


IBM Spectrum Archive overview
This chapter provides an overview of the IBM Spectrum Archive product family and the individual components of the IBM Spectrum Archive Enterprise Edition (EE).
This chapter includes the following topics:
2.1 Introduction to IBM Spectrum Archive and LTFS
LTFS is the first file system that works with LTO tape technology and IBM Enterprise tape drives, providing ease of use and portability for open systems tape storage.
|
Note: Throughout this publication, the terms supported tape libraries, supported tape drives, and supported tape media are used to represent the following tape libraries, tape drives, and tape media. Unless otherwise noted, as of the date of publication, IBM Spectrum Archive EE supports these libraries:
•IBM TS4500 tape library1
•IBM TS4300 tape library
•IBM TS3310 tape library
•IBM LTO Ultrium 9, 8, 7, 6, or 5 tape drives, and IBM TS1160 (3592 60E,60F, 60G, or 60S), TS1155 (3592 55F or 55G), TS1150, or TS1140 tape drives
•LTO Ultrium 9, 8, M83, 7, 6, and 5, and 3592 JB, JC, JD, JE, JK, JL, JM, JV, JY, and JZ tape media
For more information about the latest system requirements, see IBM Documentation.
For the latest IBM Spectrum Archive Library Edition Support Matrix (supported tape library and tape drive firmware levels, see IBM Support’s Fix Central web page.
|
1 IBM TS1160, TS1155, TS1150, and IBM TS1140 support on IBM TS4500 and IBM TS3500 tape libraries only.
2 TS3500 does not support the LTO-9 tape drive.
3 Uninitialized M8 media (MTM 3589-452) is only supported on the following tape libraries in IBM Spectrum Archive EE: TS4500, TS4300, and TS3310. TS3500 will only support pre-initialized media.
With this application, accessing data that is stored on an IBM tape cartridge is as easy and intuitive as the use of a USB flash drive. Tapes are self-describing, and you can quickly recall any file from a tape cartridge without having to read the whole tape cartridge from beginning to end. Furthermore, any LTFS-capable system can read a tape cartridge that is created by any other LTFS-capable system (regardless of the operating system). Any LTFS-capable system can identify and retrieve the files that are stored on it. LTFS-capable systems have the following characteristics:
•Files and directories are shown to you as a directory tree listing.
•More intuitive searches of tape cartridges and library content are now possible because of the addition of file tagging.
•Files can be moved to and from LTFS tape cartridges by using the familiar drag method that is common to many operating systems.
•Many applications that were written to use files on disk can now use files on tape cartridges without any modification.
•All standard File Open, Write, Read, Append, Delete, and Close functions are supported.
•No need for another external tape management system or database tracking the content of each tape.
Archival data storage requirements are growing at over 60% annually. The LTFS format is an ideal option for long-term archiving of large files that must be easily shared with others. This option is especially important because the tape media that it uses (LTO and 3592) are designed to have a 10+ years lifespan (depending on the number of read/write passes).
Industries that most benefit from this tape file system are the banking, digital media, medical, geophysical, and entertainment industries. Many users in these industries use Linux or Macintosh systems, which are fully compatible with LTFS.
LTO Ultrium tape cartridges from earlier LTO generations (that is, LTO-1 through LTO-4) cannot be partitioned and be used by LTFS/IBM Spectrum Archive. Also, if LTO Ultrium 4 tape cartridges are used in an LTO Ultrium 5 tape drive to write data, the LTO-4 tape cartridge is treated as an unpartitioned LTO-5 tape cartridge. Even if an application can manage partitions, it is not possible to partition the LTO-4 media that is mounted in an LTO Ultrium 5 drive.
Starting with the release of IBM Spectrum Archive EE v1.2, corresponding Write Once, Read Many (WORM) tape cartridges are supported in an IBM Spectrum Archive EE solution that operates supported IBM Enterprise tape drives. With the same release, tape drives in mixed configurations are supported. For more information, see 6.21, “Tape drive intermix support” on page 208.
Although LTFS presents the tape cartridge as a disk drive, the underlying hardware is still a tape cartridge and is therefore sequential in nature. Tape does not allow random access. Data is always appended to the tape, and there is no overwriting of files. File deletions do not erase the data from tape, but instead erase the pointers to the data. So, although with LTFS you can simultaneously copy two (or more) files to an LTFS tape cartridge, you get better performance if you copy files sequentially.
To operate the tape file system, the following components are needed:
•Software in the form of an open source LTFS package
•Data structures that are created by LTFS on tape
Together, these components can manage a file system on the tape media as though it is a disk file system for accessing tape files, including the tape directory tree structures. The metadata of each tape cartridge, after it is mounted, is cached to the server. Therefore, metadata operations, such as browsing the directory or searching for a file name, do not require any tape movement and are quick.
2.1.1 Tape media capacity with IBM Spectrum Archive
Table 2-1 lists the tape drives and media that are supported by LTFS. The table also gives the native capacity of supported media, and raw capacity of the LTFS data partition on the media.
Table 2-1 Tape media capacity with IBM Spectrum Archive
|
Tape drive
|
Tape media1
| ||
|
Advanced type E data (JE)
|
20000 GB (18626 GiB)
|
19485 GB (18147 GiB)
| |
|
|
Advanced type E WORM data (JV)
|
20000 GB (18626 GiB)
|
19485 GB (18147 GiB)
|
|
|
Advanced type D data (JD)
|
15000 GB (13969 GiB)
|
14562 GB (13562 GiB)
|
|
|
Advanced Type D WORM data (JZ)
|
15000 GB (13969 GiB)
|
14562 GB (13562 GiB)
|
|
|
Advanced Type C data (JC)
|
7000 GB (6519 GiB)
|
6757 GB (6293 GiB)
|
|
|
Advanced Type C WORM data (JY)
|
7000 GB (6519 GiB)
|
6757 GB (6293 GiB)
|
|
|
Advanced Type E economy tape (JM)
|
5000 GB (4656 GiB)
|
4870 GB (4536 GiB)
|
|
|
Advanced Type D economy tape (JL)
|
3000 GB (1862 GiB)
|
2912 GB (1804 GiB)
|
|
|
Advanced Type C economy tape (JK)
|
900 GB (838 GiB)
|
869 GB (809 GiB)
|
|
Advanced type D data (JD)
|
15000 GB (13969 GiB)
|
14562 GB (13562 GiB)
| |
|
Advanced type D WORM data (JZ)
|
15000 GB (14969 GiB)
|
14562 GB (13562 GiB)
| |
|
Advanced type C data (JC)
|
7000 GB (6519 GiB)
|
6757 GB (6293 GiB)
| |
|
Advanced type C WORM data (JY)
|
7000 GB (6519 GiB)
|
6757 GB (6293 GiB)
| |
|
Advanced type D economy data (JL)
|
3000 GB (1862 GiB)
|
2912 GB (1804 GiB)
| |
|
|
Advanced type C economy data (JK)
|
900 GB (838 GiB)
|
869 GB (809 GiB)
|
|
Advanced type D data (JD)
|
10,000 GB (9313 GiB)
|
9687 GB (9022 GiB)
| |
|
Advanced type D WORM data (JZ)
|
10,000 GB (9313 GiB)
|
9687 GB (9022 GiB)
| |
|
Advanced type C data (JC)
|
7000 GB (6519 GiB)
|
6757 GB (6293 GiB)
| |
|
Advanced type C WORM data (JY)
|
7000 GB (6519 GiB)
|
6757 GB (6293 GiB)
| |
|
Advanced type D economy data (JL)
|
3000 GB (2794 GiB)
|
2912 GB (2712 GiB)
| |
|
Advanced type C economy data (JK)
|
900 GB (838 GiB)
|
869 GB (809 GiB)
| |
|
Advanced data type C (JC)
|
4000 GB (3725 GiB)
|
3650 GB (3399 GiB)
| |
|
Advanced data type C WORM (JY)
|
4000 GB (3725 GiB)
|
3650 GB (3399 GiB)
| |
|
Advanced data (JB)
|
1600 GB (1490 GiB)
|
1457 GB (1357 GiB)
| |
|
Advanced type C economy data (JK)
|
500 GB (465 GiB)
|
456 GB (425 GiB)
| |
|
IBM LTO Ultrium 9 tape drive
|
LTO 9
|
18000 GB (16764 GiB)
|
17549 GB (16344 GiB)
|
|
IBM LTO Ultrium 8 tape drive
|
LTO 8
|
12000 GB (11175 GiB)
|
11711 GB (10907 GiB)
|
|
LTO 8 (M8)
|
9000 GB (8382 Gib)
|
8731 GB (8132 GiB)
| |
|
IBM LTO Ultrium 7 tape drive
|
LTO 7
|
6000 GB (5588 GiB)
|
5731 GB (5338 GiB)
|
|
IBM LTO Ultrium 6 tape drive
|
LTO 6
|
2500 GB (2328 GiB)
|
2408 GB (2242 GiB)
|
|
IBM LTO Ultrium 5 tape drive
|
LTO 5
|
1500 GB (1396 GiB)
|
1425 GB (1327 GiB)
|
1 WORM media are not supported by IBM Spectrum Archive SDE and IBM Spectrum Archive LE, only with EE.
2 The actual usable capacity is greater when compression is used.
4 Values that are given are the default size of the LTFS data partition, unless otherwise indicated.
5 TS1160, TS1155, TS1150, and TS1140 tape drives support enhanced partitioning for cartridges.
6 Media that are formatted on a 3592 drive must be read on the same generation of drive. For example, a JC cartridge that was formatted by a TS1150 tape drive cannot be read on a TS1140 tape drive.
2.1.2 Comparison of the IBM Spectrum Archive products
The following sections give a brief overview of the IBM Spectrum Archive software products that are available at the time of writing. Their main features are summarized in Table 2-2.
|
Note: IBM LTFS Storage Manager (LTFS SM) was discontinued from marketing effective 12/14/2015. IBM support for the LTFS SM was discontinued 05/01/2020.
|
Table 2-2 LTFS product comparison
|
Name
|
License required
|
Market
|
Tape Library support
|
Integrates with IBM Spectrum Scale
|
|
IBM Spectrum Archive Single Drive Edition (SDE)
|
No
|
Entry - Midrange
|
No
|
No
|
|
IBM Spectrum Archive Library Edition (LE)
|
ILAN license (free)
or
commercial license (for support from IBM)
|
Midrange - Enterprise
|
Yes
|
No
|
|
IBM Spectrum Archive Enterprise Edition (EE)
|
Yes
|
Enterprise
|
Yes
|
Yes
|
2.1.3 IBM Spectrum Archive Single Drive Edition
The IBM Spectrum Archive SDE provides direct, intuitive, and graphical access to data that is stored with the supported IBM tape drives and libraries that use the supported Linear Tape-Open (LTO) Ultrium tape cartridges and IBM Enterprise tape cartridges. It eliminates the need for more tape management and software to access data. The LTFS format is the first file system that works with tape technology that provides ease of use and portability for open systems tape storage. With this system, accessing data that is stored on an IBM tape cartridge is as easy and intuitive as using a USB flash drive.
Figure 2-1 shows the IBM Spectrum Archive SDE user view, which resembles standard file folders.

Figure 2-1 IBM Spectrum Archive SDE user view
It runs on Linux, Windows, and MacOS, and with the operating system’s graphical File Manager, reading data on a tape cartridge is as easy as dragging file data sets. Users can run any application that is designed for disk files against tape data without concern for the fact that the data is physically stored on tape. IBM Spectrum Archive SDE allows access to all of the data in a tape cartridge that is loaded on a single drive as though it were on an attached disk drive.
It supports stand-alone versions of LTFS, such as those running on IBM, HP, Quantum, FOR-A, 1 Beyond, and other platforms.
IBM Spectrum Archive SDE software, systems, tape drives and media requirements
The most current software, systems, tape drives and media requirements can be found at the IBM Spectrum Archive Single Drive Edition IBM Documentation web page.
Select the most current IBM Spectrum Archive SDE version and then select Planning. The Supported tape drives and media, system requirements, and required software topics are displayed.
IBM Spectrum Archive SDE supports the use of multiple tape drives at one time. The method for using multiple tape drives depends on the operating system being used.
For Linux and Mac OS X users, it is possible to use multiple tape drives by starting multiple instances of the LTFS software, each with a different target tape device name in the -o devname parameter. For more information, see the Mounting media by using the ltfs command topic at IBM Documentation.
For Windows users, the LTFS software detects each of the installed tape drives, and it is possible to assign a different drive letter to each drive by using the configuration window. For more information, see the Assigning a drive letter to a tape drive topic at IBM Documentation.
|
Note: A certain level of tape drive firmware is required to fully use IBM Spectrum Archive SDE functions. To find the supported firmware version and for more information about connectivity and configurations, see the IBM System Storage Interoperation Center (SSIC) web page.
|
Migration path to IBM Spectrum Archive EE
There is no direct migration path from IBM Spectrum Archive SDE to IBM Spectrum Archive EE software. Any IBM Spectrum Archive SDE software must be uninstalled before IBM Spectrum Archive EE is installed. Follow the uninstallation procedure that is documented in the IBM Linear Tape File System Installation and Configuration, SG24-8090.
Data tapes that are used by IBM Spectrum Archive SDE version 1.3.0 or later can be imported into IBM Spectrum Archive EE. For more information about this procedure, see 6.19.1, “Importing” on page 202. Tapes that were formatted in LTFS 1.0 format by older versions of IBM Spectrum Archive are automatically upgraded to LTFS 2.4 format on first write.
2.1.4 IBM Spectrum Archive Library Edition
IBM Spectrum Archive LE uses the open, non-proprietary LTFS format that allows any application to write files into a large archive. It provides direct, intuitive, and graphical access to data that is stored on tape cartridges within the supported IBM tape libraries that use either LTO or IBM Enterprise supported tape drives.
Figure 2-2 shows the user view of multiple IBM Spectrum Archive tapes appearing as different library folders.

Figure 2-2 IBM Spectrum Archive LE User view of multiple LTFS tape cartridges
In addition, IBM Spectrum Archive LE enables users to create a single file system mount point for a logical library that is managed by a single instance of IBM Spectrum Archive, which runs on a single computer system.
The LTFS metadata of each tape cartridge, after it is mounted, is cached in server memory. So, even after the tape cartridge is ejected, the tape cartridge metadata information remains viewable and searchable, with no remounting required. Every tape cartridge and file is accessible through the operating system file system commands, from any application. This improvement in search efficiency can be substantial, considering the need to search hundreds or thousands of tape cartridges that are typically found in tape libraries.
IBM Spectrum Archive LE software, systems, tape drives and media requirements
The most current software, systems, tape drives and media requirements can be found at the IBM Spectrum Archive Library Edition IBM Documentation website.
Select the most current IBM Spectrum Archive LE version and then select Planning. The Supported tape drives and media, system requirements, and required software topics will be displayed.
For more information about connectivity and configurations, see the SSIC website.
Migration path to IBM Spectrum Archive EE
There is no direct migration path from IBM Spectrum Archive LE to IBM Spectrum Archive EE software. Any IBM Spectrum Archive LE software must be uninstalled before IBM Spectrum Archive EE is installed. Follow the uninstall procedure that is described at this IBM Documentation web page.
Data tapes that were created and used by IBM Spectrum Archive LE Version 2.1.2 or later can be imported into IBM Spectrum Archive EE. For more information about this procedure, see 6.19.1, “Importing” on page 202.
2.1.5 IBM Spectrum Archive Enterprise Edition
As enterprise-scale data storage, archiving, and backup expands, there is a need to lower storage costs and improve manageability. IBM Spectrum Archive EE provides such a solution that offers IBM Spectrum Scale users a new low-cost, scalable storage tier.
IBM Spectrum Archive EE provides seamless integration of LTFS with IBM Spectrum Scale by providing an IBM Spectrum Archive tape tier under IBM Spectrum Scale. IBM Spectrum Scale policies are used to move files between online disks storage and IBM Spectrum Archive tape tiers without affecting the IBM Spectrum Scale namespace.
IBM Spectrum Archive EE uses IBM Spectrum Archive LE for the movement of files to and from the physical tape devices and cartridges. IBM Spectrum Archive EE can manage multiple IBM Spectrum Archive LE nodes in parallel, so bandwidth requirements between IBM Spectrum Scale and the tape tier can be satisfied by adding nodes and tape devices as needed.
Figure 2-3 shows the IBM Spectrum Archive EE system view with IBM Spectrum Scale providing the global namespace and IBM Spectrum Archive EE installed on two IBM Spectrum Scale nodes. IBM Spectrum Archive EE can be installed on one or more IBM Spectrum Scale nodes. Each IBM Spectrum Archive EE instance has dedicated tape drives that are attached in the same tape library partition. IBM Spectrum Archive EE instances share tape cartridges and LTFS index. The workload is distributed over all IBM Spectrum Archive EE nodes and their attached tape drives.

Figure 2-3 IBM Spectrum Archive EE system view
A local or remote IBM Spectrum Archive LE node serves as a migration target for IBM Spectrum Scale, which transparently archives data to tape based on policies set by the user.
IBM Spectrum Archive EE provides the following benefits:
•A low-cost storage tier in an IBM Spectrum Scale environment.
•An active archive or big data repository for long-term storage of data that requires file system access to that content.
•File-based storage in the LTFS tape format that is open, self-describing, portable, and interchangeable across platforms.
•Lowers capital expenditure and operational expenditure costs by using cost-effective and energy-efficient tape media without dependencies on external server hardware or software.
•Provides unlimited capacity scalability for the IBM supported tape libraries and keeping offline tape cartridges on shelves.
•Allows the retention of data on tape media for long-term preservation (over 10 years).
•Provides efficient recalls of files from tape with Recommended Access Order (RAO) supported tape drives and media. For more information, see 6.14.4, “Recommend Access Order” on page 193, and Table 3-1, “Linux system requirements” on page 50.
•Provides the portability of large amounts of data by bulk transfer of tape cartridges between sites for disaster recovery and the initial synchronization of two IBM Spectrum Scale sites by using open-format, portable, self-describing tapes.
•Provides ease of management for operational and active archive storage.
Figure 2-4 provides a conceptual overview of processes and data flow in IBM Spectrum Archive EE.

Figure 2-4 IBM Spectrum Archive EE data flow
IBM Spectrum Archive EE can be used for a low-cost storage tier, data migration, and archive needs as described in the following use cases.
Operational storage
The use of an IBM Spectrum Archive tape tier as operational storage is useful when a significant portion of files on an online disk storage system is static, meaning the data does not change. In this case, it is more efficient to move the content to a lower-cost storage tier, for example, to a physical tape cartridge. The files that are migrated to the IBM Spectrum Archive tape tier remain online, meaning they are accessible at any time from IBM Spectrum Scale under the IBM Spectrum Scale namespace.
With IBM Spectrum Archive EE, the user specifies files to be migrated to the IBM Spectrum Archive tape tier by using standard IBM Spectrum Scale scan policies. IBM Spectrum Archive EE then manages the movement of IBM Spectrum Scale file data to IBM Spectrum Archive tape cartridges. It also edits the metadata of the IBM Spectrum Scale files to point to the content on the IBM Spectrum Archive tape tier.
Access to the migrated files through the IBM Spectrum Scale file system remains unchanged with the file data provided at the data rate and access times of the underlying tape technology. The IBM Spectrum Scale namespace is unchanged after migration, which makes the placement of files in the IBM Spectrum Archive tape tier not apparent to users and applications.
Active archive
The use of an IBM Spectrum Archive tape tier as an active archive is useful when there is a need for a low-cost, long-term archive for data that is maintained and accessed for reference. IBM Spectrum Archive satisfies the needs of this type of archiving by using open-format, portable, self-describing tapes. In an active archive, the LTFS-file system is the main storage for the data. The IBM Spectrum Scale file system, with its limited disk capacity, is used as a staging area, or cache, in front of IBM Spectrum Archive.
IBM Spectrum Scale policies are used to stage and destage data from the IBM Spectrum Scale disks space to the IBM Spectrum Archive tape cartridges. The tape cartridges from the archive can be exported for vaulting or for moving data to another location. Because the exported data is in the LTFS format, it can be read on any LTFS-compatible system.
2.2 IBM Spectrum Scale
IBM Spectrum Scale is a cluster file system solution, which means that it provides concurrent access to one or more file systems from multiple nodes. These nodes can all be SAN-attached, network-attached, or both, which enables high-performance access to this common set of data to support a scale-out solution or provide a high availability platform.
The entire file system is striped across all storage devices, typically disk and flash storage subsystems.
|
Note: IBM Spectrum Scale is a member of the IBM Spectrum product family. The most recent version at the time of writing is Version 5.1.2. The first version with the name IBM Spectrum Scale is Version 4.1.1. The prior versions, Versions 4.1.0 and 3.5.x, are still called GPFS. Both IBM Spectrum Scale and GPFS are used interchangeably in this book.
|
For more information about current documentation and publications for IBM Spectrum Scale, see this IBM Documentation web page.
2.2.1 Overview
IBM Spectrum Scale can help you achieve Information Lifecycle Management (ILM) efficiencies through powerful policy-driven automated tiered storage management. The IBM Spectrum Scale ILM toolkit helps you manage sets of files, pools of storage, and automate the management of file data. By using these tools, IBM Spectrum Scale can automatically determine where to physically store your data regardless of its placement in the logical directory structure. Storage pools, file sets, and user-defined policies can match the cost of your storage resources to the value of your data.
You can use IBM Spectrum Scale policy-based ILM tools to perform the following tasks:
•Create storage pools to provide a way to partition a file system’s storage into collections of disks or a redundant array of independent disks (RAID) with similar properties that are managed together as a group.
IBM Spectrum Scale has the following types of storage pools:
– A required system storage pool that you create and manage through IBM Spectrum Scale.
– Optional user storage pools that you create and manage through IBM Spectrum Scale.
– Optional external storage pools that you define with IBM Spectrum Scale policy rules and manage through an external application, such as IBM Spectrum Archive EE.
•Create file sets to provide a way to partition the file system namespace to allow administrative operations at a finer granularity than that of the entire file system.
•Create policy rules that are based on data attributes to determine initial file data placement and manage file data placement throughout the life of the file.
2.2.2 Storage pools
Physically, a storage pool is a collection of disks or RAID arrays. You can use storage pools to group multiple storage systems within a file system. By using storage pools, you can create tiers of storage by grouping storage devices based on performance, locality, or reliability characteristics. For example, one pool can be an enterprise class storage system that hosts high-performance FC disks and another pool might consist of numerous disk controllers that host a large set of economical SATA disks.
There are two types of storage pools in an IBM Spectrum Scale environment: Internal storage pools and external storage pools. Internal storage pools are managed within IBM Spectrum Scale. External storage pools are managed by an external application, such as IBM Spectrum Archive EE. For external storage pools, IBM Spectrum Scale provides tools that you can use to define an interface that IBM Spectrum Archive EE uses to access your data.
IBM Spectrum Scale does not manage the data that is placed in external storage pools. Instead, it manages the movement of data to and from external storage pools. You can use storage pools to perform complex operations such as moving, mirroring, or deleting files across multiple storage devices, which provide storage virtualization and a single management context.
Internal IBM Spectrum Scale storage pools are meant for managing online storage resources. External storage pools are intended for use as near-line storage and for archival and backup operations. However, both types of storage pools provide you with a method to partition file system storage for the following considerations:
•Improved price-performance by matching the cost of storage to the value of the data
•Improved performance by:
– Reducing the contention for premium storage
– Reducing the impact of slower devices
– Allowing you to retrieve archived data when needed
•Improved reliability by providing for:
– Replication based on need
– Better failure containment
– Creation of storage pools as needed
2.2.3 Policies and policy rules
IBM Spectrum Scale provides a means to automate the management of files by using policies and rules. If you correctly manage your files, you can use and balance efficiently your premium and less expensive storage resources. IBM Spectrum Scale supports the following policies:
•File placement policies are used to place automatically newly created files in a specific storage pool.
•File management policies are used to manage files during their lifecycle by moving them to another storage pool, moving them to near-line storage, copying them to archival storage, changing their replication status, or deleting them.
A policy is a set of rules that describes the lifecycle of user data that is based on the file’s attributes. Each rule defines an operation or definition, such as migrate to a pool and replicate the file. The rules are applied for the following uses:
•Initial file placement
•File management
•Restoring file data
When a file is created or restored, the placement policy determines the location of the file’s data and assigns the file to a storage pool. All data that is written to that file is placed in the assigned storage pool. The placement policy that is defining the initial placement of newly created files and the rules for placement of restored data must be installed into IBM Spectrum Scale by running the mmchpolicy command. If an IBM Spectrum Scale file system does not have a placement policy that is installed, all the data is stored into the system storage pool. Only one placement policy can be installed at a time.
If you switch from one placement policy to another, or change a placement policy, that action has no effect on files. However, newly created files are always placed according to the currently installed placement policy.
The management policy determines file management operations, such as migration and deletion. To migrate or delete data, you must run the mmapplypolicy command. You can define the file management rules and install them in the file system together with the placement rules. As an alternative, you can define these rules in a separate file and explicitly provide them to mmapplypolicy by using the -P option. In either case, policy rules for placement or migration can be intermixed. Over the life of the file, data can be migrated to a different storage pool any number of times, and files can be deleted or restored.
With Version 3.1, IBM Spectrum Scale introduced the policy-based data management that automates the management of storage resources and the data that is stored on those resources. Policy-based data management is based on the storage pool concept. A storage pool is a collection of disks or RAIDs with similar properties that are managed together as a group. The group under which the storage pools are managed together is the file system.
IBM Spectrum Scale provides a single name space across all pools. Files in the same directory can be in different pools. Files are placed in storage pools at creation time by using placement policies. Files can be moved between pools based on migration policies and files can be removed based on specific policies.
For more information about the SQL-like policy rule language, see IBM Spectrum Scale: Administration Guide, which is available at this IBM Documentation web page.
IBM Spectrum Scale V3.2 introduced external storage pools. You can set up external storage pools and GPFS policies that allow the GPFS policy manager to coordinate file migrations from a native IBM Spectrum Scale online pool to external pools in IBM Spectrum Archive EE. The GPFS policy manager starts the migration through the HSM client command-line interface embedded in the IBM Spectrum Archive EE solution.
For more information about GPFS policies, see 6.11, “Migration” on page 165.
2.2.4 Migration or premigration
The migration or premigration candidate selection is identical to the IBM Spectrum Scale native pool-to-pool migration/premigration rule. The Policy Engine uses the eeadm migrate or eeadm premigrate command for the migration or premigration of files from a native storage pool to an IBM Spectrum Archive EE tape cartridge pool.
There are two different approaches that can be used to drive an IBM Spectrum Archive EE migration through GPFS policies: Manual and automated. These approaches are only different in how the mmapplypolicy command (which performs the policy scan) is started.
Manual
The manual IBM Spectrum Scale driven migration is performed when the user or a UNIX cron job runs the mmapplypolicy command with a predefined migration or premigration policy. The rule covers the migration or premigration of files from the system pool to the external IBM Spectrum Scale pool, which means that the data is physically moved to the external tape pool, which must be defined in IBM Spectrum Archive EE.
Automated
The GPFS threshold migration is performed when the user specifies a threshold policy and the GPFS policy daemon is enabled to monitor the storage pools in the file system for that threshold. If a predefined high threshold is reached (which means the filling level of the storage pool reached the predefined high water mark), the monitor daemon automatically starts the mmapplypolicy command to perform an inode scan.
For more information about migration, see 6.11, “Migration” on page 165.
2.2.5 Active File Management
IBM Spectrum Scale Active File Management (AFM) is a scalable, high-performance file-system caching layer that is integrated with the IBM Spectrum Scale cluster file system. AFM is based on a home-cache model. A single home provides the primary file storage that is exported. One or more caches provide a view into the exported home file system without storing the file data locally. Upon file access in the cache, the data is fetched from home and stored in cache.
Another way to get files transferred from home to cache is through prefetching. Prefetching can use the IBM Spectrum Scale policy engine to quickly identify files that match certain criteria.
When files are created or changed in cache, they can be replicated back to home. A file that was replicated back to home can be evicted in cache. In this case, the user still sees the file in cache (the file is uncached), but the actual file content is stored in home. Eviction is triggered by the quota that is set on the AFM file set and can evict files based on size or last recent used criteria.
Cache must be an IBM Spectrum Scale independent file set. Home can be an IBM Spectrum Scale file system, a Network File System (NFS) export from any other file system, or a file server (except for the disaster-recovery use case). The caching relationship between home and cache can be based on the NFS or native IBM Spectrum Scale protocol. In the latter case, home must be an IBM Spectrum Scale file system in a different IBM Spectrum Scale cluster. The examples in this Redpaper that feature AFM use an NFS protocol at the home cluster.
The AFM relation is typically configured on the cache file set in one specific mode. The AFM mode determines where files can be processed (created, updated, and deleted) and how files are managed by AFM according to the file state. See Figure 2-5 on page 31 for AFM file states.
|
Important: IBM Spectrum Archive EE V1.2.3.0 is the first release that started supporting IBM Spectrum Scale AFM with IBM Spectrum Scale V4.2.2.3. AFM has multiple cache modes that can be created. However, IBM Spectrum Archive EE supports only the independent-writer (IW) cache mode.
|
Independent-writer
The IW cache mode of AFM makes the AFM target home for one or more caches. All changes in the caches are replicated to home asynchronously. Changes to the same data are applied in the home file set so that the changes are replicated from the caches. There is no cross-cache locking. Potential conflicts must be resolved at the respective cache site.
A file in the AFM cache can have different states as shown in Figure 2-5. File states can be different depending on the AFM modes.
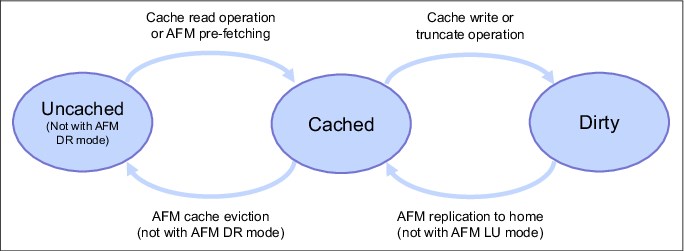
Figure 2-5 AFM file state transitions
Uncached
When an AFM relation is created between cache and home, and files are available in home, these files can be seen in cache without being present. This state means that the file metadata is present in the cache, but the file content is still on home. Such files are in status uncached. In addition, the uncached status is achieved by evicting files from the cache.
Cached
When an uncached file is accessed in cache for a read or write operation, the file is fetched from home. Fetching is the process of copying a file from home to cache. Files fetched from home to cache are in cached state. Another way to fetch files from home to cache is by using the AFM prefetch command (mmafmctl prefetch). This command can use the policy engine to identify files quickly, according to certain criteria.
Dirty
When a cached file in the AFM cache is modified, that file is marked as dirty, indicating that it is a candidate for replication back to home. The dirty status of the file is reset to cached if the file has been replicated to home. When a file is deleted in cache, this delete operation is also done on home.
For information about how to configure AFM with IBM Spectrum Archive EE, see 7.10.3, “IBM Spectrum Archive EE migration policy with AFM” on page 246. For use cases, see Figure 8-11, “IBM Spectrum Archive use case for university Scientific Data Archive” on page 286.
2.2.6 Scale Out Backup and Restore
Scale Out Backup and Restore (SOBAR) is an IBM Spectrum Scale data protection mechanism for Disaster Recovery (DR) incidents. SOBAR is used to back up and restore IBM Spectrum Scale files that are managed by IBM Spectrum Protect for Space Management.
The idea of SOBAR is to have all the file data pre-migrated or migrated to the IBM Spectrum Protect server and periodically back up the file system configuration and metadata of all the directories and files into the IBM Spectrum Protect server.
When the file system recovery is needed, the file system is restored by using the configuration, and all the directories or files are restored by using the metadata. After the recovery, the files are in stub format (HSM migrated state) and can be recalled from the IBM Spectrum Protect server on-demand.
Because the recovery processes only the metadata and does not involve recalling or copying the file data, the recovery is fast with significantly reduced recovery time objective (RTO). This is especially true for large file systems.
For more information, see this IBM Documentation web page.
As of this writing, SOBAR is not supported on the IBM Spectrum Archive managed file systems for DR. However, from version 1.3.1.2, IBM Spectrum Archive supports a procedure that uses SOBAR to performed a planned data migration between two file systems.
By using SOBAR, a file system can be migrated without recalling the file data from tapes. For more information, see 6.27, “File system migration” on page 231.
2.3 OpenStack SwiftHLM
The Swift High Latency Media (SwiftHLM) project seeks to create a high-latency storage back end that makes it easier for users to perform bulk operations of data tiering within a Swift data ring. SwiftHLM enables IBM Spectrum Scale, IBM Spectrum Archive, and IBM Spectrum Protect as the key products for this software-defined hybrid storage with object interface to tape technology. Data is produced at significantly higher rates than a decade ago.
The storage and data management solutions of the past can no longer keep up with the data demands of today. The policies and structures that decide and execute how that data is used, discarded, or retained determines how efficiently the data is used. The need for intelligent data management and storage is more critical now than ever before.
Traditional management approaches hide cost-effective, high-latency media (HLM) storage, such as tape or optical disk archive back ends, underneath a traditional file system. The lack of HLM-aware file system interfaces and software makes it difficult for users to understand and control data access on HLM storage. Coupled with data-access latency, this lack of understanding results in slow responses and potential timeouts that affect the user experience.
The Swift HLM project addresses this challenge. Running OpenStack Swift on top of HLM storage allows you to cheaply store and efficiently access large amounts of infrequently used object data. Data that is stored on tape storage can be easily adopted to an Object Storage data interface. SwiftHLM can be added to OpenStack Swift (without modifying Swift) to extend Swift’s interface.
This ability allows users to explicitly control and query the state (on disk or on HLM) of Swift object data, including efficient pre-fetch of bulk objects from HLM to disk when those objects must be accessed. This function, previously missing in Swift, provides similar functions as Amazon Glacier does through the Glacier API or the Amazon S3 Lifecycle Management API.
BDT Tape Library Connector (open source) and IBM Spectrum Archive or IBM Spectrum Protect are examples of HLM back ends that provide important and complex functions to manage HLM resources (tape mounts and unmounts to drives, serialization of requests for tape media, and tape drive resources). They can use SwiftHLM functions for a proper integration with Swift.
Although access to data that is stored on HLM can be done transparently without the use of SwiftHLM, this process does not work well in practice for many important use cases and other reasons. SwiftHLM function can be orthogonal and complementary to Swift (ring to ring) tiering (source). The high-level architecture of the low cost, high-latency media storage solution is shown in Figure 2-6 on page 34.
For more information, see Implementing OpenStack SwiftHLM with IBM Spectrum Archive EE or IBM Spectrum Protect for Space Management, REDP-5430.

Figure 2-6 High-level SwiftHLM architecture
2.4 IBM Spectrum Archive EE dashboard
IBM Spectrum Archive EE provides dashboard capabilities that allow customers to visualize their data through a graphical user interface (GUI). By using the dashboard, you can see the following things without logging in to a system and typing commands by using a web-browser:
•See whether a system is running without error. If there is an error, see what kind of error is detected.
•See basic tape-related configurations like how many pools and how much space is available.
•See time-scaled storage consumption for each tape pool.
•See the throughput for each drive for migration and recall.
•See current running/waiting tasks
This monitoring feature consists of multiple components that are installed in the IBM Spectrum Archive EE nodes as well as dedicating an external node for displaying the dashboard.
The dashboard consists of the following components:
•Logstash
•Elasticsearch
•Grafana
Logstash is used for data collection, and should be installed on all IBM Spectrum Archive EE nodes. The data that is collected by Logstash is then sent to Elasticsearch on the external monitoring node where it can query data quickly and send it to the Grafana component for visualization. Figure 2-7 shows the IBM Spectrum Archive EE Dashboard architecture.

Figure 2-7 IBM Spectrum Archive Dashboard architecture
The Dashboard views are System Health, Storage, Activity, Config, and Task. Figure 2-8 shows an example of the IBM Spectrum Archive EE Dashboard Activity view.

Figure 2-8 IBM Spectrum Archive EE Dashboard activity view
For more information on configuring the Dashboard within your environment, see the IBM Spectrum Archive Enterprise Edition Dashboard Deployment Guide, which is available at this IBM Documentation web page.
2.5 IBM Spectrum Archive EE REST API
The Representational State Transfer (REST) API for IBM Spectrum Archive Enterprise Edition can be used to access data on the IBM Spectrum Archive Enterprise Edition system. Starting with Version 1.2.4, IBM Spectrum Archive EE provides the configuration information through its REST API. The GET operation returns the array of configured resources similar to CLI commands, but in well-defined JSON format.
They are equivalent to what the eeadm task list and eeadm task show commands display. With the REST API, you can automate these queries and integrate the information into your applications including the web/cloud.
For installation instructions, see 4.4, “Installing a RESTful server” on page 83.
For usage examples including commonly used parameters, see 6.26, “IBM Spectrum Archive REST API” on page 219.
2.6 Types of archiving
It is important to differentiate between archiving and the HSM process that is used by IBM Spectrum Archive EE. When a file is migrated by IBM Spectrum Archive EE from your local system to tape storage, a placeholder or stub file is created in place of the original file. Stub files contain the necessary information to recall your migrated files and remain on your local file system so that the files appear to be local. This process contrasts with archiving, where you often delete files from your local file system after archiving them.
The following types of archiving are used:
•Archive with no file deletion
•Archive with deletion
•Archive with stub file creation (HSM)
•Compliant archiving
Archiving with no file deletion is the typical process that is used by many backup and archive software products. In the case of IBM Spectrum Protect, an archive creates a copy of one or more files in IBM Spectrum Protect with a set retention period. It is often used to create a point-in-time copy of the state of a server’s file system and this copy is kept for an extended period. After the archive finishes, the files are still on the server’s file system.
Contrast this with archiving with file deletion where after the archive finishes the files that form part of the archive are deleted from the file system. This is a feature that is offered by the IBM Spectrum Protect archive process. Rather than a point-in-time copy, it can be thought of as a point-in-time move as the files are moved from the servers’ file system into IBM Spectrum Protect storage.
If the files are needed, they must be manually retrieved back to the file system. A variation of this is active archiving, which is a mechanism for moving data between different tiers of storage depending on its retention requirements. For example, data that is in constant use is kept on high-performance disk drives, and data that is rarely referenced or is required for long-term retention is moved to lower performance disk or tape drives.
IBM Spectrum Archive EE uses the third option, which instead of deleting the archived files, it creates a stub file in its place. If the files are needed, they are automatically retrieved back to the file system by using the information that is stored in the stub file when they are accessed.
The final type of archiving is compliant archiving, which is a legislative requirement of various countries and companies data retention laws, such as Sarbanes-Oxley in the US. These laws require a business to retain key business information. Failure to comply with these laws can result in fines and sanctions. Essentially, this type of archiving results in data being stored by the backup software without the possibility of it being deleted before a defined period elapses. In certain cases, it can never be deleted.
|
Important: IBM Spectrum Archive EE is not a compliant archive solution.
|
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.