
Defining and Prioritizing Master Data
Abstract
This chapter discusses how to identify and prioritize the master data in a multi-domain scope, including cross-domain dependencies and how to determine domain implementation order. It covers the process and issues that can occur if the implementation order is not executed correctly, as well as how to address conflicts with the business definition of master data.
This chapter covers how to identify, define, and prioritize master data and data domains in a multi-domain model. It discusses the cross-functional usage of master data, how to address conflicts with the business definition of master data, how to determine domain implementation order, and the process and issues that can occur if the implementation order is not executed correctly.
The term Master Data Management (MDM) domain refers to a specific data domain where identification and control of the master data is focused. Customer, Product, Locations, Finance, and Employee domains have been among the most commonly targeted data domains where MDM initiatives are focused. The focus on these domains has evolved from data management practices associated to customer data integration (CDI), product integration management (PIM), accounts receivable (AR), and human resources (HR) practices. These data management practices have paved the road for the introduction of MDM as a more common discipline using a data domain based approach.
Companies will typically begin their MDM focus in one domain area, and then expand to more domains with implementation of a multi-domain program model. In some cases there may be a multi-domain strategy from the start, but usually a single domain like Customer or Product will still be the starting point and set the tone for subsequent domains. When taking this multi-domain leap, it is critical to determine each domain’s master data elements and what aspects of MDM planning and execution are repeatable and scalable across the domains. With that in mind, this chapter offers guidance and questions that are important to consider when pursing a multi-domain model.
Ideally, the domains where master data analysis and MDM practices can be applied will be clearly defined in a company’s enterprise architecture, such as in an Enterprise Information Model (EIM). However, such an architecture and models often reflect a target state that is only partially implemented and without firm plans for how other key pieces of the architecture design will be implemented. To be successful, a MDM program needs to lock into and provide value to current state operations and where enterprise level or operational initiatives are in progress. Master data exist regardless of how advanced a company is with its enterprise architecture strategies. If an enterprise architecture design cannot provide a firm point of reference for defining MDM domains, it can instead be derived from other reference points, such as from a review of subject areas in an enterprise data warehouse or from the operational model and functional architecture.
Identifying Domains
Although certain domains, such as Customer, Product, Locations, and Employee, are the most commonly referenced, the domain types and mix can vary due to a company’s industry orientation and business model. They may also be influenced by system architecture, such as if a company has implemented an integrated business suite of applications that has an underlying data architecture and predefined data models.
Here are some industry-oriented examples of how domains are often defined:
• Manufacturing domains: Customers, Product, Suppliers, Materials, Items, Locations
• Health care domains: Members, Providers, Products, Claims, Clinical, Actuarial
• Financial services domains: Customers, Accounts, Products, Locations, Actuarial
• Education domains: Students, Faculty, Locations, Materials, Courses
Identifying Master Data
Regardless of how the domains are determined, the concept of master data and how this data is identified and managed needs to be consistent across a company’s systems and processes. Master data should be clearly defined and distinguished from or related to other types of data, such as reference data and transactional data. Here are definitions for these types of data.
• Master data: Data representing key data entities critical to a company operations and analytics because of how it interacts and provides context to transactional data
• Transactional data: Data associated with or resulting from specific business transactions
• Reference data: Data typically represented by code set values used to classify or categorize other types of data, such as master data and transactional data
• Metadata: Descriptive information about data entities and elements such as the definition, type, structure, lineage, usage, changes, and so on
While each of these types of data will be used together for operational and analytical purposes, and all may be in the scope of a data governance charter, the source control and quality management of the master data will have different priorities, requirements, challenges, and practices than will the other data types. MDM is the application of discipline and control over master data to achieve a consistent, trusted, and shared representation of the master data. Therefore, reference data and metadata associated with a master data element should also be included in the MDM scope if any control or consistency problems with the reference data or metadata data will affect the integrity of the master data element. For example, many code sets act as reference data to qualify a master data element or provide a list of values expected to be populated in the master data field. In such cases, the reference data associated with the master data element should be in the MDM scope.
The MDM and data governance programs work together to focus on managing and controlling the elements, definitions, and business processes that influence the creation and change of master data. Clearly recognizing and defining this are perhaps the most challenging and foundational actions within a MDM program. MDM and data governance efforts can be and often are initiated with objectives to pull the business entities and definitions together, but this is a much more complicated process that requires attention from many resources to ensure a coordinated approach. If the MDM Program Management Office (PMO) and data governance are not prepared with sufficient resources and support to help pull this information together and coordinate the analysis process, the progress and maturity of the MDM program will be impeded until this work can be completed. The MDM PMO scope and its relationship with data governance are discussed in more detail in Chapter 4.
To fully evaluate the master data and the master data characteristics within a domain, the following artifacts should be inventoried, gathered, and reviewed for each domain:
• Data models: Conceptual, logical, and physical models that organize and document business concepts, data entities, and data elements and the relationships between them
• Data dictionary: A listing of the data elements, definitions, and other metadata information associated with a data model
• Functional architecture: Depicts how systems and processes interact within each other within a functional scope
• Source to target mapping: Describes the data element mapping between a target system and source system
• Data life cycle: Depicts the flow of data across application and process areas from data creation to retirement.
• CRUD analysis: Indicates where permissions to create, read, update, and delete have been assigned to various groups for certain types of data
All of these are artifacts are extremely valuable for evaluating the scope, consistency, and use of master data. Unfortunately, not all these artifacts are likely to be available or in a complete form for each data domain in scope. The data governance or MDM program management office should consider opportunities to assist with the initiation or completion of any of these artifacts where needed. Figure 2.1 shows an example of inventorying these artifacts with each data domain in the MDM program scope.
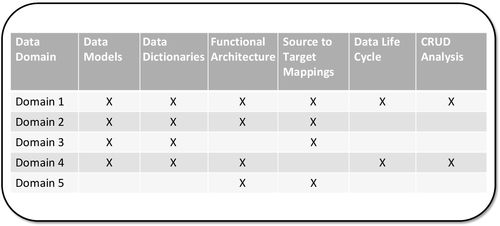
These artifacts should also be the basis for defining key metrics that will demonstrate the value and progress for how MDM practices can drive the alignment and consistency of the master data across these areas and artifacts. For example, an initial analysis of these types of artifacts and data assets is likely to reveal many gaps or conflicts with master data definitions, alignment, lineage, usage, and control. From this type of assessment, current state baselines can be determined, leading to quality improvement objectives that can be implemented and tracked as ongoing quality metrics for each domain. Examples of these type measurements are provided in Chapter 11. This type of data asset inventory and analysis by domain should also be leveraged to help scope the data governance, data quality management, and metadata management practices needed for the MDM plan and approach for each domain.
Identifying Sources of Master Data
Within a company there can be many silos of information. For the most part, lines of business (LOBs) operate autonomously. Granted, they have distinct objectives, budgets, targets, processes, and metrics which justify most of their independent operations. But when it comes to data, LOBs are highly dependent on data from multiple domain areas that can have various degrees of quality and present different systems of reference.
Take the Customer and Account domains as examples. Certain entities within the Customer domain, such as individual customers or business customers and the associated contacts are spread throughout the company with a multitude of different transactions attached to them at the many disparate systems, such as customer relationship management (CRM), enterprise resource planning (ERP), supply chain management (SCM), asset management, service management, and data warehouse.
The Account domain is no different. In many industries, a customer may have multiple accounts. For example, a couple finances a car, and the father is a cosigner with a son (who is not living with them) on another car financing. In this example, there are three customers (father, mother, and son); and two accounts (one for the couple’s car, another for the son’s car financed with the father). If the parents are still making the payments for their son’s car, they may want to have the billing address for that account to be different from their son’s home address, even though the son might be the primary person on the account. Many other combinations are possible. In any event, many nontransactional attributes remain associated at the account level, not at the customer level. Therefore, there is a need to have a master account as an independent entity. Like data related to customer entities, the account entity will have duplicated, fragmented, and inconsistent information spread across multiple-source systems.
Recognizing a certain entity exists within the major information technology (IT) systems is not difficult. Business units will know immediately what category of information they need and use. The problem lies at the granular level. Unless a company has implemented a data hub architecture and has a comprehensive metadata management solution in place, there is unlikely to be a centralized location or team with detailed information about all elements across the enterprise applications that relate to a certain entity and their degree of completeness, uniqueness, validity, consistency, and accuracy. That should not be confused with lack of business understanding of their functions. Business users do understand their processes and what pieces of information are needed to complete a given task. But a clear, enterprise-level understanding of the data and the source of truth is typically missing in the absence of an MDM focus and comprehensive data-quality-analysis capabilities.
For example, a particular task might be to mail correspondence to customers. All that is needed for someone to perform this process is the customer name and billing address. Furthermore, this person cares about it on a unit basis. That means, to send one correspondence, he or she needs one customer name and one address. There is no need to look at other attributes of the customer, nor is it necessary to know whether the same customer exists multiple times in the system, and if so, if all the records have the same address. However, if the same customer exists multiple times and all the addresses are the same, it means sending multiple copies of the same correspondence to the same person, which incurs additional costs (and probably annoys the customer). And if the addresses are different, it is likely that only one is correct—therefore, the extra copies are sent to the wrong location, also wasting money and effort.
When evaluating sources of information, remember to consider the many locations and forms where data is maintained. It is not unusual for companies to have pockets of data in diverse locations and forms of storage. Organizations might even have full-blown business processes that totally depend on manually maintained spreadsheets or local databases. The business need normally starts small (e.g., a newly created or recently improved process requires a new piece of information related to a certain entity). Modifying existing software applications might be too expensive or take too long. That particular LOB decides to take the matter into its own hands and augment some existing information with the new data needed, maintaining it on a local data store or spreadsheet. Later, more data is added. All of a sudden, what started small becomes large and extremely critical to business operations. Those sources of information cannot be ignored. They need to be accounted for and leveraged accordingly.
Conduct a data life cycle and CRUD analysis to identify a comprehensive list of all sources. Don’t ignore anything. Until all elements for the entities in scope are evaluated thoroughly, no data source should be underestimated, but in the final analysis, not all elements associated with a domain are necessarily in scope as master data. This topic is discussed next.
Determining the Master Data Elements
Once the sources of master data are identified, the next step is to determine what master data elements will be in scope. What is in scope should be an exercise that coordinates PMO and data governance, with appropriate data stewards and business analysts involved who are familiar with the domain’s data and business process areas. Keep in mind that while the business areas will be able to identify what data entities and elements they rely on, they may not have a sufficient understanding about all the elements associated with those entities, nor may they understand the level of quality. That happens for the following reasons:
• Operational business processes use only a subset of all entity attributes at a time—i.e., a narrow view of the data
• Operational business processes use only a few rows of information at a time—i.e., a shallow view of the data
Figure 2.2 shows a narrow and shallow view of domain data due to specific business processes that use just a small percentage of an overall data set at a time.
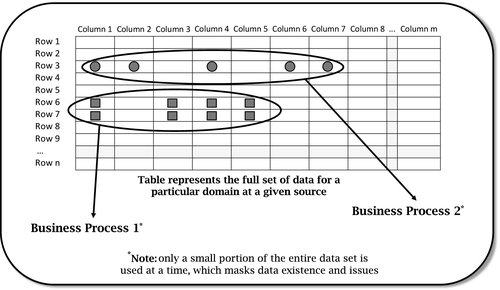
There is nothing wrong with business processes having a narrow and shallow view of the data. They fulfill a certain business need very well. Obviously, however, there are certain business groups that want or need to analyze data a bit more deeply. Those are usually analytical teams looking for particular trends within an overall data set. However, those analyses can still be narrow and segmented by source.
The next step is to compile a comprehensive list of master elements in a given domain. To do this, it is necessary to conduct a very detailed, wide, and deep analysis of the many elements associated with those entities at the various sources. Data must be profiled at length from a technical and business point of view. Once the comprehensive list is compiled, a simple approach is to classify the elements as master data (nontransactional), transactional data, or reference data. Transactional attributes will generally be out of scope, whereas some reference data may be in scope. Ultimately, it should be a PMO and data governance decision as to what elements are classified as master data.
For example, the following types of assessments should be performed to help with the final analysis and the master data decisions:
• If a data element is not populated at all, that is a strong indication that it is not used and can be disregarded. The data elements in this group can be categorized as out of scope for data mastering. Also, keep in mind that a data element may not be populated but still could be a candidate for master data classification. For example, the data exist in the source system but were not pulled across into a data hub or data warehouse, or a new data entity was modeled to support new data elements expected in the future, but the data have not yet been made available.
• If an element is only scarcely populated, that indicates that the element is most likely not used and could potentially be disregarded. However, the scarce population of an element may be due to its definition and intended usage. This needs to be evaluated before disregarding the element. For example, let’s say that a populated end date indicates that a contract has expired, while lack of an end date indicates an active contract. If the end date is scarcely populated, that means there are many active contracts, and so a scarcely populated end date field should not be ignored. However, depending on the type of business and contract term expectations, if contract expirations should frequently occur and those end dates should trigger specific contract renewal attention, the fact that this element is scarcely populated may indicate that there is a data entry or business process issues that must be further examined. Exercise caution before completely ignoring a data element. When in doubt, confirm with the business and provide it with the data profile results. Those results are invaluable to supporting a well-made decision.
• An element that is always populated with the same value is practically in the same category as an element that is never populated. It is common for software applications and database rules and constraints to assign default values to certain fields. It the default value is never modified, chances are that the element is not used by the business and can be ignored. Treat elements in this group as you would treat them if they were never populated. Mark them as out of scope and obtain a final sign-off, which is likely to happen with little dispute.
• Typical data profile techniques should be applied to help with the data analysis. Frequency distribution, pattern analysis, redundancy analysis, type identification, primary and foreign key evaluation, and other statistical measurements are just a few of many methods that support the evaluation of data fields and the making of a final decision on in-scope or out-of-scope exercises.
Some master data elements will exist in one source but not in others, and some will overlap. The quality of the data (or lack thereof) will vary widely by source, which means that every source must be profiled independently and meticulously. IT and the business must work together in this activity. The data-profiling activity can be quite technical, but it is necessary to have a wide and deep view into the data for proper analysis. Proper alignment and collaboration between data governance and IT are critical factors. Figure 2.3 depicts a simple template example of inventorying the master data with each domain, including the most critical data elements (CDEs). An actual inventory list may have many more columns to capture additional source and reference information that is helpful for the analysis.
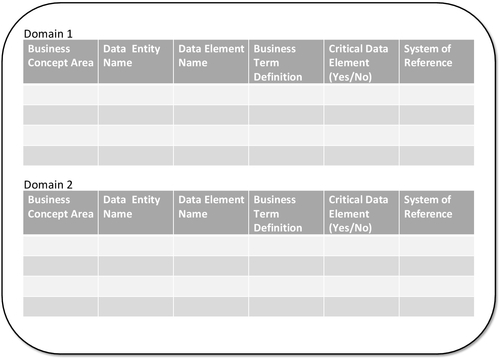
Defining the Most Critical Data Elements
The master data elements were identified in the previous discussion, but the question now is: What set of information from multiple sources (or even within a single source) belongs to the same entity, and which of the elements are most critical to the business and analytical operations? While conducting the narrow/shallow analysis, this is an opportunity to also have these business process areas identify their CDEs. As part of compiling the master data list, the identified CDEs should be clearly tagged, as this will be a valuable subclassification of the master data that can be leveraged later for focusing on data quality measurement and business term standardization efforts.
The compiling of a master data element list is likely to reflect various data inconsistencies that exist within and across the sources involved. These data issues will need to be examined in relation to the data quality management, data integration, and entity resolution practices. Those practices will be covered in detail in later chapters of this book, but certainly the outcome of the exercise to identify and list a domain’s master data can help raise the initial visibility to many data quality and consistency issues.
Business Definition Conflicts
When analyzing the master data, it would not be unusual to find variations with the definition of the subject areas, data entities, and the business terms for the data elements. This is because siloed applications and their data models will have been defined and implemented without the benefit of many, if any, enterprise standards. Engaging data analysts and information architects to conduct an enterprisewide analysis to evaluate the semantic consistency of a domain’s key entities and business terms should be a planned activity supported by the MDM PMO and data governance. The master data inventory previously described and represented in Figure 2.3 will also support the ability to evaluate the business term definition conflicts and overlaps that are likely to exist within or across domains. How to address these conflicts and build enterprise standard definitions will be discussed further in Chapters 6 and 10.
Prioritizing Domains
MDM business case and investment decisions should be driving the overall MDM strategy based on priorities that are typically associated with risk mitigation, revenue growth, cost reduction, or business efficiency. However, there can be many strategic, operational, and technical reasons that influence domain implementation order. The MDM priorities will also be influenced by the IT roadmap, business process needs, analytical needs, and executive sponsorship.
Starting an MDM initiative with focus on the Customer or Product domain certainly makes sense since the operability and sustainability of most companies rests on customer and product dynamics. Almost all the manufacturing, sales, marketing, financial, service, and analytical functions in a company are tied to these customer and product master elements; therefore, this typically is a natural starting point for MDM. And once these most critical domains are addressed, it will be easier for other domain programs to follow suit as part of a broader MDM strategy and plan.
When planning a multi-domain program, sufficient time is needed to work out the right implementation approach, examine business impacts, determine critical path dependencies, and to define the ongoing program management model. Not fully addressing these items will likely lead to various program impacts and priority adjustments. It is the business functions and transactional areas that are the primary creators and consumers of the master data. And since most transactional areas will interact with master data from multiple domains, the domain implementation plan and order can have a significant impact on business operations. Although the result of a successfully executed MDM initiative will provide many benefits for business operations and analytic functions, these initiatives will drive data and process changes that can be disruptive if the changes are not handled well. Quotes, orders, fulfillment, claims, payment, and service delivery are all major process areas that can be easily disrupted by master data changes due to MDM initiatives. And, of course, if not handled well, such changes can cause customer abrasion that will negatively affect customer satisfaction and loyalty, which in turn can affect a company’s bottom line and become a very unwanted, highly visible problem.
For all domains in the scope of an MDM program, it is critical to inventory the business processes, consumer areas, and life cycle of the master data. Be sure to understand how MDM changes will affect these dynamics and ensure that these stakeholders are represented in the domain MDM plans and data governance structure. More discussion of this point will be provided in the subsequent chapters of this book.
Conclusion
This chapter covered how to identify and define master data, how to associate master data with data domains, and how to prioritize the implementation of data domains in a multi-domain model. This included a discussion about when metadata, reference data, scarcely populated data elements, or even some unpopulated data elements may need to be included within the MDM scope. Also explained was how to address cross-functional conflicts with the business definition of master data and how to identify the most critical master data elements to ensure that these elements will have the highest priority for quality control across the MDM practice areas.
Be sure to define, analyze, plan, and prioritize master data wisely. Ensure that the MDM domain definition is well aligned with enterprise architecture strategies and business model concepts. When considering domain priorities, review the business impacts and change management needs associated with the MDM objectives. Stay focused on the overall multi-domain strategy and plan, but also aim at the near-term objectives that can establish quick successes and be executed within a reasonable time frame. Longer-term objectives can change, and they are often influenced by the execution and success of the nearer-term objectives.