
The ELK community is quite large, and it's growing rapidly as it is gaining more and more attention. Let's take a look at some of the already existing successful ELK Stack implementations.
LinkedIn is a business oriented social networking site, which is mainly used for professional networking. LinkedIn was launched in May 5, 2003. As of March 2015, LinkedIn reports more than 364 million acquired users, in more than 200 countries and territories.
Refer to http://www.slideshare.net/TinLe1/elk-atlinked-in.
LinkedIn has millions of multiple data centers, tens of thousands of servers, hundreds of billions of log records. It is a challenge to log, index, search, store, visualize, and analyze all of these logs all day, every day. Also, security in terms of access control, storage, and transport has to be maintained. As data grows, the system will scale to more data centers, more servers, and will produce even more logs. It needs an efficient log analytics pipeline that can handle data at this scale.
The log analytics solution that LinkedIn is looking for, must meet the following:
- It is horizontally scalable, so that more nodes can be added when needed
- It is fast, and quick, and as close to real-time as possible
- It is inexpensive
- It is flexible
- It has a large user community and supports availability
- It is open source
ELK Stack proved to match all these criteria. ELK is currently used across many teams in LinkedIn. This is what the current ELK Stack implementation at LinkedIn looks like:
- 100 plus ELK clusters across 20 plus teams and six data centers
- Some of the larger clusters have:
- Greater than 32 billion docs (30+ TB)
- Daily indices that average 3.0 billion docs (~3 TB)
The current architecture for ELK Stack at LinkedIn uses Elasticsearch, Logstash, Kibana, and Kafka.
Note
Apache Kafka: Kafka is a high throughput distributed messaging system, which was invented by LinkedIn, and open sourced in 2011. It is a fast, scalable, distributed, and durable messaging system which proves useful for systems that produce huge amounts of data. More details can be found at the Kafka site http://kafka.apache.org.
Kafka is a common data-transport layer across LinkedIn. Kafka handles around 1.1 trillion messages per day, a 200 TB per day input, and a 700 TB per day output. The architecture is spread across 1100 brokers, over 50 plus clusters, which includes around 32000 topics and 350 thousands partitions.
LinkedIn generates lots of data, so reliable transport, queuing, storing, and indexing is very essential. It has to take data from various sources, such as Java, Scala, Python, Node.js, Go, and so on. Obviously, the data format was different across these sources so transformations were needed.
LinkedIn uses dedicated clusters for logs in each data center. They have individual Kafka topics per application, and it acts as a common logging transport for all services, languages, and frameworks. To ingest logs from Kafka to Logstash, they used their own Kafka input plugin; later, they started using KCC (Kafka console consumer) using a pipe input plugin.
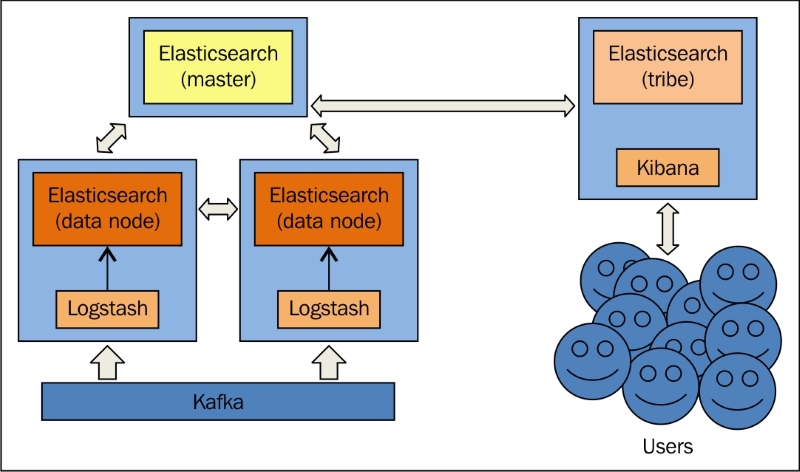
ELK at LinkedIn
An example configuration of a Logstash pipe plugin using KCC is as follows:
pipe {
type => "mobile"
command => "/opt/bin/kafka-console-consumer/kafka-console-consumer.sh
--formatter com.linkedin.avro.KafkaMessageJsonWithHexFormatter
--property schema.registry.url=http://schema-server.example.com:12250/schemaRegistry/schemas
--autocommit.interval.ms=60000
--zookeeper zk.example.com:12913/kafka-metrics
--topic log_stash_event
--group logstash1"
codec => "json"
}