
Microsoft Dynamics AX 2012 has the ability to run jobs in the batch by leveraging the abilities of the batch framework. The batch framework has two main purposes:
- Enabling the scheduling of jobs.
- Providing a mechanism to split jobs up into smaller parts and run them in parallel. By doing so, the batch job has a larger throughput and the response time is much better.
We want the service that we created earlier to use the same batch framework so that it has better performance. There are different approaches to this, and each has its advantages and disadvantages. The two most commonly used approaches can be described as the following:
- The individual task approach
- The helper approach
This approach will divide the batch job into a number of work units that are also known as runtime tasks. For each work unit, a runtime task will be created. So, you will have a one-to-one relation between work units and runtime tasks.
When your batch job is executed in batch, it is only responsible for creating the tasks for every unit of work to be done. Once the batch job is done creating tasks, it will be finished, and the batch framework will continue to work on the created runtime tasks in parallel. In the following diagram, you can see that a processing task is created for every record, which represents a unit of work:
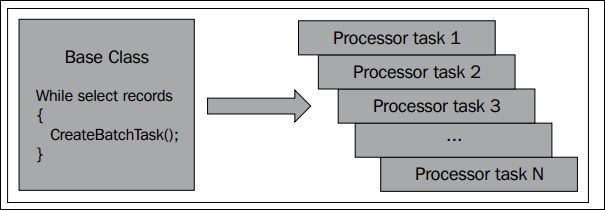
The advantages of using this approach are:
- It scales perfectly along with the schedule of the batch framework. It is possible to set up the batch framework to use a different number of threads depending on a time window during the day. The batch job will scale the number of threads depending on the number of threads that have been set up for that time window and either use or yield resources.
- Assuming that your business logic is well designed, less effort is required to make your batch job multithread-aware.
- You can easily create dependencies between the individual tasks.
The disadvantages of using this approach are:
- As some batch jobs may create a large number of tasks, there will be a lot of records in the batch framework's tables. This will have a negative impact on performance as the framework needs to check dependencies and constraints before running each of the tasks.
- Though this approach is ideal to scale the schedule of the batch framework, you do not have control over the amount of threads that are processing your batch job on each of the batch servers. Once your task is assigned to a batch group picked up by an AOS, all of the free thread slots will be used for the processing of your tasks.
The second approach that you can use to split up the work is by using helpers. Instead of creating an individual task for every unit of work to be done, we create a fixed number of threads. This resolves the issue that we faced with the individual tasks where there were too many batch tasks being created in the batch framework tables.
After creating a fixed number of helper threads, we need to introduce a staging table to keep track of the work to be done. The helpers themselves look into this staging table to determine the next thing to be done when they have finished their current task.
The steps to be followed when creating batch jobs that use this approach are as follows:
- Create a staging table that contains the work list.
- Create your batch job and let it be responsible for queuing the work in the staging table.
- Build a worker class that can deal with the processing of one staging table record (contains business logic).
- Create a helper class that is able to pick the next task and call the worker.
- Add code to the batch job to spawn helper threads until the desired number of helpers is available.
As for the staging table, you need to provide the following fields in the staging table:
- An identifier field
- A reference field that may point to a record or contain information that helps the workers know what needs to be done
- A status field to keep track of what's done and what needs to be done
Also, keep in mind that helpers must use pessimistic locking to retrieve the records from the staging table. This is to make sure that two helper threads do not select the same record and start working on the same task. In the following diagram, you can see that although a record is created for each unit of work, only 10 helpers are created, independent of the amount of records to be processed in the work queue:
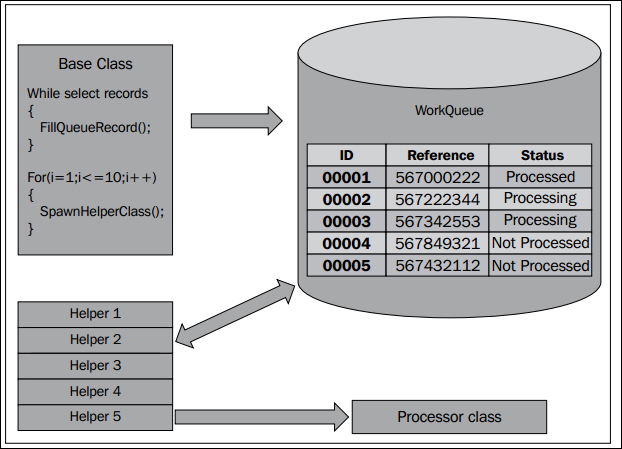
The advantages of using this approach are:
- You have control over the number of threads that are processing your batch job. This can be useful when you want your tasks to leave threads open on the AOS for other batch jobs when scaling the number of threads available for batch processing on the AOS instance.
- The batch tables are not filled with a huge number of tasks as only a fixed number of helper threads are created. This lowers the performance hit when checking dependencies and constraints.
- If you put a little effort into a generic solution for this approach, you can reuse the same staging table for different batch jobs.
The disadvantages of using this approach are:
- Because the number of threads is fixed, this approach does not scale as well as the individual task approach. Scaling up the number of threads on the AOS servers will not result in more working threads or higher throughput.
- It is a little more work to create the staging table needed for the helper threads to keep track of the work to be done as compared to spawning runtime tasks.
- This approach is not suitable to process a huge number of small tasks as maintaining the staging table would have a negative influence on the performance and throughput.
Tip
Useful link
If you want to learn more about these two approaches, you can find a series of blog posts on this topic on the MSDN blog of the Dynamics AX Performance Team. The first blog post of the series can be found at http://blogs.msdn.com/b/axperf/archive/2012/02/24/batch-parallelism-in-ax-part-i.aspx.
Now that we know the differences between these approaches, we can go ahead and update our SysOperation service to provide multithreading support. Because implementing both approaches would take too long, we will use only the individual task approach. Firstly, we have to extend our service class from the SysOperationServiceBase class. The declaration should look like the following code:
class CVRRentalDueDateReminderService extends SysOperationServiceBase
{
}This is needed because the
SysOperatonServiceBase class contains methods that allow us to work with the batch header and check whether the code is running in the batch.
Next, we add a new operation to our service. This operation differs from the existing one because it does not do the work itself; instead, it creates runtime tasks that do the work. The full code listing is as follows:
[SysEntryPointAttribute(true)]
public void checkDueDatesMulti(CVRRentalDueDateReminderContract _dueDateReminderContract)
{
QueryRun queryRun;
CVRMember cvrMember;
BatchHeader batchHeader;
SysOperationServiceController runTaskController;
CVRRentalDueDateReminderContract runTaskContract;
Query taskQuery;
// Get the query from the data contract
queryRun = new QueryRun(_dueDateReminderContract.getQuery());
// Loop all the members in the query
while (queryRun.next())
{
// Get the current member record
cvrMember = queryRun.get(tableNum(CVRMember));
// Create a new controller for the runtime task
runTaskController = new SysOperationServiceController( classStr(CVRRentalDueDateReminderService), methodStr(CVRRentalDueDateReminderService, checkDueDates));
// Get a data contract for the controller
runTaskContract = runTaskController.getDataContractObject('_dueDateReminderContract'),
// create a query for the task
taskQuery = new Query(queryStr(CVRMember));
taskQuery.dataSourceTable(tableNum(CVRMember)).addRange(fieldNum(CVRMember, Id)).value(cvrMember.Id);
// set variables for the data contract
runTaskContract.setQuery(taskQuery);
runTaskContract.parmNumberOverdueDays(_dueDateReminderContract.parmNumberOverdueDays());
// If running in batch
if(this.isExecutingInBatch())
{
// If we do not have a batch header yet
if(!batchHeader)
{
// Get one
batchHeader = this.getCurrentBatchHeader();
}
// Create a runtime task
batchHeader.addRuntimeTask(runTaskController, this.getCurrentBatchTask().RecId);
}
else
{
// Not in batch, just run the controller here
runTaskController.run();
}
}
// After all of the runtime tasks are created, save the batchheader
if(batchHeader)
{
// Saving the header will create the batch records and add dependencies where needed
batchHeader.save();
}
}Let's break up the code and take a look at it piece by piece. The top part of the method remains roughly the same just up to the query part. We still get the query from the data contract and loop all of the results:
// Get the query from the data contract
queryRun = new QueryRun(_dueDateReminderContract.getQuery());
// Loop all the members in the query
while (queryRun.next())
{
// Get the current member record
cvrMember = queryRun.get(tableNum(CVRMember));What follows is more interesting. Instead of running our business logic, we create a controller for the runtime task and point to the
checkDueDates() method. In this example, we have chosen to reuse the same data contract and service operation that we created earlier to act as the runtime task:
runTaskController = new SysOperationServiceController(
classStr(CVRRentalDueDateReminderService),
methodStr(CVRRentalDueDateReminderService, checkDueDates));
// Get a data contract for the controller
runTaskContract = runTaskController.getDataContractObject('_dueDateReminderContract'),After creating a controller, a data contract is constructed to pass to the runtime task. We reuse the same contract that is also used by the job service. Because of this, we need to create a query object that contains a range on the member's Id field, as shown in the following code snippet:
// Get a data contract for the controller
runTaskContract = runTaskController.getDataContractObject('_dueDateReminderContract'),
// create a query for the task
taskQuery = new Query(queryStr(CVRMember));
taskQuery.dataSourceTable(tableNum(CVRMember)).addRange(fieldNum(CVRMember, Id)).value(cvrMember.Id);
// set variables for the data contract
runTaskContract.setQuery(taskQuery);
runTaskContract.parmNumberOverdueDays(_dueDateReminderContract.parmNumberOverdueDays());What follows is the part that will create the runtime tasks. First, a batch header instance will be constructed if we do not have one already. The batch header class is used to contain the information on the runtime tasks that we add to the running batch job. Once the batch header class is instructed to save this information, the actual records are created in the batch table along with all of the dependencies, as shown in the following code:
// If running in batch
if(this.isExecutingInBatch())
{
// If we do not have a batch header yet
if(!batchHeader)
{
// Get one
batchHeader = this.getCurrentBatchHeader();
}
// Create a runtime task
batchHeader.addRuntimeTask(runTaskController, this.getCurrentBatchTask().RecId);
}
else
{
// Not in batch, just run the controller here
runTaskController.run();
}
}
// After all of the runtime tasks are created, save the
// batchheader
if(batchHeader)
{
// Saving the header will create the batch records and add
// dependencies where needed
batchHeader.save();
}