
Metadata Management
Abstract
This chapter covers the discipline and practice of metadata management in a multi-domain Master Data Management (MDM) model. In addition, it discusses a standard approach to defining, identifying, and managing enterprise-level metadata assets such as enterprise business terms, reference data, data models, data dictionaries, and other artifacts that express the data flow and life cycle; as well as how well-organized and -maintained metadata is critical to the efficiency and success of data governance and data analysis.
This chapter covers the discipline of metadata management in a multi-domain Master Data Management (MDM) model. It discusses a standard approach to defining, identifying, and managing enterprise-level metadata assets such as enterprise business terms, reference data, data models, data dictionaries, and other artifacts that express the flow and life cycle of data. Well-organized and -maintained metadata is critical to the efficiency and success of multiple data management activities, especially data governance and data analysis. Metadata management is perceived as difficult to implement, tedious, and with low return on investment (ROI). Although metadata can be complex to manage, its benefits are extremely valuable. This chapter will expand on how metadata management lower costs and risks associated with manipulating data assets.
Metadata Management in the Context of Multi-Domain MDM
“Metadata is data about data.” You probably have heard this definition many times before. While not incorrect, that statement is too simplistic and masks a lot of significant information about metadata. A more comprehensive definition is provided by the National Information Standards Organization (NISO):
Metadata is structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use, or manage an information resource.
Still, not all metadata is equal. There are many categories of metadata, and different experts will have different categorizations. Our discussion will cover the following categories, which were originally defined by Ralph Kimball, who is a respected author on the subject of data warehousing and business intelligence:
• Business metadata—Includes glossaries of business definitions and reference libraries of business rules, data qualities, and algorithms
• Technical metadata—Includes physical data structures, interfaces, data models, data lineage, and transformations
• Process or operational metadata—Includes statistics about data movement such as frequency, record counts, component by component analysis, and other pieces of information collected for quality assurance (QA) purposes
One major mistake is to handle all metadata the same way. The management of business metadata, for example, is quite different from the management of technical and operational metadata. Another mistake is to fail to prioritize metadata definitions within their proper categories. One of the reasons that metadata management projects fail is because companies try to move from having no metadata at all to documenting every single data element all at once. Metadata should be prioritized accordingly. More on managing metadata categories and prioritization will be discussed later in this chapter.
Metadata management is an important discipline in any company. Just like data governance, metadata management should be a practice employed with or without an MDM implementation. The methodologies and tools behind metadata management are invaluable to formally document data assets, their use, and their life cycle across the many data systems in a company. Proper metadata information will capture the context required to fully understand data elements and their usage. Metadata management, along with Data Quality Management (DQM), becomes a critical element to properly support data governance. Data governance without formally captured data definitions relies on a few individuals with subject matter expertise to describe those terms. This reliance on individuals instead of formal practices is vulnerable to misinterpretation and might lead to incorrect governance.
While data governance and metadata management can and should exist even without MDM, the opposite is not recommended. A multi-domain MDM implementation is about bringing many disparate systems together by combining or linking data from multiple lines of business (LOBs) into a single location. This is sure to amplify the already-existing challenges related to proper understanding and governance of data assets. LOBs are likely operating in siloes and have their own definitions, standards, and rules. The moment that data from multiple systems are combined, the chance of disputes and misunderstandings are likely to increase. MDM becomes more difficult to succeed without a formal discipline to capture definitions, data life cycles, data models, business rules, data quality standards, and data transformations. These elements are important not only to establish rules on how to master data, but also to keep data consistent with time.
The more domains and master data are managed, the greater the need for metadata management. Complexity increases at a rapid pace as more data are integrated, more data models are established, and more business functions share the same information. One may wonder if MDM is truly beneficial, considering the increased need to manage and govern data at an enterprise level. Fortunately, the answer is a resounding yes. This is a matter of allocating the appropriate level of effort at the right task. Companies today spend a lot of time and money on managing duplicated information, developing and maintaining redundant systems, and dealing with the consequences of low-quality information and the ensuing bad decision making, among many issues. Metadata management helps in two major categories:
• It proactively prevents issues by properly documenting multiple aspects about enterprise data.
• It helps to identify areas in need of improvement. Improvement not only in metadata itself, but also on governance, stewardship and quality of data.
Metadata management has many more advantages, which will be described throughout this chapter. Let’s start by exploring a typical company and its data sources in a scenario where collecting metadata information would be valuable.
Metadata in a Typical Company
A typical company will have islands of metadata across the enterprise. Figure 10.1 depicts the most important areas where metadata collection will be vastly beneficial.
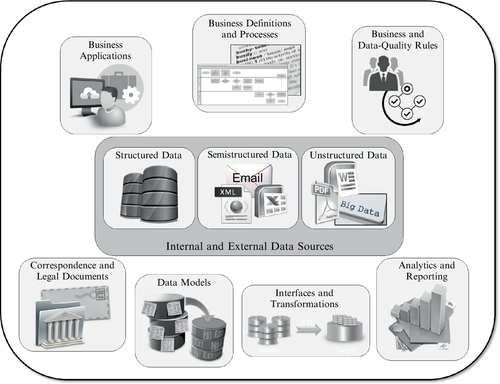
Metadata management is about capturing the definition, context, description, and lineage of all this information spread across the enterprise and storing it in an easily accessible repository for quick retrieval and wide distribution. Imagine being able to query a business term, know its definition and what business processes use it, understand its business rules and data-quality requirements, recognize its connection to technical elements, and track its usage and transformations across all systems, processes, reports, and documents across the enterprise. That is what metadata management can achieve if done properly. This information is invaluable to business teams, information technology (IT), data stewardship, and data governance.
Here are the advantages of metadata management to business teams:
• Clear definitions of business terms, without ambiguity or dispute
• Origin of data, and its life cycle details and transformations
• The capability to identify data elements behind business processes and assess the impact if any of them changes
• The ability to locate which IT systems maintain data elements relative to those business terms and where to go to retrieve or change them
• Knowledge about all data elements referenced or contained within legal documents and reports, as well as their context
• Understanding of business and data-quality rules associated with each business definition
Here are the advantages of metadata management to technical teams:
• Data lineage allows technical teams to identify where data come from and where they are going, which is crucial for ensuring effective maintenance and making future changes.
• Documentation on data transformations allows technical teams to quickly assess and react to new business requirements or questions about existing issues.
• Data lineage and transformations are essential to understanding existing interface implementations or future interface requirements.
• Complete and accurate metadata information tremendously facilitates future data migration or integration projects. By properly recognizing current states, it becomes much easier to estimate the effort required to upgrade them and to carry on actual upgrades. Companies go through many rounds of system changes, and typically, the effort is chaotic each time due to lack of proper understanding of existing metadata.
• The linkage between technical data elements and their business definitions and usage is essential when validating potentially incomplete requirements. Systems are getting more complex with time, and certain requirements can be misstated due to a lack of complete comprehension of existing definitions and implementations. Proper metadata documentation can be used to confirm assumptions.
Here are the benefits of metadata management to data governance and stewardship:
• Unambiguous definition captured in a metadata repository facilitates good governance. Data governance is in charge of creating enterprise policies, standards, and procedures. If there is no agreement among the many involved LOBs about enterprise-level data element definitions, the rules needed to govern them are also unclear.
• Data stewardship is about making sure that data is fit for use, which clearly depends on proper documentation of business usage of the data, context, and business and data-quality rules. This information is better captured and managed in a metadata repository to ensure the meaning of the data is available to confirm general business user beliefs.
• Data quality is a critical discipline underneath governance and stewardship. But data quality is not an absolute statistic; rather, it is relative to a purpose. Proper metadata information enables the documentation of that purpose unambiguously, and consequently, successfully guides data-quality efforts essential to governance and stewardship.
• Companies face many rules and regulations, and any type of noncompliance can have damaging consequences. Legal departments typically do a good job at understanding a potential compliance issue, but the problem is usually related to communicating and enforcing compliance. A metadata repository enables the dissemination of information by publishing rules and regulations related to data elements. Furthermore, since a metadata repository also documents the usage of the data, it facilitates compliance monitoring by data governance.
Master data is captured and maintained as structured data in traditional database management systems. But companies will have master data in many other forms and sources as well. Correspondences, emails, publications, social media, reports, reference data, and other elements will carry master data and any data associated with the master data. Those sources need to be understood and documented properly to identify if any master data need to be acquired from them or if the associated data are relevant to business practices.
Let’s explore the islands of metadata depicted in Figure 10.1 and what kind of metadata information in each of them would be beneficial to capture in a metadata repository to support a well-implemented multi-domain MDM program. Remember that metadata management is valuable to any company looking to improve its data management practices, but good MDM implementation will include metadata management as a fundamental discipline.
Internal and External Data Sources
Every company will have structured data sources. As said previously, master data are stored and maintained structurally in traditional database systems. Metadata management is a must to properly convey the definition, usage, and maintenance of master data. The type of metadata captured from structured data sources is exclusively technical, such as data types, technical definitions, data transformations, and so on. This information is critical to stewards and technical teams to continuously provide high-quality support on master data to business teams. But metadata about master data is not the only element that should be captured from structured sources. Other data types, such as transactional and reference data, are certainly important to the business, and their definitions must be captured too. Furthermore, these other data types are likely to either affect or be affected by master data.
Semistructured sources, such as Extensible Markup Language (XML) documents, spreadsheets, and emails are also important resources of information. Metadata around the definition, context, and usage of semistructured information can influence decisions about what attributes related to master data should be captured at an enterprise level. In addition, understanding those sources can be critical to analytics and business intelligence. Do not ignore metadata information related to those sources. Many interfaces rely on XML files to distribute data. That means that the metadata information about those XML files are important to capture. Interfaces can be extremely complex and difficult to maintain if not properly documented.
Unstructured data can be very challenging to document and govern. For one, technology is still maturing when it comes to interpreting unstructured data sources. Likewise, metadata on unstructured sources can be very difficult to capture since the data in them are fuzzy. Big data are not necessarily unstructured, but a vast majority of sources of big data, such as social media, are. Capturing customer sentiment, for example, is one way that companies try to leverage social media data in their analytics. But it can be difficult to define what data to capture if metadata about those sources are not understood. Other sources of unstructured data, such as Microsoft Word and Adobe Acrobat Portable Document Format (PDF) documents, can also contain important information related to master data elements. Without metadata, the understanding of those sources is limited.
Data Models
Conceptual, logical, and physical data models are instrumental to convey, validate, and implement a solution that correctly meets business needs. But that is not the only consideration. A well-designed model is invaluable to support the integrity and quality of data, ease of maintenance, and scalability. Most metadata tools can automatically connect to popular data modeling tools and extract metadata information valuable to technical and business teams, data stewards, and data governance.
Much of the time, companies do not pay enough attention to data models and consider them a secondary artifact. The truth is that data models are extremely important, and they should be built by experienced people and reviewed by data modeling peers and data architects. Furthermore, conceptual and logical data models should be used to validate business definitions, understanding, and requirements. This can ensure that the ensuing physical model and eventual implementation are easy to maintain and extend if necessary. Unfortunately, project priorities and delivery timelines often force the implementation of a physical model while precluding the completion of conceptual and logical models. This will lead to later problems related to data lineage and traceability from enterprise data models to physical applications.
Conceptual and logical data models can serve as a connection between business terms, their definitions, and where they physically reside in the multiple sources of data in the company. If this information is properly captured in a metadata repository, the maintenance and governance of data are facilitated. When implemented sources follow proper data modeling best practices, the resulting product is much more robust, and data quality enforced through database constraints can be confirmed via the metadata tool for the benefit of all interested parties.
Master data are typically at the core of all data models across the enterprise. The understanding and dissemination of those models foster the comprehension of the relationships of master data within the multiple domains and their transactional counterparts.
Interfaces and Transformations
Since the advent of distributed computing, one of the purposes was for multiple systems to collaborate and coordinate their use of shared resources. This architecture should naturally lead to more specialized systems and consequently higher modularization, which obviously are very desirable outcomes. Higher modularization means that applications are written to serve a specific purpose, are used by distinct teams, and are maintained by specialized groups. All this leads to greater understanding and easier maintenance of the data behind those applications.
However, business processes are getting more complex, and applications are getting more flexible. More complex business processes typically require new functionality. Instead of adding more specialized applications, companies customize the more flexible applications to support the new requirements. Of course, this is not always bad, as there is an obvious advantage to using what is already available. However, it is possible to end up with applications running functions that were not originally designed for them. For example, a customer relationship management (CRM) system might be customized to run functionality that should have been deployed in an enterprise resource planning (ERP) system, or vice versa.
The reasons for this vary. They could be lack of available resources to develop the new functionality in the right technology, or the fact that the target users do not have access to a certain application. The bottom line is that this development could lead to additional data needed in a system that was not necessary before. Proper interfaces and transformation documentation are essential to handle this type of scenario.
In addition, every company will have a multitude of distributed applications, both internal and external. Vendor offerings are becoming more numerous and complex, with real-time applications available for integration. That means that more data are moving around, and as they do, they may undergo transformations. Metadata management can help documenting how data are mapped from one system to another and how they are transformed. This information is critical to understanding what data is required where, how data is changed as it moves around, and what impact an eventual change will have on all involved systems.
To be sure, capturing interface and transformation logic is important for any data element, but it is even more so for master data because they are more pervasive and subject to change as time passes. Also, data security is typically more important to maintain when dealing with master data. Customer information, for example, is extremely sensitive, and having the knowledge at your fingertips about what interfaces receive and send customer information is quite powerful. Product data can also be confidential, and its exposure could risk losing a very important competitive advantage. Again, knowledge of where that information is at all times is a must.
Analytics and Reporting
Bad decision making can happen due to either low-quality information or incorrect understanding of data elements in a particular context. DQM helps with the first issue, while metadata management helps with the second. Therefore, complete and accurate metadata information in support of analytics and reports is valuable to ensure that critical business decisions are based on correctly interpreted information.
The issue that metadata management can help address is to ensure that decision making is taking place and involving unambiguously defined data elements, that the context for those decisions is correct, and that the impact of any change to the underlying data elements is proactively determined. This overall assessment requires a combination of properly characterized data elements and their lineage to analytical components and reports.
Master data elements from multiple domains lie at the core of most analytics and reporting. Thus, metadata information on master data elements for multiple domains will have this additional benefit.
Correspondence and Legal Documents
Similar to analytics and reporting, correspondence and other legal documents contain important data. As such, it is necessary to understand where the data are coming from and their definitions in given contexts. In addition, there is the even-higher risk of noncompliance issues being exposed and subject to legal action.
Metadata information, such as definitions and lineage, can ensure that the right source is being used to determine what correspondence to send, to whom, and what content it should contain. As discussed throughout this book, the amount of duplicate and conflicting information across the company is overwhelming. The integration component of a multi-domain MDM will address the issue of uncovering the single version of the truth, and the data-quality component will make certain that the data are fit for usage. Still, there is the need to make sure that the data used across the many legal documents are sourced correctly, and if any changes do occur, the affected correspondence can be easily determined and changed accordingly.
Privacy issues are an increasing concern. Many companies still struggle with making sure that sensitive information is protected. But it is hard to do this if you cannot track where all the sensitive information is. Data lineage information is essential to having this knowledge at your fingertips. Data governance can highly benefit from this in order to ensure that proper policies, procedures, and compliance rules are followed.
Business Definitions and Processes
As described previously, metadata management can be divided into business, technical, and operational areas. The elusive enterprise business glossary is the foundation of the business metadata. This is where the entire data set of business definitions resides. Imagine having a single repository with all business terms clearly explained. That is what a business glossary can do for you. It allows the creation of a business-level glossary for the enterprise, and if necessary, specialization of certain terms at the organizational level.
Related to business processes, the intent is to capture in the metadata repository the definition of the processes, as well as the business terms associated with them—it is not to capture the actual process flow. This allows lineage between business definitions, business processes, and the data elements associated with them. Impact analysis can be quickly performed to assess the effect of any changes, which could be due to regulatory mandates, functionality improvements, mergers and acquisitions, new requirements, and so on.
As the discipline of multi-domain MDM grows, metadata around business definitions and processes becomes more critical. The integration of data across multiple sources requires larger collaboration and governance, which consequently leads to a higher need for coordination. In data management, effective coordination requires less ambiguity and more knowledge and understanding of the data elements, as well as their definition and usage across the multiple organizations within the company.
Business and Data-Quality Rules
In addition to definitions, there are many other characteristics of business terms that should be captured. One such category is business and data-quality rules. It is not sufficient to just describe a business term—it is important to clearly establish the rules around it. This is no easy task. Business is getting more complex, and rules can be quite difficult to document and keep updated. However, having a single location with clearly defined characterization of all rules surrounding business practices is pivotal.
Along with business rules, it is very important to document the expectations about the fitness of the data that is supporting those business definitions and processes. This is central information to DQM. It is often said that data quality is not maintained for its own sake—it is about data’s fitness for use. A metadata tool is the perfect instrument to capture what is expected by the business regarding data health.
Entity resolution was previously described as one of the critical tasks within a multi-domain MDM program. There is a large number of data-quality rules behind entity resolution, and if these rules are not clearly stated, incorrect design and implementation, which can be very costly and present high compliance risk, can result. Data clustering is one of the key components of entity resolution, and proper business expectations regarding false positives and false negatives must be stated. Survivorship is another key component, and the expected quality of this is important to substantiate the decisions made about what source to use to create a golden record.
Business Applications’ User Interfaces
A vast majority of business functions are carried on via a user interface (UI) to a business application. Of course, those business applications have other components behind them, such as data sources, middleware, and interfaces to other systems. But those have already been covered in other discussions in this book. Let’s cover the UI component here.
Application UI is a user-friendly mechanism to expose data to users. It allows users to create, read, update, and delete information. However, it is not always obvious how data fields on the screen are related to business terms and processes. Since the UI is a window to data sources, it works as the connection between the business metadata and the technical metadata.
The association of UI elements and the database elements behind them, such as tables, columns, functions, and stored procedures, is normally provided by high-quality software. On the other hand, the association between UI elements and business terms is less straightforward. It is possible that a certain business term may be resolved by one application as multiple fields in the UI, or that a business term is referenced in more than one application UI. An example of the former is a customer name shown as separate fields such as First, Middle, and Last Name in one application, but as Full Name in another. An example of the latter is product taxonomy available in multiple applications.
The bottom line is that if there is good metadata information about UI elements and traceability to their data terms, it becomes much easier to understand the data life cycle. A business term tied to a business process can easily be traced to all applications, as well as to individual data elements and their usage in interfaces, analytics, correspondence, and so on.
Metadata Management Goals
It was stated earlier in this chapter that not all metadata is the same and that companies mistakenly attempt to go from no metadata information to exhaustive documentation instantly, with no transition. The previous section covered the many sources of information in the company from which collecting metadata can be extremely valuable. However, just like data quality, metadata documentation should not be kept just for the sake of it. Metadata must bring value to the enterprise by lowering costs, increasing revenues, lowering risks, or any combination.
Prioritization of metadata should not only happen based on the category of metadata, but also on the source of data and data elements within each source. For example, when prioritizing categories of metadata, creating an enterprise business glossary might have a higher priority than describing data transformations. Second, within a business glossary, stating business rules might be initially more important than creating a lineage between business terms and business applications. Finally, within the business glossary, prioritizing data elements associated with a given domain might be more important, depending on the MDM order.
Figure 10.2 depicts typical internal drivers and external factors that are most likely to influence the prioritization of what metadata information to capture. It also shows some of the categories of metadata collected from the many sources throughout the company.
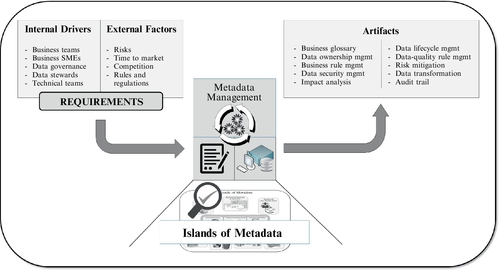
Figure 10.3 depicts how tactical artifacts from metadata management form the foundation of an overall strategic improvement of the enterprise. By supporting many key activities and minimizing negative effects, metadata artifacts lay the groundwork for success.
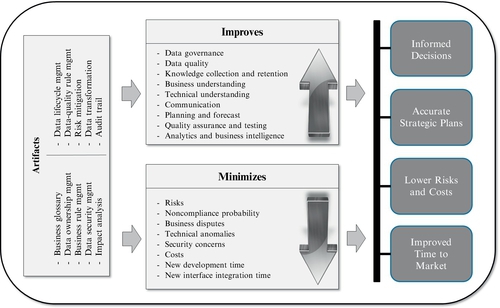
Figure 10.3 indicates the following areas improved by metadata management:
• Data governance: The key to governance is knowledge. Metadata management supports data governance and business teams with a deep understanding of their data assets. It provides data governance with the capability required to monitor existing policies, assist existing business teams, and plan future changes. Data integration is fundamental to a multi-domain MDM program, and the more that data are integrated, the more governance is needed.
• Data quality: The first step to achieving good data quality is to understand what high-quality data really means to the business. A good metadata repository will have the required data-quality expectations to serve the business well. Clearly, documented data-quality rules are essential when designing and implementing a multi-domain MDM hub.
• Business understanding: A metadata repository is the proper vehicle to use for capturing and disseminating information. There are so much data and different nomenclatures around all the assets in the company. Maintaining a proper inventory will avoid many issues and misinterpretations.
• Technical understanding: Data mapping and accompanying transformations are very important in many technical activities. Data migration, extract, transform, and load (ETL) operations, interface development, and real-time calls are just some of the tasks that can benefit from comprehensive metadata documentation. Without it, companies have to rely on fragmented documentation and the actual source code.
• Knowledge collection and retention: A metadata repository is the perfect tool to use to document data. Companies normally underestimate how many rules exist behind every data element. A lot of these rules are known only to a handful of subject matter experts (SMEs). They are not formally captured anywhere, and if those SMEs leave, so does the knowledge they possess if it is not documented.
• Communication: A metadata tool facilitates the dissemination of information, which is the basis of communication. Communicating definitions, context, business and data-quality rules, data life cycles, and all other elements surrounding data is key to encouraging knowledge and dialogue. Increased dialogue will bring up more clarifications and lead to fewer mistakes.
• Planning and forecast: The more information, the better the planning. If there is enough information about where data elements are used, the easier it is to estimate and plan future changes. If a phased MDM approach is in place, metadata information can help plan better for each of them.
• QA and testing: Several metadata artifacts are useful to QA teams. In a data migration project, for example, data mapping is a critical element of testing whether data conversion was done correctly. Many times, QA is performed based only on requirements, which can fail to identify where all data elements are used. Data lineage can help fill the gaps in the requirements.
• Analytics: Business intelligence is not only about using good data, but also about understanding the data being used. The documentation provided around data will certainly increase the probability that analysis is done correctly.
Figure 10.3 also indicates how metadata management can help minimize undesired conditions, such as the following:
• Risks: Stated plainly and simply, more knowledge leads to less risk. Decisions are made based on correct assumptions, and guesswork is reduced.
• Noncompliance probability: Legal organizations generally have a good understanding about noncompliance rules issued by specific authorities in their respective fields and industries, but those same organizations typically lack knowledge of the many data elements across the company related to those rules and consequently are vulnerable to noncompliance. Documentation on full data life cycles and transformations lead to better tracking of sensitive information.
• Business disputes: A business glossary and a business process glossary bring clarity to potential divergences and differences of nomenclatures throughout the many organizations within a company.
• Technical bugs: Many times, bugs are caused by missed dependencies. A full data lineage can indicate where dependencies exist, and if any changes do occur, what other components might be affected.
• Security concerns: Sensitive data elements need to be tracked properly to account for any undesirable exposure. Master data especially can be very susceptible to security issues, and as such, understanding their context and flow can proactively prevent negative effects.
• Costs: Reduced costs is an automatic consequence of increased positive effects while decreasing negative ones.
Overall, it is clear that these factors can lead to better-informed decisions, more accurate strategic plans, lower risks and costs, and improved time to market. A data-driven organization is more apt to plan, act, react, and adjust to market forces.
Organizing Metadata Management
Not all metadata is the same, and not all metadata should be managed in the same way. For example, building a business glossary is very different from documenting transformations on an ETL interface. Therefore, it is recommended to separate the management of metadata into separate tracks. Business metadata should be managed as part of a business track, while technical and operational metadata should be managed as part of a technical track. Figure 10.4 depicts that idea.
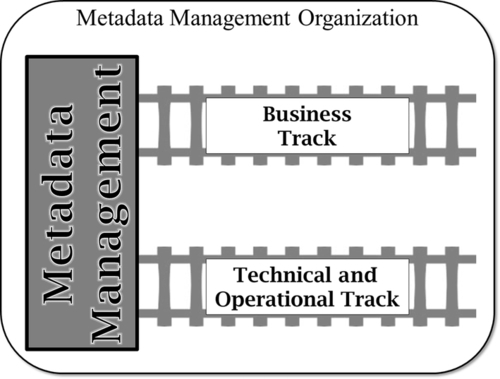
Each of these tracks will have different drivers, requirements, processes, and complementary artifacts. Let’s cover those tracks next.
Business Track Organization
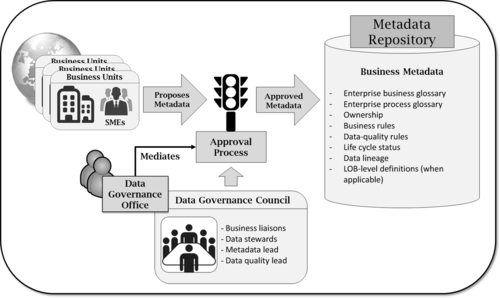
As you might expect, a business track will handle business metadata. Figure 10.5 depicts a process of collecting business metadata in a global organization with distributed business units. SMEs submit metadata information to a centralized governing body, which will review them, manage a voting process, and approve or reject them. Approved information is collected into a metadata repository for easy distribution across the enterprise. Of course, the more business definitions, processes, systems, rules, and data can be shared and defined at the enterprise level, the better. But there is always going to be a need to specialize certain terms at the LOB level. That is all right, so long as there is an attempt to establish an enterprise definition first.
Technical Track Organization
Technical and operational metadata can be better managed by a technical track. Figure 10.6 depicts a process of collecting technical and operational metadata from multiple sources across the company. Technical metadata can come from many different places. Metadata tools will often offer plug-ins that can automatically collect metadata using many different technologies. For example, metadata from databases, ETL tools, XML files, and data modeling tools are likely to be either automatically or semiautomatically loaded. Other sources might have to be manually entered.
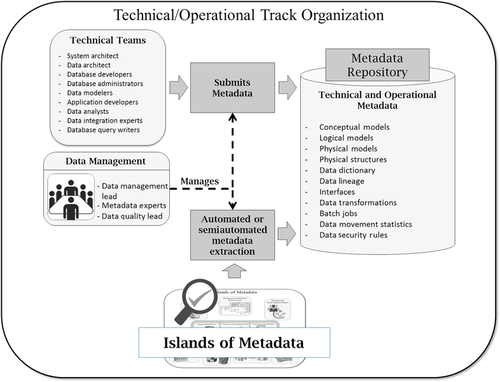
One major difference between the technical and business tracks is the approval process. When technical data elements are loaded, they likely have already been through some type of review. For example, data models should have been revised by data modeling peers and a data architect; or data sources are generally at the production level, and hence they have been designed and tested, so there is no question about what to load. The same is applicable for other sources of data already deployed across the organization. Still, a data management board is recommended to oversee what goes into the repository.
Be sure to maximize what can be automated. Be creative. A real-life example from our past experience is parsing source code, such as Procedural Language/Structured Query Language (PL/SQL) stored procedure, Java, and JavaServer Pages (JSP), to extract data mapping. If source code is developed following a recognizable set of patterns, it is possible to write regular expressions to identify those patterns and extract important metadata information. Still, much metadata information will come in the form of spreadsheets and other media that cannot be automatically parsed. Those will have to be manually loaded into the metadata repository.
Connecting the Business and Technical Tracks
The management of business and technical/operational metadata is quite different. But obviously, there is a connection. Behind business rules and definitions lie data elements, which exist in multiple systems throughout the enterprise. A mapping can be created between business terms and their equivalent technical counterparts. Through data lineage, it is possible to establish this relationship. The result is astounding, as one can locate a given business term and trace it to multiple applications, data sources, interfaces, reports, models, analytics, reports, and other elements. It is the ultimate goal of metadata management: search for a business term, learn and understand its definition, and track it throughout the entire enterprise. Imagine how powerful this information is to data governance, data quality, data stewards, and business and technical teams.
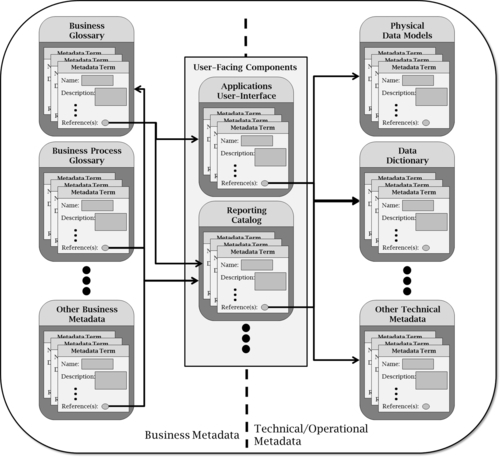
Figure 10.7 depicts a simplified data lineage to convey this idea. Notice the application UI is being used as a connecting point. Business terms are mapped to labels on the screens of multiple applications, which are mapped to databases, which in turn can potentially be mapped to many other elements. This daisy-chain effect allows any metadata object to be a starting point that can be navigated from wherever data are flowing.
Conclusion
This chapter covered the discipline of metadata management. It is obvious that metadata management is not only beneficial to companies implementing multi-domain MDM. It is a core discipline for companies looking to improve their data management practices. Still, in a multi-domain MDM implementation, whether it is a one-time deployment or a phased approach, properly documenting metadata will avoid many issues.
A multi-domain MDM program amplifies the need for collaboration from both business and technical teams. A metadata tool becomes the conduit to foment this collaboration. It provides a standard approach to define, identify, and manage enterprise-level metadata assets such as business terms, reference data, data models, data dictionaries, and other artifacts used throughout the enterprise that express the flows and life cycles of data. All these artifacts are fundamental to business practices, as well as data governance, data stewardship, data quality, and data integration.