
11
Testing
Testing is central to creating working software. Here's the canonical statement describing the importance of testing:
Any program feature without an automated test simply doesn't exist.
That's from Kent Beck's book, Extreme Programming Explained: Embrace Change.
We can distinguish several kinds of testing:
- Unit testing: This applies to independent units of software: functions, classes, or modules. The unit is tested in isolation to confirm that it works correctly.
- Integration testing: This combines units to be sure they integrate properly.
- System testing: This tests an entire application or a system of interrelated applications to be sure that the aggregated suite of software components works properly (also often known as end-to-end testing). This is often used for acceptance testing, to confirm software is fit for use.
- Performance testing: This assures that a unit, subsystem, or whole system meets performance objectives (also often known as load testing). In some cases, performance testing includes the study of resources such as memory, threads, or file descriptors. The goal is to be sure that software makes appropriate use of system resources.
These are some of the more common types. There are even more ways to use testing to identify software defects or potential defects. In this chapter, we'll focus on unit testing.
It's sometimes helpful to summarize a test following the Gherkin language. In this test specification language, each scenario is described by GIVEN-WHEN-THEN steps. Here's an example:
- GIVEN n = 52
- AND k = 5
- WHEN we compute binomial coefficient, c = binom(n, k)
- THEN the result, c, is 2,598,960
This approach to writing tests describes the given starting state, the action to perform, and the resulting state after the action. It can help us provide meaningful names for unit test cases even when we're not using Gherkin-based tools.
In this chapter, we'll look at the following recipes:
- Test tool setup
- Using docstrings for testing
- Testing functions that raise exceptions
- Handling common
doctestissues - Unit testing with the
unittestmodule - Combining
unittestanddoctesttests - Unit testing with the
pytestmodule - Combining
pytestanddoctesttests - Testing things that involve dates or times
- Testing things that involve randomness
- Mocking external resources
We'll start with setting up test tools. Python comes with everything we need. However, the pytest tool is so handy, it seems imperative to install it first. Once this tool is available, we can use it to run a variety of kinds of unit tests.
Test tool setup
Python has two built-in testing frameworks. The doctest tool examines docstrings for examples that include the >>> prompt. While this is widely used for unit testing, it can also be used for some kinds of integration testing.
The other built-in testing framework uses classes defined in the unittest module. The tests are extensions to the TestCase class. This, too, is designed primarily for unit testing, but can also be applied to integration and performance testing. These tests are run using the unittest tool.
It turns out there's a tool that lets us run both kinds of tests. It's very helpful to install the pytest tool. This mini-recipe will look at installing the pytest tool and using it for testing.
How to do it…
This needs to be installed separately with a command like the following:
python -m pip install pytest
Why it works…
The pytest tool has sophisticated test discovery. It can locate doctest test cases, as well as unittest test cases. It has its own, slightly simpler approach to writing tests.
We have to follow a couple of simple guidelines:
- Put all the tests into modules with names that begin with
test_ - If an entire package of tests will be created, it helps to have the directory named
tests
All the examples from this book use the pytest tool to be sure they're correct.
The pytest tool searches modules with the appropriate name, looking for the following:
unittest.TestCasesubclass definitions- Functions with names that start with
test_
When executed with the --doctest-modules option, the tool looks for blocks of text that appear to have doctest examples in them.
There's more…
The pytest tool has very handy integration with the coverage package, allowing you to run tests and see which lines of code were exercised during the testing and which need to be tested. The pytest-cov plugin can be useful for testing complex software.
When using the pytest-cov plugin, it's important to pass the –-cov option to define which modules need to be tracked by the coverage tool. In many projects, all of the project's Python files are collected into a single directory, often named src. This makes it easy to use --cov=src to gather test coverage information on the application's modules.
Using docstrings for testing
Good Python includes docstrings inside every module, class, function, and method. Many tools can create useful, informative documentation from docstrings. Here's an example of a function-level docstring, from the Writing clear documentation strings with RST markup recipe in Chapter 3, Function Definitions:
def Twc(T: float, V: float) -> float:
"""Computes the wind chill temperature
The wind-chill, :math:'T_{wc}', is based on
air temperature, T, and wind speed, V.
:param T: Temperature in °C
:param V: Wind Speed in kph
:returns: Wind-Chill temperature in °C
:raises ValueError: for low wind speeds or high Temps
"""
if V < 4.8 or T > 10.0:
raise ValueError(
"V must be over 4.8 kph, T must be below 10°C")
return (
13.12 + 0.6215 * T
- 11.37 * V ** 0.16 + 0.3965 * T * V ** 0.16
)
One important element of a docstring is an example. The examples provided in docstrings can become unit-test cases. An example often fits the GIVEN-WHEN-THEN model of testing because it shows a unit under test, a request to that unit, and a response.
In this recipe, we'll look at ways to turn examples into proper automated test cases.
Getting ready
We'll look at a small function definition as well as a class definition. Each of these will include docstrings that include examples that can be used as automated tests.
We'll use a function to compute the binomial coefficient of two numbers. It shows the number of combinations of n things taken in groups of size k. For example, how many ways a 52-card deck can be dealt into 5-card hands is computed like this:
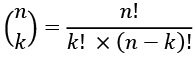
This can be implemented by a Python function that looks like this:
from math import factorial
def binom(n: int, k: int) -> int:
return factorial(n) // (factorial(k) * factorial(n-k))
This function does a computation and returns a value. Since it has no internal state, it's relatively easy to test. This will be one of the examples used for showing the unit testing tools available.
We'll also look at a class that uses lazy calculation of the mean and median. This is similar to the classes shown in Chapter 7, Basics of Classes and Objects. The Designing classes with lots of processing and Using properties for lazy attributes recipes both have classes similar to this.
This Summary class uses an internal Counter object that can be interrogated to determine the mode:
from statistics import median
from collections import Counter
class Summary:
def __init__(self) -> None:
self.counts: Counter[int] = collections.Counter()
def __str__(self) -> str:
return f"mean = {self.mean:.2f}
median = {self.median:d}"
def add(self, value: int) -> None:
self.counts[value] += 1
@property
def mean(self) -> float:
s0 = sum(f for v, f in self.counts.items())
s1 = sum(v * f for v, f in self.counts.items())
return s1 / s0
@property
def median(self) -> float:
return statistics.median(self.counts.elements())
The add() method changes the state of this object. Because of this state change, we'll need to provide more sophisticated examples to show how an instance of the Summary class behaves.
How to do it...
We'll show two variations in this recipe. The first variation can be applied to largely stateless operations, such as the computation of the binom() function. The second is more appropriate for stateful operations, such as the Summary class. We'll look at them together because they're very similar, even though they apply to different kinds of applications.
The general outline of both recipes will be the following:
- Put examples of the function or class into the docstrings for the module, function, method, or class. The exact location is chosen to provide the most clarity to someone reading the code.
- Run the
doctestmodule as a program:python -m doctest Chapter_11/ch11_r01.py
Writing examples for stateless functions
This recipe starts by creating the function's docstring, and then adds an example of how the function works:
- Start the docstring with a summary:
def binom(n: int, k: int) -> int: """ Computes the binomial coefficient. This shows how many combinations exist of *n* things taken in groups of size *k*. - Include the parameter definitions:
:param n: size of the universe :param k: size of each subset - Include the return value definition:
:returns: the number of combinations - Mock up an example of using the function at Python's
>>>prompt:>>> binom(52, 5) 2598960 - Close the docstring with the appropriate quotation marks:
"""
Writing examples for stateful objects
This recipe also starts with writing a docstring. The docstring will show several steps using the stateful object to show the state changes:
- Write a class-level docstring with a summary. It can help to leave some blank lines in front of the
doctestexample:class Summary: """ Computes summary statistics. - Extend the class-level docstring with concrete examples. In this case, we'll write two. The first example shows that the
add()method has no return value but changes the state of the object. Themean()method reveals this state, as does the__str__()method:>>> s = Summary() >>> s.add(8) >>> s.add(9) >>> s.add(9) >>> round(s.mean, 2) 8.67 >>> s.median 9 >>> print(str(s)) mean = 8.67 median = 9 - Finish with the triple quotes to end the docstring for this class:
""" - Write the method-level docstring with a summary. Here's the
add()method:def add(self, value: int) -> None: """ Adds a value to be summarized. :param value: Adds a new value to the collection. """ self.counts[value] += 1 - Here's the
mean()property. A similar string is required for themedian()property and all other methods of the class:@property def mean(self) -> float: """ Returns the mean of the collection. """ s0 = sum(f for v, f in self.counts.items()) s1 = sum(v * f for v, f in self.counts.items()) return s1 / s0
Because this uses floating-point values, we've rounded the result of the mean. Floating-point might not have the exact same text representation on all platforms and an exact test for equality may fail tests unexpectedly because of minor platform number formatting differences.
When we run the doctest program, we'll generally get a silent response because the test passed. We can add a -v command-line option to see an enumeration of the tests run.
What happens when something doesn't work? Imagine that we changed the expected output to have a wrong answer. When we run doctest, we'll see output like this:
*********************************************************************
File "Chapter_11/ch11_r01.py", line 80, in ch10_r01.Summary
Failed example:
s.median
Expected:
10
Got:
9
This shows where the error is. It shows an expected value from the test example, and the actual answer that failed to match the expected answer. At the end of the entire test run, we might see a summary line like the following:
*********************************************************************
1 items had failures:
1 of 7 in ch11_r01.Summary
13 tests in 13 items.
12 passed and 1 failed.
***Test Failed*** 1 failures.
This final summary of the testing shows how many tests were found in the docstring examples, and how many of those tests passed and failed.
How it works...
The doctest module includes a main program—as well as several functions—that scan a Python file for examples. The scanning operation looks for blocks of text that have a characteristic pattern of a >>> line followed by lines that show the response from the command.
The doctest parser creates a small test case object from the prompt line and the block of response text. There are three common cases:
- No expected response text: We saw this pattern when we defined the tests for the
add()method of theSummaryclass. - A single line of response text: This was exemplified by the
binom()function and themean()method. - Multiple lines of response: Responses are bounded by either the next
>>>prompt or a blank line. This was exemplified by thestr()example of theSummaryclass.
The doctest module executes each line of code shown with a >>> prompt. It compares the actual results with the expected results. Unless special annotations are used, the output text must precisely match the expectation text. In general cases, every space counts.
The simplicity of this testing protocol imposes some software design requirements. Functions and classes must be designed to work from the >>> prompt. Because it can become awkward to create very complex objects as part of a docstring example, our class design must be kept simple enough that it can be demonstrated at the interactive prompt. These constraints can be beneficial to keep a design understandable.
The simplicity of the comparison of the results can create some complications. Note, for example, that we rounded the value of the mean to two decimal places. This is because the display of floating-point values may vary slightly from platform to platform.
As a specific example, Python 3.5.1 (on macOS) shows 8.666666666666666 where the old, unsupported, Python 2.6.9 (also on macOS) showed 8.6666666666666661. The values are equal in many of the decimal digits. We'll address this float comparison issue in detail in the Handling common doctest issues recipe later in this chapter.
There's more...
One of the important considerations in test design is identifying edge cases. An edge case generally focuses on the limits for which a calculation is designed.
There are, for example, two edge cases for the binomial function:
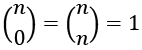
We can add these to the examples to be sure that our implementation is sound; this leads to a function that looks like the following:
def binom(n: int, k: int) -> int:
"""
Computes the binomial coefficient.
This shows how many combinations exist of
*n* things taken in groups of size *k*.
:param n: size of the universe
:param k: size of each subset
:returns: the number of combinations
>>> binom(52, 5)
2598960
>>> binom(52, 0)
1
>>> binom(52, 52)
1
"""
return factorial(n) // (factorial(k) * factorial(n - k))
In some cases, we might need to test values that are outside the valid range of values. These cases aren't really ideal for putting into the docstring, because they can clutter an explanation of what is supposed to happen with details of things that should never normally happen.
In addition to reading docstrings, the tool also looks for test cases in a global variable named __test__. This variable must refer to a mapping. The keys to the mapping will be test case names, and the values of the mapping must be doctest examples. Generally, each value will need to be a triple-quoted string.
Because the examples in the __test__ variable are not inside the docstrings, they don't show up when using the built-in help() function. Nor do they show up when using other tools to create documentation from source code. This might be a place to put examples of failures or complex exceptions.
We might add something like this:
__test__ = {
"GIVEN_binom_WHEN_0_0_THEN_1":
"""
>>> binom(0, 0)
1
""",
"GIVEN_binom_WHEN_52_52_THEN_1":
"""
>>> binom(52, 52)
1
""",
}
In this __test__ mapping, the keys are descriptions of the test. The values are the expected behavior we'd like to see at the Python >>> prompt. Indentation is used to help separate the keys from the values.
These test cases are found by the doctest program and included in the overall suite of tests. We can use this for tests that don't need to be as visible as the docstring examples.
See also
- In the Testing functions that raise exceptions and Handling common doctest issues recipes later in this chapter, we'll look at two additional
doctesttechniques. These are important because exceptions can often include a traceback, which may include object IDs that can vary each time the program is run.
Testing functions that raise exceptions
Good Python includes docstrings inside every module, class, function, and method. One important element of a docstring is an example. This can include examples of common exceptions. There's one complicating factor, however, to including exceptions.
When an exception is raised, the traceback messages created by Python are not completely predictable. The message may include object ID values that are impossible to predict or module line numbers that may vary slightly depending on the context in which the test is executed. The matching rules doctest uses to compare expected and actual results aren't appropriate when exceptions are involved.
Our testing frameworks provide ways to be sure the right exceptions are raised by a test case. This will involve using a special doctest provision for identifying the traceback messages exceptions produce.
Getting ready
We'll look at a small function definition as well as a class definition. Each of these will include docstrings that include examples that can be used as formal tests.
Here's a function from the Using docstrings for testing recipe, shown earlier in this chapter, that computes the binomial coefficient of two numbers. It shows the number of combinations of n things taken in groups of k. For example, it shows how many ways a 52-card deck can be dealt into 5-card hands. Here's the formal definition:

This defines a small Python function that we can write like this:
def binom(n: int, k: int) -> int:
"""
Computes the binomial coefficient.
This shows how many combinations of
*n* things taken in groups of size *k*.
:param n: size of the universe
:param k: size of each subset
:returns: the number of combinations
>>> binom(52, 5)
2598960
>>> binom(52, 0)
1
>>> binom(52, 52)
1
"""
return factorial(n) // (factorial(k) * factorial(n - k))
This function does a simple calculation and returns a value. We'd like to include some additional test cases in the __test__ variable to show what this does when given values outside the expected ranges.
How to do it...
We start by running the binom function we defined previously:
- Run the function at the interactive Python prompt to collect the actual exception details.
- Create a global
__test__variable at the end of the module. One approach is to build the mapping from all global variables with names that start withtest_:__test__ = { n: v for n, v in locals().items() if n.startswith("test_") } - Define each test case as a global variable with a block of text containing the
doctestexample. These must come before the final creation of the__test__mapping. We've included a note about the test as well as the data copied and pasted from interactive Python:test_GIVEN_n_5_k_52_THEN_ValueError = """ GIVEN n=5, k=52 WHEN binom(n, k) THEN exception >>> binom(52, -5) Traceback (most recent call last): File "/Users/slott/miniconda3/envs/cookbook/lib/python3.8/doctest.py", line 1328, in __run compileflags, 1), test.globs) File "<doctest __main__.__test__.GIVEN_binom_WHEN_wrong_relationship_THEN_ValueError[0]>", line 1, in <module> binom(5, 52) File "/Users/slott/Documents/Python/Python Cookbook 2e/Code/ch11_r01.py", line 24, in binom return factorial(n) // (factorial(k) * factorial(n-k)) ValueError: factorial() not defined for negative values """ - Change the function call in the example to include a
doctestdirective comment,IGNORE_EXCEPTION_DETAIL. The three lines that start withFile...will be ignored. TheValueError:line will be checked to be sure that the test produces the expected exception. The>>> binom(5, 52)line in the example must be changed to this:>>> binom(5, 52) # doctest: +IGNORE_EXCEPTION_DETAIL
We can now use a command like this to test the entire module's features:
python -m doctest -v Chapter_11/ch11_r01.py
Because each test is a separate global variable, we can easily add test scenarios. All of the names starting with test_ will become part of the final __test__ mapping that's used by doctest.
How it works...
The doctest parser has several directives that can be used to modify the testing behavior. The directives are included as special comments with the line of code that performs the test action.
We have two ways to handle tests that include an exception:
- We can use a
# doctest: +IGNORE_EXCEPTION_DETAILdirective and provide a full traceback error message. This was shown in the recipe. The details of the traceback are ignored, and only the final exception line is matched against the expected value. This makes it very easy to copy an actual error and paste it into the documentation. - We can use a
# doctest: +ELLIPSISdirective and replace parts of the traceback message with.... This, too, allows an expected output to elide details and focus on the last line that has the actual error. This requires manual editing, a way to introduce problems into the test case.
For this second kind of exception example, we might include a test case like this:
test_GIVEN_negative_THEN_ValueError = """
GIVEN n=52, k=-5 WHEN binom(n, k) THEN exception
>>> binom(52, -5) # doctest: +ELLIPSIS
Traceback (most recent call last):
...
ValueError: factorial() not defined for negative values
"""
The test case uses the +ELLIPSIS directive. The details of the error traceback have had irrelevant material replaced with .... The relevant material has been left intact and the actual exception message must match the expected exception message precisely.
This requires manual editing of the traceback message. A mistake in the editing can lead to a test failing not because the code is broken, but because the traceback message was edited incorrectly.
These explicit directives help make it perfectly clear what our intent is. Internally, doctest can ignore everything between the first Traceback... line and the final line with the name of the exception. It's often helpful to people reading examples to be explicit by using directives.
There's more...
There are several more comparison directives that can be provided to individual tests:
+ELLIPSIS: This allows an expected result to be generalized by replacing details with....+IGNORE_EXCEPTION_DETAIL: This allows an expected value to include a complete traceback message. The bulk of the traceback will be ignored, and only the final exception line is checked.+NORMALIZE_WHITESPACE: In some cases, the expected value might be wrapped onto multiple lines to make it easier to read. Or, it might have spacing that varies slightly from standard Python values. Using this directive allows some flexibility in the whitespace for the expected value.+SKIP: The test is skipped. This is sometimes done for tests that are designed for a future release. Tests may be included prior to the feature being completed. The test can be left in place for future development work, but skipped in order to release a version on time.+DONT_ACCEPT_TRUE_FOR_1: This covers a special case that was common in Python 2. BeforeTrueandFalsewere added to the language, values1and0were used instead. Thedoctestalgorithm for comparing expected results to actual results can honor this older scheme by matchingTruend1.+DONT_ACCEPT_BLANKLINE: Normally, a blank line ends an example. In the case where the example output includes a blank line, the expected results must use the special syntax<blankline>. Using this shows where a blank line is expected, and the example doesn't end at this blank line. When writing a test for thedoctestmodule itself, the expected output will actually include the characters<blankline>. Outsidedoctest's own internal tests, this directive should not be used.
See also
- See the Using docstrings for testing recipe earlier in this chapter. This recipe shows the basics of
doctest. - See the Handling common doctest issues recipe later in this chapter. This shows other special cases that require
doctestdirectives.
Handling common doctest issues
Good Python includes docstrings inside every module, class, function, and method. One important element of a docstring is an example. While doctest can make the example into a unit test case, the literal matching of the expected text output against the actual text can cause problems. There are some Python objects that do not have a consistent text representation.
For example, object hash values are randomized. This often results in the order of elements in a set collection being unpredictable. We have several choices for creating test case example output:
- Write tests that can tolerate randomization (often by converting to a sorted structure)
- Stipulate a value for the
PYTHONHASHSEEDenvironment variable - Require that Python be run with the
-Roption to disable hash randomization entirely
There are several other considerations beyond simple variability in the location of keys or items in a set. Here are some other concerns:
- The
id()andrepr()functions may expose an internal object ID. No guarantees can be made about these values - Floating-point values may vary across platforms
- The current date and time cannot meaningfully be used in a test case
- Random numbers using the default seed are difficult to predict
- OS resources may not exist, or may not be in the proper state
doctest examples require an exact match with the text. This means our test cases must avoid unpredictable results stemming from hash randomization or floating-point implementation details.
Getting ready
We'll look at three separate versions of this recipe. The first will include a function where the output includes the contents of a set. Because the order of items in a set can vary, this isn't as easy to test as we'd like. There are two solutions to this kind of problem: we can make our software more testable by sorting the set, or we can make the test more flexible by eliding some details of the results.
Here's a definition of a Row object that's read by the raw_reader() function. The function creates a set of expected column names from Row._fields. If the actual header field names don't match the expected field names, an exception is raised, and the exception contains the value of the set object in the expected variable:
import csv
from typing import Iterator, NamedTuple, TextIO
class Row(NamedTuple):
date: str
lat: str
lon: str
time: str
def raw_reader(data_file: TextIO) -> Iterator[Row]:
"""
Read from a given file if the data has columns that match Row's definition.
"""
row_field_names = set(Row._fields)
data_reader = csv.DictReader(data_file)
reader_field_names = set(
cast(Sequence[str], data_reader.fieldnames))
if not (reader_field_names >= row_field_names):
raise ValueError(f"Expected {row_field_names}")
for row in data_reader:
yield Row(**{k: row[k] for k in row_field_names})
Testing the preceding function is difficult because the exception exposes the value of a set, row_field_names, and the order of items within a set is unpredictable.
The second example will be a class that doesn't have a __repr__() definition. The default definition of the __repr__() method will expose an internal object ID. Since these vary, the test results will vary. There are two solutions here also: we can change the class definition to provide a more predictable string output from __repr__() or we can change the test to ignore the details:
class Point:
def __init__(self, lat: float, lon: float) -> None:
self.lat = lat
self.lon = lon
@property
def text(self):
ns_hemisphere = "S" if self.lat < 0 else "N"
ew_hemisphere = "W" if self.lon < 0 else "E"
lat_deg, lat_ms = divmod(abs(self.lat), 1.0)
lon_deg, lon_ms = divmod(abs(self.lon), 1.0)
return (
f"{lat_deg:02.0f}°{lat_ms*60:4.3f}′{ns_hemisphere} "
f"{lon_deg:03.0f}°{lon_ms*60:4.3f}′{ew_hemisphere}"
)
We'll also look at a real-valued function so that we can work with floating-point values:
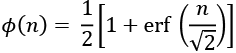
This function is the cumulative probability density function for standard z-scores. After normalizing a variable, the mean of the z-score values for that variable will be zero, and the standard deviation will be one. See the Creating a partial function recipe in Chapter 9, Functional Programming Features (link provided in Preface), for more information on the idea of normalized scores.
This function, ![]() , tells us what fraction of the population is below a given z-score. For example,
, tells us what fraction of the population is below a given z-score. For example, ![]() : half the population has a z-score below zero.
: half the population has a z-score below zero.
Here's the Python implementation:
from math import sqrt, pi, exp, erf
def phi(n: float) -> float:
return (1 + erf(n / sqrt(2))) / 2
def frequency(n: float) -> float:
return phi(n) - phi(-n)
These two functions involve some rather complicated numeric processing. The unit tests have to reflect the floating-point precision issues.
How to do it...
We'll look at set ordering and object representation in three mini-recipes. We'll start with set ordering, then look at object IDs, and finally, floating-point values.
Writing doctest examples with unpredictable set ordering
We'll start by importing the libraries we need.
- Import the necessary libraries and define the
raw_reader()function, as shown earlier. - Create a "happy path"
doctestexample that shows how the function is expected to work. Rather than creating a file for this kind of test, we can use an instance of theStringIOclass from theiopackage. We can show the expected behavior with a file that has the expected column names:>>> from io import StringIO >>> mock_good_file = StringIO('''lat,lon,date,time ... 32.8321,-79.9338,2012-11-27,09:15:00 ... ''') >>> good_row_iter = iter(raw_reader(mock_good_file)) >>> next(good_row_iter) Row(date='2012-11-27', lat='32.8321', lon='-79.9338', time='09:15:00') - Create a
doctestthat shows the exception raised when the function is provided with improper data. Again, we'll create a file-like object using aStringIOobject:>>> from io import StringIO >>> mock_bad_file = StringIO('''lat,lon,date-time,notes ... 32.8321,-79.9338,2012-11-27T09:15:00,Cooper River" ... ''') >>> bad_row_iter = iter(raw_reader(mock_bad_file)) >>> next(bad_row_iter) Traceback (most recent call last): File "/Applications/PyCharm CE.app/Contents/plugins/python-ce/helpers/pycharm/docrunner.py", line 138, in __run exec(compile(example.source, filename, "single", File "<doctest ch11_r03.raw_reader[6]>", line 1, in <module> next(bad_row_iter) File "Chapter_11/ch11_r03.py", line 74, in raw_reader raise ValueError(f"Expected {expected}") ValueError: Expected {'lat', 'lon', 'time', 'date'} - This test has a problem. The
ValueErrorresults will tend to be inconsistent. One alternative for fixing this is to change the function to raiseValueError(f"Expected {sorted(expected)}"). This imposes a known order on the items by creating a sorted list. - An alternative is to change the test to use a
# doctest: +ELLIPSISdirective. This means changing the>>> next(bad_row_iter)line in the test, and using ellipsis on the exception displayed in the expected output to look like this:>>> from io import StringIO >>> mock_bad_file = StringIO('''lat,lon,date-time,notes ... 32.8321,-79.9338,2012-11-27T09:15:00,Cooper River" ... ''') >>> bad_row_iter = iter(raw_reader(mock_bad_file)) >>> next(bad_row_iter) # doctest: +ELLIPSIS Traceback (most recent call last): File "/Applications/PyCharm CE.app/Contents/plugins/python-ce/helpers/pycharm/docrunner.py", line 138, in __run exec(compile(example.source, filename, "single", File "<doctest ch11_r03.raw_reader[6]>", line 1, in <module> next(bad_row_iter) File "Chapter_11/ch11_r03.py", line 74, in raw_reader raise ValueError(f"Expected {expected}") ValueError: Expected {...}
When writing a doctest, we must impose an order on the items in the set, or we must tolerate unpredictable item ordering in the displayed value of the set. In this case, we used doctest: +ELLIPSIS. The expected output of ValueError: Expected {...} omitted the unpredictable details of the error message.
Writing doctest examples with object IDs
Ideally, our applications won't display object IDs. These are highly variable and essentially impossible to predict. In some cases, we want to test a piece of code that may involve displaying an object ID:
- Import the necessary libraries and define the
Pointclass, as shown earlier. - Define a "happy path"
doctestscenario to show that the class performs its essential methods correctly. In this case, we'll create aPointinstance and use thetextproperty to see a representation of thePoint:>>> Point(36.8439, -76.2936).text '36°50.634 N 076°17.616W'
N 076°17.616W'
- When we define a test that displays the object's representation string, the test will include results that include the unpredictable object ID. The
doctestmight look like the following:>>> Point(36.8439, -76.2936) <ch11_r03.Point object at 0x107910610> - We need to change the test by using a
# doctest: +ELLIPSISdirective. This means changing the>>> Point(36.8439, -76.2936)line in the test, and using an ellipsis on the exception displayed in the expected output to look like this:>>> Point(36.8439, -76.2936) # doctest: +ELLIPSIS <ch11_r03.Point object at ...>
Either we must define __repr__() or avoid tests where __repr__() may be used. Or, we must tolerate unpredictable IDs in the displayed value. In this case, we used # doctest: +ELLIPSIS to change the expected output to <ch11_r03.Point object at ...>, which elided the object ID from the expected output.
The PYTHONPATH environment variable value can have an impact on the class names that are displayed. In order to be sure this test works in all contexts, it's helpful to include an ellipsis before the module name as well:
>>> Point(36.8439, -76.2936) #doctest: +ELLIPSIS
<...ch11_r03.Point object at ...>
The ellipsis in front of the module name allows some changes in the test context. For example, it allows the same unit test to be run from an IDE or after the module has been installed in a virtual environment.
Writing doctest examples for floating-point values
We have two choices when working with float values. We can round the values to a certain number of decimal places. An alternative is to use the math.isclose() function. We'll show both:
- Import the necessary libraries and define the
phi()andfrequency()functions as shown previously. - For each example, include an explicit use of
round():>>> round(phi(0), 3) 0.5 >>> round(phi(-1), 3) 0.159 >>> round(phi(+1), 3) 0.841 - An alternative is to use the
isclose()function from themathmodule:>>> from math import isclose >>> isclose(phi(0), 0.5) True >>> isclose(phi(1), 0.8413, rel_tol=.0001) True >>> isclose(phi(2), 0.9772, rel_tol=1e-4)
Because float values can't be compared exactly, it's best to display values that have been rounded to an appropriate number of decimal places. It's sometimes nicer for readers of examples to use round() because it may be slightly easier to visualize how the function works, compared to the isclose alternative.
How it works...
Because of hash randomization, the hash keys used for sets are unpredictable. This is an important security feature, used to defeat a subtle denial-of-service attack. For details, see http://www.ocert.org/advisories/ocert-2011-003.html.
Since Python 3.7, dictionary keys are guaranteed to be kept in insertion order. This means that an algorithm that builds a dictionary will provide a consistent sequence of key values even if the internal hashing used for key lookup is randomized.
The same ordering guarantee is not made for sets. Interestingly, sets of integers tend to have a consistent ordering because of the way hash values are computed for numbers. Sets of other types of objects, however, will not show consistent ordering of items.
When confronted with unpredictable results like set ordering or internal object identification revealed by __repr__(), we have a testability issue. We can either change the software to be more testable, or we can change the test to tolerate some unpredictability.
Most floating-point implementations are reasonably consistent. However, there are few formal guarantees about the last few bits of any given floating-point number. Rather than trusting that all of the bits have exactly the right value, it's often a good practice to round the value to a precision consistent with other values in the problem domain.
Being tolerant of unpredictability can be taken too far, allowing the test to tolerate bugs. In general, we often need to move beyond the capabilities of doctest. We should use doctest to demonstrate the happy path features, but edge cases and exceptions may be better handled with pytest cases.
There's more...
We can run the tests using this command-line option too:
python3 -R -m doctest Chapter_11/ch11_r03.py
This will turn off hash randomization while running doctest on a specific file, ch11_r03.py.
The tox tool will report the value of the PYTHONHASHSEED environment variable used when the test was run. We often see something like this in the output:
python run-test-pre: PYTHONHASHSEED='803623355'
(Your output may be different because the seed value is random.) This line of output provides the specific hash seed value used for randomization. We can set this environment value when running a test. Forcing a specific hash seed value will lead to consistent ordering of items in sets.
See also
- The Testing things that involve dates or times recipe, in particular, the
now()method of datetime requires some care. - The Testing things that involve randomness recipe shows how to test processing that involves
random. - This recipe focused on set ordering, object ID, and floating-point issues with
doctestexpected results. We'll look atdatetimeandrandomin the Testing things that involve dates or times and Testing things that involve randomness recipes later in this chapter. - We'll look at how to work with external resources in the Mocking external resources recipe later in this chapter.
Unit testing with the unittest module
The unittest module allows us to step beyond the examples used by doctest. Each test case can have one more scenario built as a subclass of the unittest.TestCase class. These use result checks that are more sophisticated than the literal text matching used by the doctest tool.
The unittest module also allows us to package tests outside docstrings. This can be helpful for tests for edge cases that might be too detailed to be helpful documentation. Often, doctest cases focus on the happy path—the most common use cases, where everything works as expected. We can use the unittest module to define test cases that are both on as well as off the happy path.
This recipe will show how we can use the unittest module to create more sophisticated tests. It will step beyond simple text comparison to use the more sophisticated assertion methods of the unittest.TestCase class.
Getting ready
It's sometimes helpful to summarize a test following ideas behind the Gherkin language. In this test specification language, each scenario is described by GIVEN-WHEN-THEN steps. For this case, we have a scenario like this:
Scenario: Summary object can add values and compute statistics.
Given a Summary object
And numbers in the range 0 to 1000 (inclusive) shuffled randomly
When all numbers are added to the Summary object
Then the mean is 500
And the median is 500
The unittest.TestCase class doesn't precisely follow this three-part structure. A TestCase generally has these two parts:
- A
setUp()method must implement the Given steps of the test case. It can also handle the When steps. This is rare but can be helpful in cases where the When steps are very closely bound to the Given steps. - A
runTest()method must handle the Then steps to confirm the results using a number of assertion methods to confirm the actual results match the expected results. Generally, it will also handle the When steps.
An optional tearDown() method is available for those tests that need to perform some cleanup of left-over resources. This is outside the test's essential scenario specification.
The choice of where to implement the When steps is tied to the question of reuse. For example, a class or function may have a number of methods to take different actions or make a number of state changes. In this case, it makes sense to pair each When step with a distinct Then step to confirm correct operation. A runTest() method can implement both When and Then steps. A number of subclasses can share the common setUp() method.
As another example, a class hierarchy may offer a number of alternative implementations for the same algorithm. In this case, the Then step confirmation of correct behavior is in the runTest() method. Each alternative implementation has a distinct subclass with a unique setup() method for the Given and When steps.
We'll create some tests for a class that is designed to compute some basic descriptive statistics. We'd like to provide sample data that's larger than anything we'd ever choose to enter as doctest examples. We'd like to use thousands of data points rather than two or three.
Here's an outline of the class definition that we'd like to test. We'll only provide the methods and some summaries, omitting implementation details. The bulk of the code was shown in the Using docstrings for testing recipe earlier in this chapter:
import collections
from statistics import median
from typing import Counter
class Summary:
def __init__(self) -> None: ...
def __str__(self) -> str: ...
def add(self, value: int) -> None: ...
@property
def mean(self) -> float: ...
@property
def median(self) -> float: ...
@property
def count(self) -> int: ...
@property
def mode(self) -> List[Tuple[int, int]]: ...
Because we're not looking at the implementation details, we can think of this as opaque-box testing; the implementation details are not known to the tester. To emphasize that, we replaced code with … placeholders as if this was a type stub definition.
We'd like to be sure that when we use thousands of samples, the class performs correctly. We'd also like to ensure that it works quickly; we'll use this as part of an overall performance test, as well as a unit test.
How to do it...
We'll need to create a test module and a subclass of unittest.TestCase in that module. It's common to keep the tests separate from the module's code:
- Create a file with a name related to the module under test. If the module was named
summary.py, then a good name for a test module would betest_summary.py. Using the "test_" prefix makes the test easier to find by tools likepytest. - We'll use the
unittestmodule for creating test classes. We'll also be using therandommodule to scramble the input data:import unittest import random - Import the module under test:
from Chapter_11.ch11_r01 import Summary - Create a subclass of
unittest.TestCase. Provide this class with a name that shows the intent of the test. If we try to adopt a name based on the Given, When, and Then steps, the names could become very long. Since we rely onunittestto discover all subclasses ofTestCase, we don't have to type this class name more than once, and the length isn't a real problem:class GIVEN_data_WHEN_1k_samples_THEN_mean_median( unittest.TestCase): - Define a
setUp()method in this class that handles the Given step of the test. We've created a collection of1,001samples ranging in value from0to1,000. The mean is500exactly, and so is the median. We've shuffled the data into a random order. This creates a context for the test scenario:def setUp(self): self.summary = Summary() self.data = list(range(1001)) random.shuffle(self.data) - Define a
runTest()method that handles the When step of the test. This performs the state changes:def runTest(self): for sample in self.data: self.summary.add(sample) - Add assertions to implement the Then steps of the test. This confirms that the state changes worked properly:
self.assertEqual(500, self.summary.mean) self.assertEqual(500, self.summary.median) - To make it very easy to run, we might want to add a main program section. With this, the test can be run at the OS command prompt by running the test module itself:
if __name__ == "__main__": unittest.main()
If our test module is called test_summary.py, we can also use this command to find unittest.TestCase classes in a module and run them:
python -m unittest tests/test_summary.py
We can also run tests with the pytest tool using the following command:
python -m pytest tests/test_summary.py
These commands will find all the test cases in the given file. The resulting collection of cases will be executed. If all of the assertions pass, then the test suite will pass and the test run will be successful overall.
How it works...
We're using several parts of the unittest module:
- The
TestCaseclass is used to define one test case. The class can have asetUp()method to create the unit and possibly the request. The class must have at least arunTest()to make a request of the unit and check the response. - The
unittest.main()function does several things: - It creates an empty
TestSuitethat will contain all theTestCaseobjects. - It uses a default loader to examine a module and find all of the
TestCaseinstances in the current module. These classes are loaded into theTestSuiteobject. - It then runs the
TestSuiteobject and displays a summary of the results.
When we run this module, we'll see output that looks like this:
---------------------------------------------------------------------
Ran 1 test in 0.005s
OK
As each test is passed, a . is displayed. This shows that the test suite is making progress. The summary shows the number of tests run and the time. If there are failures or exceptions, the counts shown at the end will reflect these.
Finally, there's a summary line of OK to show – in this example – all the tests passed.
If we change the test slightly to be sure that it fails, we'll see the following output:
F
======================================================================
FAIL: test_mean (Chapter_11.test_ch11_r04.GIVEN_Summary_WHEN_1k_samples_THEN_mean_median)
----------------------------------------------------------------------
Traceback (most recent call last):
File "Chapter_11/ch11_r04.py", line 22, in runTest
self.assertEqual(501, self.summary.mean)
AssertionError: 501 != 500.0
----------------------------------------------------------------------
Ran 1 test in 0.004s
FAILED (failures=1)
Instead of a . for a passing test, a failing test displays an F. This is followed by the traceback from the assertion that failed. To force the test to fail, we changed the expected mean to 501, which is not the computed mean value of 500.0.
There's a final summary of FAILED. This includes (failures=1) to show the reason why the suite as a whole is a failure.
There's more...
In this example, we have two Then steps inside the runTest() method. If one fails, the test stops as a failure, and the other step is not exercised.
This is a weakness in the design of this test. If the first assertion fails, we may not get all of the diagnostic information we might want. We should avoid having a sequence of otherwise independent assertions in the runTest() method. When multiple assertions can be true or false independently, we can break these into multiple, separate TestCase instances. Each independent failure may provide more complete diagnostic information.
In some cases, a test case may involve multiple assertions with a clear dependency. When one assertion fails, the remaining assertions are expected to fail. In this case, the first failure generally provides all the diagnostic information that's required.
These two scenarios suggest that clustering the test assertions is a design trade-off between simplicity and diagnostic detail. There's no single, best approach. We want the test case failures to provide help in locating the root cause bug.
When we want more diagnostic details, we have two general choices:
- Use multiple test methods instead of
runTest(). Instead of a single method, we can create multiple methods with names that start withtest_. The default implementation of the test loader will execute thesetUp()method and each separatetest_method when there is no overallrunTest()method. This is often the simplest way to group a number of related tests together. - Use multiple subclasses of the
testcasesubclass, each with a separate Then step. SincesetUp()is common, this can be inherited.
Following the first alternative, the test class would look like this:
class GIVEN_Summary_WHEN_1k_samples_THEN_mean_median(
unittest.TestCase):
def setUp(self):
self.summary = Summary()
self.data = list(range(1001))
random.shuffle(self.data)
for sample in self.data:
self.summary.add(sample)
def test_mean(self):
self.assertEqual(500, self.summary.mean)
def test_median(self):
self.assertEqual(500, self.summary.median)
We've refactored the setUp() method to include the Given and When steps of the test. The two independent Then steps are refactored into their own separate test_mean() and test_median() methods. Because there is no runTest() method, there are two separate test methods for separate Then steps.
Since each test is run separately, we'll see separate error reports for problems with computing mean or computing median.
Some other assertions
The TestCase class defines numerous assertions that can be used as part of the Then steps; here are a few of the most commonly used:
assertEqual()andassertNotEqual()compare actual and expected values using the default==operator.assertTrue()andassertFalse()require a single Boolean expression.assertIs()andassertIsNot()use theiscomparison to determine whether the two arguments are references to the same object.assertIsNone()andassertIsNotNone()useisto compare a given value withNone.assertIn()andassertNotIn()use theinoperator to see if an item exists in a given collection.assertIsInstance()andassertNotIsInstance()use theisinstance()function to determine whether a given value is a member of a given class (or tuple of classes).assertAlmostEqual()andassertNotAlmostEqual()round the given values to seven decimal places to see whether most of the digits are equal.assertGreater(),assertGreateEqual(),assertLess(), andassertLessEqual()all implement the comparison operations between the two argument values.assertRegex()andassertNotRegex()compare a given string using a regular expression. This uses thesearch()method of the regular expression to match the string.assertCountEqual()compares two sequences to see whether they have the same elements, irrespective of order. This can be handy for comparing dictionary keys and sets too.
There are still more assertion methods available in the TestCase class. A number of them provide ways to detect exceptions, warnings, and log messages. Another group provides more type-specific comparison capabilities. This large number of specialized methods is one reason why the pytest tool is used as an alternative to the unittest framework.
For example, the mode feature of the Summary class produces a list. We can use a specific assertListEqual() assertion to compare the results:
class GIVEN_Summary_WHEN_1k_samples_THEN_mode(unittest.TestCase):
def setUp(self):
self.summary = Summary()
self.data = [500] * 97
# Build 903 elements: each value of n occurs n times. for i in range(1, 43):
self.data += [i] * i
random.shuffle(self.data)
for sample in self.data:
self.summary.add(sample)
def test_mode(self):
top_3 = self.summary.mode[:3]
self.assertListEqual(
[(500, 97), (42, 42), (41, 41)], top_3)
First, we built a collection of 1,000 values. Of those, 97 are copies of the number 500. The remaining 903 elements are copies of numbers between 1 and 42. These numbers have a simple rule—the frequency is the value. This rule makes it easier to confirm the results.
The setUp() method shuffled the data into a random order. Then the Summary object was built using the add() method.
We used a test_mode() method. This allows expansion to include other Then steps in this test. In this case, we examined the first three values from the mode to be sure it had the expected distribution of values. assertListEqual() compares two list objects; if either argument is not a list, we'll get a more specific error message showing that the argument wasn't of the expected type.
A separate tests directory
In larger projects, it's common practice to sequester the test files into a separate directory, often called tests. When this is done, we can rely on the discovery application that's part of the unittest framework and the pytest tool. Both applications can search all of the files of a given directory for test files. Generally, these will be files with names that match the pattern test*.py. If we use a simple, consistent name for all test modules, then they can be located and run with a simple command.
The unittest loader will search each module in the directory for all classes that are derived from the TestCase class. This collection of classes within the larger collection of modules becomes the complete TestSuite. We can do this with the following command:
$ python -m unittest discover -s tests
This will locate all test cases in all test modules in the tests directory of a project.
See also
- We'll combine
unittestanddoctestin the Combining unittest and doctest tests recipe next in this chapter. We'll look at mocking external objects in the Mocking external resources recipe later in this chapter. - The Unit testing with the pytest module recipe later in this chapter covers the same test case from the perspective of the
pytestmodule.
Combining unittest and doctest tests
In some cases, we'll want to combine unittest and doctest test cases. For examples of using the doctest tool, see the Using docstrings for testing recipe earlier in this chapter. For examples of using the unittest tool, see the Unit testing with the unittest module recipe, earlier in this chapter.
The doctest examples are an essential element of the documentation strings on modules, classes, methods, and functions. The unittest cases will often be in a separate tests directory in files with names that match the pattern test_*.py.
In this recipe, we'll look at ways to combine a variety of tests into one tidy package.
Getting ready
We'll refer back to the example from the Using docstrings for testing recipe earlier in this chapter. This recipe created tests for a class, Summary, that does some statistical calculations. In that recipe, we included examples in the docstrings.
The class started with a docstring like this:
class Summary:
"""
Computes summary statistics.
>>> s = Summary()
>>> s.add(8)
>>> s.add(9)
>>> s.add(9)
>>> round(s.mean, 2)
8.67
>>> s.median
9
>>> print(str(s))
mean = 8.67
median = 9
"""
The methods have been omitted here so that we can focus on the example provided in the class docstring.
In the Unit testing with the unittest module recipe earlier in this chapter, we wrote some unittest.TestCase classes to provide additional tests for this class. We created test class definitions like this:
class GIVEN_Summary_WHEN_1k_samples_THEN_mean_median(
unittest.TestCase):
def setUp(self):
self.summary = Summary()
self.data = list(range(1001))
random.shuffle(self.data)
for sample in self.data:
self.summary.add(sample)
def test_mean(self):
self.assertEqual(500, self.summary.mean)
def test_median(self):
self.assertEqual(500, self.summary.median)
This test creates a Summary object; this is the implementation of the Given step. It then adds a number of values to that Summary object. This is the When step of the test. The two test_ methods implement two Then steps of this test.
It's common to see a project folder structure that looks like this:
project-name/
statstools/
summary.py
tests/
test_summary.py
README.rst
requirements.txt
tox.ini
We have a top-level folder, project-name, that matches the project name in the source code repository.
Within the top-level directory, we would have some overheads that are common to large Python projects. This would include files such as README.rst with a description of the project, requirements.txt, which can be used with pip to install extra packages, and perhaps tox.ini to automate testing.
The directory statstools contains a module file, summary.py. This has a module that provides interesting and useful features. This module has docstring comments scattered around the code. (Sometimes this directory is called src.)
The directory tests should contain all the module files with tests. For example, the file tests/test_summary.py has the unittest test cases in it. We've chosen the directory name tests and a module named test_*.py so that they fit well with automated test discovery.
We need to combine all of the tests into a single, comprehensive test suite. The example we'll show uses ch11_r01 instead of some cooler name such as summary. Ideally, a module should have a memorable, meaningful name. The book content is quite large, and the names are designed to match the overall chapter and recipe outline.
How to do it...
To combine unittests and doctests we'll start with an existing test module, and add a load_tests() function to include the relevant doctests with the existing unittest test cases. The name must be load_tests() to be sure the unittest loader will use it:
- Locate the
unittestfile and the module being tested; they should have similar names. For this example, the code available for this book has a module ofch11_r01.pyand tests intest_ch11_r04.py. These example names don't match very well. In most cases, they can have names that are more precise parallels. To usedoctesttests, import thedoctestmodule. We'll be combiningdoctestexamples withTestCaseclasses to create a comprehensive test suite. We'll also need therandommodule so we can control the random seeds in use:import doctest import unittest import random - Import the module that contains the module with strings that have
doctestexamples in them:import Chapter_11.ch11_r01 - To implement the
load_testsprotocol, include aload_tests()function in the test module. We'll combine the standard tests, automatically discovered byunittestwith the additional tests found by thedoctestmodule:def load_tests(loader, standard_tests, attern): dt = doctest.DocTestSuite(Chapter_11.ch11_r01) standard_tests.addTests(dt) return standard_tests
The loader argument to the load_test() function is the test case loader currently being used; this is generally ignored. The standard_tests value will be all of the tests loaded by default. Generally, this is the suite of all subclasses of TestCase. The function updates this object with the additional tests. The pattern value was the value provided to the loader to locate tests; this is also ignored.
When we run this from the OS command prompt, we see the following:
(cookbook) slott@MacBookPro-SLott Modern-Python-Cookbook-Second-Edition % PYTHONPATH=. python -m unittest -v Chapter_11/test_ch11_r04.py
test_mean (Chapter_11.test_ch11_r04.GIVEN_Summary_WHEN_1k_samples_THEN_mean_median) ... ok
test_median (Chapter_11.test_ch11_r04.GIVEN_Summary_WHEN_1k_samples_THEN_mean_median) ... ok
test_mode (Chapter_11.test_ch11_r04.GIVEN_Summary_WHEN_1k_samples_THEN_mode) ... ok
runTest (Chapter_11.test_ch11_r04.GIVEN_data_WHEN_1k_samples_THEN_mean_median) ... ok
Summary (Chapter_11.ch11_r01)
Doctest: Chapter_11.ch11_r01.Summary ... ok
test_GIVEN_n_5_k_52_THEN_ValueError (Chapter_11.ch11_r01.__test__)
Doctest: Chapter_11.ch11_r01.__test__.test_GIVEN_n_5_k_52_THEN_ValueError ... ok
test_GIVEN_negative_THEN_ValueError (Chapter_11.ch11_r01.__test__)
Doctest: Chapter_11.ch11_r01.__test__.test_GIVEN_negative_THEN_ValueError ... ok
test_GIVEN_str_THEN_TypeError (Chapter_11.ch11_r01.__test__)
Doctest: Chapter_11.ch11_r01.__test__.test_GIVEN_str_THEN_TypeError ... ok
binom (Chapter_11.ch11_r01)
Doctest: Chapter_11.ch11_r01.binom ... ok
----------------------------------------------------------------------
Ran 9 tests in 0.032s
OK
This shows us that the unittest test cases were included as well as doctest test cases.
How it works...
The unittest.main() application uses a test loader to find all of the relevant test cases. The loader is designed to find all classes that extend TestCase. We can supplement the standard tests with tests created by the doctest module. This is implemented by including a load_tests() function. This name is used to locate additional tests. The load_tests() name (with all three parameters) is required to implement this feature.
Generally, we can import a module under test and use the DocTestSuite to build a test suite from the imported module. We can, of course, import other modules or even scan the README.rst documentation for more examples to test.
There's more...
In some cases, a module may be quite complicated; this can lead to multiple test modules. The test modules may have names such as tests/test_module_feature_X.py to show that there are tests for separate features of a very complex module. The volume of code for test cases can be quite large, and keeping the features separate can be helpful.
In other cases, we might have a test module that has tests for several different but closely related small modules. A single test module may employ inheritance techniques to cover all the modules in a package.
When combining many smaller modules, there may be multiple suites built in the load_tests() function. The body might look like this:
import doctest
import Chapter_11.ch11_r01 as ch11_r01
import Chapter_11.ch11_r08 as ch11_r08
import Chapter_11.ch11_r09 as ch11_r09
def load_tests(loader, standard_tests, pattern):
for module in (
ch11_r01, ch11_r08, ch11_r09
):
dt = doctest.DocTestSuite(module)
standard_tests.addTests(dt)
return standard_tests
This will incorporate doctests from multiple modules into a single, large test suite. Note that the examples from ch11_r03.py can't be included in this test. The tests include some object repr() strings in the test_point examples that don't precisely match when the test is combined into a suite in this way. Rather than fix the tests, we'll change tools and use pytest.
See also
- For examples of
doctest, see the Using docstrings for testing recipe, earlier in the chapter. For examples ofunittest, see the Unit testing with the unittest module recipe, earlier in this chapter.
Unit testing with the pytest module
The pytest tool allows us to step beyond the examples used by doctest. Instead of using a subclass of unittest.TestCase, the pytest tool lets us use function definitions. The pytest approach uses Python's built-in assert statement, leaving the test case looking somewhat simpler. The pytest test design avoids using the complex mix of assertion methods.
The pytest tool is not part of Python; it needs to be installed separately. Use a command like this:
python -m pip install pytest
In this recipe, we'll look at how we can use pytest to simplify our test cases.
Getting ready
The ideas behind the Gherkin language can help to structure a test. In this test specification language, each scenario is described by GIVEN-WHEN-THEN steps. For this recipe, we have a scenario like this:
Scenario: Summary object can add values and compute statistics.
Given a Summary object
And numbers in the range 0 to 1000 (inclusive) shuffled randomly
When all numbers are added to the Summary object
Then the mean is 500
And the median is 500
A pytest test function doesn't precisely follow the Gherkin three-part structure. A test function generally has two parts:
- If necessary, fixtures, which can establish some of the Given steps. In some cases, fixtures are designed for reuse and don't do everything required by a specific test. A fixture can also tear down resources after a test has finished.
- The body of the function will usually handle the When steps to exercise the object being tested and the Then steps to confirm the results. In some cases, it will also handle the Given steps to prepare the object's initial state.
We'll create some tests for a class that is designed to compute some basic descriptive statistics. We'd like to provide sample data that's larger than anything we'd ever enter as doctest examples. We'd like to use thousands of data points rather than two or three.
Here's an outline of the class definition that we'd like to test. We'll only provide the methods and some summaries. The bulk of the code was shown in the Using docstrings for testing recipe. This is just an outline of the class, provided as a reminder of what the method names are:
import collections
from statistics import median
from typing import Counter
class Summary:
def __init__(self) -> None: ...
def __str__(self) -> str: ...
def add(self, value: int) -> None: ...
@property
def mean(self) -> float: ...
@property
def median(self) -> float: ...
@property
def count(self) -> int: ...
@property
def mode(self) -> List[Tuple[int, int]]: ...
Because we're not looking at the implementation details, we can think of this as opaque box testing. The code is in an opaque box. To emphasize that, we omitted the implementation details from the preceding code, using … placeholders as if this was a type stub definition.
We'd like to be sure that when we use thousands of samples, the class performs correctly. We'd also like to ensure that it works quickly; we'll use this as part of an overall performance test, as well as a unit test.
How to do it...
We'll begin by creating our test file:
- Create a test file with a name similar to the module under test. If the module was named
summary.py, then a good name for a test module would betest_summary.py. Using thetest_ prefixmakes the test easier to find. - We'll use the
pytestmodule for creating test classes. We'll also be using therandommodule to scramble the input data. We've included a# type: ignorecomment because the release ofpytestused for this book (version 5.2.2) lacks type hints:from pytest import * # type: ignore import random - Import the module under test:
from Chapter_11.ch11_r01 import Summary - Implement the Given step as a fixture. This is marked with the
@fixturedecorator. It creates a function that can return a useful object, data for creating an object, or a mocked object. The type needs to be ignored by themypytool:@fixture # type: ignore def flat_data(): data = list(range(1001)) random.shuffle(data) return data - Implement the When and Then steps as a test function with a name visible to
pytest. This means the name must begin withtest_. When a parameter to a test function is the name of a fixture function, the results of the fixture function are provided at runtime. This means the shuffled set of 1001 values will be provided as an argument value for theflat_dataparameter:def test_flat(flat_data): - Implement a When step to perform an operation on an object:
summary = Summary() for sample in flat_data: summary.add(sample) - Implement a Then step to validate the outcome:
assert summary.mean == 500 assert summary.median == 500
If our test module is called test_summary.py, we can often execute it with a command like the following:
python -m pytest tests/test_summary.py
This will invoke the pytest package as a main application. It will search the given file for functions with names starting with test_ and execute those test functions.
How it works...
We're using several parts of the pytest package:
- The
@fixturedecorator can be used to create reusable test fixtures with objects in known states, ready for further processing. - The
pytestapplication does several things: - It searches the given path for all functions with names that start with
test_in a given module. It can search for modules with names that begin withtest_. Often, we'll collect these files in a directory namedtests. - All functions marked with
@fixtureare eligible to be executed automatically as part of the test setup. This makes it easy to provide a list of fixture names as parameters. When the test is run,pytestwill evaluate each of these functions. - It then runs all of the
test_*functions and displays a summary of the results.
When we run the pytest command, we'll see output that looks like this:
====================== test session starts =======================
platform darwin -- Python 3.8.0, pytest-5.2.2, py-1.8.0, pluggy-0.13.0
rootdir: /Users/slott/Documents/Writing/Python/Python Cookbook 2e/Modern-Python-Cookbook-Second-Edition
collected 1 item
Chapter_11/test_ch11_r06.py . [100%]
======================= 1 passed in 0.02s ========================
As each test is passed, a . is displayed. This shows that the test suite is making progress. The summary shows the number of tests run and the time. If there are failures or exceptions, the counts on the last line will reflect this.
If we change the test slightly to be sure that it fails, we'll see the following output:
===================== test session starts ======================
platform darwin -- Python 3.8.0, pytest-5.2.2, py-1.8.0, pluggy-0.13.0
rootdir: /Users/slott/Documents/Writing/Python/Python Cookbook 2e/Modern-Python-Cookbook-Second-Edition
collected 2 items
Chapter_11/test_ch11_r06.py F. [100%]
=========================== FAILURES ===========================
__________________________ test_flat ___________________________
flat_data = [540, 395, 212, 290, 121, 370, ...]
def test_flat(flat_data):
summary = Summary()
for sample in flat_data:
summary.add(sample)
assert summary.mean == 500
> assert summary.median == 501
E assert 500 == 501
E + where 500 = <Chapter_11.ch11_r01.Summary object at 0x10ce56910>.median
Chapter_11/test_ch11_r06.py:26: AssertionError
================= 1 failed, 1 passed in 0.06s ==================
Instead of a . for a passing test, a failing test displays an F. This is followed by a comparison between actual and expected results showing the assert statement that failed.
There's more...
In this example, we have two Then steps inside the test_flat() function. These are implemented as two assert statements. If the first one fails, the test stops as a failure, and the other step is not exercised. This test failure mode means we won't get all of the diagnostic information we might want.
When we want more diagnostic details, we can use multiple test functions. All of the functions can share a common fixture. In this case, we might want to create a second fixture that depends on the flat_data fixture and builds the Summary object to be used by a number of tests:
@fixture # type: ignore
def summary_object(flat_data):
summary = Summary()
for sample in flat_data:
summary.add(sample)
return summary
def test_mean(summary_object):
assert summary_object.mean == 500
def test_median(summary_object):
assert summary_object.median == 500
Since each test is run separately, we'll see separate error reports for problems with the computing mean or computing median.
See also
- The Unit testing with the unittest module recipe in this chapter covers the same test case from the perspective of the
unittestmodule.
Combining pytest and doctest tests
In most cases, we'll have a combination of pytest and doctest test cases. For examples of using the doctest tool, see the Using docstrings for testing recipe. For examples of using the pytest tool, see the Unit testing with the pytest module recipe.
The doctest examples are an essential element of the documentation strings on modules, classes, methods, and functions. The pytest cases will often be in a separate tests directory in files with names that match the pattern test_*.py.
In this recipe, we'll combine the doctest examples and the pytest test cases into one tidy package.
Getting ready
We'll refer back to the example from the Using docstrings for testing recipe. This recipe created tests for a class, Summary, that does some statistical calculations. In that recipe, we included examples in the docstrings.
The class started like this:
class Summary:
"""
Computes summary statistics.
>>> s = Summary()
>>> s.add(8)
>>> s.add(9)
>>> s.add(9)
>>> round(s.mean, 2)
8.67
>>> s.median
9
>>> print(str(s))
mean = 8.67
median = 9
"""
The methods have been omitted here so that we can focus on the example provided in the docstring.
In the Unit testing with the pytest module recipe, we wrote some test functions to provide additional tests for this class. These tests were put into a separate module, with a name starting with test_, specifically test_summary.py. We created fixtures and function definitions like these:
@fixture # type: ignore
def flat_data():
data = list(range(1001))
random.shuffle(data)
return data
def test_flat(flat_data):
summary = Summary()
for sample in flat_data:
summary.add(sample)
assert summary.mean == 500
assert summary.median == 500
This test creates a Summary object; this is the Given step. It then adds a number of values to that Summary object. This is the When step of the test. The two assert statements implement the two Then steps of this test.
It's common to see a project folder structure that looks like this:
project-name/
statstools/
summary.py
tests/
test_summary.py
README.rst
requirements.txt
tox.ini
We have a top-level folder, project-name, that matches the project name in the source code repository.
The directory tests should contain all the module files with tests. For example, it should contain the tests/test_summary.py module with unit test cases in it. We've chosen the directory name tests and a module named test_*.py so that they fit well with the automated test discovery features of the pytest tool.
We need to combine all of the tests into a single, comprehensive test suite. The example we'll show uses ch11_r01 instead of a cooler name such as summary. As a general practice, a module should have a memorable, meaningful name. The book's content is quite large, and the names are designed to match the overall chapter and recipe outline.
How to do it...
It turns out that we don't need to write any Python code to combine the tests. The pytest module will locate test functions. It can also be used to locate doctest cases:
- Locate the unit test file and the module being tested. In general, the names should be similar. For this example, we have the
ch11_r01.pymodule with the code being tested. The test cases, however, are intest_ch11_r06.pybecause they were demonstrated earlier in this chapter, in Unit testing with the pytest module. - Create a shell command to run the unit test suite, as well as to examine a module for
doctestcases:pytest Chapter_11/test_ch11_r06.py --doctest-modules Chapter_11/ch11_r01.py
When we run this from the OS command prompt we see the following:
$ pytest Chapter_11/test_ch11_r06.py --doctest-modules Chapter_11/ch11_r01.py
===================== test session starts ======================
platform darwin -- Python 3.8.0, pytest-5.2.2, py-1.8.0, pluggy-0.13.0
rootdir: /Users/slott/Documents/Writing/Python/Python Cookbook 2e/Modern-Python-Cookbook-Second-Edition
collected 9 items
Chapter_11/test_ch11_r06.py .... [ 44%]
Chapter_11/ch11_r01.py ..... [100%]
====================== 9 passed in 0.05s =======================
The pytest command worked with both files. The dots after Chapter_11/test_ch11_r06.py show that four test cases were found in this file. This was 44% of the test suite. The dots after Chapter_11/ch11_r01.py show that five test cases were found; this was the remaining 66% of the suite.
This shows us that the pytest test cases were included as well as doctest test cases. What's helpful is that we don't have to adjust anything in either of the test suites to execute all of the available test cases.
How it works...
The pytest application has a variety of ways to search for test cases. The default is to search the given paths for all functions with names that start with test_ in a given module. It will also search for all subclasses of unittest.TestCase. If we provide a directory, it will search it for all modules with names that begin with test_. Often, we'll collect these files in a directory named tests.
The --doctest-modules command-line option is used to mark modules that contain doctest examples. These examples are also processed by pytest as test cases.
This level of sophistication in finding and executing a variety of types of tests makes pytest a very powerful tool. It makes it easy to create tests in a variety of forms to create confidence that our software will work as intended.
There's more...
Adding the -v option provides a more detailed view of the tests found by pytest. Here's how the additional details are displayed:
===================== test session starts ======================
platform darwin -- Python 3.8.0, pytest-5.2.2, py-1.8.0, pluggy-0.13.0 -- /Users/slott/miniconda3/envs/cookbook/bin/python
cachedir: .pytest_cache
rootdir: /Users/slott/Documents/Writing/Python/Python Cookbook 2e/Modern-Python-Cookbook-Second-Edition
collected 9 items
Chapter_11/test_ch11_r06.py::test_flat PASSED [ 11%]
Chapter_11/test_ch11_r06.py::test_mean PASSED [ 22%]
Chapter_11/test_ch11_r06.py::test_median PASSED [ 33%]
Chapter_11/test_ch11_r06.py::test_biased PASSED [ 44%]
Chapter_11/ch11_r01.py::Chapter_11.ch11_r01.Summary PASSED [ 55%]
Chapter_11/ch11_r01.py::Chapter_11.ch11_r01.__test__.test_GIVEN_n_5_k_52_THEN_ValueError PASSED [ 66%]
Chapter_11/ch11_r01.py::Chapter_11.ch11_r01.__test__.test_GIVEN_negative_THEN_ValueError PASSED [ 77%]
Chapter_11/ch11_r01.py::Chapter_11.ch11_r01.__test__.test_GIVEN_str_THEN_TypeError PASSED [ 88%]
Chapter_11/ch11_r01.py::Chapter_11.ch11_r01.binom PASSED [100%]
====================== 9 passed in 0.05s =======================
Each individual test is identified, providing us with a detailed explanation of the test processing. This can help confirm that all of the expected doctest examples were properly located in the module under test.
Another handy feature for managing a large suite of tests is the -k option to locate a subset of tests; for example, we can use -k median to locate the test with median in the name. The output looks like this:
$ pytest -v Chapter_11/test_ch11_r06.py --doctest-modules Chapter_11/ch11_r01.py -k 'median'
===================== test session starts ======================
platform darwin -- Python 3.8.0, pytest-5.2.2, py-1.8.0, pluggy-0.13.0 -- /Users/slott/miniconda3/envs/cookbook/bin/python
cachedir: .pytest_cache
rootdir: /Users/slott/Documents/Writing/Python/Python Cookbook 2e/Modern-Python-Cookbook-Second-Edition
collected 9 items / 8 deselected / 1 selected
Chapter_11/test_ch11_r06.py::test_median PASSED [100%]
=============== 1 passed, 8 deselected in 0.02s ================
This is one of many tools for focusing the test processing on tests that have failed recently to help the process of debugging and retesting.
See also
- For examples of
doctest, see the Using docstrings for testing recipe earlier in this chapter. - The Unit testing with the pytest module recipe, earlier in this chapter, has the
pytesttest cases used for this recipe. - For examples of the
unittestversion of these tests, see the Unit testing with the unittest module recipe earlier in this chapter.
Testing things that involve dates or times
Many applications rely on functions like datetime.datetime.now() or time.time() to create a timestamp. When we use one of these functions with a unit test, the results are essentially impossible to predict. This is an interesting dependency injection problem here: our application depends on a class that we would like to replace only when we're testing. The datetime package must be tested separately and a replacement used when testing our application.
One option is to design our application to avoid now() and utcnow(). Instead of using these methods directly, we can create a factory function that emits timestamps. For test purposes, this function can be replaced with one that produces known results. It seems awkward to avoid using the now() method in a complex application.
Another option is to avoid direct use of the datetime class entirely. This requires designing classes and modules that wrap the datetime class. A wrapper class that produces known values for now() can then be used for testing. This, too, seems needlessly complex.
In this recipe, we'll write tests with datetime objects. We'll need to create mock objects for datetime instances to create repeatable test values.
Getting ready
We'll work with a small function that creates a CSV file. This file's name will include the date and time in the format of YYYYMMDDHHMMSS as a long string of digits. We'll create files with names that look like this:
extract_20160704010203.json
This kind of file-naming convention might be used by a long-running server application. The name helps match a file and related log events. It can help to trace the work being done by the server.
We'll use a function like this to create these files:
import datetime
import json
from pathlib import Path
from typing import Any
def save_data(base: Path, some_payload: Any) -> None:
now_date = datetime.datetime.utcnow()
now_text = now_date.strftime("extract_%Y%m%d%H%M%S")
file_path = (base / now_text).with_suffix(".json")
with file_path.open("w") as target_file:
json.dump(some_payload, target_file, indent=2)
This function has the use of utcnow(), which produces a distinct value each time this is run. Since this value is difficult to predict, it makes test assertions difficult to write.
To create a reproducible test output, we can create a mock version of the datetime module. We can patch the test context to use this mock object instead of the actual datetime module. Within the mocked module, we can create a mock class with a mock utcnow() method that will provide a fixed, easy-to-test response.
For this case, we have a scenario like this:
Scenario: save_date function writes JSON data to a date-stamped file.
Given a base directory Path
And a payload object {"primes": [2, 3, 5, 7, 11, 13, 17, 19]}
And a known date and time of 2017-9-10 11:12:13 UTC
When save_data(base, payload) function is executed
Then the output file of "extract_20170910111213.json"
is found in the base directory
And the output file has a properly serialized version
of the payload
And the datetime.datetime.utcnow() function was called once
to get the date and time
This can be implemented as a pytest test case.
How to do it...
This recipe will focus on using the pytest tool for testing, as well as patching mock objects into the context required by the object under test:
- We'll need to import a number of modules required by the module we're testing:
import datetime import json from pathlib import Path - We'll also need the core tools for creating mock objects and test fixtures. The
pytestmodule doesn't seem to have complete type hints, so we'll use a special comment to tellmypyto ignore this module:from unittest.mock import Mock, patch from pytest import * # type: ignore - Also, we'll need the module we're going to test:
import Chapter_11.ch11_r08 - We must create an object that will behave like the
datetimemodule for the purposes of the test scenario. This module must contain a class, also nameddatetime. The class must contain a method,utcnow(), which returns a known object rather than a date that changes each time the test is run. We'll create a fixture, and the fixture will return this mock object with a small set of attributes and behaviors defined:@fixture # type: ignore def mock_datetime(): return Mock( wraps="datetime", datetime=Mock( utcnow=Mock( return_value=datetime.datetime( 2017, 9, 10, 11, 12, 13)) ), ) - We also need a way to isolate the behavior of the filesystem into test directories. The
tmpdirfixture is built in topytestand provides temporary directories into which test files can be written safely. - We can now define a test function that will use the
mock_datetimefixture, which creates a mock object; thetmpdirfixture, which creates an isolated working directory for test data; and themonkeypatchfixture, which lets us adjust the context of the module under test (by omitting any type hints, we'll avoid scrutiny frommypy):def test_save_data(mock_datetime, tmpdir, monkeypatch): - We can use the
monkeypatchfixture to replace an attribute of theChapter_11.ch11_r08module. Thedatetimeattribute will be replaced with the object created by themock_datetimefixture. Between the fixture definitions and this patch, we've created a Given step that defines the test context:monkeypatch.setattr( Chapter_11.ch11_r08, "datetime", mock_datetime) - We can now exercise the
save_data()function in a controlled test environment. This is the When step that exercises the code under test:data = {"primes": [2, 3, 5, 7, 11, 13, 17, 19]} Chapter_11.ch11_r08.save_data(Path(tmpdir), data) - Since the date and time are fixed by the mock object, the output file has a known, predictable name. We can read and validate the expected data in the file. Further, we can interrogate the mock object to be sure it was called exactly once with no argument values. This is a Then step to confirm the expected results:
expected_path = ( Path(tmpdir) / "extract_20170910111213.json") with expected_path.open() as result_file: result_data = json.load(result_file) assert data == result_data mock_datetime.datetime.utcnow.assert_called_once_with()
We can execute this test with pytest to confirm that our save_data() function will create the expected file with the proper content.
How it works...
The unittest.mock module has a wonderfully sophisticated class definition, the Mock class. A Mock object can behave like other Python objects, but generally only offers a limited subset of behaviors. In this example, we've created three different kinds of Mock objects.
The Mock(wraps="datetime", …) object mocks a complete module. It will behave, to the extent needed by this test scenario, like the standard library datetime module. Within this object, we created a mock class definition but didn't assign it to any variable.
The Mock(utcnow=…) object is the mock class definition inside the mock module. We've created an attribute with the return_value attribute. This acts like a method definition and returns a mock object.
The Mock(return_value=…) object behaves like a function or method. We provide the return value required for this test.
When we create an instance of Mock that provides the return_value (or side_effect) attribute, we're creating a callable object. Here's an example of a mock object that behaves like a very dumb function:
>>> from unittest.mock import *
>>> dumb_function = Mock(return_value=12)
>>> dumb_function(9)
12
>>> dumb_function(18)
12
We created a mock object, dumb_function, that will behave like a callable—a function—that only returns the value 12. For unit testing, this can be very handy, since the results are simple and predictable.
What's more important is this feature of the Mock object:
>>> dumb_function.mock_calls
[call(9), call(18)]
The dumb_function() tracked each call. We can then make assertions about these calls. For example, the assert_called_with() method checks the last call in the history:
>>> dumb_function.assert_called_with(18)
If the last call really was dumb_function(18), then this succeeds silently. If the last call doesn't match the assertion, then this raises an AssertionError exception that the unittest module will catch and register as a test failure.
We can see more details like this:
>>> dumb_function.assert_has_calls([call(9), call(18)])
This assertion checks the entire call history. It uses the call() function from the Mock module to describe the arguments provided in a function call.
The patch() function can reach into a module's context and change any reference in that context. In this example, we used patch() to tweak a definition in the __main__ module—the one currently running. In many cases, we'll import another module, and will need to patch that imported module. Because the import statement is part of running the module under test, the details of patching depend on the execution of the import and import as statements. It can sometimes help to use the debugger to see the context that's created when a module under test is executed.
There's more...
In this example, we created a mock for the datetime module that had a very narrow feature set for this test. The module contained a class, named datetime.
The Mock object that stands in for the datetime class has a single attribute, utcnow(). We used the special return_value keyword when defining this attribute so that it would return a fixed datetime instance. We can extend this pattern and mock more than one attribute to behave like a function. Here's an example that mocks both utcnow() and now():
@fixture # type: ignore
def mock_datetime_now():
return Mock(
name='mock datetime',
datetime=Mock(
name='mock datetime.datetime',
utcnow=Mock(
return_value=datetime.datetime(
2017, 7, 4, 1, 2, 3)
),
now=Mock(
return_value=datetime.datetime(
2017, 7, 4, 4, 2, 3)
)
)
)
The two mocked methods, utcnow() and now(), each create a different datetime object. This allows us to distinguish between the values. We can more easily confirm the correct operation of a unit test.
We can add the following assertion to confirm that the utcnow() function was used properly by the unit under test:
mock_datetime_now.datetime.utcnow.assert_called_once_with()
This will examine the self.mock_datetime mock object. It looks inside this object at the datetime attribute, which we've defined to have a utcnow attribute. We expect that this is called exactly once with no argument values.
If the save_data() function has a bug and doesn't make a proper call to utcnow(), this assertion will detect that problem. We see the following two parts in each test with a mock object:
- The result of the mocked
datetimewas used properly by the unit being tested - The unit being tested made appropriate requests to the mocked
datetimeobject
In some cases, we might need to confirm that an obsolete or deprecated method is never called. We might have something like this to confirm that another method is not used:
assert mock_datetime_now.datetime.now.mock_calls == []
This kind of testing is used when refactoring software. In this example, the previous version may have used the now() method. After the change, the function is required to use the utcnow() method. We've included a test to be sure that the now() method is no longer being used.
See also
- The Unit testing with the unittest module recipe earlier in this chapter has more information about the basic use of the
unittestmodule.
Testing things that involve randomness
Many applications rely on the random module to create random values or put values into a random order. In many statistical tests, repeated random shuffling or random selection is done. When we want to test one of these algorithms, any intermediate results or details of the processing are essentially impossible to predict.
We have two choices for trying to make the random module predictable enough to write meaningful unit tests:
- Set a known seed value; this is common, and we've made heavy use of this in many other recipes
- Use
unittest.mockto replace therandommodule with something predictable
In this recipe, we'll look at ways to unit test algorithms that involve randomness.
Getting ready
Given a sample dataset, we can compute a statistical measure such as a mean or median. A common next step is to determine the likely values of these statistical measures for some overall population. This can be done by a technique called bootstrapping.
The idea is to resample the initial set of data repeatedly. Each of the resamples provides a different estimate of the statistical measures for the population. This can help us understand the population from which the sample was taken.
In order to be sure that a resampling algorithm will work, it helps to eliminate randomness from the processing. We can resample a carefully planned set of data with a non-randomized version of the random.choice() function. If this works properly, then we have confidence the randomized version will also work.
Here's our candidate resampling function. This does sampling with replacement:
import random
from typing import List, Iterator
def resample(population: List[int], N: int) -> Iterator[int]:
for i in range(N):
sample = random.choice(population)
yield sample
We would normally apply this random resample() function to populate a Counter object that tracks each distinct value for a particular statistical measure. For our example, we'll track alternative values of the mean based on resampling. The overall resampling procedure looks like this:
def mean_distribution(population: List[int], N: int):
means: Counter[float] = collections.Counter()
for _ in range(1000):
subset = list(resample(population, N))
measure = round(statistics.mean(subset), 1)
means[measure] += 1
return means
This evaluates the resample() function 1000 times. This will lead to a number of subsets, each of which may have a distinct value for the measure we're estimating, the mean. These values are used to populate the means collection.
The histogram for mean_distribution will provide a helpful estimate for population variance. This estimate of the variance will help bracket a range for the overall population's most likely mean values.
Here's what the output looks like:
>>> random.seed(42)
>>> population = [8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68]
>>> mean_distribution(population, 4).most_common(5)
[(7.8, 51), (7.2, 45), (7.5, 44), (7.1, 41), (7.7, 40)]
This shows us that the most likely value for the mean of the overall population could be between 7.1 and 7.8. There's more to this kind of analysis than we're showing here. Our focus is on testing the resample() function.
The test for resample involves a scenario like the following:
Given a random number generator where choice() always return the sequence [23, 29, 31, 37, 41, 43, 47, 53]
When we evaluate resample(any 8 values, 8)
Then the expected results are [23, 29, 31, 37, 41, 43, 47, 53]
And the random choice() was called 8 times
This scenario describes a configuration where the random.choice() function provides a fixed sequence of values. Given a fixed sequence, then the resample() function will also provide a fixed sequence of values.
How to do it...
We'll define a mock object that can be used instead of the random.choice() function. With this fixture in place, the results are fixed and predictable:
- We'll also need the core tools for creating mock objects and test fixtures.
pytestdoesn't seem to have complete type hints, so we'll use a special comment to tellmypyto ignore this module:from types import SimpleNamespace from unittest.mock import Mock, patch, call from pytest import * # type: ignore - Also, we'll need the module we're going to test:
import Chapter_11.ch11_r09 - We'll need an object that will behave like the
choice()function inside therandommodule. We'll create a fixture, and the fixture will return both the mocked function and the expected data that the mock object will use. We'll package the two items into an object usingSimpleNamespaceas a container. The resulting object will have attributes based on the local variables created inside this function:@fixture # type: ignore def mock_random_choice(): expected_resample_data = [ 23, 29, 31, 37, 41, 43, 47, 53] mock_choice=Mock( name='mock random.choice()', side_effect=expected_resample_data) return SimpleNamespace(**locals()) - We can now define a test function that will use the
mock_random_choicefixture, which creates a mock object, and themonkeypatchfixture, which lets us adjust the context of the module under test (by omitting any type hints, we'll avoid scrutiny frommypy):def test_resample(mock_random_choice, monkeypatch): - We can use the
monkeypatchfixture to replace an attribute of therandommodule that was imported in theChapter_11.ch11_r08module. Thechoiceattribute will be replaced with the mock function created by themock_random_choicefixture. Between the fixture definitions and this patch, we've created a Given step that defines the test context:monkeypatch.setattr( Chapter_11.ch11_r09.random, "choice", mock_random_choice.mock_choice) - We can now exercise the
resample()function in a controlled test environment. This is the When step that exercises the code under test:data = [2, 3, 5, 7, 11, 13, 17, 19] resample_data = list( Chapter_11.ch11_r09.resample(data, 8)) - Since the random choices are fixed by the mock object, the result is fixed. We can confirm that the data created by the
mock_randommodule was used for resampling. We can also confirm that the mocked choice function was properly called with the input data:assert ( resample_data == mock_random_choice.expected_resample_data) mock_random_choice.mock_choice.assert_has_calls( 8 * [call(data)])
We can execute this test with pytest to confirm that our resample() function will create the output based on the given input and the random.choice() function.
How it works...
When we create an instance of the Mock class, we must provide the methods and attributes of the resulting object. When the Mock object includes a named argument value, this will be saved as an attribute of the resulting object.
When we create an instance of Mock that provides the side_effect named argument value, we're creating a callable object. The callable object will return the next value from the side_effect sequence each time the Mock object is called. This gives us a handy way to mock iterators.
Here's an example of a mock object that uses the side_effect attribute to behave like an iterator:
>>> from unittest.mock import *
>>> mocked_iterator = Mock(side_effect=[11, 13])
>>> mocked_iterator()
11
>>> mocked_iterator()
13
>>> mocked_iterator()
Traceback (most recent call last):
File "/Users/slott/miniconda3/envs/cookbook/lib/python3.8/doctest.py", line 1328, in __run
compileflags, 1), test.globs)
File "<doctest examples.txt[53]>", line 1, in <module> mocked_iterator()
File "/Users/slott/miniconda3/envs/cookbook/lib/python3.8/unittest/mock.py", line 965, in __call__
return _mock_self._mock_call(*args, **kwargs) File "/Users/slott/miniconda3/envs/cookbook/lib/python3.8/unittest/mock.py", line 1027, in _mock_call
result = next(effect)
StopIteration
First, we created a Mock object and assigned it to the name mocked_iterator. The side_effect attribute of this Mock object provides a shortlist of two distinct values that will be returned.
The example then evaluates mocked_iterator() two times. Each time, the next value is returned from the side_effect list. The third attempt raises a StopIteration exception that would end the processing of the for statement.
We can see the call history using the mock_calls attribute of a Mock object:
>>> mocked_iterator.mock_calls
[call(), call(), call()]
This behavior allows us to write a test that detects certain kinds of improper uses of a function or a method. In particular, checking the mock_calls attribute reveals how many times the function was used, and what argument values were used with each call.
There's more...
The resample() function has an interesting pattern to it. When we take a step back from the details, we see this:
def resample(X, Y):
for _ in range(Y):
yield another_function(X)
The X argument value (called population in the actual code) is simply passed through to another function. For testing purposes, it doesn't matter what the value of X is. What we're testing is that the parameter's value in the resample() function is provided as the argument to the another_function() function, untouched.
The mock library provides an object called sentinel that can be used to create an argument value in these circumstances. When we refer to an attribute name as sentinel, it creates a distinct object. We might use sentinel.POPULATION as a kind of mock for a collection of values. The exact collection doesn't matter since it's simply passed as an argument to another function (called random.choice() in the actual code).
In this kind of pattern, the object is opaque. It passes through the resample() function untouched and unexamined. In this case, an object created by sentinel is a useful alternative to creating a list of realistic-looking values.
Here's how this use of sentinels can change this test:
def test_resample_2(monkeypatch):
mock_choice=Mock(
name='mock random.choice()',
side_effect=lambda x: x
)
monkeypatch.setattr(
Chapter_11.ch11_r09.random,
"choice",
mock_choice)
resample_data = list(Chapter_11.ch11_r09.resample(
sentinel.POPULATION, 8))
assert resample_data == [sentinel.POPULATION]*8
mock_choice.assert_has_calls(
8 * [call(sentinel.POPULATION)])
We still need to mock the random.choice() function. We've used a variation of the mock object's side_effect feature. Given a callable object (like a lambda) the side_effect object is called to produce the answer. In this case, it's a lambda object that returns the argument value.
We provide the sentinel.POPULATION object to the resample() function. The same sentinel should be provided to the mocked random.choice() function. Because the random.choice() function was monkey-patched to be a mock object, we can examine the mock. The Mock object yields the original argument value, sentinel.POPULATION. We expect this to be called a total of N times, where the N parameter is set to 8 in the test case.
The value of 8 appears twice in the expected results. This creates a "brittle" test. A small change to the code or to the Given step conditions may lead to several changes in the Then steps expected results. This assures us that the test did not work by accident, but can only be passed when the software truly does the right thing.
When an object passes through a mock untouched, we can write test assertions to confirm this expected behavior. If the code we're testing uses the population object improperly, the test can fail when the result is not the untouched sentinel object. Also, the test may raise an exception because sentinel objects have almost no usable methods or attributes.
This test gives us confidence the population of values is provided, untouched, to the random.choice() function and the N parameter value is the size of the returned set of items from the population. We've relied on a sentinel object because we know that this algorithm should work on a variety of Python types.
See also
- The Using set methods and operators and Creating dictionaries – inserting and updating recipes in Chapter 4, Built-In Data Structures Part 1: Lists and Sets, and the Using cmd for creating command-line applications recipe in Chapter 6, User Inputs and Outputs, show how to seed the random number generator to create a predictable sequence of values.
- In Chapter 7, Basics of Classes and Objects, there are several other recipes that show an alternative approach, for example, Using a class to encapsulate data + processing, Designing classes with lots of processing, Optimizing small objects with __slots__, and Using properties for lazy attributes.
- Also, in Chapter 8, More Advanced Class Design, see the Choosing between inheritance and extension – the is-a question, Separating concerns via multiple inheritance, Leveraging Python's duck typing, Creating a class that has orderable objects, and Defining an ordered collection recipes.
Mocking external resources
In earlier recipes in this chapter, Testing things that involve dates or times and Testing things that involve randomness, we wrote tests for involving resources with states that we could predict and mock. In one case, we created a mock datetime module that had a fixed response for the current time. In the other case, we created a mock random module that returned a fixed response from the choice() function.
In some cases, we need to mock objects that have more complex state changes. A database, for example, would require mock objects that respond to create, retrieve, update, and delete requests. Another example is the overall OS with a complex mixture of stateful devices, including the filesystem, and running processes.
In the Testing things that involve dates or times recipe, we looked briefly at how the pytest tool provides a tmpdir fixture. This fixture creates a temporary directory for each test, allowing us to run tests without conflicting with other activities going on in the filesystem. Few things are more horrifying than testing an application that deletes or renames files and watching the test delete important files unexpectedly and raise havoc.
A Python application can use the os, subprocess, and pathlib modules to make significant changes to a running computer. We'd like to be able to test these external requests in a safe environment, using mocked objects, and avoid the horror of corrupting a working system with a misconfigured test.
In this recipe, we'll look at ways to create more sophisticated mock objects. These will allow the safe testing of changes to precious OS resources like files, directories, processes, users, groups, and configuration files.
Getting ready
We'll revisit an application that makes a number of OS changes. In Chapter 10, Input/Output, Physical Format, and Logical Layout, the Replacing a file while preserving the previous version recipe showed how to write a new file and then rename it so that the previous copy was always preserved.
A thorough set of test cases would present a variety of failures. This would help provide confidence that the function behaves properly.
The essential design was a definition of a class of objects, and a function to write one of those objects to a file. Here's the code that was used:
from pathlib import Path
import csv
from dataclasses import dataclass, asdict, fields
from typing import Callable, Any
@dataclass
class Quotient:
numerator: int
denominator: int
def save_data(output_path: Path, data: Quotient) -> None:
with output_path.open("w", newline="") as output_file:
headers = [f.name for f in fields(Quotient)]
writer = csv.DictWriter(output_file, headers)
writer.writeheader()
writer.writerow(asdict(data))
This solves the core problem of replacing a file's content. Beyond this core problem, we want to be sure that the output file is always available in a form that's usable.
Consider what happens when there's a failure in the middle of the save_data() function. For example, the supplied data is invalid. In this case, the file would be partially rewritten, and useless to other applications. Leaving a corrupted file presents a potentially serious problem in a complex application like a web server where many clients need access to this file. When it becomes corrupted, a number of users may see the website crash.
Here's a function that wraps the save_data() function with some more sophisticated file handling:
def safe_write(
output_path: Path, data: Iterable[Quotient]) -> None:
ext = output_path.suffix
output_new_path = output_path.with_suffix(f"{ext}.new")
save_data(output_new_path, data)
# Clear any previous .{ext}.old
output_old_path = output_path.with_suffix(f"{ext}.old")
output_old_path.unlink(missing_ok=True)
# Try to preserve current as old
try:
output_path.rename(output_old_path)
except FileNotFoundError as ex:
# No previous file. That's okay.
Pass
# Try to replace current .{ext} with new .{ext}.new
try:
output_new_path.rename(output_path)
except IOError as ex:
# Possible recovery...
output_old_path.rename(output_path)
The safe_write() function uses the save_data() function to do the core work of preserving the objects. Additionally, it handles a number of failure scenarios.
It's important to test failures in each one of the steps of this function. This leads us to one of a number of scenarios:
- Everything works – sometimes called the "happy path"
- The
save_data()function raises an exception, leaving a file corrupted - The
output_old_path.unlink()function raises an exception other than aFileNotFoundErrorexception - The
output_path.rename()function raises an exception other than aFileNotFoundErrorexception - The
output_new_path.rename()function raises an exception other than anIOErrorexception
There's a sixth scenario that requires a complex double failure. The output_new_path.rename() function must raise an IOError exception followed by a problem performing an output_old_path.rename(). This scenario requires the output_path to be successfully renamed to the output_old_path, but after that, the output_old_path cannot be renamed back to its original name. This situation indicates a level of filesystem damage that will require manual intervention to repair. It also requires a more complex mock object, with a list of exceptions for the side_effect attribute.
Each of the scenarios listed previously can be translated into Gherkin to help clarify precisely what it means; for example:
Scenario: save_data() function is broken.
Given A faulty set of data, faulty_data, that causes a failure in the save_data() function
And an existing file, "important_data.csv"
When safe_write("important_data.csv", faulty_data)
Then safe_write raises an exception
And the existing file, "important_data.csv" is untouched
This can help use the Mock objects to provide the various kinds of external resource behaviors we need. Each scenario implies a distinct fixture to reflect a distinct failure mode.
Among the five scenarios, three describe failures of an OS request made via one of the various Path objects that get created. This suggests a fixture to create a mocked Path object. Each scenario is a different parameter value for this fixture; the parameters have different points of failure.
How to do it...
We'll use separate testing techniques. The pytest package offers the tmpdir and tmp_path fixtures, which can be used to create isolated files and directories. In addition to an isolated directory, we'll also want to use a mock to stand in for parts of the application we're not testing:
- Identify all of the fixtures required for the various scenarios. For the happy path, where the mocking is minimal, the
pytest.tmpdirfixture is all we need. For scenario two, where thesave_data()function is broken, the mocking involves part of the application, not OS resources. For the other three, methods ofPathobjects will raise exceptions. - This test will use a number of features from the
pytestandunittest.mockmodules. It will be creatingPathobjects, and test functions defined in theChapter_10.ch10_r02module:from unittest.mock import Mock, sentinel from pytest import * # type: ignore from pathlib import Path import Chapter_10.ch10_r02 - Write a test fixture to create the original file, which should not be disturbed unless everything works correctly. We'll use a
sentinelobject to provide some text that is unique and recognizable as part of this test scenario:@fixture # type: ignore def original_file(tmpdir): precious_file = tmpdir/"important_data.csv" precious_file.write_text( hex(id(sentinel.ORIGINAL_DATA)), encoding="utf-8") return precious_file - Write a function that will replace the
save_data()function. This will create mock data used to validate that thesafe_write()function works. In this, too, we'll use asentinelobject to create a unique string that is recognizable later in the test:def save_data_good(path, content): path.write_text( hex(id(sentinel.GOOD_DATA)), encoding="utf-8") - Write the "happy path" scenario. The
save_data_good()function can be given as theside_effectof aMockobject and used in place of the originalsave_data()function. This confirms that thesafe_write()function implementation really does use thesave_data()function to create the expected resulting file:def test_safe_write_happy(original_file, monkeypatch): mock_save_data = Mock(side_effect=save_data_good) monkeypatch.setattr( Chapter_10.ch10_r02, 'save_data', mock_save_data) data = [ Chapter_10.ch10_r02.Quotient(355, 113) ] Chapter_10.ch10_r02.safe_write( Path(original_file), data) actual = original_file.read_text(encoding="utf-8") assert actual == hex(id(sentinel.GOOD_DATA)) - Write a mock for scenario two, in which the
save_data()function fails to work correctly. This requires the test to include asave_data_failure()function to write recognizably corrupt data, and then raise an unexpected exception. This simulates any of a large number of OS exceptions related to file access permissions, resource exhaustion, as well as other problems like running out of memory:def save_data_failure(path, content): path.write_text( hex(id(sentinel.CORRUPT_DATA)), encoding="utf-8") raise RuntimeError("mock exception") - Finish scenario two, using this alternate function as the
side_effectof aMockobject. In this test, we need to confirm that aRuntimeErrorexception was raised, and we also need to confirm that the corrupt data did not overwrite the original data:def test_safe_write_scenario_2(original_file, monkeypatch): mock_save_data = Mock(side_effect=save_data_failure) monkeypatch.setattr( Chapter_10.ch10_r02, 'save_data', mock_save_data) data = [ Chapter_10.ch10_r02.Quotient(355, 113) ] with raises(RuntimeError) as ex: Chapter_10.ch10_r02.safe_write( Path(original_file), data) actual = original_file.read_text(encoding="utf-8") assert actual == hex(id(sentinel.ORIGINAL_DATA))
This produces two test scenarios that confirm the safe_write() function will work in a number of common scenarios. We'll turn to the remaining three scenarios in the There's more… section later in this recipe.
How it works...
When testing software that makes OS, network, or database requests, it's imperative to include cases where the external resource fails. The principal tool for doing this is the pytest.monkeypatch fixture; we can replace Python library functions with mock objects that raise exceptions instead of working correctly.
In this recipe, we used the monkeypatch.setattr() method to replace an internal function, save_data(), used by the function we're testing, safe_write(). For the happy path scenario, we replaced the save_data() function with a Mock object that wrote some recognizable data. Because we're using the pytest.tmpdir fixture, the file was written into a safe, temporary directory, where it could be examined to confirm that new, good data replaced the original data.
For the first of the failure scenarios, we used the monkeypatch fixture to replace the save_data() function with a function that both wrote corrupt data and also raised an exception. This is a way to simulate a broad spectrum of application failures. We can imagine that save_data() represents a variety of external requests including database operations, RESTful web service requests, or even computations that could strain the resources of the target system.
We have two ways to provide sensible failures. In this scenario, the save_data_failure() function was used by a Mock object. This function replaced the save_data() function and raised an exception directly. The other way to provide a failure is to provide an exception or exception class as the value of the side_effect parameter when creating a Mock object; for example:
>>> a_mock = Mock(side_effect=RuntimeError)
>>> a_mock(1)
Traceback (most recent call last):
...
RuntimeError
This example creates a mock object, a_mock, that always raises a RuntimeError when it's called.
Because the side_effect attribute can also work with a list of values, we can use the following to create an unreliable resource:
>>> b_mock = Mock(side_effect=[42, RuntimeError])
>>> b_mock(1)
42
>>> b_mock(2)
Traceback (most recent call last):
...
RuntimeError
This example creates a mock object, b_mock, which will return an answer for the first request, but will raise a specified exception for the second request.
These test scenarios also made use of the sentinel object. When we reference any sentinel attribute, a unique object is created. This means that sentinel.GOOD_DATA is never equal to sentinel.CORRUPT_DATA. sentinel objects aren't strings, but we can use hex(id(sentinel.GOOD_DATA)) to create a unique string that can be used within the test to confirm that an object provided as an argument value was used without further processing or tampering.
There's more...
The remaining three scenarios are very similar; they all have the following test function:
def test_safe_write_scenarios(
original_file, mock_pathlib_path, monkeypatch):
mock_save_data = Mock(side_effect=save_data_good)
monkeypatch.setattr(
Chapter_10.ch10_r02, 'save_data', mock_save_data)
data = [
Chapter_10.ch10_r02.Quotient(355, 113)
]
with raises(RuntimeError) as exc_info:
Chapter_10.ch10_r02.safe_write(mock_pathlib_path, data)
assert exc_info.type == RuntimeError
assert exc_info.value.args in {("3",), ("4",), ("5",)}
actual = original_file.read_text(encoding="utf-8")
assert actual == hex(id(sentinel.ORIGINAL_DATA))
assert mock_save_data.called_once()
assert mock_pathlib_path.rename.called_once()
This function provides the save_data_good() mock for the save_data() function. Each scenario will raise a RuntimeError exception, but the exception will be from different Path operations. In all three cases, the new data is inaccessible, but the original data remains usable in the original file. This is confirmed by checking the original file's content to be sure it has the original data.
We want to use three different versions of the mock_pathlib_path mock object to implement the three different scenarios. When we look inside the safe_write() function, we see that the original Path object is used to create two additional paths, one for the new file and one as the path for a backup of the previous edition of the original file.
These two additional path instances are created by using the with_suffix() method of a Path. This leads us to the following sketch of what the mock object needs to contain:
new_path = Mock(rename=Mock(side_effect= ? ))
old_path = Mock(unlink=Mock(side_effect= ? ))
original_path = Mock(
with_suffix=Mock(side_effect=[new_path, old_path]),
rename=Mock(side_effect= ? )
)
The original_path mock will be returned by the fixture. This Mock object behaves like a Path object and provides the with_suffix() method to create the mock representation for the new path and the old path. Each of these paths is used in slightly different ways.
The old_path has the unlink() method used. In scenario three, this fails to work.
In addition to providing the other path objects, the original_path must be renamed to become a backup. In scenario four, this fails to work.
The new_path will have a rename performed to make it the replacement copy of the file. In scenario five, this fails to work, forcing the function to put the old file back into place.
These small changes replace the ?'s in the preceding outline. We can use a parameterized fixture to spell out these three alternatives. First, we'll package the choices as three separate dictionaries that provide the side_effect values:
scenario_3 = {
"original": None, "old": RuntimeError("3"), "new": None}
scenario_4 = {
"original": RuntimeError("4"), "old": None, "new": None}
scenario_5 = {
"original": None, "old": None, "new": RuntimeError("5")}
Given these three definitions, we can plug the values into a fixture via the request.params object provided by pytest. We've marked the fixture to be ignored by mypy:
@fixture(params=[scenario_3, scenario_4, scenario_5]) # type: ignore
def mock_pathlib_path(request):
new_path = Mock(rename=Mock(side_effect=request.param["new"]))
old_path = Mock(unlink=Mock(side_effect=request.param["old"]))
original_path = Mock(
with_suffix=Mock(side_effect=[new_path, old_path]),
rename=Mock(side_effect=request.param["original"])
)
return original_path
Because this fixture has three parameters, any test using this fixture is run three times, once with each of the parameter values. This lets us reuse the test_safe_write_scenarios test case to be sure it works with a variety of system failures.
Here's what the output from pytest looks like. It shows the two unique scenarios followed by test_safe_write_scenarios using three different parameter values:
Chapter_11/test_ch11_r10.py::test_safe_write_happy PASSED [ 20%]
Chapter_11/test_ch11_r10.py::test_safe_write_scenario_2 PASSED [ 40%]
Chapter_11/test_ch11_r10.py::test_safe_write_scenarios[mock_pathlib_path0] PASSED [ 60%]
Chapter_11/test_ch11_r10.py::test_safe_write_scenarios[mock_pathlib_path1] PASSED [ 80%]
Chapter_11/test_ch11_r10.py::test_safe_write_scenarios[mock_pathlib_path2] PASSED [100%]
We've created a variety of mock objects to inject failures throughout a complex function. This sequence of tests helps provide confidence that the implementation supports the five defined scenarios.
See also
- The Testing things that involve dates or times and Testing things that involve randomness recipes earlier in this chapter show techniques for dealing with unpredictable data.
- The Reading complex formats using regular expressions recipe in Chapter 10, Input/Output, Physical Format, and Logical Layout, shows how to parse a complex log file. In the Using multiple contexts for reading and writing files recipe in Chapter 10, Input/Output, Physical Format, and Logical Layout, the complex log records were written to a
CSVfile. - For information on chopping up strings to replace parts, see the Rewriting an immutable string recipe in Chapter 1, Numbers, Strings, and Tuples.
- Elements of this can be tested with the
doctestmodule. See the Using docstrings for testing recipe earlier in this chapter for examples. It's also important to combine these tests with any doctests. See the Combining unittest and doctest tests recipe earlier in this chapter for more information on how to do this.