
Chapter 10. Data Consolidation and Integration
10.1. Introduction
Once the master data model issues have been resolved, the project reaches the point where data from the identified source data sets can be consolidated into the master environment. To develop the master repository, there are a number of considerations that must be thought out. First of all, one must always keep in mind that there are two aspects to consolidation and integration: the initial migration of data from source data and the ongoing integration of data instances created, modified, or removed from the master environment. The first aspect will be familiar to anyone involved in building a data warehouse or in any kind of data cleansing activity; the second aspect essentially moves inlined integration (which embeds consolidation tasks within operational services that are available any time new information is brought into the system) and consolidation into production systems as a way of preserving the consistency of the master data set.
So what is data integration? The most common understanding is that data integration comprises the processes for collecting data from different sources and making that data accessible to specific applications. Because data integration has largely been used for building data warehouses, it is often seen as part of collecting data for analysis, but as we see more operational data sharing activities, we can see that data integration has become a core service necessary for both analytics and operations. In this chapter, we explore the techniques employed in extracting, collecting, and merging data from various sources. The intention is to identify the component services required for creating the virtual data set that has a single instance and representation for every unique master data object and then use the data integration and consolidation services to facilitate information sharing through the master data asset.
2 Data federation. Complete master records are materialized on demand from the participating data sources.
3 Data propagation. Master data are synchronized and shared with (or “exported to”) participating applications.
10.2. Information Sharing
The approaches to information sharing via an MDM system differ based on application business requirements, especially in the areas of enterprise data consistency, data currency and synchronization, and data availability and latency. Because a successful MDM initiative is driven by information sharing, as data is consolidated into the repository, the participating applications will derive the benefit of using master data. Information is shared using data integration tools in three ways, as shown in the sidebar.
10.2.1. Extraction and Consolidation
One significant responsibility of data integration services is the ability to essentially extract the critical information from different sources and ensure that a consolidated view is engineered into the target architecture. Data extraction presupposes that the technology is able to access data in a variety of source applications as well as being able to select and extract data instance sets into a format that is suitable for exchange. Essentially, the capability involves gaining access to the right data sources at the right times to facilitate ongoing information exchange; consequently, data integration products are designed to seamlessly incorporate the following elements:
Data transformation. Between the time that the data instances are extracted from the data source and delivered to the target location, data rules may be triggered to transform the data into a format that is acceptable to the target architecture. These rules may be engineered directly within the data integration tool or may be alternate technologies embedded within the tool.
Data monitoring. A different aspect of applying business rules is the ability to introduce filters to monitor the conformance of the data to business expectations (such as data quality) as it moves from one location to another. The monitoring capability provides a way to incorporate the types of data rules both discovered and defined during the data profiling phase to proactively validate data and distinguish records that conform to defined data quality expectations and those that do not, providing measurements for the ongoing auditing necessary for data stewardship and governance.
Data consolidation. As data instances from different sources are brought together, the integration tools use the parsing, standardization, harmonization, and matching capabilities of the data quality technologies to consolidate data into unique records in the master data model.
Each of these capabilities contributes to the creation and consistency of the master repository. In those MDM programs that are put in place either as a single source of truth for new applications or as a master index for preventing data instance duplication, the extraction, transformation, and consolidation can be applied at both an acute level (i.e., at the point that each data source is introduced into the environment) and on an operational level (i.e., on a continuous basis, applied to a feed from the data source).
10.2.2. Standardization and Publication Services
One might consider data integration from a services-oriented perspective. In this approach, we don't think about extraction and transformation but rather view each source data system “publishing” its data to other service consumers. That service would take the data from internal, private persistence, transform it to the standardized exchange format, and then make it available for consumers. In this approach, transformations are handled within the source system's service layer, and no other application would need to be aware of how data instances had to be manipulated or transformed into the standardized form.
The benefit is that if all systems publish data into a standard schema, using standard semantics, this approach eliminates the need for a subsequent harmonization stage for master data objects. That way, the work is done at the end points and the workload is shared at the points where it can most easily be enforced close to the point of capture instead of waiting for the MDM layer that is consuming that data to carry that performance load.
10.2.3. Data Federation
Although the holy grail of MDM is a single master data source completely synchronized with all enterprise applications, MDM can be created by combining core identifying data attributes along with associated relevant data attributes into a master repository, as well as an indexing capability that acts as a registry for any additional data that is distributed across the enterprise. In some cases, though, only demographic identifying data is stored within the master repository, with the true master record essentially materialized as a compendium of attributes drawn from various sources indexed through that master registry. In essence, accessing the master repository requires the ability to decompose the access request into its component queries and assemble the results into the master view.
This type of federated information model is often serviced via Enterprise Application Integration (EAI) or Enterprise Information Integration (EII) styles of data integration tools. This capability is important in MDM systems built on a registry framework or using any framework that does not maintain all attributes in the repository for materializing views on demand. This style of master data record materialization relies on the existence of a unique identifier with a master registry that carries both core identifying information and an index to locations across the enterprise holding the best values for designated master attributes.
10.2.4. Data Propagation
The third component of data integration—data propagation—is applied to support the redistribution and sharing of master data back to the participating applications. Propagation may be explicit, with replicated, read-only copies made available to specific applications, may be deployed through replication with full read/write access that is subsequently consolidated, or may be incorporated more strategically using a service-oriented approach. MDM applications that employ the replication approach will push data from the master repository to one or more replication locations or servers, either synchronously or asynchronously, using guaranteed delivery data exchange. Again, EAI products are suitable to this aspect of data integration.
The alternate approach involves the creation of a service layer on top of the master repository to supplement each application's master data requirements. At one extreme, the master data is used as a way to ensure against the creation of duplicate data. At the other extreme, the applications that participate in the MDM program yield their reliance on their own version of the data and instead completely rely on the data that have been absorbed into the master repository. This range of capabilities requires that the access (both request and delivery) be provided via services, and that in turn depends on the propagation of data out of the repository and delivery to the applications.
10.3. Identifying Information
As we discussed in Chapter 8, every record that will be incorporated into a master repository or registry must be uniquely identifiable. Within every master data model, some set of data attribute values can be combined to provide a candidate key that is used to distinguish each record from every other. We have referred to these underlying data attributes as the “identifying attributes,” and the specific values are “identifying information.”Chapter 8 provided a method for determining identifying attributes, and at the point of developing the integration framework, we employ those identifying attributes and their values to develop the master registry.
10.3.1. Indexing Identifying Values
No matter which architectural approach is taken for assembling the underlying MDM system, there must be an identification service that is queried whenever an application wants to access any master records. This service must ensure satisfaction of the uniqueness constraint that for every entity within the system there is one and only one entry, no entity is duplicated within the system, and that if the entity has not been registered within the system, the service will not locate an entry. The identification service is supported through the use of a registry of entities that is indexed using the values contained within the identifying attributes.
In simplest terms, the index maps the combination of the identifying attribute values to the master record. Therefore, whenever an application wants to access an existing master record, the identification service should take the identifying attribute values as input, locate the registration entry within the index, and locate the master record. If there is no record for the entity, there will be no entry within the index for that set of identifying values. A straightforward approach for creating this indexed registry is a simple one-to-one mapping created from the composed identifying values and a pointer to the location of the master record. This table can be indexed by sorting the composed identifying values, thereby optimizing the ability to look up any specific record.
It is also important to note that to some extent, the concept of uniqueness itself is not necessarily cast in stone. The number of attributes that essentially qualify unique identification may be greater or fewer depending on the business requirements. For example, to a catalog company, two records may represent the same person if they share a name and address, but a surgeon may require a lot more data to ensure that the person on the operating table is the one needing surgery. In other words, the same set of records may be judged to be unique or not depending on the business client's perspective.
10.3.2. The Challenge of Variation
The indexed master registry of identifying values works well under one condition: that there is never a situation where there are variations in the identifying attributes for a specific entity. For example, as is displayed in Figure 10.1, many values may be assigned to an identifying attribute that might represent the same entity.
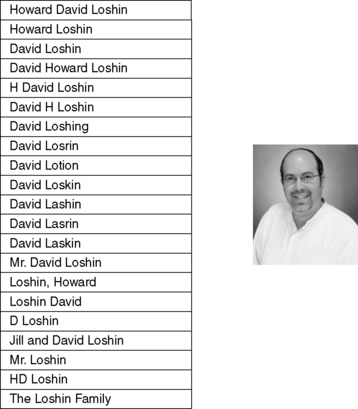 |
| ▪Figure 10.1 Multiple variant identifying values represent the same entity. |
Alternatively, as is seen in Figure 10.2, it is possible that a combination of identifying values (name “is an author”) may seem to refer to the same underlying entity but in reality map to two separate individuals. Performing a search for books written by “David Loshin” will return a list of books with “David Loshin” as the author, yet there are actually two authors who have the same (relatively unusual) name!
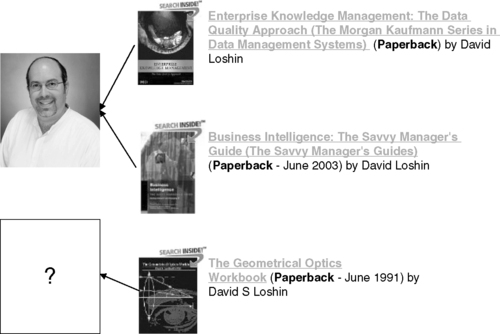 |
| ▪Figure 10.2 Of these three books authored by “David Loshin,” only two are attributable to me! |
The upshot is that there will be exceptions to the notion that every unique entity is likely to be referenced using variations of the identifying values. Consequently, the master identification service needs to incorporate a technique called identity resolution that finds close matches when an exact match cannot be found. Identity resolution relies on techniques that have been incorporated into data quality tools, and these sections review how these techniques are applied to enhance the master identification service.
10.4. Consolidation Techniques for Identity Resolution
Although the techniques used for data cleansing, scrubbing, and duplicate elimination have been around for a long time, their typical application was for static data cleanups, as part of preparation for migration of data into a data warehouse or migrations for application modernization. However, tools to help automate the determination of a “best record” clearly meet the needs of a master data consolidation activity as well, which is the reason that data quality tools have emerged as a critical component of MDM.
10.4.1. Identity Resolution
As introduced in Section 10.3, identity resolution refers to the ability to determine that two or more data representations can be resolved into one representation of a unique object. This resolution is not limited to people's names or addresses, because even though the bulk of data (and consequently, the challenge) is made up of person or business names or addresses, there is significant need for the resolution of records associated with other kinds of data, such as product names, product codes, object descriptions, reference data, and so forth.
For a given data population, identity resolution can be viewed as a two-stage process. The first stage is one of discovery and will combine data profiling activities with a manual review of data. Typically, simple probabilistic models can be evolved that then feed into the second stage, which is one of similarity scoring and matching for the purpose of record linkage. The model is then applied to a much larger population of records, often taken from different sources, to link and presumably to automatically establish (within predefined bounds) that some set of records refers to the same entity.
Usually, there are some bounds to what can be deemed an automatic match, and these bounds do not just depend on the quantification of similarity but must be defined based on the application. For example, there is a big difference between trying to determine if the same person is being mailed two catalogs instead of one and determining if the individual boarding the plane is on the terrorist list.
Identity resolution is similar, and it employs the tools and processes used for the determination of duplicates for the purpose of duplicate elimination or for value-added processes like householding. The following data quality tool functions are of greatest value to the master data integration process:
▪ Parsing and standardization. Data values are subjected to pattern analysis, and value segments are recognized and then put into a standard representation.
▪ Data transformation. Rules are applied to modify recognized errors into acceptable formats.
▪ Record matching. This process is used to evaluate “similarity” of groups of data instances to determine whether or not they refer to the same master data object.
In a number of cases, the use of data quality technology is critical to the successful implementation of a master data management program. As the key component to determining variance in representations associated with the same real-world object, data quality techniques are used both in launching the MDM activity and in governing its continued trustworthiness.
10.4.2. Parsing and Standardization
The first step in identity resolution is to separate the relevant components of the identifying attribute values and organize them in a manner that is manipulated in a predictable way. However, identifying values such as names, descriptions, or locations often reflects a semistructured view, with the critical tokens being peppered throughout a character string. As was shown in Figure 10.1, “David Loshin,” “Loshin, David,” “H David Loshin,” and “Howard Loshin” are examples of ways that a name can be represented; the important tokens, though, are first_name, middle_name, and last_name, each of which may (or may not) be provided within a specific name string. The important tokens are segregated using data parsing tools.
Data parsing tools enable the data analyst to define patterns that can be fed into rules engines that are used to distinguish between valid and invalid data values and to identify important tokens within a data field. When a specific pattern is matched, actions may be triggered. When a valid pattern is parsed, the separate components may be extracted into a standard representation. When an invalid pattern is recognized, the application may attempt to transform the invalid value into one that meets expectations.
Many data issues are attributable to situations where slight variance in representation of data values introduces confusion or ambiguity. For example, consider the different ways telephone numbers are formatted. Even though some have digits, some have alphabetic characters, and all use different special characters for separation, we all recognize each one as being a telephone number. However, to determine if these numbers are accurate (perhaps by comparing them to a master customer directory) or to investigate whether duplicate numbers exist when there should be only one for each supplier, the values must be parsed into their component segments (area code, exchange, and line) and then transformed into a standard format.
The human ability to recognize familiar patterns contributes to our ability to characterize variant data values belonging to the same abstract class of values; people recognize different types of telephone numbers because they conform to frequently used patterns. When an analyst can describe the format patterns that all can be used to represent a data object (e.g., Person Name, Product Description, etc.), a data quality tool can be used to parse data values that conform to any of those patterns and even transform them into a single, standardized form that will simplify the assessment, similarity analysis, and cleansing processes. Pattern-based parsing can automate the recognition and subsequent standardization of meaningful value components.
As data sources are introduced into the MDM environment, the analysts must assemble a mechanism for recognizing the supplied data formats and representations and then transform them into a canonical format in preparation for consolidation. Developed patterns are integrated with the data parsing components, with specific data transformations introduced to effect the standardization.
10.4.3. Data Transformation
Data standardization results from mapping the source data into a target structural representation. Customer name data provides a good example—names may be represented in thousands of semistructured forms, and a good standardizer will be able to parse the different components of a customer name (e.g., first name, middle name, last name, initials, titles, generational designations) and then rearrange those components into a canonical representation that other data services will be able to manipulate.
Data transformation is often rule based—transformations are guided by mappings of data values from their derived position and values in the source into their intended position and values in the target. Standardization is a special case of transformation, employing rules that capture context, linguistics, and idioms that have been recognized as common over time through repeated analysis by the rules analyst or tool vendor.
Interestingly, data integration tools usually provide data transformation ability and could perhaps even be used to support data quality activities. The distinction between data transformation engines and data parsing and standardization tools often lies in the knowledge base that is present in the data quality tools that drive the data quality processes.
10.4.4. Normalization
In some instances, there are different underlying data value domains for the same data element concept. For example, one data set describing properties may represent the number of bathrooms in terms of unites and fractions (e.g., 1½ baths), whereas another data set describing properties may represent the number of bathrooms using decimals (0.5 ½ bath, 0.75 = a bathroom with a shower stall, and 1.0 is a bathroom with a tub and shower). A frequent occurrence is the use of code tables to represent encoded values, or different precision used for quantified values (gallons versus liters). In these cases, before the data can be used, the values must be normalized into a reference framework defined for each master data attribute. The normalization rules are applied as part of the data transformation task.
In essence, these underlying data domains constitute reference data sets, which themselves are a part of a master data environment. The difference between reference data and master data is subtle. For many purposes, reference data may be completely encompassed within the metadata stack, as discussed in Chapter 6.
10.4.5. Matching/Linkage
Record linkage and matching is employed in identity recognition and resolution, and it incorporates approaches used to evaluate “similarity” of records for customer data integration or master data management the same way it is used in duplicate analysis and elimination, merge/purge, householding, data enhancement, and cleansing. One of the most common data quality problems involves two sides of the same coin:
1 When there are multiple data instances that actually refer to the same real-world entity
2 Where there is the perception that a record does not exist for a real-world entity when in fact it really does
These are both instances of false negatives, where two sets of identifying data values should have matched, but did not. In the first situation, similar, yet slightly variant representations in data values may have been inadvertently introduced into the system. In the second situation, a slight variation in representation prevents the identification of an exact match of the existing record in the data set.
This is a fundamental issue for master data management, as the expectation is that the master repository will hold a unique representation for every entity. This implies that the identity resolution service can analyze and resolve object entities as a component service of all participating applications. These issues are addressed through a process called similarity analysis, in which the degree of similarity between any two records is scored, most often based on weighted approximate matching between the set of identifying attribute values between the two records. If the score is above a specific threshold, the two records are deemed to be a match and are presented to the end client as most likely to represent the same entity. It is through similarity analysis that slight variations are recognized, data values are connected, and that linkage is subsequently established.
Attempting to compare each record against all the others to provide a similarity score is not only ambitious but also time consuming and computationally intensive. Most data quality tool suites use advanced algorithms for blocking records that are more likely to contain matches into smaller sets, whereupon different approaches are taken to measure similarity. Identifying similar records within the same data set probably means that the records are duplicated and may be subjected to cleansing or elimination. Identifying similar records in different sets may indicate a link across the data sets, which facilitates cleansing, knowledge discovery, and reverse engineering—all of which contribute to master data aggregation. It is the addition of blocking, similarity scoring, and approximate matching that transforms the simplistic master index into an identity resolution service, and it is the approximate matching that truly makes the difference.
10.4.6. Approaches to Approximate Matching
There are two basic approaches to matching. Deterministic matching, like parsing and standardization, relies on defined patterns and rules for assigning weights and scores for determining similarity. Alternatively, probabilistic matching relies on statistical techniques for assessing the probability that any pair of records represents the same entity. Deterministic algorithms are predictable in that the patterns matched and the rules applied will always yield the same matching determination. Performance, however, is tied to the variety, number, and order of the matching rules. Deterministic matching works out of the box with relatively good performance, but it is only as good as the situations anticipated by the rules developers.
Probabilistic matching relies on the ability to take data samples for “training” purposes by looking at the expected results for a subset of the records and tuning the matcher to self-adjust based on statistical analysis. These matchers are not reliant on rules, so the results may be nondeterministic. However, because the probabilities can be refined based on experience, probabilistic matchers are able to improve their matching precision as more record sets are analyzed.
Which approach is better? In the abstract, this question may be premature when asked outside of a specific business context. There are pros and cons to both methods in terms of accuracy, precision, tunability, oversight, consistency, and performance, and before selecting either one, one must assess what the business needs are, how matching fits into the consolidation strategy, how it is used in the unique identification service, and what the service-level expectations are.
However, combining deterministic and probabilistic matching may ultimately be the best approach. By enabling some degree of deterministic rule-based control, a large part of organization-specific matching requirements can be met, and in the instances where no corporate lore exists, the probabilistic approach can supplement the balance of the needs. Of course, that can be described the opposite way as well: the probabilistic approach can hit a large part of the statistically relevant match opportunities, and the deterministic rules can be applied where there is not enough support from the probabilistic approach.
Another potential trick to improve the precision of matching is to use the discovered relationships between data instances to help in determining the likelihood that two instances refer to the same real-world entity. For example, for some reasons people may use several different names for themselves in different environments, and names are grossly inadequate in many cases. However, the knowledge derived from identity resolution coupled with known relationships will help narrow down matching.
10.4.7. The Birthday Paradox versus the Curse of Dimensionality
The ability to assign similarity scores takes the number of data attributes and their value variance into consideration. However, no matter how carefully you have selected your identifying attributes, there are two concepts that will interfere with consistently predictable identity resolution: the birthday paradox and the curse of dimensionality.
The birthday paradox is associated with the probability that a set of randomly selected individuals within a small population will share the same birthday. It turns out that when the population size is 23, there is a greater than 50% chance that two people share a birth date (month and date), and that for 57 or more people, the probability is greater than 99% that two people share a birth date. In other words, within a relatively small population, there is a great chance that two different people share the same piece of identifying information, and this suggests that even with a carefully selected set of identifying attributes, there is still a chance that enough overlap between two distinct entities will be incorrectly determined to represent the same entity, leading to false positives.
On the other hand, we can view the set of selected identifying attributes as referring to a multidimensional space and that each set of values represents a point in that space. Similarity scoring is equivalent to seeking out points in the multidimensional space that are near enough to each other to potentially represent the same true location. However, the curse of dimensionality refers to the increase in the “volume” of the search space as one adds additional dimensions. Two random points on a one-inch line are more likely to be close together than two random points in a 1-inch square, which in turn are more likely to be closer together than two random points in a 1-inch cube, and so on as more dimensions are added. The implication is that as one adds more data elements to the set of identifying attributes, the chance that two similar records will not be recognized as such increases, leading to false negatives.
So in turn we have an even greater paradox: one concept suggests adding more attributes, whereas the other suggests restricting the set of identifying attributes. The upshot is that in the presence of variant data values, there is always going to be some uncertainty regarding the identity resolution service, and it requires governance and oversight to maintain a level of predictability.
10.5. Classification
Most sets of data objects can be organized into smaller subsets as they reflect some commonalities, and master data objects are no exception. Master data objects can often be classified within logical hierarchies or taxonomies; sometimes these are based on predefined classes, whereas interestingly, other data sets are self-organized. For example, products may be segmented into one set of categories when manufactured, another set when transferred from the factory to the warehouse, and yet another set when presented for sale. This means that different applications will have different views of master data and suggests that entity classification enhances the ability to integrate applications with a master data repository.
Forcing a classification scheme requires a significant amount of prior knowledge of the objects, how their attribution defines the segmentation, and even the categories for classification. Many business clients can clearly articulate the taxonomies and classification criteria for the data their applications use, whereas in other environments the data can be subjected to an assessment and analysis in order to construct the hierarchies and categories.
10.5.1. Need for Classification
Why do master data systems use classification? The reasons have less to do with the management of the systems and more to do with the application requirements and how the data items are used. Overall, classification improves the consolidation process by providing a blocking mechanism that naturally reduces the search space when trying to locate matches for a specific query. In a way that is similar to unique identification, classification is a service that is driven by the content embedded within structured data. For example, customers may be categorized based on their geographical location, their purchasing patterns, or personal demographics such as age and gender. These classification frameworks can be applied to customer-facing applications to enable a customer service representative to provide the appropriate level of service to that customer.
Alternatively, searching and locating matching entries within a master product database may be limited when solely relying on the specific words that name or describe each object. Because different terms are used to describe similar products, the data entities may require detailed type classification based on semantics. For example, “leatherette,” “faux leather,” “vinyl,” “pleather,” “synthetic leather,” and “patent leather” are all terms used to describe synthetic material that resembles leather. However, the use of any of these terms within a product description would indicate conceptual similarity among those products, but that would not necessarily be detected based on the text alone.
10.5.2. Value of Content and Emerging Techniques
Linking entities together based on the text tokens, such as first name or product code, restricts a master environment from most effectively organizing objects according to defined taxonomies. The classification process is intended to finesse the restriction by incorporating intelligence driven by the content and context. For example, a robust classifier can be trained to determine that the terms listed in Section 9.5.1 refer to synthetic leather, which in turn can be used to link entities together in which the descriptions have wide variance (e.g., a “vinyl pocketbook” and a “pleather purse” refer to the same type of product).
Text analysis of the semistructured or unstructured data can assign conceptual tags to text strings that delineate the text tokens that indicate their general semantics, and these semantic tags can be mapped to existing or emerging hierarchies. The result is that over time, an intelligent classification system can establish a “concept-based” connectivity between business terms, which then supports the precision of the categorization. Approaches such as text mining, text analysis, semantic analysis, meta-tagging, and probabilistic analysis all contribute to classification.
10.6. Consolidation
Consolidation is the result of the tasks applied to data integration. Identifying values are parsed, standardized, and normalized across the same data domains; subjected to classification and blocking schemes; and then submitted to the unique identification service to analyze duplicates, look for hierarchical groupings, locate an existing record, or determine that one does not exist. The existence of multiple instances of the same entity raises some critical questions shown in the sidebar.
The answers to the questions frame the implementation and tuning of matching strategies and the resulting consolidation algorithms. The decision to merge records into a single repository depends on a number of different inputs, and these are explored in greater detail in Chapter 9.
▪ What are the thresholds that indicate when matches exist?
▪ When are multiple instances merged into a single representation in a master repository as opposed to registration within a master registry?
▪ If the decision is to merge into a single record, are there any restrictions or constraints on how that merging may be done?
▪ At what points in the processing stream is consolidation performed?
▪ If merges can be done in the hub, can consuming systems consume and apply that merge event?
▪ Which business rules determine which values are forwarded into the master copy—in other words, what are the survivorship rules?
▪ If the merge occurs and is later found to be incorrect, can you undo the action?
▪ How do you apply transactions against the merged entity to the subsequently unmerged entities after the merge is undone?
10.6.1. Similarity Thresholds
When performing approximate matching, what criteria are used for distinguishing a match from a nonmatch? With exact matching, it is clear whether or not two records refer to the same object. With approximate matching, however, there is often not a definitive answer, but rather some point along a continuum indicating the degree to which two records match. Therefore, it is up to the information architect and the business clients to define the point at which two values are considered to be a match, and this is specified using a threshold score.
When identifying values are submitted to the integration service, a search is made through the master index for potential matches, and then a pair-wise comparison is performed to determine the similarity score. If that similarity score is above the threshold, it is considered a match. We can be more precise and actually define three score ranges: a high threshold above which indicates a match; a low threshold under which is considered not a match; and any scores between those thresholds, which require manual review to determine whether the identifying values should be matched or not.
This process of incorporating people into the matching process can have its benefits, especially in a learning environment. The user may begin the matching process by specifying specific thresholds, but as the process integrates user decisions about what kinds of questionable similarity values indicate matches and which do not, a learning heuristic may both automatically adjust the thresholds as well as the similarity scoring to yield a finer accuracy of similarity measurement.
10.6.2. Survivorship
Consolidation, to some extent, implies merging of information, and essentially there are two approaches: on the one hand, there is value in ensuring the existence of a “golden copy” of data, which suggests merging multiple instances as a cleansing process performed before persistence (if using a hub). On the other hand, different applications have different requirements for how data is used, and merging records early in the work streams may introduce inconsistencies for downstream processing, which suggests delaying the merging of information until the actual point of use. These questions help to drive the determination of the underlying architecture.
Either way, operational merging raises the concept of survivorship. Survivorship is the process applied when two (or more) records representing the same entity contain conflicting information to determine which record's value survives in the resulting merged record. This proc-ess must incorporate data or business rules into the consolidation process, and these rules reflect the characterization of the quality of the data sources as determined during the source data analysis described in Chapter 2, the kinds of transactions being performed, and the business client data quality expectations as discussed in Chapter 5.
Ultimately, every master data attribute depends on the data values within the corresponding source data sets identified as candidates and validated through the data requirements analysis process. The master data attribute's value is populated as directed by a source-to-target mapping based on the quality and suitability of every candidate source. Business rules delineate valid source systems, their corresponding priority, qualifying conditions, transformations, and the circumstances under which these rules are applied. These rules are applied at different locations within the processing streams depending on the business application requirements and how those requirements have directed the underlying system and service architectures.
Another key concept to remember with respect to survivorship is the retention policy for source data associated with the master view. Directed data cleansing and data value survivorship applied when each data instance is brought into the environment provides a benefit when those processes ensure the correctness of the single view at the point of entry. Yet because not all data instances imported into the system are used, cleansing them may turn out to be additional work that might not have been immediately necessary. Cleansing the data on demand would limit the work to what is needed by the business process, but it introduces complexity in managing multiple instances and history regarding when the appropriate survivorship rules should have been applied.
A hybrid idea is to apply the survivorship rules to determine its standard form, yet always maintain a record of the original (unmodified) input data. The reason is that a variation in a name or address provides extra knowledge about the master object, such as an individual's nickname or a variation in product description that may occur in other situations. Reducing each occurrence of a variation into a single form removes knowledge associated with potential aliased identifying data, which ultimately reduces your global knowledge of the underlying object. But if you can determine that the input data is just variations of one (or more) records that are already known, storing newly acquired versions linked to the cleansed form will provide greater knowledge moving forward, as well as enabling traceability.
10.6.3. Integration Errors
We have already introduced the concepts of the two types of errors that may be encountered during data integration. The first type of error is called a false positive, and it occurs when two data instances representing two distinct real-life entities are incorrectly assumed to refer to the same entity and are inadvertently merged into a single master representation. False positives violate the uniqueness constraint that a master representation exists for every unique entity. The second type of error is called a false negative, and it occurs when two data instances representing the same real-world entity are not determined to match, with the possibility of creating a duplicate master representation. False negatives violate the uniqueness constraint that there is one and only one master representation for every unique entity.
Despite the program's best laid plans, it is likely that a number of both types of errors will occur during the initial migration of data into the master repository, as additional data sets are merged in and as data come into the master environment from applications in production. Preparing for this eventuality is an important task:
▪ Determine the risks and impacts associated with both types of errors and raise the level of awareness appropriately. For example, false negatives in a marketing campaign may lead to a prospective customer being contacted more than once, whereas a false negative for a terrorist screening may have a more devastating impact. False positives in product information management may lead to confused inventory management in some cases, whereas in other cases they may lead to missed opportunities for responding to customer requests for proposals.
▪ Devise an impact assessment and resolution scheme. Provide a process for separating the unique identities from the merged instance upon identification of a false positive, in which two entities are incorrectly merged, and determine the distinguishing factors that can be reincorporated into the identifying attribute set, if necessary. Likewise, provide a means for resolving duplicated data instances and determining what prevented those two instances from being identified as the same entity.
These tasks both suggest maintaining historical information about the way that the identity resolution process was applied, what actions were taken, and ways to unravel these actions when either false positives or false negatives are identified.
10.6.4. Batch versus Inline
There are two operational paradigms for data consolidation: batch and inline. The batch approach collects static views of a number of data sets and imports them into a single location (such as a staging area or loaded into a target database), and then the combined set of data instances is subjected to the consolidation tasks of parsing, standardization, blocking, and matching, as described in Section 10.4. The inline approach embeds the consolidation tasks within operational services that are available at any time new information is brought into the system. Inlined consolidation compares every new data instance with the existing master registry to determine if an equivalent instance already exists within the environment. In this approach, newly acquired data instances are parsed and standardized in preparation for immediate comparison against the versions managed within the master registry, and any necessary modifications, corrections, or updates are applied as the new instance either is matched against existing data or is identified as an entity that has not yet been seen.
The approaches taken depend on the selected base architecture and the application requirements for synchronization and for consistency. Batch consolidation is often applied as part of the migration process to accumulate the data from across systems that are being folded into a master environment. The batch processing allows for the standardization of the collected records to seek out unique entities and resolve any duplicates into a single identity. Inlined consolidation is the approach used in operations mode to ensure that as data come into the environment, they are directly synchronized with the master.
10.6.5. History and Lineage
Knowing that both false positives and false negatives will occur directs the inclusion of a means to roll back modifications to master objects on determination that an error has occurred. The most obvious way to enable this capability is to maintain a full history associated with every master data value. In other words, every time a modification is made to a value in a master record, the system must log the change that was made, the source of the modification (e.g., the data source and set of rules triggered to modify the value), and the date and time that the modification was made. Using this information, when the existence of an error is detected, a lineage service can traverse the historical record for any master data object to determine at which point a change was made that introduced the error.
Addressing the error is more complicated, because not only does the error need to be resolved through a data value rollback to the point in time that the error was introduced, but any additional modifications dependent on that flawed master record must also be identified and rolled back. The most comprehensive lineage framework will allow for backtracking as well as forward tracking from the rollback point to seek out and resolve any possible errors that the identified flaw may have triggered. However, the forward tracking may be overkill if the business requirements do not insist on complete consistency—in this type of situation, the only relevant errors are the ones that prevent business tasks from successfully completing; proactively addressing potential issues may not be necessary until the impacted records are actually used.
10.7. Additional Considerations
The process of data integration solves a technical challenge to consolidate data into the master repository, but there are other considerations that may impact the process from a nontechnical aspect, especially when it comes to information rights: ownership, usage, access, and so on. Within these areas, questions regarding how the master data asset is (or may be) used to intersect with those questioning whether the data can be used within specific contexts. Here we explore some straightforward examples where policies overrule use.
10.7.1. Data Ownership and Rights of Consolidation
The appeal of mastering disparate data sets that represent the same conceptual data objects often leads to an enthusiasm for consolidation in which individuals may neglect to validate that data ownership issues will not impede the program. In fact, many organizations use data sourced from external parties to conduct their business operations, and that external data may appear to suitably match the same business data objects that are to be consolidated into the master repository. This may sound like an excellent opportunity to incorporate an additional data set into the master repository, but in fact there are likely to be issues regarding ownership of the data and contractual obligations relating to the ways that the data are used, including the following:
Licensing arrangements. Data providers probably license the use of the data that are being provided, as opposed to “selling” the data for general use. This means that the data provider contract will be precise in detailing the ways that the data are licensed, such as for review by named individuals, for browsing and review purposes directly through provided software, or for comparisons but not copied or stored. License restrictions will prevent consolidating the external data into the master.
Usage restrictions. More precisely, some external data may be provided or shared for a particular business reason and may not be used for any other purpose. This differs subtly from the licensing restrictions in that many individuals may be allowed to see, use, or even copy the data, but only for the prescribed purpose. Therefore, using the data for any other purpose that would be enabled by MDM would violate the usage agreement.
Segregation of information. In this situation, information provided to one business application must deliberately be quarantined from other business applications because of a “business-sensitive” nature, which also introduces complexity in terms of data consolidation.
Obligations on termination. Typically, when the provider arrangement ends, the data customer is required to destroy all copies of provided data; if the provider data have been integrated into a master repository, to what degree does that comingling “infect” the master? This restriction would almost make it impossible to include external data in a master repository without introducing significant safeguards to identify data sources and to provide selective rollback.
10.7.2. Access Rights and Usage Limitations
Alternatively, there may be data sets that are consolidated into a master view, with the constraint that the visibility of certain data attributes and their values is limited based on designated access rights. For example, in a health care environment, a patient's health record may contain information accumulated from many sources, yet there are different roles that may have access to different parts of the health record, ranging from the identifying information (which may be necessary to validate patient identity) to the entire health history, access to which being limited to the patients themselves and primary caregivers. Disclosure of protected information to the wrong individual may have compliance and legal ramifications, necessitating strict compliance to managing security and access to authorized individuals based on their roles.
In addition, individuals within different roles may have different levels of access to the master data. Different roles may have different access capabilities (determination of record existence, read, read/write, read/write/delete, etc.), and at the same time specific attributes may be protected in accordance to role-based permissions. Role-based access control coupled with user authentication can be deployed as a collection of access controls ensuring conformance to specified access and usage limitation policies. Conformance to these policies is managed in accordance with the data governance framework, enabling access management services to become incorporated as part of the master data service layer.
10.7.3. Segregation Instead of Consolidation
The question of information segregation arises in environments that manage similar data sets for lines of business that are restricted from interaction. In these kinds of environments, one potential intention for master data management is not bringing all the line-of-business data sets into one massive repository but rather to be used as a management initiative to ensure that restricted line of business data sets are not mixed together. The master registry can be used to ensure against inadvertent consolidation by managing the data lineage (as described in Section 10.6.5) and determining at any point if data sources have been compromised.
10.8. Summary
The central driver of master data management is the ability to locate the variant representations of any unique entity and unify the organization's view to that entity. The process by which this is accomplished must be able to access the candidate data sets, extract the appropriate identifying information, and then correctly assess similarity to a degree that allows for linkage between records and consolidation of the data into an application service framework that permits access to the unified view. The technical components of this process—parsing, standardization, matching and identity resolution, and consolidation—must be integrated within two aspects of the master environment: the underlying technical infrastructure and models that support the implementation, and the governance framework that oversees the management of information access and usage policies.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.