
Chapter 2
Understanding Oracle Database Architecture
In This Chapter
![]() Structuring memory
Structuring memory
![]() Checking the physical structures
Checking the physical structures
![]() Applying the irreducible logic of the logical structures
Applying the irreducible logic of the logical structures
Understanding the Oracle architecture is paramount to managing a database. If you have a sound knowledge of the way Oracle works, it can help all sorts of things:
![]() Troubleshooting
Troubleshooting
![]() Recovery
Recovery
![]() Tuning
Tuning
![]() Sizing
Sizing
![]() Scaling
Scaling
As they say, that list can go on and on. That’s why a solid knowledge of the inner workings of Oracle is so important.
In this chapter, we break down each process, file, and logical structure. Despite the dozens of different modules in the database, you should come away with a good understanding of what they are, why they’re there, and how they work together. This chapter is more conceptual than it is hands-on, but it gives you a solid base for moving forward as you begin working with Oracle.
Defining Databases and Instances
In Oracle speak, an instance is the combination of memory and processes that are part of a running installation. The database is the physical component or the files. You might hear people use the term database instance to refer to the entire running database. However, it’s important to understand the distinction between the two.
Here are some rules to consider:
![]() An instance can exist without a database. Yes, it’s true. You can start an Oracle instance and not have it access any database files. Why would you do this?
An instance can exist without a database. Yes, it’s true. You can start an Oracle instance and not have it access any database files. Why would you do this?
• This is how you create a database. There’s no chicken-or-egg debate here. You first must start an Oracle instance; you create the database from within the instance.
• An Oracle feature called Automatic Storage Management uses an instance but isn’t associated with a database.
![]() A database can exist without an instance but would be useless. It’s just a bunch of magnetic blips on the hard drive.
A database can exist without an instance but would be useless. It’s just a bunch of magnetic blips on the hard drive.
![]() An instance can access only one database. When you start your instance, the next step is to mount that instance to a database. An instance can mount only one database at a time.
An instance can access only one database. When you start your instance, the next step is to mount that instance to a database. An instance can mount only one database at a time.
![]() You can set up multiple instances to access the same set of files or one database. Clustering is the basis for the Oracle Real Application Clusters feature. Many instances on several servers accessing one central database allows for scalability and high availability.
You can set up multiple instances to access the same set of files or one database. Clustering is the basis for the Oracle Real Application Clusters feature. Many instances on several servers accessing one central database allows for scalability and high availability.
Deconstructing the Oracle Architecture
You can break down the Oracle architecture into the following three main parts:
![]() Memory: The memory components of Oracle (or any software, for that matter) are what inhabit the RAM on the computer. These structures exist only when the software is running. For example, they instantiate when you start an instance. Some of the structures are required for a running database; others are optional. You can also modify some to change the behavior of the database, whereas others are static.
Memory: The memory components of Oracle (or any software, for that matter) are what inhabit the RAM on the computer. These structures exist only when the software is running. For example, they instantiate when you start an instance. Some of the structures are required for a running database; others are optional. You can also modify some to change the behavior of the database, whereas others are static.
![]() Processes: Again, Oracle processes exist only when the instance is running. The running instance has some core mandatory processes, whereas others are optional, depending on what features are enabled. These processes typically show up on the OS process listing.
Processes: Again, Oracle processes exist only when the instance is running. The running instance has some core mandatory processes, whereas others are optional, depending on what features are enabled. These processes typically show up on the OS process listing.
![]() Files and structures: Files associated with the database exist all the time as long as a database is created. If you install only the Oracle software, no database files exist. The files show up as soon as you create a database. As with memory and process, some files are required, whereas others are optional. Files contain your actual database objects: the things you create as well as the objects required to run the database. The logical structures are such things as tables, indexes, and programs.
Files and structures: Files associated with the database exist all the time as long as a database is created. If you install only the Oracle software, no database files exist. The files show up as soon as you create a database. As with memory and process, some files are required, whereas others are optional. Files contain your actual database objects: the things you create as well as the objects required to run the database. The logical structures are such things as tables, indexes, and programs.
Maybe you could say that the Oracle architecture has two-and-a-half parts. Because files contain the structures, we lump those two together.
The following sections get into more detail about each of these main components.
Walking Down Oracle Memory Structures
Oracle has many different memory structures for the various parts of the software’s operation.
Knowing these things can greatly improve how well your database runs:
![]() What each structure does
What each structure does
![]() How to manage it
How to manage it
In most cases, more memory can improve your database’s performance. However, sometimes it’s best to use the memory you have to maximize performance.
 For example, are you one of those power users who likes to have ten programs open at once, constantly switching between applications on your desktop? You probably know what we’re talking about. The more programs you run, the more memory your computer requires. In fact, you may have found that upgrading your machine to more memory seems to make everything run better. On the other hand, if you are really a computer nerd, you might go into the OS and stop processes that you aren’t using to make better use of the memory you have. Oracle works in much the same way.
For example, are you one of those power users who likes to have ten programs open at once, constantly switching between applications on your desktop? You probably know what we’re talking about. The more programs you run, the more memory your computer requires. In fact, you may have found that upgrading your machine to more memory seems to make everything run better. On the other hand, if you are really a computer nerd, you might go into the OS and stop processes that you aren’t using to make better use of the memory you have. Oracle works in much the same way.
Trotting around the System Global Area
The System Global Area (SGA) is a group of shared memory structures. It contains things like data and SQL. It is shared between Oracle background processes and server processes.
 The SGA is made up of several parts called the SGA components:
The SGA is made up of several parts called the SGA components:
![]() Shared pool
Shared pool
![]() Database buffer cache
Database buffer cache
![]() Redo log buffer
Redo log buffer
![]() Large pool
Large pool
![]() Java pool
Java pool
![]() Streams pool
Streams pool
The memory areas are changed with initialization parameters.
![]() You can modify each parameter individually for optimum tuning (only for the experts).
You can modify each parameter individually for optimum tuning (only for the experts).
![]() You can tell Oracle how much memory you want the SGA to use (for everyone else).
You can tell Oracle how much memory you want the SGA to use (for everyone else).
 Say you want Oracle to use 1GB of memory. The database actually takes that 1GB, analyzes how everything is running, and tunes each component for optimal sizing. It even tells you when it craves more.
Say you want Oracle to use 1GB of memory. The database actually takes that 1GB, analyzes how everything is running, and tunes each component for optimal sizing. It even tells you when it craves more.
Shared pool
Certain objects and devices in the database are used frequently. Therefore, it makes sense to have them ready each time you want to do an operation. Furthermore, data in the shared pool is never written to disk.
The shared pool itself is made up of four main areas:
![]() Library cache
Library cache
![]() Dictionary cache
Dictionary cache
![]() Server Result cache
Server Result cache
![]() Reserved Pool
Reserved Pool
A cache is a temporary area in memory created for a quick fetch of information that might otherwise take longer to retrieve. For example, the caches mentioned in the preceding list contain precomputed information. Instead of a user having to compute values every time, the user can access the information in a cache.
The library cache
The library cache is just like what it’s called: a library. More specifically, it is a library of ready-to-go SQL statements.
Each time you execute a SQL statement, a lot happens in the background. This background activity is called parsing. Parsing can be quite expensive in terms of processing power.
During parsing, some of these things happen:
![]() The statement syntax is checked to make sure you typed everything correctly.
The statement syntax is checked to make sure you typed everything correctly.
![]() The objects you’re referring to are checked. For example, if you’re trying to access a table called EMPLOYEE, Oracle makes sure it exists in the database.
The objects you’re referring to are checked. For example, if you’re trying to access a table called EMPLOYEE, Oracle makes sure it exists in the database.
![]() Oracle makes sure that you have permission to do what you’re trying to do.
Oracle makes sure that you have permission to do what you’re trying to do.
![]() The code is converted into a database-ready format. The format is called byte-code or p-code.
The code is converted into a database-ready format. The format is called byte-code or p-code.
![]() Oracle determines the optimum path or plan. This is by far the most expensive part.
Oracle determines the optimum path or plan. This is by far the most expensive part.
Every time you execute a statement, the information is stored in the library cache. That way, the next time you execute the statement not much has to occur (such as checking permissions).
The dictionary cache
The dictionary cache is also frequently used for parsing when you execute SQL. You can think of it as a collection of information about you and the database’s objects. It can check background-type information.
The dictionary cache is also governed by the rules of the Least Recently Used (LRU) algorithm: If it’s not the right size, information can be evicted. Not having enough room for the dictionary cache can impact disk usage. Because the definitions of objects and permission-based information are stored in database files, Oracle has to read disks to reload that information into the dictionary cache. This is more time-consuming than getting it from the memory cache. Imagine a system with thousands of users constantly executing SQL . . . an improperly sized dictionary cache can really hamper performance.
Like the library cache, you can’t control the size of the dictionary cache directly. As the overall shared pool changes in size, so does the dictionary cache.
The server result cache
The server result cache has two parts:
![]() SQL result cache: This cache lets Oracle see that the requested data — requested by a recently executed SQL statement — might be stored in memory. This situation lets Oracle skip the execution part of the, er, execution, for lack of a better term, and go directly to the result set if it exists.
SQL result cache: This cache lets Oracle see that the requested data — requested by a recently executed SQL statement — might be stored in memory. This situation lets Oracle skip the execution part of the, er, execution, for lack of a better term, and go directly to the result set if it exists.
What if your data changes? Well, we didn’t say this is the end-all-performance-woes feature. The SQL result cache works best on relatively static data (like the description of an item on an e-commerce site).
Should you worry about the result cache returning incorrect data? Not at all. Oracle automatically invalidates data stored in the result cache if any of the underlying components are modified.
![]() PL/SQL function result cache: The PL/SQL function result cache stores the results of a computation. For example, say you have a function that calculates the value of the dollar based on the exchange rate of the Euro. You might not want to store that actual value since it changes constantly. Instead, you have a function that calls on a daily or hourly rate to determine the value of the dollar. In a financial application, this call could happen thousands of times an hour. Therefore, instead of the function executing, it goes directly to the PL/SQL result cache to get the data between the rate updates. If the rate does change, Oracle re-executes the function and updates the result cache.
PL/SQL function result cache: The PL/SQL function result cache stores the results of a computation. For example, say you have a function that calculates the value of the dollar based on the exchange rate of the Euro. You might not want to store that actual value since it changes constantly. Instead, you have a function that calls on a daily or hourly rate to determine the value of the dollar. In a financial application, this call could happen thousands of times an hour. Therefore, instead of the function executing, it goes directly to the PL/SQL result cache to get the data between the rate updates. If the rate does change, Oracle re-executes the function and updates the result cache.
The reserved pool
When Oracle needs to allocate a large chunk (over 5 KB) of contiguous memory in the shared pool, it allocates the memory in the reserved pool. Dedicating the reserved pool to handle large memory allocations improves performance and reduces memory fragementation.
Least Recently Used algorithm
If the library cache is short on space, objects are thrown out. Statements that are used the most stay in the library cache the longest. The more often they’re used, the less chance they have of being evicted if the library cache is short on space.
The library cache eviction process is based on what is called the Least Recently Used (LRU) algorithm. If your desk is cluttered, what do you put away first? The stuff you use the least.
Heap area
There aren’t a lot of interesting things to say about the heap area within the context of this book. Basically, the heap area is a bunch of smaller memory components in the shared pool. Oracle determines their sizes and tunes them accordingly.
Only the nerdiest of Oracle DBAs search the dark nether-regions of the Internet for heap area information. It’s not readily available from Oracle in the documentation, and the information you do find may or may not be accurate. If all I have done was make you more curious, look at the dynamic performance view in the database called V$SGASTAT to get a list of all the other heap area memory component names.
You can’t change the size of the library cache yourself. The shared pool’s overall size determines that. If you think too many statements are being evicted, you can boost the overall shared pool size if you’re tuning it yourself. If you’re letting Oracle do the tuning, it grabs free memory from elsewhere.
Database buffer cache
The database buffer cache is typically the largest portion of the SGA. It has data that comes from the files on disk. Because accessing data from disk is slower than from memory, the database buffer cache’s sole purpose is to cache the data in memory for quicker access.
The database buffer cache can contain data from all types of objects:
![]() Tables
Tables
![]() Indexes
Indexes
![]() Materialized views
Materialized views
![]() System data
System data
In the phrase database buffer cache, the term buffer refers to database blocks. A database block is the minimum amount of storage that Oracle reads or writes. All storage segments that contain data are made up of blocks. When you request data from disk, at minimum Oracle reads one block. Even if you request only one row, many rows in the same table are likely to be retrieved. The same goes if you request one column in one row. Oracle reads the entire block, which most likely has many rows, and all columns for that row.
It’s feasible to think that if your departments table has only ten rows, the entire thing can be read into memory even if you’re requesting the name of only one department.
Buffer cache state
The buffer cache controls what blocks get to stay depending on available space and the block state (similar to how the shared pool decides what SQL gets to stay). The buffer cache uses its own version of the LRU algorithm.
A block in the buffer cache can be in one of three states:
![]() Free: Not currently being used for anything
Free: Not currently being used for anything
![]() Pinned: Currently being accessed
Pinned: Currently being accessed
![]() Dirty: Block has been modified but not yet written to disk
Dirty: Block has been modified but not yet written to disk
Free blocks
Ideally, free blocks are available whenever you need them. However, that probably isn’t the case unless your database is so small that the whole thing can fit in memory.
The LRU algorithm works a little differently in the buffer cache than it does in the shared pool. It scores each block and then times how long it has been since it was accessed. For example, a block gets a point each time it’s touched. The higher the points, the less likely the block will be flushed from memory. However, it must be accessed frequently or the score decreases. A block has to work hard to stay in memory if the competition for memory resources is high.
Giving each block a score and time prevents this type of situation from arising: A block is accessed heavily at the end of the month for reports. Its score is higher than any other block in the system. That block is never accessed again. It sits there wasting memory until the database is restarted or another block finally scores enough points to beat it out. The time component ages it out very quickly after you no longer access it.
Pinned blocks
A block currently being accessed is a pinned block. The block is locked (or pinned) into the buffer cache so it cannot be aged out of the buffer cache while the Oracle process (often representing a user) is accessing it.
Dirty blocks
A modified block is a dirty block. To make sure your changes are kept across database shutdowns, these dirty blocks must be written from the buffer cache to disk. The database names dirty blocks in a dirty list or write queue.
You might think that every time a block is modified, it should be written to disk to minimize lost data. This isn’t the case — not even when there’s a commit (when you save your changes permanently)! Several structures help prevent lost data.
Furthermore, Oracle has a gambling problem. System performance would crawl if you wrote blocks to disk for every modification. To combat this, Oracle plays the odds that the database is unlikely to fail and writes blocks to disk only in larger groups. Don’t worry; it’s not even a risk against lost data. Oracle is getting performance out of the database right now at the possible expense of a recovery taking longer later. Because failures on properly managed systems rarely occur, it’s a cheap way to gain some performance. However, it’s not as if Oracle leaves dirty blocks all over without cleaning up after itself.
Block write triggers
What triggers a block write and therefore a dirty block?
![]() The database is issued a shutdown command.
The database is issued a shutdown command.
![]() A full or partial checkpoint occurs — that’s when the system periodically dumps all the dirty buffers to disk.
A full or partial checkpoint occurs — that’s when the system periodically dumps all the dirty buffers to disk.
![]() A recovery time threshold, set by you, is met; the total number of dirty blocks causes an unacceptable recovery time.
A recovery time threshold, set by you, is met; the total number of dirty blocks causes an unacceptable recovery time.
![]() A free block is needed and none are found after a given amount of searching.
A free block is needed and none are found after a given amount of searching.
![]() Certain data definition language (DDL) commands. (DDL commands are SQL statements that define objects in a database. You find out more about DDL in Chapter 6.)
Certain data definition language (DDL) commands. (DDL commands are SQL statements that define objects in a database. You find out more about DDL in Chapter 6.)
![]() Every three seconds.
Every three seconds.
![]() Other reasons. The algorithm is complex, and we can’t be certain with all the changes that occur with each software release.
Other reasons. The algorithm is complex, and we can’t be certain with all the changes that occur with each software release.
The fact is the database stays pretty busy writing blocks in an environment where there are a lot changes.
Redo log buffer
The redo log buffer is another memory component that protects you from yourself, bad luck, and Mother Nature. This buffer records every SQL statement that changes data. The statement itself and any information required to reconstruct it is called a redo entry. Redo entries hang out here temporarily before being recorded on disk. This buffer protects against the loss of dirty blocks.
Dirty blocks aren’t written to disk constantly.
Imagine that you have a buffer cache of 1,000 blocks, and 100 of them are dirty. Then imagine a power supply goes belly up in your server, and the whole system comes crashing down without any dirty buffers being written. That data is all lost, right? Not so fast. . . .
The redo log buffer is flushed when these things occur:
![]() Every time there’s a commit to data in the database
Every time there’s a commit to data in the database
![]() Every three seconds
Every three seconds
![]() When the redo buffer is 1/3 full
When the redo buffer is 1/3 full
![]() Just before each dirty block is written to disk
Just before each dirty block is written to disk
Why does Oracle bother maintaining this whole redo buffer thingy when instead, it could just write the dirty buffers to disk for every commit? It seems redundant.
![]() The file that records this information is sequential. Oracle always writes to the end of the file. It doesn’t have to look up where to put the data. It just records the redo entry. A block exists somewhere in a file. Oracle has to find out where, go to that spot, and record it. Redo buffer writes are very quick in terms of I/O.
The file that records this information is sequential. Oracle always writes to the end of the file. It doesn’t have to look up where to put the data. It just records the redo entry. A block exists somewhere in a file. Oracle has to find out where, go to that spot, and record it. Redo buffer writes are very quick in terms of I/O.
![]() One small SQL statement could modify thousands or more database blocks. It’s much quicker to record that statement than wait for the I/O of thousands of blocks. The redo entry takes a split second to write, which reduces the window of opportunity for failure. It also returns your commit only if the write is successful. You know right away that your changes are safe. In the event of failure, the redo entry might have to be re-executed during recovery, but at least it isn’t lost.
One small SQL statement could modify thousands or more database blocks. It’s much quicker to record that statement than wait for the I/O of thousands of blocks. The redo entry takes a split second to write, which reduces the window of opportunity for failure. It also returns your commit only if the write is successful. You know right away that your changes are safe. In the event of failure, the redo entry might have to be re-executed during recovery, but at least it isn’t lost.
Large pool
We’re not referring to the size of your neighbor’s swimming pool. Not everyone uses the optional large pool component. The large pool relieves the shared pool of sometimes-transient memory requirements.
These features use the large pool:
![]() Oracle Recovery Manager
Oracle Recovery Manager
![]() Oracle Shared Server
Oracle Shared Server
![]() Parallel processing
Parallel processing
![]() I/O-related server processes
I/O-related server processes
Because many of these activities aren’t constant and allocate memory only when they’re running, it’s more efficient to let them execute in their own space.
 Without a large pool configured, these processes steal memory from the shared pool’s SQL area. That can result in poor SQL processing and constant resizing of the SQL area of the shared pool. Note: The large pool has no LRU. Once it fills up (if you size it too small) the processes revert to their old behavior of stealing memory from the shared pool.
Without a large pool configured, these processes steal memory from the shared pool’s SQL area. That can result in poor SQL processing and constant resizing of the SQL area of the shared pool. Note: The large pool has no LRU. Once it fills up (if you size it too small) the processes revert to their old behavior of stealing memory from the shared pool.
Java pool
The Java pool isn’t a swimming pool filled with coffee (Okay, we’re cutting off the pool references.) The Java pool is an optional memory component.
Starting in Oracle 8i, the database ships with its own Java Virtual Machine (JVM), which can execute Java code out of the SGA. In our experience, this configuration is relatively rare. In fact, we see this where Oracle-specific tools are installed.
However, don’t let that discourage you from developing your own Java-based Oracle applications. The fact is, even though Oracle has its own Java container, many other worthwhile competing alternatives are out there.
Streams pool
The streams pool is used only if you’re using Oracle Streams functionality. Oracle Streams is an optional data replication technology where you replicate (reproduce) the same transactions, data changes, or events from one database to another (sometimes remote) database. You would do this if you wanted the same data to exist in two different databases. The streams pool stores buffered queue messages and provides the memory used to capture and apply processes. By default, the value of this pool is zero and increases dynamically if Oracle Streams is in use.
Program Global Area
The Program Global Area (PGA) contains information used for private or session-related information that individual users need.
Again, PGA used to be allocated out of the shared pool. In Oracle 9i, a memory structure called the instance PGA held all private information as needed. This alleviated the need for the shared pool to constantly resize its SQL area to meet the needs of individual sessions. Because the amount of users constantly varies, as do their private memory needs, the instance PGA was designed for this type of memory usage.
The PGA contains the following:
![]() Session memory
Session memory
• Login information
• Information such as settings specific to a session (for example, what format to use when dates are displayed)
![]() Private SQL area
Private SQL area
• Variables that might be assigned values during SQL execution
• Work areas for processing specific internal SQL actions: sorting, hash-joins, bitmap operations
• Cursors
Managing Memory
You have basically three ways to manage the memory in your instance:
![]() Automatically by letting Oracle do all the work
Automatically by letting Oracle do all the work
![]() Manually by tuning individual parameters for the different memory areas
Manually by tuning individual parameters for the different memory areas
![]() Combination of automatic and manual by using your knowledge of how things operate, employing Oracle’s advice infrastructure, and letting Oracle take over some areas
Combination of automatic and manual by using your knowledge of how things operate, employing Oracle’s advice infrastructure, and letting Oracle take over some areas
First, a quick note on Oracle automation. Through the last several releases of Oracle, the database has become more automated in areas that were previously manual and even tedious at times. This isn’t to say that soon it will take no special skill to manage an Oracle database. Exactly the opposite: When more mundane operations are automated, it frees you up as the DBA to focus on the more advanced features.
We’ve had great success implementing automated features for clients. It frees up our resources to focus on things such as high availability and security, areas that require near full-time attention. Thank goodness we don’t have to spend hours watching what SQL statements are aging out of the shared pool prematurely, resulting in performance problems.
We recommend that you manage memory automatically in Oracle 12c. For that reason, we cover only automatic management in this chapter.
Managing memory automatically
When you create your database, you can set one new parameter that takes nearly all memory tuning out of your hands: MEMORY_TARGET. By setting this parameter, all the memory areas discussed earlier in this chapter are automatically sized and managed. After you type show parameter memory_target in SQL*Plus (the SQL command-line interface available in Oracle), you see this output on the screen:
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
memory_target big integer 756M
Automatic memory management lets you take hold of the amount of memory on the system and then decide how much you want to use for the database.
It’s never obvious what value you should choose as a starting point. Answer these questions to help set the value:
![]() How much memory is available?
How much memory is available?
![]() How many databases will ultimately be on the machine?
How many databases will ultimately be on the machine?
![]() How many users will be on the machine? (If many, we allocate 4MB per user for process overhead.)
How many users will be on the machine? (If many, we allocate 4MB per user for process overhead.)
![]() What other applications are running on the machine?
What other applications are running on the machine?
Before the users get on the machine, consider taking no more than 40 percent of the memory for Oracle databases. Use this formula:
(GB of memory × .40) / Number of Eventual Databases = GB for MEMORY_TARGET per database
For example, if your machine had 8GB of memory and will ultimately house two databases similar in nature and only 100 users each, we would have this equation: (8 × .40) / 2 = 1.6GB for MEMORY_TARGET per database.
To help determine whether you have enough memory, Oracle gives you some pointers if you know where to look. It’s called the Memory Target Advisor. Find it from the command line in the form of the view V$MEMORY_TARGET_ADVICE. As seen in Figure 2-1, find it in the Database Control home page by clicking Advisor Central⇒Memory Advisors⇒Advice.

Figure 2-1: MEMORY_TARGET offers advice.
Whatever you choose for the MEMORY_TARGET setting isn’t all the memory Oracle uses. That’s why you should have an idea of how many sessions there will be before you make the final determination.
For instance, this parameter covers only memory used by the SGA and PGA. Every single session that connects to the database requires memory associated with its OS or server process. This memory requirement adds up. One of our clients has nearly 3,000 simultaneous connections eating up about 16GB of memory outside the SGA and PGA. The client’s machine has 64GB of memory, and the MEMORY_TARGET is set at 16GB.
Following the Oracle Processes
When you start and initiate connections to the Oracle instance, many processes are involved, including
![]() The component of the Oracle instance that uses the Oracle programs
The component of the Oracle instance that uses the Oracle programs
![]() Code to gain access to your data
Code to gain access to your data
There are no processes when the Oracle instance is shut down. Some of the processes are mandatory, and others are optional depending on the features you’ve enabled. It can also depend on your OS.
Three types of processes are part of the instance:
![]() Background processes are involved in running the Oracle software itself.
Background processes are involved in running the Oracle software itself.
![]() Server processes negotiate the actions of the users.
Server processes negotiate the actions of the users.
![]() User processes commonly work outside the database server itself to run the application that accesses the database.
User processes commonly work outside the database server itself to run the application that accesses the database.
Background processes
In Oracle 12c, you can have over 200 background processes. We say “over 200” because it varies by operating system. If this sounds like a lot, don’t be scared. Many are multiples of the same process (for parallelism and taking advantage of systems with multiple CPUs). Table 2-1 shows the most common background processes.
By default, no processes have more than one instance of their type started. More advanced tuning features involve parallelism. To see a complete list of all the background processes on your OS, query V$BGPROCESS.
Table 2-1 Common Background Processes
|
Background Process Name |
Description |
|
PMON |
The process monitor manages the system’s server processes. It cleans up failed processes by releasing resources and rolling back uncommitted data. |
|
SMON |
The system monitor is primarily responsible for instance recovery. If the database crashes and redo information must be read and applied, the SMON takes care of it. It also cleans and releases temporary space. |
|
DBWn |
The database writer’s sole job is taking dirty blocks from the dirty list and writing them to disk. There can be up to 20 of them, hence the n. It starts as DBW0 and continues with DBW1, DBW2, and so on. After DBW9, it continues with DBWa through DBWj. An average system won’t see more than a few of these. |
|
LGWR |
The log writer process flushes the redo log buffer. It writes the redo entries to disk and signals a completion. |
|
CKPT |
The checkpoint process is responsible for initiating check points. A check point is when the system periodically dumps all the dirty buffers to disk. Most commonly, this occurs when the database receives a shutdown command. It also updates the data file headers and the control files with the check point information so the SMON know where to start recovery in the event of a system crash. |
|
ARCn |
Up to 30 archiver processes (0–9, a–t) are responsible for copying filled redo logs to the archived redo storage area. If your database isn’t running in archive mode, this process shuts down. |
|
CJQ0 |
The job queue coordinator checks for scheduled tasks within the database. These jobs can be set up by the user or can be internal jobs for maintenance. When it finds a job that must be run it spawns the following goodie. |
|
J000 |
A job queue process slave actually runs the job. There can be up to 1,000 of them (000–999). |
|
DIA0 |
The diagnosability process resolves deadlock situations and investigates hanging issues. |
|
VKTM |
The virtual keeper of time sounds like a fantasy game character but simply provides a time reference within the database. |
|
LREG |
The listener registration process, which registers database instance and dispatcher information with the Oracle listener process. This allows incoming user connections to get from the listener to the database. |
|
MMON |
The manageablity monitor process supports the Automatic Workload Repository (AWR) by capturing statistics, monitoring threasholds, and taking snapshots. This is related to performance tuning and troubleshooting. |
|
MMNL |
The manageability monitor lite’s job is to write Active Session History (ASH) statistics from ASH buffer in the SGA to disk. This is related to performance tuning and troubleshooting. |
Other background processes exist, as you can tell by the “over 200” number we stated at the beginning of this section. However, those described in Table 2-1 are the most common, and you will find them on almost all Oracle installations. When you engage some of Oracle’s more advanced functionality, you’ll see other processes.
It’s very easy to see these background processes if you have an Oracle installation available on Linux or UNIX. In Figure 2-2, the ps –ef|grep ora_ portion lists the background processes. This situation works very well because all background processes begin with ora_.
User and server processes
Because user and server processes are intertwined, we discuss the two together. However, they are distinct and separate processes. As a matter of fact, they typically run on separate machines. A very simple example: When you start SQL*Plus on a Windows client, you get a user process called sqlplus.exe. The user process represents a user’s session in the database. When a connection is made to the database on a Linux machine, you get a connection to a process named something like oracle<database_name> or ora_S000_<database_name>.

Figure 2-2: The Oracle background process list.
The server process serves and exists on the database server. It does anything the user requests of it. It is responsible for reading blocks into the buffer cache. It changes the blocks if requested. It can create objects.
Server processes can be one of two types:
![]() Dedicated
Dedicated
![]() Shared
Shared
The type depends on how your application operates and how much memory you have. You’re first presented with the choice of dedicated or shared when you create your database with Oracle’s Database Configuration Assistant (DBCA). However, you can change it one way or the other later on.
Dedicated server architecture
Each user process gets its own server process. This is the most common Oracle configuration. It allows a server process to wait on you. If the resources can support dedicated connections, this method also is the most responsive. However, it can also use the most memory. Even if you’re not doing anything, that server process is waiting for you.
Not that it’s a bad thing. Imagine, though, 5,000 users on the system sitting idle most of the time. If your applications can’t use connection pools (similar to shared server processes), your database probably won’t survive and perform adequately for more than a day.
Shared server architecture
Just as the name implies, the server processes are shared. Now, instead of a server process waiting on you hand and foot, you have only one when you need it.
Think of a server process as a timeshare for Oracle. It’s more cost-effective (in terms of memory), and you almost always have one available when you need it (provided the infrastructure is properly configured).
On a system with 5,000 mostly idle users, you might be able to support them with only 50 server processes. You must do these things for this to work properly:
![]() Make sure the number of concurrent database requests never exceeds the number of shared servers configured.
Make sure the number of concurrent database requests never exceeds the number of shared servers configured.
![]() Make sure users don’t hold on to the processes for long periods. This works best in a fast transaction-based environment like an e-commerce site.
Make sure users don’t hold on to the processes for long periods. This works best in a fast transaction-based environment like an e-commerce site.
![]() Have a few extra CPU cycles available. All the interprocess communication seems to have small CPU cost associated with it over dedicated server processes.
Have a few extra CPU cycles available. All the interprocess communication seems to have small CPU cost associated with it over dedicated server processes.
The fact is shared server configurations are less common in today’s environment where memory is cheap. Most applications these days get around the problems associated with too many dedicated servers by using advanced connection pooling on the application server level.
You should know about some other limitations: DBA connections must have a dedicated server. Therefore, a shared server environment is actually a hybrid. Shared servers can coexist with a dedicated server.
Many different types of files are required (and optional) to run an Oracle database:
![]() Data files
Data files
![]() Control files
Control files
![]() Redo log files
Redo log files
![]() Archive log files
Archive log files
![]() Server and initialization parameter files
Server and initialization parameter files
Knowing what each of these files does greatly increases your database management success.
Getting Physical with Files
Many types of files are created with your database. Some of these files are for storing raw data. Some are used for recovery. Some are used for housekeeping or maintenance of the database itself. In the next few sections, we take a look at the various file types and what they’re responsible for storing.
Data files: Where the data meets the disk
Data files are the largest file types in an Oracle database. They store all the actual data you put into your database as well as the data Oracle requires to manage the database. Data files are a physical structure: They exist whether the database is open or closed.
Data files are also binary in nature. You can’t read them yourself without starting an instance and executing queries. The data is stored in an organized format broken up into Oracle blocks.
Whenever a server process reads from a data file, it does so by reading at the very least one complete block. It puts that block into the buffer cache so that data can be accessed, modified, and so on.
It’s also worth noting that the data file is physically created using OS blocks. OS blocks are different from Oracle blocks. OS blocks are physical, and their size is determined when you initially format the hard drive.
You should know the size of your OS block. Make sure that it’s equal to, or evenly divisible into, your Oracle block.
Most of the time Oracle data files have an extension of .DBF (short for database file). But the fact of the matter is that file extensions in Oracle don’t matter. You could name it .XYZ, and it would function just fine.
We feel it is best practice to stick with .DBF because that extension is used in 95 percent of databases.
In every data file, the very first block stores the block header. To be specific, depending on your Oracle block size, the data file header block may be several blocks. By default, the header block is 64k. Therefore, if your Oracle block size is 4k, then 16 header blocks are at the beginning of the file. These header blocks are for managing the data file’s internal workings. They contain
![]() Backup and recovery information
Backup and recovery information
![]() Free space information
Free space information
![]() File status details
File status details
Lastly, a tempfile is a special type of database file. Physically, it’s just like a regular data file, but it holds only temporary information. For example, a tempfile is used if you perform sorts on disk or if you’re using temporary tables. The space is then freed to the file either immediately after your operation is done or as soon as you log out of the system.
Figure 2-3 shows that by executing a simple query against V$TEMPFILE and V$DATAFILE you can see a listing of the data files in your database.

Figure 2-3: Data files listed.
Control files
The control file is a very important file in the database — so important that you have several copies of it. These copies are placed so that losing a disk on your system doesn’t result in losing all of your control files.
Typically, control files are named with the extension .CTL or .CON. Any extension will work, but if you want to follow best practice, those two are the most popular.
Control files contain the following information:
![]() Names and locations of your data files and redo log files
Names and locations of your data files and redo log files
![]() Recovery information
Recovery information
![]() Backup information
Backup information
![]() Checkpoint information
Checkpoint information
![]() Archiving information
Archiving information
![]() Database name
Database name
![]() Log history
Log history
![]() Current logging information
Current logging information
Control files contain a host of other internal information as well. Typically, control files are some of the smaller files in the database. It’s difficult to tell you how big they are because it varies depending on the following:
![]() How many files your database has
How many files your database has
![]() How much backup information you’re storing in them
How much backup information you’re storing in them
![]() What OS you’re using
What OS you’re using
As mentioned earlier, it’s important that you have several copies of your control files. If you were to lose all of your control files in an unfortunate failure, it is a real pain to fix.
Redo log files
Redo log files store the information from the log buffer. They’re written to by the Log Writer (LGWR). Again, you can’t read these binary files without the help of the database software.
Typically, redo log files are named with the extension .LOG or .RDO. It can be anything you want, but best practice indicates one of those two extensions. Also, redo log files are organized into groups and members. Every database must have at least two redo log groups.
Redo log files contain all the information necessary to recover lost data in your database. Every SQL statement that you issue changing data can be reconstructed by the information saved in these files.
Redo log files don’t record select statements. If you forget what you selected, you’re just going to have to remember that on your own!
The optimal size for your redo log files depends on how many changes you make to your database. The size is chosen by you when you set up the database and can be adjusted later. When the LGWR is writing to a redo log file, it does so sequentially. It starts at the beginning of the file and once it is filled up, it moves on to the next one. This is where the concept of groups comes in. Oracle fills each group and moves to the next. Once it has filled all the groups, it goes back to the first. You could say they are written to in a circular fashion. If you have three groups, it would go something like 1,2,3,1,2,3, . . . and so on.
Each time a group fills and the writing switches, it’s called a log switch operation. These things happen during a log switch operation:
![]() The LGWR finishes writing to the current group.
The LGWR finishes writing to the current group.
![]() The LGWR starts writing to the next group.
The LGWR starts writing to the next group.
![]() A database check point occurs.
A database check point occurs.
![]() The DBWR writes dirty blocks out of the buffer cascade.
The DBWR writes dirty blocks out of the buffer cascade.
How fast each group fills up is how you determine its size. By looking at all the things that occur when a log switch happens, you might agree that it is a fairly involved operation. For this reason, you don’t want frequent log switches.
The general rule is that you don’t want to switch log files more often than every 15–30 minutes. If you find that happening, consider increasing the size of each group.
Because these redo log files may be involved in recovery operations, don’t lose them. Similar to control files, redo log files should be configured with mirrored copies of one another. And, as with control files, each member should be on a separate disk device. That way, if a disk fails and the database goes down, you still have recovery information available. You should not lose any data.
Each copy within a group is called a member. A common configuration might be three groups with two members apiece, for a total of six redo log files. The group members are written to simultaneously by the log writer.
![]() How many groups are appropriate? The most common configuration we come across is three. You want enough that the first group in the list can be copied off and saved before the LGWR comes back around to use it. If it hasn’t been copied off, the LGWR has to wait until that operation is complete. This can severely impact your system. Thankfully, we rarely see this happen.
How many groups are appropriate? The most common configuration we come across is three. You want enough that the first group in the list can be copied off and saved before the LGWR comes back around to use it. If it hasn’t been copied off, the LGWR has to wait until that operation is complete. This can severely impact your system. Thankfully, we rarely see this happen.
![]() How many members are appropriate? It depends on how paranoid you are. Two members on two disks seems to be pretty common. However, it isn’t uncommon to see three members on three disks. More than that and you’re just plain crazy. Well, not really. It’s just that the more members you have, the more work the LGWR has to do. It can impact system performance while at the same time offering very little return.
How many members are appropriate? It depends on how paranoid you are. Two members on two disks seems to be pretty common. However, it isn’t uncommon to see three members on three disks. More than that and you’re just plain crazy. Well, not really. It’s just that the more members you have, the more work the LGWR has to do. It can impact system performance while at the same time offering very little return.
We commonly get this question: “If my disks are mirrored at the hardware level, do I need more than one member on each group? After all, if a disk fails, I have another one right there to pick up the slack.”
Unfortunately, you get different answers depending on who you ask. Ask us, and we’ll recommend at least two members for each group:
![]() Oracle still recommends two members for each group as a best practice.
Oracle still recommends two members for each group as a best practice.
![]() Depending on how your hardware is set up, you may have the same disk controller writing to your disk mirrors. What if that controller writes corrupt gibberish? Now both your copies are corrupted. Separating your members across two different disks with different controllers is the safest bet.
Depending on how your hardware is set up, you may have the same disk controller writing to your disk mirrors. What if that controller writes corrupt gibberish? Now both your copies are corrupted. Separating your members across two different disks with different controllers is the safest bet.
Moving to the archives
Archive log files are simply copies of redo log files. They’re no different from redo log files except that they get a new name when they’re created.
Most archive log files have the extension .ARC, .ARCH, or .LOG. We try to use .ARC as that seems most common.
Not all databases have archive log files. It depends on whether you turn on archiving. By turning on archiving, you can recover from nearly any type of failure providing two things:
![]() You have a full backup.
You have a full backup.
![]() You haven’t lost all copies of the redo or archive logs.
You haven’t lost all copies of the redo or archive logs.
There is a small amount of overhead with database archiving:
![]() I/O cost: The ARCn process has to copy each redo log group as it fills up.
I/O cost: The ARCn process has to copy each redo log group as it fills up.
![]() CPU cost: It takes extra processing to copy the redo logs via the ARCn process.
CPU cost: It takes extra processing to copy the redo logs via the ARCn process.
![]() Storage cost: You have to keep all the archive logs created between each backup.
Storage cost: You have to keep all the archive logs created between each backup.
Relatively speaking, each of these costs is small in terms of the return you get: recovering your database without so much as losing the dot over an i. We typically recommend that, across the board, all production databases archive their redo logs.
Sometimes, archiving isn’t needed, such as in a test database used for testing code. You can easily just copy your production database to revive a broken test. We’re not recommending not archiving on test databases. Sometimes the test database is important enough to archive. We’re just saying that sometimes you can get by without incurring the extra overhead.
You should keep archive log files for recovery between each backup. Say you’re doing a backup every Sunday. Now say that your database loses files due to a disk failure on Wednesday. The recovery process would be restoring the lost files from the last backup and then telling Oracle to apply the archive log files from Sunday all the way up to the failure on Wednesday. It’s called rolling forward, and we talk about it in Chapter 8.
Like control files and redo log files, it’s best practice to have more than one copy of each of your archive log files. They should go to two different destinations on different devices, just like the others. You can’t skip over a lost archive log.
Server and initialization parameter files
Server and initialization parameter files are the smallest files on your system:
![]() PFILE, or parameter file, is a text version that you can read and edit with a normal text editor.
PFILE, or parameter file, is a text version that you can read and edit with a normal text editor.
![]() SPFILE, or server parameter file, is a binary copy that you create for the database to use after you make changes.
SPFILE, or server parameter file, is a binary copy that you create for the database to use after you make changes.
Typically, these files end with an .ORA extension. Personally, we have never seen anything but that. It’s best practice for you to continue the tradition.
PFILEs and SPFILEs have information about how your running database is configured. This is where you configure the following settings:
![]() Memory size
Memory size
![]() Database and instance name
Database and instance name
![]() Archiving parameters
Archiving parameters
![]() Processes
Processes
![]() Over 1,900 other parameters
Over 1,900 other parameters
Wait, what was that? Over 1900 parameters to configure and tweak? Don’t be frightened. The fact is 99 percent of your database configuration is done with about 30 of the main parameters. The rest of the parameters are for uncommon configurations that require more expert adjustment. As a matter of fact, of those 1,900, over 1,600 are hidden. Sorry if we scared you a little there. We just want you to have the whole picture.
Whenever you start your database, the very first file read is the parameter file. It sets up all your memory and process settings and tells the instance where the control files are located. It also has information about your archiving status.
In Chapter 4, we cover how the PFILEs and SPFILEs are located under the directory where you installed the database software. This directory is called the ORACLE_HOME:
![]() Linux/UNIX: $ORACLE_HOME/dbs
Linux/UNIX: $ORACLE_HOME/dbs
![]() Windows: %ORACLE_HOME%database
Windows: %ORACLE_HOME%database
It should have a specific naming structure. For example, if your database name is dev12c, the files would be named as follows:
![]() The PFILE would be called initdev12c.ora.
The PFILE would be called initdev12c.ora.
![]() The SPFILE would be called spfiledev12c.ora.
The SPFILE would be called spfiledev12c.ora.
By naming them this way and putting them in the appropriate directory, Oracle automatically finds them when you start the database. Else, you have to tell Oracle where they are every time you start the database; that just isn’t convenient.
We recommend you keep the PFILE and SPFILE in the default locations with the default naming convention for ease of administration.
Applying Some Logical Structures
After you know the physical structures, you can break them into more logical structures. All the logical structures that we talk about are in the data files. Logical structures allow you to organize your data into manageable and, well, logical, pieces.
Without logical breakdown of the raw, physical storage, your database would
![]() Be difficult to manage
Be difficult to manage
![]() Be poorly tuned
Be poorly tuned
![]() Make it hard to find data
Make it hard to find data
![]() Require the highly trained and special skill set of a madman
Require the highly trained and special skill set of a madman
Figure 2-4 shows the relationship of logical to physical objects. The arrow points in the direction of a one-to-many relationship.
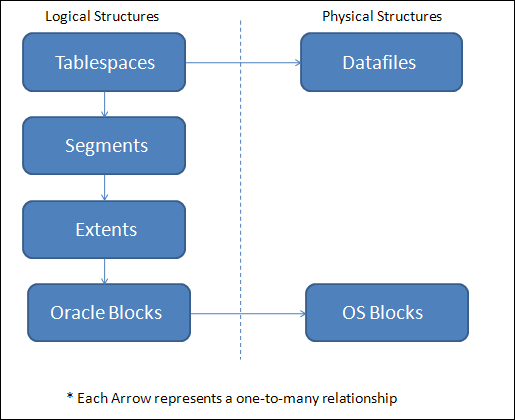
Figure 2-4: The relationship between logical and physical structures in the database.
Tablespaces
Tablespaces are the first level of logical organization of your physical storage.
Every 12c database should have the following tablespaces:
![]() SYSTEM: Stores the core database objects that are used for running the database itself.
SYSTEM: Stores the core database objects that are used for running the database itself.
![]() SYSAUX: For objects that are auxiliary and not specifically tied to the core features of the database.
SYSAUX: For objects that are auxiliary and not specifically tied to the core features of the database.
![]() UNDO: Stores the rollback or undo segments used for transaction recovery.
UNDO: Stores the rollback or undo segments used for transaction recovery.
![]() TEMP: For temporary storage.
TEMP: For temporary storage.
Each tablespace is responsible for organizing one or more data files. Typically, each tablespace might start attached to one data file, but as the database grows and your files become large, you may decide to add storage in the form of multiple data files.
So what’s the next step to getting your database up and running? You create some areas to store your data. Say your database is going to have sales, human resources, accounting data, and historical data. You might have the following tablespaces:
![]() SALES_DATA
SALES_DATA
![]() SALES_INDEX
SALES_INDEX
![]() HR_DATA
HR_DATA
![]() HR_INDEX
HR_INDEX
![]() ACCOUNTING_DATA
ACCOUNTING_DATA
![]() ACCOUNTING_INDEX
ACCOUNTING_INDEX
![]() HISTORY_DATA
HISTORY_DATA
![]() HISTORY_INDEX
HISTORY_INDEX
Separating tables and indexes both logically and physically is common in a database.
![]() Because tablespaces must have at least one data file associated with them, you can create them so data files are physically on separate devices and therefore improve performance.
Because tablespaces must have at least one data file associated with them, you can create them so data files are physically on separate devices and therefore improve performance.
![]() You can harden our databases against complete failure. Tablespaces can be backed up and recovered from one another independently. Say you lose a data file in the SALES index tablespace. You can take only the SALES_INDEX tablespace offline to recover it while human resources, accounting, and anyone accessing historical data is none the wiser.
You can harden our databases against complete failure. Tablespaces can be backed up and recovered from one another independently. Say you lose a data file in the SALES index tablespace. You can take only the SALES_INDEX tablespace offline to recover it while human resources, accounting, and anyone accessing historical data is none the wiser.
We discuss actual tablespace creation in Chapter 7.
Keep in mind that when deciding on the logical organization, it pays to sit down and map out all the different activities your database will support. If possible, create tablespaces for every major application and its associated indexes.
If your database has especially large subsets of data, sometimes it pays to separate that data from your regular data as well. For example, say you’re storing lots of still pictures. Those pictures probably never change. If you have a tablespace dedicated to them, you can make it read only. The tablespace is taken out of the checkpointing process. You can also back it up once, and then do it again only after it changes. That reduces the storage required for backups, plus it speeds up your backup process.
Segments
Segments are the next logical storage structure after tablespaces. Segments are objects in the database that require physical storage and include the following:
![]() Tables
Tables
![]() Indexes
Indexes
![]() Materialized views
Materialized views
![]() Partitions
Partitions
These object examples are not segments and don’t store actual data:
![]() Views
Views
![]() Procedures
Procedures
![]() Synonyms
Synonyms
![]() Sequences
Sequences
The latter list of objects don’t live in a tablespace with segments. They’re pieces of code that live in the SYSTEM tablespace.
Whenever you create a segment, specify what tablespace you want it to be part of. This helps with performance.
For example, you probably want the table EMPLOYEES stored in the HR_DATA tablespace. In addition, if you have an index on the LAST_NAME column of the EMPLOYEES table, you want to make sure it is created in the HR_INDEXES tablespace. That way, when people are searching for and retrieving employee information, they’re not trying to read the index off the same data file that the table data is stored in.
Extents
Extents are like the growth rings of a tree. Whenever a segment grows, it gains a new extent. When you first create a table to store items, it gets its first extent. As you insert data into that table, that extent fills up. When the extent fills up, it grabs another extent from the tablespace.
When you first create a tablespace, it’s all free space. When you start creating objects, that free space gets assigned to segments in the form of extents. Your average tablespace is made up of used extents and free space.
When all the free space is filled, that data file is out of space. That’s when your DBA skills come in and you decide how to make more free space available for the segments to continue extending.
Extents aren’t necessarily contiguous. For example, when you create an items table and insert the first 1,000 items, it may grow and extend several times. Now your segment might be made up of five extents. However, you also create a new table. As each table is created in a new tablespace, it starts at the beginning of the data file. After you create your second table, your first table may need to extend again. Its next extent comes after the second extent. In the end, all objects that share a tablespace will have their extents intermingled.
This isn’t a bad thing. In years past, before Oracle had better algorithms for storage, DBAs spent a lot of their time and efforts trying to coalesce these extents. It was called fragmentation. It’s a thing of the past but we still see people getting all up in arms about it. Don’t get sucked in! Just let it be. Oracle 12c is fully capable of managing such situations.
I also want to mention situations where you have multiple data files in a tablespace. If a tablespace has more than one data file, the tablespace automatically creates extents in a round-robin fashion across all the data files. This is another Oracle performance feature.
Say you have one large table that supports most of your application. It lives in a tablespace made of four data files. As the table extends, Oracle allocates the extents across each data file like this:
1,2,3,4,1,2,3,4,1,2,3,4 . . . and so on
This way, Oracle can take advantage of the data spread across many physical devices when users access data. It reduces contention on segments that have a lot of activity.
Oracle blocks
We’ve mentioned Oracle blocks at least twice before. We had to mention them when talking about the buffer cache and data files. Here in this section we can fill in a little more information.
An Oracle block is the minimum unit that Oracle will read or write at any given time.
Oracle usually reads and writes more than one block at once, but that’s up to Oracle these days. You used to have more direct control of how Oracle managed its reads and writes of blocks, but now functionality is automatically tuned. You can tune it manually to a certain extent, but most installations are best left to Oracle.
Regardless, blocks are the final logical unit of storage. Data from your tables and indexes are stored in blocks. The following things happen when you insert a new row into a table:
![]() Oracle finds the segment.
Oracle finds the segment.
![]() Oracle asks that segment if there’s any room.
Oracle asks that segment if there’s any room.
![]() The segment returns a block that’s not full.
The segment returns a block that’s not full.
![]() The row or index entry is added to that block.
The row or index entry is added to that block.
If no blocks are free for inserts, the segment grabs another free extent from the tablespace. By the way, all this is done by the server process to which you’re attached.
Oracle blocks also have a physical counterpart just like the data files do. Oracle blocks are made up of OS blocks. It is the formatted size of the minimum unit of storage on the device.
Oracle blocks should be evenly divisible by your OS block size. Oracle blocks should never be smaller than your OS block size. We discuss Oracle block sizing more in Chapter 4.
Pluggable Databases
Now that you have a good understanding of the pieces and parts of databases and instances, we’ve saved the best for last as we throw a new concept at you in an attempt to muddy the waters. Welcome to pluggable databases. New in Oracle 12c is an optional architecture where you have one or more smaller subsets of schemas, data tables, indexes, and data dictionaries running as Pluggable Databases (PDB) inside a larger, superset Container Database (CDB).
The Container Database acts as a root database instance and each of the Pluggable Databases run within that single Container Database as tenants. We call this a multi-tenancy architecture where one CDB contains multiple tenant PDBs. Each PDB contains only the schemas, database, indexes, and mini split data dictionary to remain self-contained within the larger supporting CDB. For example, we could have separate PDBs for our sales, Human Resources, and new products departments withing our larger CDB. This breaks a previous database “rule” where now we have multiple databases (the PDBs) inside a single database instance (the CDB).
Why in the world would you want to do this? Well, the first reason is to be cool kid within your group of Oracle friends. The reason you tell your boss is you are supporting the cloud in 12c via multi-tenancy; he may not know what that means but he’ll put it in his report to his boss. Seriously, think about the benefits of off-loading rudunant physical structures and overhead memory and background processes to a larger CDB rather supporting multiple copies for each PDB. This allows you to consolidate more databases as PDB tenants into a CDB while consuming few resources. In very larger environments such as data center consolidation or where server resources are constrained, these saves are very useful.
Also consider the pluggable part of PDBs; you can create them easily by cloning exiting PDB copies and you can move them between CDBs (unplug and plug) as needed to support migrations, upgrades, and testing. The pluggable architecture gives you a high degree of granular control of your PDBs. The self-contained architecture of the PDBs make this pluggable flexibility possible and is a great potential benefit as you manage multiple databases.