
![]()
Deep Learning with Python TensorFlow 2.0
In this chapter, you will be using TensorFlow 2.0 and Keras API to implement different types of neural networks in Python. From TensorFlow 2.0, Google has officially adopted Keras as the main API to run TensorFlow scripts.
In this chapter, you will study three different types of Neural Networks: Densely Connected Neural Network, Recurrent Neural Network, and Convolutional Neural Network, with TensorFlow 2.0.
9.1. Densely Connected Neural Network
A densely connected neural network (DNN) is a type of neural network where all the nodes in the previous layer are connected to all the nodes in the subsequent layer of a neural network. A DNN is also called a multilayer perceptron.
A densely connected neural network is mostly used for making predictions on tabular data. Tabular data is the type of data that can be presented in the form of a table.
In a neural network, we have an input layer, one or multiple hidden layers, and an output layer. An example of a neural network is shown below:
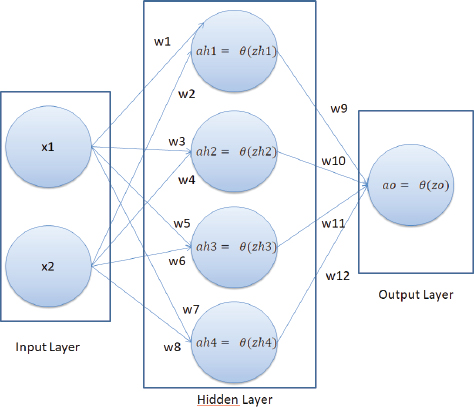
In our neural network, we have two nodes in the input layer (since there are two features in the input), one hidden layer with four nodes, and one output layer with one node since we are doing binary classification. The number of hidden layers, along with the number of neurons per hidden layer, depends upon you.
In the above neural network, the x1 and x2 are the input features, and the ao is the output of the network. Here, the only attribute we can control is the weights w1, w2, w3, ….. w12. The idea is to find the values of weights for which the difference between the predicted output ao in this case and the actual output (labels).
A neural network works in two steps:
1.Feed Forward
2.Backpropagation
I will explain both these steps in the context of our neural network.
9.1.1. Feed Forward
In the feed forward step, the final output of a neural network is created. Let’s try to find the final output of our neural network.
In our neural network, we will first find the value of zh1, which can be calculated as follows:
![]()
Using zh1, we can find the value of ah1, which is:
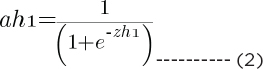
In the same way, you find the values of ah2, ah3, and ah4.
To find the value of zo, you can use the following formula:
![]()
Finally, to find the output of the neural network ao:

9.1.2. Backpropagation
The purpose of backpropagation is to minimize the overall loss by finding the optimum values of weights. The loss function we are going to use in this section is the mean squared error, which is in our case represented as:
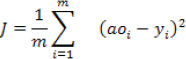
Here, ao is the predicted output from our neural network, and y is the actual output.
Our weights are divided into two parts. We have weights that connect input features to the hidden layer and the hidden layer to the output node. We call the weights that connect the input to the hidden layer collectively as wh (w1, w2, w3 …… w8), and the weights connecting the hidden layer to the output as wo (w9, w10, w11, w12).
The backpropagation will consist of two phases. In the first phase, we will find dcost/dwo (which refers to the derivative of the total cost with respect to wo, weights in the output layer). By the chain rule, dcost/dwo can be represented as the product of dcost/dao * dao/dzo * dzo/dwo. (d here refers to a derivative.) Mathematically:
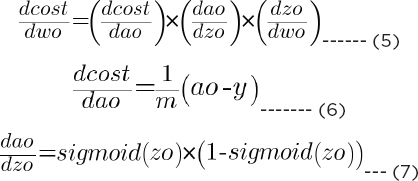
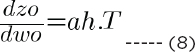
In the same way, you find the derivative of cost with respect to bias in the output layer, i.e., dcost/dbo, which is given as:
![]()
Putting 6, 7, and 8 in equation 5, we can get the derivative of cost with respect to the output weights.
The next step is to find the derivative of cost with respect to hidden layer weights wh and bias bh. Let’s first find the derivative of cost with respect to hidden layer weights:
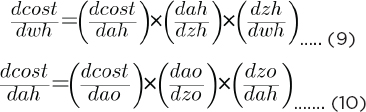
The values of dcost/dao and dao/dzo can be calculated from equations 6 and 7, respectively. The value of dzo/dah is given as:
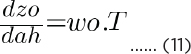
Putting the values of equations 6, 7, and 11 in equation 11, you can get the value of equation 10.
Next, let’s find the value of dah/dzh:
![]()
and,
![]()
Using equation 10, 12, and 13 in equation 9, you can find the value of dcost/dwh.
9.1.3. Implementing a Densely Connected Neural Network
In this section, you will see how to implement a densely connected neural network with TensorFlow, which predicts whether or not a banknote is genuine or not, based on certain features such as variance, skewness, curtosis, and entropy of several banknote images. Let’s begin without much ado. The following script upgrades the existing TensorFlow version. I always recommend doing this.
Script 1:
pip install --upgrade tensorflow
To check if you are actually running TensorFlow 2.0, execute the following command.
Script 2:
1. import tensorflow as tf
2. print(tf.__version__)
You should see 2.x.x in the output, as shown below:
Output:
2.1.0
§ Importing Required Libraries
Let’s import the required libraries.
Script 3:
1. importseaborn as sns
2. import pandas as pd
3. importnumpy as np
4. fromtensorflow.keras.layers import Dense, Dropout, Activation
5. fromtensorflow.keras.models import Model, Sequential
6. fromtensorflow.keras.optimizers import Adam
§ Importing the Dataset
The dataset that we are going to use can be downloaded free from the following GitHub resource. The dataset is also available by the name “banknotes.csv” in the Datasets folder in the GitHub repository.
Script 4:
1. # reading data from CSV File
2. banknote_data = pd.read_csv(“https://raw.githubusercontent.com/AbhiRoy96/Banknote-Authentication-UCI-Dataset/master/bank_notes.csv”)
The following script plots the first five rows of the dataset.
Script 5:
1. banknote_data.head()
Output:
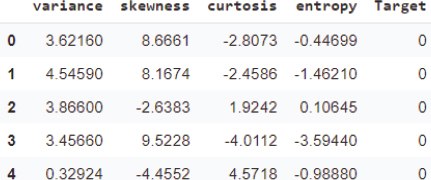
The output shows that our dataset contains five columns. Let’s see the shape of our dataset.
Script 6:
1. banknote_data.shape
The output shows that our dataset has 1372 rows and 5 columns.
Output:
(1372, 5)
Let’s plot a count plot to see the distribution of data with respect to the values in the class that we want to predict.
Script 7:
1. sns.countplot(x=’Target’, data=banknote_data)
Output:
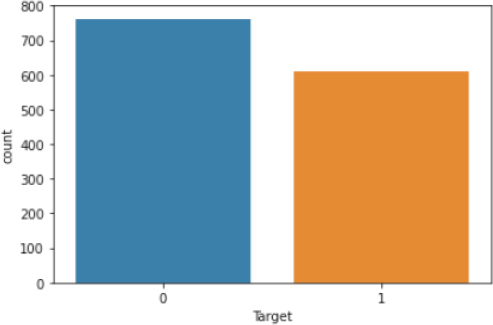
The output shows that the number of fake notes (represented by 1) is slightly less than the number of original banknotes.
The task is to predict the values for the “Target” column, based on the values in the first four columns. Let’s divide our data into features and target labels.
Script 8:
1. X = banknote_data.drop([‘Target’], axis=1).values
2. y = banknote_data[[‘Target’]].values
3.
4. print(X.shape)
5. print(y.shape)
Output:
(1372, 4)
(1372, 1)
The variable X contains our feature set while the variable y contains target labels.
§ Dividing Data into Training and Test Sets
Deep learning models are normally trained on one set of data and are tested on another set. The dataset used to train a deep learning model is called a training set, and the dataset used to evaluate the performance of the trained deep learning model is called the test set.
We will divide the total data into an 80 percent training set and a 20 percent test set. The following script performs that task.
Script 9:
1. from sklearn.model_selection import train_test_split
2. X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
Before you train your deep learning model, it is always a good practice to scale your data. The following script applies standard scaling to the training and test sets.
Script 10:
1. fromsklearn.preprocessing import StandardScaler
2. sc = StandardScaler()
3. X_train = sc.fit_transform(X_train)
4. X_test = sc.transform(X_test)
§ Creating a Neural Network
To create a neural network, you can use the Sequential class from the tensorflow.keras.models module. To add layers to your model, you simply need to call the add method and pass your layer to it. To create a dense layer, you can use the Dense class.
The first parameter to the Dense class is the number of nodes in the dense layer, and the second parameter is the dimension of the input. The activation function can be defined by passing a string value to the activation attribute of the Dense class. It is important to mention that the input dimensions are only required to be passed to the first dense layer. The subsequent dense layers can calculate the input dimensions automatically from the number of nodes in the previous layers.
The following script defines a method create_model. The model takes two parameters: learning_rate and dropout_rate. Inside the model, we create an object of the Sequential class and add three dense layers to the model. The layers contain 12, 6, and 1 nodes, respectively. After each dense layer, we add a dropout layer with a dropout rate of 0.1. Adding dropout after each layer avoids overfitting. After you create the model,
you need to compile it via the compile method. The compile method takes the loss function, the optimizer, and the metrics as parameters. Remember, for binary classification, the activation function in the final dense layer will be sigmoid, whereas the loss function in the compile method will be binary_crossentropy.
Script 11:
def create_model(learning_rate, dropout_rate):
#create sequential model
model = Sequential()
#adding dense layers
model.add(Dense(12, input_dim=X_train.shape[1], activation=’relu’))
model.add(Dropout(dropout_rate))
model.add(Dense(6, activation=’relu’))
model.add(Dropout(dropout_rate))
model.add(Dense(1, activation=’sigmoid’))
#compiling the model
adam = Adam(lr=learning_rate)
model.compile(loss=’binary_crossentropy’, optimizer=adam, metrics=[‘accuracy’])
return model
Next, we need to define the default dropout rate, learning rate batch size, and the number of epochs. The number of epochs refers to the number of times the whole dataset is used for training, and the batch size refers to the number of records, after which the weights are updated.
1. dropout_rate = 0.1
2. epochs = 20
3. batch_size = 4
4. learn_rate = 0.001
The following script creates our model.
Script 12:
1. model = create_model(learn_rate, dropout_rate)
You can see your model architecture via the plot_model() method of the tensorflow.keras.utils module.
Script 13:
1. from tensorflow.keras.utils import plot_model
2. plot_model(model, to_file=’model_plot1.png’, show_shapes=True, show_layer_names=True)
Output:
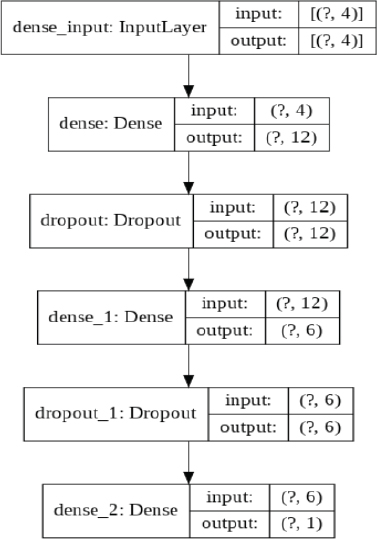
From the above output, you can see that the input layer contains four nodes, the input to the first dense layers is 4, while the output is 12. Similarly, the input to the second dense layer is 12, while the output is 6. Finally, in the last dense layer, the input is 6 nodes, while the output is 1 since we are making a binary classification. Also, you can see a dropout layer after each dense layer.
To train the model, you need to call the fit method on the model object. The fit method takes the training features and targets as parameters, along with the batch size, the number of epochs, and the validation split. The validation split refers to the split in the training data during training.
Script 14:
1. model_history = model.fit(X_train, y_train, batch_size=batch_
2. size, epochs=epochs, validation_split=0.2, verbose=1)
The result from the last five epochs is shown below:
Output:
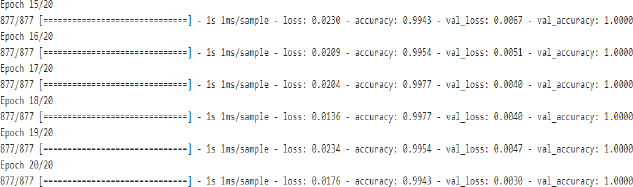
Our neural network is now trained. The “val_accuracy” of 1.0 in the last epoch shows that on the training set, our neural network is making predictions with 100 percent accuracy.
§ Evaluating the Neural Network Performance
We can now evaluate its performance by making predictions on the test set. To make predictions on the test set, you have to pass the set to the evaluate() method of the model, as shown below:
Script 15:
1. accuracies = model.evaluate(X_test, y_test, verbose=1)
2. print(“Test Score:”, accuracies[0])
3. print(“Test Accuracy:”, accuracies[1])
Output:
275/275 [==============================] - 0s 374us/sample - loss: 0.0040 - accuracy: 1.0000
Test Score: 0.00397354013286531
Test Accuracy: 1.0
The output shows an accuracy of 100 percent on the test set. The loss value of 0.00397 is shown. Remember, lower the loss, higher the accuracy.
Let’s now plot the accuracy on the training and test sets to see if our model is overfitting or not.
Script 16:
1. importmatplotlib.pyplot as plt
2. plt.plot(model_history.history[‘accuracy’], label = ‘accuracy’)
3. plt.plot(model_history.history[‘val_accuracy’], label = ‘val_accuracy’)
4. plt.legend([‘train’,’test’], loc=’lowerleft’)
Output:
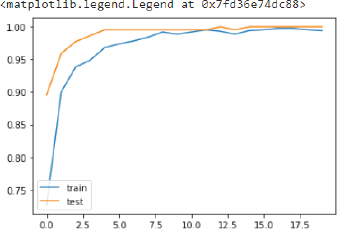
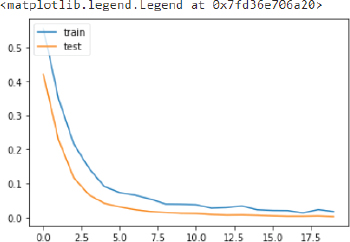
The above curve meets near 1 and then becomes stable which shows that our model is not overfitting.
Similarly, the loss values for test and training sets can be printed as follows:
Script 17:
1. plt.plot(model_history.history[‘loss’], label = ‘loss’)
2. plt.plot(model_history.history[‘val_loss’], label = ‘val_loss’)
3. plt.legend([‘train’,’test’], loc=’upper left’)
Output:
And this is it. You have successfully trained a neural network for classification. In the next section, you will see how to create and train a recurrent neural network for stock price prediction.
9.2. Recurrent Neural Networks (RNN)
9.2.1. What Is an RNN and LSTM?
This section explains what a recurrent neural network (RNN) is, what is the problem with RNN, and how a long short-term memory network (LSTM) can be used to solve the problems with RNN.
§ What Is an RNN?
A recurrent neural network is a type of neural network that is used to process data that is sequential in nature, e.g., stock price data, text sentences, or sales of items.
Sequential data is a type of data where the value of data at time step T depends upon the values of data at timesteps less than T. For instance, sound waves, text sentences, stock market prices, etc. In the stock market price prediction problem, the value of the opening price of a stock at a given data depends upon the opening stock price of the previous days.
The difference between the architecture of a recurrent neural network and a simple neural network is presented in the following figure:
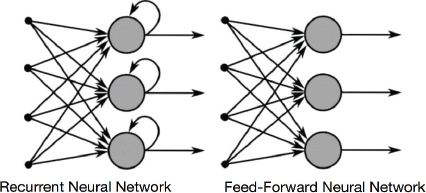
In a recurrent neural network, at each time step, the previous output of the neuron is also multiplied by the current input via a weight vector. You can see from the above figure that the output from a neuron is looped back into for the next time step. The following figure makes this concept further clear:
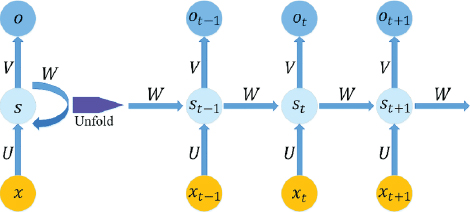
Here, we have a single neuron with one input and one output. On the right side, the process followed by a recurrent neural network is unfolded. You can see that at time step t, the input is multiplied by weight vector U, while the previous output at time t–1, i.e., St–1 is multiplied by the weight vector W, the sum of the input vector XU + SW becomes the output at time T. This is how a recurrent neural network captures the sequential information.
§ Problems with RNN
A problem with the recurrent neural network is that while it can capture a shorter sequence, it tends to forget longer sequences.
For instance, it is easier to predict the missing word in the following sentence because the Keyword “Birds” is present in the same sentence.
“Birds fly in the ___.”
RNN can easily guess that the missing word is “Clouds” here.
However, RNN cannot remember longer sequences such as the one …
“Mike grew up in France. He likes to eat cheese, he plays piano……………………………………………………………………………………….. and he speaks _______ fluently”.
Here, the RNN can only guess that the missing word is “French” if it remembers the first sentence, i.e., “Mike grew up in France.”
The recurrent neural networks consist of multiple recurrent layers, which results in a diminishing gradient problem. The diminishing gradient problem is that during the backpropagation of the recurrent layer, the gradient of the earlier layer becomes infinitesimally small, which virtually makes neural network initial layers stop from learning anything.
To solve this problem, a special type of recurrent neural network, i.e., Long Short-Term Memory (LSTM) has been developed.
§ What Is an LSTM?
LSTM is a type of RNN which is capable of remembering longer sequences, and hence, it is one of the most commonly used RNN for sequence tasks.
In LSTM, instead of a single unit in the recurrent cell, there are four interacting units, i.e., a forget gate, an input gate, an update gate, and an output gate. The overall architecture of an LSTM cell is shown in the following figure:

Let’s briefly discuss all the components of LSTM:
§ Cell State
The cell state in LSTM is responsible for remembering a long sequence. The following figure describes the cell state:
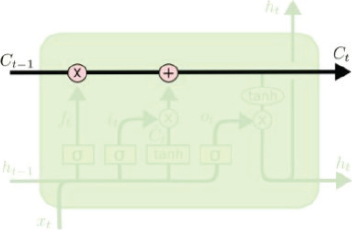
The cell state contains data from all the previous cells in the sequence. The LSTM is capable of adding or removing information to a cell state. In other words, LSTM tells the cell state which part of previous information to remember and which information to forget.
§ Forget Gate
The forget gate basically tells the cell state which information to retain from the information in the previous step and which information to forget. The working and calculation formula for the forget gate is as follows:
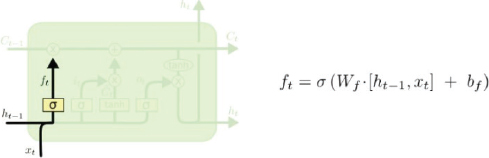
§ Input Gate
The forget gate is used to decide which information to remember or forget. The input gate is responsible for updating or adding any new information in the cell state. The input gate has two parts: an input layer, which decides which part of the cell state is to be updated, and a tanh layer, which actually creates a vector of new values that are added or replaced in the cell state. The working of the input gate is explained in the following figure:

§ Update Gate
The forget gate tells us what to forget, and the input gate tells us what to add to the cell state. The next step is to actually perform these two operations. The update gate is basically used to perform these two operations. The functioning and the equations for the update gate are as follows:
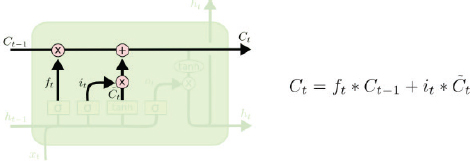
§ Output Gate
Finally, you have the output gate, which outputs the hidden state and the output, just like a common recurrent neural network. The additional output from an LSTM node is a cell state, which runs between all the nodes in a sequence. The equations and the functioning of the output gate are depicted by the following figure:
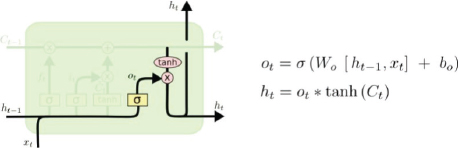
In the following sections, you will see how to use LSTM for solving different types of Sequence problems.
9.3. Predicting Future Stock Prices via LSTM in Keras
Stock price prediction is one of the most common applications of many to one or many to many sequence problems.
In this section, we will predict the opening stock price of the Facebook company, using the opening stock price of the previous 60 days. The training set consists of the stock price data of Facebook from 1st January 2015 to 31st December 2019, i.e., five years. The dataset can be downloaded from this site:
https://finance.yahoo.com/quote/FB/history?p=FB.
The test data will consist of the opening stock prices of the Facebook company for the month of January 2020. The training file fb_train.csv and the test file fb_test.csv are also available in the Datasets folder in the GitHub repository. Let’s begin with the coding now.
9.3.1. Training the Stock Prediction Model
In this section, we will train our stock prediction model on the training set.
Before you train the stock market prediction model, upload the TensorFlow version by executing the following command on Google collaborator (https://colab.research.google.com/).
Script 18:
pip install --upgrade tensorflow
If your files are placed on Google Drive, and you want to access them in Google Collaborator, to do so, you have to first mount the Google Drive inside your Google Collaborator environment via the following script:
Script 19:
1. # mounting google drive
2. from google.colab import drive
3. drive.mount(‘/gdrive’)
Next, to import the training dataset, execute the following script:
Script 20:
1. # importing libraries
2. import pandas as pd
3. import numpy as np
4.
5. #importing dataset
6. fb_complete_data = pd.read_csv(“/gdrive/My Drive/datasets/fb_train.csv”)
Running the following script will print the first five rows of the dataset.
Script 21:
1. #printing dataset header
2. fb_complete_data.head()
Output:
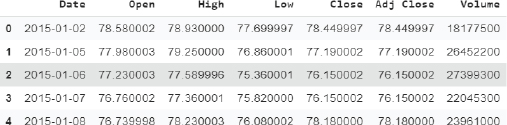
The output shows that our dataset consists of seven columns. However, in this section, we are only interested in the Open column. Therefore, we will select the Open column from the dataset. Run the following script to do so.
Script 22:
1. #filtering open column
2. fb_training_processed = fb_complete_data[[‘Open’]].values
Next, we will scale our dataset.
Script 23:
1. #scaling features
2. from sklearn.preprocessing import MinMaxScaler
3. scaler = MinMaxScaler(feature_range = (0, 1))
4.
5. fb_training_scaled = scaler.fit_transform(fb_training_processed)
If you check the total length of the dataset, you will see it has 1257 records, as shown below:
Script 24:
1. len(fb_training_scaled)
Output:
1257
Before we proceed further, we need to divide our data into features and labels. Our feature set will consist of 60 timesteps of 1 feature. The feature set basically consists of the opening stock price of the past 60 days, while the label set will consist of the opening stock price of 61st day. Based on the opening stock prices of the previous days, we will be predicted the opening stock price for the next day.
Script 25:
1. #training features contain data of last 60 days
2. #training labels contain data of 61st day
3.
4. fb_training_features= []
5. fb_training_labels = []
6. for i in range(60, len(fb_training_scaled)):
7.![]() fb_training_features.append(fb_training_scaled[i-60:i, 0])
fb_training_features.append(fb_training_scaled[i-60:i, 0])
8.![]() fb_training_labels.append(fb_training_scaled[i, 0])
fb_training_labels.append(fb_training_scaled[i, 0])
We need to convert our data into Numpy array before we can use as input with Keras. The following script does that:
Script 26:
1. #converting training data to numpy arrays
2. X_train = np.array(fb_training_features)
3. y_train = np.array(fb_training_labels)
Let’s print the shape of our dataset.
Script 27:
1. print(X_train.shape)
2. print(y_train.shape)
Output:
(1197, 60)
(1197,)
We need to reshape our input features into 3-dimensional format.
Script 28:
1. converting data into 3D shape
2. X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
The following script creates our LSTM model. We have 4 LSTM layers with 100 nodes each. Each LSTM layer is followed by a dropout layer to avoid overfitting. The final dense has one node since the output is a single value.
Script 29:
1. #importing libraries
2. import numpy as np
3. import matplotlib.pyplot as plt
4. from tensorflow.keras.layers import Input, Activation, Dense, Flatten, Dropout, Flatten, LSTM
5. from tensorflow.keras.models import Model
Script 30:
1. #defining the LSTM network
2.
3. input_layer = Input(shape = (X_train.shape[1], 1))
4. lstm1 = LSTM(100, activation=’relu’, return_sequences=True)(input_layer)
5. do1 = Dropout(0.2)(lstm1)
6. lstm2 = LSTM(100, activation=’relu’, return_sequences=True)(do1)
7. do2 = Dropout(0.2)(lstm2)
8. lstm3 = LSTM(100, activation=’relu’, return_sequences=True)(do2)
9. do3 = Dropout(0.2)(lstm3)
10. lstm4 = LSTM(100, activation=’relu’)(do3)
11. do4 = Dropout(0.2)(lstm4)
12.
13. output_layer = Dense(1)(do4)
14. model = Model(input_layer, output_layer)
15. model.compile(optimizer=’adam’, loss=’mse’)
Next, we need to convert the output y into a column vector.
Script 31:
1. print(X_train.shape)
2. print(y_train.shape)
3. y_train= y_train.reshape(-1,1)
4. print(y_train.shape)
Output:
(1197, 60, 1)
(1197,)
(1197, 1)
The following script trains our stock price prediction model on the training set.
Script 32:
1. #training the model
2. model_history = model.fit(X_train, y_train, epochs=100, verbose=1, batch_size = 32)
You can see the results for the last five epochs in the output.
Output:
Epoch 96/100
38/38 [==============================] - 11s 299ms/step - loss: 0.0018
Epoch 97/100
38/38 [==============================] - 11s 294ms/step - loss: 0.0019
Epoch 98/100
38/38 [==============================] - 11s 299ms/step - loss: 0.0018
Epoch 99/100
38/38 [==============================] - 12s 304ms/step - loss: 0.0018
Epoch 100/100
38/38 [==============================] - 11s 299ms/step - loss: 0.0021
Our model has been trained. Next, we will test our stock prediction model on the test data.
9.3.2. Testing the Stock Prediction Model
The test data should also be converted into the right shape to test our stock prediction model. We will do that later. Let’s first import the data and then remove all the columns from the test data except the Open column.
Script 33:
1. #creating test set
2. fb_testing_complete_data = pd.read_csv(“/gdrive/My Drive/datasets/fb_test.csv”)
3. fb_testing_processed = fb_testing_complete_data[[‘Open’]].values
Let’s concatenate the training and test sets. We do this to predict the first value in the test set. The input will be the data from the past 60 days, which is basically the data from the last 60 days in the training set.
Script 34:
1. fb_all_data = pd.concat((fb_complete_data[‘Open’], fb_testing_complete_data[‘Open’]), axis=0)
The following script creates our final input feature set.
Script 35:
1. test_inputs = fb_all_data [len(fb_all_data) - len(fb_testing_complete_data) - 60:].values
2. print(test_inputs.shape)
You can see that the length of the input data is 80. Here, the first 60 records are the last 60 records from the training data, and the last 20 records are the 20 records from the test file.
Output:
(80,)
We need to scale our data and convert it into a column vector.
Script 36:
1. test_inputs = test_inputs.reshape(-1,1)
2. test_inputs = scaler.transform(test_inputs)
3. print(test_inputs.shape)
Output:
(80, 1)
As we did with the training data, we need to divide our input data into features and labels. Here is the script that does that.
Script 37:
1. fb_test_features = []
2. for i in range(60, 80):
3.![]() fb_test_features.append(test_inputs[i-60:i, 0])
fb_test_features.append(test_inputs[i-60:i, 0])
Let’s now print our feature set.
Script 38:
1. X_test = np.array(fb_test_features)
2. print(X_test.shape)
Output:
(20, 60)
Our feature set is currently 2-dimensional. But the LSTM algorithm in Keras accepts only data in 3-dimensional. The following script converts our input features into a 3-dimensional shape.
Script 39:
1. #converting test data into 3D shape
2. X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
3. print(X_test.shape)
Output:
(20, 60, 1)
Now is the time to make predictions on the test set. The following script does that:
Script 40:
1. #making predictions on test set
2. y_pred = model.predict(X_test)
Since we scaled our input feature, we need to apply the inverse_transform() method of the scaler object on the predicted output to get the original output values.
Script 41:
1. #converting scaled data back to original data
2. y_pred = scaler.inverse_transform(y_pred)
Finally, to compare the predicted output with the actual stock price values, you can plot the two values via the following script:
Script 42:
1. #plotting original and predicted stock values
2. plt.figure(figsize=(8,6))
3. plt.plot(fb_testing_processed, color=’red’, label=’Actual Facenook Stock Price’)
4. plt.plot(y_pred, color=’green’, label=’Predicted Face Stock Price’)
5. plt.title(‘Facebook Stock Prices’)
6. plt.xlabel(‘Date’)
7. plt.ylabel(‘Stock Price’)
8. plt.legend()
9. plt.show()
Output:
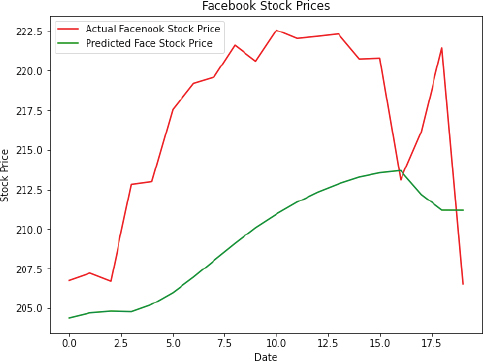
The output shows that our algorithm has been able to partially capture the trend of the future opening stock prices for Facebook data.
In the next section, you will see how to perform image classification using a convolutional neural network.
9.4. Convolutional Neural Network
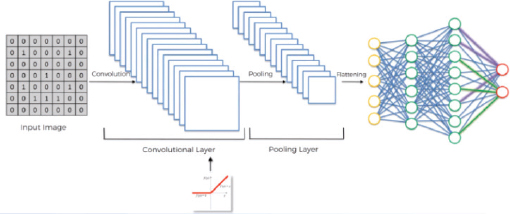
A convolutional neural network is a type of neural network that is used to classify spatial data, for instance, images, sequences, etc. In an image, each pixel is somehow related to some other pictures. Looking at a single pixel, you cannot guess the image. Rather you have to look at the complete picture to guess the image. A CNN does exactly that. Using a kernel or feature detects, it detects features within an image. A combination of these images then forms the complete image, which can then be classified using a densely connected neural network. The steps involved in a Convolutional Neural Network have been explained in the next section.
9.4.1. Image Classification with CNN
In this section, you will see how to perform image classification using CNN. Before we go ahead and see the steps involved in the image classification using a convolutional neural network, we first need to know how computers see images.
§ How Do Computers See Images?
When humans see an image, they see lines, circles, squares, and different shapes. However, a computer sees an image differently. For a computer, an image is no more than a 2-D set of pixels arranged in a certain manner. For greyscale images, the pixel value can be between 0–255, while for color images, there are three channels: red, green, and blue. Each channel can have a pixel value between 0–255.
Look at the following image 9.1.
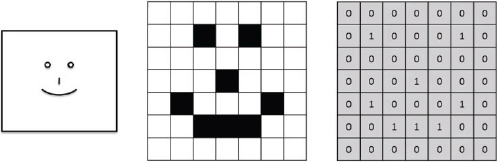
Image 9.1: How computers see images
Here, the box on the leftmost is what humans see. They see a smiling face. However, a computer sees it in the form of pixel values of 0s and 1s, as shown on the right-hand side. Here, 0 indicates a white pixel, whereas 1 indicates a black pixel. In the real-world, 1 indicates a white pixel, while 0 indicates a black pixel.
Now, we know how a computer sees images. The next step is to explain the steps involved in the image classification using a convolutional neural network.
The following are the steps involved in image classification with CNN:
1.The Convolution Operation
2.The ReLu Operation
3.The Pooling Operation
4.Filattening and Fully Connected Layer.
§ The Convolution Operation
The convolution operation is the first step involved in the image classification with a convolutional neural network.
In a convolution operation, you have an image and a feature detector. The values of the feature detector are initialized randomly. The feature detector is moved over the image from left to right. The values in the feature detector are multiplied by the corresponding values in the image, and then all the values in the feature detector are added. The resultant value is added to the feature map.
Look at the following image, for example:
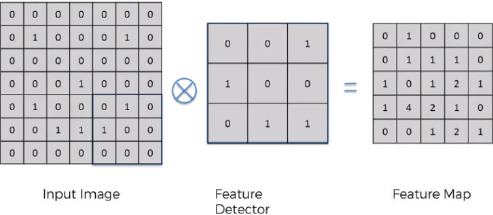
In the above image, we have an input image of 7 x 7. The feature detector is of the size 3 x 3. The feature detector is placed over the image at the top left of the input image, and then the pixel values in the feature detector are multiplied by the pixel values in the input image. The result is then added. The feature detector then moves to N step towards the right. Here, N refers to stride. A stride is basically the number of steps that a feature detector takes from left to right and then from top to bottom to find a new value for the feature map.
In reality, there are multiple feature detectors. As shown in the following image:

Each feature detector is responsible for detecting a particular feature in the image.
§ The ReLu Operation
In a ReLu operation, you simply apply the ReLu activation function on the feature map generated as a result of the convolution operation. A convolution operation gives us linear values. The ReLu operation is performed to introduce non-linearity in the image.
In the ReLu operation, all the negative values in a feature map are replaced by 0. All the positive values are left untouched.
Suppose we have the following feature map:
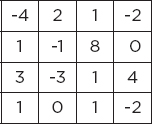
When the ReLu function is applied on the feature map, the resultant feature map looks like this:
§ The Pooling Operation
A pooling operation is performed in order to introduce spatial invariance in the feature map. Pooling operation is performed after convolution and ReLu operation.
Let’s first understand what spatial invariance is. If you look at the following three images, you can easily identify that these images contain cheetahs.

Here, the second image is disoriented, and the third image is distorted. However, we are still able to identify that all the three images contain cheetahs based on certain features.
Pooling does exactly that. In pooling, we have a feature map and then a pooling filter, which can be of any size. Next, we move the pooling filter over the feature map and apply the pooling operation. There can be many pooling operations such as max pooling, min pooling, and average pooling. In max pooling, we choose the maximum value from the pooling filter. Pooling not only introduces spatial invariance but also reduces the size of an image.
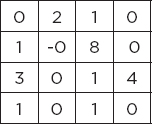
Look at the following image. Here, in the 3rd and 4th rows and 1st and 2nd columns, we have four values 1, 0, 1, and 4. When we apply max pooling on these four pixels, the maximum value will be chosen, i.e., you can see 4 in the pooled feature map.

§ Flattening and Fully Connected Layer
The pooled feature maps are flattened to form a one-dimensional vector to find more features from an image, as shown in the following figure:

The one-dimensional vector is then used as input to a densely or fully connected neural network layer that you saw in Chapter 4. This is shown in the following image:
9.4.2. Implementing CNN with TensorFlow Keras
In this section, you will see how to implement CNN for image classification in TensorFlow Keras. We will create CNN that is able to classify an image of fashion items such as shirt, pants, trousers, sandals into one of the 10 predefined categories. So, let’s begin without much ado.
Execute the following script to make sure that you are running the latest version of TensorFlow.
Script 43:
1. pip install --upgrade tensorflow
2.
3. import tensorflow as tf
4. print(tf.__version__)
Output:
2.3.0
The following script imports the required libraries and classes.
Script 44:
1. #importing required libraries
2. import numpy as np
3. import matplotlib.pyplot as plt
4. from tensorflow.keras.layers import Input, Conv2D, Dense, Flatten, Dropout, MaxPool2D
5. from tensorflow.keras.models import Model
The following script downloads the Fashion MNIST dataset that contains images of different fashion items along with their labels. The script divides the data into training images and training labels and test images and test labels.
Script 45:
1. #importing mnist datase
2. mnist_data = tf.keras.datasets.fashion_mnist
3.
4. #dividing data into training and test sets
5. (training_images, training_labels), (test_images, test_labels) = mnist_data .load_data()
The images in our dataset are greyscale images, where each pixel value lies between 0 and 255. The following script normalizes pixel values between 0 and 1.
Script 46:
1. #scaling images
2. training_images, test_images = training_images/255.0, test_images/255.0
Let’s print the shape of our training data.
Script 47:
1. print(training_images.shape)
Output:
(60000, 28, 28)
The above output shows that our training dataset contains 60,000 records (images). Each image is 28 pixels wide and 28 pixels high.
Let’s print an image randomly from the test set:
Script 48:
1. #plotting image number 9 from test set
2. plt.figure()
3. plt.imshow(test_images[9])
4. plt.colorbar()
5. plt.grid(False)
6. plt.show()
Output:
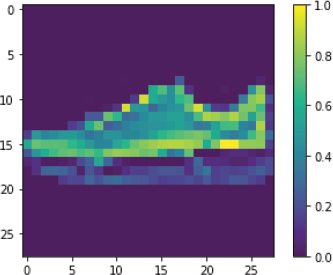
The output shows that the 9th image in our test set is the image of a sneaker.
The next step is to change the dimensions of our input images. CNN in Keras expects data to be in the format Width-Height-Channels. Our images contain width and height but no channels. Since the images are greyscale, we set the image channel to 1, as shown in the following script:
Script 49:
1. #converting data into the right shape
2. training_images = np.expand_dims(training_images, -1)
3. test_images = np.expand_dims(test_images, -1)
4. print(training_images.shape)
Output:
(60000, 28, 28, 1)
The next step is to find the number of output classes. This number will be used to define the number of neurons in the output layer.
Script 50:
1. #printing number of output classes
2. output_classes = len(set(training_labels))
3. print(“Number of output classes is: “, output_classes)
Output:
Number of output classes is: 10
As expected, the number of the output classes in our dataset is 10.
Let’s print the shape of a single image in the training set.
Script 51:
1. training_images[0].shape
Output:
(28, 28, 1)
The shape of a single image is (28, 28, 1). This shape will be used to train our convolutional neural network. The following script creates a model for our convolutional neural network.
Script 52:
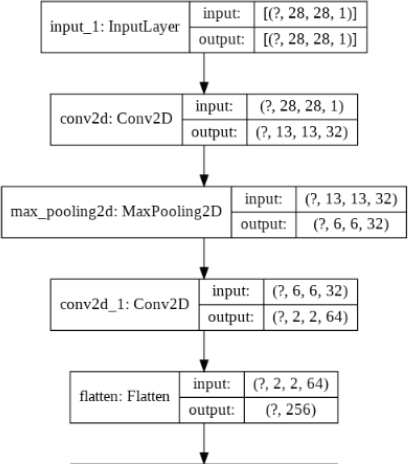
1. #Developing the CNN model
2.
3. input_layer = Input(shape = training_images[0].shape )
4. conv1 = Conv2D(32, (3,3), strides = 2, activation= ‘relu’) (input_layer)
5. maxpool1 = MaxPool2D(2, 2)(conv1)
6. conv2 = Conv2D(64, (3,3), strides = 2, activation= ‘relu’) (maxpool1)
7. #conv3 = Conv2D(128, (3,3), strides = 2, activation= ‘relu’)(conv2)
8. flat1 = Flatten()(conv2)
9. drop1 = Dropout(0.2)(flat1)
10. dense1 = Dense(512, activation = ‘relu’)(drop1)
11. drop2 = Dropout(0.2)(dense1)
12. output_layer = Dense(output_classes, activation= ‘softmax’)(drop2)
13.
14. model = Model(input_layer, output_layer)
The model contains one input layer, two convolutional layers, one flattening layer, one hidden dense layer, in one output layer. The number of filters in the first convolutional layer is 32, while in the second convolutional layer, it is 64. The kernel size for both convolutional layers is 3 x 3, with a stride of 2. After the first convolutional layer, a max-pooling layer with a size 2 x 2 and stride 2 has also been defined.
It is important to mention that while defining the model layers, we used Keras Functional API. With Keras functional API, to connect the previous layer with the next layer, the name of the previous layer is passed inside the parenthesis at the end of the next layer.
The following line compiles the model.
Script 53:
1. #compiling the CNN model
2. model.compile(optimizer = ‘adam’, loss= ‘sparse_categorical_crossentropy’, metrics =[‘accuracy’])
Finally, execute the following script to print the model architecture.
Script 54:
1. from tensorflow.keras.utils import plot_model
2. plot_model(model, to_file=’model_plot1.png’, show_shapes=True, show_layer_names=True)
Output:
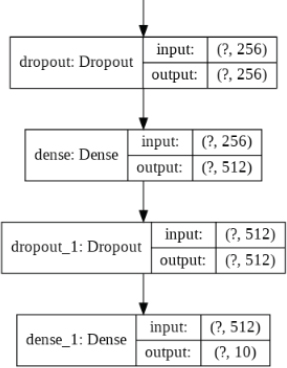
The following script trains the image classification model.
Script 55:
1. #training the CNN model
2. model_history = model.fit(training_images, training_labels, epochs=20, validation_data=(test_images, test_labels), verbose=1)
The results from the last five epochs are shown in the output.
Output:
Let’s plot the training and test accuracies for our model.
Script 56:
1. #plotting accuracy
2. import matplotlib.pyplot as plt
3.
4. plt.plot(model_history.history[‘accuracy’], label = ‘accuracy’)
5. plt.plot(model_history.history[‘val_accuracy’], label = ‘val_accuracy’)
6. plt.legend([‘train’,’test’], loc=’lower left’)
The following output shows that training accuracy is higher, and test accuracy starts to flatten after 88 percent. We can say that our model is overfitting.
Output:

Let’s make a prediction on one of the images in the test set. Let’s predict the label for image 9. We know that image 9 contains a sneaker, as we saw earlier by plotting the image.
Script 57:
1. #making predictions on a single image
2. output = model.predict(test_images)
3. prediction = np.argmax(output[9])
4. print(prediction)
Output:
7
The output shows number 7. The output will always be a number since deep learning algorithms work only with numbers. The numbers correspond to the following labels:
0: T-shirt op
1: Trousers
2: Pullover
3: Dress
4: Coat
5: Sandals
6: Shirt
7: Sneakers
8: Bag
9: Ankle boot
The above list shows that the number 7 corresponds to sneakers. Hence, the prediction by our CNN is correct.
In this chapter, you saw how to implement different types of deep neural networks, i.e., a densely connected neural network, a recurrent neural network, and a convolutional neural network with TensorFlow 2.0 and Keras library in Python.
| Hands-on Time – Exercise |
| Now, it is your turn. Follow the instructions in the exercises below to check your understanding of the deep learning algorithms in TensorFlow 2.0. The answers to these exercises are provided after chapter 10 in this book. |
Exercise 9.1
Question 1
What should be the input shape of the input image to the convolutional neural network?
A.Width, Height
B.Height, Width
C.Channels, Width, Height
D.Width, Height, Channels
Question 2
We say that a model is overfitting when:
A.Results on test set are better than train set
B.Results on both test and training sets are similar
C.Results on the training set are better than the results on the test set
D.None of the above
Question 3
The ReLu activation function is used to introduce:
A.Linearity
B.Non-linearity
C.Quadraticity
D.None of the above
Exercise 9.2
Using the CFAR 10 image dataset, perform image classification to recognize the image. Here is the dataset:
1. cifar_dataset = tf.keras.datasets.cifar10