
Data Types
You already got an aperçu of the first point, how the CPU can manipulate a certain data type, in Chapter 2 with the native code version of computeIterativelyFaster(), which used two add instructions to add two 64–bit integers, as shown in Listing 4–1.
Listing 4–1. Adding Two 64–bit Integers
448: e0944002 adds r4, r4, r2
44c: e0a55003 adc r5, r5, r3
Because the ARM registers are 32-bit wide, two instructions are needed to add two 64–bit integers; the lowest 32-bit integers are stored in one register (r4), and the highest 32-bit are stored in another register (r5). Adding two 32-bit values would require a single instruction.
Let's now consider the trivial C function, shown in Listing 4–2, which simply returns the sum of two 32-bit values passed as parameters.
Listing 4–2. Sum of Two Values
int32_t add_32_32 (int32_t value1, int32_t value2)
{
return value1 + value2;
}
The assembly code for this function is shown in Listing 4–3.
Listing 4–3. Assembly Code
000016c8 <add_32_32>:
16c8: e0810000 add r0, r1, r0
16cc: e12fff1e bx lr
As expected, only one instruction is needed to add the two values (and bxlr is the equivalent of return). We can now create new functions that are very much like add_32_32, but with different types for value1 and value2. For example, add_16_16 adds two int16_t values, as shown in Listing 4–4, and add_16_32 adds an int16_t value and an int32_t value, as shown in Listing 4–5.
Listing 4–4. add_16_16's C and Assembly
int16_t add_16_16 (int16_t value1, int16_t value2)
{
return value1 + value2;
}
000016d0 <add_16_16>:
16d0: e0810000 add r0, r1, r0
16d4: e6bf0070 sxth r0, r0
16d8: e12fff1e bx lr
Listing 4–5. add_16_32's C And Assembly
int32_t add_16_32 (int16_t value1, int32_t value2)
{
return value1 + value2;
}
000016dc <add_16_32>:
16dc: e0810000 add r0, r1, r0
16e0: e12fff1e bx lr
You can see that adding two 16- values required an additional instruction in order to convert the result from 16-bit to 32-bit.
Listing 4–6 shows five more functions, repeating basically the same algorithm but for different data types.
Listing 4–6. More Assembly Code
000016e4 <add_32_64>:
16e4: e0922000 adds r2, r2, r0
16e8: e0a33fc0 adc r3, r3, r0, asr #31
16ec: e1a00002 mov r0, r2
16f0: e1a01003 mov r1, r3
16f4: e12fff1e bx lr
000016f8 <add_32_float>:
16f8: ee070a10 fmsr s14, r0
16fc: eef87ac7 fsitos s15, s14
1700: ee071a10 fmsr s14, r1
1704: ee777a87 fadds s15, s15, s14
1708: eefd7ae7 ftosizs s15, s15
170c: ee170a90 fmrs r0, s15
1710: e12fff1e bx lr
00001714 <add_float_float>:
1714: ee070a10 fmsr s14, r0
1718: ee071a90 fmsr s15, r1
171c: ee377a27 fadds s14, s14, s15
1720: ee170a10 fmrs r0, s14
1724: e12fff1e bx lr
00001728 <add_double_double>:
1728: ec410b16 vmov d6, r0, r1
172c: ec432b17 vmov d7, r2, r3
1730: ee366b07 faddd d6, d6, d7
1734: ec510b16 vmov r0, r1, d6
1738: e12fff1e bx lr
0000173c <add_float_double>:
173c: ee060a10 fmsr s12, r0
1740: eeb77ac6 fcvtds d7, s12
1744: ec432b16 vmov d6, r2, r3
1748: ee376b06 faddd d6, d7, d6
174c: ec510b16 vmov r0, r1, d6
1750: e12fff1e bx lr
NOTE: The generated native code may differ from what is shown here as a lot depends on the context of the addition. (Code that is inline may look different as the compiler may reorder instructions or change the register allocation.)
As you can see, using a smaller type is not always beneficial to performance as it may actually require more instructions, as demonstrated in Listing 4–4. Besides, if add_16_16 were called with two 32-bit values as parameters, these two values would first have to be converted to 16-bit values before the actual call, as shown in Listing 4–7. Once again, the sxth instruction is used to convert the 32-bit values into 16-bit values by performing a “sign extend” operation.
Listing 4–7. Calling add_16_16 With Two 32-Bit Values
00001754 <add_16_16_from_32_32>:
1754: e6bf0070 sxth r0, r0
1758: e6bf1071 sxth r1, r1
175c: eaffffdb b 16d0 <add_16_16>
Comparing Values
Let's now consider another basic function, which takes two parameters and returns 0 or 1 depending on whether the first parameter is greater than the second one, as shown in Listing 4–8.
Listing 4–8. Comparing Two Values
int32_t cmp_32_32 (int32_t value1, int32_t value2)
{
return (value1 > value2) ? 1 : 0;
}
Again, we can see the assembly code for this function and its variants in Listing 4–9.
Listing 4–9. Comparing Two Values In Assembly
00001760 <cmp_32_32>:
1760: e1500001 cmp r0, r1
1764: d3a00000 movle r0, #0 ; 0x0
1768: c3a00001 movgt r0, #1 ; 0x1
176c: e12fff1e bx lr
00001770 <cmp_16_16>:
1770: e1500001 cmp r0, r1
1774: d3a00000 movle r0, #0 ; 0x0
1778: c3a00001 movgt r0, #1 ; 0x1
177c: e12fff1e bx lr
00001780 <cmp_16_32>:
1780: e1500001 cmp r0, r1
1784: d3a00000 movle r0, #0 ; 0x0
1788: c3a00001 movgt r0, #1 ; 0x1
178c: e12fff1e bx lr
00001790 <cmp_32_64>:
1790: e92d0030 push {r4, r5}
1794: e1a04000 mov r4, r0
1798: e1a05fc4 asr r5, r4, #31
179c: e1550003 cmp r5, r3
17a0: e3a00000 mov r0, #0 ; 0x0
17a4: ca000004 bgt 17bc <cmp_32_64+0x2c>
17a8: 0a000001 beq 17b4 <cmp_32_64+0x24>
17ac: e8bd0030 pop {r4, r5}
17b0: e12fff1e bx lr
17b4: e1540002 cmp r4, r2
17b8: 9afffffb bls 17ac <cmp_32_64+0x1c>
17bc: e3a00001 mov r0, #1 ; 0x1
17c0: eafffff9 b 17ac <cmp_32_64+0x1c>
000017c4 <cmp_32_float>:
17c4: ee070a10 fmsr s14, r0
17c8: eef87ac7 fsitos s15, s14
17cc: ee071a10 fmsr s14, r1
17d0: eef47ac7 fcmpes s15, s14
17d4: eef1fa10 fmstat
17d8: d3a00000 movle r0, #0 ; 0x0
17dc: c3a00001 movgt r0, #1 ; 0x1
17e0: e12fff1e bx lr
000017e4 <cmp_float_float>:
17e4: ee070a10 fmsr s14, r0
17e8: ee071a90 fmsr s15, r1
17ec: eeb47ae7 fcmpes s14, s15
17f0: eef1fa10 fmstat
17f4: d3a00000 movle r0, #0 ; 0x0
17f8: c3a00001 movgt r0, #1 ; 0x1
17fc: e12fff1e bx lr
00001800 <cmp_double_double>:
1800: ee060a10 fmsr s12, r0
1804: eeb77ac6 fcvtds d7, s12
1808: ec432b16 vmov d6, r2, r3
180c: eeb47bc6 fcmped d7, d6
1810: eef1fa10 fmstat
1814: d3a00000 movle r0, #0 ; 0x0
1818: c3a00001 movgt r0, #1 ; 0x1
181c: e12fff1e bx lr
00001820 <cmp_float_double>:
1820: ee060a10 fmsr s12, r0
1824: eeb77ac6 fcvtds d7, s12
1828: ec432b16 vmov d6, r2, r3
182c: eeb47bc6 fcmped d7, d6
1830: eef1fa10 fmstat
1834: d3a00000 movle r0, #0 ; 0x0
1838: c3a00001 movgt r0, #1 ; 0x1
183c: e12fff1e bx lr
1840: e3a00001 mov r0, #1 ; 0x1
1844: e12fff1e bx lr
Using the long type appears to be slower than using the short and int types because of the higher number of instructions having to be executed. Similarly, using the double type and mixing float and double seems to be slower than using the float type alone.
NOTE: The number of instructions alone is not enough to determine whether code will be slower or not. Because not all instructions take the same amount of time to complete, and because of the complex nature of today's CPUs, one cannot simply count the number of instructions to know how much time a certain operation will take.
Other Algorithms
Now that we have seen what difference data types can make on the generated code, it is time to see how slightly more sophisticated algorithms perform when dealing with more significant amounts of data.
Listing 4–10 shows three simple methods: one that sorts an array by simply calling the static Arrays.sort() method, one that finds the minimum value in an array, and one that adds all the elements in an array.
Listing 4–10. Sorting, Finding, and Summing in Java
privatestaticvoid sort (int array[]) {
Arrays.sort(array);
}
private static int findMin (int array[]) {
int min = Integer.MAX_VALUE;
for (int e :array) {
if (e < min) min = e;
}
return min;
}
private static int addAll (int array[]) {
int sum = 0;
for (int e :array) {
sum += e; // this could overflow but we'll ignore that
}
return sum;
}
Table 4-2 shows how many milliseconds each of these functions took to complete when given an array of one million random elements. In addition to these, the results for the variants of these methods (using short, long, float, and double types) are also shown. Refer to Chapter 6 for more information on how to measure execution times.
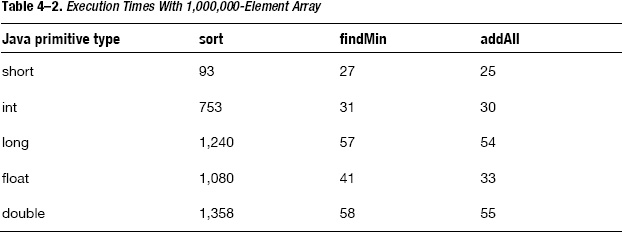
We can make a couple of comments on these results:
- Sorting the
shortarray is much faster than sorting any of the other arrays. - Working with 64–bit types (long or double) is slower than working with 32-bit types.
Sorting Arrays
Sorting an array of 16-bit values can be much faster than sorting an array of 32- or 64–bit values simply because it is using a different algorithm. While the int and long arrays are sorted using some version of Quicksort algorithm, the short array was sorted using counting sort, which sorts in linear time. Using the short type in that case is killing two birds with one stone: less memory is consumed (2 megabytes instead of 4 for the array of int values, and 8 megabytes for the array of long values) and performance is improved.
NOTE: Many wrongly believe Quicksort is always the most efficient sorting algorithm. You can refer to Arrays.java in the Android source code to see how each type of array is sorted.
A less common solution is to use multiple arrays to store your data. For example, if your application needs to store many integers all in the range 0 to 100,000, then you may be tempted to allocate an array of 32-bit values for storage as the short type can be used only to store values from -32,768 to 32,767. Depending on how values are distributed, you may end up with many values equal to or less than 32,767. In such an event, it may be beneficial to use two arrays: one for all the values between 0 and 32,767 (that is, an array of short values), and one for all values greater than 32,767 (an array of int values). While this most likely would result in a greater complexity, the memory savings and potential performance increase may make that solution worthwhile, and perhaps even allow you to optimize the implementation of certain methods. For example, a method that finds the maximum element may only have to go through the array of int values. (Only if the array of int values is empty would it go through the array of short values.)
One of the types that was not shown in Listing 4–9 and Table 4-2 is the boolean type. In fact, sorting an array of boolean values makes little sense. However, there may be occasions where you need to store a rather large number of boolean values and refer to them by index. For that purpose, you could simply create an array. While this would work, this would result in many bits being wasted as 8 bits would be allocated for each entry in the array when actually a boolean value can only be true or false. In other words, only one bit is needed to represent a boolean value. For that purpose, the BitSet class was defined: it allows you to store boolean values in an array (and allows you to refer to them by index) while at the same time using the minimum amount of memory for that array (one bit per entry). If you look at the public methods of the BitSet class and its implementation in BitSet.java, you may notice a few things that deserve your attention:
BitSet's backend is an array oflongvalues. You may achieve better performance using an array ofintvalues. (Tests showed a gain of about 10% when switching to anintarray.)- Some notes in the code indicate some things should be changed for better performance (for example, see the comment starting with
FIXME). - You may not need all the features from that class.
For all these reasons, it would be acceptable for you to implement your own class, possibly based on BitSet.java to improve performance.
Defining Your Own Classes
Listing 4–11 shows a very simple implementation that would be acceptable if the array does not need to grow after the creation of the object, and if the only operations you need to perform are to set and get the value of a certain bit in the array, for example as you implement your own Bloom filter. When using this simple implementation versus BitSet, tests showed performance improved by about 50%. We achieved even better performance by using a simple array instead of the SimpleBitSet class: using an array alone was about 50% faster than using a SimpleBitSet object (that is, using an array was 4 times faster than using a BitSet object). This practice actually goes against the encapsulation principle of object-oriented design and languages, so you should do this with care.
Listing 4–11. Defining Your Own BitSet-like Class
public class SimpleBitSet {
private static final int SIZEOF_INT = 32;
private static final int OFFSET_MASK = SIZEOF_INT - 1; // 0x1F
private int[] bits;
SimpleBitSet(int nBits) {
bits = new int[(nBits + SIZEOF_INT - 1) / SIZEOF_INT];
}
void set(int index, boolean value) {
int i = index / SIZEOF_INT;
int o = index & OFFSET_MASK;
if (value) {
bits[i] |= 1 << o; // set bit to 1
} else {
bits[i] &= ~(1 << o); // set bit to 0
}
}
boolean get(int index) {
int i = index / SIZEOF_INT;
int o = index & OFFSET_MASK;
return 0 != (bits[i] & (1 << o));
}
}
Alternatively, if most bits are set to the same value, you may want to use a SparseBooleanArray to save memory (possibly at the cost of performance). Once again, you could use the Strategy pattern discussed in Chapter 2 to easily select one implementation or the other.
All in all, these examples and techniques can be summarized as follows:
- When dealing with large amounts of data, use the smallest type possible that meets your requirements. For example, choose an array of
shortvalues over an array ofintvalues, for both performance and memory consumption reasons. Usefloatinstead ofdoubleif you don't need the extra precision (and useFloatMathclass if needed). - Avoid conversions from one type to another. Try to be consistent and use a single type in your computations, if possible.
- Reinvent the wheel if necessary to achieve better performance, but do it with care.
Of course, these rules are not set in stone. For example, you may find yourself in a situation where converting from one type to another could actually give better performance, despite the conversion overhead. Be pragmatic and fix a problem only when you determine there is a one.
More often than not, using less memory is a good rule to follow. In addition to simply leaving more memory available for other tasks, using less memory can improve performance as CPUs use caches to quickly access data or instructions.