
Chapter 6. Metadata Management for MDM
6.1. Introduction
At a purely technical level, there is a significant need for coordination to oversee and guide the information management aspects of an enterprise initiative such as MDM. The political and organizational aspects of this coordination are addressed as part of the governance program that must accompany an MDM program. However, all aspects of determining need, planning, migration strategy, and future state require a clarified view of the information about the data that is used within the organization—its metadata.
It is easy for us to fall into the trap of referring to metadata by its industry- accepted definition: data about the data. This relatively benign description does not provide the depth of understanding that adds value to the MDM deployment. Instead, the metadata associated with an enterprise master data set does more than just describe the size and types of each data element. It is the historically distributed application and data silos that are impacted by the variance in meaning and structure that necessitated MDM in the first place. Therefore, to develop a model, framework, and architecture that provide a unified view across these applications, there must be a control mechanism, or perhaps even a “clearing house,” for unifying the view when possible and for determining when that unification is not possible.
In fact, the scale of metadata management needed for transitioning enterprise data sets into a master data environment differs from the relatively simple data dictionary-style repositories that support individual applications. Sizes and types are just the tip of the iceberg. Integration of records from different data sets can only be done when it is clear that data elements have the same meaning, that their valid data domains are consistent, that the records represent similar or the same real-world entities. Not only that, but there are more complex dependencies as well: Do client applications use the same entity types? Do different applications use different logical names for similar objects? How is access for reading and writing data objects controlled? These and many other important variable aspects must be addressed.
There is value in looking at a conceptual view of master metadata that starts with basic building blocks and grows to maintain comprehensive views of the information that is used to help an organization achieve its business objectives. The metadata stack described in this chapter is driven by business objectives from the top down and from the bottom up, and it is intended to capture as much information as necessary to drive the following elements:
▪ The analysis of enterprise data for the purpose of structural and semantic discovery
▪ The correspondence of meanings to data element types
▪ The determination of master data element types
▪ The models for master data object types
▪ The interaction models for applications touching master data
▪ The information usage scenarios for master data
▪ The data quality directives
▪ Access control and management
▪ The determination of core master services
▪ The determination of application-level master services
▪ Business policy capture and correspondence to information policies
We can look at seven levels of metadata that are critical to master data management, starting from the bottom up:
Business definitions. Look at the business terms used across the organizations and the associated meanings
Reference metadata. Detail data domains (both conceptual domains and corresponding value domains) as well as reference data and mappings between codes and values
Data element metadata. Focus on data element definitions, structures, nomenclature, and determination of existence along a critical path of a processing stream
Information architecture. Coagulates the representations of data elements into cohesive entity structures, shows how those structures reflect real-world objects, and explores how those objects interact within business processes
Data governance management. Concentrates on the data rules governing data quality, data use, access control, and the protocols for rule observance (and processes for remediation of rule violations)
Business metadata. Capture the business policies that drive application design and implementation, the corresponding information policies that drive the implementation decisions inherent in the lower levels of the stack, and the management and execution schemes for the business rules that embody both business and information policies
Given this high-level description of a metadata stack, the challenge is to look at how these levels interact as part of an overall metadata management strategy. This view, shown as a whole in Figure 6.1, enables us to consider metadata as a “control panel,” because the cumulative knowledge embedded within the metadata management framework will ultimately help to determine of the most appropriate methods for delivering a master data asset that is optimally suited to the organization. In this chapter, we will look at each layer of metadata from the bottom up and review its relevance to the master data management framework.
 |
| ▪Figure 6.1 The MDM metadata stack. |
Valuable work has been invested in developing standards for managing metadata repositories and registries as part of an International Standards Organization activity. The resulting standard for Metadata Registries, ISO/IEC 11179 (see www.metadata-stds.org), is an excellent resource for learning more about metadata management, and some of the material in this chapter refers to the 11179 standard.
One word of caution, though: the rampant interconnectedness of the information that is to be captured within the metadata model implies that analysts must take an iterative approach to collecting the enterprise knowledge. Business process models will reveal new conceptual data elements; relationships between master data object types may not be completely aligned until business process flows are documented. The effective use of metadata relies on its existence as a living artifact, not just a repository for documentation.
Within this stack, there are many components that require management. Although numerous metadata tools may supplement the collection of a number of these components, the thing to keep in mind is not the underlying tool but the relevance of each component with respect to MDM, and the processes associated with the collection and use of master metadata. Standard desktop tools can be used as an initial pass for capturing master metadata. Once processes are in place for reaching consensus across the stakeholder community as to what will ultimately constitute the metadata asset, requirements can be identified for acquiring a metadata management tool.
6.2. Business Definitions
One of the key technical drivers for MDM is the reconciliation of meanings that have diverged in accordance with distributed application development. Therefore, it should come as no surprise that the foundation of master metadata is based on collecting (and, one hopes, standardizing) the definitions for the business terms commonly used across the organization. This layer initiates the high-level notions that are associated with business activities, and the process of collecting the information allows an open environment for listing the business concepts and terms that are commonly used. Then, as concepts are identified, there is an opportunity for the stakeholders to explore the differences and commonalities between the concepts, standardize definitions when possible, and distinguish between concepts when it is not possible to standardize their meanings.
6.2.1. Concepts
A concept represents a core unit of thought, such as a “person,” “product,” or “supplier.” A concept is associated with core characteristics. For example, a “residential property” is associated with a geographic region, a mailing address, an owner, an appraised value, possibly a mortgage, and a real estate tax assessment, among others. In turn, the characteristics may themselves be concepts as well.
Each environment may have a specific set of concepts that are relevant to the business processes, and some concepts transcend specific divisions, organizations, or even industries. Within the organization, a good place to seek out concepts is with the business process model, as was described in Chapter 2. At the macro level, standards for information exchange among participants within the same industry provide an ample resource from which concepts can be identified as well.
As part of the process of enumerating business concepts, participants may find that some concepts are referred to with a variety of words or phrases. At the same time, one may discover that certain words are overloaded and refer to more than a single concept. Collecting the concepts and their names leads to the next component of the business definitions layer: business terms.
6.2.2. Business Terms
How is the term “customer” used? Many words and terms are used so frequently within a business environment that they eventually lose their precise meaning in deference to a fuzzy understanding of the core concept. Alternatively, many organizations have a regimented lingo that confuses almost everyone except for the hardcore organizational veterans. Both ends of this spectrum reflect different aspects of the same problem: organizational knowledge locked inside individual's minds, with no framework for extracting that knowledge and clarifying it in a way that can be transferred to others within the organization. It is this gap that the business terms component is intended to alleviate, which naturally follows from the identification of the business concepts described in Section 6.2.1.
Given a list of business concepts, the next step is to identify the different terms used in reference to each concept and create a mapping through which the subject matter experts can browse. The simplest approach is to develop a direct mapping between the concept and its various aliases. For example, for the concept of “customer,” the terms “customer” and “account” may have the same intention. However, this process should not be limited to developing a direct mapping between terms and concepts, but it should also include any business terms used in any type of reference. This will include the different terms used for the concept “customer” as well as the terms used for the characteristics of a customer (“customer type,” “relationship start date,” “contact mechanism,” etc.).
6.2.3. Definitions
The metadata asset also supports a process for determining what each business term means in each of its contexts. Again, referring back to the business processes, evaluate the use of the business term, connect it to a business concept, and seek a clear definition for each business term in relation to a business concept drawn from an authoritative source. The range of authoritative sources includes internal documentation and external directives. For example, the concept of a “customer” may exist in one form in relation to the sales staff based on internal memos and corporate dictates. However, when reporting the count of customers in regulatory reports to government bodies, the definition of the “customer” concept may be taken from the regulatory guidelines. Both are valid uses of a concept, but it may turn out that ultimately, based on the different definitions, the business term “customer” actually is defined in two different ways, meaning that the term is used in reference to two different concepts! This dichotomy must be documented, and the semantics component (see Section 6.2.4) is the best place to capture that.
The definitions component harmonizes term usage and enables users to distinguish concepts based on classification by authoritative source. This includes the listing of authoritative sources and prioritization key for those sources so that if there is a conflict between two definitions, one can use the prioritization key to break the tie. Recognize though, that if one were to assess the different uses of the same business terms and find multiple definitions, it may turn out that despite the use of the same term, we really have multiple concepts that must be distinguished through some type of qualification. This is also documented as part of the semantics component.
6.2.4. Semantics
The semantics components is intended to capture information about how business terms are mapped to concepts, whether business terms are mapped to multiple concepts, and whether concepts are mapped to multiple business terms, as well as to describe how the business concepts are related within the organization. To some extent, the semantics component captures the interconnectedness of the business concepts, business terms, and the definitions. Documenting business definitions using prioritized authoritative sources is a relatively formal practice that some people may find constraining, especially when attempting to shoehorn multiple concepts into one specific definition. The semantic component enables a more fluid practice, allowing the coexistence of concepts that are similarly named as long as their meanings are qualified.
This is the component in which practitioners collect similar concepts and terms together, qualify their meanings, and determine if there is any overlap among or between them. If there is, then the relationship is documented; if not, then the specific differences must be clearly specified and a means for distinguishing the meanings in application contexts determined.
6.3. Reference Metadata
One might question the difference between “master data” and “reference data,” as in some cases both appear to be the same thing. For our purposes, “reference data” refers to the collections of values that are used to populate the existing application data stores as well as the master data model. This section looks at two core constructs: data domains and mappings.
6.3.1. Conceptual Domains
An evaluation of the business concepts will reveal hierarchies associating specific logical notions or objects together. For example, there is a concept of a “U.S. state,” which represents a geopolitical subregion of a country (another concept) named “United States of America,” which in its own right is a concept. Whereas the “U.S. state” conceptual domain is composed of the concepts representing each of the states of the Unites States of America—Alabama, Alaska, and so forth through Wyoming—the conceptual domain does not direct the way the concepts are represented; this is done using value domains.
Despite the fact that they are “conceptual,” there will typically be some basic representation for the objects that compose the domain set. Continuing the “U.S. state” example, there must be some representation of each of the states that conveys the standard agreed-to meaning. Therefore, one of any number of value domains may be selected as that basic representation, as we see in the next section.
6.3.2. Value Domains
A value domain is a collection of representations of the values in a conceptual domain. To continue our example, we can define a collection of character strings that refer to each of the states of the United States of America: “Alabama,” “Alaska,” and so on.
As Figure 6.2 shows, different value domains may be associated with a single conceptual domain. In this case, U.S. states are represented by their full names, by their U.S. Postal Service two-character codes, by Federal Information Processing System (FIPS) two-digit codes, or even by graphical images showing each state's boundaries. Each of these data sets is a value domain, each has a unique representation for a concept (each individual state) that is included in the higher-level concept (U.S. states), and, in fact, each value in one value domain maps to a corresponding value in the other value domains. This means that we may have data sets that are intended to represent the same concept yet use different value sets in representation; capturing this information within the metadata repository enables making the necessary links when determining ways to integrate and consolidate data sets.
 |
| ▪Figure 6.2 Value domains for the conceptual domain of U.S. states. |
On the other hand, we may have a value domain that is used to represent different conceptual domains. Figure 6.3 shows a value domain consisting of the numerals 0, 1, 2, 3, 4, 5, and 6 used to represent four different conceptual domains. So even though the same values are used, their use across different data does not necessarily imply that the data sets represent the same business concepts. Again, capturing this in the metadata repository is critical when considering approaches to data integration and consolidation.
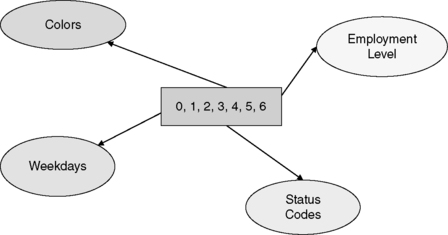 |
| ▪Figure 6.3 The same value domain may be used for different conceptual domains. |
6.3.3. Reference Tables
For any given conceptual domain, there must be a way to document the connection with a specific value domain and how the values within the value domain refer to the objects within the conceptual domain. Reference tables essentially capture this information by providing a direct one-to-one mapping between an enumeration of the basic representation of a value domain representing the conceptual domain and a value domain used in an application data context. These are often manifested in the organization as “code tables” or “lookup tables.”
For each of the conceptual domains shown in Figure 6.3 that use the same value domain, there is a direct reference table showing the relationship between concept to value. Consider the example of “Weekdays” presented in Table 6.1.
6.3.4. Mappings
Another artifact of the historical variance of data representations is that different information architects may have selected different value domains to represent objects within the same conceptual domain. Yet before integrating records drawn from different data sets, one must know when different value domains are used to represent the same conceptual domain. Contrast the reference table in Table 6.2 for weekdays with the one in Table 6.1. The same conceptual domain is associated with two different value domains, and to appropriately establish that two records contain the same weekday value, one must know the mapping demonstrating equivalence between the two value domains.
| Weekday | Value |
|---|---|
| Sunday | SU |
| Monday | MO |
| Tuesday | TU |
| Wednesday | WE |
| Thursday | TH |
| Friday | FR |
| Saturday | SA |
Empirical data analysis (such as that performed using data analytics or data profiling tools) can reveal the mappings between value domains within the context of the conceptual domain. A mapping for our weekday example would show the relationship between the reference data sets (Table 6.3).
6.4. Data Elements
At the next level of the metadata stack, we start to see the objects used to create the information models used in the different application data sets. According to the ISO/IEC 11179 standard, a data element is “a unit of data for which the definition, identification, representation and permissible values are specified by means of a set of attributes.” More simply, a data element is the basic building block for data models, and each data element is specified in terms of a definition, a name, a representation, and a set of valid values.
All data assets are composed of data elements, intentionally or not. Data sets designed before the use of comprehensive data modeling tools still conform to the use of data elements, although the associated constraints may not have been formally defined. In these cases, data analytics tools can again be used to evaluate the de facto rules, which can then be reverse-engineered and validated with subject matter experts.
Ultimately, the master metadata repository should maintain information about every data element that might contribute to the master data asset. However, the scope of analyzing, validating, and formally capturing metadata about every single data element may prove to be overwhelming and could become a bottleneck to MDM success. Therefore, it may be worthwhile to initially concentrate on the critical data elements.
6.4.1. Critical Data Elements
Of the thousands of data elements that could exist within an organization, how would one distinguish “critical” data elements from your everyday, run-of-the-mill data elements? There is a need to define what a critical data element means within the organization, and some examples were provided earlier in this chapter. For an MDM program, the definition of a critical data element should frame how all instances of each conceptual data element are used within the context of each business application use. For example, if the master data is used within a purely analytical/reporting scenario, the definition might consider the dependent data elements used for quality analytics and reporting (e.g., “A critical data element is one that is used by one or more external reports.”)
On the other hand, if the master data asset is driving operational applications, the definition might contain details regarding specific operational data use (e.g., “A critical data element is one that is used to support part of a published business policy or is used to support regulatory compliance.”). Some other examples define critical data elements as follows:
▪ “… supporting part of a published business policy”
▪ “… contributing to the presentation of values published in one or more external reports”
▪ “… supporting the organization's regulatory compliance initiatives”
▪ “containing personal information protected under a defined privacy or confidentiality policy”
▪ “containing critical information about an employee”
▪ “containing critical information about a supplier”
▪ “containing detailed information about a product”
▪ “required for operational decision processing”
▪ “contributing to key performance indicators within an organizational performance scorecard”
Critical data elements are used for establishing information policy and, consequently, business policy compliance, and they must be subjected to governance and oversight, especially in an MDM environment.
6.4.2. Data Element Definition
As data elements will ultimately reflect the instantiation of the concepts and business terms described in Section 6.2, it is important to capture precise definitions of the data elements that will contribute to the master model. In fact, one might consider the requirements to precisely define data elements to be as great, if not greater than that for business terms.
Section 4.1 and Section 4.2 of Part 4 of the ISO/IEC 11179 standard provide guidance for data definitions, and we can apply these to the definition of a data element. A definition should state what the data element is (not what it “does” or what is isn't), be stated with descriptive phrases, not rely on uncommon abbreviations, and be expressed without incorporating definitions of other data concepts or elements. In addition, a definition should state the essential meaning of the data element, be precise and unambiguous, be concise, and avoid circular reasoning. Avoid using a data element's functional use as its definition or including procedural information.
6.4.3. Data Formats
In modern data modeling environments, every data element is attributed by a data type (e.g., integer, varchar, timestamp) and a size or length, but there are still many data environments that are less structured. Older file-based systems were defined with specific data element sizes but without enforcing any rules regarding data type compliance. As part of the data format component of the metadata repository, each captured data element will also be attributed with the format of the valid value set.
This may be limited to data type, such as CHAR(2) for a “U.S. state” data element that uses a U.S. Postal Service state postal code for its value domain. Alternatively, the format may contain a more complex formatting information that reflects a greater degree of constraint, such as limiting North American Numbering Plan telephone numbers to data type of CHAR(12) and a format “999-999-9999,” where the 9's represent digits only; any value that does not conform to the format must be invalid. Lastly, specifying an enumerated data value domain to a data element provides a greater degree of format constraint, because the data element's value must be selected from that set of values.
6.4.4. Aliases/Synonyms
Recognizing that different data elements ultimately contain data that represent the same underlying business concept allows the metadata analyst to establish a relationship between those data elements in that they are aliases or synonyms. Synonym data elements may or may not share the same value domains, data element formats, names, and other components, but through their connections within the metadata hierarchy one can determine that they represent the same notions and must be associated.
This observation underscores the value of the hierarchical layering of master metadata. This value is driven by the exposure of concept and type inheritance, because it provides the ability to determine that two data elements refer to the same concept, even if empirically they look completely different. Let us revisit our example of documenting mappings between value domains associated with the same conceptual domain from Section 6.3.4. Suppose the metadata analyst were presented with two data elements. The first is called “DayOfWeek” and details are presented in Table 6.4; the second is called “Weekday” and details also are presented in Table 6.4.
| Data Element Name | Data Element Type | Value Domain |
|---|---|---|
| DayOfWeek Metadata DayOfWeek | Integer(1) | WD Value 1 |
| Weekday Metadata Weekday | CHAR(2) | WD Value 2 |
In isolation, other than slight similarity between the names, empirical analysis of the data elements' values would not suggest any similarity between them, yet the connectivity established in the metadata registry shows that both data elements employ data value domains that are mapped together. Documenting data element synonyms is valuable when determining data extract and transformation rules for master data integration.
6.5. Information Architecture
For MDM, we would expect to see two views of information models: the current state view consisting of the existing models used to represent master objects and the conformed model to be used for the master repository. In fact, there may be an additional model defined as well as a canonical model used for exchange or migration between existing models and the master model.
Both the logical models and their physical counterparts are constructed from the data elements documented in the previous level of the metadata stack. And within the information architecture level, we see a logically “interleaved” assembly, driven on the conceptual front by descriptions of master data object types and their structure and driven on the more concrete front using defined data models.
6.5.1. Master Data Object Class Types
Analysts can speculate on which master data object class types exist within the organization. Typical lists start with customer, product, employee, and supplier—the conceptual entities with which the organization does business. Yet there is a difference between the conceptual entities that the applications are expected to use and the actual instances in which these entities are documented and ultimately managed.
Analysis of the data sets from the bottom up and the business processes from the top down will help subject matter experts identify recurring concepts, manifested as information entities that share similar, if not identical structures. These similar entities reflect themes that are commonly used across the application fabric, and patterns will emerge to expose the conceptual master objects in the organization. Cataloging the details of agreed-to master data object types that are used (or will be used) helps in later processes for mapping existing instance models to the master model for each object type. In turn, a focused review of the data objects that are used and shared across applications will reveal a more comprehensive list of potential master data objects.
This component of the metadata model is used to maintain the set of master object types and will incorporate a list of the master object concepts with a logical enumeration of the high-level structure. More important, this layer should also document the relationships that are manifested through the business process and work flows.
6.5.2. Master Entity Models
Having articulated the types of each master object used in the organization, a resolved master model for each object type will be developed as the core representation. Each logical model reflects the attribution for the master object, referring to data elements defined at the data element layer. This will, by default, also provide the associated agreed-to definitions for the data elements.
The existence of defined models drives three management activities related to application migration and development. First, the model becomes the default for persistence of master data. Although the actual architecture will depend on many operational and functional requirements, the core model managed within the metadata repository is the logical starting point for any stored data systems. Second, within each business area, there must be object models suitable for application program manipulation, and these object models must correspond to the persistent view. Third, master data will be shared among applications, some of which may be legacy applications that require wrappers and facades along with transformations into and back out of the master model, suggesting the need for defined exchange model for information sharing.
6.5.3. Master Object Directory
To facilitate the development of a migration strategy for legacy applications, as well as to document entity use for planning and impact analysis, the metadata repository should also maintain a directory that maps the applications that use specific master objects. The mapping should describe whether the application uses the version of the master data object as presented by the MDM environment or whether the application uses an internal data structure that represents (and perhaps copies data in from and out to) a corresponding master data object structure. In other words, this component tracks how master object types are mapped to the applications that use them.
6.5.4. Relational Tables
Lastly, the metadata repository will maintain the actual relational data models for both the master object types and the instance representations used by the applications.
6.6. Metadata to Support Data Governance
In Chapter 4 we looked at the necessity for data governance as part of MDM. Data governance, which is a collection of processes for overseeing the alignment of data use with achieving business objectives, is supported through documenting the directives for oversight derived from the information policies associated with the business policies that are managed at the highest level of the metadata stack. At this level, we capture the information quality rules and how they are applied to the information objects, as well as the service level agreements (SLAs) that dictate the contract between data suppliers and data consumers in terms of data quality metrics, measurement, and information acceptability.
6.6.1. Information Usage
Just as we maintain a mapping from the logical use of master data objects to their use by applications, a more general mapping from the data entities and their associated data elements to their application use can be maintained within the metadata repository. This mapping is critical for assessing the need for data transformations, data migrations, and the development of functional infrastructure supporting the movement of instance data from the application silo to the master data asset.
6.6.2. Information Quality
The business policies and their corresponding information policies provide the context for assessing the available data sources and how those data sources are used to populate the master data asset. More important, that process also will result in sets of data rules and directives that indicate quantifiable measures of information quality. These rules are managed as content and can even be linked to tools that automate data inspection, monitoring, event notification, and continuous reporting of master data quality.
6.6.3. Data Quality SLAs
A key component of establishing data governance is through the use of SLAs. That data quality SLA should delineate the location in the processing stream that it covers, the data elements covered by the agreement, and additional aspects of overseeing the quality, as listed in the sidebar. All of these will be documented as metadata within the repository, which will simplify the data stewards' ability to manage observance of the agreements.
▪ Business impacts associated with potential flaws in the data elements
▪ Data quality dimensions associated with each data element
▪ Assertions regarding the expectations for quality for each data element for each identified dimension
▪ Methods for measuring conformance to those expectations (automated or manual)
▪ The acceptability threshold for each measurement
▪ The individual to be notified in case the acceptability threshold is not met
▪ An explanation of how often monitoring is taking place
▪ A clarification of how results and issues will be reported
▪ A description of to whom and how often issues are reported
▪ The times for expected resolution or remediation of the issue
▪ A description of the escalation strategy that will be enforced when the resolution times are not met
▪ A process for logging issues, tracking progress in resolution, and measuring performance in meeting the SLA
6.6.4. Access Control
Consolidating data instances into a master data view presents some potential issues regarding security and privacy, necessitating policies for access rights and observing access control according to those policies. Consider that capturing identifying information in a master registry does not only enable the consolidation of data—it also enables the segregation of data when needed. For business processes that must enforce policies restricting access to protected information, policy compliance can be automated in an auditable manner.
There must be defined roles associated with master data access, whether by automated process or by individuals. In turn, each of these roles will be granted certain rights of access, which can restrict access at a level as granular as the data element level within record sets limited by specified filters. Individuals and stakeholders within the organization are then assigned roles and corresponding access rights; these assignments are archived within the metadata repository as well.
6.7. Services Metadata
Master data management is largely seen as providing value to client applications by virtue of providing access to a high quality data asset of uniquely identifiable master objects synchronized across the enterprise. However, it turns out that master service consolidation is a strong motivating factor for MDM, even (at times) trumping the value of the consolidated data asset. The process of analyzing the use of master data objects exposes the ways in which different applications create, access, modify, and retire similar objects, and this analysis helps in determining which data sets represent recognized master object types. The by-product of this analysis is not just knowledge of the master objects but also knowledge about the functionality applied to those objects.
The upshot is that as consolidated multiple master object views are aggregated into a single master model, the functionality associated with the life cycle of master objects can also be consolidated as well—there is no need to have three or four processes for creating a new customer or product when one will suffice. This becomes particularly valuable when add-on software applications are integrated into the environment—applications whose licensing, maintenance, and operations costs can be reduced when the data sets they were intended to support become reduced into a single master view.
6.7.1. Service Directory
There will be two collections of services. The first is an enumeration of the essential services employed by client business applications at a conceptual level, such as “create a customer” or “update a telephone number.” Master services can be segmented as well into core object services that address typical data life cycle events, such as “create or modify an object,” or business services applied as part of the business process workflow, such as “generate invoice” or “initiate product shipment.”
The second collection is a current view of the (possibly multiple) ways that each conceptual master service is actually deployed within the current environment. This is intended to assist in the development of an implementation road map by identifying the functional components to be ultimately replaced that will require an engineered wrapper during the migration process.
6.7.2. Service Users
In addition to documenting the list of services and the way each is currently deployed, the services metadata layer will also list the clients of the services. This is a list of both automated clients and individuals that invoke the functionality that will ultimately be implemented within the set of enumerated services. This inverse mapping from service to client also is used in impact analysis and migration planning, both for the determination of risk during the transition from the legacy framework to the MDM environment and for ongoing management, maintenance, and improvement of master data services.
6.7.3. Interfaces
There are metadata representing the different types of services and the users of those services. What is left will comprise the third component of master data services metadata, which captures the interfaces used by the clients (both automated and human) to invoke those services. Consolidating functionality into services must ensure that the newly created services support the application's current functional requirements, and that includes details about the different ways the services must be invoked and, consequently, any necessary parameterization or customization for the service layer. Alternatively, as functions are evaluated and their invocation methods reviewed, it may become apparent that even though the functionality appears to be the same across a set of applications, the ways that the functionality is invoked may signal discrete differences in the effects intended to occur. Capturing this information interface layer will help analysts to make this assessment.
6.8. Business Metadata
As we have seen, a master data environment can be valuable because it gives analysts the ability to consolidate more than just data, or even services; doing so will provide expected benefits in terms of improving data quality and reducing the complexity of developing and maintaining system functionality. Additional, and potentially greater, value can be achieved through the implementation of business policies imposed on the ways that processes interact with master objects.
It is one thing to consider the integration of all customer data records, and another to impose policy constraints such as those regarding the protection of private personal information or the segregation of access between different groups. In fact, many policies used to run the business correspond to information policies applied to master data, creating the opportunity for organizations to manage and control the observance of business policies as part of the MDM program.
Driving policy observance via metadata requires that the business policies themselves be documented and that their relationship to information policies be made explicit. In turn, the subject matter experts determine how the information policies reflect specific business rules to be applied to the data. The successive refinement of business policies down to information business rules opens opportunities for automating the way that business rule observance is monitored as well as rolling up to gauge business policy compliance. Business rules engines can be used to implement the monitoring of compliance and how that compliance rolls back up along the hierarchy, as is shown in Figure 6.4.
 |
| ▪Figure 6.4 Observance of business rules can be rolled up to report policy compliance. |
As an example, consider a business policy that restricts the organization from sharing customer information with trusted partners if the customer is under the age of 13 unless the organization has the customer's parental consent. This business policy, expressed in natural language, restricts a business process (“information sharing”) based on attribution of specific data instances (namely, birth date and parental consent). Therefore, this business policy suggests a number of information policies:
▪ The organization must capture customer birth date.
▪ The organization must conditionally capture parental consent.
▪ Only records for customers over the age of 13 and those that are under the age of 13 with parental consent may be shared.
In turn, there are business rules to be imposed regarding the structure of the master model, the completeness of the master records, and the implementation of the constraint during the process for data extraction in preparation for sharing. Each of these aspects represents pieces of knowledge to be documented and controlled via the master metadata repository.
6.8.1. Business Policies
At a simplistic level, a business policy is a statement that guides or constrains a business process as a way of controlling the outcome as well as side effects of the business process. Business policies, which may be either documented or undocumented, reflect general practices to be observed by those within an organization along with those that do business with the organization.
Business policies are expressed in natural language, but requiring subject matter experts to capture these policies within the metadata repository is a way to encourage more precision in expressing policies. The objective is to specify business policies in a manner that can be linked to the ways that the applications enforce them. Presumably, it may be possible to meet this objective by using information already managed within the metadata repository: concepts, business terms, business definitions, and semantics that are associated with commonly used business language. Business policies are more likely to be well structured if they have been specified using terms with agreed-to definitions.
6.8.2. Information Policies
The difference between a business policy and an information policy is that a business policy guides the business process whereas an information policy guides information architecture and application design. An information policy specifies one (of possibly many) information management requirements to support the observance of business policies. In the data-sharing example in Section 6.8, one business policy translated into three information policies. In turn, an information policy may guide the specification of one or more business rules.
6.8.3. Business Rules
A business rule specifies one particular constraint or directive associated with a data element, a collection of data elements, one record, a set of records, and so forth. A rule may specify a constraint and be used to filter or distinguish compliant data instances from noncompliant ones, and it could also trigger one or more actions to be taken should some condition evaluate to true. One or more business rules can be derived from an information policy, and documenting these rules within the metadata repository enables the application of the rules to be automated via an associated rules engine. The metadata repository provides a centralized location for the subject matter to be reviewed by experts before it is deployed into the rules engine.
6.9. Summary
The metadata requirements for master data management exceed the typical demands of application development, because the ability to consolidate and integrate data from many sources is bound to be hampered by variant business terms, definitions, and semantics. But once a decision is made to use metadata as a lever for enabling the migration to the master data environment, it is wise to consider the more sophisticated means for enterprise information management that can be activated via the metadata management program. The general processes for metadata management have been articulated here; evaluating the specific needs within an organization should lead to the definition of concrete information and functional requirements. In turn, the MDM team should use these requirements to identify candidate metadata management tools that support the types of activities described in this chapter.
Finally, the technology should not drive the process, but it should be the other way around. Solid metadata management supports more than just MDM—good enterprise information management relies on best practices in activating the value that metadata provides.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.