
Chapter 20. On Working with Ops
In this chapter, I will discuss how an analysis team can effectively interact with and support an ops team. The concept of an independent “analysis team” is still new in information security, and there are no experts at this yet. There are, however, a good number of traps we can avoid.
This chapter is divided into two major sections. The first section is a brief discussion of the roles and stresses of operations environments. The second section attempts to classify major operational workflows—how operations environments are likely to execute decisions—and provides some guidelines for ensuring that ops and analytics can effectively support each other.
Ops Environments: An Overview
A Security Operations Center (SOC) is an organization focused on active security incident response.1 The SOC’s role is to process information about the state of an organization’s security and respond to that information; they are effectively first responders to security alerts. Everything that goes wrong in information security ends up on the SOC floor.
SOC work is stressful; the stress comes from the constant flow of alerts the SOC must process. The penalty for conducting an attack is very low, and because of this, any open network is subject to a constant stream of attacks. New attacks do not replace old attacks; they supplement them. Any analyst with more than a month’s experience may be conversant with attacks that have been going on for more than five years. Attacks are constant, increasing, and fire off alerts all the time.
SOC work is tedious. Because the penalty for attacking is so low, attackers run non-threatening attacks all the time. Analysts must differentiate between the constant stream of nonthreatening attacks and the constant stream of potentially threatening attacks. Operational SOC work is a constant process of picking up alerts, validating that they aren’t threats, and moving on to the next alerts.
SOC work is frustrating. Due to internal siloing, user pushback, and omnipresent vulnerabilities, the things that an analyst can actually do to defend a network are limited. They can tweak defenses, pull machines off the network for remediation, and write reports. Aggressive defenses require fights, and the security organization has to be careful about which fights it picks.
Because of these factors, analysts are always choked for time. I want to emphasize this point: the most valuable resource in any SOC is analyst time. Well-run SOCs have service level agreements (SLAs) and IDS configurations that produce just enough alerts for the SOC to handle, but this is a fraction of the potential problems they could be addressing but don’t have the resources to address.
The most important thing for any analytics group to understand is that analysts are stressed, working at capacity, and don’t have a lot of spare cycles. Good SOC managers often limit access to analysts for precisely this reason—they don’t have a lot of time to spend on the ivory tower.
For analysis teams, this means that building and maintaining trust is critical. The material in this chapter is unsexy but critically important; I really consider it more important than anything involving machine learning, pattern recognition, or classification. The reason it’s important is because there are so many areas where a well-equipped and aware analysis team can improve ops without looking to build a better IDS. There’s a lot of important work to be done on inventory, task allocation, data parsing, workflow management, visualization, and deduplication. Spend your time here, and you’re more likely to make a concrete difference.
Operational Workflows
In this section, we will discuss five operational workflows. These workflows are:
- Escalation
-
The basic workflow on most operational floors. Escalation workflow progressively filters alerts from frontline analysts to backend experts.
- Sector
-
Sector workflow is an alternate to escalation workflow where alerts are allocated to specialized teams of analysts based on the alert, its targets, and its impact.
- Hunting
-
Hunting is a specialized form of data analysis done by experienced analysts. It tends to be self-directed and driven by analyst intuition; the output may be alerts or security action, but it also produces TTPs for junior analysts to operate.
- Hardening
-
Hardening is a situational reaction to audits or alerts about new threats, and consists of taking an inventory and then triaging vulnerable assets in that inventory.
- Forensic
-
Forensic workflow is a situational reaction to an alert about a host within the network being compromised.
Escalation Workflow
The most common form of operational workflow is the escalation workflow, a helpdesk-like process of promotion. This workflow is characterized by multiple tiers of analysts who progressively filter information to experts. If you peruse standards such NIST 800-61 or best practices guides, you will see some variant of this workflow discussed. It’s not uncommon to find tools for managing these workflows that come directly from helpdesk management. For example, Remedy is a bread-and-butter tool for managing escalation workflows in helpdesks or ops floors.
In an escalation workflow, the inputs are alerts, and the outputs are security decisions. These decisions are primarily reports, but can also include incident responses such as forensic analysis, or changes to the instrumentation. Figure 20-1 shows an example of this workflow with the key characteristics of the process. An escalation workflow is initiated by alerts, generally dropped into a SIEM console by one or more sensors. Tier 1 analysts grab the alerts and process them. When a tier 1 analyst can’t process an alert, he escalates it to a tier 2 analyst, and so on until the last tier is reached (which is generally tier 3).

Figure 20-1. Escalation workflow
Tiers are based on seniority, skill, and responsibilities. Tier 1 analysts are primarily alert processors—this is a junior and generalist position where the analyst learns the ropes of an organization. Ideally, tier 1 work is heavily workflow-based; analysts should have very well-defined processes to help them move through the enormous volume of false positives they process.
Higher-tier analysts are increasingly autonomous and specialized. Precisely how many tiers an organization offers is up in the air. I generally prefer to refer to “junior,” “senior,” and “expert” analysts to clearly delineate responsibilities. Senior (tier 2) analysts begin to specialize and are more autonomous than junior analysts, but are still focused primarily on SIEM. Expert (tier 3) analysts have a deep understanding of the organization’s network traffic and are usually experts on critical fields within the system.
As a reactive process, the escalation workflow is a necessary component for incident response. However, the approach is well known for burnout—a rule of thumb is that tier 1 analysts will last between six months and a year before leaving or being promoted to tier 2. This hefty turnover, especially in the lower tiers, results in concomitant training costs and a constant problem of knowledge management.
Analysis teams working with an escalation workflow should look into processes to help analysts handle more alerts and processes that provide awareness of false negatives. Given the turnover in analysis teams, the most effective place to start working is on improving the reproducibility and throughput of junior analyst work. Inventory and organizational information are particularly useful here—much of what a junior analyst does is based on determining what the target of the alert is, and whether that target is vulnerable to the problem raised by the alert.
Also of use are tools that speed up looking up and representing anomalous behavior and building up the inventory and other situational information. Much of a tier 1 analyst’s work is threat assessment: based on an indicator such as an IP address, has this host talked to us recently? If a scan is seen, who responded to the scan? Automating these types of queries so the analyst simply has to process rather than fetch the data can result in a faster turnaround time and reduce errors.
At a more strategic level, the analysis team can evaluate the coverage provided by the detection systems. Coverage metrics (see Chapter 19) can help to estimate how many problems are slipping past the detectors.
Sector Workflow
The sector workflow is an alternative to the escalation workflow that divides alerts into discrete areas of expertise. In information security, sector workflows are rare—in my experience, the overwhelming majority of ops floors use an escalation workflow, and the majority of tools are written to support it. That said, sector workflows are common outside of information security, in air traffic control, combat information centers, and the like.
Figure 20-2 shows the basic process. A sector workflow is a “foundational” workflow in the same way that an escalation workflow is: it begins with alerts delivered to the SIEM console and ends with analysts deciding on defensive actions. However, whereas an escalation workflow assumes analysts are generalists and assigns alerts to tier 1 analysts without preference, a sector workflow assigns alerts to analysts based on different sectors of expertise.

Figure 20-2. Sector workflow
Exactly how tasks are divided into sectors is the major challenge in building a sector workflow. Done well, it enables analysts to develop deep expertise on a particular network or class of problems. Done poorly, analysts end up in feast or famine situations—a disproportionate number of alerts end up in the hands of a small group of analysts, while the remainder are stuck occupying space.
An analysis team can support sector workflows by reviewing and evaluating sector allocation. A number of different partitioning techniques exist, including:
- Network-based
-
Divide the network into subnets and allocate subnetworks to analysts as their domains. Analysts working in subnet sectors should be divided by workload, rather than total number of IP addresses.
- Service-based
-
Service-based sectors assign analysts to particular services, such as web servers, email, and the like. Service-based allocation requires a good understanding of what services are available, which ones are critical, and which ones are as yet undiscovered.
- Publish/Subscribe
-
In a publish/subscribe system, analysts choose which assets on the network to monitor. This requires that the analysts have a good understanding of what assets are important.
- Attack-based
-
In an attack-based system, analysts are divided by classes of attacks. For example, an attack-based division might have teams handling spam, DDoS attacks, scanning, etc.
Hunting Workflow
Hunting is a specialized form of exploratory data analysis focused on filling in gaps on network attributes. In contrast to the other workflows discussed in this chapter, a hunting workflow is open-ended and analyst-driven; it is a senior analyst activity.
Hunting requires both skilled analysis and an environment that facilitates open queries. Figure 20-3 shows a hunting workflow; this workflow is similar to the workflows for exploratory data analysis in Chapter 11 and is really a refinement of those workflows to deal with the realities of how hunting starts and proceeds. Hunting is characterized, in comparison to the generic EDA process, by the following:
-
It is predicated on deep expertise on the observed environment. An analyst begins the hunting process by finding unexpected or unknown behavior on a network, which requires the analyst to have a pretty good intuition for how the network normally behaves.
-
It works with the data in place. When an analyst is hunting, she is generally focused on an aberration in the network as currently observed. The tools or capabilities that are in place are what the analyst can use.
-
It generally produces a very concrete product: either an answer to a security question, or TTPs (tools, techniques, and procedures) for junior analysts.
-
It depends heavily on raw data sources such as logfiles, packet dumps, and flow records.

Figure 20-3. Hunting workflow
Hardening Workflow
Hardening is the process of assessing a network for potential vulnerabilities and then reconfiguring the network to reduce the potential for damaging attacks. In comparison to the escalation and sector workflows, hardening is situational—it is generally triggered as part of an audit or in response to an announced vulnerability, as opposed to being a continuous process.
Figure 20-4 shows the key components of a hardening workflow. As this figure shows, the workflow begins with the ops team receiving information on a potential vulnerability. This information is generally acquired in one of two ways: either the team is continuously auditing the network for vulnerable systems and receives an alert about such a system, or the team has received information on a new common mode vulnerability. In either case, the hardening workflow is inventory-driven—after receiving a notification, the ops team must create an inventory of vulnerable assets.

Figure 20-4. Hardening workflow
After identifying vulnerable assets, the ops team must decide on courses of action. This phase is triage-oriented—in general, there are more assets than the team can effectively address, and in some cases the assets cannot be patched or rectified (a particular problem with embedded systems). As a result, the ops team will usually end up with a prioritized list of courses of action: some hosts will be patched before others, and some hosts will not be patched but taken offline or heavily blocked.
When executed on a regular basis (as part of a process of continuous audit and identification), hardening is a proactive defensive strategy and can reduce the workload on other parts of the ops team. That said, hardening depends heavily on quality inventory—identifying vulnerable assets is the core of a hardening workflow, and it is easy to skip assets.
There are several ways that an analysis team can improve hardening work. The first is by working to improve the quality of inventory by mapping and assessing the assets in a network continuously, rather than simply as part of the hardening process (see Chapter 7 for more information on assessment). In addition, analytics work on population and locality (see Chapter 14 for more information) can help inform operations by giving them an understanding of how heavily used an asset is and the potential impact of its loss.
A hardening scenario
Consider a situation where vulnerability researchers publicize a widespread vulnerability in a common HTTP library (let’s call it Heartbleed). This kind of vulnerability is likely announced through some vulnerability clearinghouse such as US-CERT, although it may also appear on mailing lists or occasionally as a front-page newspaper item. On receipt of the announcement, the SOC team must create a mechanism to determine which hosts within the network are vulnerable to an exploit.
The SOC team collates information from multiple sources and determines that the vulnerability is limited to a specific set of versions of Nginx, Apache, and a family of embedded web servers. At this time, the hardening workflow forks into two different courses of action: one for software, one for embedded. The Nginx and Apache servers can (theoretically) be identified and patched. The embedded web servers are barely identifiable, as the vulnerable installation has passed through three different manufacturers and now runs a dozen different host strings.
Based on this information, the SOC team scans the network on ports 80 and 443 for web servers and creates an inventory of those servers. Of the 100 web servers they find, 60 are not vulnerable, and 40 are. Of the 40 vulnerable web servers, 4 of them are mission critical—they cannot be shut down and patched without affecting the company’s core business processes. After interviewing the team running those servers, the SOC team determines that the servers do not have to communicate across the network’s border. They prepare to aggressively lock down those servers, allowing access from a limited set of networks within the company. The remaining 36 servers are patched.
Forensic Workflow
A forensic workflow refers to an investigation into breaches or damage. This is, like hardening, a situational workflow, but one driven by a confirmed alert. A forensic workflow is about assessing damage: determining what assets within a network have been infected, what damage the attacker did, and how to prevent the attack from recurring.
Figure 20-5 is a high-level description of a forensic workflow. As the figure shows, the workflow begins with a confirmed incident—evidence of an attack, or an alert from a user. From this information, the ops team identifies hosts that have been compromised. This is done by isolating indicators of compromise (IOCs) from infected hosts and using this information to identify the extent of damage throughout the network.
Like the hardening workflow, a forensic workflow is largely asset-based; the metric for success is based on examining a list of assets. However, in a forensic workflow that list of assets grows dynamically during the investigation process—identifying a new IOC necessitates examining hosts on the network for evidence of that IOC. A forensic workflow consequently resembles a graph walk where each node is an asset, and the links are paths of communication.
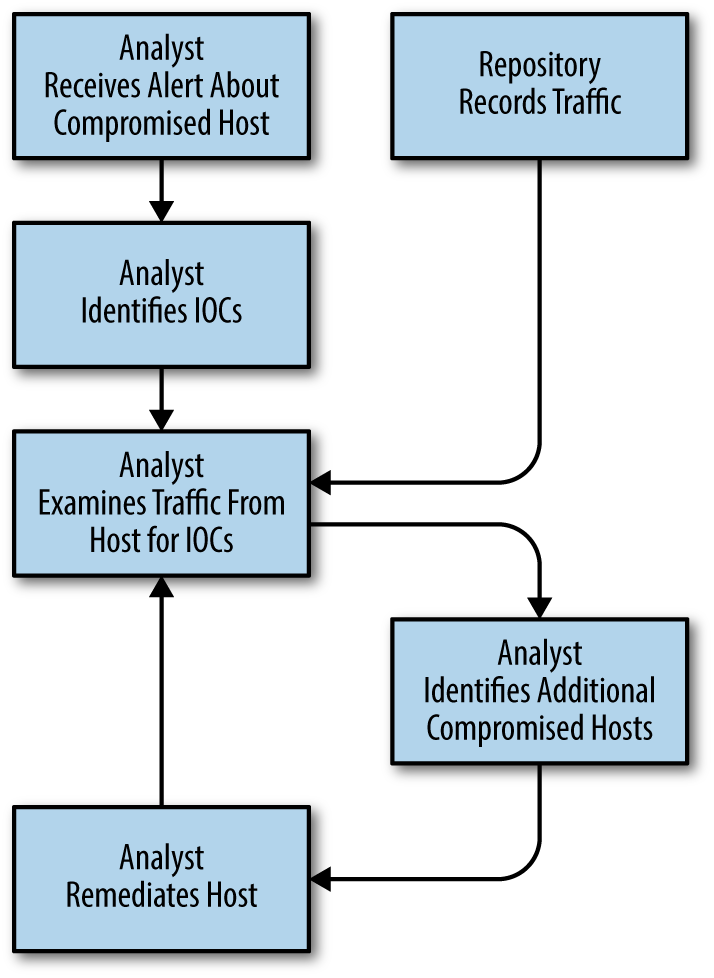
Figure 20-5. Forensic workflow
Switching Workflows
The workflows described here aren’t set in stone, and it’s not uncommon to see an ops floor use some combination of them. In particular, an analysis shop might use an escalation workflow for its tier 1 analysts, while tier 2 analysts use a sector workflow and tier 3 analysts are working in a hunting flow. Workflows may also be situational and temporary; this is particularly true for forensic, hardening, and hunting workflows, which happen due to specific events and should have clearly defined end states.
Further Readings
-
J. Bollinger, B. Enrigh, and M. Valites, Crafting the InfoSec Playbook: Security Monitoring and Incident Response Master Plan (Sebastopol, CA: O’Reilly Media, 2015).
-
P. Cichonski et al., “Computer Security Incident Handling Guide,” NIST Special Publication 800-61r2, available at http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf.
-
C. Zimmerman, “Ten Strategies of a World-Class Cybersecurity Operations Center,” MITRE, available at https://www.mitre.org/publications/all/ten-strategies-of-a-world-class-cybersecurity-operations-center.
-
The Argus group website, particularly http://www.arguslab.org/anthrosec.html. Among its many projects, the lab run by Simon Ou at the University of South Florida runs the only anthropological study of CSIRTs that I know of. I can’t stress how important their work on analyst stress (in particular their model for burnout) is.
-
The ThreatHunting Project: Hunting for Adversaries in Your IT Environment.
1 SOCs have a number of different names. I personally prefer the chewier but more descriptive Computer Security Incident Response Team (CSIRT).