
Translating a Risk Assessment into a Risk Mitigation Plan
The next step is to translate the risk assessment into a risk mitigation plan. The mitigation plan will include the details on how and when to implement the countermeasures.
Here are three important considerations when developing the mitigation plan:
- Cost to implement the countermeasures
- Time to implement the countermeasures
- Operational impact of the countermeasures
Cost to Implement
Many of the countermeasures to be implemented will need to be purchased. Therefore, being able to accurately identify the costs of these countermeasures is important. On the surface, the cost of the countermeasure may be simple to calculate. However, there are frequently hidden costs.
Costs can include the following items:
- Initial purchase cost
- Facility costs
- Installation costs
- Training costs
FYI
If hidden costs are discovered, they may affect the decision to implement the countermeasure. If the difference between the original estimate and the actual cost is significant, the countermeasure may no longer be cost effective. In that case, a cost-benefit analysis should be redone. If the results show that the countermeasure changes the original cost-benefit analysis, the data should be presented to management. Management could decide to still go forward or stop the purchase of the countermeasure.
One of the common problems that creeps up in this stage is a lack of money. Ideally, the risk assessment should accurately identify the cost of the countermeasure, but, if new costs are discovered, they may cause problems. The new cost may be beyond the original budgeted amount, which may move the cost of the countermeasure from a budgeted item to an unfunded requirement. Unfunded requirements may simply have to wait until the next year for implementation.
Initial Purchase Cost
The cost of the initial purchase is the price of the product. For software, such as a software vulnerability scanner, the cost is the retail price minus any discounts given to the organization. For hardware, such as a router or server, the initial purchase cost is the price of the hardware.
Some countermeasures may be developed internally. For example, this chapter has mentioned scripts used as a countermeasure. If the organization has a talented administrator, he or she may be able to easily write the script. Writing the script won’t take much time or prevent the completion of other tasks.
On the other hand, if scripting is a new function for the administrator, the decision may be made to calculate the labor costs. The administrator will take a significant amount of time to write the first script but will spend less and less time on subsequent scripts because they will become easier and easier to complete.
The initial purchase price is usually identified accurately in the risk assessment. If a product is being purchased, the price can be verified with the vendor.
Facility Costs
Facility requirements include space, power, and air-conditioning, but sometimes these requirements are overlooked. If they’re needed but not identified, they can cause significant problems with the schedule and may even affect the accuracy of the cost-benefit analysis.
Many people have the impression that a server room has unlimited space, but that’s rarely the case. Servers are usually mounted in equipment bays, which are about the width and depth of a home refrigerator and about six feet tall. FIGURE 11-1 shows how equipment is mounted in an equipment bay.

FIGURE 11-1 Equipment bays hosting servers and other components.
The bay on the left has four large servers. They could be large 32-processor systems with 2 terabytes (TB) of memory. The bay on the right has seven smaller servers. These could be smaller four-processor systems with 32 gigabytes (GB) of random access memory (RAM). The applications hosted on the servers dictate the size. For example, a database server hosting a very large database requires more resources than a file server used to host user files.
Equipment bays commonly host other components, as can be seen in Figure 11-1, which shows patch panels, disk drive arrays, a tape drive, and more.
As an example of facility costs, the mitigation plan calls for adding two additional servers to an existing server room that has only two bays. They won’t fit into the existing bays. Either equipment has to be removed from these bays or another bay added. If this requirement wasn’t identified before, it will add additional cost for the countermeasure.
 NOTE
NOTE
Figure 11-1 shows spaces between the servers, but they are illustrated only so the various components can be seen. However, in an actual bay, these spaces wouldn’t be there. Either the server and components would be mounted right on top of each other, or metal plates, which help counteract the airflow through the bay, would be installed to cover the spaces.
Besides space, air-conditioning and power requirements should also be considered. Air-conditioning units provide a certain level of cooling power. For example, the air-conditioning unit needed to keep a 1,000-square-foot home cool is much smaller than one needed to keep a 3,000-square-foot home cool. Similarly, the air-conditioning unit used to keep two bays cool may not be able to keep three bays cool.
Power is another consideration. Regarding power, two things need to be considered—power capacity and power source.
First, the server room must be able to support the additional power. Using the power requirements of a home as an example, if 15 different kitchen appliances are connected into a power strip through a single outlet, circuit breakers would pop, or, worse, a fire may be started. That single outlet has a limit, and, similarly, so does a server room.
If the power supplied to the server room is already at its limit, the additional servers and equipment bays cannot be supported until additional power is added. Routing additional power to the server room will add additional cost for the countermeasure.
Second, the power may need to be supplied by different sources. Failover clusters add additional servers for redundancy. If any single server fails in a failover cluster, another server will pick up the load, ensuring that the service continues to function. However, what if power fails? A power failure can be a single point of failure.
Sometimes, servers in failover clusters are placed on different power grids. In FIGURE 11-2, the equipment bays on the left are connected to Power Grid A, and the equipment bays on the right are connected to Power Grid B. Some of the failover cluster servers could be placed in bays using Power Grid A and some of the servers in bays using Power Grid B.
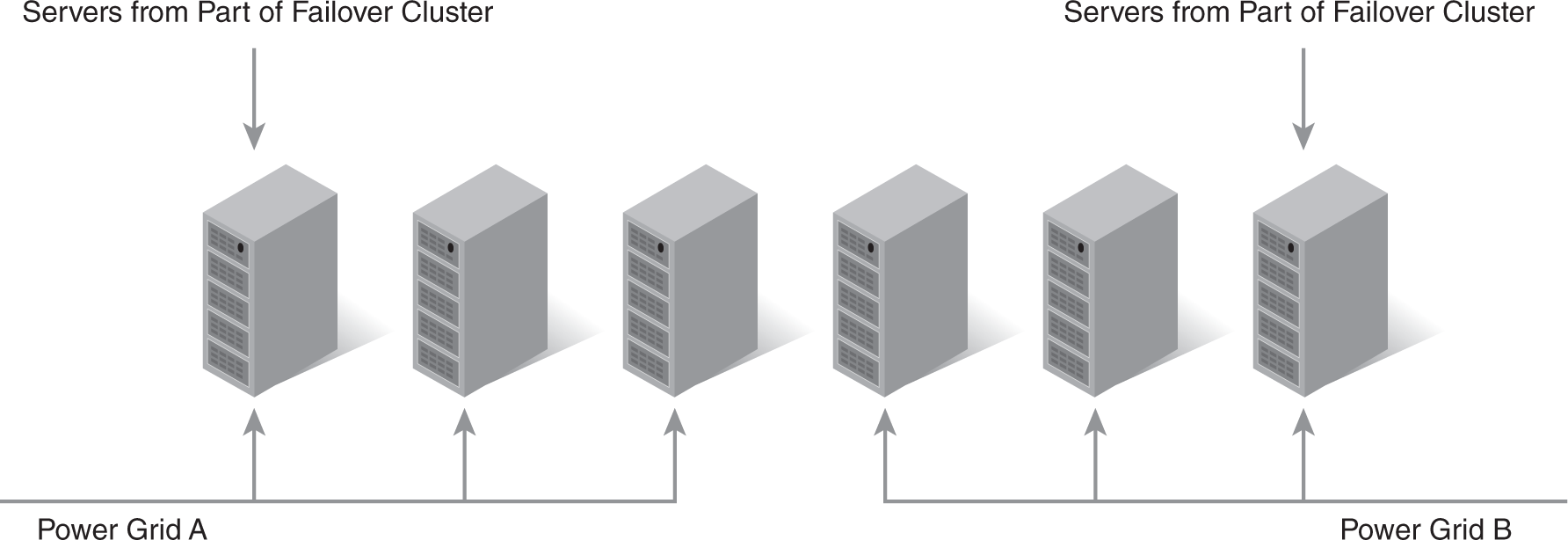
FIGURE 11-2 Failover cluster servers connected to different power grids.
If Power Grid A suffers a failure, the servers on Power Grid B will still operate. Of course, this configuration requires that the server room be supplied by power from different power grids. If it isn’t, alternatives can be considered. The power could be modified to supply power to the room from a different power grid. Some organizations place failover cluster servers in different locations to ensure that each server is on a different power grid.
Another method of providing alternative sources is using a different uninterruptible power supply (UPS). A UPS can be a simple portable unit used on a home computer or a room filled with banks of batteries.
If power fails, the UPS will provide power for a short amount of time. For some less-critical systems, a UPS allows a system to shut down logically. For critical systems, a UPS provides time for generators to power on and stabilize. After the generators have stabilized, power is switched from the UPS system to the generators, which provide long-term power.
Most countermeasures won’t require additional facility costs. However, if facility costs are required, the overall costs for the countermeasure will increase significantly. These additional costs may be so high that the cost-benefit analysis shows that adding the countermeasure no longer makes fiscal sense.
Installation Costs
In-house administrators will install most countermeasures. However, some sophisticated countermeasures may require outside help. Occasionally, the extra expense is warranted to have the vendor install and configure the countermeasure to be sure it has been installed correctly. This decision is often dependent on the level of expertise of staff.
As an example, a small school with a library has not received any E-Rate funding discounts from the Federal Communications Commission (FCC) in the past. These discounts subsidize the cost of Internet access. However, the library wants to apply for the discounts. It must comply with the Children’s Internet Protection Act (CIPA) to filter the content to ensure that children are protected from offensive content.
The library could decide to purchase a proxy server to comply. The proxy server can be used with a subscription to filter offensive content. However, the school may not have the expertise to install and configure the proxy server easily. Instead of taking the chance of making mistakes and being on the wrong side of the CIPA law, the school could decide to outsource this.
In this example, the installation costs will add to the cost of the countermeasure.
Training Costs
Another overlooked cost is training. The new countermeasure may be the greatest thing since the invention of the personal computer, but, if no one knows how to operate it, it will sit in the corner gathering dust. Technical training can be expensive, costing as much as $6,500 to send a single administrator to a weeklong training session.
Many companies will host training on location. Costs may be as much as $20,000 to send a trainer to the company to train 15 or so people.
Obviously, technical training costs can quickly add up, and, as with other costs, they can significantly add to the total cost of a countermeasure. In addition to the final cost, they may also affect the schedule. Implementation of the countermeasure may need to be delayed until personnel have been trained.
Time to Implement
The time to implement the countermeasure can vary widely. Some implementations can be completed within days or weeks, whereas some may take months. Considering the entire process is important when identifying timelines.
For example, creating a written account management policy may seem like a simple and quick procedure, and a security expert could probably draft an account management policy within a day. However, that policy is not the IT account management policy. All policies need senior management approval and buy-in; therefore, the draft needs to be routed to senior management for review.
 TIP
TIP
A risk assessment includes a plan of action and milestones (POAM), which is a valuable tracking tool, especially for complex projects. Once the time and schedule for a countermeasure have been identified, the POAM will need to be updated with this data.
Management will more than likely want changes, some of which may be stylistic and some of which may be content related. To get managers’ buy-in, the policy needs to be their policy. The more changes they make, the more they own it. If a policy isn’t edited at least once, perhaps management really isn’t buying into it.
A policy owned by management will be supported by management. If management doesn’t support the policy, no one will.
Just because management’s review of a policy may take only 20 minutes doesn’t mean the policy will be done in the 20 minutes after completion of the first draft. Unless there’s been a recent high-level security incident, a written security policy is not likely to be a top priority. It will take time to rise to the top of the managers’ in pile.
With all of this in mind, an estimate of 30 days may be made for the completion of the policy. Routing the policy through proper management personnel may take a couple of weeks. Changes will be made to the policy; then, it will be resubmitted for final approval and signature, which may take another week or so.
Some timelines could be much more complex. For example, FIGURE 11-3 represents a company’s current web server configuration. The web server is in the demilitarized zone (DMZ) and accesses a back-end database hosted on a different server. The server supports an online business that has enjoyed explosive growth in the past two years and is currently generating millions of dollars in revenue a year.

FIGURE 11-3 Web server with back-end database server.
A recent outage resulted in tens of thousands of dollars in lost sales. Combined with indirect costs, management estimates the company lost over $100,000. Managers want to prevent outages like this in the future. However, even after engineers identify a solution, its implementation will take much longer than 30 days.
After management has approved the solution, additional servers need to be purchased to create the configuration shown in FIGURE 11-4. This plan expands the web server into a web farm. The back-end database server will be protected with a failover cluster.
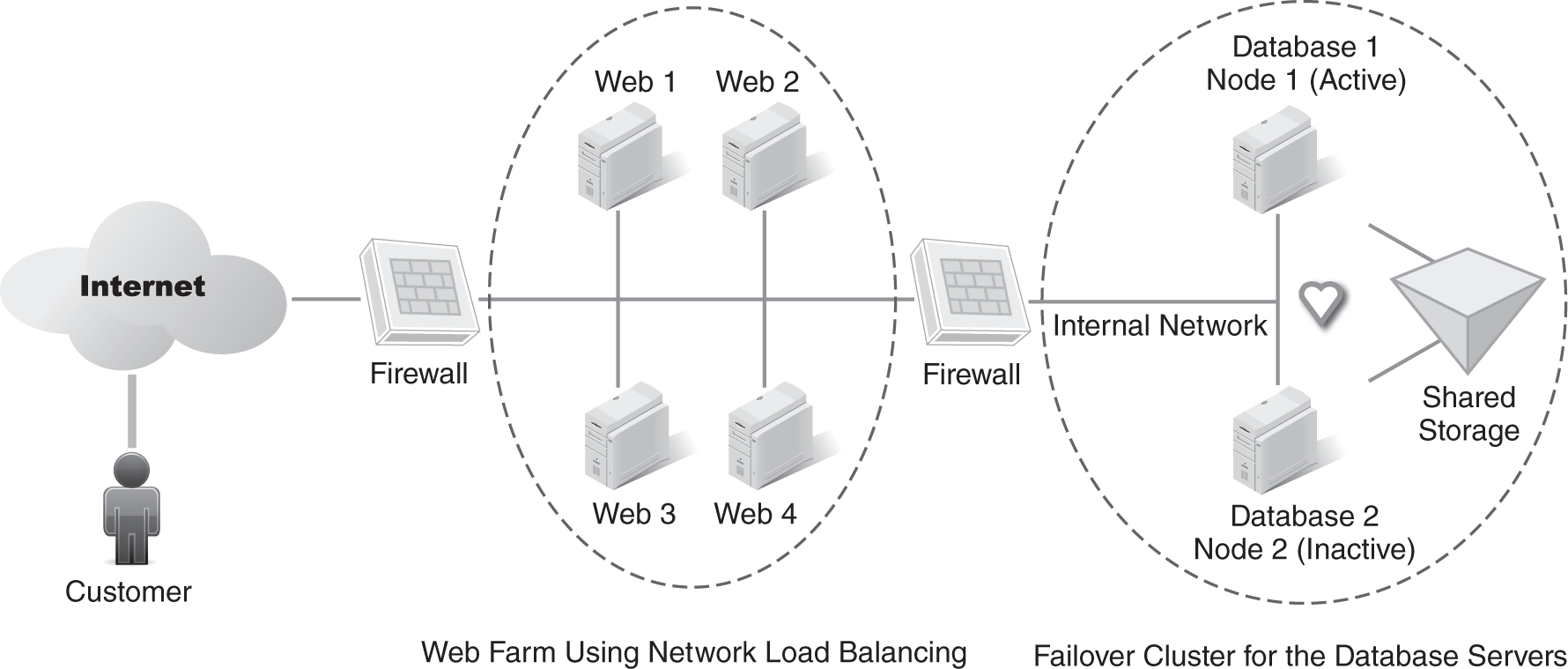
FIGURE 11-4 Here, a single web server has been replaced by a web farm.
A web farm consists of multiple servers using network load balancing. The first client connects to web 1, the next client connects to web 2, and so on. At any given time, each of the servers has about the same load. Web farms allow an organization to easily scale out by adding additional servers. For example, an administrator can add a server to the web farm if there is a surge in demand. Additionally, if one of the servers in the web farm fails, network load balancing ensures that clients aren’t directed to the failed server.
A failover cluster provides fault tolerance for the database server. Node 1 is active, and node 2 is inactive. Node 2 monitors the health of node 1 by monitoring its heartbeat. If node 1 fails, node 2 takes over.
TIP
Tracking countermeasures is important and doesn’t have to be complex, just accurate. For example, if a policy is submitted to the chief information officer (CIO) for review, a comment can be made in the POAM or other tracking document to that effect and can be as simple as “submitted draft to CIO on April 14.”
Clearly, there are differences between Figures 11-3 and 11-4. The new configuration adds four servers and two different technologies. It will require much more planning than the implementation of a written account policy.
Several things need to be considered in the new configuration: the server room may not have equipment bay space, the added servers may exceed the power capabilities of the room, or air-conditioning capacity may need to be added. The timeline could include the following steps:
- Adding an additional equipment bay—The bay should be the same size as other bays and be installed the same way, which ensures that it takes full advantage of the existing air-conditioning. Adding another bay assumes the room will support it. If it won’t, then the problem may be bigger.
- Adding additional air-conditioning capacity—An additional unit may need to be added or the existing unit upgraded.
- Adding power from a different power source—If the facility supports it, the choice may be made to separate the power. For example, power can be rerouted so that two of the web servers and one of the failover cluster nodes are on different power grids. This configuration will help prevent a loss of power on one power grid from taking down the website.
- Balancing servers on different power grids—If additional power sources are added, all the servers in the server room may need to be balanced.
- Purchasing servers and hardware—This plan requires a minimum of four new servers. The two database servers in the failover cluster need to have matching hardware, so two new servers are required. They should be designed to work with a failover cluster. After verifying the failover cluster is operational, the old database server can be repurposed as a web farm server. Depending on the capabilities of the existing servers, the choice may be made to replace the old servers with six new servers.
- Providing training to administrators—Configuring and administering failover clusters can become complex. If administrators haven’t worked with a failover cluster before, they will need training. Network load balancing is easy to work with, but administrators might need training for this, too.
- Installing and configuring servers—This step depends on the experience of the administrators. For example, the installation and configuration of the failover clusters could be outsourced. Many of the companies that sell failover cluster solutions also provide installation support.
- Testing—Before the system goes live, the web farm and failover cluster need to be tested to verify that they will work as expected because every system will have technical issues that need to be resolved.
- Implementing—The original configuration is switched over to the new configuration, sometimes in a phased implementation. For example, the failover cluster may be implemented first; once it’s stable, the web farm can be implemented.
TIP
A system or service should be able to be scaled up or scaled out when demand is increased. Scale up means that additional resources are added to a server. For example, the processor could be upgraded or additional RAM added. Scale out means that additional servers are added to the service. A web farm with network load balancing supports scaling out without changing the core application. In this case, the core application is the web application hosted on the web servers.
TIP
Implementing the new configuration is time consuming and expensive, but the cost is justified based on the loss of over $100,000 during a recent outage. Moreover, these countermeasures are needed to ensure the availability of the website to help ensure that it continues to generate revenue.
Operational Impact
On one hand, the more secure a system is, the harder it is to use. On the other hand, the easier it is to use, the less secure it is. In short, any countermeasure can have an impact on normal operations.
Operational impact should be identified as early as possible so steps can be taken to minimize it. For example, the goal is to minimize the traffic allowed through the firewall, which could be realized through the implementation of an implicit deny philosophy.
An implicit deny philosophy starts by blocking all traffic and then adding rules to identify allowed traffic. The firewall allows traffic that matches an explicit rule and blocks all other traffic. Even if the firewall doesn’t have a rule to explicitly deny certain traffic, it is implicitly denied.
The challenge is to identify what traffic is allowed. One way would be to block all traffic and wait until people complain, but that method would be sure to impact operations.
A better method would be to enable extensive logging on the existing firewall. The log can then be analyzed to determine what traffic the firewall currently allows. Most logs can be imported into other tools for better analysis. For example, a text log can be imported into a database, which makes analyzing the data much easier than if it were in a text file.
Just because traffic is going through the network doesn’t mean it should be. For example, the written security policy may state that Network News Transfer Protocol (NNTP) traffic is restricted. NNTP uses Transmission Control Protocol (TCP) port 119. A review of the traffic log may show a substantial amount of traffic using this port. This situation should be investigated to see whether the security policy is out of date or perhaps someone made an unauthorized change on the firewall to allow this traffic.
Traffic that looks unfamiliar should be investigated and not just blocked without consideration. For example, a company may have a line of business (LOB) application used for ordering parts and supplies from vendors that is using port 5678. If this port is blocked, the application will be blocked, and employees will no longer be able to use the LOB application to order parts and supplies. Clearly, that will have a detrimental effect on operations.