
Chapter 8. Data Modeling for MDM
8.1. Introduction
In Chapter 2, we looked at collecting business data requirements, and in Chapter 6 and Chapter 7, we looked at the documentation and annotation of metadata for proposed master data objects and existing replicas of master data objects. But a core issue for MDM is the ability to capture, consolidate, and then deliver the master representation for each uniquely identifiable entity. At this point, assume that the MDM team has successfully traversed the critical initial stages of the master data management program—most important, clarifying the business need, assessing the information architectures, and profiling available data sets to identify candidate sources for materializing the master data asset.
Having used our tools and techniques to determine our master data types and determine where master data are located across organization applications, we are now at a point when we must consider bringing the data together into a managed environment. Yet here we have a challenge: the data sources that contribute to the creation of the master representation may have variant representations, but at some point there must be distinct models for the managing and subsequent sharing of master data.
In this chapter we look at the issues associated with developing models for master data—from extraction, consolidation, persistence, and delivery. We explore the challenges associated with the variant existing data models and then look at some of the requirements for developing the models used for extraction, consolidation, persistence, and sharing. It is important to realize that becoming a skilled practitioner of data modeling requires a significant amount of training and experience, and this chapter is mostly intended to highlight the more significant issues to be considered when developing models for MDM.
8.2. Aspects of the Master Repository
For the most part in the previous chapters, we have shied away from making any assumptions about the logical or physical formats of a persistent “master repository,” because there are different architectural styles that will rely on different sets of master data elements. The details of these different architectural styles are treated in greater detail in Chapter 9, but the common denominator among the different styles is the need to model the identifying attributes of each master entity. As we will see in Chapter 10, the ability to index the master registry and consolidate records drawn from multiple data sources hinges on matching records against those same identifying attributes.
8.2.1. Characteristics of Identifying Attributes
Within every master data model, some set of data attribute values can be combined to provide a candidate key that is used to distinguish each record from every other, and because each unique object can be presumably identified using this combination of data values, the underlying data attributes are referred to as the “identifying attributes,” and the specific values are “identifying information.” Identifying attributes are those data elements holding the values used to differentiate one entity instance from every other entity instance.
For example, consider a master object for a “consulting agreement.” For the most part, legal documents like consulting agreements are largely boilerplate templates, attributed by the specifics of a business arrangement, such as the names of the counterparties, the statement of work, and financial details. One might consider that one agreement could be distinguished from another based on the names of the counterparties, yet every agreement is in relation to a specific set of counterparties for specific tasks and may not cover other sets of tasks or statements of work. Therefore, that pair of attributes (the name of the organization specifying the engagement and the one being contracted to perform the tasks) is not sufficient to identify the agreement itself. Instead, one must look to the set of attributes that essentially creates a unique key. In this case, we might add on the date of the agreement and a task order identifier to differentiate one agreement from all others.
8.2.2. Minimal Master Registry
No matter which architectural approach is used, the common denominator is the existence of a set of data attributes to formulate a keyed master index that can be used to resolve unique identities. This index is the resource consulted when new records are presented into the master environment to determine if there is an existing master data instance. As the following chapters will show, the master index may hold a number of common data attributes. However, the minimal set of attributes is the set of identifying attributes.
8.2.3. Determining the Attributes Called “Identifying Attributes”
Identifying attributes are interesting in that their usefulness depends on their content. The implication is that a set of data attributes is determined to be made up of identifying attributes because the assigned values in each record essentially describe the individual object represented by the record, whether that is a person, a company, a product, or some other entity. Therefore, the combination of values within each set of identifying attributes projected across the entire set must be unique, suggesting that any unique key is a candidate. The challenge with determining what the identifying attributes are lies in recognizing that defined key attributes (such as generated identifiers or generated primary or surrogate keys) do not naturally describe the represented object. A generated key tells you nothing about the record itself. In fact, generated keys are only useful inside the individual system and cannot be used across systems unless you develop a cross-referencing system to transform and map identifiers from one system to those in another.
The objective of the process for determining identifying attributes is to find the smallest set of data attributes within a data set whose values are unique across the data set and the potential combination of values in a new record that is not likely to duplicate those found in one of the existing records. In other words, the data values are unique for the initial data set and are expected to remain unique for any newly introduced records. To do this, one heuristic is to use what amounts to a reverse decision tree:
1 Limit the data elements to those that are truly descriptive of the represented entity.
2 Let the identifying information element set I begin with the empty set.
3 Seek out the data element d whose values are the most distinct.
4 Add d to the identifying information element set I.
5 If, for each record, the composed values in the data elements from I are not unique, return to step 3.
6 Information element set I is complete.
This process should yield a set of data elements that can be used to uniquely identify every individual entity. Remember that the uniqueness must be retained even after the data set has been migrated into the master environment as well as in production as the master data set grows.
In practice, this process will be performed using a combination of tools and careful consideration. Realize that data profiling tools will easily support the analysis. Frequency analysis, null value analysis, and uniqueness assessment are all functions that are performed by a data profiler and whose results are used to determine good value sets for identifying attributes.
8.3. Information Sharing and Exchange
If, as we have discussed before, the basic concept of MDM is to provide transparent access to a unified representation of each uniquely identifiable data instance within a defined entity class, it means that no matter what the ultimate representation will be, there must be models to accommodate absorbing data from multiple data sets, combining those data sets, identifying and eliminating duplicates, addressing potential mismatches, consolidating records, creating a master index or registry, and then publishing the master data back out to client applications. Basically, the essence of MDM revolves around data sharing and interchange.
8.3.1. Master Data Sharing Network
There are a number of interchanges of data within an MDM environment, as Figure 8.1 shows.
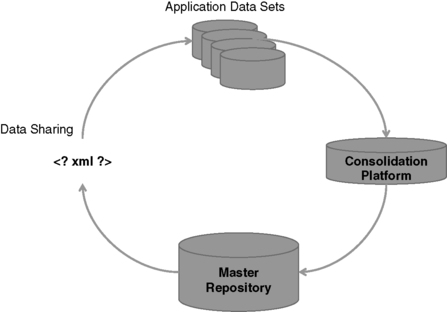 |
| ▪Figure 8.1 Data interchange within the MDM environment. |
As part of the initial data integration and consolidation process, data will be extracted from the source data sets and moved to a consolidation platform. After the master consolidation process is complete, the core master records will be moved to a master repository. (Note that implementations may merge the consolidation platform with the persistent repository.) Third, master records are made available to the application system (via query/publication services) and must be properly packaged. Last, the applications will need to unbundle the data from the exchange model in preparation for reintegration.
8.3.2. Driving Assumptions
Again we face a challenge: despite the fact that we have been able to identify sources of master data, the underlying formats, structures, and content are bound to be different. To accommodate the conceptual master repository, though, all of the data in these different formats and structures need to be consolidated at some point into a centralized resource that can both accommodate those differences and, in turn, feed the results of the consolidation back into those different original representations when necessary. This implies the following:
1 There must be a representative model into which data from source systems is extracted as a prelude to consolidation.
2 There must be a consolidated master representation model to act as the core repository.
3 Processes for capturing data, resolving the variant references into a single set, selecting the “best” record, and transforming the data into the repository model must be defined.
4 Processes must be created to enable the publication and sharing of master data back to the participating applications
Most of these issues are dependent on two things: creating suitable and extensible models for master data and providing the management layer that can finesse the issue of legacy model differences.
To meet the objectives of the MDM initiative, the data from participating business applications will eventually be extracted, transformed, and consolidated within a master data object model. Once the master data repository is populated, depending on the architectural style selected for the MDM implementation, there will be varying amounts of coordinated interaction between the applications and the master repository, either directly, or indirectly through the integration process flow.
Figure 8.2 presents a deeper look into the general themes of master data integration: connectors attach to production data sources and data sets are extracted and are then transformed into a canonical form for consolidation and integrated with what will have evolved into the master data asset. The integrated records populate the master repository, which then serves as a resource to the participating applications through a service layer. This service layer becomes the broker through which interactions occur between the applications and the master data asset. This means that we must look at both the conceptual issues of modeling an extraction and exchange model along with a manageable centralized repository that can be used for consolidation, identity management, publication, and access management.
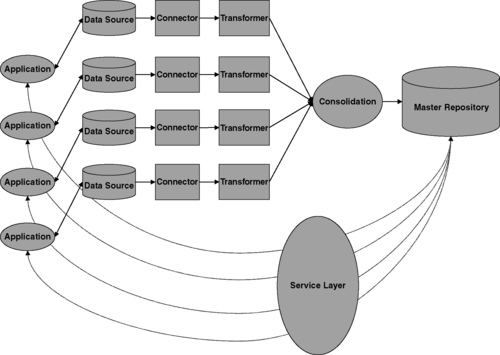 |
| ▪Figure 8.2 The master data integration process flow. |
8.3.3. Two Models: Persistence and Exchange
The conclusion is that we actually need at least two models: one for data exchange and sharing and one for persistence. We'll use the term “repository model” for the persistent view and “exchange model” for the exchange view.
8.4. Standardized Exchange and Consolidation Models
Master data are distributed across data sets supporting numerous enterprise applications, each with its own data/object models and data life cycle processes. As Figure 8.3 shows, different data sets may capture similar information about master data objects, but there are likely to be differences in the content across both the syntactic and the semantic dimensions.
 |
| ▪Figure 8.3 Different metadata representing similar objects. |
Syntactic differences refer to the structure of the objects, such as differences in column sizes or the specific data attributes collected within each table. In our example, consider the difference in the column lengths for the field representing a customer's last name—in one table it is 30 characters long, whereas in the other it is 40 characters long. Semantic differences refer to the underlying meaning—for example, in one data set a “customer” is a person to whom an item has shipped, whereas in another data set a “customer” is someone who has purchased an item.
The master exchange model must be able to accommodate data from all the source data sets. Subtle differences may be irrelevant out of context, but in the consolidation process, merging data sets together implies that the specific data instances in each set represent the same business concepts. Therefore, great precision in both definition and structure are necessary to ensure that the resulting master data set accurately reflects reality. The details of the source metadata are easily captured and managed in an enterprise metadata registry. This provides the basic information for the data model used for data exchange.
8.4.1. Exchange Model
The exchange model should be a standard representation for capturing the attributes relevant to the common business data elements to support the MDM program. This standard representation will be able to accommodate all of the data attribute types and sizes to enable information to be captured about each master object type. This scenario expects that the exchange model's set of data attributes will not prohibit the collection of any important (i.e., shared) attributes from each of the application models, and the format and structures for each attribute must support all the formats and structures used for that attribute across the many variant models.
The process for creating a canonical representation for the exchange model involves the steps shown in the following sidebar.
The resulting model for exchange can be manifested in different ways. A simple representation consists of a fixed-field table, where each field length for each attribute is as wide as the largest data element that holds values for that attribute. Other file formats might include data elements separated by special characters. More sophisticated approaches would rely on standard design schema such as XML to model data instances. Either way, the exchange representation is basically a linearized (that is, one whose relational structure is flattened to fit within a transferable message) format of the most “liberal” size representation for each data element. This does not mean forcing all applications to be modified to meet this model, but rather adopting an exchange model that does not eliminate any valuable data from contributing to the matching and linkage necessary for integration.
2 Enumeration of master data attributes. This requires reviewing the different representations associated with the business requirements that suggest the components of the conceptual master data object and then listing each of the data attributes with its corresponding metadata: table, data element name(s), sizes, and so on. For example, one customer data set may maintain names and addresses, whereas another may maintain names, addresses, and telephone numbers.
3 Resolution of master attribute structure. Some conceptual data attributes may be represented using multiple columns, whereas some data fields may hold more than one attribute. Some attributes are managed within wide tables, whereas others are associated using relational structures. This step requires clarifying the names and definitions of the core data attributes, determining a table structure that is best suited to exchange, and documenting how the source data sets are mapped to each core attribute.
4 Resolution of master attribute type. At this point the structure has been defined, but the type and size of each master representation of each element still needs to be defined to hold any of the values managed within any of the source data attributes.
8.4.2. Using Metadata to Manage Type Conversion
Metadata constraints must be employed when transforming data values into and out of the standardized format to prevent inappropriate type conversions. For example, in one system, numeric identifiers may be represented as decimal numbers, whereas in another the same identifiers may be represented as alphanumeric character strings. For the purposes of data extraction and sharing, the modeler will select one standard representation for the exchange model to characterize that identifier, and services must be provided to ensure that data values are converted into and out of that standardized format when (respectively) extracted from or published back to the client systems.
8.4.3. Caveat: Type Downcasting
There is one issue that requires some careful thought when looking at data models for exchange. Extracting data in one format from the contributing data sources and transforming that data into a common standardized form benefits the consolidation process, and as long as the resulting integrated data are not cycled back into application data sets, the fact that the exchange model is set to accommodate the liberal set of data values is not an issue.
The problem occurs when copying data from the exchange model back into the application data sets when the application data elements are not of a size large enough to accommodate the maximum sized values. In the example shown in Figure 8.3, the exchange model would have to allow for a length of 40 for the “Last Name” data attribute. However, the data element for LastName in the table called “CUSTOMER” only handles values of length 30. Copying a value for last name from the exchange model back into the CUSTOMER table might imply truncating part of the data value.
The risk is that the result of truncation is that the stored value is no longer the same as the perceived master data value. This could cause searches to fail, create false positive matches in the application data set, or even cause false positive matches in the master data set during the next iteration of the consolidation phase. If these risks exist, it is worth evaluating the effort to align the application data set types with the ones in the exchange model. One approach might be considered drastic but ultimately worth the effort: recasting the types in the application data stores that are of insufficient type or size into ones that are not inconsistent with the standardized model. Although this approach may appear to be invasive, it may be better to bite the bullet and upgrade insufficient models into sufficient ones instead of allowing the standardized representative model to devolve into a least-common-denominator model that caters to the weakest links in the enterprise information chain.
8.5. Consolidation Model
There may also be a master data model used for consolidating data instances that will have a logical structure that both reflects the views provided by the source data sets and provides a reasonable (perhaps even partially denormalized) relational structure that can be used as an efficient key-oriented index. This model is optimized for the consolidation process (as we will describe in Chapter 10) and may be an adaptation of the ultimate model used for persisting master data objects.
The process for designing this model is an iterative one—more careful data element definitions may impact the table structure or even suggest a different set of master data attributes. Experimentation with source data values, target data representations, and the determination of identifying values will lead to adjustments in the set of data elements to drive consolidation. Guidance from the MDM solution provider may drive the consolidation model, either because of the analysis necessary for the initial migration and subsequent inline integration or because of the underlying matching and identity resolution services that support the master consolidation process. Fortunately, many MDM solutions provide base models for common master data objects (such as customer, or product) that can be used as a starting point for the modeling process.
8.6. Persistent Master Entity Models
Let's turn to the persistent master model. As previously discussed, a master data management initiative is intended to create a registry that uniquely enumerates all instances from a class of information objects that are relevant to a community of participants. In turn the registry becomes the focal point of application functionality for the different stages of the information object's life cycle: creation, review, modification, and retirement.
8.6.1. Supporting the Data Life Cycle
Supporting life cycle activities requires more comprehensive oversight as the expectations of the trustworthiness of the data grow and the number of participants increases. This becomes implicit in the system development life cycle for MDM, in which the quality of the managed content has to be ensured from the beginning of the project and as the sidebar that follows suggests.
Taking these points into consideration will help ensure that the models designed for master data management will be flexible enough to allow for growth while ensuring that the quality of the information is not compromised. To some extent, the modeling process is iterative, because there are interdependencies between the decisions regarding architecture, decisions regarding the services to be provided, decisions regarding data standards, and decisions regarding the models. To this end, there are some concepts that are valuable to keep in mind during this iterative process.
2 The policies and protocols governing the extraction, consolidation, and historical management of entity information need to be addressed before any extraction, transformation, or linkage management applications are designed in order to make sure that the proper controls are integrated into the MDM solution. Realize that as a by-product of the data integration process, some policies may emerge from the ETL and data quality processes, may be applied to the master data asset, but may also be pushed further back in the processing streams to help in flagging issues early in the information streams.
3 The models to be used for consolidation must be robust enough to capture the data extracted from the participant applications as well as complete enough for the resolution of identities and consolidation into a master index.
4 The models must also support the functional components to support creating, breaking, and remediating errors in entity linkage.
8.6.2. Universal Modeling Approach
One way to do this is to develop the model in a way that provides flexibility when considering that real-world entities may play multiple roles in multiple environments yet carry identifying information relevant to the long-term business expectations associated with a master representation. One approach is to use universal model representations for common data objects that can be adapted to contain as many (or as few) attributes as required. In turn, subclassed entities can be derived from these core representations to take advantage of entity inheritance.
For example, look at an organization that, among its master data object types, has a “customer” master object and an “employee” master object. The customer object contains information about identifying the specific customer: first name, last name, middle initial, customer identifier, and a link to a set of contact mechanisms. The employee object contains information about identifying the specific employee: first name, last name, middle initial, employee number, and a link to a set of contact information. For the most part, in this case “customers” and “employees” are both individuals, with mostly the same degree of attribution.
If the conceptual representations for customer and employee are basically the same (with some minor adjustments), it is reasonable to consider a common representation for “individual” and then take one of two approaches. The first is to develop subclasses for both “customer” and “employee” that are derived from the base “individual” entity, except both are enhanced with their own unique attributes. The second approach is to use the core underlying model for each individual and augment that model with their specific roles. This allows for inheritance of shared characteristics within the model.
In Figure 8.4, we see the use of a core model object for a person, which is then associated with one or more roles. For our example, we would have a customer role type and an employee role type. The beauty of this approach is that it enables identity resolution centered on the individual in a way that is isolated from the context in which the entity appears. An employee may also be a customer and may appear in both data sets, providing two sources of identifying values for the individual. The universal modeling approach provides the flexibility to hierarchically segregate different levels of description relevant to the end-client application as opposed to the attributes for MDM.
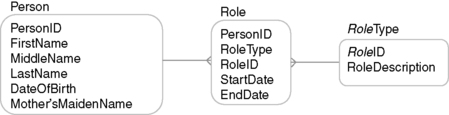 |
| ▪Figure 8.4 Example of employing a universal model object. |
8.6.3. Data Life Cycle
The persistent model must consistently support, within the master environment, the business operations that the client applications are expected to perform. If the master model is solely used as a lookup table for identity resolution and materialization of a master record on demand, then the requirements will be different than if the master data system is used as the sole resource for both operational and analytical applications.
Data life cycle events will be documented as a result of the process modeling. The typical CRUD (create, read, update, and delete) actions will be determined as a by-product of use cases, and the persistent model must reflect the core services supporting the defined requirements.
8.7. Master Relational Model
The universal modeling approach also paves the way for capturing the relationships that exist across the different master entity hierarchies, both through the inheritance chain and the entity landscape.
8.7.1. Process Drives Relationships
There are three kinds of relationships we want to capture:
Reflexive relationships. The existence of data instances in the same or different data sets referring to the same real-world object. Our example of an individual who plays both an employee role and a customer role demonstrates this type of relationship.
Process relationships. The connectivity associated with the business processes as reflected in the process model, use cases, and the business rules. Assertions regarding the way the business operates reveal the types of relationships at a high level (such as “customer buys products”), and this will be captured in the enterprise master model, especially in the context of transactional operations.
Analytical relationships. The connectivity that is established as a result of analyzing the data. An example might look at the set of customers and the set of suppliers and see that one of the customers works for one of the suppliers.
In essence, the “relationships” described here actually document business policies and could be characterized as business metadata to be captured in the metadata management system (as described in Chapter 6).
8.7.2. Documenting and Verifying Relationships
A process for verifying the modeled relationships is valuable, because it provides some level of confidence that both the explicit relationships and any discovered relationships are captured within the master models. From a high-level perspective, this can be done by reviewing the business process model and the metadata repository for data accesses, because the structure of any objects that are touched by more than one activity should be captured within the master models.
8.7.3. Expanding the Model
Lastly, there are two scenarios in which the master models are subject to review and change. The first is when a client application must be modified to reflect changes in the dependent business processes, and this would require modifications to its underlying model. The second, which may be more likely, occurs when a new application or data set is to be incorporated into the master data environment.
The first scenario involves augmenting the existing business process models with the tasks and data access patterns associated with the inclusion of the new application capabilities. The second scenario may also demand revision of the business process model, except when one is simply integrating a data set that is unattached to a specific application. In both cases, there are situations in which the models will be expanded. One example is if there is a benefit to the set of participating client applications for including additional data attributes. Another example is if the inclusion of a new data set creates a situation in which the values in the existing set of identifying attributes no longer provide unique identification, which would drive the creation of a new set of identifying attributes. A third example involves data attributes whose types and sizes cannot be accommodated within the existing models, necessitating a modification.
8.8. Summary
The creation of data models to accommodate the master data integration and management processes requires a combination of the skills a data modeler has acquired and the understanding of the business process requirements expected during a transition to a master data environment. The major issues to contend with for data modeling involve the following:
▪ Considering the flow and exchange of master data objects through the enterprise
▪ The iterative review of the business process model and discovered metadata to determine the identifying data attributes for the master data
▪ The creation of a data model for consolidation
▪ The creation of a core master data model for persistent storage of master data
It is wise to consider using a universal modeling approach, and an excellent resource for universal data models is Len Silverston's books (The Data Model Resource Book, volumes 1 and 2). The books provide a library of common data models that are excellent as starting points for developing your own internal master data object models.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.