crontab
[root@ltfseesrv ~]# crontab -l
00 0,6,12,18 * * * /usr/lpp/mmfs/bin/mmapplypolicy gpfs -P /root/premigration_policy.txt -B 20000 -m 16
6.11.4 Replicas and redundant copies
This section introduces how replicas and redundant copies are used with IBM Spectrum Archive EE and describes how to create replicas of migrated files during the migration process.
Overview
IBM Spectrum Archive EE enables the creation of a replica of each IBM Spectrum Scale file during the migration process. The purpose of the replica function is to enable creating multiple LTFS copies of each GPFS file during migration that can be used for disaster recovery, including across two tape libraries at two different locations.
The first replica is the primary copy, and more replicas are called redundant copies. Redundant copies must be created in tape cartridge pools that are different from the pool of the primary copy and from the pools of other redundant copies. Up to two redundant copies can be created (for a total of three copies of the file on various tapes).
The tape cartridge where the primary copy is stored and the tape cartridges that contain the redundant copies are referenced in the GPFS inode with an IBM Spectrum Archive EE DMAPI attribute. The primary copy is always listed first.
For transparent recalls such as double-clicks of a file or through application reads, IBM Spectrum Archive EE always performs the recall by using the primary copy tape. The primary copy is the first tape cartridge pool that is defined by the migration process. If the primary copy tape cannot be accessed, including recall failures, then IBM Spectrum Archive EE automatically tries the recall task again by using the remaining replicas if they are available during the initial migration process. This automatic retry operation is transparent to the transparent recall requester.
For selective recalls initiated by the eeadm recall command, an available copy is selected from the available replicas and the recall task is generated against the selected tape cartridge. There are no retries. The selection is based on the available copies in the tape library, which is supplied by the -l option in a two-tape library environment.
When a migrated file is recalled for a write operation or truncated, the file is marked as resident and the pointers to tape are dereferenced. The remaining copies are no longer referenced and are removed during the reconciliation process. In the case where a migrated file is truncated to 0, it does not generate a recall from tape. The truncated 0 file is marked as resident only.
Redundant copies are written to their corresponding tape cartridges in the IBM Spectrum Archive EE format. These tape cartridges can be reconciled, exported, reclaimed, or imported by using the same commands and procedures that are used for standard migration without replica creation.
Creating replicas and redundant copies
You can create replicas and redundant copies during automated IBM Spectrum Scale policy-based migrations or during manual migrations by running the eeadm migrate (or eeadm premigrate) command.
If an IBM Spectrum Scale scan is used and you use a scan policy file to specify files for migration, you must modify the OPTS line of the policy file to specify the tape cartridge pool for the primary replica and different tape cartridge pools for each redundant copy. The tape cartridge pool for the primary replica (including primary library) is listed first, followed by the tape cartridge pools for each copy (including a secondary library), as shown in Example 6-67.
A pool cannot be listed more than once in the OPTS line. If a pool is listed more than once per line, the file is not migrated. Example 6-67 shows the OPTS line in a policy file, which makes replicas of files in two tape cartridge pools in a single tape library.
Example 6-67 Extract from IBM Spectrum Scale policy file for replicas
OPTS '-p PrimPool@PrimLib CopyPool@PrimLib'
For more information about IBM Spectrum Scale policy files, see 6.11.2, “Threshold-based migration” on page 168.
If you are running the eeadm migrate (or eeadm premigrate) command, a scan list file must be passed along with the designated pools to which the user wants to migrate the files. This process can be done by calling eeadm migrate <inputfile> -p <list_of_pools> [OPTIONS] (or eeadm premigrate).
Example 6-68 shows what the scan list looks like when selecting files to migrate.
Example 6-68 Example scan list file
[root@ltfs97 /]# cat migrate.txt
-- /ibm/glues/document10.txt
-- /ibm/glues/document20.txt
Example 6-69 shows how one would run a manual migration using the eeadm migrate command on the scan list from Example 6-68 to two tapes.
Example 6-69 Creation of replicas during migration
[root@kyoto prod]# eeadm migrate migrate.txt -p pool1 pool2
2019-01-08 15:52:39 GLESL700I: Task migrate was created successfully, task id is 18866.
2019-01-08 15:52:39 GLESM896I: Starting the stage 1 of 3 for migration task 18866 (qualifying the state of migration candidate files).
2019-01-08 15:52:39 GLESM897I: Starting the stage 2 of 3 for migration task 18866 (copying the files to 2 pools).
2019-01-08 15:53:26 GLESM898I: Starting the stage 3 of 3 for migration task 18866 (changing the state of files on disk).
2019-01-08 15:53:26 GLESL038I: Migration result: 2 succeeded, 0 failed, 0 duplicate, 0 duplicate wrong pool, 0 not found, 0 too small to qualify for migration, 0 too early for migration.
IBM Spectrum Archive EE attempts to create redundant copies as efficiently as possible with a minimum number of mount and unmount steps. For example, if all tape drives are loaded with tape cartridges that belong only to the primary copy tape cartridge pool, data is written to them before IBM Spectrum Archive EE begins loading the tape cartridges that belong to the redundant copy tape cartridge pools. For more information, see 3.7, “Sizing and settings” on page 61.
By monitoring the eeadm task list and the eeadm task show command as the migration is running, you can observe the status of the migration task, as shown in Example 6-70.
Example 6-70 Migration task status
[root@mikasa1 ~]# eeadm task list
TaskID Type Priority Status #DRV CreatedTime(-0700) StartedTime(-0700)
7014 migrate M waiting 0 2019-01-08_16:11:28 2019-01-08_16:11:28
[root@mikasa1 ~]# eeadm task list
TaskID Type Priority Status #DRV CreatedTime(-0700) StartedTime(-0700)
7014 migrate M running 0 2019-01-08_16:11:28 2019-01-08_16:11:28
[root@mikasa1 ~]# eeadm task show 7014
=== Task Information ===
Task ID: 7014
Task Type: migrate
Command Parameters: eeadm migrate mig -p pool2@lib_saitama test2@lib_saitama
Status: running
Result: -
Accepted Time: Tue Jan 8 16:11:28 2019 (-0700)
Started Time: Tue Jan 8 16:11:28 2019 (-0700)
Completed Time: -
In-use Resources: 0000078PG24E(JCB745JC):pool2:G0:lib_saitama
Workload: 2 files. 2 replicas.
4566941 bytes to copy. 1 copy tasklets on pool2@lib_saitama.
4566941 bytes to copy. 1 copy tasklets on test2@lib_saitama.
Progress: -
0/1 copy tasklets completed on pool2@lib_saitama.
0/1 copy tasklets completed on test2@lib_saitama.
Result Summary: -
[root@mikasa1 ~]# eeadm task show 7014
=== Task Information ===
Task ID: 7014
Task Type: migrate
Command Parameters: eeadm migrate mig -p pool2@lib_saitama test2@lib_saitama
Status: completed
Result: succeeded
Accepted Time: Tue Jan 8 16:11:28 2019 (-0700)
Started Time: Tue Jan 8 16:11:28 2019 (-0700)
Completed Time: Tue Jan 8 16:12:14 2019 (-0700)
Workload: 2 files. 2 replicas.
4566941 bytes to copy. 1 copy tasklets on pool2@lib_saitama.
4566941 bytes to copy. 1 copy tasklets on test2@lib_saitama.
Progress: -
1/1 copy tasklets completed on pool2@lib_saitama.
1/1 copy tasklets completed on test2@lib_saitama.
Result Summary: 2 succeeded, 0 failed, 0 duplicate, 0 duplicate wrong pool, 0 not found, 0 too small, 0 too early.
(GLESM899I) All files have been successfully copied on pool2/lib_saitama.
(GLESM899I) All files have been successfully copied on test2/lib_saitama.
For more information and command syntax, see the eeadm migrate command in 6.11, “Migration” on page 165.
Considerations
Consider the following points when replicas are used:
•Redundant copies must be created in different tape cartridge pools. The pool of the primary replica must be different from the pool for the first redundant copy, which, in turn, must be different from the pool for the second redundant copy.
•The migration of a premigrated file does not create replicas.
If offsite tapes are required, redundant copies can be exported out of the tape library and shipped to an offsite location after running the eeadm tape export or eeadm tape offline, depending on how the data should be kept. A second option would be to create the redundant copy in a different tape library.
6.11.5 Data Migration
Because of the need to upgrade tape generations or reuse tape cartridges, IBM Spectrum Archive EE allows users to specify to which tape cartridges they want their data to be migrated. Use the eeadm tape datamigrate command to perform pool-to-pool file migrations. This is ideal to use when newer tape generations are being introduced into the user’s environment and the older generations are no longer needed.
Data on older generation media can be moved as a whole within a pool or specific tapes can be chosen in chunks. Example 6-71 shows how users can use the eeadm tape datamigrate command to migrate their data from an older generation pool to a newer one.
Example 6-71 Migrating data to newer generation tape pool
[root@mikasa1 ~]# eeadm tape datamigrate -p test3 -d test4 -l lib2
2021-03-24 04:23:29 GLESL700I: Task datamigrate was created successfully, task ID is 1155.
2021-03-24 04:23:29 GLESR216I: Multiple processes started in parallel. The maximum number of processes is unlimited.
2021-03-24 04:23:29 GLESL385I: Starting the "eeadm tape datamigrate" command by the reclaim operation.
Processing 1 tapes in the following list of tapes from source pool test3. The files on the tapes are moved to the tapes in target pool test4:
2021-03-24 04:23:29 GLESR212I: Source candidates: JCA561JC .
2021-03-24 04:23:29 GLESL677I: Files on tape JCA561JC will be copied to tape JCB370JC.
2021-03-24 04:28:55 GLESL081I: Tape JCA561JC successfully reclaimed as datamigrate process, formatted, and unassigned from tape pool test3.
2021-03-24 04:28:55 GLESL080I: Reclamation complete as the datamigrate command. 1 tapes reclaimed, 1 tapes unassigned from the tape pool.
For the eeadm tape datamigrate command syntax, see “The eeadm <resource type> <action> --help command” on page 317.
|
Note: If the tapes are not specified for eeadm tape reclaim, the tapes being reclaimed remain in the source pool. If the tapes are specified with the eeadm tape datamigrate command, those tapes will be removed from the source pool after the reclamation completes.
|
In addition to the pool-to-pool data migration, users can perform in-pool data migration by configuring the pool settings and modifying the media_restriction or format type to make older generation media become append_fenced. By doing so, in addition to securing future migration tasks go to newer generation media this also enables users to run reclamation on those older generation tape cartridges and have assurance that the data is reclaimed onto the new generation medias.
When changing the media_restriction attribute of the pool, the format type is also automatically updated to the highest generation drive available to the cluster. The format attribute is automatically updated only after each time the media_restriction is modified. If new drive and media generations are added to a cluster with media_restriction already set, users are expected to update format or media_restriction manually to support new media generations.
Example 6-72 on page 181 shows the automatic format update when changing the media_restriction attribute from JC to JE when there are TS1160, TS1155, and TS1150 drives.
Example 6-72 Updating pool media_restriction
[root@mikasa1 prod]# eeadm pool show test3 -l lib_saitama
Attribute Value
poolname test3
poolid 99096daa-0beb-4791-b24f-672804a56440
devtype 3592
mediarestriction JC
format E08 (0x55)
worm no (0)
nodegroup G0
fillpolicy Default
owner System
mountlimit 0
lowspacewarningenable yes
lowspacewarningthreshold 0
nospacewarningenable yes
mode normal
[root@mikasa1 prod]# eeadm pool set test3 -l lib_saitama -a mediarestriction -v JE
[root@mikasa1 prod]# eeadm pool show test3 -l lib_saitama
Attribute Value
poolname test3
poolid 99096daa-0beb-4791-b24f-672804a56440
devtype 3592
mediarestriction JE
format 60F (0x57)
worm no (0)
nodegroup G0
fillpolicy Default
owner System
mountlimit 0
lowspacewarningenable yes
lowspacewarningthreshold 0
nospacewarningenable yes
mode normal
All tapes within test3 that fall under the restriction of JE media and 60F format type are all appendable tapes, and everything else is now append_fenced.
6.11.6 Migration hints and tips
This section provides preferred practices for successfully managing the migration of files.
Overlapping IBM Spectrum Scale policy rules
After a file is migrated to a tape cartridge pool and is in the migrated state, it cannot be migrated to other tape cartridge pools (unless it is first recalled in “resident” state).
It is preferable that you do not use overlapping IBM Spectrum Scale policy rules within different IBM Spectrum Scale policy files that can select the same files for migration to different tape cartridge pools. If a file is already migrated, a later migration fails.
In this example, an attempt is made to migrate four files to tape cartridge pool pool2. Before the migration attempt, tape JCB610JC, which is defined in a different tape cartridge pool (pool1), already contains three of the four files. The state of the files on these tape cartridges before the migration attempt is displayed by the eeadm file state command as shown in Example 6-73.
Example 6-73 Before migration
[root@mikasa1 prod]# eeadm file state *.bin
Name: /ibm/gpfs/prod/fileA.ppt
State: migrated
ID: 11151648183451819981-3451383879228984073-1939041988-3068866-0
Replicas: 1
Tape 1: JCB610JC@pool1@lib_saitama (tape state=appendable)
Name: /ibm/gpfs/prod/fileB.ppt
State: migrated
ID: 11151648183451819981-3451383879228984073-1844785692-3068794-0
Replicas: 1
Tape 1: JCB610JC@pool1@lib_saitama (tape state=appendable)
Name: /ibm/gpfs/prod/fileC.ppt
State: migrated
ID: 11151648183451819981-3451383879228984073-373707969-3068783-0
Replicas: 1
Tape 1: JCB610JC@pool1@lib_saitama (tape state=appendable)
Name: /ibm/gpfs/prod/fileD.ppt
State: resident
The attempt to migrate the files to a different tape cartridge pool produces the results that are shown in Example 6-74.
Example 6-74 Attempted migration of already migrated files
[root@mikasa1 prod]# eeadm migrate mig -p pool2@lib_saitama
2019-01-09 15:07:18 GLESL700I: Task migrate was created successfully, task id is 7110.
2019-01-09 15:07:18 GLESM896I: Starting the stage 1 of 3 for migration task 7110 (qualifying the state of migration candidate files).
2019-01-09 15:07:18 GLESM897I: Starting the stage 2 of 3 for migration task 7110 (copying the files to 1 pools).
2019-01-09 15:07:30 GLESM898I: Starting the stage 3 of 3 for migration task 7110 (changing the state of files on disk).
2019-01-09 15:07:31 GLESL159E: Not all migration has been successful.
2019-01-09 15:07:31 GLESL038I: Migration result: 1 succeeded, 3 failed, 0 duplicate, 0 duplicate wrong pool, 0 not found, 0 too small to qualify for migration, 0 too early for migration.
If the IBM Spectrum Archive EE log is viewed, the error messages that are shown in Example 6-75 explain the reason for the failures.
Example 6-75 Migration errors reported in the IBM Spectrum Archive EE log file
2019-01-09T15:07:18.713348-07:00 saitama2 mmm[22592]: GLESM148E(00710): File /ibm/gpfs/prod/fileA.ppt is already migrated and will be skipped.
2019-01-09T15:07:18.714413-07:00 saitama2 mmm[22592]: GLESM148E(00710): File /ibm/gpfs/prod/fileB.ppt is already migrated and will be skipped.
2019-01-09T15:07:18.715196-07:00 saitama2 mmm[22592]: GLESM148E(00710): File /ibm/gpfs/prod/fileC.ppt is already migrated and will be skipped.
The files on tape JCB610JC (fileA.ppt, fileB.ppt, and fileC.ppt) are already in storage pool pool1. Therefore, the attempt to migrate them to storage pool pool2 produces a migration result of Failed. Only the attempt to migrate the resident file fileD.ppt succeeds.
If the aim of this migration was to make redundant replicas of the four PPT files in the pool2 tape cartridge pool, the method that is described in 6.11.4, “Replicas and redundant copies” on page 177 must be followed instead.
IBM Spectrum Scale policy for the .SPACEMAN directory
Prevent migration of the .SPACEMAN directory of an IBM Spectrum Scale by excluding the directory with an IBM Spectrum Scale policy rule. An example is shown in Example 6-63 on page 171.
Automated IBM Spectrum Scale policy-driven migration
To ensure that a specified GPFS file system is migrated only once, run the mmapplypolicy command with the --single-instance option. The --single-instance option ensures that multiple mmapplypolicy commands are not running in parallel because it can take longer than two minutes to migrate a list of files to tape cartridges.
Tape format
For more information about the format of tapes that are created by the migration process, see 10.2, “Formats for IBM Spectrum Scale to IBM Spectrum Archive EE migration” on page 325.
Migration Policy
A migration policy is used to make your lives easier. When run, IBM Spectrum Scale performs a scan of all candidate files in the IBM Spectrum Archive name space to be migrated onto tape. This process saves the user lots of time because they do not need to manually search their file system and find candidate files for migrations. This feature is especially important when there are millions of files created. For use cases on migration policy, see 7.10, “Use cases for mmapplypolicy” on page 244.
6.12 Premigration
A premigrated file is a file that the content is on both disk and tape. To change a file to a premigrated state, you have two options:
•Recalling migrated files:
a. The file initially is only on a disk (the file state is resident).
b. The file is migrated to tape by running eeadm migrate. After this migration, the file is a stub on the disk (the file state is migrated) and the IDs of the tapes containing the redundant copies are written to an IBM Spectrum Archive EE DMAPI attribute.
c. The file is recalled from tape by using a recall for read when a client attempts to read from the file. The content of the file is on both disk and tape (the file state is premigrated).
•Premigrating files:
a. The file initially is only on disk (the file state is resident).
b. The file is premigrated to tape by running eeadm premigrate. The IDs of the tapes that contain the redundant copies are written to an IBM Spectrum Archive EE DMAPI attribute.
Premigration works similar to migration:
•The premigration scan list file has the same format as the migration scan list file.
•Up to two more redundant copies are allowed (the same as with migration).
•Manual premigration is available by running either eeadm premigrate or mmapplypolicy.
•Automatic premigration is available by running eeadm premigrate through the mmapplypolicy/mmaddcallback command or a cron job.
•Migration hints and tips are applicable to premigration.
For the eeadm migrate command, each migrate task is achieved internally by splitting the work into three steps:
1. Writing the content of the file to tapes, including redundant copies.
2. Writing the IDs of the tapes that contain the redundant copies of the file, which are written to an IBM Spectrum Archive EE DMAPI attribute.
3. Stubbing the file on disk.
For premigration, step 3 is not performed. The omission of this step is the only difference between premigration and migration.
6.12.1 Premigration with the eeadm premigrate command
The eeadm premigrate command is used to premigrate non-empty regular files to tape. The command syntax is the same as for the eeadm migrate command. The following is an example of the syntax:
eeadm premigrate <inputfile> -p <list_of_pools> [OPTIONS]
The <input_file> file includes the list of non-empty regular files to be premigrated. Each line of this file must end with either of the following format.
•Each line ends with -- <filename> with a space before and after the double dash (the file list record format of the mmapplypolicy command).
•Each line contains a file name with an absolute path or a relative path that is based on the working directory. This format is unavailable when you run the command with the --mmbackup option.
Specified files are saved to the specified target tape cartridge pool. Optionally, the target tape cartridge pool can be followed by up to two more tape cartridge pools (for redundant copies) separated by commas.
6.12.2 Premigration running the mmapplypolicy command
To perform premigration by running the mmapplypolicy command, the THRESHOLD clause is used to determine the files for premigration. There is no IBM Spectrum Scale premigrate command, and the default behavior is to not premigrate files.
The THRESHOLD clause can have the following parameters to control migration and premigration:
THRESHOLD (high percentage, low percentage, premigrate percentage)
If no premigrate threshold is set with the THRESHOLD clause or a value is set greater than or equal to the low threshold, then the mmapplypolicy command does not premigrate files. If the premigrate threshold is set to zero, the mmapplypolicy command premigrates all files.
For example, the following rule premigrates all files if the storage pool occupancy is 0 - 30%. When the storage pool occupancy is 30% or higher, files are migrated until the storage pool occupancy drops below 30%. Then, it continues by premigrating all files:
RULE 'premig1' MIGRATE FROM POOL 'system' THRESHOLD (0,30,0) TO POOL 'ltfs'
The rule in the following example takes effect when the storage pool occupancy is higher than 50%. Then, it migrates files until the storage pool occupancy is lower than 30%, after which it premigrates the remaining files:
RULE 'premig2' MIGRATE FROM POOL 'system' THRESHOLD (50,30,0) TO POOL 'ltfs'
The rule in the following example is configured so that if the storage pool occupancy is below 30%, it selects all files that are larger than 5 MB for premigration. Otherwise, when the storage pool occupancy is 30% or higher, the policy migrates files that are larger than 5 MB until the storage pool occupancy drops below 30%.
Then, it continues by premigrating all files that are larger than 5 MB:
RULE 'premig3' MIGRATE FROM POOL 'system' THRESHOLD (0,30,0) TO POOL 'ltfs' WHERE( AND (KB_ALLOCATED > 5120))
The rule in the following example is the preferred rule when performing premigrations only. It requires a callback to perform the stubbing. If the storage pools occupancy is below 100%, it selects all files larger than 5 MB for premigration. If you set the threshold to 100% the storage pools occupancy will never exceed this value, and so migrations will not be performed. In this case, a callback is needed to run the stubbing. For an example of a callback, see 7.10.2, “Creating active archive system policies” on page 245.
RULE ‘premig4’ MIGRATE FROM POOL ‘system’ THRESHOLD (0,100,0) TO POOL ‘ltfs’ WHERE (FILE_SIZE > 5242880)
6.13 Preserving file system objects on tape
Symbolic links, empty regular files, and empty directories are some file system objects that do not contain data or content. When you save these types of file system objects, you cannot use migration and premigration commands. HSM is used to move data to and from tapes, that is, for space management.
Because these file system objects do not have data, they cannot be processed by migration or premigration. A new driver (called the save driver) was introduced to save these file system objects to tape.
The following items (data and metadata that is associated with an object) are written and read to and from tapes:
•File data for non-empty regular files
•Path and file name for all objects
•Target symbolic name only for symbolic links
•User-defined extended attributes for all objects except symbolic links
The following items are not written and read to and from tapes:
•Timestamps
•User ID and group ID
•ACLs
To save these file system objects on tape, you have two options:
•Calling the eeadm save command directly with a scan list file
•An IBM Spectrum Scale policy with the mmapplypolicy command
6.13.1 Saving file system objects with the eeadm save command
The eeadm save command is used to save symbolic links, empty regular files, and empty directories to tape. The command syntax is the same as the eeadm migrate or eeadm premigrate commands. The following is the syntax of the eeadm save command:
eeadm save <inputfile> -p <list_of_pools> [OPTIONS]
The <inputfile> file includes the list of file system objects (symbolic links, empty regular files, and empty directories) to be saved. Each line of this file must follow either of the following format.
•Each line ends with -- <filename> with a space before and after the double dash (the file list record format of the mmapplypolicy command).
•Each line contains a file name with an absolute path or a relative path that is based on the working directory. This format is unavailable when you run the command with the --mmbackup option.
All file system objects are saved to the specified target tape cartridge pool. Optionally, the target tape cartridge pool can be followed by up to two more tape cartridge pools (for redundant copies) separated by commas.
|
Note: This command is not applicable for non-empty regular files.
|
6.13.2 Saving file system objects with policies
Migration and premigration cannot be used for file system objects that do not occupy space for data. To save file system objects, such as symbolic links, empty regular files, and empty directories with an IBM Spectrum Scale policy, the IBM Spectrum Scale list rule must be used.
A working policy sample of IBM Spectrum Scale list rules to save these file system objects without data to tape can be found in the /opt/ibm/ltfsee/share/sample_save.policy file. The only change that is required to the following sample policy file is the specification of the cartridge pool (in blue colored letters).
These three list rules can be integrated into IBM Spectrum Scale policies. Example 6-76 shows the sample policy.
Example 6-76 Sample policy to save file system objects without data to tape
/*
Sample policy rules
to save
symbolic links,
empty directories and
empty regular files
*/
RULE
EXTERNAL LIST 'emptyobjects'
EXEC '/opt/ibm/ltfsee/bin/ltfseesave'
OPTS '-p sample_pool@sample_library'
define(DISP_XATTR,
CASE
WHEN XATTR($1) IS NULL
THEN '_NULL_'
ELSE XATTR($1)
END
)
RULE 'symoliclinks'
LIST 'emptyobjects'
DIRECTORIES_PLUS
/*
SHOW ('mode=' || SUBSTR(MODE,1,1) ||
' stime=' || DISP_XATTR('dmapi.IBMSTIME') ||
' ctime=' || VARCHAR(CHANGE_TIME) ||
' spath=' || DISP_XATTR('dmapi.IBMSPATH'))
*/
WHERE
( /* if the object is a symbolic link */
MISC_ATTRIBUTES LIKE '%L%'
)
AND
(
PATH_NAME NOT LIKE '%/.SpaceMan/%'
)
AND
(
( /* if the object has not been saved yet */
XATTR('dmapi.IBMSTIME') IS NULL
AND
XATTR('dmapi.IBMSPATH') IS NULL
)
OR
( /* if the object is modified or renamed after it was saved */
TIMESTAMP(XATTR('dmapi.IBMSTIME')) < TIMESTAMP(CHANGE_TIME)
OR
XATTR('dmapi.IBMSPATH') != PATH_NAME
)
)
RULE 'directories'
LIST 'emptyobjects'
DIRECTORIES_PLUS
/*
SHOW ('mode=' || SUBSTR(MODE,1,1) ||
' stime=' || DISP_XATTR('dmapi.IBMSTIME') ||
' ctime=' || VARCHAR(CHANGE_TIME) ||
' spath=' || DISP_XATTR('dmapi.IBMSPATH'))
*/
WHERE
( /* if the object is a directory */
MISC_ATTRIBUTES LIKE '%D%'
)
AND
(
PATH_NAME NOT LIKE '%/.SpaceMan'
AND
PATH_NAME NOT LIKE '%/.SpaceMan/%'
)
AND
(
( /* directory's emptiness is checked in the later processing */
/* if the object has not been saved yet */
XATTR('dmapi.IBMSTIME') IS NULL
AND
XATTR('dmapi.IBMSPATH') IS NULL
)
OR
( /* if the object is modified or renamed after it was saved */
TIMESTAMP(XATTR('dmapi.IBMSTIME')) < TIMESTAMP(CHANGE_TIME)
OR
XATTR('dmapi.IBMSPATH') != PATH_NAME
)
)
RULE 'emptyregularfiles'
LIST 'emptyobjects'
/*
SHOW ('mode=' || SUBSTR(MODE,1,1) ||
' stime=' || DISP_XATTR('dmapi.IBMSTIME') ||
' ctime=' || VARCHAR(CHANGE_TIME) ||
' spath=' || DISP_XATTR('dmapi.IBMSPATH'))
*/
WHERE
( /* if the object is a regular file */
MISC_ATTRIBUTES LIKE '%F%'
)
AND
(
PATH_NAME NOT LIKE '%/.SpaceMan/%'
)
AND
(
( /* if the size = 0 and the object has not been saved yet */
FILE_SIZE = 0
AND
XATTR('dmapi.IBMSTIME') IS NULL
AND
XATTR('dmapi.IBMSPATH') IS NULL
)
OR
( /* if the object is modified or renamed after it was saved */
FILE_SIZE = 0
AND
(
TIMESTAMP(XATTR('dmapi.IBMSTIME')) < TIMESTAMP(CHANGE_TIME)
OR
XATTR('dmapi.IBMSPATH') != PATH_NAME
)
)
)
6.14 Recall
In space management solutions, there are two different types of recall possibilities: Transparent and selective recall processing. Both are possible with the current IBM Spectrum Archive EE implementation.
Transparent recalls are initiated by an application that tries to read, write, or truncate a migrated file while not being aware that it was migrated. The specific I/O request that initiated the recall of the file is fulfilled, with a possible delay because the file data is not available immediately (it is on tape).
For transparent recalls, it is difficult to do an optimization because it is not possible to predict when the next transparent recall will happen. Some optimization is already possible because within the IBM Spectrum Archive EE task queue, the requests are run in an order that is based on the tape and the starting block to which a file is migrated. This becomes effective only if requests happen close together in time.
Furthermore, with the default IBM Spectrum Archive EE settings, there is a limitation of up to only 60 transparent recalls possible on the IBM Spectrum Archive EE task queue. A sixtyish request appears only if one of the previous 60 transparent recall requests completes. Therefore, the ordering can happen only on this small 60 transparent recall subset. It is up to the software application to send the transparent recalls in parallel to have multiple transparent recalls to run at the same time.
Selective recalls are initiated by users that are aware that the file data is on tape and they want to transfer it back to disk before an application accesses the data. This action avoids delays within the application that is accessing the corresponding files.
Contrary to transparent recalls, the performance objective for selective recalls is to provide the best possible throughput for the complete set of files that is being recalled, disregarding the response time for any individual file.
However, to provide reasonable response times for transparent recalls in scenarios where recall of many files is in progress, the processing of transparent recalls are modified to have higher priority than selective recalls. Selective recalls are performed differently than transparent recalls, and so they do not have a limitation like transparent recalls.
Recalls have higher priority than other IBM Spectrum Archive EE operations. For example, if there is a recall request for a file on a tape cartridge being reclaimed or for a file on the tape cartridge being used as reclamation target, the reclamation task is stopped, the recall or recalls from the tape cartridge that is needed for recall are served, and then the reclamation resumes automatically.
Recalls also have higher priority over tape premigration processes. They are optimized across tapes and optimized within a tape used for premigration activities. The recalls that are in close proximity are given priority.
6.14.1 Transparent recall
Transparent recall processing automatically returns migrated file data to its originating local file system when you access it. After the data is recalled by reading the file, the HSM client leaves the copy of the file in the tape cartridge pool, but changes it to a premigrated file because an identical copy exists on your local file system and in the tape cartridge pool. If you do not modify the file, it remains premigrated until it again becomes eligible for migration. A transparent recall process waits for a tape drive to become available.
If you modify or truncate a recalled file, it becomes a resident file. The next time your file system is reconciled, MMM marks the stored copy for deletion.
The order of selection from the replicas is always the same. The primary copy is always selected first from which to be recalled. If this recall from the primary copy tape fails or is not accessible, then IBM Spectrum Archive EE automatically retries the transparent recall operation against the other replicas if they exist.
|
Note: Transparent recall is used most frequently because it is activated when you access a migrated file, such as reading a file.
|
6.14.2 Selective recall using the eeadm recall command
The eeadm recall command performs selective recalls of migrated files to the local file system. This command performs selective recalls in multiple ways:
•Using a recall list file
•Using an IBM Spectrum Scale scan list file
•From the output of another command
•Using an IBM Spectrum Scale scan list file that is generated through an IBM Spectrum Scale policy and the mmapplypolicy command
With multiple tape libraries configured, the eeadm recall command requires the -l option to specify the tape library from which to recall. When a file is recalled, the recall can occur on any of the tapes (that is, either primary or redundant copies) from the specified tape library. The following conditions are applied to determine the best replica:
•The condition of the tape
•If a tape is mounted
•If a tape is mounting
•If there are tasks that are assigned to a tape
If conditions are equal between certain tapes, the primary tape is preferred over the redundant copy tapes. The secondary tape is preferred over the third tape. These rules are necessary to make the tape selection predictive. However, there are no automatic retries likes with transparent recalls.
For example, if a primary tape is not mounted but a redundant copy is, the redundant copy tape is used for the recall task to avoid unnecessary mount operations.
If the specified tape library does not have any replicas, IBM Spectrum Archive EE automatically resubmits the request to the other tape library to process the bulk recalls:
•Three copies: TAPE1@Library1 TAPE2@Library1 TAPE3@Library2
– If -l Library1 → TAPE1 or TAPE2
– If -l Library2 → TAPE3
•Two copies: TAPE1@Library1 TAPE2@Library1
– If -l Library1 → TAPE1 or TAPE2
– If -l Library2 → TAPE1 or TAPE2
The eeadm recall command
The eeadm recall command is used to recall non-empty regular files from tape. The eeadm recall command uses the following syntax:
•eeadm recall <inputfile> [OPTIONS]
The <inputfile> may contain one of two formats. Each line ends with “-- <filename>” with a space before and after the double dash. Or each line contains a file name with an absolute path or a relative path that is based on the working directory.The eeadm recall command with the output of another command.
The eeadm recall command can take as input the output of other commands through a pipe. In Example 6-77, all files with names ending with .bin are recalled under the /ibm/gpfs/prod directory, including subdirectories. Therefore, it is convenient to recall whole directories with a simple command.
Example 6-77 The eeadm recall command with the output of another command
[root@saitama2 prod]# find /ibm/gpfs/prod -name "*.bin" -print | eeadm recall -l lib_saitama
2019-01-09 15:55:02 GLESL277I: The "eeadm recall command" is called without specifying an input file waiting for standard input.
If necessary press ^D to exit.
2019-01-09 15:55:02 GLESL268I: 4 file name(s) have been provided to recall.
2019-01-09 15:55:03 GLESL700I: Task selective_recall was created successfully, task id is 7112.
2019-01-09 15:55:09 GLESL263I: Recall result: 4 succeeded, 0 failed, 0 duplicate, 0 not migrated, 0 not found, 0 unknown.
6.14.3 Read Starts Recalls: Early trigger for recalling a migrated file
IBM Spectrum Archive EE can define a stub size for migrated files so that the stub size initial bytes of a migrated file are kept on disk while the entire file is migrated to tape. The migrated file bytes that are kept on the disk are called the stub. Reading from the stub does not trigger a recall of the rest of the file. After the file is read beyond the stub, the recall is triggered. The recall might take a long time while the entire file is read from tape because a tape mount might be required, and it takes time to position the tape before data can be recalled from tape.
When Read Start Recalls (RSR) is enabled for a file, the first read from the stub file triggers a recall of the complete file in the background (asynchronous). Reads from the stubs are still possible while the rest of the file is being recalled. After the rest of the file is recalled to disks, reads from any file part are possible.
With the Preview Size (PS) value, a preview size can be set to define the initial file part size for which any reads from the resident file part does not trigger a recall. Typically, the PS value is large enough to see whether a recall of the rest of the file is required without triggering a recall for reading from every stub. This process is important to prevent unintended massive recalls. The PS value can be set only smaller than or equal to the stub size.
This feature is useful, for example, when playing migrated video files. While the initial stub size part of a video file is played, the rest of the video file can be recalled to prevent a pause when it plays beyond the stub size. You must set the stub size and preview size to be large enough to buffer the time that is required to recall the file from tape without triggering recall storms.
Use the following dsmmigfs command options to set both the stub size and preview size of the file system being managed by IBM Spectrum Archive EE:
dsmmigfs Update -STUBsize
dsmmigfs Update -PREViewsize
The value for the STUBsize is a multiple of the IBM Spectrum Scale file system’s block size. this value can be obtained by running the mmlsfs <filesystem>. The PREViewsize parameter must be equal to or less than the STUBsize value. Both parameters take a positive integer in bytes.
Example 6-78 shows how to set both the STUBsize and PREViewsize on the IBM Spectrum Scale file system.
Example 6-78 Updating STUBsize and PREViewsize
[root@kyoto prod]# dsmmigfs Update -STUBsize=3145728 -PREViewsize=1048576 /ibm/gpfs
IBM Spectrum Protect
Command Line Space Management Client Interface
Client Version 8, Release 1, Level 6.0
Client date/time: 01/11/2019 12:42:20
(c) Copyright by IBM Corporation and other(s) 1990, 2018. All Rights Reserved.
ANS9068I dsmmigfs: dsmmigfstab file updated for file system /ibm/gpfs.
For more information about the dsmmigfs update command, see IBM Documentation.
6.14.4 Recommend Access Order
The Recommended Access Order (RAO) is a feature provided by drives1 that serves a method to enable efficient recalls of files from a single cartridge. Drives that support RAO will give the most efficient access order when reading multiple records in a tape cartridge.
In a recall, IBM Spectrum Archive EE will queue the tasks to send requests in an order that is based on tape and starting blocks (refer to 6.14, “Recall” on page 190). This reading optimization is efficient when significantly large numbers of files that are located in linear positions of the tape are requested. However, in a case where the requested files are distributed across multiple bands and wraps, this optimization method was not as effective since the data could not be read efficiently with a simple linear read.
RAO was introduced to address such cases. Though additional calculation time will be needed to create the recommended reading order of files, effective use of RAO will decrease read time significantly in an ideal case.
Figure 6-1 is a conceptual diagram displaying the seeking path of five files based on block order. The dotted arrows represents the servo head seek path, in this case, starting from File 1 and ending with File 5.
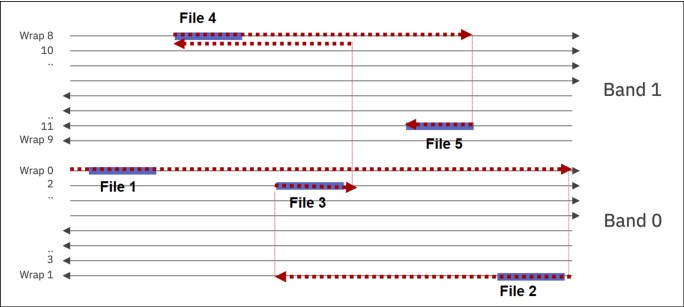
Figure 6-1 A conceptual diagram displaying the seek path of files based on block order
In contrast, Figure 6-2 shows the servo head movement when same files are read based on RAO. When compared with the previous figure, the total seek path length represented with the dotted arrow will be significantly shorter in RAO, therefore indicating that the total recall time will be reduced.

Figure 6-2 A conceptual diagram displaying the seek path of files based on RAO
Though RAO is a powerful feature, there are cases where it will not be effective. As addressed above, one example of such cases is when there are massive numbers of files to read from a cartridge. In such cases, a block sorted read of a cartridge is the more reasonable choice.
To address such cases, IBM Spectrum Archive EE provides an automatic transition of the two methods during recall requests.
This automatic transition includes the following features:
•File queuing on recall requests to same cartridges
When possible, multiple recall requests to a single cartridge will be joined into a single RAO request queue. In this case, the RAO requests will be joined up to a 2,700 file queue in prospect to reduce the total reading time.
•RAO usage decision on cases where large number of files are recalled
IBM Spectrum Archive EE will automatically switch to a block order recalling method when recall requests sum to 5,400 file mark for a single cartridge.2
•RAO usage decision on supported cartridges and drives
RAO function will not be used if there are no compatible drives and media available in the library. Refer to the IBM Documentation - Supported tape drives and media for compatible drives and media.
|
Note: For more information on RAO interface specification, refer to the INCITS 503-202x: Information technology - SCSI Stream Commands - 5 (SSC-5) Overview standard document.
|
Manual configuration of RAO
IBM Spectrum Archive EE provides a RAO global and local enabling/disabling switch for manually controlling the RAO feature.
Leaving the RAO usage on (or in “auto”) is generally recommended in most cases, though turning the RAO feature off may come to consideration if:
•Recalls are always made with large numbers of files (more than 5400 files) from a single cartridge, at a time.
•IBM Spectrum Archive EE is unable to support the RAO feature since there are no supported drives or media in the library.
RAO function can be globally enabled or disabled with the recall_use_rao option in the eeadm cluster set command. The default setting is “auto”. Example shows how to disable and enable the RAO feature.Globally configuring the RAO feature
[root@mikasa1 ~]# eeadm cluster set -a recall_use_rao -v disable
2021-10-11 16:29:58 GLESL802I: Updated attribute recall_use_rao.
[root@mikasa1 ~]# eeadm cluster set -a recall_use_rao -v auto
2021-10-11 16:30:58 GLESL802I: Updated attribute recall_use_rao.
Current settings can be found with the cluster show command (see Example 6-79).
Example 6-79 Showing current settings of the RAO feature
[root@mikasa1 ~]# eeadm cluster show
Attribute Value
..
recall_use_rao auto
The global RAO usage switch can be overridden locally in a recall command with the --use-rao option (see Example 6-80).
Example 6-80 Overriding global RAO switch with local recall command
..
6.15 Recalling files to their resident state
This section describes the eeadm recall command using the --resident option. However, this command should rarely be used. The eeadm recall --resident command is used to repair a file or object by changing the state to Resident when the tape (or tapes) that are used for migration, premigration, or save are not available.
The eeadm recall --resident command will recall the files back initially if the files are migrated then mark the files resident and remove the link between disk and tape. If the files are already premigrated the recall operation will be skipped and will just mark the files resident. This option removes metadata on IBM Spectrum Scale, which is used for keeping the file/object state.
A typical usage of the eeadm recall --resident command is a user accidentally migrates/premigrates one or more files to the wrong tape or has forgotten to make a copy.
Example 6-81 shows the output of making a file resident.
Example 6-81 Making a migrated file resident again
[root@mikasa1 recallsample]# eeadm file state migrecfile2.txt
Name: /ibm/gpfs/recallsample/migrecfile2.txt
State: migrated
ID: 11151648183451819981-8790189057502350089-1392721861-159785-0
Replicas: 1
Tape 1: MB0241JE@Arnoldpool@lib1 (tape state=appendable)
[root@mikasa1 recallsample]# eeadm recall migreclist.txt --resident
2021-03-21 07:17:26 GLESL268I: 1 file name(s) have been provided to recall.
2021-03-21 07:17:26 GLESL700I: Task selective_recall was created successfully, task ID is 1089.
2021-03-21 07:17:29 GLESL839I: All 1 file(s) has been successfully processed.
2021-03-21 07:17:29 GLESL845I: Succeeded: 1 resident, 0 already_resident
[root@mikasa1 recallsample]# eeadm file state migrecfile2.txt
Name: /ibm/gpfs/recallsample/migrecfile2.txt
State: resident
|
Note: migreclist.txt contains the list of files to be recalled. In this case, it contains only ‘migrecfile2.txt’.
|
6.16 Reconciliation
This section describes file reconciliation with IBM Spectrum Archive EE and presents considerations for the reconciliation process.
HSM is not notified upon moves, renames, or deletions of files in IBM Spectrum Scale. Therefore, over time the metadata of migrated files on IBM Spectrum Scale can diverge from their equivalents on LTFS. The goal of the reconciliation function is to synchronize the IBM Spectrum Scale namespace with the corresponding LTFS namespace (per tape cartridge) and the corresponding LTFS attributes (per tape cartridge).
The reconciliation process resolves any inconsistencies that develop between files in the IBM Spectrum Scale and their equivalents in IBM Spectrum Archive EE. When files are deleted, moved, or renamed in IBM Spectrum Scale, the metadata of those files becomes out of sync with their copies in LTFS.
By performing file reconciliation, it is possible to synchronize the IBM Spectrum Scale namespace and attributes that are stored in LTFS (on tape cartridges) with the current IBM Spectrum Scale namespace and attributes. Note however that the reconciliation works on only tape cartridges that were used in IBM Spectrum Archive EE. Tapes that were not used in LTFS Library Edition (LE) cannot be reconciled.
For each file that was deleted in IBM Spectrum Scale, the reconciliation process deletes the corresponding LTFS files and symbolic links. If the parent directory of the deleted symbolic link is empty, the parent directory is also deleted. This process frees capacity resources that were needed for storing the LTFS index entries of those deleted files.
For each IBM Spectrum Scale file that was moved or renamed in IBM Spectrum Scale, the reconciliation process updates for each LTFS instance (replica) of that IBM Spectrum Scale file the LTFS extended attribute that contains the IBM Spectrum Scale path and the LTFS symbolic link.
Reconciliation can be performed on one or more GPFS file systems, one or more tape cartridge pools, or a set of tape cartridges. When the reconciliation process involves multiple tape cartridges, multiple IBM Spectrum Archive EE nodes and tape drives can be used in parallel. However, because recall tasks have priority, only available tape drives are used for reconciliation. After reconciliation is started, the tape cartridge cannot be unmounted until the process completes.
The synchronization and update to the IBM Spectrum Archive EE tapes can be time consuming and normally only required before any eeadm tape export command. Normally if files are deleted from the IBM Spectrum Scale file systems, merely the update for the amount of reclaimable space is sufficient information. In other words, as files are deleted, administrators only want to know how much space can be reclaimed. Thus starting with v1.3.0.0, the default for eeadm tape reconcile is to only update internal metadata information in order to correctly reflect the Reclaimable% column of the eeadm tape list command. In order to update the tape (like previous to v1.3.0.0), the --commit-to-tape option should be supplied as part of the eeadm tape reconcile command.
The following list presents limitations of the reconciliation process:
1. Only one reconciliation process can be started at a time. If an attempt is made to start a reconciliation process while another process is running, the attempt fails. The eeadm tape reconcile command fails and the following failure message appears:
GLESL098E: The same type of task or conflicting task was previously requested and it is running. Wait for completion of the task and try again.
2. After a reconciliation process is started, new migration tasks are prevented until the reconciliation process completes on the reconciling tapes. However, if any migration tasks are running, the reconciliation process does not begin until all migration tasks complete.
3. Recalls from a tape cartridge being reconciled are not available while the reconciliation process is updating the index for that tape cartridge, which is a short step in the overall reconciliation process.
The command outputs in the following examples show the effect that reconciliation has on the Reclaimable% column after that file is deleted from the IBM Spectrum Scale file system. Example 6-82 shows the initial file state of a single file on tape.
Example 6-82 Display the file state of a migrated file
[root@ueno ~]# eeadm file state /gpfs/gpfs0/cmt/md1/files/LTFS_EE_FILE_mQH4oCZXQZKSXc6cYZjAuXPnAFq56QBWJmY66PcuVnAIW6BkrK_gzCwGJ.bin
Name: /gpfs/gpfs0/cmt/md1/files/LTFS_EE_FILE_mQH4oCZXQZKSXc6cYZjAuXPnAFq56QBWJmY66PcuVnAIW6BkrK_gzCwGJ.bin
State: premigrated
ID: 9226311045824247518-17452468188422870573-2026950408-6649759-0
Replicas: 3
Tape 1: P1B064JE@ueno@perf_lib (tape state=appendable)
Tape 2: P1B076JE@kanda@perf_lib (tape state=appendable)
Tape 3: P1B073JE@shimbashi@perf_lib (tape state=appendable)
The file is also present on the IBM Spectrum Scale file system, as shown in Example 6-83.
Example 6-83 List the file on the IBM Spectrum Scale file system
[root@ueno ~]# ls -hl /gpfs/gpfs0/cmt/md1/files/LTFS_EE_FILE_mQH4oCZXQZKSXc6cYZjAuXPnAFq56QBWJmY66PcuVnAIW6BkrK_gzCwGJ.bin
-rw------- 1 root root 1.8G Nov 12 15:29 /gpfs/gpfs0/cmt/md1/files/LTFS_EE_FILE_mQH4oCZXQZKSXc6cYZjAuXPnAFq56QBWJmY66PcuVnAIW6BkrK_gzCwGJ.bin
At this point, this file can be removed with the rm command. After the file is removed, IBM Spectrum Archive EE has the reclaimable space information from eeadm tape list for these tapes (see Example 6-84).
Example 6-84 Tape list tn IBM Spectrum Archive EE
[root@ueno ~]# eeadm tape list | egrep "Tape|P1B064JE|P1B076JE|P1B073JE"
Tape ID Status State Usable(GiB) Used(GiB) Available(GiB) Reclaimable% Pool Library Location Task ID
P1B073JE ok appendable 18147 18137 9 0% shimbashi perf_lib homeslot -
P1B064JE ok appendable 18147 18134 12 0% ueno perf_lib drive -
P1B076JE ok appendable 18147 18140 6 0% kanda perf_lib homeslot -
If you perform a reconciliation of the tape now using the default settings, IBM Spectrum Archive EE only updates the amount of reclaimable space on the tape within the internal metadata structure, as shown in Example 6-85.
Example 6-85 Reconcile the tape
[root@ueno ~]# eeadm tape reconcile P1B064JE -p ueno
2018-12-07 12:31:21 GLESL700I: Task reconcile was created successfully, task id is 5585.
2018-12-07 12:31:21 GLESS016I: Reconciliation requested.
2018-12-07 12:31:22 GLESS050I: GPFS file systems involved: /gpfs/gpfs0 .
2018-12-07 12:31:22 GLESS210I: Valid tapes in the pool: MB0247JE P1B064JE P1B067JE P1B063JE P1B074JE .
2018-12-07 12:31:22 GLESS049I: Tapes to reconcile: P1B064JE .
2018-12-07 12:31:22 GLESS134I: Reserving tapes for reconciliation.
2018-12-07 12:31:22 GLESS135I: Reserved tapes: P1B064JE .
2018-12-07 12:31:22 GLESS054I: Creating GPFS snapshots:
2018-12-07 12:31:22 GLESS055I: Deleting the previous reconcile snapshot and creating a new one for /gpfs/gpfs0 ( gpfs0 ).
2018-12-07 12:31:25 GLESS056I: Searching GPFS snapshots:
2018-12-07 12:31:25 GLESS057I: Searching GPFS snapshot of /gpfs/gpfs0 ( gpfs0 ).
2018-12-07 12:31:44 GLESS060I: Processing the file lists:
2018-12-07 12:31:44 GLESS061I: Processing the file list for /gpfs/gpfs0 ( gpfs0 ).
2018-12-07 12:33:52 GLESS141I: Removing stale DMAPI attributes:
2018-12-07 12:33:52 GLESS142I: Removing stale DMAPI attributes for /gpfs/gpfs0 ( gpfs0 ).
2018-12-07 12:33:52 GLESS063I: Reconciling the tapes:
2018-12-07 12:33:52 GLESS248I: Reconcile tape P1B064JE.
2018-12-07 12:37:19 GLESS002I: Reconciling tape P1B064JE complete.
2018-12-07 12:37:19 GLESS249I: Releasing reservation of tape P1B064JE.
2018-12-07 12:37:19 GLESS058I: Removing GPFS snapshots:
2018-12-07 12:37:19 GLESS059I: Removing GPFS snapshot of /gpfs/gpfs0 ( gpfs0 ).
If you now list the tapes with eeadm tape list, you may see that the reclaimable space percentage be increased due to the deleted files (because it is in percentage and not in GBs, the size of deletion need to be large to see a percentage change).
6.17 Reclamation
The space on tape that is occupied by deleted files is not reused during normal IBM Spectrum Archive EE operations. New data is always written after the last index on tape. The process of reclamation is similar to the same named process in IBM Spectrum Protect environment because all active files are consolidated onto a new, empty, second tape cartridge. This process improves overall tape usage and utilization.
When files are deleted, overwritten, or edited on IBM Spectrum Archive EE tape cartridges, it is possible to reclaim the space. The reclamation function of IBM Spectrum Archive EE frees tape space that is occupied by non-referenced files and non-referenced content that is present on the tape. The reclamation process copies the files that are referenced by the LTFS index of the tape cartridge being reclaimed to another tape cartridge, updates the GPFS/IBM Spectrum Scale inode information, and then reformats the tape cartridge that is being reclaimed.
6.17.1 Reclamation considerations
The following considerations should be reviewed before the reclamation function is used:
•Reconcile before reclaiming tape cartridges
It is preferable to perform a reconciliation of the set of tape cartridges that are being reclaimed before the reclamation process is initiated. For more information, see 6.16, “Reconciliation” on page 197. If this is not performed, the reclamation might fail with a message that recommends to perform a reconcile.
•Scheduled reclamation
It is preferable to schedule periodically reclamation for the IBM Spectrum Archive EE tape cartridge pools.
•Recall priority
Recalls are prioritized over reclamation. If there is a recall request for a file on a tape cartridge that is being reclaimed or for a file on the tape cartridge being used as the reclamation target, the reclamation task is stopped for the recall. After the recall is complete, the reclamation resumes automatically.
•Tape drives used for reclamation
To reclaim a tape cartridge, two tape drives with the “g” role attribute on the same node will be used. When multiple tapes cartridges are specified for reclamation, the reclaim function will try to use as many tape drives as it needs to process the multiple reclamation in parallel. There is an option to the command to limit the number of concurrent reclamation process thus limiting the number of tape drives that will be used at once.
Use the eeadm tape reclaim command to start reclamation of a specified tape cartridge pool or of certain tape cartridges within a specified tape cartridge pool. The eeadm tape reclaim command is also used to specify thresholds that indicate when reclamation is performed by the percentage of the available capacity on a tape cartridge.
Example 6-86 shows the results of reclaiming a single tape cartridge 058AGWL5.
Example 6-86 Reclamation of a single tape cartridge
[root@mikasa1 ~]# eeadm tape reclaim JCB370JC -p pool1 -l lib2
2021-03-24 04:08:49 GLESL700I: Task reclaim was created successfully, task ID is 1149.
2021-03-24 04:08:49 GLESR216I: Multiple processes started in parallel. The maximum number of processes is unlimited.
2021-03-24 04:08:49 GLESL084I: Start reclaiming 1 tapes in the following list of tapes:
2021-03-24 04:08:49 GLESR212I: Source candidates: JCB370JC .
2021-03-24 04:08:49 GLESL677I: Files on tape JCB370JC will be copied to tape JCA561JC.
2021-03-24 04:14:30 GLESL085I: Tape JCB370JC successfully reclaimed, it remains in tape pool Arnoldpool2.
2021-03-24 04:14:30 GLESL080I: Reclamation complete. 1 tapes reclaimed, 0 tapes unassigned from the tape pool.
At the end of the process, the tape cartridge is reformatted. The tape remains in the tape cartridge pool unless the “--unassign” option is specified. For more information, see , “The eeadm <resource type> --help command” on page 316.
6.18 Checking and repairing tapes
There are three tape states that can occur on a tape which helps inform the user to perform a check. Once the root cause of the status is determined use the eeadm tape validate command to perform a check on the tapes and update the state back to appendable. All three states will prevent further migration and recall tasks to those tapes effected, therefore it is important to resolve the issues found and clear the states. The following are the check tape states:
•check_tape_library
tapes fall into this state when they fail to get mounted to a drive, or is stuck in a drive and failed to get unmounted.
•require_validate
tapes fall into this state when the system detects some metadata mismatches on the tape.
•check_key_server
tapes fall into this state when there is a single tape that failed a write or read requiring an encryption key from an encryption key server.
Example 6-87 shows a tape in the check_key_server state and using the eeadm tape validate to restore its state back to appendable or full after fixing the encryption key server.
Example 6-87 Restoring a check_key_server tape back to appendable
[root@saitama2 ~]# eeadm tape list -l lib_mikasa
Tape ID Status State Usable(GiB) Used(GiB) Available(GiB) Reclaimable% Pool Library Location Task ID
MB0021JM error check_key_server 0 0 0 0% pool2 lib_mikasa homeslot -
[root@saitama2 ~]# eeadm tape validate MB0021JM -p pool2 -l lib_mikasa
2019-01-10 11:27:24 GLESL700I: Task tape_validate was created successfully, task id is 7125.
2019-01-10 11:28:41 GLESL388I: Tape MB0021JM is successfully validated.
[root@saitama2 ~]# eeadm tape list -l lib_mikasa
Tape ID Status State Usable(GiB) Used(GiB) Available(GiB) Reclaimable% Pool Library Location Task ID
MB0021JM ok appendable 4536 4536 0 0% pool2 lib_mikasa homeslot -
Two other tape states exist that require the user to replace the tapes. These two states occur when a tape encounters a read or write failure, and can be remedied by using the eeadm tape replace command. This command moves the data off the bad tape and onto an appendable tape within the same pool maintaining the migration order and finally removing the bad tape from the pool. The following are the two replacement tape states:
•need_replace
The IBM Spectrum Archive EE system detected one or more permanent read errors on this tape
•require_replace
The IBM Spectrum Archive EE system detected a permanent write error on the tape.
Example 6-88 shows the output of running the eeadm tape replace command
Example 6-88 eeadm tape replace
[root@mikasa1 prod]# eeadm tape replace JCB206JC -p test -l lib_mikasa
2018-10-09 10:51:58 GLESL700I: Task tape_replace was queued successfully, task id is 27382.
2018-10-09 10:51:58 GLESL755I: Kick reconcile before replace against 1 tapes.
2018-10-09 10:52:57 GLESS002I: Reconciling tape JCB206JC complete.
2018-10-09 10:52:58 GLESL756I: Reconcile before replace was finished.
2018-10-09 10:52:58 GLESL753I: Starting tape replace for JCB206JC.
2018-10-09 10:52:58 GLESL754I: Found a target tape for tape replace (MB0241JE).
2018-10-09 10:55:05 GLESL749I: Tape replace for JCB206JC is successfully done.
For more information about the various tape cartridge states, see 10.1.4, “Tape status codes” on page 320.
6.19 Importing and exporting
The import and export processes are the mechanisms for moving data on the LTFS written tape cartridges into or out of the IBM Spectrum Archive EE environment.
6.19.1 Importing
Import tape cartridges to your IBM Spectrum Archive EE system by running the eeadm tape import <list_of_tapes> -p <pool> [-l <library>] [OPTIONS] command.
When you import a tape cartridge, the eeadm tape import command performs the following actions:
1. Adds the specified tape cartridge to the IBM Spectrum Archive EE library
2. Assigns the tape to the designated pool
3. Adds the file stubs in an import directory within the IBM Spectrum Scale file system
Example 6-89 shows the import of an LTFS tape cartridge that was created on a different LTFS system into a directory that is called FC0257L8 in the /ibm/gpfs file system.
Example 6-89 Import an LTFS tape cartridge
[root@ginza ~] eeadm tape import FC0257L8 -p pool1 -P /ibm/gpfs/
2019-02-26 09:52:15 GLESL700I: Task import was created successfully, task id is 2432
2019-02-26 09:54:33 GLESL064I: Import of tape FC0257L8 complete.
Importing file paths
The default import file path for the eeadm tape import command is /{GPFS file system}/IMPORT. As shown in Example 6-90, if no other parameters are specified on the command line, all files are restored to the ../IMPORT/{VOLSER} directory under the GPFS file system.
Example 6-90 Import by using default parameters
[root@saitama2 ~]# eeadm tape import JCB610JC -p test3 -l lib_saitama
2019-01-10 13:33:12 GLESL700I: Task import was created successfully, task id is 7132.
2019-01-10 13:34:51 GLESL064I: Import of tape JCB610JC complete.
[root@saitama2 ~]# ls -las /ibm/gpfs/IMPORT/
JCB610JC/
Example 6-91 on page 203 shows the use of the -P parameter, which can be used to redirect the imported files to an alternative directory. The VOLSER is still used in the directory name, but you can now specify a custom import file path by using the -P option. If the specified path does not exist, it is created.
Example 6-91 Import by using the -P parameter
[root@saitama2 gpfs]# eeadm tape import JCB610JC -p test3 -l lib_saitama -P /ibm/gpfs/alternate
2019-01-10 14:20:54 GLESL700I: Task import was created successfully, task id is 7139.
2019-01-10 14:22:30 GLESL064I: Import of tape JCB610JC complete.
[root@saitama2 gpfs]# ls /ibm/gpfs/alternate/
JCB610JC
With each of these parameters, you have the option of renaming imported files by using the --rename parameters. This option will only rename any imported files with conflicting names by appending the suffix “_i” where i is a number from 1 to n.
Importing offline tape cartridges
For more information about offline tape cartridges, see 6.19.2, “Exporting tape cartridges” on page 204. Offline tape cartridges can be reimported to the IBM Spectrum Scale namespace by running the eeadm tape online command.
When the tape cartridge is offline and outside the library, the IBM Spectrum Scale offline files on disk or the files on tape cartridge should not be modified.
Example 6-92 shows an example of making an offline tape cartridge online.
Example 6-92 Online an offline tape cartridge
[root@saitama2 ~]# eeadm tape online JCB610JC -p test3 -l lib_saitama
2019-01-10 14:42:36 GLESL700I: Task import was created successfully, task id is 7143.
2019-01-10 14:44:11 GLESL064I: Import of tape JCB610JC complete.
6.19.2 Exporting tape cartridges
Export tape cartridges from your IBM Spectrum Archive EE system by running the eeadm tape export command. When you export a tape cartridge, the process removes the tape cartridge from the IBM Spectrum Archive EE library. The tape cartridge is reserved so that it is no longer a target for file migrations. It is then reconciled to remove any inconsistencies between it and IBM Spectrum Scale.
The export process then removes all files from the IBM Spectrum Scale file system that exist on the exported tape cartridge. The files on the tape cartridges are unchanged by the export, and are accessible by other LTFS systems.
Export considerations
Consider the following information when planning IBM Spectrum Archive EE export activities:
•If you put different logical parts of an IBM Spectrum Scale namespace (such as the project directory) into different LTFS tape cartridge pools, you can export tape cartridges that contain the entire IBM Spectrum Scale namespace or only the files from a specific directory within the namespace.
Otherwise, you must first recall all the files from the namespace of interest (such as the project directory), then migrate the recalled files to an empty tape cartridge pool, and then export that tape cartridge pool.
•Reconcile occurs automatically before the export is processed.
Although the practice is not preferable, tape cartridges can be physically removed from IBM Spectrum Archive EE without exporting them. In this case, no changes are made to the IBM Spectrum Scale inode. The following results can occur:
•Causes a file operation that requires access to the removed tape cartridge to fail. No information as to where the tape cartridges are is available.
•Files on an LTFS tape cartridge can be replaced in IBM Spectrum Archive EE without reimporting (that is, without updating anything in IBM Spectrum Scale). This process is equivalent to a library going offline and then being brought back online without taking any action in the IBM Spectrum Scale namespace or management.
|
Important: If a tape cartridge is removed from the library without the use of the export utility, modified, and then reinserted in the library, the behavior can be unpredictable.
|
Exporting tape cartridges
The normal export of an IBM Spectrum Archive EE tape cartridge first reconciles the tape cartridge to correct any inconsistencies between it and IBM Spectrum Scale. Then, it removes all files from the IBM Spectrum Scale file system that exist on the exported tape cartridge.
Example 6-93 shows the typical output from the export command.
Example 6-93 Export a tape cartridge
[root@mikasa1 recallsample]# eeadm tape export JCB370JC -p test3-l lib2 --remove
2021-03-24 03:30:16 GLESL700I: Task export_remove was created successfully, task ID is 1139.
2021-03-24 03:30:16 GLESS134I: Reserving tapes.
2021-03-24 03:30:16 GLESS269I: JCB370JC is mounted. Moving to homeslot.
2021-03-24 03:31:13 GLESS135I: Reserved tapes: JCB370JC .
2021-03-24 03:31:13 GLESL719I: Reconcile as a part of an export is starting.
2021-03-24 03:32:48 GLESS002I: Reconciling tape JCB370JC complete.
2021-03-24 03:32:49 GLESL632I: Reconcile as a part of an export finishes
2021-03-24 03:32:49 GLESL073I: Tape export for JCB370JC was requested.
2021-03-24 03:34:19 GLESM399I: Removing tape JCB370JC from pool test3 (Force).
2021-03-24 03:34:19 GLESL762I: Tape JCB370JC was forcefully unassigned from pool test3 during an export operation. Files on the tape cannot be recalled. Run the "eeadm tape import" command for the tape to recall the files again.
2021-03-24 03:34:19 GLESL074I: Export of tape JCB370JC complete.
2021-03-24 03:34:19 GLESL490I: The export command completed successfully for all tapes.
Example 6-94 on page 205 shows how the normal exported tape is displayed as exported by running the eeadm info tapes command.
Example 6-94 Display status of normal export tape cartridge
# eeadm tape list
Tape ID Status State Usable(GiB) Used(GiB) Available(GiB) Reclaimable% Pool Library Location Task ID
FC0260L8 ok appendable 10907 7 10899 0% temp liba homeslot -
UEF108M8 ok appendable 5338 46 5292 0% pool4 liba homeslot -
DV1993L7 ok appendable 5338 37 5301 0% pool4 liba homeslot -
FC0255L8 ok exported 0 0 0 0% - liba homeslot -
If errors occur during the export phase, the tape goes to the export state. However, some of the files that belong to that tape might still remain in the file system and still have a reference to that tape. Such an error can occur when an export is happening and while reconciliation occurs one starts to modify the files belonging to the exporting tape. In such a scenario, see 9.5, “Software” on page 303 on how to clean up the remaining files on the IBM Spectrum Scale file system.
Regarding full replica support, Export/Import does not depend on the primary/redundant copy. When all copies are exported, the file is exported.
Table 6-1 lists a use case example where a file was migrated to three physical tapes: TAPE1, TAPE2, TAPE3. The file behaves as shown by export operations.
Table 6-1 Export operations use case scenario of file with three tapes
|
Operation
|
File
|
|
TAPE1 is exported.
|
File is available (IBMTPS has TAPE2/TAPE3).
|
|
TAPE1/TAPE2 is exported.
|
File is available (IBMTPS has TAPE3).
|
|
TAPE1/TAPE2/TAPE3 is exported.
|
File is removed from GPFS.
|
6.19.3 Offlining tape cartridges
Offline tape cartridges from your IBM Spectrum Archive EE system by running the eeadm tape offline command. This process marks all files from the tape cartridges or tape cartridge pool that are specified and marks them offline and those files cannot be accessed. However, the corresponding inode of each file is kept in IBM Spectrum Scale. Those files can be brought back to the IBM Spectrum Scale namespace by making online the tape cartridge by using the eeadm tape online command.
If you want to move tape cartridges to an off-site location for DR purposes but still retain files in the IBM Spectrum Scale file system, follow the procedure that is described here. In Example 6-95, tape JCB610JC contains redundant copies of five MPEG files that must be moved off-site.
Example 6-95 Offlining a tape cartridge
[root@saitama2 ~]# eeadm tape offline JCB610JC -p test3 -l lib_saitama -o "Moved to storage room B"
2019-01-10 14:39:55 GLESL700I: Task tape_offline was created successfully, task id is 7141.
2019-01-10 14:39:55 GLESL073I: Offline export of tape JCB610JC has been requested.
If you run the eeadm tape list command, you can see the offline status of the tape cartridge, as shown in Example 6-96.
Example 6-96 Display status of offline tape cartridges
[root@saitama2 ~]# eeadm tape list -l lib_saitama
Tape ID Status State Usable(GiB) Used(GiB) Available(GiB) Reclaimable% Pool Library Location Task ID
JCA561JC ok offline 0 0 0 0% pool2 lib_saitama homeslot -
JCA224JC ok appendable 6292 0 6292 0% pool1 lib_saitama homeslot -
JCC093JC ok appendable 6292 496 5796 0% pool1 lib_saitama homeslot -
JCB745JC ok append_fenced 6292 0 0 0% pool2 lib_saitama homeslot -
It is now possible to physically remove tape JCA561JC from the tape library so that it can be sent to the off-site storage location.
Regarding full replica support, Offlining/Onlining does not depend on the primary/redundant copy. When all copies are offlined, the file is offline.
Table 6-2 lists a use case example where a file was migrated to three physical tapes: TAPE1, TAPE2, TAPE3. The file behaves as shown by offline operations.
Table 6-2 Export operations use case scenario of file with three tapes
|
Operation
|
File
|
|
TAPE1 is offline.
|
File is available (can recall).
|
|
TAPE1/TAPE2 are offline.
|
File is available (can recall).
|
|
TAPE1/TAPE2/TAPE3 are offline.
|
File is offline (cannot recall).
|
|
TAPE1/TAPE2 are offline exported, and then TAPE3 is exported.
|
File is offline (cannot recall, and the file will be only recalled from TAPE1/TAPE2 once they are online).
|
Example 6-97 shows the file state when the tape host has been offlined.
Example 6-97 Offline file state
[root@saitama2 prod]# eeadm file state *.bin
Name: /ibm/gpfs/prod/file1
State: migrated (check tape state)
ID: 11151648183451819981-3451383879228984073-1435527450-974349-0
Replicas: 1
Tape 1: JCB610JC@test3@lib_saitama (tape state=offline)
6.20 Drive Role settings for task assignment control
IBM Spectrum Archive EE allows users to configure their drives to allow or disallow specific tasks. Each of the attributes corresponds to the tape drive’s capability to perform a specific type of task. Here are the attributes:
•Migration
•Recall
•Generic
Table 6-3 lists the available IBM Spectrum Archive EE drive attributes for the attached physical tape drives.
Table 6-3 IBM Spectrum Archive EE drive attributes
|
Attributes
|
Description
|
|
Migration
|
If the Migration attribute is set for a drive, that drive can process migration tasks. If not, IBM Spectrum Archive EE never runs migration tasks by using that drive. Save tasks are also allowed/disallowed through this attribute setting. It is preferable that there be at least one tape drive that has this attribute set to Migration.
|
|
Recall
|
If the Recall attribute is set for a drive, that drive can process recall tasks. If not, IBM Spectrum Archive EE never runs recall tasks by using that drive. Both automatic file recall and selective file recall are enabled/disabled by using this single attribute. There is no way to enable/disable one of these two recall types selectively. It is preferable that there be at least one tape drive that has this attribute set to Recall.
|
|
Generic
|
If the Generic attribute is set for a drive, that drive can process generic tasks. If not, IBM Spectrum Archive EE never runs generic tasks by using that drive. IBM Spectrum Archive EE creates and runs miscellaneous generic tasks for administrative purposes, such as formatting tape, checking tape, reconciling tape, reclaiming a tape, and validating a tape. Some of those tasks are internally run with any of the user operations. It is preferable that there be at least one tape drive that has this attribute set to Generic. For reclaiming tape, at least two tape drives are required, so at least two drives need the Generic attribute.
|
To set these attributes for a tape drive, the attributes can be specified when adding a tape drive to IBM Spectrum Archive EE. Use the following command syntax:
eeadm drive assign <drive serial> -n <node_id> -r
The -r option requires a decimal numeric parameter. A logical OR applies to set the three attributes: Migrate (4), Recall (2), and Generic (1). For example, a number of 6 for -r allows migration and recall task while copy and generic task are disallowed. All of the attributes are set by default.
To check the current active drive attributes, the eeadm drive list command is useful. This command shows each tape drive’s attributes, as shown in Example 6-98.
Example 6-98 Check current IBM Spectrum Archive EE drive attributes
[root@saitama2 prod]# eeadm drive list -l lib_saitama
Drive S/N State Type Role Library Node ID Tape Node Group Task ID
0000078PG24E mounted TS1160 mrg lib_saitama 6 JD0321JD G0 -
0000078PG20E not_mounted TS1160 mrg lib_saitama 2 - G0 -
0000078D9DBA not_mounted TS1155 mrg lib_saitama 2 - G0 -
00000000A246 not_mounted TS1155 mrg lib_saitama 2 - G0 -
0000078PG24A not_mounted TS1160 mrg lib_saitama 6 - G0 -
0000078D82F4 unassigned - --- lib_saitama - - - -
The letters m, r, and g are shown when the corresponding attribute Migration, Recall, and Generic are set to on. If an attribute is not set, “-” is shown instead.
The role of an assigned drive can be modified by using the eeadm drive set command. For example, the following command changes the role to Migrate and Recall.
eeadm drive set <drive serial> -a role -v mr
The configuration change takes effect after the on-going process has completed.
|
Drive attributes setting hint: In a multiple nodes environment, it is expected that the reclaim driver works faster if two tape drives that are used for reclaim are assigned to a single node. For that purpose, tape drives with the Generic attribute should be assigned to a single node and all of other drives of the remaining nodes should not have the Generic attribute.
|
6.21 Tape drive intermix support
This section describes the physical tape drive intermix support
This enhancement has these objectives:
•Use IBM LTO-9 tapes and drives in mixed configuration with older IBM LTO (LTO-8, M8, 7, 6, and 5) generations
•Use 3592 JC/JD/JE cartridges along with IBM TS1160, TS1155, TS1150, and TS1140 drives in mixed environments
|
Note: An intermix of LTO and TS11xx tape drive technology and media on a single library is not supported by IBM Spectrum Archive EE.
|
The following main use cases are expected to be used by this feature:
•Tape media and technology migration (from old to new generation tapes)
•Continue using prior generation formatted tapes (read or write) with the current technology tape drive generation
To generate and use a mixed tape drive environment, you must define the different LTO or TS11xx drive types with the creation of the logical library partition (within your tape library) to be used along with your IBM Spectrum Archive EE setup.
When LTO-9, 8, M8, 7, 6, and 5 tapes are used in a tape library, correct cartridges and drives are selected by IBM Spectrum Archive EE to read or write the required data. For more information, see this IBM Documentation web page.
When 3592 JC, JD, and JE tapes are used in a tape library and IBM TS1160, TS1155, TS1150, and TS1140 drives are used correct tapes and drives are selected by IBM Spectrum Archive EE to read or write the required data.
With this function, a data migration between different generations of tape cartridges can be achieved. You can select and configure which TS11xx format (TS1155, TS1150, or TS1140) is used by IBM Spectrum Archive EE for operating 3592 JC tapes. The default for IBM Spectrum Archive EE is always to use and format to the highest available capacity. The TS1160 supports only recalls of JC media formatted using TS1140.
The eeadm tape assign command can be used for pool configuration when new physical tape cartridges are added to your IBM Spectrum Archive EE setup:
eeadm tape assign <list_of_tapes> -p <pool> [-l <library>] [OPTIONS]
WORM support for the IBM TS1160, TS1155, TS1150, and TS1140 tape drives
From the long-term archive perspective, there is sometimes a requirement to store files without any modification that is ensured by the system. You can deploy Write Once Read Many (WORM) tape cartridges in your IBM Spectrum Archive EE setup. Only 3592 WORM tapes that can be used with IBM TS1160, TS1155, TS1150, or TS1140 drives are supported.
|
Note: LTO WORM tapes are not supported for IBM Spectrum Archive EE.
|
For more information about IBM tape media and WORM tapes, see this website.
6.21.1 Objective for WORM tape support
The IBM Spectrum Archive EE objective for WORM tapes is to store files without any modifications, which is ensured by the system, but with the following limitations:
•Only ensure that the file on tape is immutable if the user uses only IBM Spectrum Archive EE:
– Does not detect the case where an appended modified index is at the end of tape by using a direct SCSI command.
– From LTFS format perspective, this case can be detected but it needs time to scan every index on the tape. This feature is not provided in the release of IBM Spectrum Archive EE on which this book is based.
•Does not ensure that the file cannot be modified through GPFS in the following ways:
– Migrate the immutable files to tape.
– Recall the immutable files to disk.
– Change the immutable attribute of the file on disk and modify.
6.21.2 Function overview for WORM tape support
The following features are present to support 3592 WORM tapes:
•WORM attribute to the IBM Spectrum Archive EE pool attributes.
•A WORM pool can have only WORM cartridges.
•Files that have GPFS immutable attributes can still be migrated to normal pools.
Example 6-99 shows how to set the WORM attribute to an IBM Spectrum Archive EE pool by using the eeadm pool create command.
Example 6-99 Set the WORM attribute to an IBM Spectrum Archive EE pool
[root@saitama2 prod]# eeadm pool create myWORM --worm physical
There is also an IBM Spectrum Scale layer that can provide a certain immutability for files within the GPFS file system. You can apply immutable and appendOnly restrictions either to individual files within a file set or to a directory. An immutable file cannot be changed or renamed. An appendOnly file allows append operations, but not delete, modify, or rename operations.
An immutable directory cannot be deleted or renamed, and files cannot be added or deleted under such a directory. An appendOnly directory allows new files or subdirectories to be created with 0-byte length. All such new created files and subdirectories are marked as appendOnly automatically.
The immutable flag and the appendOnly flag can be set independently. If both immutability and appendOnly are set on a file, immutability restrictions are in effect.
To set or unset these attributes, use the following IBM Spectrum Scale command options:
•mmchattr -i yes|no
This command sets or unsets a file to or from an immutable state:
– -i yes
Sets the immutable attribute of the file to yes.
– -i no
Sets the immutable attribute of the file to no.
•mmchattr -a yes|no
This command sets or unsets a file to or from an appendOnly state:
– -a yes
Sets the appendOnly attribute of the file to yes.
– -a no
Sets the appendOnly attribute of the file to no.
|
Note: Before an immutable or appendOnly file can be deleted, you must change it to mutable or set appendOnly to no (by using the mmchattr command).
|
Storage pool assignment of an immutable or appendOnly file can be changed. An immutable or appendOnly file is allowed to transfer from one storage pool to another.
To display whether a file is immutable or appendOnly, run this command:
mmlsattr -L myfile
The system displays information similar to the output that is shown in Example 6-100.
Example 6-100 Output of the mmlsattr -L myfile command
file name: myfile
metadata replication: 2 max 2
data replication: 1 max 2
immutable: no
appendOnly: no
flags:
storage pool name: sp1
fileset name: root
snapshot name:
creation Time: Wed Feb 22 15:16:29 2012
Windows attributes: ARCHIVE
6.21.3 The effects of file operations on immutable and appendOnly files
After a file is set as immutable or appendOnly, the following file operations and attributes work differently from the way they work on regular files:
•delete
An immutable or appendOnly file cannot be deleted.
•modify/append
An immutable file cannot be modified or appended. An appendOnly file cannot be modified, but it can be appended.
|
Note: The immutable and appendOnly flag check takes effect after the file is closed. Therefore, the file can be modified if it is opened before the file is changed to immutable.
|
•mode
An immutable or appendOnly file’s mode cannot be changed.
•ownership, acl
These attributes cannot be changed for an immutable or appendOnly file.
•timestamp
The time stamp of an immutable or appendOnly file can be changed.
•directory
If a directory is marked as immutable, no files can be created, renamed, or deleted under that directory. However, a subdirectory under an immutable directory remains mutable unless it is explicitly changed by the mmchattr command.
If a directory is marked as appendOnly, no files can be renamed or deleted under that directory. However, 0-byte length files can be created.
For more information about IBM Spectrum Scale V5.1.2 immutable and appendOnly limitations, see IBM Documentation.
Example 6-101 shows the output that you receive while working, showing, and changing the IBM Spectrum Scale immutable or appendOnly file attributes.
Example 6-101 Set or change an IBM Spectrum Scale file immutable file attribute
[root@ltfsee_node0]# echo "Jan" > jan_jonas.out
[root@ltfsee_node0]# mmlsattr -L -d jan_jonas.out
file name: jan_jonas.out
metadata replication: 1 max 2
data replication: 1 max 2
immutable: no
appendOnly: no
flags:
storage pool name: system
fileset name: root
snapshot name:
creation time: Mon Aug 31 15:40:54 2015
Windows attributes: ARCHIVE
Encrypted: yes
gpfs.Encryption: 0x454147430001008C525B9D470000000000010001000200200008000254E60BA4024AC1D50001000100010003000300012008921539C65F5614BA58F71FC97A46771B9195846A9A90F394DE67C4B9052052303A82494546897FA229074B45592D61363532323261642D653862632D346663632D383961332D346137633534643431383163004D495A554E4F00
EncPar 'AES:256:XTS:FEK:HMACSHA512'
type: wrapped FEK WrpPar 'AES:KWRAP' CmbPar 'XORHMACSHA512'
KEY-a65222ad-e8bc-4fcc-89a3-4a7c54d4181c:ltfssn2
[root@ltfsee_node0]# mmchattr -i yes jan_jonas.out
[root@ltfsee_node0]# mmlsattr -L -d jan_jonas.out
file name: jan_jonas.out
metadata replication: 1 max 2
data replication: 1 max 2
immutable: yes
appendOnly: no
flags:
storage pool name: system
fileset name: root
snapshot name:
creation time: Mon Aug 31 15:40:54 2015
Windows attributes: ARCHIVE READONLY
Encrypted: yes
gpfs.Encryption: 0x454147430001008C525B9D470000000000010001000200200008000254E60BA4024AC1D50001000100010003000300012008921539C65F5614BA58F71FC97A46771B9195846A9A90F394DE67C4B9052052303A82494546897FA229074B45592D61363532323261642D653862632D346663632D383961332D346137633534643431383163004D495A554E4F00
EncPar 'AES:256:XTS:FEK:HMACSHA512'
type: wrapped FEK WrpPar 'AES:KWRAP' CmbPar 'XORHMACSHA512'
KEY-a65222ad-e8bc-4fcc-89a3-4a7c54d4181c:ltfssn2
[root@ltfsee_node0]# echo "Jonas" >> jan_jonas.out
-bash: jan_jonas.out: Read-only file system
[root@ltfsee_node0]#
These immutable or appendOnly file attributes can be changed at any time by the IBM Spectrum Scale administrator, so IBM Spectrum Scale is not able to provide an complete immutability.
If you are working with IBM Spectrum Archive EE and IBM Spectrum Scale and you plan implementing a WORM solution along with WORM tape cartridges, these two main assumptions apply:
•Only files that have IBM Spectrum Scale with the immutable attribute ensure no modification.
•The IBM Spectrum Scale immutable attribute is not changed after it is set unless it is changed by an administrator.
Consider the following limitations when using WORM tapes together with IBM Spectrum Archive EE:
•WORM tapes are supported only with IBM TS1160, TS1155, TS1150, and TS1140 tape drives (3592 JV, JY, JZ).
•If IBM Spectrum Scale immutable attributes are changed to yes after migration, the next migration fails against the same WORM pool.
•IBM Spectrum Archive EE supports the following operations with WORM media:
– Migrate
– Recall
– Offline export and offline import
•IBM Spectrum Archive EE does not support the following operations with WORM media:
– Reclaim
– Reconcile
– Export and Import
For more information about the IBM Spectrum Archive EE commands, see 10.1, “Command-line reference” on page 316.
6.22 Obtaining the location of files and data
This section describes how to obtain information about the location of files and data by using IBM Spectrum Archive EE.
You can use the eeadm file state command to discover the physical location of files. To help with the management of replicas, this command also indicates which tape cartridges are used by a particular file, how many replicas exist, and the health state of the tape.
Example 6-102 shows the typical output of the eeadm file state command. Some files are on multiple tape cartridges, some are in a migrated state, and others are premigrated only.
Example 6-102 Files location
[root@saitama2 prod]# eeadm file state *.bin
Name: /ibm/gpfs/prod/file1.bin
State: premigrated
ID: 11151648183451819981-3451383879228984073-1435527450-974349-0
Replicas: 2
Tape 1: JCB610JC@test3@lib_saitama (tape state=appendable)
Tape 2: JD0321JD@test4@lib_saitama (tape state=appendable)
Name: /ibm/gpfs/prod/file2.bin
State: migrated
ID: 11151648183451819981-3451383879228984073-2015134857-974348-0
Replicas: 2
Tape 1: JCB610JC@test3@lib_saitama (tape state=appendable)
Tape 2: JD0321JD@test4@lib_saitama (tape state=appendable)
Name: /ibm/gpfs/prod/file3.bin
State: migrated
ID: 11151648183451819981-3451383879228984073-599546382-974350-0
Replicas: 2
Tape 1: JCB610JC@test3@lib_saitama (tape state=appendable)
Tape 2: JD0321JD@test4@lib_saitama (tape state=appendable)
Name: /ibm/gpfs/prod/file4.bin
State: migrated
ID: 11151648183451819981-3451383879228984073-2104982795-3068894-0
Replicas: 1
Tape 1: JD0321JD@test4@lib_saitama (tape state=appendable)
For more information about supported characters for file names and directory path names, see IBM Documentation.
6.23 Obtaining system resources, and tasks information
This section describes how to obtain resource inventory information and information about ongoing migration and recall tasks with IBM Spectrum Archive EE. You can use the eeadm task list command to obtain information about current tasks and the eeadm task show to see detailed information about the task. To view IBM Spectrum Archive EE system resources use any of the following commands:
•eeadm tape list
•eeadm drive list
•eeadm pool list
•eeadm node list
•eeadm nodegroup list
Example 6-103 shows the command that is used to display all IBM Spectrum Archive EE tape cartridge pools.
Example 6-103 Tape cartridge pools
[root@saitama2 prod]# eeadm pool list
Pool Name Usable(TB) Used(TB) Available(TB) Reclaimable% Tapes Type Library Node Group
myWORM 0.0 0.0 0.0 0% 0 - lib_saitama G0
pool1 64.1 3.9 60.2 0% 10 3592 lib_saitama G0
test2 6.1 0.0 6.1 0% 1 3592 lib_saitama G0
Example 6-104 shows the serial numbers and status of the tape drives that are used by IBM Spectrum Archive EE.
Example 6-104 Drives
[root@saitama2 prod]# eeadm drive list
Drive S/N State Type Role Library Node ID Tape Node Group Task ID
0000078PG24E mounted TS1160 mrg lib_saitama 6 JD0321JD G0 -
0000078PG20E not_mounted TS1160 mrg lib_saitama 2 - G0 -
0000078D9DBA not_mounted TS1155 mrg lib_saitama 2 - G0 -
To view all the IBM Spectrum Archive EE tape cartridges, run the command that is shown in Example 6-105.
Example 6-105 Tape cartridges
[root@saitama2 prod]# eeadm tape list
Tape ID Status State Usable(GB) Used(GB) Available(GB) Reclaimable% Pool Library Location Task ID
JCA561JC ok offline 0 0 0 0% pool2 lib_saitama homeslot -
JCA224JC ok appendable 6292 0 6292 0% pool1 lib_saitama homeslot -
JCC093JC ok appendable 6292 496 5796 0% pool1 lib_saitama homeslot -
Regularly monitor the output of IBM Spectrum Archive EE tasks to ensure that tasks are progressing as expected by using the eeadm task list and eeadm task show command. Example 6-106 shows a list of active tasks.
Example 6-106 Active tasks
[root@saitama2 prod]# eeadm task list
TaskID Type Priority Status #DRV CreatedTime(-0700) StartedTime(-0700)
7168 selective_recall H running 0 2019-01-10_16:27:30 2019-01-10_16:27:30
7169 selective_recall H waiting 0 2019-01-10_16:27:30 2019-01-10_16:27:30
The eeadm node list command (see Example 6-107) provides a summary of the state of each IBM Spectrum Archive EE component node.
Example 6-107 eeadm node list
[root@saitama2 prod]# eeadm node list
Node ID State Node IP Drives Ctrl Node Library Node Group Host Name
4 available 9.11.244.44 2 yes(active) lib_saitama G0 saitama2
2 available 9.11.244.43 3 yes lib_saitama G0 saitama1
3 available 9.11.244.42 1 yes(active) lib_mikasa G0 mikasa2
1 available 9.11.244.24 2 yes lib_mikasa G0 mikasa1
The eeadm task show command (see Example 6-108) provides a summary of the specified active task in IBM Spectrum Archive EE. The task id corresponds to the task id that is reported by the eeadm task list command.
Example 6-108 Detailed outlook of recall task
[root@saitama2 prod]# eeadm task show 7168 -v
=== Task Information ===
Task ID: 7168
Task Type: selective_recall
Command Parameters: eeadm recall mig -l lib_saitama
Status: running
Result: -
Accepted Time: Thu Jan 10 16:27:30 2019 (-0700)
Started Time: Thu Jan 10 16:27:30 2019 (-0700)
Completed Time: -
In-use Libraries: lib_saitama
In-use Node Groups: G0
In-use Pools: test3
In-use Tape Drives: 0000078PG20E
In-use Tapes: JCB610JC
Workload: 3 files, 5356750 bytes in total to recall in this task.
Progress: 1 completed (or failed) files / 3 total files.
Result Summary: -
Messages:
2019-01-10 16:27:30.421251 GLESM332W: File /ibm/gpfs/prod/LTFS_EE_FILE_2dEPRHhh_M.bin is not migrated.
6.24 Monitoring the system with SNMP
You can use SNMP traps to receive notifications about system events. There are many processes that should be reported through SNMP. Starting with IBM Spectrum Archive EE v1.2.4.0, IBM Spectrum Archive EE uses SNMP to monitor the system and send alerts when the following events occur:
•IBM Spectrum Archive EE component errors are detected.
•Recovery actions are performed on failed components.
•At the end of an eeadm cluster start and eeadm cluster stop command, and at the successful or unsuccessful start or stop of each component of an IBM Spectrum Archive EE node.
•When the remaining space threshold for a pool is reached.
The MIB file is installed in /opt/ibm/ltfsee/share/IBMSA-MIB.txt on each node. It should be copied to the /usr/share/snmp/mibs/ directory on each node.
Table 6-4 lists SNMP traps that can be issued, showing the error message that is generated, along with the trap name, severity code, and the OID for each trap.
Table 6-4 SNMP error message information
|
Description
|
Name
|
Severity
|
OID
|
|
GLESV100I: IBM Spectrum Archive EE successfully started or restarted.
|
ibmsaInfoV100StartSuccess
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.100
|
|
GLESV101E: IBM Spectrum Archive EE failed to start.
|
ibmsaErrV101StartFail
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.101
|
|
GLESV102W: Part of IBM Spectrum Archive EE nodes failed to start.
|
ibmsaDegradeV102PartialStart
|
Warning
|
1.3.6.1.4.1.2.6.246.1.2.31.0.102
|
|
GLESV103I: IBM Spectrum Archive EE successfully stopped.
|
ibmsaInfoV103StopSuccess
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.103
|
|
GLESV104E: IBM Spectrum Archive EE failed to stop.
|
ibmsaErrV104StopFail
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.104
|
|
GLESV300E: GPFS error has been detected.
|
ibmsaErrV300GPFSError
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.300
|
|
GLESV301I: GPFS becomes operational.
|
ibmsaInfoV301GPFSOperational
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.301
|
|
GLESV302I: The IBM Spectrum Archive LE successfully started.
|
ibmsaInfoV302LEStartSuccess
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.302
|
|
GLESV303E: The IBM Spectrum Archive LE failed to start.
|
ibmsaErrV303LEStartFail
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.303
|
|
GLESV304I: The IBM Spectrum Archive LE successfully stopped.
|
ibmsaInfoV304LEStopSuccess
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.304
|
|
GLESV305I: IBM Spectrum Archive LE is detected.
|
ibmsaInfoV305LEDetected
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.305
|
|
GLESV306E: IBM Spectrum Archive LE process does not exist.
|
ibmsaErrV306LENotExist
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.306
|
|
GLESV307E: IBM Spectrum Archive LE process is not responding.
|
ibmsaErrV307LENotRespond
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.307
|
|
GLESV308I: IBM Spectrum Archive LE process is now responding.
|
ibmsaInfoV308LERespond
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.308
|
|
GLESV309I: The process 'rpcbind' started up.
|
ibmsaInfoV309RpcbindStart
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.309
|
|
GLESV310E: The process 'rpcbind' does not exist.
|
ibmsaErrV310RpcbindNotExist
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.310
|
|
GLESV311I: The process 'rsyslogd' started up.
|
ibmsaInfoV311RsyslogdStart
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.311
|
|
GLESV312E: The process 'rsyslogd' does not exist.
|
ibmsaErrV312RsyslogdNotExist
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.312
|
|
GLESV313I: The process 'sshd' started up.
|
ibmsaInfoV313SshdStart
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.313
|
|
GLESV314E: The process 'sshd' does not exist.
|
ibmsaErrV314SshdNotExist
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.314
|
|
GLESV315I: The IBM Spectrum Archive EE service (MMM) successfully started
|
ibmsaInfoV315MMMStartSuccess
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.315
|
|
GLESV316E: The IBM Spectrum Archive EE service (MMM) failed to start.
|
ibmsaErrV316MMMStartFail
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.316
|
|
GLESV317I: The IBM Spectrum Archive EE service (MMM) successfully stopped.
|
ibmsaInfoV317MMMStopSuccess
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.317
|
|
GLESV318I: The IBM Spectrum Archive EE service (MMM) is detected.
|
ibmsaInfoV318MMMDetected
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.318
|
|
GLESV319E: The IBM Spectrum Archive EE service (MMM) does not exist.
|
ibmsaErrV319MMMNotExist
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.319
|
|
GLESV320E: The IBM Spectrum Archive EE service (MMM) is not responding.
|
ibmsaErrV320MMMNotRespond
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.320
|
|
GLESV321I: The IBM Spectrum Archive EE service (MMM) now responding.
|
ibmsaInfoV321MMMRespond
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.321
|
|
GLESV322I: The IBM Spectrum Archive EE service (MD) successfully started.
|
ibmsaInfoV322MDStartSuccess
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.322
|
|
GLESV323E: The IBM Spectrum Archive EE service (MD) failed to start.
|
ibmsaErrV323MDStartFail
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.323
|
|
GLESV324I: The IBM Spectrum Archive EE service (MD) successfully stopped.
|
ibmsaInfoV324MDStopSuccess
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.324
|
|
GLESV325I: The IBM Spectrum Archive EE service (MD) is detected.
|
ibmsaInfoV325MDDetected
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.310.325
|
|
GLESV326E: The IBM Spectrum Archive EE service (MD) does not exist.
|
ibmsaErrV326MDNotExist
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.326
|
|
GLESV327E: The IBM Spectrum Archive EE service (MD) is not responding.
|
ibmsaErrV327MDNotRespond
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.327
|
|
GLESV328I: The IBM Spectrum Archive EE service (MD) is now responding.
|
ibmsaInfoV328MDRespond
|
Information
|
1.3.6.1.4.1.2.6.246.1.2.31.0.328
|
|
GLESM609W: Pool space is going to be small.
|
ibmsaWarnM609PoolLowSpace
|
Warning
|
1.3.6.1.4.1.2.6.246.1.2.31.0.609
|
|
GLESM613E: There is not enough space available on the tapes in a pool for migration.
|
ibmsaErrM613NoSpaceForMig
|
Error
|
1.3.6.1.4.1.2.6.246.1.2.31.0.613
|
6.25 Configuring Net-SNMP
It is necessary to modify the /etc/snmp/snmpd.conf and /etc/snmp/snmptrapd.conf configuration file to receive SNMP traps. These files should be modified on each node that has IBM Spectrum Archive EE installed and running.
To configure Net-SNMP, complete the following steps on each IBM Spectrum Archive EE node:
1. Open the /etc/snmp/snmpd.conf configuration file.
2. Add the following entry to the file:
master agentx
trap2sink <managementhost>
The variable <managementhost> is the host name or IP address of the host to which the SNMP traps are sent.
3. Open the /etc/snmp/snmptrapd.conf configuration file.
4. Add the following entry to the file:
disableauthorization yes
5. Restart the SNMP daemon by running the following command:
[root@ltfs97 ~]# systemctl restart snmpd.service
6.25.1 Starting and stopping the snmpd daemon
Before IBM Spectrum Archive EE is started, you must start the snmpd daemon on all nodes where IBM Spectrum Archive EE is running.
To start the snmpd daemon, run the following command:
[root@ltfs97 ~]# systemctl start snmpd.service
To stop the snmpd daemon, run the following command:
[root@ltfs97 ~]# systemctl stop snmpd.service
To restart the snmpd daemon, run the following command:
[root@ltfs97 ~]# systemctl restart snmpd.service
6.25.2 Example of an SNMP trap
Example 6-109 shows the type of trap information that is received by the SNMP server.
Example 6-109 SNMP trap example of an IBM Spectrum Archive EE node that has a low pool threshold
2018-11-26 09:08:42 tora.tuc.stglabs.ibm.com [UDP: [9.11.244.63]:60811->[9.11.244.63]:162]:
DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (147206568) 17 days, 0:54:25.68 SNMPv2-MIB::snmpTrapOID.0 = OID: IBMSA-MIB::ibmsaWarnM609PoolLowSpace IBMSA-MIB::ibmsaMessageSeverity.0 = INTEGER: warning(40) IBMSA-MIB::ibmsaJob.0 = INTEGER: other(7) IBMSA-MIB::ibmsaEventNode.0 = STRING: "tora.tuc.stglabs.ibm.com" IBMSA-MIB::ibmsaMessageText.0 = STRING: "GLESM609W: Pool space is going to be small, library: lib_tora, pool: je_pool1, available capacity: 23.6(TiB), threshold: 30(TiB)"
6.26 IBM Spectrum Archive REST API
The IBM Spectrum Archive EE REST API gives users another interface to interact with the IBM Spectrum Archive EE product. REST uses http GET operations to return status information about IBM Spectrum Archive EE. This section covers the GET operations for the IBM Spectrum Archive EE Rest API.
The IBM Spectrum Archive EE REST API can be accessed in two ways. The first is through a terminal window with the curl command and the second way is through a web browser. Both ways output the same data. In this section, the curl command is used.
The following are supported GET operations when executing rest commands:
•pretty
Specify for pretty-printing. The default value is false.
•sort: <string>(,<string>...)
Specify field name or names to use as sort key. The default sort order is ascending. Use the “-” sign to sort in descending order.
•fields: <string>(,<string>...)
Specify field names that are to be included in the response.
|
Note: The examples in this section are all performed on the server with the REST RPM installed and uses localhost to request resources. When accessing the REST API over a remote server, replace localhost with the server ip with the rest rpms installed.
|
6.26.1 Pools endpoint
IBM Spectrum Archive EE rest pools endpoint returns all information in JSON objects about each pool created thus far within the environment.
The following is an example command of calling the pools endpoint using localhost:
curl -X GET ‘http://localhost:7100/ibmsa/v1/pools/’
The following is the response data returned when requesting for the pools endpoint:
•id: <string>
UUID of Pool, assigned by system at the creation of pool.
•name: <string>
User-specified name of pool.
•capacity: <number>
Total capacity of tapes assigned to the pool, in bytes. The capacity = used_space + free_space.
•mode: <string>
The current operational mode of the pool. Access to the member tapes is temporarily disabled when this field is set to “disabled”, “relocation_source”, or “relocation_destination”. under normal operating conditions, the field is set to “normal”. If an internal error occurs, the field is set to an empty string.
•used_space: <number>
Used space of the pool, in bytes. The used_space = active_space + reclaimable_space.
•free_space: <number>
Free space of the pool, in bytes.
•active_space: <number>
Active space (used space consumed by active-referred files) of the pool, in bytes.
•reclaimable_space: <number>
The reclaimable space (used space consumed by unreferred files) of the pool, in bytes. Note that this is the amount of estimated size of the unreferenced space that is available for reclamation on the assigned tapes.
•non_appendable_space: <number>
The total capacity, in bytes, of tapes in the pool that cannot be written to in the format specified for the pool, and that don’t match the media_restriction value for the pool. The format and the media_restriction values are provided as attributes of the pool.
•num_of_tapes: <number>
Number of tapes assigned to the pool.
•format_class: <string>
The format class of the pool.
•media_restriction: <string>
The media_restriction setting is stored in the regular expression of the bar code value. The media_restriction is used to define the type of cartridge that can be used for writing. The cartridge media type that is represented by the last two letters of the cartridge bar code is used in this field. The string can be either “^.{6}XX$”, “^.{8}$”, or “unknown”. The “^.{6}XX$” represents any 6 characters followed by type “XX “, where “XX “ is one of the following cartridge media types: L5, L6, L7, L8, M8, L9, JB, JC, JD, JE, JK, JL, JY, or JZ. The “^.{8}$” represents any 8 characters, and means that any cartridge media type is acceptable. A value of “unknown” means that there is an error condition.
•device_type: <string>
Tape device type that can be added to the pool. Can be either 3592, LTO, or left blank.
•worm: <string>
WORM type. Can be either physical, no, or unknown.
•fill_policy: <string>
Tape fill policy.
•owner: <string>
Owner.
•mount_limit: <number>
Maximum number of drives that can be used for migration. 0 means unlimited.
•low_space_warning_enable: <bool>
Whether monitoring thread sends SNMP trap for low space pool.
•low_space_warning_threshold: <number>
SNMP notification threshold value for free pool size in bytes. 0 when no threshold is set.
•no_space_warning_enable: <bool>
Whether monitoring thread sends SNMP trap for no space pool.
•library_name: <string>
Library name to which the pool belongs.
•library_id: <string>
Library ID (serial number) to which the pool belongs.
•node_group: <string>
Node group name to which the pool belongs.
The following parameters are available to be passed in to filter specific pools:
•name: <string>
Filter the list of pools by name. Only the pools that match the criteria are returned in the response.
•library_name: <string>
Filter the list of pools by library name. Only the pools that match the criteria are returned in the response.
Example 6-110 shows how to request the pools resource through curl commands.
Example 6-110 REST pool command
[root@tora ~]# curl -X GET 'http://localhost:7100/ibmsa/v1/pools?pretty=true'
[
{
"active_space": 0,
"capacity": 0,
"device_type": "3592",
"fill_policy": "Default",
"format_class": "60F",
"free_space": 0,
"id": "f244d0eb-e70d-4a7f-9911-0e3e1bd12720",
"library_id": "65a7cbb5-8005-4197-b2a5-31c0d6f6e1c0",
"library_name": "lib_tora",
"low_space_warning_enable": false,
"low_space_warning_threshold": 0,
"media_restriction": "^.{8}$",
"mode": "normal",
"mount_limit": 0,
"name": "pool3",
"no_space_warning_enable": false,
"nodegroup_name": "G0",
"non_appendable_space": 0,
"num_of_tapes": 1,
"owner": "System",
"reclaimable%": 0,
"reclaimable_space": 0,
"used_space": 0,
"worm": "no"
},
{
"active_space": 0,
"capacity": 0,
"device_type": "",
"fill_policy": "Default",
"format_class": "E08",
"free_space": 0,
"id": "bab56eb2-783e-45a9-b86f-6eaef4e8d316",
"library_id": "65a7cbb5-8005-4197-b2a5-31c0d6f6e1c0",
"library_name": "lib_tora",
"low_space_warning_enable": false,
"low_space_warning_threshold": 2199023255552,
"media_restriction": "^.{8}$",
"mode": "normal",
"mount_limit": 0,
"name": "pool1",
"no_space_warning_enable": false,
"nodegroup_name": "G0",
"non_appendable_space": 0,
"num_of_tapes": 0,
"owner": "System",
"reclaimable%": 0,
"reclaimable_space": 0,
"used_space": 0,
"worm": "no"
}
]
Example 6-111 shows how to call pools with specifying specific fields and sorting the output in descending order.
Example 6-111 REST API pools endpoint
[root@tora ~]# curl -X GET 'http://localhost:7100/ibmsa/v1/pools?pretty=true&fields=capacity,name,library_name,free_space,num_of_tapes,device_type&sort=-free_space'
[
{
"capacity": 0,
"device_type": "3592",
"free_space": 0,
"library_name": "lib_tora",
"name": "pool3",
"num_of_tapes": 1
},
{
"capacity": 0,
"device_type": "",
"free_space": 0,
"library_name": "lib_tora",
"name": "pool1",
"num_of_tapes": 0
}
]
6.26.2 Tapes endpoint
The tapes endpoint returns an array of JSON objects regarding tape information. The following is an example command of calling tapes:
curl -X GET ‘http://localhost:7100/ibmsa/v1/tapes’
The following is the response data when requesting the tapes endpoint:
•id: <string>
Tape ID. Because barcode is unique within a tape library only, the id is in format of <barcode>@<library_id>.
•barcode: <string>
Barcode of the tape.
•state: <string>
The string indicates the state of the tape. The string can be either “appendable”, “append_fenced”, “offline”, “recall_only”, “unassigned”, “exported”, “full”, “data_full”, “check_tape_library”, “need_replace”, “require_replace”, “require_validate”, “check_key_server”, “check_hba”, “inaccessible”, “non_supported”, “duplicated”, “missing”, “disconnected”, “unformatted”, “label_mismatch”, “need_unlock”, and “unexpected_cond”. If the string is “unexpected_cond”, it is probably an error occurred.
•status: <string>
The string indicates the severity level of the tape's status. The string can be either “error”, “degraded”, “warning”, “info”, or “ok”.
•media_type: <string>
Media type of a tape. Media type is set even if the tape is not assigned to any pool yet. Empty string if the tape is not supported by IBM Spectrum Archive.
•media_generation: <string>
Media generation of a tape. Media generation determines a possible format that the tape can be written in.
•format_density: <string>
Format of a tape. Empty string if the tape is not assigned to any pool.
•worm: <bool>
Whether WORM is enabled for the tape.
•capacity: <number>
Capacity of the tape, in bytes. capacity = used_space + free_space.
•Appendable: <string>
A tape that can be written in the format that is specified by the pool attributes, and on the cartridge media type that is specified by the pool attributes, is appendable. The format and the cartridge media type are provided as attributes of the pool to which the tape belongs. The string can be either “yes”, “no”, or it can be empty. If the tape falls into a state such as “append_fenced” or “inaccessible”, the string becomes “no”. If the string is empty, the tape is not assigned to any pool.
•used_space: <number>
Used space of the tape, in bytes. used_space = active_space + reclaimable_space.
•free_space: <number>
Free space of the tape, in bytes.
•active_space: <number>
Active space (used space consumed by active-referred files) of the tape, in bytes.
•reclaimable_space: <number>
Reclaimable space (used space consumed by unreferred files) of the tape, in bytes. This amount is the estimated size of the unreferenced space that is available for reclamation on the tape.
•address: <number>
Address of this tape.
•drive_id: <string>
Drive serial number that the tape is mounted on. Empty string if the tape is not mounted.
•offline_msg: <string>
Offline message that can be specified when performing tape offline.
•task_id: <string>
The task_id of the task which using this tape.
•location_type: <string>
The location type of the tape. The string can be either “robot”, “homeslot”, “ieslot”, “drive”, or empty. If the string is empty, the tape is missing.
•library_id: <string>
Library ID (serial number) to which the pool is belongs.
•library_name: <string>
Library name that the pool is belongs to
•pool_id: <string>
Pool ID to which this tape is assigned. Empty string if the tape is not assigned to any pool.
The following are available parameters to use to filter tape requests:
•barcode: <string>
Filter the list of tapes by barcode. Only the tapes that match the criteria are returned in the response.
•library_name: <string>
Filter the list of tapes by library name. Only the tapes that match the criteria are returned in the response.
•pool_id: <string>
Filter the list of tapes by pool ID. Only the tapes that match the criteria are returned in the response.
•pool_name: <string>
Filter the list of tapes by pool name. Only the tapes that match the criteria are returned in the response.
6.26.3 Libraries endpoint
The libraries endpoint returns information regarding the library that the node is connected to, such as the library ID, name and model type. The following is an example of the libraries curl command:
curl -X GET ‘http://localhost:7100/ibmsa/v1/libraries/’
The following is the response data that is returned when requesting this endpoint:
•id: <string>
Serial number of the library.
•name: <string>
User-defined name of the library.
•model: <string>
Mode type of the library.
•serial: <string>
The serial number of the library.
•scsi_vendor_id: <string>
The vendor ID of the library.
•scsi_firmware_revision: <string>
The firmware revision of the library.
•num_of_drives: <number>
The number of tape drives that are assigned to the logical library.
•num_of_ieslots: <number>
The number of I/E slots that are assigned to the logical library.
•num_of_slots: <number>
The number of storage slots that are assigned to the logical library.
•host_device_name: <string>
The Linux device name of the library.
•host_scsi_address: <string>
The current data path to the tape drive from the assigned node, in the decimal notation of host.bus.target.lun.
•errors: <array>
An array of strings that represents errors. If no error is found, an empty array is returned.
The available filtering parameter for the libraries endpoint is the name of the library.
6.26.4 Nodegroups endpoint
The nodegroups endpoint returns information regarding the node groups that the nodes are part of, such as the nodegroup ID, name, number of nodes, library ID, and library name. The following is an example of calling the nodegroups endpoint:
curl -X GET ‘http://localhost:7100/ibmsa-rest/v1/nodegroups/’
The following is the response data that is returned when requesting this endpoint:
•id: <string>
Nodegroup ID. Because nodegroup name is unique within a tape library only, the ID is in format of <nodegroup_name>@<library_id>.
•name: <string>
User-specified name of the node group.
•num_of_nodes: <number>
The number of nodes assigned to the node group.
•library_id: <string>
The library ID (serial number) to which the node group belongs.
•library_name: <string>
The name of the library to which the node group belongs.
The available filtering parameters for nodegroups are name (nodegroup name), and library_name. These parameters filter out nodegroups that do not meet the values that were passed in.
6.26.5 Nodes endpoint
The nodes endpoint returns information about each EE node assigned to the cluster. The following is an example of calling the nodes endpoint:
curl -X GET ‘http://localhost:7100/ibmsa/v1/nodes/’
The following is the response data when requesting the nodes endpoint:
•id: <number>
The node ID, which is the same value as the corresponding value in the IBM Spectrum Scale node IDs.
•ip: <string>
The IP address of the node. Specifically, this is the ‘Primary network IP address’ in GPFS.
•hostname: <string>
The host name of the node (the ‘GPFS daemon node interface name’ in GPFS).
•port: <number>
The port number for LTFS.
•state: <string>
The LE status of the node.
•num_of_drives: <number>
The number of drives attached to the node.
•control_node: <bool>
True if the node is configured as control node.
•active_control_node: <bool>
True if the node is configured as a control node and is active.
•enabled: <bool>
True, if the node is enabled
•library_id: <string>
The library ID of the library to which the node is attached.
•library_name: <string>
The name of the library to which the node is attached.
•nodegroup_id: <string>
The ID of the nodegroup to which the node is belongs.
•nodegroup_name: <string>
The name of the nodegroup to which the node is belongs.
The available filtering parameters for the nodes endpoint are library_name and nodegroup_name. These parameters will filter out nodes that do not match the passed in values.
6.26.6 Drives endpoint
The drives endpoint returns information about each visible drive within the EE cluster. The following is an example of calling the drives endpoint:
curl -X GET ‘http://localhost:7100/ibmsa/v1/drives/’
The following is the response data when requesting the drives endpoint:
•id: <string>
Serial number of the drive.
•state: <string>
The drive state. For more information, see Table 10-1, “Status and state codes for eeadm drive list” on page 317.
•status: <string>
The string indicates the severity level of the tape's status.
•type: <string>
Drive type, which can be empty if a drive is not assigned to any node group.
•role: <string>
Three character string to represent the drive role. Can be empty if a drive is not assigned to any node group.
•address: <number>
The address of the drive within the library.
•tape_barcode: <string>
The barcode of a tape to which the drive is mounted. Empty if no tape is mounted on the drive.
•task_id: <string>
The task_id of the task which is using this drive.
•library_id: <string>
The ID of the library to which the drive belongs.
•library_name: <string>
The name of the library to which the drive belongs.
•nodegroup_name: <string>
The name of a nodegroup to which the drive is assigned.
•node_id: <string>
The ID of the node to which the drive is assigned.
•node_hostname: <string>
The host name of the node to which the drive is assigned. This field can be empty if a drive is not assigned to any node.
•scsi_vendor_id: <string>
The vendor ID of the drive.
•scsi_product_id: <string>
The product ID of the drive.
•scsi_firmware_revision: <string>
The firmware revision of the drive.
•host_device_name: <string>
The linux device name of the drive.
•host_scsi_address: <string>
The current data path to the tape drive from the assigned node, in the decimal notation of host.bus.target.lun.
The available filtering parameters for the drive endpoint are library_name and nodegroup_name. These parameters will filter out drives that do not match the passed drives in values.
6.26.7 Task endpoint
The tasks endpoint returns information about all or specific active tasks. The following is an example of calling the tasks endpoint:
curl -X GET ‘http://localhost:7100/ibmsa/v1/tasks/’
curl -X GET ‘http://localhost:7100/ibmsa/v1/tasks/<id>’
The following is the response data when requesting the tasks endpoint:
•id: <string>
The task ID. Because the task id is overwritten after the task id reaches the upper limit, the id is in the format of <task_id>@<created_time>.
•task_id: <number>
The same value as the corresponding value in the IBM Spectrum Archive task ID.
•type: <string>
The task type which meets the eeadm commands. A value of “unknown” means that there is an error condition.
•cm_param: <string>
The eeadm command that user input. If the type is “transparent_recall”, the field is empty.
•result: <string>
The result for completed tasks. The string can be either “succeeded”, “failed”, “aborted”, “canceled”, “suspended” or it can be empty. If the string is empty, the task is not completed.
•status: <string>
The status for the task. The string can be either “waiting”, “running”, “interrupted”, “suspending”, “canceling”, “completed” or it can be empty. If the string is empty, an internal error occurs.
•inuse_libs: <string array>
The libraries that the task is currently using. The value is a string array of library.name.
•inuse_node_groups: <string array>
The node groups that the task is currently using. The value is a string array of nodegroup.name.
•inuse_drives: <string array>
The drives that the task is currently using. The value is a string array of drive.id.
•inuse_pools: <string array>
The pools that the task is currently using. The value is a string array of pool.name.
•inuse_tapes: <string array>
The tapes that the task is currently using. The value is a string array of tape.barcode.
•node_hostname: <string>
•The host name of the node to which the drive is assigned. This field can be empty if a drive is not assigned to any node.
All timestamps response data return in the following UTC format:
<yyy>-<MM>-<dd>T<HH>:<mm>:<ss>.<SSS>Z
•created_time: <string>
The time when the task was accepted by MMM.
•started_time: <string>
The time when the task was started.
•completed_time: <string>
The time when the task was determined to be completed by MMM.
The following are filtering parameters for the tasks endpoint:
•task_id: <number>
If you specify the parameter and the task id was overwritten, you can get the latest one.
If you specify the parameter and one of start_created_time and end_created_time, start_created_time and end_created_time do not work.
•start_created_time: <string>
Filter out the tasks which created_time is earlier than this parameter.
The format is <yyyy>-<MM>-<dd>T<HH>:<mm>
•end_created_time: <string>
Filter out the tasks that created_time is later than this parameter.
The format is <yyyy>-<MM>-<dd>T<HH>:<mm>
•type: <string>
Filter the list of tasks by the task type.
•result: <string>
Filter the list of tasks by the task result.
•status: <string>
Filter the list of tasks by the task status.
6.27 File system migration
When refreshing the disk storage and/or IBM Spectrum Scale nodes, the IBM Spectrum Scale file system may need to be migrated to a new file system. The file system migration can be within the IBM Spectrum Scale cluster or between the two different IBM Spectrum Scale clusters.
The migration process of a file system managed by IBM Spectrum Archive used to be time consuming because all the files on the source file system needed to be recalled from tapes and copied to the target file system. From version 1.3.2.0, it supports a migration procedure using SOBAR feature of IBM Spectrum Scale. By using SOBAR, the stub files on the source file system are re-created on the target file system as stub files. The file system migration can be completed without recalling/copying file data from tapes.
The procedure is referred to as System Migration using SOBAR feature and requires prior review by IBM. For more information, see this IBM Documentation web page.
1 Refer to 3.3, “System requirements” on page 50 for RAO supported hardware.
2 The 5,400 file mark is based on laboratory experimental data. In the experiment, we compared the effect of recalling N number of 20MB files with the RAO method versus the starting block order method. The total net recall time indicated that the starting block order method becomes more efficient just over N=5,000 files, and the RAO performance are significantly less effective by N=10,000 files.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.