
9
Functional Programming Features
Introduction
The idea of functional programming is to focus on writing small, expressive functions that perform the required data transformations. Combinations of functions can often create code that is more succinct and expressive than long strings of procedural statements or the methods of complex, stateful objects. This chapter focuses on functional programming features of Python more than procedural or object-oriented programming.
This provides an avenue for software design distinct from the strictly object-oriented approach used elsewhere in this book. The combination of objects with functions permits flexibility in assembling an optimal collection of components.
Conventional mathematics defines many things as functions. Multiple functions can be combined to build up a complex result from previous transformations. When we think of mathematical operators as functions, an expression like ![]() , can be expressed as two separate functions. We might think of this as
, can be expressed as two separate functions. We might think of this as ![]() and
and ![]() . We can combine them as
. We can combine them as ![]() .
.
Ideally, we can also create a composite function from these two functions:

Creating a new composite function, ![]() , can help to clarify how a program works. It allows us to take a number of small details and combine them into a larger knowledge chunk.
, can help to clarify how a program works. It allows us to take a number of small details and combine them into a larger knowledge chunk.
Since programming often works with collections of data, we'll often be applying a function to all the items of a collection. This happens when doing data extraction and transformation. It also happens when summarizing data. This fits nicely with the mathematical idea of a set builder or set comprehension.
There are three common patterns for applying one function to a set of data:
- Mapping: This applies a function to all the elements of a collection,
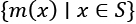 . We apply some function,
. We apply some function,  , to each item, x, of a larger collection,
, to each item, x, of a larger collection, 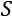 .
. - Filtering: This uses a function to select elements from a collection,
 . We use a function,
. We use a function,  , to determine whether to pass or reject each item, x, from the larger collection,
, to determine whether to pass or reject each item, x, from the larger collection, 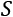 .
. - Reducing: This summarizes the items of a collection. One of the most common reductions is creating a sum of all items in a collection, , written as
 . Other common reductions include finding the smallest item, the largest one, and the product of all items.
. Other common reductions include finding the smallest item, the largest one, and the product of all items.
We'll often combine these patterns to create more complex composite applications. What's important here is that small functions, such as ![]() and
and ![]() , can be combined via built-in higher-order functions such as
, can be combined via built-in higher-order functions such as map(), filter(), and reduce(). The itertools module contains many other higher-order functions we can use to build an application.
The items in a collection can be any of Python's built-in types. In some cases, we'll want to use our own class definitions to create stronger mypy type-checking. In this chapter, we'll look at three data structures that can be validated more strictly: immutable NamedTuples, immutable frozen dataclasses, and mutable dataclasses. There's no single "best" or "most optimal" approach. Immutable objects can be slightly easier to understand because the internal state doesn't change. Using one of these structures leads us to write functions to consume objects of one type and produce a result built from objects of a distinct type.
Some of these recipes will show computations that could also be defined as properties of a class definition created using the @property decorator. This is yet another design alternative that can limit the complexity of stateful objects. In this chapter, however, we'll try to stick to a functional approach, that is, transforming objects rather than using properties.
In this chapter, we'll look at the following recipes:
- Writing generator functions with the
yieldstatement - Applying transformations to a collection
- Using stacked generator expressions
- Picking a subset – three ways to filter
- Summarizing a collection – how to reduce
- Combining map and reduce transformations
- Implementing "there exists" processing
- Creating a partial function
- Simplifying complicated algorithms with immutable data structures
- Writing recursive generator functions with the
yield fromstatement
Most of the recipes we'll look at in this chapter will work with all of the items in a single collection. The approach Python encourages is to use a for statement to assign each item within the collection to a variable. The variable's value can be mapped to a new value, used as part of a filter to create a subset of the collection, or used to compute a summary of the collection.
We'll start with a recipe where we will create functions that yield an iterable sequence of values. Rather than creating an entire list (or set, or some other collection), a generator function yields the individual items of a collection. Processing items individually saves memory and may save time.
Writing generator functions with the yield statement
A generator function is designed to apply some kind of transformation to each item of a collection. The generator is called "lazy" because of the way values must be consumed from the generator by a client. Client functions like the list() function or implicit iter() function used by a for statement are common examples of consumers. Each time a function like list() consumes a value, the generator function must consume values from its source and use the yield statement to yield one result back to the list() consumer.
In contrast, an ordinary function can be called "eager." Without the yield statement, a function will compute the entire result and return it via the return statement.
A consumer-driven approach is very helpful in cases where we can't fit an entire collection in memory. For example, analyzing gigantic web log files is best done in small doses rather than by creating a vast in-memory collection.
This lazy style of function design can be helpful for decomposing complex problems into a collection of simpler steps. Rather than building a single function with a complex set of transformations, we can create separate transformations that are easier to understand, debug, and modify. This combination of smaller transformations builds the final result.
In the language of Python's typing module, we'll often be creating a function that is an Iterator. We'll generally clarify this with a type, like Iterator[str], to show that a function generates string objects. The typing module's Generator type is an extension of the typing module's Iterator protocol with a few additional features that won't figure in any of these recipes. We'll stick with the more general Iterator.
The items that are being consumed will often be from a collection described by the Iterable type. All of Python's built-in collections are Iterable, as are files. A list of string values, for example, can be viewed as an Iterable[str].
The general template for these kinds of functions looks like this:
def some_iter(source: Iterable[P]) -> Iterator[Q]: …
The source data will be an iterable object – possibly a collection, or possibly another generator – over some type of data, shown with the type variable P. This results in an iterator over some type of data, shown as the type variable Q.
The generator function concept has a sophisticated extension permitting interaction between generators. Generators that interact are termed coroutines. To write type annotations for coroutines, the Generator type hint is required. This can provide the type value that's sent, as well as the type value of a final return. When these additional features aren't used, Generator[Q, None, None] is equivalent to Iterator[Q].
Getting ready
We'll apply a generator to some web log data using the generator to transform raw text into more useful structured objects. The generator will isolate transformation processing so that a number of filter or summary operations can be performed.
The log data has date-time stamps represented as string values. We need to parse these to create proper datetime objects. To keep things focused in this recipe, we'll use a simplified log produced by a web server written with Flask.
The entries start out as lines of text that look like this:
[2016-06-15 17:57:54,715] INFO in ch10_r10: Sample Message One
[2016-06-15 17:57:54,715] DEBUG in ch10_r10: Debugging
[2016-06-15 17:57:54,715] WARNING in ch10_r10: Something might have gone wrong
We've seen other examples of working with this kind of log in the Using more complex structures – maps of lists recipe in Chapter 8, More Advanced Class Design. Using REs from the String parsing with regular expressions recipe in Chapter 1, Numbers, Strings, and Tuples, we can decompose each line into a more useful structure.
The essential parsing can be done with the regular expression shown here:
pattern = re.compile(
r"[ (?P<date>.*?) ]s+"
r" (?P<level>w+) s+"
r"ins+(?P<module>.+?)"
r":s+ (?P<message>.+)",
re.X
)
This regular expression describes a single line and decomposes the timestamp, severity level, module name, and message into four distinct capture groups. We can match this pattern with a line of text from the log and create a match object. The match object will have four individual groups of characters without the various bits of punctuation like [, ], and :.
It's often helpful to capture the details of each line of the log in an object of a distinct type. This helps make the code more focused, and it helps us use mypy to confirm that types are used properly. Here's a NamedTuple that can be used to save data from the regular expression shown previously:
class RawLog(NamedTuple):
date: str
level: str
module: str
message: str
The idea is to use the regular expression and the RawLog class to create objects like the ones shown in the following example:
RawLog(date='2016-04-24 11:05:01,462', level='INFO', module='module1', message='Sample Message One')
This shows a RawLog instance with values assigned to each attribute. This will be much easier to use than a single string of characters or a tuple of character strings.
We have many choices for converting the log from a sequence of strings into a more useful RawLog data type. Here are a couple of ideas:
- We can read the entire log into memory. Once the entire log is in memory, we can use the
splitlines()method of the string to break the data into a list of log lines. If the log is large, this may be difficult. - What seems like a better idea is to convert each line, separately, from a string into a
RawLoginstance. This will consume much less memory. We can apply filters or do summarization on the lines without having to create large lists of objects.
The second approach can be built using a generator function to consume source lines and emit transformed RawLog results from each line. A generator function is a function that uses a yield statement. When a function has a yield, it builds the results incrementally, yielding each individual value in a way that can be consumed by a client. The consumer might be a for statement or it might be another function that needs a sequence of values, like the list() function.
This problem needs two separate examples of generator functions. We'll look at the transformation of a string into a tuple of fields in detail, and then apply the same recipe to transforming the date into a useful datetime object.
How to do it...
To use a generator function for transforming each individual line of text into a more useful RawLog tuple, we'll start by defining the function, as follows:
- Import the
remodule to parse the line of the log file:import re - Define a function that creates
RawLogobjects. It seems helpful to include_iterin the function name to emphasize that the result is an iterator overRawLogtuples, not a single value. The parameter is an iterable source of log lines:def parse_line_iter( source: Iterable[str]) -> Iterator[RawLog]: - The
parse_line_iter()transformation function relies on a regular expression to decompose each line. We can define this inside the function to keep it tightly bound with the rest of the processing:pattern = re.compile( r"[ (?P<date>.*?) ]s+" r" (?P<level>w+) s+" r"ins+(?P<module>.+?)" r":s+ (?P<message>.+)", re.X ) - A
forstatement will consume each line of the iterable source, allowing us to create and then yield eachRawLogobject in isolation:for line in source: - The body of the
forstatement can map each string instance that matches the pattern to a newRawLogobject using the match groups:if match := pattern.match(line): yield RawLog(*cast(Match, match).groups())
Here's some sample data, shown as a list of string values:
>>> log_lines = [
... '[2016-04-24 11:05:01,462] INFO in module1: Sample Message One',
... '[2016-04-24 11:06:02,624] DEBUG in module2: Debugging',
... '[2016-04-24 11:07:03,246] WARNING in module1: Something might have gone wrong'
... ]
Here's how we use this function to emit a sequence of RawLog instances:
>>> for item in parse_line_iter(log_lines):
... pprint(item)
RawLog(date='2016-04-24 11:05:01,462', level='INFO', module='module1', message='Sample Message One')
RawLog(date='2016-04-24 11:06:02,624', level='DEBUG', module='module2', message='Debugging')
RawLog(date='2016-04-24 11:07:03,246', level='WARNING', module='module1', message='Something might have gone wrong')
We've used a for statement to iterate through the results of the parse_line_iter() function, one object at a time. We've used the pprint() function to display each RawLog instance.
We could also collect the items into a list collection using something like this:
>>> details = list(parse_date_iter(data))
In this example, the list() function consumes all of the items produced by the parse_line_iter() function. It's essential to use a function such as list() or a for statement to consume all of the items from the generator. A generator is a relatively passive construct: until data is demanded, it doesn't do any work.
If we don't use a function or for statement to consume the data, we'll see something like this:
>>> parse_line_iter(data)
<generator object parse_line_iter at 0x10167ddb0>
The value of the parse_line_iter() function is a generator. It's not a collection of items, but a function that will produce items, one at a time, on demand from a consumer.
How it works...
Python has a sophisticated construct called an iterator that lies at the heart of generators and collections. An iterator will provide each value from a collection while doing all of the internal bookkeeping required to maintain the state of the process. A generator function fits the protocol of an iterator: it provides a sequence of values and maintains its own internal state.
Consider the following common piece of Python code:
for i in some_collection:
process(i)
Behind the scenes, something like the following is going on:
the_iterator = iter(some_collection)
try:
while True:
i = next(the_iterator)
process(i)
except StopIteration:
pass
Python evaluates the iter() function on a collection to create an iterator object for the collection, assigning it to the the_iterator variable. The iterator is bound to the collection and maintains some internal state information. The example code shown previously uses next() on the_iterator to get each value. When there are no more values in the collection, the next() function raises the StopIteration exception.
Each of Python's collection types implements the special method, __iter__(), required to produce an iterator object. The iterator produced by a Sequence or Set will visit each item in the collection. The iterator produced by a Mapping will visit each key for the mapping. We can use the values() method of a mapping to iterate over the values instead of the keys. We can use the items() method of a mapping to visit a sequence of (key, value) two-tuples. The iterator for a file will visit each line in the file.
The iterator concept can also be applied to functions. A function with a yield statement is called a generator function. It implements the protocol for an iterator. To do this, the generator returns itself in response to the iter() function. In response to the next() function, it yields the next value.
When we apply list() to a collection or a generator function, the same essential mechanism used by the for statement (the iter() and next() functions) will consume the individual values. The items are then combined into a sequence object.
Evaluating next() on a generator function is interesting. The statements of the generator function's body are evaluated until the yield statement. The value computed by the expression in yield becomes the result of next(). Each time next() is evaluated, the function resumes processing with the statement after yield and continues to the next yield statement, until the return statement, or until there are no more statements in the function's body.
To see how the yield statement works, look at this small function, which yields two objects:
>>> def gen_func():
... print("pre-yield")
... yield 1
... print("post-yield")
... yield 2
Here's what happens when we evaluate next():
>>> y = gen_func()
>>> next(y)
pre-yield
1
>>> next(y)
post-yield
2
The first time we evaluated next(), the first print() function was evaluated, then the yield statement produced a value. The function's processing was suspended and the >>> prompt was given. The second time we evaluated the next() function, the statements between the two yield statements were evaluated. The function was again suspended and a >>> prompt was displayed.
What happens next? There are no more yield statements in the function's body, so we observe the following:
>>> next(y)
Traceback (most recent call last):
File "<pyshell...>", line 1, in <module>
next(y)
StopIteration
The StopIteration exception is raised at the end of a generator function. Generally, a function's processing is ended by a return statement. Python allows us to omit the return statement, using an implicit return at the end of the indented block of statements.
In this example, the creation of the RawLog object depends on the order of the fields in NamedTuple precisely matching the order of the collected data from the regular expression used to parse each line. In the event of a change to the format, we may need to change the regular expression and the order of the fields in the class.
There's more...
The core value of creating applications around generator functions comes from being able to break complex processing into two parts:
- The transformation or filter to map to each item in the source of the data
- The source set of data with which to work
We can apply this recipe a second time to clean up the date attributes in each RawLog object. The more refined kind of data from each log line will follow this class definition:
class DatedLog(NamedTuple):
date: datetime.datetime
level: str
module: str
message: str
This has a proper datetime.datetime object for the timestamp. The other fields remain as strings. Instances of DatedLog are easier to sort and filter by date or time than instances of RawLog.
Here's a generator function that's used to refine each RawLog object into a DatedLog object:
def parse_date_iter(
source: Iterable[RawLog]) -> Iterator[DatedLog]:
for item in source:
date = datetime.datetime.strptime(
item.date, "%Y-%m-%d %H:%M:%S,%f"
)
yield DatedLog(
date, item.level, item.module, item.message
)
Breaking overall processing into several small generator functions confers several significant advantages. First, the decomposition makes each function succinct and focused on a specific task. Second, it makes the overall composition somewhat more expressive of the work being done.
We can combine these two generators in the following kind of composition:
>>> for item in parse_date_iter(parse_line_iter(log_lines)):
... pprint(item)
DatedLog(date=datetime.datetime(2016, 4, 24, 11, 5, 1, 462000), level='INFO', module='module1', message='Sample Message One')
DatedLog(date=datetime.datetime(2016, 4, 24, 11, 6, 2, 624000), level='DEBUG', module='module2', message='Debugging')
DatedLog(date=datetime.datetime(2016, 4, 24, 11, 7, 3, 246000), level='WARNING', module='module1', message='Something might have gone wrong')
The parse_line_iter() function will consume lines from the source data, creating RawLog objects when they are demanded by a consumer. The parse_data_iter() function is a consumer of RawLog objects; from this, it creates DatedLog objects when demanded by a consumer. The outer for statement is the ultimate consumer, demanding DataLog objects.
At no time will there be a large collection of intermediate objects in memory. Each of these functions works with a single object, limiting the amount of memory used.
See also
- In the Using stacked generator expressions recipe, we'll combine generator functions to build complex processing stacks from simple components.
- In the Applying transformations to a collection recipe, we'll see how the built-in
map()function can be used to create complex processing from a simple function and an iterable source of data. - In the Picking a subset – three ways to filter recipe, we'll see how the built-in
filter()function can also be used to build complex processing from a simple function and an iterable source of data.
Applying transformations to a collection
Once we've defined a generator function, we'll need to apply the function to a collection of data items. There are a number of ways that generators can be used with collections.
In the Writing generator functions with the yield statement recipe earlier in this chapter, we created a generator function to transform data from a string into a more complex object. Generator functions have a common structure, and generally look like this:
def new_item_iter(source: Iterable) -> Iterator:
for item in source:
new_item = some transformation of item
yield new_item
The function's type hints emphasize that it consumes items from the source collection. Because a generator function is a kind of Iterator, it will produce items for another consumer. This template for writing a generator function exposes a common design pattern.
Mathematically, we can summarize this as follows:

The new collection, N, is a transformation, ![]() , applied to each item, x, of the source,
, applied to each item, x, of the source, ![]() . This emphasizes the transformation function,
. This emphasizes the transformation function, ![]() , separating it from the details of consuming the source and producing the result.
, separating it from the details of consuming the source and producing the result.
This mathematical summary suggests the for statement can be understood as a kind of scaffold around the transformation function. There are two additional forms this scaffolding can take. We can write a generator expression and we can use the built-in map() function. This recipe will examine all three techniques.
Getting ready...
We'll look at the web log data from the Writing generator functions with the yield statement recipe. This had date as a string that we would like to transform into a proper datetime object to be used for further computations. We'll make use of the DatedLog class definition from that earlier recipe.
The text lines from the log were converted into RawLog objects. While these are a handy starting point because the attributes were cleanly separated from each other, this representation had a problem. Because the attribute values are strings, the datetime value is difficult to work with. Here's the example data, shown as a sequence of RawLog objects:
>>> data = [
... RawLog("2016-04-24 11:05:01,462", "INFO", "module1", "Sample Message One"),
... RawLog("2016-04-24 11:06:02,624", "DEBUG", "module2", "Debugging"),
... RawLog(
... "2016-04-24 11:07:03,246",
... "WARNING",
... "module1",
... "Something might have gone wrong",
... ),
... ]
We can write a generator function like this to transform each RawLog object into a more useful DatedLog instance:
import datetime
def parse_date_iter(
source: Iterable[RawLog]) -> Iterator[DatedLog]:
for item in source:
date = datetime.datetime.strptime(
item.date, "%Y-%m-%d %H:%M:%S,%f"
)
yield DatedLog(
date, item.level, item.module, item.message
)
This parse_date_iter() function will examine each item in the source using a for statement. A new DatedLog item is built from the datetime object and three selected attributes of the original RawLog object.
This parse_date_iter() function has a significant amount of scaffolding code around an interesting function. The for and yield statements are examples of scaffolding. The date parsing, on the other hand, is the distinctive, interesting part of the function. We need to extract this distinct function, then we'll look at the three ways we can use the function with simpler scaffolding around it.
How to do it...
To make use of different approaches to applying a generator function, we'll start with a definition of a parse_date() generator, then we'll look at three ways the generator can be applied to a collection of data:
- Refactor the transformation into a function that can be applied to a single row of the data. It should produce an item of the result type from an item of the source type:
def parse_date(item: RawLog) -> DatedLog: date = datetime.datetime.strptime( item.date, "%Y-%m-%d %H:%M:%S,%f") return DatedLog( date, item.level, item.module, item.message) - Create a unit test case for this isolated from the collection processing. Here's a doctest example:
>>> item = RawLog("2016-04-24 11:05:01,462", "INFO", "module1", "Sample Message One") >>> parse_date(item) DatedLog(date=datetime.datetime(2016, 4, 24, 11, 5, 1, 462000), level='INFO', module='module1', message='Sample Message One')
This transformation can be applied to a collection of data in three ways: a generator function, a generator expression, and via the map() function.
Using a for statement
We can apply the parse_date() function to each item of a collection using a for statement. This was shown in the Writing generator functions with the yield statement recipe earlier in this chapter. Here's what it looks like:
def parse_date_iter(
source: Iterable[RawLog]) -> Iterator[DatedLog]:
for item in source:
yield parse_date(item)
This version of the parse_date_iter() generator function uses the for statement to collect each item in the source collection. The results of the parse_date() function are yielded one at a time to create the DatedLog values for the iterator.
Using a generator expression
We can apply the parse_date() function to each item of a collection using a generator expression. A generator expression includes two parts – the mapping function, and a for clause enclosed by ():
- Write the mapping function, applied to a variable. The variable will be assigned to each individual item from the overall collection:
parse_date(item) - Write a
forclause that assigns objects to the variable used previously. This value comes from some iterable collection,source, in this example:for item in source - The expression can be the return value from a function that provides suitable type hints for the source and the resulting expression. Here's the entire function, since it's so small:
def parse_date_iter( source: Iterable[RawLog]) -> Iterator[DatedLog]: return (parse_date(item) for item in source)
This is a generator expression that applies the parse_date() function to each item in the source collection.
Using the map() function
We can apply the parse_date() function to each item of a collection using the map() built-in function. Writing the map() function includes two parts – the mapping function and the source of data – as arguments:
- Use the
map()function to apply the transformation to the source data:map(parse_date, source) - The expression can be the return value from a function that provides suitable type hints for the source and the resulting expression. Here's the entire function, since it's so small:
def parse_date_iter( source: Iterable[RawLog]) -> Iterator[DatedLog]: return map(parse_date, source)
The map()function is an iterator that applies the parse_date() function to each item from the source iterable. It yields objects created by the parse_date() function.
It's important to note that the parse_date name, without () is a reference to the function object. It's a common error to think the function must be evaluated, and include extra, unnecessary uses of ().
Superficially, all three techniques are equivalent. There are some differences, and these will steer design in a particular direction. The differences include:
- Only the
forstatement allows additional statements like context managers or atryblock to handle exceptions. In the case of very complex processing, this can be an advantage. - The generator expression has a relatively fixed structure with
forclauses andifclauses. It fits the more general mathematical pattern of a generator, allowing Python code to better match the underlying math. Because the expression is not limited to a named function or a lambda object, this can be very easy to read. - The
map()function can work with multiple, parallel iterables. Usingmap(f, i1, i2, i3)may be easier to read thanmap(f, zip(i1, i2, i3)). Because this requires a named function or a lambda object, this works well when the function is heavily reused by other parts of an application.
How it works...
The map() function replaces some common code that acts as a scaffold around the processing. We can imagine that the definition looks something like this:
def map(f: Callable, source: Iterable) -> Iterator:
for item in source:
yield f(item)
Or, we can imagine that it looks like this:
def map(f: Callable, source: Iterable) -> Iterator:
return (f(item) for item in iterable)
Both of these conceptual definitions of the map() function summarize the core feature of applying a function to a collection of data items. Since they're equivalent, the final decision must emphasize code that seems both succinct and expressive to the target audience.
To be more exacting, we can introduce type variables to show how the Callable, Iterable, and Iterator types are related by the map() function:
P = TypeVar("P")
Q = TypeVar("Q")
F = Callable[[P], Q]
def map(transformation: F, source: Iterable[P]) -> Iterator[Q]: ...
This shows how the callable can transform objects of type P to type Q. The source is an iterable of objects of type P, and the result will be an iterator that yields objects of type Q. The transformation is of type F, a function we can describe with the Callable[[P], Q] annotation.
There's more...
In this example, we've used the map() function to apply a function that takes a single parameter to each individual item of a single iterable collection. It turns out that the map() function can do a bit more than this.
Consider this function:
>>> def mul(a, b):
... return a*b
And these two sources of data:
>>> list_1 = [2, 3, 5, 7]
>>> list_2 = [11, 13, 17, 23]
We can apply the mul() function to pairs drawn from each source of data:
>>> list(map(mul, list_1, list_2))
[22, 39, 85, 161]
This allows us to merge two sequences of values using different kinds of operators. The map() algorithm takes values from each of the input collections and provides that group of values to the mul() function in this example. In effect, this is [mul(2, 11), mul(3, 13), mul(5, 17), mul(7, 23)].
This builds a mapping using pairs. It's similar to the built-in zip() function. Here's the code, which is – in effect – zip() built using this feature of map():
>>> def bundle(*args):
... return args
>>> list(map(bundle, list_1, list_2))
[(2, 11), (3, 13), (5, 17), (7, 23)]
We needed to define a small helper function, bundle(), that takes any number of arguments and returns the internal tuple created by assigning positional arguments via the *args parameter definition.
When we start looking at generator expressions like this, we can see that a great deal of programming fits some common overall patterns:
- Map:
 becomes
becomes (m(x) for x in S). - Filter:
 becomes
becomes (x for x in S if f(x)). - Reduce: This is a bit more complex, but common reductions include sums and counts. For example,
 becomes
becomes sum(x for x in S). Other common reductions include finding the maximum or the minimum of a set of a data collection.
See also
- In the Using stacked generator expressions recipe, later in this chapter, we will look at stacked generators. We will build a composite function from a number of individual mapping operations, written as various kinds of generator functions.
Using stacked generator expressions
In the Writing generator functions with the yield statement recipe, earlier in this chapter, we created a simple generator function that performed a single transformation on a piece of data. As a practical matter, we often have several functions that we'd like to apply to incoming data.
How can we stack or combine multiple generator functions to create a composite function?
Getting ready
This recipe will apply several different kinds of transformations to source data. There will be restructuring of the rows to combine three rows into a single row, data conversions to convert the source strings into useful numbers or date-time stamps, and filtering to reject rows that aren't useful.
We have a spreadsheet that is used to record fuel consumption on a large sailboat. It has rows that look like this:
|
Date |
Engine on |
Fuel height |
|
Engine off |
Fuel height |
|
|
Other notes |
||
|
10/25/2013 |
08:24 |
29 |
|
13:15 |
27 |
|
|
calm seas - anchor solomon's island |
||
|
10/26/2013 |
09:12 |
27 |
|
18:25 |
22 |
|
|
choppy - anchor in jackson's creek |
Example of saiboat fuel use
For more background on this data, see the Slicing and dicing a list recipe in Chapter 4, Built-In Data Structures Part 1: Lists and Sets.
As a sidebar, we can gather this data from a source file. We'll look at this in detail in the Reading delimited files with the csv module recipe in Chapter 10, Input/Output, Physical Format, and Logical Layout:
>>> from pathlib import Path
>>> import csv
>>> with Path('data/fuel.csv').open() as source_file:
... reader = csv.reader(source_file)
... log_rows = list(reader)
>>> log_rows[0]
['date', 'engine on', 'fuel height']
>>> log_rows[-1]
['', "choppy -- anchor in jackson's creek", '']
We've used the csv module to read the log details. csv.reader() is an iterable object. In order to collect the items into a single list, we applied the list() function to the generator function. We printed at the first and last item in the list to confirm that we really have a list-of-lists structure.
We'd like to apply transformations to this list-of-lists object:
- Convert the date and time strings into two date-time values
- Merge three rows into one row
- Exclude header rows that are present in the data
If we create a useful group of generator functions, we can have software that looks like this:
>>> total_time = datetime.timedelta(0)
>>> total_fuel = 0
>>> for row in datetime_gen:
... total_time += row.engine_off-row.engine_on
... total_fuel += (
... float(row.engine_on_fuel_height)-
... float(row.engine_off_fuel_height)
... )
>>> print(
... f"{total_time.total_seconds()/60/60 =:.2f}, "
... f"{total_fuel =:.2f}")
The combined generator function output has been assigned to the datetime_gen variable. This generator will yield a sequence of single rows with starting information, ending information, and notes. We can then compute time and fuel values and write summaries.
When we have more than two or three functions that are used to create the datetime_gen generator, the statement can become very long. In this recipe, we'll build a number of transformational steps into a single pipeline of processing.
How to do it...
We'll decompose this into three separate sub-recipes:
- Restructure the rows. The first part will create the
row_merge()function to restructure the data. - Exclude the header row. The second part will create a
skip_header_date()filter function to exclude the header row. - Create more useful row objects. The final part will create a function for additional data transformation, starting with
create_datetime().
Restructuring the rows
The first part of this three-part recipe will create the row_merge() function to restructure the data. We need to combine three rows into a useful structure. To describe this transformation, we'll define two handy types; one for the raw data, and one for the combined rows:
- Define the input and output data structures. The
csv.Readerclass will create lists of strings. We've described it with theRawRowtype. We'll restructure this into aCombinedRowinstance. The combined row will have some extra attributes; we've called themfiller_1,filler_2, andfiller_3, with values of cells that will be empty in the input data. It's slightly easier to keep the structure similar to the original CSV columns. We'll remove the filler fields later:RawRow = List[str] class CombinedRow(NamedTuple): # Line 1 date: str engine_on_time: str engine_on_fuel_height: str # Line 2 filler_1: str engine_off_time: str engine_off_fuel_height: str # Line 3 filler_2: str other_notes: str filler_3: str - The function's definition will accept an iterable of
RawRowinstances. It will behave as an iterator overCombinedRowobjects:def row_merge( source: Iterable[RawRow]) -> Iterator[CombinedRow]: - The body of the function will consume rows from the
sourceiterator. The first column provides a handy way to detect the beginning of a new three-row cluster of data. When the first column is empty, this is additional data. When the first column is non-empty, the previous cluster is complete, and we're starting a new cluster. The very last cluster of three rows also needs to be emitted:cluster: RawRow = [] for row in source: if len(row[0]) != 0: if len(cluster) == 9: yield CombinedRow(*cluster) cluster = row.copy() else: cluster.extend(row) if len(cluster) == 9: yield CombinedRow(*cluster)
This initial transformation can be used to convert a sequence of lines of CSV cell values into CombinedRow objects where each of the field values from three separate rows have their own, unique attributes:
>>> pprint(list(row_merge(log_rows)))
[CombinedRow(date='date', engine_on_time='engine on', engine_on_fuel_height='fuel height', filler_1='', engine_off_time='engine off', engine_off_fuel_height='fuel height', filler_2='', other_notes='Other notes', filler_3=''),
CombinedRow(date='10/25/13', engine_on_time='08:24:00 AM', engine_on_fuel_height='29', filler_1='', engine_off_time='01:15:00 PM', engine_off_fuel_height='27', filler_2='', other_notes="calm seas -- anchor solomon's island", filler_3=''),
CombinedRow(date='10/26/13', engine_on_time='09:12:00 AM', engine_on_fuel_height='27', filler_1='', engine_off_time='06:25:00 PM', engine_off_fuel_height='22', filler_2='', other_notes="choppy -- anchor in jackson's creek", filler_3='')]
We've extracted three CombinedRow objects from nine rows of source data. The first of these CombinedRow instances has the headings and needs to be discarded. The other two, however, are examples of raw data restructured.
We don't exclude the rows in the function we've written. It works nicely for doing row combinations. We'll stack another function on top of it to exclude rows that aren't useful. This separates the two design decisions and allows us to change the filter function without breaking the row_merge() function shown here.
There are several transformation steps required to make the data truly useful. We need to create proper datetime.datetime objects, and we need to convert the fuel height measurements into float objects. We'll tackle each of these as a separate, tightly focused transformation.
Excluding the header row
The first three rows from the source CSV file create a CombinedRow object that's not very useful. We'll exclude this with a function that processes each of the CombinedRow instances but discards the one with the labels in it:
- Define a function to work with an
Iterablecollection ofCombinedRowobjects, creating an iterator ofCombinedRowobjects:def skip_header_date( source: Iterable[CombinedRow] ) -> Iterator[CombinedRow]: - The function's body is a
forstatement to consume each row of the source:for row in source: - The body of the
forstatement yields good rows and uses thecontinuestatement to reject the undesirable rows by skipping over them:if row.date == "date": continue yield row
This can be combined with the row_merge() function shown in the previous recipe to provide a list of the desirable rows of good data that's useful:
>>> row_gen = row_merge(log_rows)
>>> tail_gen = skip_header_date(row_gen)
>>> pprint(list(tail_gen))
[CombinedRow(date='10/25/13', engine_on_time='08:24:00 AM', engine_on_fuel_height='29', filler_1='', engine_off_time='01:15:00 PM', engine_off_fuel_height='27', filler_2='', other_notes="calm seas -- anchor solomon's island", filler_3=''),
CombinedRow(date='10/26/13', engine_on_time='09:12:00 AM', engine_on_fuel_height='27', filler_1='', engine_off_time='06:25:00 PM', engine_off_fuel_height='22', filler_2='', other_notes="choppy -- anchor in jackson's creek", filler_3='')]
The row_merge() function on the first line is a generator that produces a sequence of CombinedRow objects; we've assigned the generator to the row_gen variable. The skip_header_date() function on the second line consumes data from the row_gen generator, and then produces a sequence of CombinedRow objects. We've assigned this to the tail_gen variable, because this data is the tail of the file.
We created a list of the objects to show the two good rows in the example data. Printing this list shows the collected data.
Creating more useful row objects
The dates and times in each row aren't very useful as separate strings. We'd really like rows with the dates and times combined into datetime.datetime objects. The function we'll write can have a slightly different form because it applies to all the rows in a simple way. For these kinds of transformations, we don't need to write the for statement inside the function; it can be applied externally to the function:
- Define a new
NamedTupleinstance that specifies a more useful type for the time values:class DatetimeRow(NamedTuple): date: datetime.date engine_on: datetime.datetime engine_on_fuel_height: str engine_off: datetime.datetime engine_off_fuel_height: str other_notes: str - Define a simple mapping function to convert one
CombinedRowinstance into a singleDatetimeRowinstance. We'll create an explicit generator expression to use this single-row function on an entire collection of data:def convert_datetime(row: CombinedRow) -> DatetimeRow: - The body of this function will perform a number of date-time computations and create a new
DatetimeRowinstance. This function's focus is on date and time conversions. Other conversions can be deferred to other functions:travel_date = datetime.datetime.strptime( row.date, "%m/%d/%y").date() start_time = datetime.datetime.strptime( row.engine_on_time, "%I:%M:%S %p").time() start_datetime = datetime.datetime.combine( travel_date, start_time) end_time = datetime.datetime.strptime( row.engine_off_time, "%I:%M:%S %p").time() end_datetime = datetime.datetime.combine( travel_date, end_time) return DatetimeRow( date=travel_date, engine_on=start_datetime, engine_off=end_datetime, engine_on_fuel_height=row.engine_on_fuel_height, engine_off_fuel_height=row.engine_off_fuel_height, other_notes=row.other_notes )
We can stack the transformation functions to merge rows, exclude the header, and perform date time conversions. The processing may look like this:
>>> row_gen = row_merge(log_rows)
>>> tail_gen = skip_header_date(row_gen)
>>> datetime_gen = (convert_datetime(row) for row in tail_gen)
Here's the output from the preceding processing:
>>> pprint(list(datetime_gen))
[DatetimeRow(date=datetime.date(2013, 10, 25), engine_on=datetime.datetime(2013, 10, 25, 8, 24), engine_on_fuel_height='29', engine_off=datetime.datetime(2013, 10, 25, 13, 15), engine_off_fuel_height='27', other_notes="calm seas -- anchor solomon's island"),
DatetimeRow(date=datetime.date(2013, 10, 26), engine_on=datetime.datetime(2013, 10, 26, 9, 12), engine_on_fuel_height='27', engine_off=datetime.datetime(2013, 10, 26, 18, 25), engine_off_fuel_height='22', other_notes="choppy -- anchor in jackson's creek")]
The expression (convert_datetime(row) for row in tail_gen) applies the convert_datetime() function to each of the rows produced by the tail_gen generator expression. This expression has the valid rows from the source data.
We've decomposed the reformatting, filtering, and transformation problems into three separate functions. Each of these three steps does a small part of the overall job. We can test each of the three functions separately. More important than being able to test is being able to fix or revise one step without completely breaking the entire stack of transformations.
How it works...
When we write a generator function, the argument value can be a collection of items, or it can be any other kind of iterable source of items. Since generator functions are iterators, it becomes possible to create a pipeline of generator functions.
A mapping generator function consumes an item from the input, applies a small transformation, and produces an item as output. In the case of a filter, more than one item could be consumed for each item that appears in the resulting iterator.
When we decompose the overall processing into separate transformations, we can make changes to one without breaking the entire processing pipeline.
Consider this stack of three generator functions:
>>> row_gen = row_merge(log_rows)
>>> tail_gen = skip_header_date(row_gen)
>>> datetime_gen = (convert_datetime(row) for row in tail_gen)
>>> for row in datetime_gen:
... print(f"{row.date}: duration {row.engine_off-row.engine_on}")
In effect, the datetime_gen object is a composition of three separate generators: the row_merge() function, the skip_header_date() function, and an expression that involves the convert_datetime() function. The final for statement shown in the preceding example will be gathering values from the datetime_gen generator expression by evaluating the next() function repeatedly.
Here's the step-by-step view of what will happen to create the needed result:
- The
forstatement will consume a value from thedatetime_gengenerator. - The
(convert_datetime(row) for row in tail_gen)expression must produce a value for its consumer. To do this, a value must be consumed from thetail_gengenerator. The value is assigned to therowvariable, then transformed by theconvert_datetime()function. - The
tail_gengenerator must produce a value from theskip_header_date()generator function. This function may read several rows from its source until it finds a row where thedateattribute is not the column header string,"date". The source for this is the output from therow_merge()function. - The
row_merge()generator function will consume multiple rows from its source until it can assemble aCombinedRowinstance from nine source cells spread across three input rows. It will yield the combined row. The source for this is a list-of-lists collection of the raw data. - The source collection of rows will be processed by a
forstatement inside the body of therow_merge()function. This statement will consume rows from thelog_rowsgenerator.
Each individual row of data will pass through this pipeline of steps. Small, incremental changes are made to the data to yield rows of distinct types. Some stages of the pipeline will consume multiple source rows for a single result row, restructuring the data as it is processed. Other stages consume and transform a single value.
The entire pipeline is driven by demand from the client. Each individual row is processed separately. Even if the source is a gigantic collection of data, processing can proceed very quickly. This technique allows a Python program to process vast volumes of data quickly and simply.
There's more...
There are a number of other conversions required to make this data useful. We'll want to transform the start and end time stamps into a duration. We also need to transform the fuel height values into floating-point numbers instead of strings.
We have three ways to handle these derived data computations:
- We can add the computations as properties of the
NamedTupledefinition. - We can create additional transformation steps in our stack of generator functions.
- We can also add
@propertymethods to the class definition. In many cases, this is optimal.
The second approach is often helpful when the computations are very complex or involve collecting data from external sources. While we don't need to follow this approach with this specific recipe, the design is a handy way to see how transformations can be stacked to create a sophisticated pipeline.
Here's how we can compute a new NamedTuple that includes a duration attribute. First, we'll show the new DurationRow definition:
class DurationRow(NamedTuple):
date: datetime.date
engine_on: datetime.datetime
engine_on_fuel_height: str
engine_off: datetime.datetime
engine_off_fuel_height: str
duration: float
other_notes: str
Objects of this class can be produced by a function that transforms a DatetimeRow into a new DurationRow instance. Here's a function that's used to build new objects from the existing data:
def duration(row: DatetimeRow) -> DurationRow:
travel_hours = round(
(row.engine_off-row.engine_on).total_seconds()/60/60, 1
)
return DurationRow(
date=row.date,
engine_on=row.engine_on,
engine_off=row.engine_off,
engine_on_fuel_height=row.engine_on_fuel_height,
engine_off_fuel_height=row.engine_off_fuel_height,
other_notes=row.other_notes,
duration=travel_hours
)
Many of the fields are simply preserved without doing any processing. Only one new field is added to the tuple definition.
A more complete definition of the leg of a journey would involve a more useful measure of fuel height. Here's the relevant class definition:
class Leg(NamedTuple):
date: datetime.date
engine_on: datetime.datetime
engine_on_fuel_height: float
engine_off: datetime.datetime
engine_off_fuel_height: float
duration: float
other_notes: str
Here's a function that's used to build Leg objects from the DurationRow objects built previously:
def convert_height(row: DurationRow) -> Leg:
return Leg(
date=row.date,
engine_on=row.engine_on,
engine_off=row.engine_off,
duration=row.duration,
engine_on_fuel_height=
float(row.engine_on_fuel_height),
engine_off_fuel_height=
float(row.engine_off_fuel_height),
other_notes=row.other_notes
)
This concept drives the definition of a composite leg_duration_iter() function. This function is composed of a number of functions, each of which can be applied to items of collections. We've stacked the functions into a series of transformations, as shown here:
def leg_duration_iter(source: Iterable[str]) -> Iterator[Leg]:
merged_rows = row_merge(log_rows)
tail_gen = skip_header_date(merged_rows)
datetime_gen = (convert_datetime(row) for row in tail_gen)
duration_gen = (duration(row) for row in datetime_gen)
height_gen = (convert_height(row) for row in duration_gen)
return height_gen
The transformations in this stack fall into two general types:
- Generator functions,
row_merge()andskip_header_date(): These two functions have aforstatement and some complex additional processing. Therow_merge()function has an internal list,cluster, that accumulates three rows before yielding a result. Theskip_header_date()function can consume more than one row before emitting a row; it's a filter, not a transformation. - Generator expressions that map a function against a collection of data: The functions
convert_datetime(),duration(), andconvert_height()all perform small transformations. We use a generator expression to apply the function to each item in the source collection.
We now have a sophisticated computation that's defined in a number of small and (almost) completely independent chunks. We can modify one piece without having to think deeply about how the other pieces work.
The filter processing of skip_header_date() can be built using the built-in filter() higher-order function. We'll look at filtering in the Picking a subset – three ways to filter recipe in this chapter.
The generator expression (duration(row) for row in datetime_gen) can also be written as map(duration, datetime_gen). Both apply a function against a source of data. When first looking at a stack of transformations, it seems easier to work with an explicit generator expression. Later, it can be replaced with the slightly simpler-looking built-in map() function.
See also
- See the Writing generator functions with the yield statement recipe for an introduction to generator functions.
- See the Slicing and dicing a list recipe in Chapter 4, Built-In Data Structures Part 1: Lists and Sets, for more information on the fuel consumption dataset.
- See the Combining map and reduce transformations recipe for another way to combine operations.
- The Picking a subset – three ways to filter recipe covers the filter function in more detail.
Picking a subset – three ways to filter
Choosing a subset of relevant rows can be termed filtering a collection of data. We can view a filter as rejecting bad rows or including the desirable rows. There are several ways to apply a filtering function to a collection of data items.
In the Using stacked generator expressions recipe, we wrote the skip_header_date() generator function to exclude some rows from a set of data. The skip_header_date() function combined two elements: a rule to pass or reject items and a source of data. This generator function had a general pattern that looks like this:
def data_filter_iter(source: Iterable[T]) -> Iterator[T]:
for item in source:
if item should be passed:
yield item
The data_filter_iter() function's type hints emphasize that it consumes items from an iterable source collection. Because a generator function is a kind of iterator, it will produce items of the same type for another consumer. This function design pattern exposes a common underlying pattern.
Mathematically, we might summarize this as follows:

The new collection, N, is each item, x, of the source, ![]() , where a filter function,
, where a filter function, ![]() , is true. This mathematical summary emphasizes the filter function,
, is true. This mathematical summary emphasizes the filter function, ![]() , separating it from the details of consuming the source and producing the result.
, separating it from the details of consuming the source and producing the result.
This mathematical summary suggests the for statement is little more than scaffolding code. Because it's less important than the filter rule, it can help to refactor a generator function and extract the filter from the other processing.
If the for statement is scaffolding, how else can we apply a filter to each item of a collection? There are three techniques we can use:
- We can write an explicit
forstatement. This was shown in the previous recipe, Using stacked generator expressions, in this chapter. - We can write a generator expression.
- We can use the built-in
filter()function.
Getting ready...
In this recipe, we'll look at the web log data from the Writing generator functions with the yield statement recipe. This had date as a string that we would like to transform into a proper timestamp.
The text lines from the log were converted into RawLog objects. While these were handy because the attributes were cleanly separated from each other, this representation had a problem. Because the attribute values are strings, the datetime value is difficult to work with. Here's the example data, shown as a sequence of RawLog objects.
In the Applying transformations to a collection recipe shown earlier in this chapter, we used a generator function, parse_date_iter(), to transform each RawLog object into a more useful DatedLog instance. This made more useful data, as shown in the following example:
>>> data = [
... DatedLog(date=datetime.datetime(2016, 4, 24, 11, 5, 1, 462000), level='INFO', module='module1', message='Sample Message One'),
... DatedLog(date=datetime.datetime(2016, 4, 24, 11, 6, 2, 624000), level='DEBUG', module='module2', message='Debugging'),
... DatedLog(date=datetime.datetime(2016, 4, 24, 11, 7, 3, 246000), level='WARNING', module='module1', message='Something might have gone wrong')
... ]
It's often necessary to focus on a subset of the DatedLog instances. We may need to focus on a particular module, or date range. This leads to a need to extract a useful subset from a larger set.
For this example, we'll focus initially on filtering the data using the module name attribute of each DatedLog instance. This decision can be made on each row in isolation.
There are three distinct ways to create the necessary filters. We can write a generator function, we can use a generator expression, or we can use the built-in filter() function. In all three cases, we have to separate some common for-and-if code from the unique filter condition. We'll start with the explicit for and if statements, then show two other ways to filter this data.
How to do it...
The first part of this recipe will use explicit for and if statements to filter a collection of data:
- Start with a draft version of a generator function with the following outline:
def draft_module_iter( source: Iterable[DatedLog] ) -> Iterator[DatedLog]: for row in source: if row.module == "module2": yield row - The
ifstatement's decision can be refactored into a function that can be applied to a single row of the data. It must produce aboolvalue:def pass_module(row: DatedLog) -> bool: return row.module == "module2" - The original generator function can now be simplified:
def module_iter( source: Iterable[DatedLog]) -> Iterator[DatedLog]: for item in source: if pass_module(item): yield item
The pass_module() function can be used in three ways. As shown here, it can be part of a generator function. It can also be used in a generator expression, and with the filter() function. We'll look at these as separate parts of this recipe.
While this uses two separate function definitions, it has the advantage of separating the filter rule from the boilerplate for and if processing. The pass_module() function helps to highlight the possible reasons for change. It keeps this separate from the parts of the processing unlikely to change.
There are two other ways we can write this function: in a generator expression and with the built-in filter() function. We'll show these in the next two sections.
Using a filter in a generator expression
A generator expression includes three parts – the item, a for clause, and an if clause – all enclosed by ():
- Write the output object, which is usually the variable from the
forclause. The variable will be assigned to each individual item from the overall collection:item - Write a
forclause that assigns objects to the variable used previously. This value comes from some iterable collection, which issourcein this example:for item in source - Write an
ifclause using the filter rule function,pass_module():if pass_module (item) - The expression can be the return value from a function that provides suitable type hints for the source and the resulting expression. Here's the entire function, since it's so small:
def module_iter( source: Iterable[DatedLog]) -> Iterator[DatedLog]: return (item for item in source if pass_module(item))
This is a generator expression that applies the pass_module() function to each item in the source collection to determine whether it passes and is kept, or whether it is rejected.
Using the filter() function
Using the filter() function includes two parts – the decision function and the source of data – as arguments:
- Use the
filter()function to apply the function to the source data:filter(pass_module, data) - We can use this as follows:
>>> for row in filter(pass_module, data): ... pprint(row)
The filter() function is an iterator that applies the pass_module() function as a rule to pass or reject each item from the data iterable. It yields the rows for which the pass_module() function returns true.
It's important to note that the pass_module name, without (), is a reference to the function object. It's a common error to think the function must be evaluated and include extra ().
How it works...
A generator expression must include a for clause to provide a source of data items from a collection. The optional if clause can apply a condition that preserves the items. A final expression defines the resulting collection of objects. Placing a filter condition in an if clause can make the combination of a source filter and final expression very clear and expressive of the algorithm.
Generator expressions have an important limitation. As expressions, they cannot use statement-oriented features of Python. One important statement is a try-except block to handle exceptional data conditions. Because this can't be used in a simple generator expression, we may resort to a more elaborate for-and-if construct.
The filter() function replaces the common boilerplate code. We can imagine that the definition for the built-in function looks something like this:
def filter(
f: Callable[[P], bool], source: Iterable[P]
) -> Iterator[P]:
for item in source:
if f(item):
yield item
Or, we can imagine that the built-in filter() function looks like this:
def filter(
f: Callable[[P], bool], source: Iterable[P]
) -> Iterator[P]:
return (item for item in source if f(item))
Both of these definitions summarize the core feature of the filter() function: some data is passed and some data is rejected. This is handy shorthand that eliminates some boilerplate code for using a function to test each item in an iterable source of data.
There's more...
Sometimes, it's difficult to write a simple rule to pass data. It may be clearer if we write a rule to reject data. For example, a rule to reject all names that match a regular expression might be easier to imagine than the logically equivalent pass rule:
pattern = re.compile(r"moduled+")
def reject_modules(row: DatedLog) -> bool:
return bool(pattern.match(row.module))
We can use a reject rule instead of a pass rule in a number of ways. Here's a for...if...continue...yield pattern of statements. This will use the continue statement to skip the rejected items and yield the remaining items:
>>> def reject_modules_iter(
... source: Iterable[DatedLog]) -> Iterator[DatedLog]:
... for item in source:
... if reject_modules(item):
... continue
... yield item
This has the advantage of letting us write rejected rows to a log for debugging purposes. The simpler alternative is this:
for item in collection:
if not reject_modules(item):
yield item
We can also use a generator expression like this:
(item for item in data if not reject_modules(item))
We can't, however, easily use the filter() function with a rule that's designed to reject data. The filter() function is designed to work with pass rules only.
We can, however, create a lambda object to compute the inverse of the reject function, turning it into a pass function. The following example shows how this works:
filter(lambda item: not reject_modules(item), data)
The lambda object is a small, anonymous function. A lambda is effectively a function that's been reduced to just two elements: the parameter list and a single expression. We wrapped the reject_modules () function to create a kind of not_reject_modules () function via a lambda object.
In the itertools module, we use the filterfalse() function. We can also use from itertools import filterfalse. This function lets us work with reject rules instead of pass rules.
See also
- In the Using stacked generator expressions recipe, earlier in this chapter, we placed a function like this in a stack of generators. We built a composite function from a number of individual mapping and filtering operations written as generator functions.
Summarizing a collection – how to reduce
A reduction is the generalized concept behind computing a sum or a product of a collection of numbers. Computing statistical measures like mean or variance are also reductions. In this recipe, we'll look at several summary techniques.
In the introduction to this chapter, we noted that there are three processing patterns that Python supports elegantly: map, filter, and reduce. We saw examples of mapping in the Applying transformations to a collection recipe and examples of filtering in the Picking a subset – three ways to filter recipe. It's relatively easy to see how these higher-level functions define generic operations.
The third common pattern is reduction. In the Designing classes with lots of processing and Extending a collection: a list that does statistics recipes, we looked at class definitions that computed a number of statistical values. These definitions relied—almost exclusively—on the built-in sum() function. This is one of the more common reductions.
In this recipe, we'll look at a way to generalize summation, leading to ways to write a number of different kinds of reductions that are similar. Generalizing the concept of reduction will let us build on a reliable foundation to create more sophisticated algorithms.
Getting ready
One of the most common reductions is the sum. Other reductions include the product, minimum, maximum, average, variance, and even a simple count of values. The mathematics of summation help us to see how an operator is used to convert a collection of values into a single value.
This abstraction provides ways for us to understand Python's capabilities. With this foundation, it can be made clear how extensions to the built-in reductions can be designed.
Here's a way to think of the mathematical definition of the sum function using an operator, ![]() , applied to values in a collection, C:
, applied to values in a collection, C:

We've expanded the definition of sum by folding the ![]() operator into the sequence of values,
operator into the sequence of values, ![]() . This idea of folding in the
. This idea of folding in the ![]() operator captures the meaning of the built-in
operator captures the meaning of the built-in sum() function.
Similarly, the definition of product looks like this:

Here, too, we've performed a different fold on a sequence of values. Folding involves two items: a binary operator and a base value. For sum, the operator was ![]() and the base value was zero. For product, the operator is
and the base value was zero. For product, the operator is ![]() and the base value is one.
and the base value is one.
This idea of a fold is a generic concept that underlies Python's reduce(). We can apply this to many algorithms, potentially simplifying the definition.
How to do it...
Let's start by importing the function we need:
- Import the
reduce()function from thefunctoolsmodule:from functools import reduce - Pick the operator. For
sum, it's . For
. For product, it's . These can be defined in a variety of ways. Here's the long version. Other ways to define the necessary binary operators will be shown later:
. These can be defined in a variety of ways. Here's the long version. Other ways to define the necessary binary operators will be shown later:
def mul(a, b): return a * b - Pick the base value required. For
sum, it's zero. Forproduct, it's one. This allows us to define aprod()function that computes a generic product:def prod(values): return reduce(mul, values, 1)
We can use this to define a function based on this product reduction. The function looks like this:
def factorial(n: int) -> int:
return prod(range(1, n+1))
Here's the number of ways that a 52-card deck can be arranged. This is the value 52:
>>> factorial(52)
80658175170943878571660636856403766975289505440883277824000000000000
There are a lot of a ways a deck can be shuffled.
How many five-card hands are possible? The binomial calculation uses a factorial:

Here's the Python implementation:
>>> factorial(52)//(factorial(5)*factorial(52-5))
2598960
For any given shuffle, there are about 2.6 million different possible poker hands.
How it works...
The reduce() function behaves as though it has this definition:
T = TypeVar("T")
def reduce(
fn: Callable[[T, T], T],
source: Iterable[T],
base: T) -> T:
result = base
for item in source:
result = fn(result, item)
return result
The type shows how there has to be a unifying type, T. The given function, fn(), must combine two values of type T and return another value of the same type T. The base value is an object of the type T, and the result of the reduce() function will be a value of this type also.
Furthermore, this reduce operation must iterate through the values from left to right. It will apply the given binary function, fn(), between the previous result and the next item from the source collection.
There's more...
When designing a new application for the reduce() function, we need to provide a binary operator. There are three ways to define the necessary binary operator. First, we can use a complete function definition like this:
def mul(a: int, b: int) -> int:
return a * b
There are two other choices. We can use a lambda object instead of a complete function:
l_mul: Callable[[int, int], int] = lambda a, b: a * b
A lambda object is an anonymous function boiled down to just two essential elements: the parameters and the return expression. There are no statements inside a lambda, only a single expression. In this case, the expression uses the desired operator, ![]() .
.
We can use a lambda object like this:
def prod2(values: Iterable[int]) -> int:
return reduce(lambda a, b: a*b, values, 1)
This provides the multiplication function as a lambda object without the overhead of a separate function definition.
When the operation is one of Python's built-in operators, it can also import the definition from the operator module:
from operator import add, mul
This works nicely for all the built-in arithmetic operators.
Note that logical reductions using the Boolean operators and and or are different from other arithmetic reductions. Python's Boolean operators have a short-circuit feature: when we evaluate the expression False and 3/0 and the result is False, the operation on the right-hand side of the and operator, 3/0, is never evaluated; the exception won't be raised. The or operator is similar: when the left side is True, the right-hand side is never evaluated.
The built-in functions any() and all() are reductions using logic operators. The any() function is, effectively, a kind of reduce() using the or operator. Similarly, the all() function behaves as if it's a reduce() with the and operator.
Maxima and minima
We can use the reduce() function to compute a customized maximum or minimum as well. This is a little more complex because there's no trivial base value that can be used. We cannot start with zero or one because these values might be outside the range of values being minimized or maximized.
Also, the built-in max() and min() functions must raise exceptions for an empty sequence. These functions don't fit perfectly with the way the sum() and reduce() functions work. The sum() and reduce() functions have an identity element that is the result of why they're operating against an empty sequence. Some care must be exercised to define a proper identity element for a customized min() or max().
We can imagine that the built-in max() function has a definition something like the following:
def mymax(source: Iterable[T]) -> T:
try:
base = source[0]
max_rule = lambda a, b: a if a > b else b
return reduce(max_rule, source, base)
except IndexError:
raise ValueError
This function will pick the first value from the sequence as a base value. It creates a lambda object, named max_rule, which selects the larger of the two argument values. We can then use this base value and the lambda object. The reduce() function will locate the largest value in a non-empty collection. We've captured the IndexError exception so that evaluating the mymax() function on an empty collection will raise a ValueError exception.
Potential for abuse
Note that a fold (or reduce(), as it's called in Python) can be abused, leading to poor performance. We have to be cautious about using a reduce() function without thinking carefully about what the resulting algorithm might look like. In particular, the operator being folded into the collection should be a simple operation such as adding or multiplying. Using reduce() changes the complexity of an ![]() operation into
operation into ![]() .
.
Imagine what would happen if the operator being applied during the reduction involved a sort over a collection. A complex operator—with ![]() complexity—being used in a
complexity—being used in a reduce() function would change the complexity of the overall reduce() to ![]() . For a collection of 10,000 items, this goes from approximately 132,800 operations to over 1,328,000,000 operations. What may have taken 6 seconds could take almost 16 hours.
. For a collection of 10,000 items, this goes from approximately 132,800 operations to over 1,328,000,000 operations. What may have taken 6 seconds could take almost 16 hours.
Combining the map and reduce transformations
In the other recipes in this chapter, we've been looking at map, filter, and reduce operations. We've looked at each of these in isolation:
- The Applying transformations to a collection recipe shows the
map()function. - The Picking a subset – three ways to filter recipe shows the
filter()function. - The Summarizing a collection – how to reduce recipe shows the
reduce()function.
Many algorithms will involve combinations of functions. We'll often use mapping, filtering, and reduction to produce a summary of available data. Additionally, we'll need to look at a profound limitation of working with iterators and generator functions; namely, this limitation:
An iterator can only produce values once.
If we create an iterator from a generator function and a collection of data, the iterator will only produce the data one time. After that, it will appear to be an empty sequence.
Here's an example:
>>> typical_iterator = iter([0, 1, 2, 3, 4])
>>> sum(typical_iterator)
10
>>> sum(typical_iterator)
0
We created an iterator over a sequence of values by manually applying the iter() function to a literal list object. The first time that the sum() function used the value of typical_iterator, it consumed all five values. The next time we try to apply any function to typical_iterator, there will be no more values to be consumed; the iterator will appear empty.
This one-time-only restriction may force us to cache intermediate results so that we can perform multiple reductions on the data. Creating intermediate collection objects will consume memory, leading to a need for the careful design of very complex processes for very large collections of data.
Getting ready
In the Using stacked generator expressions recipe, we looked at data that required a number of processing steps. We merged rows with a generator function. We filtered some rows to remove them from the resulting data. Additionally, we applied a number of mappings to the data to convert dates and times into more useful information.
We'd like to supplement this with two more reductions to get some average and variance information. These statistics will help us understand the data more fully.
In the Using stacked generator expressions recipe, earlier in this chapter, we looked at some sailboat data. The spreadsheet was badly organized, and a number of steps were required to impose a more useful structure on the data.
In that recipe, we looked at a spreadsheet that is used to record fuel consumption on a large sailboat. It has rows that look like this:
|
Date |
Engine on |
Fuel height |
|
Engine off |
Fuel height |
|
|
Other notes |
||
|
10/25/2013 |
08:24 |
29 |
|
13:15 |
27 |
|
|
calm seas - anchor solomon's island |
||
|
10/26/2013 |
09:12 |
27 |
|
18:25 |
22 |
|
|
choppy - anchor in jackson's creek |
Example of saiboat fuel use
The initial processing was a sequence of operations to change the organization of the data, filter out the headings, and compute some useful values. We'll build on that earlier processing with some additional steps.
How to do it...
To do a complex transformation of a collection, it can help to restate each piece of the transformation. We want to look for examples of map, filter, and reduce operations. We can implement these individually and combine them into sophisticated composite operations built from easy-to-understand pieces. Let's get started:
- It helps to start with the line of code as a goal. In this case, we'd like a function to sum the fuel use per hour. This can follow a common three-step design pattern. First, we normalize the data with
row_merge(). Then, we use mapping and filtering to create more useful objects withclean_data_iter().Finally, we want to be summarize using the
total_fuel()function. See the Using stacked generator expressions recipe for more information on this kind of design. Here's the goal expression:>>> round( ... total_fuel(clean_data_iter(row_merge(log_rows))), ... 3) 7.0 - Define a generator for any structural normalization that's required. For this example, we have to combine three input rows to create each output row. We'll reuse the functions from earlier recipes:
from Chapter_09.ch08_r03 import row_merge, CombinedRow, log_rows - Define the target data structure created by the cleaning and enrichment step. We'll use a mutable dataclass in this example. The fields coming from the normalized
CombinedRowobject can be initialized directly. The other five fields will be computed by several separate functions. Because they'll be computed later, they're given an initial value offield(init=False):from dataclasses import dataclass, field @dataclass class Leg: date: str start_time: str start_fuel_height: str end_time: str end_fuel_height: str other_notes: str start_timestamp: datetime.datetime = field(init=False) end_timestamp: datetime.datetime = field(init=False) travel_hours: float = field(init=False) fuel_change: float = field(init=False) fuel_per_hour: float = field(init=False) - Define the overall data cleansing and enrichment data function. This will build the enriched
Legobjects from the sourceCombinedRowobjects. We'll build this from seven simpler functions. In addition to functions to compute the five derived fields, there's a function to do the initial conversion to aLeginstance, and afilterfunction to reject the header row that's present in the source data. The implementation is a stack ofmap()andfilter()operations that will derive data from the source fields:def clean_data( source: Iterable[CombinedRow]) -> Iterator[Leg]: leg_iter = map(make_Leg, source) fitered_source = filter(reject_date_header, leg_iter) start_iter = map(start_datetime, fitered_source) end_iter = map(end_datetime, start_iter) delta_iter = map(duration, end_iter) fuel_iter = map(fuel_use, delta_iter) per_hour_iter = map(fuel_per_hour, fuel_iter) return per_hour_iter - Write the
make_Leg()function to createLeginstances fromCombinedRowinstances. This does the minimal amount of work required and doesn't compute any of the uninitialized fields:def make_Leg(row: CombinedRow) -> Leg: return Leg( date=row.date, start_time=row.engine_on_time, start_fuel_height=row.engine_on_fuel_height, end_time=row.engine_off_time, end_fuel_height=row.engine_off_fuel_height, other_notes=row.other_notes, ) - Write the
reject_date_header()function used byfilter()to remove the heading rows. If needed, this can be expanded to remove blank lines or other bad data from the source. The idea is to pass good data as soon as possible in the processing stage. In this example, good data has only one rule – thedateattribute is not equal to the string"date":def reject_date_header(row: Leg) -> bool: return not (row.date == "date") - Write the data conversion functions. We'll start with the time strings, which need to become
datetimeobjects. Both the start time and end time require similar algorithms. We can refactor the common code into a timestamp function that builds a singledatetimeobject from a date string and time string:def timestamp( date_text: str, time_text: str ) -> datetime.datetime: date = datetime.datetime.strptime( date_text, "%m/%d/%y").date() time = datetime.datetime.strptime( time_text, "%I:%M:%S %p").time() timestamp = datetime.datetime.combine( date, time) return timestamp - Mutate the
Leginstances with additional values. Both of these functions compute new values and also update theLegobject so it includes the computed values. This is an optimization that avoids the creation of intermediate objects:def start_datetime(row: Leg) -> Leg: row.start_timestamp = timestamp( row.date, row.start_time) return row def end_datetime(row: Leg) -> Leg: row.end_timestamp = timestamp( row.date, row.end_time) return row - Compute the derived duration from the time stamps. Here's a function that must be performed after the previous two:
def duration(row: Leg) -> Leg: travel_time = row.end_timestamp - row.start_timestamp row.travel_hours = round( travel_time.total_seconds() / 60 / 60, 1) return row - Compute any other metrics that are needed for the analyses. This includes creating the height values that are converted into float numbers. The final calculation is based on two other calculated results:
def fuel_use(row: Leg) -> Leg: end_height = float(row.end_fuel_height) start_height = float(row.start_fuel_height) row.fuel_change = start_height - end_height return row def fuel_per_hour(row: Leg) -> Leg: row.fuel_per_hour = row.fuel_change / row.travel_hours return row
The fuel_per_hour() function's calculation depends on the entire preceding stack of calculations. The travel hours duration is derived from the start and end time stamps. Each of these computations is done separately to clarify and emphasize the computation. This approach tends to divorce the computations from considerations about the overall data structure in use. It also permits changes to the computations separate from changes to the overall data structure.
How it works...
The idea is to create a composite operation that follows this template:
- Normalize the structure. This often requires a generator function to read data in one structure and yield data in a different structure.
- Filter and cleanse each item. This may involve a simple filter, as shown in this example. We'll look at more complex filters later.
- Derive data via mappings or via lazy properties of class definitions. A class with lazy properties is a reactive object. Any change to the source property should cause changes to the computed properties.
In more complex applications, we might need to look up reference data or decode coded fields. All of the additional complexity can be refactored into separate functions.
Once we've completed the preliminary computations, we have data that can be used for a variety of analyses. Many times, this is a reduce operation. The initial example computes a sum of fuel use. Here are two other examples:
from statistics import *
def avg_fuel_per_hour(source: Iterable[Leg]) -> float:
return mean(row.fuel_per_hour for row in source)
def stdev_fuel_per_hour(source: Iterable[Leg]) -> float:
return stdev(row.fuel_per_hour for row in source)
These functions apply the mean() and stdev() functions to the fuel_per_hour attribute of each row of the enriched data.
We might use this as follows:
>>> round(
... avg_fuel_per_hour(clean_data_iter(row_merge(log_rows))),
... 3)
0.48
Here, we've used the clean_data_iter(row_merge(log_rows)) mapping pipeline to cleanse and enrich the raw data. Then, we applied a reduction to this data to get the value we're interested in.
We now know that a 30" tall tank is good for about 60 hours of motoring. At 6 knots, this sailboat can go about 360 nautical miles on a full tank of fuel. Additional data can refine this rough estimate into a range based on the variance or standard deviation of the samples.
There's more...
As we noted, we can only perform one iteration on an iterable source of data. If we want to compute several averages, or the average as well as the variance, we'll need to use a slightly different design pattern.
In order to compute multiple summaries of the data, we'll need to create a concrete object of some kind that can be summarized repeatedly:
def summary(raw_data: Iterable[List[str]]) -> None:
data = tuple(clean_data_iter(row_merge(raw_data)))
m = avg_fuel_per_hour(data)
s = 2 * stdev_fuel_per_hour(data)
print(f"Fuel use {m:.2f} ±{s:.2f}")
Here, we've created a tuple from the cleaned and enriched data. This tuple can produce any number of iterators. Having this capability means we can compute two summaries from this tuple object.
We can also use the tee() function in the itertools module for this kind of processing:
from itertools import tee
def summary_t(raw_data: Iterable[List[str]]):
data1, data2 = tee(clean_data_iter(row_merge(raw_data)), 2)
m = avg_fuel_per_hour(data1)
s = 2 * stdev_fuel_per_hour(data2)
print(f"Fuel use {m:.2f} ±{s:.2f}")
We've used tee() to create two clones of the iterable output from clean_data_iter(row_merge(log_rows)). We can use one of the clones to compute a mean and the other clone to compute a standard deviation.
This design involves a large number of transformations of source data. We've built it using a stack of map, filter, and reduce operations. This provides a great deal of flexibility.
Implementing "there exists" processing
The processing patterns we've been looking at can all be summarized with the universal quantifier, ![]() , meaning for all. It's been an implicit part of all of the processing definitions:
, meaning for all. It's been an implicit part of all of the processing definitions:
- Map: For all items in the source,
 , apply the
, apply the mapfunction,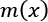 . We can change notation to have an explicit use of the universal quantifier:
. We can change notation to have an explicit use of the universal quantifier: 
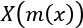 .
. - Filter: For all items in the source, pass those for which the
filterfunction istrue. Here, also, we've used the universal quantifier to make this explicit: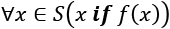 .
. - Reduce: For all items in the source, use the given operator and base value to compute a summary. The universal quantification is implicit in the definition of operators like
 .
.
There are also cases where we are only interested in locating a single item. We often describe these cases as a search to show there exists at least one item where a condition is true. This can be called the existential quantifier, ![]() , meaning there exists.
, meaning there exists.
We'll need to use some additional features of Python to create generator functions that stop when the first value matches some predicate. This will let us build generators that locate a single item in ways that are similar to generators that work with all items.
Getting ready
Let's look at an example of an existence test.
We might want to know whether a number is prime or composite. A prime number has no factors other than 1 and itself. Other numbers, with multiple factors, are called composite. For example, the number 5 is prime because it has only the numbers 1 and 5 as factors. The number 42 is composite because it has the numbers 2, 3, and 7 as prime factors.
We can define a prime predicate, P(n), like this:

A number, n, is prime if there does not exist a value of i (between 2 and the number) that divides the number evenly. If n is zero and the modulus is i, then i is a factor of n.
We can move the negation around and rephrase this as follows:

A number, n, is composite (non-prime) if there exists a value, i, between 2 and the number itself that divides the number evenly. For a test to see if a number is prime, we don't need to know all the factors. The existence of a single factor shows the number is composite.
The overall idea is to iterate through the range of candidate numbers. Once we've found a factor, we can break early from any further iteration. In Python, this early exit from a for statement is done with the break statement. Because we're not processing all values, we can't easily use any of the built-in higher-order functions such as map(), filter(), or reduce(). Because break is a statement, we can't easily use a generator expression, either; we're constrained to writing a generator function.
(The Fermat test is generally more efficient than this, but it doesn't involve a simple search for the existence of a factor.)
How to do it...
In order to build this kind of search function, we'll need to create a generator function that will complete processing at the first match. One way to do this is with the break statement, as follows:
- Define a generator function to skip items until a test is passed. The generator can yield the first value that passes the predicate test. The generator will require a predicate function,
fn. The definition can rely onTypeVarbecause the actual type doesn't matter. The type must match between the source of the data,source, and the predicate function,fn:T_ = TypeVar("T_") Predicate = Callable[[T_], bool] def find_first( fn: Predicate, source: Iterable[T_] ) -> Iterator[T_]: for item in source: if fn(item): yield item break - Define the specific predicate function. For our purposes, a
lambdaobject will do. Since we're testing for being prime, we're looking for any value that divides the target number,n, evenly. Here's the expression:lambda i: n % i == 0 - Apply the
find_first()search function with the given range of values and predicate. If thefactorsiterable has an item, thennis composite. Otherwise, there are no values in thefactorsiterable, which meansnis a prime number:import math def prime(n: int) -> bool: factors = find_first( lambda i: n % i == 0, range(2, int(math.sqrt(n)+1)) ) return len(list(factors)) == 0
As a practical matter, we don't need to test every single number between two and n to see whether n is prime. It's only necessary to test values, i, such that ![]() .
.
How it works...
In the find_first() function, we introduce a break statement to stop processing the source iterable. When the for statement stops, the generator will reach the end of the function and return normally.
The process that is consuming values from this generator will be given the StopIteration exception. This exception means the generator will produce no more values. The find_first() function raises an exception, but it's not an error. It's the normal way to signal that an iterable has finished processing the input values.
In this case, the StopIteration exception means one of two things:
- If a value has been yielded, the value is a factor of
n. - If no value was yielded, then
nis prime.
This small change of breaking early from the for statement makes a dramatic difference in the meaning of the generator function. Instead of processing all values from the source, the find_first() generator will stop processing as soon as the predicate is true.
This is different from a filter, where all the source values will be consumed. When using the break statement to leave the for statement early, some of the source values may not be processed.
See also
- We looked at how to combine mapping and filtering in the Using stacked generator expressions recipe, earlier in this chapter.
- We look at lazy properties in the Using properties for lazy attributes recipe in Chapter 7, Basics of Classes and Objects. Also, this recipe looks at some important variations of map-reduce processing.
There's more...
In the itertools module, there is an alternative to the find_first() function. This will be shown in this example. The takewhile() function uses a predicate function to take values from the input while the predicate function is true. When the predicate becomes false, then the function stops processing values.
To use takewhile(), we need to invert our factor test. We need to consume values that are non-factors until we find the first factor. This leads to a change in the lambda from lambda i: n % i == 0 to lambda i: n % i != 0.
Let's look at two examples. We'll test 47 and 49 for being prime. We need to check numbers in the range 2 to ![]() :
:
>>> from itertools import takewhile
n = 47
list(takewhile(lambda i: n % i != 0, range(2, 8)))
[2, 3, 4, 5, 6, 7]
n = 49
list(takewhile(lambda i: n % i != 0, range(2, 8)))
[2, 3, 4, 5, 6]
For a prime number, like 47, none of the values are factors. All the non-factors pass the takewhile() predicate. The resulting list of non-factors is the same as the set of values being tested. The collection of non-factors from the takewhile() function and the range(2, 8) object are both [2, 3, 4, 5, 6, 7].
For a composite number, like 49, many non-factors pass the takewhile() predicate until a factor is found. In this example, the values 2 through 6 are not factors of 49. The collection of non-factors, [2, 3, 4, 5, 6], is not the same as the set of values collection that was tested, [2, 3, 4, 5, 6, 7].
Using the itertooks.takewhile() function leads us to a test that looks like this:
def prime_t(n: int) -> bool:
tests = set(range(2, int(math.sqrt(n) + 1)))
non_factors = set(takewhile(lambda i: n % i != 0, tests))
return tests == non_factors
This creates two intermediate set objects, tests and non_factors. If all of the tested values are also not factors, the number is prime.
The built-in any() function is also an existential test. It can also be used to locate the first item that matches a given criteria. In the following example, we'll use any() to see if any of the test numbers in the tests range is a factor. If there are no factors, the number is prime:
def prime_any(n: int) -> bool:
tests = range(2, int(math.sqrt(n) + 1))
has_factors = any(n % t == 0 for t in tests)
return not has_factors
The itertools module
There are a number of additional functions in the itertools module that we can use to simplify complex map-reduce applications:
filterfalse(): It is the companion to the built-infilter()function. It inverts the predicate logic of thefilter()function; it rejects items for which the predicate istrue.zip_longest(): It is the companion to the built-inzip()function. The built-inzip()function stops merging items when the shortest iterable is exhausted. Thezip_longest()function will supply a given fill value to pad short iterables so they match the longest ones.starmap(): It is a modification of the essentialmap()algorithm. When we performmap(function, iter1, iter2), an item from each of the two iterables is provided as two positional arguments to the given function.starmap()expects a single iterable to provide a tuple that contains all the argument values for the function.
There are still other functions in this module that we might use, too:
accumulate(): This function is a variation on the built-insum()function. This will yield each partial total that's produced before reaching the final sum.chain(): This function will combine iterables in order.compress(): This function uses one iterable as a source of data and the other as a source of selectors. When the item from the selector is true, the corresponding data item is passed. Otherwise, the data item is rejected. This is an item-by-item filter based on true-false values.dropwhile(): While the predicate to this function istrue, it will reject values. Once the predicate becomesfalse, it will pass all remaining values. Seetakewhile().groupby(): This function uses a key function to control the definition of groups. Items with the same key value are grouped into separate iterators. For the results to be useful, the original data should be sorted into order by the keys.islice(): This function is like asliceexpression, except it applies to an iterable, not a list. Where we uselist[1:]to discard the first row of a list, we can useislice(iterable, 1)to discard the first item from an iterable.takewhile(): While the predicate istrue, this function will pass values. Once the predicate becomesfalse, stop processing any remaining values. Seedropwhile().tee(): This splits a single iterable into a number of clones. Each clone can then be consumed separately. This is a way to perform multiple reductions on a single iterable source of data.
There are a variety of ways we can use generator functions. The itertools module provides a number of ready-built higher-order functions that we can extend with generator functions. Building on the itertools foundation can provide a great deal of confidence that the final algorithm will work reliably.
See also
- In the Using stacked generator expressions recipe, earlier in this chapter, we made extensive use of immutable class definitions.
- See https://projecteuler.net/problem=10 for a challenging problem related to prime numbers less than 2 million. Parts of the problem seem obvious. It can be difficult, however, to test all those numbers for being prime.
Creating a partial function
When we look at functions such as reduce(), sorted(), min(), and max(), we see that we'll often have some argument values that change very rarely, if at all. In a particular context, they're essentially fixed. For example, we might find a need to write something like this in several places:
reduce(operator.mul, ..., 1)
Of the three parameters for reduce(), only one – the iterable to process – actually changes. The operator and the base value arguments are essentially fixed at operator.mul and 1.
Clearly, we can define a whole new function for this:
def prod(iterable):
return reduce(operator.mul, iterable, 1)
However, Python has a few ways to simplify this pattern so that we don't have to repeat the boilerplate def and return statements.
The goal of this recipe is different from providing general default values. A partial function doesn't provide a way for us to override the defaults. A partial function has specific values bound in a kind of permanent way. This leads to creating possibly many partial functions, each with specific argument values bound in advance.
Getting ready
Some statistical modeling is done with standard scores, sometimes called z-scores. The idea is to standardize a raw measurement onto a value that can be easily compared to a normal distribution, and easily compared to related numbers that are measured in different units.
The calculation is this:

Here, x is a raw value, ![]() is the population mean, and
is the population mean, and ![]() is the population standard deviation. The value z will have a mean of 0 and a standard deviation of 1. We can use this value to spot outliers – values that are suspiciously far from the mean. We expect that (about) 99.7% of our z values will be between -3 and +3.
is the population standard deviation. The value z will have a mean of 0 and a standard deviation of 1. We can use this value to spot outliers – values that are suspiciously far from the mean. We expect that (about) 99.7% of our z values will be between -3 and +3.
We could define a function to compute standard scores, like this:
def standardize(mean: float, stdev: float, x: float) -> float:
return (x - mean) / stdev
This standardize() function will compute a z-score from a raw score, x. When we use this function in a practical context, we'll see that there are two kinds of argument values for the parameters:
- The argument values for
meanandstdevare essentially fixed. Once we've computed the population values, we'll have to provide the same two values to thestandardize()function over and over again. - The value for the
xparameter will vary each time we evaulate thestandardize()function. The value of thexparameter will change frequently, but the values for themeanandstdevwill remain essentially fixed each time the function is used.
Let's work with a collection of data samples with two variables, x and y. The data is defined by the Row class:
@dataclass
class Row:
x: float
y: float
A collection of these Row items looks like this:
data_1 = [Row(x=10.0, y=8.04),
Row(x=8.0, y=6.95),
Row(x=13.0, y=7.58),
Row(x=9.0, y=8.81),
Row(x=11.0, y=8.33),
Row(x=14.0, y=9.96),
Row(x=6.0, y=7.24),
Row(x=4.0, y=4.26),
Row(x=12.0, y=10.84),
Row(x=7.0, y=4.82),
Row(x=5.0, y=5.68)]
As an example, we'll compute a standardized value for the x attribute. This means computing the mean and standard deviation for the x values. Then, we'll need to apply the mean and standard deviation values to standardize data in both of our collections. This looks like this:
import statistics
mean_x = statistics.mean(item.x for item in data_1)
stdev_x = statistics.stdev(item.x for item in data_1)
for row in data_1:
z_x = standardize(mean_x, stdev_x, row.x)
print(row, z_x)
Providing the mean_x, stdev_x values each time we evaluate the standardize() function can clutter an algorithm with details that aren't deeply important. In some more complex algorithms, the clutter can lead to more confusion than clarity. We can use a partial function to simplify this use of standardize() with some relatively fixed argument values.
How to do it...
To simplify using a function with a number of relatively fixed argument values, we can create a partial function. This recipe will show two ways to create a partial function:
- Using the
partial()function from thefunctoolsmodule to build a new function from the fullstandardize()function. - Creating a
lambdaobject to supply argument values that don't change.
Using functools.partial()
- Import the
partialfunction fromfunctools:from functools import partial - Create a new function using
partial(). We provide the base function, plus the positional arguments that need to be included. Any parameters that are not supplied when the partial is defined must be supplied when the partial is evaluated:z = partial(standardize, mean_x, stdev_x)
We've provided fixed values for the first two parameters, mean and stdev, of the standardize() function. We can now use the z() function with a single value, z(a), and it will apply standardize(mean_x, stdev_x, a). Stated another way, the partial function, z(a), is equivalent to a full function with values bound to mean_x and stdev_x.
Creating a lambda object
- Define a
lambdaobject that binds the fixed parameters:lambda x: standardize(mean_x, stdev_x, x) - Assign this
lambdato a variable to create a callable object,z():z = lambda x: standardize(mean_x, stdev_x, x)
This also provides fixed values for the first two parameters, mean and stdev, of the standardize() function. We can now use the z() lambda object with a single value, z(a), and it will apply standardize(mean_x, stdev_x, a).
How it works...
Both techniques create a callable object – a function – named z() that has the values for mean_x and stdev_x already bound to the first two positional parameters. With either approach, we can now have processing that can look like this:
for row in data_1:
print(row, z(row.x))
We've applied the z() function to each set of data. Because the z() function has some parameters already applied, its use is simplified.
There's one significant difference between the two techniques for creating the z() function:
- The
partial()function binds the actual values of the parameters. Any subsequent change to the variables that were used doesn't change the definition of the partial function that's created. After creatingz = partial(standardize(mean_x, stdev_x)), changing the value ofmean_Xorstdev_Xdoesn't have an impact on the partial function,z(). - The
lambdaobject binds the variable name, not the value. Any subsequent change to the variable's value will change the way the lambda behaves. After creatingz = lambda x: standardize(mean_x, stdev_x, x), changing the value ofmean_xorstdev_xchanges the values used by thelambdaobject,z().
We can modify the lambda slightly to bind specific values instead of names:
z = lambda x, m=mean_x, s=stdev_x: standardize(m, s, x)
This extracts the current values of mean_x and stdev_x to create default values for the lambda object. The values of mean_x and stdev_x are now irrelevant to the proper operation of the lambda object, z().
There's more...
We can provide keyword argument values as well as positional argument values when creating a partial function. While this works nicely in general, there are a few cases where it doesn't work.
The reduce() function, interestingly, can't be trivially turned into a partial function. The parameters aren't in the ideal order for creating a partial. The reduce() function appears to be defined like this:
def reduce(function, iterable, initializer=None)
If this were the actual definition, we could do this:
prod = partial(reduce(mul, initializer=1))
Practically, the preceding example doesn't work because the definition of reduce() is a bit more complex than it might appear. The reduce() function doesn't permit named argument values.
This means that we're forced to use the lambda technique:
>>> from operator import mul
>>> from functools import reduce
>>> prod = lambda x: reduce(mul, x, 1)
We've used a lambda object to define a function, prod(), with only one parameter. This function uses reduce() with two fixed parameters and one variable parameter.
Given this definition for prod(), we can define other functions that rely on computing products. Here's a definition of the factorial function:
>>> factorial = lambda x: prod(range(2, x+1))
>>> factorial(5)
120
The definition of factorial() depends on prod(). The definition of prod() is a kind of partial function that uses reduce() with two fixed parameter values. We've managed to use a few definitions to create a fairly sophisticated function.
In Python, a function is an object. We've seen numerous ways that functions can be arguments to a function. A function that accepts or returns another function as an argument is sometimes called a higher-order function.
Similarly, functions can also return a function object as a result. This means that we can create a function like this:
def prepare_z(data):
mean_x = statistics.mean(item.x for item in data_1)
stdev_x = statistics.stdev(item.x for item in data_1)
return partial(standardize, mean_x, stdev_x)
Here, we've defined a function over a set of (x, y) samples. We've computed the mean and standard deviation of the x attribute of each sample. We then created a partial function that can standardize scores based on the computed statistics. The result of this function is a function we can use for data analysis. The following example shows how this newly created function is used:
z = prepare_z(data_1)
for row in data_2:
print(row, z(row.x))
When we evaluated the prepare_z() function, it returned a function. We assigned this function to a variable, z. This variable is a callable object; it's the function z(), which will standardize a score based on the sample mean and standard deviation.
Simplifying complex algorithms with immutable data structures
The concept of a stateful object is a common feature of object-oriented programming. We looked at a number of techniques related to objects and state in Chapter 7, Basics of Classes and Objects, and Chapter 8, More Advanced Class Design. A great deal of the emphasis of object-oriented design is creating methods that mutate an object's state.
When working with JSON or CSV files, we'll often be working with objects that have a Python dict object that defines the attributes. Using a dict object to store an object's attributes has several consequences:
- We can trivially add and remove new attributes to the dictionary. We're not limited to simply setting and getting defined attributes. This makes it difficult for
mypyto check our design carefully. TheTypedDicttype hint suggests a narrow domain of possible key values, but it doesn't prevent runtime use of unexpected keys. - A
dictobject uses a somewhat larger amount of memory than is minimally necessary. This is because dictionaries use a hashing algorithm to locate keys and values. The hash processing requires more memory than other structures such aslistortuple. For very large amounts of data, this can become a problem.
The most significant issue with stateful object-oriented programming is that it can be challenging to understand the state changes of an object. Rather than trying to understand the state changes, it may be easier to create entirely new objects with a state that can be simply mapped to the object's type. This, coupled with Python type hints, can sometimes create more reliable, and easier to test, software.
In some cases, we can also reduce the amount of memory by avoiding stateful objects in the first place. We have two techniques for doing this:
- Using class definitions with
__slots__: See the Optimizing small objects with __slots__ recipe for this. These objects are mutable, so we can update attributes with new values. - Using immutable
tuplesorNamedTuples: See the Designing classes with little unique processing recipe for some background on this. These objects are immutable. We can create new objects, but we can't change the state of an object. The cost savings from less memory overall have to be balanced against the additional costs of creating new objects.
Immutable objects can be somewhat faster than mutable objects – but the more important benefit is for algorithm design. In some cases, writing functions that create new immutable objects from old immutable objects can be simpler and easier to test and debug than algorithms that work with stateful objects. Writing type hints can help with this process.
As we noted in the Using stacked generator expressions and Implementing "there exists" processing recipes, we can only process a generator once. If we need to process it more than once, the iterable sequence of objects must be transformed into a complete collection like a list or tuple.
This often leads to a multi-phase process:
- Initial extraction of the data: This might involve a database query or reading a
.csvfile. This phase can be implemented as a function that yields rows or even returns a generator function. - Cleansing and filtering the data: This may involve a stack of generator expressions that can process the source just once. This phase is often implemented as a function that includes several map and filter operations.
- Enriching the data: This, too, may involve a stack of generator expressions that can process the data one row at a time. This is typically a series of map operations to create new, derived data from existing data. This often means separate class definitions for each enrichment step.
- Reducing or summarizing the data: This may involve multiple summaries. In order for this to work, the output from the enrichment phase needs to be a collection object that can be iterated over more than once.
In some cases, the enrichment and summary processes may be interleaved. As we saw in the Creating a partial function recipe, we might do some summarization followed by more enrichment.
Getting ready
Let's work with a collection of data samples with two variables, x and y. The data is defined by the DataPair class:
DataPair = NamedTuple("DataPair", [("x", float), ("y", float)])
A collection of these DataPair items looks like this:
data_1 = [DataPair(x=10.0, y=8.04),
DataPair(x=8.0, y=6.95),
DataPair(x=13.0, y=7.58),
DataPair(x=9.0, y=8.81),
DataPair(x=11.0, y=8.33),
DataPair(x=14.0, y=9.96),
DataPair(x=6.0, y=7.24),
DataPair(x=4.0, y=4.26),
DataPair(x=12.0, y=10.84),
DataPair(x=7.0, y=4.82),
DataPair(x=5.0, y=5.68)]
In this example, we'll apply a number of computations to rank order this data using the y value of each pair. This requires creating another data type for the y-value ranking. Computing this ranking value requires sorting the data first, and then yielding the sorted values with an additional attribute value, the y rank order.
There are two approaches to this. First, we can change the initial design in order to replace NamedTuple with a mutable class that allows an update for each DataPair with a y-rank value. The alternative is to use a second NamedTuple to carry the y-rank value.
Applying a rank-order value is a little bit like a state change, but it can be done by creating new immutable objects instead of modifying the state of existing objects.
How to do it...
We'll build immutable rank order objects that will contain our existing DataPair instances. This will involve defining a new class and a function to create instances of the new class:
- Define the enriched
NamedTuplesubclass. We'll include the original data as an element of this class rather than copying the values from the original class:class RankYDataPair(NamedTuple): y_rank: int pair: DataPair - The alternative definition can look like this. For simple cases, this can be helpful. The behavior is identical to the class shown previously:
RankYDataPair = NamedTuple("RankYDataPair", [ ("y_rank", int), ("pair", DataPair) ]) - Define the enrichment function. This will be a generator that starts with
DataPairinstances and yieldsRankYDataPairinstances:def rank_by_y( source: Iterable[DataPair] ) -> Iterator[RankYDataPair]: - Write the body of the enrichment. In this case, we're going to be rank ordering, so we'll need sorted data, using the original
yattribute. We're creating new objects from the old objects, so the function yields instances ofRankYDataPair:all_data = sorted(source, key=lambda pair: pair.y) for y_rank, pair in enumerate(all_data, start=1): yield RankYDataPair(y_rank, pair)
We can use this in a longer expression to parse the input text, cleanse each row, and then rank the rows. The use of type hints can make this clearer than an alternative involving stateful objects. In some cases, there can be a very helpful improvement in the clarity of the code.
How it works...
The result of the rank_by_y() function is a new object that contains the original object, plus the result of the enrichment. Here's how we'd use this stacked sequence of generators, that is, rank_by_y(), cleanse(), and text_parse():
>>> data = rank_by_y(cleanse(text_parse(text_1)))
>>> pprint(list(data))
[RankYDataPair(y_rank=1, pair=DataPair(x=4.0, y=4.26)),
RankYDataPair(y_rank=2, pair=DataPair(x=7.0, y=4.82)),
RankYDataPair(y_rank=3, pair=DataPair(x=5.0, y=5.68)),
RankYDataPair(y_rank=4, pair=DataPair(x=8.0, y=6.95)),
RankYDataPair(y_rank=5, pair=DataPair(x=6.0, y=7.24)),
RankYDataPair(y_rank=6, pair=DataPair(x=13.0, y=7.58)),
RankYDataPair(y_rank=7, pair=DataPair(x=10.0, y=8.04)),
RankYDataPair(y_rank=8, pair=DataPair(x=11.0, y=8.33)),
RankYDataPair(y_rank=9, pair=DataPair(x=9.0, y=8.81)),
RankYDataPair(y_rank=10, pair=DataPair(x=14.0, y=9.96)),
RankYDataPair(y_rank=11, pair=DataPair(x=12.0, y=10.84))]
The data is in ascending order by the y value. We can now use these enriched data values for further analysis and calculation. The original immutable objects are part of the new ranked objects.
The Python type hints work well with the creation of new objects. Consequently, this technique can provide strong evidence that a complex algorithm is correct. Using mypy can make immutable objects more appealing.
Finally, we may sometimes see a small speed-up when we use immutable objects. This is not guaranteed and depends on a large number of factors. Using the timeit module to assess the performance of the alternative designs is essential.
We can use a test like the one shown in the following example to gather timing details:
import timeit
from textwrap import dedent
tuple_runtime = timeit.timeit(
"""list(rank_by_y(data))""",
dedent("""
from ch09_r09 import text_parse, cleanse, rank_by_y, text_1
data = cleanse(text_parse(text_1))
"""),
)
print(f"tuple {tuple_runtime}")
This example imports the timeit module and a handy tool from the textwrap module to de-indent (dedent) text. This lets us have blocks of Python code as an indented string. The test code is list(rank_by_y_dc(data)). This will be processed repeatedly to gather basic timing information. The other block of code is the one-time setup. This is an import to bring in a number of functions and a statement to gather the raw data and save it in the variable data. This setup is done once; we don't want to measure the performance here.
There's more...
The alternative design uses a mutable dataclass. This relies on a type definition that looks like this:
@dataclass
class DataPairDC:
x: float
y: float
y_rank: int = field(init=False)
This definition shows the two initial values of each data pair and the derived value that's computed during the rank ordering computation. We'll need a slightly different cleansing function. Here's a cleanse_dc() function to produce these DataPairDC objects:
def cleanse_dc(
source: Iterable[List[str]]) -> Iterator[DataPairDC]:
for text_item in source:
try:
x_amount = float(text_item[0])
y_amount = float(text_item[1])
yield DataPairDC(x=x_amount, y=y_amount)
except Exception as ex:
print(ex, repr(text_item))
This function is nearly identical to the cleanse() function for immutable objects. The principle difference is the class used in the yield statement and the related type hint.
Here's the ranking function:
def rank_by_y_dc(
source: Iterable[DataPairDC]) -> Iterable[DataPairDC]:
all_data = sorted(source, key=lambda pair: pair.y)
for y_rank, pair in enumerate(all_data, start=1):
pair.y_rank = y_rank
yield pair
This does two things. First, it yields a sequence of DataPairDC instances. As a side effect, it also updates each object, setting the y_rank attribute. This additional state change can be obscure in a complex application.
See also
- In the Using stacked generator expressions recipe, earlier in this chapter, we also made extensive use of immutable class definitions.
Writing recursive generator functions with the yield from statement
Many algorithms can be expressed neatly as recursions. In the Designing recursive functions around Python's stack limits recipe, we looked at some recursive functions that could be optimized to reduce the number of function calls.
When we look at some data structures, we see that they involve recursion. In particular, JSON documents (as well as XML and HTML documents) can have a recursive structure. A JSON document might include a complex object that contains other complex objects within it.
In many cases, there are advantages to using generators for processing these kinds of structures. In this recipe, we'll look at ways to handle recursive data structures with generator functions.
Getting ready
In this recipe, we'll look at a way to search for all matching values in a complex data structure. When working with complex JSON documents, they often contain dict-of-dict, dict-of-list, list-of-dict, and list-of-list structures. Of course, a JSON document is not limited to two levels; dict-of-dict really means dict-of-dict-of.... Similarly, dict-of-list really means dict-of-list-of.... The search algorithm must descend through the entire structure looking for a particular key or value.
A document with a complex structure might look like this:
document = {
"field": "value1",
"field2": "value",
"array": [
{"array_item_key1": "value"},
{"array_item_key2": "array_item_value2"}
],
"object": {
"attribute1": "value",
"attribute2": "value2"
},
}
This shows a document that has four keys, field, field2, array, and object. Each of these keys has a distinct data structure as its associated value. Some of the values are unique, while some are duplicated. This duplication is the reason why our search must find all instances inside the overall document.
The core algorithm is a depth-first search. The output from this function will be a list of paths that identify the target value. Each path will be a sequence of field names or field names mixed with index positions.
In the previous example, the value "value" can be found in three places:
["array", 0, "array_item_key1"]: This path starts with the top-level field namedarray, then visits item zero of a list, then a field namedarray_item_key1.["field2"]: This path has just a single field name where the value is found.["object", "attribute1"]: This path starts with the top-level field namedobject, then the child,attribute1, of that field.
The find_value() function yields both of these paths when it searches the overall document for the target value. Before looking at the recipe itself, let's take a quick look at a conceptual overview of this search function. This is not intended to be useful code. Instead, it shows how the different types are handled. Consider the if statements in this snippet:
def find_path(value, node, path=None):
path = path or []
if isinstance(node, dict):
for key in node.keys():
# find_value(value, node[key], path+[key])
# This may yield multiple values
elif isinstance(node, list):
for index in range(len(node)):
# find_value(value, node[index], path+[index])
# This may yield multiple values
else:
# a primitive type
if node == value:
yield path
There are three alternatives expressed in the find_path() if statement:
- When the
nodevalue is a dictionary, the value of each key must be examined. The values may be any kind of data, so we'll use thefind_path()function recursively on each value. This will yield a sequence of matches. - If the
nodevalue is a list, the items for each index position must be examined. The items may be any kind of data, so we'll use thefind_path()function recursively on each value. This will yield a sequence of matches. - The other choice is for the
nodevalue to be a primitive type, one ofint,float,str,bool, orNone. If thenodevalue is thetargetvalue, we've found one instance, and can yield this path to this match.
There are two ways to handle the recursion. One is like this:
for match in find_value(value, node[key], path+[key]):
yield match
The for statement seems to be scaffolding around a simple idea. The other way, using yield from, can be simpler and a bit clearer. This lets us remove a lot of for statement scaffolding.
How to do it...
We'll start by sketching out some replacement code for each branch in the conceptual code shown in the Getting ready section of this recipe. We will then create the complete function for traversing the complex data structure:
- Start with a template function to examine the various alternatives:
def find_path( value: Any, node: JSON_DOC, path: Optional[List[Node_Id]] = None ) -> Iterator[List[Node_Id]]: if path is None: path = [] if isinstance(node, dict): # apply find_path to each key elif isinstance(node, list): # applu find_path to each item in the last else: # str, int, float, bool, None if node == value: yield path - For a recursive function reference, write out the complete
forstatement. Use this for initial debugging to ensure things work. Here's how to look at each key of a dictionary. This replaces the# apply find_path to each keyline in the preceding code. Test this to be sure the recursion works properly:for key in sorted(node.keys()): for match in find_path (value, node[key], path+[key]): yield match - Replace the inner
forwith ayield fromstatement once we're sure things work:for key in sorted(node.keys()): yield from find_path(value, node[key], path+[key]) - This has to be done for the list case as well. Start an examination of each item in the list:
for index in range(len(node)): for match in find_path(value, node[index], path + [index]): yield match - Replace the inner
forwith ayield fromstatement:for index in range(len(node)): yield from find_path(value, node[index], path + [index])
The complete depth-first find_path() search function will look like this:
def find_path(
value: Any,
node: JSON_DOC,
path: Optional[List[Node_Id]] = None
) -> Iterator[List[Node_Id]]:
if path is None:
path: List[Node_Id] = []
if isinstance(node, dict):
for key in sorted(node.keys()):
yield from find_path(value, node[key], path + [key])
elif isinstance(node, list):
for index in range(len(node)):
yield from find_path(
value, node[index], path + [index])
else: # str, int, float, bool, None
if node == value:
yield path
When we use the find_path() function, it looks like this:
>>> list(find_path('array_item_value2', document))
[['array', 1, 'array_item_key2']]
The find_path() function is an iterator, yielding a number of values. We consumed all the results to create a list. In this example, the list had one item, ['array', 1, 'array_item_key2']. This item was the list of nodes on the path to the matching item.
We can then evaluate document['array'][1]['array_item_key2'] to find the referenced value.
When we look for a non-unique value, we might see a list like this:
>>> list(find_value('value', document))
[['array', 0, 'array_item_key1'],
['field2'],
['object', 'attribute1']]
The resulting list has three items. Each of these is a list of keys on the path to an item with the target value of value.
How it works...
The yield from X statement is shorthand for:
for item in X:
yield item
This lets us write a succinct recursive algorithm that will behave as an iterator and properly yield multiple values.
This can also be used in contexts that don't involve a recursive function. It's entirely sensible to use a yield from statement anywhere that an iterable result is involved. It's a big simplification for recursive functions, however, because it preserves a clearly recursive structure.
There's more...
Another common style of definition assembles a list using append operations. We can rewrite this into an iterator and avoid the overhead of building a list object.
When factoring a number, we can define the set of prime factors like this:

If the value, x, is prime, it has only itself in the set of prime factors. Otherwise, there must be some prime number, n, which is the least factor of x. We can assemble a set of factors starting with n and then append all factors of ![]() . To be sure that only prime factors are found, n must be prime. If we search ascending values of n, we'll find prime factors before finding composite factors.
. To be sure that only prime factors are found, n must be prime. If we search ascending values of n, we'll find prime factors before finding composite factors.
The eager approach builds a complete list of factors. A lazy approach can generate factors for a consumer. Here's an eager list-building function:
import math
def factor_list(x: int) -> List[int]:
limit = int(math.sqrt(x) + 1)
for n in range(2, limit):
q, r = divmod(x, n)
if r == 0:
return [n] + factor_list(q)
return [x]
This factor_list() function will search all numbers, n, such that ![]() . This function builds a
. This function builds a list object. If a factor, n, is found, it will start a list with that factor. It will extend the list, [n], with the factors built from x // n. If there are no factors of x, then the value is prime, and this returns a list with only the value of x.
Consider what happens when we evaluate factor_list(42). When n is 2, we'll compute [2] + factor_list(21). Computing factor_list(21) leads to computing [3] + factor_list(7). When factor_list(7) finds no factors, it returns [7], and as the recursive invocations of this function finish their work, the final result is [2, 3, 7].
This will search for composite numbers as well as prime numbers, wasting time. For example, after testing 2 and 3, this will also test 4 and 6, even though they're composite and all of their factors have already been tested.
We can rewrite this as an iterator by replacing the recursive calls with yield from. The function will look like this:
def factor_iter(x: int) -> Iterator[int]:
limit = int(math.sqrt(x) + 1)
for n in range(2, limit):
q, r = divmod(x, n)
if r == 0:
yield n
yield from factor_iter(q)
return
yield x
As with the list-building version, this will search numbers, n, such that ![]() . When a factor is found, the function will yield the factor, followed by any other factors found by a recursive call to
. When a factor is found, the function will yield the factor, followed by any other factors found by a recursive call to factor_iter(). If no factors are found, the function will yield the prime number and nothing more.
Using an iterator allows us to build any kind of collection from the factors. Instead of being limited to always creating a list object, we can create a multiset using the collections.Counter class. It would look like this:
>>> from collections import Counter
>>> Counter(factor_iter(384))
Counter({2: 7, 3: 1})
This shows us that:
![]()
In some cases, this kind of multiset can be easier to work with than a simple list of factors.
What's important is that the multiset was created directly from the factor_iter() iterator without creating an intermediate list object. This kind of optimization lets us build complex algorithms that aren't forced to consume large volumes of memory.
See also
- In the Designing recursive functions around Python's stack limits recipe, earlier in this chapter, we covered the core design patterns for recursive functions. This recipe provides an alternative way to create the results.