
Managing XML: Transforming and Connecting
7.1 Introduction
XML documents rarely exist in a vacuum. As you read in Section 6.6, “The Post-Schema-Validation Infoset (PSVI),” and as you will see in Chapter 10, “Introduction to XQuery 1.0,” XML documents being queried often conform to (that is, are validated against) an XML Schema and they may be transformed into an instance of the XQuery Data Model.
XML documents interact in many ways with their environment. For instance, they can be transformed from one structure to a different structure, or they can be transformed into some user-friendly format such as HTML1 or PDF.2 They are frequently modularized to place some information into one physical resource (e.g., a file) and other information into a different resource. They reference one another in various ways, both simple and complex.
In this chapter, we explore several of the more important ways in which XML documents interact with their environments and how those interactions are related to querying XML. To select but one example, any system for querying XML must decide whether or not to include in the data being queried those resources that might be related in some modular way or resources that are referenced from one document into another.
7.2 Transforming, Formatting, and Displaying XML
XML documents, as a glance at any example in this book will convince you, are not especially pretty to look at. All those angle brackets – and even the presence of the elements and attributes themselves – make the document more difficult to read and understand.
It is for this reason that the W3C has created two languages for “reshaping” documents in various ways. One of these, which we cover in Section 7.2.1, is a language for transforming the content and structure of XML documents into any of several other forms, including HTML or plain text, as well as new XML documents. The other, briefly discussed in Section 7.2.2, provides a mechanism by which XML documents can be converted into formats suitable for printing or viewing, such as PostScript and PDF (or even Microsoft’s Rich Text Format, RTF).
What does this have to do with querying XML? Well, in order to transform an XML document into some other form, you have to be able to find the elements, text, and so forth in the original document that you want to be represented in the result. Finding those things requires querying the input document, as you’ll see in, for instance, Example 7-2.
In addition, when you’re querying XML documents – or collections of documents – it’s quite likely that you’ll sometimes want to represent the result in a different form than your query language produces directly. As you’ll see in Chapter 11, “XQuery 1.0 Definition,” XQuery is capable of producing whatever XML structure you might need as a result of its query operations. But XQuery can produce only XML as its output, while your application might require query results to be displayed in HTML or even plain text – or in PDF. In such situations, the results of XQuery operations can be further transformed into those other formats using technologies described in this section.
7.2.1 Extensible Stylesheet Language Transformations (XSLT)
XSLT 1.03 is a language (developed by the W3C’s XSL Working Group, where “XSL” means “Extensible Stylesheet Language”) designed for transforming XML documents into another form. The name “XSLT” stands for “XSL Transformations.” The specification for XSLT 1.0 contains provisions – called output methods – for producing (new) XML documents from such transformations, for producing HTML documents, or for producing plain text. It also allows implementations to provide additional output methods that produce formats other than these three.
XSLT 1.0 depends on XPath 1.0 as the language in which search and matching criteria are expressed – that is, as its query language. XSLT 1.0 was one of the driving forces behind the development of XPath 1.0 and was arguably its most important “customer.” When the W3C began development of an XML querying language (the language that became XPath 1.0), it recognized that there was significant overlap between the requirements of XPath and of the planned XML query language. As a result the charter to develop XQuery included responsibility for developing a new version of XPath at the same time.
At the same time that XPath 2.0 and XQuery 1.0 were being developed, a new version of XSLT (known, naturally, as XSLT 2.0)4 was being specified. The details of XSLT 2.0 differ in significant ways from those of XSLT 1.0, but the overall goals and mechanisms remain the same. XSLT 2.0 adds XHTML5 to the choices of output methods.
XSLT is a functional language without side effects (which, as you’ll see in Chapter 11, “XQuery 1.0 Definition,” is a characteristic of XQuery, too), in which you can write stylesheets that are based on templates used to process various components of the input XML documents. This design leads to a number of characteristics, most of them specifically intended to make your stylesheets very robust, and makes it possible for your stylesheets to be executed efficiently (which, of course, doesn’t guarantee that all XSLT engines are efficient). An important characteristic of XSLT, one that is probably the greatest source of confusion to programmers used to more conventional languages like Java and C, is that the concept of iteration is applied in only a very limited sense; instead, capabilities that would employ iteration in a Java program must normally6 be written using recursion in XSLT. (A further artifact of this design principle is that variables, once created and given a value, never change their values! That is the nature of functional languages. While this might sound insane to some readers, it makes great sense in a language built on principles of recursion.)
XSLT is a language expressed in XML, which makes it possible to manipulate XSLT stylesheets with ordinary XML tools, including XSLT (it’s possible to transform stylesheets into other stylesheets!), and XQuery (perhaps to determine what stylesheets dealing with particular situations are available in a repository). Since XSLT is expressed in XML, all of its features and functionality are expressed as XML elements and attributes. These elements are defined to be in a namespace that is often identified by the namespace prefix “xsl:”. In this book, wherever we use XSLT, we’ll apply that prefix.
To get a sense of XSLT’s use, let’s consider the reduced movie example in Example 7-1; this example omits most of the data in our “real” movie document (see Appendix A: The Example).


In this example, our three movies are represented only by their titles, the years in which they were released, and the names of their directors. An XSLT stylesheet might be written to transform this data into a new document based on directors’ names instead; that new document could be an XML document, an HTML (or, in XSLT 2.0, XHTML) document, or just plain text. Such a stylesheet appears in Example 7-2, which transforms the XML from Example 7-1 into an XML document that contains only directors.


It’s beyond the scope of this book to explain that stylesheet in detail, but a brief summary will be useful. The line that reads “<xs1:output method=“xml”” instructs the stylesheet to produce XML as a result of the transformation. The lines containing ”<xsl: template match=” each start a template that is invoked whenever templates are being applied and the “match=” expression is satisfied. Inside the double quotes (“…”) following the “match=” is an XPath expression that identifies the criteria determining whether or not the template is to be applied. As you’ll discover in Chapter 9, “XPath 1.0 and XPath 2.0,” the notation “/” specifies the root node (you learned in Chapter 6, “The XML Information Set (Infoset) and Beyond,” that the root node is not the same as the element node for the document element, <movies>). This template is invoked as soon as the stylesheet is executed, and it is invoked exactly once since there is always exactly one root node in a well-formed XML document. Notice that this template contains nothing other than ”<apply-templates/>.” That instruction says “Using the current context (in this case, the root node), invoke every template whose match expression identifies some child node.”
In this case, there is only one template whose match expression matches a child of the root node: the template whose match expression contains “movies.” That template is invoked once for each element whose name is “movies” that occurs within the current context. And, of course, since the <movies> element is the document element, there is only one of them, so the template is invoked exactly once. The content of this template is a single element: <movie-directors>. This element is not in the xsl:namespace, so it is not an instruction to XSLT, but it is intended to be part of the result of the transformation. Therefore, that element is put into the result tree and its content, <xsl:apply-templates/>, is evaluated. Since this element is in the xsl:namespace, it is executed. As before, the <apply-templates> element instructs the XSLT processor to start applying templates whose match expression matches some child of “this” element – in this case, children of the <movies> element. In this document, these are the three <movie> elements.
The third template’s “match=” attribute instructs the XSLT processor to invoke this template whenever a <movie> element is encountered in the current context while templates are being applied. Since the <movies> element is the context in which templates are now being applied and there are three <movie> elements, this template will be invoked three times. The elements in that template instruct the processor to create a new ”<director>“ element within the <movie-directors> element that the “movies” template generated. It also creates an attribute, title, for that element and assigns it a value that is computed from the value (that’s what the curly braces mean) of the <title> element that is a child of the <movie> element being processed. Next, this template creates a <name> element within the <director> element, inserting the value of the <givenName> element contained in the <director> element that is, in turn, contained in the <movie> element being processed. The template then inserts a single space and finally inserts the value of the <familyName> element contained in the <director> element.
The result of this transformation is seen in Result 7-1.

If the output method of the stylesheet had instead been “text,” the output would be that seen in Result 7-2.
Result 7-2 Result of Reduced Movie Transformation to Text
Note that the movie titles are not represented in the text output, because plain text has no analog to attributes.
A common use of stylesheets is to transform XML data for display in a web browser, which normally involves HTML instead of XML or plain text. A somewhat different stylesheet, seen in Example 7-3, might produce HTML for a web page, as illustrated in Result 7-3 and Figure 7-1.



It’s obvious that XSLT offers significant power in transforming XML documents to various other forms, including new XML documents (as in Result 7-1). Normally, you would write queries to retrieve information directly from the original XML documents. However, there may sometimes be a reason to transform those original documents into some new XML form before querying them. For example, your existing queries might require the XML to be in some format other than that in which the XML already exists. Your queries might assume that the XML data is in the form of a SOAP7 (SOAP once stood for “Simple Object Access Protocol”) message or that it can be validated against a particular XML Schema, and so forth. XSLT is a tool to be considered in such circumstances.
Because of the ability of XSLT to perform sophisticated data location and structural transformation of XML documents, it is sometimes viewed as a way of querying XML. We don’t categorize XSLT as an XML querying facility, although it can serve that purpose in limited situations – especially when your intent is to retrieve and reorganize data from within a single XML document.
We find it far more likely that you might wish to query your XML documents in another language, such as XQuery, and then perhaps transform the results into HTML, plain text, or some other form (perhaps the one discussed in Section 7.2.2).
At the time of writing, we were aware of very few XSLT 2.0 implementations, so this section has concentrated on the more widely implemented (and used) first version of XSLT. We believe that, when XQuery 1.0 and XPath 2.0 are finally released and we start seeing implementations of them, more and more implementations of XSLT 2.0 will begin to appear.
7.2.2 Extensible Stylesheet Language: Formatting Objects (XSL FO)
The original mission of the W3C’s XSL Working Group was to define a true stylesheet language for XML that would serve approximately the same purpose that CSS (Cascading Style Sheets)8 serves for HTML and that DSSSL9 serves for SGML10 – to determine the visual display characteristics of documents on a computer display and/or on paper. As you read in Section 7.2.1, the XSL Working Group is also responsible for the XSLT specification.
The XSL specification (which many people, including us, call “XSL FO” to clearly distinguish it from XSLT) defines, like XSLT, a number of XML elements and attributes that allow an application to control such formatting characteristics as page structure, font and size of text, list element numbering, and image placement as well as structural characteristics such as tables, blocks of text (e.g., paragraphs), and footnotes. The elements defined by XSL FO are placed into a specific namespace, often indicated by the namespace prefix “fo:”.
XSL FO is not intended to be, nor is it utilized as, a language for querying XML documents. Its purpose is strictly to give instructions to a formatting engine on how to apply formatting to an XML document for display, so it is not discussed further in this book. However, it can be a valuable tool in an application that must publish, in a reader-friendly format, XML documents (which may be the results of XML queries). A typical workflow for such an application is seen in Figure 7-2.

7.3 The Relationships between XML Documents
This section, as its title suggests, deals with technology intended to help define and strengthen the relationships between two or more XML documents. While we believe that the material in this section is interesting, useful, and relevant, you should take note of this caveat lector. The technologies described in this section have not been widely implemented and are not in common use, and at least some of them have not yet reached the final recommendation stage in the W3C.
If these factors make the section of little interest to you, then you might want to skip ahead to Section 7.4.
7.3.1 XML Inclusions (XInclude)
Virtually all programmers are familiar with the ability to modularize program code. Modularization is a process in which an entity is broken into several parts that can then be reassembled into the desired whole. In the context of programming, programs are frequently written as a set of modules, each containing code that performs specific, usually closely related tasks. The code in those modules is then invoked by code in other modules, only one of which is the “main” module that is invoked to initiate execution of the program as a whole. One of the advantages of this approach is that modules providing widely needed functionality can be reused by many different applications simply by making them available to those other applications. One effect of this advantage is that, if a module must be changed, the programmer needs to make the change in one place only. Programs that uses that module will behave consistently, since they all use the same code.
Documents can be, and frequently are, modularized in the same manner. For example, a book typically has multiple components, such as chapters, appendices, tables, and figures. Those components may be written and updated by different people, at different times, using different tools. They are all brought together to form the final book. When a document, such as a book, is represented in some source form on a computer, each of the components might be stored in separate files.
XML documents are no different in this respect. It’s quite common to create certain XML resources (such as computer files) that each contain some frequently used XML and to cause those resources to be incorporated into some ultimate document. In an application requiring many documents, all of which tend to use the same set of terms, an XML resource might be created that contains a glossary of those terms. Instead of the glossary’s being written for each of the documents that need it, it can be written once and incorporated into all of those documents.
The W3C has published a specification (not yet a final recommendation) for including XML resources into other XML resources. This spec, known as XML Inclusions (XInclude),11 “introduces a generic mechanism for merging XML documents.” In fact, this specification actually defines the mechanism for merging the Infosets of XML documents into a single Infoset; you should not expect this facility to merge two serialized XML documents into a single character string.
The XML language itself provides a facility known as external entities, by which information contained in various resources can be incorporated into an XML document while that document is being parsed. External entities can be used only by XML documents that declare them as part of a DTD (including an internal DTD subset), and the material contained in them need not be XML. That material can, of course, be XML, but it can also be ordinary text or even binary data, such as graphics (which are, not parsed). External entities – both parsed and unparsed – provide one way of modularizing XML documents. The capability is very widely employed by many XML documents.
XInclude, by contrast, provides a way of merging (the Infosets of) XML documents into a single XML document (that is, a single Infoset). This merger is unrelated to parsing an XML source into an Infoset, because it occurs only after all of the related documents have been parsed. It also has nothing to do with validation, using either a DTD or an XML Schema; such validation is not defined in the XInclude spec, although, of course, it can be applied before or after the merger takes place.
XInclude is expressed in XML and defines only two elements, both included in a namespace that is frequently indicated with the namespace prefix “xi:”. The first of the elements, xi: include, is permitted to have at most one child, xi:fallback, xi:include has a number of attributes. One attribute, parse, indicates whether the included material is to be parsed as XML (that is, with an Infoset to be merged) or as ordinary text; if “text” is specified, then the encoding attribute might be used to specify the character set encoding of the text. Another pair of attributes, href and xpointer, are used to identify the material to be included. When the parse attribute indicates that the included material is text, the xpointer attribute is prohibited and only the href attribute is used; when XML is indicated, either or both of the href and xpointer attributes can be used. It’s interesting to note that the source text of XML documents can be included as ordinary text simply by specifying “text” as the value of the parse attribute. Such inclusions cause the included material to be represented in the including document’s Infoset as a series of character information items (which, in the XQuery Data Model, are transformed into a text node).
That last paragraph is, to say the least, a bit of a mouthful. A few examples might help make it somewhat clearer. Table 7-1 illustrates some of the more meaningful combinations of attributes.
Table 7-1
| Example xi:include Element | Interpretation |
| <xi:include parse=“xml” …/> | The material to be included is well-formed XML (the encoding attribute is not needed since the encoding of XML can be determined automatically; if it is present, it’s ignored). |
| <xi: include parse=“text” encoding=“UTF-8” …/> | The material to be included is plain text, encoded in UTF-8. |
| <xi:include parse=“text” encoding=“UTF-8” xpointer=“…” …/> | Error: The xpointer attribute is prohibited with parse=“text”. |
| <xi:include parse=“text” encoding=“UTF-8” href=“…”/> | The text located by the value of the href attribute is included in the XML document at the point where the <xi:include> element appears. |
| <xi: include parse=“xml” xpointer=“…” …/> | The XML document located by the value of the xpointer attribute is included in the XML document at the point where the <xi:include> element appears. |
The value of the href attribute is an ordinary URI (Uniform Resource Identifier) reference or IRI (Internationalized Resource Identifier) reference that specifies the location of the resource to be included. When the material being included is XML, the value of the xpointer attribute is an XPointer (see Section 7.3.2) that identifies the portion of the resource to be included; if the xpointer attribute is absent, then the entire resource is included.
The xi:fallback element, which can appear only as a child of the xi:include element, allows the including document to specify content to be used when the resource indicated by the href or xpointer attributes of the xi:include element cannot be retrieved (e.g., because it does not exist, is temporarily unreachable, or is protected in some way).
In our collection of movies, we have discovered that we have a large number of films starring Teri Garr. We could avoid constantly recoding the fragment shown in Example 7-4 if we use XInclude, as shown in Example 7-5, to incorporate her data.

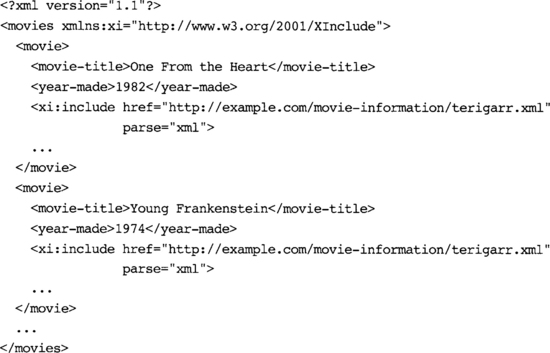
Of course, that <xi:include> element required at least as many keystrokes as Teri’s <actress> element, but it illustrates the mechanism. It provides one additional advantage: Should we ever discover that we’ve misspelled Teri’s name, we can change it in exactly one place (terigarr.xml) and that change will be automatically incorporated everywhere we used that XInclude element.
This particular example could have just as easily used an external parsed entity. However, XInclude offers features that external parsed entities don’t provide. For example, external parsed entities require that the external entity be declared and named (in a DTD, typically the internal DTD subset) and then invoked separately; XInclude provides inclusions with all of the information specified in exactly one place. Furthermore, it’s normally a fatal error if an external entity cannot be retrieved (e.g., because a URI is unreachable), but XInclude allows specification of a fallback value in the event that the referenced material cannot be retrieved.
XInclude allows references to the document in which the <xi:include> element appears, as long as those references are not to the <xi:include> element itself or to one of its parents (thus avoiding “inclusion loops”). This might serve, for example, to cause a complex element that appears at one place in a document to be included (“copied”) in many other places in that same document.
The question we have not yet addressed is how this facility interacts with various querying mechanisms, such as XPath and XQuery. Remember that XInclude operates on Infosets, not on any other representation of the XML documents involved. As you’ll learn in Chapter 10, “Introduction to XQuery 1.0,” XQuery 1.0 and XPath 2.0 both operate on XML documents that are represented in the XQuery Data Model – which can be constructed from an Infoset representation of a document or from a PSVI representation. Although neither the XPath 2.0 spec nor the XQuery spec explicitly recognizes XInclude, it is clear to us that XInclude processing precedes any querying of the (now-merged) documents, simply because the XInclude processing operates on the Infoset from which the data model instance is derived. We would be quite surprised if the answer were different if XPath 1.0 were used for querying.
7.3.2 XML Pointer Language (XPointer)
If you’re familiar with Uniform Resource Identifiers (URIs),12 then you will recognize that URI references are allowed to include a fragment identifier. A fragment identifier in a URI reference comprises the characters following the number sign (#) and consists of “additional reference information to be interpreted by the user agent,” such interpretation being dependent on the nature of the data being retrieved.
For example, in HTML documents, one might find a link like this one:
![]()
This link includes a URI reference containing a fragment identifier (“IRIComparison”). When that link is followed, the HTML document found at the location indicated by the URI (“www.w3.org/TR/2004/REC-xml-names11”) is retrieved and the “user agent” (a browser, usually) looks for an HTML element with an attribute named “id” whose value is identical to the value of the fragment identifier. Once that element is found, the user agent (browser) positions the document so that the portion starting with that identified element is displayed in the viewing window.
URI references containing this sort of fragment identifier work well in HTML, but they are not sufficiently powerful for all meaningful fragment identification in the larger XML world. The XPointer specifications define an extensible system for XML addressing. There are currently four specifications covering the XPointer language: XPointer Framework,13 XPointer element() Scheme,14 XPointer xmlns() Scheme,15 and XPointer xpointer() Scheme.16
The XPointer Framework defines an extensible system for XML addressing, which is then used by various “schemes” to define fragment identifier languages. XPointer defines two sorts of pointers: shorthand pointers and scheme-based pointers.
Shorthand Pointers
A shorthand pointer is merely an identifier (in XML terminology, an NCName)17 and identifies at most one element in the target resource’s Infoset – the first element that has a matching NCName as an identifier (such as one defined by either an XML Schema or a DTD against which the document has been validated). Shorthand pointers provide a rough analog of HTML fragment behavior.
Scheme-Based Pointers
A scheme-based pointer contains one or more pointer parts; a pointer part is a portion of a pointer that contains a scheme name and some pointer data conforming to the definition of the scheme identified by that name. A software component that handles an XPointer scheme is called an XPointer processor; such components need not be distinct software applications or modules, but they might be an integral component of some other application – possibly including a query facility. Although the XPointer specifications define only three schemes at present, the W3C may in the future add more schemes, and the creation of application-specific schemes is explicitly accommodated in the XPointer Framework. In fact, the Internet Engineering Task Force (IETF) once published an Internet Draft describing an xpathl() scheme18 (we have not, however, been able to find any evidence that this draft was ever accepted as an IETF RFC).
Each pointer part has a scheme name and (within parentheses) data conforming to the named scheme. When a pointer contains multiple parts, the XPointer processor must evaluate them from left to right. If a processor doesn’t support a particular scheme, then it skips that pointer part. If a pointer part doesn’t identify any part of an XML resource (that is, a subresource), then it is skipped and evaluation continues with the next pointer part (if any). As soon as one pointer part identifies a subresource, evaluation of the pointer stops and the identified subresource is the result of the pointer as a whole – meaning that the identified subresource is the thing to which the pointer points.
XPointer (like XInclude) operates on Infosets and not on the serialized form of XML documents. However, the way in which the XPointer Framework is specified, an XPointer processor might operate on a PSVI representation of an XML document or even on an XQuery Data Model representation.
Conveniently, XPointers have been designed so that they can serve as fragment identifiers in URI references. For example, the following URI reference using a shorthand pointer identifies the XML element corresponding to arguably the worst film ever made, Plan 9 from Outer Space, in an XML document representing movies:
![]()
The three XPointer schemes defined by the W3C correspond to the three references cited earlier in this section.
The xmlns() Scheme
One of these, the xmlns() scheme, has the sole purpose of adding a prefix/namespace binding to the namespace binding context that is used by other schemes; it never identifies a subresource. Since pointer parts are processed left to right, the binding added by a scheme-based pointer using the xmlns() scheme is available only to subsequence scheme-based pointer parts.
The element() Scheme
The element() scheme allows basic addressing of elements in target XML resources. This scheme does not permit the identification of any other component of an XML resource, such as attributes, comments, or processing instructions. If the data within the parentheses following the scheme name (“element”) is solely an NCName, then it serves to identify the first element in the document that has an identifier identical to that NCName. If the data within the parentheses comprises a sequence of slash/integer pairs (such as “/2/15/3,” called a child sequence), the XPointer processor must identify the top-level element indicated by the first integer (the second top-level element, in this case), then the child element indicated by the next integer (the 15th one), and so forth. If the data comprises an NCName followed by a child sequence, then the step-by-step location of elements is performed starting at the element located by the NCName.
The xpointer() Scheme
The xpointer() scheme is the most powerful and the most complex of the three schemes defined by the W3C. This scheme is based on XPath 1.0 (see Chapter 9, “XPath 1.0 and XPath 2.0”) but adds the ability to address character strings, specific points in an XML resource, and ranges of components in a resource. It gives access to all nodes of XML documents (and external parsed entities) except for the XML declaration and any associated DTDs, which are omitted because they are not explicitly represented in a document’s Infoset or PSVI.
A point is a location in an Infoset that has no content or children – for example, the location between two adjacent nodes or after a particular character within a text node. A range is an identification of all of the Infoset components lying between two points.
Like XPath 1.0, the xpointer() scheme uses iterative selection, in which each component of a given xpointer() operates on the result of the previous component. Components in XPath 1.0 return node sets (unordered collections of nodes), while the components in an xpointer() operate on location sets (unordered collections of locations). A location is either a node, a point, or a range. Selection of portions of the Infoset in both XPath and in the xpointer() scheme is done through three main constructs: axes, predicates, and functions. An axis is an operator that identifies a sequence of candidate components that might be located, while a predicate tests those candidate components according to specified criteria. Functions might generate new candidate components or perform some other task.
Consider the XML fragment illustrated in Example 7-4. The xpointer() scheme would allow us to identify the portion of the fragment shown in Figure 7-3 but not the portion shown in Figure 7-4.


An XPointer that identifies the first of the points in Figure 7-3 appears in Example 7-6.
The point in Figure 7-4 is invalid because a point cannot occur within an element name – a meaningless concept in an Infoset. The range in that figure is invalid for a similar reason.
The fact that XPointer’s xpointer() scheme is based on XPath 1.0 (with a few extensions) should make it evident that, if XPath is (as we believe it to be) a tool for querying XML, then the xpointer() scheme is also a tool for querying XML – and perhaps a slightly more powerful tool, at that! The element() scheme could also be considered a querying tool, since it allows identification (that is, location) of an element by its identity. According to the W3C’s website, several implementations of XPointer existed in late 2002 and several more were planned.
7.3.3 XML Linking Language (XLink)
XPointer, as you read in Section 7.3.2, provides the ability to “point into” an XML resource (i.e., an XML document or an external parsed entity), identifying specific elements and other locations of interest, such as points and ranges. Many of us, based on our experience with HTML and the links that it provides through its <a> tag, might think that an XPointer is all the linking capability that we need. For many purposes – such as HTML web pages – that’s probably true.
However, for many applications, a more general definition of link is needed. For example, an indexing facility that correlates documents based on their content might not have the authority to make modifications to those documents; therefore, links among them must be stored external to the documents themselves. Another application where more complex links are useful is in document reviewing; a review of a particular part of a document might include several different parts, such as a comment on the paragraph, the identification of the paragraph itself, and perhaps a suggested resolution of the comment.
The XML Linking Language, also known as XLink,19 defines an XML syntax for the creation of both basic unidirectional links and more complex links among resources, not all of them necessarily XML resources. A link is an explicit relationship between resources or portions of resources, expressed in the form of a linking element. Resources and portions of resources are addressed by URI references, and all of the resources associated by a link are said to participate in the link.
The XPointer specification discussed in Section 7.3.2 could be considered a little unusual because it doesn’t actually define any XML syntax, instead specifying a syntax that can be used (for example) as part of a URI reference. Similarly, XLink is unusual in that it defines no XML elements but instead defines XML attributes (in a namespace that is often indicated by the namespace prefix “xlink:”) that can be applied to ordinary elements of XML documents.
According to the XLink specification, an element “conforms to XLink” if it contains an attribute whose name is “xlink:type” and whose value is chosen from a short list of alternatives (e.g., “simple,” “extended,” “locator”) and if it also adheres to a number of constraints associated with the specified xlink:type value. The XLink rules for those constraints are a little complex and aren’t critical to the subject of this book, so we’ll look at only a few of them, to illustrate how XLink works and how it relates to querying XML.
Simple links (defined by elements having an attribute xlink:type=“simple”) provide an outbound-only link (that is, from “here” to some other indicated location) with exactly two participating resources; they correspond to the link capabilities supported by HTML’s <a> and <img> tags. An example of an element that creates a simple link is shown in Example 7-7. The XML fragment in that example uses a <SeeAlso> element that has two attributes, both from the xlink: namespace. The xlink:type attribute indicates a simple link, and the xlink:href attribute contains a relative URI reference containing only a fragment identifier (implying that the reference is to the same document containing this fragment).

Extended links are more complex. They include inbound links (from somewhere else to “here”), third-party links (from “there” to “yonder”), and multiresource links. They may require definition (in a DTD, for example) of new elements specifically to provide link-specific information, such as the rules for traversing from one participant in a link to another. Extended links are often stored in places other than the resources that they associate, particularly when those resources are read-only or are expensive to update and when those resources are not in an XML format.
The film world (as any look at the Internet Movie Database, or IMDB,20 will demonstrate) can be quite complex. Films have directors, cast members, crew members, scripts, locations, and so forth. But the director of a given film is very often the director of one or more other films. And most actors and actresses appear in several films. Some directors appear in the cast of films they (or others) direct. Some cast members are also producers, or editors, or script writers. In short, the world of movies is not a neat hierarchy that fits cleanly into an XML tree – in spite of the fact that we’ve chosen movies for our sample application.
Instead, the relationships between movies, the people involved in them, and so forth are complex and have a great many linkages. XLink’s extended links provides a useful way to specify those linkages.
Let’s consider an example that involves some movies, directors, and cast members we enjoy.
• Dustin Hoffman appears in the cast of many films; among them (in no particular order) are Tootsie, Little Big Man, The Graduate, and Midnight Cowboy.
• Sydney Pollack has directed a number of films; they include Jeremiah Johnson, Out of Africa, Tootsie, and This Property Is Condemned. He also appeared in Tootsie.
• Midnight Cowboy starred both Dustin Hoffman and Jon Voight.
• Tootsie starred Hoffman, Bill Murray, Teri Garr, and Jessica Lange.
• The Graduate starred Hoffman, Anne Bancroft, and Katherine Ross.
• Little Big Man starred Hoffman, Faye Dunaway, and Chief Dan George.
• Jeremiah Johnson starred Robert Redford and Will Geer.
• Out of Africa starred Meryl Streep, Klaus Maria Brandauer, and Robert Redford.
• This Property Is Condemned starred Natalie Wood, Robert Redford, and Charles Bronson.
Starting with just Dustin Hoffman and only four of his films plus Sydney Pollack and four of his films, we’ve now got eight films and 15 people. If we were to include all of the credited cast members, the crew, the producers, etc., undoubtedly 200 people or more would be involved. And merely linking to one other movie for each of those people would cause our data collection to grow very quickly indeed!
Let’s see how XLink might address this problem. Assuming that we were sufficiently imaginative when designing the XML documents for capturing our movie data, we would probably have one document for movies and another for people. Therefore, we might have created documents containing fragments like those shown in Example 7-8.





Notice that the <movie> elements in Example 7-8 have no child elements (or attributes) that identify who directed them, who produced them, or who starred in them. Similarly, the <person> elements don’t indicate what roles they played in what films. By using the facilities of XLink, we can establish all of those relationships without changing the documents themselves. We could create a separate document that contains nothing but the links between people and films, indicating what relationships they have.
To do this, we need to define the elements that appear in that separate linkage document; those elements will use the various xlink: attributes defined by XLink. For the purposes of this example, let’s limit ourselves to tracking only two sorts of relationships between movies and people and the corresponding inverse relationships: the director or directors of a movie, the movies directed by a person, the principal players in a movie, and the movies in which a person played.
Using DTD notation (see Chapter 5, “Structural Metadata”), we could define elements to track these relationships as illustrated in Example 7-9.

That doesn’t look terribly complicated, but this is meant to be a simple example. In this example, a locator (xlink:type= “locator”) is a type of link that simply identifies a resource that participates in an XLink. Elements with that particular attribute definition can appear only as a child of an element with an xlink:type=“extended” attribute. The document in Example 7-10 shows how we might use these elements to capture the information we want about our movies and people.



To relieve the tedium of including all of the players in our (very small) sample, we’ve omitted most of them, as indicated by the ellipsis.
Our design captures relationships between people and movies, but it doesn’t indicate anything that a program can or should do with those relationships. In the most simplistic view of things, an application willing to process these Xlinks (that is, an XLink processor) would probably interrogate the relationships document, searching for a person or movie of interest and then allowing traversals to the movies and/or people of interest.
We could make those traversals somewhat more explicit by adding elements that define arcs between various components. An arc is an optional type of link (xlink:type=“arc”) that makes relationships between resources (xlink:type=“resource”) explicit along with the rules governing the traversals between those resources. We illustrate a possible design for a new element that defines arcs between our movies and people, as shown in Example 7-11.


The visit element defines an arc from one resource to another; the xlink:show attribute specifies what the XLink processor should do when the arc is followed. The values (new and replace) might function in a display application to open a new window to display the target resource or to replace the display in the current window with the target resource. Example 7-12 illustrates the use of the visit element.

Notice that there are two instances of the visit element in Example 7-12. The first allows a traversal from Sydney’s information to the information about Tootsie, while the second defines the reverse traversal.
The document in Example 7-10 shows the relationships based on directors and on players, but it doesn’t adequately capture the fact that Sydney Pollack was both a director of several of our movies and a player in at least one of them. A different design of these linkages would have done a better job of capturing that information. Similarly, we don’t indicate what role (or, as happens sometimes, roles) a single actor or actress might play in a film. And we haven’t planned very well for queries to discover all of the people involved in a single movie. The reader is invited to explore alternate linkage designs that capture those relationships between movies and people.
Unlike XPointers, which could be described as XPath++, while serving a similar function for querying XML, XLink is not itself any sort of querying capability. However, XLink allows the description of complex relationships between resources, and applications that query XML documents may need the ability to traverse such relationships in order to find the data they seek. There are, of course, other ways of achieving similar goals by using application-defined relationships, much as relational databases allow applications to include SQL statements that join information from multiple tables. Any given XML querying facility might use a join-like approach, an approach of exploring XLinks, or both. We are not aware of any widely used language for querying XML that navigates Xlinks, but they may arise in the future.
7.4 Relationship Constraints: Enforcing Consistency
SQL provides a type of constraint, called a primary key, that allows the database system itself to enforce uniqueness of the values stored in a particular column of a table; it also provides a second sort of constraint, a foreign key, that allows the database management system (DBMS) to ensure that a reference from a row in one table to a row of another (usually different but possibly the same) table identifies a row that has the same value in the target table’s primary key. These constraints, together referred to as referential integrity constraints, provide a very powerful mechanism for enforcing consistency between the rows in one table and the rows in another.
The XML specification itself provides a mechanism21 that allows XML document authors to ensure that selected elements are uniquely identified (and identifiable) within a document. As you read in Section 5.2.2, “Relatively Simple, Easy to Write, and Easy to Read,” elements can be declared to have an attribute whose type has attribute type ID. The value of such an attribute must be unique among the values of all such attributes in a given XML document. Correspondingly, elements may also be defined to have one or more attributes whose attribute type is IDREF or IDREFS. The values of such attributes must be identical to the value of some attribute of attribute type ID in the same XML document.
In the relational database world, the functionality corresponding to attributes of type ID is provided by primary keys and unique constraints. The functionality corresponding to attributes of types IDREF and IDREFS is provided by foreign keys. Thus, basic XML (without support from any additional specification) provides functionality analogous to SQL’s PRIMARY KEY and FOREIGN KEY constraints. Of course, this is a good thing, but notice that we said “analogous to” and not “the same as” – that’s because SQL’s foreign keys are allowed to reference rows in tables other than the table in which the foreign key is defined. By contrast, XML’s IDREF values can (and must) reference other elements only in the same document.
Adding XML Schema to the equation raises the bar considerably. XML Schema (as you read in Section 5.3.2, “Simple Types [Primitive Types and Derived Types]”), supports the derived types ID, IDREF, and IDREFS. Although we didn’t discuss the semantics of those types explicitly in Chapter 5, “Structural Metadata,” XML Schema provides roughly the same behavior for values of those types that the XML specification and its DTDs do. One significant difference is that XML Schema allows elements as well as attributes to be given a type of ID, IDREF, or IDREFS. However, XML Schema still does not support the notion that an element of type ID can be referenced by an element or attribute of type IDREF in a separate document.
Instead, XML Schema provides three new constructs that support referential integrity constraints. These constructs, which are included as part of the definition of an element, provide simple uniqueness constraints (similar to those provided by attributes and elements with the type ID), key constraints (similar to a uniqueness constraint but with the specified values mandatory), and referencing constraints (which mandate that specified values correspond to matching key or unique constraints).
Let’s explore an example. In our database of movies, we have observed that there are never any movies with both the same title and same year of release. (In the real world, that situation might arise, of course. But not in our database!) That immediately suggests that the combination of title and yearReleased would satisfy a unique constraint.
In an XML Schema for describing our data, we could provide a simple unique constraint by using declarations like those seen in Example 7-13. Note the <xs:unique> component at the bottom of the movie element declaration.


In that <xs:unigue> element (for which the name attribute is mandatory, the value of which must itself be unique), the child <xs:selector> element identifies a node set – the set of <movie> nodes that are children of the “current” node (the <movies> node). The <xs:field> element identifies the descendants and/or attributes of the nodes that are in that node set, forming a second node set for each node in the <movie> node set; in this case, we’ve declared that there are two nodes in that second node set – the <title> child element and the <yearReleased> child element. The way to read the <xs:unique> declaration is “for each child element named movie, the combination of that element’s children named title and yearReleased must be unique within the containing <movies> element.”
The declarations in Example 7-13 have one characteristic that may or may not be desirable: while the <xs:unique> element prohibits the existence in any single XML document of two <movie> elements whose combined <title> and <yearReleased> child elements have equal content, it makes no requirement that the declarations of those child elements be nonnillable (this means that the elements must not be declared with an attribute named xsi:nillable whose value is “true”). It also allows the possibility that one or more <movie> elements might be missing a <title> child element and/or a <yearReleased> child element.
If we wanted to require that both fields be nonnillable and that every member of the node set chosen by the <xs:selector> have exactly one <title> child element and exactly one <year-Released> element, we would replace the <xs:unique> element with the <xs:key> element that you see in Example 7-14. When you use an <xs:key> constraint, you should not declare any of the <xs:field> elements to refer to descendant elements or attributes that are optional.

Now that we know how to create both a unique constraint and a key constraint for an element, we can consider how to use such constraints to ensure that other elements that claim to reference a <movie> element actually reference a movie that exists. In the SQL world, this role is played by a type of referential constraint called a foreign key constraint.
In XML Schema, that role is played by the <xs:keyref > element. That element has two required attributes: name and refer. Like the eponymous attribute of the <xs:unique> and <xs:key> elements, the name attribute of the <xs:keyref> element is required, as is the refer attribute. The value of the refer attribute must be equal to the value of the name attribute of an <xs:unique> or <xs:key> element declared in the same XML Schema. The content of the <xs:keyref > element comprises the usual <xs:selector> element and one or more <xs:field> elements. In this element, the number of <xs:field> children must be the same as the number of <xs:field> elements in the <xs:unique> or <xs:key> constraint identified by the name attribute.
In our movies database, we have the requirements that every review in the database be a review of exactly one movie and that that movie also be in the database. We could express this constraint via code like that in Example 7-15.


Note that the <xs:keyref > element contains one <xs:field> whose xpath attribute specifies the name of a child element (title), while the other specifies the name of an attribute (@yearMovieReleased). The <xs:field> elements can identify any descendant or attribute (including attributes of descendants), as long as the number of <xs:field> child elements in the <xs:unique> or <xs:key> element is equal to the number in the <xs:keyref > element.
In this chapter, the discussion of XPointer describes the behavior of shorthand pointers, which behave somewhat like HTML’s <a> tag: They match the (first) element with an ID-typed attribute whose value is identical to the NCName in the shorthand pointer. Unlike XML’s IDREF semantics, the shorthand pointer can identify a point in an XML document other than the one in which the pointer itself is located. This improves the analogy with SQL’s foreign keys, even to the error that occurs if the referenced point doesn‘t exist. Similarly, XPointer’s element() scheme, when only an NCName is used, offers that same functionality.
SQL provides syntax for joining information from multiple tables based on the foreign key relationships, thus allowing query authors to create queries with greater chances of correct behavior. Unfortunately, we are unaware of widely accepted XML querying facilities that take advantage of ID/IDREF relationships by supporting joins of information in XML documents based on those relationships.22 Perhaps some future version of XQuery will consider this possibility, but it’s far too soon to say.
7.5 Chapter Summary
In this chapter, we’ve examined several W3C specifications that deal with managing XML in ways that interact (more or less – but mostly less) with querying XML. XSLT arguably provides a type of XML querying capability, but it is specialized for transforming XML documents rather than specifically searching within documents or identifying documents within collections. XSL FO, as we saw, is a formatting language and has nothing to do with querying XML, but it is very useful for publishing the results of queries in reader-friendly formats.
XInclude allows the modularization of XML documents and does so in a way that makes it possible to query the result of the merger of the various modules. XPointer can provide an IDREF-like capability through its shorthand pointers and its element() scheme; its xpointer() scheme is an extension of XPath and is thus powerful enough to easily be considered a tool for querying XML. XLink provides the ability to define sophisticated linkages between and among XML resources, but it offers very little in the form of querying XML documents. Until popular XML querying languages such as XPath and XQuery support the sort of relationships created through ID/IDREF-typed attributes and elements, through XPointer utilization, or through XLink capabilities, none of these will offer the same promise that SQL’s referential constraint-based joins provide.
1HTML 4.01 Specification (Cambridge, MA: World Wide Web Consortium, 2003). Available at: http://www.w3.org/TR/html401.
2PDF, or Portable Document Format, is a specification created by Adobe Systems, Inc., http://www.adobe.com.
3XSL Transformations (XSLT) Version 1.0 (Cambridge, MA: World Wide Web Consortium, 1999). Available at: http://www.w3.org/TR/xslt.
4XSL Transformations (XSLT) Version 2.0 (Cambridge, MA: World Wide Web Consortium, 2004). Available at: http://www.w3.org/TR/xslt20/.
5XHTML 1.0 The Extensible Hypertext Markup Language (Second Edition) A Reformulation of HTML 4 in XML 1.0 (Cambridge, MA: World Wide Web Consortium, 2002). Available at: http://www.w3.org/TR/xhtmll.
6XSLT 1.0 provides the element <xsl:for-each>, which applies a specified transformation to each node in a selected node set; this is often viewed as a type of iteration. Similarly, XSLT 2.0 provides <xsl:for-each>, in this version applying the specified transformation to each item in a selected sequence, as well as a new <xsl:for-each-group> element that allocates items in a sequence into groups (based on some common criteria) and then evaluates a “sequence constructor” once for each group. The behavior of those XSLT 2.0 elements is also often viewed as a type of iteration.
7SOAP Version 1.2 Part 0: Primer (Cambridge, MA: World Wide Web Consortium, 2003). Available at: http://www.w3.org/TR/soapl2-part0/. SOAP Version 1.2 Part 1: Messaging Framework (Cambridge, MA: World Wide Web Consortium, 2003). Available at: http://www.w3.org/TR/soapl2-partl/. SOAP Version 1.2 Part 2: Adjuncts (Cambridge, MA: World Wide Web Consortium, 2003). Available at: http://www.w3.org/TR/soapl2-part2/.
8Cascading Style Sheets, Level 2, http://www.w3.org/TR/REC-CSS1 (Cambridge, MA: World Wide Web Consortium, 1998) and Cascading Style Sheets, Level 2 CSS2 Specification, http://www.w3.org/TR/REC-CSS2 (Cambridge, MA: World Wide Web Consortium, 1996).
9ISO/IEC 10179:1996, Information Technology – Processing Languages – Document Style Semantics and Specification Language (DSSSL), (Geneva, Switzerland: International Organization for Standardization, 1996).
10ISO 8879:1986, Information Processing – Text and Office Systems – Standard Generalized Markup Language (SGML), (Geneva, Switzerland: International Organization for Standardization, 1986).
11XML Inclusions (XInclude) Version 1.0 (Cambridge, MA: World Wide Web Consortium, 2004). Available at: http://www.w3.org/TR/xinclude/.
12Uniform Resource Identifiers (URI): Generic Syntax (Internet Engineering Task Force, 1998). Available at: http://ietf.org/rfc/rfc2396.txt.
13XPointer Framework (Cambridge, MA: World Wide Web Consortium, 2003). Available at: http://www.w3.org/TR/2003/REC-xptr-framework/.
14XPointer elementi) Scheme (Cambridge, MA: World Wide Web Consortium, 2003). Available at: http://www.w3.org/TR/2003/REC-xptr-element/.
15XPointer xmlnsQ Scheme (Cambridge, MA: World Wide Web Consortium, 2003). Available at: http://www.w3.org/TR/2003/REC-xptr-xmlns/.
16XPointer xpointerQ Scheme (Cambridge, MA: World Wide Web Consortium, 2002). Available at: http://www.w3.org/TR/2002/WD-xptr-xpointer/.
17An NCName is a “noncolonized” name – that is, a name without any colons embedded in it. By contrast, a QName is a “qualified” name that is qualified by a namespace prefix. The namespace prefix and the “local part” of the QName are each NCNames.
18S. St. Laurent, The XPointer xpath1() Scheme (2002). Available at: http://www.simonstl.com/ietf/draft-stlaurent-xpath-frag-OO.html.
19XML Linking Language (Xlink) Version 1.0 (Cambridge, MA: World Wide Web Consortium, 2001). Available at: http://www.w3.org/TR/xlink/.
20Internet Movie Database, http://imdb.com.
21http://www.w3.org/TR/REC-xml#NT-TokenizedType.
22In SQL, foreign keys are permitted to reference tables that are in other databases, while XML’s ID/IDREF capabilities are relevant only within a single XML document. This inherently limits the ability of XML querying languages to use ID/IDREF as a mechanism to join information from multiple separate documents.