


IBM Spectrum Archive Enterprise Edition use cases
This chapter describes various use case examples for IBM Spectrum Archive Enterprise Edition (IBM Spectrum Archive EE).
This chapter includes the following topics:
8.1 Overview of use cases
The typical use cases for IBM Spectrum Archive EE can be broken into three categories: Archive, tiered storage, and data exchange, as shown in Figure 8-1.

Figure 8-1 Typical use cases for IBM Spectrum Archive EE
For more information about each use case, see Figure 8-2, Figure 8-3 on page 277, and Figure 8-4 on page 278.
8.1.1 Use case for archive
Figure 8-2 summarizes the requirements, solution, and benefits of an IBM Spectrum Archive EE use case for archiving data.

Figure 8-2 Use case for archive
Some of the requirements for the archive use case are:
•Large amount of data, larger files
•Infrequently accessed
•Longer retention periods
•Easy data access
The solution is based on archive storage that is based on IBM Spectrum Scale, IBM Spectrum Archive EE, and standard file system interfaces
Some of the archive use case benefits are:
•Simplicity with file system interface
•Scalable with IBM Spectrum Scale and IBM Spectrum Archive EE
•Low TCO with IBM tape
8.1.2 Use case for tiered and scalable storage
Figure 8-3 summarizes the requirements, solution, and benefits of an IBM Spectrum Archive EE use case for tiered and scalable storage.

Figure 8-3 Use case for tiered and scalable storage
Some of the requirements for the tiered and scalable use case are:
•Archive to file systems
•Simple backup solution
•Easy data access for restore
The solution is based on archive storage that is based on IBM Spectrum Scale, IBM Spectrum Archive EE, and standard file system interfaces
Some of the tiered and scalable use case benefits are:
•Easy to use with standard copy tools
•Scalable with IBM Spectrum Scale and IBM Spectrum Archive EE
•Low TCO with IBM tape
8.1.3 Use case data exchange
Figure 8-4 summarizes the requirements, solution, and benefits of an IBM Spectrum Archive EE use case for data exchange.
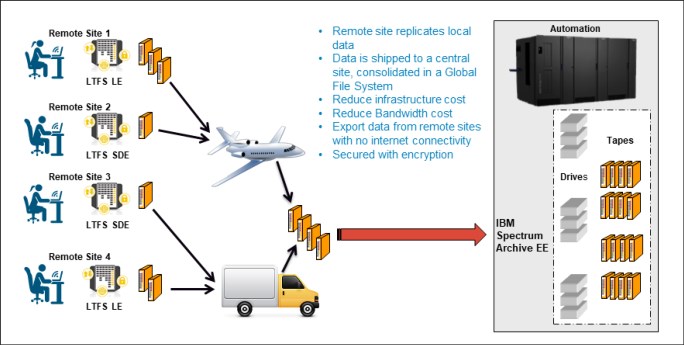
Figure 8-4 Use case for data exchange
Some of the requirements for the data exchange use case are:
•Export entire directories to tape
•Import files and directories with seamless data access
•Leverage global name space
The solution is based on IBM Spectrum Scale, IBM Spectrum Archive EE, and standard file system interfaces using export and import functions
Some of the data exchange use case benefits are:
•Export of tape copies
•Efficient import without reading data
•Import and export within global namespace
8.2 Media and Entertainment
As visual effects get more sophisticated, the computational demands of media and entertainment rose sharply. In response, Pixit Media became the United Kingdom’s leading provider of post-production software-defined solutions that are based on IBM Spectrum Storage technology, which provides reliable performance and cost-efficiency to support blockbuster growth.
Their business challenge is to keep audiences spellbound with their output. Media and Entertainment companies must share, store, and access huge files that traditional infrastructure solutions are failing to deliver. To meet this transformation, Pixit Media put consistent performance and chart-topping scalability in the limelight through software-defined solutions that are based on IBM Spectrum Storage technology that helps customers create hit after hit.
Figure 8-5 shows how a studio’s workflow and applications can talk to IBM Spectrum Scale, which is backed by industry-standard servers and disk arrays that serve as the global single namespace file system.

Figure 8-5 Pixit Media workflow using IBM Spectrum Scale
Pixit Media also began offering solutions that are based on IBM Spectrum Archive EE. They commented that:
“Most of our clients have complex requirements when it comes to archiving a project. They want to move it to a reliable media on a project-by-project basis but without having to manually manage the library. IBM Spectrum Archive EE can offer these customers a worry-free, centralized approach to managing this process, which can be set up in just two or three days and scale out extremely quickly.”1
8.3 Media and Entertainment
The customer is the nation’s premier regional sports network providing a unique and special experiences for local sports fans, sponsors, teams, and media partners across 4 different regions of the United States. All production and post production videos are stored on high-speed storage. However many of these post production videos will never be accessed again so there is no need to occupy space on the high-speed storage. The customer will migrate these post production videos to tape using IBM Spectrum Archive EE.
If the post production videos are ever needed again, they can transparently be recalled back to the high-speed storage. The user data files can be viewed as a normal file system to the Media Asset Management (MAM) system while providing a seamless integration into environments. The mission is to preserve these assets and provide rapid access. Figure 8-6 shows an IBM Spectrum Archive use case for media and entertainment.

Figure 8-6 IBM Spectrum Archive use case for media and entertainment
8.4 High-Performance Computing
Institutions and universities have long used High-Performance Computing (HPC) resources to gather, store, and process their deep wealth of data which is often kept indefinitely. One key step within this process is the ability to easily transfer, share, and discuss the data within their own research teams and others. But this is often a major hurdle for the researchers.
Data transfers, with Globus, overcome this hurdle by providing a secure and unified interface to their research data. Globus handles the complexities behind the details of large-scale data transfers (such as tuning performance parameters), maintains security, monitors progress, and validates correctness. Globus includes a “fire and forget” model where users submit the data transfer task and are notified by Globus when the task is complete. Therefore, researchers can concentrate only on performing their research.
Every data transfer task has a source endpoint and a destination endpoint. The endpoints are described as the different locations where data can be moved to or from using the Globus transfer, sync, and sharing service. For the IBM Spectrum Scale file system and IBM Spectrum Archive EE tape usage, the following terminology is used:
•Data is archived when you use the IBM Spectrum Scale file system as a destination endpoint and it is cached until it is migrated to tape.
•Data is restored or recalled when you use the IBM Spectrum Scale file system as a source endpoint and might require a bulk recall of data from tape before the actual data transfers can occur.
When recalls from tape through IBM Spectrum Archive EE are required, the ability to optimize the bulk recalls is important because it can require a significant amount of time to complete. Without optimizations, the tape recalls look randomized because there is no queue to be able to group tape recalls which are on the same tape or within the same area of tape. Therefore, a lot of time will be consumed by locating or rewinding times on the tape, and on the unmounting or mounting of the target tape.
Therefore, starting with Globus Connect Server (GCS) version 5.4, Globus introduced a feature called “posix staging” to allow the files to be prestaged to a disk cache before performing the data transfer. With IBM Spectrum Scale and IBM Spectrum Archive EE, this feature allows the optimization of bulk recalls from tape, prestaging them to the IBM Spectrum Scale file system before being accessed by Globus. This process is done through Globus by calling a specific “staging app” to generate the bulk recalls inside IBM Spectrum Archive EE. A bulk recall can contain up to 64 staging requests per data transfer task.
Figure 8-7 shows Globus integration with IBM Spectrum Archive for archiving and recalling, including prestaging capabilities. Globus will likely interleave staging and transfer operations during the processing of the transfer task to improve performance.

Figure 8-7 Globus archive integration with IBM Spectrum Archive EE
For more information about the Globus posix staging feature, see this web page.
8.5 Healthcare
Amsterdam University Medical Center (UMC), location VUmc is enabling ground breaking research with scalable, cost-effective storage for big data. With its storage requirements skyrocketing that must be kept for decades, they needed to reevaluate its infrastructure to continue conducting cutting-edge research in a secure and cost-effective way. Working with a partner, the medical center helped researchers migrate from NAS drives to a centralized storage platform that is based on IBM Spectrum Storage solutions.
With IBM Spectrum Scale and IBM Spectrum Archive EE solutions at the heart of its centralized storage environment, Amsterdam UMC, location, VUmc supports its clinicians, researchers, and administrators with the resources they need to work effectively. The promise is to deliver a solution with which users can find the exact data they are looking for easily and quickly, when and where they need it, and without disruptions.
When users or researchers have a new storage request, they are presented with a menu that contains three storage options: gold, silver, and bronze. The gold option is on disk, while the silver and bronze options are on tape (see Figure 8-8). Even when the data is on tape, it is accessible from the online tape archive that provides the lower cost per TB and makes the entire solution environmentally friendly and green.

Figure 8-8 Storage request options based on policies
Now the solution helps to achieve 99% faster data migrations, which enables IT to focus on value-added development. The centralized data architecture ensures VUmc can fully support its clinicians, researchers, and administrators with the resources they need to accelerate discoveries and conduct innovative research.
For more information, see this IBM Support web page.
8.6 Genomics
The customer is one of the largest genomics research facilities in North America, integrating sequencing, bioinformatics, data management, and genomics research. Their mission is to deliver analysis to support personalized treatment to individual cancer patients where the Standard of Care has failed. Hundreds of PBs of data has been moved from old filers to the IBM Spectrum Archive EE system, at a rate of 1.2 PB per month to tape. 2 sets of tape storage pools are used to be able to exchange/share the data with a remote education institute.
The software engineers have also optimized the recall of massive genomics data for their researchers, allowing for quick access to TBs of their migrated genomics data. Figure 8-9 shows a high-level archive for a genomics data archive.

Figure 8-9 IBM Spectrum Archive use case for genomics data archive
8.7 Archive of research and scientific data for extended periods
This research institute routinely manages large volumes of data generated internally and collected by other institutes. To support its ongoing projects, the institute must archive and store the data for many years. However, because most of the data is infrequently accessed, the research institute was looking for a cost-efficient archiving solution that would allow transparent user access.
In addition, the research institute needed a solution that would facilitate the fast import and export of large data volumes. Figure 8-10 shows the high-level architecture to archive research and scientific data for longs periods.

Figure 8-10 IBM Spectrum Archive use case for archiving research/scientific data for long periods of time
Figure 8-10 also shows the redundancy of the archive data from the backup solution. Both archive and backup solutions are storing data on lower cost tape storage. The copies are in two independent systems offering more options for stricter data security requirements.
8.8 University Scientific Data Archive
This university specializes in transportation research. This solution was designed to meet the long-term storage needs of the scientific research community, the university refers to it as the Scientific Data Archive. Scientific research frequently gathers data that need to be available for subsequent dissemination, follow-on research studies, compliance or review of provenance, and other purposes, sometimes with commitment to maintain these data sets for decades.
The proposed solution will be a storage system residing in two locations, providing network access to multiple organizational units within the university, each with their own respective permission models. The primary objective of the Scientific Data Archive is to provide cost-effective, resilient, long-term storage for research data and supporting research computing infrastructure. The archive will be a storage facility operated the university’s Storage Management Team, in cooperation with other units on campus. This facility will deliver service to research organizations on campus. Figure 8-11 show the architecture for the university’s archive.

Figure 8-11 IBM Spectrum Archive use case for university Scientific Data Archive
8.9 Oil and gas
An oil and gas managed service provider collects offshore seismic data for analysis. The solution uses the leading technology based on IBM Power Linux, IBM Spectrum Scale, and IBM Spectrum Archive EE as a seismic data repository. The seismic data is collected from vessels. The technology for both acquisition and processing of seismic data has evolved dramatically over time. Today, a modern seismic vessel typically generates 4-5 TBs of new raw data per day, which once processed will generate 10 to 100 times more data in different formats.
For data that needs to be online but not accessed very frequently, tape is by far more attractive than spinning disk. Hybrid storage solutions with automated and policy-driven movement of data between different storage tiers including tape is required for such large data repositories.
Figure 8-12 shows an IBM Spectrum Archive Oil and Gas archive use case.

Figure 8-12 IBM Spectrum Archive use case for oil and gas
A video of every leading Managed Service Provider in the Nordics with thousands of servers using tape as an integral part of their seismic data management is available at this website.
8.10 S3 Object Interface
For many traditional file-based workloads, tape is a popular option for its cold storage economics. But more recently, the idea of a “S3 on Tape” concept grew in popularity, where a hot or warm tier of object storage is used with a cold tier backed by tape. Going one step further, some customers even want to have a “unified data sharing” capability where the same data, file. or object is accessible across multiple protocols (such as NFS, SMB, S3) regardless of whether the file is on disk or on tape.
Therefore, as more and more companies leverage the advantage of object storage and applications, the storage of the data becomes an important role. Data must be easily accessed (regardless of protocol) and should not be tied to a specific tier. Access should be in parallel, support tape throughput, and always on access.
IBM Spectrum Scale object storage combines the benefits of IBM Spectrum Scale with OpenStack Swift, which is the most widely used open source object store. This object storage system uses a distributed architecture with no central point of control, providing greater scalability, redundancy, and the ability to access the objects via Swift API or the S3 API. But IBM Spectrum Scale object storage requires the deployment of “Protocol Nodes” within the IBM Spectrum Scale cluster.
For more information, see this IBM Documentation web page.
Other than the IBM Spectrum Scale object storage, there is the option of using MinIO, which provides the “S3 on Tape” concept. MinIO is a high-performance, open source, S3 compatible, enterprise hardened object storage. In NAS Gateway mode, MinIO provides the S3-compatible environment that serves as the object storage endpoint. MinIO leverages the IBM Spectrum Scale file system including multiple instances of MinIO NAS Gateways as a distributed object storage.
The MinIO NAS Gateway is a simple translator for all S3 API calls, and writes the files on the IBM Spectrum Scale file system as normal files. This MinIO NAS Gateway provides an important feature called global 1-to-1 data sharing, which means that every object is a single file on IBM Spectrum Scale (one object to one file). Any S3 object can be seen as a file through IBM Spectrum Scale, including SMB/NFS, and any file created through IBM Spectrum Scale, including SMB/NFS, can be seen as an object using the S3 API. You can also create a separate NAS Gateway directory for only S3 data.
When you use MinIO with IBM Spectrum Scale and IBM Spectrum Archive EE, MinIO handles all the S3 API calls while IBM Spectrum Scale provides the lifecycle management of the objects to either remain on disk for hot or warm tier or on tape for the cold tier though the powerful policy engine (see Figure 8-13).

Figure 8-13 High level MinIO with IBM Spectrum Archive architecture
To the S3 object user, all objects appear as they are in the object storage, available on disk, and accessible using standard S3 GET or HEAD methods. Thus, it is simple to use it as any standard S3 object storage, but it offers the advantage of tape economics for older objects which have not been accessed for some time.
8.11 AFM use cases
This section covers the use of a home and cache sites, and delves into two typical use cases of IBM Spectrum Archive EE with IBM Spectrum Scale AFM explaining the Centralized Archive Repository scenario and the Asynchronous Archive Replication scenario.
Active file management (AFM) uses a home-and-cache model in which a single home provides the primary storage of data, and exported data is cached in a local GPFS file system:
Home A home site is an NFS export of a remote cluster. This export can be a local file system in the remote cluster, a GPFS file system, or a GPFS fileset in the remote cluster. AFM is supported when a remote file system is mounted on the cache cluster using GPFS protocols. This configuration requires that a multicluster setup exists between the home and cache before AFM can use the home cluster’s file system mount for AFM operations.
Cache A cache site is a remote cluster with a GPFS fileset that has a mount point to the exported NFS file system of the home cluster’s file system. A cache site uses a proprietary protocol over NFS. Each AFM-enabled fileset has a single home cluster associated with it (represented by the host name of the home server).
8.11.1 Centralized archive repository
In an environment where data needs to be allocated together to create a bigger picture, archiving, or for disaster recovery planning, users can create a centralized archive repository. This repository uses a single home cluster that can have multiple NFS exports to many cache sites.
In this setup, IBM Spectrum Archive EE is configured on the home cluster to archive all the data generated from each cache cluster. The idea behind this solution is to have a single home repository that has a large disk space, and multiple cache sites that cannot afford large disk space.
|
Note: AFM supports multiple cache modes, and this solution can be used with single writer or independent writer. However, with the release of IBM Spectrum Archive EE v1.2.3.0, only the independent writer is currently supported.
|
When files are generated on the cache clusters, they are asynchronously replicated to the home site. When these files are no longer being accessed on the cache clusters, the files can be evicted, freeing up disk space at the cache clusters. They can then be migrated onto tape at the home cluster. If evicted files need to be accessed again at the cache clusters, they can simply be recovered by opening the file for access or by using AFM’s prefetch operation to retrieve multiple files back to disk from the home site.
Figure 8-14 shows a configuration of a single home cluster with multiple cache clusters to form a centralized archive repository.

Figure 8-14 Centralized archive repository
Some examples of customers who can benefit from this solution are research groups that are spread out geographically and rely on each group’s data, such as universities. Medical groups and media companies can also benefit.
8.11.2 Asynchronous archive replication
Asynchronous archive replication is an extension to the stretched cluster configuration. In it, users require the data created is replicated to a secondary site and can be migrated to tape at both sites. By incorporating IBM Spectrum Scale AFM to the stretched cluster idea, there are no limits on how far away the secondary site is located. In addition to geolocation capabilities, data created on home or cache is asynchronously replicated to the other site.
Asynchronous archive replication requires two remote clusters configured, one being the home cluster and the other being a cache cluster with the independent writer mode. By using the independent writer mode in this configuration, users can create files at either site and the data/metadata is asynchronously replicated to the other site.
|
Note: With independent writer, the cache site always wins during file modifications. If files are created at home, only metadata is transferred to the cache at the next update or refresh. To obtain the file’s data from the home site at the cache site, use AFM’s prefetch operation to get the data or open specific files. The data is then propagated to the cache nodes.
|
Figure 8-15 shows a configuration of an asynchronous archive replication solution between a home and cache site.

Figure 8-15 Asynchronous archive replication
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.