
2. Some Technical Background
2.1 About Our Setup
We’re about to get down—funk style—with some coding. The chapters in this book started life as Jupyter notebooks. If you’re unfamiliar with Jupyter notebooks, they are a very cool environment for working with Python code, text, and graphics in one browser tab. Many Python-related blogs are built with Jupyter notebooks. At the beginning of each chapter, I’ll execute some lines of code to set up the coding environment.
The content of mlwpy.py is shown in Appendix A. While from module import * is generally not recommended, in this case I’m using it specifically to get all of the definitions in mlwpy.py included in our notebook environment without taking up forty lines of code. Since scikit-learn is highly modularized—which results in many, many import lines—the import * is a nice way around a long setup block in every chapter. %matplotlib inline tells the notebook system to display the graphics made by Python inline with the text.
In [1]:
from mlwpy import * %matplotlib inline
2.2 The Need for Mathematical Language
It is very difficult to talk about machine learning (ML) without discussing some mathematics. Many ML textbooks take that to an extreme: they are math textbooks that happen to discuss machine learning. I’m going to flip that script on its head. I want you to understand the math we use and to have some intuition from daily life about what the math-symbol-speak means when you see it. I’m going to minimize the amount of math that I throw around. I also want us—that’s you and me together on this wonderful ride—to see the math as code before, or very shortly after, seeing it as mathematical symbols.
Maybe, just maybe, after doing all that you might decide you want to dig into the mathematics more deeply. Great! There are endless options to do so. But that’s not our game. We care more about the ideas of machine learning than using high-end math to express them. Thankfully, we only need a few ideas from the mathematical world:
Simplifying equations (algebra),
A few concepts related to randomness and chance (probability),
Graphing data on a grid (geometry), and
A compact notation to express some arithmetic (symbols).
Throughout our discussion, we’ll use some algebra to write down ideas precisely and without unnecessary verbalisms. The ideas of probability underlie many machine learning methods. Sometimes this is very direct, as in Naive Bayes (NB); sometimes it is less direct, as in Support Vector Machines (SVMs) and Decision Trees (DTs). Some methods rely very directly on a geometric description of data: SVMs and DTs shine here. Other methods, such as NB, require a bit of squinting to see how they can be viewed through a geometric lens. Our bits of notation are pretty low-key, but they amount to a specialized vocabulary that allows us to pack ideas into boxes that, in turn, fit into larger packages. If this sounds to you like refactoring a computer program from a single monolithic script into modular functions, give yourself a prize. That’s exactly what is happening.
Make no mistake: a deep dive into the arcane mysteries of machine learning requires more, and deeper, mathematics than we will discuss. However, the ideas we will discuss are the first steps and the conceptual foundation of a more complicated presentation. Before taking those first steps, let’s introduce the major Python packages we’ll use to make these abstract mathematical ideas concrete.
2.3 Our Software for Tackling Machine Learning
The one tool I expect you to have in your toolbox is a basic understanding of good, old-fashioned procedural programming in Python. I’ll do my best to discuss any topics that are more intermediate or advanced. We’ll be using a few modules from the Python standard library that you may not have seen: itertools, collections, and functools.
We’ll also be making use of several members of the Python number-crunching and data science stack: numpy, pandas, matplotlib, and seaborn. I won’t have time to teach you all the details about these tools. However, we won’t be using their more complicated features, so nothing should be too mind-blowing. We’ll also briefly touch on one or two other packages, but they are relatively minor players.
Of course, much of the reason to use the number-crunching tools is because they form the foundation of, or work well with, scikit-learn. sklearn is a great environment for playing with the ideas of machine learning. It implements many different learning algorithms and evaluation strategies and gives you a uniform interface to run them. Win, win, and win. If you’ve never had the struggle—pleasure?—of integrating several different command-line learning programs . . . you didn’t miss anything. Enjoy your world, it’s a better place. A side note: scikit-learn is the project’s name; sklearn is the name of the Python package. People use them interchangeably in conversation. I usually write sklearn because it is shorter.
2.4 Probability
Most of us are practically exposed to probability in our youth: rolling dice, flipping coins, and playing cards all give concrete examples of random events. When I roll a standard six-sided die—you role-playing gamers know about all the other-sided dice that are out there—there are six different outcomes that can happen. Each of those events has an equal chance of occurring. We say that the probability of each event is . Mathematically, if I—a Roman numeral one, not me, myself, and I—is the case where we roll a one, we’ll write that as . We read this as “the probability of rolling a one is one-sixth.”
We can roll dice in Python in a few different ways. Using NumPy, we can generate evenly weighted random events with np.random.randint. randint is designed to mimic Python’s indexing semantics, which means that we include the starting point and we exclude the ending point. The practical upshot is that if we want values from 1 to 6, we need to start at 1 and end at 7: the 7 will not be included. If you are more mathematically inclined, you can remember this as a half-open interval.
In [2]:
np.random.randint(1, 7)
Out[2]:
4
If we want to convince ourselves that the numbers are really being generated with equal likelihoods (as with a perfect, fair die), we can draw a chart of the frequency of the outcomes of many rolls. We’ll do that in three steps. We’ll roll a die, either a few times or many times:
In [3]:
few_rolls = np.random.randint(1, 7, size=10) many_rolls = np.random.randint(1, 7, size=1000)
We’ll count up how many times each event occurred with np.histogram. Note that np.histogram is designed around plotting buckets of continuous values. Since we want to capture discrete values, we have to create a bucket that surrounds our values of interest. We capture the ones, I, by making a bucket between 0.5 and 1.5.
In [4]:
few_counts = np.histogram(few_rolls, bins=np.arange(.5, 7.5))[0] many_counts = np.histogram(many_rolls, bins=np.arange(.5, 7.5))[0] fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 3)) ax1.bar(np.arange(1, 7), few_counts) ax2.bar(np.arange(1, 7), many_counts);

There’s an important lesson here. When dealing with random events and overall behavior, a small sample can be misleading. We may need to crank up the number of examples—rolls, in this case—to get a better picture of the underlying behavior. You might ask why I didn’t use matplotlib’s built-in hist function to make the graphs in one step. hist works well enough for larger datasets that take a wider range of values but, unfortunately, it ends up obfuscating the simple case of a few discrete values. Try it out for yourself.
2.4.1 Primitive Events
Before experimenting, we assumed that the probability of rolling a one is one out of six. That number comes from . We can test our understanding of that ratio by asking, “What is the probability of rolling an odd number?” Well, using Roman numerals to indicate the outcomes of a roll, the odd numbers in our space of events are I, III, V. There are three of these and there are six total primitive events. So, we have . Fortunately, that gels with our intuition.
We can approach this calculation a different way: an odd can occur in three ways and those three ways don’t overlap. So, we can add up the individual event probabilities: . We can get probabilities of compound events by either counting primitive events or adding up the probabilities of primitive events. It’s the same thing done in two different ways.
This basic scenario gives us an in to talk about a number of important aspects of probability:
The sum of the probabilities of all possible primitive events in a universe is 1.
P(I) + P(II) + P(III) + P(IV) + P(V) + P(VI) = 1.
The probability of an event not occurring is 1 minus the probability of it occurring. P(even) = 1 – P(not even) = 1 – P(odd). When discussing probabilities, we often write “not” as ¬, as in P(¬even). So, P(¬even) = 1 – P(even).
There are nonprimitive events. Such a compound event is a combination of primitive events. The event we called odd joined together three primitive events.
A roll will be even or odd, but not both, and all rolls are either even or odd. These two compound events cover all the possible primitive events without any overlap. So, P(even) + P(odd) = 1.
Compound events are also recursive. We can create a compound event from other compound events. Suppose I ask, “What is the probability of getting an odd or a value greater than 3 or both?” That group of events, taken together, is a larger group of primitive events. If I attack this by counting those primitive events, I see that the odds are odd = {I, III, V} and the big values are big = {IV, V, VI}. Putting them together, I get {I, III, IV, V, VI} or . The probability of this compound event is a bit different from the probability of odds being and the probability of greater-than-3 being . I can’t just add those probabilities. Why not? Because I’d get a sum of one—meaning we covered everything—but that only demonstrates the error. The reason is that the two compound events overlap: they share primitive events. Rolling a five, V, occurs in both subgroups. Since they overlap, we can’t just add the two together. We have to add up everything in both groups individually and then remove one of whatever was double- counted. The double-counted events were in both groups—they were odd and big. In this case, there is just one double-counted event, V. So, removing them looks like P(odd) + P(big) – P(odd and big). That’s .
2.4.2 Independence
If we roll two dice, a few interesting things happen. The two dice don’t communicate or act on one another in any way. Rolling a I on one die does not make it more or less likely to roll any value on the other die. This concept is called independence: the two events—rolls of the individual dice—are independent of each other.
For example, consider a different set of outcomes where each event is the sum of the rolls of two dice. Our sums are going to be values between 2 (we roll two Is) and 12 (we roll two VIs). What is the probability of getting a sum of 2? We can go back to the counting method: there are 36 total possibilities (6 for each die, times 2) and the only way we can roll a total of 2 is by rolling two Is which can only happen one way. So, We can also reach that conclusion—because the dice don’t communicate or influence each other—by rolling I on die 1 and I on die 2, giving . If events are independent, we can multiply their probabilities to get the joint probability of both occurring. Also, if we multiply the probabilities and we get the same probability as the overall resulting probability we calculated by counting, we know the events must be independent. Independent probabilities work both ways: they are an if-and-only-if.
We can combine the ideas of (1) summing the probabilities of different events and (2) the independence of events, to calculate the probability of getting a total of three P(3). Using the event counting method, we figure that this event can happen in two different ways: we roll (I, II) or we roll (II, I) giving 2/36 = 1/18. Using probability calculations, we can write:
Phew, that was a lot of work to verify the answer. Often, we can make use of shortcuts to reduce the number of calculations we have to perform. Sometimes these shortcuts are from knowledge of the problem and sometimes they are clever applications of the rules of probability we’ve seen so far. If we see multiplication, we can mentally think about the two-dice scenario. If we have a scenario like the dice, we can multiply.
2.4.3 Conditional Probability
Let’s create one more scenario. In classic probability-story fashion, we will talk about two urns. Why urns? I guess that, before we had buckets, people had urns. So, if you don’t like urns, you can think about buckets. I digress.
The first urn UI has three red balls and one blue ball in it. The second urn UII has two red balls and two blue balls. We flip a coin and then we pull a ball out of an urn. If the coin comes up heads, we pick from UI; otherwise, we pick from UII. We end up at UI half the time and then we pick a red ball of those times. We end up at UII the other half of the time and we pick a red ball of those times. This scenario is like wandering down a path with a few intersections. As we walk along, we are presented with a different set of options at the next crossroads.
If we sketch out the paths, it looks like Figure 2.1. If we count up the possibilities, we will see that under the whole game, we have five red outcomes and three blue outcomes. . Simple, right? Not so fast, speedy! This counting argument only works when we have equally likely choices at each step. Imagine we have a very wacky coin that causes me to end up at Urn I 999 out of 1000 times: then our chances of picking a red ball would end up quite close to the chance of just picking a red ball from Urn I. It would be similar to almost ignoring the existence of Urn II. We should account for this difference and, at the same time, make use of updated information that might come along the way.

Figure 2.1 A two-step game from coins to urns.
If we play a partial game and we know that we’re at Urn I—for example, after we’ve flipped a head in the first step—our odds of picking a red ball are different. Namely, the probability of picking a red ball—given that we are picking from Urn I—is . In mathematics, we write this as . The vertical bar, |, is read as “given”. Conditioning—a commonly verbed noun in machine learning and statistics—constrains us to a subset of the primitive events that could possibly occur. In this case, we condition on the occurrence of a head on our coin flip.
How often do we end up picking a red ball from Urn I? Well, to do that we have to (1) get to Urn I by flipping a head, and then (2) pick a red ball. Since the coin doesn’t affect the events in Urn I—it picked Urn I, not the balls within Urn I—the two are independent and we can multiply them to find the joint probability of the two events occurring. So, . The order here may seem a bit weird. I’ve written it with the later event—the event that depends on UI—first and the event that kicks things off, UI, second. This order is what you’ll usually see in written mathematics. Why? Largely because it places the | UI next to the P(UI). You can think about it as reading from the bottom of the diagram back towards the top.
Since there are two nonoverlapping ways to pick a red ball (either from Urn I or from Urn II), we can add up the different possibilities. Just as we did for Urn I, for Urn II we have . Adding up the alternative ways of getting red balls, either out of Urn I or out of Urn II, gives us: . Mon dieu! At least we got the same answer as we got by the simple counting method. But now, you know what that important vertical bar, P(|), means.
2.4.4 Distributions
There are many different ways of assigning probabilities to events. Some of them are based on direct, real-world experiences like dice and cards. Others are based on hypothetical scenarios. We call the mapping between events and probabilities a probability distribution. If you give me an event, then I can look it up in the probability distribution and tell you the probability that it occurred. Based on the rules of probability we just discussed, we can also calculate the probabilities of more complicated events. When a group of events shares a common probability value—like the different faces on a fair die—we call it a uniform distribution. Like Storm Troopers in uniform, they all look the same.
There is one other, very common distribution that we’ll talk about. It’s so fundamental that there are multiple ways to approach it. We’re going to go back to coin flipping. If I flip a coin many, many times and count the number of heads, here’s what happens as we increase the number of flips:
In [5]:
import scipy.stats as ss b = ss.distributions.binom for flips in [5, 10, 20, 40, 80]: # binomial with .5 is result of many coin flips success = np.arange(flips) our_distribution = b.pmf(success, flips, .5) plt.hist(success, flips, weights=our_distribution) plt.xlim(0, 55);

If I ignore that the whole numbers are counts and replace the graph with a smoother curve that takes values everywhere, instead of the stair steps that climb or descend at whole numbers, I get something like this:
In [6]:
b = ss.distributions.binom n = ss.distributions.norm for flips in [5, 10, 20, 40, 80]: # binomial coin flips success = np.arange(flips) our_distribution = b.pmf(success, flips, .5) plt.hist(success, flips, weights=our_distribution) # normal approximation to that binomial # we have to set the mean and standard deviation mu = flips * .5, std_dev = np.sqrt(flips * .5 * (1-.5)) # we have to set up both the x and y points for the normal # we get the ys from the distribution (a function) # we have to feed it xs, we set those up here norm_x = np.linspace(mu-3*std_dev, mu+3*std_dev, 100) norm_y = n.pdf(norm_x, mu, std_dev) plt.plot(norm_x, norm_y, 'k'); plt.xlim(0, 55);

You can think about increasing the number of coin flips as increasing the accuracy of a measurement—we get more decimals of accuracy. We see the difference between 4 and 5 out of 10 and then the difference between 16, 17, 18, 19, and 20 out of 40. Instead of a big step, it becomes a smaller, more gradual step. The step-like sequences become progressively better approximated by the smooth curves. Often, these smooth curves are called bell-shaped curves—and, to keep the statisticians happy, yes, there are other bell-shaped curves out there. The specific bell-shaped curve that we are stepping towards is called the normal distribution.
The normal distribution has three important characteristics:
Its midpoint has the most likely value—the hump in the middle.
It is symmetric—can be mirrored—about its midpoint.
As we get further from the midpoint, the values fall off more and more quickly.
There are a variety of ways to make these characteristics mathematically precise. It turns out that with suitable mathese and small-print details, those characteristics also lead to the normal distribution—the smooth curve we were working towards! My mathematical colleagues may cringe, but the primary feature we need from the normal distribution is its shape.
2.5 Linear Combinations, Weighted Sums, and Dot Products
When mathematical folks talk about a linear combination, they are using a technical term for what we do when we check out from the grocery store. If your grocery store bill looks like:
Product |
Quantity |
Cost Per |
|---|---|---|
Wine |
2 |
12.50 |
Orange |
12 |
.50 |
Muffin |
3 |
1.75 |
you can figure out the total cost with some arithmetic:
In [7]:
(2 * 12.50) + (12 * .5) + (3 * 1.75)
Out[7]:
36.25
We might think of this as a weighted sum. A sum by itself is simply adding things up. The total number of items we bought is:
In [8]:
2 + 12 + 3
Out[8]:
17
However, when we buy things, we pay for each item based on its cost. To get a total cost, we have to add up a sequence of costs times quantities. I can phrase that in a slightly different way: we have to weight the quantities of different items by their respective prices. For example, each orange costs $0.50 and our total cost for oranges is $6. Why? Besides the invisible hand of economics, the grocery store does not want us to pay the same amount of money for the bottle of wine as we do for an orange! In fact, we don’t want that either: $10 oranges aren’t really a thing, are they? Here’s a concrete example:
In [9]:
# pure python, old-school quantity = [2, 12, 3] costs = [12.5, .5, 1.75] partial_cost = [] for q,c in zip(quantity, costs): partial_cost.append(q*c) sum(partial_cost)
Out[9]:
36.25
In [10]:
# pure python, for the new-school, cool kids quantity = [2, 12, 3] costs = [12.5, .5, 1.75] sum(q*c for q,c in zip(quantity,costs))
Out[10]:
36.25
Let’s return to computing the total cost. If I line up the quantities and costs in NumPy arrays, I can run the same calculation. I can also get the benefits of data that is more organized under the hood, concise code that is easily extendible for more quantities and costs, and better small- and large-scale performance. Whoa! Let’s do it.
In [11]:
quantity = np.array([2, 12, 3]) costs = np.array([12.5, .5, 1.75]) np.sum(quantity * costs) # element-wise multiplication
Out[11]:
36.25
This calculation can also be performed by NumPy with np.dot. dot multiplies the elements pairwise, selecting the pairs in lockstep down the two arrays, and then adds them up:
In [12]:
print(quantity.dot(costs), # dot-product way 1 np.dot(quantity, costs), # dot-product way 2 quantity @ costs, # dot-product way 3 # (new addition to the family!) sep=' ')
36.25 36.25 36.25
If you were ever exposed to dot products and got completely lost when your teacher started discussing geometry and cosines and vector lengths, I’m so, so sorry! Your teacher wasn’t wrong, but the idea is no more complicated than checking out of the grocery store. There are two things that make the linear combination (expressed in a dot product): (1) we multiply the values pairwise, and (2) we add up all those subresults. These correspond to (1) a single multiplication to create subtotals for each line on a receipt and (2) adding those subtotals together to get your final bill.
You’ll also see the dot product written mathematically (using q for quantity and c for cost) as Σi qici. If you haven’t seen this notation before, here’s a breakdown:
The Σ, a capital Greek sigma, means add up,
The qi ci means multiply two things, and
The i ties the pieces together in lockstep like a sequence index.
More briefly, it says, “add up all of the element-wise multiplied q and c.” Even more briefly, we might call this the sum product of the quantities and costs. At our level, we can use sum product as a synonym for dot product.
So, combining NumPy on the left-hand side and mathematics on the right-hand side, we have:
Sometimes, that will be written as briefly as qc. If I want to emphasize the dot product, or remind you of it, I’ll use a bullet (•) as its symbol: q • c. If you are uncertain about the element-wise or lockstep part, you can use Python’s zip function to help you out. It is designed precisely to march, in lockstep, through multiple sequences.
In [13]:
for q_i, c_i in zip(quantity, costs): print("{:2d} {:5.2f} --> {:5.2f}".format(q_i, c_i, q_i * c_i)) print("Total:", sum(q*c for q,c in zip(quantity,costs))) # cool-kid method
2 12.50 --> 25.00 12 0.50 --> 6.00 3 1.75 --> 5.25 Total: 36.25
Remember, we normally let NumPy—via np.dot—do that work for us!
2.5.1 Weighted Average
You might be familiar with a simple average—and now you’re wondering, “What is a weighted average?” To help you out, the simple average—also called the mean—is an equally weighted average computed from a set of values. For example, if I have three values (10, 20, 30), I divide up my weights equally among the three values and, presto, I get thirds: . You might be looking at me with a distinct side eye, but if I rearrange that as you might be happier. I simply do sum(values)/3: add them all up and divide by the number of values. Look what happens, however, if I go back to the more expanded method:
In [14]:
values = np.array([10.0, 20.0, 30.0]) weights = np.full_like(values, 1/3) # repeated (1/3) print("weights:", weights) print("via mean:", np.mean(values)) print("via weights and dot:", np.dot(weights, values))
weights: [0.3333 0.3333 0.3333] via mean: 20.0 via weights and dot: 20.0
We can write the mean as a weighted sum—a sum product between values and weights. If we start playing around with the weights, we end up with the concept of weighted averages. With weighted averages, instead of using equal portions, we break the portions up any way we choose. In some scenarios, we insist that the portions add up to one. Let’s say we weighted our three values by . Why might we do this? These weights could express the idea that the first option is valued twice as much as the other two and that the other two are valued equally. It might also mean that the first one is twice as likely in a random scenario. These two interpretations are close to what we would get if we applied those weights to underlying costs or quantities. You can view them as two sides of the same double-sided coin.
In [15]:
values = np.array([10, 20, 30]) weights = np.array([.5, .25, .25]) np.dot(weights, values)
Out[15]:
17.5
One special weighted average occurs when the values are the different outcomes of a random scenario and the weights represent the probabilities of those outcomes. In this case, the weighted average is called the expected value of that set of outcomes. Here’s a simple game. Suppose I roll a standard six-sided die and I get $1.00 if the die turns out odd and I lose $.50 if the die comes up even. Let’s compute a dot product between the payoffs and the probabilities of each payoff. My expected outcome is to make:
In [16]:
# odd, even payoffs = np.array([1.0, -.5]) probs = np.array([ .5, .5]) np.dot(payoffs, probs)
Out[16]:
0.25
Mathematically, we write the expected value of the game as E(game) = Σi pivi with p being the probabilities of the events and v being the values or payoffs of those events. Now, in any single run of that game, I’ll either make $1.00 or lose $.50. But, if I were to play the game, say 100 times, I’d expect to come out ahead by about $25.00—the expected gain per game times the number of games. In reality, this outcome is a random event. Sometimes, I’ll do better. Sometimes, I’ll do worse. But $25.00 is my best guess before heading into a game with 100 tosses. With many, many tosses, we’re highly likely to get very close to that expected value.
Here’s a simulation of 10000 rounds of the game. You can compare the outcome with np.dot(payoffs, probs) * 10000.
In [17]:
def is_even(n): # if remainder 0, value is even return n % 2 == 0 winnings = 0.0 for toss_ct in range(10000): die_toss = np.random.randint(1, 7) winnings += 1.0 if is_even(die_toss) else -0.5 print(winnings)
2542.0
2.5.2 Sums of Squares
One other, very special, sum-of-products is when both the quantity and the value are two copies of the same thing. For example, 5 · 5 + (–3). (–3) + 2 · 2 + 1 · 1 = 52 + 32 + 22 + 12 = 25 + 9 + 4 + 1 = 39. This is called a sum of squares since each element, multiplied by itself, gives the square of the original value. Here is how we can do that in code:
In [18]:
values = np.array([5, -3, 2, 1]) squares = values * values # element-wise multiplication print(squares, np.sum(squares), # sum of squares. ha! np.dot(values, values), sep=" ")
[25 9 4 1] 39 39
If I wrote this mathematically, it would look like: .
2.5.3 Sum of Squared Errors
There is another very common summation pattern, the sum of squared errors, that fits in here nicely. In this case of mathematical terminology, the red herring is both red and a herring. If I have a known value actual and I have your guess as to its value predicted, I can compute your error with error = predicted – actual.
Now, that error is going to be positive or negative based on whether you over- or underestimated the actual value. There are a few mathematical tricks we can pull to make the errors positive. They are useful because when we measure errors, we don’t want two wrongs—overestimating by 5 and underestimating by 5—to cancel out and make a right! The trick we will use here is to square the error: an error of 5 → 25 and an error of –5 → 25. If you ask about your total squared error after you’ve guessed 5 and –5, it will be 25 + 25 = 50.
In [19]:
errors = np.array([5, -5, 3.2, -1.1]) display(pd.DataFrame({'errors':errors, 'squared':errors*errors}))
|
errors |
squared |
|---|---|---|
0 |
5.0000 |
25.0000 |
1 |
-5.0000 |
25.0000 |
2 |
3.2000 |
10.2400 |
3 |
-1.1000 |
1.2100 |
So, a squared error is calculated by error2 = (predicted - actual)2. And we can add these up with . This sum reads left to right as, “the sum of (open paren) errors which are squared (close paren).” It can be said more succinctly: the sum of squared errors. That looks a lot like the dot we used above:
In [20]:
np.dot(errors, errors)
Out[20]:
61.45
Weighted averages and sums of squared errors are probably the most common summation forms in machine learning. By knowing these two forms, you are now prepared to understand what’s going on mathematically in many different learning scenarios. In fact, much of the notation that obfuscates machine learning from beginners—while that same notation facilitates communication amongst experts!—is really just compressing these summation ideas into fewer and fewer symbols. You now know how to pull those ideas apart.
You might have a small spidey sense tingling at the back of your head. It might be because of something like this: c2 = a2 + b2. I can rename or rearrange those symbols and get . Yes, our old friends—or nemeses, if you prefer—Euclid and Pythagoras can be wrapped up as a sum of squares. Usually, the a and b are distances, and we can compute distances by subtracting two values—just like we do when we compare our actual and predicted values. Hold on to your seats. An error is just a length—a distance—between an actual and a predicted value!
2.6 A Geometric View: Points in Space
We went from checking out at the grocery store to discussing sums of squared errors. That’s quite a trip. I want to start from another simple daily scenario to discuss some basic geometry. I promise you that this will be the least geometry-class-like discussion of geometry you have ever seen.
2.6.1 Lines
Let’s talk about the cost of going to a concert. I hope that’s suitably nonacademic. To start with, if you drive a car to the concert, you have to park it. For up to 10 (good) friends going to the show, they can all fit in a minivan—packed in like a clown car, if need be. The group is going to pay one flat fee for parking. That’s good, because the cost of parking is usually pretty high: we’ll say $40. Let’s put that into code and pictures:
In [21]:
people = np.arange(1, 11) total_cost = np.ones_like(people) * 40.0 ax = plt.gca() ax.plot(people, total_cost) ax.set_xlabel("# People") ax.set_ylabel("Cost (Parking Only)");

In a math class, we would write this as total_cost = 40.0. That is, regardless of the number of people—moving back and forth along the x-axis at the bottom—we pay the same amount. When mathematicians start getting abstract, they reduce the expression to simply y = 40. They will talk about this as being “of the form” y = c. That is, the height or the y-value is equal to some constant. In this case, it’s the value 40 everywhere. Now, it doesn’t do us much good to park at the show and not buy tickets—although there is something to be said for tailgating. So, what happens if we have to pay $80 per ticket?
In [22]:
people = np.arange(1, 11) total_cost = 80.0 * people + 40.0
Graphing this is a bit more complicated, so let’s make a table of the values first:
In [23]:
# .T (transpose) to save vertical space in printout display(pd.DataFrame({'total_cost':total_cost.astype(np.int)}, index=people).T)
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|---|---|---|---|---|---|---|---|---|---|---|
total_cost |
120 |
200 |
280 |
360 |
440 |
520 |
600 |
680 |
760 |
840 |
And we can plot that, point-by-point:
In [24]:
ax = plt.gca() ax.plot(people, total_cost, 'bo') ax.set_ylabel("Total Cost") ax.set_xlabel("People");

So, if we were to write this in a math class, it would look like:
total_cost = ticket_cost × people + parking_cost
Let’s compare these two forms—a constant and a line—and the various ways they might be written in Table 2.1.
Table 2.1 Examples of constants and lines at different levels of language.
Name |
Example |
Concrete |
Abstract |
Mathese |
|---|---|---|---|---|
Constant |
total = parking |
total = $40 |
y = 40 |
y = c |
Line |
total = |
total = |
y = 80x + 40 |
y = mx + b |
|
ticket × person + parking |
80 × person + 40 |
|
|
I want to show off one more plot that emphasizes the two defining components of the lines: m and b. The m value—which was the $80 ticket price above—tells how much more we pay for each person we add to our trip. In math-speak, it is the rise, or increase in y for a single-unit increase in x. A unit increase means that the number of people on the x-axis goes from x to x + 1. Here, I’ll control m and b and graph it.
In [25]:
# paint by number # create 100 x values from -3 to 3 xs = np.linspace(-3, 3, 100) # slope (m) and intercept (b) m, b = 1.5, -3 ax = plt.gca() ys = m*xs + b ax.plot(xs, ys) ax.set_ylim(-4, 4) high_school_style(ax) # helper from mlwpy.py ax.plot(0, -3,'ro') # y-intercept ax.plot(2, 0,'ro') # two steps right gives three steps up # y = mx + b with m=0 gives y = b ys = 0*xs + b ax.plot(xs, ys, 'y');

Since our slope is 1.5, taking two steps to the right results in us gaining three steps up. Also, if we have a line and we set the slope of the line m to 0, all of a sudden we are back to a constant. Constants are a specific, restricted type of horizontal line. Our yellow line which passes through y = −3 is one.
We can combine our ideas about np.dot with our ideas about lines and write some slightly different code to draw this graph. Instead of using the pair (m, b), we can write an array of values w = (w1, w0). One trick here: I put the w0 second, to line up with the b. Usually, that’s how it is written in mathese: the w0 is the constant.
With the ws, we can use np.dot if we augment our xs with an extra column of ones. I’ll write that augmented version of xs as xs_p1 which you can read as “exs plus a column of ones.” The column of ones serves the role of the 1 in y = mx + b. Wait, you don’t see a 1 there? Let me rewrite it: y = mx + b = mx + b · 1. See how I rewrote b → b · 1? That’s the same thing we need to do to make np.dot happy. dot wants to multiply something times w1 and something times w0. We make sure that whatever gets multiplied by w0 is a 1.
I call this process of tacking on a column of ones the plus-one trick or +1 trick and I’ll have more to say about it shortly. Here’s what the plus-one trick does to our raw data:
In [26]:
# np.c_[] lets us create an array column-by-column xs = np.linspace(-3, 3, 100) xs_p1 = np.c_[xs, np.ones_like(xs)] # view the first few rows display(pd.DataFrame(xs_p1).head())
|
0 |
1 |
|---|---|---|
0 |
-3.0000 |
1.0000 |
1 |
-2.9394 |
1.0000 |
2 |
-2.8788 |
1.0000 |
3 |
-2.8182 |
1.0000 |
4 |
-2.7576 |
1.0000 |
Now, we can combine our data and our weights very concisely:
In [27]:
w = np.array([1.5, -3]) ys = np.dot(xs_p1, w) ax = plt.gca() ax.plot(xs, ys) # styling ax.set_ylim(-4, 4) high_school_style(ax) ax.plot(0, -3,'ro') # y-intercept ax.plot(2, 0,'ro'); # two steps to the right should be three whole steps up

Here are the two forms we used in the code: ys = m*xs + b and ys = np.dot(xs_p1, w). Mathematically, these look like y = mx + b and y = wx+. Here, I’m using x+ as an abbreviation for the x that has ones tacked on to it. The two forms defining ys mean the same thing. They just have some differences when we implement them. The first form has each of the components standing on its own. The second form requires x+ to be augmented with a 1 and allows us to conveniently use the dot product.
2.6.2 Beyond Lines
We can extend the idea of lines in at least two ways. We can progress to wiggly curves and polynomials—equations like f(x) = x3 + x2 + x + 1. Here, we have a more complex computation on one input value x. Or, we can go down the road to multiple dimensions: planes, hyperplanes, and beyond! For example, in f(x, y, z) = x + y + z we have multiple input values that we combine together. Since we will be very interested in multivariate data—that’s multiple inputs—I’m going to jump right into that.
Let’s revisit the rock concert scenario. What happens if we have more than one kind of item we want to purchase? For example, you might be surprised to learn that people like to consume beverages at concerts. Often, they like to consume what my mother affectionately refers to as “root beer.” So, what if we have a cost for parking, a cost for the tickets, and a cost for each root beer our group orders. To account for this, we need a new formula. With rb standing for root beer, we have:
total_cost = ticket_cost × number_people + rb_cost × number_rbs + parking_cost
If we plug in some known values for parking cost, cost per ticket, and cost per root beer, then we have something more concrete:
total_cost = 80 × number_people + 10 × number_rbs + 40
With one item, we have a simple two-dimensional plot of a line where one axis direction comes from the input “how many people” and the other comes from the output “total cost”. With two items, we now have two how many’s but still only one total_cost, for a total of three dimensions. Fortunately, we can still draw that somewhat reasonably. First, we create some data:
In [28]:
number_people = np.arange(1, 11) # 1-10 people number_rbs = np.arange(0, 20) # 0-19 rootbeers # numpy tool to get cross-product of values (each against each) # in two paired arrays. try it out: np.meshgrid([0, 1], [10, 20]) # "perfect" for functions of multiple variables number_people, number_rbs = np.meshgrid(number_people, number_rbs) total_cost = 80 * number_people + 10 * number_rbs + 40
We can look at that data from a few different angles—literally. Below, we show the same graph from five different viewpoints. Notice that they are all flat surfaces, but the apparent tilt or slope of the surface looks different from different perspectives. The flat surface is called a plane.
In [29]:
# import needed for 'projection':'3d' from mpl_toolkits.mplot3d import Axes3D fig,axes = plt.subplots(2, 3, subplot_kw={'projection':'3d'}, figsize=(9, 6)) angles = [0, 45, 90, 135, 180] for ax,angle in zip(axes.flat, angles): ax.plot_surface(number_people, number_rbs, total_cost) ax.set_xlabel("People") ax.set_ylabel("RootBeers") ax.set_zlabel("TotalCost") ax.azim = angle # we don't use the last axis axes.flat[-1].axis('off') fig.tight_layout()
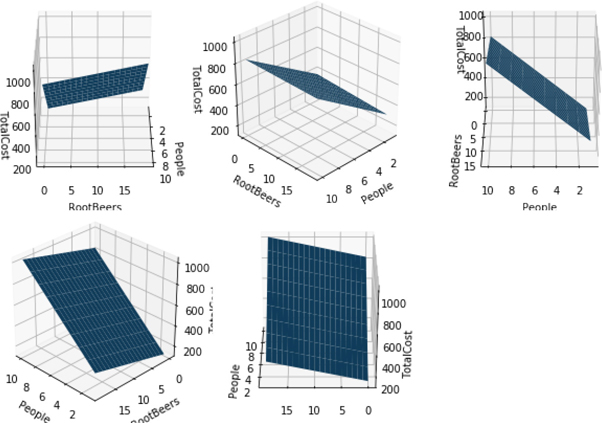
It is pretty straightforward, in code and in mathematics, to move beyond three dimensions. However, if we try to plot it out, it gets very messy. Fortunately, we can use a good old-fashioned tool—that’s a GOFT to those in the know—and make a table of the outcomes. Here’s an example that also includes some food for our concert goers. We’ll chow on some hotdogs at $5 per hotdog:
total_cost = 80 × number_people + 10 × number_rbs + 5 × number_hotdogs + 40
We’ll use a few simple values for the counts of things in our concert-going system:
In [30]:
number_people = np.array([2, 3]) number_rbs = np.array([0, 1, 2]) number_hotdogs = np.array([2, 4]) costs = np.array([80, 10, 5]) columns = ["People", "RootBeer", "HotDogs", "TotalCost"]
I pull off combining several numpy arrays in all possible combinations, similar to what itertools’s combinations function does, with a helper np_cartesian_product. It involves a bit of black magic, so I’ve hidden it in mlwpy.py. Feel free to investigate, if you dare.
In [31]:
counts = np_cartesian_product(number_people, number_rbs, number_hotdogs) totals = (costs[0] * counts[:, 0] + costs[1] * counts[:, 1] + costs[2] * counts[:, 2] + 40) display(pd.DataFrame(np.c_[counts, totals], columns=columns).head(8))
|
People |
RootBeer |
HotDogs |
TotalCost |
|
|---|---|---|---|---|---|
0 |
2 |
0 |
2 |
210 |
|
1 |
2 |
0 |
4 |
220 |
|
2 |
3 |
0 |
2 |
290 |
|
3 |
3 |
0 |
4 |
300 |
|
4 |
2 |
1 |
2 |
220 |
|
5 |
2 |
1 |
4 |
230 |
|
6 |
3 |
1 |
2 |
300 |
|
7 |
3 |
1 |
4 |
310 |
|
The assignment to totals—on lines 6–8 in the previous cell—is pretty ugly. Can we improve it? Think! Think! There must be a better way! What is going on there? We are adding several things up. And the things we are adding come from being multiplied together element-wise. Can it be? Is it a dot product? Yes, it is.
In [32]:
costs = np.array([80, 10, 5]) counts = np_cartesian_product(number_people, number_rbs, number_hotdogs) totals = np.dot(counts, costs) + 40 display(pd.DataFrame(np.column_stack([counts, totals]), columns=columns).head(8))
|
People |
RootBeer |
HotDogs |
TotalCost |
|
|---|---|---|---|---|---|
0 |
2 |
0 |
2 |
210 |
|
1 |
2 |
0 |
4 |
220 |
|
2 |
3 |
0 |
2 |
290 |
|
3 |
3 |
0 |
4 |
300 |
|
4 |
2 |
1 |
2 |
220 |
|
5 |
2 |
1 |
4 |
230 |
|
6 |
3 |
1 |
2 |
300 |
|
7 |
3 |
1 |
4 |
310 |
|
Using the dot product gets us two wins: (1) the line of code that assigns to total is drastically improved and (2) we can more or less arbitrarily extend our costs and counts without modifying our calculating code at all. You might notice that I tacked the +40 on there by hand. That’s because I didn’t want to go back to the +1 trick—but I could have.
Incidentally, here’s what would have happened in a math class. As we saw with the code-line compression from repeated additions to dot, details often get abstracted away or moved behind the scenes when we break out advanced notation. Here’s a detailed breakdown of what happened. First, we abstract by removing detailed variable names and then replacing our known values by generic identifiers:
We take this one step further in code by replacing the wx sums with a dot product:
The weird [3, 2, 1] subscript on the w indicates that we aren’t using all of the weights. Namely, we are not using the w0 in the left-hand term. w0 is in the right-hand term multiplying 1. It is only being used once. The final coup de grâce is to perform the +1 trick:
To summarize, instead of y = w3x3 + w2x2 + w1x1 + w0, we can write y = wx+.
2.7 Notation and the Plus-One Trick
Now that you know what the plus-one trick is, I want to show a few different ways that we can talk about a table of data. That data might be made of values, such as our expense sheet for the trip to the ball park. We can take the table and draw some brackets around it:
We can also refer to the parts of it: D = (x, y). Here, x means all of the input features and y means the output target feature. We can emphasize the columns:
f is the number of features. We’re counting backwards to synchronize our weights with the discussion in the prior section. In turn, the weights were backwards so we could count down to the constant term at w0. It is quite a tangled web.
We can also emphasize the rows:
Think of ei as one example. n is the number of examples.
Also, for mathematical convenience—really—we will often use the augmented versions, the plus-one trick, of D and x:
Let’s break that down:
If we want to use that with a 2D formula, we end up writing: y = w2x2 + w1x1 + w0. And we can compress that as: y = w[2,1]•x + w0. Again, the w[2,1] is hinting that we aren’t using w0 in the •. Still, there is a certain ugliness about the w0 tacked on at the end. We can compress even further if we use an augmented version of x:
Now, our 2D formula looks like y = w2x2 + w1x1 + w0x0. Note the additional x0. That fits nicely into y = w • x+, where w is (w2, w1, w0). The augmented version of w now includes w0, which was previously a weight without a home. When I want to remind you that we are dealing with x+ or D+, I’ll say we are using the +1 trick. We’ll connect this mathematical notation to our Python variables in Section 3.3.
2.8 Getting Groovy, Breaking the Straight-Jacket, and Nonlinearity
So, we just took an unsuspecting line and extended it past its comfort zone—maybe past yours as well. We did it in one very specific way: we added new variables. These new variables represented new graphical dimensions. We moved from talking about lines to talking about planes and their higher-dimensional cousins.
There is another way in which we can extend the idea of a line. Instead of adding new information—more variables or features—we can add complexity to the information we already have. Imagine moving from y = 3 to y = 2x + 3 to y = x2 + 2x + 3. In each case, we’ve added a term to the equation. As we add terms there, we go from a flat line to a sloped line to a parabola. I’ll show these off graphically in a second. The key point is: we still only have one input variable. We’re simply using that single input in different ways.
Mathematicians talk about these extensions as adding higher-order or higher-power terms of the original variable to the equation. As we extend our powers, we get all sorts of fancy names for the functions: constant, linear, quadratic, cubic, quartic, quintic, etc. Usually, we can just call them n-th degree polynomials, where n is the highest non-zero power in the expression. A 2nd degree polynomial—for example, y = x2 + x + 1—is also called a quadratic polynomial. These give us single-bend curves called parabolas.
np.poly1d gives us an easy helper to define polynomials by specifying the leading coefficients on each term in the polynomial. For example, we specify 2x2 + 3x + 4 by passing in a list of [2, 3, 4]. We’ll use some random coefficients to get some interesting curves.
In [33]:
fig, axes = plt.subplots(2, 2) fig.tight_layout() titles = ["$y=c_0$", "$y=c_1x+c_0$", "$y=c_2x^2+c_1x+c_0$", "$y=c_3x^3+c_2x^2+c_1x+c_0$"] xs = np.linspace(-10, 10, 100) for power, (ax, title) in enumerate(zip(axes.flat, titles), 1): coeffs = np.random.uniform(-5, 5, power) poly = np.poly1d(coeffs) ax.plot(xs, poly(xs)) ax.set_title(title)

Massaging the general forms of these equations towards our earlier linear equation y1 = c1x + c0 gets us to things like y2 = c2x2 + c1x + c0. One quick note: x = x1 and 1 = x0. While I can insert suitable mathese here, trust me that there are very good reasons to define 00 = 1. Taken together, we have
You know what I’m about to say. Go ahead, play along and say it with me. You can do it. It’s a dot product! We can turn that equation into code by breaking up the xi and the coefficients ci and then combining them with a np.dot.
In [34]:
plt.Figure((2, 1.5)) xs = np.linspace(-10, 10, 101) coeffs = np.array([2, 3, 4]) ys = np.dot(coeffs, [xs**2, xs**1, xs**0]) # nice parabola via a dot product plt.plot(xs, ys);

2.9 NumPy versus “All the Maths”
Since the dot product is so fundamental to machine learning and since NumPy’s np.dot has to deal with the practical side of Pythonic computation—as opposed to the pure, Platonic, mathematical world of ideals—I want to spend a few minutes exploring np.dot and help you understand how it works in some common cases. More importantly, there is one common form that we’d like to use but can’t without some minor adjustments. I want you to know why. Here goes.
We talked about the fact that np.dot multiples things element-wise and then adds them up. Here’s just about the most basic example with a 1D array:
In [35]:
oned_vec = np.arange(5) print(oned_vec, "-->", oned_vec * oned_vec) print("self dot:", np.dot(oned_vec, oned_vec))
[0 1 2 3 4] --> [ 0 1 4 9 16] self dot: 30
The result is the sum of squares of that array. Here’s a simple example using a row and a column:
In [36]:
row_vec = np.arange(5).reshape(1, 5) col_vec = np.arange(0, 50, 10).reshape(5, 1)
Notice that row_vec is shaped like a single example and col_vec is shaped like a single feature.
In [37]:
print("row vec:", row_vec, "col_vec:", col_vec, "dot:", np.dot(row_vec, col_vec), sep=' ')
row vec: [[0 1 2 3 4]] col_vec: [[ 0] [10] [20] [30] [40]] dot: [[300]]
So, far, we’re mostly good. But what happens if we swap the order? You might expect to get the same answer: after all, in basic arithmetic 3 × 5 = 5 × 3. Let’s check it out:
In [38]:
out = np.dot(col_vec, row_vec) print(out)
[[ 0 0 0 0 0] [ 0 10 20 30 40] [ 0 20 40 60 80] [ 0 30 60 90 120] [ 0 40 80 120 160]]
Cue Dorothy: “Toto, I’ve a feeling we’re not in Kansas anymore.” What happened here? We’ll focus on one output element—the 20 in the second-from-the-top row—to get a handle on the craziness we unleashed. Where does it comes from? Well, we never really defined how the output is produced—except to say that it does a sum product on two 1D arrays. Let’s remedy that.
Pick an element in the output, out[1, 2]. That’s row 1 and column 2, if we start our counting from zero. out[1, 2] has the value 20. Where does this 20 come from? It comes from taking a dot product on row 1 of col_vec with column 2 of row_vec. That’s actually the definition of what np.dot does. The source values are col_vec[1,:] which is [10] and row_vec[:, 2] which is [2]. Putting those together gives 10 × 2 → 20 with no additional summing needed because we only have one value in each. You can go through a similar process for the other entries.
Mathematically, this is written as outij = dot(lefti., right.j) where dot is our friendly sum product over 1D things. So, the output row i comes from the left input’s row i and the output’s column j comes from the right input column j. Taking from each row and each column gives a 5 × 5 result.
If we apply the same logic to the to the row-column case, we see
In [39]:
out = np.dot(row_vec, col_vec) out
Out[39]:
array([[300]])
The result is 1 × 1, so out[0, 0] comes from row 0 of row_vec and column 0 of col_vec. Which is exactly the sum product over [0, 1, 2, 3, 4] and [0, 10, 20, 30, 40], which gives us 0*0 + 1*10 + 2*20 + 3*30 + 4*40. Great.
2.9.1 Back to 1D versus 2D
However, when we use a mix of 1D and 2D inputs, things are more confusing because the input arrays are not taken at face value. There are two important consequences for us: (1) the order matters in multiplying a 1D and a 2D array and (2) we have to investigate the rules np.dot follows for handling the 1D array.
In [40]:
col_vec = np.arange(0, 50, 10).reshape(5, 1) row_vec = np.arange(0, 5).reshape(1, 5) oned_vec = np.arange(5) np.dot(oned_vec, col_vec)
Out[40]:
array([300])
If we trade the order, Python blows up on us:
In [41]:
try: np.dot(col_vec, oned_vec) # *boom* except ValueError as e: print("I went boom:", e)
I went boom: shapes (5,1) and (5,) not aligned: 1 (dim 1) != 5 (dim 0)
So, np.dot(oned_vec, col_vec) works and np.dot(col_vec, oned_vec) fails. What’s going on? If we look at the shapes of the guilty parties, we can get a sense of where things break down.
In [42]:
print(oned_vec.shape, col_vec.shape, sep=" ")
(5,) (5, 1)
You might consider the following exercise: create a 1D numpy array and look at its shape using .shape. Transpose it with .T. Look at the resulting shape. Take a minute to ponder the mysteries of the NumPy universe. Now repeat with a 2D array. These might not be entirely what you were expecting.
np.dot is particular about how these shapes align. Let’s look at the row cases:
In [43]:
print(np.dot(row_vec, oned_vec)) try: print(np.dot(oned_vec, row_vec)) except: print("boom")
[30] boom
Here is a summary of what we found:
form |
left-input |
right-input |
success? |
|---|---|---|---|
|
(5,) |
(5, 1) |
works |
|
(5, 1) |
(5,) |
fails |
|
(1, 5) |
(5,) |
works |
|
(5,) |
(1, 5) |
fails |
For the working cases, we can see what happens if we force-reshape the 1D array:
In [44]:
print(np.allclose(np.dot(oned_vec.reshape(1, 5), col_vec), np.dot(oned_vec, col_vec)), np.allclose(np.dot(row_vec, oned_vec.reshape(5, 1)), np.dot(row_vec, oned_vec)))
True True
Effectively, for the cases that work, the 1D array is bumped up to (1, 5) if it is on the left and to (5, 1) if it is on the right. Basically, the 1D receives a placeholder dimension on the side it shows up in the np.dot. Note that this bumping is not using NumPy’s full, generic broadcasting mechanism between the two inputs; it is more of a special case.
Broadcasting two arrays against each other in NumPy will result in the same shape whether you are broadcasting a against b or b against a. Even so, you can mimic np.dot(col_vec, row_vec) with broadcasting and multiplication. If you do that, you get the “big array” result: it’s called an outer product.
With all of that said, why do we care? Here’s why:
In [45]:
D = np.array([[1, 3], [2, 5], [2, 7], [3, 2]]) weights = np.array([1.5, 2.5])
This works:
In [46]:
np.dot(D,w)
Out[46]:
array([ -7.5, -12. , -18. , -1.5])
This fails:
In [47]:
try: np.dot(w,D) except ValueError: print("BOOM. :sadface:")
BOOM. :sadface:
And sometimes, we just want the code to look like our math:
What do we do if we don’t like the interface we are given? If we are willing to (1) maintain, (2) support, (3) document, and (4) test an alternative, then we can make an interface that we prefer. Usually people only think about the implementation step. That’s a costly mistake.
Here is a version of dot that plays nicely with a 1D input as the first argument that is shaped like a column:
In [48]:
def rdot(arr,brr): 'reversed-argument version of np.dot' return np.dot(brr,arr) rdot(w, D)
Out[48]:
array([ -7.5, -12. , -18. , -1.5])
You might complain that we are going through contortions to make the code look like the math. That’s fair. Even in math textbooks, people will do all sorts of weird gymnastics to make this work: w might be transposed. In NumPy, this is fine, if it is 2D. Unfortunately, if it is only a 1D NumPy array, transposing does nothing. Try it yourself! Another gymnastics routine math folks will perform is to transpose the data—that is, they make each feature a row. Yes, really. I’m sorry to be the one to tell you about that. We’ll just use rdot—short for “reversed arguments to np.dot”—when we want our code to match the math.
Dot products are ubiquitous in the mathematics of learning systems. Since we are focused on investigating learning systems through Python programs, it is really important that we (1) understand what is going on with np.dot and (2) have a convenient and consistent form for using it. We’ll see rdot in our material on linear and logistic regression. It will also play a role in several other techniques. Finally, it is fundamental in showing the similarities of a wide variety of learning algorithms.
2.10 Floating-Point Issues
Prepare yourself to be grumpy.
In [49]:
1.1 + 2.2 == 3.3
Out[49]:
False
I can hear you now. You want your money back—for this book, for your Python program, for everything. It’s all been a lie. Drama aside, what is happening here? The issue is floating-point numbers and our expectations. In the Python code above, all of the values are floats:
In [50]:
type(1.1), type(2.2), type(1.1+2.2), type(3.3)
Out[50]:
(float, float, float, float)
float is short for floating-point number, and floats are how decimal values are usually represented on a computer. When we use floats in our programs, we are often thinking about two different types of numbers: (1) simple decimal values like 2.5 and (2) complicated real numbers like π which go on forever, even though we may get away with approximations like 3.14. Both of these have complications when we go from our thoughts about these numbers to the computer’s number-crunching machinery.
Here are a few facts:
Computer memory is finite. We can’t physically store an infinite number of digits for any numerical value.
Some numbers that interest us have an infinite number of decimal places ( and π, I’m looking at you).
Computers store all of their information in bits—that’s base-2 numbers, or binary.
There are different infinite-digit numbers when we write them in decimal versus binary.
Because of points one and two, we have to approximate the values we store. We can get close, but we can never be exact. Because of points three and four, when we convert from a seemingly innocent decimal number like 3.3 to binary, it may become much more complicated—it might have repeating digits, like does in a decimal representation. Putting these pieces together means that we can’t rely on exact comparisons for floating-point values.
So, what can we do? We can ask if values are close enough:
In [51]:
np.allclose(1.1 + 2.2, 3.3)
Out[51]:
True
Here, numpy is checking if the numbers are the same for many, many decimal places—out to the point where the difference is insignificant. If we care, we can define our own tolerance for what is and isn’t significant.
2.11 EOC
2.11.1 Summary
We covered a lot of ideas in this chapter and laid the groundwork to talk about learning in an intelligent way. In many cases, we won’t be diving into mathematical details of learning algorithms. However, when we talk about them, we will often appeal to probability, geometry, and dot products in our descriptions. Hopefully, you now have better intuitions about what these terms and symbols mean—particularly if no one has taken the time to explain them to you in a concrete fashion before.
2.11.2 Notes
While we took an intuitive approach to describing distributions, they have concrete mathematical forms which can be extended to multiple dimensions. The discrete uniform distribution looks like:
Here, k is the number of possible events—six for a typical die or two for a coin flip. The equation for the normal distribution is
The e, combined with a negative power, is responsible for the fast dropoff away from the center. vm, a magic value, is really just there to make sure that all the possibilities sum up to one like all good distributions: it is but I won’t quiz you on that. The center and spread are normally called the mean and standard deviation and written with μ and σ which are the lowercase Greek mu and sigma. The normal distribution shows up everywhere in statistics: in error functions, in binomial approximations (which we used to generate our normal shapes), and in central limit theorems.
Python uses 0-based indexing while mathematicians often use 1-based indexing. That’s because mathematicians are generally counting things and computer scientists have historically cared about offsets: from the start, how many steps do I need to move forward to get to the item I need? If I’m at the start of a list or an array, I have to take zero steps to get the first item: I’m already there. A very famous computer scientist, Edsger Dijkstra, wrote an article called “Why numbering should start at zero.” Check it out if you are interested and want to win on a computer-science trivia night.
In my mathematical notation, I’m following classic Python’s lead and letting both ( ) and [ ] represent ordered things. { } is used for unordered groups of things—imagine putting things in a large duffel bag and then pulling them back out. The duffel bag doesn’t remember the order things were put in it. In a relatively recent change, Python dictionaries in Python 3.7 now have some ordering guarantees to them. So, strictly speaking—after upgrading to the latest Python—I’m using the curly braces in the mathematical set sense.
The phrase “there must be a better way!”—particularly in the Python community—deserves a hat tip to Raymond Hettinger, a core Python developer. His Python talks are legendary: find them on YouTube and you’ll learn something new about Python.