
Exercises
9.1 (Class Average: Writing Grades to a Plain Text File) Figure 3.2 presented a class-average script in which you could enter any number of grades followed by a sentinel value, then calculate the class average. Another approach would be to read the grades from a file. In an IPython session, write code that enables you to store any number of grades into a
grades.txtplain text file.9.2 (Class Average: Reading Grades from a Plain Text File) In an IPython session, write code that reads the grades from the
grades.txtfile you created in the previous exercise. Display the individual grades and their total, count and average.9.3 (Class Average: Writing Student Records to a CSV File) An instructor teaches a class in which each student takes three exams. The instructor would like to store this information in a file named
grades.csvfor later use. Write code that enables an instructor to enter each student’s first name and last name as strings and the student’s three exam grades as integers. Use thecsvmodule to write each record into thegrades.csvfile. Each record should be a single line of text in the following CSV format:firstname,lastname,exam1grade,exam2grade,exam3grade9.4 (Class Average: Reading Student Records from a CSV File) Use the
csvmodule to read thegrades.csvfile from the previous exercise. Display the data in tabular format.9.5 (Class Average: Creating a Grade Report from a CSV File) Modify your solution to the preceding exercise to create a grade report that displays each student’s average to the right of that student’s row and the class average for each exam below that exam’s column.
9.6 (Class Average: Writing a Gradebook Dictionary to a JSON File) Reimplement Exercise 9.3 using the
jsonmodule to write the student information to the file in JSON format. For this exercise, create a dictionary of student data in the following format:gradebook_dict = {'students': [student1dictionary, student2dictionary, ...]}Each dictionary in the list represents one student and contains the keys
'first_name','last_name','exam1','exam2'and'exam3', which map to the values representing each student’s first name (string), last name (string) and three exam scores (integers). Output thegradebook_dictin JSON format to the filegrades.json.9.7 (Class Average: Reading a Gradebook Dictionary from a JSON File) Reimplement Exercise 9.4 using the
jsonmodule to read thegrades.jsonfile created in the previous exercise. Display the data in tabular format, including an additional column showing each student’s average to the right of that student’s three exam grades and an additional row showing the class average on each exam below that exam’s column.9.8 (
pickleObject Serialization and Deserialization) We mentioned that we prefer to use JSON for object serialization due to the Python documentation’s stern security warnings aboutpickle. However,picklehas been used to serialize objects for many years, so you’re likely to encounter it in Python legacy code. According to the documentation, “If you are doing your ownpicklewriting and reading, you’re safe (provided no one else has access to thepicklefile, of course.)”14 Reimplement your solutions to Exercises 9.6–9.7 using thepicklemodule’sdumpfunction to serialize the dictionary into a file and itsloadfunction to deserialize the object. Pickle is a binary format, so this exercise requires binary files. Use the file-open mode'wb'to open the binary file for writing and'rb'to open the binary file for reading. Functiondumpreceives as arguments an object to serialize and a file object in which to write the serialized object. Functionloadreceives the file object containing the serialized data and returns the original object. The Python documentation suggests thepicklefile extension.p.9.9 (Telephone-Number Word Generator) In Exercise 5.12, you created a telephone-number word-generator program. Modify that program to write its output to a text file.
9.10 (Project: Analyzing a Book from Project Gutenberg) A great source of plain text files is the collection of over 57,000 free e-books at Project Gutenberg:
https:// www.gutenberg.org These books are out of copyright in the United States. For information about Project Gutenberg’s Terms of Use and copyright in other countries, see:
https:// www.gutenberg.org/ wiki/ Gutenberg:Terms_of_Use Download the text-file version of Pride and Prejudice from Project Gutenberg
https:// www.gutenberg.org/ ebooks/ 1342 Create a script that reads Pride and Prejudice from a text file. Produce statistics about the book, including the total word count, the total character count, the average word length, the average sentence length, a word distribution containing frequency counts of all words, and the top 10 longest words. In the “Natural Language Processing (NLP)” chapter, you’ll find lots of more sophisticated techniques for analyzing and comparing such texts.
Each Project Gutenberg e-book begins and ends with some additional text, such as licensing information, which is not part of the e-book itself. You may want to remove that text from your copy of the book before analyzing its text.
9.11 (Project: Visualizing Word Frequencies with a Word Cloud) A word cloud visualizes words, displaying more frequently occurring words in larger fonts. In this exercise, you’ll create a word cloud that visualizes the top 200 words in Pride and Prejudice. You’ll use the open-source
wordcloudmodule’s15WordCloudclass to generate a word cloud with just a few lines of code.To install
wordcloud, open your Anaconda Prompt (Windows), Terminal (macOS/Linux) or shell (Linux) and enter the command:conda install -c conda-forge wordcloudYou create and configure a
WordCloudobject as follows:from wordcloud import WordCloudwordcloud = WordCloud(colormap='prism', background_color='white')Using the techniques from the previous exercise, create a
frequenciesdictionary containing the frequencies of the top-200 words in Pride and Prejudice. Then execute the following statements to generate a rectangular word cloud and save its image to a file on disk:wordcloud = wordcloud.fit_words(frequencies)wordcloud = wordcloud.to_file('PrideAndPrejudice.png')You can then double-click the
PrideAndPrejudice.pngimage file on your system to view it. In the “Natural Language Processing” chapter, we’ll show you how to place your word clouds into shapes. For example, we placed our Romeo and Juliet word cloud into a heart.9.12 (Project: State-of-the-Union Speeches) Text files of all U.S. Presidents’ State-of-the-Union speeches are available online. Download one of these speeches. Write a script that reads the speech from the file, then displays statistics about the speech, including the total word count, the total character count, the average word length, the average sentence length, a word distribution of the words frequencies, and the top 10 longest words. In the “Natural Language Processing (NLP)” chapter, you’ll find lots of more sophisticated techniques for analyzing and comparing such texts.
9.13 (Project: Building a Basic Sentiment Analyzer) We’ll do lots of sentiment analysis in the data-science chapters. For example, we’ll look at large numbers of tweets from Twitter on various topics, determining whether people had positive or negative opinions about those topics. We’ll see that many software packages have built-in sentiment-analysis capabilities. In this exercise, you’ll build a basic sentiment analyzer. A basic way to do this is to search online for files of positive words (like happy, pleasant, …) and files of negative words (like sad, angry, …). Then, search through a text to see how many positive words and how many negative words it contains. Based on those counts, rate the text as positive, negative or neutral.
9.14 (Project: Basic Similarity Detection via Average Sentence Length and Average Word Length) Who actually wrote William Shakespeare’s works? Some researchers believe that Sir Francis Bacon may have authored some or all of these works. Download one of Shakespeare’s works and one of Bacon’s works from Project Gutenberg. For each, calculate the average sentence length and average word length. Are these close? Compute other statistics as well.
9.15 (Project: Working with CSV Datasets Using the
csvModule) In the Intro to Data Science section, we loaded the Titanic disaster dataset into a pandasDataFrame, then usedDataFramecapabilities to perform some simple analysis of that data. For this exercise, use thecsvmodule to read the Titanic disaster dataset, then manually count the records that contain a value for the age column. Those that do not will have the value'NA'. For only those records that have an age value, calculate the average age. For this exercise, investigate and use thecsvmodule’sDictReaderclass.9.16 (Working with the
diamonds.csvDataset in Pandas) In this book’s data-science chapters, you’ll work extensively with datasets, many in CSV format. You’ll frequently use pandas to load datasets and prepare their data for use in machine-learning studies. Datasets are available for almost anything you’d want to study. There are numerous dataset repositories from which you can download datasets in CSV and other formats. In this chapter, we mentioned:https:// vincentarelbundock.github.io/ Rdatasets/ datasets.html and
https:// github.com/ awesomedata/ awesome-public-datasets The Kaggle competition site:16
https:// www.kaggle.com/ datasets?filetype=csv has approximately 11,000 datasets with over 7500 in CSV format. The U.S. government’s
data.govsite:https:// catalog.data.gov/ dataset?res_format=CSV&_res_format_limit=0 has over 300,000 datasets with approximately 19,000 in CSV format.
In this exercise, you’ll use the diamonds dataset to perform tasks similar to those you saw in the Intro to Data Science section. This dataset is available as
diamonds.csvfrom various sources, including the Kaggle and Rdatasets sites listed above. The dataset contains information on 53,940 diamonds, including each diamond’s carats, cut, color, clarity, depth, table (flat top surface), price and x, y and z measurements. The Kaggle site’s web page for this dataset describes each column’s content.17Perform the following tasks to study and analyze the diamonds dataset:
Download
diamonds.csvfrom one of the dataset repositories.Load the dataset into a pandas
DataFramewith the following statement, which uses the first column of each record as the row index:df = pd.read_csv('diamonds.csv', index_col=0)Display the first seven rows of the
DataFrame.Display the last seven rows of the
DataFrame.Use the
DataFramemethoddescribe(which looks only at the numerical columns) to calculate the descriptive statistics for the numerical columns—carat,depth,table,price,x,yandz.Use
Seriesmethoddescribeto calculate the descriptive statistics for the categorical data (text) columns—cut,colorandclarity.What are the unique category values (use the
Seriesmethodunique)?Pandas has many built-in graphing capabilities. Execute the
%matplotlibmagic to enable Matplotlib support in IPython. Then, to view histograms of each numerical data column, call yourDataFrame’shistmethod. The following figure shows the results for theDataFrame’s seven numerical columns: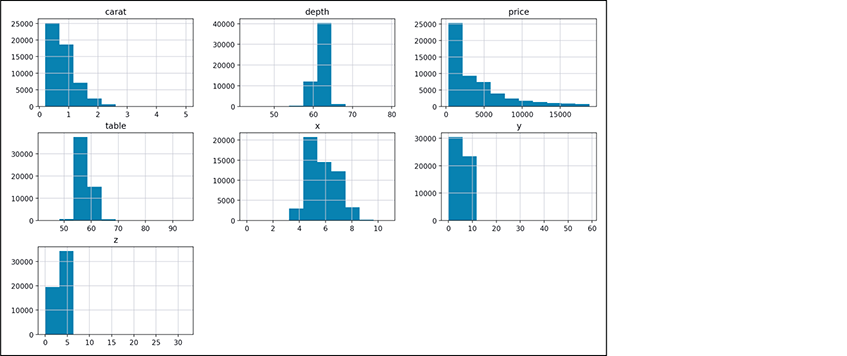
9.17 (Working with the
Iris.csvDataset in Pandas) Another popular dataset for machine-learning novices is the Iris dataset, which contains 150 records of information about three Iris plant species. Like this diamonds dataset, the Iris dataset is available from various online sources, including Kaggle. Investigate the Iris dataset’s columns,18 then perform the following tasks to study and analyze the dataset:Download
Iris.csvfrom one of the dataset repositories.Load the dataset into a pandas
DataFramewith the following statement, which uses the first column of each record as the row index:df = pd.read_csv('Iris.csv', index_col=0)Display the
DataFrame’shead.Display the
DataFrame’stail.Use the
DataFramemethoddescribeto calculate the descriptive statistics for the numerical data columns—SepalLengthCm,SepalWidthCm,PetalLengthCmandPetalWidthCm.Pandas has many built-in graphing capabilities. Execute the
%matplotlibmagic to enable Matplotlib support in IPython. Then, to view histograms of each numerical data column, call yourDataFrame’shistmethod.
9.18 (Project: Anscombe’s Quartet CSV) Locate a CSV file online containing the data for Anscombe’s Quartet. Load the data into a pandas
DataFrame. Investigate pandas built-in scatter-plot capability for plotting x-y coordinate pairs and use it to plot the x-y coordinate pairs in Anscombe’s Quartet.9.19 (Challenging Project: A Crossword-Puzzle Generator) Most people have worked crossword puzzles, but few have ever attempted to generate one by hand. Generating a crossword puzzle is suggested here as a string-manipulation and file-processing project requiring substantial sophistication and effort.
There are many issues you must resolve to get even the most straightforward crossword-puzzle-generator application working. For example, how do you represent the grid of squares of a crossword puzzle inside the computer? Consider using a two-dimensional list where each element is one square. Some of those elements will be “black” and some will be “white.” Some of the “white” cells will include a number that corresponds to a number in your across and down clues.
You need a source of words (i.e., a computerized dictionary) that can be directly referenced by the script. In what form should these words be stored to facilitate the complex manipulations required by the application? Consider using a Python dictionary for this purpose.
You’ll want to generate the clues portion of the puzzle, in which the word definitions for each across and down word are printed. Merely printing a version of the blank puzzle itself is not a simple problem, especially if you’d like the black-squared regions to be symmetric as they often are in published crossword puzzles.
9.20 (Challenging Project: A Spell Checker) Many apps you use daily have built-in spell checkers. In the “Natural Language Processing,” “Machine Learning” and “Deep Learning” chapters, you’ll learn techniques that can be used to build sophisticated spell checkers. In this project, you’ll take a simpler, more mechanical approach. You’ll need a computerized dictionary as a source of words.
Why do we type so many words incorrectly? In some cases, it’s because we do not know the correct spelling, so we guess. In some cases, it’s because we transpose two letters (e.g., “defualt” instead of “default”). Sometimes we accidentally double-type a letter (e.g., “hanndy” instead of “handy”). Sometimes we type a nearby key instead of the one we intended (e.g., “biryhday” instead of “birthday”), and so on.
Design and implement a spell-checker application. Create a text file that has some words spelled correctly and some misspelled. Your script should look up each word in the dictionary. Your script should point out each incorrect word and suggest some correct alternatives that might have been what was intended.
For example, you can try all possible single transpositions of adjacent letters to discover that the word “default” is a direct match for “default.” Of course, this implies that your application will check all other single transpositions, such as “edfault,” “dfeault,” “deafult,” “defalut” and “defautl.” When you find a new transposition that matches a word in the dictionary, print it in a message, such as
Did you mean "default"?Implement other tests, such as replacing each double letter with a single letter, and any other tests you can develop to improve the value of your spell checker.