
Introduction to XQuery 1.0
10.1 Introduction
In Chapter 9, “XPath 1.0 and XPath 2.0,” we presented one language for querying XML documents, XPath. In this chapter, you’ll be introduced to a much more powerful language for querying XML called XQuery.
We start with a brief history of the language. We think it’s useful to know the background of a language’s development, because it gives some insight into how and why things are as they are, but feel free to skip this section if it doesn’t interest you.
Next, we look at the specs that laid the foundation for the design of the language – the Requirements and the Use Cases. These two specs tell us what the language is for (what problems the language is meant to solve) and give us some examples of its expected use. Then we give an overview of the XQuery suite of specifications (there are nine of them, as well as three related XML specs) and say how they are related.
With this background, we are ready to dive into the XQuery Data Model and the XQuery type system. The XQuery Data Model is one of the features that sets XQuery apart from XPath 1.0 and XSLT 1.0. Every XQuery operates over an instance of the XQuery Data Model, and its result is an instance of the XQuery Data Model.
We leave a detailed description of the syntax and semantics of XQuery for the next chapter (Chapter 11, “XQuery 1.0 Definition”). In this chapter we describe the functions and operators of the language, and the formal description of the semantics of the language.
We said that the output of an XQuery is an instance of the XQuery Data Model – clearly, we need some way to communicate those data to the outside world. One way is to serialize the output Data Model (i.e., create an XML representation of it). We describe serialization in the last section of this chapter.
After reading this chapter, you should know a good deal about the XQuery language – certainly enough to start using it.
10.2 A Brief History
Like its relational database predecessor, SQL, XQuery was designed from the start to be a nonprocedural language in which query authors express the sources of the data they wish to query and the rules they wish to have applied to those data in order to achieve the answers they need. In neither language does the query author specify how the system produces those answers. XQuery goes beyond XPath – even XPath 2.0 – in its ability to bring together information from multiple documents simultaneously, correlating the data in those documents based on common characteristics, and producing answers that cannot be determined from one document alone.
Also like SQL, XQuery was not created out of whole cloth. Instead, it is the offspring of a number of earlier languages that explored how to query XML without every quite achieving widespread acceptance in the XML or data management communities. Some of the ancestors of XQuery were designed with the needs of the document community in mind, while others were oriented more toward the data community (and XQuery addresses both communities with equal vigor).
One of the philosophical ancestors of XQuery is a language called XQL.1 The first draft of a specification for XQL was written in February 1998 by Jonathan Robie, then with Software AG. The XQL FAQ says that “XQL is a query language that uses XML as a data model, and it is very similar to XSL Patterns,” and that it has a number of implementations. Design of XQL apparently ceased in mid-1999, after the language was submitted as a candidate for consideration at the W3C’s QL 98 Workshop.2
Another language named XQL was also submitted by three researchers from Fujitsu Labs to that same Workshop.3 The two languages appear to be unrelated, in spite of the choice of name. It seems unlikely that there were any implementations of this second XQL other than the initial research implementation.
A language named XML-QL4 was submitted to the W3C as a Note by a number of researchers (Alin Deutsch, Mary Fernandez, Daniela Florescu, Alon Levy, and Dan Suciu) from industry and academia. XML-QL, like the Fujitsu XQL, explicitly drew aspects of its design from SQL, as well as from other research query languages for semistructured data. The W3C Note states that “XML-QL can express queries, which extract pieces of data from XML documents, as well as transformations, which, for example, can map XML data between DTDs and can integrate XML data from different sources.”
A project named Lore5 (Lightweight Object REpository) at Stanford University that ran from about 1996 through 2000, headed by Jennifer Widom, provided a database system for semistructured data. A principle component of Lore was a declarative query language for XML, known as Lorel (Lore Language). Lore and Lorel took an object-oriented approach to managing semistructured data, minimizing dependencies on predetermined schema information about the data being queried.
Another research language, YATL,6 was developed by Sophie Cluet and Jérôme Siméon at INRIA to “query, convert and integrate XML data.” (By “integrate,” the authors meant the ability to bring together information from multiple data sources in one query.) YATL was not intended to be computationally complete, but to capture a large and useful class of data transformations. The language is “able to resolve structural conflicts between sources and features high-level primitives for the manipulation of collections and references.”
The language that contributed most directly to the creation of XQuery was named Quilt,7 designed by Don Chamberlin, Jonathan Robie, and Daniela Florescu. The last two of these designers appear earlier as participants in the creation of other XML querying languages. Don Chamberlin may be best known as one of the inventors of the premiere relational data management language: SQL. Quilt was presented to the W3C’s XML Query Working Group as a proposed starting point for the language that has become known as XQuery. Quilt originated “when the authors attempted to apply XML query languages such as XML-QL, XPath, XQL, YATL, and XSQL to a variety of use cases,” finding that each language had distinct advantages and disadvantages. By selecting the strongest notions from each, as well as from SQL and OQL,8 they created a language that met the requirements of the XML Query Working Group, was implementable, and retained a deep reliance on the structure of XML itself.
XQuery is manifestly not Quilt, but its relationship with that language is easily discerned. Just as the world owes a great deal to Don Chamberlin and Ray Boyce for the creation of SQL as a language to access relational databases, Quilt’s inventors are to be recognized for giving their talents to the immediate parent of XQuery 1.0.
In this chapter, you’ll read about the data model underlying XQuery 1.0 (and XPath 2.0) and its relationship to XML Schema and to the Infoset (see Chapters 5, “Structural Metadata” and 6, “The XML Information Set (Infoset) and Beyond,” respectively). In Chapter 11, “XQuery 1.0 Definition,” you’ll learn more details about XQuery syntax and semantics, the function library defined for the language, and how results can be transformed into character strings of XML markup.
10.3 Requirements
Like any well-run software project, the XQuery effort started with a set of requirements. The XQuery Requirements9 specification describes what the XQuery language sets out to achieve. The latest version is annotated with colored bullets to show which requirements have been met, so you can track progress against requirements. The XQuery Requirements specification provides an overview of the guiding principles of the language, so it is an appropriate place to start this overview of the XQuery 1.0 language. Today’s XQuery Requirements document owes much to the pioneering 1998 paper by David Maier, “Database Desiderata for an XML Query Language.”10
As an aside, the XQuery Requirements specification raises an interesting question on naming. Its full title is “XML Query (XQuery) Requirements.” If you look at the full titles of the other specifications in the XQuery suite, there is no consistent convention for using “XML Query” vs. “XQuery.” The Use Cases specification has “XML Query” in its title, the Data Model specification has “XQuery,” and the Requirements specification has “XML Query (XQuery).” Some of the specification titles include “XPath” or its alter ego, “XML Path.” “XQuery” seems to have become the term applied to “XQuery 1.0 and XPath 2.0” in common parlance. Throughout this book we use “XQuery” to mean exactly that – the language described by “XQuery 1.0: An XML Query Language,”11 which includes most of12 the language described by “XML Path Language (XPath) 2.O.”13, 14 We overload the word “XQuery” – it might also mean “XQuery query expression,” as in “writing an XQuery” or “running XQueries.” Overloading the word is unfortunate, but the alternative is to talk about “running XQuery query expressions.” We use the term “XPath” when talking about that part of XQuery explicitly, for example when we talk about XPath requirements. And we use “Querying XML” when talking about the more general problem of doing queries against XML data.
One more general comment before we look at the XQuery requirements. The XQuery specifications use the terms “must,” “may,” and “should” in a special way. Some link to RFC 2119;15 others include an abbreviated RFC 2119-like definition in the body of the specification. Below we quote the definitions from the “XQuery Requirements,” and we use boldface in the text of this book when those terms are meant to have their special meaning.
• must – This word means that the item is an absolute requirement.
• should – This word means that there may exist valid reasons not to treat this item as a requirement, but the full implications should be understood and the case carefully weighed before discarding this item.
• may – This word means that an item deserves attention, but further study is needed to determine whether the item should be treated as a requirement.
10.3.1 General Requirements for XQuery
XQuery is a declarative language, which must not mandate any evaluation strategy, such as the order of evaluation of parts of a query. A declarative language describes what the processor should do rather than how to do it. This makes for relatively simple, readable queries that can be optimized by the XQuery processor. It is independent of any particular protocol, so that XQueries16 can run in any environment.
XQuery may have more than one syntax, but it must have one syntax that is human-readable and one syntax that is XML. The XML syntax must “reflect the underlying structure of the query.” This pair of requirements led to XQueryX,17 a language for describing an XQuery in XML. One can safely assume that any XML representation that “reflects the underlying structure of the query” will not be “convenient for humans to read and write,” hence the need for two syntaxes. With XQueryX, a query can be created, modified, and even queried using standard XML tools. You’ll read more about XQueryX later (Chapter 12, “XQueryX”).
XQuery 1.0 does not include any update functionality, which many consider a serious shortcoming. It is clear that, from the start of the XQuery effort, update capability was considered to be important for inclusion in some version of XQuery, but not necessarily the first version. The first XQuery Requirements specification18 (January 2000) said only that XQuery must leave the door open for update to be included in XQuery in a future version. The latest XQuery Requirements says the same.
10.3.2 Data Model Requirements
The XQuery Requirements document describes requirements for the Data Model separately – an indication of the importance of the Data Model in XQuery. We describe the XQuery Data Model in detail in Section 10.6. In this section, we review the requirements for that Data Model.
The XQuery language is defined as an operation over an instance of the XQuery Data Model. The XQuery Language takes an instance of the Data Model as input, and returns an instance of the Data Model as output (i.e., the XQuery language is closed with respect to the XQuery Data Model). The XQuery Requirements document says that only information that can be found in the Infoset and the PSVI (see Chapter 6, “The XML Information Set (Infoset) and Beyond”) can be used to construct an instance of the XQuery Data Model. This is not the same as saying that an instance of the Data Model can only be constructed from an instance of the Infoset or from a PSVI – on the contrary, it can be constructed directly by a program, or as the result of an XQuery. But no information that does not exist in either the Infoset or the PSVI specifications can ever find its way into an instance of the XQuery Data Model. (Some readers might claim that the fact that the XQuery Data Model can represent heterogeneous sequences is an exception to that rule, but we disagree – the information in those sequences is still limited to the information that can exist in an Infoset or PSVI instance.)
The XQuery Requirements document also says that the XQuery Data Model must provide a mapping from any instance of the Infoset or PSVI to an instance of the XQuery Data Model. The Data Model must represent the character data available in the Infoset and data types and structure types defined in XML Schema. Interestingly, there are no requirements for mapping from the XQuery Data Model to any other data model. The Serialization specification does define an output mapping from the XQuery Data Model to HTML, XML, XHTML or text, but not (directly) to an Infoset or a PSVI.
The XQuery Data Model must represent “collections.” Collections can be collections of documents – returned by the fn:collection( ) function – or ordered collections (sequences) of documents, nodes, and/or values. There is, as you read in Chapter 6, no notion of a collection or a sequence in the Infoset.
Queries must run whether or not a (complete) Schema is available. This leads to a quagmire of how to deal with data that are untyped (when there is no Schema available) or only partially typed (when there is a Schema available, but it only validates some of the data).
10.3.3 XQuery Functionality Requirements
The XQuery Requirements document includes some basic functionality requirements – XQuery must be able to aggregate and sort results, must include support for universal and existential quantifiers, and must support composition of expressions. The XQuery Requirements document (unsurprisingly) says a lot about the ability to deal with structure. XQuery must support operations on hierarchy and sequence; combine information from different parts of a document (or parts of different documents); and preserve, transform, and/or create structures in results, including intermediate results.
There is a requirement that XQuery must support null values. This has led to some interesting debates among members of the SQL community (where “null” is a well-understood, well-defined term) and the XML community (who have mapped “null” to its closest relative in the XQuery Data Model, the empty sequence). Of course, the XML community prevailed. Similarly, the requirement that “queries must be able to express simple conditions on text, including conditions on text that spans element boundaries” has been punted on, with a reference to the fn:string( ) function (which returns the string value of a node or value, as defined by the PSVI). We’ll just have to wait for some future XQuery Full-Text specification to get true full-text query capability from XQuery.
One requirement that has not been met in XQuery 1.0 is to support both interdocument and intradocument references. Support for XPointer was discussed, but the XPointer Recommendation19 was published too late (March 2003) to be considered. Another is the requirement to provide access to a document’s Schema (if it has one) – this was felt to be too complex for the first version of the language.
10.3.4 XPath 2.0 Requirements
The XPath 2.0 requirements are laid out in “XPath Requirements Version 2.0.”20 XQuery 1.0 includes XPath 2.0 as a subset of the language, so the XPath 2.0 requirements had a big influence on XQuery 1.0 requirements.
While XQuery 1.0 is a brand new language, XPath 1.0 has been around since 1999 and has many users. So XPath 2.0 must be backward-compatible with XPath 1.0. One common use of XPath 1.0 is in XSLT, so XPath 2.0 needs to satisfy XSLT users as well as XQuery users, by providing a common “core” expression language for both XSLT 2.0 and XQuery 1.0. Naturally, it is extremely desirable for the syntax and semantics of XPath-in-XSLT and XPath-in-XQuery to be the same.
XPath 2.0 extends the type system of XPath 1.0 considerably. XPath 1.0 has a simple type system in which every expression evaluates to one of four available types – node-set, Boolean, number, or string. By contrast, XPath 2.0 must support the data types and structure types defined by XML Schema.
Finally, the XPath 2.0 Requirements include lots of detailed requirements for functionality that had been requested by real-world users. This is one of the advantages of a 2.0 specification – there is a wealth of user experience to call upon when gathering requirements.
10.4 Use Cases
The XQuery Requirements document briefly describes a set of “usage scenarios” for XQuery, showing that XQuery is meant to apply in a very broad range of situations. The “XML Query Use Cases”21 describes use cases across that range. The Use Cases specification is a good starting point for the XQuery beginner, particularly for someone who likes to see concrete examples (as opposed to the more formal descriptions in, say, the Data Model or Formal Semantics specifications).
Note that the purpose of the Use Cases specification is very different from that of a test suite. The use cases illustrate some of the functionality of XQuery, but there is no attempt to exercise every operation or permutation. The Use Cases specification includes some 77 queries, while a test suite could be expected to include many thousands. Anyone starting to test an implementation, or to test her own understanding, would do well to start with the use cases and the examples in the XQuery Language specification (thoughtfully supplied as script files).22
• One or more DTDs describing the input data. Only one of the use cases comes with an XML Schema – Use Case “STRONG,” “queries that exploit strongly typed data,” needs an XML Schema to represent the data types.
• One or more pieces of sample data. The data are represented in the queries as an XML document at the end of a URL, introduced using the doc function – e.g., “for $b in doc(“http://bstorel.example.com/bib.xml”)/bib/book.”
Let’s take a look at one of the use cases, to give a feel for what an actual XQuery does and looks like. The very first query in the Use Cases specification is fairly simple – it is reproduced in Example 10-1.



“List books published by Addison-Wesley after 1991, including their year and title.”


This simple example illustrates:
• The F, W, and R of the FLWOR expression.
• XPath integration – the query includes several path expressions.
• Data input via the doc ( ) function, and output using element construction.
Since this is a fairly representative example of an XQuery, let’s describe what the query does informally, to give you the general flavor of the XQuery language.
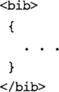
This is a constructed element. One of the strengths of XQuery (over, say, XPath 1.0) is that XQuery lets you construct XML on the fly like this, so you can output sensible XML as the result of a query. The result of the query is a bib element, and the content of bib is the result of evaluating the XQuery expression enclosed in curly braces.
![]()
This is the for clause (the “F” in “FLWOR”). It says we should iterate over the sequence produced by evaluating the expression after the keyword in. That is, consider each member of the sequence in turn, assigning the value of each member of that sequence to the variable $b. The expression after the keyword in is an XPath expression, beginning with an invocation of the built-in function doc ( ). The XPath expression says we should take the document represented by the URI “http://bstorel.example.com/bib.xml,” select its children elements named bib, and select their children elements named book.
![]()
This is the where clause (the “W” in “FLWOR”). The where clause says we should not consider all the members of the sequence indicated by the for clause (all books), but we should only consider those books where the condition is true – in this case, where the publisher is “Addison-Wesley” and the year is 1991.

This is the return clause (the “R” in “FLWOR”). For each book that satisfies the where clause, construct an element called book with an attribute year. The value of the year attribute and the content of the book element are both XQuery expressions (delineated by curly braces, since they are inside an element constructor). Note that the result is a single bib element containing multiple book elements – one for each book in the for-clause sequence that satisfies the where-clause condition.
The careful reader will have noticed that the “L” and “O” in “FLWOR” are missing from this particular use case. The let clause assigns values to variables inside the for iteration. It’s a convenience, but a very important one. The order by clause lets you define an ordering of the result sequence.
The use cases are grouped into the following scenarios:
• XMP – Experiences and Exemplars. Simple queries about books, chapters, and reviews to get you started.
• TREE – Queries that preserve hierarchy. These queries operate over a flexible “book” structure, to produce highly structured, ordered output such as a table of contents.
• SEQ – Queries based on Sequence. Queries across a medical report that illustrate the importance of order (such as “what Instruments were used in the first two Actions after the second Incision?”).
• R – Access to Relational Data. Queries across an XML View of three relational tables that might be part of an auction system – USERS, ITEMS, and BIDS.
• SGML – Standard Generalized Markup Language. Some example queries taken from a conference on SGML (the ancestor of XML).
• STRING – String Search. Some examples use the “contains” function, which looks for a string inside a node. These use cases simultaneously illustrate the need for a full-text search capability in XQuery, and the limitations of the contains function (which does substring, as opposed to token-based, search).
• NS – Queries Using Namespaces. Illustrates XQuery across data from different sources, disambiguated by using different namespaces.
• PARTS – Recursive Parts Explosion. Recursive queries to create a “parts explosion” (bill of materials, or BOM) from data stored in a relational database.
• STRONG – Queries that exploit strongly typed data. These queries make use of the type information in an XML Schema. The example data and Schema are for purchase orders.
10.5 The XQuery 1.0 Suite of Specifications
XQuery 1.0 is defined by the W3C in a collection of several specifications, some of which are shared with the specification of XPath 2.0. The sheer size of that collection is intimidating to many readers, but we believe that it seems much more reasonable when we look at what each specification does and how it accomplishes its goals.
Figure 10-1 illustrates how each of the XQuery specifications, and other related specifications, fit into the overall scheme of things.

Specifications developed in whole or in part by the W3C’s XML Query Working Group are shaded in Figure 10-1, while other specifications are left unshaded. Specifications represented by boxes to which the arrows point are dependent on documents represented by boxes from which those arrows originate. For example, the XQuery 1.0 Language spec is dependent on the XPath 2.0 and XQuery 1.0 Data Model spec, the XPath 2.0 and XQuery 1.0 Functions & Operators spec, and the XPath 2.0 and XQuery 1.0 Formal Semantics spec. In addition, it is indirectly dependent on the XML specs, the Namespaces specs, and the XML Schema specs. It is not, however, dependent on the XPath 2.0 Language spec.
The group of documents that include the Data Model, the Functions & Operators, the Formal Semantics, XQuery 1.0, and XPath 2.0 seem to have complex relationships among themselves. In fact, the relationships are not as complex as they may appear, as you’ll see in this section.
10.5.1 XQuery 1.0 Language Specification
The syntax and much of the dynamic semantics of XQuery (that is, the behavior of the language and its component parts at run time) are defined in a rather lengthy and detailed specification23 of the XQuery 1.0 language. That document specifies a human-readable syntax for XQuery. (A separate document24 specifies an XML syntax for XQuery about which you’ll read in Chapter 12, “XQueryX.”) What is XQuery, though? The XQuery specification says this:
XQuery is designed to meet the requirements identified by the W3C XML Query Working Group and the use cases that demonstrate the validity of the requirements. It is designed to be a language in which queries are concise and easily understood. It is also flexible enough to query a broad spectrum of XML information sources, including both databases and documents.
We agree with most of that statement, although we occasionally find ourselves wondering about the “easily understood” aspect.
The XQuery specification, as indicated in Figure 10-1, depends on several other specifications. Because XQuery operates on, and constructs, instances of the Data Model, its most important dependency is on the Data Model specification,25 about which you read in this chapter. The design of XQuery and the details of its operation are heavily influenced by the Data Model. (Of course, the converse is also true, which isn’t surprising since the two specifications were written concurrently by the same Working Group.)
The other two documents on which the XQuery specification depends are the Formal Semantics spec26 and the Functions & Operators (sometimes called “F&O”) spec.27
10.5.2 XPath 2.0 and XQuery 1.0 Formal Semantics
The word formal, as used by the XQuery specifications, means “a strict, mathematical definition” and the word semantics means “meanings.” Therefore, the Formal Semantics spec defines the meaning of expressions in a strict mathematical manner. The part of the Formal Semantics spec that defines the meanings of expressions is not normative – that is, a definition in the XQuery language spec takes precedence over the formal definition, if they disagree. However, the static typing feature is defined only here, so its definition is normative. Sometimes, we refer to static typing as the static semantics of XQuery and the determination of the meanings of expressions as the dynamic semantics.
Static typing is a way of determining the data types of XQuery expressions without considering any specific data values. It is static typing that allows XQuery implementations to support XQuery as a strongly typed query language more efficiently – for example, to assist the query optimizer in producing an effective query evaluation plan. It also allows many errors to be detected earlier than they otherwise would be. Without the use of the static typing feature, XQuery is still a strongly typed language, but the type determination is done at query evaluation time, and errors are often detected later than they would have been under a static typing implementation. When operating on untyped data, XQuery is a weakly-typed language (perhaps “untyped” would be more appropriate).
The Formal Semantics spec defines static typing pessimistically. That is, the rules derive the types of all expressions in a manner that guarantees that no type errors can occur at query evaluation time. One of the side effects of this approach is that queries that might run without type errors – when used with a particular set of data – are prohibited from being evaluated because of the very possibility of a type error with some set of data. Consequently, we believe that the marketplace will demand both XQuery implementations that support static typing and implementations that do not.
10.5.3 XPath 2.0 and XQuery 1.0 Functions & Operators
The Functions and Operators (F&O) specification, covered in detail in Section 10.9, defines a large collection of functions that users can invoke in their XQuery expressions, as well as a number of “hidden” functions that the XQuery spec uses to define the semantics of its operators. In general, any operator in a programming language can be represented by a function with one or two arguments. Each of the operators in XQuery is defined in the XQuery 1.0 language spec by referencing the equivalent function in the F&O spec. These so-called “backup” functions cannot be invoked directly from XQuery expression – they exist only for definitional purposes and are not necessarily implemented as functions by any specific XQuery implementation.
The F&O spec contributes to both the strong typing of XQuery and to the definition of the language’s semantics. It is an extension of the XQuery spec that is published separately for convenience – and to avoid creating an (even more) intimidatingly large combined spec.
10.5.4 XQuery 1.0 Serialization
The Serialization specification28 was not mentioned in Section 10.5.1 because XQuery does not depend on it. Instead, the Serialization spec depends on XQuery (as well as on XSLT 2.0, which is discussed in Chapter 7, “Managing XML: Transforming and Connecting”). Serialization is covered in greater detail in Section 10.10.
Serialization is the process by which Data Model instances are transformed into character strings that represent those values in a form convenient to transport over the web, to print, to be read by a human, or to be parsed by an XML parser. Some Data Model instances represent XML documents; serializing such instances results in the so-called “angle bracket,” character string form of XML documents – the form you see printed throughout this book, for example. Other Data Model instances represent atomic values, and serializing them results in character strings that form literals in the lexical space of their data types.
The Serialization specification provides facilities for producing XML strings that are suitable for treatment as XML documents or well-formed XML external parsed entities. It also provides the ability to produce XHTML, provided the value being serialized conforms to the requirements of the XHTML specification,29 and the ability to produce HTML.30 Finally, it provides the ability to generate ordinary text corresponding to the string value of the XML value being serialized. (Incidentally, serialization doesn’t have to mean “conversion to a character string” – one might serialize a Data Model instance to some compact binary representation for exchange between processes – even though the XQuery and XPath Serialization spec only provides for serialization to a sequence of characters.)
10.5.5 XQueryX
The XQueryX specification defines an XML syntax in which XQuery expressions can be coded. It does so by defining an XML Schema to specify an XML vocabulary that XQueryX documents must use. In order to avoid the necessity of redefining all of the semantics of XQuery merely for the sake of having a second syntax, the spec also defines an XSLT 1.0 stylesheet that (literally or metaphorically) serves to transform XQueryX documents into XQuery’s “human-readable” syntax, after which the semantics are well-defined.
We discuss XQueryX in more detail in Chapter 12.
10.6 The Data Model
The “XQuery 1.0 and XPath 2.0 Data Model” specification31 is central to the definition of XQuery. The type system represented in the Data Model (and defined formally in the Formal Semantics specification)32 has fueled more discussion in the Working Groups than the rest of the XQuery specifications put together. The XQuery Data Model (XDM) is the most comprehensive in the XML world, encompassing the Infoset and the PSVI and more.
We said in Chapter 6, “The XML Information Set (Infoset) and Beyond,” that the Infoset is an abstract representation of the core information in an XML document, and that the PSVI (Post-Schema-Validation Infoset) is an Infoset with additional information about validity and data and structure types, produced by validating the document against an XML Schema. The XQuery Data Model is, at its simplest, a tree representation of the PSVI. However, the PSVI cannot model everything that the XQuery Data Model needs to deal with. The PSVI, like the Infoset, can only model well-formed XML documents, while the XQuery Data Model needs to represent an XML document, a node, a value, or a sequence of (a mixture of) any of these. That is, the XQuery Data Model needs to be able to represent anything that can be the output of a query, or the intermediate results of a query, as well as anything that can be the input to a query. The XQuery Data Model also needs to represent the value of any expression that can be part of a query. We will talk about the Data Model tree in the rest of this section, but bear in mind that this may not be a true tree at all – i.e., it may not have a single root.
There are seven kinds of nodes in the XQuery Data Model tree, corresponding almost exactly to the seven kinds defined in the XPath 1.0 Data Model. Document Element, text, attribute, namespace, processing instruction, and comment nodes are common to both. The XQuery Data Model’s document node, which is the root of the tree, is more permissive than its XPath 1.0 cousin. In an XQuery Data Model instance, there is at most one document node that, if it exists, sits at the top of the tree. There are no data corresponding to this node – it is a notional node, created so that the tree has a single root. It must not have an attribute, namespace, or document node as a child, but, unlike its XPath 1.0 cousin the root node, it may be empty, and it may have more than one element child node.
For intermediate (by which we mean “not serialized”) query results, the tree might not have a document node at all. In such cases, the Serialization specification33 insists that a document node must be added as part of the serialization process.
XQuery Data Model instances can be constructed in a number of ways. The XQuery Data Model specification describes how to construct an XDM instance from an Infoset or a PSVI, but instances can also be created directly, either as the output of an XQuery or via direct construction by an application.
The XQuery Data Model specification defines an XQuery Data Model instance as a sequence of items, where each item is either a node or a value. Nodes in the XQuery Data Model map roughly to Information Items in the Infoset, with properties and accessor functions. Every value has an associated type name.
10.6.1 Data Model Instances
The term Data Model instance is equivalent to the phrase “value in the context of the Data Model.” The following are examples of valid Data Model instances:
• Atomic values of an atomic type defined by XML Schema Part 234
In short, a Data Model instance is any value that satisfies the requirements of the Data Model specification.
Every specification in the XQuery collection depends entirely on the Data Model, operates on Data Model instances, and/or produces Data Model instances. The only spec that violates that rule is Serialization, which operates on Data Model instances and produces sequences of characters that represent those Data Model instances.
XQuery is an XML transformation language in the same sense that XSLT is. XSLT, you’ll recall from Chapter 7, “Managing XML: Transforming and Connecting,” is the W3C’s XML Transformation language. But what does XSLT really do? It uses XPath to identify nodes in a document that is being processed and produces new nodes in a new document that the XSLT process creates. Similarly, XQuery allows you to process one or more input documents and to create any of several types of XML values as a result of that processing.
XQuery defines two mechanisms for the construction of new Data Model instances. As you will see in detail in Chapter 11, “XQuery 1.0 Definition,” XQuery allows you to construct a Data Model instance using constructors (XQuery expressions that evaluate to XML in one form or another). Direct constructors use an XML-like notation to specify the Data Model values you wish to construct, and computed constructors use a notation based on computed expressions. A direct element constructor, for instance, is one in which the name of the element is known a priori – that is, it’s a constant, literal sequence of characters. A computed element constructor is, by contrast, one in which the name of the element is not known in advance, but is specified by means of an expression.
Both sorts of constructors can be used to construct element nodes (including their attributes, namespace declarations, and content), processing instruction nodes, comment nodes, and text nodes. Document nodes cannot be created using direct constructors, but they can be created with computed constructors.
10.6.2 What Is an XQuery Data Model Instance?
To understand what makes up an XQuery Data Model instance, we start with the set of cascading definitions in the XQuery Data Model specification:
• Every instance of the data model is a sequence.
• A sequence is an ordered collection of zero or more items.
• An item is either a node or an atomic value.
• Every node is one of the seven kinds of nodes defined in [the Data Model specification]. Nodes form a tree that consists of a root node plus all the nodes that are reachable directly or indirectly from the root node via the dm:children, dm:attributes, and dm:namespaces accessors. Every node belongs to exactly one tree, and every tree has exactly one root node.
• An atomic value is a value in the value space of an atomic type.
• An atomic type is a primitive simple type or a type derived by restriction from another atomic type.
• There are 24 primitive simple types: the 19 defined in [Schema Part 2] and xdt : anyAtomicType, xdt:untyped, xdt:untypedAtomic, xdt:dayTimeDuration, and xdt:yearMonthDuration, defined in [the XQuery Data Model specification].
These definitions completely describe what constitutes an XQuery Data Model instance, if you understand “the seven kinds of nodes,” the accessor functions dm:children, dm:attributes, and dm:namespaces, and the XQuery type system. The seven kinds of nodes are defined partly in terms of the Data Model accessor functions – abstract functions in the “dm:” namespace.
10.6.3 The Seven Kinds of Nodes
Before we discuss the seven kinds of nodes represented in the XQuery Data Model and their properties, we need to make it clear that the term node is not necessarily being used in its most common meaning – XQuery Data Model nodes do not necessarily form part of a tree. XQuery’s seven kinds of nodes strongly resemble the seven kinds of nodes in the XPath 1.0 Data Model (see Section 6.5, “The XPath 1.0 Data Model”), where, with the exception of attributes, they really are nodes of a tree.
The seven kinds of nodes in the XQuery Data Model are: document, element, attribute, namespace, processing instruction (PI), comment, and text nodes. (Note: These are the seven kinds of nodes at the time of writing – namespace nodes are somewhat redundant, and may be dropped before XQuery reaches Recommendation). Each node kind has a number of properties. There is a set of accessor functions defined on nodes – abstract functions in the “dm:” namespace, which are not exposed in XQuery (though some of the XQuery accessor functions, such as string ( ) and data ( ), are defined in terms of these abstract functions).
Properties
In Section 6.3, “The Infoset Information Items and Their Properties,” we looked at the properties of each Infoset Information Item in detail. The XQuery Data Model specification does not directly define properties of nodes; it only talks about how to construct each property from an Infoset or a PSVI, and gives some general rules. While this is not the most convenient way to read about the XQuery Data Model definitions, we know that it is complete, since the XQuery Data Model cannot contain any information that cannot be derived from an Infoset or a PSVI. Of course, programs are free to construct Data Model instances directly; i.e., a Data Model instance might not really be derived from either an Infoset or a PSVI, but it must be identical to a Data Model instance that might have been derived from an Infoset or a PSVI for the same data.
In the following lists we take one node kind – the element node – and examine each property. We continue to employ the convention of referring to property names in square brackets [ ]. The following XQuery Data Model properties of the Element Node map closely to the Infoset properties:
• [children] – derived from the [children] property of the Element Information Item in the Infoset (or PSVI), except that character information items are collected together to form text nodes (as in the PSVI).
• [parent] – derived from the [parent] property of the Element Information Item in the Infoset (or PSVI), except that an attribute’s owner element is included as the attribute’s parent.
• [base-uri] – derived from the [base uri] property of the Element Information Item in the Infoset (or PSVI).
• [node-name] – derived from the [local name] and [namespace name] Infoset properties.
• [attributes] – derived from the [attributes] property of the Element Information Item in the Infoset (or PSVI).
• [namespaces] – derived from the [in-scope namespaces] Infoset (or PSVI) property.
The XQuery Data Model also includes information from the Schema contributions to the Infoset (the PSVI) if they are available. The following XQuery Data Model properties of the Element Information Item map closely to PSVI properties:
• [nilled] – true if the PSVI properties [validity] and [nil] are “valid” and “true,” respectively, and otherwise false; also false if the Data Model instance is constructed from an Infoset.
• [type-name] – derived from the [validity], [validation attempted], [type definition], and [type definition namespace] of the PSVI. xdt:untyped if the Data Model instance is constructed from an Infoset. If the element node has an anonymous type definition, then the processor building the Data Model instance must invent a name for that anonymous type.
• [is-id], [is-idref] – If the Data Model instance is constructed from a PSVI, then [is-id] and [is-idref] are derived from the [type name] Data Model property. If the [type name] is xs:id, then [is-id] is true; otherwise, [is-id] is false. If the [type name] is xs:idref or xs:idrefs, then [is-idref] is true; otherwise, [is-idref] is false.
If the Data Model instance is constructed from an Infoset, then [type name] is always xdt:untyped, so we cannot derive [is-id] or [is-idref] from that – in that case, [is-id] and [is-idref] are always false for an element node, and are derived from the [attribute type] Infoset property for an attribute node.
Finally, there are two properties of an Element Node that do not map directly to any Infoset or PSVI property (though the values of these two properties can be derived from either an Infoset or a PSVI):
• [string-value] – the [string-value] property of an Element Information Item, sometimes referred to as the string value of an element, is the concatenation of all the descendant (not just the child) text nodes. The string value of a text node is the value of its [content] property, which in turn is either a string containing all the [character code] properties of the character information items in the Element Information Item (if constructed from an Infoset), or the [schema normalized value]35 of the Element Information Item (if constructed from a PSVI).
• [typed-value] – if the Data Model instance is derived from an Infoset (i.e., there is no XML Schema involved), then the typed value of an element is its string value, represented as a typed value, with the type xdt:untypedAtomic. If the Data Model instance is derived from a PSVI (i.e., there is a Schema), then there is a set of rules for determining the typed value based on the type of the element (see the subsection entitled “More on [typed-value]”). In the simplest case, where the element is of complex type (i.e., the element has one or more attributes and/or child elements) with element-only content (i.e., the element has child elements but no text nodes), the typed-value is undefined.
Both string value and typed value are new in the XQuery Data Model; i.e., they don’t exist in the Infoset or PSVI. They mean what you would expect from their names. Let’s look at Example 10-2 to be completely clear.



Example 10-2 shows a cut-down version of our movie example, with just title, yearReleased, and director. Example 10-3 shows a possible XML Schema that might be used to validate the cut-down movie example. Once the movie example has been validated against the schema, the element yearReleased has a string value of “the string ‘1981’” but a typed value of “the integer 1981”. Both look the same on paper (i.e., after serialization). You can do arithmetic with “the integer 1981” – e.g., add “the integer 10” to it. You can do string manipulation with “the string ‘1981’” – e.g., find the first character (string of length 1). But you cannot do arithmetic on “the string ‘1981’” or string manipulation on “the integer 1981”. Note that the string value of movie is “the string ‘An American Werewolf in Londonl981LandisJohn”’, and the typed value of movie is undefined.
More on [typed-value]
The [typed-value] property of an element node deserves some more explanation. In the previous section, we said that the XQuery Data Model introduces two properties that don’t exist in either the Infoset or the PSVI – [string-value] and [typed-value]. These are clearly useful, yielding a string and an item (or sequence of items) with an atomic type (date, integer, etc.), respectively. The idea is that if you want to do operations that are specific to certain data types (such as arithmetic), then you should use the typed value of an element. While it’s easy to see what the string value of any element should be, it’s not always obvious what the typed value of an element should be. For example, in the previous section we said that the typed value of the element movie in Example 10-2 is undefined, and it’s difficult to imagine what the typed value could possibly be.36 The rules for deriving the typed value are a little complicated – we think it’s worth summarizing them here.
If the Data Model instance is derived from an Infoset (i.e., there is no XML Schema involved), then the typed value of an element is its string value, represented as a typed value, with the type xdt:untypedAtomic.
If the Data Model instance is derived from a PSVI (i.e., there is a Schema), then the way the typed value is derived depends on the Schema type of the element. If the element has only simple content (the element may have attributes, but no children), then:
• If the Schema type of the element is xs:anySimpleType – the typed value is the [schema normalized value], represented as type xdt:untypedAtomic.
• If the Schema type of the element is some atomic type – the typed value is derived from the [schema normalized value] in some obvious way (e.g., if the element has a Schema type of xs:integer, then the typed value will be an xs:integer).
• If the Schema type of the element is a union or list type, then special rules apply (we leave it as an exercise for the reader to find these rules in the XQuery Data Model spec, Section 3.3.1.2).
If the Data Model instance is derived from a PSVI and the element has anything other than simple content, then:
• If the Schema type of the element is xdt:untyped, or if the element has mixed content (text and child elements) – the typed value is the string value represented as xdt:untypedAtomic.
• If the element is empty – the typed value is the empty sequence.
• If the element has a complex type with element–only content – the typed value is undefined, and the typed-value accessor will raise an error.
These rules are not at all obvious – for example, the typed value of the parent element in
![]()
is “some text 42” as xdt:untypedAtomic, since parent has mixed content. But take away “some text” to give
![]()
and the typed value of parent is undefined, since it has element-only content. This is somewhat surprising, but it does follow the spirit of the typed value as something on which you can do data type-dependent operations such as arithmetic and string manipulation.
Before we leave [typed-value], we should point out another wrinkle that may lead to surprising results. The XQuery Data Model spec explicitly says that a conforming implementation may store either the string value or the typed value of an element, and that, whichever one it stores, it may derive the other from it. At first glance, that seems reasonable – if the string value of an element is “the string ‘1981’”, the type is xs:integer, and the typed value is “the integer 1981”, then you can store only the string value and the type. You can derive the typed value “the integer 1981” whenever you want to access it – you don’t need to store it. But what if the string value is “the string ‘0001981’” and the type is xs:integer – can you get away with storing only the typed value and the type? If the XQuery Data Model instance only contains the typed value “the integer 1981”, then it will derive the string value “the string ‘1981’” and not the original string value, “the string ‘0001981’”. The spec says that’s OK – specifically, it says that “some variations in the string value of a node are defined as insignificant…. Any string that is a valid lexical representation of the typed value is acceptable.”
Accessors – Toward an API
The XQuery Data Model is different from its predecessors (the XML Infoset and the XPath 1.0 Data Model) in two important ways – it has a sophisticated type system, and it (arguably) has an API. The type system is described in Section 10.7. The API consists of a set of accessors – functions in the “dm:” namespace that are defined for each kind of node – that are not exposed to the end user. These accessors define what information is available from the Data Model. They are used in the definition of some of the functions described in the Functions and Operators specification (see Section 10.9.1).
The most important accessors are dm:string-value and dm:typed-value. These are defined for each of the seven kinds of nodes, and they return the contents of the [string-value] and [typed-value] properties, respectively. Table 10-1 shows the result of applying the XQuery Data Model accessors to the XQuery Data Model node kinds. The table is incomplete – some of the accessors have been left out for brevity, and the Namespace node kind has not been included. At the time of writing, the Namespace node kind is in doubt and may be removed from the XQuery Data Model. This would be a good move, as it seems the Namespace node kind is an exception to almost every Data Model rule (e.g., dm:node-name returns the [prefix] property of a Namespace node rather than the name of a node).


Table 10-2 shows another way of looking at accessor/property mapping. This table shows how to retrieve the value of each of the XQuery Data Model properties using an accessor or an XQuery (user-accessible) function. Under Function, we have put a “–” where there is no function available. For some properties, there is no need for a function because an XPath axis is available – you don’t need a special function to get the value of the parent, children, or attributes of an element. The absence of functions for type-name, on the other hand, requires some explanation.
Table 10-2
Accessing XQuery Data Model Properties

*returns the [base-uri] of the parent (owner) element.
†returns the [base-uri] of the parent.
‡always xdt:untypedAtomic.
The user-accessible function for type-name has been intentionally left out of the XQuery specifications. In most cases, you need to know the type-name of a node only so that you can check that type-name against a known type-name. For example, you might want to check to see if a variable named $a is an xs:integer. If there were a function f n : type-name (), you might say something like “if fn:type-name ($a) eq ‘xs:integer’”. This would only succeed if the type of $a were xs:integer, and it would fail if the type of $a were any type derived from xs:integer. A better way to test for type is to say, “if $a instance of xs:integer”. The instance of expression will evaluate to true if $ a is an xs:integer, or if $ a is of any type derived from xs:integer. This principle – subtype substitutability – is considered fundamental to XQuery, so you must use instance of for type-checking instead of explicitly checking the [type-name] property against a known type name. Access to the [type-name] property and other XML Schema-related metadata (such as base-type, facets, etc.) may be added in a future version of the XQuery Data Model.
Finally, there is no function to directly access the [namespaces] property. There is a namespace XPath axis, but it is deprecated in XPath 2.0. And you can use a combination of fn:in-scope-prefixes ( ) (which returns the prefixes for the in-scope namespaces) and fn:namespace-uri-for-prefix( ) (which returns the namespace URI for a given prefix) to find all the namespace information in the [namespaces] property.
10.6.4 The Data Model as Tree – Representing a Well-Formed Document
Let’s look at our movie example again and see what a Data Model tree might look like.
Figure 10-2 shows a representation of a Data Model instance for the movie example in Example 10-2, validated according to the XML Schema in Example 10-3. The figure is not complete – it does not show every property for every node. The tree is similar to the XPath 1.0 Data Model Tree (in Section 6.5, “The XPath 1.0 Data Model”). Some of the terminology has changed – the Root Node is now the Document Node; the [expanded-name] property is now called the [node-name]; the comment [string-value] property is now called [content], and so on. The main difference is that every node now has type information, either explicitly – in the [type-name] and [typed-value] properties – or implicitly, via the definition of the dm:type-name and dm:typed-value accessors.

Figure 10-2 shows that the XQuery Data Model definition is not as clean or as symmetrical as one might like it to be. For example, it would be nice to say that every node has a string value ([string-value]) and a typed value ([typed-value]). While the “leaf” element nodes title, yearReleased, familyName, and givenName each have a string value and a typed value with the expected contents, some of the contents are surprising:
• The document node has a typed value of:
“An American Werewolf in Londonl98lLandisJohn-FolseyGeorge, Jr. GuberPeterPetersJon9 8Agutter-JennyfemaleAlex Price”
as xdt:untypedAtomic (one might have expected xs:string).
• The typed value of the movie element is undefined (one might have expected the string value as xs:string).
• The comment node has neither a [string-value] nor a [typed-value] property, but the string value of the comment is the value of its [content] property, and the typed value of the comment is its string value as xs:string.
• Similarly, the text nodes have neither a [string-value] nor a [typed-value] property. Like the comment node, the text node’s string value is the value of its [content] property, but its typed value is its string value as xdt:untypedAtomic (not as xs:string).
10.6.5 The Data Model as Sequence – Representing an Arbitrary Sequence
One of the challenges the XQuery Data Model addresses is that of typed XML – the other is that of arbitrary sequences. The XML Infoset models only well-formed XML documents, while the XQuery Data Model must model an arbitrary sequence of documents, nodes, and/or atomic values. That’s because the XML Infoset only needs to provide an abstract representation of the information in an XML document, for consumption by an XML processor (e.g., a stylesheet processor), while the XQuery Data Model must represent any input to, and any output from, a query.
To emphasize this difference between a model of an XML document and a model of arbitrary sequences, Figure 10-3 is a diagram of an XQuery Data Model instance of the result of a query. Suppose we want to find the title and director of every movie released before 1985. The movies document and XML Schema are included in Appendix A: The Example – they look like many instances of Example 7-1 wrapped in a <movies> tag. A possible XQuery is shown in Example 10-4, with the serialized result in Example 10-5.



Note that the result shown in Example 10-5 is not a well-formed XML document, since it does not have a single top-level element.37 This result is a sequence of (title-string, director) sequences, where “title-string” is the string that makes up the title (the atomic value ‘An American Werewolf in London’, as opposed to the element node ‘<title>An American Werewolf in London</title>‘). Since the XQuery Data Model cannot represent sequences of sequences, this got flattened to a single sequence of (title-string, director, title-string, director, …). If this were a final result that we wanted to use as, say, input to a printed report, we would probably use element constructors to format the result (see Chapter 11). Let’s assume that this is an intermediate result where it is important to have a typed (atomic) value as well as some XML. Figure 10-3 shows (part of) the XQuery Data Model for the result in Example 10-5.
Figure 10-3 illustrates the power of the XQuery Data Model to represent arbitrary sequences. Again, this arbitrary sequence might include any atomic value (a string, integer, or date), an element with no parent, an attribute with no parent, a well-formed XML document including a document node, or any combination of these.
10.7 The XQuery Type System
In Section 10.6, we saw how the XQuery Data Model represents the values, structure, and type information in an XML document, an XML fragment, a node, a value, or a sequence of any of these. Each item in the XQuery Data Model has at least a value and a type name. In this section, we look at the XQuery type system in a bit more detail – why it’s there, what it consists of, and how it affects queries.
10.7.1 What Is a Type System Anyway?
A type system is a system of splitting entities up into named sets. In general programming, an entity may be a value (“Hello”, 5, 24th October 1956, …), or a variable ($a, Inum, …), or it may be something more abstract like the input and output parameters of a function or the result of evaluating an expression. In XML-land it may also be a piece of structure – an XML element with some attributes and some children.
As we saw in Section 10.6.3, the type of an entity is useful because we can define the operations that are allowed on each type – you cannot do arithmetic on strings, and you cannot find the first character of a date. It is not clear what the result of “Hello” + 5 or substring(42, 1) should be. Weakly-typed languages such as Perl are easy to use because you don’t have to think about data types too much – you don’t have to declare variables, and values are cast at run time to whatever type makes most sense. In Perl, the result of “Hello” + 5 is “Hello5”, and the result of substring(42, 1) is “4”. Many programmers argue that this is undesirable behavior. If the processor sees “Hello” + 5, then something has probably gone wrong, and it is “more correct” to return an error than to return a best-guess answer that is likely to be wrong. A strongly typed language such as Java or SQL will return an error for “Hello” + 5 or substring(42, 1). People who write in a strongly typed language have to do a little more work, but the result is a more robust application
A strongly typed language such as Java or SQL may do type checking at compile time (static typing) or at run time (dynamic typing). Static typing is more efficient than dynamic typing, because it identifies type errors earlier. That is, in a static typing environment, a type error will be returned very quickly during the compile phase, while in a dynamic typing environment, a program or query may run almost to completion before detecting and returning a type error. On the other hand, the processor may not have complete information at compile time. With pessimistic static typing, the processor returns a type error whenever there may be a type error at run time, but if this pessimistic static type check succeeds, then the processor can confidently proceed with the rest of the program or query without bothering with any further type checking. So pessimistic static type checking gains efficiency at the expense of some false type errors.
XQuery is a strongly typed language – every entity (every element, attribute, atomic value, etc.) has both a value and a type name, and functions and operators are defined to work only on some (combinations of) types. XQuery has an optional static typing feature, which uses pessimistic static typing. If an XQuery engine implements the XQuery static typing feature, it must do pessimistic static typing – i.e., it may sometimes throw false type errors, but it must never return a dynamic type error. If an XQuery engine does not implement the XQuery static typing feature, it must report dynamic type errors, and it may report some static type errors.
Dynamic vs. static typing has been the subject of many hours of discussions in the XQuery Working Group. We expect the debate to be resolved in the marketplace as XQuery vendors produce dynamic-only, static-only, and hybrid implementations.
10.7.2 XML Schema Types
The XQuery type system is based on the types defined in XML Schema Part 2: Datatypes38 and the structure types defined in XML Schema Part 1: Structures.39
Datatypes (simple types)
Every item (document, node, or atomic value) in the XQuery Data Model has both a value and a named type. If the item is an atomic value, an attribute node, or an element node with simple content (that is, an element node with no children), then it has a data type in the straightforward sense that “Hello” has the data type “string” and 5 has the data type “integer”.
XML Schema defines 19 built-in, atomic, primitive data types.
• built-in – defined as part of XML Schema, as opposed to user-derived (user-defined) data types.
• atomic – a single, indivisible data type definition, as opposed to list (a data type defined as a list of atomic data types) or union (a data type defined as the union of one or more data types).
• primitive – a data type that is not defined in terms of other data types. For example, xs:decimal40 is a primitive data type, while xs:integer is a derived data type, defined as a special case of xs:decimal where fractionDigits is 0.
In addition to those 19 built-in, atomic, primitive data types, XML Schema defines 25 built-in, atomic, derived data types. These 44 built-in data types are defined in terms of a value space – the set of values that “belong” to the data type – and a lexical space – the set of valid literals for a data type. It follows that each value in the value space of a data type can be serialized (written down) as one or more literals in the lexical space of that data type. Each data type also has some fundamental facets – properties of the data type such as whether the values in the value space have a defined order, whether the value space is bounded, whether the cardinality of the value space is finite or infinite, and so forth.
In addition to these 44 built-in data types, XML Schema allows for user-derived (user-defined) data types based on the built-in data types. These user-derived data types may combine the built-in data types using list or union, or they may restrict the value space (and hence the lexical space) of a built-in via some constraining facets – properties that restrict the value space, such as length, or an enumeration of allowable values.
Finally, XML Schema defines one top-level data type, xs:anySimpleType. A top-level data type (sometimes called an ur41 data type) is a type from which all other types of a certain category are derived. In XML Schema, xs:ranySimpleType is defined as the base type of all the primitive types. (Note this is not the universe of all possible types, as we will see later in this chapter.)
Confused? OK, let’s look at a few examples. We start by looking at a couple of data types that everyone is familiar with.
xs:decimal is a built-in, atomic, primitive data type in XML Schema. Its value space is “the set of the values i × 10−n, where i and n are integers such that n >= 0” (the word integer here is used to represent the standard mathematical concept of an integer, which XML Schema does not attempt to define). The lexical space of xs:decimal is “a finite-length sequence of decimal digits (#x30-#x39) separated by a period as a decimal indicator…. An optional leading sign is allowed. … Leading and trailing zeroes are optional. If the fractional part is zero, the period and following zero(es) can be omitted.” So 42, 1234.5678, and +888888.00000 are all valid representations of xs:decimal, but Hello, -42, 1234, 5678 and 1,234.5678 are not. xs:decimal has a defined ordering relation (a fundamental facet) – “x < y if y – x is positive”. And xs:decimal has nine constraining facets – totalDigits, fractionDigits, pattern, whiteSpace, enumeration, maxInclusive, maxExclusive, minInclusive, and minExclusive. That means that, for example, you can define a data type based on xs:decimal that is restricted to four total digits and two fraction digits (+1.34, 4256, or 98.50, but not 4256.1 or 98.504).
xs:integer is a built-in, atomic, derived data type in XML Schema. It is derived from xs:decimal by defining the fractionDigits facet to be 0. Its value space is “the infinite set {…,-2,-1, 0, 1, 2, …}.” The lexical space of xs:integer is “a finite-length sequence of decimal digits (#x30-#x39) with an optional leading sign.” So 42, 1234, and +888888 are all valid representations of xs:integer, but Hello, --42, 1234, 5678, and 95.80 are not. xs:integer has the same ordering as xs:decimal and the same constraining facets (though fractionDigits must be 0). That means you can define a data type based on xs:integer that is restricted by setting maxInclusive to 42 (+12, 42, or 9 but not 43 or 1.5).
The 44 primitive and derived built-in data types in XML Schema cover all the string, numeric, and binary types commonly used in programming and query languages – integer, decimal, float, double, string, positive integer, byte, hexadecimal, etc. – plus 9 data types for dealing with dates and times – date, time, dateTime, duration, gYearMonth, gYear, gMonthDay, gDay, and gMonth.42
Structure Types (Complex Types)
Earlier in this section we said that Datatypes are useful because, when you define an operation, you can specify which Datatypes make sense with that operation. So if you write a program to reserve seats on an airplane, you want to be sure that it assigns a passenger name to a flight. If someone reversed the passenger name and flight number when making a reservation, you want the program to notice that mistake and throw an error, rather than assigning passenger “UA42” to flight “John Doe.” XML contains structure as well as values, and we want to run checks on the structure of XML for the same reasons we want to check the values – to ensure robustness of programs when the input is incorrect.
XML Schema defines a type system for XML structures (complex types) as well as values (simple types). A complex type definition constrains elements in the following ways:
• Defines the presence and content of attributes allowed in the element. The complex type defines the name, simple type, occurrence information, and optionally the default value of each attribute that may be associated with this element.
• Defines the elements that may be children of this element, and their order and type.
• Defines whether the element has mixed content – child elements plus text nodes – or child elements only.
Note that the type of an element with simple content is a simple type. For example, the title element – <title>American Werewolf in London</title> – is of type xs:string. There is no structure type (complex type) associated with this element – if you know that it is an element whose content is of type xs:string, you know everything there is to know about its Datatype and structure.
To complete the XML Schema type hierarchy, XML Schema adds one more abstract type, xs:anyType, to sit at the top (root) of the hierarchy. xs:anySimpleType is a subtype of xs:anyType. Every complex type is a subtype of xs:anyType.43 See XML Schema Part 2 for a diagram of the XML Schema type hierarchy.44
There are no built-in complex types as such, though there is a Schema Type Library45 covering some common structures. Example 10-6 shows a simple example, the text structure type.


10.7.3 From XML Schema to the XQuery Type System
The XML Schema type system gives us a solid basis for a query type system, but it does not go quite far enough. An XML Schema processor performs validation on an XML document, given an XML Schema document, and produces a Post Schema-Validation Infoset (PSVI), containing validation status and type information for each element and attribute. This is not enough for an XQuery Data Model.
• XML Schema validation provides a normalized string value and a type name for each element and attribute. It’s left to the XQuery Data Model builder to create a typed value based on the string value and type name.
• XML Schema only deals with well-formed XML documents. The XQuery Data Model must be able to represent documents, nodes, atomic values, and arbitrary sequences of any of these.
• XQuery does not require XML Schema validation. Although an XQuery Data Model might be built from a PSVI, it might also be built directly by an application.
• XQuery adds two atomic types that are subtypes of xs:duration (xdt:yearMonthDuration46 and xdt:dayTimeDuration).
• Every item in XQuery has a type. The XQuery Type System adds types for items for which an explicit type cannot be found.
This last point deserves a bit more explanation. The XQuery Type System adds the following abstract types:
• xdt:untyped – is a special type, meaning that no type information is available. For example, an element or attribute in an XML document that has not been validated against an XML Schema is of type xdt:untyped, xdt : untyped is a subtype of xs:anyType, and it cannot be a base type for user-derived types.
• xdt:anyAtomicType – is a subtype of xs:anySimpleType. It is a little more restrictive than xs:anySimpleType, encompassing all the subtypes of xs:anySimpleType except xs:IDREFS, xs:NMTOKENS, xs:ENTITIES, and user-defined list and union types, xdt:untypedAtomic is useful for defining function signatures, where arguments may belong to any of the primitive atomic types (or xdt:untypedAtomic).
• xdt:untypedAtomic – if an item has this type, we know that it is an atomic value, but it has not been validated against an XML Schema.
10.7.4 Types and Queries
The XQuery Data Model is at the core of the XQuery language, since every XQuery has an instance of the Data Model as input and output. And the XQuery type system is at the core of the Data Model. Both are somewhat complex (and in places controversial). But they provide useful extensions to existing data model and type systems from XML, XPath 1.0, and XML Schema. The Data Model defines exactly what an XQuery processes and what it is expected to return as a result. The type system determines which queries are legal and which are not. And the matter of static typing vs. dynamic typing determines the efficiency and robustness of XQueries.
We expect the XQuery Data Model and type system to be the foundation of all XML processing, not just XQuery, over time.
10.8 XQuery 1.0 Formal Semantics and Static Typing
The Formal Semantics specification defines the static semantics of XQuery, particularly the rules for determining the static types of expressions.
These static semantics are defined in a formal, mathematical manner, making XQuery one of relatively few languages to be defined so formally. In this section, we show you how to read the formal specifications. The Formal Semantics spec also defines most of the dynamic semantics of XQuery using the same sort of formal notation. However, the normative (“official”) specification of the dynamic semantics is given in the XQuery 1.0 spec itself. We do not (definitely not!) include all of the formal definitions from the spec, but we do illustrate the technique through a sampling of the notations in use.
Before we get into the thick of Formal Semantics, let’s explore what it means to determine the static type of an expression. The static type of an expression is a data type that is determinable without seeing any instance data on which the expression might be evaluated. In some languages, it is called the compiled type or the declared type of an expression. This is in contrast to the dynamic type, also known as the run-time type or the most-specific type.
Consider the XQuery expression in Example 10-7.
As you will learn in Chapter 11, this expression includes the following components: declare a variable, $i, whose data type is xs:integer; assign the value 3 to that variable; compute the value resulting from adding 5 to the value of the variable; return the result of that computation. The question we will answer is this: What is the static type of that XQuery expression?
The first step is to determine the type of the variable $i. That part is easy, because the variable declaration makes it explicit: xs:integer. Next, we need to determine the type of the literal being assigned to the variable as its initial value. The literal is “3,” which is apparently an integer – that is, a value of type xs:integer (while it is also a value of type xs:decimal, the XQuery specs treat a number without any decimal point – such as 3.0 – as a value of type xs:integer). Assigning a value of type xs:integer to a variable of type xs:integer does nothing to the type of the variable. (For that matter, assigning a value of type xs:decimal to the same variable would not change the type of the variable, but it would require a data conversion of the initial value to the type of the variable.)
The third step requires determining the type of the literal “5”; again, its type is xs:integer. Fourth, the type of the arithmetic expression “$i + 5” must be determined. Since the expression represents the sum of two values of type xs:integer, the type of the expression itself is xs:integer. Returning the result of evaluating that arithmetic expression does nothing to the type of the expression, so the type of the value returned is xs:integer – and that is the type of the entire XQuery expression in Example 10-7.
10.8.1 Notations
The Formal Semantics spec is intimidating to readers who are not versed in the formal notation used in the document. Once we got used to the notation, it became much less intimidating and we were able to follow the rules without too much difficulty. But we warn you: Undertake the reading of the Formal Semantics spec (and, for that matter, this section) only if you’re prepared to deal with the difficulties associated with the notations used.
Let’s look at the notation using a few examples, some of which are taken directly from the Formal Semantics spec itself. This notation depends on the concepts of judgments, inference rules, and mapping rules. A judgment is a statement about whether some property holds (“is a fact”) or not. An inference rule states that some judgment holds if and only if other specified judgments also hold. A mapping rule describes how an ordinary XQuery expression is mapped onto a “core XQuery expression.”
In Example 10-8, the symbol “=>“ means “evaluates to,” a colon (“:”) separates an expression from a type name, and the “turnstile” symbol (which should be “|–” but is simulated in the Formal Semantics spec by “|–” because of HTML and font limitations) separates the name of an environment from a judgment regarding something in that environment. In the Formal Semantics, an environment is a context in which objects can exist; XQuery’s static context and dynamic context are the environments used in the spec.
Judgments don’t always use the symbols “=>“ and “:”. They are sometimes written using ordinary English words (“is” or “raises,” for example).
In each example contained in Example 10-8, we provide an English summary of what the example shows, followed by the actual text of the judgment. We have used italics to indicate symbolic values to distinguish them from literal values.
Example 10-8 Sample Formal Semantics Judgments
The following judgment always holds, because 3 always evaluates to 3.
![]()
The following judgment holds if, and only if, Film is depressing
![]()
The following judgment holds when Expr evaluates to Value
![]()
For example, this judgment holds for many older movies
![]()
The following judgment holds if Expr has the type Type
![]()
For example, in our sample data, this judgment holds
![]()
The following judgment holds when Expr raises the error Error
![]()
For example, this judgment always holds
![]()
The following judgment holds when, in the static environment statEnv (that is, in the static context), an expression Expr has type Type
![]()
For example, in our sample data, the following judgment always holds
![]()
In Example 10-9, we illustrate a couple of inference rules. The notation for inference rules can be read like this: If all of the judgments above the horizontal line (called premises) hold, then the judgments below the horizontal line (called conclusions) also hold.
Example 10-9 Sample Formal Semantics Inference Rules
Without any premises, the conclusion always holds
![]()
Given these two premises, the conclusion holds
![]()
The preceding inference rule can be generalized
![]()
If two expressions Expr1 and Expr2 are known to have the static types Type1 and Type2 (the two premises above the line), then it is the case that the expression below the line, “Expr1, Expr2” (the sequence of the two expressions Expr1 and Expr2), must have the static type “Type1, Type2,” which is the sequence of types Type1 and Type2.

Simplifying things a bit, the Formal Semantics only has to define the semantics for core XQuery expressions – all other XQuery expressions are rewritten (for the purposes of the Formal Semantics) into core XQuery expressions. (An XQuery core expression is one of a small set of expression types that are the basis for the full set of expression types.) This rewriting is accomplished by the introduction of one more notation, called a mapping rule or a normalization judgment. Mapping rules specify precisely how XQuery expressions are rewritten into XQuery core expressions. In Example 10-10, the mapping rules use double-equals (“==”) to separate the original object from the rewritten object, while the subscripts indicate the kind of object being mapped. The mapping is always performed in the static context, the use of “staticEnv |–” would be redundant and is omitted.
Example 10-10 Sample Formal Semantics Mappings
Map an object of a specified type to a rewritten object

Map an arbitrary expression into a core expression

After you’ve absorbed the notation, you have the tools necessary to read the Formal Semantics – the judgments, inference rules, and mapping rules – and understand how the spec defines the precise semantics of XQuery expressions. The spec is little more than a rather large collection of judgments and rules, with explanatory text to help interpret many of them. Unfortunately, it is difficult to prove that the spec is complete – that is, that it has specified the semantics of every nook and cranny of the XQuery language. Obviously, the Working Group believes that it has accomplished that goal, but omissions are still occasionally found.
10.8.2 Static Typing
In Example 10-8, you saw a judgment involving the type of an expression: Expr => Type. Let’s modify it very slightly to account for the static environment: statEnv |– Expr => Type. As you know, that judgment is interpreted like this: The judgment holds when, in the static environment (called statEnv), expression Expr has type Type. That judgment is the basis for XQuery’s static typing rules. Judgments of this kind are used in inference rules, called type inference rules because they tell us (and the XQuery system) how to infer the type of an expression based on the types of subexpressions.
Consider another simple XQuery expression: let $i : = 10, $j : = 20 return $i + $j. Because the input literal “10” is easily determined to be an integer, as is the literal “20” (see Example 10-11 for an example of the inference rule that lets us know this fact), and because the associated type inference rules tell us that both variables $i and $j are integers (because they are not given an explicit type, but are instead assigned values that are integers), and that the sum of two integer variables is also an integer, type inferencing tells us that the result of the entire XQuery is an integer.
Example 10-11 Inference Rule Determining the Static Type of an Integer Literal
Inference rule from the specification:
![]()
Putting the inference rule to work with real data:
![]()
We’re not going to mince words: reading the Formal Semantics to prove all of the statements in the preceding paragraph is not trivial. In fact, it’s rather difficult and requires close attention to a lot of detail. We urge you to take a look at the Formal Semantics specification and, if you are interested in really learning what it has to say, reading it from the beginning in order to be sure that you have all of the concepts before starting on the details.
In spite of the difficulties associated with reading the specification, implementers of XQuery should seriously consider inclusion of static typing in their implementation. We are told repeatedly about the significant improvements in code optimization for XQuery expressions when static typing is implemented and enabled. There are, of course, situations in which static typing is less relevant, or even completely meaningless. For example, XQueries written to query XML documents that are not associated with an XML Schema do not often benefit from static typing.
One more thing: Static typing as specified in the Formal Semantics spec is pessimistic. It might have been possible, using optimistic typing, to refine the algorithms to calculate a more specific static type for an expression, but the dynamic type of the expression’s result might in some cases fail to be an instance of the predicted type. The use of pessimistic typing guarantees that no result will ever fail to be an instance of the predicted type.
10.8.3 Dynamic Semantics
The dynamic semantics of XQuery are, as we said earlier, defined normatively in the XQuery 1.0 specification. However, the Formal Semantics specifies the dynamic semantics in the same formal way that the static typing is specified, using judgments, inference rules, and mappings. Consider again the simple XQuery expression from Section 10.8.2: let $i := 10, $j := 20 return $i + $j.
The dynamic semantics tell us that the value of an integer literal is determined solely by the literal (see Example 10-12 for the inference rule that covers this, noting the use of dynEnv, the dynamic environment), that the value of a variable to which that value is assigned is that same value, that the value of adding two integers together is the sum of those two integers, and that the value of an expression that returns an integer value is that value.
Example 10-12 Inference Rule Determining the Value of an Integer Literal
An inference rule taken from the spec:
![]()
Putting the inference rule to work with real data:
![]()
Again, we urge interested readers to sit down with a copy of the Formal Semantics specification and work through a few examples.
10.9 Functions and Operators
Many modern programming languages define relatively small core languages, providing the great majority of their functionalities through a collection of subprograms, often called a function library. XQuery has followed this model and, as a result, the XQuery suite of specifications includes one dedicated to functions and operators, Functions and Operators, or F&O.
The very name of the F&O specification requires some explanation. The document includes the specification for a large number of functions that can be invoked from your XQuery expressions. F&O also defines the operators of the XQuery language, but it defines them in terms of functions. These “backup” functions are not available to users to invoke in XQuery expressions.
The Functions and Operators spec is divided into several major sections, each of which is devoted to specific data types; for example, the title of F&O’s Section 6 is “Functions and Operators on Numerics.” Many of those sections are divided into subsections addressing classes of operations and other activities on values of the section’s type; for example, Section 6.2 deals with operators on numeric values, Section 6.3 covers comparison of numeric values, and Section 6.4 addresses functions on numeric values.
10.9.1 Functions
The F&O spec fills many pages with definitions of functions that can be invoked from XQuery code. Each user-invocable function is defined in its own subsection of the F&O spec. That subsection has the same name as the function it defines. The syntax of the function – called its signature – is given in a shaded box, followed by a summary of the function’s actions. The function signature includes the name of the function, the name and data types of each of its parameters (if any), and the data type of the value that it returns.
As the first example below illustrates, some functions defined in F&O are overloaded, meaning that there are two or more functions with the same name. XQuery 1.0 does not support overloading of user-defined functions, but it does allow for the “built-in” functions defined in F&O to be overloaded by the number of parameters (not by the data types of those parameters). Therefore, function fn:substring-bef ore ( ) has two signatures: one with two parameters and one with three. However, no F&O function of any given name has two or more signatures that each have the same number of parameters with the intent of choosing the specific function based on the specific data type of the arguments to the function invocation.
In cases where the semantics are complex, the summary is typically followed by a list of steps that, taken in order, define the function’s semantics precisely. Many such subsections also include one or more examples.
7.5.4 fn.substring-before

Summary: Returns the substring of the value of $arg1 that precedes in the value of $arg1 the first occurrence of a sequence of collation units that provides a minimal match to the collation units of $arg2 according to the collation that is used.
If the value of $arg1 or $arg2 is the empty sequence, it is interpreted as the zero-length string.
If the value of $arg2 is the zero-length string, then the function returns the zero-length string.
If the value of $argl does not contain a string that is equal to the value of $arg2, then the function returns the zero-length string.
The collation used by the invocation of this function is determined according to the rules in 7.3.1 Collations. If the specified collation does not support collation units, an error ·may· be raised [err:FOCH0004].
7.5.4.1 Examples
CollationA used in these examples is a collation in which both “-” and “*” are ignorable collation units.
“Ignorable collation unit” is equivalent to “ignorable collation element” in [Unicode Collation Algorithm].

“CollationA”) returns “ “. The second argument contains only ignorable collation units and is equivalent to the zero-length string.
9.3.1 fn:not

Summary: $arg is first reduced to an effective Boolean value by applying the fn:boolean( ) function. Returns true if the effective Boolean value is false, and false if the effective Boolean value is true.
15.1.9 fn:reverse

Summary: Reverses the order of items in a sequence. If $arg is the empty sequence, the empty sequence is returned.
For detailed type semantics, see Section 7.2.9 The fn:reverse functionFS

10.9.2 Operators
In XQuery, numeric addition is represented by the plus sign (“+”). However, the semantics of that operator are not defined in the XQuery 1.0 specification, nor are they fully defined in the Formal Semantics. Instead, they are defined in an operator function specified in F&O: op:numeric-add( ). Similarly, determining whether two numeric values are equal in XQuery uses the syntax element “eq”; the semantics of that operator are defined in F&O’s op numeric-equal ( ). We say that these functions are used to “back up” the operators themselves.
In this section, we’ll introduce you to the way in which F&O defines its operator functions and illustrate a small number of these functions. As you need to learn the semantics of various XQuery operators, you should consult the Functions and Operators specification for those details.
The operator-backing functions, like the user-invocable functions, are each given a complete subsection of the F&O spec. The subsection has the same name as the operator-backing function that it defines. The syntax (signature) of the function is given in a shaded box, followed by a summary of the function’s actions.
In cases where the semantics are complex, the summary may be followed by a list of steps that, taken in order, define the function’s semantics precisely. The operator-backing functions usually (but, we regret to say, not always) contain a statement of the operators for which they provide the semantics. Finally, many such subsections include one or more examples.
As you read the specifications of the operator functions in the F&O spec, you’ll notice that none of them have optional parameters (that is, parameters whose data types have the question mark indicating optionality – which, in this context, would mean that the argument can be the empty sequence). That’s because the XQuery and XPath language specs deal with operator arguments that are the empty sequence before the operator function is even invoked. This contrasts with the parameters of the nonoperator functions (the “fn:functions”), which are often optional.
Here is a copy of the subsection dealing with op:numeric-equal().
6.3.1 op:numeric-equal
Summary: Returns true if and only if the value of $argl is equal to the value of $arg2. For xs:float and xs:double values, positive zero and negative zero compare equal. inf equals inf and -inf equals -inf. NaN does not equal itself.
This function backs up the “eq” and “ne” operators on numeric values.
6.2.6 op:numeric-mod
![]()
Summary: Backs up the “mod” operator. Informally, this function returns the remainder resulting from dividing $argl, the dividend, by $arg2, the divisor. The operation a mod b for operands that are xs:integer or xs:decimal, or types derived from them, produces a result such that (a idiv b) *b+ (a mod b) is equal to a and the magnitude of the result is always less than the magnitude of b. This identity holds even in the special case that the dividend is the negative integer of largest possible magnitude for its type and the divisor is -1 (the remainder is 0). It follows from this rule that the sign of the result is the sign of the dividend.
For xs:integer and xs:decimal operands, if $arg2 is zero, then an error is raised [err:FOAR0001].
For xs:float and xs:double operands, the following rules apply:
• If either operand is NaN, the result is NaN.
• If the dividend is positive or negative infinity, or the divisor is positive or negative zero (0), or both, the result is NaN.
• If the dividend is finite and the divisor is an infinity, the result equals the dividend.
• If the dividend is positive or negative zero and the divisor is finite, the result is the same as the dividend.
• In the remaining cases, where neither positive or negative infinity, nor positive or negative zero, nor NaN is involved, the result obeys (a idiv b)*b+(a mod b) = a. Division is truncating division, analogous to integer division, not [IEEE 754-1985] rounding division; i.e., additional digits are truncated, not rounded to the required precision.
10.10 XQuery 1.0 and XSLT 2.0 Serialization
Just as the FLWOR expression needs a return clause to say exactly what gets returned, XQuery needs a way to transform its results (which are, remember, Data Model instances) into a serialized form (that is, output in some readable – and parsable – way). Of course, not every XQuery result has to be serialized. In many case, the results are used by other XQuery expressions or passed through some API to another process that can use Data Model instances directly.
Serialization, according to the XSLT 2.0 and XQuery 1.0 Serialization spec, is “the process of converting an instance of the Data Model into a sequence of octets.” We normally prefer to say that the result is a sequence of characters, but a Data Model instance may include data whose type is base64Binary or hexBinary, which is truly serialized as “octets.” Serialization is a well-defined operation for most, but not all, “legal” Data Model instances; for example, it is not possible to serialize a sequence of attributes that do not belong to an element. In addition, some Data Model instances cannot be serialized given a particular set of serialization parameters. It’s also worth noting that there are many possible serializations of many Data Model instances, but the Serialization spec narrows the selection down to just one.
Every Data Model instance is a sequence of items. Before that sequence can be serialized, it must first be normalized in order to ensure that the result of serialization is a well-formed XML document or external general parsed entity. Normalization involves the following steps (adapted from the Serialization spec), performed in the order given here, with the result of each step used as input to the next step.
1. Create a new empty sequence, S1. If the sequence submitted for serialization is not the empty sequence, each item in the sequence submitted for serialization is copied in order into S1.
2. Create a new empty sequence, S2. For each item in S1, if the item is atomic, the lexical representation of the item is obtained by casting it to an xs:string (using the rules for casting to xs:string that are defined in Functions and Operators) and that string representation is copied to S2. Otherwise, the item (which, not being atomic, is a node) is copied to S2.
3. Create a new empty sequence, S3. For each subsequence of adjacent strings in S2, a single string, equal to the values of the strings in the subsequence concatenated in order, each separated by a single space, is copied to S3. All other items are simply copied to S3.
4. Create a new empty sequence, S4. For each item in S3, if the item is a string, create a text node in S4 whose string value is equal to the string. All other items are simply copied to S4.
5. Create a new empty sequence, S5. For each item in S4, if the item is a document node, copy its children to S5. All other items are simply copied to S5.
6. It is a serialization error if an item in S5 is an attribute node or a namespace node. Otherwise, construct a new sequence, S6, that comprises a single document node, and copy all the items in S5 (which are all nodes) as children of that document node in S6.
The result tree rooted at the document node that is created by the final step of this sequence normalization process is the data model instance to which the rules of the appropriate output method (see the following subsections) are applied.
There are a number of serialization parameters that affect the precise behavior of serialization. These are summarized in Table 10-3, taken directly from the Serialization spec.
Table 10-3
| Parameter | Permitted Values |
| byte-order-mark | One of the enumerated values yes or no. This parameter indicates whether the serialized sequence of octets is to be preceded by a Byte Order Mark. (See Section 5.1 of [Unicode Encoding].) The actual octet order used is implementation-dependent. If the concept of a Byte Order Mark is not meaningful in connection with the value of the encoding parameter, the byte-order-mark parameter is ignored. |
| cdata-section-elements | A list of expanded QNames, possibly empty. |
| doctype-public | A string of Unicode characters. This parameter may be absent. |
| doctype-system | A string of Unicode characters. This parameter may be absent. |
| encoding | A string of Unicode characters in the range #x21 to #x7E (that is, printable ASCII characters); the value SHOULD be a charset registered with the Internet Assigned Numbers Authority [IANA], [RFC2278] or begin with the characters x-or X- (in which case, any sequence of characters in that range is permitted). |
| escape-uri-attributes | One of the enumerated values yes or no. |
| include-content-type | One of the enumerated values yes or no. |
| indent | One of the enumerated values yes or no. |
| media-type | A string of Unicode characters specifying the media type (MIME content type) [RFC2046]; the charset parameter of the media type MUST NOT be specified explicitly in the value of the media-type parameter. If the destination of the serialized output is annotated with a media type, this parameter MAY be used to provide such an annotation. For example, it MAY be used to set the media type in an HTTP header. |
| method | An expanded QName with a empty namespace URI, and the local part of the name equal to one of xml, xhtml, html or text, or having a nonempty namespace URI. If the namespace URI is nonnull, the parameter specifies an implementation-defined output method. |
| normalization-form | One of the enumerated values NFC, NFD, NFKC, NFKD, fully normalized, or none, or an implementation-defined value. |
| omit-xml-declaration | One of the enumerated values yes or no. |
| standalone | One of the enumerated values yes or no. |
| undeclare-namespaces | One of the enumerated values yes or no. |
| use-character-maps | A list of pairs, possibly empty, with each pair consisting of a single Unicode character and a string of Unicode characters. |
| version | A string of Unicode characters. |
There are four defined output methods: XML, XHTML, HTML, and text. In the next sections, we discuss each of them briefly, but we refer you to the Serialization spec for details.
10.10.1 XML Output Method
As its name suggests, the XML output method is used to serialize a Data Model instance into XML.
Once the Data Model instance – a sequence of items – has been normalized, if the document node has a single element node child and no text node children, then the Data Model instance is serialized as a well-formed XML document entity that is required to conform to the Namespaces recommendation.47 If the document node does not satisfy that condition (single element node child and no text node children), then the serialized result is a well-formed XML external general parsed entity. That entity must satisfy a specific condition. Let’s let URI be some URI that identifies the entity and version be the relevant version of XML (either 1.0 or 1.1). If the entity is referenced within a trivial XML document element like this:

then the document that results from incorporation of the entity must be a well-formed XML document conforming to the Namespaces Recommendation.
The document that is produced, either directly (when the specified condition is satisfied) or indirectly (the trivial document), could, if desired, be parsed to produce a reconstructed tree. That hypothetical reconstructed tree must be highly similar to the original result tree (that is, the tree corresponding to the Data Model instance being serialized) because it is supposed to faithfully represent the original Data Model instance. The following differences are permitted in order to take into account various properties (of various node types) that are considered unimportant for this comparison.
• If the document was produced by adding a document wrapper as described earlier, then it will contain an extra top-level element (wxd, in our example) as the document element.
• The orders of attribute and namespace nodes in the two trees are allowed to be different.
• The following properties of corresponding nodes in the two trees are allowed to be different:
– The base-uri property of document nodes and element nodes.
– The document-uri and unparsed-entities properties of document nodes.
– The type-name and typed-value properties of element and attribute nodes.
– The nilled property of element nodes.
– The content property of text nodes, due to the effect of the indent and use-character-maps parameters.
• The reconstructed tree is also permitted to contain additional attributes and text nodes resulting from the expansion of default and fixed values in its DTD or schema.
• The type annotations of the nodes in the two trees are allowed to be different. (Type annotations in a result tree are discarded when the tree is serialized. Any new type annotations obtained by parsing the document will depend on whether the serialized XML document is assessed against a schema, and this could result in type annotations that are different from those in the original result tree.)
• The reconstructed tree may contain additional namespace nodes if the serialization process did not undeclare one or more namespaces and the initial instance of the data model contained an element node with a namespace node that declared some prefix, but a child element of that node did not have any namespace node that declared the same prefix.
• The reconstructed tree might not have every namespace node that the original result tree has, because the process of creating an instance of the data model ignores namespace declarations in some circumstances.
• If the indent parameter has the value yes:
– Additional text nodes consisting of whitespace characters might be present in the reconstructed tree.
– Text nodes in the original result tree that contained only whitespace characters might correspond to text nodes in the reconstructed tree that contain additional whitespace characters that were not present in the original result tree.
• The reconstructed tree might contain additional nodes due to the effect of character mapping in the character expansion phase, and the values of attribute nodes and text nodes in the reconstructed tree might be different from those in the result tree, due to the effects of URI expansion, character mapping, and Unicode Normalization in the character expansion phase of serialization.
One issue raised by that last bulleted point is that serialization of the original result tree will preserve certain characters – CR (carriage return), NEL (new line), and LINE SEPARATOR – when they appear in text nodes only by serializing them as either entity references or character references (e.g., “
,” “…,” and “
,” or equivalents). Similarly, several characters – CR (carriage return), TAB, LF (Line Feed), NEL (new line), and LINE SEPARATOR – are properly preserved when they appear in attribute nodes only by serializing them as either entity references or character references (e.g., “
,” “	,” “
,” “…,” and “
,” or equivalents).
Various serialization parameters affect the precise behavior of the XML output method. If serialization is a topic that interests you, we encourage you to read more about the effects of these parameters in the Serialization specification.
10.10.2 XHTML Output Method
The XHTML output method causes the Data Model instance to be serialized as XML, using the HTML compatibility guidelines contained in the XHTML Recommendation. The author of the XQuery (or XSLT 2.0 stylesheet) must make sure that the Data Model instance conforms to the requirements of the XHTML Recommendation (and whether it conforms to XHTML Strict, XHTML Transitional, XHTML Frameset, or XHTML Basic), because the serialization process will not raise an error if the Data Model instance does not conform.
In general, serialization using this output method follows the same rules as the XML output method. There are a few exceptions, based on the HTML compatibility guidelines in the XHTML Recommendation, that are intended to ensure that the output can be rendered by HTML rendering agents such as browsers. These exceptions are:
• Serializers are not allowed to use the minimized form of an empty XHTML element whose content model is not EMPTY (such as a title or paragraph without content). That is, a serializer is required to output (for example) <p></p> and not <p/>.
• By contrast, serializers are required to use the minimized form of an empty XHTML element whose content model is EMPTY (for example, <br />), because the alternative syntax (such as, <br></br>) that XML allows gives unpredictable results in much existing software. Furthermore, the serializer must include a space before the trailing /> for such minimized forms.
• Serializers cannot use the entity reference ’ which, although valid in XML and thus in XHTML, is not defined in HTML – it may not be recognized by all HTML user agents, such as older browsers.
• Serializers are encouraged, whenever possible, to output namespace declarations so that they are consistent with the requirements of the XHTML DTD. That DTD requires the namespace declaration xmlns=”http://www.w3.org/1999/xhtml” to appear on – but only on – the html element. Serializers are required to output namespace declarations that are consistent with the namespace nodes present in the result tree, but they are prohibited from outputting redundant namespace declarations on elements where the DTD would make them invalid.
• If the Data Model instance includes a head element in the XHTML namespace and the include-content-type serialization parameter has the value yes, serializers are required to add a meta element as the first child element of the head element, specifying the character encoding actually used. In addition, the content type must be set to the value given for the media-type parameter (if any). If a meta element has been added to the head element as described earlier, then the serializer is required to discard any meta element child having an http-equiv attribute with the value “Content-Type” that was originally specified as a child of the head element.
• Serializers must apply URI escaping to URI attribute values if the escape-uri-attributes parameter has the value yes, except that relative URIs cannot be turned into absolute URIs.
• If the indent parameter has the value yes, serializers are allowed to add or remove whitespace as they serialize the result tree, but only as long as they do not change the way that a conforming HTML user agent would render the output.
10.10.3 HTML Output Method
As one would expect, the HTML output method is used to serialize Data Model instances as HTML. The xsl:output element’s version attribute specifies the version of the HTML Recommendation to be generated. If the serializer does not support the version of HTML specified by this attribute, it will signal an error.
In addition, there are special rules for HTML markup of elements, especially related to the presence or absence of namespaces and namespace nodes. Other special rules govern the serialization of parameter values.
As with the XML and XHTML output methods, the precise behavior of the HTML output method is affected by various serialization parameters. If serialization is a topic of interest, the Serialization specification should be consulted for details of the effects of those parameters.
10.10.4 Text Output Method
The text output method is used to serialize Data Model instances into their string values, without any escaping. Serializers are allowed to serialize newline characters as any character used on the chosen platform as conventional line endings.
Serializers are required to use the encoding parameter to identify the mechanism to be used in converting the characters of a Data Model instance string value into a sequence of octets. The UTF-8 and UTF-16 encodings are mandated for all serializers, and serializers may support any other encodings their markets require. Similarly, serializers are required to use the normalization-form parameter to determine what Unicode normalization is performed during serialization. Values of NFC (Normalization Form C) and none must be supported, but other forms may be supported in addition.
We recommend that you consult the Serialization spec to learn the effects of other serialization parameters.
10.11 Chapter Summary
In this chapter we gave some background to the XQuery language, then described the features of the language in some detail.
In the introduction, we gave some of the historical context and motivation for an XML query language. Then we described the requirements and use cases specifications, both essential for framing what the XQuery language is meant to achieve, and gave an overview of the XQuery suite of specifications.
Armed with this background information, you read about the XQuery Data Model and type system, which, though based on XPath 1.0 and the XML Schema, extend both to provide a firm foundation for XML processing. Then you saw how the Formal Semantics spec formally defines the semantics of the XQuery language.
You also read about the Functions and Operators defined in XQuery, and, finally, you saw how XQuery can serialize its output to XML.
Now that you have a broad overview of XQuery, you are ready for the next chapter, in which we describe the gory details of the XQuery syntax and semantics.
1XQL FAQ, Jonathan Robie (1999). Available at: http://www.ibiblio.org/xql/.
2QL ‘98 – Query Languages 1998 (Cambridge, MA: World Wide Web Consortium, 1998) Available at: http://www.w3.org/TandS/QL/QL98/.
3XQL: A Query Language for XML Data, Hiroshi Ishikawa, Kazumi Kubota, Yasu-hiko Kanemasa. Available at: http://www.w3.org/TandS/QL/QL98/pp/flab.txt.
4XML-QL: A Query Language for XML, (Cambridge, MA: World Wide Web Consortium, 1998). Available at: http://www.w3.org/TR/NOTE-xml-ql/.
5See http://www-db.stanford.edu/lore/.
6Sophie Cluet and Jérôme Siméon, YATL: A Functional and Declarative Language for XML (2000). Available at: http://www-db.research.bell-labs.com/user/simeon/icfp.ps.
7Don Chamberlin, Jonathan Robie, and Daniela Florescu, Quilt (2000). See http://www.almaden.ibm.com/cs/people/chamberlin/quilt.html.
8Rick Cattell et al, The Object Database Standard: ODMG-93, Release 1.2 (San Francisco: Morgan Kaufmann, 1996).
9XML Query (XQuery) Requirements, (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xquery-requirements/.
10David Maier, Database Desiderata for an XML Query Language (1998). Available at: http://www.w3.org/TandS/QL/QL98/pp/maier.html.
11XQuery 1.0: An XML Query Language, (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xquery/.
12XPath 2.0 is very nearly a true subset of XQuery 1.0. One exception is that some of the XPath axes are optional in XQuery.
13XML Path Language (XPath) 2.0, (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xpath20/.
14In fact both documents are created from the same source, so the description of, e.g., path expressions is identical in the XQuery and the XPath language specifications.
15S. Bradner, Key Words for Use in RFCs to Indicate Requirement Levels (Cambridge, MA: Harvard University Press, 1997). Available at: http://www.ietf.org/rfc/rfc2119.txt.
16In this book, we use the word “XQueries” as the plural of “XQuery” when we mean “more than one XQuery expression.”
17XML Syntax for XQuery 1.0 (XQueryX), (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xqueryx/.
18XML Query Requirements, (Cambridge, MA: World Wide Web Consortium, 2000). Available at: http://www.w3.org/TR/2000/WD-xmlquery-req-20000131.
19XPointer Framework (Cambridge, MA: World Wide Web Consortium, 2003). Available at: http://www.w3.org/TR/xptr-framework/.
20XPath Requirements Version 2.0 (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xpath20req/.
21XML Query Use Cases (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xquery-use-cases/.
22See http://www.w3.org/XML/Query for a pointer to the “grammar test pages,” which includes an XQuery parser applet and query scripts derived from the examples in the Use Cases and Language specs.
23XQuery 1.0: An XML Query Language, W3C Last Call Working Draft (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xquery/.
24XML Syntax for XQuery 1.0 (XQueryX), W3C Last Call Working Draft (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xqueryx/.
25XQuery 1.0 and XPath 2.0 Data Model, W3C Last Call Working Draft (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xpath-datamodel/.
26XQuery 1.0 and XPath 2.0 Formal Semantics, W3C Last Call Working Draft (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xquery-semantics/.
27XQuery 1.0 and XPath 2.0 Functions and Operators, W3C Last Call Working Draft (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xpath-functions/.
28XSLT 2.0 and XQuery 1.0 Serialization, W3C Last Call Working Draft (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xslt-xquery-serialization/.
29XHTML™ 1.0 The Extensible HyperText Markup Language, A Reformulation of HTML 4 in XML 1.0, W3C Recommendation (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xhtml/; a corresponding specification for XHTML 1.1 is Available at: http://www.w3.org/TR/xhtmll/.
30HTML 4.01 Specification, W3C Recommendation (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/html401/.
31XQuery 1.0 and XPath 2.0 Data Model, (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xpath-datamodel/.
32XQuery 1.0 and XPath 2.0 Formal Semantics, (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xquery-semantics/.
33XSLT 2.0 and XQuery 1.0 Serialization, World Wide Web Consortium (Cambridge, MA: 2005). Available at: http://www.w3.org/TR/xslt-xquery-serialization/.
34XML Schema Part 2: Datatypes Second Edition (Cambridge, MA: World Wide Web Consortium, 2004). Available at: http://www.w3.org/TR/xmlschema-l/.
35The [schema normalized value] is a property in the PSVI, added during Schema validation. The [schema normalized value] of a text node is a string containing all the [character code] properties of the character information items in the Element Information Item, with some whitespace normalization applied (according to the value of the element’s whiteSpace facet).
More generally, the [schema normalized value] in the PSVI is similar to the string value of an element, except that it takes into account only direct child text nodes (the string value includes all descendant text nodes).
36The Data Model spec does say, “Regardless of how an instance of the data model is constructed, every node and atomic value in the data model must have a typed-value that is consistent with its type.” We can only speculate that, in the case of an element like the movie element, a typed value is said to exist but is undefined. This seems odd.
37See the XSLT 2.0 and XQuery 1.0 Serialization spec at http://www.w3.org/TR/xslt-xquery-serialization/ for a way to serialize the XQuery Data Model as XML or HTML.
38XML Schema Part 2: Datatypes Second Edition, (Cambridge, MA: World Wide Web Consortium, 2004). Available at: http://w3.org/TR/xmlschema-2/.
39XML Schema Part 1: Structures Second Edition, (Cambridge, MA: World Wide Web Consortium, 2004). Available at: http://w3.org/TR/xmlschema-l.
40Throughout this book, we adopt the common practice of using the namespace prefix “xs:” to denote the XML Schema built-in Datatypes. Later, we use “xdt:” to denote XQuery-only built-in Datatypes.
41The prefix ur comes from German and means “proto” or “first” or “original.” The ur type is the type from which all other types are derived and is thus a prototype for other types.
42The date/time types beginning with “g” are sometimes referred to as “the Australian Datatypes” – a pun on the common Australian greeting “g’ day (gDay).”
43The type hierarchy diagram would be more symmetrical if there were an abstract type xs:anyComplexType, but there isn’t.
44See http://w3.org/TR/xmlschema-2/#built-in-datatypes.
45The Complete XML Schema Type Library (Cambridge, MA: World Wide Web Consortium, 2001). Available at: http://www.w3.org/2001/03/XMLSchema/TypeLibrary.xsd.
46As mentioned in a previous footnote, we adopt the common convention of using the “xdt:” (XQuery data type) namespace prefix with types defined by XQuery.
47Namespaces in XML, W3C Recommendation (Cambridge, MA: World Wide Web Consortium, 1999). Available at: http://www.w3.org/TR/REC-xml-names. Namespaces in XML 1.1, W3C Recommendation (Cambridge, MA: World Wide Web Consortium, 2004). Available at: http://www.w3.org/TR/xml-namesll.