
Chapter 7. Identifying Master Metadata and Master Data
7.1. Introduction
After a determination is made regarding the development and deployment of an MDM program, a number of architectural decisions need to be addressed, including the determination of an architectural approach, the analysis of tools and technology to support the operational aspects of MDM, the evaluation of existing technical capabilities underlying those operational aspects, and the identification of component services to meet enterprise requirements. However, to some extent the questions raised by this decision-making process are premature. Before determining how to manage the enterprise master data asset, more fundamental questions need to be asked and comprehensively explored regarding the assets themselves, such as the following:
▪ Which data objects are highlighted within the business processes as master data objects?
▪ Which data elements are associated with each of the master data objects?
▪ Which data sets would contribute to the organization's master data?
▪ How do we locate and isolate master data objects that exist within the enterprise?
▪ How can we employ approaches for metadata and data standards for collecting and managing master metadata?
▪ How do we assess the variances between the different representations in order to determine standardized models for data extraction and data consolidation?
▪ How do we apply techniques to consolidate instances in a standardized representation into a single view?
Because of the ways that diffused application architectures have evolved within different divisions within the organization, it is likely that despite the conceptually small number of core master objects used, there are going to be many ways that these objects are modeled, represented, and stored.
For example, there may be different applications that require details of sets of products, such as product category. Any application that maintains product details data will rely on a defined data model that maintains the category. Yet one application will track category through classification codes, others may maintain both codes and category descriptions, and others may embed the category data within other attributes. Those that maintain the product category codes and descriptions will do it differently. Scan through the product data sets within your own organization, and you are likely to find “CATEGORY” and “CTGRY_CODE” attributes with a wide range of field lengths.
The same thing can be said for customer data. Applications managing contact information for individual customers depend on data sets that maintain the customer's name. As noted in Chapter 5, whereas one application contains data elements to store an individual's full name, others may break up the name into its first, middle, and last parts. And even for those that have data elements for the given and family names of a customer, various names and field lengths are employed, as Figure 7.1 illustrates.
 |
| ▪Figure 7.1 Variance in data types for similar data elements. |
These variations may pose a barrier to consolidation (and subsequent ongoing data synchronization), but they also are a rich source of knowledge about the ways that the core objects are attributed. The definition of a data object's data type is sometimes consistent with the application use, but just as often as not, the lengths and types are based on speculation of how the data elements will be used over time. In the latter case, there are opportunities for reviewing data element usage with respect to architecture, as part of a process for identifying the objects that represent master data.
The challenges are not limited to determining what master objects are used but rather to incorporating the need to find where master objects are used and to chart a strategy for standardizing, harmonizing, and consolidating their components in a way that enables the presentation of a master data asset. When the intention is to create an organizational asset that is not just another data silo, it is imperative that your organization provide the means for both the consolidation and integration of master data as well as facilitate the most effective and appropriate sharing of that master data.
7.2. Characteristics of Master Data
The master data identification process consists of two main activities. One is a top-down process for reviewing the enterprise data model(s) and any documented business process models to identify which data objects are critical within the many business application work streams. The other is a bottom-up process that evaluates the enterprise data assets to find applications that use data structures that reflect what can be identified as master data objects and resolve them into a proposed master data environment. Both approaches examine business process dependence on information and the ways that the data objects are categorized and organized for the different business purposes. Ultimately, the path taken to identify master data will probably combine aspects of both approaches, coupled with some feet-on-on-the-ground knowledge along with some common sense.
7.2.1. Categorization and Hierarchies
Let's review our definition of master data from Chapter 1:
Master data objects are those core business objects used in the different applications across the organization, along with their associated metadata, attributes, definitions, roles, connections, and taxonomies. Master data objects are those key “things” that matter the most—the things that are logged in our transaction systems, measured and reported in reporting systems, and analyzed in analytical systems.
Aside from the preceding description, though, master data objects share certain characteristics:
▪ The real-world objects modeled within the environment as master data objects will be referenced in multiple business areas and business processes. For example, the concept of a “vendor” is relevant to procurement, purchasing, accounting, and finance.
▪ Master data objects are referenced in both transaction and analytical system records. Both the sales and the customer service systems may log and process the transactions initiated by a customer. Those same activities may be analyzed for the purposes of segmentation, classification, and marketing.
▪ Master data objects may be classified within a semantic hierarchy, with different levels of classification, attribution, and specialization applied depending on the application. For example, we may have a master data category of “party,” which in turn is comprised of “individuals” or “organizations.” Those parties may also be classified based on their roles, such as “prospect,” “customer,” “supplier,” “vendor,” or “employee.”
▪ Master data objects may have specialized application functions to create new instances as well as to manage the updating and removal of instance records. Each application that involves “supplier” interaction may have a function enabling the creation of a new supplier record.
▪ They are likely to have models reflected across multiple applications, possibly embedded in legacy data structure models or even largely unmodeled within flat file structures.
▪ They are likely to be managed separately in many systems associated with many different applications, with an assumption within each that their version is the only correct version.
For any conceptual master data type there will be some classifications or segmentations that naturally align along hierarchies, such as corporate ownership for organizations, family households for individuals, or product classification. However, the ways that even some of these hierarchical classification schemes (also referred to as “taxonomies”) are applied to the data instances themselves might cross multiple segments. For example, a “party” may represent either an individual or an organization; however, a party categorized as an individual may be further classified as both a “customer” and an “employee.”
As a valuable by-product of evaluating and establishing the hierarchies and taxonomies, we gain a degree of consistency that relates operations to reporting. The same master data categories and their related taxonomies would then be used for transactions, reporting, and analysis. For example, the headers in a monthly sales report may be derived from the master data categories and their qualifiers (e.g., sales by customer by region by time period). Enabling transactional systems to refer to the same data objects as the subsequent reporting systems ensures that the analysis reports are consistent with the transaction systems.
7.2.2. Top-Down Approach: Business Process Models
The top-down approach seeks to determine which business concepts are shared in practice across the different business processes. Because the operations of a business are guided by defined performance management goals, an efficient organization will define its business policies to be aligned with the organization's strategic imperatives and then implement business processes that support those policies. A business process, in this environment, is a coordinated set of activities intended to achieve a desired goal or produce a desired output product. Business process models are designed to capture both the high level and detail of the business process, coupled with the underlying business rules originating from the business objectives and subsequent auxiliary material that accompanies the corresponding definitions.
The traditional approach to designing business applications involves documenting the end clients' needs and then refining the ways that available technical solutions can be used to meet those needs. In essence, business objectives lead to formalizing the business policies. Those business policies then drive the definition of functional and informational requirements. The applications are then designed to implement these requirements as business logic operating on the underlying data objects.
Although as a matter of fact many application architectures emerge organically, the developed business applications are always intended to implement the stated business policies. Therefore, application designers should always strive to synchronize the way they implement policies with the ways that other applications in the enterprise implement business policies. To do this, the organization must maintain the relationships between business strategy and the components of the application's model:
▪ The business policies derived from the business objectives
▪ Business process models that reflect the work streams
▪ The orchestrations and the functional specifications that define high-level process-oriented services
▪ The common semantics (for terms and facts) associated with the data objects and their corresponding business rules
Given an understanding of the way that a business application can be designed and implemented, we can apply the top-down approach to identifying the sources for master data by reviewing the business process models and identifying which data objects are critical within the processing streams of more than one application. What we will find is that individual business activities depend on the sharing or exchange of data objects. Those objects that would be shared are the ones that analysts can anticipate to be managed as master data.
Each shared data object has underlying metadata, a role within the business process, as well as its representation within the environment, suggesting a characterization as key data entities (as was discussed in Chapter 4). These key data entities reflect the business terms employed within the process, and those business terms are eventually rolled up into facts about the business process and its operations. Those key data entities that appear with relevant frequency as touch points within the business process models become the logical candidates for data mastering.
7.2.3. Bottom-Up Approach: Data Asset Evaluation
The bottom-up approach seeks to identify the master data objects that are already in use across the organization. This approach evaluates the enterprise data assets to locate applications using what are, in effect, replicas of master data objects and then enable their resolution into a proposed master data environment This is more of a widespread assessment of the data sets performed using data discovery tools and documenting the discoveries within a metadata management framework, as suggested in Chapter 6. This process incorporates these stages, which are examined in greater detail in this chapter:
▪ Identifying structural and semantic metadata and managing that metadata in a centralized resource
▪ Collecting and analyzing master metadata from empirical analysis
▪ Evaluating differences between virtually replicated data structures and resolving similarity in structure into a set of recognized data elements
▪ Unifying semantics when possible and differentiating meanings when it is not possible
▪ Identifying and qualifying master data
▪ Standardizing the representative models for extraction, persistence, and sharing of data entities managed as master data objects
7.3. Identifying and Centralizing Semantic Metadata
One of the objectives of a master data management program is to facilitate the effective management of the set of key data entity instances that are distributed across the application environment as a single centralized master resource. But before we can materialize a single master record for any entity, we must be able to do the following:
1 Discover which data resources contain entity information.
2 Determine which data resources act as the authoritative source for each attribute.
3 Understand which of the entity's attributes carry identifying information.
4 Extract identifying information from the data resource.
5 Transform the identifying information into a standardized or canonical form.
6 Establish similarity to other records that have been transformed into a standardized form.
Fully blown, this process entails cataloging the data sets, their attributes, formats, data domains, definitions, contexts, and semantics, not just as an operational resource, but rather in a way that can be used to catalog existing data elements and automate master data consolidation, along with governing the ongoing application interactions with the MDM service layers.
In other words, to manage the master data, one must first be able to manage the master metadata. But as there is a need to resolve multiple variant models into a single view, the interaction with the master metadata must facilitate resolution of the following elements:
▪ Format at the element level
▪ Structure at the instance level
▪ Semantics across all levels
7.3.1. Example
In Figure 7.2, we look at the example of the two different representations for “customer” first displayed in Figure 7.1. Note that we are only looking at resolving the representations for data entities, not their actual values—that is discussed in Chapter 10 on data consolidation.
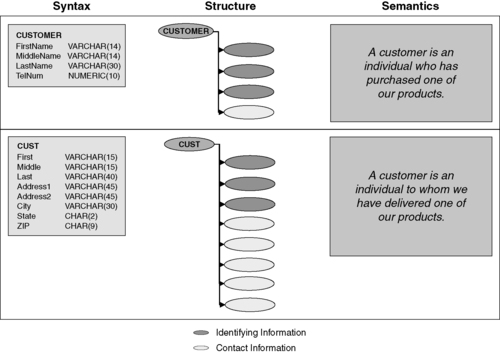 |
| ▪Figure 7.2 Preparation for a master data integration process must resolve the differences between the syntax, structure, and semantics of different source data sets. |
The first representation has four attributes (FirstName, MiddleName, LastName, and TelNum), whereas the second representation has eight (First, Middle, Last, Address1, Address2, City, State, and Zip). The data elements are reviewed at the three levels (syntactic, structural, and semantic). At the syntactic level, we can compare the data types and sizes directly and see that there are apparently minor differences—first and middle names are of length 14 in the top example but are of length 15 in the bottom; there is a similar difference for the corresponding last name fields.
At the structural level, though, we see some more pointed differences. Reviewing the data elements shows that each of these entities contains data related to two different aspects of the “person” master data type. One aspect is the identifying information, which incorporates the data values used to make a distinction between specific instances, such as name or assigned identifiers (social security numbers, customer account numbers, etc.). The other aspect is related entity data that is not necessarily required for disambiguation. In this example, there are data elements associated with contact information that could potentially have been isolated as its own conceptual master data object type.
Lastly, reviewing the semantics of the business terms associated with the data entities reveals another subtle difference between the two data models. In one application, the concept of customer refers to those who have “purchased one of our products,” whereas the other defines a customer as a person to whom we have “delivered one of our products.” The latter definition is a bit broader than the first in some ways (e.g., items such as marketing material sent free of charge to prospects may be categorized as products) and is limiting in others (e.g., service customers are not included).
7.3.2. Analysis for Integration
The sidebar highlights the three stages in master data resolution that need to dovetail as a prelude to any kind of enterprise-wide integration, suggesting three corresponding challenges for MDM.
1 Collecting and analyzing master metadata so that there is a comprehensive catalog of existing data elements
2 Resolving similarity in structure to identify differences requiring structural reorganization for application interaction
3 Understanding and unifying master data semantics to ensure that objects with different underlying data types are not inadvertently consolidated in error
7.3.3. Collecting and Analyzing Master Metadata
One approach involves analyzing and documenting the metadata associated with all data objects across the enterprise, in order to use that information to guide analysts seeking master data. The challenge with metadata is that to a large extent it remains sparsely documented. However, many of the data sets may actually have some of the necessary metadata documented. For example, relational database systems allow for querying table structure and data element types, and COBOL copybooks reveal some structure and potentially even some alias information about data elements that are components of a larger logical structure.
On the other hand, some of the data may have little or no documented metadata, such as fixed-format or character-separated files. If the objective is to collect comprehensive and consistent metadata, as well as ensure that the data appropriately correlates to its documented metadata, the analysts must be able to discover the data set's metadata, and for this, data profiling is the tool of choice. Data profiling tools apply both statistical and analytical algorithms to characterize data sets, and the result of this analysis can drive the empirical assessment of structure and format metadata while simultaneously exposing embedded data models and dependencies.
Discoveries made through the profiling process should be collected into a metadata repository, and this consolidated metadata repository will eventually enumerate the relevant characteristics associated with each data set in a standardized way, including the data set name, its type (such as different storage formats, including relational tables, indexed flat VSAM file, or comma-separated files), and the characteristics of each of its columns/attributes (e.g., length, data type, format pattern, among others).
At the end of this process, we will not just have a comprehensive catalog of all data sets, but we will also be able to review the frequency of metamodel characteristics, such as frequently used names, field sizes, and data types. Capturing these values with a standard representation allows the metadata characteristics themselves to be subjected to the kinds of statistical analysis that data profiling provides. For example, we can assess the dependencies between common attribute names (e.g., “CUSTOMER”) and their assigned data types (e.g., VARCHAR(20)) to identify (and potentially standardize against) commonly used types, sizes, and formats.
7.3.4. Resolving Similarity in Structure
Despite the expectations that there are many variant forms and structures for your organization's master data, the different underlying models of each master data object are bound to share many commonalities. For example, the structure for practically any “residential” customer table will contain a name, an address, and a telephone number. Interestingly, almost any vendor or supplier data set will probably also contain a name, an address, and a telephone number. This similarity suggests the existence of a de facto underlying concept of a “party,” used as the basis for both customer and vendor. In turn, the analyst might review any model that contains those same identifying attributes as a structure type that can be derived from or is related to a party type.
Collecting the metadata for many different applications that rely on the same party concept allows the analyst to evaluate and document the different data elements that attribute a party in its different derivations. That palette of attributes helps the analyst to assess how each model instance maps to a growing catalog of data models used by each master data entity type.
There are two aspects to analyzing structure similarity for the purpose of identifying master data instances. The first is seeking out overlapping structures, in which the core attributes determined to carry identifying information for one data object are seen to overlap with a similar set of attributes in another data object. The second is identifying where one could infer “organic derivation” or inheritance of core attributes in some sets of data objects that are the same core data attributes that are completely embedded within other data objects, as in the case of the “first name,” “middle name,” and “last name” attributes that are embedded within both structures displayed in Figure 7.2. Both cases indicate a structural relationship. When related attributes carry identifying information, the analyst should review those objects to determine if they indeed represent master objects.
7.4. Unifying Data Object Semantics
The third challenge focuses on the qualitative differences between pure syntactic or structural metadata (as we can discover through the profiling process) and the underlying semantic metadata. This involves more than just analyzing structure similarity. It involves understanding what the data mean, how that meaning is conveyed, how that meaning “connects” data sets across the enterprise, how the data are used, and approaches to capturing semantics as an attribute of your metadata framework.
As a data set's metadata are collected, the semantic analyst must approach the business client to understand that data object's business meaning. One step in this process involves reviewing the degree of semantic consistency in how data element naming relates to overlapping data types, sizes, and structures, such as when “first” and “first name” both refer to an individual's given name. The next step is to document the business meanings assumed for each of the data objects, which involves asking questions such as these:
▪ What are the definitions for the individual data elements?
▪ What are the definitions for the data entities composed of those data elements?
▪ Are there authoritative sources for the definitions?
▪ Do similar objects have different business meanings?
The answers to these question not only help in determining which data sets truly refer to the same underlying real-world objects, they also contribute to an organizational resource that can be used to standardize a representation for each data object as its definition is approved through the data governance process. Managing semantic metadata as a central asset enables the metadata repository to grow in value as it consolidates semantics from different enterprise data collections.
7.5. Identifying and Qualifying Master Data
Many master data object types are largely similar and reflect generic structural patterns (such as party, location, time, etc.). We can attempt to leverage standard or universal models and see if it is necessary to augment these models based on what is discovered empirically. This essentially marries the top-down and the bottom-up approaches and enables the analyst to rely on “off-the-shelf” master data models that have been proven in other environments. Those universal models can be adapted as necessary to meet the business needs as driven by the business application requirements.
Once the semantic metadata has been collected and centralized, the analyst's task of identifying master data should be simplified. As more metadata representations of similar objects and entities populate the repository, the frequency with which specific models or representations appear will provide a basis for assessing whether the attributes of a represented object qualify the data elements represented by the model as master data. By adding characterization information for each data set's metadata profile, more knowledge is added to the process of determining the source data sets that are appropriate for populating a master data repository, which will help in the analyst's task.
7.5.1. Qualifying Master Data Types
The many data types that abound, especially within the scope of the built-in types, complicate the population of the metadata repository. Consider that numbers can be used for quantity as easily as they can be used for codes, but a data profile does not necessarily indicate which way the values are being used within any specific column. One approach to this complexity is to simplify the characterization of the value set associated with each column in each table.
At the conceptual level, designating a value set using a simplified classification scheme reduces the level of complexity associated with data variance and allows for loosening the constraints when comparing multiple metadata instances. For example, we can limit ourselves to the six data value classes shown in the sidebar.
1 Boolean or flag. There are only two valid values, one representing “true” and one representing “false.”
2 Time/date stamp. A value that represents a point in time.
3 Magnitude. A numeric value on a continuous range, such as a quantity or an amount.
4 Code enumeration. A small set of values, either used directly (e.g., using the colors “red” and “blue”) or mapped as a numeric enumeration (e.g., 1 = “red,” 2 = “blue”).
5 Handle. A character string with limited duplication across the set, which may be used as part of an object name or description (e.g., name or address_line_1 fields contain handle information).
6 Cross-reference. An identifier (possibly machine-generated) that either is uniquely assigned to the record or provides a reference to that identifier in another data set.
7.5.2. The Fractal Nature of Metadata Profiling
At this point, each data attribute can be summarized in terms of a small number of descriptive characteristics: its data type, length, data value domain, and so on. In turn, each data set can be described as a collection of its component attributes. Looking for similar data sets with similar structures, formats, and semantics enables the analyst to assess each data set's “identifying attribution,” try to find the collections of data sets that share similar characteristics, and determine if they represent the same objects.
Using data profiling to assess data element structure allows the analyst to collect structural metadata into a metadata repository. The analysis to evaluate the data attributes to find the ones that share similar characteristics is supplemented by data profiling and parsing/standardization tools, which also help the analyst to track those attributes with similar names. The analyst uses profiling to examine the data value sets and assign them into value classes and then uses the same tools again to detect similarities between representative data metamodels.
In essence, the techniques and tools we can use to determine the sources of master data objects are essentially the same types of tools that we will use later to consolidate the data into a master repository. Using data profiling, parsing, standardization, and matching, we can facilitate the process of identifying which data sets (tables, files, spreadsheets, etc.) represent which master data objects.
7.5.3. Standardizing the Representation
The analyst is now presented with a collection of master object representations. But as a prelude to continuing to develop the consolidation process, decisions must be made as part of the organization's governance process. To consolidate the variety of diverse master object representations into an environment in which a common master representation can be materialized, the relevant stakeholders need to agree on common representations for data exchange and for persistence, as well as the underlying semantics for those representations. This common model can be used for both data exchange and master data persistence itself; these issues are explored further in Chapter 8.
As discussed in Chapter 4, MDM is a solution that integrates tools with policies and procedures for data governance, so there should be a process for defining and agreeing to data standards. It is critical that a standard representation be defined and agreed to so that the participants expecting to benefit from master data can effectively share the data, and the techniques discussed in Chapter 10 will support the organization's ability to share and exchange data.
7.6. Summary
This chapter has considered the challenge of master data discovery. That process depends on the effective collection of metadata from the many application data sets that are subject to inclusion in the master data repository. This depends on a process for analyzing enterprise metadata—assessing the similarity of syntax, structure, and semantics as a prelude to identifying enterprise sources of master data.
Because the objective in identifying and consolidating master data representations requires empirical analysis and similarity assessment as part of the resolution process, it is reasonable to expect that tools will help in the process. Luckily, the same kinds of tools and techniques that will subsequently be used to facilitate data integration can also be employed to isolate and catalog organizational master data.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.