
1
Numbers, Strings, and Tuples
This chapter will look at some of the central types of Python objects. We'll look at working with different kinds of numbers, working with strings, and using tuples. These are the simplest kinds of data Python works with. In later chapters, we'll look at data structures built on these foundations.
Most of these recipes assume a beginner's level of understanding of Python 3.8. We'll be looking at how we use the essential built-in types available in Python—numbers, strings, and tuples. Python has a rich variety of numbers, and two different division operators, so we'll need to look closely at the choices available to us.
When working with strings, there are several common operations that are important. We'll explore some of the differences between bytes—as used by our OS files, and strings—as used by Python. We'll look at how we can exploit the full power of the Unicode character set.
In this chapter, we'll show the recipes as if we're working from the >>> prompt in interactive Python. This is sometimes called the read-eval-print loop (REPL). In later chapters, we'll change the style so it looks more like a script file. The goal in this chapter is to encourage interactive exploration because it's a great way to learn the language.
We'll cover these recipes to introduce basic Python data types:
- Working with large and small integers
- Choosing between
float,decimal, andfraction - Choosing between
true divisionandfloor division - Rewriting an immutable
string Stringparsing with regular expressions- Building complex strings with
f-strings - Building complex strings from lists of characters
- Using the Unicode characters that aren't on our keyboards
- Encoding strings – creating ASCII and UTF-8 bytes
- Decoding bytes – how to get proper characters from some bytes
- Using tuples of items
- Using
NamedTuplesto simplify item access in tuples
We'll start with integers, work our way through strings, and end up working with simple combinations of objects in the form of tuples and NamedTuples.
Working with large and small integers
Many programming languages make a distinction between integers, bytes, and long integers. Some languages include distinctions for signed versus unsigned integers. How do we map these concepts to Python?
The easy answer is that we don't. Python handles integers of all sizes in a uniform way. From bytes to immense numbers with hundreds of digits, they're all integers to Python.
Getting ready
Imagine you need to calculate something really big. For example, we want to calculate the number of ways to permute the cards in a 52-card deck. The factorial 52! = 52 × 51 × 50 × ... × 2 × 1, is a very, very large number. Can we do this in Python?
How to do it...
Don't worry. Really. Python has one universal type of integer, and this covers all of the bases, from individual bytes to numbers that fill all of the memory. Here are the steps to use integers properly:
- Write the numbers you need. Here are some smallish numbers: 355, 113. There's no practical upper limit.
- Creating a very small value—a single
byte—looks like this:>>> 2 2Or perhaps this, if you want to use base 16:
>>> 0xff 255 - Creating a much, much bigger number with a calculation using the
**operator ("raise to power") might look like this:>>> 2**2048 323...656
This number has 617 digits. We didn't show all of them.
How it works...
Internally, Python has two representations for numbers. The conversion between these two is seamless and automatic.
For smallish numbers, Python will generally use 4-byte or 8-byte integer values. Details are buried in CPython's internals; they depend on the facilities of the C compiler used to build Python.
For numbers over sys.maxsize, Python switches to internally representing integer numbers as sequences of digits. Digit, in this case, often means a 30-bit value.
How many ways can we permute a standard deck of 52 cards? The answer is 52! ≈ 8 × 1067. Here's how we can compute that large number. We'll use the factorial function in the math module, shown as follows:
>>> import math
>>> math.factorial(52)
80658175170943878571660636856403766975289505440883277824000000000000
Yes, this giant number works perfectly.
The first parts of our calculation of 52! (from 52 × 51 × 50 × ... down to about 42) could be performed entirely using the smallish integers. After that, the rest of the calculation had to switch to largish integers. We don't see the switch; we only see the results.
For some of the details on the internals of integers, we can look at this:
>>> import sys
>>> import math
>>> math.log(sys.maxsize, 2)
63.0
>>> sys.int_info
sys.int_info(bits_per_digit=30, sizeof_digit=4)
The sys.maxsize value is the largest of the small integer values. We computed the log to base 2 to find out how many bits are required for this number.
This tells us that our Python uses 63-bit values for small integers. The range of smallish integers is from -263 ... 263 - 1. Outside this range, largish integers are used.
The values in sys.int_info tell us that large integers are a sequence of 30-bit digits, and each of these digits occupies 4 bytes.
A large value like 52! consists of 8 of these 30-bit-sized digits. It can be a little confusing to think of a digit as requiring 30 bits in order to be represented. Instead of the commonly used symbols, 0, 1, 2, 3, …, 9, for base-10 numbers, we'd need 230 distinct symbols for each digit of these large numbers.
A calculation involving big integer values can consume a fair bit of memory. What about small numbers? How can Python manage to keep track of lots of little numbers like one and zero?
For some commonly used numbers (-5 to 256), Python can create a secret pool of objects to optimize memory management. This leads to a small performance improvement.
There's more...
Python offers us a broad set of arithmetic operators: +, -, *, /, //, %, and **. The / and // operators are for division; we'll look at these in a separate recipe named Choosing between true division and floor division. The ** operator raises a number to a power.
For dealing with individual bits, we have some additional operations. We can use &, ^, |, <<, and >>. These operators work bit by bit on the internal binary representations of integers. These compute a binary AND, a binary Exclusive OR, Inclusive OR, Left Shift, and Right Shift respectively.
See also
- We'll look at the two division operators in the Choosing between true division and floor division recipe, later in this chapter.
- We'll look at other kinds of numbers in the Choosing between float, decimal, and fraction recipe, which is the next recipe in this chapter.
- For details on integer processing, see https://www.python.org/dev/peps/pep-0237/.
Choosing between float, decimal, and fraction
Python offers several ways to work with rational numbers and approximations of irrational numbers. We have three basic choices:
- Float
- Decimal
- Fraction
With so many choices, when do we use each?
Getting ready
It's important to be sure about our core mathematical expectations. If we're not sure what kind of data we have, or what kinds of results we want to get, we really shouldn't be coding yet. We need to take a step back and review things with a pencil and paper.
There are three general cases for math that involve numbers beyond integers, which are:
- Currency: Dollars, cents, euros, and so on. Currency generally has a fixed number of decimal places. Rounding rules are used to determine what 7.25% of $2.95 is, rounded to the nearest penny.
- Rational Numbers or Fractions: When we're working with American units like feet and inches, or cooking measurements in cups and fluid ounces, we often need to work in fractions. When we scale a recipe that serves eight, for example, down to five people, we're doing fractional math using a scaling factor of
5/8. How do we apply this scaling to2/3cup of rice and still get a measurement that fits an American kitchen gadget? - Irrational Numbers: This includes all other kinds of calculations. It's important to note that digital computers can only approximate these numbers, and we'll occasionally see odd little artifacts of this approximation. Float approximations are very fast, but sometimes suffer from truncation issues.
When we have one of the first two cases, we should avoid floating-point numbers.
How to do it...
We'll look at each of the three cases separately. First, we'll look at computing with currency. Then, we'll look at rational numbers, and after that, irrational or floating-point numbers. Finally, we'll look at making explicit conversions among these various types.
Doing currency calculations
When working with currency, we should always use the decimal module. If we try to use the values of Python's built-in float type, we can run into problems with the rounding and truncation of numbers:
- To work with currency, we'll do this. Import the
Decimalclass from thedecimalmodule:>>> from decimal import Decimal - Create
Decimalobjects from strings or integers. In this case, we want 7.25%, which is 7.25/100. We can compute the value usingDecimalobjects. We could have usedDecimal('0.0725')instead of doing the division explicitly. The result is a hair over $0.21. It's computed correctly to the full number of decimal places:>>> tax_rate = Decimal('7.25')/Decimal(100) >>> purchase_amount = Decimal('2.95') >>> tax_rate * purchase_amount Decimal('0.213875') - To round to the nearest penny, create a
pennyobject:>>> penny = Decimal('0.01') - Quantize your data using this
pennyobject:>>> total_amount = purchase_amount + tax_rate * purchase_amount >>> total_amount.quantize(penny) Decimal('3.16')
This shows how we can use the default rounding rule of ROUND_HALF_EVEN.
Every financial wizard (and many world currencies) have different rules for rounding. The Decimal module offers every variation. We might, for example, do something like this:
>>> import decimal
>>> total_amount.quantize(penny, decimal.ROUND_UP)
Decimal('3.17')
This shows the consequences of using a different rounding rule.
Fraction calculations
When we're doing calculations that have exact fraction values, we can use the fractions module. This provides us with handy rational numbers that we can use. In this example, we want to scale a recipe for eight down to five people, using 5/8 of each ingredient. When we need 2![]() cups of sugar, what does that turn out to be?
cups of sugar, what does that turn out to be?
To work with fractions, we'll do this:
- Import the
Fractionclass from thefractionsmodule:>>> from fractions import Fraction - Create
Fractionobjects from strings, integers, or pairs of integers. If you create fraction objects from floating-point values, you may see unpleasant artifacts of float approximations. When the denominator is a power of 2, –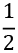 ,
, 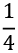 , and so on, converting from float to fraction can work out exactly. We created one fraction from a string,
, and so on, converting from float to fraction can work out exactly. We created one fraction from a string, '2.5'. We created the second fraction from a floating-point calculation,5/8. Because the denominator is a power of 2, this works out exactly:>>> sugar_cups = Fraction('2.5') >>> scale_factor = Fraction(5/8) >>> sugar_cups * scale_factor Fraction(25, 16) - The result,
 , is a complex-looking fraction. What's a nearby fraction that might be simpler?
, is a complex-looking fraction. What's a nearby fraction that might be simpler?
>>> Fraction(24,16) Fraction(3, 2)
We can see that we'll use almost a cup and a half of sugar to scale the recipe for five people instead of eight.
Floating-point approximations
Python's built-in float type can represent a wide variety of values. The trade-off here is that float often involves an approximation. In a few cases—specifically when doing division that involves powers of 2—it can be as exact as fraction. In all other cases, there may be small discrepancies that reveal the differences between the implementation of float and the mathematical ideal of an irrational number:
- To work with
float, we often need to round values to make them look sensible. It's important to recognize that allfloatcalculations are an approximation:>>> (19/155)*(155/19) 0.9999999999999999 - Mathematically, the value should be
1. Because of the approximations used forfloat, the answer isn't exact. It's not wrong by much, but it's wrong. In this example, we'll useround(answer, 3)to round to three digits, creating a value that's more useful:>>> answer = (19/155)*(155/19) >>> round(answer, 3) 1.0 - Know the error term. In this case, we know what the exact answer is supposed to be, so we can compare our calculation with the known correct answer. This gives us the general error value that can creep into floating-point numbers:
>>> 1-answer 1.1102230246251565e-16
For most floating-point errors, this is the typical value—about 10-16. Python has clever rules that hide this error some of the time by doing some automatic rounding. For this calculation, however, the error wasn't hidden.
This is a very important consequence.
Don't compare floating-point values for exact equality.
When we see code that uses an exact == test between floating-point numbers, there are going to be problems when the approximations differ by a single bit.
Converting numbers from one type into another
We can use the float() function to create a float value from another value. It looks like this:
>>> float(total_amount)
3.163875
>>> float(sugar_cups * scale_factor)
1.5625
In the first example, we converted a Decimal value into float. In the second example, we converted a Fraction value into float.
It rarely works out well to try to convert float into Decimal or Fraction:
>>> Fraction(19/155)
Fraction(8832866365939553, 72057594037927936)
>>> Decimal(19/155)
Decimal('0.12258064516129031640279123394066118635237216949462890625')
In the first example, we did a calculation among integers to create a float value that has a known truncation problem. When we created a Fraction from that truncated float value, we got some terrible - looking numbers that exposed the details of the truncation.
Similarly, the second example tries to create a Decimal value from a float value that has a truncation problem, resulting in a complicated value.
How it works...
For these numeric types, Python offers a variety of operators: +, -, *, /, //, %, and **. These are for addition, subtraction, multiplication, true division, truncated division, modulo, and raising to a power, respectively. We'll look at the two division operators in the Choosing between true division and floor division recipe.
Python is adept at converting numbers between the various types. We can mix int and float values; the integers will be promoted to floating-point to provide the most accurate answer possible. Similarly, we can mix int and Fraction and the results will be a Fraction object. We can also mix int and Decimal. We cannot casually mix Decimal with float or Fraction; we need to provide explicit conversions in that case.
It's important to note that float values are really approximations. The Python syntax allows us to write numbers as decimal values; however, that's not how they're processed internally.
We can write a value like this in Python, using ordinary base-10 values:
>>> 8.066e+67
8.066e+67
The actual value used internally will involve a binary approximation of the decimal value we wrote. The internal value for this example, 8.066e+67, is this:
>>> (6737037547376141/(2**53))*(2**226)
8.066e+67
The numerator is a big number, 6737037547376141. The denominator is always 253. Since the denominator is fixed, the resulting fraction can only have 53 meaningful bits of data. This is why values can get truncated. This leads to tiny discrepancies between our idealized abstraction and actual numbers. The exponent (2226) is required to scale the fraction up to the proper range.
Mathematically,  .
.
We can use math.frexp() to see these internal details of a number:
>>> import math
>>> math.frexp(8.066E+67)
(0.7479614202861186, 226)
The two parts are called the mantissa (or significand) and the exponent. If we multiply the mantissa by 253, we always get a whole number, which is the numerator of the binary fraction.
The error we noticed earlier matches this quite nicely: 10-16 ≈ 2-53.
Unlike the built-in float, a Fraction is an exact ratio of two integer values. As we saw in the Working with large and small integers recipe, integers in Python can be very large. We can create ratios that involve integers with a large number of digits. We're not limited by a fixed denominator.
A Decimal value, similarly, is based on a very large integer value, as well as a scaling factor to determine where the decimal place goes. These numbers can be huge and won't suffer from peculiar representation issues.
Why use floating-point? Two reasons: Not all computable numbers can be represented as fractions. That's why mathematicians introduced (or perhaps discovered) irrational numbers. The built-in float type is as close as we can get to the mathematical abstraction of irrational numbers. A value like ![]() , for example, can't be represented as a fraction. Also, float values are very fast on modern processors.
, for example, can't be represented as a fraction. Also, float values are very fast on modern processors.
There's more...
The Python math module contains several specialized functions for working with floating-point values. This module includes common elementary functions such as square root, logarithms, and various trigonometry functions. It also has some other functions such as gamma, factorial, and the Gaussian error function.
The math module includes several functions that can help us do more accurate floating-point calculations. For example, the math.fsum() function will compute a floating-point sum more carefully than the built-in sum() function. It's less susceptible to approximation issues.
We can also make use of the math.isclose() function to compare two floating-point values to see if they're nearly equal:
>>> (19/155)*(155/19) == 1.0
False
>>> math.isclose((19/155)*(155/19), 1)
True
This function provides us with a way to compare floating-point numbers meaningfully for near-equality.
Python also offers complex numbers. A complex number has a real and an imaginary part. In Python, we write 3.14+2.78j to represent the complex number ![]() . Python will comfortably convert between float and complex. We have the usual group of operators available for complex numbers.
. Python will comfortably convert between float and complex. We have the usual group of operators available for complex numbers.
To support complex numbers, there's the cmath package. The cmath.sqrt() function, for example, will return a complex value rather than raise an exception when extracting the square root of a negative number. Here's an example:
>>> math.sqrt(-2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: math domain error
>>> cmath.sqrt(-2)
1.4142135623730951j
This is essential when working with complex numbers.
See also
- We'll talk more about floating-point numbers and fractions in the Choosing between true division and floor division recipe.
- See https://en.wikipedia.org/wiki/IEEE_floating_point
Choosing between true division and floor division
Python offers us two kinds of division operators. What are they, and how do we know which one to use? We'll also look at the Python division rules and how they apply to integer values.
Getting ready
There are several general cases for division:
- A div-mod pair: We want both parts – the quotient and the remainder. The name refers to the division and modulo operations combined together. We can summarize the quotient and remainder as
 .
. We often use this when converting values from one base into another. When we convert seconds into hours, minutes, and seconds, we'll be doing a div-mod kind of division. We don't want the exact number of hours; we want a truncated number of hours, and the remainder will be converted into minutes and seconds.
- The true value: This is a typical floating-point value; it will be a good approximation to the quotient. For example, if we're computing an average of several measurements, we usually expect the result to be floating-point, even if the input values are all integers.
- A rational fraction value: This is often necessary when working in American units of feet, inches, and cups. For this, we should be using the
Fractionclass. When we divideFractionobjects, we always get exact answers.
We need to decide which of these cases apply, so we know which division operator to use.
How to do it...
We'll look at these three cases separately. First, we'll look at truncated floor division. Then, we'll look at true floating-point division. Finally, we'll look at the division of fractions.
Doing floor division
When we are doing the div-mod kind of calculations, we might use the floor division operator, //, and the modulo operator, %. The expression a % b gives us the remainder from an integer division of a // b. Or, we might use the divmod() built-in function to compute both at once:
- We'll divide the number of seconds by 3,600 to get the value of
hours. The modulo, or remainder in division, computed with the%operator, can be converted separately intominutesandseconds:>>> total_seconds = 7385 >>> hours = total_seconds//3600 >>> remaining_seconds = total_seconds % 3600 - Next, we'll divide the number of seconds by 60 to get
minutes; the remainder is the number of seconds less than 60:>>> minutes = remaining_seconds//60 >>> seconds = remaining_seconds % 60 >>> hours, minutes, seconds (2, 3, 5)
Here's the alternative, using the divmod() function to compute quotient and modulo together:
- Compute quotient and remainder at the same time:
>>> total_seconds = 7385 >>> hours, remaining_seconds = divmod(total_seconds, 3600) - Compute quotient and remainder again:
>>> minutes, seconds = divmod(remaining_seconds, 60) >>> hours, minutes, seconds (2, 3, 5)
Doing true division
A true value calculation gives as a floating-point approximation. For example, about how many hours is 7,386 seconds? Divide using the true division operator:
>>> total_seconds = 7385
>>> hours = total_seconds / 3600
>>> round(hours, 4)
2.0514
We provided two integer values, but got a floating-point exact result. Consistent with our previous recipe, when using floating-point values, we rounded the result to avoid having to look at tiny error values.
This true division is a feature of Python 3 that Python 2 didn't offer by default.
Rational fraction calculations
We can do division using Fraction objects and integers. This forces the result to be a mathematically exact rational number:
- Create at least one
Fractionvalue:>>> from fractions import Fraction >>> total_seconds = Fraction(7385) - Use the
Fractionvalue in a calculation. Any integer will be promoted to aFraction:>>> hours = total_seconds / 3600 >>> hours Fraction(1477, 720) - If necessary, convert the exact fraction into a floating-point approximation:
>>> round(float(hours),4) 2.0514
First, we created a Fraction object for the total number of seconds. When we do arithmetic on fractions, Python will promote any integers to be fractions; this promotion means that the math is done as precisely as possible.
How it works...
Python has two division operators:
- The
/true division operator produces a true, floating-point result. It does this even when the two operands are integers. This is an unusual operator in this respect. All other operators preserve the type of the data. The true division operation – when applied to integers – produces afloatresult. - The
//truncated division operator always produces a truncated result. For two integer operands, this is the truncated quotient. When floating-point operands are used, this is a truncated floating-point result:>>> 7358.0 // 3600.0 2.0
See also
- For more on the choice between floating-point and fractions, see the Choosing between float, decimal, and fraction recipe.
- See https://www.python.org/dev/peps/pep-0238/
Rewriting an immutable string
How can we rewrite an immutable string? We can't change individual characters inside a string:
>>> title = "Recipe 5: Rewriting, and the Immutable String"
>>> title[8] = ''
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
Since this doesn't work, how do we make a change to a string?
Getting ready
Let's assume we have a string like this:
>>> title = "Recipe 5: Rewriting, and the Immutable String"
We'd like to do two transformations:
- Remove the part up to the
: - Replace the punctuation with
_, and make all the characters lowercase
Since we can't replace characters in a string object, we have to work out some alternatives. There are several common things we can do, shown as follows:
- A combination of slicing and concatenating a string to create a new string.
- When shortening, we often use the
partition()method. - We can replace a character or a substring with the
replace()method. - We can expand the string into a list of characters, then join the string back into a single string again. This is the subject of a separate recipe, Building complex strings with a list of characters.
How to do it...
Since we can't update a string in place, we have to replace the string variable's object with each modified result. We'll use an assignment statement that looks something like this:
some_string = some_string.method()
Or we could even use an assignment like this:
some_string = some_string[:chop_here]
We'll look at a few specific variations of this general theme. We'll slice a piece of a string, we'll replace individual characters within a string, and we'll apply blanket transformations such as making the string lowercase. We'll also look at ways to remove extra _ that show up in our final string.
Slicing a piece of a string
Here's how we can shorten a string via slicing:
- Find the boundary:
>>> colon_position = title.index(':')The
indexfunction locates a particular substring and returns the position where that substring can be found. If the substring doesn't exist, it raises an exception. The following expression will always be true:title[colon_position] == ':'. - Pick the substring:
>>> discard, post_colon = title[:colon_position], title[colon_position+1:] >>> discard 'Recipe 5' >>> post_colon ' Rewriting, and the Immutable String'
We've used the slicing notation to show the start:end of the characters to pick. We also used multiple assignment to assign two variables, discard and post_colon, from the two expressions.
We can use partition(), as well as manual slicing. Find the boundary and partition:
>>> pre_colon_text, _, post_colon_text = title.partition(':')
>>> pre_colon_text
'Recipe 5'
>>> post_colon_text
' Rewriting, and the Immutable String'
The partition function returns three things: the part before the target, the target, and the part after the target. We used multiple assignment to assign each object to a different variable. We assigned the target to a variable named _ because we're going to ignore that part of the result. This is a common idiom for places where we must provide a variable, but we don't care about using the object.
Updating a string with a replacement
We can use a string's replace() method to create a new string with punctuation marks removed. When using replace to switch punctuation marks, save the results back into the original variable. In this case, post_colon_text:
>>> post_colon_text = post_colon_text.replace(' ', '_')
>>> post_colon_text = post_colon_text.replace(',', '_')
>>> post_colon_text
'_Rewriting__and_the_Immutable_String'
This has replaced the two kinds of punctuation with the desired _ characters. We can generalize this to work with all punctuation. This leverages the for statement, which we'll look at in Chapter 2, Statements and Syntax.
We can iterate through all punctuation characters:
>>> from string import whitespace, punctuation
>>> for character in whitespace + punctuation:
... post_colon_text = post_colon_text.replace(character, '_')
>>> post_colon_text
'_Rewriting__and_the_Immutable_String'
As each kind of punctuation character is replaced, we assign the latest and greatest version of the string to the post_colon_text variable.
We can also use a string's translate() method for this. This relies on creating a dictionary object to map each source character's position to a resulting character:
>>> from string import whitespace, punctuation
>>> title = "Recipe 5: Rewriting an Immutable String"
>>> title.translate({ord(c): '_' for c in whitespace+punctuation})
Recipe_5__Rewriting_an_Immutable_String
We've created a mapping with {ord(c): '_' for c in whitespace+punctuation} to translate any character, c, in the whitespace+punctuation sequence of characters to the '_' character. This may have better performance than a sequence of individual character replacements.
Removing extra punctuation marks
In many cases, there are some additional steps we might follow. We often want to remove leading and trailing _ characters. We can use strip() for this:
>>> post_colon_text = post_colon_text.strip('_')
In some cases, we'll have multiple _ characters because we had multiple punctuation marks. The final step would be something like this to clean up multiple _ characters:
>>> while '__' in post_colon_text:
... post_colon_text = post_colon_text.replace('__', '_')
This is yet another example of the same pattern we've been using to modify a string in place. This depends on the while statement, which we'll look at in Chapter 2, Statements and Syntax.
How it works...
We can't—technically—modify a string in place. The data structure for a string is immutable. However, we can assign a new string back to the original variable. This technique behaves the same as modifying a string in place.
When a variable's value is replaced, the previous value no longer has any references and is garbage collected. We can see this by using the id() function to track each individual string object:
>>> id(post_colon_text)
4346207968
>>> post_colon_text = post_colon_text.replace('_','-')
>>> id(post_colon_text)
4346205488
Your actual ID numbers may be different. What's important is that the original string object assigned to post_colon_text had one ID. The new string object assigned to post_colon_text has a different ID. It's a new string object.
When the old string has no more references, it is removed from memory automatically.
We made use of slice notation to decompose a string. A slice has two parts: [start:end]. A slice always includes the starting index. String indices always start with zero as the first item. A slice never includes the ending index.
The items in a slice have an index from start to end-1. This is sometimes called a half-open interval.
Think of a slice like this: all characters where the index i is in the range start ≤ i < end.
We noted briefly that we can omit the start or end indices. We can actually omit both. Here are the various options available:
title[colon_position]: A single item, that is, the:we found usingtitle.index(':').title[:colon_position]: A slice with the start omitted. It begins at the first position, index of zero.title[colon_position+1:]: A slice with the end omitted. It ends at the end of the string, as if we saidlen(title).title[:]: Since both start and end are omitted, this is the entire string. Actually, it's a copy of the entire string. This is the quick and easy way to duplicate a string.
There's more...
There are more features for indexing in Python collections like a string. The normal indices start with 0 on the left. We have an alternate set of indices that use negative numbers that work from the right end of a string:
title[-1]is the last character in the title,'g'title[-2]is the next-to-last character,'n'title[-6:]is the last six characters,'String'
We have a lot of ways to pick pieces and parts out of a string.
Python offers dozens of methods for modifying a string. The Text Sequence Type — str section of the Python Standard Library describes the different kinds of transformations that are available to us. There are three broad categories of string methods: we can ask about the string, we can parse the string, and we can transform the string to create a new one. Methods such as isnumeric() tell us if a string is all digits.
Here's an example:
>>> 'some word'.isnumeric()
False
>>> '1298'.isnumeric()
True
Before doing comparisons, it can help to change a string so that it has the same uniform case. It's frequently helpful to use the lower() method, thus assigning the result to the original variable:
>>> post_colon_text = post_colon_text.lower()
We've looked at parsing with the partition() method. We've also looked at transforming with the lower() method, as well as the replace() and translate() methods.
See also
- We'll look at the string as list technique for modifying a string in the Building complex strings from lists of characters recipe.
- Sometimes, we have data that's only a stream of bytes. In order to make sense of it, we need to convert it into characters. That's the subject of the Decoding bytes – how to get proper characters from some bytes recipe.
String parsing with regular expressions
How do we decompose a complex string? What if we have complex, tricky punctuation? Or—worse yet—what if we don't have punctuation, but have to rely on patterns of digits to locate meaningful information?
Getting ready
The easiest way to decompose a complex string is by generalizing the string into a pattern and then writing a regular expression that describes that pattern.
There are limits to the patterns that regular expressions can describe. When we're confronted with deeply nested documents in a language like HTML, XML, or JSON, we often run into problems, and can't use regular expressions.
The re module contains all of the various classes and functions we need to create and use regular expressions.
Let's say that we want to decompose text from a recipe website. Each line looks like this:
>>> ingredient = "Kumquat: 2 cups"
We want to separate the ingredient from the measurements.
How to do it...
To write and use regular expressions, we often do this:
- Generalize the example. In our case, we have something that we can generalize as:
(ingredient words): (amount digits) (unit words) - We've replaced literal text with a two-part summary: what it means and how it's represented. For example,
ingredientis represented aswords, whileamountis represented asdigits. Import theremodule:>>> import re - Rewrite the pattern into Regular expression (RE) notation:
>>> ingredient_pattern = re.compile(r'([ws]+):s+(d+)s+(w+)')We've replaced representation hints such as ingredient words, a mixture of letters and spaces, with [
ws]+. We've replaced amount digits withd+. And we've replaced single spaces withs+to allow one or more spaces to be used as punctuation. We've left the colon in place because, in the regular expression notation, a colon matches itself.For each of the fields of data, we've used
()to capture the data matching the pattern. We didn't capture the colon or the spaces because we don't need the punctuation characters.REs typically use a lot of
characters. To make this work out nicely in Python, we almost always use raw strings. Ther'prefix tells Python not to look at thecharacters and not to replace them with special characters that aren't on our keyboards. - Compile the pattern:
>>> pattern = re.compile(pattern_text) - Match the pattern against the input text. If the input matches the pattern, we'll get a
matchobject that shows details of the matching:>>> match = pattern.match(ingredient) >>> match is None False >>> match.groups() ('Kumquat', '2', 'cups') - Extract the named groups of characters from the
matchobject:>>> match.group(1) 'Kumquat' >>> match.group(2) '2' >>> match.group(3) 'cups'
Each group is identified by the order of the capture ()s in the regular expression. This gives us a tuple of the different fields captured from the string. We'll return to the use of tuples in the Using tuples recipe. This can be confusing in more complex regular expressions; there is a way to provide a name, instead of the numeric position, to identify a capture group.
How it works...
There are a lot of different kinds of string patterns that we can describe with RE.
We've shown a number of character classes:
wmatches any alphanumeric character (a to z, A to Z, 0 to 9)dmatches any decimal digitsmatches any space or tab character
These classes also have inverses:
Wmatches any character that's not a letter or a digitDmatches any character that's not a digitSmatches any character that's not some kind of space or tab
Many characters match themselves. Some characters, however, have a special meaning, and we have to use to escape from that special meaning:
- We saw that
+as a suffix means to match one or more of the preceding patterns.d+matches one or more digits. To match an ordinary+, we need to use+. - We also have
*as a suffix, which matches zero or more of the preceding patterns.w*matches zero or more characters. To match a*, we need to use*. - We have
?as a suffix, which matches zero or one of the preceding expressions. This character is used in other places, and has a different meaning in the other context. We'll see it used in(?P<name>...), where it is inside()to define special properties for the grouping. .matches any single character. To match a.specifically, we need to use..
We can create our own unique sets of characters using [] to enclose the elements of the set. We might have something like this:
(?P<name>w+)s*[=:]s*(?P<value>.*)
This has a w+ to match any number of alphanumeric characters. This will be collected into a group called name.
It uses s* to match an optional sequence of spaces.
It matches any character in the set [=:]. Exactly one of the characters in this set must be present.
It uses s* again to match an optional sequence of spaces.
Finally, it uses .* to match everything else in the string. This is collected into a group named value.
We can use this to parse strings, like this:
size = 12
weight: 14
By being flexible with the punctuation, we can make a program easier to use. We'll tolerate any number of spaces, and either an = or a : as a separator.
There's more...
A long regular expression can be awkward to read. We have a clever Pythonic trick for presenting an expression in a way that's much easier to read:
>>> ingredient_pattern = re.compile(
... r'(?P<ingredient>[ws]+):s+' # name of the ingredient up to the ":"
... r'(?P<amount>d+)s+' # amount, all digits up to a space
... r'(?P<unit>w+)' # units, alphanumeric characters
... )
This leverages three syntax rules:
- A statement isn't finished until the
()characters match. - Adjacent string literals are silently concatenated into a single long string.
- Anything between
#and the end of the line is a comment, and is ignored.
We've put Python comments after the important clauses in our regular expression. This can help us understand what we did, and perhaps help us diagnose problems later.
We can also use the regular expression's "verbose" mode to add gratuitous whitespace and comments inside a regular expression string. To do this, we must use re.X as an option when compiling a regular expression to make whitespace and comments possible. This revised syntax looks like this:
>>> ingredient_pattern_x = re.compile(r'''
... (?P<ingredient>[ws]+):s+ # name of the ingredient up to the ":"'
... (?P<amount>d+)s+ # amount, all digits up to a space'
... (?P<unit>w+) # units, alphanumeric characters
... ''', re.X)
We can either break the pattern up or make use of extended syntax to make the regular expression more readable.
See also
- The Decoding Bytes – How to get proper characters from some bytes recipe
- There are many books on Regular expressions and Python Regular expressions in particular, like Mastering Python Regular Expressions (https://www.packtpub.com/application-development/mastering-python-regular-expressions)
Building complex strings with f-strings
Creating complex strings is, in many ways, the polar opposite of parsing a complex string. We generally find that we use a template with substitution rules to put data into a more complex format.
Getting ready
Let's say we have pieces of data that we need to turn into a nicely formatted message. We might have data that includes the following:
>>> id = "IAD"
>>> location = "Dulles Intl Airport"
>>> max_temp = 32
>>> min_temp = 13
>>> precipitation = 0.4
And we'd like a line that looks like this:
IAD : Dulles Intl Airport : 32 / 13 / 0.40
How to do it...
- Create an
f-stringfrom the result, replacing all of the data items with{}placeholders. Inside each placeholder, put a variable name (or an expression.) Note that the string uses the prefix off'. Thefprefix creates a sophisticated string object where values are interpolated into the template when the string is used:f'{id} : {location} : {max_temp} / {min_temp} / {precipitation}' - For each name or expression, an optional
:data typecan be appended to the names in the template string. The basic data type codes are:sfor stringdfor decimal numberffor floating-point numberIt would look like this:
f'{id:s} : {location:s} : {max_temp:d} / {min_temp:d} / {precipitation:f}'
- Add length information where required. Length is not always required, and in some cases, it's not even desirable. In this example, though, the length information ensures that each message has a consistent format. For strings and decimal numbers, prefix the format with the length like this:
19sor3d. For floating-point numbers, use a two-part prefix like5.2fto specify the total length of five characters, with two to the right of the decimal point. Here's the whole format:>>> f'{id:3d} : {location:19s} : {max_temp:3d} / {min_temp:3d} / {precipitation:5.2f}' 'IAD : Dulles Intl Airport : 32 / 13 / 0.40'
How it works...
f-strings can do a lot of relatively sophisticated string assembly by interpolating data into a template. There are a number of conversions available.
We've seen three of the formatting conversions—s, d, f—but there are many others. Details can be found in the Formatted string literals section of the Python Standard Library: https://docs.python.org/3/reference/lexical_analysis.html#formatted-string-literals.
Here are some of the format conversions we might use:
bis for binary, base 2.cis for Unicode character. The value must be a number, which is converted into a character. Often, we use hexadecimal numbers for these characters, so you might want to try values such as0x2661through0x2666to see interesting Unicode glyphs.dis for decimal numbers.Eandeare for scientific notations.6.626E-34or6.626e-34, depending on whichEorecharacter is used.Fandfare for floating-point. For not a number, thefformat shows lowercasenan; theFformat shows uppercaseNAN.Gandgare for general use. This switches automatically betweenEandF(oreandf) to keep the output in the given sized field. For a format of20.5G, up to 20-digit numbers will be displayed usingFformatting. Larger numbers will useEformatting.nis for locale-specific decimal numbers. This will insert,or.characters, depending on the current locale settings. The default locale may not have 1,000 separators defined. For more information, see thelocalemodule.ois for octal, base 8.sis for string.Xandxare for hexadecimal, base 16. The digits include uppercaseA-Fand lowercasea-f, depending on whichXorxformat character is used.%is for percentage. The number is multiplied by 100 and includes the%.
We have a number of prefixes we can use for these different types. The most common one is the length. We might use {name:5d} to put in a 5-digit number. There are several prefixes for the preceding types:
- Fill and alignment: We can specify a specific filler character (space is the default) and an alignment. Numbers are generally aligned to the right and strings to the left. We can change that using
<,>, or^. This forces left alignment, right alignment, or centering, respectively. There's a peculiar = alignment that's used to put padding after a leading sign. - Sign: The default rule is a leading negative sign where needed. We can use
+to put a sign on all numbers,-to put a sign only on negative numbers, and a space to use a space instead of a plus for positive numbers. In scientific output, we often use{value: 5.3f}. The space makes sure that room is left for the sign, ensuring that all the decimal points line up nicely. - Alternate form: We can use the
#to get an alternate form. We might have something like{0:#x},{0:#o}, or{0:#b}to get a prefix on hexadecimal, octal, or binary values. With a prefix, the numbers will look like0xnnn,0onnn, or0bnnn. The default is to omit the two-character prefix. - Leading zero: We can include
0to get leading zeros to fill in the front of a number. Something like{code:08x}will produce a hexadecimal value with leading zeroes to pad it out to eight characters. - Width and precision: For integer values and strings, we only provide the width. For floating-point values, we often provide
width.precision.
There are some times when we won't use a {name:format} specification. Sometimes, we'll need to use a {name!conversion} specification. There are only three conversions available:
{name!r}shows the representation that would be produced byrepr(name).{name!s}shows the string value that would be produced bystr(name); this is the default behavior if you don't specify any conversion. Using!sexplicitly lets you add string-type format specifiers.{name!a}shows the ASCII value that would be produced byascii(name).- Additionally, there's a handy debugging format specifier available in Python 3.8. We can include a trailing equals sign,
=, to get a handy dump of a variable or expression. The following example uses both forms:>>> value = 2**12-1 >>> f'{value=} {2**7+1=}' 'value=4095 2**7+1=129'
The f-string showed the value of the variable named value and the result of an expression, 2**7+1.
In Chapter 7, Basics of Classes and Objects, we'll leverage the idea of the {name!r} format specification to simplify displaying information about related objects.
There's more...
The f-string processing relies on the string format() method. We can leverage this method and the related format_map() method for cases where we have more complex data structures.
Looking forward to Chapter 4, Built-In Data Structures Part 1: Lists and Sets, we might have a dictionary where the keys are simple strings that fit with the format_map() rules:
>>> data = dict(
... id=id, location=location, max_temp=max_temp,
... min_temp=min_temp, precipitation=precipitation
... )
>>> '{id:3s} : {location:19s} : {max_temp:3d} / {min_temp:3d} / {precipitation:5.2f}'.format_map(data)
'IAD : Dulles Intl Airport : 32 / 13 / 0.40'
We've created a dictionary object, data, that contains a number of values with keys that are valid Python identifiers: id, location, max_temp, min_temp, and precipitation. We can then use this dictionary with format_map() to extract values from the dictionary using the keys.
Note that the formatting template here is not an f-string. It doesn't have the f" prefix. Instead of using the automatic formatting features of an f-string, we've done the interpolation "the hard way" using the format_map() method.
See also
- More details can be found in the Formatted string literals section of the Python Standard Library: https://docs.python.org/3/reference/lexical_analysis.html#formatted-string-literals
Building complicated strings from lists of characters
How can we make complicated changes to an immutable string? Can we assemble a string from individual characters?
In most cases, the recipes we've already seen give us a number of tools for creating and modifying strings. There are yet more ways in which we can tackle the string manipulation problem. In this recipe, we'll look at using a list object as a way to decompose and rebuild a string. This will dovetail with some of the recipes in Chapter 4, Built-In Data Structures Part 1: Lists and Sets.
Getting ready
Here's a string that we'd like to rearrange:
>>> title = "Recipe 5: Rewriting an Immutable String"
We'd like to do two transformations:
- Remove the part before
: - Replace the punctuation with
_and make all the characters lowercase
We'll make use of the string module:
>>> from string import whitespace, punctuation
This has two important constants:
string.whitespacelists all of the ASCII whitespace characters, including space and tab.string.punctuationlists the ASCII punctuation marks.
How to do it...
We can work with a string exploded into a list. We'll look at lists in more depth in Chapter 4, Built-In Data Structures Part 1: Lists and Sets:
- Explode the string into a
listobject:>>> title_list = list(title) - Find the partition character. The
index()method for a list has the same semantics as theindex()method has for a string. It locates the position with the given value:>>> colon_position = title_list.index(':') - Delete the characters that are no longer needed. The
delstatement can remove items from a list. Unlike strings, lists are mutable data structures:>>> del title_list[:colon_position+1] - Replace punctuation by stepping through each position. In this case, we'll use a
forstatement to visit every index in the string:>>> for position in range(len(title_list)): ... if title_list[position] in whitespace+punctuation: ... title_list[position]= '_' - The expression
range(len(title_list))generates all of the values between0andlen(title_list)-1. This assures us that the value ofpositionwill be each value index in the list. Join the list of characters to create a new string. It seems a little odd to use a zero-length string,'', as a separator when concatenating strings together. However, it works perfectly:>>> title = ''.join(title_list) >>> title '_Rewriting_an_Immutable_String'
We assigned the resulting string back to the original variable. The original string object, which had been referred to by that variable, is no longer needed: it's automatically removed from memory (this is known as "garbage collection"). The new string object replaces the value of the variable.
How it works...
This is a change in representation trick. Since a string is immutable, we can't update it. We can, however, convert it into a mutable form; in this case, a list. We can make whatever changes are required to the mutable list object. When we're done, we can change the representation from a list back to a string and replace the original value of the variable.
Lists provide some features that strings don't have. Conversely, strings provide a number of features lists don't have. As an example, we can't convert a list into lowercase the way we can convert a string.
There's an important trade-off here:
- Strings are immutable, which makes them very fast. Strings are focused on Unicode characters. When we look at mappings and sets, we can use strings as keys for mappings and items in sets because the value is immutable.
- Lists are mutable. Operations are slower. Lists can hold any kind of item. We can't use a list as a key for a mapping or an item in a set because the list value could change.
Strings and lists are both specialized kinds of sequences. Consequently, they have a number of common features. The basic item indexing and slicing features are shared. Similarly, a list uses the same kind of negative index values that a string does: list[-1] is the last item in a list object.
We'll return to mutable data structures in Chapter 4, Built-In Data Structures Part 1: Lists and Sets.
See also
- We can also work with strings using the internal methods of a string. See the Rewriting an immutable string recipe for more techniques.
- Sometimes, we need to build a string, and then convert it into bytes. See the Encoding strings – creating ASCII and UTF-8 bytes recipe for how we can do this.
- Other times, we'll need to convert bytes into a string. See the Decoding Bytes – How to get proper characters from some bytes recipe for more information.
Using the Unicode characters that aren't on our keyboards
A big keyboard might have almost 100 individual keys. Fewer than 50 of these are letters, numbers, and punctuation. At least a dozen are function keys that do things other than simply insert letters into a document. Some of the keys are different kinds of modifiers that are meant to be used in conjunction with another key—for example, we might have Shift, Ctrl, Option, and Command.
Most operating systems will accept simple key combinations that create about 100 or so characters. More elaborate key combinations may create another 100 or so less popular characters. This isn't even close to covering the vast domain of characters from the world's alphabets. And there are icons, emoticons, and dingbats galore in our computer fonts. How do we get to all of those glyphs?
Getting ready
Python works in Unicode. There are thousands of individual Unicode characters available.
We can see all the available characters at https://en.wikipedia.org/wiki/List_of_Unicode_characters, as well as at http://www.unicode.org/charts/.
We'll need the Unicode character number. We may also want the Unicode character name.
A given font on our computer may not be designed to provide glyphs for all of those characters. In particular, Windows computer fonts may have trouble displaying some of these characters. Using the following Windows command to change to code page 65001 is sometimes necessary:
chcp 65001
Linux and macOS rarely have problems with Unicode characters.
How to do it...
Python uses escape sequences to extend the ordinary characters we can type to cover the vast space of Unicode characters. Each escape sequence starts with a character. The next character tells us exactly how the Unicode character will be represented. Locate the character that's needed. Get the name or the number. The numbers are always given as hexadecimal, base 16. Websites describing Unicode often write the character as U+2680. The name might be DIE FACE-1. Use unnnn with up to a four-digit number. Or, use N{name} with the spelled-out name. If the number is more than four digits, use Unnnnnnnn with the number padded out to exactly eight digits:
>>> 'You Rolled u2680'
'You Rolled  '
>>>'You drew u0001F000'
'You drew
'
>>>'You drew u0001F000'
'You drew  '
>>> 'Discard N{MAHJONG TILE RED DRAGON}'
'Discard '
'
>>> 'Discard N{MAHJONG TILE RED DRAGON}'
'Discard '
Yes, we can include a wide variety of characters in Python output. To place a character in the string, we need to use \. For example, we might need this for Windows file paths.
How it works...
Python uses Unicode internally. The 128 or so characters we can type directly using the keyboard all have handy internal Unicode numbers.
When we write:
'HELLO'
Python treats it as shorthand for this:
'u0048u0045u004cu004cu004f'
Once we get beyond the characters on our keyboards, the remaining thousands of characters are identified only by their number.
When the string is being compiled by Python, uxxxx, Uxxxxxxxx, and N{name} are all replaced by the proper Unicode character. If we have something syntactically wrong—for example, N{name with no closing }—we'll get an immediate error from Python's internal syntax checking.
Back in the String parsing with regular expressions recipe, we noted that regular expressions use a lot of characters and that we specifically do not want Python's normal compiler to touch them; we used the r' prefix on a regular expression string to prevent from being treated as an escape and possibly converted into something else. To use the full domain of Unicode characters, we cannot avoid using as an escape.
What if we need to use Unicode in a Regular expression? We'll need to use \ all over the place in the Regular expression. We might see this: '\w+[u2680u2681u2682u2683u2684u2685]\d+'. We couldn't use the r' prefix on the string because we needed to have the Unicode escapes processed. This forced us to double the used for Regular expressions. We used uxxxx for the Unicode characters that are part of the pattern. Python's internal compiler will replace uxxxx with Unicode characters and \w with a required w internally.
When we look at a string at the >>> prompt, Python will display the string in its canonical form. Python prefers to use ' as a delimiter, even though we can use either ' or " for a string delimiter. Python doesn't generally display raw strings; instead, it puts all of the necessary escape sequences back into the string:
>>> r"w+"
'\w+'
We provided a string in raw form. Python displayed it in canonical form.
See also
- In the Encoding strings – creating ASCII and UTF-8 bytes and the Decoding Bytes – How to get proper characters from some bytes recipes, we'll look at how Unicode characters are converted into sequences of bytes so we can write them to a file. We'll look at how bytes from a file (or downloaded from a website) are turned into Unicode characters so they can be processed.
- If you're interested in history, you can read up on ASCII and EBCDIC and other old-fashioned character codes here: http://www.unicode.org/charts/.
Encoding strings – creating ASCII and UTF-8 bytes
Our computer files are bytes. When we upload or download from the internet, the communication works in bytes. A byte only has 256 distinct values. Our Python characters are Unicode. There are a lot more than 256 Unicode characters.
How do we map Unicode characters to bytes to write to a file or for transmission?
Getting ready
Historically, a character occupied 1 byte. Python leverages the old ASCII encoding scheme for bytes; this sometimes leads to confusion between bytes and proper strings of Unicode characters.
Unicode characters are encoded into sequences of bytes. There are a number of standardized encodings and a number of non-standard encodings.
Plus, there also are some encodings that only work for a small subset of Unicode characters. We try to avoid these, but there are some situations where we'll need to use a subset encoding scheme.
Unless we have a really good reason not to, we almost always use UTF-8 encoding for Unicode characters. Its main advantage is that it's a compact representation of the Latin alphabet, which is used for English and a number of European languages.
Sometimes, an internet protocol requires ASCII characters. This is a special case that requires some care because the ASCII encoding can only handle a small subset of Unicode characters.
How to do it...
Python will generally use our OS's default encoding for files and internet traffic. The details are unique to each OS:
- We can make a general setting using the
PYTHONIOENCODINGenvironment variable. We set this outside of Python to ensure that a particular encoding is used everywhere. When using Linux or macOS, useexporttosetthe environment variable. For Windows, use thesetcommand, or the PowerShellSet-Itemcmdlet. For Linux, it looks like this:export PYTHONIOENCODING=UTF-8 - Run Python:
python3.8 - We sometimes need to make specific settings when we open a file inside our script. We'll return to this topic in Chapter 10, Input/Output, Physical Format and, Logical Layout. Open the file with a given encoding. Read or write Unicode characters to the file:
>>> with open('some_file.txt', 'w', encoding='utf-8') as output: ... print( 'You drew U0001F000', file=output ) >>> with open('some_file.txt', 'r', encoding='utf-8') as input: ... text = input.read() >>> text 'You drew '
'
We can also manually encode characters, in the rare case that we need to open a file in bytes mode; if we use a mode of wb, we'll need to use manual encoding:
>>> string_bytes = 'You drew U0001F000'.encode('utf-8')
>>> string_bytes
b'You drew xf0x9fx80x80'
We can see that a sequence of bytes (xf0x9fx80x80) was used to encode a single Unicode character, U+1F000, ![]() .
.
How it works...
Unicode defines a number of encoding schemes. While UTF-8 is the most popular, there is also UTF-16 and UTF-32. The number is the typical number of bits per character. A file with 1,000 characters encoded in UTF-32 would be 4,000 8-bit bytes. A file with 1,000 characters encoded in UTF-8 could be as few as 1,000 bytes, depending on the exact mix of characters. In UTF-8 encoding, characters with Unicode numbers above U+007F require multiple bytes.
Various OSes have their own coding schemes. macOS files can be encoded in Mac Roman or Latin-1. Windows files might use CP1252 encoding.
The point with all of these schemes is to have a sequence of bytes that can be mapped to a Unicode character and—going the other way—a way to map each Unicode character to one or more bytes. Ideally, all of the Unicode characters are accounted for. Pragmatically, some of these coding schemes are incomplete.
The historical form of ASCII encoding can only represent about 100 of the Unicode characters as bytes. It's easy to create a string that cannot be encoded using the ASCII scheme.
Here's what the error looks like:
>>> 'You drew U0001F000'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character 'U0001f000' in position 9: ordinal not in range(128)
We may see this kind of error when we accidentally open a file with a poorly chosen encoding. When we see this, we'll need to change our processing to select a more useful encoding; ideally, UTF-8.
Bytes versus strings: Bytes are often displayed using printable characters. We'll see b'hello' as shorthand for a five-byte value. The letters are chosen using the old ASCII encoding scheme, where byte values from 0x20 to 0x7F will be shown as characters, and outside this range, more complex-looking escapes will be used.
This use of characters to represent byte values can be confusing. The prefix of b' is our hint that we're looking at bytes, not proper Unicode characters.
See also
- There are a number of ways to build strings of data. See the Building complex strings with f"strings" and the Building complex strings from lists of characters recipes for examples of creating complex strings. The idea is that we might have an application that builds a complex string, and then we encode it into bytes.
- For more information on UTF-8 encoding, see https://en.wikipedia.org/wiki/UTF-8.
- For general information on Unicode encodings, see http://unicode.org/faq/utf_bom.html.
Decoding bytes – how to get proper characters from some bytes
How can we work with files that aren't properly encoded? What do we do with files written in ASCII encoding?
A download from the internet is almost always in bytes—not characters. How do we decode the characters from that stream of bytes?
Also, when we use the subprocess module, the results of an OS command are in bytes. How can we recover proper characters?
Much of this is also relevant to the material in Chapter 10, Input/Output, Physical Format and Logical Layout. We've included this recipe here because it's the inverse of the previous recipe, Encoding strings – creating ASCII and UTF-8 bytes.
Getting ready
Let's say we're interested in offshore marine weather forecasts. Perhaps this is because we own a large sailboat, or perhaps because good friends of ours have a large sailboat and are departing the Chesapeake Bay for the Caribbean.
Are there any special warnings coming from the National Weather Services office in Wakefield, Virginia?
Here's where we can get the warnings: https://forecast.weather.gov/product.php?site=CRH&issuedby=AKQ&product=SMW&format=TXT.
We can download this with Python's urllib module:
>>> import urllib.request
>>> warnings_uri= 'https://forecast.weather.gov/product.php?site=CRH&issuedby=AKQ&product=SMW&format=TXT'
>>> with urllib.request.urlopen(warnings_uri) as source:
... warnings_text = source.read()
Or, we can use programs like curl or wget to get this. At the OS Terminal prompt, we might run the following (long) command:
$ curl 'https://forecast.weather.gov/product.php?site=CRH&issuedby=AKQ&product=SMW&format=TXT' -o AKQ.html
Typesetting this book tends to break the command onto many lines. It's really one very long line.
The code repository includes a sample file, Chapter_01/National Weather Service Text Product Display.html.
The forecast_text value is a stream of bytes. It's not a proper string. We can tell because it starts like this:
>>> warnings_text[:80]
b'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.or'
The data goes on for a while, providing details from the web page. Because the displayed value starts with b', it's bytes, not proper Unicode characters. It was probably encoded with UTF-8, which means some characters could have weird-looking xnn escape sequences instead of proper characters. We want to have the proper characters.
While this data has many easy-to-read characters, the b' prefix shows that it's a collection of byte values, not proper text. Generally, a bytes object behaves somewhat like a string object. Sometimes, we can work with bytes directly. Most of the time, we'll want to decode the bytes and create proper Unicode characters from them.
How to do it…
- Determine the coding scheme if possible. In order to decode bytes to create proper Unicode characters, we need to know what encoding scheme was used. When we read XML documents, there's a big hint provided within the document:
<?xml version="1.0" encoding="UTF-8"?>When browsing web pages, there's often a header containing this information:
Content-Type: text/html; charset=ISO-8859-4Sometimes, an HTML page may include this as part of the header:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">In other cases, we're left to guess. In the case of US weather data, a good first guess is UTF-8. Other good guesses include ISO-8859-1. In some cases, the guess will depend on the language.
- The codecs — Codec registry and base classes section of the Python Standard Library lists the standard encodings available. Decode the data:
>>> document = forecast_text.decode("UTF-8") >>> document[:80] '<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.or'The
b'prefix is no longer used to show that these are bytes. We've created a proper string of Unicode characters from the stream of bytes. - If this step fails with an exception, we guessed wrong about the encoding. We need to try another encoding. Parse the resulting document.
Since this is an HTML document, we should use Beautiful Soup. See http://www.crummy.com/software/BeautifulSoup/.
We can, however, extract one nugget of information from this document without completely parsing the HTML:
>>> import re
>>> title_pattern = re.compile(r"<h3>(.*?)</h3>")
>>> title_pattern.search( document )
<_sre.SRE_Match object; span=(3438, 3489), match='<h3>There are no products active at this time.</h>
This tells us what we need to know: there are no warnings at this time. This doesn't mean smooth sailing, but it does mean that there aren't any major weather systems that could cause catastrophes.
How it works...
See the Encoding strings – creating ASCII and UTF-8 bytes recipe for more information on Unicode and the different ways that Unicode characters can be encoded into streams of bytes.
At the foundation of the operating system, files and network connections are built up from bytes. It's our software that decodes the bytes to discover the content. It might be characters, images, or sounds. In some cases, the default assumptions are wrong and we need to do our own decoding.
See also
- Once we've recovered the string data, we have a number of ways of parsing or rewriting it. See the String parsing with regular expressions recipe for examples of parsing a complex string.
- For more information on encodings, see https://en.wikipedia.org/wiki/UTF-8 and http://unicode.org/faq/utf_bom.html.
Using tuples of items
What's the best way to represent simple (x,y) and (r,g,b) groups of values? How can we keep things that are pairs, such as latitude and longitude, together?
Getting ready
In the String parsing with regular expressions recipe, we skipped over an interesting data structure.
We had data that looked like this:
>>> ingredient = "Kumquat: 2 cups"
We parsed this into meaningful data using a regular expression, like this:
>>> import re
>>> ingredient_pattern = re.compile(r'(?P<ingredient>w+):s+(?P<amount>d+)s+(?P<unit>w+)')
>>> match = ingredient_pattern.match(ingredient)
>>> match.groups()
('Kumquat', '2', 'cups')
The result is a tuple object with three pieces of data. There are lots of places where this kind of grouped data can come in handy.
How to do it...
We'll look at two aspects to this: putting things into tuples and getting things out of tuples.
Creating tuples
There are lots of places where Python creates tuples of data for us. In the Getting ready section of the String parsing with regular expressions recipe, we showed you how a regular expression match object will create a tuple of text that was parsed from a string.
We can create our own tuples, too. Here are the steps:
- Enclose the data in
(). - Separate the items with
,:>>> from fractions import Fraction >>> my_data = ('Rice', Fraction(1/4), 'cups')
There's an important special case for the one-tuple, or singleton. We have to include an extra ,, even when there's only one item in the tuple:
>>> one_tuple = ('item', )
>>> len(one_tuple)
1
The () characters aren't always required. There are a few times where we can omit them. It's not a good idea to omit them, but we can see funny things when we have an extra comma:
>>> 355,
(355,)
The extra comma after 355 turns the value into a singleton tuple.
Extracting items from a tuple
The idea of a tuple is for it to be a container with a number of items that's fixed by the problem domain: for example, for (red, green, blue) color numbers, the number of items is always three.
In our example, we've got an ingredient, and amount, and units. This must be a three-item collection. We can look at the individual items in two ways:
- By index position; that is, positions are numbered starting with zero from the left:
>>> my_data[1] Fraction(1, 4) - Using multiple assignment:
>>> ingredient, amount, unit = my_data >>> ingredient 'Rice' >>> unit 'cups'
Tuples—like strings—are immutable. We can't change the individual items inside a tuple. We use tuples when we want to keep the data together.
How it works...
Tuples are one example of the more general Sequence class. We can do a few things with sequences.
Here's an example tuple that we can work with:
>>> t = ('Kumquat', '2', 'cups')
Here are some operations we can perform on this tuple:
- How many items in
t?>>> len(t) 3 - How many times does a particular value appear in
t?>>> t.count('2') 1 - Which position has a particular value?
>>> t.index('cups') 2 >>> t[2] 'cups' - When an item doesn't exist, we'll get an exception:
>>> t.index('Rice') Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: tuple.index(x): x not in tuple - Does a particular value exist?
>>> 'Rice' in t False
There's more…
A tuple, like a string, is a sequence of items. In the case of a string, it's a sequence of characters. In the case of a tuple, it's a sequence of many things. Because they're both sequences, they have some common features. We've noted that we can pluck out individual items by their index position. We can use the index() method to locate the position of an item.
The similarities end there. A string has many methods it can use to create a new string that's a transformation of a string, plus methods to parse strings, plus methods to determine the content of the strings. A tuple doesn't have any of these bonus features. It's—perhaps—the simplest possible data structure.
See also
- We looked at one other sequence, the list, in the Building complex strings from lists of characters recipe.
- We'll also look at sequences in Chapter 4, Built-In Data Structures Part 1: Lists and Sets.
Using NamedTuples to simplify item access in tuples
When we worked with tuples, we had to remember the positions as numbers. When we use a (r,g,b) tuple to represent a color, can we use "red" instead of zero, "green" instead of 1, and "blue" instead of 2?
Getting ready
Let's continue looking at items in recipes. The regular expression for parsing the string had three attributes: ingredient, amount, and unit. We used the following pattern with names for the various substrings:
r'(?P<ingredient>w+):s+(?P<amount>d+)s+(?P<unit>w+)')
The resulting data tuple looked like this:
>>> item = match.groups()
('Kumquat', '2', 'cups')
While the matching between ingredient, amount, and unit is pretty clear, using something like the following isn't ideal. What does "1" mean? Is it really the quantity?
>>> Fraction(item[1])
Fraction(2, 1)
We want to define tuples with names, as well as positions.
How to do it...
- We'll use the
NamedTupleclass definition from the typing package:>>> from typing import NamedTuple - With this base class definition, we can define our own unique tuples, with names for the items:
>>> class Ingredient(NamedTuple): ... ingredient: str ... amount: str ... unit: str - Now, we can create an instance of this unique kind of tuple by using the classname:
>>> item_2 = Ingredient('Kumquat', '2', 'cups') - When we want a value, we can use
nameinstead of the position:>>> Fraction(item_2.amount) Fraction(2, 1) >>> f"Use {item_2.amount} {item_2.unit} fresh {item_2.ingredient}" 'Use 2 cups fresh Kumquat'
How it works...
The NamedTuple class definition introduces a core concept from Chapter 7, Basics of Classes and Objects. We've extended the base class definition to add unique features for our application. In this case, we've named the three attributes each Ingredient tuple must contain.
Because a NamedTuple class is a tuple, the order of the attribute names is fixed. We can use a reference like the expression item_2[0] as well as the expression item_2.ingredient. Both names refer to the item in index 0 of the tuple, item_2.
The core tuple types can be called "anonymous tuples" or maybe "index-only tuples." This can help to distinguish them from the more sophisticated "named tuples" introduced through the typing module.
Tuples are very useful as tiny containers of closely related data. Using the NamedTuple class definition makes them even easier to work with.
There's more…
We can have a mixed collection of values in a tuple or a named tuple. We need to perform conversion before we can build the tuple. It's important to remember that a tuple cannot ever be changed. It's an immutable object, similar in many ways to the way strings and numbers are immutable.
For example, we might want to work with amounts that are exact fractions. Here's a more sophisticated definition:
>>> class IngredientF(NamedTuple):
... ingredient: str
... amount: Fraction
... unit: str
These objects require some care to create. If we're using a bunch of strings, we can't simply build this object from three string values; we need to convert the amount into a Fraction instance. Here's an example of creating an item using a Fraction conversion:
>>> item_3 = IngredientF('Kumquat', Fraction('2'), 'cups')
This tuple has a more useful value for the amount of each ingredient. We can now do mathematical operations on the amounts:
>>> f'{item_3.ingredient} doubled: {item_3.amount*2}'
'Kumquat doubled: 4'
It's very handy to specifically state the data type within NamedTuple. It turns out Python doesn't use the type information directly. Other tools, for example, mypy, can check the type hints in NamedTuple against the operations in the rest of the code to be sure they agree.
See also
- We'll look at class definitions in Chapter 7, Basics of Classes and Objects.