
Structural Metadata
5.1 Introduction
In Chapter 4, we provided a brief discussion of several types of metadata. In this chapter, you’ll read more about structural metadata. In particular, you’ll learn what Document Type Definitions (or DTDs) are and how they add value to XML documents, about XML Schema and the additional values that it provides, and about other structural metadata specification languages.
You’ll recall that Chapter 4 described structural metadata thusly: Structural metadata is metadata that describes the structure, type, and relationships of data. In this chapter, we explore how each of those aspects of data – its structures, its types, and its relationships – can be specified for XML documents. We also discuss how that metadata can be used to ensure that a specific XML document is valid according to the metadata that has been provided to describe the document.
As you’ll discover in Chapter 6, “The XML Information Set (Infoset) and Beyond,” metadata exists – or can be constructed – even for XML documents for which no explicit metadata description has been provided. Simply by parsing a single XML document, it is possible to describe the structure of that single document and some of the relationships between various parts of the data that it contains. It is also possible to infer some information about the types of some of that data. But that is rarely sufficient for meaningful applications, so this chapter will focus on metadata that has been provided to (potentially) describe one or more, perhaps many, XML documents.
When multiple documents conform to a single structural metadata definition, such as those covered in this chapter, it becomes possible to express meaningful queries across all of those documents. Such queries can depend on the documents’ structural characteristics as well as the data contained in the documents.
Other reasons for using structural metadata for XML documents include the ability to guarantee certain types of data integrity – for example, all purchase orders can be required to have ship-to addresses or all books can be required to have titles. Similarly, document creation tools (such as XML editors) can use structural metadata to prevent data entry errors while a document is still in the process of being created.
5.2 DTDs
The first form of explicit metadata that many people encounter is the DTD, or Document Type Definition. The syntax and usage of DTDs are defined as part of the specification for XML.1
In the XML specification, we find the following definition: “The XML document type declaration contains or points to markup declarations that provide a grammar for a class of documents.” The markup declarations that a document type declaration contains or to which a document type declaration points is, in fact, a Document Type Definition. When the DTD is contained within the document type declaration, it’s referred to as an internal subset DTD (which is illustrated in Example 5-10); when the document type declaration points to the DTD, that DTD is called an external subset DTD (as illustrated in Example 5-11).2
The definition of those markup declarations states that “A markup declaration is an element type declaration, an attribute list declaration, an entity declaration, or a notation declaration.”
Let’s dissect those definitions a little bit before getting into the details of DTDs. First, a DTD provides a grammar for a class of XML documents. That means, of course, that a specific DTD might describe a very large number of documents or only a single document. Second, by providing a grammar, it describes the possible elements and attributes that those documents might contain and the relationships among them. What it does not do, though, is specify the data types of any data values that might be contained in those elements and attributes.3
The term element type declaration doesn’t necessarily imply the declaration of an ordinary data type, like string or integer, for an element’s content. Quite often, it implies specification of the structure of the element’s content – that is, the structural type of the element.
DTDs use a non-XML syntax to provide those markup declarations. The use of a non-XML syntax has some advantages, but there are significant disadvantages as well. The most important disadvantage is that an XML parser cannot be used to extract information from a DTD; instead, a distinct DTD parser is required.
5.2.1 SGML Heritage
One reason for the non-XML syntax of DTDs is its heritage. DTDs were invented as a metadata description language for the Standard General Markup Language (SGML).4 As we learned in Chapter 1, “XML” is defined as a subset of SGML, so it’s natural that XML originally depended on DTDs for its metadata description language. Why SGML used a non-SGML syntax for DTDs is unclear, but that decision was inherited by XML.
The SGML standard, Annex B, “Basic Concepts,” provides a brief DTD tutorial, but the complete specification of DTDs in SGML is found in Clause 11, “Markup Declarations: Document Type Definition.” Like many standards, the SGML standard is tedious and even difficult to read, but a fairly casual perusal of SGML’s DTD specification would be enough to persuade most readers that XML’s DTDs are a subset of SGML’s, in the same manner that XML is itself a subset of SGML.
5.2.2 Relatively Simple, Easy to Write, and Easy to Read
It is beyond the scope of this chapter (indeed, of this book) to give a complete presentation of XML DTDs. However, a review of the major components of DTDs and their syntax will be useful in understanding how they provide structural metadata for XML documents.
XML documents may contain a document type declaration. XML documents that do not contain such a declaration must be well formed but, using the rules of XML only, cannot be valid because there is no metadata information against which they can be validated. A significant fraction of XML documents found “in the wild” today fall into this category. However, there are also a great many XML documents that are also intended to be valid according to the declarations contained in DTDs.
An XML document that includes a document type declaration can be validated against the DTD provided by, or identified by, that declaration. A valid document is one whose structure adheres to the structure, including constraints, defined by the markup declarations contained in that DTD, as determined by a validating parser.
A document type declaration in an XML document must occur as part of the document’s prolog. It has the syntax shown in Example 5-1.

Note that this may include a reference to some DTD resource (e.g., a file) separate from the document itself (called, as we said earlier in this chapter, the external subset), or it may contain internal DTD declarations surrounded by square brackets (the internal subset), or it may contain both (in that order). The ability to reference an external subset from many documents makes it easy to ensure that all of those documents are consistently constructed. The ability to include an internal subset in each document makes it possible to allow the documents to differ in some way while ensuring that each of those documents remains self-consistent.
We observe that the syntax of the document type declaration doesn’t follow most of the rules of what we normally consider to be “XML.” For example, the document type declaration is surrounded by angle brackets (<…>), but there’s that exclamation point (!) after the left angle bracket and there’s neither a slash (/) preceding the right angle bracket nor a separate closing tag. This characteristic applies to all of the components of DTDs.
Example 5-2 illustrates what a document type declaration might look like in an actual XML document.
In this example, the document type declaration specifies an external subset by means of a system file name, and no internal subset is specified. The name specified for the DOCTYPE (bibliography, in this case) must match the name of the root element of every document that depends on the DTD.
DTDs are defined using markup declarations (parsed entity references, not covered in this book, can also be used to aid in readability). Markup declarations come in several forms: element declarations, attribute list declarations, entity declarations, notation declarations, processing instruction declarations, and comments. For our purposes in this chapter, we need consider only element declarations and attribute list declarations.
The names provide clear indication of their uses: Element declarations specify the element structure within an XML document and constrain the content of the elements they declare, while attribute list declarations specify the sets of attributes that can appear with particular elements and constrain the content of those attributes.
An element declaration specifies the name of the element and the rules that its content must follow; these rules are called the content model of the element. The content of an element can be required to be empty or can be permitted to have any content at all (a mixture of text and element children that are declared in the DTD but not specified in the element declaration). Between those two extremes, a DTD can specify that an element may have mixed content (that is, ordinary text, possibly intermixed with specified element children) or that it may have only (specified) element children. Example 5-3 illustrates element declarations for each of these four alternatives, while Example 5-4 provides a sample usage of each of those declared elements. We note in passing that all elements must be declared in the DTD as “global” elements – that is, elements that can appear anywhere in an XML document – except for elements used purely in mixed content.

In Example 5-3, the element named catalogued is required to be empty. Of course, in an instance XML document, you may specify this element either as <catalogued/> or as <catalogued></catalogued>, because there is no semantic difference between those representations. Elements declared to be EMPTY may nonetheless have attribute list declarations associated with them.
There are a couple of good reasons to declare an element to be EMPTY. The element can be optional, so its presence indicates some fact about the document and its absence indicates the opposite fact. For example, the catalogued element might appear as part of an XML document’s book element to indicate that information about the book has been entered into a catalog, while the absence of that catalogued element could mean that the book has not been catalogued.
An element declared to be EMPTY that is not optional isn’t very helpful unless it is declared to have one or more attributes. For example, our catalogued element could be defined to have an attribute named date, the value of which might indicate the date on which the information about the containing book element was catalogued. And, of course, the optionality of an element and the definition of attributes for that element can be used together.
The element named review is permitted to have any content at all, including an arbitrary mixture of text and child elements. The child elements have to be declared somewhere in the DTD, but they are not cited in the definition of an element declared as ANY.
The content of the title element can be a mixture of ordinary text (indicated as #PCDATA) and child elements taken from ital, bold, and under but no others. They can appear in any order and any number of times.
The author element’s content is limited strictly to child elements, and they must be a salutation element, a given element, a family element, and a suffix element, in that order. The use of the comma between child element names indicates that the elements must appear one after the other; another possibility would be a vertical bar (|) to indicate a choice of two elements. Some of the child elements are optional, as indicated by the question mark (?); other possibilities for this occurrence indicator are an asterisk (*) to indicate that the child element may appear zero or more times and a plus (+) to indicate that the child must appear at least one time. The absence of this indicator requires that the child element appear exactly once.

Example 5-4 contains a number of “snippets” of XML – elements that are presumably part of some complete XML document – that illustrate the implications of the declarations in Example 5-3.
Note that, as required, the element catalogued is empty. The review element has mixed content that includes a number of child elements that were not specified as part of the review element’s definition.
By contrast, the example of the title element contains mixed content, but it includes only child elements that were specified in the element’s definition. It’s worth pointing out that it is not possible in DTDs to restrict the order in which such child elements can appear or the number of times that they can appear.
Finally, the author example demonstrates that the content must comprise only child elements and that they must appear in the sequence specified. Notice that the suffix element does not appear; this omission is valid because it was declared to be optional.
Element declarations can (optionally) have attribute list declarations associated with them. The syntax of an attribute list declaration can be seen in Example 5-5.

element-name specifies the element to which the attribute list declaration applies. The syntax of DTDs does not require that the attribute list declarations appear close to their associated element declarations, though it makes for easier reading if the attribute declarations immediately follow the associated element declarations. An attribute list declaration isn’t required to actually declare any attributes; we haven’t seen many examples of this in the wild, but it’s valid anyway.
Each attribute is given a unique (within the associated element) attribute-name, and each attribute has a specific attribute-type and an attribute-default. Attribute types are either the keyword CDATA,5 one of a list of “token” types, a notation reference, or a list of specific identifiers that are permitted, as shown in Example 5-6.

An element is allowed to have at most one attribute whose type is ID (and, in our experience, the most common name for such attributes is id), and the value of that attribute must be unique among the values of all attributes of type ID throughout the containing document.
Attributes whose types are IDREF or IDREFS have values that must match the ID attribute of some element in the same document. Attributes of type ENTITY or ENTITIES have values that must be the names of unparsed entities declared in the DTD (we do not cover the concept of unparsed entities in this book). Attributes declared to be of type NMTOKEN or NMTOKENS have values that are valid identifiers (“name tokens”).
An attribute whose type is a list of one or more identifiers is obviously related to one whose type is NMTOKEN or NMTOKENS. However, if the explicit list is specified, then the values of that attribute must be one of the specified identifiers.
An attribute of type NOTATION has values that identify notations declared in the DTD (we do not cover notations in this book). No element can have more than a single attribute declared of type NOTATION.
The attribute declaration may declare a specific value that is the default value for the attribute whenever it is omitted from an instance of the containing element. If that specific value is preceded by “#FIXED”, then the attribute must be included in all element instances and its value is never allowed to be different from the specified value.
An attribute default may place additional limits on the values that an attribute can take. If the default is specified to be “#REQUIRED”, then the attribute has no default and must be specified for every use of the element in which it is declared. If the default is “#IMPLICIT”, then the attribute is optional.
Example 5-7 illustrates several variations of attribute declarations.

This review of DTDs covered only those characteristics that determine the structure of XML documents that are expected to be valid with respect to their DTDs. There are other features of DTDs that are useful in defining a document type, but that don’t affect the instance documents structurally.
In Section 5.2.4 is a complete example of an XML document and its associated DTD.
5.2.3 Limited Capabilities, Especially with Respect to Data Types
DTDs have a number of limitations in their descriptions of instance documents. One of these, mentioned in Section 5.2.2, makes it impossible for a DTD to govern the sequence of child elements in an element defined to have mixed content. As you saw in the discussion of Example 5-3, such an element in an instance document is allowed to have a mixture of ordinary text and any number of each of the child elements cited in its definition, in any order.
As a result, each of the occurrences of the para element illustrated in Example 5-8 are valid with respect to the DTD fragment in the same example.


Recall that the origin of DTDs is in SGML and that the principle purpose of SGML is to mark up text. When marking up, say, paragraphs of ordinary text, it’s entirely appropriate that the DTD not specify the sequence in which child elements may occur, the number of times they may occur, or the interweaving of those elements and plain text. This gives the authors of that text considerable flexibility in marking up the text for the eventual readers’ consumption.
However, when the text being marked up must be highly structured, such as a formal description of an automobile, one might wish to adopt some rules, such as the following:
• Use the automobile element to identify which automobile is being discussed.
• Continue with more plain text, optionally marked up for appearance (e.g., italics, boldface).
• Use the price element to specify the cost of the automobile.
• Optionally, include more plain text.
• Use the availability element to state when deliveries will start.
• Continue with more plain text.
• Optionally, use any number of feature elements to cite features of the automobile.
• Continue with more plain text, optionally marked up for appearance.
DTDs are unable to express such sets of structural rules. One might wish for the ability to define a mixed-content automobile element such as the DTD fragment illustrated in Example 5-9, but it’s simply not possible according to the current rules for DTDs.

Another limitation of DTDs concerns the data types that it supports. Essentially, the only data type that DTDs support is text. The content of every nonempty element is either child elements, ordinary text, or a mixture of the two. “Ordinary text” is represented as PCDATA (or “parsed character data”). Attributes are limited to contain text, either in the form of CDATA (which is ordinary character data, or text) or in the form of one of the more specialized types, such as ID, IDREF, ENTITY, or NOTATION. While each of those types have certain semantics associated with them (for example, the ID type requires that the value of the attribute be unique among all attributes of type ID in the instance document), their values are in fact nothing more than character strings, or text.
But consider the retail-price attribute declared in Example 5-7. Most people would expect an attribute with that name to represent some sort of monetary value, perhaps in U.S. dollars, Japanese yen, or Turkish lira. Such values are by nature numeric, and one might want to be able to validate them as numbers and manipulate them using numeric operations, such as addition and multiplication.
Unfortunately, DTDs provide no way to specify that the values of attributes or the content of elements are limited to numeric data, dates, or any other type beyond textual data. As a result, it is perfectly valid, if perhaps meaningless, to find a book element in an instance XML document that contains a retail-price attribute whose value is “Twenty One Dollars and Thirty Nine Cents” or even “If you have to ask, you can’t afford it.” Such values would clearly be rather unhelpful to applications that wish to compute the average retail price of all books referenced in a bibliography!
Writing queries to retrieve information from XML documents and to report and analyze that information depends to some degree on being able to reliably use data values in the manner in which the documents’ authors intended them to be used. Without enforceable rules about the detailed structure of the XML (structural typing) and about the values of attributes and the content of elements (data typing) within that XML, the act of writing queries is necessarily more an art than a science.
5.2.4 An Example Document and DTD
It’s frequently easier to understand concepts when a concrete example is available to illustrate the uses of those concepts. DTDs are no exception to that broad rule.
Let’s see what a complete example – both an instance XML document and its associated DTD – would contain. The instance document (including an internal subset DTD) can be seen in Example 5-10 and the external subset DTD in Example 5-11. In this example, the internal subset DTD adds a declaration for a new global element, named author, that can be used in the document itself.





5.3 XML Schema
In Section 5.2, we explored DTDs and the ways in which they specify the structural metadata for XML documents. Among other things, we learned that DTDs have some deficiencies that may prevent certain important classes of applications from accomplishing their goals. Among these are the inability to specify certain types of limitations on the content of elements and the inability to specify the data types required for both attribute values and element content.
In this section, we discuss another W3C specification that supports the definition of structural metadata for XML documents. This specification, usually called “XML Schema” or just “Schema,” was published in 2001 as three documents. The first is a primer6 and is not normative but is intended more as a tutorial to illustrate various important features of the normative parts.
The second part7 specifies the XML document structures that XML Schema can be used to specify. As we’ll see shortly, XML Schema structure definitions are considerably more powerful than those supported by DTDs. The last part8 provides a number of data types that can be used to specify the types of attribute values and element content.
XML Schema, especially Part 1, has sometimes been criticized for its complexity. Although the documents themselves are somewhat difficult to read and grasp, the facilities that XML Schema provides have proven to be extremely valuable to applications of all sorts. Not surprisingly, more requirements have been submitted for future versions of XML Schema by enterprise-level users as well as by individuals. Like many standards, it seems likely that Schema’s complexity is likely to increase along with corresponding improvements in its capabilities.
The development of XML Schema, which began in late 1998, came about because of increasing use of XML for purposes beyond simple document markup. DTDs, as we said in Section 5.2.3, have several shortcomings with respect to complex XML requirements. One of these is the inability to express the sorts of complex structures, and constraints on those structures, that applications were beginning to require in their XML documents. The other, of course, was the desire to express the data types of values found in XML documents, enabling much more powerful manipulation of that data. (We observe that XML Schema lacks some of the capabilities of DTDs, the most important one being the ability to specify and use entities.)9
We explore the capabilities of XML Schema with respect to these requirements over the next few sections. However, we think it’s worth observing that most people are intimidated by the complexity of XML Schema Part 1: Structures, when they first start to read, understand, and use it. We agree that the document and the language are rather complex, but we also believe that diligent study and experimentation will allow most users to write meaningful XML Schemas and begin to appreciate the power that it provides.
In our discussion of XML Schema, we start off gently, illustrating – through a couple of relatively simple examples – XML Schema documents’ “look and feel.” Next, we cover the data type facilities provided by XML Schema, followed by some exploration of the structural capabilities it provides. We end up with a modest example that puts it all together.
5.3.1 Exploring an XML Schema
The first thing you’ll notice about the XML Schema in Example 5-12 is that, unlike a DTD, an XML Schema is itself written in XML – that is, it is an XML document. This simple fact means that all of the many XML tools built to edit, process, and transform XML documerits can be employed for handling XML Schema documents. (Another important side effect of this fact is that XML Schema documents can be queried in the same manner as other XML documents.)
This example, by the way, is taken directly from XML Schema Part 0 (the primer).


There’s a lot of information to absorb in this example, so we’ll take it in small chunks.
The very first line, paired with the very last line, identifies this bit of XML as an XML Schema document. The portion of the line that reads
![]()
defines a namespace by means of a Uniform Resource Identifier (URI) and a corresponding prefix by which the namespace will be referenced within this particular document. Namespaces10 are used as qualifiers for element names, attribute names, and such in XML documents. To put it another way, namespaces allow a developer to define a group of names without having to check that none of his names clashes with any other name.
As with qualifiers for identifiers in any language, this permits multiple objects with the “same name” to be differentiated based on the value of the qualifier. (For example, SQL users are familiar with the ability to create multiple columns with the name PRICE, provided those columns are in different tables. The table name is used as a qualifier for the column name to ensure that the proper column is uniquely identified. Similarly, Java programmers are able to qualify the names of classes with the name of the package that contains them, which prevents any confusion arising from the coincidence of a class contained in one package having a name that is the same as the name of a class contained in a different package.)
Throughout this XML Schema document, the namespace prefix xs: is used to reference the namespace identified by the URI http://www.w3.org/2001/XMLSchema. It’s allowable for an XML document to contain multiple prefixes that reference the same namespace, but it’s rather uncommon except in applications that use Schema documents that are composed of fragments with different authors.
The content of the (optional) element <xs:annotation> serves to document all or part of an XML Schema document as well as providing information to applications that might process the schema document. In the schema in Example 5-12, the content of the <xs:annotation> element is nothing more than an <xs:documentation> element, but XML Schema permits <xs:appinfo> elements as well.11
![]()
defines an element that documents based on this XML Schema can include. (This particular element, purchaseOrder, happens to be the “root” of the structure definition; as such, it has to be the first declaration in the schema.) The element’s name, as you can readily ascertain, is purchaseOrder. The type of that element is perhaps a little less obvious.
Many people new to XML tend to think of a “type” as something like an integer, floating-point, or character string, as this Schema document uses to define the comment element:
![]()
In most modern programming languages (and in XML as a markup language), the word type is somewhat broader than that. In the XML context, it describes the legitimate content of an element or attribute. Sometimes, that type might be a simple type (which, as discussed in Section 5.3.2, corresponds to ordinary data types), but it might also be a complex type (a structure type, as discussed in Section 5.3.3).
Complex types can be given an explicit name, or they can be anonymous. In this case, the type of the element purchaseOrder is a complex type named PurchaseOrderType. Another way of saying the same thing is that the complex type PurchaseOrderType defines the content model of the purchaseOrder element. But what does that mean? To determine that, we have to read only a little further, where we see:
![]()
which is where the PurchaseOrderType complex type is defined, repeated in Example 5-13.


This is, obviously, a named complex type. Its definition tells us that a usage of the PurchaseOrderType (such as in the definition of the purchaseOrder element) has only child element content – that is, no mixed content is allowed – and that those children must be a sequence of elements. The first element is named shipTo and the second is named billTo; both are of type USAddress. After the billTo element, there are any number of instances of the comment element (including none at all), which was defined earlier. Finally, elements defined to be of the PurchaseOrderType must contain one additional element, whose name is items and whose type is Items. Elements defined to be of PurchaseOrderType must also have an attribute named orderDate, whose type is xsd:date.
Subsequent lines in Example 5-12 define the two complex types USAddress and Items. Consider the snippet of the Items element definition that appears in Example 5-14.

This defines the element named quantity to have a simple (not complex) type, and that simple type is based on an XML Schema built-in type named positiveinteger. However, the <xs:restriction> element within this simple type definition limits the values of the quantity element’s content to the range 1 through 99.
With this relatively simple example and brief explanation under our belts, let’s explore the primitive and other simple types provided by XML Schema Part 1.
5.3.2 Simple Types (Primitive Types and Derived Types)
XML Schema Part 2: Datatypes defines a fairly large set of data types that can be used to specify the types of attributes and of element content.
In that document, a data type is defined to be “a 3-tuple, consisting of (a) a set of distinct values, called its value space; (b) a set of lexical representations, called its lexical space; and (c) a set of facets that characterize properties of the value space, individual values, or lexical items.” While some of that terminology might not be familiar, it’s not particularly complex, so let’s break it down.
In an abstract sense, a data type is really nothing more than a collection of values. In effect, it is the mathematical domain over which some collection of operations can act. XML Schema, quite helpfully, goes somewhat further than that abstract definition, by distinguishing between the set of values involved and the manner(s) in which those values can be represented as a sequence of characters. For example, the character sequences “1,” “01,” and “0000000000001” are all lexical representations of the number we commonly call “one.” Some data types may allow other representations as well, such as “1.0” and “0.1E1.”
In the context of XML Schema, the values belonging to a data type can be specified in several ways: axiomatically (that is, from fundamental notions, such as mathematical rules), by enumeration, or by restricting the values belonging to another data type. The lexical representations are character strings that represent the values.
The set of facets cited in the XML Schema Part 2 definition of data type provides a way for XML Schema to define precisely what characteristics the value of a data type may have. For example, a character string value has a length, and the character string type uses two specific facets, minLength and maxLength, to specify the minimum allowed length and the maximum allowed length, respectively. For example, the character string represented by “Querying XML” has a length of 12 characters.
Many implementations of a character string type limit the lengths of character string values to approximately 4 billion characters (even though others might have no limit other than the size of available storage). Every character string must contain at least zero characters – that is, negative lengths are not permitted, but zero-length strings are. Therefore, the minimum value of the minLength and maximum value of the maxLength facets for the character string type for some implementations might have the values zero and 4 billion, respectively.
XML Schema provides a number of built-in primitive data types as well as a number of additional built-in types that are derived from the built-in primitives. A derived type is a type that is derived from another simple type, normally by restricting the set of values allowed; the derivation may also arise from forming a list of values of another data type or by forming the union of two or more data types (meaning the union of their value spaces and their lexical spaces). Primitive types are limited to those specified by XML Schema Part 2, while derived types include not only those provided by part 2 but also those that might be provided by applications.
We could derive our own type based on the character string type, applying further restrictions on the maximum and minimum lengths. For example, we might need a type to represent U.S. postal codes (ZIP codes), which must always have at least five characters and can have no more than 10 characters. The minimum- and maximum-length facets of such a derived type, possibly named ziPcodes, would thus be 5 and 10, respectively.
The (built-in) primitive types defined by XML Schema are shown in the first column of Table 5-1; the built-in types that are derived from each of those primitive types are shown in the second column. Notice that some derived types have yet more types derived from them. Unless we indicate otherwise, each of these derivations is done by restricting the values of the type from which the derivation is performed. We note that the actual names of each of these types is associated with the namespace for which the xs:prefix is commonly used. Readers should consult XML Schema Part 2 for the specific meaning of each of these types.
Table 5-1
| Primitive Types | Derived Types | Source of Derived Type |
| string | normalizedString | |
| token | normalizedString | |
| language | token | |
| NMTOKEN | token | |
| NMTOKENS | NMTOKEN (derived by list) | |
| Name | token | |
| NCName | Name | |
| ID | NCName | |
| IDREF | NCName | |
| IDREFS | IDREF (derived by list) | |
| ENTITY | NCName | |
| ENTITIES | ENTITY (derived by list) | |
| boolean decimal | integer | |
| nonPositiveInteger | integer | |
| negativeinteger | nonPositiveInteger | |
| long | integer | |
| int | long | |
| short | int | |
| byte | short | |
| nonNegativeInteger | integer | |
| unsignedLong | nonNegativelnteger | |
| unsignedInt | unsignedLong | |
| unsignedshort | unsignedlnt | |
| unsignedByte | unsignedshort | |
| positiveinteger | nonNegativeInteger | |
| float | ||
| double | ||
| duration | ||
| dateTime | ||
| date | ||
| time | ||
| gYearMonth | ||
| gYear | ||
| gMonthDay | ||
| gDay | ||
| gMonth | ||
| hexBinary | ||
| base64Binary | ||
| anyURI | ||
| QName | ||
| NOTATION |
All of the built-in data types of XML Schema belong to the XML Schema namespace, often indicated by the prefix “xs:.” The corresponding namespace URI is: http://www.w3.org/2001/ XMLSchema. Any namespace prefix can be used, as long as it is associated with the appropriate namespace URI. Application-defined schemas can derive additional types from any type in that list, but those application-defined derived types must belong to an application-defined namespace (that is, not the namespace indicated in this chapter by the prefix xs:).
In the sample schema in Example 5-12, the line that reads

defines an element (USPrice) whose content is of type xs:decimal.
XML Schema Part 2 spends a considerable fraction of its size specifying various characteristics of data types, their facets, and their limitations. Much of that space provides an XML representation of the XML Schema definition of the types themselves. That material is beyond the scope of this book, as is describing each of the built-in types.
5.3.3 Complex Types and Structures
A detailed presentation of the XML Schema facilities defined in Part 2 would easily fill a book as large as this one. Rather than attempt to compress that amount of information into a few pages, this section discusses only the fundamental concepts that are especially relevant to querying XML documents.
As we told you in Section 5.3, XML Schema’s ability to describe rules for constructing XML documents, especially the structure of element content, significantly exceeds that of DTDs in several ways. Conversely, it is possible by using combinations of XML Schema’s facilities to represent any content model that can be represented by a DTD.
Example 5-12 illustrates a number of XML Schema’s abilities to specify complex types and structures, so we’ll use that sample Schema to describe some of the features, starting off by recapping some of what we said in Section 5.3.1. Consider the lines in Example 5-15 that we copied from Example 5-12.

The <xs:complexType> element is used in an XML Schema to define a named complex type that can then be used in one or more element declarations to specify the content model and attributes of those elements. For instance, in Example 5-15 we see two elements, shipTo and billTo, that are defined to be of a single type, USAddress. There must, of course, be a definition of a type with that name elsewhere, and a definition elsewhere (see Example 5-12) provides that (complex) type. This instance of <xs:complexType> defines a type named PurchaseOrderType, which can then serve as the type of some element declared in this schema.
The <xs:sequence> element specifies that the object in which it is contained (a complex type definition, in this case) contains a sequence of child elements that must appear in the specified order.
The <xs:element> element declares an element that is used as the content of the object in which it is contained (in this case, the sequence). In the case of the first instance of <xs:element>, the shipTo element is declared as the first element in the sequence comprising the complex type named PurchaseOrderType. Several features of the <xs:element> element are illustrated in this snippet. First, you see that both the shipTo and billTo elements are declared with the USAddress type, showing both that elements can be declared to have a complex type that is defined elsewhere in the schema and that multiple elements can be declared to have the same (named) complex type.
Second, note that the comment element is declared with the attribute minOccurs, which is given a value of 0. As the name implies, use of this attribute requires that the element being defined must occur a minimum number of times; the value 0 means that the comment is optional. The corresponding maxOccurs attribute could be specified but is not in this case. The default value for both attributes is 1. The absence of the maxOccurs attribute thus means that the comment element can appear a maximum of once. If the intent is to permit the element to occur any number of times, the maxOccurs attribute can be given the value “unbounded.”
The <xs:attribute> element specifies that all elements declared to be based on PurchaseOrderType have this one attribute, named orderDate, whose data type is xsd:date.
In the definition of the complex type items found in Example 5-16, you’ll see that Items is a sequence, the first element of which is an element named item.

The interesting thing about the declaration of the item element is its type. Let’s zoom in a little closer on the initial lines of the definition of the item element in Example 5-17.

Note that the type of the item element is another complex type but that this type isn’t given a name – it’s an anonymous complex type, indicated by the absence of a name attribute on the <xs:complexType> element.
The anonymous type of the item element is a sequence, the first two components being elements named productName and quantity. Comparing the declarations of those two elements, we see that the first is declared to be of type xs:string, while the second is of type xs:positiveInteger. However, the two declarations are significantly different in construction. The type of the productName element is specified through use of the type attribute, while the type of the quantity element has a child element, <xs:simpleType>.
In the case of the quantity element, the use of <xs:simpleType> is required in order to define the element to have a restriction on its values (in this case to be no less than 1, the smallest value of a positive integer, and no greater than 99, as indicated by the maxExclusive attribute’s value).
When you need to declare an element that has both a simple type (such as xs:string, xsd:positiveInteger, or xsd:date) and an attribute, you (counterintuitive though it may be) cannot just use the type attribute but must instead declare the element as an <xs:complexType> with <xs:simpleContent>. Example 5-12 contains no instance of such an element, so we’ve illustrated this situation in Example 5-18.

Table 5-2 compares and contrasts some of common features of XML Schema Part 2 with similar features of DTDs. The table’s three columns identify an item of interest, the XML Schema approach, and the DTD approach, respectively. The items in the XML Schema column and the DTD column are not identical in semantics; major differences between the two technologies make exact comparisons difficult in some cases.
Table 5-2
Features of XML Schema Part 1: Structures
| Feature | XML Schema | DTD |
| Syntax | XML document | Non-XML |
| Simple types | Part 2’s xs:types | Strings and string-like attribute types |
| Occurrence constraints | minOccurs, maxOccurs attributes | ?,*, + |
| Complex type definition | <xs:complexType> | No real analog |
| Mixed content | #PCDATA used with element names as alternatives | |
| Sequence of child elements | <xs:sequence> | Element names separated by commas |
| Choice of child elements | <xs:choice> | Element names separated by vertical bar |
| Groups | <xs:group> | Parameter entities, parenthesized sequences, or parenthesized choices |
| Entities | No analog | <!ENTITY> |
| Type derivation | Yes | No |
| Type re-use | Yes | No |
5.4 Other Schema Languages for XML
XML Schema, especially the aspects defined in Part 1, is a complex language with great flexibility and power. It is somewhat intimidating when first encountered (which some products ameliorate through the use of a graphical user interface, or GUI). Many people find XML Schema instance documents difficult to read and interpret. As a consequence, other ways of expressing structural metadata for XML have been devised (though not in the context of the W3C).
5.4.1 RELAX NG
One of the best-known alternative schema languages is RELAX NG.12 The RELAX NG tutorial13 describes the language as “based on RELAX and TREX.” RELAX14 (regular language description for XML) is an earlier effort by Murata Mokoto to provide a schema language for XML documents, while TREX15 (tree regular expressions for XML) is a language designed by James Clark of the Thai Open Source Software Center for the same purpose. (The “NG” in the name is widely assumed to stand for “New Generation,” but that’s not officially part of the name.)
Like XML Schema, RELAX NG is a language that specifies structural metadata (which it calls a “pattern”) for XML documents and thus “identifies a class of XML documents consisting of those documents that match the pattern.” Also like schemas defined using XML Schema, RELAX NG schemas are themselves XML documents. Unlike XML Schema, RELAX NG provides both the “formal” XML syntax and an equivalent non-XML syntax called the “compact syntax.”
RELAX NG’s XML syntax is, in some ways, reminiscent of XML Schema’s syntax. For example, elements are declared with an <element> element, while attributes are declared with <attribute> elements. Instead of using the occurrence indicators (?, *, and +) used by XML Schema, RELAX NG uses elements <optional>, <zeroOrMore>, and <oneOrMore>. The <mixed> element allows arbitrary interleaving of ordinary text and (specified) child elements, analogous to XML Schema’s <complexType mixed= “true”>.
RELAX NG depends on a number of W3C specifications, including Namespaces. It also allows applications to reference externally defined data types, including those defined by XML Schema Part 2. Specific RELAX NG schemas are allowed to use data types defined in one namespace (such as the XML Schema namespace indicated by the prefix xs:) for some elements in the schema and data types defined in another namespace for other elements. Implementations of RELAX NG are allowed to choose the externally defined data types that are permitted in the schemas they support.
Example 5-19 contains an illustrative RELAX NG schema expressed in the full syntax, while Example 5-20 contains the compact syntax for the same schema.


5.4.2 Schematron
Yet another schema language, which serves a somewhat narrower purpose than RELAX NG, is Schematron.16 Schematron is a “language for specifying assertions about arbitrary patterns in XML documents” and can be used in conjunction with (in fact, embedded within) other schema languages, including XML Schema and RELAX NG. Like XML Schema and RELAX NG, Schematron depends on several W3C specifications, including Namespaces. Unlike those other two languages, Schematron is not grammar-based but uses XPath path expressions to express the structures and constraints of the XML documents it describes.
Schematron uses <assert> elements to make positive assertions about an XML document; when that document is validated against a Schematron schema instance with an assertion and the test for that assertion fails, the application that invoked the validation is notified and can take whatever action it deems appropriate. Schematron <assert> elements may include a test attribute that specifies, in XPath notation, a predicate that evaluates to a Boolean value corresponding to the truth of the assertion. The <report> element can make negative assertions about a document.
The <assert> and <report> elements are always children of a <rule> element, which includes a context attribute that identifies the context in which the <assert> and <report> elements are evaluated. Example 5-21 shows a simple Schematron rule that could be used to validate an XML document containing the element <car><wheel/><wheel/><wheel/><wheel/></car>.

Note that this rule specifies that the context of the rule is a car element, that it asserts that the car element must contain exactly four wheel elements, and that human-readable text corresponding to the formal assertion test=” count (wheel) = 4” is included. The rule also includes the assertion that the car element must not contain a propeller element, along with human-readable text corresponding to that negative assertion, test=“propeller”.
5.4.3 Decisions, Decisions, Decisions
You’ve just had a brief survey of each of three schema languages, and you might be a bit confused about which one to use. After all, learning a schema language can be a considerable commitment, particularly when you end up with huge collections of instance XML documents that are expected to validate against schémas in that language.
XML Schema has the advantage of being supported by the W3C and thus is likely to fit quite nicely into applications that depend on other W3C recommendations. It has the further advantage of being extremely powerful and flexible. In exchange, it is rather complex and intimidating.
RELAX NG is less powerful and flexible than XML Schema, meaning that it cannot express every possible construct that XML Schema can express. But it is arguably easier to learn and, when the compact syntax is used, usually found to be easier to read – and perhaps easier to write. It has another possible advantage in that it doesn’t come “bundled” with a particular set of simple types but can use any simple type library that the application chooses.
Schematron is not really a complete schema language. Instead, it is a language in which constraints on data can be expressed. In general, the constraints that can be expressed in Schematron are somewhat more powerful than those that either XML Schema or RELAX NG can express. Consequently, some applications might choose to use both XML Schema and Schematron (or both RELAX NG and Schematron) concurrently to validate XML instance documents.
While it’s not obvious to us which of the various schema languages are likely to capture the greatest mind share, we suspect that XML Schema will be used by most enterprises simply because of its W3C support and the significant number of tools and other applications that depend on it.
5.5 Deriving an Implied Schema from a DTD
As suggested by Example 5-22 and Example 5-23, it’s possible to transform one structural metadata language into another. The RELAX NG specifications include a document17 that describes the relationship between XML’s DTDs and RELAX NG schemas. A number of XML tools (including products such as Altova’s XMLSpy and Sonic Software’s Stylus Studio, cited here only because we are personally familiar with their capabilities) provide the ability to convert from DTDs to XML Schemas. (Interestingly, Stylus Studio performs the transformation by means of a tool, Trang, licensed from the Thai Open Source Software Center, the home of TREX.)
For comparison purposes, Example 5-22 shows the internal subset DTD equivalent to the RELAX NG schema shown in Example 5-19 and Example 5-20, while Example 5-23 holds a corresponding XML Schema document. This particular XML Schema document was produced by XMLSpy, transforming the DTD into an XML Schema. Other XML Schemas could be created that have the same effect, perhaps using named types instead of anonymous types.

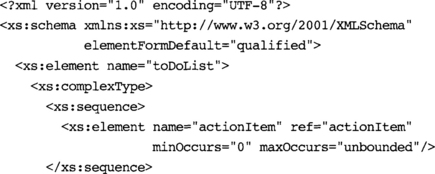

5.6 Chapter Summary
In this chapter, we have illustrated and discussed several mechanisms that allow the specification of structural and data type metadata for XML documents. Each of the methods has its adherents and its detractors. Each also has its own set of capabilities. As we saw, DTDs are in many ways less flexible and powerful than XML Schemas, but they are arguably easier to read and may suffice when more complex structures or specific data types are not required. RELAX NG may be attractive when its compact syntax is appropriate but well-defined data types are needed in element and attribute definitions.
The benefits for querying XML documents, when structural and data type metadata for those documents exists, is clear. If each of a group of XML documents is known to have the structure implied by the XML Schema shown in Example 5-12, we could retrieve information from each of those documents based on that structure. For example, we could ask for the order date of every purchase shipped to New York City but billed to an address in San Francisco. The query might be worded (in pseudo-code) thusly:
Return the value of the orderDate attribute of each purchaseOrder element in which (a) the value of the content of the city element that is a child of the shipTo element is “New York” and the value of the content of the state element that is a child of the shipTo element is “NY” and (b) the value of the content of the city element that is a child of the billTo element is “San Francisco” and the value of the content of the state element that is a child of the billTo element is “CA”.
Writing such a query is trivial when the documents are known to adhere to the structure required by that schema but difficult and unreliable when the documents have arbitrary structures.
1Extensible Markup Language (XML) 1.1 (Cambridge, MA: World Wide Web Consortium, 2004). Available at: http://www.w3.org/TR/xmlll.
2Internal subset DTDs, since they are specified within a specific XML document, are relevant only to that specific document. By contrast, external subset DTDs may be referenced by many XML documents.
3Technically, as you’ll read in Example 5-11, DTDs can specify a very limited set of data types for some attributes.
4ISO 8879:1986(E), Information Processing – Text and Office Systems – Standard Generalized Markup Language (SGML) (Geneva, Switzerland: International Organization for Standardization, 1986).
5CDATA, CDATA, and #PCDATA: XML documents are allowed to contain “CDATA sections,” which allow the documents to contain literal left angle brackets and ampersands (that is, without being represented as character references or entities); in a CDATA section, the appearance of ”<title>“ is treated as ordinary character data and not as markup. Attribute declarations may declare the data type of an attribute to be CDATA, or character data; perhaps surprisingly, the value of an attribute declared to be CDATA cannot contain left angle brackets or ampersands. The keyword #PCDATA derives historically from the term parsed character data, which means that character data is expected, but it must be parsed to determine whether it contains markup.
6XML Schema Part 0: Primer (Cambridge, MA: World Wide Web Consortium, 2001). Available at: http://www.w3.org/TR/2001/REC-xmlschema-0-20010502/.
7XML Schema Part 1: Structures (Cambridge, MA: World Wide Web Consortium, 2001). Available at: http://www.w3.org/TR/2001/REC-xmlschema-1-20010502/.
8XML Schema Part 2: Datatypes (Cambridge, MA: World Wide Web Consortium, 2001). Available at: http://www.w3.org/TR/2001/REC-xmlschema-2-20010502/
9We have been told that the decision not to support entities in XML Schema was intentional: In SGML, as well as in the pre-Schema days of XML, entities were often used in the same way as macros in programming languages, thereby obfuscating DTDs to the point where they became almost useless. The intent of XML Schema was to offer more appropriate mechanisms, such as groups, attribute groups, include, import, redefine, and so forth.
10Namespaces in XML 1.1 (Cambridge, MA: World Wide Web Consortium, 2004). Available at: http://www.w3.org/TR/xml-namesll.
11The <xs:documentation> element children of an <xs:annotation> element is intended for human consumption and is permitted to contain user-defined elements and attributes as needed. By contrast, the <xs:appinfo> element children are intended for use by software; it also may contain user-defined elements and attributes, as needed by the software that utilizes this element. The XML Schema Recommendation does not limit what user-defined elements and attributes are allowed in either the <xs:annotation> or <xs:appinfo> element.
12RELAX NG Specification (OASIS, 2001). Available at: http://www.relaxng.org/spec-20011203.html.
13RELAX NG Tutorial (OASIS, 2001). Available at: http://www.relaxng.org/tutorial-20011203.html.
14ISO/IEC TR 22250-1, Document Description and Processing Languages – Regular Language Description for XML (RELAX) – Part 1: RELAX Core (Geneva, Switzerland: International Organization for Standardization, 2001).
15James Clark, TREX – Tree Regular Expressions for XML Language Specification, James Clark (Bangkok, Thailand: Thai Open Source Software Center, 2001). Available at: http://www.thaiopensource.com/trex/spec.html.
16Rick Jelliffe, The Schematron Assertion Language 1.5. Available at http://xml.ascc.net/resource/schematron/Schematron2000.html.
17RELAX NG DTD Compatibility (OASIS, 2001). Available at: http://relaxng.org/compatibility.html.