
12
Web Services
Many problems can be solved by offering a centralized software service to a number of remote clients. Since the 90s, this kind of networking has been called the World Wide Web, and the centralized applications are called web services. Web clients have evolved to include browsers, mobile applications, and other web services, creating a sophisticated, interlinked network of computing. Providing a web service involves solving several interrelated problems. The applicable protocols must be followed, each with its own unique design considerations. One of the foundations for providing web services is the various standards that define the Hypertext Transfer Protocol (HTTP).
One of the use cases for HTTP is to provide web services. In this case, the standard HTTP requests and responses will exchange data in formats other than HTML and images preferred by browsers. One of the most popular formats for encoding information is JSON. We looked at processing JSON documents in the Reading JSON documents recipe in Chapter 10, Input/Output, Physical Format, and Logical Layout.
A web service client can prepare documents in JSON. The server includes a Python application that creates response documents, also in JSON notation. The HTTP status codes are used to indicate the success or failure of each individual request. A status of 200 OK often indicates success, and 400 Bad Request indicates an error in the request.
The documents exchanged by a web service and a client encode a representation of an object's state. A client application in JavaScript may have an object state that is sent to a server. A server in Python may transfer a representation of an object state to a client. This concept is called Representational State Transfer (REST). A service using REST processing is often called RESTful.
Most Python web service applications follow the Web Services Gateway Interface (WSGI). The WSGI standard defines a web service as a function that returns a response document. The web service function is given a standardized request implemented as a dictionary, plus a secondary function used to set a status and headers.
There are several places to look for detailed information on the overall WSGI standard:
- PEP 3333: See https://www.python.org/dev/peps/pep-3333/.
- The Python standard library: It includes the
wsgirefmodule. This is the reference implementation in the standard library. - The Werkzeug project: See http://werkzeug.pocoo.org. This is an external library with numerous WSGI utilities. This is used widely to implement WSGI applications.
A good RESTful implementation should also provide a great deal of information about the service being used. One way to provide this information is through the OpenAPI specification. For information on the OpenAPI (formerly known as Swagger) specification, see http://swagger.io/specification/.
The core of the OpenAPI specification is a JSON schema specification. For more information on this, see http://json-schema.org.
The two foundational ideas are as follows:
- We write a specification for the requests that are accepted by the service and the responses returned by the service. This specification is written in JSON, making it accessible to client applications written in a variety of languages.
- We provide the specification at a fixed URL, often
/openapi.yaml. This can be queried by a client to determine the details of how the service works.
Creating OpenAPI documents can be challenging. The swagger-spec-validator project can help. See https://github.com/p1c2u/openapi-spec-validator. This is a Python package that we can use to confirm that a document meets the OpenAPI requirements.
In this chapter, we'll look at a number of recipes for creating RESTful web services and also serving static or dynamic content. We'll look at the following recipes:
- Defining the card model
- Using the Flask framework for RESTful APIs
- Parsing the query string in a request
- Making REST requests with urllib
- Parsing the URL path
- Parsing a JSON request
- Implementing authentication for web services
Central to web services is a WSGI-based application server. The Flask framework provides this. Flask allows us to write view functions that handle the detailed processing of a request to create a response. We'll start with a data model for playing cards and then move to a simple Flask-based server to present instances of Card objects. From there, we'll add features to make a more useful web service.
Defining the card model
In several of these recipes, we'll look at a web service that emits playing cards from either a deck or a shoe. This means we'll be transferring the representation of Card objects.
This is often described as Representational State Transfer – REST. We need to define our class of objects so we can create a useful representation of the state of each Card instance. A common representation is JSON notation.
It might be helpful to think of this as recipe zero. This data model is based on a recipe from Chapter 7, Basics of Classes and Objects. We'll expand it here in this chapter and use it as a foundation for the remaining recipes in this chapter. In the GitHub repo for this chapter, this recipe is available as card_model.py
Getting ready
We'll rely on the Card class definition from the Using dataclasses for mutable objects recipe in Chapter 7, Basics of Classes and Objects. We'll also rely on JSON notation. We looked at parsing and creating JSON notation in Chapter 10, Input/Output, Physical Format, and Logical Layout, in the Reading JSON and YAML documents recipe.
How to do it…
We'll decompose this recipe into an initial step, followed by steps for each individual method of the class:
- Define the overall class, including the attributes of each
Cardinstance. We've used thefrozen=Trueoption to make the object immutable:from dataclasses import dataclass, asdict @dataclass(frozen=True) class Card: rank: int suit: str - Add a method to create a version of the card's attributes in a form that's readily handled by the JSON serialization. We'll call this the
serialize()method. Because the attributes are an integer and a string, we can use thedataclasses.asdict()function to create a useful, serializable representation. We've created a dictionary with a key that names the class,__class__, and a key that contains a dictionary used to create instances of the dataclass__init__:def serialize(self) -> Dict[str, Any]: return { "__class__": self.__class__.__name__, "__init__": asdict(self) } - Add a method to deserialize the preceding object into a new instance of the
Cardclass. We've made this a class method, so the class will be provided as an initial parameter value. This isn't necessary but seems to be helpful if we want to make this a superclass of a class hierarchy:@classmethod def deserialize(cls: Type, document: Dict[str, Any]) -> 'Card': if document["__class__"] != cls.__name__: raise TypeError( f"Cannot make {cls.__name__} " f"from {document['__class__']}" ) return Card(**document["__init__"]) - This needs to be a separate module,
card_model.py, so it can be imported into other recipes. Unit tests are appropriate to be sure that the various methods work as promised.
Given this class, we can create an instance of the class like this:
>>> c = Card(1, "\u2660")
>>> repr(c)
"Card(rank=1, suit=' ')"
>>> document = c.serialize()
>>> document
{'__class__': 'Card', '__init__': {'rank': 1, 'suit': ''}}
')"
>>> document = c.serialize()
>>> document
{'__class__': 'Card', '__init__': {'rank': 1, 'suit': ''}}
The serialize() method of the object, c, provides a dictionary of integer and text values. We can then dump this in JSON notation as follows:
>>> json.dumps(document)
'{"__class__": "Card", "__init__": {"rank": 1, "suit": "\\u2660"}}'
This shows the JSON-syntax string created from the serialized Card instance.
We can use Card.deserialize() on the document to recreate a copy of the Card instance. This pair of operations lets us prepare a Card for the transfer of the representation of the internal state, and build on the object that reflects the representation of the state.
How it works…
We've broken the web resource into three distinct pieces. At the core is the Card class that models a single playing card, with rank and suit attributes. We've included methods to create Python dictionaries from the Card object. Separately, we can dump and load these dictionaries as JSON-formatted strings. We've kept the various representations separated.
In our applications, we'll work with the essential Card objects. We'll only use the serialization and JSON formatting for transfer between client and server applications.
See http://docs.oasis-open.org/odata/odata-json-format/v4.0/odata-json-format-v4.0.html for more information on the JSON-formatting of data for web services.
There's more…
We'll also need a Deck class as a container of Card instances. An instance of this Deck class can create Card objects. It can also act as a stateful object that can deal cards. Here's the class definition:
import random
from typing import List, Iterator, Union, overload
class Deck:
SUITS = (
"N{black spade suit}",
"N{white heart suit}",
"N{white diamond suit}",
"N{black club suit}",
)
def __init__(self, n: int = 1) -> None:
self.n = n
self.create_deck(self.n)
def create_deck(self, n: int = 1) -> None:
self.cards = [
Card(r, s)
for r in range(1, 14)
for s in self.SUITS for _ in range(n)
]
random.shuffle(self.cards)
self.offset = 0
def deal(self, hand_size: int = 5) -> List[Card]:
if self.offset + hand_size > len(self.cards):
self.create_deck(self.n)
hand = self.cards[self.offset : self.offset + hand_size]
self.offset += hand_size
return hand
def __len__(self) -> int:
return len(self.cards)
@overload
def __getitem__(self, position: int) -> Card:
...
@overload
def __getitem__(self, position: slice) -> List[Card]:
...
def __getitem__(self, position: Union[int, slice]) -> Union[Card, List[Card]]:
return self.cards[position]
def __iter__(self) -> Iterator[Card]:
return iter(self.cards)
The create_deck() method uses a generator to create all 52 combinations of the thirteen ranks and four suits. Each suit is defined by a single character: ![]() ,
, ![]() ,
, ![]() , or
, or ![]() . The example spells out the Unicode character names using
. The example spells out the Unicode character names using N{} sequences in the class variable, SUITS.
If a value of n is provided when creating the Deck instance, the container will create multiple copies of the 52-card deck. This multideck shoe is sometimes used to speed up play by reducing the time spent shuffling. It can also make card counting somewhat more difficult. Furthermore, a shoe can be used to take some cards out of play. Once the sequence of Card instances has been created, it is shuffled using the random module. For repeatable test cases, a fixed seed can be provided.
The deal() method will use the value of self.offset to determine where to start dealing. This value starts at 0 and is incremented after each hand of cards is dealt. The hand_size argument determines how many cards will be in the next hand. This method updates the state of the object by incrementing the value of self.offset so that the cards are dealt just once.
The various @overload definitions of __getitem__() are required to match the way Python deals with list[position] and list[index:index]. The first form has the type hint __getitem__(self, position: int) -> Any. The second form has the type hint __getitem__(self, position: slice) -> Any. We need to provide both overloaded type hints. The implementation passes the argument value – either an integer or a slice object – through to the underlying self.cards instance variable, which is a list collection.
Here's one way to use this class to create Card objects:
>>> from Chapter_12.card_model import Deck
>>> import random
>>> random.seed(42)
>>> deck = Deck()
>>> cards = deck.deal(5)
>>> cards
[Card(rank=3, suit=' '), Card(rank=6, suit='
'), Card(rank=6, suit=' '),
Card(rank=7, suit=''), Card(rank=1, suit=''),
Card(rank=6, suit='')]
'),
Card(rank=7, suit=''), Card(rank=1, suit=''),
Card(rank=6, suit='')]
To create a sensible test, we provided a fixed seed value. The script created a single deck using Deck(). We can then deal a hand of five Card instances from the deck.
In order to use this as part of a web service, we'll also need to produce useful output in JSON notation. Here's an example of how that would look:
>>> import json
>>> json_cards = list(card.to_json() for card in deck.deal(5))
>>> print(json.dumps(json_cards, indent=2, sort_keys=True))
[
{
"__class__": "Card",
"rank": 10,
"suit": "u2662"
},
{
"__class__": "Card",
"rank": 5,
"suit": "u2660"
},
{
"__class__": "Card",
"rank": 10,
"suit": "u2663"
},
{
"__class__": "Card",
"rank": 5,
"suit": "u2663"
},
{
"__class__": "Card",
"rank": 3,
"suit": "u2663"
}
]
We've used deck.deal(5) to deal a hand with five more cards from the deck. The expression list(card.to_json() for card in deck.deal(5)) will use the to _json() method of each Card object to emit the small dictionary representation of that object. The list of dictionary structure was then serialized into JSON notation. The sort_keys=True option is handy for creating a repeatable test case. It's not generally necessary for RESTful web services.
Now that we have a definition of Card and Deck, we can write RESTful web services to provide Card instances from the Deck collection. We'll use these definitions throughout the remaining recipes in this chapter.
Using the Flask framework for RESTful APIs
Many web applications have several layers. The layers often follow this pattern:
- A presentation layer. This might run on a mobile device or a computer's browser. This is the visible, external view of the application. Because of the variety of mobile devices and browsers, there may be many clients for an application.
- An application layer. This is often implemented as a RESTful API to provide web services. This layer does the processing to support the web or mobile presentation. This can be built using Python and the Flask framework.
- A persistence layer. This handles the retention of data and transaction state over a single session as well as across multiple sessions from a single user. This is often a database, but in some cases the OS filesystem is adequate.
The Flask framework is very helpful for creating the application layer of a web service. It can serve HTML and JavaScript to provide a presentation layer. It can work with the filesystem or any database to provide persistence.
Getting ready
First, we'll need to add the Flask framework to our environment. This generally relies on using pip or conda to install the latest release of Flask and the other related projects, itsdangerous, Jinja2, click, MarkupSafe, and Werkzeug.
This book was written using the conda environment manager. This creates virtual environments that permit easy upgrades and the installation of additional packages. Other virtual environment managers can be used as well. In the following example, a conda environment named temp was the current active environment.
The installation looks like the following:
(temp) % pip install flask
Collecting flask
Using cached Flask-1.1.1-py2.py3-none-any.whl (94 kB)
Collecting Werkzeug>=0.15
Downloading Werkzeug-1.0.0-py2.py3-none-any.whl (298 kB)
|████████████████████████████████| 298 kB 1.7 MB/s
Collecting Jinja2>=2.10.1
Downloading Jinja2-2.11.1-py2.py3-none-any.whl (126 kB)
|████████████████████████████████| 126 kB 16.2 MB/s
Collecting click>=5.1
Downloading click-7.1.1-py2.py3-none-any.whl (82 kB)
|████████████████████████████████| 82 kB 2.5 MB/s
Collecting itsdangerous>=0.24
Using cached itsdangerous-1.1.0-py2.py3-none-any.whl (16 kB)
Collecting MarkupSafe>=0.23
Downloading MarkupSafe-1.1.1-cp38-cp38-macosx_10_9_x86_64.whl (16 kB)
Installing collected packages: Werkzeug, MarkupSafe, Jinja2, click, itsdangerous, flask
Successfully installed Jinja2-2.11.1 MarkupSafe-1.1.1 Werkzeug-1.0.0 click-7.1.1 flask-1.1.1 itsdangerous-1.1.0
We can see that Werkzeug, Jinja2, and MarkupSafe were installed in this environment. The Flask project identified these dependencies and the conda tool downloaded and installed them for us.
The Flask framework allows us to create our application as a Python module. Functions in the module can be used to handle a specific pattern of URL paths.
We'll look at some core card-dealing functions using the class definitions shown in the card model recipe earlier in this chapter. The Card class defines a simple playing card. The Deck class defines a deck or shoe of cards.
For our RESTful web service, we'll define a route to a resource that looks like this:
/dealer/hand/?cards=5
This route can be part of a complete URL: http://127.0.0.1:5000/dealer/hand/?cards=5.
The route has three important pieces of information:
- The first part of the path,
/dealer/, is an overall web service. In a more complex environment, this can be to send requests to the appropriate processor. - The next part of the path,
hand/, is a specific resource, a hand of cards. - The query string,
?cards=5, defines thecardsparameter for the query. The numeric value is the size of the hand being requested. It should be limited to a range of 1 to 52 cards. A value that's out of range will get a400status code because the query is invalid.
We'll leverage Flask's route parsing to separate the path elements and map them to view function definitions. The return value from a Flask view function has an implicit status of 200 OK. We can use the abort() function to stop processing with a different status code.
How to do it...
We'll build a Flask application to create Card instances from a Deck object. This will require the card_model module. It will also require various elements of the Flask framework. We'll define a function to manage the Deck object. Finally, we'll map a specific path to a view function to deal Card instances:
- Import some core definitions from the
flaskpackage. TheFlaskclass defines the overall application. Therequestobject holds the current web request. Thejsonify()function returns a JSON-format object from a Flask view function. Theabort()function returns an HTTP error status and ends the processing of the request. TheResponseobject is used as a type hint:from flask import Flask, jsonify, request, abort, Response from http import HTTPStatus from typing import Optional - Import the underlying classes,
CardandDeck. Ideally, these are imported from a separate module. It should be possible to test all of their features outside the web services environment:from Chapter_12.card_model import Card, Deck - In order to control the shuffle, we'll also need the
randommodule. This can be used to force a specific seed for testing or pick a suitably random seed for normal use:import os import random - Create the
Flaskobject. This is the overall web services application. We'll call the Flask applicationdealer, and we'll also assign the object to a global variable,dealer:dealer = Flask("dealer") - Create any objects used throughout the application. Be sure to create a unique name that doesn't conflict with any of Flask's internal attributes. Stateful global objects must be able to work in a multi-threaded environment, or threading must be explicitly disabled:
deck: Optional[Deck] = NoneFor this recipe, the implementation of the
Deckclass is not thread-safe, so we'll rely on having a single-threaded server. For a multi-threaded server, thedeal()method would use theLockclass from thethreadingmodule to define an exclusive lock to ensure proper operation with concurrent threads. - Define a function to access or initialize the global object. When request processing first starts, this will initialize the object. Subsequently, the cached object can be returned. This can be extended to apply thread locks and handle persistence if needed:
def get_deck() -> Deck: global deck if deck is None: random.seed(os.environ.get("DEAL_APP_SEED")) deck = Deck() return deck - Define a route—a URL pattern—to a view function that performs a specific request. This is a decorator, placed immediately in front of the function. It will bind the function to the Flask application:
@dealer.route("/dealer/hand") - Define the view function for this route. A view function retrieves data or updates the application state. In this example, the function does both:
def deal() -> Response: try: hand_size = int(request.args.get("cards", 5)) assert 1 <= hand_size < 53 except Exception as ex: abort(HTTPStatus.BAD_REQUEST) deck = get_deck() cards = deck.deal(hand_size) response = jsonify([card.to_json() for card in cards]) return response
Flask parses the string after the ? in the URL—the query string—to create the request.args value. A client application or browser can set this value with a query string such as ?cards=13. This will deal 13-card hands for bridge.
If the hand size value from the query string is validated, then using the int() function will check the syntax, and the assert statement will check the range of values. If the value is inappropriate, the abort() function will end processing and return an HTTP status code of 400. This indicates that the request was unacceptable. This is a minimal response, with no more detailed content. Adding a text message is often a good idea to clarify why the request was deemed invalid.
The real work of this route is the statement cards = deck.deal(hand_size). The idea here is to wrap existing functionality in a web framework. Ideally, the features can be fully tested without the web application; the web application embeds the application's processing in the RESTful protocol.
The response is created by the jsonify() function: this creates a Response object. The body of the response will be a Python list of Card objects represented in JSON notation. If we need to add headers to the response, we can update the response.headers attribute to include additional information.
Here's the main program that runs the server:
if __name__ == "__main__":
dealer.run(use_reloader=True, threaded=False)
We've included the debug=True option to provide rich debugging information in the browser as well as the Flask log file. Once the server is running, we can open a browser to see http://localhost:5000/. This will return a batch of five cards. Each time we refresh, we get a different batch of cards.
Entering a URL in the browser executes a GET request with a minimal set of headers. Since our WSGI application doesn't require any specific headers and responds to all HTTP methods, it will return a result.
The result is a JSON document with five cards. Each card is represented by class name, rank, and suit information:
[
{
"__class__": "Card",
"suit": "u2663",
"rank": 6
},
{
"__class__": "Card",
"suit": "u2662",
"rank": 8
},
{
"__class__": "Card",
"suit": "u2660",
"rank": 8
},
{
"__class__": "Card",
"suit": "u2660",
"rank": 10
},
{
"__class__": "Card",
"suit": "u2663",
"rank": 11
}
]
To see more than five cards, the URL can be modified. For example, this will return a bridge hand: http://127.0.0.1:5000/dealer/hand/?cards=13.
How it works...
A Flask application consists of an application object with a number of individual view functions. In this recipe, we created a single view function, deal(). Applications often have numerous functions. A complex website may have many applications, each of which has many functions.
A route is a mapping between a URL pattern and a view function. This makes it possible to have routes that contain parameters that can be used by the view function.
The @dealer.route decorator is the technique used to add each route and view function into the overall Flask instance. The view function is bound into the overall application based on the route pattern.
The run() method of a Flask object does the following kinds of processing. This isn't precisely how Flask works, but it provides a broad outline of some important steps:
- It waits for an HTTP request. Flask follows the WSGI standard: the request arrives in the form of a dictionary, known as "the WSGI environment."
- It creates a Flask
Requestobject from the WSGI environment. Therequestobject has all of the information from the request, including all of the URL elements, query string elements, and any attached documents. - Flask then examines the various routes, looking for a route that matches the request's path:
- If a route is found, then the view function is executed. The function's return value must be a
Responseobject. - If a route is not found, a
404 NOT FOUNDresponse is sent automatically.
- If a route is found, then the view function is executed. The function's return value must be a
- The WSGI interface includes a function that's used to send a status and headers. This function also starts sending the response. The
Responseobject that was returned from the view function is provided as a stream of bytes to the client.
A Flask application can contain a number of methods that make it very easy to provide a web service with multiple routes and access to a number of related resources.
There's more...
If we're writing a complex RESTful application server, we often want some additional qualification tests applied to each request. Some web services can provide responses in a variety of formats, including JSON and HTML. A client needs to specify which format of response it wants. There are two common ways to handle this:
- An
Acceptheader can describe the syntax the client software expects. - A query string with
$format=jsonin it is another way to specify what format the response should be.
This rule will reject requests that lack an Accept header. The rule will also reject requests with an Accept header that fails to specifically mention JSON. This is quite restrictive and means the web server won't respond unless JSON is specifically requested.
We've seen the Flask @dealer.route decorator. Flask has a number of other decorators that can be used to define various stages in request and response processing. In order to apply a test to the incoming request, we can use the @dealer.before_request decorator. All of the functions with this decoration will be invoked prior to the request being processed.
We can add a function here to examine the request to see if it's possible for the Flask server to return the expected response format. The function looks like this:
@dealer.before_request
def check_json() -> Optional[Response]:
if "json" in request.headers.get("Accept", "*/*"):
return None
if "json" == request.args.get("$format", "html"):
return None
abort(HTTPStatus.BAD_REQUEST)
When a @flask.before_request decorator fails to return a value (or returns None), then processing will continue. The routes will be checked, and a view function will be evaluated to compute the response. If a value is returned by this function, that is the result of the web service's request. In this case, the abort() function was used to stop processing and create a response. A little more friendly check_json() function might include an error message in the abort() function.
In this example, if the Accept header includes json or the $format query parameter is json, then the function returns None. This means that the normal view function will then be found to process the request.
We can now use a browser's address window to enter a URL like the following:
http://127.0.0.1:5000/dealer/hand/?cards=13&$format=json
This will return a 13-card hand, and the request now explicitly requests the result in JSON format. It is instructive to try other values for $format as well as omitting the $format key entirely.
This example has a subtle semantic issue. The GET method changes the state of the server. It is generally a bad idea to have GET requests with inconsistent results. Having consistent results from a GET request is termed "idempotent."
HTTP supports a number of methods that parallel database CRUD operations. Create is done with POST, Retrieve is done with GET, Update is done with PUT, and Delete maps to DELETE.
This idea leads to the idea that a web service's GET operation should be idempotent. A series of GET operations – without any other POST, PUT, or DELETE – should return the same result each time. In this example, each GET returns a different result. Since the deal service is not idempotent, the GET method may not be the best choice.
To make it easy to explore using a browser, we've avoided checking the method in the Flask route. If this was changed to responding to POST requests, the route decorator should look like the following:
@dealer.route('/dealer/hand/', methods=['POST'])
Doing this makes it difficult to use a browser to see that the service is working. In the Making REST requests with urllib recipe, we'll look at creating a client, and switching to using POST for this method.
See also
- See https://flask.palletsprojects.com/en/1.1.x/ to learn more about the Flask framework. There are a number of closely related projects, all used widely to build web services.
- Also, https://www.packtpub.com/web-development/mastering-flask has more information on mastering Flask.
Parsing the query string in a request
A URL is a complex object. It contains at least six separate pieces of information. More information can be included via optional elements.
A URL such as http://127.0.0.1:5000/dealer/hand/?cards=13&$format=json has several fields:
httpis the scheme.httpsis for secure connections using encrypted sockets.127.0.0.1can be called the authority, although "network location" is a more common term. Sometimes it's called the host. This particular IP address means the localhost and is a kind of loopback to your computer. The name localhost maps to this IP address.5000is the port number and is part of the authority./dealer/hand/is the path to a resource.cards=13&$format=jsonis a query string, and it's separated from the path by the?character.
The query string can be quite complex. While not an official standard, it's possible (and common) for a query string to have a repeated key. The following query string is valid, though perhaps confusing:
?cards=6&cards=4&cards=4
We've repeated the cards key. The web service should provide a six-card hand and two separate four-card hands.
The ability to repeat a key in the query string complicates the possibility of using a Python dictionary to keep the keys and values from a URL query string. There are several possible solutions to this problem:
- Each key in the dictionary can be associated with a
listthat contains all of the values. This is awkward for the most common case where a key is not repeated. In the common case, each key's list of values would have only a single item. This solution is implemented via theparse_qs()function in theurllib.parsemodule. - Each key is only saved once and the first (or last) value is kept; the other values are dropped. This is awful and isn't the way the query string was designed to be used.
- Instead of a dictionary, the query string can be represented as a list of (
key,value) pairs. This also allows keys to be duplicated. For the common case with unique keys, the list can be converted to a dictionary. For the uncommon case, the duplicated keys can be handled some other way. This is implemented by theparse_qsl()function in theurllib.parsemodule.
There are better ways to handle a query string. We'll look at a more sophisticated structure that behaves like a dictionary with single values for the common case and a more complex object for the rare cases where a field key is duplicated and has multiple values. This will let us model the common case as well as the edge cases comfortably.
Getting ready
Flask depends on another project, Werkzeug. When we install Flask using pip, the requirements will lead pip to also install the Werkzeug toolkit. Werkzeug has a data structure that provides an excellent way to handle query strings.
We'll be extending the Using the Flask framework for RESTful APIs recipe from earlier in this chapter.
How to do it...
We'll start with the code from the Using the Flask framework for RESTful APIs recipe to use a somewhat more complex query string. We'll add a second route that deals multiple hands. The size of each hand will be specified in a query string that allows repeated keys:
- Start with the Using the Flask framework for RESTful APIs recipe. We'll be adding a new view function to an existing web application.
- Define a
route—a URL pattern—to a view function that performs a specific request. This is a decorator, placed immediately in front of the function. It will bind the function to the Flask application. We've used hands in the route to suggest multiple hands will be dealt:@dealer.route("/dealer/hands") - Define a view function that responds to requests sent to the particular route:
def multi_hand() -> Response: - Within the
multi_hand()view function, there are two methods to extract the values from a query string. We can use therequest.args.get()method for a key that will occur once. For repeated keys, use therequest.args.getlist()method. This returns a list of values. Here's a view function that looks for a query string such as?card=5&card=5to deal two five-card hands:dealer.logger.debug(f"Request: {request.args}") try: hand_sizes = request.args.getlist( "cards", type=int) except ValueError as ex: abort(HTTPStatus.BAD_REQUEST) dealer.logger.info(f"{hand_sizes=}") if len(hand_sizes) == 0: hand_sizes = [13, 13, 13, 13] if not(1 <= sum(hand_sizes) < 53): abort(HTTPStatus.BAD_REQUEST) deck = get_deck() hands = [ deck.deal(hand_size) for hand_size in hand_sizes]response = jsonify( [ { "hand": i, "cards": [ card.to_json() for card in hand ] } for i, hand in enumerate(hands) ] ) return response
This function will get all of the cards keys from the query string. If the values are all integers, and each value is in the range 1 to 52 (inclusive), then the values are valid, and the view function will return a result. If there are no cards key values in the query, then four hands of 13 cards will be dealt.
The response will be a JSON representation of a list of hands. Each hand is represented as a dictionary with two keys. The "hand" key has a hand ID. The "cards" key has the sequence of individual Card instances. Each Card instance is expanded into a dictionary using the to_json() method of the Card class.
Here's the small main program that will run this module as a Flask server:
if __name__ == "__main__":
dealer.run(use_reloader=True, threaded=False)
Once the server is running, we can open a browser to see this URL:
http://localhost:5000/?cards=5&cards=5&$format=json
The result is a JSON document with two hands of five cards. We've used … to elide some details to emphasize the structure of the response:
[
{
"cards": [
{
"__class__": "Card",
"rank": 11,
"suit": "u2660"
},
{
"__class__": "Card",
"rank": 8,
"suit": "u2662"
},
...
],
"hand": 0
},
{
"cards": [
{
"__class__": "Card",
"rank": 3,
"suit": "u2663"
},
{
"__class__": "Card",
"rank": 9,
"suit": "u2660"
},
...
],
"hand": 1
}
]
Because the web service parses the query string, it's trivial to add more complex hand sizes to the query string. The example includes the $format=json based on the Using the Flask framework for RESTful APIs recipe.
How it works...
The werkzeug module defines a Multidict class. This is a handy data structure for working with headers and query strings. This is an extension to the built-in dictionary. It allows multiple, distinct values for a given key.
We can build something like this using the defaultdict class from the collections module. The definition would be defaultdict(list). The problem with this definition is that the value of every key is a list, even when the list only has a single item as a value.
The advantage provided by the Multidict class is the variations on the get() method. The get() method returns the first value when there are many copies of a key or the only value when the key occurs only once. This has a default parameter, as well. This method parallels the method of the built-in dict class.
The getlist() method, however, returns a list of all values for a given key. This method is unique to the Multidict class. We can use this method to parse more complex query strings.
One common technique that's used to validate query strings is to pop items as they are validated. This is done with the pop() and poplist() methods. These will remove the key from the Multidict class. If any keys remain after checking all the valid keys, these extras can be considered syntax errors, and the web request can be rejected with abort(HTTPStatus.BAD_REQUEST). Adding an error message with details would be a helpful addition to the arguments to this function.
There's more...
The query string uses relatively simple syntax rules. There are one or more key-value pairs using = as the punctuation between the key and value. The separator between each pair is the & character. Because of the meaning of other characters in parsing a URL, there is one other rule that's important – the keys and values must be encoded.
The URL encoding rules require that certain characters be replaced with HTML entities. The technique is called percent encoding. The "&" character, for example, needs to be encoded as %26. Here's an example showing this encoding:
>>> from urllib.parse import urlencode
>>> urlencode({'n':355,'d':113})
'n=355&d=113'
>>> urlencode({'n':355,'d':113,'note':'this&that'})
'n=355&d=113¬e=this%26that'
The value this&that was encoded to this%26that, replacing the & with %26. This transformation is undone by request parsing in Flask.
There's a short list of characters that must have the %-encoding rules applied. This comes from RFC 3986 – refer to section 2.2, Reserved Characters. The list includes these characters:
! * ' ( ) ; : @ & = + $ , / ? # [ ] %
Generally, the JavaScript code associated with a web page will handle encoding query strings. If we're writing an API client in Python, we need to use the urlencode() function to properly encode query strings. Flask handles the decoding automatically for us.
There's a practical size limit on the query string. Apache HTTPD, for example, has a LimitRequestLine configuration parameter with a default value of 8190. This limits the overall URL to this size.
In the OData specifications (http://docs.oasis-open.org/odata/odata/v4.0/), there are several kinds of values that are suggested for the query options. This specification suggests that our web services should support the following kinds of query option:
- For a URL that identifies an entity or a collection of entities, the
$expandand$selectoptions can be used. Expanding a result means that the query will provide additional details such as related items. Theselectquery will impose additional criteria to filter the collection. - A URL that identifies a collection should support
$filter,$search,$orderby,$skip, and$topoptions. These options don't make sense for a URL that returns a single item. The$filterand$searchoptions accept complex conditions for finding data. The$orderbyoption defines a particular order to impose on the results. The$topand$skipoptions are used to page through data. If the count is large, it's common to use the$topoption to limit the results to a specific number that will be shown on a web page. The value of the$skipoption determines which page of data will be shown. For example,$top=20&$skip=40would be page 3 of the results—the top20after skipping40. - A collection URL can also support a
$countoption. This changes the query fundamentally to return the count of items instead of the items themselves.
Generally, it can be helpful for all URLs to support the $format option to specify the format of the result. We've been focusing on JSON, but a more sophisticated service might offer CSV or YAML output or even XML. With the format in the URL as part of the query string, special headers aren't required and some preliminary exploration can be done with browser queries.
See also
- See the Using the Flask framework for RESTful APIs recipe earlier in this chapter for the basics of using Flask for web services.
- In the Making REST requests with urllib recipe, later in this chapter, we'll look at how to write a client application that can prepare complex query strings.
Making REST requests with urllib
A web application has two essential parts:
- A client: This can be a user's browser, but may also be a mobile device app. In some cases, a web server may be a client of other web servers.
- A server: This provides the web services and resources we've been looking at, in the Using the Flask framework for RESTful APIs, and Parsing the query string in a request recipes, as well as other recipes, such as Parsing a JSON request and Implementing authentication for web services.
A browser-based client will generally be written in JavaScript. Mobile apps are written in a variety of languages, with a focus on Java or Kotlin for Android devices and Objective-C with Swift for iOS devices.
There are several user stories that involve RESTful API clients written in Python. How can we create a Python program that is a client of RESTful web services?
Getting ready
We'll assume that we have a web server based on the Using the Flask framework for RESTful APIs, and the Parsing the query string in a request recipes earlier in this chapter. Currently, these server examples do not provide an OpenAPI specification. In the Parsing the URL path recipe, later in this chapter, we'll add an OpenAPI specification.
A server should provide a formal OpenAPI specification of its behavior. For the purposes of this recipe, we'll assume that an OpenAPI specification exists. We'll break the specification down into the major sections of the document.
First, the openapi block states which version of the OpenAPI specification will be followed:
openapi: 3.0.3
The info block provides some identifying information about the service:
info:
title: Python Cookbook Chapter 12, recipe 4.
description: Parsing the query string in a request
version: "1.0"
A client will often check the version to be sure of the server's version. An unexpected version number may mean the client is out of date and should suggest an upgrade to the user.
The servers block is one way to identify the base URL for all of the individual paths that the server handles. This is often redundant since the client gets the specification by making an initial request to the server:
servers:
- url: "http://127.0.0.1:5000/dealer"
The paths block lists each of the paths and describes the kinds of requests that each path can handle. In this case, there are two paths. The first path is /hands and expects a query string with the hand sizes; this uses HTML form-encoding of the data values. Here's what this fragment looks like in YAML notation:
paths:
/hands:
get:
parameters:
- name: cards
in: query
style: form
explode: true
schema:
type: integer
responses:
"200":
description: cards for each hand size in the query
content:
application/json:
schema:
type: array
items:
type: object
properties:
hand:
type: integer
cards:
type: array
items:
$ref: "#/components/schemas/Card"
A components block in the OpenAPI specification provides common definitions shared by the paths. A value with a $ref key can have a value of a path to an item in the components block. This often provides schema details used to validate requests and replies.
The OpenAPI document provides us with some guidance on how to consume these services using Python's urllib module. It also describes what the expected responses should be, giving us guidance on how to handle the responses.
The detailed resource definitions are provided in the paths section of the specification. The /hands path, for example, shows the details of how to make a request for multiple hands.
When we provide a URL built from the server url value and the path in the OpenAPI specification, we also need to provide a method. When the HTTP method is get, then the specification declares the parameters must be provided in the query. The cards parameter in the query provides an integer number of cards, and it can be repeated multiple times.
The response will include at least the response described. In this case, the HTTP status will be 200, and the body of the response has a minimal description. It's possible to provide a more formal schema definition for the response, but we'll omit that from this example.
We can combine the built-in urllib library with OpenAPI specification details to make RESTful API requests.
How to do it...
- Import the
urllibcomponents that are required. We'll be making URL requests, and building more complex objects, such as query strings. We'll need theurllib.requestandurllib.parsemodules for these two features. Since the expected response is in JSON, then thejsonmodule will be useful as well:import urllib.request import urllib.parse import json from typing import Dict, Any - Define a function to make the request to be sent to the server:
def query_build_1() -> None: - Define the query string that will be used. In this case, all of the values happen to be fixed. In a more complex application, some might be fixed and some might be based on user inputs:
query = {"hand": 5} - Use the query to build the pieces of the full URL. We can use a
ParseResultobject to hold the relevant parts of the URL. This class isn't graceful about missing items, so we must provide explicit""values for parts of the URL that aren't being used:full_url = urllib.parse.ParseResult( scheme="http", netloc="127.0.0.1:5000", path="/dealer" + "/hand", params="", query=urllib.parse.urlencode(query), fragment="", ) - Build a final
Requestinstance. We'll use the URL built from a variety of pieces. We'll explicitly provide an HTTP method (browsers tend to useGETas a default). Also, we can provide explicit headers, including theAcceptheader to state the results accepted by the client. We've provided theHTTP Content-Typeheader to state the request consumed by the server, and provided by our client script:request2 = urllib.request.Request( url=urllib.parse.urlunparse(full_url), method="GET", headers={"Accept": "application/json",}, ) - Open a context to process the response. The
urlopen()function makes the request, handling all of the complexities of the HTTP protocol. The finalresultobject is available for processing as a response:with urllib.request.urlopen(request2) as response: - Generally, there are three attributes of the response that are of particular interest:
print(response.getcode()) print(response.headers) print(json.loads(response.read().decode("utf-8")))
The status is the final status code from the server. We expect a status 200 for a normal, successful request. The code values are defined in the http module. The headers attribute includes all of the headers that are part of the response. We might, for example, want to check that the response.headers['Content-Type'] is the expected application/json.
The value of response.read() is the bytes downloaded from the server. We'll often need to decode these to get proper Unicode characters. The utf-8 encoding scheme is very common. The Content-Type header can provide an override in the rare case this encoding is not used. We can use json.loads() to create a Python object from the JSON document.
When we run this, we'll see the following output:
200
Content-Type: application/json
Content-Length: 367
Server: Werkzeug/0.11.10 Python/3.5.1
Date: Sat, 23 Jul 2016 19:46:35 GMT
[{'suit': ' ', 'rank': 4, '__class__': 'Card'},
{'suit': '', 'rank': 4, '__class__': 'Card'},
{'suit': '
', 'rank': 4, '__class__': 'Card'},
{'suit': '', 'rank': 4, '__class__': 'Card'},
{'suit': ' ', 'rank': 9, '__class__': 'Card'},
{'suit': '', 'rank': 1, '__class__': 'Card'},
{'suit': '', 'rank': 2, '__class__': 'Card'}]
', 'rank': 9, '__class__': 'Card'},
{'suit': '', 'rank': 1, '__class__': 'Card'},
{'suit': '', 'rank': 2, '__class__': 'Card'}]
The initial 200 is the status, showing that everything worked properly. There were four headers provided by the server. Finally, the internal Python object was an array of small dictionaries that provided information about the cards that were dealt.
To reconstruct Card objects, we'd need to use a slightly more clever JSON parser. See the Reading JSON documents recipe in Chapter 10, Input/Output, Physical Format, and Logical Layout.
How it works...
We've built up the request through several explicit steps:
- The query data started as a dictionary with keys and values,
{"hand": 5}. - The
urlencode()function turned the query data into a query string, properly encoded. - The URL as a whole started as individual components in a
ParseResultobject. This makes each piece visible, and changeable. For this particular API, the pieces are largely fixed. In other APIs, the path and the query portion of the URL might both have dynamic values. - A
Requestobject was built from the URL, method, and a dictionary of headers. This example did not provide a separate document as the body of a request. If a complex document is sent, or a file is uploaded, this is also done by providing details to theRequestobject. - The
urllib.request.urlopen()function sends the request and will read the response.
The step-by-step assembly isn't required for a simple application. In simple cases, a literal string value for the URL might be acceptable. At the other extreme, a more complex application may print out intermediate results as a debugging aid to be sure that the request is being constructed correctly.
The other benefit of spelling out the details like this is to provide a handy avenue for unit testing. See Chapter 11, Testing, for more information. We can often decompose a web client into request building and request processing. The request building can be tested carefully to be sure that all of the elements are set properly. The request processing can be tested with dummy results that don't involve a live connection to a remote server.
There's more...
User authentication is often an important part of a web service. For HTML-based websites – where user interaction is emphasized – people expect the server to understand a long-running sequence of transactions via a session. The person will authenticate themselves once (often with a username and password) and the server will use this information until the person logs out or the session expires.
For RESTful web services, there is rarely the concept of a session. Each request is processed separately, and the server is not expected to maintain a complex long-running transaction state. This responsibility shifts to the client application. The client is required to make appropriate requests to build up a complex document that can be presented as a single transaction.
For RESTful APIs, each request may include authentication information. We'll look at this in detail in the Implementing authentication for web services recipe later in this chapter. For now, we'll look at providing additional details via headers. This will fit comfortably with our RESTful client script.
There are a number of ways that authentication information is provided to a web server:
- Some services use the
HTTP Authorizationheader. When used with the Basic mechanism, a client can provide a username and password with each request. - Some services will use a header with a name such as
Api-Key. The value for this header might be a complex string that has encoded information about the requestor. - Some services will invent a header with a name such as
X-Auth-Token. This may be used in a multi-step operation where a username and password credentials are sent as part of an initial request. The result will include a string value (a token) that can be used for subsequent API requests. Often, the token has a short expiration period and must be renewed.
Generally, all of these methods require the Secure Socket Layer (SSL) protocol to transmit the credentials securely. This is available as the https scheme. In order to handle the SSL protocol, the servers (and sometimes the clients) must have proper certificates. These are used as part of the negotiation between client and server to set up the encrypted socket pair.
All of these authentication techniques have a feature in common – they rely on sending additional information in headers. They differ slightly in which header is used, and what information is sent. In the simplest case, we might have something like the following:
request = urllib.request.Request(
url = urllib.parse.urlunparse(full_url),
method = "GET",
headers = {
'Accept': 'application/json',
'X-Authentication': 'seekrit password',
}
)
This hypothetical request would be for a web service that requires a password provided in an X-Authentication header. In the Implementing authentication for web services recipe later in this chapter, we'll add an authentication feature to the web server.
The OpenAPI specification
Many servers will explicitly provide a specification as a file at a fixed, standard URL path of /openapi.yaml or /openapi.json. The OpenAPI specification was formerly known as Swagger.
If it's available, we may be able get a website's OpenAPI specification in the following way:
def get_openapi_spec() -> Dict[str, Any]:
with urllib.request.urlopen(
"http://127.0.0.1:5000/dealer/openapi.json"
) as spec_request:
openapi_spec = json.load(spec_request)
return openapi_spec
Not all servers offer OpenAPI specifications. It's widely used, but not required.
The OpenAPI specification can be in JSON or YAML notation. While JSON is very common, some people find YAML easier to work with. Most of the examples for this book were prepared in YAML notation for that reason.
Once we have the specification, we can use it to get the details for the service or resource. We can use the technical information in the specification to build URLs, query strings, and headers.
Adding the OpenAPI resource to the server
For our little demonstration server, an additional view function is required to provide the OpenAPI specification. We can update the ch12_r02.py module to respond to a request for openapi.yaml.
There are several ways to handle this important information:
- A separate, static file: Flask can serve static content, but it's often more efficient to have a server like Gunicorn handle static files.
- Embed the specification as a large blob of text in the module: We could, for example, provide the specification as the docstring for the module or another global variable.
- Create a Python specification object in proper Python syntax: This can then be encoded into JSON and transmitted.
Here's a view function to send a separate file:
from flask import send_file
@dealer.route('/dealer/openapi.yaml')
def openapi_1() -> Response:
# Note. No IANA registered standard as of this writing.
response = send_file(
"openapi.yaml",
mimetype="application/yaml")
return response
This doesn't involve too much application programming. The drawback of this approach is that the specification is separate from the implementation module. While it's not difficult to coordinate the implementing module and the specification, any time two things must be synchronized it invites problems.
A second approach is to embed the OpenAPI specification into the module docstring. Often, we'll need to parse the docstring to use it in the server to validate input from clients. We can use yaml.load() to build the specification as a Python object from the string. Here's a view function to send the module docstring:
from flask import make_response
specification = yaml.load(__doc__, Loader=yaml.SafeLoader)
@dealer.route("/dealer/openapi.yaml")
def openapi_2() -> Response:
response = make_response(
yaml.dump(specification).encode("utf-8"))
response.headers["Content-Type"] = "application/yaml"
return response
This has the advantage of being part of the module that implements the web service. It has the disadvantage of requiring that we check the syntax of the docstring to be sure that it's valid YAML. This is in addition to validating that the module implementation actually conforms to the specification.
A third option is to write the OpenAPI specification as a Python document and serialize this into JSON notation:
from flask import make_response
specification = {
"openapi": "3.0.3",
"info": {
"description": "Parsing the query string in a request",
"title": "Python Cookbook Chapter 12, recipe 2.",
"version": "1.0",
},
"servers": [{"url": "http://127.0.0.1:5000/dealer"}],
"paths": {
...
},
"components": {
...
}
}
@dealer.route("/dealer/openapi.json")
def openapi_3() -> Response:
return jsonify(specification)
This makes use of Flask's jsonify() function to translate a specification written as a Python data structure into JSON notation.
In all cases, there are several benefits to having a formal specification available:
- Client applications can download the specification to confirm the server's features.
- When examples are included, the specification becomes a series of test cases for both client and server. This can form a contract used to validate clients as well as servers.
- The various details of the specification can also be used by the server application to provide validation rules, defaults, and other details. If the OpenAPI specification is a Python data structure, pieces of it can be used to create JSON schema validators.
As seen previously, there are only a few lines of code required to provide the OpenAPI specification. It provides helpful information to clients. The largest cost is the intellectual effort to carefully define the API and write down the contract in the formal language of the OpenAPI specification.
See also
- The Parsing the query string in a request recipe earlier in this chapter introduces the core web service.
- The Implementing Authentication for web services recipe later in this chapter will add authentication to make the service more secure.
Parsing the URL path
A URL is a complex object. It contains at least six separate pieces of information. More data can be included via optional elements.
A URL such as http://127.0.0.1:5000/dealer/hand/player_1?$format=json has several fields:
httpis the scheme.httpsis for secure connections using encrypted sockets.127.0.0.1can be called the authority, although network location is more commonly used.5000is the port number and is often considered to be part of the authority./dealer/hand/player_1is the path to a resource.$format=jsonis a query string.
The path to a resource can be quite complex. It's common in RESTful web services to use the path information to identify groups of resources, individual resources, and even relationships among resources.
In this recipe, we'll see how Flask lets us parse complex URL patterns.
Getting ready
Most web services provide access to some kind of resource. In the Using the Flask framework for RESTful APIs, and Parsing the query string in a request recipes earlier in this chapter, the resource was identified on the URL path as a hand or hands. This is – in a way – misleading.
There are actually two resources that are involved in the example web service:
- A
deck, which can be shuffled to produce one or more random hands - A
hand, which was treated as a transient response to a request
To make matters potentially confusing, the hand resource was created via a GET request instead of the more common POST request. This is confusing because a GET request is never expected to change the state of the server. Ideally, each time a GET request is made, the response is the same; however, in this case, we've broken that expectation.
For simple explorations and technical spikes, GET requests are helpful. Because a browser can make GET requests, these are a handy way to explore some aspects of web services design.
We'll redesign this service to provide explicit access to a randomized instance of the Deck class. One feature of each deck will be hands of cards. This parallels the idea of Deck as a collection and Hands as a resource within the collection:
/dealer/decks: APOSTrequest will create a newdeckobject. The response to this request is a token in the form of a string that is used to identify the unique deck./dealer/deck/{id}/hands: AGETrequest to this will get ahandobject from the given deck identifier. The query string will specify how many cards. The query string can use the$topoption to limit how many hands are returned. It can also use the$skipoption to skip over some hands and get cards for later hands.
These queries will be difficult to perform from a browser; they will require an API client. One possibility is to use the Postman tool. We'll leverage the Making REST requests with urllib recipe earlier in this chapter as the starting point for a client to process these more complex APIs.
How to do it...
We'll decompose this into two parts: server and client.
Server
We'll build the server based on previous examples. Start with the Parsing the query string in a request recipe earlier in this chapter as a template for a Flask application. We'll be changing the view functions in that example:
- We'll import the various modules needed to make use of the Flask framework. We'll define a Flask application and set a few handy global configuration parameters to make debugging slightly easier:
from http import HTTPStatus from flask import ( Flask, jsonify, request, abort, url_for, Response ) from Chapter_12.card_model import Card, Deck dealer = Flask("ch12_r04") dealer.DEBUG = True dealer.TESTING = True - Import any additional modules. In this case, we'll use the
uuidmodule to create a unique token string to identify a shuffled deck:import uuid - Define the global state. This includes the collection of decks. It also includes the random number generator. For testing purposes, it can help to have a way to force a particular seed value:
import os import random decks: Optional[Dict[str, Deck]] = None - Define a function to create or access the global state information. When request processing first starts, this will initialize the object. Subsequently, the cached object can be returned:
def get_decks() -> Dict[str, Deck]: global decks if decks is None: random.seed(os.environ.get("DEAL_APP_SEED")) # Database connection might go here. decks = {} return decks - Define a route – a URL pattern – to a view function that performs a specific request. Because creating a deck is a state change, the route should only handle
HTTP POSTrequests. In this example, the route creates a new instance in the collection of decks. Write the decorator, placed immediately in front of the function. It will bind the function to the Flask application:@dealer.route("/dealer/decks", methods=["POST"]) - Define the view function that supports this resource. We'll use the parsed query string for the number of decks to create. Any exception from an invalid number of decks will lead to a bad request response. The response will include the
UUIDfor a newly created deck. This will also be in theLocationheader of the response:def make_deck() -> Response: try: dealer.logger.info(f"make_deck {request.args}") n_decks = int(request.args.get("decks", 1)) assert 1 <= n_decks except Exception as ex: abort(HTTPStatus.BAD_REQUEST) decks = get_decks() id = str(uuid.uuid1()) decks[id] = Deck(n=n_decks) response_json = jsonify(status="ok", id=id) response = make_response( response_json, HTTPStatus.CREATED) response.headers["Location"] = url_for( "get_one_deck_count", id=id) response.headers["Content-Type"] = "application/json" return responseThe response has a status of
201Createdinstead of the default200 OK. The body will be a small JSON document with astatusfield and theidfield to identify the deck created. - Define a route to get a hand from a given deck. In this case, the route must include the specific deck ID to deal from. The
<id>makes this a path template instead of a simple, literal path. Flask will extract the<id>field from the path in the request URL:@dealer.route("/dealer/decks/<id>", methods=["GET"]) - Define a view function that has parameters that match the template. Since the template included
<id>, the view function has a parameter namedidas well. Flask handles the URL parsing, making the value available as a parameter. There are three parts: validating the request, doing the work, and creating the finalresponseobject:def get_hands(id: str) -> Response: decks = get_decks() if id not in decks: dealer.logger.error(id) abort(HTTPStatus.NOT_FOUND) try: cards = int(request.args.get("cards", 13)) top = int(request.args.get("$top", 1)) skip = int(request.args.get("$skip", 0)) assert ( skip * cards + top * cards <= len(decks[id].cards) ), "$skip, $top, and cards larger than the deck" except (ValueError, AssertionError) as ex: dealer.logger.error(ex) abort(HTTPStatus.BAD_REQUEST) subset = decks[id].cards[ skip * cards : skip * cards + top * cards] hands = [ subset[h * cards : (h + 1) * cards] for h in range(top) ] response = jsonify( [ { "hand": i, "cards": [card.to_json() for card in hand] } for i, hand in enumerate(hands) ] ) return response
The validation checks several parts of the request:
- The value of the
idparameter must be one of the keys to thedeckscollection. Otherwise, the function makes a404 NOT FOUNDresponse. In this example, we don't provide much of an error message. A more complete error might use the optional description, like this:abort(HTTPStatus.NOT_FOUND, description=f"{id} not found") - The values of
$top,$skip, andcardsare extracted from the query string. For this example, all of the values should be integers, so theint()function is used for each value. A rudimentary sanity check is performed on the query parameters. An additional check on the combination of values is also a good idea; you are encouraged to add checks.
The real work of the view function creates a hand of cards. The subset variable is the portion of the deck being dealt. We've sliced the deck to start after skip sets of cards; we've included just top sets of cards in this slice. From that slice, the hands sequence decomposes the subset into the top number of hands, each of which has cards in it.
The response preparation converts the sequence of Card objects to JSON via the jsonify() function. The default status set by the jsonify() function is 200 OK, which is appropriate here because this query is an idempotent GET request. Each time a query is sent, the same set of cards will be returned.
Client
This will be similar to the client module from the Making REST requests with urllib recipe:
- Import the essential modules for working with RESTful APIs:
import urllib.request import urllib.parse import urllib.error import json - Define a function to make the
POSTrequest that will create a new, shuffled deck. We've called thisno_spec_create_new_deck()to emphasize that it doesn't rely on the OpenAPI specification. The return value will be a document containing the deck's unique identifier assigned by the server:def no_spec_create_new_deck( size: int = 6) -> Dict[str, Any]: - This starts by defining the query and using the query to create the URL. The URL is built in pieces, by creating a
ParseResultobject manually. This will be collapsed into a single string:query = {"size": size} full_url = urllib.parse.urlunparse( urllib.parse.ParseResult( scheme="http", netloc="127.0.0.1:5000", path="/dealer" + "/decks", params="", query=urllib.parse.urlencode({"size": size}), fragment="" ) ) - Build a
Requestobject from the URL, method, and headers:request = urllib.request.Request( url=full_url, method="POST", headers={"Accept": "application/json",} ) - Send the request and process the response object. For debugging purposes, it can be helpful to print status and header information. We need to make sure that the status was the expected
201. The response document should be a JSON serialization of a Python dictionary. This client confirms thestatusfield in the response document isokbefore using the value in theidfield:try: with urllib.request.urlopen(request) as response: assert ( response.getcode() == 201 ), f"Error Creating Deck: {response.status}" print(response.headers) document = json.loads( response.read().decode("utf-8")) print(document) assert document["status"] == "ok" return document except Exception as ex: print("ERROR: ex") print(ex.read()) raise - Define the function to make the
GETrequest to fetch one or more hands from the new deck. We've called thisno_spec_get_hands()to emphasize that it doesn't rely on the OpenAPI specification. Theidparameter is the unique deck ID from the document returned by theno_spec_create_new_deck()function. The return value will be a document containing the requested hands:def no_spec_get_hands( id: str, cards: int = 13, limit: int = 4 ) -> Dict[str, Any]: - This starts by defining the query and using the query to create the URL. The URL is built in pieces, by creating a
ParseResultobject manually. This will be collapsed into a single string:query = {"$top": limit, "cards": cards} full_url = urllib.parse.urlunparse( urllib.parse.ParseResult( scheme="http", netloc="127.0.0.1:5000", path="/dealer" + f"/decks/{id}/hands", params="", query=urllib.parse.urlencode(query), fragment="" ) ) - Make the
Requestobject using the full URL, the method, and the standard headers:request = urllib.request.Request( url=full_url, method="GET", headers={"Accept": "application/json",} ) - Send the request and process the response. We'll confirm that the response is
200 OK. The response can then be parsed to get the details of the cards that are part of the requested hand:with urllib.request.urlopen(request) as response: assert ( response.getcode() == 200 ), f"Error Fetching Hand: {response.status}" hands = json.loads( response.read().decode("utf-8")) return hands
We have two functions that produce the expected results. We can combine them like this:
create_doc = no_spec_create_new_deck(6)
print(create_doc)
id = create_doc["id"]
hands = no_spec_get_hands(id, cards=6, limit=2)
for hand in hands:
print(f"Hand {hand['hand']}")
pprint(hand['cards'])
print()
This will produce output that looks like this:
{'id': '53f7c70e-adcc-11ea-8e2d-6003089a7902', 'status': 'ok'}
Hand 0
[{'__class__': 'Card', '__init__': {'rank': 3, 'suit': ''}},
{'__class__': 'Card', '__init__': {'rank': 5, 'suit': ''}},
{'__class__': 'Card', '__init__': {'rank': 8, 'suit': '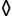 '}},
{'__class__': 'Card', '__init__': {'rank': 12, 'suit': '
'}},
{'__class__': 'Card', '__init__': {'rank': 12, 'suit': ' '}},
{'__class__': 'Card', '__init__': {'rank': 12, 'suit': '
'}},
{'__class__': 'Card', '__init__': {'rank': 12, 'suit': ' '}},
{'__class__': 'Card', '__init__': {'rank': 6, 'suit': '
'}},
{'__class__': 'Card', '__init__': {'rank': 6, 'suit': ' '}}]
Hand 1
[{'__class__': 'Card', '__init__': {'rank': 13, 'suit': ''}},
{'__class__': 'Card', '__init__': {'rank': 10, 'suit': '
'}}]
Hand 1
[{'__class__': 'Card', '__init__': {'rank': 13, 'suit': ''}},
{'__class__': 'Card', '__init__': {'rank': 10, 'suit': '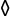 '}},
{'__class__': 'Card', '__init__': {'rank': 4, 'suit': ''}},
{'__class__': 'Card', '__init__': {'rank': 2, 'suit': ''}},
{'__class__': 'Card', '__init__': {'rank': 13, 'suit': ''}},
{'__class__': 'Card', '__init__': {'rank': 5, 'suit': ''}}]
'}},
{'__class__': 'Card', '__init__': {'rank': 4, 'suit': ''}},
{'__class__': 'Card', '__init__': {'rank': 2, 'suit': ''}},
{'__class__': 'Card', '__init__': {'rank': 13, 'suit': ''}},
{'__class__': 'Card', '__init__': {'rank': 5, 'suit': ''}}]
Your results will vary because of the use of a random shuffle in the server. For integration testing purposes, the random seed should be set in the server to produce fixed sequences of cards. The first line of output shows the ID and status from creating the deck. The next block of output is the two hands of six cards each.
How it works...
The server defines two routes that follow a common pattern for a collection and an instance of the collection. It's typical to define collection paths with a plural noun, decks. Using a plural noun means that the CRUD operations (Create, Retrieve, Update, and Delete) are focused on creating instances within the collection.
In this case, the Create operation is implemented with a POST method of the /dealer/decks path. Retrieve could be supported by writing an additional view function to handle the GET method of the /dealer/decks path. This would expose all of the deck instances in the decks collection.
If Delete is supported, this could use the DELETE method of /dealer/decks. Update (using the PUT method) doesn't seem to fit with the idea of a server that creates random decks.
Within the /dealer/decks collection, a specific deck is identified by the /dealer/decks/<id> path. The design calls for using the GET method to fetch several hands of cards from the given deck.
The remaining CRUD operations—Create, Update, and Delete—don't make much sense for this kind of Deck object. Once the Deck object is created, then a client application can interrogate the deck for various hands.
Deck slicing
The dealing algorithm makes several slices of a deck of cards. The slices are based on the fact that the size of a deck, D, must contain enough cards for the number of hands, h, and the number of cards in each hand, c. The number of hands and cards per hand must be no larger than the size of the deck:
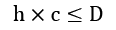
The social ritual of dealing often involves cutting the deck, which is a very simple shuffle done by the non-dealing player. We'll ignore this nuance since we're asking an impartial server to shuffle for us.
Traditionally, each hth card is assigned to each hand, Hn:

The idea in the preceding formula is that hand H0 has cards ![]() , hand H1 has cards
, hand H1 has cards ![]() , and so on. This distribution of cards looks fairer than simply handing each player the next batch of c cards.
, and so on. This distribution of cards looks fairer than simply handing each player the next batch of c cards.
This social ritual isn't really necessary for our software, and our Python program deals cards using slices that are slightly easier to compute with Python:
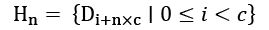
The Python code creates hand H0 with cards ![]() , hand H1 has cards
, hand H1 has cards ![]() , and so on. Given a random deck, this is just as fair as any other allocation of cards. It's slightly simpler to enumerate in Python because it involves a simpler kind of list slicing. For more information on slicing, see the Slicing and dicing a list recipe in Chapter 4, Built-In Data Structures Part 1: Lists and Sets.
, and so on. Given a random deck, this is just as fair as any other allocation of cards. It's slightly simpler to enumerate in Python because it involves a simpler kind of list slicing. For more information on slicing, see the Slicing and dicing a list recipe in Chapter 4, Built-In Data Structures Part 1: Lists and Sets.
The client side
The client side of this transaction is a sequence of RESTful requests. The first request, to create a new deck, uses POST. The response includes the identity of the created object. The server put the information in two places in the response:
- It was in the body of the document, a JSON-encoded dictionary, in the
idkey. - It was in a
Locationheader in the response.
This kind of redundancy is common, and it allows the client more flexibility. The value in the body of the response document is only the UUID for the deck. The value in the header, however, is the full URL required to get the details of the deck.
Looking at the client code, there's a fair number of lines tied up with building URL strings. It would be simpler for the URLs to be provided by the server. This is a design pattern called Hypertext as the Engine of State (HATEOS.) It's advantageous to have the server provide relevant URLs, and save the client from the complication of computing a value that's already part of the server's internal processing. Not all RESTful servers do this well, but examples like the GitHub API are worth careful study because of their sophisticated use of URL links in the responses.
There's more...
We'll look at some features that we should consider adding to the server:
- Checking for JSON in the
Acceptheader - Providing the OpenAPI specification
It's common to use a header to distinguish between RESTful API requests and other requests to a server. The Accept header can provide a MIME type that distinguishes requests for JSON content from requests for user-oriented content.
The @dealer.before_request decorator can be used to inject a function that filters each request. This filter can distinguish proper RESTful API requests based on the following requirements:
- The
Acceptheader must include a MIME type that includesjson. Typically, the full MIME string isapplication/json. - Additionally, we can make an exception for the
openapi.jsonandopenapi.yamlfiles. These specific cases can be treated as a RESTful API request irrespective of any other indicators, like a proper Accept header, slightly simplifying debugging for client applications.
Here's the additional code to implement this:
@dealer.before_request
def check_json() -> Optional[Response]:
exceptions = {"/dealer/openapi.yaml", "/dealer/openapi.json"}
if request.path in exceptions:
return None
if "json" in request.headers.get("Accept", "*/*"):
return None
if "json" == request.args.get("$format", "html"):
return None
abort(HTTPStatus.BAD_REQUEST)
If the Accept header or the $format query string parameter doesn't specify a JSON response document, this filter will abort the request with a 400 BAD REQUEST response. A more explicit error message must not divulge too much information about the server's implementation. With care, we can expand abort() with the optional description parameter to return a more detailed message, focused carefully on a failure to meet the specification, avoiding any information about the implementation.
Providing an OpenAPI specification
A well-behaved RESTful API provides the OpenAPI specification for the various services available. This is generally packaged in the /openapi.json or /openapi.yaml route. This doesn't necessarily mean that a literal file is available. Instead, this path is used as a focus to provide the detailed interface specification in JSON notation following the OpenAPI 3.0 specification.
We've defined the route, /openapi.json, and bound a function, openapi3_json(), to this route. This function will create a JSON representation of a global object, specification:
@dealer.route("/dealer/openapi.json")
def openapi3_json() -> Response:
response = make_response(
json.dumps(specification, indent=2).encode("utf-8"))
response.headers["Content-Type"] = "application/json"
return response
The specification object has the following outline. Some of the details have been replaced with ... to emphasize the overall structure. The overview is as follows:
spec_yaml = """
openapi: 3.0.3
info:
title: Python Cookbook Chapter 12, recipe 4.
description: Parsing the URL path
version: "1.0"
servers:
- url: http://127.0.0.1:5000/dealer
paths:
/decks:
...
/decks/{id}:
...
/decks/{id}/hands:
...
components:
schemas:
...
parameters:
...
"""
specification = yaml.load(spec_yaml, Loader=yaml.SafeLoader)
It seems slightly easier to write the OpenAPI specification in YAML notation. We can parse the block of text, and emit either YAML or JSON notation as required.
Two of the paths correspond to the two @dealer.route decorators in the server. We've included a third, potentially helpful path in the specification. It's often helpful to start the design of a server with an OpenAPI specification, discuss the design when it's still only a document, and then build the code to meet the specification.
Note the small syntax difference. Flask uses /decks/<id>/hands where the OpenAPI specification uses /decks/{id}/hands. This small thing means we can't trivially copy and paste between Python and OpenAPI documents.
Here are the details of the /decks path. This shows the input parameters that come from the query string. It also shows the details of the 201 response that contains the deck ID information:
/decks:
post:
operationId: make_deck
parameters:
- name: size
in: query
description: number of decks to build and shuffle
schema:
type: integer
default: 1
responses:
"201":
description: Create a deck, returns a unique deck id.
headers:
Location:
schema:
type: string
format: uri
description: URL for new deck
content:
application/json:
schema:
type: object
properties:
id:
description: deck_id used for later queries
type: string
status:
description: response status
type: string
enum: ["ok", "problem"]
"400":
description: Request doesn't accept JSON or size invalid
content: {}
The response includes the Location header in addition to the content of the form application/json. The Location header can be used by a client to confirm the object created by the server.
The /decks/{id}/hands path has a similar structure. It defines all of the parameters that are available in the query string. It also defines the various responses: a 200 response that contains the cards and defines the 404 response when the ID value was not found.
We've omitted some of the details of the parameters for each path. We've also omitted details on the structure of the deck. The outline, however, summarizes the RESTful API:
- The
openapikey must be at least 3.0.3. The standard follows semantic versioning standards. See https://swagger.io/specification/#versions. - The
infosection can provide a great deal of information. This example only has the minimal requirements of title, description, and version. - The
serverssection defines a base URL used for this service. - The
pathssection identifies all of the paths that provide a response on this server. This shows the/decksand the/decks/{id}/handspaths.
The openapi3_json() function transforms this Python object into JSON notation and returns it. This implements what the client will see as a page named openapi.json. The internal specification object, however, is a Python data structure that can be used as a contract to permit the consistent validation of request documents and parameter values.
Using the OpenAPI specification
In the client programming, we used literal values for building the URL. The examples looked like the following:
full_url = urllib.parse.urlunparse(
urllib.parse.ParseResult(
scheme="http",
netloc="127.0.0.1:5000",
path="/dealer" + "/decks",
params="",
query=urllib.parse.urlencode({"size": size}),
fragment=""
)
)
Rather than building a URL, we can gather the information from the OpenAPI specification. When we look at the /decks path, shown above, we see the operationId key associated with the path and method. The value of this key can be used to provide unique, visible names to each path and method combination. This can serve as a useful index for a client.
Here's an overview of the steps to make use of operationId values:
path, operation = find_path_op(openapi_spec, "make_deck")
base_url = openapi_spec["servers"][0]["url"]
query = {"size": size}
query_text = urllib.parse.urlencode(query)
full_url = f"{base_url}{path}?{query_text}"
First, we searched all of the paths for the path with an operationId value of "make_deck". The base_url value is found in the servers block at the top of the OpenAPI specification. The query_text value is a URL encoded form of a dictionary with the required parameter. The value of the full_url variable combines the base_url, path, and the query_text.
The OpenAPI specification is a formal contract for working with a RESTful API. Rather than building a URL, the details for the URL were extracted from known locations in the OpenAPI specification. This can simplify client applications. It also supports automated testing for clients and servers. Finally, using the OpenAPI specification avoids the client making assumptions about how the server works.
See also
- See the Making REST requests with urllib and Parsing the query string in a request recipes earlier in this chapter for more examples of RESTful web services.
Parsing a JSON request
Many web services involve a request to create a new persistent object or make an update to an existing persistent object. In order to implement these kinds of operations, the application will need input from the client.
A RESTful web service will generally accept input (and produce output) in the form of JSON documents. For more information on JSON, see the Reading JSON documents recipe in Chapter 10, Input/Output, Physical Format, and Logical Layout.
Flask provides the capability to parse JSON input from web clients. This makes it possible to have a client provide sophisticated documents to a web server.
Getting ready
We'll extend the Flask application from the Parsing the query string in a request recipe earlier in this chapter to add a user registration feature; this will add a player who can then request cards. The player is a resource that will involve the essential CRUD operations:
- A client can do a
POSTto the/playerspath to create a new player. This will include a payload of a document that describes the player. The service will validate the document, and if it's valid, create a new, persistentPlayerinstance. The response will include the ID assigned to the player. If the document is invalid, a response will be sent back detailing the problems. - A client can do a
GETto the/playerspath to get the list of players. - A client can do a
GETto the/players/<id>path to get the details of a specific player. - A client can do a
PUTto the/players/<id>path to update the details of a specific player. As with the initialPOST, this requires a payload document that must be validated. - A client can do a
DELETEto the/players/<id>path to remove a player.
As with the Parsing the query string in a request recipe, earlier in this chapter, we'll implement both the client and the server portion of these services. The server will handle the essential POST and one of the GET operations. We'll leave the PUT and DELETE operations as exercises for the reader.
We'll need a JSON validator. See https://pypi.python.org/pypi/jsonschema/2.5.1. This is particularly good. It's helpful to have an OpenAPI specification validator as well. See https://pypi.python.org/pypi/swagger-spec-validator.
If we install the swagger-spec-validator package, this also installs the latest copy of the jsonschema project. Here's how the whole sequence might look:
(cookbook) % python -m pip install swagger-spec-validator
Collecting swagger-spec-validator
Downloading https://files.pythonhosted.org/packages/bf/09/03a8d574d4a76a0ffee0a0b0430fb6ba9295dd48bb09ea73d1f3c67bb4b4/swagger_spec_validator-2.5.0-py2.py3-none-any.whl
Requirement already satisfied: six in /Users/slott/miniconda3/envs/cookbook/lib/python3.8/site-packages (from swagger-spec-validator) (1.12.0)
Collecting jsonschema
Using cached https://files.pythonhosted.org/packages/c5/8f/51e89ce52a085483359217bc72cdbf6e75ee595d5b1d4b5ade40c7e018b8/jsonschema-3.2.0-py2.py3-none-any.whl
Requirement already satisfied: pyyaml in /Users/slott/miniconda3/envs/cookbook/lib/python3.8/site-packages (from swagger-spec-validator) (5.1.2)
Requirement already satisfied: attrs>=17.4.0 in /Users/slott/miniconda3/envs/cookbook/lib/python3.8/site-packages (from jsonschema->swagger-spec-validator) (19.3.0)
Requirement already satisfied: setuptools in /Users/slott/miniconda3/envs/cookbook/lib/python3.8/site-packages (from jsonschema->swagger-spec-validator) (42.0.2.post20191203)
Requirement already satisfied: pyrsistent>=0.14.0 in /Users/slott/miniconda3/envs/cookbook/lib/python3.8/site-packages (from jsonschema->swagger-spec-validator) (0.15.5)
Installing collected packages: jsonschema, swagger-spec-validator
Successfully installed jsonschema-3.2.0 swagger-spec-validator-2.5.0
We used the python -m pip command to install the swagger-spec-validator package. This installation also checked that six, jsonschema, pyyaml, attrs, setuptools, and pyrsistent were already installed. Once all of these packages are installed, we can use the openapi_spec_validator module that is installed by the swagger-spec-validator project.
How to do it...
We'll decompose this recipe into three parts: the OpenAPI specification that's provided by the server, the server, and an example client.
The OpenAPI specification
Let's start by defining the outline.
- Here's the outline of the OpenAPI specification, defined as text in YAML notation:
spec_yaml = """ openapi: 3.0.3 info: title: Python Cookbook Chapter 12, recipe 5. description: Parsing a JSON request version: "1.0" servers: - url: http://127.0.0.1:5000/dealer paths: /players: ... /players/{id}: ... components: schemas: ... parameters: ...The first fields,
openapi,info, andservers, are essential boilerplate for RESTful web services. Thepathsandcomponentswill be filled in with the URLs and the schema definitions that are part of the service. - Here's the schema definition used to validate a new player. This goes inside the
schemassection undercomponentsin the overall specification. The overall input document is formally described as having a type of object. There are four properties of that object:- An email address, which is a string with a specific format
- A name, which is a string
- A Twitter URL, which is a string with a given format
- A
lucky_number, which is an integer:Player: type: object properties: email: type: string format: email name: type: string twitter: type: string format: uri lucky_number: type: integer
- Here's the overall
playerspath that's used to create a new player. This path defines thePOSTmethod to create a new player. This parameter for this method will be provided the body of the request, and it follows the player schema shown previously, included in thecomponentssection of the document:/players: post: operationId: make_player requestBody: content: application/json: schema: $ref: '#/components/schemas/Player' responses: "201": description: Player created content: application/json: schema: type: object properties: player: $ref: "#/components/schemas/Player" id: type: string "403": description: Player is invalid or a duplicate content: {} - Here's the definition of a path to get details about a specific player. That path is similar to the one shown in the Parsing the URL path recipe. The
playerkey is provided in the URL. The response when a player ID is valid is shown in detail. The response has a defined schema that also uses the player schema definition in thedefinitionssection:/players/{id}: get: operationId: get_one_player parameters: - $ref: "#/components/parameters/player_id" responses: "200": description: The details of a specific player content: application/json: schema: type: object properties: player: $ref: '#/components/schemas/Player' example: player: email: [email protected] name: example twitter: https://twitter.com/PacktPub lucky_number: 13 "404": description: Player ID not found content: {}
This specification will be part of the server. It can be provided by a view function defined in the @dealer.route('/openapi.json') route.
Server
We'll begin by leaning on one of the recipes from earlier in this chapter:
- Start with the Parsing the query string in a request recipe as a template for a Flask application. We'll be changing the view functions:
from http import HTTPStatus from flask import ( Flask, jsonify, request, abort, url_for, Response) - Import the additional libraries required. We'll use the JSON schema for validation. We'll also compute hashes of strings to serve as useful external identifiers in URLs. Because there aren't type hints in this library, we'll have to use the
#type: ignorecomment so themypytool doesn't examine this code closely:from jsonschema import validate # type: ignore from jsonschema.exceptions import ValidationError # type: ignore import hashlib - Create the application. The specification is a global variable with a large block of text in YAML notation. We'll parse this block of text to create a useful Python data structure:
from Chapter_12.card_model import Card, Deck specification = yaml.load( spec_yaml, Loader=yaml.SafeLoader) dealer = Flask("ch12_r05") - Define the global state. This includes the collection of players. In this example, we don't have a more sophisticated type definition than
Dict[str, Any]. We'll rely on the JSONSchema validation using the schema defined in the OpenAPI specification:JSON_Doc = Dict[str, Any] players: Optional[Dict[str, JSON_Doc]] = None - Define a function to create or access the global state information. When request processing first starts, this will initialize the object. Subsequently, the cached object can be returned:
def get_players() -> Dict[str, JSON_Doc]: global players if players is None: # Database connection and fetch might go here players = {} return players - Define the route for posting to the overall collection of
players:@dealer.route("/dealer/players", methods=["POST"]) - Define the function that will parse the input document, validate the content, and then create the persistent
playerobject. This function can follow a common four-step design for making persistent changes:- Validate the input JSON document. The schema is exposed as part of the overall OpenAPI specification. We'll extract a particular piece of this document and use it for validation.
- Create a key and confirm that it's unique. Often we'll use a hash that's derived from the data as a key. In this case, we'll hash their Twitter ID to create an easy-to-process unique key. We might also create unique keys using the
uuidmodule. - Persist the new document in the database. In this example, it's only a single statement,
players[id] = document. This follows the ideal that a RESTful API is built around classes and functions that already provide a complete implementation of the features. - Build a response document.
Here's how this function can be implemented:
def make_player() -> Response: try: document = request.get_json() except Exception as ex: # Document wasn't proper JSON. abort(HTTPStatus.BAD_REQUEST) player_schema = ( specification["components"]["schemas"]["Player"] ) try: validate(document, player_schema) except ValidationError as ex: # Document did't pass schema rules abort( HTTPStatus.BAD_REQUEST, description=ex ) players = get_players() id = hashlib.md5( document["twitter"].encode("utf-8")).hexdigest() if id in players: abort( HTTPStatus.BAD_REQUEST, description="Duplicate player") players[id] = document response = make_response( jsonify(player=document, id=id), HTTPStatus.CREATED) response.headers["Location"] = url_for( "get_one_player", id=str(id)) response.headers["Content-Type"] = "application/json" return response
We can add other methods to see multiple players or individual players. These will follow the essential designs of the Parsing the URL path recipe. We'll look at these in the next section.
Client
This will be similar to the client module from the Parsing the URL path recipe, earlier in this chapter:
- Import several essential modules for working with RESTful APIs. Because the
openapi_spec_validatormodule, version 0.2.8 doesn't have type hints, we need to make suremypyignores it, and use a# type: ignorecomment:import urllib.request import urllib.parse import json from openapi_spec_validator import validate_spec # type: ignore from typing import Dict, List, Any, Union, Tuple - Write a function to get and validate the server's OpenAPI specification. We'll make two additional checks, first to make sure the title is for the expected service, and second, that it's the expected version of the service:
def get_openapi_spec() -> ResponseDoc: """Get the OpenAPI specification.""" openapi_request = urllib.request.Request( url="http://127.0.0.1:5000/dealer/openapi.json", method="GET", headers={"Accept": "application/json",}, ) with urllib.request.urlopen(openapi_request) as response: assert response.getcode() == 200 openapi_spec = json.loads( response.read().decode("utf-8")) validate_spec(openapi_spec) assert ( openapi_spec["info"]["title"] == "Python Cookbook Chapter 12, recipe 5." ) assert ( openapi_spec["info"]["version"] == "1.0" ) return openapi_spec - We'll use a small helper function to transform the specification into a mapping. The mapping will use
OperationIdto refer to a given path and operation. This makes it easier to locate the path and method required to perform the desired operation:Path_Map = Dict[str, Tuple[str, str]] def make_path_map(openapi_spec: ResponseDoc) -> Path_Map: operation_ids = { openapi_spec["paths"][path][operation] ["operationId"]: (path, operation) for path in openapi_spec["paths"] for operation in openapi_spec["paths"][path] if ( "operationId" in openapi_spec["paths"][path][operation] ) } return operation_ids - Define a structure for the user-supplied input to this client. Since many web service clients are browser-based applications, there may be a form presented to the user. This dataclass contains the inputs supplied from the user's interaction with the client application:
@dataclass class Player: player_name: str email_address: str other_field: int handle: str - Define a function to create a player. This function uses the OpenAPI specification to locate the path for a specific operation. This function creates a document with the required attributes. From the URL and the document, it builds a complete
Requestobject. In the second part, it makes the HTTP request. Here's the first part:def create_new_player( openapi_spec: ResponseDoc, path_map: Path_Map, input_form: Player) -> ResponseDoc: path, operation = path_map["make_player"] base_url = openapi_spec["servers"][0]["url"] full_url = f"{base_url}{path}" document = { "name": input_form.player_name, "email": input_form.email_address, "lucky_number": input_form.other_field, "twitter": input_form.handle, } request = urllib.request.Request( url=full_url, method="POST", headers={ "Accept": "application/json", "Content-Type": "application/json", }, data=json.dumps(document).encode("utf-8"), ) - Once the request object has been created, we can use
urllibto send it to the server to create a new player. According to the OpenAPI specification, the response document should include a field named status. In addition to the status code of201, we'll also check this field's value:try: with urllib.request.urlopen(request) as response: assert ( response.getcode() == 201 ) document = json.loads( response.read().decode("utf-8")) print(document) return document except urllib.error.HTTPError as ex: print(ex.getcode()) print(ex.headers) print(ex.read()) raise
We can also include other queries in this client. We might want to retrieve all players or retrieve a specific player. These will follow the design shown in the Parsing the URL path recipe.
How it works...
Flask automatically examines inbound documents to parse them. We can simply use request.json to leverage the automated JSON parsing that's built into Flask.
If the input is not actually JSON, then the Flask framework will return a 400 BAD REQUEST response. This can happen when our server application references the json property of the request and the document isn't valid JSON. We can use a try statement to capture the 400 BAD REQUEST response object and make changes to it, or possibly return a different response.
We've used the jsonschema package to validate the input document against the schema defined in the OpenAPI specification. This validation process will check a number of features of the JSON document:
- It checks if the overall type of the JSON document matches the overall type of the schema. In this example, the schema required an object, which is a dictionary-like JSON structure.
- For each property defined in the schema and present in the document, it confirms that the value in the document matches the schema definition. This starts by confirming the value fits one of the defined JSON types. If there are other validation rules, like a format or a range specification, or a number of elements for an array, these constraints are checked also. This check proceeds recursively through all levels of the schema.
- If there's a list of required fields, it checks that all of these are actually present in the document.
For this recipe, we've kept the details of the schema to a minimum. A common feature that we've omitted in this example is the list of required properties. We should provide considerably more detailed attribute descriptions.
We've kept the database update processing to a minimum in this example. In some cases, the database insert might involve a much more complex process where a database client connection is used to execute a command that changes the state of a database server. The get_decks() and get_players() functions, for example, can involve more processing to get a database connection and configure a client object.
There's more...
The OpenAPI specification allows examples of response documents. This is often helpful in several ways:
- It's common to start a design by creating the sample documents to be sure they cover all the necessary use cases. If the examples demonstrate that the application will be useful, a schema specification can be written to describe the examples.
- Once the OpenAPI specification is complete, a common next step is to write the server-side programming. Example documents in the schema serve as seeds for growing unit test cases and acceptance test cases.
- For users of the OpenAPI specification, a concrete example of the response can be used to design the client and write unit tests for the client-side programming.
We can use the following code to confirm that a server has a valid OpenAPI specification. If this raises an exception, either there's no OpenAPI document or the document doesn't properly fit the OpenAPI schema:
>>> from openapi_spec_validator import validate_spec_url
>>> validate_spec_url('http://127.0.0.1:5000/dealer/openapi.json')
If the URL provides a valid OpenAPI specification, there's no further output. If the URL doesn't work or doesn't provide a valid specification, an OpenAPIValidationError exception is raised.
Location header
The 201 CREATED response included a small document with some status information. The status information included the key that was assigned to the newly created record.
It's also possible for a 201 CREATED response to have an additional Location header in the response. This header will provide a URL that can be used to recover the document that was created. For this application, the location would be a URL, like the following example: http://127.0.0.1:5000/dealer/players/75f1bfbda3a8492b74a33ee28326649c. The Location header can be saved by a client. A complete URL is slightly simpler than creating a URL from a URL template and a value.
A good practice is to provide both the key and the full URL in the body of the response. This allows a server to also provide multiple URLs for related resources, allowing the client to choose among the alternatives, avoiding the client having to build URLs to the extent possible.
The server can build the URLs using the Flask url_for() function. This function takes the name of a view function and any parameters that come from the URL path. It then uses the route for the view function to construct a complete URL. This will include all the information for the currently running server. After the header is inserted, the Response object can be returned.
Additional resources
The server should be able to respond with a list of players. Here's a minimal implementation that simply transforms the data into a large JSON document:
@dealer.route("/dealer/players", methods=["GET"])
def get_all_players() -> Response:
players = get_players()
response = make_response(jsonify(players=players))
response.headers["Content-Type"] = "application/json"
return response
A more sophisticated implementation would support the $top and $skip query parameters to page through the list of players. Additionally, a $filter option might be useful to implement a search for a subset of players.
In addition to the generic query for all players, we need to implement a method that will return an individual player. This kind of view function looks like the following code:
@dealer.route("/dealer/players/<id>", methods=["GET"])
def get_one_player(id: str) -> Response:
players = get_players()
if id not in players:
abort(HTTPStatus.NOT_FOUND,
description=f"Player {id} not found")
response = make_response(jsonify(player=players[id]))
response.headers["Content-Type"] = "application/json"
return response
This function confirms that the given ID is a proper key value in the database. If the key is not in the database, the database document is transformed into JSON notation and returned.
See also
- See the Parsing the URL path recipe earlier in this chapter for other examples of URL processing.
- The Making REST requests with urllib recipe earlier in this chapter shows other examples of query string processing.
Implementing authentication for web services
Security is a pervasive issue throughout application design, implementation, and ongoing operational support. Every part of an application will have security considerations. Parts of the implementation of security will involve two closely related issues:
- Authentication: A client must provide some evidence of who they are. This might involve signed certificates or it might involve credentials like a username and password. It might involve multiple factors, such as an SMS message to a phone that the user should have access to. The web server must validate this authentication.
- Authorization: A server must define areas of authority and allocate these to groups of users. Furthermore, individual users must be defined as members of the authorization groups.
Application software must implement authorization decisions. For Flask, the authorization can be part of each view function. The connection of individual to group and group to view function defines the resources available to any specific user.
There are a variety of ways that authentication details can be provided from a web client to a web server. Here are a few of the alternatives:
- Certificates: Certificates that are encrypted and include a digital signature as well as a reference to a Certificate Authority (CA): These are exchanged by the Secure Socket Layer (SSL) as part of setting up an encrypted channel. In some environments, both client and server must have certificates and perform mutual authentication. In other environments, the server provides a certificate of authenticity, but the client does not.
- HTTP headers:
- Usernames and passwords can be provided in the
Authorizationheader. There are a number of schemas; the Basic schema is simple but requires SSL. - The
Api-Keyheader can be used to provide a key used to authorize access to APIs or services. - Bearer tokens from third parties can be provided in the
Authorizationheader using a bearer token. For details, see http://openid.net.
Additionally, there's a question of how the user authentication information gets loaded into a web server. There are a lot of business models for granting access to web services. For this example, we'll look at a model where users access the "sign in" form and fill in their essential information.
This kind of design leads to a mixture of routes. Some routes must be authorized for an anonymous user – someone who has not yet signed up. Some routes must be authorized to allow a user to log in. Once a user logs in with valid credentials, they are no longer anonymous, and other routes are authorized to known users.
In this recipe, we'll configure HTTPS in a Flask container to support secure connections. With a secure connection, we can leverage the Authorization header to provide credentials with each request. This means we'll need to use the secure password hashing capabilities of the Werkzeug project.
Getting ready
We'll implement a version of HTTP-based authentication using the Authorization header. There are two variations on this theme in use with secure sockets:
- HTTP basic authentication: This uses a simple username and password string. It relies on the SSL layer to encrypt the traffic between the client and server.
- HTTP bearer token authentication: This uses a token generated by a separate authorization server. The authorization server does two important things for user access control. First, it validates user credentials and issues an access token. Second, it validates access tokens to confirm they are valid. This implies the access token is an opaque jumble of characters.
Both of these variations require SSL. Because SSL is so pervasive, it means HTTP basic authentication can be used without fear of exposing user credentials. This can be a simplification in RESTful API processing since each request can include the Authorization header when secure sockets are used between the client and server.
Configuring SSL
Much of the process of getting and configuring certificates is outside of the realm of Python programming. What is relevant for secure data transfers is having clients and servers that both use SSL to communicate. The protocol either requires both sides to have certificates signed by a CA, or both sides to share a common self-signed certificate.
For this recipe, we'll share a self-signed certificate between web clients and the web server. The OpenSSL package provides tools for creating self-signed certificates.
There are two parts to creating a certificate with OpenSSL:
- Create a configuration file with a name like
cert.confthat looks like the following:[req] distinguished_name = req_distinguished_name x509_extensions = v3_req prompt = no [req_distinguished_name] countryName = "US" stateOrProvinceName = "Nevada" localityName = "Las Vegas" organizationName = "ItMayBeAHack" organizationalUnitName = "Chapter 12" commonName = www.yourdomain.com # req_extensions [ v3_req ] # http://www.openssl.org/docs/apps/x509v3_config.html subjectAltName = IP:127.0.0.1You'll need to change the values associated with
countryName,stateOrProvinceName,localityName,organizationName, andcommonNameto be more appropriate to where you live. ThesubjectAltNamemust be the name the server will be using. In our case, when running from the desktop, the server is almost always known by the localhost IP address of127.0.0.1. - Run the Open SSL application to create a secret key as well as the certificate with a public key. The command is rather long. Here's how it looks:
% openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout demo.key -out demo.cert -config cert.confThis makes a request (
req) to create a self-signed certificate (-x509) with no encryption of the private key(-nodes). The certificate will be good for the next 365 days (-days 365). A new RSA key pair will be created using 2,048 bits (-newkey rsa:2048) and it will be written to a local file named demo.key (-keyout demo.key). The certificate is written to demo.cert (-out demo.cert).
These two steps create two files: demo.key and demo.cert. We'll use these files to secure the server. The certificate file, demo.cert, can be shared with all clients to create a secure channel with the server. The clients don't get the private key in the demo.key file; that's private to the server configuration, and should be treated carefully. The private key is required to decode any SSL requests encrypted with the public key.
To work with secure servers, we'll use the requests library. The urllib package in the standard library can work with HTTPS, but the setup is complex and confusing; it's easier to work with requests.
The installation looks like the following:
% python -m pip install requests
Collecting requests
Downloading https://files.pythonhosted.org/packages/1a/70/1935c770cb3be6e3a8b78ced23d7e0f3b187f5cbfab4749523ed65d7c9b1/requests-2.23.0-py2.py3-none-any.whl (58kB)
|████████████████████████████████| 61kB 1.3MB/s
Requirement already satisfied: idna<3,>=2.5 in /Users/slott/miniconda3/envs/cookbook/lib/python3.8/site-packages (from requests) (2.8)
Requirement already satisfied: certifi>=2017.4.17 in /Users/slott/miniconda3/envs/cookbook/lib/python3.8/site-packages (from requests) (2020.4.5.1)
Requirement already satisfied: chardet<4,>=3.0.2 in /Users/slott/miniconda3/envs/cookbook/lib/python3.8/site-packages (from requests) (3.0.4)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /Users/slott/miniconda3/envs/cookbook/lib/python3.8/site-packages (from requests) (1.25.6)
Installing collected packages: requests
Successfully installed requests-2.23.0
This shows how requests has been added to our current virtual environment via a pip install.
Users and credentials
In order for users to be able to supply a username and a password, we'll need to store some user information on the server. There's a very important rule about user credentials:
Never store credentials. Never.
It should be clear that storing plain text passwords is an invitation to a security disaster. What's less obvious is that we can't even store encrypted passwords. When the key used to encrypt the passwords is compromised, that will also lead to a loss of all of the user identities.
How can a user's password be checked if we do not store the password?
The solution is to store a hash of the original password. Each time a user wants to log in, the user's password input is hashed and compared with the original hash. If the two hash values match, then the new password entered must have matched the original password when the hash was saved. What's central is the extreme difficulty of recovering a password from a hash value.
There is a three-step process to create the initial hash value for a password:
- Create a random salt value. Generally, at least 16 bytes from
os.urandom()can be used. The Python secrets module has some handy functions for creating a string of bytes usable for salt. - Use the salt plus the password to create a hash value. Generally, one of the
hashlibfunctions is used. The most secure hashes come fromhashlib.pbkdf2_hmac(). - Save the digest algorithm name, the salt value, and the final hash value. Often this is combined into a single string that looks like
method$salt$hash. The method is the hash method, for example,md5. The$separates the algorithm name, thesalt, and the hash values. The password is not saved.
The output might look like this:
md5$vvASgIJS$df7b094ce72240a0cf05c603c2396e64
This example password hash records an algorithm of md5, a salt of vvASgIJS, and a hex-encoded hash of the salt plus the password.
The presence of a unique, random salt assures that two people with the same password will not have the same hash value. This means exposure of the hashed credentials is relatively unhelpful because each hash is unique even if all of the users chose the password "Hunter2."
When a password needs to be checked, a similar process is followed to create a hash of the candidate password:
- Given the username, locate the saved hash value. This will have a three-part structure of
method$salt$hash. The method is the algorithm name, for example,md5. - Use the named method, the saved salt (
vvASgIJSin the example above), plus the candidate password to create a computedhashvalue. - If the computed hash bytes match the original
hashportion of the saved password, the password must match. We've made sure the digest algorithm and salt values both match; therefore, the password is the only degree of freedom. The password is never saved nor checked directly. The password cannot (easily) be recovered from the hash, only guessed. Using a slow algorithm like PBKDF2 makes guessing difficult.
We don't need to write these algorithms ourselves. We can rely on the werkzeug.security module to provide a generate_password_hash() function to hash a password and a check_password_hash() function to check a password. These use a hash method named pbkdf2:sha256 to create very secure hashes of passwords.
We'll define a simple class to retain user information as well as the hashed password. We can use Flask's g object to save the user information during request processing.
The Flask view function decorator
There are several alternatives for handling authentication checks:
- If almost every route has the same security requirements, then the
@dealer.before_requestfunction can be used to validate allAuthorizationheaders. This would require some exception processing for the/openapi.jsonroute and the self-service route that allows an unauthorized user to create their new username and password credentials. - When some routes require authentication and some don't, it works out well to introduce a decorator for the routes that need authentication.
A Python decorator is a function that wraps another function to extend its functionality. The core technique looks like this:
from functools import wraps
def decorate(function):
@wraps(function)
def decorated_function(*args, **kw):
# processing before
result = function(*args, **kw)
# processing after
return result
return decorated_function
The idea is to replace a given function with a new function, decorated_function, built by the operation of the decorator. Within the body of this new, decorated function, it executes the original function. Some processing can be done before and some processing can be done after the function is decorated.
In a Flask context, we must put our application-specific decorators after the @route decorator:
@dealer.route('/path/to/resource')
@decorate
def view_function():
return make_result('hello world', 200)
We've wrapped a function, view_function(), with the @decorate decorator. We can write a decorator to check authentication to be sure that the user is known.
How to do it...
We'll decompose this recipe into four parts:
- Defining the
Userclass - Defining a view decorator
- Creating the server
- Creating an example client
The User class definition will include password hashing and comparison algorithms. This will isolate the details from the rest of the application. The view decorator will be applied to most of the functions in the server. Once we've built a server, it helps to have a client we can use for integration and acceptance testing.
Defining the User class
This class definition provides an example of a definition of an individual User class:
- Import modules that are required to create a
Userclass definition and check the password:from dataclasses import dataclass, field, asdict from typing import Optional from werkzeug.security import ( generate_password_hash, check_password_hash) - Start the definition of the
Userclass. We'll base this on the dataclass because it provides a number of useful methods for initialization and object serialization:@dataclass class User: - Most of the time, we'll create users from a JSON document. We'll expect the field names to match these attribute names. This allows us to use
User(**doc)to build aUserobject from a JSON document that has been deserialized into a dictionary:name: str email: str twitter: str lucky_number: int password: Optional[str] = field( default="md5$x$", repr=False) - Define a method for setting the password hash. This uses the
generate_password_hash()function from thewerkzeug.securitymodule:def set_password(self, password: str) -> None: self.password = generate_password_hash( password ) - Define an algorithm for checking a password hash value. This also relies on the
werkzeug.securitymodule for thecheck_password_hash()function:def check_password(self, password: str) -> bool: return check_password_hash( self.password, password)
Here's a demonstration of how this class is used:
>>> details = {'name': 'Noriko',
... 'email': '[email protected]',
... 'lucky_number': 8,
... 'twitter': 'https://twitter.com/PacktPub'}
>>> u = User(**details)
>>> u.set_password('OpenSesame')
>>> u.check_password('opensesame')
False
>>> u.check_password('OpenSesame')
True
We created a user with details that might have been provided by filling out an HTML form, designed to allow first-time users to sign in. The password is provided separately because it is not stored with the rest of the data.
This test case can be included in the class docstring. See the Using docstrings for testing recipe in Chapter 11, Testing, for more information on this kind of test case.
We can use json_dumps(asdict(u)) to create a JSON serialization of each User object. This can be saved in a database to register website users.
Defining a view decorator
The decorator will be applied to view functions that require authorization. We'll decorate most view functions, but not all of them. The decorator will inject an authorization test in front of the view function processing:
- We'll need a number of type definitions:
from typing import Dict, Optional, Any, Callable, Union from http import HTTPStatus from flask import ( Flask, jsonify, request, abort, url_for, Response) - Import the
@wrapsdecorator fromfunctools. This helps define decorators by assuring that the new function has the original name and docstring copied from the function that is being decorated:from functools import wraps - In order to check passwords, we'll need the
base64module to help decompose the value of theAuthorizationheader. We'll also need to report errors and update the Flask processing context using the globalgobject:from functools import wraps import base64 from flask import g - We'll provide a type hint for the decorator. This defines the two classes of view functions that can be decorated. Some view functions have parameter values parsed from the URL path. Other view functions don't receive parameter values. All view functions return
flask.Responseobjects:ViewFunction = Union[ Callable[[Any], Response], Callable[[], Response]] - As a global, we'll also create a default
Userinstance. This is the user identity when no valid user credentials are available. This ensures there is always aUserobject available. A default can be simpler than a lot ofifstatements looking for aNoneobject instead of a validUserinstance:DEFAULT_USER = User(name="", email="", twitter="", lucky_number=-1) - Define the decorator function. All decorators have this essential outline. We'll replace the
processing hereline in the next step:def authorization_required(view_function: ViewFunction) -> ViewFunction: @wraps(view_function) def decorated_function(*args, **kwargs): processing here return decorated_function - Here are the processing steps to examine the header. In case of a request without any authorization information, default values are provided that are expected to (eventually) fail. The idea is to make all processing take a consistent amount of time and avoid any timing differences. When a problem is encountered during an authorization check, the decorator will abort processing with
401 UNAUTHORIZEDas the status code with no additional information. To prevent hackers from exploring the algorithm, there are no helpful error messages; all of the results are identical even though the root causes are different:header_value = request.headers.get( "Authorization", "BASIC :") kind, data = header_value.split() if kind == "BASIC": credentials = base64.b64decode(data) else: credentials = base64.b64decode("Og==") usr_bytes, _, pwd_bytes = credentials.partition(b":") username = usr_bytes.decode("ascii") password = pwd_bytes.decode("ascii") user_database = get_users() user = user_database.get(username, DEFAULT_USER) if not user.check_password(password): abort(HTTPStatus.UNAUTHORIZED) g.user = user_database[username] return view_function(*args, **kwargs)
There are a number of conditions that must be successfully passed before the view function is executed:
- An
Authorizationheader must be present. If not, a default is provided that will fail. - The header must specify BASIC authentication. If not, a default is provided that will fail.
- The value must include a username:password string encoded using
base64. If not, a default is provided that will fail. - The username must be a known username. If not, the value of
DEFAULT_USERis used; this user has a hashed password that's invalid, leading to an inevitable failure in the final step. - The computed hash from the given password must match the expected password hash.
Failure to follow these rules will lead to a 401 UNAUTHORIZED response. To prevent leaking information about the service, no additional information on the details of the failure are provided.
For more information on status codes in general, see https://tools.ietf.org/html/rfc7231. For details on the 401 status, see https://tools.ietf.org/html/rfc7235#section-3.1.
Creating the server
This parallels the server shown in the Parsing a JSON request recipe. We'll define two kinds of routes. The first route has no authentication requirements because it's used to sign up new users. The second route will require user credentials:
- Create a local self-signed certificate. For this recipe, we'll assume the two filenames are
demo.certanddemo.key. - Import the modules required to build a server. Also import the
Userclass definition:from flask import Flask, jsonify, request, abort, url_for from http import HTTPStatus from Chapter_12.ch12_r06_user import User, asdict - Include the
@authorization_requireddecorator definition. - Define a route with no authentication. This will be used to create new users. A similar view function was defined in the
Parsing a JSON requestrecipe:@dealer.route("/dealer/players", methods=["POST"]) - Define the function to handle the route. This function will validate the JSON document to be sure it matches the required schema, then build and save the new
Userinstance. The schema is defined by the OpenAPI specification. This first half of the view function will validate the JSON document:def make_player() -> Response: try: document = request.json except Exception as ex: # Document wasn't even JSON. # We can fine-tune the error message here. abort(HTTPStatus.BAD_REQUEST) player_schema = ( specification["components"]["schemas"]["Player"] ) try: validate(document, player_schema) except ValidationError as ex: abort( HTTPStatus.BAD_REQUEST, description=ex.message) - Continue the view function by first ensuring the user is not already present in the collection. After checking to prevent duplication, create and save the new
Userinstance. The response will include information about theUserobject, including aLocationheader with the link to the new resource:user_database = get_users() id = hashlib.md5( document["twitter"].encode("utf-8")).hexdigest() if id in user_database: abort( HTTPStatus.BAD_REQUEST, description="Duplicate player") password = document.pop('password') new_user = User(**document) new_user.set_password(password) user_database[id] = new_user response = make_response( jsonify( player=redacted_asdict(new_user), id=id), HTTPStatus.CREATED ) response.headers["Location"] = url_for( "get_player", id=str(id)) return responseEach user gets assigned a cryptic internal ID. The assigned ID is computed from a hex digest of their Twitter handle. The idea is to use a value that's likely to be unique based on some external resource identification.
- Define a route to show user details. This requires authentication. A similar view function was defined in the Parsing a JSON request recipe. This version uses the
@authorization_requireddecorator. This also uses a function to redact passwords from the user database record:@dealer.route("/dealer/players/<id>", methods=["GET"]) @authorization_required def get_player(id) -> Response: user_database = get_users() if id not in user_database: abort(HTTPStatus.NOT_FOUND, description=f"{id} not found") response = make_response( jsonify( player=redacted_asdict(user_database[id]) ) ) response.headers["Content-Type"] = "application/json" return response - Here's the
redacted_asdict()function. This appliesasdict()and then removes thepasswordattribute to be sure even the hash value derived from the password isn't disclosed:def redacted_asdict(user: User) -> Dict[str, Any]: """Build the dict of a User, but redact 'password'.""" document = asdict(user) document.pop("password", None) return document
Most of the other routes will have similar @authorization_required decorators. Some routes, such as the /openapi.json route, will not require authorization.
Starting the server
To be secure, the Flask server requires Secure Socket Layer (SSL) protocols. These require a certificate and a key for the certificate. These were created in the Configuring SSL section, earlier in this recipe, leaving two files, demo.key and demo.cert. We can use those when we start a Flask server from the command line:
% export PYTHONPATH=Chapter_12
% FLASK_APP=Chapter_12.ch12_r06_server flask run --cert demo.cert --key demo.key
* Serving Flask app "Chapter_12.ch12_r06_server"
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on https://127.0.0.1:5000/ (Press CTRL+C to quit)
The export PYTHONPATH sets an environment variable to be sure Chapter_12 is seen by Python as a place to search for importable modules.
The FLASK_APP=Chapter_12.ch12_r06_server flask run --cert demo.cert --key demo.key command does these two things:
- First, it sets the
FLASK_APPvariable naming the specific module to look for a Flask instance to execute. - Second, it executes the
flask runcommand using the self-signed certificate and key we created earlier. This will start a server that uses the HTTPS protocol.
This works well for testing and demonstration purposes. For production use, access is more commonly handled by embedding the Flask application in a server like the Gunicorn server. See https://flask.palletsprojects.com/en/1.1.x/deploying/wsgi-standalone/?highlight=gunicorn#gunicorn for the basics of running a Flask app from within a Gunicorn server. The Gunicorn command has options to employ the SSL certificate and key files.
When you try to use this with a browser, you will be warned by the browser that the certificate is self-signed and may not be trustworthy.
Creating an example client
It's always helpful to create a client for a web service. It's useful for integration and performance testing because it can rigorously test the conformance of the service against the OpenAPI specification. It also serves as a sample for client implementations in other languages to show how the API should be used:
- Import the libraries required. The OpenAPI Spec Validator project we're using doesn't have complete type hints, so we'll use
# type: ignoreto preventmypyfrom scrutinizing it:from pprint import pprint from typing import Dict, List, Any, Union, Tuple import requests from openapi_spec_validator import validate_spec # type: ignore - We'll define two generic type hints to describe two slightly different classes of objects that happen to use a common underlying representation. The
OpenAPIspec type hint and the genericResponseDoctype hint both describe one aspect of generic JSON data structures: they are often a dictionary with string keys and a variety of values. We provide two names because these are used in different contexts. As this application evolves, these types may also evolve. The reasons for changes could potentially be distinct, so we'll give them different type hints:OpenAPISpec = Dict[str, Any] ResponseDoc = Dict[str, Any] - We'll define a handy function to fetch the server's OpenAPI specification. We'll make a few checks to confirm that it's the expected specification and the version is usable by this client:
def get_openapi_spec() -> OpenAPISpec: response = requests.get( url="https://127.0.0.1:5000/dealer/openapi.json", headers={"Accept": "application/json",}, verify="demo.cert", ) assert response.status_code == 200 openapi_spec = response.json() validate_spec(openapi_spec) assert ( openapi_spec["info"]["title"] == "Python Cookbook Chapter 12, recipe 6." ) assert ( openapi_spec["info"]["version"] == "1.0" ) pprint(openapi_spec) return openapi_spec - Once we have the OpenAPI specification, we'll need to create a useful mapping from the
operationIdattribute values to the operation and path information required to make a request:Path_Map = Dict[str, Tuple[str, str]] def make_path_map(openapi_spec: OpenAPISpec) -> Path_Map: """Mapping from operationId values to path and operation.""" operation_ids = { openapi_spec["paths"][path][operation]["operationId"]: (path, operation) for path in openapi_spec["paths"] for operation in openapi_spec["paths"][path] if "operationId" in openapi_spec["paths"][path][operation] } return operation_ids - When we create a player, it adds a username and password to the server's database. This requires a document that fits the defined schema in the Open API specification. We'll define a function that has an open-ended type hint of
Dict[str, Any]. The document's validity will be checked by the server. We must also provide a verify option to therequests.post()function. Because our server is working with a self-signed certificate, we must provide eitherverify=False(to bypass the validation of the certificate) or a path to locate known certificates that are trustworthy even if they're not signed by a CA. Since we created our own certificate, both the client and server can share it:def create_new_player( openapi_spec: OpenAPISpec, path_map: Path_Map, document: Dict[str, Any] ) -> ResponseDoc: path, operation = path_map["make_player"] base_url = openapi_spec["servers"][0]["url"] full_url = f"{base_url}{path}" response = requests.post( url=full_url, headers={"Accept": "application/json"}, json=document, verify="demo.cert" ) assert response.status_code == 201 document = response.json() assert "id" in document return document - Instead of error checking and logging, we've used
assertstatements. These can be helpful for debugging and creating the first version. A more complete implementation would have more detailed error checking. - Create a function to query the new
Playerinformation. This request requires basic-style authentication, which therequestsmodule handles for us. We can provide a two-tuple with the assigned ID and the password. This will be used to build a properAuthorizationheader:def get_one_player( openapi_spec: ResponseDoc, path_map: Path_Map, credentials: Tuple[str, str], player_id: str, ) -> ResponseDoc: path_template, operation = path_map["get_one_player"] base_url = openapi_spec["servers"][0]["url"] path_instance = path_template.replace( "{id}", player_id) full_url = f"{base_url}{path_instance}" response = requests.get( url=full_url, headers={"Accept": "application/json"}, auth=credentials, verify="demo.cert" ) assert response.status_code == 200 player_response = response.json() return player_response["player"] - The
verify="demo.cert"assures that the SSL protocol is used with the expected host. Theauth=credentialsoption assures that the given username and password are used to get access to the requested resources. - The main script to create and query a player might look like the following step. We can start by getting the OpenAPI specification and extracting the relevant path information. A new player document is defined and used with the
create_new_payer()function. The return value is the assigned player ID. The assigned ID, paired with the original password, can be used to query password-protected resources on the server:def main(): spec = get_openapi_spec() paths = make_path_map(spec) player = { "name": "Noriko", "email": "[email protected]", "lucky_number": 7, "twitter": "https://twitter.com/PacktPub", "password": "OpenSesame", } create_doc = create_new_player(spec, paths, player) id = create_doc["id"] credentials = (id, "OpenSesame") get_one_player(spec, paths, credentials, id)
Because the client and server both share a copy of the self-signed certificate, the client will find the server to be trustworthy. The use of certificates to secure the channel is an important part of overall network security in these kinds of RESTful APIs.
How it works...
There are three parts to this recipe:
- Using SSL to provide a secure channel: A secure channel makes it possible to exchange usernames and passwords directly. The use of a common certificate assures both parties can trust each other.
- Using best practices for password hashing: Saving passwords in any form is a security risk. Rather than saving plain passwords or even encrypted passwords, we save a computed hash value. This hash includes the password and a random salt string. This assures us that it's expensive and difficult to reverse engineer passwords from hashed values.
- Using a decorator for secure view functions: This decorator distinguishes between routes that require authentication and routes that do not require authentication. This permits a server to provide an OpenAPI specification to clients, but no other resources until proper credentials are provided.
The combination of techniques is important for creating trustworthy RESTful web services. What's helpful here is that the security check on the server is a short @authorization_required decorator, making it easy to add to be sure that it is in place on the appropriate view functions.
There's more...
When we start testing the various paths that lead to the use of abort(), we'll find that our RESTful interface doesn't completely provide JSON responses. The default behavior of Flask is to provide an HTML error response when the abort() function is used. This isn't ideal, and it's easy to correct.
We need to do the following two things to create JSON-based error messages:
- We need to provide some error handling functions to our Flask application that will provide the expected errors using the
jsonify()function. - We'll also find it helpful to supplement each
abort()function with a description parameter that provides additional details of the error.
Here's a snippet from the make_player() function. This is where the input JSON document is validated to be sure it fits with the OpenAPI specification. This shows how the error message from validation is used by the description parameter of the abort() function:
try:
validate(document, player_schema)
except ValidationError as ex:
abort(HTTPStatus.BAD_REQUEST, description=ex.message)
Once we provide descriptions to the abort() function, we can then add error handler functions for each of the HTTPStatus codes returned by the application's view functions. Here's an example that creates a JSON response for HTTPStatus.BAD_REQUEST errors:
@dealer.errorhandler(HTTPStatus.BAD_REQUEST)
def badrequest_error(ex):
return jsonify(
error=str(ex)
), HTTPStatus.BAD_REQUEST
This will create a JSON response whenever the statement abort(HTTPStatus.BAD_REQUEST) is used to end processing. This ensures that your error messages have the expected content type. It also provides a consistent way to end processing when it can't be successful.
See also
- The proper SSL configuration of a server generally involves using certificates signed by a CA. This involves a certificate chain that starts with the server and includes certificates for the various authorities that issued the certificates. See https://www.ssl.com/faqs/what-is-a-certificate-authority/ for more information.
- Many web service implementations use servers such as Gunicorn or NGINX. These servers generally handle HTTP and HTTPS issues outside our application. They can also handle complex chains and bundles of certificates. For details, see http://docs.gunicorn.org/en/stable/settings.html#ssl and also http://nginx.org/en/docs/http/configuring_https_servers.html.
- More sophisticated authentication schemes include OAuth. See https://oauth.net/2/ for information on other ways to handle user authentication.