
8. Modules, Packages, and Distribution
Large Python programs are organized into modules and packages. In addition, a large number of modules are included in the Python standard library. This chapter describes the module and package system in more detail. In addition, it provides information on how to install third-party modules and distribute source code.
Modules and the import Statement
Any Python source file can be used as a module. For example, consider the following code:

To load this code as a module, use the statement import spam. The first time import is used to load a module, it does three things:
1. It creates a new namespace that serves as a container for all the objects defined in the corresponding source file. This is the namespace accessed when functions and methods defined within the module use the global statement.
2. It executes the code contained in the module within the newly created namespace.
3. It creates a name within the caller that refers to the module namespace. This name matches the name of the module and is used as follows:

It is important to emphasize that import executes all of the statements in the loaded source file. If a module carries out a computation or produces output in addition to defining variables, functions, and classes, you will see the result. Also, a common confusion with modules concerns the access to classes. Keep in mind that if a file spam.py defines a class Spam, you must use the name spam.Spam to refer to the class.
To import multiple modules, you can supply import with a comma-separated list of module names, like this:
import socket, os, re
The name used to refer to a module can be changed using the as qualifier. Here’s an example:

When a module is loaded using a different name like this, the new name only applies to the source file or context where the import statement appeared. Other program modules can still load the module using its original name.
Changing the name of the imported module can be a useful tool for writing extensible code. For example, suppose you have two modules, xmlreader.py and csvreader.py, that both define a function read_data(filename) for reading some data from a file, but in different input formats. You can write code that selectively picks the reader module like this:

Modules are first class objects in Python. This means that they can be assigned to variables, placed in data structures such as a list, and passed around in a program as a data. For instance, the reader variable in the previous example simply refers to the corresponding module object. Underneath the covers, a module object is a layer over a dictionary that is used to hold the contents of the module namespace. This dictionary is available as the _ _dict_ _ of a module, and whenever you look up or change a value in a module, you’re working with this dictionary.
The import statement can appear at any point in a program. However, the code in each module is loaded and executed only once, regardless of how often you use the import statement. Subsequent import statements simply bind the module name to the module object already created by the previous import. You can find a dictionary containing all currently loaded modules in the variable sys.modules. This dictionary maps module names to module objects. The contents of this dictionary are used to determine whether import loads a fresh copy of a module.
Importing Selected Symbols from a Module
The from statement is used to load specific definitions within a module into the current namespace. The from statement is identical to import except that instead of creating a name referring to the newly created module namespace, it places references to one or more of the objects defined in the module into the current namespace:
![]()
The from statement also accepts a comma-separated list of object names. For example:
from spam import foo, bar
If you have a very long list of names to import, the names can be enclosed in parentheses. This makes it easier to break the import statement across multiple lines. Here’s an example:
![]()
In addition, the as qualifier can be used to rename specific objects imported with from. Here’s an example:
![]()
The asterisk (*) wildcard character can also be used to load all the definitions in a module, except those that start with an underscore. Here’s an example:
from spam import * # Load all definitions into current namespace
The from module import * statement may only be used at the top level of a module. In particular, it is illegal to use this form of import inside function bodies due to the way in which it interacts with function scoping rules (e.g., when functions are compiled into internal bytecode, all of the symbols used within the function need to be fully specified).
Modules can more precisely control the set of names imported by from module import * by defining the list _ _all_ _. Here’s an example:
![]()
Importing definitions with the from form of import does not change their scoping rules. For example, consider this code:
![]()
In this example, the definition of foo() in spam.py refers to a global variable a. When a reference to foo is placed into a different namespace, it doesn’t change the binding rules for variables within that function. Thus, the global namespace for a function is always the module in which the function was defined, not the namespace into which a function is imported and called. This also applies to function calls. For example, in the following code, the call to bar() results in a call to spam.foo(), not the redefined foo() that appears in the previous code example:

Another common confusion with the from form of import concerns the behavior of global variables. For example, consider this code:

Here, it is important to understand that variable assignment in Python is not a storage operation. That is, the assignment to a in the earlier example is not storing a new value in a, overwriting the previous value. Instead, a new object containing the value 42 is created and the name a is made to refer to it. At this point, a is no longer bound to the value in the imported module but to some other object. Because of this behavior, it is not possible to use the from statement in a way that makes variables behave similarly as global variables or common blocks in languages such as C or Fortran. If you want to have mutable global program parameters in your program, put them in a module and use the module name explicitly using the import statement (that is, use spam.a explicitly).
Execution as the Main Program
There are two ways in which a Python source file can execute. The import statement executes code in its own namespace as a library module. However, code might also execute as the main program or script. This occurs when you supply the program as the script name to the interpreter:
% python spam.py
Each module defines a variable, _ _name_ _, that contains the module name. Programs can examine this variable to determine the module in which they’re executing. The top-level module of the interpreter is named _ _main_ _. Programs specified on the command line or entered interactively run inside the _ _main_ _ module. Sometimes a program may alter its behavior, depending on whether it has been imported as a module or is running in _ _main_ _. For example, a module may include some testing code that is executed if the module is used as the main program but which is not executed if the module is simply imported by another module. This can be done as follows:

It is common practice for source files intended for use as libraries to use this technique for including optional testing or example code. For example, if you’re developing a module, you can put code for testing the features of your library inside an if statement as shown and simply run Python on your module as the main program to run it. That code won’t run for users who import your library.
The Module Search Path
When loading modules, the interpreter searches the list of directories in sys.path. The first entry in sys.path is typically an empty string '', which refers to the current working directory. Other entries in sys.path may consist of directory names, .zip archive files, and .egg files. The order in which entries are listed in sys.path determines the search order used when modules are loaded. To add new entries to the search path, simply add them to this list.
Although the path usually contains directory names, zip archive files containing Python modules can also be added to the search path. This can be a convenient way to package a collection of modules as a single file. For example, suppose you created two modules, foo.py and bar.py, and placed them in a zip file called mymodules.zip. The file could be added to the Python search path as follows:
![]()
Specific locations within the directory structure of a zip file can also be used. In addition, zip files can be mixed with regular pathname components. Here’s an example:
sys.path.append("/tmp/modules.zip/lib/python")
In addition to .zip files, you can also add .egg files to the search path. .egg files are packages created by the setuptools library. This is a common format encountered when installing third-party Python libraries and extensions. An .egg file is actually just a .zip file with some extra metadata (e.g., version number, dependencies, etc.) added to it. Thus, you can examine and extract data from an .egg file using standard tools for working with .zip files.
Despite support for zip file imports, there are some restrictions to be aware of. First, it is only possible import .py, .pyw, .pyc, and .pyo files from an archive. Shared libraries and extension modules written in C cannot be loaded directly from archives, although packaging systems such as setuptools are sometimes able to provide a workaround (typically by extracting C extensions to a temporary directory and loading modules from it). Moreover, Python will not create .pyc and .pyo files when .py files are loaded from an archive (described next). Thus, it is important to make sure these files are created in advance and placed in the archive in order to avoid poor performance when loading modules.
Module Loading and Compilation
So far, this chapter has presented modules as files containing pure Python code. However, modules loaded with import really fall into four general categories:
• Code written in Python (.py files)
• C or C++ extensions that have been compiled into shared libraries or DLLs
• Packages containing a collection of modules
• Built-in modules written in C and linked into the Python interpreter
When looking for a module (for example, foo), the interpreter searches each of the directories in sys.path for the following files (listed in search order):
1. A directory, foo, defining a package
2. foo.pyd, foo.so, foomodule.so, or foomodule.dll (compiled extensions)
3. foo.pyo (only if the -O or -OO option has been used)
4. foo.pyc
5. foo.py (on Windows, Python also checks for .pyw files.)
Packages are described shortly; compiled extensions are described in Chapter 26, “Extending and Embedding Python.” For .py files, when a module is first imported, it’s compiled into bytecode and written back to disk as a .pyc file. On subsequent imports, the interpreter loads this precompiled bytecode unless the modification date of the .py file is more recent (in which case, the .pyc file is regenerated). .pyo files are used in conjunction with the interpreter’s -O option. These files contain bytecode stripped of line numbers, assertions, and other debugging information. As a result, they’re somewhat smaller and allow the interpreter to run slightly faster. If the -OO option is specified instead of -O, documentation strings are also stripped from the file. This removal of documentation strings occurs only when .pyo files are created—not when they’re loaded. If none of these files exists in any of the directories in sys.path, the interpreter checks whether the name corresponds to a built-in module name. If no match exists, an ImportError exception is raised.
The automatic compilation of files into .pyc and .pyo files occurs only in conjunction with the import statement. Programs specified on the command line or standard input don’t produce such files. In addition, these files aren’t created if the directory containing a module’s .py file doesn’t allow writing (e.g., either due to insufficient permission or if it’s part of a zip archive). The -B option to the interpreter also disables the generation of these files.
If .pyc and .pyo files are available, it is not necessary for a corresponding .py file to exist. Thus, if you are packaging code and don’t wish to include source, you can merely bundle a set of .pyc files together. However, be aware that Python has extensive support for introspection and disassembly. Knowledgeable users will still be able to inspect and find out a lot of details about your program even if the source hasn’t been provided. Also, be aware that .pyc files tend to be version-specific. Thus, a .pyc file generated for one version of Python might not work in a future release.
When import searches for files, it matches filenames in a case-sensitive manner—even on machines where the underlying file system is case-insensitive, such as on Windows and OS X (such systems are case-preserving, however). Therefore, import foo will only import the file foo.py and not the file FOO.PY. However, as a general rule, you should avoid the use of module names that differ in case only.
Module Reloading and Unloading
Python provides no real support for reloading or unloading of previously imported modules. Although you can remove a module from sys.modules, this does not generally unload a module from memory. This is because references to the module object may still exist in other program components that used import to load that module. Moreover, if there are instances of classes defined in the module, those instances contain references back to their class object, which in turn holds references to the module in which it was defined.
The fact that module references exist in many places makes it generally impractical to reload a module after making changes to its implementation. For example, if you remove a module from sys.modules and use import to reload it, this will not retroactively change all of the previous references to the module used in a program. Instead, you’ll have one reference to the new module created by the most recent import statement and a set of references to the old module created by imports in other parts of the code. This is rarely what you want and never safe to use in any kind of sane production code unless you are able to carefully control the entire execution environment.
Older versions of Python provided a reload() function for reloading a module. However, use of this function was never really safe (for all of the aforementioned reasons), and its use was actively discouraged except as a possible debugging aid. Python 3 removes this feature entirely. So, it’s best not to rely upon it.
Finally, it should be noted that C/C++ extensions to Python cannot be safely unloaded or reloaded in any way. No support is provided for this, and the underlying operating system may prohibit it anyways. Thus, your only recourse is to restart the Python interpreter process.
Packages
Packages allow a collection of modules to be grouped under a common package name. This technique helps resolve namespace conflicts between module names used in different applications. A package is defined by creating a directory with the same name as the package and creating the file _ _init_ _.py in that directory. You can then place additional source files, compiled extensions, and subpackages in this directory, as needed. For example, a package might be organized as follows:

The import statement is used to load modules from a package in a number of ways:
• import Graphics.Primitive.fill
This loads the submodule Graphics.Primitive.fill. The contents of this module have to be explicitly named, such as Graphics.Primitive.fill.floodfill(img,x,y,color).
• from Graphics.Primitive import fill
This loads the submodule fill but makes it available without the package prefix; for example, fill.floodfill(img,x,y,color).
• from Graphics.Primitive.fill import floodfill
This loads the submodule fill but makes the floodfill function directly accessible; for example, floodfill(img,x,y,color).
Whenever any part of a package is first imported, the code in the file _ _init_ _.py is executed. Minimally, this file may be empty, but it can also contain code to perform package-specific initializations. All the _ _init_ _.py files encountered during an import are executed. Therefore, the statement import Graphics.Primitive.fill, shown earlier, would first execute the _ _init_ _.py file in the Graphics directory and then the _ _init_ _.py file in the Primitive directory.
One peculiar problem with packages is the handling of this statement:
from Graphics.Primitive import *
A programmer who uses this statement usually wants to import all the submodules associated with a package into the current namespace. However, because filename conventions vary from system to system (especially with regard to case sensitivity), Python cannot accurately determine what modules those might be. As a result, this statement just imports all the names that are defined in the _ _init_ _.py file in the Primitive directory. This behavior can be modified by defining a list, _ _all_ _, that contains all the module names associated with the package. This list should be defined in the package _ _init_ _.py file, like this:
![]()
Now when the user issues a from Graphics.Primitive import * statement, all the listed submodules are loaded as expected.
Another subtle problem with packages concerns submodules that want to import other submodules within the same package. For example, suppose the Graphics.Primitive.fill module wants to import the Graphics.Primitive.lines module. To do this, you can simply use the fully specified named (e.g., from Graphics.Primitives import lines) or use a package relative import like this:
![]()
In this example, the . used in the statement from . import lines refers to the same directory of the calling module. Thus, this statement looks for a module lines in the same directory as the file fill.py. Great care should be taken to avoid using a statement such as import module to import a package submodule. In older versions of Python, it was unclear whether the import module statement was referring to a standard library module or a submodule of a package. Older versions of Python would first try to load the module from the same package directory as the submodule where the import statement appeared and then move on to standard library modules if no match was found. However, in Python 3, import assumes an absolute path and will simply try to load module from the standard library. A relative import more clearly states your intentions.
Relative imports can also be used to load submodules contained in different directories of the same package. For example, if the module Graphics.Graph2D.plot2d wanted to import Graphics.Primitives.lines, it could use a statement like this:
![]()
Here, the .. moves out one directory level and Primitives drops down into a different package directory.
Relative imports can only be specified using the from module import symbol form of the import statement. Thus, statements such as import ..Primitives.lines or import .lines are a syntax error. Also, symbol has to be a valid identifier. So, a statement such as from .. import Primitives.lines is also illegal. Finally, relative imports can only be used within a package; it is illegal to use a relative import to refer to modules that are simply located in a different directory on the filesystem.
Importing a package name alone doesn’t import all the submodules contained in the package. For example, the following code doesn’t work:
![]()
However, because the import Graphics statement executes the _ _init_ _.py file in the Graphics directory, relative imports can be used to load all the submodules automatically, as follows:

Now the import Graphics statement imports all the submodules and makes them available using their fully qualified names. Again, it is important to stress that a package relative import should be used as shown. If you use a simple statement such as import module, standard library modules may be loaded instead.
Finally, when Python imports a package, it defines a special variable, _ _path_ _, which contains a list of directories that are searched when looking for package submodules (_ _path_ _ is a package-specific version of the sys.path variable). _ _path_ _ is accessible to the code contained in _ _init_ _.py files and initially contains a single item with the directory name of the package. If necessary, a package can supply additional directories to the _ _path_ _ list to alter the search path used for finding submodules. This might be useful if the organization of a package on the file system is complicated and doesn’t neatly match up with the package hierarchy.
Distributing Python Programs and Libraries
To distribute Python programs to others, you should use the distutils module. As preparation, you should first cleanly organize your work into a directory that has a README file, supporting documentation, and your source code. Typically, this directory will contain a mix of library modules, packages, and scripts. Modules and packages refer to source files that will be loaded with import statements. Scripts are programs that will run as the main program to the interpreter (e.g., running as python scriptname). Here is an example of a directory containing Python code:

You should organize your code so that it works normally when running the Python interpreter in the top-level directory. For example, if you start Python in the spam directory, you should be able to import modules, import package components, and run scripts without having to alter any of Python’s settings such as the module search path.
After you have organized your code, create a file setup.py in the top most directory (spam in the previous examples). In this file, put the following code:

In the setup() call, the py_modules argument is a list of all of the single-file Python modules, packages is a list of all package directories, and scripts is a list of script files. Any of these arguments may be omitted if your software does not have any matching components (i.e., there are no scripts). name is the name of your package, and version is the version number as a string.
The call to setup() supports a variety of other parameters that supply various metadata about your package. Table 8.1 shows the most common parameters that can be specified. All values are strings except for the classifiers parameter, which is a list of strings such as ['Development Status :: 4 - Beta', 'Programming Language :: Python'] (a full list can be found at http://pypi.python.org).
Table 8.1 Parameters to setup()

Creating a setup.py file is enough to create a source distribution of your software. Type the following shell command to make a source distribution:
![]()
This creates an archive file such as spam-1.0.tar.gz or spam-1.0.zip in the directory spam/dist. This is the file you would give to others to install your software. To install, a user simply unpacks the archive and performs these steps:
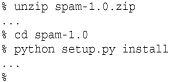
This installs the software into the local Python distribution and makes it available for general use. Modules and packages are normally installed into a directory called "site-packages" in the Python library. To find the exact location of this directory, inspect the value of sys.path. Scripts are normally installed into the same directory as the Python interpreter on UNIX-based systems or into a "Scripts" directory on Windows (found in "C:Python26Scripts" in a typical installation).
On UNIX, if the first line of a script starts with #! and contains the text "python", the installer will rewrite the line to point to the local installation of Python. Thus, if you have written scripts that have been hard-coded to a specific Python location such as /usr/local/bin/python, they should still work when installed on other systems where Python is in a different location.
The setup.py file has a number of other commands concerning the distribution of software. If you type 'python setup.py bdist', a binary distribution is created in which all of the .py files have already been precompiled into .pyc files and placed into a directory structure that mimics that of the local platform. This kind of distribution is needed only if parts of your application have platform dependencies (for example, if you also have C extensions that need to be compiled). If you run 'python setup.py bdist_wininst' on a Windows machine, an .exe file will be created. When opened, a Windows installer dialog will start, prompting the user for information about where the software should be installed. This kind of distribution also adds entries to the registry, making it easy to uninstall your package at a later date.
The distutils module assumes that users already have a Python installation on their machine (downloaded separately). Although it is possible to create software packages where the Python runtime and your software are bundled together into a single binary executable, that is beyond the scope of what can be covered here (look at a third-party module such as py2exe or py2app for further details). If all you are doing is distributing libraries or simple scripts to people, it is usually unnecessary to package your code with the Python interpreter and runtime as well.
Finally, it should be noted that there are many more options to distutils than those covered here. Chapter 26 describes how distutils can be used to compile C and C++ extensions.
Although not part of the standard Python distribution, Python software is often distributed in the form of an .egg file. This format is created by the popular setuptools extension (http://pypi.python.org/pypi/setuptools). To support setuptools, you can simply change the first part of your setup.py file as follows:

Installing Third-Party Libraries
The definitive resource for locating third-party libraries and extensions to Python is the Python Package Index (PyPI), which is located at http://pypi.python.org. Installing third-party modules is usually straightforward but can become quite involved for very large packages that also depend on other third-party modules. For the more major extensions, you will often find a platform-native installer that simply steps you through the process using a series of dialog screens. For other modules, you typically unpack the download, look for the setup.py file, and type python setup.py install to install the software.
By default, third-party modules are installed in the site-packages directory of the Python standard library. Access to this directory typically requires root or administrator access. If this is not the case, you can type python setup.py install --user to have the module installed in a per-user library directory. This installs the package in a per-user directory such as "/Users/beazley/.local/lib/python2.6/site-packages" on UNIX.
If you want to install the software somewhere else entirely, use the --prefix option to setup.py. For example, typing python setup.py install --prefix=/home/beazley/pypackages installs a module under the directory /home/beazley/pypackages. When installing in a nonstandard location, you will probably have to adjust the setting of sys.path in order for Python to locate your newly installed modules.
Be aware that many extensions to Python involve C or C++ code. If you have downloaded a source distribution, your system will have to have a C++ compiler installed in order to run the installer. On UNIX, Linux, and OS X, this is usually not an issue. On Windows, it has traditionally been necessary to have a version of Microsoft Visual Studio installed. If you’re working on that platform, you’re probably better off looking for a precompiled version of your extension.
If you have installed setuptools, a script easy_install is available to install packages. Simply type easy_install pkgname to install a specific package. If configured correctly, this will download the appropriate software from PyPI along with any dependencies and install it for you. Of course, your mileage might vary.
If you would like to add your own software to PyPI, simply type python setup.py register. This will upload metadata about the latest version of your software to the index (note that you will have to register a username and password first).