
It’s time to plug in a real search engine. We’ll start with SWISH-E, which is freely available in source form from http://sunsite.berkeley.edu/SWISH-E/. It’s a Unix-style program that compiles, most comfortably, in a GNU environment. What if you want to use SWISH-E on Windows NT? There are a variety of solutions:
- Port SWISH-E to Win32.
If you’re more ambitious than I am, you could convert the program into a Win32 console application.
- Build a Win32 version of SWISH-E.
This isn’t the same thing as a native port. Rather, it’s a build that uses a Win32-based GNU environment. Several of these are freely available. I’ve used MingW32 (http://programming.ccp14.ac.uk/mingw32/~janjaap/mingw32/index.html) successfully with SWISH-E.
- Find a SWISH-E Win32 binary.
I found a Win32 SWISH-E binary at http://www.geocities.com/CapeCanaveral/Lab/1652/software.html. I’m sure there are others elsewhere.
- Buy a copy of WebSite Pro.
If you’re using this NT-based web server from O’Reilly & Associates, it includes a version of SWISH-E.
- Run SWISH-E on Unix.
SWISH-E will compile and run effortlessly on a Unix system. How does that help you use it in an NT environment? Think in terms of clustered components. Let’s say your primary web server is NT-based and that it supports Active-Server-Pages- or Cold-Fusion-based applications. That doesn’t mean your search system has to run on the primary server. It’s delightfully easy to build a web site as a loosely coupled cluster of servers, bound together with file sharing and URLs.
For example, if your NT server exports Network File System (NFS) drives, a Linux-based indexer can mount the NT drives in order to index them. Or, since NFS isn’t standard with NT, you can go the other route. NT can mount Linux drives exported by Samba as Windows-style Server Message Block (SMB) shares. Then you can copy the NT-based content to the Linux server. Either way, the Linux-based SWISH-E indexer can now index the content. The same Linux SWISH-E, under the control of an Apache-based Perl script, can search the content and return results to browsers.
Note that although the indexer and search engine may live on the Linux server, there is no need to serve found documents from that server. The search-results script already has to translate the pathname returned by the searcher into a URL. It’s trivial to redirect hits produced by a search server at search.yoursite.com to a primary document server at www.yoursite.com. Why would you want to do that? It’s a form of load balancing. And you may want the pageviews produced by the search engine to show up in the same log file, and in the same format, as pageviews produced by the site’s navigation system.
The point is that web APIs make it easy to build heterogenous clusters. As a result, you can avail yourself of the widest possible selection of tools. Lots of useful tools born in the Unix environment run best there. Sometimes it’s less trouble to host them on a Unix box than to port them to NT. The reverse holds true as well: a Unix-oriented site or intranet can profit by having an NT box as a member of its cluster. Thanks to URL middleware, you really can have the best of both worlds!
SWISH stands for Simple Web Indexing System for Humans, and, while not the world’s fanciest or most powerful search tool, SWISH-E is admirably simple to use. To index files, you just point it at a bunch of directories and let it rip. For our two-docbase example, here’s the SWISH-E configuration file:
IndexDir /web/Docbase/ProductAnalysis/docs IndexDir /netscape/suitespot/news-udell/spool/analyst
If the configuration file is called
swish-e.conf, here’s the indexing command:
swish-e -f index.swish -c swish-e.conf
The indexer walks each root recursively, so we’ll pick up
analyst/contacts and analyst/sources. The resulting index is named
index.swish.
There are more elaborate ways to run the indexer. You can restrict it
to certain classes of files, such as .htm or
.html—though we wouldn’t want to do
that here, because we’d miss the numerically named conference
messages. Or you can exclude classes of directories, so that if the
pathname component /img/ denotes
GIF or JPEG files, the
indexer can skip those. SWISH-E can also build
field indexes based on <meta> tags. To
activate that feature, add a directive like this to
SWISH-E :
MetaNames company product analyst duedate
After reindexing with this directive in effect, there are now two ways to search. The command:
swish-e -f index.swish -w Microsoft
returns documents whose HTML bodies contain “Microsoft.” However, the command:
swish-e -f index.swish -w "company=Microsoft"
returns only documents that contain <META NAME="company" CONTENT= "Microsoft">. Users of the ProductAnalysis
docbase will greatly appreciate this capability. There’s a huge
difference between the diffuse set of documents that merely mention
Microsoft and the more focused set that is actually
about Microsoft products.
If fielded search is such a powerful technique, why is it so seldom
deployed? It requires a data-preparation discipline that many sites
lack. A key advantage of a Docbase-like system is that it automates
data preparation and delivers consistent, well-formed
<meta> tags.
Note that SWISH-E is quite literal in its parsing
of <meta> tags. It will match
<meta name="company" content="Microsoft">,
because it doesn’t care about the case of the tag or its
attributes. But it won’t match <META NAME=company CONTENT=Microsoft>, because it expects the attributes to
be quoted. As we saw in Chapter 6, the
Docbase::Input module does quote
<meta> tag attributes.
Let’s load a batch of search results into a Perl variable. We can do that the plain old-fashioned way, using backtick evaluation of a search command to capture its output:
$search_results = `swish-e -f index.swish -w ldap`;
Here’s what ends up in $search_results:
# Swish-e format 1.3 # # Saved as: index.swish # DocumentProperties: Enabled # Search words: ldap # Number of hits: 4 668 /web/Docbase/ProductAnalysis/docs/1999-04-15-000006.htm "Microsoft | IIS 5.0 | IIS 5.0" 1266 601 /web/Docbase/ProductAnalysis/docs/1999-04-15-000014.htm "Netscape | Directory Server 4.0 | Directory Server" 1312 360 /netscape/suitespot/news-udell/spool/analyst/sources/27 "27" 584 311 /netscape/suitespot/news-udell/spool/analyst/contacts/142 "142" 662
We need to classify these results relative to the abstract structure we’ve defined, populate an instance of that structure, and pass it to Search::SearchResults in order to produce a web page that displays the results. Example 8.3 shows a search script that does that.
Example 8-3. A SWISH Search Driver
#! /usr/bin/perl -w
use strict;
use Search::SearchResults;
use Search::SwishClassifier;
my $results = `swish-e -f index.swish -w ldap`; # run the search
my $sc = Search::SwishClassifier->new(); # instantiate a classifer
$sc->classify($results); # classify results
my $LoH = $sc->getResults(); # fetch results
$sr = Search::SearchResults->new # format results
($LoH,'DATE','desc','SUBTYPE','asc'),
print $sr->Results(); # print resultsWe’ve seen how Search::SearchResults works. How does Search::SwishClassifier produce the list-of-hashes that it passes to Search::SearchResults ? The answer turns out to be an interesting case study in object-oriented Perl, combining inheritance with polymorphism.
To understand why both approaches are needed, consider what
Search::SwishClassifier has to do. It receives a
batch of results from the SWISH-E searcher. For
each result, it has to map specific values (e.g.,
Netscape) to the abstract markers (e.g.,
SUBTYPE) required by
Search::SearchResults. It builds a hash of these
mappings and accumulates these hashes in a list.
Parallel versions of this module for other engines ( e.g., Search::ExciteClassifier or Search::MicrosoftIndexClassifier) would need to do exactly the same tasks, so it makes sense for each of these engine-specific classifiers to inherit from a base class, Search::Classifier, shown in Example 8.4.
Example 8-4. Base Class for Classifier Modules
package Search::Classifier;
use strict;
my $LoH = [];
sub new
{
my ($pkg) = @_;
my $self = {};
bless $self,$pkg;
return $self;
}
sub getResults # return my LoH
{
my $self = shift;
return $LoH;
}
sub addResult # accumulate into my LoH
{
my ($self,$hash) = @_;
push (@{$LoH},$hash);
}
1;The Search::Classifier module is nothing more than
a private list-of-hashes variable, an addResult(
) method that adds a hash to the LoH, and a
getResults( ) method that returns the LoH. The
SWISH-E search script uses the specific module
Search::SwishClassifier, but when it calls
$sc->getResults( ), no implementation of
getResults( ) is found. Perl therefore climbs up
the inheritance chain, finds getResults( ) in
the base class, and invokes that method. The same will hold true for
scripts that process MS Index Server’s, Excite’s, or any
other engine’s results. An engine-specific classifier will
inherit bookkeeping capability from an engine-neutral superclass.
But there’s another dimension to this problem. The results that Search::SwishClassifier sees come from multiple docbases. So while it is necessarily engine-specific, it must also be docbase-neutral. In the current example, it has to recognize hits on the ProductAnalysis docbase and hits on the analyst newsgroups. The code that does that recognition needs to be docbase-specific but engine-neutral. That means it should be packaged by docbase rather than by engine.
We’ll write a mapping module for each of the two docbases we’ve built so far. Search::ProductAnalysisMapper will know how to map search hits on the Product-Analysis docbase into the abstract LoH. Likewise, Search::ConferenceMapper will know how to map hits on newsgroups into that abstract structure. Because these modules will be called by all the Classifiers, they can’t depend on anything engine-specific. A ProductAnalysis hit produced by SWISH-E differs from the same one produced by another engine but also shares something in common. What differs is the way in which each engine formats the pathname and the doctitle. But the pathname and doctitle themselves are the same. There are really two kinds of recognition that need to occur, according to the division of labor shown in Table 8.6:
Table 8-6. Responsibilities of Mappers and Classifiers
|
Per-Docbase Mappers |
Per-Engine Classifiers |
|---|---|
|
Can identify that a raw search hit is of its own type, regardless of the engine that supplies the hit |
Can identify the pathname and doctitle in a raw search hit, regardless of the hit’s docbase of origin |
|
Given a pathname and doctitle, can map these to the abstract LoH and return an instance of that structure |
Can invite each Mapper to process each pathname and doctitle |
|
Can add an entry to its unordered SearchResults structure |
Figure 8.5 depicts the relationships among Classifiers, sets of search results, and Mappers.

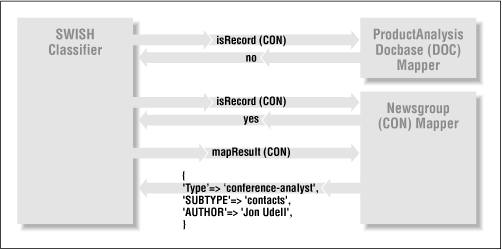
Figure 8.6 shows the transactions between a Classifier and a set of Mappers for an individual search result.
Should the Mappers inherit from a base Mapper class that abstracts their common behavior? That sounds reasonable, but let’s first write a Mapper to see how it interacts with the Classifiers. Example 8.5 presents Search::ProductAnalysisMapper.
Example 8-5. The Mapper for ProductAnalysis Records
#! /usr/bin/perl -w
use strict;
package Search::ProductAnalysisMapper;
my $app = "ProductAnalysis";
my $docbase_type = "Docbase-$app";
use Docbase::Docbase;
my $db = Docbase::Docbase->new($app);
my $basepath = "$db->{docbase_web_absolute}/$app/docs/";
my $indexed_fields = $db->getDefaultValue('indexed_fields'),
my $cgi_prefix = "http://hostname" . "$db->{docbase_cgi_relative}";
sub new
{
my ($pkg) = @_;
my $self = {'type' => 'ProductAnalysis'};
bless $self,$pkg;
return $self;
}
sub isRecord # look for my docbase signature
{
my ($self,$record) = @_;
return ( $record =~ m#($basepath)# );
}
sub mapResult # map pathname, doctitle into LoH
{
my ($self,$pathname,$doctitle) = @_;
my $result = {};
$result = fieldsFromPathname($result,$pathname);
$result = fieldsFromDoctitle($result,$doctitle);
$result = fieldsViaPathname($result,$pathname);
$result = fieldsFromDocbase($result);
return $result;
}
sub fieldsFromDoctitle # extract info from doctitle
{
my ($result,$doctitle) = @_;
my ($company, $product, $title) = split(/ | /,$doctitle);
$result->{SUBTYPE} = $company;
$result->{TITLE} = "$product | $title";
return $result;
}
sub fieldsFromPathname # extract info from pathname
{
my ($result,$pathname) = @_;
$pathname =~ m#($basepath)(.{10,10})#;
$result->{DATE} = $2;
$result->{PATH} = $pathname;
return $result;
}
sub fieldsViaPathname # extract info from file
{
my ($result,$pathname) = @_;
my $metafields = $db->getMetadata($pathname);
$result->{AUTHOR} = $metafields->{analyst};
open(F,$pathname) or die "cannot open $pathname $!";
my $summary = '';
while (<F>)
{
if ( m#<td align="left" class="summary">([^<]+)</td>#i )
{
$summary = $1;
last;
}
}
close F;
$result->{SUMMARY} = $summary;
return $result;
}
sub fieldsFromDocbase # supply docbase-specific info
{
my $result = shift;
$result->{TYPE} = $docbase_type;
$result->{PATH} =~ m#docs/([^.]+)#;
my $recnum = $1;
$result->{URL} =
"$cgi_prefix/doc-view.pl?app=$app&index=$indexed_fields->[0]&doc=$recnum";
return $result;
}
1;
The
$basepath variable captures the invariant essence
of the docbase. No matter which engine indexed a given record, the
search result will contain this pattern. Well, that’s not quite
true. The basepath may vary from engine to engine depending on
whether, or at what point, it converts a filesystem-oriented path
into a web-server-oriented path. But we can safely assume that we can
synchronize our Mappers on one or the other of these styles. It
won’t matter which, because in either case the Mapper will form
the final URL.
The isRecord( ) method answers the question:
“Does this raw search result contain the docbase signature of
my class?” The mapResult( ) method
receives a pathname and a doctitle that, it assumes, pertain to its
own class. It performs a series of docbase-specific steps to map its
arguments into an instance of the SearchResults structure. Note how
each of these steps—fieldsFromPathname( ),
fieldsFromDoctitle( ),
fieldsViaDoctitle( )—both receives and
hands back a hashtable. Each of these methods specializes in a
different data source. The hashtable grows incrementally as
it’s passed from one data-source expert to the next. Note also
how fieldsViaPathname( ), responsible for those
things that can’t be found directly in the pathname or the
doctitle, calls Docbase::Docbase::getMetadata( )
to fill the AUTHOR slot. When all the data-source
experts have run, mapResult( ) returns the
completed hashtable.
What, if anything, might Search::ProductAnalysisMapper inherit from a hypothetical base class called Search::Mapper? The Mapper for newsgroups is shown in Example 8.6. Let’s see what commonality emerges.
Example 8-6. The Mapper for Newsgroup Search Results
use strict;
package Search::ConferenceMapper;
my $docbase_type = 'conference-analyst';
my $newshost = 'hostname';
my %months = (
'Jan','01',
'Feb','02',
'Mar','03',
'Apr','04',
'May','05',
'Jun','06',
'Jul','07',
'Aug','08',
'Sep','09',
'Oct','10',
'Nov','11',
'Dec','12',
);
my $basepath = '/netscape/suitespot/news-udell/spool/analyst';
sub new
{
my ($pkg) = @_;
my $self = {'type' => 'Conference'};
bless $self,$pkg;
return $self;
}
sub isRecord
{
my ($self,$record) = @_;
return ( $record =~ m#($basepath)# );
}
sub mapResult
{
my ($self,$pathname,$doctitle) = @_;
my $result = {};
$result = fieldsFromPathname($result,$pathname);
$result = fieldsFromDoctitle($result,$doctitle);
$result = fieldsViaPathname($result,$pathname);
$result = fieldsFromDocbase($result);
return $result;
}
sub fieldsFromDoctitle
{
my ($result,$doctitle) = @_;
return $result;
}
sub fieldsFromPathname
{
my ($result,$pathname) = @_;
$pathname =~ m#($basepath)/(w+)/(d+)#;
$result->{PATH} = "$1/$2/$3";
$result->{SUBTYPE} = "$2";
return $result;
}
sub fieldsViaPathname
{
my ($result,$pathname) = @_;
open (F, $pathname) or die "cannot open pathname $pathname $!";
while (<F>)
{
last if ( m#^
#); # end of headers
if ( m#(Subject: )(.+)# ) # Subject: Classifiers and mappers
{ $result->{TITLE} = $2; }
if ( m#(Date: )(.+)# ) # Tue, 04 Aug 1998 13:00:49 -0400
{
my $date = $2;
$date =~ m#[^d]+(d{2,2})s+(w+)s+(d+)#;
$result->{DATE} = "$3-$months{$2}-$1";
}
if ( m#(From: )(.+)# ) # From: Jon Udell <[email protected]>
{
my $author = $2;
$author =~ s#s+<[^>]+>##;
$result->{AUTHOR} = $author;
}
if ( m#(Message-ID: )(.+)# )
{
my $msgid = "news://$newshost/$2";
$result->{URL} = $msgid;
}
}
$result->{SUMMARY} = <F>;
close F;
return $result;
}
sub fieldsFromDocbase
{
my $result = shift;
$result->{TYPE} = $docbase_type;
return $result;
}
1;Again isRecord( ) identifies the docbase
signature, and mapResult( ) calls a series of
data-source experts—minus fieldsFromDoctitle(
), since conference messages aren’t HTML
documents—and returns a completed hash. But these data-source
experts differ from the others in exactly the ways that define the
differences between the two docbases. Can we boost
isRecord( ) and mapResult(
) into a superclass? Nope. They only make sense in the
context of their own modules’ data and methods. Nevertheless,
it’s significant that these identically named methods exist in
both Mappers. To see why, we need to look at one of the specific
Classifiers.
Example 8.7 shows Search::SwishClassifier, the member of the Classifier family that specializes in SWISH.
Example 8-7. The Classifier for SWISH-E Results
package Search::SwishClassifier;
use Search::Classifier;
@ISA = ('Search::Classifier'),
use strict;
use Search::ConferenceMapper;
my $con = Search::ConferenceMapper->new();
use Search::ProductAnalysisMapper;
my $pa = Search::ProductAnalysisMapper->new();
sub new
{
my ($pkg) = @_;
my $self = {};
bless $self,$pkg;
return $self;
}
sub classify
{
my ($self,$results) = @_;
my @resultlist = split (/
/,$results);
foreach my $raw_result (@resultlist) # for each search result
{
foreach my $obj ($pa, $con) # for each Mapper
{
if ( $obj->isRecord($raw_result) ) # ask Mapper to claim result
{
print STDERR "Found: $obj->{type}
";
$raw_result =~ m#(d+)([^"]+)(")([^"]+)#; # parse path and doctitle
my $pathname = $2;
my $doctitle = $4;
my $href = # hand path/doctitle
$obj->mapResult($pathname,$doctitle); # to Mapper
$self->addResult($href); # add hashtable to
} # unordered LoH
}
}
}
1;
Search::SwishClassifier creates a Mapper for each
kind of docbase. For each search hit, it invites each of these
Mappers to claim the hit as its own. When a Mapper does claim a hit,
Search::SwishClassifier extracts the pathname and
the doctitle. Then it asks the Mapper to map this pair of values into
an abstract result instance. Finally, it calls
$self->addResult( ) to add that instance to the
unordered LoH that its base class,
Search::Classifier, is
accumulating.
This isn’t inheritance; it’s just polymorphism. If Java rather than Perl were the implementation language, we could expect to see something like this:
public interface Mapper
{
public boolean isRecord (String searchResult );
public Hashtable mapResult (String pathname, String doctitle);
...Then, each Mapper would begin like this:
public class ConferenceMapper implements Mapper
{
public ConferenceMapper() {}
...It’s fascinating to see how you can get exactly the same effect in Perl. Well, OK, not quite exactly. The Perl modules don’t know that they implement the Mapper interface, so the compiler can’t warn you if you deviate from it. But it’s not hard to pretend that the interface really exists, and when you do, things work out just fine.