
Chapter 13. On Fumbling
Up to this point, we have discussed a number of techniques for collecting and analyzing data. We must now marry this with attacker behavior.
Recall from Chapter 3 the distinction between anomaly and signature detection. A focus of this book is on identifying viable mechanisms for detecting and dealing with anomalies, and to find these mechanisms, we must identify general attacker behaviors. Fumbling, which is the topic of this chapter, is the first of several such behaviors.
Fumbling refers to the process of systematically failing to connect to a target using a reference. That reference might be an IP address, a URL, or an email address. What makes fumbling suspicious is that a legitimate user should be given the references he needs. When you start at a new company, they tell you the name of the email server; you don’t have to guess it.
Attackers don’t have access to that information. They must guess, steal, or scout that data from the system, and they will make mistakes. Often, those mistakes are huge and systematic. Identifying these mistakes and differentiating them from innocent errors is a valuable first step for analysis.
In this chapter, we will look at models of normal user behavior that are violated by attackers. This chapter integrates a variety of results from previous chapters, including material on email, network traffic, and social network analysis.
Fumbling: Misconfiguration, Automation, and Scanning
We’ll use the term fumble to refer generically to any failed attempt by a host to access a resource. A fumble in TCP means that a host wasn’t able to reach a particular host address/port combination, whereas a fumble in HTTP refers to the inability to access a URL. Individual fumbles are expected and are not automatically suspicious. What’s more of a concern is a tendency toward repeated fumbling. Fumbling as an aggregate behavior can happen for several reasons: an error in lookup or configuration, automated software, and scanning.
Lookup Failures
Fumbles usually happen because the destination doesn’t exist in the first place. This can be a transient phenomenon due to misaddressing or movement, or it can be due to someone addressing a resource that never existed.
Keep in mind that people rarely enter addresses by hand. Most users will never directly enter an IP address, instead relying on DNS to moderate their communications. Similarly, apart from a TLD, users rarely enter URLs by hand, instead copying or clicking them from other applications. When someone does enter a faulty address or URL, it usually means that something further up the chain of lookup protocols that got him there failed.
When a target moves, misaddressing is a common phenomenon. In the case of a misaddress, the target does exist, but the source is misinformed about the address. For example, an attacker may enter the wrong name or IP address, or use an earlier IP address after a host moves.
Every site has unused IP addresses and port numbers. For instance, a /24 (class C) address space allows 254 addresses (2 more are reserved for special purposes), but the network usually uses only a fraction of them. An unused address or port number is called dark space. Legitimate users rarely try to access dark space, but attackers almost always do. However, knocking on the door of an unused IP address or port is not dangerous in itself, and is so common that tracking it isn’t worthwhile.
Misaddressing is often a common mode failure, meaning that it will not be limited to one or two users, but to a large community. The classic example of a misaddress is somebody sending a message to a mailing list and mistyping a URL. When this happens, you don’t see one or two errors, and you don’t see individual errors. You see the exact same meaningless string occurring over and over again, coming from dozens if not hundreds of sites. If you see a large number of fumbles coming from different sites, all identical and all indicating a misspelling, then it’s a good sign that the error has a common cause such as a misconfigured DNS server, a faulty redirect on the web server, or an email with the wrong URL.
Automation
People are impatient. Very often, when they can’t actually reach a site, they may retry once, but then they’ll go off and find something better to do with their time. Conversely, automated systems retry connections as a reliability measure, and will often return after a relatively short interval to see if the target is up and running.
On a network traffic feed, this means that a protocol that is human-driven (SSH, HTTP, Telnet) is likely to have a lower failure rate per connection than protocols that are largely automated (SMTP, peer-to-peer communications).
Scanning
Scanning is the most common form of attack traffic observed on the network. If you own a nontrivial chunk of IP space (say, a /24 or more), you will literally be scanned thousands of times a day.
Scanning is one of the great sources for bogus security figures. If you classify a scan as an attack, then you can claim to be dealing with thousands of attacks per day. Attacks you’re going to do precisely nothing about, but still thousands. Scanning is easy, fun, and stupid amusement for script kiddies.
Imagine that your network is a two-dimensional grid, where the x-axis shows your IP addresses and the y-axis shows the ports. The grid will then have 65,536 by k cells, where k is the total number of IP addresses. Now, every time a scanner hits a target (an IP/port combination), mark a cell. If you’re interested in all the capabilities of a single host, you may open up a connection to every port it has, resulting in a single vertical line on the grid: a vertical scan. The complement to a vertical scan is a horizontal scan, where the attacker communicates with every host on the network, but only on a specific port.
As a rule of thumb, defenders scan vertically and attackers horizontally. The difference is primarily opportunistic—attackers scan a network horizontally because they are uninterested in the targets outside of the vulnerabilities they can exploit. An attacker who is interested in a specific target may well scan it vertically. Defenders scan vertically because they can’t predict what an attacker will hit.
If an attacker knows something about the structure of a network ahead of time, she may use a hit list, a list of IP addresses that she knows or suspects may be vulnerable. An example of a common hit-list attack is where the attacker begins by using a blind scan of a network to identify SSH hosts and then, sometime later, uses that list to begin password attacks.1
Identifying Fumbling
There are two stages to identifying the process of fumbling. The first is determining what, in a protocol, means that a user failed to correctly access a resource. In other words, what does a failed access “look” like?
The second stage is determining whether the failure is consistent or transient, global or local. Fumbling false positives can include misconfigurations, transient changes to the network (such as a DNS record updating), and user mistakes. Fumbling identification requires differentiating a pattern of intent from random phenomena.
There are a number of different techniques for identifying fumbling. These include:
-
Communication with dark addresses. If a host is trying to contact dark (nonexistent but routable) addresses, it’s a good indication that the host doesn’t know your network configuration.
-
Address spread. Most hosts communicate with a small and disparate set of addresses internally. If you see hosts that are talking to a disproportionately large set of targets over a short time, that’s a warning sign.
-
Failed sessions. With TCP, you can examine flag combinations to see if the flow looks like a real session. If you have a payload, you can look to see if an actual service ran during the session. If a host doesn’t engage in anything but the most cursory interaction, that’s a good sign that it’s fumbling through targets on the network.
-
Spikes in ICMP alerts. If a host is contacting dark ports or hosts, odds are that you’ll see a jump in ICMP traffic to the outside world providing error messages.
-
Service-specific spikes. Depending on the service you’re looking at, it may have “not found” messages—DNS NXDOMAIN messages, SMTP bounces, etc. A jump in these with a single source is a warning sign.
IP Fumbling: Dark Addresses and Spread
Let us begin by considering fumbling at the IP level, without access to any other information provided by protocols such as TCP or services such as HTTP. At this level, there are two techniques for identifying fumbling: communication with dark addresses, and communication with excessive addresses (spread).
A dark address is any IP address within a network that does not currently host an asset. As discussed earlier, any nontrivial network will likely have dark addresses, and legitimate users have no reason to contact them. At the IP level, the best way to determine if communications were to a dark address is to maintain a network map; see Chapter 19 for an in-depth discussion on processes for doing so.
That said, a network map is not relying on actual network information—it’s relying on a model of the network that was constructed some time before the event. At the most extreme end, a map of a DHCP network has a limited viable lifetime, but even a statically addressed network will see new services and hosts arrive on a regular basis. When using a network map, make sure to regularly test its integrity using one of the other techniques listed in this section.
Once you’ve constructed a map, it’s a matter of combining the map with incoming traffic data to determine whether or not a host is communicating with a dark address. Example 13-1 shows this process using SiLK and the example datafile. In this example, we construct an IP set from the list of dark addresses, then use it to partition out legitimate users from hosts.
Example 13-1. Dark space and spread construction using SiLK
$ cat hosts.txt
10.128.5.8
$ rwsetbuild hosts.txt > light.set
$ cat > network.txt
10.128.5.0/24
$ rwsetbuild network.txt | rwsettool --difference - light.set > dark.set
$ rwsetcat --count-ip network.set light.set dark.set
network.set:256
light.set:1
dark.set:255
$ rwfilter --dipset=dark.set --pass=stdout fumbling_example.rwf | rwuniq --field=sip
--packets --dip-distinct | head -3
sIP| Packets|dIP-Distin|
10.3.64.3| 277| 254|
10.45.9.23| 284| 254|I use the term spread to refer to the number of distinct addresses a host communicates with. As a rule of thumb, individual users talk with a relatively limited number of addresses within a particular network. Figure 13-1 shows this behavior in action. In this figure, there are seven dark and one lit addresses—the legitimate user only talks to the one lit address, while the scanners contact all eight addresses within the network. The end result is that the number of distinct IP addresses a legitimate host talks to hangs at around one address (plus or minus some error), while the scanners talk to a much higher ratio.

Figure 13-1. Communications with dark addresses and spread
In SiLK, you can calculate spread using rwuniq --dip-distinct, as
shown in Example 13-1. Spread is easily estimated
via histograms. The example shown in Figure 13-2 is a bit
exaggerated for a legitimate network, but only in the sense that the
number of scanners is too small—on large internet-facing networks,
I expect SSH scanning to dwarf legitimate SSH traffic.

Figure 13-2. A histogram showing spread in action
TCP Fumbling: Failed Sessions
Identifying failed TCP connections requires some understanding of the TCP state machine and how it works. As we’ve discussed before, TCP imposes the illusion of a stream-based protocol on top of the packet-based IP. This simulation of a stream is produced using the TCP state machine, shown in Figure 13-3.

Figure 13-3. The TCP state machine, from texample.net
Under normal circumstances, a TCP session consists of a sequence of handshake packets that set up initial state:
-
On the client side, the transition is from SYN_SENT (client sends an initial SYN packet) to ESTABLISHED (client receives a SYN|ACK packet from server, sends an ACK in response), and then to normal session operations.
-
On the server side, the transition is from LISTEN to SYN_RCVD (receives a SYN, sends a SYN|ACK), and then to ESTABLISHED (receives an ACK).
-
For either side, closure consists of at least two packets (CLOSE_WAIT to LAST_ACK or FIN_WAIT_1 to CLOSING/FIN_WAIT_2 to TIME_WAIT).
The net result of these transitions is that a well-behaved TCP/IP session requires at least three packets simply to set up the connection. This is overhead required by TCP, and does not include any communications done by the protocol itself. Throw in a standard MTU of 1,500 bytes, and most legitimate sessions are going to consist of at least several dozen packets.
Automated retry attempts add another layer of complexity to the
problem. RFC 1122 establishes basic guidelines for TCP retransmission
attempts and recommends a minimum of three retransmissions before
giving up on a connection. The actual retry value is usually
softcoded and stack-dependent; for example, in Linux systems, the
number of retries generally defaults to three and is controlled by the
tcp_retries1 TCP variable. In Windows systems, the
TcpMaxConnectRetransmissions registry value in
HKLMSYSTEMCurrentControlSetServicesTcpipParameters governs this behavior.
An analyst can identify fumbling by looking at a variety of indicators, depending on the type of data the operator has available and the degree of accuracy necessary. I will discuss several here, such as unidirectional flow filtering, looking for dark ports, and seeing spikes in alert messages.
Unidirectional flow filtering
If you have access to both sides of a session (i.e., client to server, server to client), identifying complete sessions is simply a matter of joining the two sides together. In the absence of that information, it’s still possible to guess whether packets are part of a whole session.
In my personal experience, I find flows to be more effective than individual packets for detecting fumbling. A fumbling attacker doesn’t interact with a service proper because there is no payload to examine. At the same time, identifying fumbling involves looking for multiple identically addressed packets that occur around the same time, which is the textbook definition of a flow.
Depending on the amount of information needed and the precision required, a number of different heuristics can identify fumbles in TCP flows. The basic techniques involve looking at flags, packet counts, or payload size and packet count.
Flags are a good indicator of fumbling, but using them is complicated by a messy collection of corner cases happily exploited by scanners to differentiate different IP stack implementations. Recall from Figure 13-3 that a client sends an ACK flag only after receiving an initial SYN + ACK from the server. In the absence of a response, the client should not send an ACK flag; consequently, flows with a SYN and no ACK flag are a good indicator of a fumble. There exists the potential that a response came outside of the timeout of the flow collector, but that’s rare in applied cases.
Attackers craft packets with odd flag combinations in order to determine stack and firewall configurations. The best known of these combinations is the “Christmas tree” packet (so called because all flags are lit up like a Christmas tree), setting SYN ACK FIN PUSH URG RST. Combinations of flags with both SYN and FIN high are common as well. When dealing with long-lived protocols (such as SSH), it’s not uncommon to encounter a packet consisting solely of an ACK. These packets are TCP keep-alive packets and are not fumbling.
Another odd nonfumbling behavior is backscatter. Backscatter occurs when a host opens a connection to an existing server using a spoofed address, and the server sends the corresponding response to the original spoofed address. Figure 13-4 shows this in more detail, but here’s a brief walkthrough of the process:
-
The host at 100.2.3.99 targets 11.65.80.99 and sends a spoofed packet claiming to be from 39.8.44.3.
-
11.65.80.99 receives the spoofed packet and responds as normal to the IP address it sees the message originating from: 39.8.44.3.
-
39.8.44.3 receives a packet acknowledging an open session from 11.65.80.99 and is now confused.
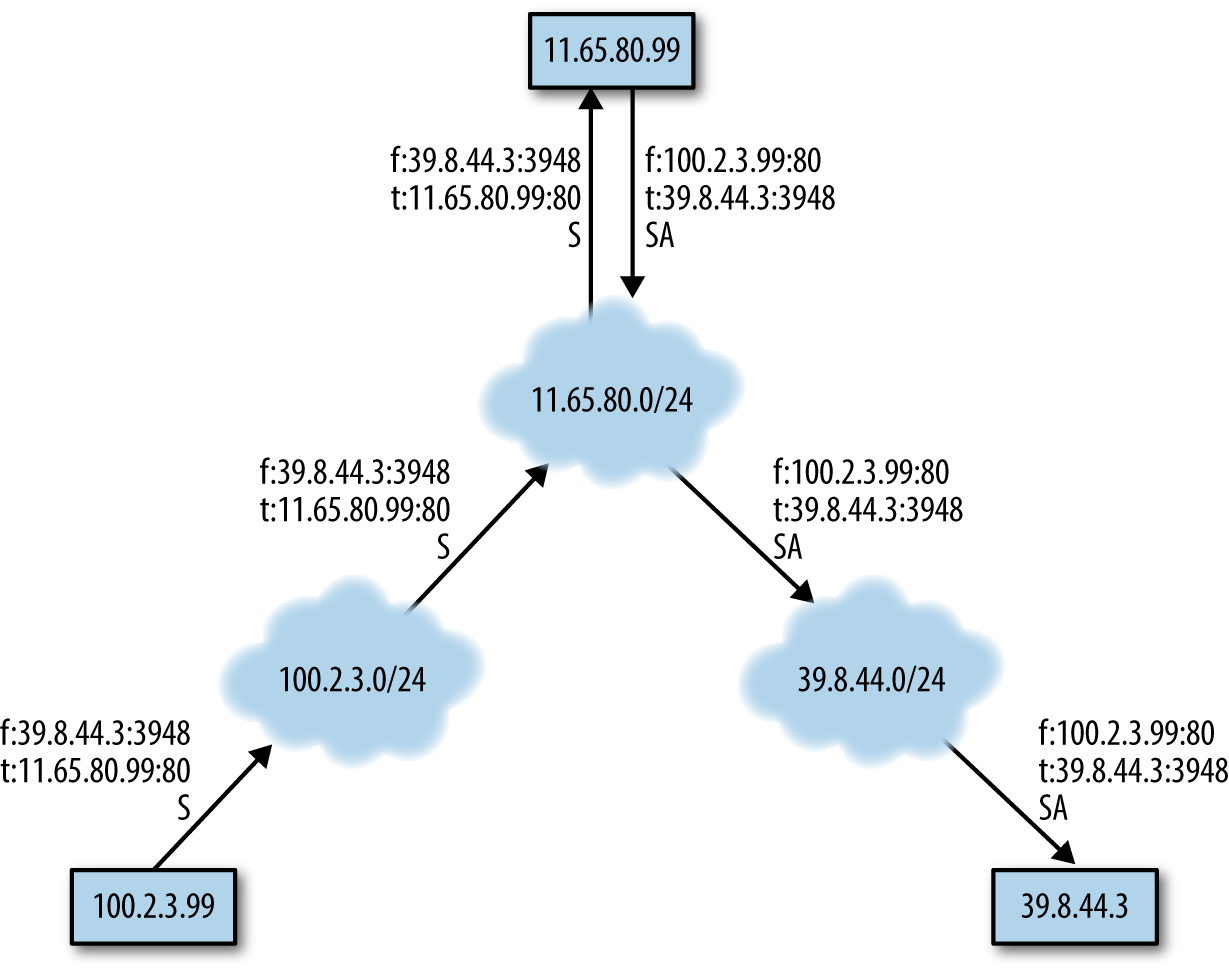
Figure 13-4. Backscatter in action
The larger a network is, the more backscatter it will receive—so much so that there are several organizations running internet telescopes around large dark spaces in order to estimate and characterize this network background radiation. On a large enough network, you will see enough backscatter that, at first glance, it will be confused with fumbling.
An easy, if rough, indicator of whether a flow shows a complete session is to simply look at the number of packets. A legitimate TCP session requires at least three packets of overhead before it considers transmitting service data. Furthermore, most stacks set their retry value to between three and five packets. These rules provide a simple filter: TCP flows that have five packets or less are likely to be fumbles.
Flow size can be complemented by looking at the ratio of packet size to number of packets. TCP SYN packets contain a number of TCP options of variable length. During a failed connection, the host will send the same SYN packet options repeatedly. Consequently, if a flow is an n-packet SYN fumble, we can expect that the total number of bytes sent is n×(40 + k), where k is the total size of the options.
Dark ports and UDP fumbling
When working with TCP and UDP, you can expand the concept of dark space to include not only addresses, but ports. Scanners usually scan across a limited set of services—SSH, SMTP, anything that has a vulnerability to exploit. The number of hosts running these services is generally vanishingly small relative to the total number of addresses on the network. Using a network map, you can identify scanners using the same dark address techniques discussed for IP in general, just adding in port numbers.
Dark ports are more critical for UDP than TCP—the rubrics discussed earlier for identifying failed sessions make it possible to identify a failed TCP connection straight from the flow. It’s rarely possible to identify a failed UDP connection from the UDP traffic itself. TCP has symmetry baked into the protocol, whereas UDP doesn’t provide any guarantees of delivery. If a UDP service provides some form of symmetry or other reciprocity, that’s a service-specific attribute. In order of preference, dark ports and ICMP traffic are the best ways to identify UDP fumbling.
ICMP Messages and Fumbling
ICMP is actually designed to inform a user that she has failed to make a connection. ICMP type 3 messages (destination unreachable) are supposed to be sent to a host to indicate that the target network (code 0), host (code 1), or port (code 3) cannot be reached by the client packet. ICMP also provides messages indicating that a route is unknown (code 7) or administratively prohibited (code 13).
With the exception of pings, ICMP messages appear in response to failures in other protocols. Several messages, such as host or net unreachable, originate from some point other than the destination address—generally the nearest router. ICMP messages may also be filtered, depending on the policies of the network in question, and consequently not received by your sensors.
This asymmetry means that when tracking fumbling from ICMP traffic, it is more productive to look for the responses. If you see a sudden spike in messages originating from a router, it’s a good bet that the target it’s sending the messages to has been probing that router’s network. You can then look at the host’s traffic to identify what it communicated with that might be suspicious.
Fumbling at the Service Level
Service-level fumbling commonly results from scanning, automated exploits, and a number of scouting tools. Unlike network-level fumbling, service-level fumbling is usually clearly identifiable as such because there are error codes in most major services that are logged and can be used to differentiate illegitimate connections from legitimate requests.
HTTP Fumbling
Recall that each HTTP transaction returns a three-digit status code, with the 4xx family of status codes reserved for client errors. In the 4xx family, the two most important and common access errors are 404 (not found) and 401 (unauthorized).
404 indicates that a resource was not available at the URL specified by the requestor, and is the most common HTTP error in existence. Users will often trigger 404 errors by hand, such as when they mistype a complex URL. Misconfiguration will often cause problems as well, such as when someone publicizes a URL that doesn’t exist.
These types of errors, from a misconfigured URL announcement or
fat-fingering, are relatively easy to identify. Fat-fingering should be relatively rare. Fat-fingered URLs will rarely
repeat—if one user is mistyping, he’ll mistype slightly differently
each time. At the same time, since fat-fingering is an individual
mistake, the same fat-fingering will not appear from multiple
locations. If you see the same mistake coming from multiple discrete
locations, that is more likely to be a result of a misconfigured URL
announcement. Such an announcement may be identifiable by examining
the HTTP Referer header. If the Referer points to a site you have
control over, then you can identify and fix the error on that site.
The third common source for 404 errors is bots scanning HTTP sites for well-known vulnerabilities. Because most modern HTTP sites are built on top of a collection of other applications, they often carry vulnerabilities from one or more of their component applications. These vulnerabilities are well known, placed in common locations, and consequently hunted for by bots everywhere. The URLs referenced in Example 13-2 are all associated with phpMyAdmin, a common MySQL database management tool.
Example 13-2. Botnets attempting to fetch common URLs
223.85.245.54 - - [16/Feb/2013:20:10:12 -0500]
"GET /pma/scripts/setup.php HTTP/1.1" 404 390 "-" "ZmEu"
223.85.245.54 - - [16/Feb/2013:20:10:15 -0500]
"GET /MyAdmin/scripts/setup.php HTTP/1.1" 404 394 "-" "ZmEu"
188.230.44.113 - - [17/Feb/2013:16:54:05 -0500]
"GET http://www.scanproxy.net:80/p-80.html HTTP/1.0" 404 378 "-"
194.44.28.21 - - [18/Feb/2013:06:20:07 -0500]
"GET /w00tw00t.at.blackhats.romanian.anti-sec:) HTTP/1.1" 404 410
"-" "ZmEu"
194.44.28.21 - - [18/Feb/2013:06:20:07 -0500]
"GET /phpMyAdmin/scripts/setup.php HTTP/1.1" 404 397 "-" "ZmEu"
194.44.28.21 - - [18/Feb/2013:06:20:08 -0500]
"GET /phpmyadmin/scripts/setup.php HTTP/1.1" 404 397 "-" "ZmEu"
194.44.28.21 - - [18/Feb/2013:06:20:08 -0500]
"GET /pma/scripts/setup.php HTTP/1.1" 404 390 "-" "ZmEu"
194.44.28.21 - - [18/Feb/2013:06:20:09 -0500]
"GET /myadmin/scripts/setup.php HTTP/1.1" 404 394 "-"Unlike the 404 errors discussed earlier, 404 scanning is generally identifiable by being completely unrelated to the actual structure of a site. Attackers are guessing that something is there and are going by the documentation and common practice to try to reach a vulnerable target.
401 errors are authentication errors, and come from HTTP’s basic access authentication mechanism—which you should never use. 401 authentication was baked into the HTTP standard early on,3 and uses unencrypted base64-encoded passwords to authenticate a user’s access to protected directories.
Basic access authentication is a disaster and should not be used by any modern web server. If you do see 401 errors in your system logs, you should identify and eliminate the source of them on your server. Unfortunately, basic authentication still occasionally pops up in embedded systems as the only form of authentication available.
SMTP Fumbling
For our purposes, SMTP fumbling occurs when a host sends mail to a nonexistent address. Depending on SMTP server configurations, this will result in one of three actions: a rejection, a bounce, or (in the case of a catch-all configuration) redirection to a catch-all account. All of these events should be logged by the SMTP server that makes the final routing decision.
Analyzing SMTP fumbles runs into the same problem that analyzing all SMTP traffic does: spam. There are a lot of failed addresses sent in SMTP messages because spammers will send mail to every conceivable address.5 Fumbling (misaddressing) may exist, but these efforts are relatively innocuous and likely to be drowned in spam. At the same time, the reasons for attackers to fumble (reconnaissance) are effectively pointless because spammers don’t probe to see whether an address exists; they spam it.
There may be one good reason to analyze failed SMTP addresses: uncovering deception. In several APT-type spear-phishing emails, I’ve seen the attackers seed the To: line with realistic-looking but fake addresses. I assume that the addresses are either out of date due to enterprise turnover or intentionally added to provide the mail with a veneer of legitimacy.
DNS Fumbling
Generally, failed DNS lookups result in an NXDOMAIN message, so if someone is fumbling with DNS (e.g., probing a domain for common names such as mail.domain, smtp.domain, www.domain, etc.) you can expect to see a spike in NXDOMAIN messages.
One potential false positive here is ISP-based DNS hijacking. When an ISP engages in DNS hijacking, it will not send an NXDOMAIN response, instead sending an IP address pointing to some internal service it controls. Check your upstream DNS services by sending bogus domains and verify that you actually get NXDOMAIN messages back.
Detecting and Analyzing Fumbling
Until some brilliant researcher comes up with a better technique, scan detection will boil down to testing for X events of interest across a Y-sized time window.
Stephen Northcutt
Fumbling alarms can be used to detect scans, spam, and other phenomena where the attacker has next to no knowledge about the target network. In this section, we will discuss the creation of fumbling alerts, forensic analysis of fumbling, and re-engineering the network to more easily identify fumbling.
Building Fumbling Alarms
When tracking fumbles, the goal is to raise an alarm when there’s suspicion that fumbling is not simply accidental. To do so, the alarm must first collect fumbling events using the rules discussed previously in this chapter. Mechanisms include:
-
Creating or consulting a map of targets to determine whether the attacker is reaching a real target.
-
Examining traffic for evidence of a failure to connect. Examples of failures to connect include:
-
Asymmetric TCP sessions, or TCP sessions without ACK flags
-
HTTP 404 records
-
Email bounce logs
-
Innocuous fumbling (a false positive) is generally the result of some form of misconfiguration or miscommunication to the target. For example, if the DNS name for destination.com is moved from IP address A to IP address B, until the change thoroughly propagates through the DNS system, users will accidentally visit address A instead of B. These types of errors, when they occur, will come from multiple sources and will be consistent. Supposing that address C on the same network is dark (that is, it has no domain name), normal users may accidentally visit A for a while, but they will not visit C. Suspicious fumbling involves users who visit multiple nonexistent destinations; a user may visit A due to a configuration error, and she might possibly visit C due to chance, but if she visits A and C, then she’s more likely scouting out a target.
Distinguishing malicious fumbling from innocuous failures is therefore, as Northcutt says, about deciding on a threshold—the number of events tolerated before you raise an alert. There are several techniques available for doing so, and simple thresholds on any of the constructs discussed in this chapter will support this approach; this process is covered in depth in Chapter 11.
An alternative approach is sequential hypothesis testing (SHT), a technique developed by Abraham Wald during World War II. The SHT approach is not in itself a statistical test, but a process for determining how many tests to conduct. For scan detection, the gold standard approach was developed by by Jaeyeon Jung et al. in their 2004 paper “Fast Portscan Detection Using Sequential Hypothesis Testing,” presented at the IEEE Symposium on Security and Privacy.
Another approach, taken from network traffic development, is a leaky bucket algorithm. These algorithms imitate the titular “leaky bucket” by maintaining a counter that, left to its own devices, decrements to zero over time. The bucket is “filled” when events occur, and drains at a constant rate over time. When the bucket exceeds a predefined threshold, it raises an alert. Figure 13-5 shows an example of a leaky bucket in action.

Figure 13-5. A leaky bucket algorithm in action
Both sequential hypothesis testing and leaky buckets facilitate the fast analysis of scanning phenomena. However, the thing about malicious fumbling is that the attackers, generally, have no particular reason to be subtle. If someone is scanning a site, he’s going to hit everything quickly. Statistical methods are primarily useful to find the attacker quickly, and consequently have more use in active defense rather than in alarm generation.
Put another way, the challenge in fumbling detection is not in detecting the phenomena quickly; it’s figuring out what’s going on outside of the fantastically obvious scans that can easily consume all of your time and effort. Internet background radiation comprises an enormous number of transient phenomena, and those are lost in the noise of obvious attacks.
Forensic Analysis of Fumbling
Scanning qua scanning is basically of no interest. Every idiot on the planet scans the internet, and a number of them scan it multiple times daily. There is some worm-based scanning (such as with Code Red and SQL Slammer, if you want to get truly Jurassic) that has gone on for years without any noticeable effect. Scanning is like rain: it’s going to happen, and the real problem is identifying the damage that it causes.
When receiving a scan alarm, there are several basic questions to ask:
-
Who responded to the scanner? As far as I’m concerned, scanners can visit as much of my dark space as they like. What I’m really concerned about is whether anyone in my network talked back to the scanner, and what they did afterward. More specific questions include:
-
Did the scanner have a serious conversation with any host? Attack software usually rolls scanning and exploit into a two-step process. Consequently, my first question about any scan is whether it ended before the true exploit.
-
Did any responding host have suspicious conversations afterward? Suspicious conversations include communications with external hosts (especially if it’s an internal server), receipt of a file, and communications on odd ports.
-
-
Did the scanner find out something about my network I didn’t know? Inventories are always at least slightly out of date, and attacks are taking place all the time. Given that, it makes sense to take advantage of the scanner’s hard work for our own benefit. Questions to address this include:
-
Did the scanner identify previously unknown hosts? If something that isn’t already in your inventory responds to the fumbler, you need to identify, assess, and harden it.
-
Did the scanner identify previously unknown services?
-
-
What else did the scanner do? Bots usually do multiple things at one time, and it’s good to check whether the scanner scanned other ports, engaged in other types of probes, or tried multiple types of attacks.
There are several good questions to ask about fumblers in general. For example:
-
What else did the fumbler do? If the same address or source is sending mail to multiple targets, it’s likely to be a spammer and, much like a scanner, is using a bot as a utility knife kind of tool.
-
Are there preferred targets? This particularly applies to fumbling with email addresses, because IP addresses are drawn from a much smaller pool. Are there common target addresses on your network? If so, they’re good candidates for further instrumentation.
Engineering a Network to Take Advantage of Fumbling
Fumbling often takes advantage of common network configurations and assumptions. Most obviously, attackers scan common ports like 22 because they expect to encounter services there. You can take advantage of these assumptions to place more sensitive instrumentation, such as full packet capture, in certain places on the network.
Because malicious scans exploit the regularity of most target sites, you can make the lives of attackers a bit harder by configuring your site in a somewhat irregular way:
- Rearrange addresses
-
Most scanning is linear: the attacker will hit address X, then X+1, and so on. Most administrators and DHCP implementations also assign addresses linearly. It’s not uncommon to have a /24 or /27 where the upper half is entirely dark. Rearranging addresses so that they’re scattered evenly across the network, or leaving large empty gaps elsewhere in the network, is a simple method that creates dark space.
- Move targets
-
Port assignments are largely a social convention, and most modern applications should be able to handle a service located on an unorthodox port. Especially when dealing with internal services, which shouldn’t be accessed by the outside world, port reassignment is a cheap mechanism to frustrate more basic scanners.
1 See E. Alata et al., “Lessons Learned from the Deployment of a High-Interaction Honeypot,” Proceedings of the Sixth European Dependable Computing Conference, Coimbra, Portugal, 2006.
2 They’d better show up if you’re doing scan detection!
4 Googlebot is a notable exception to this, and Google provides instructions on how to verify it.
5 I once logged on to an account I had never used and was greeted by 3,000 spam messages.