


Planning for IBM Spectrum Archive Enterprise Edition
This chapter provides planning information that is related to the IBM Spectrum Archive Enterprise Edition (EE). Review the Planning section in the IBM Spectrum Archive EE that is available at this IBM Documentation web page.
The most current information for IBM Spectrum Archive EE hardware and software configurations, notices, and limitations can always be found in the readme file of the software package.
This chapter includes the following topics:
3.1 IBM Spectrum Archive EE deployment options
It is important to understand the target environment which IBM Spectrum Archive Enterprise Edition will be deployed. Resources can be used as part of your deployment. Configuration flexibility is one of the many advantages of IBM software-defined storage solutions that provide high business-value while streamlining long-term data-retention storage costs.
IBM Spectrum Archive Enterprise Edition is to be installed and configured on one or more IBM Spectrum Scale nodes. IBM Spectrum Archive EE installed nodes make up an IBM Spectrum Archive EE cluster within an IBM Spectrum Scale cluster. The IBM Spectrum Archive EE nodes need to be attached to a supported tape library facility. A maximum of two tape libraries are supported for an IBM Spectrum Archive EE cluster.
From an IBM Spectrum Scale architecture perspective, the IBM Spectrum Archive EE software-defined storage can be installed and configured on an IBM Spectrum Scale Client node, an IBM Spectrum Scale Server node, or an IBM Spectrum Scale Protocol node. The node that you choose must have the supported requirements for IBM Spectrum Archive EE.
|
Note: IBM Spectrum Archive EE can NOT be installed on IBM Elastic Storage® Server (IBM ESS) nodes. See 3.3.1, “Limitations” on page 51.
|
This section describes some of the typical deployment configurations for IBM Spectrum Archive EE and provides insights to help plan for its implementation.
3.1.1 On IBM Spectrum Scale Servers
On this architecture, the IBM Spectrum Archive EE is deployed within the same server as that of the IBM Spectrum Scale. This approach is common in entry- to mid-level solutions that consolidate the architecture to a minimum solution. A common use case for this architecture is for Active Archive solutions, which require only a relatively small amount of flash or disk staging tiers for data migration to the tape tier.
Figure 3-1 shows the physical and its equivalent logical diagram that show the minimum architecture approach for IBM Spectrum Archive EE.

Figure 3-1 Deployed on IBM Spectrum Scale Server
The required software components of IBM Spectrum Scale and IBM Spectrum Archive EE are installed in one physical server either directly Fibre Channel-attached to an IBM tape library or using a storage area network. The RAID-protected LUNs and IBM tape library are configured in IBM Spectrum Scale and IBM Spectrum Archive EE as pools - flash pools, spinning disk pools and tape pools. This architecture deployment option enables automated data tiering based on user-defined policies with minimum solution components.
This architecture is also known as Long-Term Archive Retention (LTAR). However, as this solution is usually deployed for long term data archive retention, injecting high availability is highly recommended.
Figure 3-2 shows a high availability architecture approach to the minimum solution.
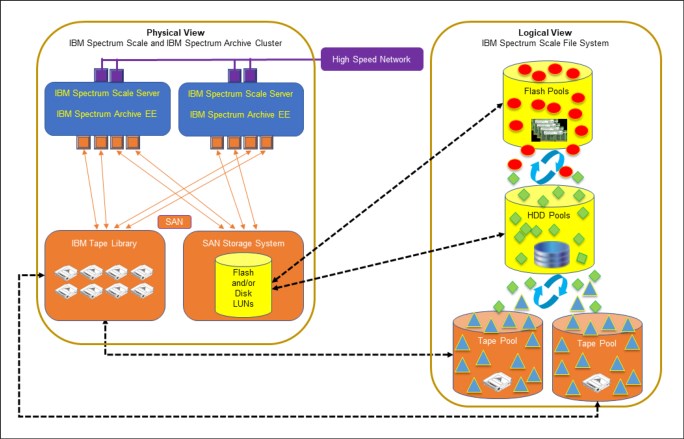
Figure 3-2 High availability approach IBM Spectrum Archive EE on IBM Spectrum Scale Servers
Two physical servers are deployed each with IBM Spectrum Scale and IBM Spectrum Archive EE software components. Both servers are connected to a storage area network which provides connectivity to a shared storage area network (SAN) storage system and an IBM tape library. This approach ensures that both servers are connected to the storage systems by way of a high-speed Fibre Channel network. The connectivity of the cluster to a shared flash or disk storage system provides high performance and high availability in the event of a server outage. For more information about configuring a multiple-node cluster, refer to 5.2.3, “Configuring a multiple-node cluster” on page 112.
Another approach to implementing high availability for data on tapes is the deployment of two or more tape pools. Policies can be configured to create up to three copies of data in the additional tape pools.
|
Note: Multiple tape pools also can be deployed on the minimum solution, as shown in Figure 3-1 on page 41.
|
3.1.2 As an IBM Spectrum Scale Client
On this architecture, the IBM Spectrum Archive EE node is deployed as a separate software-defined storage module integrating with the IBM Spectrum Scale single namespace file system with its own Storage Area Network interface to the tape platform.
Figure 3-3 shows this unique approach that leverages software-defined storage for flexibility of scaling the system.

Figure 3-3 IBM Spectrum Archive EE node as an IBM Spectrum Scale Client
The diagram shows a single node IBM Spectrum Archive EE as an IBM Spectrum Scale Client with a single tape library attached using SAN. However, it is easy to add IBM Spectrum Archive EE nodes that are attached to the same library using SAN for high-availability or higher tape-access throughput.
This is the solution approach for customers with IBM Spectrum Scale environments who want to use tapes to stream line costs for long-term archive retention. This architecture provides a platform to scale both IBM Spectrum Scale and IBM Spectrum Archive EE independently, that is by adding nodes to each of the clusters when needed. The integration of the server nodes with the storage systems can be done over the same SAN fabric considering the appropriate SAN zoning implementations. This way, scaling the IBM Spectrum Scale flash- or disk-storage capacity is accomplished by merely adding flash or disk drives to the storage server.
3.1.3 As an IBM Elastic Storage Systems IBM Spectrum Scale Client
This architecture is similar to the architecture described in 3.1.2, “As an IBM Spectrum Scale Client” on page 43. However, instead of an IBM Spectrum Scale cluster of nodes, the IBM ESS appliance is deployed. The IBM Elastic Storage Systems (ESS) is a pre-integrated, pre-tested appliance that implements the IBM Spectrum Scale file system in the form of building blocks. The IBM Spectrum Archive EE tightly integrates with the IBM ESS, enabling automated data-tiering of the file system to and from tapes based on policies.
Figure 3-4 shows this architecture wherein an IBM Spectrum Archive EE node is integrated with an IBM Spectrum Scale architecture deployed on an IBM ESS system.

Figure 3-4 IBM Spectrum Archive EE node as an IBM Spectrum Scale Client in an IBM ESS
This architecture allows the same easy scalability feature as the IBM Spectrum Scale Client described in 3.1.2, “As an IBM Spectrum Scale Client” on page 43; With this scalability feature, you can add nodes when needed. In Figure 3-4, you can add IBM ESS modules to expand the IBM Spectrum Scale cluster; or you can add IBM Spectrum Archive EE nodes to expand the file system tape facility channels. Needless to say, adding tape drives and tape cartridges to address growing tape access and storage requirements is also simple and nondisruptive.
3.1.4 As an IBM Spectrum Scale stretched cluster
An IBM Spectrum Scale stretched cluster is a high-availability solution that can be deployed across two sites over metropolitan distances of up to 300 km apart. Each site will have both IBM Spectrum Scale and IBM Spectrum Archive EE clusters integrated with a tape library. These two sites form a single namespace, thus simplifying data-access methods. Data created from one site is replicated to the other site and might be migrated to tapes based on the user-defined policies to protect data. This way, if one site failure occurs, data will still be accessible on the other site.
Figure 3-5 shows a single namespace file system IBM Spectrum Scale stretched cluster architecture deployed across two sites.

Figure 3-5 IBM Spectrum Scale Stretched Cluster across metropolitan distances of up to 300 KM
This architecture shows a good use case for deploying two tape libraries in one IBM Spectrum Scale cluster. For sites that are geographically separated by greater than 300 KM, Active File Management (AFM) might be deployed to replicate data across the sites. However, both sites are independent IBM Spectrum Scale clusters as compared to the single namespace file system over a stretched cluster.
For more information about stretched clusters, see 5.2.4, “Configuring a multiple-node cluster with two tape libraries” on page 115.
For example use cases on stretched clusters and AFM, see 8.8, “University Scientific Data Archive” on page 286 and 8.11, “AFM use cases” on page 290.
|
Note: Figure 3-5 shows the IBM Spectrum Scale cluster deployed as an IBM ESS appliance. The cluster might also be a software-defined storage deployment on IBM Spectrum Scale Server nodes as discussed in 3.1.1, “On IBM Spectrum Scale Servers” on page 40 and 3.1.2, “As an IBM Spectrum Scale Client” on page 43.
|
3.2 Data-access methods
This section describes how applications or users can access data in the IBM Spectrum Scale file system that has an integrated IBM Spectrum Archive EE facility. It is important to note that IBM Spectrum Scale is a single namespace file system by which data can be automatically tiered based on user-defined policies; and IBM Spectrum Archive EE is the channel of IBM Spectrum Scale to utilize the tape platform as a storage tier of the single namespace file system.
There are three ways of accessing data on an IBM Spectrum Archive EE deployed IBM Spectrum Scale system:
3.2.1 Data access using application or users on IBM Spectrum Scale Clients
This access method refers to compute nodes directly accessing the IBM Spectrum Scale System. Each compute node on which the applications are running, needs to have an IBM Spectrum Scale Client installed for high-speed data access to the IBM Spectrum Scale Cluster.
Figure 3-6 shows that the IBM Spectrum Scale Client is installed on the compute nodes where the applications are running.
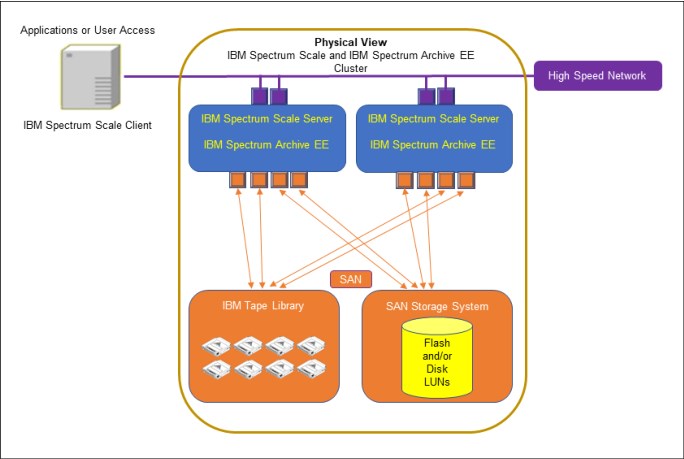
Figure 3-6 Access using IBM Spectrum Scale Client on compute node
|
Note: Each compute node must have IBM Spectrum Scale Clients installed to access the IBM Spectrum Scale Cluster. This allows high-performance (network dependent) access to the cluster.
|
3.2.2 Data access using Protocol Nodes on IBM Spectrum Scale Server Nodes with IBM Spectrum Archive EE
This access method can be more “application-friendly” because alterations or software modules are not required to be installed on the application compute-nodes. Access to the IBM Spectrum Scale Cluster is gained by using the Protocol Nodes which offers other choices of data interface. The following data interfaces might be used by the application compute-nodes through the IBM Spectrum Scale Protocol Nodes:
•Network File System (NFS)
•Server Message Block (SMB)
•Hadoop Distributed File System (HDFS)
•Object
Figure 3-7 shows this architecture where Protocol Nodes are deployed on the same servers as that of the IBM Spectrum Scale Server and IBM Spectrum Archive EE nodes.

Figure 3-7 Access using Protocol Nodes on IBM Spectrum Scale and IBM Spectrum Archive EE nodes
This architecture is usually deployed on Operational Archive and Active Archive use cases where each cluster host runs IBM Spectrum Scale and IBM Spectrum Archive EE software-defined storage modules. The scalability potential of each entity (application compute-nodes, and IBM Spectrum Scale or IBM Spectrum Archive EE nodes) remains independent of each other. This architecture might provide streamlined costs for long-term archive retention solution requirements.
Figure 3-8 shows another version of this access method, where Application Compute Nodes access the IBM Spectrum Scale Cluster using Protocol Nodes. However, this architecture deploys the Protocol Nodes in separate hosts or virtual machines. This way, scaling is much simpler, that is, you can add the required nodes when needed.
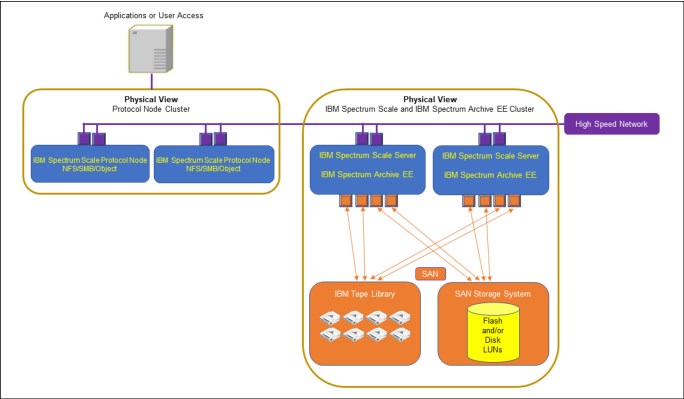
Figure 3-8 Access using Protocol Nodes on separate hosts
3.2.3 Data access using Protocol Nodes integrated with the IBM ESS
This access method is similar to Figure 3-8. However, instead of software-defined storage modules implemented on servers or hosts, the IBM Spectrum Scale system is deployed on an IBM ESS environment. The IBM Spectrum Archive EE environment is also deployed independently as an IBM Spectrum Scale Client, which provides flexible scalability for all components.
Figure 3-9 shows an IBM ESS system integrated with an IBM Spectrum Archive EE node. On this architecture, a separate cluster of Protocol Nodes are deployed to provide applications and users with access to the IBM Spectrum Scale in the IBM ESS system.

Figure 3-9 Access using Protocol Node cluster to IBM ESS
This architecture uses the pre-tested and pre-installed IBM Spectrum Scale environment as an IBM ESS appliance. Scaling this architecture is simplified, where upgrades can be deployed to the independent clusters (which make up the IBM Spectrum Scale single namespace filesystem). Also, note that IBM Spectrum Archive EE nodes can be added to this architecture for high availability or to increase tape access performance.
3.3 System requirements
IBM Spectrum Archive EE supports the Linux operating systems and hardware platforms that are shown in Table 3-1.
Table 3-1 Linux system requirements
|
Linux computers
| |
|
Supported operating systems (x86_64)
|
Red Hat Enterprise Linux Server 7.4, 7.5, 7.6, 7.7, 7.8, 7.9, 8.2, 8.3, and 8.4
|
|
Supported operating systems (ppc64le)
|
Red Hat Enterprise Linux Server 7.4, 7.5, 7.6, 7.7, 7.8, 7.9, 8.2, 8.3, and 8.4
|
|
Supported tape libraries
|
IBM Spectrum Archive Enterprise Edition supports up to two tape libraries of the following types:
•IBM TS4500 tape library (IBM LTO 5 and later generation LTO tape drives, TS1140 and later generation 3592 tape drives)
•IBM TS4300 tape library (IBM LTO 6 and later generation LTO tape drives)
•IBM TS3500 tape library (IBM LTO 5 through LTO 8 generation LTO tape drives, TS1140 and later generation 3592 tape drives)
•IBM TS3310 tape library (IBM LTO 5 and later generation LTO tape drives)
|
|
Supported tape drives
|
IBM TS1140 tape drive
|
|
IBM TS1150 tape drive
| |
|
IBM TS1155 tape drive
| |
|
IBM TS1160 tape drive
| |
|
LTO-5 tape drive
| |
|
LTO-6 tape drive
| |
|
LTO-7 tape drive
| |
|
LTO-8 tape drive
| |
|
LTO-9 tape drive
| |
|
Supported tape media
|
TS1140 media: JB, JC, JK, and JY
TS1155/TS1150 media: JC, JD, JK, JL, JY, and JZ
TS1160 media: JC, JD, JE, JK, JL, JM, JV, JY, and JZ
|
|
LTO media: LTO 9, LTO 8, LTO 7 Type M8, LTO 7, LTO 6, and LTO 5
| |
|
Recommended Access Order (RAO) support
|
IBM TS1140, IBM TS1150, IBM TS1155, IBM TS1160, and LTO-9
|
|
Server
| |
|
Processor
|
•One of the following servers:
– x86_64 processor (physical server only)
– IBM POWER® ppc64le processor (either physical server or IBM PowerVM® partition)
•Minimum: A x86_64 processor
•Preferred: Dual socket server with the latest chipset
|
|
Memory
|
•Minimum: 2 x (d) x (f) + 1 GB of RAM available for the IBM Spectrum Archive EE program:
– d: Number of tape drives
– f: Number of millions of files/directories on each tape cartridge in the system
In addition, IBM Spectrum Scale must be configured with adequate RAM.
•Example: There are six tape drives in the system and three million files are stored on each tape cartridge. The minimum required RAM is 37 GB (2 x 6 x 3 + 1 = 37).
•Preferred: 64 GB RAM and greater
|
|
Host Bus Adapter (HBA)1,
RoCE
|
•Minimum: Fibre Channel Host Bus Adapter supported by TS1160, TS1155, TS1150, TS1140, LTO-9, LTO-8, LTO-7, LTO-6, and LTO-5 tape drives
•Preferred: 8 Gbps/ 16 Gbps Dual port or Quad port Fibre Channel Host Bus Adapter
|
|
Network
|
TCP/IP based protocol network
|
|
Disk device for LTFS EE tape file system metadata
|
For more information, see 3.7, “Sizing and settings” on page 61.
|
|
One or more disk devices for the GPFS file system
|
The amount of disk space that is required depends on the IBM Spectrum Scale settings that are used.
|
1 For more information about HBA interoperability, see the IBM System Storage Interoperation Center (SSIC) web page.
3.3.1 Limitations
In this section, we describe the limitations of IBM Spectrum Archive EE.
Limitations on supported files
This section describes the limitations of IBM Spectrum Archive EE on file attributes when migrating supported files.
Maximum file size
IBM Spectrum Archive EE cannot split a file into multiple sections and distribute the sections across more than one tape. Therefore, it cannot migrate a file that is larger than the data partition size of a single tape. For more information about media types and partition sizes, see 2.1.1, “Tape media capacity with IBM Spectrum Archive” on page 19.
Maximum file name length
Consider the following points:
•A file cannot be migrated if its full path name (file name length plus path length) exceeds 1024 bytes.
•A file cannot be saved if its full path name (file name length plus path length) exceeds 1022 bytes.
Minimum file size
Consider the following points:
•A nonzero length regular file can be migrated to tape with the eeadm migrate or eeadm premigrate commands.
•The name of an empty (zero length) file, and a symbolic link and an empty directory, can be stored on tape with the eeadm save command.
File encryption and file compression
When the file encryption and file compression function of GPFS is used, the in-flight data from disk-storage to tape is in the decrypted and uncompressed form. The data is re-encrypted and recompressed by using the tape hardware function. (Tape encryption requires the library to be set up with key manager software.)
Hard links on files
Migration of files with hard links to tape is discouraged in IBM Spectrum Archive EE.
The hard link creates an alias for the data with different name or directory path without copying it. The original file and other hard links all point to the same data on disk.The view from other hard links is affected if the file that is linked from one hard link is changed.
If multiple hard links are necessary on the IBM Spectrum Archive EE managed file system, those files must be excluded from policy files; otherwise, commands can have unexpected results for the user. The following consequences can occur on running the commands:
•Migration, Recall, and Premigrate commands
If one of the hard links is specified in a migration task, all hard links of that file are shown as migrated. If multiple hard links are specified in a single migration task, the migration results in a “duplicate” error. If one of the hard links is specified in a recall task, all hard links of that file are shown as recalled. If multiple hard links are specified in a single recall task, the recall results in a “duplicate error”.
•Save commands
The hard link information is not saved with the save command because the objects contain data.
•File behavior on tape export and imports
The tape export process can cause unintentional unlinks from I-nodes. Even if all hard links indicate that they are migrated to tape, multiple hard links for a single I-node is not created during the tape import.
Limitations with IBM Spectrum Protect
If IBM Spectrum Protect clients are being used for managing the files in the same IBM Spectrum Scale cluster, the following limitations apply:
•If the IBM Spectrum Protect backup client needs to back up the files of the file system that is managed by IBM Spectrum Archive EE, you must schedule the migration process to start after the files are backed up.
Specify the --mmbackup option of the eeadm migrate command to ensure the files are backed up first before migration. For more information, see 7.26.2, “Backing up a GPFS or IBM Spectrum Scale environment” on page 265.
•If an IBM Spectrum Scale cluster is used with IBM Spectrum Archive EE, any file system that is in the same IBM Spectrum Scale cluster cannot be used with IBM Spectrum Protect for Space Management for migrating the data to IBM Spectrum Protect servers.
Limitations with IBM Spectrum Scale
This section describes the limitations of IBM Spectrum Archive EE with specific IBM Spectrum Scale functions.
Limitations on IBM Spectrum Scale features
The file system that is managed by IBM Spectrum Archive EE cannot be used with the following functions or features of IBM Spectrum Scale:
•Scale-out Backup and Recovery (SOBAR) for DR purposes
•Advanced File Management (AFM), in a mode other than Independent Writer mode
•Transparent Cloud Tiering (TCT)
Limitations with the Snapshot function
To prevent an unexpected massive recall of files from tapes, it is not recommended to use IBM Spectrum Scale file system snapshots or file set snapshots when the files are managed by IBM Spectrum Archive EE. The massive recall of files happens if a snapshot is taken after the files are migrated to tapes and then later, the user deletes the migrated files before the snapshot.
Cluster Network File System (CNFS)
To prevent a Network File System (NFS) failover from happening on an IBM Spectrum Archive EE node, do not install IBM Spectrum Archive EE on Cluster NFS (CNFS) member nodes.
IBM Spectrum Archive EE with IBM ESS
IBM Spectrum Archive EE cannot be installed on ESS IO nodes or ESS Protocol Nodes due to the HBA requirement for tape hardware connectivity.
IBM Spectrum Archive EE on an IBM Spectrum Scale Server
IBM Spectrum Archive EE can be installed on IBM Spectrum Scale NSD servers. Evaluate workload and availability needs on the combined IBM Spectrum Scale NSD and IBM Spectrum Archive EE to ensure resource requirements are sufficient.
Security-Enhanced Linux (SELinux)
The SELinux setting must be in permissive mode or disabled when deploying with IBM Spectrum Scale 5.0.4 or earlier. Starting from IBM Spectrum Scale 5.0.5, SELinux also can be set to enforcing mode.
Remote Mount
IBM Spectrum Archive EE handles only file systems that belong to the local (home) IBM Spectrum Scale cluster, but not file systems that are installed remotely.
3.4 Required software for Linux systems
This section describes the required software for IBM Spectrum Archive EE on Red Hat systems. The following RPM Package Manager Software (RPMS) must be installed and be at latest levels for a Red Hat Enterprise Linux system before installing IBM Spectrum Archive EE v1.3.2.2.
3.4.1 Required software packages for Red Hat Enterprise Linux systems
The following software modules are required to deploy IBM Spectrum Archive Enterprise Edition on Red Hat Enterprise Linux systems:
•The most current fix pack for IBM Spectrum Scale: 5.0.2, 5.0.3, 5.0.4, 5.0.5, 5.1.0, 5.1.1, 5.1.2, or subsequent releases. The following operating system software:
– attr
– Boost.Date_Time (boost-date-time)
– Boost.Filesystem (boost-filesystem)
– Boost.Program_options (boost-program-options)
– Boost.Serialization (boost-serialization)
– Boost.Thread (boost-thread)
– boost_regex
– FUSE
– fuse
– fuse-libs
– gperftools-libs
– Java virtual machine (JVM)
– libxml2
– libuuid
– libicu
– lsof
– net-snmp
– nss-softokn-freebl
– openssl
– Python 2.4 or later, but earlier than 3.0
– python3-pyxattr (required with Red Hat Enterprise Linux 8.x. Requires access to the Red Hat CodeReady Linux Builder repository)
– pyxattr (required with Red Hat Enterprise Linux 7.x)
– rpcbind
– sqlite
•HBA device driver (if one is provided by the HBA manufacturer) for the host bus adapter connecting to the tape library and attach to the tape drives.
|
Note: Java virtual machine (JVM) 1.7 or later must be installed before the “Extracting binary rpm files from an installation package” step for IBM Spectrum Archive on a Linux system during the installation of IBM Spectrum Archive Enterprise Edition.
|
3.4.2 Required software to support REST API service on RHEL systems
The optional REST API service for IBM Spectrum Archive Enterprise Edition supports RHEL systems. The following software for the REST API support must be installed on the RHEL 7.x system:
•httpd
•mod_ssl
•mod_wsgi
•Flask 0.12
Install Flask by using one of the following methods:
– Use pip: pip install Flask==0.12
|
Note: The REST API must be installed on one of the IBM Spectrum Archive Enterprise Edition nodes.
|
3.4.3 Required software to support a dashboard for IBM Spectrum Archive Enterprise Edition
IBM Spectrum Archive Enterprise Edition supports a dashboard monitor system performance, statistics, and configuration. The following software is included in the IBM Spectrum Archive EE installation package:
•Logstash 5.6.8, to collect data
•Elasticsearch 5.6.8, to store the data
•Grafana 5.0.4-1, to visualize data
|
Note: Consider the following points:
•The dashboard requires EE node and monitoring server to run on x86_64 platform. For more information about other requirements, see this IBM Support web page.
•Support for the open source packages can be acquired for a fee by contacting a third-party provider. It is not covered by the IBM Spectrum Archive Enterprise Edition license and support contract.
|
3.4.4 Required software for SwiftHLM
IBM Spectrum Archive Enterprise Edition can use SwiftHLM functions for suitable integration with Swift. The Swift High Latency Media (HLM) project can create a high-latency storage backend that makes it easier for users to perform bulk operations of data tiering within a Swift data ring.
SwiftHLM 0.2.1 is required for the optional use of SwiftHLM.
3.5 Hardware and software setup
Valid combinations of IBM Spectrum Archive EE components in an IBM Spectrum Scale cluster are listed in Table 3-2.
Table 3-2 Valid combinations for types of nodes in the IBM Spectrum Scale cluster
|
Node type
|
IBM Spectrum Scale
|
IBM Spectrum Archive internal Hierarchical Storage Management (HSM)
|
IBM Spectrum Archive LE
|
Multi-tape management module (MMM)
|
|
IBM Spectrum Scale only node
|
Yes
|
No
|
No
|
No
|
|
IBM Spectrum Archive EE node
|
Yes
|
Yes
|
Yes
|
Yes
|
All other combinations are invalid as an IBM Spectrum Archive EE system. IBM Spectrum Archive EE nodes have connections to the IBM tape libraries and drives.
Multiple IBM Spectrum Archive EE nodes enable access to the same set of IBM Spectrum Archive EE tapes. The purpose of enabling this capability is to increase the performance of the host migrations and recalls by assigning fewer tape drives to each IBM Spectrum Archive EE node. The number of drives per node depends on the HBA/switch/host combination. The idea is to have the maximum number of drives on the node such that all drives on the node can be writing or reading at their maximum speeds.
The following hardware/software/configuration setup must be prepared before IBM Spectrum Archive EE is installed:
•IBM Spectrum Scale is installed on each of the IBM Spectrum Archive EE nodes.
•The IBM Spectrum Scale cluster is created and all of the IBM Spectrum Archive EE nodes belong to the cluster.
A single NUMA node is preferable for better performance. For servers that contain multiple CPUs, the key is to remove memory from the other CPUs and group them in a single CPU to create a single NUMA node. This configuration allows all the CPUs to access the shared memory, resulting in higher read/write performances between the disk storage and tape storage.
FC switches can be added between the host and tape drives and between the host and the disk storage to create a storage area network (SAN) to further expand storage needs as required.
3.6 IBM Spectrum Archive deployment examples
This section describes some examples of IBM Spectrum Archive deployment on Lenovo severs and on a Versastack converged infrastructure.
3.6.1 Deploying on Lenovo servers
This section describes IBM Spectrum Archive deployment examples with Lenovo servers.
Minimum Lenovo server deployment
Figure 3-10 shows the minimum deployment option as shown in Figure 3-1 on page 41. It is a high level diagram of a minimum deployment where all required software components of IBM Spectrum Scale and IBM Spectrum Archive EE are installed on a Lenovo ThinkSystem SR650 server with a direct attached IBM TS4300 using Fibre-Channel connections.

Figure 3-10 Minimum deployment on Lenovo ThinkSystem SR650 server with IBM TS4300
The following example server configuration is used for a Lenovo ThinkSystem SR650 rack server:
•Forty cores (Two sockets each with 20-cores) Intel Xeon Processors
•512 GB RAM
•RAID controller
•Nine units 10 TB 3.5-inch 7.2KRPM NL SAS (RAID 6 = 6D+P+Q+Spare)
•Five units 3.84 TB 3.5-inch SATA SSD (RAID 5 = 3D+P+Spare)
•Two units 480 GB SATA Non-Hot Swap SSD for operating system
•Red Hat Enterprise Linux with Lenovo Support for Virtual Data Centers x2 socket licenses
•One unit Dual-port 16 Gbit FC HBA for tape interface
•One unit Dual-port 10/25 GbE SFP28 PCIe Ethernet adapter for network interface
•One available PCIe slot might be configured as other FC or GbE connectivity
After RAID protection of the internal flash and disk resources, the estimated usable capacity is approximately 55 TiB for the nearline SAS disks and 10 TiB for the SSDs for a total of 65 TiB. A portion of the SSD capacity can be allocated for the IBM Spectrum Scale metadata and the rest can be deployed as pools to the IBM Spectrum Scale file system.
IBM Spectrum Scale can be licensed on a per-terabyte basis with the following three license options:
•Data Access Edition
•Data Management Edition
•Erasure Code Edition.
The storage capacity to be licensed is the capacity in terabytes (TiB) from the network shared disk (NSD) in the IBM Spectrum Scale Cluster. This means that less capacity can be allocated to IBM Spectrum Scale if the required capacity of the storage tier required is less than 65 TiB, thereby reducing the IBM Spectrum Scale capacity license.
For more information about IBM Spectrum Scale licenses and licensing models, see the following IBM Documentation web pages:
The IBM TS4300 tape library is configured with two units of half-high LTO-8 tape drives, which directly connect to the Lenovo ThinkSystem SR650 server using 8Gbit Fibre-Channel connections.
IBM Spectrum Archive EE is licensed per node regardless of the capacity migrated to tapes. With node-based licensing, storing data on tapes is virtually unlimited provided if enough tape resources are available in the tape-storage tier. This node-based licensing can help realize significant savings on storage and operational costs.
In this example, we need only one IBM Spectrum Archive EE license, which is for one node that is installed with IBM Spectrum Scale. If more tape access channels are needed, more IBM Spectrum Scale with IBM Spectrum Archive EE nodes can be added to the cluster.
High-availability minimum deployment architecture on Lenovo servers
Figure 3-11 on page 59 shows the injection of high availability with the minimum deployment architecture as shown in Figure 3-2 on page 42.
Figure 3-11 on page 59 shows the high-level architecture of a high-availability minimum solution using Lenovo ThinkSystem SR650 servers. Both servers will be installed with the same software stack as that of the minimum deployment solution described in “Minimum Lenovo server deployment” on page 57.

Figure 3-11 High availability on minimum deployment IBM Spectrum Scale
Figure 3-11 shows the following high level components:
•Lenovo ThinkSystem SR650 servers
•IBM FlashSystems 5035
•IBM Storage Networking SAN48C-6 SAN switches
•IBM TS4300 tape library with LTO 8 tape drives
The difference of this architecture is that instead of internal storage for the IBM Spectrum Scale with IBM Spectrum Archive EE servers, storage capacity will now be on a shared storage system using redundant SAN Switches. In Figure 3-11, the IBM FlashSystem® FS5035 is deployed with a pair of IBM SAN48-C SAN switches for this example.
The IBM Spectrum Scale license for this architecture can be either Data Access Edition or Data Management Edition. Erasure Code Edition is not applicable because of the shared storage architecture. In Figure 3-11, both servers with IBM Spectrum Archive EE need to be licensed.
3.6.2 Deploying on Versastack converged infrastructure
Another example of deployment is to use the deployment of IBM Spectrum Archive EE system on Versastack. VersaStack is a converged infrastructure solution of network, compute and storage designed for quick deployment and rapid time to value. The solution includes Cisco Unified Computing System (UCS) integrated infrastructure together with IBM software-defined storage solutions to deliver extraordinary levels of agility and efficiency. VersaStack is backed by Cisco Validated Designs and IBM Redbooks application guides for faster infrastructure delivery and workload/application deployment.
VersaStack integrates network, compute, and storage, as follows:
•On the network and compute side, VersaStack solutions use the power of Cisco UCS integrated infrastructure. This infrastructure includes the cutting-edge Cisco UCS and the consolidated Cisco Intersight delivering simple, integrated management, orchestration and workload assurance.
•On the storage side, IBM offers storage solutions for VersaStack based on IBM Spectrum Virtualize technologies.
To set up IBM Spectrum Archive EE on the Versastack-converged infrastructure, deploy the required software components on properly-sized Cisco UCS blade servers in the UCS chassis and integrate an IBM TS4500 tape library using Cisco Multilayer Director Switch (MDS) SAN switches.
The high-level components that formulate this architecture are as follows:
•Cisco UCS 5108 Chassis
•Cisco UCS B200 M5 Servers as sized and configured respectively with IBM Spectrum Scale and IBM Spectrum Archive EE requirements
•Cisco UCS 2408 Fabric Extenders
•Cisco UCS 6454 Fabric Interconnect
•Cisco Nexus 93180 Top of Rack switches
•IBM FlashSystems 5035
•IBM Storage Networking SAN48C-6
•IBM TS4500 tape library with LTO 8 tape drives
Figure 3-12 shows a high-level overview of an IBM Spectrum Archive EE architecture deployed on Versastack.

Figure 3-12 IBM Spectrum Archive EE high level architecture on Versastack
|
Note: You must collaborate with your in-country Cisco Data Center Product Specialists for the sizing of the compute, network, and services requirements.
|
3.7 Sizing and settings
Several items must be considered when you are planning for an IBM Spectrum Scale file system, including the IBM Spectrum Archive EE HSM-managed file system and the IBM Spectrum Archive EE metadata file system. This section describes the IBM Spectrum Scale file-system aspects to help avoid the need to make changes later. This section also describes the IBM Spectrum Archive EE Sizing Tool that aids in the design of the solution architecture.
IBM Spectrum Archive EE metadata file system
IBM Spectrum Archive EE requires space for the file metadata that is stored on an IBM Spectrum Scale file system. If this metadata file system is separate from the IBM Spectrum Scale space-managed file systems, you must ensure that the size and number of inodes of the metadata file system is large enough to handle the number of migrated files.
The IBM Spectrum Archive EE metadata directory can be stored in its own IBM Spectrum Scale file system or it can share the IBM Spectrum Scale file system that is being space-managed.
When the IBM Spectrum Archive EE metadata file system is using the same IBM Spectrum Scale file system to be space-managed, it has the advantage of being flexible by sharing the resources. Space-managed and IBM Spectrum Archive EE metadata can accommodate each other by growing and shrinking as needed. Therefore, it is suggested that you use a single file system. For metadata optimization, it is preferable to put the GPFS metadata and the IBM Spectrum Archive metadata on SSDs or Flash Storage.
The size requirements of the IBM Spectrum Scale file system that is used to store the IBM Spectrum Archive EE metadata directory depends on the block size and the number of files that are migrated to IBM Spectrum Archive EE.
The following calculation produces an estimate of the minimum number of inodes that the IBM Spectrum Scale file system must have available. The calculation depends on the number of cartridges:
Number of inodes = 500 + (15 x c) (Where c is the number of cartridges.)
|
Important: If there is more than one tape library, the number of cartridges in your calculation must be the total number of cartridges in all libraries.
|
The following calculation produces an estimate of the size of the metadata that the IBM Spectrum Scale file system must have available:
Number of GBs = 10 + (3 x F x N)
where:
•F is the number of files, in millions, to migrate.
•N is the number of replicas to create.
For example, to migrate 50 million files to two tape storage pools, 310 GB of metadata is required:
10 + (3 x 50 x 2) = 310 GB
3.7.1 Redundant copies
The purpose of redundant copies is to enable the creation of multiple LTFS copies of each GPFS file during migration. One copy is considered to be the primary, and the other copies are considered the redundant copies. The redundant copies can be created only in pools that are different from the pool of the primary copy and different from the pools of other redundant copies. The maximum number of redundant copies is two. The primary copy and redundant copies can be in a single tape library or spread across two tape libraries.
Thus, to ensure that file migration can occur on redundant copy tapes, the number of tapes in the redundant copy pools must be the same or greater than the number of tapes in the primary copy pool. For example, if the primary copy pool has 10 tapes, the redundant copy pools also should have at least 10 tapes. For more information about redundant copies, see 6.11.4, “Replicas and redundant copies” on page 177.
|
Note: The most commons setup is to have two copies, that is, one primary and one copy pool with the same number of tapes.
|
3.7.2 Planning for LTO-9 Media Initialization/Optimization
The deployment of LTO-9 tape drives will require a one-time media optimization for all new LTO-9 tape cartridges. Because the process of media optimization can take an average of 40 minutes up to two hours per LTO-9 tape cartridge, refer to the suggested strategies to mitigate disruptions to normal tape operations:
•Small tape library deployments are recommended to perform media optimization to all media before beginning normal operations.
•Large tape library deployments are recommended to use as many drives to perform media optimization as possible. Then dedicate one drive for every seventeen drives to continuously load new media for optimization during normal operations.
For more information about LTO-9 media initialization and optimization, see 7.29, “LTO 9 Media Optimization” on page 272, and this Ultrium LTO web page.
|
Note: The media optimization process cannot be interrupted; otherwise, the process must restart from the beginning.
|
3.7.3 IBM Spectrum Archive EE Sizing Tool
Sizing the IBM Spectrum Archive EE system requires consideration of workload and data-access aspects to deploy the proper system resources. For this section, download the latest IBM Spectrum Archive EE Sizing Tool package, which is available at this IBM Support web page.
Before simulating configurations with the IBM Spectrum Archive EE Sizing Calculator, the workload data-characteristics first must be studied.
Understanding the workload data file sizes is key to the designing of the IBM Spectrum Scale file system. The file size of most of the data determines the suitable Data and Metadata block sizes during initial IBM Spectrum Scale deployment for new systems.
For more information about Data and Metadata, see IBM Spectrum Scale Version 5.1.2 Concepts, Planning, and Installation Guide.
For small to medium implementations like the architecture depicted in figure 3.1.1, “On IBM Spectrum Scale Servers” on page 40, it is recommended to consider flash storage for the System Pool (which is where the Metadata is stored in the file system) for performance. More Storage Pools can be designed by using flash or spinning disks depending on data tiering requirements.
|
Note: Consider the following points:
•Both Data and Metadata block sizes are defined during IBM Spectrum Scale File System creation and CAN’T be changed after.
•For workloads with extremely small file sizes in the kilobytes range, it is highly recommended to consolidate these files into zip or tar files prior to tape migration.
|
IBM Spectrum Archive EE Sizing Tool INPUT
The IBM Spectrum Archive EE Sizing Calculator is an intuitive tool that provides guidance on data entry and output explanations. The following data input sections are included:
•Data amount and access patterns: This section considers the average data size of the workload files and ingest and recall estimates. The minimum data size input is 1MB.
•Archive Retention Requirements: This section requires the data retention duration on disk (also known as Cache) before migration or premigration to the tape tier.
•Archive Capacity Requirements: This section will ask for the total projected data archive size on tapes and file replicas on tape.
•Tape Technology Selection: This section allows the user to input the target tape infrastructure to be deployed and will provide estimations on the required tape performance, quantity of tape drives and cartridges, and the number of IBM Spectrum Archive EE nodes.
IBM Spectrum Archive EE Sizing Tool OUTPUT
The tool generates the target configuration components that accommodate the data flow and retention input by the user:
•IBM Spectrum Scale Licenses: IBM Spectrum Scale is a prerequisite for IBM Spectrum Archive EE solutions. As described in the previous sections on deployment options, there are many approaches to setting up the IBM Spectrum Scale environment. Capacity-based licenses simplify this solution component, that is, configure the license with respect to the Disk Storage output of the IBM Spectrum Archive EE Sizing Calculator. However, it is recommended to add TB licenses as a buffer.
•IBM Spectrum Archive EE Licenses; Based on tape-data access throughput, this determines the required IBM Spectrum Archive EE licenses. IBM Spectrum Archive EE is licensed on a per-node basis. If the solution requires redundancy, a minimum of two nodes licenses are required.
•Disk Storage: The output for disk storage specifies the usable disk capacity requirements. It does not indicate the storage type (flash or spinning disks). However, it is recommended to deploy flash storage for Metadata. The stub files are also recommended to be in flash storage but might also be on spinning disks depending on the access patterns of the users. An external-shared storage system is recommended (but not required) for easy scaling and high availability for installations with more than one server.
•External storage servers might deploy different storage technologies such as Flash, SAS, and Nearline SAS disks that set the stage for the IBM Spectrum Scale Storage Pools. Capacity-based licensing of IBM Spectrum Scale also makes it easier to design the system, that is, license only the required disk capacity to be allocated to the IBM Spectrum Scale file system. The performance of shared external-storage systems can also be tuned by deploying more flash or disk spindles.
•Tape Storage: This output section shows the average data transfer tape to and from tape and the quantity of tape drives and tape cartridges with respect to the target total tape-archive capacity.
•IBM Spectrum Archive EE server minimum configuration: This output section indicates the minimum configuration for the IBM Spectrum Archive EE server. For optimal performance, it is recommended that each IBM Spectrum Archive EE server have at least 128GB of memory even if the sizing tool indicates any less. This section also shows the required CPU Socket requirements and Fibre Channel Host Bus Adapters or Disk Connection Adapters (for IBM ESS) architectures.
|
Note: For converged solution architectures where IBM Spectrum Scale and IBM Spectrum Archive EE are installed in one physical server, it is recommended to assign at least 128GB of memory for the IBM Spectrum Archive EE and respectively add the IBM Spectrum Scale requirements that will be deployed on the same server. Apply the same for CPU and connectivity requirements.
|
3.7.4 Performance
Performance planning is an important aspect of IBM Spectrum Archive EE implementation, specifically migration performance. The migration performance is the rate at which IBM Spectrum Archive EE can move data from disk to tape, freeing up space on disk. The number of tape drives (including tape drive generation) and servers that are required for the configuration can be determined based on the amount of data that needs to be moved per day and an estimate of the average file size of that data.
|
Note: Several components of the reference architecture affect the overall migration performance of the solution, including backend disk speeds, SAN connectivity, NUMA node configuration, and amount of memory. Thus, this migration performance data should be used as a guideline only and any final migration performance measurements should be done on the actual customer hardware.
For more migration performance information, see IBM Spectrum Archive Enterprise Edition v1.2.2 Performance.
|
The configuration that is shown in Figure 3-13 was used to run the lab performance test in this section.

Figure 3-13 IBM Spectrum Archive EE configuration used in lab performance
The performance data shown in this section was derived by using two x3850 X5 servers consisting of multiple QLogic QLE2562 8 Gb FC HBA cards. The servers were also modified by moving all the RAM memory to a single CPU socket to create a multi-CPU, single NUMA node. The HBAs were relocated so they are on one NUMA node.
This modification was made so that memory can be shared locally to improve performance. The switch used in the lab was an IBM 2498 model B40 8 Gb FC switch that was zoned out so that it had a zone for each HBA in each node. An IBM Storwize® V7000 disk storage unit was used for the disk space and either TS1150 or TS1070 drives were used in a TS4500 tape library.
Figure 3-13 shows the example configuration. This configuration is only one possibility; yours might be different.
Figure 3-14 shows a basic internal configuration of Figure 3-13 in more detail. The two x3850 X5 servers are using a single NUMA and have all the HBAs performing out of it. This configuration allows all CPUs within the servers to work more efficiently. The 8 GB Fibre Channel switch is broken up so that each zone handles a single HBA on each server.

Figure 3-14 Internal diagram of two nodes running off NUMA 0
|
Note: Figure 3-14 shows a single Fibre Channel cable going to the drive zones. However, generally you should have a second Fibre Channel cable for failover scenarios. This is the same reason why the zone that goes to the external storage unit has two Fibre Channel cables from 1 HBA on each server.
|
Figure 3-14 is one of many possible configurations and can be used as a guide for how you set up your own environment for best performances. For example, if you have more drives, you can add tape drives per zone, or add Host bus adapters (HBAs) on each server and create a zone.
Table 3-3 and Table 3-4 list the raw data of total combined transfer rate in MiB/s on multiple node configurations with various files sizes (the combined transfer rate of all drives). In these tables, N represents nodes, D represents number of drives per node, and T represents the total number of drives for the configuration.
With a TS1150 configuration of 1N4D4T, you can expect to see a combined total transfer rate of 1244.9 MBps for 10 GiB files. If that configuration is doubled to 2N4D8T, the total combined transfer rate is nearly doubled to 2315.3 MiB/s for 10 GiB files. With this information, you can estimate the total combined transfer rate for your configuration.
Table 3-3 TS1150 raw performance data for multiple node/drive configurations with 5 MiB, 10 MiB, 1 GiB, and 10 GiB files
|
Node/Drive
configuration
|
File size
| ||||
|
5 MiB
|
10 Mib
|
100 MiB
|
1 Gib
|
10 Gib
| |
|
8 Drives (2N4D8T)
|
369.0
|
577.3
|
1473.4
|
2016.4
|
2315.3
|
|
6 Drives (2N3D6T)
|
290.6
|
463.2
|
1229.5
|
1656.2
|
1835.5
|
|
4 Drives (1N4D4T)
|
211.3
|
339.3
|
889.2
|
1148.4
|
1244.9
|
|
3 Drives (1N3D3T)
|
165.3
|
267.1
|
701.8
|
870.6
|
931.0
|
|
2 Drives (1N2D2T)
|
114.0
|
186.3
|
465.8
|
583.6
|
624.3
|
Table 3-4 lists the raw performance for the LTO7 drives.
Table 3-4 LTO7 raw performance data for multiple node/drive configurations with 5 MiB, 10 MiB, 1 GiB, and 10 GiB files
|
Node/Drive
configuration
|
File size
| ||||
|
5 MiB
|
10 Mib
|
100 MiB
|
1 Gib
|
10 Gib
| |
|
8 Drives (2N4D8T)
|
365.4
|
561.8
|
1287.8
|
1731.8
|
1921.7
|
|
6 Drives (2N3D6T)
|
286.3
|
446.5
|
1057.9
|
1309.4
|
1501.7
|
|
4 Drives (1N4D4T)
|
208.5
|
328.1
|
776.7
|
885.6
|
985.1
|
|
3 Drives (1N3D3T)
|
162.9
|
254.4
|
605.5
|
668.3
|
749.1
|
|
2 Drives (1N2D2T)
|
111.0
|
178.4
|
406.7
|
439.2
|
493.7
|
Figure 3-15 shows a comparison line graph of the raw performance data obtain for TS1150 drives and LTO7 drives that use the same configurations.

Figure 3-15 Comparison between TS1150 and LTO-7 drives using multiple node/drive configurations
It is clear that by using small files, the comparison between the two types of drives is minimal. However, when migrating file sizes of 1 GiB and larger, a noticeable difference exists. Comparing the biggest configuration of 2N4D8T, the LTO peaks at a total combined transfer rate of 1921.7 MiBps. With the same configuration but with TS1150 drives, it peaks at a total combined transfer rate of 2315.3 MiBps.
3.7.5 Ports that are used by IBM Spectrum Archive EE
In addition to SSH, the software components of IBM Spectrum Archive Enterprise Edition use several TCP/UDP ports for interprocess communication within and among nodes.
The used ports are listed in Table 3-5.
Table 3-5 Ports used by IBM Spectrum Archive EE
|
Used port number
|
Required node
|
Component using the ports
|
|
7600
|
All IBM Spectrum Archive EE nodes
|
LE
|
|
7610
|
All IBM Spectrum Archive EE nodes
|
MD
|
|
The range from 7620 to (7630 + number of EE nodes)
|
The IBM Spectrum Archive EE active control node
|
MMM
|
|
RPC bind daemon port (for example, 111)
|
The IBM Spectrum Archive EE active control node
|
MMM
|
Several other ports are used by HSM. For more information, see this IBM Documentation web page.
3.8 High-level component upgrade steps
This section describes some high-level examples of IBM Spectrum Archive EE component upgrades as the need arises (see Table 3-6). Upgrading IBM Spectrum Archive EE components is easy and flexible and addresses scalability and technology refresh requirements.
Table 3-6 High level component upgrade options
|
Hardware upgrade
|
Upgrade procedure
|
|
Node server
|
IBM Spectrum Scale Node
Follow IBM Spectrum Scale procedures for node add and node delete. For more information, see:
– Node add
IBM Spectrum Archive EE node
Use IBM Spectrum Archive ltfsee_config command with remove_node and add_node options. Refer to 5.2.1, “The ltfsee_config utility” on page 105.
|
|
IBM Spectrum Scale disk storage (internal and external)
|
Method 1. Preserve GPFS cluster and GPFS file systems
Follow IBM Spectrum Scale procedure for NSD add, NSD restripe and NSD delete. For more information, see:
Method 2. Create a GPFS cluster or new GPFS file systems
Migrate the old file system to the new file system using IBM Spectrum Archive procedure “system migration using SOBAR”. Refer to 2.2.6, “Scale Out Backup and Restore” on page 32, 6.27, “File system migration” on page 231, and IBM Documentation Scale Out Backup and Restore.
|
|
Tape drives/cartridges technology upgrade
|
Method 1. IBM Spectrum Archive EE eeadm pool set command to modify the media_restriction attribute
Use IBM Spectrum Archive media_restriction attribute of a pool to gradually move data to the specified newer tape technology within a pool.
Method 2. IBM Spectrum Archive EE eeadm tape datamigrate command
Use IBM Spectrum Archive eeadm tape datamigrate command to move data from an old pool with old tape generation resources to a new pool with new tape generation resources.
For more information, see 6.11.5, “Data Migration” on page 180 for details.
|
|
Tape library
|
For more information, see 4.6, “Library replacement” on page 88.
|
|
Note: Component upgrades must be reviewed with IBM.
|
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.