
4
Built-In Data Structures Part 1: Lists and Sets
Python has a rich collection of built-in data structures. These data structures are sometimes called "containers" or "collections" because they contain a collection of individual items. These structures cover a wide variety of common programming situations.
We'll look at an overview of the various collections that are built-in and what problems they solve. After the overview, we will look at the list and set collections in detail in this chapter, and then dictionaries in Chapter 5, Built-In Data Structures Part 2: Dictionaries.
The built-in tuple and string types have been treated separately. These are sequences, making them similar in many ways to the list collection. In Chapter 1, Numbers, Strings, and Tuples, we emphasized the way strings and tuples behave more like immutable numbers than like the mutable list collection.
The next chapter will look at dictionaries, as well as some more advanced topics also related to lists and sets. In particular, it will look at how Python handles references to mutable collection objects. This has consequences in the way functions need to be defined that accept lists or sets as parameters.
In this chapter, we'll look at the following recipes, all related to Python's built-in data structures:
- Choosing a data structure
- Building lists – literals, appending, and comprehensions
- Slicing and dicing a
list - Deleting from a
list– deleting, removing, popping, and filtering - Writing list-related type hints
- Reversing a copy of a
list - Building sets – literals, adding, comprehensions, and operators
- Removing items from a
set–remove(),pop(), and difference - Writing set-related type hints
Choosing a data structure
Python offers a number of built-in data structures to help us work with collections of data. It can be confusing to match the data structure features with the problem we're trying to solve.
How do we choose which structure to use? What are the features of lists, sets, and dictionaries? Why do we have tuples and frozen sets?
Getting ready
Before we put data into a collection, we'll need to consider how we'll gather the data, and what we'll do with the collection once we have it. The big question is always how we'll identify a particular item within the collection.
We'll look at a few key questions that we need to answer to decide which of the built-in structures is appropriate.
How to do it...
- Is the programming focused on simple existence? Are items present or absent from a collection? An example of this is validating input values. When the user enters something that's in the collection, their input is valid; otherwise, their input is invalid. Simple membership tests suggest using a
set:def confirm() -> bool: yes = {"yes", "y"} no = {"no", "n"} while (answer := input("Confirm: ")).lower() not in (yes|no): print("Please respond with yes or no") return answer in yesA
setholds items in no particular order. Once an item is a member, we can't add it again:>>> yes = {"yes", "y"} >>> no = {"no", "n"} >>> valid_inputs = yes | no >>> valid_inputs.add("y") >>> valid_inputs {'yes', 'no', 'n', 'y'}We have created a
set,valid_inputs, by performing asetunion using the|operator among sets. We can't add anotheryto asetthat already containsy. There is no exception raised if we try such an addition, but the contents of the set don't change.Also, note that the order of the items in the
setisn't exactly the order in which we initially provided them. Asetcan't maintain any particular order to the items; it can only determine if an item exists in theset. If order matters, then alistis more appropriate. - Are we going to identify items by their position in the collection? An example includes the lines in an input file—the line number is its position in the collection. When we must identify an item using an index or position, we must use a
list:>>> month_name_list = ["Jan", "Feb", "Mar", "Apr", ... "May", "Jun", "Jul", "Aug", ... "Sep", "Oct", "Nov", "Dec"] >>> month_name_list[8] 'Sep' >>> month_name_list.index("Feb")We have created a list,
month_name_list, with 12 string items in a specific order. We can pick an item by providing its position. We can also use theindex()method to locate the index of an item in the list. List index values in Python always start with a position of zero. While a list has a simple membership test, the test can be slow for a very large list, and a set might be a better idea if many such tests will be needed.If the number of items in the collection is fixed—for example, RGB colors have three values—this suggests a
tupleinstead of alist. If the number of items will grow and change, then thelistcollection is a better choice than thetuplecollection. - Are we going to identify the items in a collection by a key value that's distinct from the item's position? An example might include a mapping between strings of characters—words—and integers that represent the frequencies of those words, or a mapping between a color name and the RGB tuple for that color. We'll look at mappings and dictionaries in the next chapter; the important distinction is mappings don't locate items by position the way lists do.
In contrast to a list, here's an example of a dictionary:
>>> scheme = {"Crimson": (220, 14, 60), ... "DarkCyan": (0, 139, 139), ... "Yellow": (255, 255, 00)} >>> scheme['Crimson'] (220, 14, 60)In this dictionary,
scheme, we've created a mapping from color names to the RGB color tuples. When we use a key, for example "Crimson", to get an item from the dictionary, we can retrieve the value bound to that key. - Consider the mutability of items in a
setcollection and the keys in adictcollection. Each item in asetmust be an immutable object. Numbers, strings, and tuples are all immutable, and can be collected into sets. Sincelist,dict, aresetobjects and are mutable, they can't be used as items in aset. It's impossible to build asetoflistobjects, for example.Rather than create a
setoflistitems, we must transform eachlistitem into an immutabletuple. Similarly, dictionary keys must be immutable. We can use a number, a string, or atupleas a dictionary key. We can't use alist, or aset, or any another mutable mapping as a dictionary key.
How it works...
Each of Python's built-in collections offers a specific set of unique features. The collections also offer a large number of overlapping features. The challenge for programmers new to Python is to identify the unique features of each collection.
The collections.abc module provides a kind of roadmap through the built-in container classes. This module defines the Abstract Base Classes (ABCs) underlying the concrete classes we use. We'll use the names from this set of definitions to guide us through the features.
From the ABCs, we can see that there are actually places for a total of six kinds of collections:
- Set: Its unique feature is that items are either members or not. This means duplicates are ignored:
- Mutable set: The
setcollection - Immutable set: The
frozensetcollection - Sequence: Its unique feature is that items are provided with an index position:
- Mutable sequence: The
listcollection - Immutable sequence: The
tuplecollection - Mapping: Its unique feature is that each item has a key that refers to a value:
- Mutable mapping: The
dictcollection. - Immutable mapping: Interestingly, there's no built-in frozen mapping.
Python's libraries offer a large number of additional implementations of these core collection types. We can see many of these in the Python Standard Library.
The collections module contains a number of variations of the built-in collections. These include:
namedtuple: Atuplethat offers names for each item in atuple. It's slightly clearer to usergb_color.redthanrgb_color[0].deque: A double-ended queue. It's a mutable sequence with optimizations for pushing and popping from each end. We can do similar things with alist, butdequeis more efficient when changes at both ends are needed.defaultdict: Adictthat can provide a default value for a missing key.Counter: Adictthat is designed to count occurrences of a key. This is sometimes called a multiset or a bag.OrderedDict: Adictthat retains the order in which keys were created.ChainMap: Adictthat combines several dictionaries into a single mapping.
There's still more in the Python Standard Library. We can also use the heapq module, which defines a priority queue implementation. The bisect module includes methods for searching a sorted list very quickly. This allows a list to have performance that is a little closer to the fast lookups of a dictionary.
There's more...
We can find lists of data structures in summary web pages, like this one: https://en.wikipedia.org/wiki/List_of_data_structures.
Different parts of the article provide slightly different summaries of data structures. We'll take a quick look at four additional classifications of data structures:
- Arrays: The Python
arraymodule supports densely packed arrays of values. Thenumpymodule also offers very sophisticated array processing. See https://numpy.org. (Python has no built-in or standard library data structure related to linked lists). - Trees: Generally, tree structures can be used to create sets, sequential lists, or key-value mappings. We can look at a tree as an implementation technique for building sets or dicts, rather than a data structure with unique features. (Python has no built-in or standard library data structure implemented via trees).
- Hashes: Python uses hashes to implement dictionaries and sets. This leads to good speed but potentially large memory consumption.
- Graphs: Python doesn't have a built-in graph data structure. However, we can easily represent a graph structure with a dictionary where each node has a list of adjacent nodes.
We can—with a little cleverness—implement almost any kind of data structure in Python. Either the built-in structures have the essential features, or we can locate a built-in structure that can be pressed into service. We'll look at mappings and dictionaries in the next chapter: they provide a number of important features for organizing collections of data.
See also
- For advanced graph manipulation, see https://networkx.github.io.
Building lists – literals, appending, and comprehensions
If we've decided to create a collection based on each item's position in the container—a list—we have several ways of building this structure. We'll look at a number of ways we can assemble a list object from the individual items.
In some cases, we'll need a list because it allows duplicate values. This is common in statistical work, where we will have duplicates but we don't require the index positions. A different structure, called a multiset, would be useful for a statistically oriented collection that permits duplicates. This kind of collection isn't built-in (although collections.Counter is an excellent multiset, as long as items are immutable), leading us to use a list object.
Getting ready
Let's say we need to do some statistical analyses of some file sizes. Here's a short script that will provide us with the sizes of some files:
>>> from pathlib import Path
>>> home = Path.cwd()
>>> for path in home.glob('data/*.csv'):
... print(path.stat().st_size, path.name)
1810 wc1.csv
28 ex2_r12.csv
1790 wc.csv
215 sample.csv
45 craps.csv
28 output.csv
225 fuel.csv
166 waypoints.csv
412 summary_log.csv
156 fuel2.csv
We've used a pathlib.Path object to represent a directory in our filesystem. The glob() method expands all names that match a given pattern. In this case, we used a pattern of 'data/*.csv' to locate all CSV-formatted data files. We can use the for statement to assign each item to the path variable. The print() function displays the size from the file's OS stat data and the name from the Path instance, path.
We'd like to accumulate a list object that has the various file sizes. From that, we can compute the total size and average size. We can look for files that seem too large or too small.
How to do it...
We have many ways to create list objects:
- Literal: We can create a literal display of a
listusing a sequence of values surrounded by[]characters. It looks like this:[value, ... ]. Python needs to match the[and]to see a complete logical line, so the literal can span physical lines. For more information, refer to the Writing long lines of code recipe in Chapter 2, Statements and Syntax. - Conversion Function: We can convert some other data collection into a list using the
list()function. We can convert aset, or the keys of adict, or the values of adict. We'll look at a more sophisticated example of this in the Slicing and dicing a list recipe. - Append Method: We have
listmethods that allow us to build alistone item a time. These methods includeappend(),extend(), andinsert(). We'll look atappend()in the Building a list with the append() method section of this recipe. We'll look at the other methods in the How to do it… and There's more... sections of this recipe. - Comprehension: A comprehension is a specialized generator expression that describes the items in a list using a sophisticated expression to define membership. We'll look at this in detail in the Writing a list comprehension section of this recipe.
- Generator Expression: We can use generator expressions to build
listobjects. This is a generalization of the idea of a list comprehension. We'll look at this in detail in the Using the list function on a generator expression section of this recipe.
The first two ways to create lists are single Python expressions. We won't provide recipes for these. The last three are more complex, and we'll show recipes for each of them.
Building a list with the append() method
- Create an empty list using literal syntax,
[], or thelist()function:>>> file_sizes = [] - Iterate through some source of data. Append the items to the list using the
append()method:>>> home = Path.cwd() >>> for path in home.glob('data/*.csv'): ... file_sizes.append(path.stat().st_size) >>> print(file_sizes) [1810, 28, 1790, 160, 215, 45, 28, 225, 166, 39, 412, 156] >>> print(sum(file_sizes)) 5074
We used the path's glob() method to find all files that match the given pattern. The stat() method of a path provides the OS stat data structure, which includes the size, st_size, in bytes.
When we print the list, Python displays it in literal notation. This is handy if we ever need to copy and paste the list into another script.
It's very important to note that the append() method does not return a value. The append() method mutates the list object, and does not return anything.
Generally, almost all methods that mutate an object have no return value. Methods like append(), extend(), sort(), and reverse() have no return value. They adjust the structure of the list object itself. The notable exception is the pop() method, which mutates a collection and returns a value.
It's surprisingly common to see wrong code like this:
a = ['some', 'data']
a = a.append('more data')
This is emphatically wrong. This will set a to None. The correct approach is a statement like this, without any additional assignment:
a.append('more data')
Writing a list comprehension
The goal of a list comprehension is to create an object that occupies a syntax role, similar to a list literal:
- Write the wrapping
[]brackets that surround thelistobject to be built. - Write the source of the data. This will include the target variable. Note that there's no
:at the end because we're not writing a complete statement:for path in home.glob('data/*.csv') - Prefix this with the expression to evaluate for each value of the target variable. Again, since this is only a single expression, we cannot use complex statements here:
[path.stat().st_size for path in home.glob('data/*.csv')]
In some cases, we'll need to add a filter. This is done with an if clause, included after the for clause. We can make the generator expression quite sophisticated.
Here's the entire list object construction:
>>> [path.stat().st_size
... for path in home.glob('data/*.csv')]
[1810, 28, 1790, 160, 215, 45, 28, 225, 166, 39, 412, 156]
Now that we've created a list object, we can assign it to a variable and do other calculations and summaries on the data.
The list comprehension is built around a central generator expression, called a comprehension in the language manual. The generator expression at the heart of the comprehension has a data expression clause and a for clause. Since this generator is an expression, not a complete statement, there are some limitations on what it can do. The data expression clause is evaluated repeatedly, driven by the variables assigned in the for clause.
Using the list function on a generator expression
We'll create a list function that uses the generator expression:
- Write the wrapping
list()function that surrounds the generator expression. - We'll reuse steps 2 and 3 from the list comprehension version to create a generator expression. Here's the generator expression:
list(path.stat().st_size for path in home.glob('data/*.csv'))Here's the entire
listobject:
>>> list(path.stat().st_size
... for path in home.glob('data/*.csv'))
[1810, 28, 1790, 160, 215, 45, 28, 225, 166, 39, 412, 156]
Using the explicit list() function had an advantage when we consider the possibility of changing the data structure. We can easily replace list() with set(). In the case where we have a more advanced collection class, which is the subject of Chapter 6, User Inputs and Outputs, we may use one of our own customized collections here. List comprehension syntax, using [], can be a tiny bit harder to change because [] are used for many things in Python.
How it works...
A Python list object has a dynamic size. The bounds of the array are adjusted when items are appended or inserted, or list is extended with another list. Similarly, the bounds shrink when items are popped or deleted. We can access any item very quickly, and the speed of access doesn't depend on the size of the list.
In rare cases, we might want to create a list with a given initial size, and then set the values of the items separately. We can do this with a list comprehension, like this:
sieve = [True for i in range(100)]
This will create a list with an initial size of 100 items, each of which is True. It's rare to need this, though, because lists can grow in size as needed. We might need this kind of initialization to implement the Sieve of Eratosthenes:
>>> sieve[0] = sieve[1] = False
>>> for p in range(100):
... if sieve[p]:
... for n in range(p*2, 100, p):
... sieve[n] = False
>>> prime = [p for p in range(100) if sieve[p]]
The list comprehension syntax, using [], and the list() function both consume items from a generator and append them to create a new list object.
There's more...
A common goal for creating a list object is to be able to summarize it. We can use a variety of Python functions for this. Here are some examples:
>>> sizes = list(path.stat().st_size
... for path in home.glob('data/*.csv'))
>>> sum(sizes)
5074
>>> max(sizes)
1810
>>> min(sizes)
28
>>> from statistics import mean
>>> round(mean(sizes), 3)
422.833
We've used the built-in sum(), min(), and max() methods to produce some descriptive statistics of these document sizes. Which of these index files is the smallest? We want to know the position of the minimum in the list of values. We can use the index() method for this:
>>> sizes.index(min(sizes))
1
We found the minimum, and then used the index() method to locate the position of that minimal value.
Other ways to extend a list
We can extend a list object, as well as insert one into the middle or beginning of a list. We have two ways to extend a list: we can use the + operator or we can use the extend() method. Here's an example of creating two lists and putting them together with +:
>>> home = Path.cwd()
>>> ch3 = list(path.stat().st_size
... for path in home.glob('Chapter_03/*.py'))
>>> ch4 = list(path.stat().st_size
... for path in home.glob('Chapter_04/*.py'))
>>> len(ch3)
12
>>> len(ch4)
16
>>> final = ch3 + ch4
>>> len(final)
28
>>> sum(final)
61089
We have created a list of sizes of documents with names like chapter_03/*.py. We then created a second list of sizes of documents with a slightly different name pattern, chapter_04/*.py. We then combined the two lists into a final list.
We can do this using the extend() method as well. We'll reuse the two lists and build a new list from them:
>>> final_ex = []
>>> final_ex.extend(ch3)
>>> final_ex.extend(ch4)
>>> len(final_ex)
28
>>> sum(final_ex)
61089
Previously, we noted that the append() method does not return a value. Similarly, the extend() method does not return a value either. Like append(), the extend() method mutates the list object "in-place."
We can insert a value prior to any particular position in a list as well. The insert() method accepts the position of an item; the new value will be before the given position:
>>> p = [3, 5, 11, 13]
>>> p.insert(0, 2)
>>> p
[2, 3, 5, 11, 13]
>>> p.insert(3, 7)
>>> p
[2, 3, 5, 7, 11, 13]
We've inserted two new values into a list object. As with the append() and extend() methods, the insert() method does not return a value. It mutates the list object.
See also
- Refer to the Slicing and dicing a list recipe for ways to copy lists and pick sublists from a list.
- Refer to the Deleting from a list – deleting, removing, popping, and filtering recipe for other ways to remove items from a list.
- In the Reversing a copy of a list recipe, we'll look at reversing a list.
- This article provides some insights into how Python collections work internally:
https://wiki.python.org/moin/TimeComplexity. When looking at the tables, it's important to note the expression O(1) means that the cost is essentially constant. The expression O(n) means the cost varies with the index of the item we're trying to process; the cost grows as the size of the collection grows.
Slicing and dicing a list
There are many times when we'll want to pick items from a list. One of the most common kinds of processing is to treat the first item of a list as a special case. This leads to a kind of head-tail processing where we treat the head of a list differently from the items in the tail of a list.
We can use these techniques to make a copy of a list too.
Getting ready
We have a spreadsheet that was used to record fuel consumption on a large sailboat. It has rows that look like this:
|
Date |
Engine on |
Fuel height |
|
Engine off |
||
|
Other notes |
||
|
10/25/2013 |
08:24 |
29 |
|
13:15 |
27 |
|
|
Calm seas—Anchor in Solomon's Island |
||
|
10/26/2013 |
09:12 |
27 |
|
18:25 |
22 |
|
|
choppy—Anchor in Jackson's Creek |
Example of sailboat fuel use
In this dataset, fuel is measured by height. This is because a sight-gauge is used, calibrated in inches of depth. For all practical purposes, the tank is rectangular, so the depth shown can be converted into volume since we know 31 inches of depth is about 75 gallons.
This example of spreadsheet data is not properly normalized. Ideally, all rows follow the first normal form for data: a row should have identical content, and each cell should have only atomic values. In this data, there are three subtypes of row: one with starting measurements, one with ending measurements, and one with additional data.
The denormalized data has these two problems:
- It has four rows of headings. This is something the
csvmodule can't deal with directly. We need to do some slicing to remove the rows from other notes. - Each day's travel is spread across two rows. These rows must be combined to make it easier to compute an elapsed time and the number of inches of fuel used.
We can read the data with a function defined like this:
import csv
from pathlib import Path
from typing import List, Any
def get_fuel_use(path: Path) -> List[List[Any]]:
with path.open() as source_file:
reader = csv.reader(source_file)
log_rows = list(reader)
return log_rows
We've used the csv module to read the log details. csv.reader() is an iterable object. In order to collect the items into a single list, we applied the list() function. We looked at the first and last item in the list to confirm that we really have a list-of-lists structure.
Each row of the original CSV file is a list. Here's what the first and last rows look like:
>>> log_rows[0]
['date', 'engine on', 'fuel height']
>>> log_rows[-1]
['', "choppy -- anchor in jackson's creek", '']
For this recipe, we'll use an extension of a list index expression to slice items from the list of rows. The slice, like the index, follows the list object in [] characters. Python offers several variations of the slice expression so that we can extract useful subsets of the list of rows.
Let's go over how we can slice and dice the raw list of rows to pick out the rows we need.
How to do it...
- The first thing we need to do is remove the four lines of heading from the list of rows. We'll use two partial slice expressions to divide the list by the fourth row:
>>> head, tail = log_rows[:4], log_rows[4:] >>> head[0] ['date', 'engine on', 'fuel height'] >>> head[-1] ['', '', ''] >>> tail[0] ['10/25/13', '08:24:00 AM', '29'] >>> tail[-1] ['', "choppy -- anchor in jackson's creek", '']We've sliced the list into two sections using
log_rows[:4]andlog_rows[4:]. The first slice expression selects the four lines of headings; this is assigned to theheadvariable. We don't really want to do any processing with the head, so we ignore that variable. (Sometimes, the variable name_is used for data that will be ignored.) The second slice expression selects rows from 4 to the end of the list. This is assigned to thetailvariable. These are the rows of the sheet we care about. - We'll use slices with steps to pick the interesting rows. The
[start:stop:step]version of a slice will pick rows in groups based on the step value. In our case, we'll take two slices. One slice starts on row zero and the other slice starts on row one.Here's a slice of every third row, starting with row zero:
>>> pprint(tail[0::3]) [['10/25/13', '08:24:00 AM', '29'], ['10/26/13', '09:12:00 AM', '27']]We'll also want every third row, starting with row one:
>>> pprint(tail[1::3]) [['', '01:15:00 PM', '27'], ['', '06:25:00 PM', '22']] - These two slices can then be zipped together to create pairs:
>>> list(zip(tail[0::3], tail[1::3])) [(['10/25/13', '08:24:00 AM', '29'], ['', '01:15:00 PM', '27']), (['10/26/13', '09:12:00 AM', '27'], ['', '06:25:00 PM', '22'])]We've sliced the list into two parallel groups:
- The
[0::3]slice starts with the first row and includes every third row. This will be rows zero, three, six, nine, and so on. - The
[1::3]slice starts with the second row and includes every third row. This will be rows one, four, seven, ten, and so on.We've used the
zip()function to interleave these two sequences from thelist. This gives us a sequence of three tuples that's very close to something we can work with.
- The
- Flatten the results:
>>> paired_rows = list( zip(tail[0::3], tail[1::3]) ) >>> [a+b for a, b in paired_rows] [['10/25/13', '08:24:00 AM', '29', '', '01:15:00 PM', '27'], ['10/26/13', '09:12:00 AM', '27', '', '06:25:00 PM', '22']]
We've used a list comprehension from the Building lists – literals, appending, and comprehensions recipe to combine the two elements in each pair of rows to create a single row. Now, we're in a position to convert the date and time into a single datetime value. We can then compute the difference in times to get the running time for the boat, and the difference in heights to estimate the fuel burned.
How it works...
The slice operator has several different forms:
[:]: The start and stop are implied. The expressionS[:]will create a copy of sequenceS.[:stop]: This makes a new list from the beginning to just before the stop value.[start:]: This makes a new list from the given start to the end of the sequence.[start:stop]: This picks a sublist, starting from the start index and stopping just before the stop index. Python works with half-open intervals. The start is included, while the end is not included.[::step]: The start and stop are implied and include the entire sequence. The step—generally not equal to one—means we'll skip through the list from the start using the step. For a given step, s, and a list of size |L|, the index values are .
.[start::step]: The start is given, but the stop is implied. The idea is that the start is an offset, and the step applies to that offset. For a given start, a, step, s, and a list of size |L|, the index values are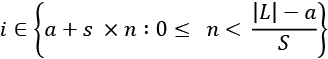 .
.[:stop:step]: This is used to prevent processing the last few items in a list. Since the step is given, processing begins with element zero.[start:stop:step]: This will pick elements from a subset of the sequence. Items prior to start and at or after stop will not be used.
The slicing technique works for lists, tuples, strings, and any other kind of sequence. Slicing does not cause the collection to be mutated; rather, slicing will make a copy of some part of the sequence. The items within the source collection are now shared between collections.
There's more...
In the Reversing a copy of a list recipe, we'll look at an even more sophisticated use of slice expressions.
The copy is called a shallow copy because we'll have two collections that contain references to the same underlying objects. We'll look at this in detail in the Making shallow and deep copies of objects recipe.
For this specific example, we have another way of restructuring multiple rows of data into single rows of data: we can use a generator function. We'll look at functional programming techniques online in Chapter 9, Functional Programming Features (link provided in the Preface).
See also
- Refer to the Building lists – literals, appending, and comprehensions recipe for ways to create lists.
- Refer to the Deleting from a list – deleting, removing, popping, and filtering recipe for other ways to remove items from a list.
- In the Reversing a copy of a list recipe, we'll look at reversing a list.
Deleting from a list – deleting, removing, popping, and filtering
There will be many times when we'll want to remove items from a list collection. We might delete items from a list, and then process the items that are left over.
Removing unneeded items has a similar effect to using filter() to create a copy that has only the needed items. The distinction is that a filtered copy will use more memory than deleting items from a list. We'll show both techniques for removing unwanted items from a list.
Getting ready
We have a spreadsheet that is used to record fuel consumption on a large sailboat. It has rows that look like this:
|
Date |
Engine on |
Fuel height |
|
Engine off |
||
|
Other notes |
||
|
10/25/2013 |
08:24 |
29 |
|
13:15 |
27 |
|
|
Calm seas—Anchor in Solomon's Island |
||
|
10/26/2013 |
09:12 |
27 |
|
18:25 |
22 |
|
|
Choppy—Anchor in Jackson's Creek |
Example of sailboat fuel use
For more background on this data, refer to the Slicing and dicing a list recipe earlier in this chapter.
We can read the data with a function, like this:
import csv
from pathlib import Path
from typing import List, Any
def get_fuel_use(path: Path) -> List[List[Any]]:
with path.open() as source_file:
reader = csv.reader(source_file)
log_rows = list(reader)
return log_rows
We've used the csv module to read the log details. csv.reader() is an iterable object. In order to collect the items into a single list, we applied the list() function. We looked at the first and last item in the list to confirm that we really have a list-of-lists structure.
Each row of the original CSV file is a list. Each of those lists contains three items.
How to do it...
We'll look at several ways to remove things from a list:
- The
delstatement. - The
remove()method. - The
pop()method. - Using the
filter()function to create a copy that rejects selected rows. - We can also replace items in a list using slice assignment.
The del statement
We can remove items from a list using the del statement. We can provide an object and a slice to remove a group of rows from the list object. Here's how the del statement looks:
>>> del log_rows[:4]
>>> log_rows[0]
['10/25/13', '08:24:00 AM', '29']
>>> log_rows[-1]
['', "choppy -- anchor in jackson's creek", '']
The del statement removed the first four rows, leaving behind the rows that we really need to process. We can then combine these and summarize them using the Slicing and dicing a list recipe.
The remove() method
We can remove items from a list using the remove() method. This removes matching items from a list.
We might have a list that looks like this:
>>> row = ['10/25/13', '08:24:00 AM', '29', '', '01:15:00 PM', '27']
We can remove the useless '' item from the list:
>>> row.remove('')
>>> row
['10/25/13', '08:24:00 AM', '29', '01:15:00 PM', '27']
Note that the remove() method does not return a value. It mutates the list in place. This is an important distinction that applies to mutable objects.
The remove() method does not return a value. It mutates the list object. It's surprisingly common to see wrong code like this:
a = ['some', 'data']
a = a.remove('data')
This is emphatically wrong. This will set a to None.
The pop() method
We can remove items from a list using the pop() method. This removes items from a list based on their index.
We might have a list that looks like this:
>>> row = ['10/25/13', '08:24:00 AM', '29', '', '01:15:00 PM', '27']
This has a useless '' string in it. We can find the index of the item to pop and then remove it. The code for this has been broken down into separate steps in the following example:
>>> target_position = row.index('')
>>> target_position
3
>>> row.pop(target_position)
''
>>> row
['10/25/13', '08:24:00 AM', '29', '01:15:00 PM', '27']
Note that the pop() method does two things:
- It mutates the
listobject. - It also returns the value that was removed.
This combination of mutation and returning a value is rare, making this method distinctive.
Rejecting items with the filter() function
We can also remove items by building a copy that passes the desirable items and rejects the undesirable items. Here's how we can do this with the filter() function:
- Identify the features of the items we wish to pass or reject. The
filter()function expects a rule for passing data. The logical inverse of that function will reject data. In our case, the rows we want have a numeric value in column two. We can best detect this with a little helper function. - Write the filter
testfunction. If it's trivial, use alambdaobject. Otherwise, write a separate function:def number_column(row, column=2): try: float(row[column]) return True except ValueError: return FalseWe've used the built-in
float()function to see if a given string is a proper number. If thefloat()function does not raise an exception, the data is a valid number, and we want to pass this row. If an exception is raised, the data was not numeric, and we'll reject the row. - Use the filter
testfunction (orlambda) with the data in thefilter()function:>>> tail_rows = list(filter(number_column, log_rows)) >>> len(tail_rows) 4 >>> tail_rows[0] ['10/25/13', '08:24:00 AM', '29'] >>> tail_rows[-1] ['', '06:25:00 PM', '22']We provided our test,
number_column()and the original data,log_rows. The output from thefilter()function is an iterable. To create a list from the iterable result, we'll use thelist()function. The result contains just the four rows we want; the remaining rows were rejected.
This design doesn't mutate the original log_rows list object. Instead of deleting the rows, this creates a copy that omits those rows.
Slice assignment
We can replace items in a list by using a slice expression on the left-hand side of the assignment statement. This lets us replace items in a list. When the replacement is a different size, it lets us expand or contract a list. This leads to a technique for removing items from a list using slice assignment.
We'll start with a row that has an empty value in position 3. This looks like this:
>>> row = ['10/25/13', '08:24:00 AM', '29', '', '01:15:00 PM', '27']
>>> target_position = row.index('')
>>> target_position
3
We can assign an empty list to the slice that starts at index position 3 and ends just before index position 4. This will replace a one-item slice with a zero-item slice, removing the item from the list:
>>> row[3:4] = []
>>> row
['10/25/13', '08:24:00 AM', '29', '01:15:00 PM', '27']
The del statement and methods like remove() and pop() seem to clearly state the intent to eliminate an item from the collection. The slice assignment can be less clear because it doesn't have an obvious method name. It does work well, however, for removing a number of items that can be described by a slice expression.
How it works...
Because a list is a mutable object, we can remove items from the list. This technique doesn't work for tuples or strings. All three collections are sequences, but only the list is mutable.
We can only remove items with an index that's present in the list. If we attempt to remove an item with an index outside the allowed range, we'll get an IndexError exception.
For example, here, we're trying to delete an item with an index of three from a list where the index values are zero, one, and two:
>>> row = ['', '06:25:00 PM', '22']
>>> del row[3]
Traceback (most recent call last):
File "/Users/slott/miniconda3/envs/cookbook/lib/python3.8/doctest.py", line 1328, in __run
compileflags, 1), test.globs)
File "<doctest examples.txt[80]>", line 1, in <module>
del row[3]
IndexError: list assignment index out of range
There's more...
There are a few places in Python where deleting from a list object may become complicated. If we use a list object in a for statement, we can't delete items from the list. Doing so will lead to unexpected conflicts between the iteration control and the underlying object.
Let's say we want to remove all even items from a list. Here's an example that does not work properly:
>>> data_items = [1, 1, 2, 3, 5, 8, 10,
... 13, 21, 34, 36, 55]
>>> for f in data_items:
... if f%2 == 0:
... data_items.remove(f)
>>> data_items
[1, 1, 3, 5, 10, 13, 21, 36, 55]
The source list had several even values. The result is clearly not right; the values of 10 and 36 remain in the list. Why are some even-valued items left in the list?
Let's look at what happens when processing data_items[5]; it has a value of eight. When the remove(8) method is evaluated, the value will be removed, and all the subsequent values slide forward one position. 10 will be moved into position 5, the position formerly occupied by 8. The list's internal index will move forward to the next position, which will have 13 in it. 10 will never be processed.
Similarly, confusing things will also happen if we insert the driving iterable in a for loop into the middle of a list. In that case, items will be processed twice.
We have several ways to avoid the skip-when-delete problem:
- Make a copy of the
list:>>> for f in data_items[:]: - Use a
whilestatement and maintain the index value explicitly:>>> position = 0 >>> while position != len(data_items): ... f = data_items[position] ... if f%2 == 0: ... data_items.remove(f) ... else: ... position += 1We've designed a loop that only increments the
positionvalue if the value ofdata_items[position]is odd. If the value is even, then it's removed, which means the other items are moved forward one position in thelist, and the value of thepositionvariable is left unchanged. - We can also traverse the
listin reverse order. Because of the way negative index values work in Python, therange()object works well. We can use the expressionrange(len(row)-1, -1, -1)to traverse thedata_itemslist in reverse order, deleting items from the end, where a change in position has no consequence on subsequent positions.
See also
- Refer to the Building lists – literals, appending, and comprehensions recipe for ways to create lists.
- Refer to the Slicing and dicing a list recipe for ways to copy lists and pick sublists from a list.
- In the Reversing a copy of a list recipe, we'll look at reversing a list.
Writing list-related type hints
The typing module provides a few essential type definitions for describing the contents of a list object. The primary type definition is List, which we can parameterize with the types of items in the list.
There are two common patterns to the types of items in lists in Python:
- Homogenous: Each item in the
listhas a common type or protocol. A common superclass is also a kind of homogeneity. A list of mixed integer and floating-point values can be described as a list of float values, because bothintandfloatsupport the same numeric protocols. - Heterogenous: The items in the
listcome from a union of a number of types with no commonality. This is less common, and requires more careful programming to support it. This will often involve theUniontype definition from thetypingmodule.
Getting ready
We'll look at a list that has two kinds of tuples. Some tuples are simple RGB colors. Other tuples are RGB colors that are the result of some computations. These are built from float values instead of integers. We might have a heterogenous list structure that looks like this:
scheme = [
('Brick_Red', (198, 45, 66)),
('color1', (198.00, 100.50, 45.00)),
('color2', (198.00, 45.00, 142.50)),
]
Each item in the list is a two-tuple with a color name, and a tuple of RGB values. The RGB values are represented as a three-tuple with either integer or float values. This is potentially difficult to describe with type hints.
We have two related functions that work with this data. The first creates a color code from RGB values. The hints for this aren't very complicated:
def hexify(r: float, g: float, b: float) -> str:
return f'#{int(r)<<16 | int(g)<<8 | int(b):06X}'
An alternative is to treat each color as a separate pair of hex digits with an expression like f"#{int(r):02X}{int(g):02X}{int(b):02X}" in the return statement.
When we use this function to create a color string from an RGB number, it looks like this:
>>> hexify(198, 45, 66)
'#C62D42'
The other function, however, is potentially confusing. This function transforms a complex list of colors into another list with the color codes:
def source_to_hex(src):
return [
(n, hexify(*color)) for n, color in src
]
We need type hints to be sure this function properly transforms a list of colors from numeric form into string code form.
How to do it…
We'll start by adding type hints to describe the individual items of the input list, exemplified by the scheme variable, shown previously:
- Define the resulting type first. It often helps to focus on the outcomes and work backward toward the source data required to produce the expected results. In this case, the result is a list of two-tuples with the color name and the hexadecimal code for the color. We could describe this as
List[Tuple[str, str]], but that hides some important details:ColorCode = Tuple[str, str] ColorCodeList = List[ColorCode]This list can be seen as being homogenous; each item will match the
ColorCodetype definition. - Define the source type. In this case, we have two slightly different kinds of color definitions. While they tend to overlap, they have different origins, and the processing history is sometimes helpful as part of a type hint:
RGB_I = Tuple[int, int, int] RGB_F = Tuple[float, float, float] ColorRGB = Tuple[str, Union[RGB_I, RGB_F]] ColorRGBList = List[ColorRGB]We've defined the two integer-based RGB three-tuple as
RGB_I, and the float-based RGB three-tuple asRGB_F. These two alternative types are combined into theColorRGBtuple definition. This is a two-tuple; the second element may be an instance of either theRGB_Itype or theRGB_Ftype. The presence of aUniontype means that this list is effectively heterogenous. - Update the function to include the type hints. The input will be a list like the
schemaobject, shown previously. The result will be a list that matches theColorCodeListtype description:def source_to_hex(src: ColorRGBList) -> ColorCodeList: return [ (n, hexify(*color)) for n, color in src ]
How it works…
The List[] type hint requires a single value to describe all of the object types that can be part of this list. For homogenous lists, the type is stated directly. For heterogenous lists, a Union must be used to define the various kinds of types.
The approach we've taken breaks type hinting down into two layers:
- A "foundation" layer that describes the individual items in a collection. We've defined three types of primitive items: the
RGB_IandRGB_Ftypes, as well as the resultingColorCodetype. - A number of "composition" layers that combine foundational types into descriptions of composite objects. In this case,
ColorRGB,ColorRGBList, andColorCodeListare all composite type definitions.
Once the types have been named, then the names are used with definition functions, classes, and methods.
It's important to define types in stages to avoid long, complex type hints that don't provide any useful insight into the objects being processed. It's good to avoid type descriptions like this:
List[Tuple[str, Union[Tuple[int, int, int], Tuple[float, float, float]]]]
While this is technically correct, it's difficult to understand because of its complexity. It helps to decompose complex types into useful component descriptions.
There's more…
There are a number of ways of describing tuples, but only one way to describe lists:
- The various color types could be described with a
NamedTupleclass. Refer to the recipe in Chapter 1, Numbers, Strings, and Tuples, Using named tuples to simplify item access in tuples recipe, for examples of this. - When all the items in a tuple are the same type, we can slightly simplify the type hint to look like this:
RGB_I = Tuple[int, ...]andRGB_F = Tuple[float, ...]. This has the additional implication of an unknown number of values, which isn't true in this example. We have precisely three values in each RGB tuple, and it makes sense to retain this narrow, focused definition. - As we've seen in this recipe, the
RGB_I = Tuple[int, int, int]andRGB_F = Tuple[float, float, float]type definitions provide very narrow definitions of what the data structure should be at runtime.
See also
- In Chapter 1, Numbers, Strings, and Tuples, the Using named tuples to simplify item access in tuples recipe provides some alternative ways to clarify types hints for tuples.
- The Writing set-related type hints recipe covers this from the view of Set types.
- The Writing dictionary-related type hints recipe discusses types with respect to dictionaries and mappings.
Reversing a copy of a list
Once in a while, we need to reverse the order of the items in a list collection. Some algorithms, for example, produce results in a reverse order. We'll look at the way numbers converted into a specific base are often generated from least-significant to most-significant digit. We generally want to display the values with the most-significant digit first. This leads to a need to reverse the sequence of digits in a list.
We have three ways to reverse a list. First, there's the reverse() method. We can also use the reversed() function, as well as a slice that visits items in reverse order.
Getting ready
Let's say we're doing a conversion among number bases. We'll look at how a number is represented in a base, and how we can compute that representation from a number.
Any value, v, can be defined as a polynomial function of the various digits, dn, in a given base, b:

A rational number has a finite number of digits. An irrational number would have an infinite series of digits.
For example, the number 0xBEEF is a base 16 value. The digits are {B = 11, E = 14, F = 15}, while the base b = 16:

We can restate this in a form that's slightly more efficient to compute:

There are many cases where the base isn't a consistent power of some number. The ISO date format, for example, has a mixed base that involves 7 days per week, 24 hours per day, 60 minutes per hour, and 60 seconds per minute.
Given a week number, a day of the week, an hour, a minute, and a second, we can compute a timestamp of seconds, ts, within the given year:

For example:
>>> week = 13
>>> day = 2
>>> hour = 7
>>> minute = 53
>>> second = 19
>>> t_s = (((week*7+day)*24+hour)*60+minute)*60+second
>>> t_s
8063599
This shows how we convert from the given moment into a timestamp. How do we invert this calculation? How do we get the various fields from the overall timestamp?
We'll need to use divmod style division. For some background, refer to the Choosing between true division and floor division recipe.
The algorithm for converting a timestamp in seconds, ts, into individual week, day, and time fields looks like this:


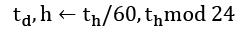
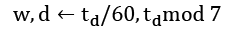
This has a handy pattern that leads to a very simple implementation. It has a consequence of producing the values in reverse order:
>>> t_s = 8063599
>>> fields = []
>>> for b in 60, 60, 24, 7:
... t_s, f = divmod(t_s, b)
... fields.append(f)
>>> fields.append(t_s)
>>> fields
[19, 53, 7, 2, 13]
We've applied the divmod() function four times to extract seconds, minutes, hours, days, and weeks from a timestamp, given in seconds. These are in the wrong order. How can we reverse them?
How to do it...
We have three approaches: we can use the reverse() method, we can use a [::-1] slice expression, or we can use the reversed() built-in function. Here's the reverse() method:
>>> fields_copy1 = fields.copy()
>>> fields_copy1.reverse()
>>> fields_copy1
[13, 2, 7, 53, 19]
We made a copy of the original list so that we could keep an unmutated copy to compare with the mutated copy. This makes it easier to follow the examples. We applied the reverse() method to reverse a copy of the list.
This will mutate the list. As with other mutating methods, it does not return a useful value. It's an error to use a statement like a = b.reverse(); the value of a will always be None.
Here's a slice expression with a negative step:
>>> fields_copy2 = fields[::-1]
>>> fields_copy2
[13, 2, 7, 53, 19]
In this example, we made a slice [::-1] that uses an implied start and stop, and the step was -1. This picks all the items in the list in reverse order to create a new list.
The original list is emphatically not mutated by this slice operation. This creates a copy. Check the value of the fields variable to see that it's unchanged.
Here's how we can use the reversed() function to create a reversed copy of a list of values:
>>> fields_copy3 = list(reversed(fields))
>>> fields_copy3
[13, 2, 7, 53, 19]
It's important to use the list() function in this example. The reversed() function is a generator, and we need to consume the items from the generator to create a new list.
How it works...
As we noted in the Slicing and dicing a list recipe, the slice notation is quite sophisticated. Using a slice with a negative step size will create a copy (or a subset) with items processed in right to left order, instead of the default left to right order.
It's important to distinguish between these three methods:
- The
reverse()method modifies thelistobject itself. As with methods likeappend()andremove(), there is no return value from this method. Because it changes the list, it doesn't return a value. - The
[::-1]slice expression creates a new list. This is a shallow copy of the original list, with the order reversed. - The
reversed()function is a generator that yields the values in reverse order. When the values are consumed by thelist()function, it creates a copy of the list.
See also
- Refer to the Making shallow and deep copies of objects recipe for more information on what a shallow copy is and why we might want to make a deep copy.
- Refer to the Building lists – literals, appending, and comprehensions recipe for ways to create lists.
- Refer to the Slicing and dicing a list recipe for ways to copy lists and pick sublists from a list.
- Refer to the Deleting from a list – deleting, removing, popping, and filtering recipe for other ways to remove items from a list.
Building sets – literals, adding, comprehensions, and operators
If we've decided to create a collection based on only an item being present—a set —we have several ways of building this structure. Because of the narrow focus of sets, there's no ordering to the items – no relative positions – and no concept of duplication. We'll look at a number of ways we can assemble a set collection from individual items.
In some cases, we'll need a set because it prevents duplicate values. It's common to summarize data by reducing a large collection to a set of distinct items. An interesting use of sets is for locating repeated items when examining a connected graph. We often think of the directories in the filesystem forming a tree from the root directory through a path of directories to a particular file. Because there are links in the filesystem, the path is not a simple directed tree, but can have cycles. It can be necessary to keep a set of directories that have been visited to avoid endlessly following a circle of file links.
The set operators parallel the operators defined by the mathematics of set theory. These can be helpful for doing bulk comparisons between sets. We'll look at these in addition to the methods of the set class.
Sets have an important constraint: they only contain immutable objects. Informally, immutable objects have no internal state that can be changed. Numbers are immutable, as are strings, and tuples of immutable objects. As we noted in the Rewriting an immutable string recipe in Chapter 1, Numbers, Strings, and Tuples, strings are complex objects, but we cannot update them; we can only create new ones. Formally, immutable objects have an internal hash value, and the hash() function will show this value.
Here's how this looks in practice:
>>> a = "string"
>>> hash(a)
4964286962312962439
>>> b = ["list", "of", "strings"]
>>> hash(b)
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: unhashable type: 'list'
The value of the a variable is a string, which is immutable, and has a hash value. The b variable, on the other hand, is a mutable list, and doesn't have a hash value. We can create sets of immutable objects like strings, but the TypeError: unhashable type exception will be raised if we try to put mutable objects into a set.
Getting ready
Let's say we need to do some analysis of the dependencies among modules in a complex application. Here's one part of the available data:
import_details = [
('Chapter_12.ch12_r01', ['typing', 'pathlib']),
('Chapter_12.ch12_r02', ['typing', 'pathlib']),
('Chapter_12.ch12_r03', ['typing', 'pathlib']),
('Chapter_12.ch12_r04', ['typing', 'pathlib']),
('Chapter_12.ch12_r05', ['typing', 'pathlib']),
('Chapter_12.ch12_r06', ['typing', 'textwrap', 'pathlib']),
('Chapter_12.ch12_r07',
['typing', 'Chapter_12.ch12_r06', 'Chapter_12.ch12_r05', 'concurrent']),
('Chapter_12.ch12_r08', ['typing', 'argparse', 'pathlib']),
('Chapter_12.ch12_r09', ['typing', 'pathlib']),
('Chapter_12.ch12_r10', ['typing', 'pathlib']),
('Chapter_12.ch12_r11', ['typing', 'pathlib']),
('Chapter_12.ch12_r12', ['typing', 'argparse'])
]
Each item in this list describes a module and the list of modules that it imports. There are a number of questions we can ask about this collection of relationships among modules. We'd like to compute the short list of dependencies, thereby removing duplication from this list.
We'd like to accumulate a set object that has the various imported modules. We'd also like to separate the overall collection into subsets with modules that have names matching a common pattern.
How to do it...
We have many ways to create set objects. There are important restrictions on what kinds of items can be collected into a set. Items in a set must be immutable.
Here are ways to build sets:
- Literal: We can create literal display of a
setusing a sequence of values surrounded by{}characters. It looks like this:{value, ... }. Python needs to match the{and}to see a complete logical line, so the literal can span physical lines. For more information, refer to the Writing long lines of code recipe in Chapter 2, Statements and Syntax. Note that we can't create an empty set with{}; this is an empty dictionary. We must useset()to create an empty set. - Conversion Function: We can convert some other data collection into a
setusing theset()function. We can convert alist, or the keys of adict, or atuple. This will remove duplicates from the collection. It's also subject to the constraint that the items are all immutable objects like strings, numbers, or tuples of immutable objects. - Add Method: The
setmethodadd()will add an item to a set. Additionally, sets can be created by a number of set operators for performing union, intersection, difference, and symmetrical difference. - Comprehension: A comprehension is a specialized generator expression that describes the items in a set using a sophisticated expression to define membership. We'll look at this in detail in the Writing a set comprehension section of this recipe.
- Generator Expression: We can use generator expressions to build
setobjects. This is a generalization of the idea of a set comprehension. We'll look at this in detail in the Using the set function on a generator expression section of this recipe.
The first two ways to create sets are single Python expressions. We won't provide recipes for these. The last three are more complex, and we'll show recipes for each of them.
Building a set with the add method
Our collection of data is a list with sublists. We want to summarize the items inside each of the sublists:
- Create an empty set into which items can be added. Unlike lists, there's no abbreviated syntax for an empty set, so we must use the
set()function:>>> all_imports = set() - Write a for statement to iterate through each two-tuple in the
import_detailscollection. This needs a nested for statement to iterate through each name in the list of imports in each pair. Use theadd()method of theall_importsset to create a complete set with duplicates removed:>>> for item, import_list in import_details: ... for name in import_list: ... all_imports.add(name) >>> print(all_imports) {'Chapter_12.ch12_r06', 'Chapter_12.ch12_r05', 'textwrap', 'concurrent', 'pathlib', 'argparse', 'typing'}
This result summarizes many lines of details, showing the set of distinct items imported. Note that the order here is arbitrary and can vary each time the example is executed.
Writing a set comprehension
The goal of a set comprehension is to create an object that occupies a syntax role, similar to a set literal:
- Write the wrapping
{}braces that surround thesetobject to be built. - Write the source of the data. This will include the target variable. We have two nested lists, so we'll two for clauses. Note that there's no
:at the end because we're not writing a complete statement:for item, import_list in import_details for name in import_list - Prefix the
forclauses with the expression to evaluate for each value of the target variable. In this case, we only want the name from the import list within each pair of items in the overall import details list-of-lists:{name for item, import_list in import_details for name in import_list}
A set comprehension cannot have duplicates, so this will always be a set of distinct values.
As with the list comprehension, a set comprehension is built around a central generator expression. The generator expression at the heart of the comprehension has a data expression clause and a for clause. As with list comprehensions, we can include if clauses to act as a filter.
Using the set function on a generator expression
We'll create a set function that uses the generator expression:
- Write the wrapping
set()function that surrounds the generator expression. - We'll reuse steps 2 and 3 from the list comprehension version to create a generator expression. Here's the generator expression:
set(name ... for item, import_list in import_details ... for name in import_list ... )Here's the entire
setobject:>>> all_imports = set(name ... for item, import_list in import_details ... for name in import_list ... ) >>> all_imports {'Chapter_12.ch12_r05', 'Chapter_12.ch12_r06', 'argparse', 'concurrent', 'pathlib', 'textwrap', 'typing'}
Using the explicit list() function had an advantage when we consider the possibility of changing the data structure. We can easily replace set() with list().
How it works…
A set can be thought of as a collection of immutable objects. Each immutable Python object has a hash value, and this numeric code is used to optimize locating items in the set. We can imagine the implementation relies on an array of buckets, and the hash value directs us to a bucket to see if the item is present in that bucket or not.
Hash values are not necessarily unique. The array of hash buckets is finite, meaning collisions are possible. This leads to some overhead to handle these collisions and grow the array of buckets when collisions become too frequent.
The hash values of integers, interestingly, are the integer values. Because of this, we can create integers that will have a hash collision:
>>> v1 = 7
>>> v2 = 7+sys.hash_info.modulus
>>> v1
7
>>> v2
2305843009213693958
>>> hash(v1)
7
>>> hash(v2)
7
In spite of these two objects having the same hash value, hash collision processing keeps these two objects separate from each other in a set.
There's more…
We have several ways to add items to a set:
- The example used the
add()method. This works with a single item. - We can use the
union()method. This is like an operator—it creates a new resultset. It does not mutate either of the operand sets. - We can use the
|union operator to compute the union of two sets. - We can use the
update()method to update one set with items from another set. This mutates a set and does not return a value.
For most of these, we'll need to create a singleton set from the item we're going to add. Here's an example of adding a single item, 3, to a set by turning it into a singleton set:
>>> collection = {1}
>>> collection
{1}
>>> item = 3
>>> collection.union({item})
{1, 3}
>>> collection
{1}
In the preceding example, we've created a singleton set, {item}, from the value of the item variable. We then used the union() method to compute a new set, which is the union of collection and {item}.
Note that union() returns a resulting object and leaves the original collection set untouched. We would need to use this as collection = collection.union({item}) to update the collection object. This is yet another alternative that uses the union operator, |:
>>> collection = collection | {item}
>>> collection
{1, 3}
We can also use the update() method:
>>> collection.update({4})
>>> collection
{1, 3, 4}
Methods like update() and add() mutate the set object. Because they mutate the set, they do not return a value. This is similar to the way methods of the list collection work. Generally, a method that mutates the collection does not return a value. The only exception to this pattern is the pop() method, which both mutates the set object and returns the popped value.
Python has a number of set operators. These are ordinary operator symbols that we can use in complex expressions:
|for set union, often typeset as .
.&for set intersection, often typeset as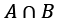 .
.^for set symmetric difference, often typeset as .
.-for set subtraction, often typeset as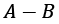 .
.
See also
- In the Removing items from a set – remove, pop, and difference recipe, we'll look at how we can update a set by removing or replacing items.
Removing items from a set – remove(), pop(), and difference
Python gives us several ways to remove items from a set collection. We can use the remove() method to remove a specific item. We can use the pop() method to remove (and return) an arbitrary item.
Additionally, we can compute a new set using the set intersection, difference, and symmetric difference operators: &, -, and ^. These will produce a new set that is a subset of a given input set.
Getting ready
Sometimes, we'll have log files that contain lines with complex and varied formats. Here's a small snippet from a long, complex log:
[2016-03-05T09:29:31-05:00] INFO: Processing ruby_block[print IP] action run (@recipe_files::/home/slott/ch4/deploy.rb line 9)
[2016-03-05T09:29:31-05:00] INFO: Installed IP: 111.222.111.222
[2016-03-05T09:29:31-05:00] INFO: ruby_block[print IP] called
- execute the ruby block print IP
[2016-03-05T09:29:31-05:00] INFO: Chef Run complete in 23.233811181 seconds
Running handlers:
[2016-03-05T09:29:31-05:00] INFO: Running report handlers
Running handlers complete
[2016-03-05T09:29:31-05:00] INFO: Report handlers complete
Chef Client finished, 2/2 resources updated in 29.233811181 seconds
We need to find all of the IP: 111.222.111.222 lines in this log.
Here's how we can create a set of matches:
>>> import re
>>> pattern = re.compile(r"IP: d+.d+.d+.d+")
>>> matches = set(pattern.findall(log))
>>> matches
{'IP: 111.222.111.222'}
The problem we have is extraneous matches. The log file has lines that look similar but are examples we need to ignore. In the full log, we'll also find lines containing text like IP: 1.2.3.4, which need to be ignored. It turns out that there is a set irrelevant of values that need to be ignored.
This is a place where set intersection and set subtraction can be very helpful.
How to do it...
- Create a
setof items we'd like to ignore:>>> to_be_ignored = {'IP: 0.0.0.0', 'IP: 1.2.3.4'} - Collect all entries from the log. We'll use the
remodule for this, as shown earlier. Assume we have data that includes good addresses, plus dummy and placeholder addresses from other parts of the log:>>> matches = {'IP: 111.222.111.222', 'IP: 1.2.3.4'} - Remove items from the
setof matches using a form of set subtraction. Here are two examples:>>> matches - to_be_ignored {'IP: 111.222.111.222'} >>> matches.difference(to_be_ignored) {'IP: 111.222.111.222'}
Both of these are operators that return new sets as their results. Neither of these will mutate the underlying set objects.
It turns out the difference() method can work with any iterable collection, including lists and tuples. While permitted, mixing sets and lists can be confusing, and it can be challenging to write type hints for them.
We'll often use these in statements, like this:
>>> valid_matches = matches - to_be_ignored
>>> valid_matches
{'IP: 111.222.111.222'}
This will assign the resulting set to a new variable, valid_matches, so that we can do the required processing on this new set.
We can also use the remove() and pop() methods to remove specific items. The remove() method raises an exception when an item cannot be removed. We can use this behavior to both confirm that an item is in the set and remove it. In this example, we have an item in the to_be_ignored set that doesn't need to exist in the original matches object, so these methods aren't helpful.
How it works...
A set object tracks membership of items. An item is either in the set or not. We specify the item we want to remove. Removing an item doesn't depend on an index position or a key value.
Because we have set operators, we can remove any of the items in one set from a target set. We don't need to process the items individually.
There's more...
We have several other ways to remove items from a set:
- In this example, we used the
difference()method and the-operator. Thedifference()method behaves like an operator and creates a new set. - We can also use the
difference_update()method. This will mutate a set in place. It does not return a value. - We can remove an individual item with the
remove()method. - We can also remove an arbitrary item with the
pop()method. This doesn't apply to this example very well because we can't control which item is popped.
Here's how the difference_update() method looks:
>>> valid_matches = matches.copy()
>>> valid_matches.difference_update(to_be_ignored)
>>> valid_matches
{'IP: 111.222.111.222'}
We applied the difference_update()method to remove the undesirable items from the valid_matches set. Since the valid_matches set was mutated, no value is returned. Also, since the set is a copy, this operation doesn't modify the original matches set.
We could do something like this to use the remove() method. Note that remove() will raise an exception if an item is not present in the set:
>>> valid_matches = matches.copy()
>>> for item in to_be_ignored:
... if item in valid_matches:
... valid_matches.remove(item)
>>> valid_matches
{'IP: 111.222.111.222'}
We tested to see if the item was in the valid_matches set before attempting to remove it. Using an if statement is one way to avoid raising a KeyError exception. An alternative is to use a try: statement to silence the exception that's raised when an item is not present:
>>> valid_matches = matches.copy()
>>> for item in to_be_ignored:
... try:
... valid_matches.remove(item)
... except KeyError:
... pass
>>> valid_matches
{'IP: 111.222.111.222'}
We can also use the pop() method to remove an arbitrary item. This method is unusual in that it both mutates the set and returns the item that was removed. For this application, it's nearly identical to remove().
Writing set-related type hints
The typing module provides a few essential type definitions for describing the contents of a set object. The primary type definition is set, which we can parameterize with the types of items in the set. This parallels the Writing list-related type hints recipe.
There are two common patterns for the types of items in sets in Python:
- Homogenous: Each item in the set has a common type or protocol.
- Heterogenous: The items in the set come from a union of a number of types with no commonality.
Getting ready
A dice game like Zonk (also called 10,000 or Greed) requires a random collection of dice to be grouped into "hands." While rules vary, there a several patterns for hands, including:
- Three of a kind.
- A "small straight" of five ascending dice (1-2-3-4-5 or 2-3-4-5-6 are the two combinations).
- A "large straight" of six ascending dice.
- An "ace" hand. This has at least one 1 die that's not part of a three of a kind or straight.
More complex games, like Yatzy poker dice (or Yahtzee™) introduce a number of other patterns. These might include two pairs, four or five of a kind, and a full house. We'll limit ourselves to the simpler rules for Zonk.
We'll use the following definitions to create the hands of dice:
from enum import Enum
class Die(str, Enum):
d_1 = "u2680"
d_2 = "u2681"
d_3 = "u2682"
d_4 = "u2683"
d_5 = "u2684"
d_6 = "u2685"
def zonk(n: int = 6) -> Tuple[Die, ...]:
faces = list(Die)
return tuple(random.choice(faces) for _ in range(n))
The Die class definition enumerates the six faces of a standard die by providing the Unicode character with the appropriate value.
When we evaluate the zonk() function, it looks like this.
>>> zonk()
(<Die.d_6: ' '>, <Die.d_1: '
'>, <Die.d_1: ' '>, <Die.d_1: ''>, <Die.d_6: ''>, <Die.d_3: '
'>, <Die.d_1: ''>, <Die.d_6: ''>, <Die.d_3: ' '>, <Die.d_2: '
'>, <Die.d_2: ' '>)
'>)
This shows us a hand with two sixes, two ones, a two, and a three. When examining the hand for patterns, we will often create complex sets of objects.
How to do it…
In our analysis of the patterns of dice in a six-dice hand, creating a Set[Die] object from the six dice reveals a great deal of information:
- When there is one dice in the set of unique values, then all six dice have the same value.
- When there are five distinct dice in the set of unique values, then this could be a small straight. This requires an additional check to see if the set of unique values is 1-5 or 2-6, which are the two valid small straights.
- When there are six distinct items in the set of unique values, then this must be a large straight.
- For two unique dice in the set, there must be three of a kind. While there may also be four of a kind or five of a kind, these other combinations aren't scoring combinations.
- The three and four matching dice cases are ambiguous. For three distinct values, the patterns are xxxyyz and xxyyzz. For four distinct values, the patterns are wwwxyz, and wwxxyz.
We can distinguish many of the patterns by looking at the cardinality of the set of distinct dice. The remaining distinctions can be made by looking at the pattern of counts. We'll also create a set for the values created by a collections.Counter object. The underlying value is int, so this will be Set[int]:
- Define the type for each item in the set. In this example, the class
Dieis the item class. - Create the
Setobject from the hand ofDieinstances. Here's how the evaluation function can begin:def eval_zonk_6(hand: Tuple[Die, ...]) -> str: assert len(hand) == 6, "Only works for 6-dice zonk." unique: Set[Die] = set(hand) - We'll need the two small straight definitions. We'll include this in the body of the function to show how they're used. Pragmatically, the value of
small_straightsshould be global and computed only once:faces = list(Die) small_straights = [ set(faces[:-1]), set(faces[1:]) ] - Examine the simple cases. The number of distinct elements in the set identifies several kinds of hands directly:
if len(unique) == 6: return "large straight" elif len(unique) == 5 and unique in small_straights: return "small straight" elif len(unique) == 2: return "three of a kind" elif len(unique) == 1: return "six of a kind!" - Examine the more complex cases. When there are three or four distinct values, the patterns can be summarized using the counts in a simple histogram. This will use a distinct type for the elements of the set. This is
Set[int], which will collect the counts instead ofSet[Die]to create the uniqueDievalues:elif len(unique) in {3, 4}: frequencies: Set[int] = set(collections.Counter(hand).values()) - Compare the items in the frequency set to determine what kind of hand this is. For the cases of four distinct
Dievalues, these can form one of two patterns: wwwxyz and wwxxyz. The first of these has afrequenciesobject withDiew occurring three times and the otherDievalues occurring once each. The second has noDiethat occurred three times, showing it's non-scoring. Similarly, when there are three distinct values, they have three patterns, two of which have the required three of a kind. The third pattern is three pairs. Interesting, but non-scoring. If one of theDiehas a frequency of three or four, that's a scoring combination. If nothing else matches and there's a one, that's a minimal score:if 3 in frequencies or 4 in frequencies: return "three of a kind" elif Die.d_1 in unique: return "ace" - Are there any conditions left over? Does this cover all possible cardinalities of dice and frequencies of dice? The remaining case is some collection of pairs and singletons without any "one" showing. This is a non-scoring Zonk:
return "Zonk!"
This shows two ways of using sets to evaluate the pattern of a collection of data items. The first set, Set[Die], looked at the overall pattern of unique Die values. The second set, Set[int], looked at the pattern of frequencies of die values.
Here's the whole function:
def eval_zonk_6(hand: Tuple[Die, ...]) -> str:
assert len(hand) == 6, "Only works for 6-dice zonk."
faces = list(Die)
small_straights = [
set(faces[:-1]), set(faces[1:])
]
unique: Set[Die] = set(hand)
if len(unique) == 6:
return "large straight"
elif len(unique) == 5 and unique in small_straights:
return "small straight"
elif len(unique) == 2:
return "three of a kind"
elif len(unique) == 1:
return "six of a kind!"
elif len(unique) in {3, 4}:
# len(unique) == 4: wwwxyz (good) or wwxxyz (non-scoring)
# len(unique) == 3: xxxxyz, xxxyyz (good) or xxyyzz (non-scoring)
frequencies: Set[int] = set(collections.Counter(hand).values())
if 3 in frequencies or 4 in frequencies:
return "three of a kind"
elif Die.d_1 in unique:
return "ace"
return "Zonk!"
This shows the two kinds of set objects. A simple set of dice is assigned to the variable unique. When the number of unique values is 3 or 4, then a second set object is created, frequencies. If 3 is in the set of frequencies, then there was a three of a kind. If 4 was in the set of frequencies, then there was a four of a kind.
How it works…
The essential property of a set is membership. When we compute a set from a collection of Die instances, the Set[Die] object will only show the distinct values. We use Set[Die] to provide guidance to the mypy program that only instances of the Die class will be collected in the set.
Similarly, when we look at the distribution of frequencies, there are only a few distinct patterns, and they can be identified by transforming the frequencies into a set of distinct values. The presence of a 3 or a 4 value in the set of frequencies provides all of the information required to discern the kind of hand. The 3 (or 4) value in the frequencies will always be the largest value, making it possible to use max(collections.Counter(hand).values()) instead of set(collections.Counter(hand).values()). Changing from a collection to an individual item will require some additional changes. We leave those for you to figure out.
There's more…
Computing the score of the hand depends on which dice were part of the winning pattern. This means that the evaluation function needs to return a more complex result when the outcome is three of a kind. To determine the points, there are two cases we need to consider:
- The value of the dice that occurred three or more times.
- It's possible to roll two triples; this pattern must be distinguished too.
We have two separate conditions to identify the patterns of unique values indicating a three of a kind pattern. The function needs some refactoring to properly identify the values of the dice occurring three or more times. We'll leave this refactoring as an exercise for you.
See also
- Refer to the Writing list-related type hints recipe in this chapter for more about type hints for lists.
- The Writing dictionary-related type hints recipe covers type hints for dictionaries.