

7.4.2Highlight of Sport Match Video
Sport match videos are also quite structured. For example, a football match has two half games, while a basketball match further divides a half game into two sets. All these characteristics provide useful time cues and constraints for sport match analysis. On the other hand, there are always some climactic events in a sport match (sometimes called a sport video or event video), such as shooting in a football match and slam-dunk in basketball match. A sport match has much uncertainty, and the time and position of an event can hardly be predicted. The generating of a sport match video cannot be controlled by program makers during the match.
7.4.2.1Characteristics of a Sport Video
In sport matches, a particular scene often has some fixed colors, movements, object distributions, etc. As a limited number of cameras have been preset in the play ground, one event often corresponds to particular change of the scene. This makes it possible to detect interesting events by the change of the scene, or the existence or appearance of certain objects. For a video clip having players, the indexing can be made based on the silhouettes of players, the colors of their clothes, and the trajectories. For a video clip toward the audience, the pose and action can be extracted as the indexing entry.
The highlight shot is often the most important part of a sport match. News reports on sport matches are always centered on highlighted events. In defining highlighted events, some prior knowledge is often used. The definition, content, and visual representation of highlighted events, vary from one sport match to another. For example, shooting in a football match is the focus, while slam-dunk and fast passing always attract much attention in a basketball match. From the point of querying view, it can be based on the detection of highlighted shots or based on the components of events, such as a ball, a goal, a board, etc. It can also be based on the type of activities, such as a free ball, a penalty, a three-point field goal, etc.
The features of a sport match can be divided into three layers, the low layer, the middle layer, and the high layer (Duan, 2003). The low-layer features include motion vectors, color distributions, etc., which can be directly extracted from images. The middle-layer features include camera motions, object regions, motions, etc., which can be derived from the low-layer features. For example, the camera motion can be estimated from the motion vector histogram. The features of the high layer correspond to events and their relation with those of middle/low layer can be established with the help of some appropriate knowledge.
7.4.2.2Structure of Table Tennis Matches
Different from a football match that has fixed time duration, a table tennis match is based on scores. It has relatively unambiguous structure. One match is composed of several repeated scenes with typical structures. In particular, the following scenes can be distinct, such as the match scene, the service scene, the break scene, the audience scene, and the replay scene. Each scene has its own particularity and property. One table tennis match is formed by three to seven sets, while, for each set, dozen of games exist. The result of each game here induces one point in the score. The repetition of the above structure units constructs a match, in which each scene happens in a fixed sequence. For example, service scene is followed by the play scene, while the replay scene goes after a highlight play. The above structure is depicted in Figure 7.14.
Example 7.5 Illustration of clustering results
According to the above-described structure, shots in a table tennis match can be clustered. Figure 7.15 shows several clusters obtained by using an unsupervised clustering, in which each column shows shots in one class.
![]()



7.4.2.3Object Detection and Tracking
For most audiences, not only the final score is important but also the level of a highlight and its incitement for each play. The ranking of a table tennis highlight can be obtained by the combination of the information of the trajectory of the ball, the position of the player, and the table.
Figure 7.16 gives an overview of object detection, tracking, and ranking of shots Chen (2006). The player position, the table position, and the ball position should first be detected. Then, both the trajectories of the player and the ball need to be extracted. Using the results of the detection and extraction, the rank (consisting of both basic rank and quality rank) for each shot is determined.
The table position detection is performed first. The table region can be specified by using the edge and the color features in a rough-fine procedure. The RGB color histogram (normalized to unity sum) of each rough table region is calculated and the histogram is obtained by uniformly quantizing the RGB color coordinates into 8 (Red), 8 (Green), and 8 (Blue) bins, respectively, resulting in a total of 512 quantized colors. Then, a radon transform is used to find the position of the table edge lines and to specify a rough boundary of the table.
After the detection of tables, the players are detected. The two players are the most drastic moving objects in the playing field. By taking into account the spatial-temporal information of the image sequence, the two biggest connected squares inclosing the players can be determined, as illustrated in Figure 7.17.
Ball detection and tracking is a challenging task. A combined analysis of the color, shape, size, and position is required. The detection of a ball candidate is based on the detection of the table region. Ball candidates can be classified into the in-table regions and the out-table regions. The consecutive losing of the in-table candidate balls indicates that the ball is out of the table. Detection of the ball in the in-table region is relatively simple compared to that of the ball in the out-table region. The latter may need a complicated process with the Bayesian decision (Chen, 2006). One tracking result is shown in Figure 7.18, in which Figure 7.18(a) through Figure 7.18(d) are four images sampled at an equal interval from a sequence. Figure 7.18(e) shows the trajectory obtained for the entire play in superposition.
7.4.2.4Highlight Ranking
To rank the highlight level precisely and in close connection with the human feeling, different levels of the human knowledge for evaluating match are considered. The ranking of a table tennis match can be divided into three layers: the basic ranking, the quality of the action, and the most sophisticated one – the feeling from the experience. The basic part describes the most common aspects of the match, which include the velocity of the ball and the players, the duration of the play for a point, and the distance between two strokes. The quality of the match involves the quality of the ball trajectory, the drastic degree of the player motion, and the consistency of the action. These fuzzy concepts are more suitable to be treated by a powerful fuzzy system. The last part mostly refers to the experience or the feeling of the referee. In the following, some details for the first two layers are provided (Chen, 2006).


Basic Ranking
The basic part of the table tennis highlight level describes the most direct feeling of a single point with the explicit knowledge and a statistical transfer from the feature detected, which is given by
where N is the number of frames and wv, wb, and wp are the weights for different factors. The highlight rank is determined by three factors. The first is the average speed of ball,
where v(i) is the speed of i-th stroke. The second is the average distance running by the ball between two consecutive strokes,
where N1 and N2 are the total numbers of strokes made by player 1 and player 2, respectively, and b1 and b2 are the ball positions at the stroking point with corresponding players. The third is the average speed of the movement of the players between two consecutive strokes,
where p1 and p2 are the corresponding player’s speed at frame i.
The function f(·) in the above three equations is a sigmoid function
It is used to convert a variable to a highlight rate so that different affection factors can be added together.
To measure the quality of the game, the basic marking unit is a stroke, including the player’s premoving, the stroking, the trajectory and speed of the ball, and the similarity and consistency between the two adjacent strokes.
The drastic degree of the motion of the player characterizes the moving variety of the players,
where p(i) and s(i) are the positions and shapes (measured from the area of minimal bounding rectangle) of the stroking player at the stroke i. Function f is the same sigmoid function defined in eq. (7.25), wp and ws are the corresponding weights.
The quality of the ball trajectory between two strokes is described by the length and velocity, for it is much more difficult to control a long trajectory of a ball flying at a high speed. This quality can be represented by
where l(i) and v(i) are the length and average velocity along the ball trajectory between the strokes i and i − 1. wl and wv are the weights, and f(·) is the sigmoid function.
Finally, the variation of strokes is composed of three factors that depict the consistency and diversification of the match for a dazzling match consists of various motion patterns, given by
where v(i), d(i), and l(n) are the average velocity, direction, and length of the ball trajectory between the strokes i and i − 1. wv, wd, and wl are the weights, and f(·) is the sigmoid function.
7.4.3 Organization of Home Video
Compared to other types of video programs, home video has some particularities according to the persons to shoot and the objects to be screened (Lienhart, 1997). It is often less structured, so the organization is a more challenging task.
7.4.3.1Characteristics of Home Video
In spite of the unrestricted content and the absence of a storyline, a typical home video has still certain structure characteristics: It contains a set of scenes, each of which is composed of ordered and temporally adjacent shots that can be organized in clusters that convey semantic meaning. The fact is that home video recording imposes temporal continuity. Unlike other video programs, home video just records the life but does not compose a story. Therefore, every shot may have the same importance. In addition, filming home video with a temporal back and forth structure is rare. For example, on a vacation trip, people do not usually visit the same site twice. In other words, the content tends to be localized in time. Consequently, discovering the scene structure above the shot level plays a key role in home video analysis. Video content organization based on shot clustering provides an efficient way of semantic video accessing and fast video editing.
Home video is not prepared for a very large audience (like broadcasting TV), but for relatives, guests, and friends. In the analysis, the purpose and filming tact should be considered. For example, the subjective feeling transferred by the video information can be decomposed into two parts: one is from motion regions that attract the attention of viewers and the other is from the general impression of the environment. At the same time, different types of camera motions should also be considered. Different camera motions may signify different changes in attention. For example, a zoom-in puts the attention of viewers more on motion regions, while a pan and tilt puts the attention of viewers more on the environment.
7.4.3.2Detection of Attention Regions
Structuring video needs the detection of motion–attention regions. This is not equivalent to the detection of video objects. The latter task needs to accurately determine the boundaries of objects and to quickly follow the changes of the objects. The former task stresses more the subjective feeling of human beings in regards to the video. In this regard, the influence of the region detection on the subjective feeling is more important than just an accurate segmentation.
Commonly, most object detection methods fail if there is no specific clear-shaped object in the background. In order to circumvent the problem of the actual object segmentation, a different concept, attention region is introduced. This attention region does not necessarily correspond to the real object but denotes the region with irregular movement compared to the camera motion. Based on the assumption that different movement from the global motion attracts more attention (supported by the common sense that irregular motion tends to be easily caught by human eyes in a static or regular moving background), these regions are regarded as somewhat important areas in contrast to the background image. The attention region detection requires less precision, since more emphasis has been placed on the degree of human attention than on the accurate object outline. Actually, it is simply done based on the outliers detected previously by the camera motion analysis. In addition, the attention region tracking process also becomes easier for its coarse boundary of the macroblocks.
The first step of attention region detection is to segment a “dominant region” from a single frame, which is illustrated in Figure 7.19. Figure 7.19(a) is a typical home video frame. This frame can be decomposed into two parts: the running boy on the grassplot, as shown in Figure 7.19(b), and the background with grasses and trees, as shown in Figure 7.19(c). The latter represents the environment and the former represents the attention region.

The detection of attention regions does not require very high precision. In other words, the accurate extraction of the object boundary is not necessary. Therefore, the detection of attention regions can be performed directly in am MPEG compressed domain. Two types of information in the compressed domain can be used Jiang (2005b):
DCT Coefficients of Macro Block: In DCT coefficients, the DC coefficient is easy to obtain. It is the direct component of the block and is eight times the average value in the block. It roughly reflects brightness and color information.
Motion Vectors of Macro Block: Motion vectors correspond to the sparse and coarse motion field. They reflect approximately the motion information.
With the motion vectors, a simple but effective four-parameter global motion model can be used to estimate the simplified camera motions (zoom, rotate, pan and tilt), given by
A common least square fitting algorithm is imposed to optimize the model parameters h0, h1, h2, and h3. This algorithm recursively examines the error produced by the current estimate of the camera parameters and generates an outlier mask, consisting of macroblocks with motion vectors not following the camera motion model, then recomputes the camera parameters and forms new outlier mask and iterates. As it operates directly on MPEG video, the motion vector preprocessing has to be done to get a dense motion vector field.
Example 7.6 Detected attention regions
Some examples of attention regions detected are shown in Figure 7.20. All of them are macroblocks characterized by different movements from the global motion. Note that these regions are quite different from real objects. They could be a part of the real object (kid’s legs in Figure 7.20(a)) or several objects as a whole (woman and kids jumping on trampoline in Figure 7.20(b), kid and little car on the road in Figure 7.20(c). Reasonably, a region drawing the viewer’s attention is not necessary to be a complete accurate semantic object.
![]()

7.4.3.3Time-weighted Model Based on Camera Motion
The detection of attention regions divides video content into two parts spatially and temporally: The attention regions and the remnant regions. Two types of features can be used to represent the content of a shot: One is the features in attention regions, which emphasize the part extracting the audience and the other is the features for other regions, which stress the global impression for the environment.
Color is often considered the most salient visual feature that attracts viewer’s attention, since the color appearance, rather than the duration, trajectory, and area of region, is counted more in the mind. Thus, an effective and inexpensive color representation in the compressed domain – the DC color histogram – is used to characterize each shot. In contrast to calculating an overall average color histogram, DC histograms of macroblocks constituting the attention regions and the background are computed, respectively. The two types of histograms form a feature vector for each shot, which holds more information than a single histogram describing the global color distribution.
As each attention region and background appears in several frames, the histograms along time can be accumulated to form a single histogram. Instead of the common average procedure, a camera motion-based weighting strategy is used, giving different importance to histograms at different times. It is well known that camera motions are always utilized to emphasize or neglect a certain object or a segment of video (i.e., to guide viewers’ attention). Actually, it can imagine a camera as a narrative eye. For example, a camera panning imitating an eye movement either to track an object or to examine a wider view of a scene and a close-up indicates the intensity of an impression. In order to reflect the different impression of the viewers affected by camera movement, a camera attention model can be defined.
Camera movement controlled by a photographer is useful for formulating the viewer attention model. However, the parameters in the four-parameter global motion model are not the true camera move, scale, and rotation angles. Thus, these parameters have to be first converted to real camera motion for attention modeling (Tan 2000), given by
where S indicates the interframe camera zoom factor (S > 1, zoom in; S < 1, zoom out), r is the rotation factor about the lens axis, aλ and bλ are the camera pan and tilt factors, L is the magnitude of camera panning (horizontal and vertical), and θ is the angle.
The next step is mapping the camera parameters to the effect they have on viewers’ attention. The camera attention can be modeled on the basis of the following assumptions (Ma, 2002).
(1)Zooming is always used to emphasize something. Zoom-in is used to emphasize the details, while zoom-out is used to emphasize an overview. The faster the zooming speed, the more important the content focused.
(2)Situations of camera panning and tilting should be divided into two types: region-tracking (with attention region) and surroundings-examining (without attention region). The former corresponds to the situation of a camera tracking a moving object, so that much attention is given to the attention region and little to the background. Camera motion of the latter situation tends to attract less attention since horizontal panning is often applied to neglect something (e. g., change to another view), if no attention region exists. The faster the panning speed, the less important the content. Additionally, unless a video producer wants to emphasize something, vertical panning is not used since it brings viewers an unstable feeling.
(3)If the camera pans/tilts too frequently or too slightly, it is considered random or unstable motion. In this case, the attention is determined only by the zoom factors.
In frames with attention regions, viewers’ attention is supposed to be split into two parts, represented by the weight of background WBG and the weight of attention region WAR as

where WAR is proportional to S and is enhanced by panning, L0 is the minimal camera pan (panning magnitude less than L 0 is regarded as random), and RL is a factor controlling the panning power to affect attention degree. In this model, a value greater than 1 means emphasis and a value less than 1 means neglect.
In frames without attention region, only background attention weight WBG is computed by
The attention degree decreases in the situation of horizontal panning (θ < π/4) and increases in the situation of vertical panning (θ ≥ π/4). f(θ) is a function representing the effect of the panning angle on the decrease or increase rate. It gets smaller while the panning angle gets nearer to π/4 because a panning in this diagonal direction tends to have little effect on the attention.
Example 7.7 Time-weighted modeling based on camera motion
Figure 7.21 shows some examples of time-weighted modeling based on camera motion. Figure 7.21(a–c) are three frames extracted from the same shot of kids playing on the lawn. Although they share a similar background, the background attention weight WBG differs in the attention model according to different camera motions of the three frames. Figure 7.21(a) is almost stationary (without the attention region), with the attention just determined by the zoom factor. Figure 7.21(b) is a left panning to track a running kid (with an attention region), thus it has less weight on the background than on the attention region. Figure 7.21(c) shows also the region tracking but has a higher panning speed than in Figure 7.21(b), and thus, it has an even smaller background weight. It is observed in Figure 7.21 that visual contents are spatially split into two attention parts, while they are temporally weighted by camera motion parameters.
![]()

7.4.3.4Strategy for Shot Organization
Using the shot features and weights obtained above, a feature vector for each shot is composed. The visual similarity between two shots is then computed. In particular, similarities of the background and that of the attention regions are computed separately, for example, by using the normalized histogram intersection. Based on the similarity among shots, similar shots can be grouped. A two-layer shot organization strategy can be used (Zhang, 2008d). In the first layer, the scene transition is detected. The place where both the attention regions and the environment change gradually indicates the change of the location and scenario. In the second layer, either the attention regions or the environment is changed (not both). This change can be the change of focus (different moving object in same environment) or the change of object position (same moving object in different environment). The change in the second layer is also called a change of the subscene.
Example 7.8 Two-layer shot organization
One example of two-layer shot organization is shown in Figure 7.22. Five frames are extracted from five consecutive shots. White sashes mark detected attention regions. The first layer organization clusters the five shots into three scenes, which are different both in attention regions and in environments. The last three shots in the scene 3 of the first layer can be further analyzed. The third and fourth shots in Figure 7.22 can be clustered together, which have similar background and similar attention regions, while the fifth shot has a different attention region from the third and fourth shots. In short, the first layer clusters shots with the semantic event, while the second layer distinguishes different moving objects.
![]()
![]()
7-1*Let HQ (k) and HD(k) be as shown in Figure Problem 7-1(a, b), respectively. Use the histogram intersection method to calculate the matching values. If HQ(k) is as shown in Figure 7-1(c), then what is the matching value now?

7-2Select a color image and make a smoothed version using some average operations. Take the original image as a database image and the smoothed image as a query image. Compute their histograms and the matching values according to eqs. (7.2), (7.4), (7.5) and (7.7), respectively.
7-3Design two different histograms and make the matching value obtained with the histogram intersection to be zero.
7-4Compute the values of four texture descriptors for a Lenna image and a Cameraman image, respectively. Compare these values and discuss the necessity of normalization.
7-5Implement the algorithm for computing the shape descriptor based on wavelet modulus maxima. Draw several geometric figures and compute the descriptor values for them. Based on the above result, discuss the sensitivity of object shape on the descriptors’ values.
7-6*There are three images shown in Figure Problem 7-6, which are silhouettes of trousers in the clothing image library. Try to select several shape descriptors to compare, discuss which descriptor is more suitable in distinguishing them from other garments, and which descriptor can best distinguish them from each other.

7-7Propose a method/scheme to combine the different types of descriptors presented in Section 7.1 into a new one. What is the advantage of this combined descriptor?
(1)What is the value of similarity between F1 and F2 according to eq. (7.16)?
(2)What is the value of similarity between F1 and F3 according to eq. (7.17)?
7-9Why has the research in content-based image retrieval been centered on semantic-based approaches in recent years? What are the significant advances in this area?
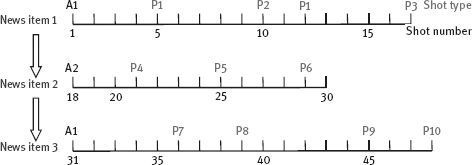
7-10How many cues can be used in structuring news programs? How can these cues be extracted from broadcasting news programs?
7-11How do you model the feeling of human beings watching a table tennis game? What kinds of factors should be considered?
7-12If possible, make some home video recordings and classify them into different categories.
![]()
1.Feature-Based Image Retrieval
–A general introduction to content-based image retrieval can be found in Zhang (2003b).
–Some early work in visual information retrieval can be found in Bimbo (1999).
–More discussion on early feature-based image retrieval can be found in Smeulders (2000).
–Different feature descriptors can be combined in feature-based image retrieval (Zhang, 2003b).
–Several texture descriptors are proposed by the international standard MPEG-7, a comprehensive comparison has been made in Xu (2006).
2.Motion-Feature-Based Video Retrieval
–Motion information can be based on the trochoid/trajectory of the moving objects in the scene (Jeannin 2000).
–Motion activity is a motion descriptor for the whole frame. It can be measured in an MPEG stream by the magnitude of motion vectors (Divakaran, 2000).
3.Object-Based Retrieval
–Even more detailed descriptions for the object-based retrieval can be found in Zhang (2004b, 2005b).
–Segmentation plays an important role in object-based retrieval. New advancements in image segmentation for CBIR can be found in Zhang (2005c).
–One way to incorporate human knowledge and experience into the loop of image retrieval is to annotate images before querying. One such example of automatic annotation can be found in Xu (2007a).
–Classification of images could help to treat the problem caused by retrieval in large databases. One novel model for image classification can be found in Xu (2007b).
–Recent advances of retrieval in the object level, the scene level, and some even high levels, can be found in Zhang (2005b, 2007e, 2015e).
–One study on CNN-based matching for retrieval can see Zhou (2016).
4.Video Analysis and Retrieval
–One method of automated semantic structure reconstruction and representation generation for broadcast news can be found in Huang (1999).
–The use of an attention model for video summarization can be found in Ma (2002).
–Different video highlights for various sport matches have been generated. See Peker (2002) for an example.
–One approach of using a parametric model for video analysis is described in Chen (2008).
–Recent research works in semantic-based visual information retrieval have advanced this field, and some examples can be found in Zhang (2007d).
–Some more details on the hierarchical organization of home video can also be found in Zhang (2015b)