
System Access and Availability
System access and availability refers to when users—including personnel and customers—need a system or service, which is an important consideration. Some systems must be operational 99.999 percent of the time. Other systems must be operational only during business hours, such as between 8:00 a.m. and 5:00 p.m., Monday through Friday.
 NOTE
NOTE
Five nines, or 99.999 percent uptime, is sometimes needed for certain services, which equates to about 5.256 minutes of downtime a year. The calculation is 60 minutes × 24 hours × 365 days × .00001.
Five nines, or 99.999 percent uptime, can be achieved. FIGURE 7-1 shows a database server protected with a two-node failover cluster. A failover cluster provides fault tolerance for a server and ensures that a service provided by a server will continue to run even if a server fails. It includes at least two servers, called nodes.
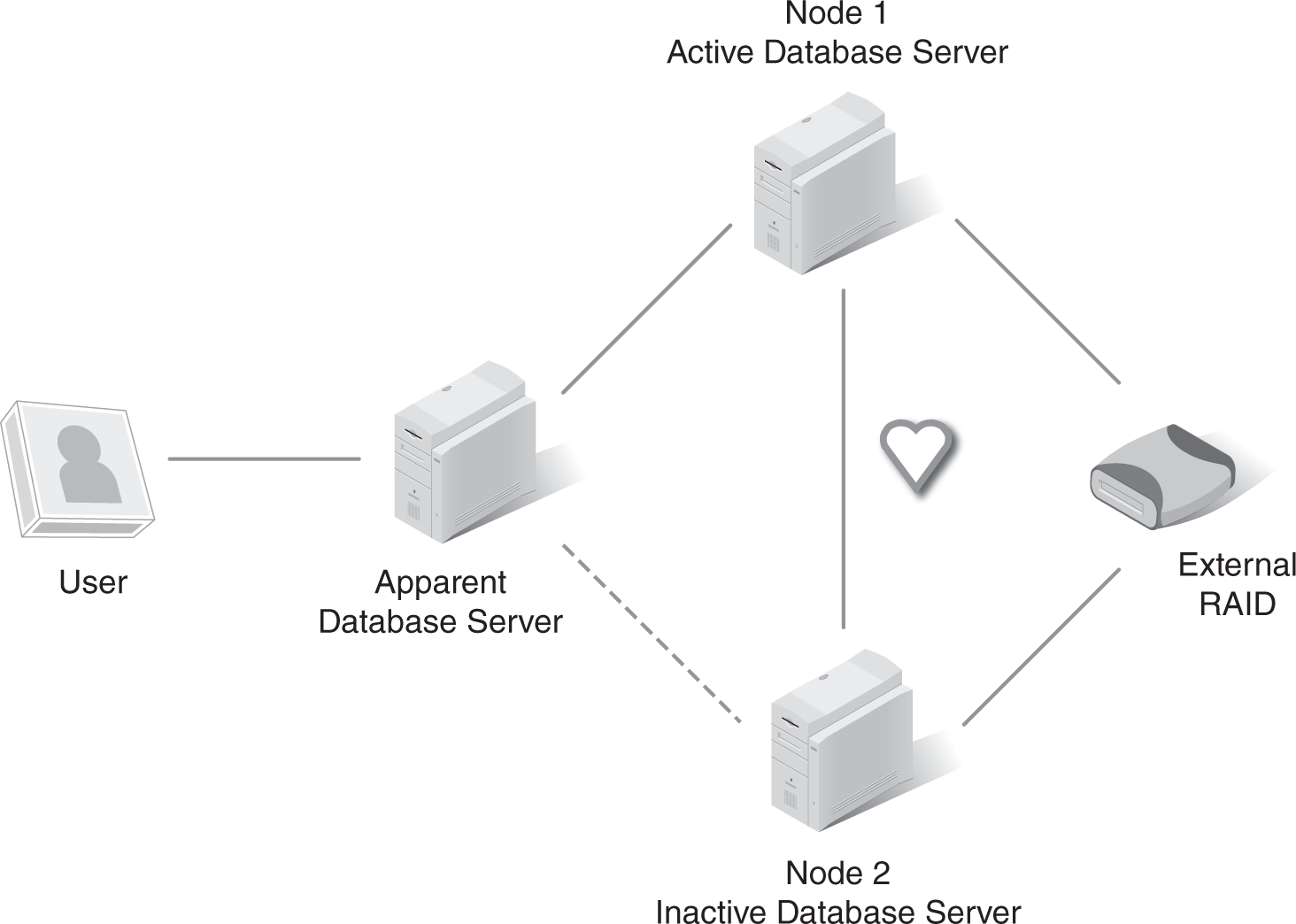
FIGURE 7-1 Database server protected with a failover cluster.
In a failover cluster, a user appears to connect to a single database server. Figure 7-1 shows this server as the apparent database server. Nodes 1 and 2 are physical servers that can actually be touched. The apparent database server is just the logical view of the active node.
While node 1 is active, node 2 is inactive. Node 1 will serve all data requests. It accesses the data on an external drive. At this point, node 2’s only job is to query node 1 and check its heartbeat as often as every 30 seconds. As long as node 1 is up, node 2 doesn’t do anything else.
However, if node 1’s heartbeat stops, indicating that node 1 has failed, node 2 goes into action by taking over the services of node 1. Because node 2 has access to the same data on the external drive, data isn’t lost. The user is still connected to the apparent database server, but data is now served from node 2. The switchover is not apparent to the end user, and, typically, service is not interrupted.
NOTE
Failover clusters can have more than two nodes. For example, multiple services can be protected in an eight-node failover cluster. In an eight-node cluster, two nodes are often inactive, and six are active.
The external drive can be a single point of failure (SPOF). An SPOF is any part of a system that can cause an entire system to fail if it fails. A hardware redundant array of independent disks (RAID) is often used to ensure that data isn’t lost, even if a drive fails.
The failover cluster also allows maintenance to be performed without any downtime because maintenance can be performed on the inactive node without affecting users. If the active node needs servicing, the nodes can be switched so that the inactive node becomes active.
Although a failover cluster can help achieve 99.999 percent uptime, it comes at a high cost. At a minimum, two powerful servers will be needed. Additionally, both servers will never be used at the same time; one will always be idle just checking to see if the other one is up. However, if maximum uptime is required, the cost is justified.
Determining which systems require 99.999 percent access and availability can be done by identifying the value of the service provided. The highly valued systems require greater protection than the lesser valued systems. Value can be measured by measuring revenue or productivity:
- Direct and indirect revenue—A web server is an example of a service that can provide direct revenue. If the web server sells products, how much revenue it earns per hour can be determined, and this figure can then be used to determine the direct costs of the outage. Indirect costs also need to be calculated, which include, for example, the cost to bring back customers that are lost during the outage.
- Productivity—Employees need services to perform their job. For example, employees may use a warehouse application that is used to manage inventory to accept products coming in and locate products that are shipping out. Management can use it to determine the value of the current inventory at any time. If this application fails, all shipments may stop. If the failure isn’t restored quickly, it may result in delayed shipments, an inaccurate inventory, and other problems. Similarly, many companies consider email a critical service today. If it fails, productivity quickly drops.
Sometimes, the value of system access and availability is underestimated. That is, until it fails. Proactive risk managers will include system access and availability requirements when identifying assets.