
There is another level of data validation in addition to a document being “well-formed.” You also want to be able to check that the document contains only elements that you expect, all the elements that you expect, and that they only appear where expected. For example, we know this is not a valid CD inventory entry:
<cd> <price>22</price> <qty>3</qty> </cd>
It's not valid because it doesn't have a title or artist field. Although we have three in stock, we can't say what it is three of.
XML files therefore usually have a Document Type Definition or “DTD” that specifies how the elements can appear. The DTD expresses which tags can appear, in what order, and how they can be nested. The DTD can be part of the same file, or stored separately in another place. A well-formed document that also has a DTD and that conforms to its DTD is called valid.
The DTD is itself written using something close to XML tags, and there is a proposal underway to align the DTD language more closely to XML. You don't need to be able to read or write a DTD to understand this chapter, but we'll go over the basics anyway. There is a way to specify that some fields are optional and thus might not be present. In other words, it's the usual type of “a foo is any number of bars followed by at least one frotz” grammar that we see throughout programming, with its own set of rules for how you express it. Here's a DTD that specifies our CD inventory XML file.
<!ELEMENT inventory (cd)* >
<!ELEMENT cd (title, artist, price, qty)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT artist (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ELEMENT qty (#PCDATA)>
White space is not significant in an XML file, so we can indent elements to suggest to the human reader how they are nested. The first line says that the outermost tag, the top-level of our document, will be named “inventory,” and this is followed by zero or more “cd” elements (that's what the asterisk indicates). Each cd element has four parts: title, artist, price, and qty, in that order. Definitions of those follow in the DTD. “#PCDATA” means that the element contains only “parsed character data,” and not tags or other XML information.
When you get down to the bottom level, every element is either “CDATA”—character data that is not examined by the parser—or “PCDATA”—parsed character data meaning the string of an element. The nesting rule automatically forces a certain simplicity on every XML document which takes on the structure known in computer science circles as a tree.
XML documents begin with a tag that says which version of XML they contain, like this:
<?xml version="1.0"?>
This line is known as the "declaration" and it may also contain additional information, in the form of more attributes, about the character set and so on. By convention, the next tag gives the name of the root element of the document. It also has the DTD nested within it, or it gives the filename if the DTD is in another file. Here's what the tag looks like when it says “the DTD is in a file called “invfile.dtd”:
<!DOCTYPE inventory SYSTEM "inv-file.dtd" >
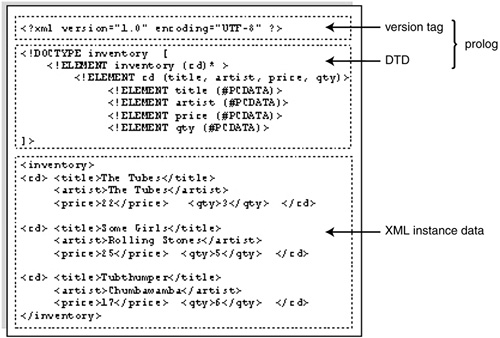
The version and DTD information is called the “prolog,” which comes at the start of an XML document. The marked-up data part of the XML file is called the “document instance.” It's an instance of the data described by the DTD.
Figure 27-2 shows the different sections of an XML document and the names given to them. This example shows how the DTD looks when it is part of the XML file, rather than a separate file.
An important recent feature of XML is “namespaces.” A “namespace” is a computer science term for a place where a bunch of names (identifiers) can exist without interfering with any other bunches of names that you might have laying around. For instance, an individual Java method forms a namespace. You can give variables in a method any names you like, and they won't collide with the names you have in any other method. A Java package forms a namespace.
When you refer to something by its full name, including the package name and class name, you unambiguously say what it is, and it cannot get mixed up with any other name that has identical parts. If we refer to “List” in our Java code, it may not be clear what we mean. If we write java.util.List or java.awt.List, we are saying which List we mean unambiguously by stating the namespace (the package) it belongs to. The reference cannot be confused with any other.
XML supports namespaces, so the markup tags that you define won't collide with any similarly named tags from someone else. When you give the name of a tag at the start of an element, you can also supply an attribute for that tag, saying which namespace it comes from. The attribute name is “xmlns” meaning “XML NameSpace,” and it looks like this:
<artist xmlns="http://www.example.com/inventory" >
Rolling Stones
</artist>
This says that the artist element, and any elements contained within it, are the ones that belong to the namespace defined at www.example.com/inventory. You define a namespace within a DTD by adding a “xmlns=something” attribute to the element's tag. By mentioning a namespace in the XML as in the example above, the CD inventory “artist” element will not be confused with any other element that uses the name “artist.” Namespaces are useful when you are building up big DTDs describing data from several domains. However, note that the Java XML parsers do not support namespaces in the current release.
Here's a longer example of a DTD giving the XML format of Shakespearean plays! This shows the power of XML—you can use it to describe just about any structured data. This example is taken from the documentation accompanying Sun's JAXP library. It was written by Jon Bosak, the chief architect of XML. You'll notice a few more DTD conventions. A “?” means that element is optional. A “+” means there must be at least one of those things, and possibly more. You can group elements together inside parentheses.
Example . DTD for Shakespeare's plays
<!-- DTD for Shakespeare J. Bosak 1994.03.01, 1997.01.02 -->
<!-- Revised for case sensitivity 1997.09.10 -->
<!-- Revised for XML 1.0 conformity 1998.01.27 (thanks to Eve Maler) -->
<!-- <!ENTITY amp "&#38;"> -->
<!ELEMENT PLAY (TITLE, FM, PERSONAE, SCNDESCR, PLAYSUBT, INDUCT?,
PROLOGUE?, ACT+, EPILOGUE?)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT FM (P+)>
<!ELEMENT P (#PCDATA)>
<!ELEMENT PERSONAE (TITLE, (PERSONA | PGROUP)+)>
<!ELEMENT PGROUP (PERSONA+, GRPDESCR)>
<!ELEMENT PERSONA (#PCDATA)>
<!ELEMENT GRPDESCR (#PCDATA)>
<!ELEMENT SCNDESCR (#PCDATA)>
<!ELEMENT PLAYSUBT (#PCDATA)>
<!ELEMENT INDUCT (TITLE, SUBTITLE*, (SCENE+|(SPEECH|STAGEDIR|SUBHEAD)+))>
<!ELEMENT ACT (TITLE, SUBTITLE*, PROLOGUE?, SCENE+, EPILOGUE?)>
<!ELEMENT SCENE (TITLE, SUBTITLE*, (SPEECH | STAGEDIR | SUBHEAD)+)>
<!ELEMENT PROLOGUE (TITLE, SUBTITLE*, (STAGEDIR | SPEECH)+)>
<!ELEMENT EPILOGUE (TITLE, SUBTITLE*, (STAGEDIR | SPEECH)+)>
<!ELEMENT SPEECH (SPEAKER+, (LINE | STAGEDIR | SUBHEAD)+)>
<!ELEMENT SPEAKER (#PCDATA)>
<!ELEMENT LINE (#PCDATA | STAGEDIR)*>
<!ELEMENT STAGEDIR (#PCDATA)>
<!ELEMENT SUBTITLE (#PCDATA)>
<!ELEMENT SUBHEAD (#PCDATA)>
The DTD says that a Shakespearean play consists of the title, followed by the FM (“Front Matter”—a publishing term), personae, a scene description, a play subtext, a possible induction, a possible prologue, at least one (and maybe many) act, then finally, an optional epilogue. I asked Jon Bosak why he didn't use white space to better format this DTD. He explained that it's hard to do for non-trivial DTDs, although people are doing it more now with schemas (data descriptions) that are truly based on XML.
One programmer recently wrote a DTD describing the format of strip cartoons and published it on the slashdot.com website. It's a very flexible data description language! You don't need to be able to read and write DTDs as part of your work, but it doesn't hurt. There are automated tools called DTD editors that let you specify data relationships in a user-friendly way and automatically generate the corresponding DTD. There are a few additional DTD entries and conventions, but this summary provides a strong enough foundation of XML to present the Java features in the rest of the chapter.